Keywords:Tesla Robotaxi, AMD MI350, OpenAI o3-pro, iFlytek AIUI, DeepSeek Nano-vLLM, Yuanrong Qixing VLA, Ant Group Ming Lite Omni, L2 mass-produced vehicles achieving L4 autonomous driving, Performance comparison between AMD MI350X and B200, Long-context processing capability of o3-pro model, AIUI full-duplex interaction technology, Vision-Language-Action model VLA
🔥 Focus
Tesla Robotaxi’s first public road appearance, Musk claims L2 mass-produced vehicles can achieve L4 autonomous driving without modification: Tesla’s Robotaxi (refreshed Model Y) has begun road testing in Austin, featuring a new Robotaxi logo but retaining the steering wheel. Musk stated that all Tesla mass-produced cars can achieve unsupervised autonomous driving. The current test vehicles are equipped with an internal test version of FSD with 4.5 times the parameters of the current FSD, expected to be optimized and rolled out within the year. The Robotaxi is planned to be open to the public on June 22, debuting in Austin. This move marks an upgrade from Tesla’s L2 FSD to L4/L5 Robotaxi, potentially accelerating the competitive landscape of the autonomous driving industry, especially posing a challenge to L4 technology route players like Waymo (Source: 量子位)

AMD releases its most powerful AI chip, the MI350 series, outperforming Nvidia’s B200: AMD CEO Lisa Su and OpenAI CEO Sam Altman jointly announced the MI350X and MI355X GPUs. These two chips use 3nm process technology, featuring 185 billion transistors and 288GB of HBM3E memory, with 1.6 times the memory capacity of Nvidia’s B200. Official data shows that the MI350 series runs Llama 3.1 405B inference 30% faster than the B200 at FP4 precision and has twice the FP64 computing power of Nvidia. AMD also previewed the MI400 series, co-developed with OpenAI, which will debut next year, further intensifying competition in the AI chip market (Source: 量子位)

OpenAI’s o3-pro model’s reasoning ability draws attention, actual performance slightly differs from official tests: OpenAI’s latest reasoning model, o3-pro, demonstrated strong capabilities in handling complex word games (e.g., generating specific answers based on the characteristics of singer Sabrina Carpenter’s song titles), prompting a former head of OpenAI’s AGI Readiness team to sarcastically comment on Apple’s previous questioning of large model reasoning abilities. However, on authoritative leaderboards like LiveBench, o3-pro’s average coding score was almost on par with o3, and its agent coding score was even lower. Fiction.LiveBench tests showed that o3-pro performed excellently in short contexts but still lagged behind Gemini 2.5 Pro in handling 192k ultra-long contexts. Ben Hylak, a former engineer at Apple and SpaceX, pointed out that o3-pro’s true capabilities heavily depend on sufficient background information input, making it more suitable as a report generator than a simple chatbot, with significant improvements in tool calling and environmental understanding (Source: 量子位)

iFLYTEK upgrades AIUI human-computer interaction platform and Robot Super Brain platform, promoting deep collaboration in smart hardware: iFLYTEK announced a major upgrade to its human-computer interaction platform, AIUI, focusing on enhancing full-duplex interaction, emotional perception and expression, and human-like memory systems. Specifically for children’s scenarios, it launched a dedicated interaction solution to improve the recognition and understanding of children’s speech. Simultaneously, its Robot Super Brain platform, based on the Spark large model, strengthened multimodal interaction, semantic understanding, and knowledge application, and introduced a “smart voice backpack” enabling existing robots to achieve voice interaction without hardware modification. These upgrades aim to elevate smart hardware from basic interaction to deep intelligent collaboration, empowering various fields such as in-vehicle systems, AI hardware, and robotics (Source: 量子位)

🎯 Trends
DeepRoute.ai collaborates with Volcengine to develop VLA physical world Agent based on Doubao large model: DeepRoute.ai CEO Zhou Guang announced a collaboration with Volcengine to jointly develop cutting-edge technologies such as Vision-Language-Action (VLA) models, utilizing the Doubao large model, aiming to create an Agent for the physical world. DeepRoute.ai’s VLA model will be launched in the consumer market in Q3 2025, featuring four core functions: spatial semantic understanding, irregular obstacle recognition, text-based guidance sign comprehension, and voice control of vehicles, aiming to enhance the safety and intelligence of assisted driving. The VLA model has completed road tests, and it is expected that more than 5 AI car models equipped with this model will be launched within the year (Source: 量子位)

