Palavras-chave:Tesla Robotaxi, AMD MI350, OpenAI o3-pro, iFlytek AIUI, Yuanqi Xing VLA, DeepSeek Nano-vLLM, Ant Group Ming Lite Omni, Veículos de produção em massa L2 alcançando autonomia de condução L4, Comparação de desempenho entre AMD MI350X e B200, Capacidade de processamento de contexto longo do modelo o3-pro, Tecnologia de interação full-duplex do AIUI, Modelo Visual-Linguagem-Ação VLA
🔥 Foco
Robotaxi da Tesla circula publicamente pela primeira vez, Musk afirma que veículos de produção L2 podem alcançar condução autónoma de nível L4 sem modificações: O Robotaxi da Tesla (Model Y renovado) já está a ser testado em Austin, com o novo logótipo Robotaxi mas mantendo o volante. Musk afirmou que todos os veículos de produção da Tesla podem alcançar condução autónoma não supervisionada. Os veículos de teste atuais estão equipados com uma versão interna do FSD com 4,5 vezes mais parâmetros que o FSD atual, prevendo-se o seu lançamento otimizado ainda este ano. O plano Robotaxi será aberto ao público a 22 de junho, com estreia em Austin. Esta medida marca a elevação do FSD de nível L2 da Tesla para Robotaxi de nível L4/L5, podendo acelerar a dinâmica competitiva da indústria de condução autónoma, especialmente desafiando os intervenientes da rota tecnológica L4 como a Waymo (Fonte: 量子位)

AMD lança o chip de IA mais potente, a série MI350, superando o desempenho do B200 da Nvidia: A CEO da AMD, Lisa Su, e o CEO da OpenAI, Sam Altman, apresentaram conjuntamente as GPUs MI350X e MI355X. Estes dois chips utilizam um processo de 3nm, possuem 185 mil milhões de transístores e 288GB de memória HBM3E, com uma capacidade de memória 1,6 vezes superior à do B200 da Nvidia. Dados oficiais mostram que a série MI350, ao executar o Llama 3.1 405B com precisão FP4, tem uma velocidade de inferência 30% mais rápida que o B200, e o seu poder de computação FP64 é o dobro do da Nvidia. A AMD também anunciou a série MI400, desenvolvida em colaboração com a OpenAI, que será lançada no próximo ano, intensificando ainda mais a concorrência no mercado de chips de IA (Fonte: 量子位)

Capacidade de inferência do modelo o3-pro da OpenAI chama a atenção, desempenho real difere ligeiramente dos testes oficiais: O mais recente modelo de inferência da OpenAI, o3-pro, demonstrou uma forte capacidade no processamento de jogos de palavras complexos (como gerar respostas específicas com base nas características dos nomes das músicas da cantora Sabrina Carpenter), levando o antigo líder da equipa AGI Readiness da OpenAI a ironizar as dúvidas anteriores da Apple sobre a capacidade de inferência dos modelos grandes. No entanto, em rankings autorizados como o LiveBench, a pontuação média de codificação do o3-pro foi quase a mesma que a do o3, e a pontuação de codificação do agente ficou até atrás. Testes do Fiction.LiveBench mostram que o o3-pro tem um desempenho excelente em contextos curtos, mas no processamento de contextos ultralongos de 192k, ainda é inferior ao Gemini 2.5 Pro. Ben Hylak, antigo engenheiro da Apple e da SpaceX, salientou que a verdadeira capacidade do o3-pro depende fortemente da entrada de informação de contexto suficiente, sendo mais adequado como gerador de relatórios do que como um simples interlocutor de chat, e apresenta melhorias significativas na chamada de ferramentas e na compreensão do ambiente (Fonte: 量子位)

iFlytek atualiza plataforma de interação homem-máquina AIUI e plataforma de supercérebro para robôs, impulsionando a colaboração profunda de hardware inteligente: A iFlytek anunciou uma grande atualização da sua plataforma de interação homem-máquina AIUI, com foco na melhoria da interação full-duplex, perceção e expressão emocional, e sistema de memória semelhante ao humano. Especificamente para cenários infantis, lançou uma solução de interação exclusiva, melhorando a capacidade de reconhecimento e compreensão da fala infantil. Simultaneamente, a sua plataforma de supercérebro para robôs, baseada no modelo grande Spark, reforçou a interação multimodal, a compreensão semântica e a aplicação de conhecimento, e lançou a “mochila de voz inteligente”, permitindo que robôs existentes realizem interação por voz sem modificação de hardware. Estas atualizações visam levar o hardware inteligente da interação básica para a colaboração inteligente profunda, capacitando vários campos como veículos, hardware de IA e robôs (Fonte: 量子位)

🎯 Tendências
DeepRoute.ai colabora com a Volcano Engine para desenvolver o Agent VLA para o mundo físico, baseado no modelo grande Doubao: O CEO da DeepRoute.ai, Zhou Guang, anunciou uma colaboração com a Volcano Engine para utilizar o modelo grande Doubao no desenvolvimento conjunto de tecnologias prospetivas, como o modelo visão-linguagem-ação (VLA), com o objetivo de criar um Agent para o mundo físico. O modelo VLA da DeepRoute.ai será lançado no mercado de consumo no terceiro trimestre de 2025, com quatro funcionalidades principais: compreensão semântica espacial, reconhecimento de obstáculos irregulares, compreensão de sinais de orientação textuais e controlo por voz do veículo, visando melhorar a segurança e a inteligência da condução assistida. Atualmente, o modelo VLA concluiu os testes em estrada, e prevê-se que mais de 5 modelos de carros de IA equipados com este modelo sejam lançados ainda este ano (Fonte: 量子位)

