Kata Kunci:Tesla Robotaxi, AMD MI350, OpenAI o3-pro, iFlytek AIUI, Yuanrong Qixing VLA, DeepSeek Nano-vLLM, Ant Group Ming Lite Omni, Mobil Level 2 produksi mencapai Level 4 mengemudi otomatis, Perbandingan kinerja AMD MI350X dengan B200, Kemampuan pemrosesan konteks panjang model o3-pro, Teknologi interaksi full-duplex AIUI, Model visual-bahasa-aksi VLA
🔥 Fokus
Robotaxi Tesla pertama kali terlihat di jalan umum, Musk menyatakan mobil produksi massal L2 dapat mencapai self-driving level L4 tanpa modifikasi: Robotaxi Tesla (Model Y versi baru) telah diuji di jalanan Austin, dengan logo Robotaxi baru pada bodinya tetapi tetap mempertahankan setir. Musk menyatakan bahwa semua mobil produksi massal Tesla dapat mencapai self-driving tanpa pengawasan. Kendaraan uji saat ini dilengkapi dengan FSD versi beta internal yang memiliki parameter 4,5 kali lipat dari FSD saat ini, dan diharapkan akan dioptimalkan serta diluncurkan tahun ini. Robotaxi direncanakan akan dibuka untuk umum pada 22 Juni, dengan peluncuran perdana di Austin. Langkah ini menandai peningkatan FSD level L2 Tesla ke Robotaxi level L4/L5, yang dapat mempercepat lanskap kompetitif industri self-driving, terutama menjadi tantangan bagi pemain dengan rute teknologi L4 seperti Waymo (Sumber: 量子位)

AMD merilis seri chip AI terkuat MI350, performa melampaui Nvidia B200: CEO AMD Su Zifeng dan CEO OpenAI Altman bersama-sama merilis GPU MI350X dan MI355X. Kedua chip ini menggunakan proses 3nm, memiliki 185 miliar transistor dan memori HBM3E 288GB, dengan kapasitas memori 1,6 kali lipat dari Nvidia B200. Data resmi menunjukkan bahwa seri MI350 memiliki kecepatan inferensi 30% lebih cepat daripada B200 saat menjalankan Llama 3.1 405B pada presisi FP4, dan dua kali lipat kekuatan komputasi FP64 Nvidia. AMD juga mengumumkan seri MI400 yang dikembangkan bersama OpenAI akan diluncurkan tahun depan, yang akan semakin memperketat persaingan di pasar chip AI (Sumber: 量子位)

Kemampuan inferensi model OpenAI o3-pro menarik perhatian, performa aktual sedikit berbeda dari pengujian resmi: Model inferensi terbaru OpenAI, o3-pro, menunjukkan kemampuan yang kuat dalam menangani permainan kata yang kompleks (seperti menghasilkan jawaban spesifik berdasarkan karakteristik judul lagu penyanyi Sabrina Carpenter), memicu sindiran dari mantan kepala tim AGI Readiness OpenAI terhadap keraguan Apple sebelumnya tentang kemampuan inferensi model besar. Namun, pada papan peringkat otoritatif seperti LiveBench, skor rata-rata pengkodean o3-pro hampir sama dengan o3, dan skor pengkodean agen bahkan tertinggal. Pengujian Fiction.LiveBench menunjukkan bahwa o3-pro berkinerja sangat baik pada konteks pendek, tetapi masih kalah dari Gemini 2.5 Pro dalam pemrosesan konteks super panjang 192k. Ben Hylak, mantan insinyur Apple dan SpaceX, menunjukkan bahwa kemampuan sebenarnya o3-pro sangat bergantung pada input informasi latar belakang yang cukup, lebih cocok sebagai generator laporan daripada objek obrolan sederhana, dan memiliki peningkatan signifikan dalam pemanggilan alat dan pemahaman lingkungan (Sumber: 量子位)

iFLYTEK meningkatkan platform interaksi manusia-mesin AIUI dan platform super brain robot, mendorong kolaborasi mendalam perangkat keras cerdas: iFLYTEK merilis pembaruan besar untuk platform interaksi manusia-mesin AIUI, dengan fokus pada peningkatan interaksi full-duplex, persepsi dan ekspresi emosi, serta sistem memori mirip manusia. Khusus untuk skenario anak-anak, diluncurkan solusi interaksi khusus untuk meningkatkan kemampuan pengenalan dan pemahaman ucapan anak-anak. Sementara itu, platform super brain robotnya yang berbasis model besar Spark memperkuat interaksi multimodal, pemahaman semantik, dan aplikasi pengetahuan, serta meluncurkan “ransel suara cerdas” yang memungkinkan robot yang ada untuk mencapai interaksi suara tanpa modifikasi perangkat keras. Peningkatan ini bertujuan untuk mendorong perangkat keras cerdas dari interaksi dasar ke kolaborasi cerdas yang mendalam, memberdayakan berbagai bidang seperti otomotif, perangkat keras AI, dan robotika (Sumber: 量子位)