DeepSeek researcher replicates vLLM with 1200 lines of code, outperforming it in some scenarios: DeepSeek researcher Yu Xingkai open-sourced the Nano-vLLM project, implementing the core functionalities of vLLM, including PagedAttention and other key technologies, with less than 1200 lines of Python code. The project aims to provide a minimal and fully readable version of vLLM for learning and understanding. Under specific test conditions with H800 hardware and the Qwen3-8B model, Nano-vLLM’s throughput even surpassed that of the original vLLM, demonstrating its efficiency. vLLM is an LLM inference and serving framework developed by UC Berkeley, known for its PagedAttention algorithm that significantly improves the throughput of LLM services (Source: 量子位)
Chinese companies use “flying hard drive cases” to circumvent US AI chip export restrictions: According to The Wall Street Journal, facing US export restrictions on high-end AI chips, Chinese companies are adopting new strategies. Engineers carry hard drives with large amounts of training data (e.g., 80TB) to overseas data centers in places like Malaysia, utilizing local servers equipped with advanced chips like Nvidia’s to train AI models. After completion, the model parameters are brought back to China. This move aims to bypass the difficulties of directly importing chips and has spurred the rise of AI data centers in Southeast Asia and the Middle East. A former US Department of Commerce official expressed concern about this practice (Source: dotey)

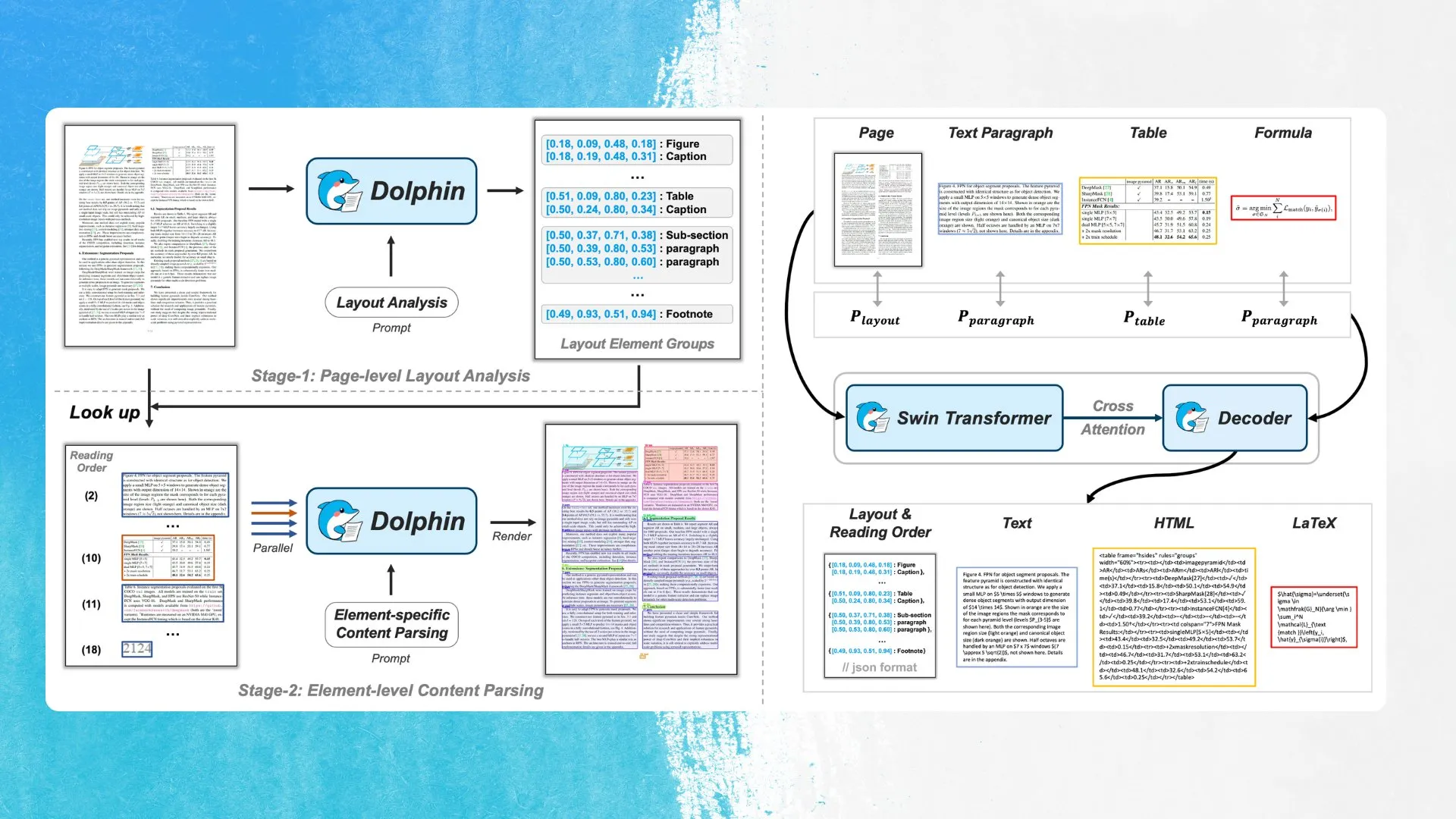
ByteDance introduces new OCR model Dolphin, employing layout element detection and parallel parsing: ByteDance has released a new OCR model, Dolphin, under the MIT license. The model first detects elements in the document layout (such as tables, formulas, etc.) and then parses each element in parallel to generate content. The model and demo are available on Hugging Face Hub. This approach aims to improve the accuracy and efficiency of recognizing complex document structures (Source: mervenoyann)
OpenAI ChatGPT enhances “Projects” feature with deep research support, voice mode, and mobile file uploads: OpenAI announced several improvements to the “Projects” feature in ChatGPT, including enhanced support for deep research, integration of voice mode, improved memory function to reference past chats within a project, and support for file uploads and model selector on mobile. These updates aim to enhance users’ ability to conduct more focused and complex work within ChatGPT (Source: kevinweil)
EuroLLM team releases preview versions of several new models, including a 22B model and a small MoE model: The EuroLLM team has released preview versions of several new models, including a 22B parameter base model and an instruction-tuned version, two vision models based on older EuroLLM versions (1.7B and 9B parameters), and a small Mixture-of-Experts (MoE) model with 0.6B active parameters and 2.6B total parameters. All these models are licensed under Apache-2.0, and initial tests show the small MoE model performs surprisingly well for its size (Source: Reddit r/LocalLLaMA)

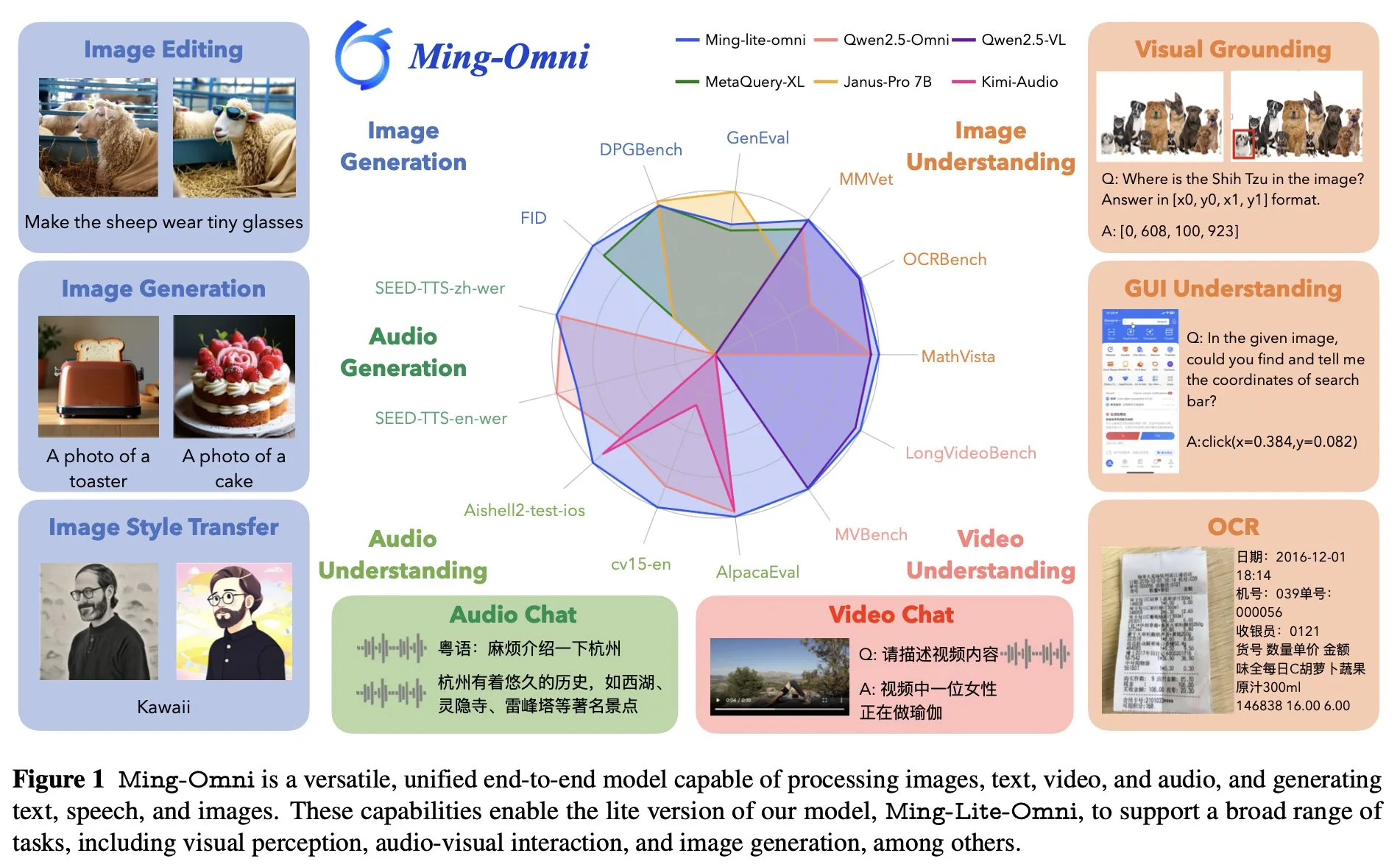
Ant Group releases end-to-end omni-model Ming Lite Omni, benchmarked against GPT-4o: Ant Group has launched the Ming Lite Omni model, capable of performing multiple functions including listening, speaking, and image generation, competing with GPT-4o in performance. Ming Lite Omni surpasses Qwen2.5VL-7B in accuracy on GUI tasks, achieves SOTA in audio understanding on several public benchmarks, and also demonstrates excellent video understanding capabilities. The model uses a Mixture-of-Experts (MoE) architecture with only 2.8B active parameters and is specifically optimized for audio and image generation, such as using BPE to reduce audio token frame rates and multi-scale learnable tokens to improve image generation quality (Source: mervenoyann)