Investigador da DeepSeek replica vLLM com 1200 linhas de código, superando o desempenho em alguns cenários: O investigador da DeepSeek, Yu Xingkai, tornou open-source o projeto Nano-vLLM, que implementa as funcionalidades principais do vLLM, incluindo tecnologias chave como PagedAttention, em menos de 1200 linhas de código Python. O projeto visa fornecer uma versão minimizada e totalmente legível do vLLM, facilitando o aprendizado e a compreensão. Em condições de teste específicas com hardware H800 e o modelo Qwen3-8B, o throughput do Nano-vLLM chegou a superar o do vLLM original, demonstrando a sua eficiência. O vLLM é um framework de inferência e serviço para LLM desenvolvido pela UC Berkeley, conhecido por melhorar significativamente o throughput dos serviços LLM com o seu algoritmo PagedAttention (Fonte: 量子位)
Empresas chinesas utilizam “caixas de disco rígido voadoras” para contornar as restrições de exportação de chips de IA dos EUA: Segundo o Wall Street Journal, face às restrições dos EUA à exportação de chips de IA de ponta, as empresas chinesas adotaram uma nova estratégia: transportar discos rígidos com grandes volumes de dados de treino (por exemplo, 80TB) através de engenheiros para centros de dados no estrangeiro, como na Malásia, utilizando servidores locais equipados com chips avançados da Nvidia para treinar modelos de IA. Após a conclusão, os parâmetros do modelo são trazidos de volta para a China. Esta medida visa contornar as dificuldades de importação direta de chips e impulsionou o surgimento de centros de dados de IA no Sudeste Asiático e no Médio Oriente. Um antigo funcionário do Departamento de Comércio dos EUA expressou preocupação com esta prática (Fonte: dotey)

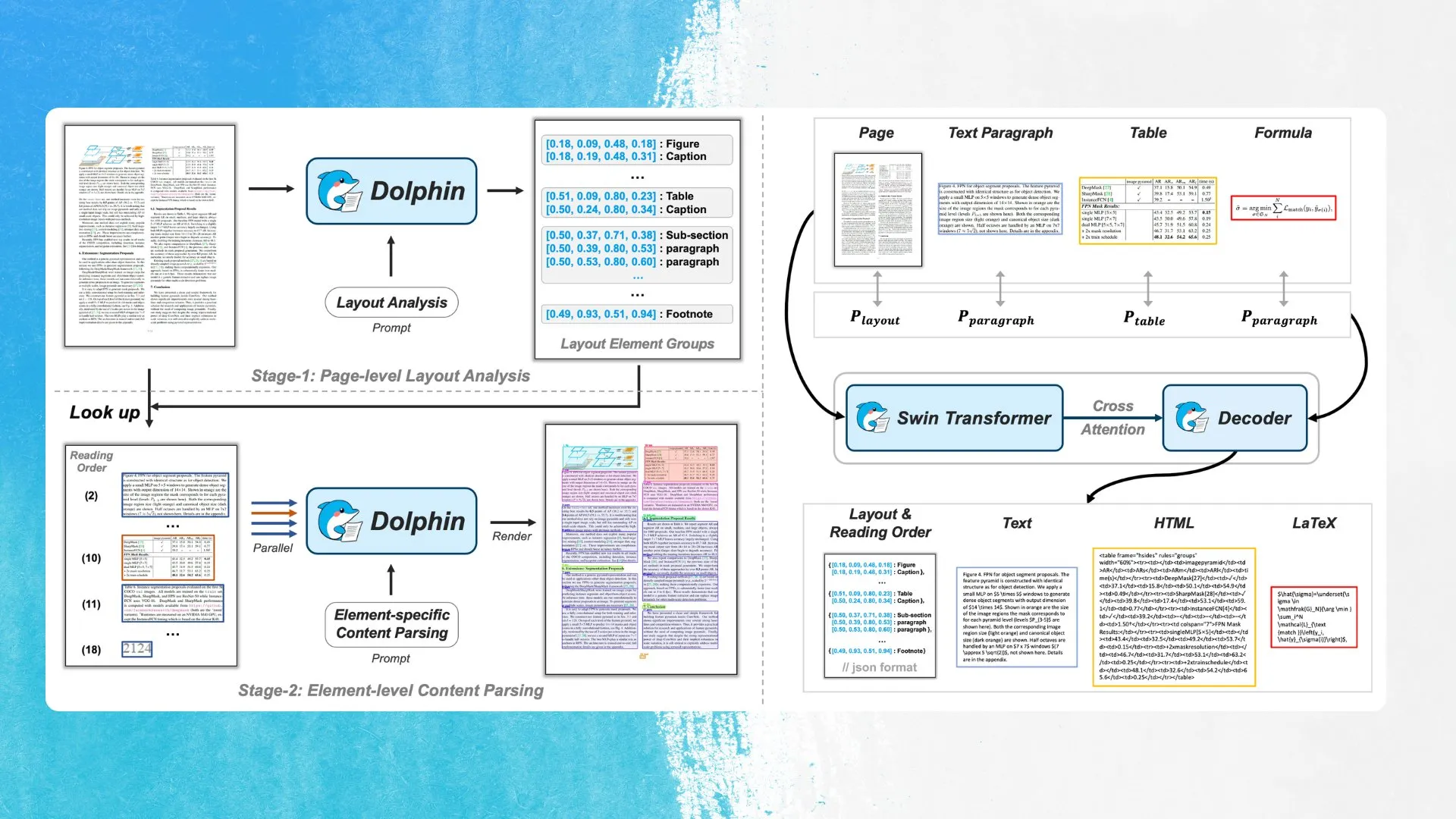
ByteDance lança novo modelo de OCR Dolphin, utilizando deteção de elementos de layout e análise paralela: A ByteDance lançou um novo modelo de OCR, o Dolphin, sob a licença MIT. O modelo deteta primeiro os elementos no layout do documento (como tabelas, fórmulas, etc.) e depois analisa cada elemento em paralelo para gerar o conteúdo. O modelo e a demonstração estão disponíveis no Hugging Face Hub. Esta abordagem visa melhorar a precisão e a eficiência no reconhecimento de estruturas de documentos complexas (Fonte: mervenoyann)
OpenAI melhora funcionalidade de “Projetos” do ChatGPT, adicionando suporte para pesquisa aprofundada, modo de voz e upload de ficheiros em dispositivos móveis: A OpenAI anunciou várias melhorias para a funcionalidade “Projects” (Projetos) no ChatGPT, incluindo suporte aprimorado para pesquisa aprofundada, integração do modo de voz, funcionalidade de memória melhorada para referenciar conversas passadas dentro do projeto, e suporte para upload de ficheiros e seletor de modelo em dispositivos móveis. Estas atualizações visam melhorar a capacidade dos utilizadores de realizar trabalhos mais focados e complexos no ChatGPT (Fonte: kevinweil)
Equipa EuroLLM lança versões de pré-visualização de vários novos modelos, incluindo um modelo de 22B e um pequeno modelo MoE: A equipa EuroLLM lançou versões de pré-visualização de vários novos modelos, incluindo um modelo base de 22B parâmetros e uma versão afinada por instrução, dois modelos de visão baseados em versões anteriores do EuroLLM (1.7B e 9B parâmetros), e um pequeno modelo de Mistura de Peritos (MoE) com 0.6B parâmetros ativos e 2.6B parâmetros totais. Todos estes modelos utilizam a licença Apache-2.0, e testes preliminares mostram que o pequeno modelo MoE tem um desempenho surpreendentemente bom para a sua escala (Fonte: Reddit r/LocalLLaMA)

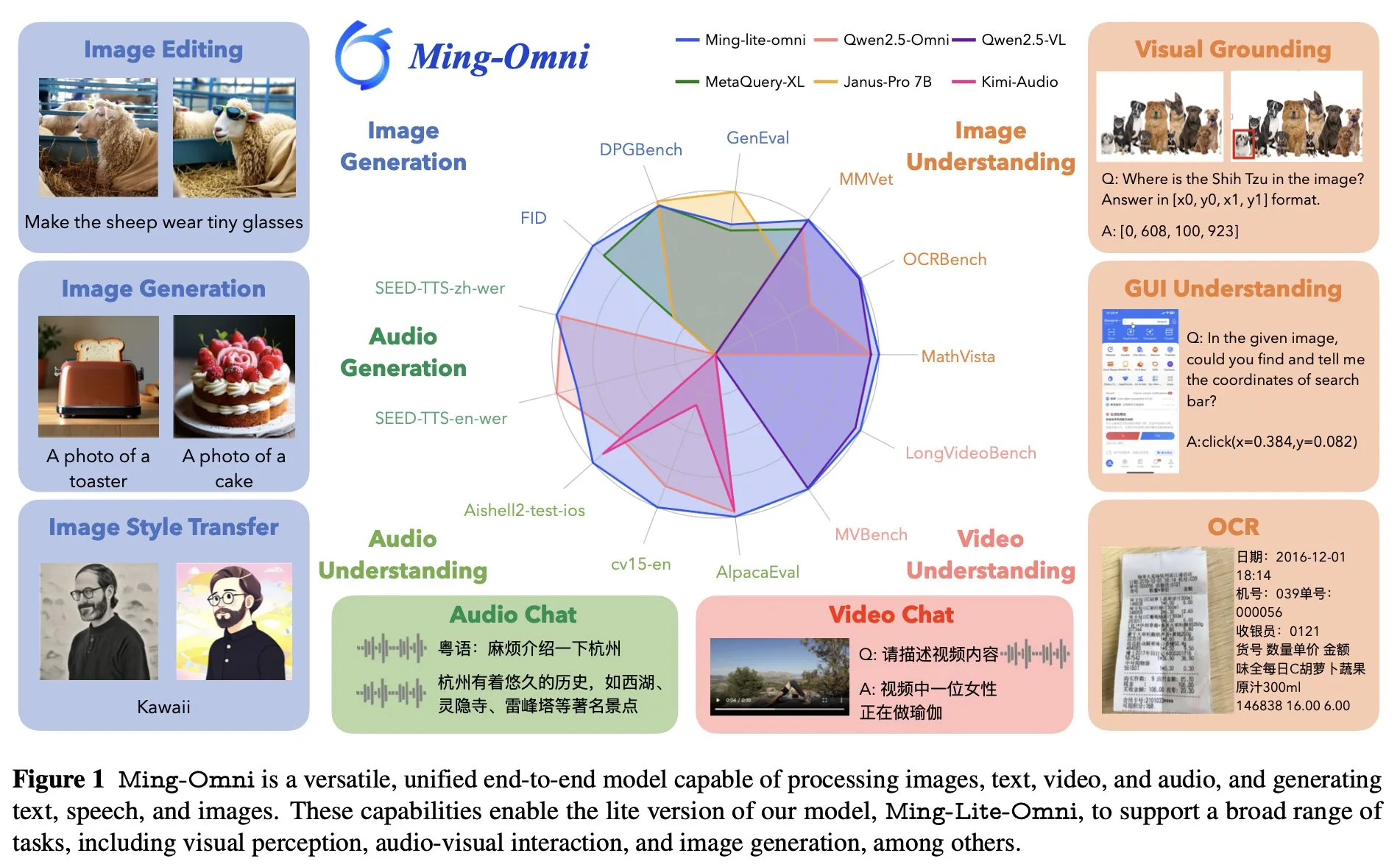
Ant Group lança modelo omnipotente de ponta a ponta Ming Lite Omni, competindo com GPT-4o: O Ant Group lançou o modelo Ming Lite Omni, capaz de realizar múltiplas funções como ouvir, falar e gerar imagens, competindo em desempenho com o GPT-4o. O Ming Lite Omni supera o Qwen2.5VL-7B em tarefas de GUI, a compreensão de áudio atinge o estado da arte (SOTA) em vários benchmarks públicos, e a capacidade de compreensão de vídeo também apresenta um desempenho excelente. O modelo utiliza uma arquitetura de Mistura de Peritos (MoE), com apenas 2.8B parâmetros ativos, e foi otimizado especificamente para a geração de áudio e imagem, como o uso de BPE para reduzir a taxa de tokens de áudio e tokens aprendíveis multiescala para melhorar a qualidade da geração de imagem (Fonte: mervenoyann)
NVIDIA e Mistral AI colaboram para construir a plataforma de nuvem de IA Mistral Compute: A NVIDIA anunciou na GTC uma parceria com a Mistral AI para criar conjuntamente uma plataforma de nuvem de IA chamada Mistral Compute. Esta medida é vista como um grande benefício para os Estados Unidos e para a comunidade open-source, visando fornecer um modelo para a construção de infraestrutura de IA global através de modelos abertos suportados por chips americanos (Fonte: arthurmensch)