🎯 Perkembangan
DeepRoute.ai bekerja sama dengan Volcengine, mengembangkan Agent dunia fisik VLA berbasis model besar Doubao: CEO DeepRoute.ai Zhou Guang mengumumkan kerja sama dengan Volcengine untuk bersama-sama mengembangkan teknologi berwawasan ke depan seperti model visual-bahasa-aksi (VLA), yang bertujuan untuk menciptakan Agent dunia fisik. Model VLA DeepRoute.ai akan diluncurkan ke pasar konsumen pada kuartal ketiga tahun 2025, dengan empat fungsi inti: pemahaman semantik spasial, pengenalan rintangan berbentuk tidak beraturan, pemahaman rambu pemandu teks, dan kontrol suara kendaraan, yang bertujuan untuk meningkatkan keselamatan dan kecerdasan bantuan mengemudi. Saat ini model VLA telah menyelesaikan uji jalan, dan diperkirakan lebih dari 5 model mobil AI yang dilengkapi model ini akan diluncurkan tahun ini (Sumber: 量子位)

Peneliti DeepSeek mereplikasi vLLM dengan 1200 baris kode, performa melampaui di beberapa skenario: Peneliti DeepSeek Yu Xingkai membuat proyek Nano-vLLM open-source, mengimplementasikan fungsi inti vLLM dengan kurang dari 1200 baris kode Python, termasuk teknologi kunci seperti PagedAttention. Proyek ini bertujuan untuk menyediakan versi vLLM yang minimal dan sepenuhnya dapat dibaca, untuk kemudahan pembelajaran dan pemahaman. Dalam kondisi pengujian spesifik pada perangkat keras H800 dan model Qwen3-8B, throughput Nano-vLLM bahkan melampaui vLLM asli, menunjukkan efisiensinya. vLLM adalah kerangka kerja inferensi dan layanan LLM yang dikembangkan oleh UC Berkeley, yang secara signifikan meningkatkan throughput layanan LLM dengan algoritma PagedAttention-nya (Sumber: 量子位)
Perusahaan Tiongkok menggunakan “kotak hard drive terbang” untuk menghindari pembatasan ekspor chip AI AS: Menurut Wall Street Journal, menghadapi pembatasan ekspor chip AI kelas atas oleh AS, perusahaan Tiongkok mengadopsi strategi baru dengan mengirimkan hard drive berisi data pelatihan dalam jumlah besar (misalnya 80TB) melalui insinyur ke pusat data di luar negeri seperti Malaysia. Di sana, mereka menggunakan server yang dilengkapi chip canggih seperti Nvidia untuk melatih model AI, kemudian membawa kembali parameter model tersebut ke Tiongkok. Langkah ini bertujuan untuk menghindari kesulitan mengimpor chip secara langsung dan telah mendorong munculnya pusat data AI di Asia Tenggara dan Timur Tengah. Mantan pejabat Departemen Perdagangan AS menyatakan keprihatinan atas hal ini (Sumber: dotey)

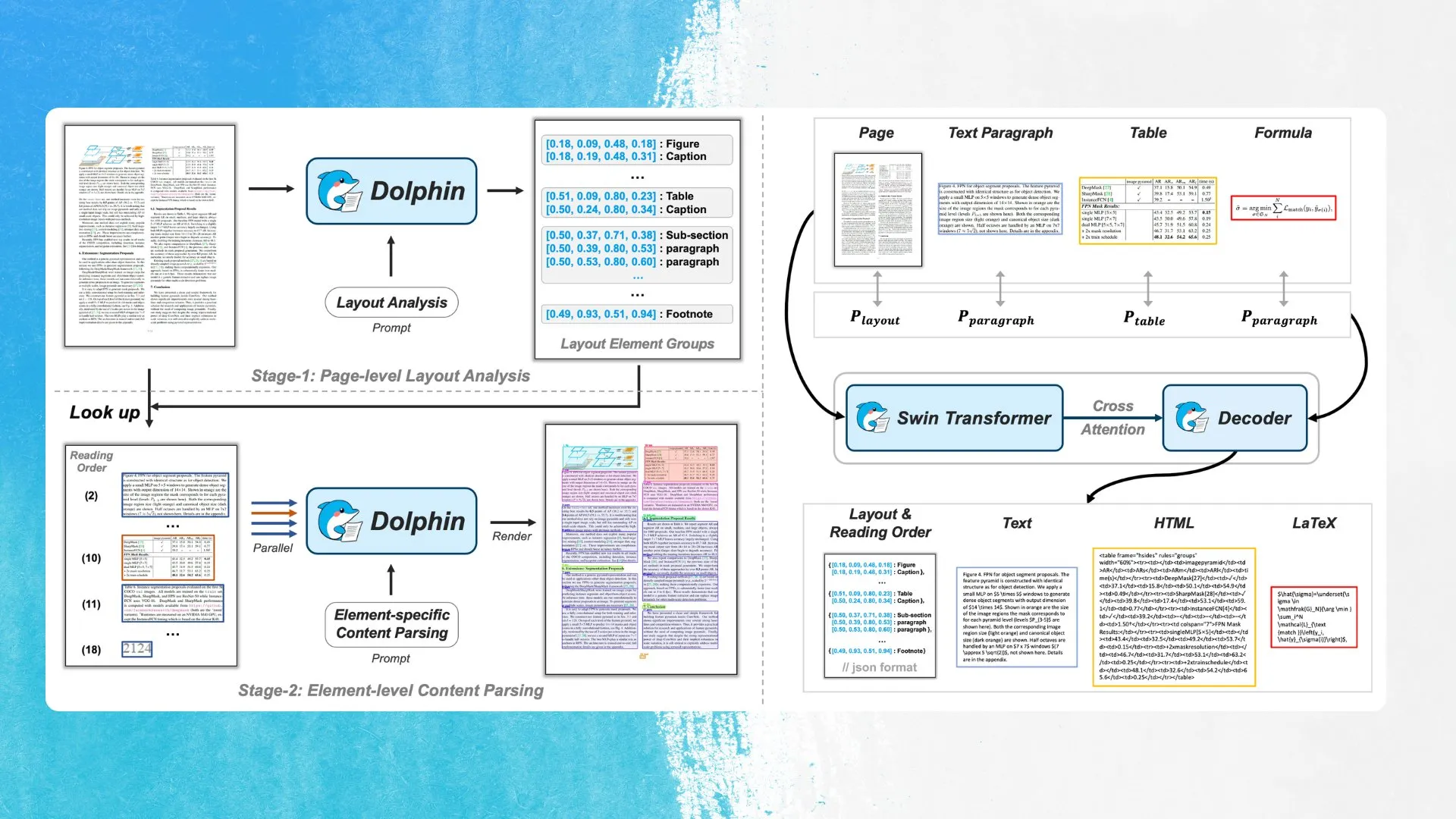
ByteDance meluncurkan model OCR baru Dolphin, menggunakan deteksi elemen tata letak dan penguraian paralel: ByteDance merilis model OCR baru bernama Dolphin di bawah lisensi MIT. Model ini pertama-tama mendeteksi elemen dalam tata letak dokumen (seperti tabel, rumus, dll.), kemudian secara paralel mengurai setiap elemen untuk menghasilkan konten. Model dan demo telah tersedia di Hugging Face Hub. Metode ini bertujuan untuk meningkatkan akurasi dan efisiensi pengenalan struktur dokumen yang kompleks (Sumber: mervenoyann)
Fungsi proyek OpenAI ChatGPT ditingkatkan, mendukung penelitian mendalam, mode suara, dan unggah file seluler: OpenAI mengumumkan beberapa peningkatan untuk fitur “Proyek” (Projects) di ChatGPT, termasuk dukungan penelitian mendalam yang ditingkatkan, integrasi mode suara, peningkatan fungsi memori untuk merujuk riwayat obrolan sebelumnya dalam proyek, serta dukungan untuk unggah file dan pemilih model di perangkat seluler. Pembaruan ini bertujuan untuk meningkatkan kemampuan pengguna dalam melakukan pekerjaan yang lebih terfokus dan kompleks di ChatGPT (Sumber: kevinweil)
Tim EuroLLM merilis pratinjau beberapa model baru, termasuk model 22B dan model MoE kecil: Tim EuroLLM merilis versi pratinjau dari beberapa model baru, termasuk model dasar 22B parameter dan versi fine-tuned instruksi, dua model visual berbasis EuroLLM versi lama (parameter 1.7B dan 9B), serta model Mixture of Experts (MoE) kecil dengan 0.6B parameter aktif dan 2.6B parameter total. Semua model ini menggunakan lisensi Apache-2.0, dan pengujian awal menunjukkan bahwa model MoE kecil ini berkinerja sangat baik untuk ukurannya (Sumber: Reddit r/LocalLLaMA)