NVIDIA and Mistral AI collaborate to build AI cloud platform Mistral Compute: NVIDIA announced at GTC a collaboration with Mistral AI to jointly build an AI cloud platform named Mistral Compute. This move is seen as a significant benefit to the US and the open-source community, aiming to provide a template for global AI infrastructure construction through open models supported by US chips (Source: arthurmensch)
Hugging Face announces full embrace of PyTorch, simplifying Transformers library: Hugging Face Chief Open Source Officer Lysandre Jik stated that given the user base has formed a consensus on PyTorch, future efforts will be concentrated on PyTorch to reduce the bloat in the Transformers library, aiming to provide a more concise toolkit. PyTorch officially welcomed this move, emphasizing that it helps maintain code simplicity (Source: reach_vb)

ByteDance introduces real-time interactive video generation technology APT2: ByteDance showcased its latest real-time interactive video generation technology, APT2 (Autoregressive Adversarial Post-Training). This technology, through autoregressive adversarial post-training, aims to achieve high-quality, real-time interactive video content generation, further advancing the field of video generation (Source: NerdyRodent)
🧰 Tools
Llama-Server Launcher: A llama.cpp server launcher with GUI, focused on CUDA performance optimization: A developer shared their personal llama-server launcher, written in Python, providing a graphical user interface (GUI). The tool aims to simplify the configuration and launching of llama.cpp services, with a special focus on CUDA performance tuning. Features include model selection, path setting, context and batch size adjustment, GPU offloading, FlashAttention, tensor splitting, and other advanced performance settings, as well as chat template selection and environment configuration management. It supports automatic retrieval of GPU and system information, analysis of GGUF model metadata, and can generate cross-platform startup scripts (.ps1/.sh) (Source: Reddit r/LocalLLaMA)
Together AI releases open-source data scientist agent: Together AI has built an open-source AI agent capable of reasoning like a data scientist. The agent can load data, write Python code, retrain models when they fail, and solve real Kaggle and DABStep tasks. This initiative aims to promote automation and popularization of AI in the field of data science (Source: percyliang)
AutoMind: An adaptive knowledge-powered agent framework for automated data science: AutoMind is a new LLM agent framework designed to overcome the limitations of existing data science agents in handling complex and innovative tasks by integrating expert knowledge bases, employing an agent knowledge tree search algorithm, and adaptive coding strategies, thereby enhancing the real-world effectiveness of automated machine learning workflows (Source: HuggingFace Daily Papers)
LlamaParse releases “Presets” feature to simplify document parsing configuration: LlamaParse has introduced a “Presets” feature, offering a series of easy-to-understand pre-configured modes to optimize settings for different use cases. These include fast, balanced, and advanced modes for general scenarios, as well as optimized modes for common use cases like invoices, research papers, technical documents, and forms, aiming to allow users to more conveniently choose between speed and accuracy (Source: jerryjliu0)
OpenWebUI adds o3-pro support, expanding model compatibility: A community developer has created a new feature for OpenWebUI, extending support for the o3-pro model by adding response API support, cost tracking, multi-key support, and web search capabilities. This allows users to use o3-pro within OpenWebUI without subscribing to the official premium plan (Source: Reddit r/OpenWebUI)
📚 Learning
Paper explores decomposing MLP activations into interpretable features via Semi-Nonnegative Matrix Factorization (SNMF): This research proposes using SNMF to directly decompose the activations of Multi-Layer Perceptrons (MLPs) to learn sparse features composed of linear combinations of co-activating neurons. These features are then mapped to their activating inputs, making them directly interpretable. Experiments show that SNMF-derived features outperform Sparse Autoencoders (SAEs) in causal steering and align with human-interpretable concepts, revealing hierarchical structures within MLP activation spaces (Source: HuggingFace Daily Papers)