Hugging Face anuncia adoção total do PyTorch, simplificando a biblioteca Transformers: O Diretor de Open Source da Hugging Face, Lysandre Jik, afirmou que, dado o consenso da base de utilizadores em torno do PyTorch, todos os esforços futuros serão concentrados no PyTorch para reduzir o inchaço da biblioteca Transformers, com o objetivo de fornecer um conjunto de ferramentas mais conciso. O PyTorch oficial congratulou-se com esta medida, salientando que ajuda a manter a simplicidade do código (Fonte: reach_vb)

ByteDance lança tecnologia de geração de vídeo interativo em tempo real APT2: A ByteDance apresentou a sua mais recente tecnologia de geração de vídeo interativo em tempo real, APT2 (Autoregressive Adversarial Post-Training). Esta tecnologia, através de pós-treino adversário autorregressivo, visa alcançar a geração de conteúdo de vídeo interativo de alta qualidade e em tempo real, impulsionando ainda mais o desenvolvimento no campo da geração de vídeo (Fonte: NerdyRodent)
🧰 Ferramentas
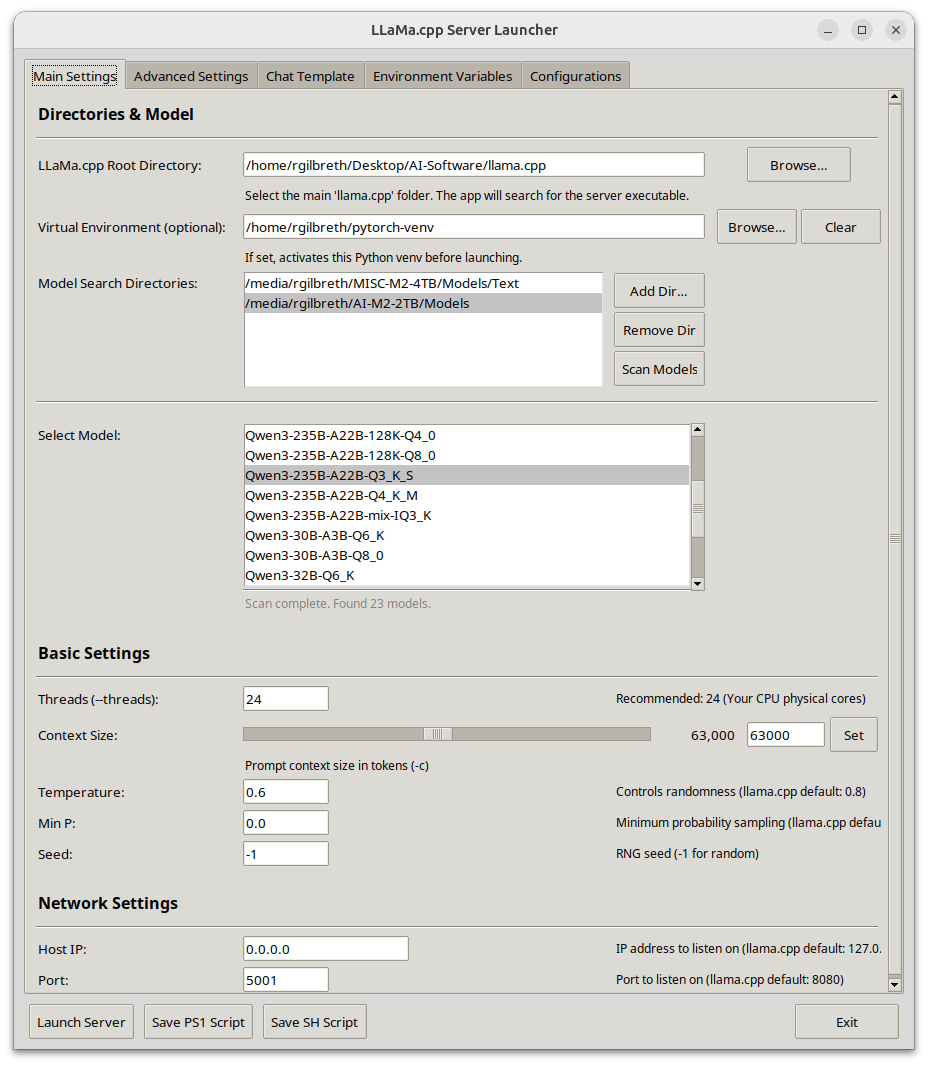
Llama-Server Launcher: um iniciador de servidor llama.cpp com GUI, focado na otimização de desempenho CUDA: Um programador partilhou o seu iniciador pessoal para o llama-server, escrito em Python e com uma interface gráfica de utilizador (GUI). A ferramenta visa simplificar a configuração e o arranque dos serviços llama.cpp, com especial atenção à otimização do desempenho CUDA. As funcionalidades incluem seleção de modelo, configuração de caminhos, ajuste do tamanho do contexto e do lote, descarga para GPU, FlashAttention, divisão de tensores e outras configurações avançadas de desempenho, bem como seleção de modelos de chat e gestão da configuração do ambiente. Suporta a obtenção automática de informações da GPU e do sistema, analisa metadados de modelos GGUF e pode gerar scripts de arranque multiplataforma (.ps1/.sh) (Fonte: Reddit r/LocalLLaMA)
Together AI lança agente de cientista de dados open-source: A Together AI construiu um agente de IA open-source capaz de raciocinar como um cientista de dados. O agente pode carregar dados, escrever código Python, treinar novamente modelos quando estes falham e resolver tarefas reais do Kaggle e DABStep. Esta iniciativa visa promover a automatização e a popularização da IA no campo da ciência de dados (Fonte: percyliang)
AutoMind: uma framework de agente adaptativo baseado em conhecimento para automatizar a ciência de dados: AutoMind é uma nova framework de agente LLM que visa superar as limitações dos atuais agentes de ciência de dados no tratamento de tarefas complexas e inovadoras, integrando bases de conhecimento especializadas, adotando um algoritmo de pesquisa em árvore de conhecimento do agente e estratégias de codificação adaptativas, de forma a melhorar a eficácia no mundo real dos processos automatizados de machine learning (Fonte: HuggingFace Daily Papers)
LlamaParse lança funcionalidade de “predefinições” para simplificar a configuração da análise de documentos: LlamaParse introduziu a funcionalidade “Presets” (Predefinições), que oferece uma série de modos pré-configurados fáceis de entender para otimizar as configurações para diferentes casos de uso. Inclui modos rápido, equilibrado e avançado para cenários genéricos, bem como modos otimizados para casos de uso comuns como faturas, artigos científicos, documentos técnicos e formulários, com o objetivo de permitir aos utilizadores escolher mais convenientemente entre velocidade e precisão (Fonte: jerryjliu0)
OpenWebUI adiciona funcionalidade de suporte ao o3-pro, expandindo a compatibilidade de modelos: Um programador da comunidade criou uma nova funcionalidade para o Open WebUI, expandindo o suporte para o modelo o3-pro através da adição de suporte à API de resposta, rastreamento de custos, suporte a múltiplas chaves e pesquisa na web. Isto permite que os utilizadores utilizem o o3-pro no Open WebUI sem necessidade de subscrever o plano premium oficial (Fonte: Reddit r/OpenWebUI)
📚 Aprendizado
Artigo explora a decomposição de ativações de MLP em características interpretáveis através da decomposição em matrizes semi-não-negativas (SNMF): Este estudo propõe o uso de SNMF para decompor diretamente as ativações de perceptrons multicamadas (MLP), a fim de aprender características esparsas, constituídas por combinações lineares de neurónios coativados, e mapear essas características para as suas entradas de ativação, tornando-as assim diretamente interpretáveis. Experiências demonstram que as características derivadas de SNMF superam os autoencoders esparsos (SAE) na orientação causal e alinham-se com conceitos humanamente interpretáveis, revelando uma estrutura hierárquica no espaço de ativação dos MLP (Fonte: HuggingFace Daily Papers)
Novo artigo propõe LoRMA: um novo paradigma para afinar LLMs através da Adaptação Multiplicativa de Baixo Rank (Low-Rank Multiplicative Adaptation): O ajuste fino tradicional de LLMs geralmente atualiza os pesos através de adição, enquanto o LoRMA explora atualizações multiplicativas. Para resolver o problema de “supressão de rank” causado por matrizes de baixo rank, o artigo introduz novas operações de expansão de rank baseadas em permutação e adição, e garante a eficiência computacional através de operações eficazes de reordenação. Experiências demonstram que o LoRMA é competitivo, oferecendo novas ideias para a adaptação de LLMs (Fonte: Reddit r/deeplearning)