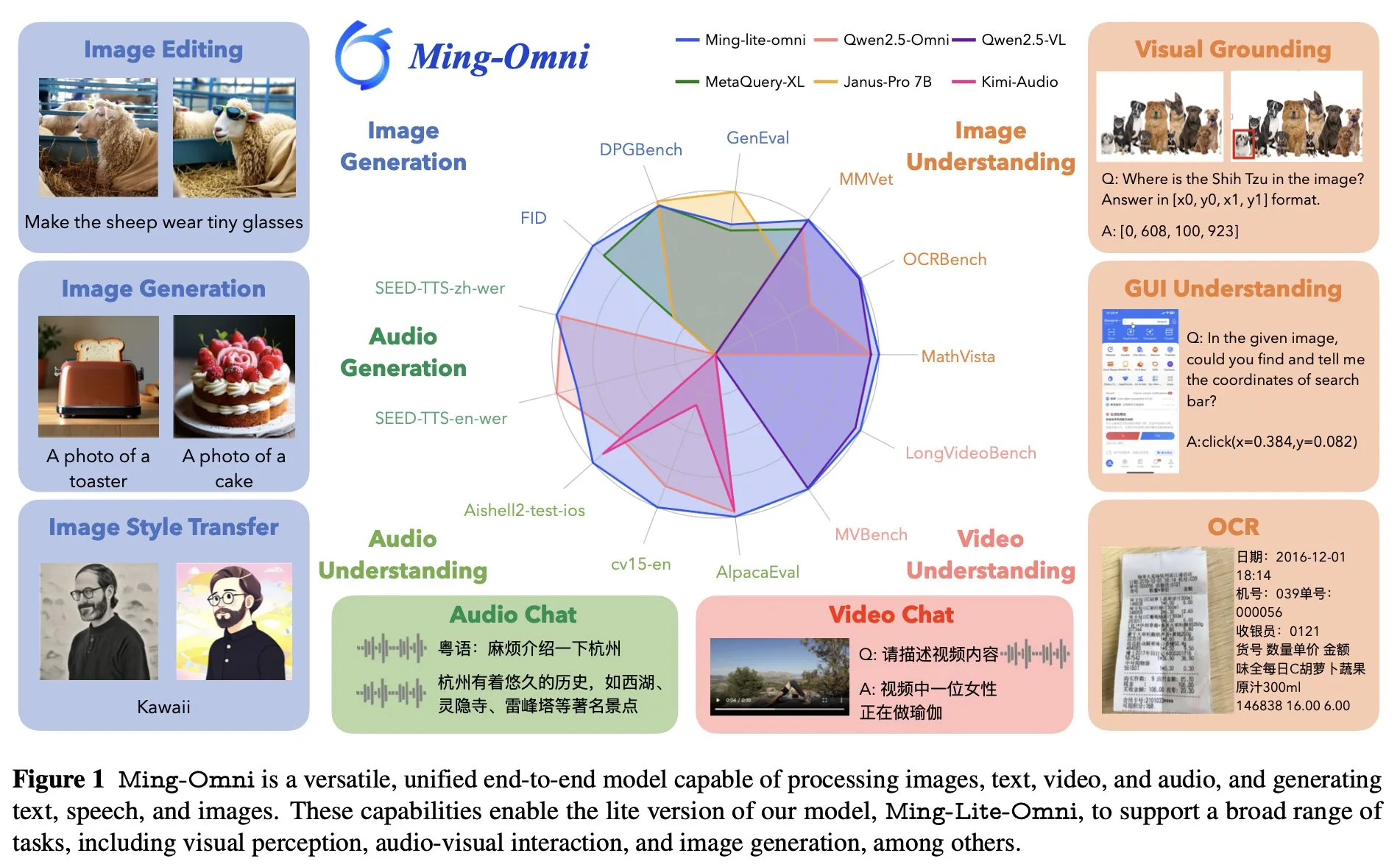
Ant Group merilis model serba bisa end-to-end Ming Lite Omni, menyaingi GPT-4o: Ant Group meluncurkan model Ming Lite Omni, yang mampu melakukan berbagai fungsi seperti mendengar, berbicara, dan menghasilkan gambar, bersaing dengan GPT-4o dalam hal performa. Ming Lite Omni melampaui Qwen2.5VL-7B dalam akurasi pada tugas GUI, pemahaman audio mencapai SOTA di beberapa benchmark publik, dan kemampuan pemahaman video juga menunjukkan kinerja yang sangat baik. Model ini menggunakan arsitektur Mixture of Experts (MoE) dengan hanya 2.8B parameter aktif, dan dioptimalkan secara khusus untuk generasi audio dan gambar, seperti menggunakan BPE untuk mengurangi frame rate token audio dan token yang dapat dipelajari multi-skala untuk meningkatkan kualitas generasi gambar (Sumber: mervenoyann)
NVIDIA dan Mistral AI bekerja sama membangun platform cloud AI Mistral Compute: NVIDIA mengumumkan di GTC kemitraan dengan Mistral AI untuk bersama-sama membangun platform cloud AI bernama Mistral Compute. Langkah ini dianggap sebagai keuntungan besar bagi Amerika Serikat dan komunitas open-source, yang bertujuan untuk menyediakan template bagi pembangunan infrastruktur AI global melalui model terbuka yang didukung oleh chip Amerika (Sumber: arthurmensch)
Hugging Face mengumumkan dukungan penuh untuk PyTorch, menyederhanakan pustaka Transformers: Chief Open Source Officer Hugging Face, Lysandre Jik, menyatakan bahwa mengingat basis pengguna telah mencapai konsensus pada PyTorch, upaya di masa depan akan difokuskan sepenuhnya pada PyTorch untuk mengurangi pembengkakan pustaka Transformers, dengan komitmen untuk menyediakan toolkit yang lebih ringkas. PyTorch secara resmi menyambut baik hal ini dan menekankan bahwa langkah ini membantu menjaga kesederhanaan kode (Sumber: reach_vb)

ByteDance meluncurkan teknologi generasi video interaktif real-time APT2: ByteDance mendemonstrasikan teknologi generasi video interaktif real-time terbarunya, APT2 (Autoregressive Adversarial Post-Training). Teknologi ini, melalui pelatihan pasca-adversarial autoregresif, bertujuan untuk mencapai generasi konten video interaktif berkualitas tinggi dan real-time, yang semakin mendorong pengembangan di bidang generasi video (Sumber: NerdyRodent)
🧰 Alat
Llama-Server Launcher: Peluncur server llama.cpp dengan GUI, fokus pada optimasi performa CUDA: Seorang pengembang membagikan peluncur llama-server pribadinya, yang ditulis dengan Python dan menyediakan antarmuka pengguna grafis (GUI). Alat ini bertujuan untuk menyederhanakan konfigurasi dan peluncuran layanan llama.cpp, dengan fokus khusus pada penyesuaian performa CUDA. Fitur-fiturnya meliputi pemilihan model, pengaturan path, penyesuaian ukuran konteks dan batch, GPU offload, FlashAttention, pengaturan performa tingkat lanjut seperti pemisahan tensor, serta pemilihan template obrolan dan manajemen konfigurasi lingkungan. Mendukung pengambilan informasi GPU dan sistem secara otomatis, menganalisis metadata model GGUF, dan dapat menghasilkan skrip peluncuran lintas platform (.ps1/.sh) (Sumber: Reddit r/LocalLLaMA)
Together AI Merilis Agen Ilmuwan Data Open Source: Together AI membangun agen AI open source yang mampu melakukan penalaran seperti ilmuwan data. Agen ini dapat memuat data, menulis kode Python, melakukan pelatihan ulang ketika model gagal, dan dapat menyelesaikan tugas nyata Kaggle dan DABStep. Langkah ini bertujuan untuk mendorong otomatisasi dan penyebaran AI di bidang ilmu data (Sumber: percyliang)