New paper proposes LoRMA: A new paradigm for fine-tuning LLMs via Low-Rank Multiplicative Adaptation: Traditional LLM fine-tuning typically updates weights additively; LoRMA explores multiplicative updates. To address the “rank collapse” issue caused by low-rank matrices, the paper introduces novel rank expansion operations based on permutation and addition, ensuring computational efficiency through effective reordering operations. Experiments demonstrate LoRMA’s competitiveness, offering a new approach to LLM adaptation (Source: Reddit r/deeplearning)
Paper proposes TaxoAdapt framework for adapting LLM-constructed multidimensional taxonomies to evolving research corpora: Addressing the challenge of organizing scientific literature, the TaxoAdapt framework dynamically adjusts LLM-generated taxonomies to specific corpora and supports multiple dimensions (e.g., methodology, task, evaluation metrics). Through iterative hierarchical classification, the framework expands the breadth and depth of the taxonomy based on the corpus’s thematic distribution, aiming to better organize and capture the evolution of scientific fields (Source: HuggingFace Daily Papers)
Paper introduces MOSAIC framework for collaborative learning in agentic systems: MOSAIC is a framework for autonomous, agentic AI systems to engage in collaborative learning in decentralized, dynamic environments. Agents selectively share and reuse modular knowledge (in the form of neural network masks) without synchronization or centralized control. Experiments show MOSAIC outperforms isolated learners in speed and performance, sometimes solving tasks that isolated agents cannot, and promotes collective efficiency and adaptability (Source: Reddit r/MachineLearning)
Paper proposes ClaimSpect framework for retrieval-augmented hierarchical analysis of complex claims: Many claims (e.g., scientific, political) are not simply true or false. The ClaimSpect framework uses retrieval-augmented generation to automatically construct a hierarchy of aspects related to a claim and enriches these aspects with perspectives from a specific corpus. This method aims to deconstruct complex claims and present different viewpoints on various aspects and their prevalence within the corpus (Source: HuggingFace Daily Papers)
Paper proposes Fine-Grained Perturbation Guidance via Attention Head Selection: This study finds that specific attention heads in diffusion models control different visual concepts (e.g., structure, style, texture quality). Based on this, the paper proposes the “HeadHunter” framework to systematically select attention heads consistent with user goals, achieving fine-grained control over generation quality and visual attributes. It also introduces SoftPAG to adjust perturbation strength. The method’s superiority in enhancing quality and style guidance was validated on models like Stable Diffusion 3 and FLUX.1 (Source: HuggingFace Daily Papers)
Paper explores that LLM unlearning should be Form-Independent: Research indicates that current LLM unlearning methods’ effectiveness is highly dependent on the form of training samples, making it difficult to generalize to different expressions of the same knowledge. The paper defines this issue as “Form-Dependent Bias” and introduces the ORT benchmark for evaluation. To address this, the paper proposes ROCR (Rank-one Concept Redirection), which achieves unlearning by redirecting the model’s perception of specific concepts. Experiments show ROCR significantly improves unlearning effectiveness and generates natural outputs (Source: HuggingFace Daily Papers)
Paper proposes UniPre3D: A unified pre-training method for 3D point cloud models based on cross-modal Gaussian Splatting: UniPre3D aims to address the challenges posed by the diverse scales of point cloud data in 3D vision by proposing the first unified pre-training method applicable to point clouds of any scale and any 3D model architecture. The method predicts Gaussian primitives as a pre-training task and utilizes differentiable Gaussian splatting to render images, enabling precise pixel-level supervision and end-to-end optimization, while integrating features from 2D pre-trained models to introduce texture knowledge (Source: HuggingFace Daily Papers)
Paper proposes StreamSplat: Online dynamic 3D reconstruction for uncalibrated video streams: StreamSplat is a fully feed-forward framework capable of online conversion of uncalibrated video streams of arbitrary length into dynamic 3D Gaussian Splatting (3DGS) representations. It achieves robust and efficient dynamic modeling through a probabilistic sampling mechanism in the static encoder for predicting 3DGS positions and a bidirectional deformation field in the dynamic decoder, aiming to address calibration, dynamic modeling, and efficiency/stability challenges in real-time dynamic scene reconstruction (Source: HuggingFace Daily Papers)