Artigo propõe a framework TaxoAdapt, permitindo que taxonomias multidimensionais construídas por LLM se adaptem a corpus de investigação em evolução: Para enfrentar o desafio da organização da literatura científica, a framework TaxoAdapt ajusta dinamicamente as taxonomias geradas por LLM para se adaptarem a corpus específicos, e suporta múltiplas dimensões (como metodologia, tarefa, métricas de avaliação). A framework, através de classificação hierárquica iterativa, expande a largura e profundidade da classificação de acordo com a distribuição temática do corpus, visando organizar e capturar melhor a evolução dos campos científicos (Fonte: HuggingFace Daily Papers)
Artigo apresenta a framework MOSAIC, realizando aprendizagem colaborativa em sistemas de agentes inteligentes: MOSAIC é uma framework para sistemas de IA autónomos e agentivos realizarem aprendizagem colaborativa em ambientes descentralizados e dinâmicos. Os agentes partilham e reutilizam seletivamente conhecimento modular (na forma de máscaras de redes neuronais), sem necessidade de sincronização ou controlo centralizado. Experiências demonstram que MOSAIC supera os aprendizes isolados em velocidade e desempenho, por vezes resolvendo tarefas que agentes isolados não conseguem, e promove o aumento da eficiência e adaptabilidade coletivas (Fonte: Reddit r/MachineLearning)
Artigo propõe a framework ClaimSpect para análise hierárquica de alegações complexas com recuperação aumentada: Muitas alegações (como científicas, políticas) não são simplesmente verdadeiras ou falsas. A framework ClaimSpect, através da geração aumentada por recuperação, constrói automaticamente uma estrutura hierárquica de aspetos relacionados com a alegação e enriquece esses aspetos com perspetivas de um corpus específico. Este método visa desconstruir alegações complexas e apresentar as diferentes visões sobre cada aspeto presentes no corpus, bem como a sua prevalência (Fonte: HuggingFace Daily Papers)
Artigo propõe a realização de Orientação por Perturbação de Grão Fino (Fine-Grained Perturbation Guidance) através da seleção de cabeças de atenção: Este estudo descobriu que cabeças de atenção específicas em modelos de difusão controlam diferentes conceitos visuais (como estrutura, estilo, qualidade da textura). Com base nisto, o artigo propõe a framework “HeadHunter”, que seleciona sistematicamente cabeças de atenção consistentes com os objetivos do utilizador, permitindo um controlo de grão fino sobre a qualidade da geração e atributos visuais, e introduz o SoftPAG para ajustar a intensidade da perturbação. Este método validou a sua superioridade na melhoria da qualidade e orientação de estilo em modelos como Stable Diffusion 3 e FLUX.1 (Fonte: HuggingFace Daily Papers)
Artigo explora que o desaprendizado de LLM deve ser independente da forma (Form-Independent): A investigação aponta que a eficácia dos métodos atuais de desaprendizado (unlearning) de LLM depende fortemente da forma das amostras de treino, dificultando a generalização para diferentes expressões do mesmo conhecimento. O artigo define este problema como “Viés Dependente da Forma” (Form-Dependent Bias) e introduz o benchmark ORT para avaliação. Para resolver este problema, o artigo propõe o método ROCR (Rank-one Concept Redirection), que realiza o desaprendizado redirecionando a perceção do modelo sobre conceitos específicos. Experiências demonstram que o ROCR melhora significativamente o efeito do desaprendizado e consegue gerar resultados naturais (Fonte: HuggingFace Daily Papers)
Artigo propõe UniPre3D: um método de pré-treino unificado para modelos de nuvem de pontos 3D baseado em Gaussian Splatting intermodal: UniPre3D visa resolver os desafios trazidos pela diversidade de escalas de dados de nuvem de pontos na visão 3D, propondo o primeiro método de pré-treino unificado que pode ser aplicado sem problemas a nuvens de pontos de qualquer escala e a modelos 3D de qualquer arquitetura. O método, ao prever primitivas Gaussianas como tarefa de pré-treino e utilizar renderização diferenciável por Gaussian Splatting para gerar imagens, alcança supervisão precisa ao nível do pixel e otimização de ponta a ponta, integrando simultaneamente características de modelos 2D pré-treinados para introduzir conhecimento de textura (Fonte: HuggingFace Daily Papers)
Artigo propõe StreamSplat: reconstrução 3D dinâmica online para fluxos de vídeo não calibrados: StreamSplat é uma framework totalmente feed-forward capaz de converter online fluxos de vídeo não calibrados de qualquer comprimento numa representação dinâmica de Gaussian Splatting 3D (3DGS). Através de um mecanismo de amostragem probabilística no codificador estático para prever posições 3DGS, e um campo de deformação bidirecional no decodificador dinâmico, realiza uma modelação dinâmica robusta e eficiente, visando resolver os desafios de calibração, modelação dinâmica e estabilidade de eficiência na reconstrução de cenas dinâmicas em tempo real (Fonte: HuggingFace Daily Papers)