AutoMind: Kerangka kerja agen berbasis pengetahuan adaptif untuk otomatisasi ilmu data: AutoMind adalah kerangka kerja agen LLM baru yang bertujuan untuk mengatasi keterbatasan agen ilmu data yang ada dalam menangani tugas yang kompleks dan inovatif dengan mengintegrasikan basis pengetahuan ahli, mengadopsi algoritma pencarian pohon pengetahuan agen, dan strategi pengkodean adaptif, sehingga meningkatkan efektivitas dunia nyata dari alur kerja pembelajaran mesin otomatis (Sumber: HuggingFace Daily Papers)
LlamaParse merilis fitur “Preset”, menyederhanakan konfigurasi penguraian dokumen: LlamaParse meluncurkan fitur “Preset”, yang menyediakan serangkaian mode pra-konfigurasi yang mudah dipahami untuk mengoptimalkan pengaturan untuk berbagai kasus penggunaan. Termasuk mode cepat, seimbang, dan lanjutan untuk skenario umum, serta mode yang dioptimalkan untuk kasus penggunaan umum seperti faktur, makalah penelitian, dokumen teknis, dan formulir, yang bertujuan untuk memungkinkan pengguna memilih antara kecepatan dan akurasi dengan lebih mudah (Sumber: jerryjliu0)
OpenWebUI menambahkan fungsionalitas dukungan o3-pro, memperluas kompatibilitas model: Pengembang komunitas membuat fungsi baru untuk Open WebUI, memperluas dukungan untuk model o3-pro dengan menambahkan dukungan API respons, pelacakan biaya, dukungan multi-kunci, dan fitur pencarian web. Ini memungkinkan pengguna untuk menggunakan o3-pro di Open WebUI tanpa perlu berlangganan paket premium resmi (Sumber: Reddit r/OpenWebUI)
📚 Pembelajaran
Paper membahas dekomposisi aktivasi MLP menjadi fitur yang dapat diinterpretasikan melalui Semi-Nonnegative Matrix Factorization (SNMF): Penelitian ini mengusulkan penggunaan SNMF untuk secara langsung mendekomposisikan aktivasi Multilayer Perceptron (MLP) guna mempelajari fitur-fitur yang jarang (sparse) dan terbentuk dari kombinasi linear neuron yang aktif bersamaan, serta memetakan fitur-fitur ini ke input aktivasinya, sehingga membuatnya dapat diinterpretasikan secara langsung. Eksperimen menunjukkan bahwa fitur yang diturunkan dari SNMF lebih unggul daripada Sparse Autoencoders (SAE) dalam hal panduan kausal dan konsisten dengan konsep yang dapat diinterpretasikan manusia, serta mengungkap struktur hierarkis dalam ruang aktivasi MLP (Sumber: HuggingFace Daily Papers)
Paper baru mengusulkan LoRMA: paradigma baru untuk fine-tuning LLM melalui Low-Rank Multiplicative Adaptation: Fine-tuning LLM tradisional biasanya memperbarui bobot melalui penambahan, sedangkan LoRMA mengeksplorasi pembaruan perkalian. Untuk mengatasi masalah “penekanan rank” yang disebabkan oleh matriks rank rendah, paper ini memperkenalkan operasi perluasan rank baru berdasarkan permutasi dan penambahan, dan memastikan efisiensi komputasi melalui operasi pengurutan ulang yang efektif. Eksperimen menunjukkan bahwa LoRMA kompetitif, memberikan ide baru untuk adaptasi LLM (Sumber: Reddit r/deeplearning)
Paper mengusulkan kerangka kerja TaxoAdapt, memungkinkan taksonomi multidimensi yang dibangun LLM beradaptasi dengan korpus penelitian yang berkembang: Untuk mengatasi kesulitan pengorganisasian literatur ilmiah, kerangka kerja TaxoAdapt dapat secara dinamis menyesuaikan taksonomi yang dihasilkan LLM agar sesuai dengan korpus tertentu, dan mendukung berbagai dimensi (seperti metodologi, tugas, metrik evaluasi). Kerangka kerja ini, melalui klasifikasi hierarkis iteratif, memperluas lebar dan kedalaman klasifikasi berdasarkan distribusi tematik korpus, bertujuan untuk mengatur dan menangkap evolusi bidang ilmiah dengan lebih baik (Sumber: HuggingFace Daily Papers)
Paper memperkenalkan kerangka kerja MOSAIC, mewujudkan pembelajaran kolaboratif dalam sistem agen: MOSAIC adalah kerangka kerja untuk sistem AI agen otonom dan cerdas untuk melakukan pembelajaran kolaboratif di lingkungan yang terdesentralisasi dan dinamis. Agen secara selektif berbagi dan menggunakan kembali pengetahuan modular (dalam bentuk Neural Network Masks), tanpa sinkronisasi atau kontrol terpusat. Eksperimen menunjukkan bahwa MOSAIC lebih unggul dalam kecepatan dan kinerja dibandingkan pembelajar yang terisolasi, terkadang mampu menyelesaikan tugas yang tidak dapat diselesaikan oleh agen yang terisolasi, dan dapat mendorong peningkatan efisiensi dan adaptabilitas kolektif (Sumber: Reddit r/MachineLearning)