Paper reviews Attentive Probing in Masked Image Modeling: As large-scale fine-tuning becomes impractical, probing has become the preferred method for evaluating Self-Supervised Learning (SSL). Standard Linear Probing (LP) fails to adequately reflect the potential of models trained with Masked Image Modeling (MIM). This paper revisits attentive probing, introducing Efficient Probing (EP), a multi-query cross-attention mechanism that reduces trainable parameters and improves speed, outperforming LP and previous attentive probing methods on multiple benchmarks (Source: HuggingFace Daily Papers)
Paper proposes PosterCraft: A new approach for high-quality aesthetic poster generation under a unified framework: PosterCraft aims to address the challenge of generating aesthetic posters, which requires not only precise text rendering but also seamless integration of abstract artistic content, compelling layout, and overall stylistic harmony. PosterCraft employs a cascaded workflow to optimize generation, including large-scale text rendering optimization, region-aware supervised fine-tuning, aesthetic text reinforcement learning, and joint visual-language feedback refinement, significantly outperforming open-source baselines in multiple experiments (Source: HuggingFace Daily Papers)
Paper proposes improving diffusion models via Token Perturbation Guidance (TPG): To address the limitations of classifier-free guidance (CFG), which requires specific training processes and is limited to conditional generation, the TPG method applies perturbation matrices directly to intermediate token representations within the diffusion network. TPG uses a norm-preserving shuffling operation to provide an effective guidance signal, enhancing generation quality without architectural changes and applicable to both conditional and unconditional generation. Experiments show TPG achieves nearly a 2x improvement in FID over the SDXL baseline for unconditional generation (Source: HuggingFace Daily Papers)
Paper proposes DreamActor-H1: Generating high-fidelity human-product demo videos via Diffusion Transformers with motion design: DreamActor-H1 is a framework based on Diffusion Transformer (DiT) aimed at generating high-quality demonstration videos of human-product interactions. The method injects paired human-product reference information and an additional masked cross-attention mechanism, while preserving identity details of both human and product (e.g., logos, textures). It utilizes 3D human mesh templates and product bounding boxes for precise motion guidance and enhances 3D consistency through structured text encoding (Source: HuggingFace Daily Papers)
Paper proposes EmbodiedGen: A Generative 3D World Engine for Embodied AI: EmbodiedGen is a foundational platform for interactive 3D world generation, designed to scalably produce high-quality, controllable, photorealistic 3D assets at low cost. These assets possess accurate physical properties, real-world scale, and adopt the Unified Robot Description Format (URDF). They can be directly imported into various physics simulation engines, supporting training and evaluation tasks for embodied AI, addressing the high cost and limited realism of traditional 3D computer graphics assets (Source: HuggingFace Daily Papers)
New research refutes Apple’s “Illusion of Thinking” paper, arguing LLMs can solve new complex problems: In response to Apple’s recent “Illusion of Thinking” paper, which claimed Large Reasoning Models (LRMs) experience an “accuracy collapse” on complex planning puzzles like the Tower of Hanoi, a follow-up commentary study suggests Apple’s conclusions primarily reflect limitations in experimental design rather than a failure of the models’ fundamental reasoning abilities. The new research argues that token budget overruns, misassessment of intentionally truncated outputs, and inclusion of mathematically unsolvable puzzle instances in the original experiment collectively led to a misjudgment of model capabilities. When experimental methods were adjusted, for example, by requiring models to output a compact Lua function generating the Tower of Hanoi solution instead of exhaustive step lists, models showed high accuracy on cases previously reported as complete failures. This indicates models are not incapable of reasoning but are constrained by output format and token limits (Source: Reddit r/LocalLLaMA)