Artigo revê a Sondagem Atenta (Attentive Probing) na modelação de imagens mascaradas: Com o ajuste fino em larga escala a tornar-se impraticável, a sondagem (probing) tornou-se a primeira escolha para a avaliação da aprendizagem auto-supervisionada (SSL). A sondagem linear padrão (LP) não reflete adequadamente o potencial dos modelos treinados por modelação de imagens mascaradas (MIM). Este artigo reexamina a sondagem atenta, introduzindo a sondagem eficiente (EP), um mecanismo de atenção cruzada multi-consulta que reduz os parâmetros treináveis e aumenta a velocidade, superando a LP e métodos anteriores de sondagem atenta em vários benchmarks (Fonte: HuggingFace Daily Papers)
Artigo propõe PosterCraft: nova abordagem para geração de pósteres estéticos de alta qualidade sob uma framework unificada: PosterCraft visa resolver os desafios da geração de pósteres estéticos, que exigem não apenas renderização precisa de texto, mas também a integração perfeita de conteúdo artístico abstrato, layouts atraentes e harmonia estilística geral. PosterCraft adota um fluxo de trabalho em cascata para otimizar a geração, incluindo otimização de renderização de texto em larga escala, ajuste fino supervisionado sensível à região, aprendizagem por reforço para texto estético e refinamento por feedback visual-linguístico conjunto, superando significativamente as linhas de base open-source em várias experiências (Fonte: HuggingFace Daily Papers)
Artigo propõe melhoria de modelos de difusão através de Orientação por Perturbação de Tokens (Token Perturbation Guidance): Para resolver as limitações da orientação independente do classificador (CFG), que requer um processo de treino específico e se limita à geração condicional, o método TPG aplica diretamente matrizes de perturbação às representações intermédias de tokens dentro da rede de difusão. O TPG utiliza uma operação de shuffling que preserva a norma para fornecer um sinal de orientação eficaz, melhorando a qualidade da geração sem alterações na arquitetura, e é aplicável tanto à geração condicional como incondicional. Experiências demonstram que o TPG melhora o FID da linha de base SDXL em quase 2 vezes na geração incondicional (Fonte: HuggingFace Daily Papers)
Artigo propõe DreamActor-H1: geração de vídeos de demonstração pessoa-produto de alta fidelidade através de Diffusion Transformers com design de movimento: DreamActor-H1 é uma framework baseada em Diffusion Transformer (DiT) que visa gerar vídeos de demonstração de interação pessoa-produto de alta qualidade. O método, através da injeção de informação de referência emparelhada pessoa-produto e um mecanismo adicional de atenção cruzada mascarada, preserva simultaneamente os detalhes de identidade da pessoa e do produto (como logótipos, texturas). Utiliza modelos de malha humana 3D e caixas delimitadoras de produtos para fornecer orientação de movimento precisa, e melhora a consistência 3D através de codificação de texto estruturada (Fonte: HuggingFace Daily Papers)
Artigo propõe EmbodiedGen: um motor de mundo 3D generativo para inteligência incorporada: EmbodiedGen é uma plataforma fundamental para a geração interativa de mundos 3D, visando gerar de forma escalável e a baixo custo ativos 3D de alta qualidade, controláveis e fotorrealistas, que possuem propriedades físicas precisas e escala do mundo real, e adotam o formato de descrição unificado de robôs (URDF). Estes ativos podem ser importados diretamente para vários motores de simulação física, apoiando tarefas de treino e avaliação de inteligência incorporada, e resolvendo os problemas de alto custo e realismo limitado dos ativos tradicionais de computação gráfica 3D (Fonte: HuggingFace Daily Papers)
Nova investigação refuta o artigo da Apple sobre a “ilusão do pensamento”, argumentando que os LLMs conseguem resolver problemas complexos novos: Em resposta ao recente artigo da Apple “Illusion of Thinking”, que afirmava que os modelos de linguagem grandes (LRM) sofrem um “colapso de precisão” em quebra-cabeças de planeamento complexos (como a Torre de Hanói), um estudo de comentário subsequente aponta que as conclusões da Apple refletem principalmente as limitações do design experimental e não uma falha fundamental na capacidade de raciocínio dos modelos. A nova investigação argumenta que o exceder do orçamento de tokens no experimento original, a avaliação incorreta de resultados intencionalmente truncados e a inclusão de instâncias de quebra-cabeças matematicamente insolúveis contribuíram conjuntamente para uma avaliação errónea das capacidades dos modelos. Ao ajustar os métodos experimentais, por exemplo, exigindo que o modelo gere uma função Lua compacta para a solução da Torre de Hanói em vez de uma lista exaustiva de passos, os modelos demonstraram alta precisão em casos anteriormente reportados como falha total, indicando que os modelos não são incapazes de raciocinar, mas sim limitados pelo formato de saída e pelas restrições de tokens (Fonte: Reddit r/LocalLLaMA)