Paper mengusulkan kerangka kerja ClaimSpect untuk analisis hierarkis klaim kompleks yang ditingkatkan dengan pengambilan (retrieval-augmented): Banyak klaim (seperti klaim ilmiah, politik) tidak sekadar benar atau salah. Kerangka kerja ClaimSpect, melalui generasi yang ditingkatkan dengan pengambilan, secara otomatis membangun struktur hierarkis aspek-aspek yang terkait dengan klaim, dan memperkaya aspek-aspek ini dengan perspektif dari korpus tertentu. Metode ini bertujuan untuk mendekonstruksi klaim kompleks dan menyajikan berbagai pandangan tentang setiap aspek beserta prevalensinya dalam korpus (Sumber: HuggingFace Daily Papers)
Paper mengusulkan implementasi Fine-Grained Perturbation Guidance melalui pemilihan attention head: Penelitian ini menemukan bahwa attention head tertentu dalam model difusi mengontrol konsep visual yang berbeda (seperti struktur, gaya, kualitas tekstur). Berdasarkan hal ini, paper mengusulkan kerangka kerja “HeadHunter”, yang secara sistematis memilih attention head yang konsisten dengan tujuan pengguna, memungkinkan kontrol halus atas kualitas generasi dan atribut visual, serta memperkenalkan SoftPAG untuk menyesuaikan intensitas perturbasi. Metode ini telah divalidasi pada model seperti Stable Diffusion 3 dan FLUX.1, menunjukkan keunggulannya dalam meningkatkan kualitas dan panduan gaya (Sumber: HuggingFace Daily Papers)
Paper membahas bahwa unlearning LLM harus bersifat Form-Independent: Penelitian menunjukkan bahwa efektivitas metode unlearning LLM saat ini sangat bergantung pada bentuk sampel pelatihan, sehingga sulit untuk digeneralisasi ke representasi pengetahuan yang sama namun berbeda bentuk. Paper ini mendefinisikan masalah ini sebagai “Form-Dependent Bias” dan memperkenalkan benchmark ORT untuk evaluasi. Untuk mengatasi masalah ini, paper mengusulkan metode ROCR (Rank-one Concept Redirection), yang mencapai unlearning dengan mengarahkan kembali persepsi model terhadap konsep tertentu. Eksperimen membuktikan bahwa ROCR secara signifikan meningkatkan efek unlearning dan dapat menghasilkan output yang alami (Sumber: HuggingFace Daily Papers)
Paper mengusulkan UniPre3D: metode pra-pelatihan terpadu untuk model titik awan 3D berbasis Gaussian Splatting lintas-modal: UniPre3D bertujuan untuk mengatasi tantangan yang ditimbulkan oleh keragaman skala data titik awan dalam visi 3D, mengusulkan metode pra-pelatihan terpadu pertama yang dapat diterapkan secara mulus pada titik awan skala apa pun dan arsitektur model 3D apa pun. Metode ini memprediksi primitif Gaussian sebagai tugas pra-pelatihan dan menggunakan rendering Gaussian Splatting yang dapat terdiferensiasi untuk gambar, mencapai pengawasan tingkat piksel yang akurat dan optimasi end-to-end, sambil mengintegrasikan fitur dari model pra-pelatihan 2D untuk memperkenalkan pengetahuan tekstur (Sumber: HuggingFace Daily Papers)
Paper mengusulkan StreamSplat: rekonstruksi 3D dinamis online untuk aliran video yang tidak terkalibrasi: StreamSplat adalah kerangka kerja feed-forward penuh yang mampu mengubah aliran video yang tidak terkalibrasi dengan panjang berapa pun secara online menjadi representasi Gaussian Splatting 3D dinamis (3DGS). Ini mencapai pemodelan dinamis yang kuat dan efisien melalui mekanisme pengambilan sampel probabilistik di encoder statis untuk memprediksi posisi 3DGS, serta bidang deformasi dua arah di decoder dinamis, yang bertujuan untuk mengatasi tantangan kalibrasi, pemodelan dinamis, dan stabilitas efisiensi dalam rekonstruksi adegan dinamis real-time (Sumber: HuggingFace Daily Papers)