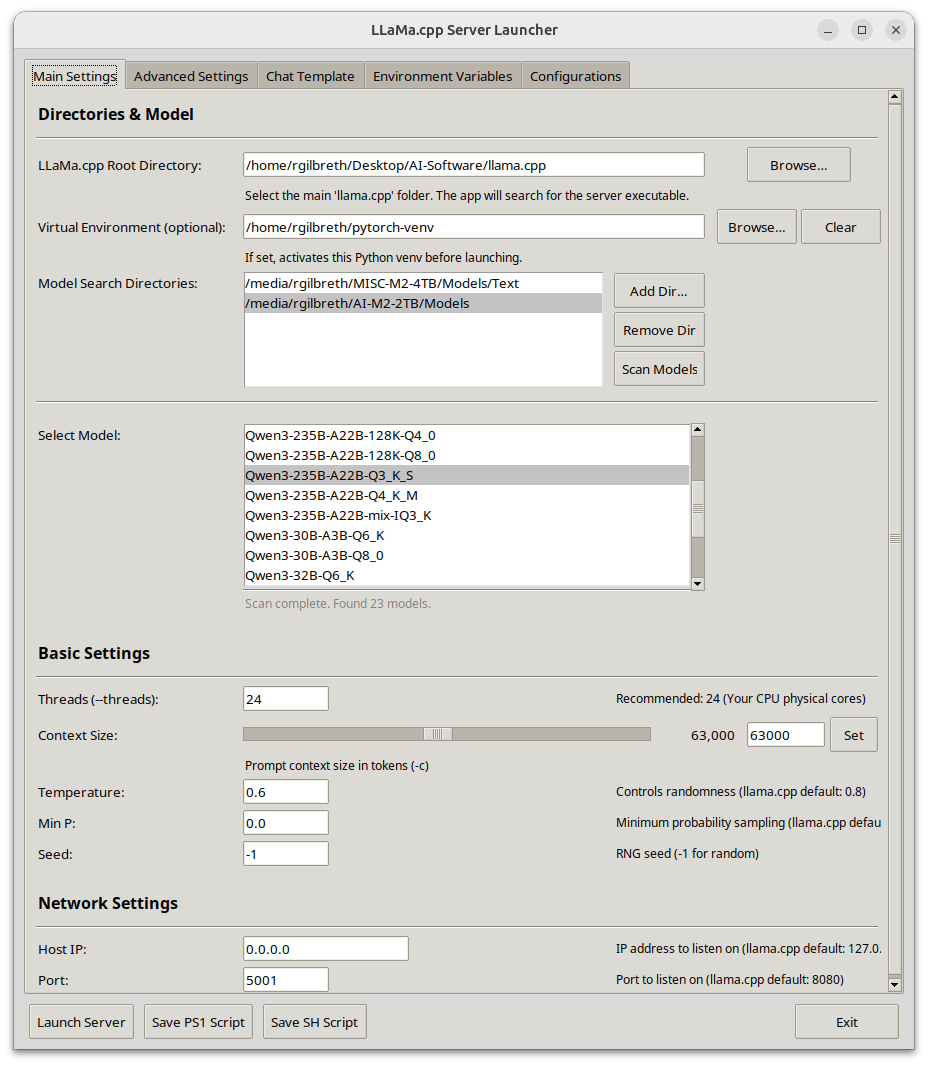
KRIS-Bench: A new benchmark for comprehensively evaluating the reasoning capabilities of image editing models from a knowledge type perspective: Southeast University and other institutions jointly released KRIS-Bench, a knowledge-based reasoning ability benchmark for image editing systems. It subdivides 22 editing tasks from three levels: factual knowledge (e.g., color, quantity), conceptual knowledge (e.g., physical common sense), and procedural knowledge (e.g., multi-step operations), evaluating 10 mainstream image editing models (including GPT-Image-1, Gemini 2.0 Flash, etc.). Results show that the closed-source model GPT-Image-1 performed best, but all models generally performed poorly on deep reasoning tasks such as procedural reasoning, natural sciences, and multi-step synthesis, revealing deficiencies in current models’ advanced cognitive abilities (Source: 量子位)
New research proposes Finetune-RAG method to fine-tune language models to resist hallucinations in RAG: Large Language Models in Retrieval Augmented Generation (RAG) are prone to hallucinations when retrieval is imperfect (e.g., presence of distracting document snippets). Finetune-RAG trains models on input samples containing both correct and incorrect contexts, enabling them to better maintain factuality. The research team released a dataset of 1600+ dual-context samples, a fine-tuned checkpoint of LLaMA 3.1-8B-Instruct, and an evaluation framework called Bench-RAG using GPT-4o. Evaluations show this method improves accuracy from 77% to 98%, with improvements in usefulness, relevance, and depth (Source: Reddit r/MachineLearning)
TeleMath: First LLM benchmark for mathematical problem-solving capabilities in the telecommunications domain released: To evaluate the ability of Large Language Models to solve domain-specific, math-intensive tasks in telecommunications, researchers have introduced the TeleMath benchmark. It comprises 500 question-answer pairs covering telecom topics like signal processing, network optimization, and performance analysis. Evaluation of various open-source LLMs shows that models designed for mathematical or logical reasoning perform better on TeleMath, while general large-parameter models often struggle. The dataset and evaluation code are open-sourced (Source: HuggingFace Daily Papers)
ChineseHarm-Bench: Benchmark for Chinese harmful content detection released: Addressing the prevalence of English-centric resources for harmful content detection, researchers have released ChineseHarm-Bench, a comprehensive, professionally annotated benchmark for detecting content harm in Chinese. The benchmark covers six representative categories, with data entirely sourced from the real world. The annotation process also produced a knowledge rule base, providing LLMs with explicit expert knowledge. Additionally, researchers proposed a knowledge-enhanced baseline method combining manually annotated rules and LLM implicit knowledge, enabling smaller models to achieve SOTA LLM performance (Source: HuggingFace Daily Papers)
New research discovers hierarchical structure of latent capabilities in language models through causal representation learning: To faithfully evaluate language model capabilities and overcome confounding effects and high computational costs, this study proposes a causal representation learning framework. The framework models observed benchmark performance as a linear transformation of a few latent capability factors. After controlling for the base model as a common confounder, it identifies causal relationships among these latent factors. Applied to data from over 1500 models on the Open LLM Leaderboard, the research uncovered a concise three-node linear causal structure, revealing a clear causal path from general problem-solving ability to instruction-following proficiency, and then to mathematical reasoning capabilities (Source: HuggingFace Daily Papers)