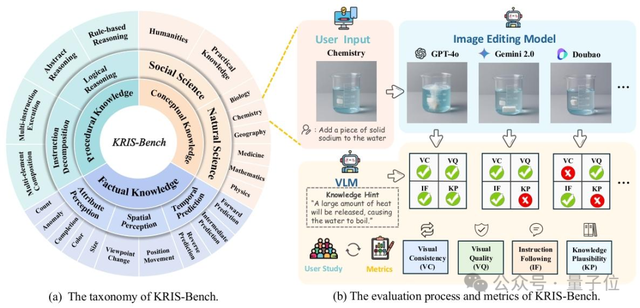
KRIS-Bench: Novo benchmark para avaliação abrangente da capacidade de raciocínio de modelos de edição de imagem da perspetiva do tipo de conhecimento: Instituições como a Universidade do Sudeste uniram-se para lançar o KRIS-Bench, um benchmark da capacidade de raciocínio de sistemas de edição de imagem baseado em conhecimento. Ele subdivide 22 tarefas de edição a partir de três níveis: conhecimento factual (como cor, quantidade), conhecimento conceptual (como senso comum físico) e conhecimento processual (como operações de múltiplos passos), para avaliar 10 modelos de edição de imagem convencionais (incluindo GPT-Image-1, Gemini 2.0 Flash, etc.). Os resultados mostram que o modelo de código fechado GPT-Image-1 teve o melhor desempenho, mas todos os modelos geralmente tiveram um desempenho fraco em tarefas de raciocínio profundo, como raciocínio processual, ciências naturais e síntese de múltiplos passos, revelando as deficiências dos modelos atuais em capacidades cognitivas avançadas (Fonte: 量子位)
Nova investigação propõe o método Finetune-RAG, afinando modelos de linguagem para resistir a alucinações em RAG: Modelos de linguagem grandes, na geração aumentada por recuperação (RAG), tendem a produzir alucinações quando a recuperação não é perfeita (por exemplo, na presença de fragmentos de documentos perturbadores). O Finetune-RAG treina o modelo com amostras de entrada contendo contextos corretos e incorretos, permitindo-lhe manter melhor a veracidade. A equipa de investigação lançou um conjunto de dados com mais de 1600 amostras de contexto duplo, um checkpoint afinado do LLaMA 3.1-8B-Instruct, e uma framework de avaliação GPT-4o chamada Bench-RAG. A avaliação mostra que este método aumentou a precisão de 77% para 98%, com melhorias também na utilidade, relevância e profundidade (Fonte: Reddit r/MachineLearning)
TeleMath: Lançado o primeiro benchmark de LLM para capacidade de resolução de problemas matemáticos no domínio das telecomunicações: Para avaliar a capacidade de modelos de linguagem grandes em resolver tarefas específicas e intensivas em matemática no domínio das telecomunicações, investigadores lançaram o benchmark TeleMath. Este benchmark contém 500 pares de perguntas e respostas, cobrindo tópicos de telecomunicações como processamento de sinais, otimização de redes e análise de desempenho. A avaliação de vários LLMs open-source mostrou que modelos projetados especificamente para raciocínio matemático ou lógico tiveram melhor desempenho no TeleMath, enquanto modelos genéricos de grande número de parâmetros frequentemente encontraram dificuldades. O conjunto de dados e o código de avaliação foram disponibilizados (Fonte: HuggingFace Daily Papers)
ChineseHarm-Bench: Lançado benchmark de deteção de conteúdo prejudicial em chinês: Face à predominância de recursos de deteção de conteúdo prejudicial em inglês, investigadores lançaram o ChineseHarm-Bench, um benchmark abrangente e profissionalmente anotado para a deteção de conteúdo prejudicial em chinês. O benchmark cobre seis categorias representativas, com dados totalmente provenientes do mundo real. O processo de anotação também produziu uma base de regras de conhecimento, fornecendo aos LLMs conhecimento explícito de especialistas. Além disso, os investigadores propuseram um método de linha de base melhorado por conhecimento, que combina regras anotadas manualmente e conhecimento implícito de LLMs, permitindo que modelos pequenos atinjam o desempenho de LLMs SOTA (Fonte: HuggingFace Daily Papers)
Nova investigação descobre estrutura hierárquica de capacidades latentes em modelos de linguagem através da aprendizagem de representação causal: Para avaliar fielmente as capacidades dos modelos de linguagem e superar os efeitos de confundimento e os altos custos computacionais, este estudo propõe uma framework de aprendizagem de representação causal. A framework modela o desempenho observado em benchmarks como uma transformação linear de um pequeno número de fatores de capacidade latente e, após controlar o modelo base como um fator de confundimento comum, identifica as relações causais entre esses fatores latentes. Aplicada a dados de mais de 1500 modelos do Open LLM Leaderboard, a investigação descobriu uma estrutura causal linear concisa de três nós, revelando um caminho causal claro desde a capacidade geral de resolução de problemas, passando pela proficiência no seguimento de instruções, até à capacidade de raciocínio matemático (Fonte: HuggingFace Daily Papers)
DeepLearning.AI lança novo curso “Orquestrando Workflows para Aplicações GenAI”: Andrew Ng anunciou uma parceria com a Astronomer para lançar um novo curso de curta duração que ensina como construir e implementar pipelines de IA generativa confiáveis usando a popular ferramenta open-source Airflow 3.0. O conteúdo do curso inclui a decomposição de workflows em tarefas discretas, agendamento de tarefas, execução paralela, recuperação de falhas e observabilidade, entre outros, com o objetivo de ajudar os alunos a transformar protótipos de notebooks Jupyter ou scripts Python em workflows prontos para produção (Fonte: DeepLearningAI)