Paper meninjau Attentive Probing dalam Masked Image Modeling: Seiring dengan fine-tuning skala besar menjadi tidak praktis, probing menjadi pilihan utama untuk evaluasi self-supervised learning (SSL). Probing linear standar (LP) gagal mencerminkan potensi model yang dilatih dengan masked image modeling (MIM) secara memadai. Paper ini meninjau kembali attentive probing, memperkenalkan efficient probing (EP), sebuah mekanisme cross-attention multi-query yang mengurangi parameter yang dapat dilatih dan meningkatkan kecepatan, serta berkinerja lebih baik daripada LP dan metode attentive probing sebelumnya di beberapa benchmark (Sumber: HuggingFace Daily Papers)
Paper mengusulkan PosterCraft: ide baru untuk generasi poster estetika berkualitas tinggi dalam kerangka kerja terpadu: PosterCraft bertujuan untuk mengatasi tantangan dalam menghasilkan poster estetika, yang tidak hanya membutuhkan rendering teks yang akurat tetapi juga integrasi mulus dari konten seni abstrak, tata letak yang menarik, dan harmoni gaya secara keseluruhan. PosterCraft mengadopsi alur kerja berjenjang untuk mengoptimalkan generasi, termasuk optimasi rendering teks skala besar, fine-tuning yang diawasi secara sadar wilayah, reinforcement learning untuk teks estetika, dan penyempurnaan umpan balik visual-bahasa gabungan, dan secara signifikan mengungguli baseline open-source dalam beberapa eksperimen (Sumber: HuggingFace Daily Papers)
Paper mengusulkan peningkatan model difusi melalui Token Perturbation Guidance (TPG): Untuk mengatasi keterbatasan classifier-free guidance (CFG) yang memerlukan proses pelatihan khusus dan hanya terbatas pada generasi bersyarat, metode TPG menerapkan matriks perturbasi secara langsung pada representasi token perantara di dalam jaringan difusi. TPG menggunakan operasi shuffling yang menjaga norma untuk memberikan sinyal panduan yang efektif, meningkatkan kualitas generasi tanpa perubahan arsitektur, dan berlaku untuk generasi bersyarat maupun tidak bersyarat. Eksperimen menunjukkan bahwa TPG mencapai peningkatan FID hampir 2x lipat pada baseline SDXL untuk generasi tidak bersyarat (Sumber: HuggingFace Daily Papers)
Paper mengusulkan DreamActor-H1: menghasilkan video demonstrasi manusia-barang dengan fidelitas tinggi melalui Diffusion Transformers yang dirancang dengan gerakan: DreamActor-H1 adalah kerangka kerja berbasis Diffusion Transformer (DiT) yang bertujuan untuk menghasilkan video demonstrasi interaksi manusia dengan produk berkualitas tinggi. Metode ini menyuntikkan informasi referensi pasangan manusia-produk dan mekanisme cross-attention tambahan yang disamarkan, sambil mempertahankan detail identitas manusia dan produk (seperti logo, tekstur). Ini menggunakan template mesh manusia 3D dan kotak pembatas produk untuk memberikan panduan gerakan yang akurat, dan meningkatkan konsistensi 3D melalui pengkodean teks terstruktur (Sumber: HuggingFace Daily Papers)
Paper mengusulkan EmbodiedGen: mesin dunia 3D generatif untuk kecerdasan yang terwujud (embodied intelligence): EmbodiedGen adalah platform dasar untuk generasi dunia 3D interaktif, yang bertujuan untuk menghasilkan aset 3D berkualitas tinggi, dapat dikontrol, dan fotorealistik secara skalabel dengan biaya rendah. Aset-aset ini memiliki atribut fisik yang akurat dan skala dunia nyata, serta mengadopsi format deskripsi robot terpadu (URDF). Aset-aset ini dapat langsung diimpor ke berbagai mesin simulasi fisika, mendukung tugas pelatihan dan evaluasi kecerdasan yang terwujud, serta mengatasi masalah biaya tinggi dan realisme terbatas dari aset grafis komputer 3D tradisional (Sumber: HuggingFace Daily Papers)
Penelitian baru membantah paper “ilusi berpikir” Apple, berpendapat LLM mampu memecahkan masalah kompleks baru: Menanggapi paper terbaru Apple “Illusion of Thinking” yang menyatakan bahwa Large Reasoning Models (LRM) akan mengalami “keruntuhan akurasi” pada teka-teki perencanaan kompleks (seperti Menara Hanoi), sebuah studi komentar lanjutan menunjukkan bahwa kesimpulan Apple terutama mencerminkan keterbatasan desain eksperimental daripada kegagalan kemampuan penalaran dasar model. Penelitian baru berpendapat bahwa dalam eksperimen asli, batas token yang terlampaui, evaluasi yang salah terhadap output yang sengaja dipotong, dan penyertaan contoh teka-teki yang secara matematis tidak dapat dipecahkan, secara bersama-sama menyebabkan salah penilaian terhadap kemampuan model. Ketika metode eksperimental disesuaikan, misalnya dengan meminta model untuk menghasilkan fungsi Lua yang ringkas untuk solusi Menara Hanoi daripada daftar langkah yang lengkap, model menunjukkan akurasi tinggi pada kasus-kasus yang sebelumnya dilaporkan gagal total, menunjukkan bahwa model bukannya tidak dapat bernalar, melainkan dibatasi oleh format output dan batasan token (Sumber: Reddit r/LocalLLaMA)