DeepLearning.AI launches new course “Orchestrating Workflows for GenAI Applications”: Andrew Ng announced a new short course in collaboration with Astronomer, teaching how to build and deploy reliable generative AI pipelines using the popular open-source tool Airflow 3.0. Course content includes breaking down workflows into discrete tasks, task scheduling, parallel execution, fault recovery, and observability, aiming to help learners transform prototype Jupyter notebooks or Python scripts into production-ready workflows (Source: DeepLearningAI)
Paper discusses optimization methods, challenges, and future directions for Compound AI Systems: With the development of LLMs and AI systems, Compound AI Systems integrating multiple components are increasingly mature in performing complex tasks. This paper systematically reviews recent advancements in optimizing Compound AI Systems, including numerical and language-based techniques. The paper formalizes the concept of Compound AI System optimization, categorizes existing methods, and highlights open research challenges and future directions in this field (Source: HuggingFace Daily Papers)
💼 Business
Disney and Universal Studios sue image generator Midjourney for copyright infringement: Disney and Universal Studios have accused Midjourney of training its model using their creative libraries (including characters from Star Wars, Frozen, Minions, etc.) without permission, and of generating and distributing a large number of derivative works, calling it an “endless pit of plagiarism.” This case once again sparks discussion about the boundaries between AI-generated content and intellectual property (Source: Reddit r/ArtificialInteligence)
NVIDIA and Deutsche Telekom partner to establish Europe’s first industrial AI cloud for manufacturers by 2026: German Federal Chancellor Friedrich Merz met with NVIDIA CEO Jensen Huang to discuss further strategic cooperation to solidify Germany’s position as a global AI leader. As part of this vision, Deutsche Telekom and NVIDIA announced a new collaboration to establish the world’s first industrial AI cloud for European manufacturers by 2026. This secure and European-compliant infrastructure will support cutting-edge innovation while ensuring full data sovereignty (Source: nvidia)

Rumors suggest Sam Altman may be diluting OpenAI non-profit control via all-stock acquisitions: OpenAI’s recent all-stock acquisitions of io ($6.5B) and Windsurf ($3B) have sparked speculation. A theory on Hacker News suggests Sam Altman might be using these deals to gradually dilute the non-profit OpenAI Inc.’s control over the for-profit entity OpenAI Global LLC (now OpenAI PBC), potentially circumventing legal restrictions on transitioning to a fully for-profit company. This move has been linked by some to Altman’s 2014 maneuvers with Reddit, though others view these acquisitions as normal strategic business initiatives (Source: Reddit r/ArtificialInteligence)
🌟 Community
Discussion continues on whether AI can truly “reason,” Apple paper sparks controversy: Apple’s recent paper claiming that Large Language Models’ (LLMs) performance on complex tasks (like the Tower of Hanoi) is not true reasoning but more like pattern matching has been widely discussed in the community. Former OpenAI employee Miles Brundage, commenting on o3-pro solving complex word games, sarcastically asked, “If this isn’t reasoning, what is?” Subsequent research pointed out that the “reasoning collapse” phenomenon in Apple’s paper might be due to limitations in experimental design (such as token limits, misassessment of unsolvable problems) rather than a deficiency in the models’ reasoning abilities. After adjusting testing methods, models performed well on previously failed tasks, suggesting that evaluating AI reasoning capabilities requires more careful experimental design (Source: o3-pro answering difficult word games attracts attention, former OpenAI employee sarcastically asks Apple: If this isn’t reasoning, what is?, Reddit r/LocalLLaMA)
Nvidia CEO Jensen Huang and Anthropic CEO Dario Amodei have significant disagreements on AI’s future: Fortune reported that Nvidia CEO Jensen Huang stated he disagrees with “almost everything” Anthropic CEO Dario Amodei says about AI. Amodei often emphasizes the potential risks of AI and its massive impact on employment, advocating for stricter controls on AI development and leadership by a few “responsible” organizations. Huang is skeptical of such views, preferring to promote the widespread application and development of AI technology. Community comments suggest Huang’s stance may be related to his business interests, as Nvidia is a major supplier of AI hardware (Source: Reddit r/ArtificialInteligence, Reddit r/ClaudeAI)