Artigo explora métodos de otimização, desafios e direções futuras para sistemas de IA compostos: Com o desenvolvimento de LLMs e sistemas de IA, os sistemas de IA compostos que integram múltiplos componentes estão a tornar-se cada vez mais maduros na execução de tarefas complexas. Este artigo revê sistematicamente os mais recentes avanços na otimização de sistemas de IA compostos, incluindo técnicas numéricas e baseadas em linguagem. O artigo formaliza o conceito de otimização de sistemas de IA compostos, classifica os métodos existentes e destaca os desafios de investigação em aberto e as direções futuras neste campo (Fonte: HuggingFace Daily Papers)
💼 Negócios
Disney e Universal Studios processam o gerador de imagens Midjourney por violação de direitos autorais: A Disney e a Universal Studios acusam o Midjourney de usar, sem permissão, o seu acervo criativo (incluindo personagens de Star Wars, Frozen, Minions, etc.) para treinar os seus modelos, e de gerar e distribuir um grande número de obras derivadas, descrevendo-o como um “plágio sem fundo”. Este caso reacende a discussão sobre os limites entre conteúdo gerado por IA e propriedade intelectual (Fonte: Reddit r/ArtificialInteligence)
NVIDIA e Deutsche Telekom colaboram para estabelecer a primeira nuvem de IA industrial para fabricantes europeus até 2026: O Chanceler Federal da Alemanha, Friedrich Merz, reuniu-se com o CEO da NVIDIA, Jensen Huang, para discutir uma maior cooperação estratégica para consolidar a Alemanha como líder global em IA. Como parte desta visão, a Deutsche Telekom e a NVIDIA anunciaram uma nova colaboração, planeando estabelecer a primeira nuvem de IA industrial do mundo para fabricantes europeus até 2026. Esta infraestrutura segura e em conformidade com as normas europeias apoiará a inovação de ponta, garantindo ao mesmo tempo a soberania total dos dados (Fonte: nvidia)

Rumores de que Sam Altman poderá diluir o controlo sem fins lucrativos da OpenAI através de aquisições totalmente em ações: As recentes aquisições da OpenAI, totalmente em ações, da io (6,5 mil milhões de dólares) e da Windsurf (3 mil milhões de dólares) geraram especulações. No Hacker News, existe a teoria de que Sam Altman poderá estar a usar estas transações para diluir gradualmente o controlo da organização sem fins lucrativos OpenAI Inc. sobre a entidade com fins lucrativos OpenAI Global LLC (agora OpenAI PBC), contornando assim possíveis restrições legais à transição para uma empresa totalmente com fins lucrativos. Esta manobra foi associada por alguns às operações de Altman com o Reddit em 2014, mas há também quem defenda que estas aquisições são movimentos estratégicos de negócio normais (Fonte: Reddit r/ArtificialInteligence)
🌟 Comunidade
Discussão sobre se a IA pode realmente “raciocinar” continua, artigo da Apple gera controvérsia: O recente artigo da Apple que afirma que o desempenho de modelos de linguagem grandes (LLM) em tarefas complexas (como a Torre de Hanói) não é verdadeiramente raciocínio, mas mais um reconhecimento de padrões, tem sido amplamente discutido pela comunidade. Miles Brundage, ex-funcionário da OpenAI, ao comentar a resolução de jogos de palavras complexos pelo o3-pro, perguntou ironicamente: “Se isto não é raciocínio, o que é?”. Investigações subsequentes apontaram que o fenómeno de “colapso do raciocínio” no artigo da Apple pode dever-se a limitações do design experimental (como limites de tokens, avaliação incorreta de problemas insolúveis) e não a uma falha na capacidade de raciocínio do próprio modelo. Após o ajuste dos métodos de teste, o modelo teve um bom desempenho em tarefas nas quais anteriormente falhou, o que sugere que a avaliação da capacidade de raciocínio da IA requer um design experimental mais cuidadoso (Fonte: o3-pro a resolver jogos de palavras difíceis atrai atenções, ex-funcionário da OpenAI ironiza a Apple: se isto não é raciocínio, o que é?, Reddit r/LocalLLaMA)
CEO da Nvidia, Jensen Huang, e CEO da Anthropic, Dario Amodei, têm divergências significativas sobre o futuro da IA: A Fortune relata que o CEO da Nvidia, Jensen Huang, afirmou discordar de quase todas as opiniões do CEO da Anthropic, Dario Amodei, sobre IA. Amodei frequentemente enfatiza os riscos potenciais da IA e o seu enorme impacto no emprego, defendendo um controlo mais rigoroso sobre o desenvolvimento da IA, liderado por um pequeno número de organizações “responsáveis”. Huang, por outro lado, é cético em relação a tais opiniões, inclinando-se mais para a promoção da ampla aplicação e desenvolvimento da tecnologia de IA. Comentários da comunidade sugerem que a posição de Huang pode estar relacionada com os seus interesses comerciais, uma vez que a Nvidia é o principal fornecedor de hardware para IA (Fonte: Reddit r/ArtificialInteligence, Reddit r/ClaudeAI)