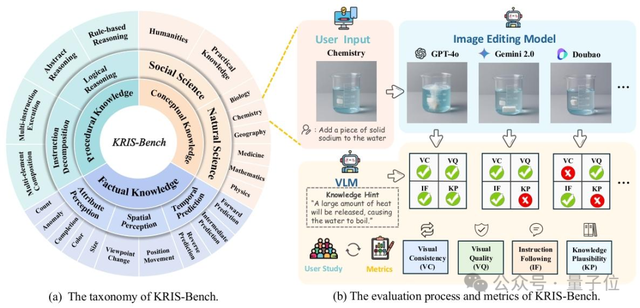
KRIS-Bench: Benchmark baru untuk mengevaluasi kemampuan penalaran model edit gambar secara komprehensif dari perspektif jenis pengetahuan: Institusi seperti Universitas Tenggara bersama-sama merilis KRIS-Bench, sebuah benchmark kemampuan penalaran sistem edit gambar berbasis pengetahuan. Ini membagi menjadi 22 tugas pengeditan dari tiga tingkatan: pengetahuan faktual (seperti warna, jumlah), pengetahuan konseptual (seperti akal sehat fisik), dan pengetahuan prosedural (seperti operasi multi-langkah), untuk mengevaluasi 10 model edit gambar utama (termasuk GPT-Image-1, Gemini 2.0 Flash, dll.). Hasilnya menunjukkan bahwa model sumber tertutup GPT-Image-1 berkinerja terbaik, tetapi semua model umumnya berkinerja buruk pada tugas penalaran mendalam seperti penalaran prosedural, ilmu alam, dan sintesis multi-langkah, mengungkapkan kekurangan model saat ini dalam kemampuan kognitif tingkat lanjut (Sumber: 量子位)
Penelitian baru mengusulkan metode Finetune-RAG, menyempurnakan model bahasa untuk menahan halusinasi dalam RAG: Model bahasa besar dalam Retrieval Augmented Generation (RAG) rentan menghasilkan halusinasi ketika pengambilan tidak sempurna (misalnya, ada fragmen dokumen yang mengganggu). Finetune-RAG melatih model pada sampel input yang berisi konteks yang benar dan salah, sehingga dapat lebih baik menjaga kebenaran. Tim peneliti merilis dataset yang berisi 1600+ sampel konteks ganda, checkpoint fine-tuned dari LLaMA 3.1-8B-Instruct, dan kerangka kerja evaluasi GPT-4o bernama Bench-RAG. Evaluasi menunjukkan bahwa metode ini meningkatkan akurasi dari 77% menjadi 98%, dan juga meningkatkan kegunaan, relevansi, dan kedalaman (Sumber: Reddit r/MachineLearning)
TeleMath: Benchmark LLM pertama untuk kemampuan pemecahan masalah matematika di bidang telekomunikasi dirilis: Untuk mengevaluasi kemampuan model bahasa besar dalam menyelesaikan tugas-tugas spesifik di bidang telekomunikasi yang padat matematika, para peneliti meluncurkan benchmark TeleMath. Benchmark ini berisi 500 pasang tanya jawab, mencakup topik telekomunikasi seperti pemrosesan sinyal, optimasi jaringan, dan analisis kinerja. Evaluasi terhadap berbagai LLM open-source menunjukkan bahwa model yang dirancang khusus untuk penalaran matematika atau logika berkinerja lebih baik di TeleMath, sedangkan model umum dengan parameter besar sering mengalami kesulitan. Dataset dan kode evaluasi telah dibuka (Sumber: HuggingFace Daily Papers)
ChineseHarm-Bench: Benchmark deteksi konten berbahaya berbahasa Mandarin dirilis: Menanggapi kenyataan bahwa sumber daya deteksi konten berbahaya yang ada sebagian besar berbahasa Inggris, para peneliti merilis ChineseHarm-Bench, sebuah benchmark deteksi bahaya konten berbahasa Mandarin yang komprehensif dan dianotasi secara profesional. Benchmark ini mencakup enam kategori representatif, dengan data yang sepenuhnya berasal dari dunia nyata. Proses anotasi juga menghasilkan basis aturan pengetahuan, yang menyediakan pengetahuan ahli eksplisit untuk LLM. Selain itu, para peneliti mengusulkan metode baseline yang ditingkatkan pengetahuan, yang menggabungkan aturan yang dianotasi secara manual dan pengetahuan implisit LLM, memungkinkan model kecil mencapai kinerja LLM SOTA (Sumber: HuggingFace Daily Papers)