Claude Code’s $20 subscription plan praised by developers for high value: Many developers have shared positive experiences on social media with Anthropic’s Claude Code $20/month subscription plan, calling it extremely cost-effective and quickly recouping its cost in projects. Users mentioned that despite some rate limits, Claude Code excels in assisting with coding, learning new languages (e.g., transitioning from C# to SwiftUI), and optimizing project instructions (e.g., CLAUDE.md files), significantly improving work efficiency. Some users are even considering canceling subscriptions to other AI programming assistance tools (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Community discusses future applications and ethical challenges of AI in psychology: As technologies like LLMs drafting therapy prompts and apps tracking emotions via phone sensors develop, AI is gradually permeating psychology. Community discussions focus on whether AI will enhance therapists’ abilities or eventually replace some jobs in clinical practice, the credibility of AI in assessment and research, its impact on psychology professional training and the job market, and the ethical and regulatory issues of AI applications, particularly data bias, privacy, and the limitations of “robot therapists.” The core concern is how to leverage AI to improve efficiency and personalized services while ensuring patient safety and preserving the therapeutic value of human connection (Source: Reddit r/artificial)
Unsloth’s 3.53bit quantized DeepSeek-R1-0528 model performs well on Aider Polyglot coding benchmark: After Unsloth team quantized the DeepSeek-R1-0528 model to 3.53bit (UD-Q3_K_XL), it achieved a 68% pass rate on the Aider Polyglot coding benchmark. The test used a context size of 40960 and Flash Attention, requiring approximately 300GB of RAM/VRAM. This result places it between Claude Sonnet 3.7 and Claude Opus 4, demonstrating the potential of quantized models to maintain high coding capabilities. Community members expressed impressiveness with the performance of running such models locally and look forward to more test results of quantized versions (Source: Reddit r/LocalLLaMA)
💡 Others
GCP global outage report disclosed: Erroneous quota policy caused service interruption: The report on Google Cloud Platform’s (GCP) recent global outage revealed that the cause was an incorrect quota policy (e.g., limiting requests to only 1 per hour) pushed to the global API management system. This led to external requests being rejected due to exceeding quotas (403 error). After engineers discovered this, they bypassed quota checks for the affected APIs. However, in the us-central1 region, an attempt to clear the old policy and write a new one caused database overload due to caching issues, resulting in a longer recovery time. Other regions recovered by gradually clearing the cache, with the entire process taking about 2 hours (Source: karminski3)

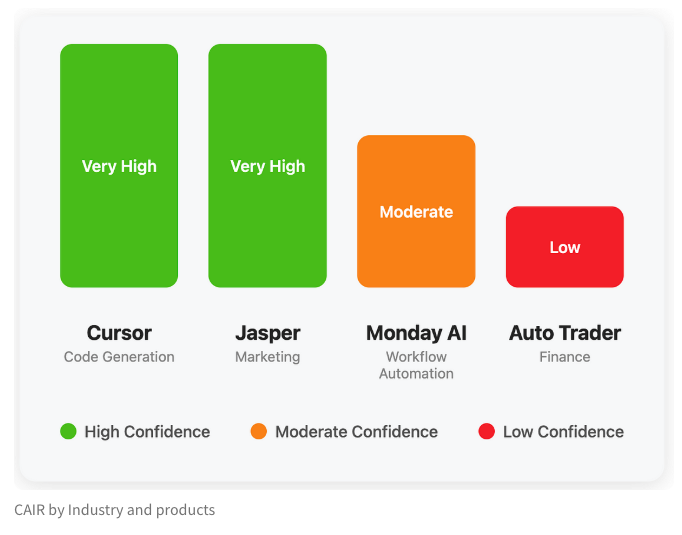
LangChain team proposes CAIR metric to assess AI product success potential: LangChain’s Harrison Chase and Assaf Elovic co-authored an article discussing why some AI products gain rapid adoption while others struggle. They argue that model capability is not the sole determinant; User Experience (UX) is crucial, and they propose the “CAIR” (Confidence in AI Results) metric. Higher CAIR correlates with higher product adoption. This framework aims to help developers identify and improve various components affecting user confidence, thereby increasing product success rates (Source: hwchase17, swyx, hwchase17, Hacubu)
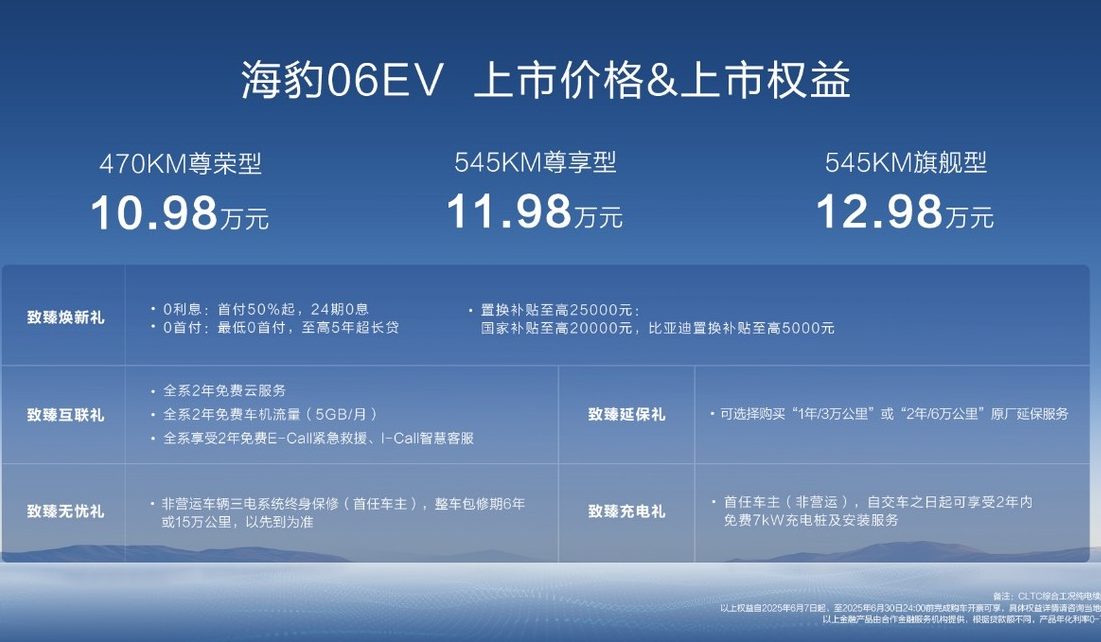
BYD launches new pure electric family coupe Seal 06EV, starting at 109,800 RMB: BYD Ocean Network launched the Seal 06EV at the Chongqing Auto Show, positioned as a trendy and quality coupe. It comes in 3 configurations with prices ranging from 109,800 to 129,800 RMB. The car is built on BYD’s e-platform 3.0 Evo, equipped with an eight-in-one intelligent electric drive and a new generation wide-temperature-range efficient heat pump system, offering CLTC ranges of 470KM and 545KM. The vehicle features a rear-wheel-drive layout, is equipped with the DiSus-C intelligent damping body control system, and carries the “Eye of the Gods C” intelligent driving assistance tri-camera version, supporting functions like highway pilot assist and automated parking (Source: 量子位)