Plano de subscrição de 20 dólares do Claude Code elogiado por programadores pela sua relação custo-benefício: Muitos programadores partilharam nas redes sociais as suas experiências positivas com o plano de subscrição mensal de 20 dólares do Anthropic Claude Code, descrevendo-o como extremamente vantajoso em termos de custo-benefício, permitindo recuperar rapidamente o investimento nos seus projetos. Os utilizadores mencionaram que, apesar de existirem certos limites de taxa, o Claude Code tem um desempenho excelente na assistência à codificação, na aprendizagem de novas linguagens (como passar de C# para SwiftUI) e na otimização de instruções de projeto (como ficheiros CLAUDE.md), aumentando significativamente a eficiência do trabalho. Alguns utilizadores consideram mesmo cancelar as subscrições de outras ferramentas de assistência à programação por IA (Fonte: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Comunidade discute futuras aplicações e desafios éticos da IA na psicologia: Com o desenvolvimento de tecnologias como LLMs a redigir sugestões terapêuticas e aplicações que rastreiam emoções através de sensores de telemóveis, a IA está gradualmente a infiltrar-se na psicologia. A discussão da comunidade foca-se em saber se a IA na prática clínica irá aumentar as capacidades dos terapeutas ou, eventualmente, substituir parte do seu trabalho, a credibilidade da IA na avaliação e investigação, o impacto na formação profissional e no mercado de trabalho da psicologia, e as questões éticas e regulatórias das aplicações de IA, especialmente o viés de dados, a privacidade e as limitações dos “terapeutas robôs”. A principal preocupação reside em como utilizar a IA para aumentar a eficiência e os serviços personalizados, garantindo simultaneamente a segurança do paciente e mantendo o valor terapêutico da ligação interpessoal (Fonte: Reddit r/artificial)
Modelo DeepSeek-R1-0528 quantizado a 3.53bit pela Unsloth apresenta bom desempenho no benchmark de codificação Aider Polyglot: A equipa da Unsloth, após quantizar o modelo DeepSeek-R1-0528 para 3.53bit (UD-Q3_K_XL), alcançou uma taxa de aprovação de 68% no benchmark de codificação Aider Polyglot. O teste utilizou um tamanho de contexto de 40960 e Flash Attention, necessitando de aproximadamente 300GB de RAM/VRAM. Este resultado situa-se entre o Claude Sonnet 3.7 e o Claude Opus 4, demonstrando o potencial dos modelos quantizados em manter uma elevada capacidade de codificação. Os membros da comunidade ficaram impressionados com o desempenho de tais modelos executados localmente e aguardam com expectativa os resultados de testes de mais versões quantizadas (Fonte: Reddit r/LocalLLaMA)
💡 Outros
Relatório de falha global do GCP revela: política de quota ilegal causou interrupção do serviço: O relatório sobre a recente falha global da Google Cloud Platform (GCP) indica que a causa foi a aplicação de uma política de quota incorreta ao sistema global de gestão de API (como limitar os pedidos a apenas 1 por hora), o que levou à rejeição de pedidos externos devido a excederem a quota (erro 403). Após a descoberta, os engenheiros contornaram a verificação de quota da API afetada. No entanto, na região us-central1, ao tentar limpar a política antiga e escrever uma nova, problemas de cache causaram sobrecarga da base de dados, prolongando o tempo de recuperação. Outras regiões adotaram uma abordagem de limpeza gradual da cache para recuperar, com todo o processo a demorar cerca de 2 horas (Fonte: karminski3)

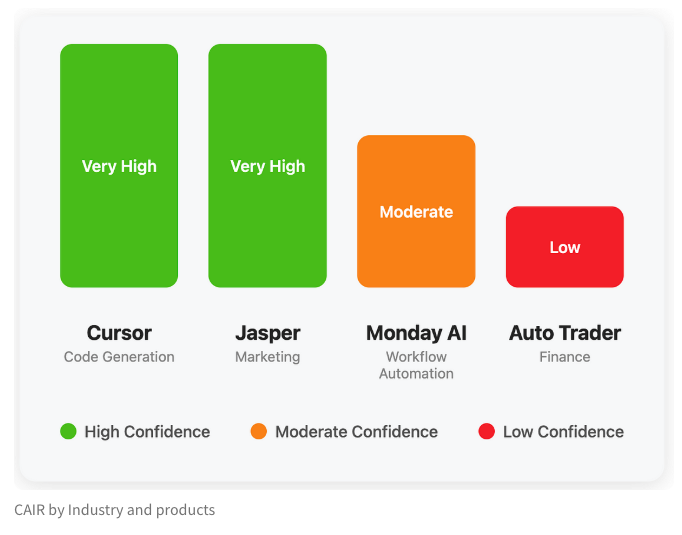
Equipa da LangChain propõe métrica CAIR para avaliar o potencial de sucesso de produtos de IA: Harrison Chase da LangChain, juntamente com Assaf Elovic, publicaram um artigo a explorar por que motivo alguns produtos de IA se popularizam rapidamente enquanto outros enfrentam dificuldades. Argumentam que a capacidade do modelo não é o único fator determinante, sendo a experiência do utilizador (UX) crucial, e propõem a métrica “CAIR” (Confidence in AI Results, Confiança nos Resultados da IA). Quanto maior o CAIR, maior a adoção do produto. Esta framework visa ajudar os programadores a identificar e melhorar os vários componentes que afetam a confiança do utilizador, aumentando assim a taxa de sucesso do produto (Fonte: hwchase17, swyx, hwchase17, Hacubu)
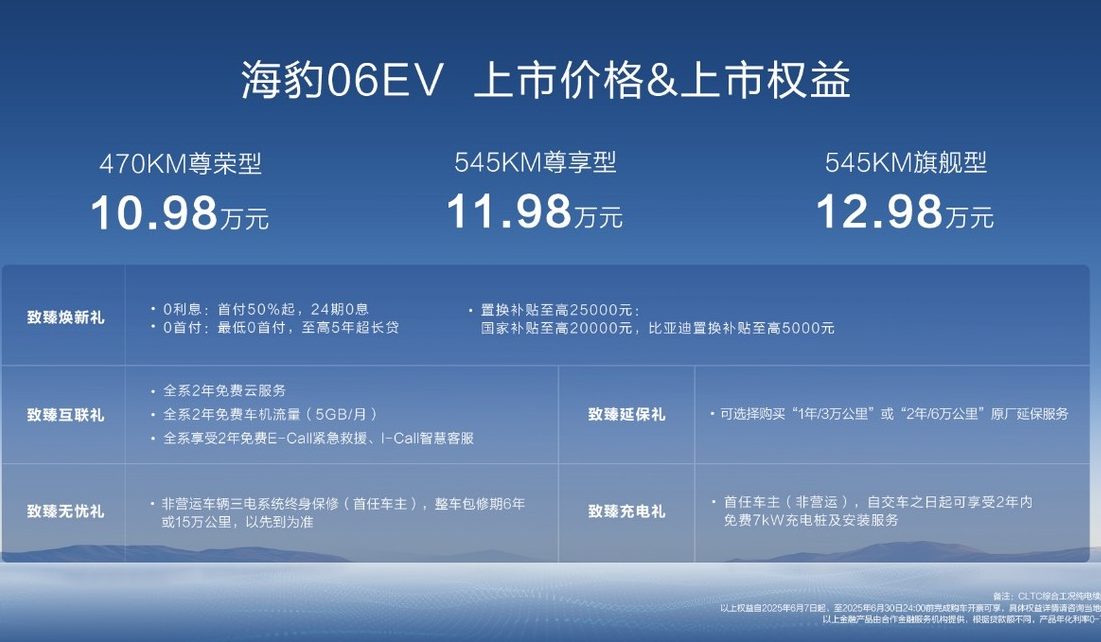
BYD lança novo coupé familiar puramente elétrico Seal 06EV, com preço a partir de 109.800 yuan: A BYD Ocean Network lançou o Seal 06EV no Salão Automóvel de Chongqing, posicionado como um coupé elegante e de qualidade, com 3 configurações e preços entre 109.800 e 129.800 yuan. O veículo é construído sobre a plataforma BYD e-platform 3.0 Evo, equipado com um sistema de propulsão elétrico inteligente oito-em-um e um sistema de bomba de calor eficiente de ampla faixa de temperatura de nova geração, oferecendo duas autonomias CLTC de 470KM e 545KM. O veículo adota uma configuração de tração traseira, está equipado com o sistema de controlo inteligente de amortecimento da carroçaria Cloud Chariot-C, e integra a versão de três câmaras do sistema de assistência à condução inteligente “Eye of the Gods C”, suportando funções como navegação assistida em autoestrada e estacionamento automático (Fonte: 量子位)