Penelitian baru menemukan struktur hierarkis kemampuan laten model bahasa melalui pembelajaran representasi kausal: Untuk mengevaluasi kemampuan model bahasa secara akurat dan mengatasi efek perancu serta biaya komputasi yang tinggi, penelitian ini mengusulkan kerangka kerja pembelajaran representasi kausal. Kerangka kerja ini memodelkan kinerja benchmark yang diamati sebagai transformasi linear dari sejumlah kecil faktor kemampuan laten, dan setelah mengontrol model dasar sebagai faktor perancu bersama, mengidentifikasi hubungan kausal antara faktor-faktor laten ini. Diterapkan pada data lebih dari 1500 model dari Open LLM Leaderboard, penelitian ini menemukan struktur kausal linear tiga node yang ringkas, mengungkapkan jalur kausal yang jelas dari kemampuan pemecahan masalah umum ke kemahiran mengikuti instruksi, dan kemudian ke kemampuan penalaran matematis (Sumber: HuggingFace Daily Papers)
DeepLearning.AI meluncurkan kursus baru “Mengatur Alur Kerja untuk Aplikasi GenAI”: Andrew Ng mengumumkan kemitraan dengan Astronomer untuk meluncurkan kursus singkat baru yang mengajarkan cara membangun dan menerapkan pipeline AI generatif yang andal menggunakan alat open-source populer Airflow 3.0. Materi kursus mencakup pemecahan alur kerja menjadi tugas-tugas diskrit, penjadwalan tugas, eksekusi paralel, pemulihan kegagalan, dan observabilitas, yang bertujuan untuk membantu pelajar mengubah prototipe notebook Jupyter atau skrip Python menjadi alur kerja yang siap produksi (Sumber: DeepLearningAI)
Paper membahas metode optimasi sistem AI komposit, tantangan, dan arah masa depan: Seiring dengan perkembangan LLM dan sistem AI, sistem AI komposit yang mengintegrasikan beberapa komponen semakin matang dalam menjalankan tugas-tugas kompleks. Paper ini secara sistematis meninjau kemajuan terbaru dalam optimasi sistem AI komposit, termasuk teknik numerik dan berbasis bahasa. Paper ini memformalkan konsep optimasi sistem AI komposit, mengklasifikasikan metode yang ada, dan menyoroti tantangan penelitian terbuka serta arah masa depan di bidang ini (Sumber: HuggingFace Daily Papers)
💼 Bisnis
Disney dan Universal Studios menggugat generator gambar Midjourney atas pelanggaran hak cipta: Disney dan Universal Studios menuduh Midjourney menggunakan pustaka kreatif mereka (termasuk karakter Star Wars, Frozen, Minions, dll.) untuk melatih modelnya tanpa izin, serta menghasilkan dan mendistribusikan sejumlah besar karya turunan, menyebutnya sebagai “plagiarisme tanpa dasar”. Kasus ini kembali memicu diskusi tentang batas antara konten yang dihasilkan AI dan kekayaan intelektual (Sumber: Reddit r/ArtificialInteligence)
NVIDIA dan Deutsche Telekom bekerja sama untuk membangun cloud AI industri pertama bagi produsen Eropa sebelum 2026: Kanselir Federal Jerman Friedrich Merz bertemu dengan CEO NVIDIA Jensen Huang untuk membahas kerja sama strategis lebih lanjut guna memperkuat posisi Jerman sebagai pemimpin AI global. Sebagai bagian dari visi ini, Deutsche Telekom dan NVIDIA mengumumkan kerja sama baru, berencana untuk membangun cloud AI industri pertama di dunia bagi produsen Eropa pada tahun 2026. Infrastruktur yang aman dan sesuai dengan norma Eropa ini akan mendukung inovasi mutakhir sambil memastikan kedaulatan data penuh (Sumber: nvidia)

Rumor Sam Altman mungkin mencairkan kontrol nirlaba OpenAI melalui akuisisi semua saham: Akuisisi OpenAI baru-baru ini terhadap io ($6,5 miliar) dan Windsurf ($3 miliar) dengan semua saham memicu spekulasi. Ada teori di Hacker News bahwa Sam Altman mungkin menggunakan transaksi ini untuk secara bertahap mencairkan kontrol organisasi nirlaba OpenAI Inc. atas entitas nirlaba OpenAI Global LLC (sekarang OpenAI PBC), sehingga berpotensi menghindari batasan hukum untuk bertransisi menjadi perusahaan yang sepenuhnya mencari keuntungan. Langkah ini oleh sebagian orang dikaitkan dengan operasi Altman di Reddit pada tahun 2014, tetapi ada juga pandangan bahwa akuisisi ini adalah langkah strategi bisnis yang normal (Sumber: Reddit r/ArtificialInteligence)
🌟 Komunitas
Diskusi tentang apakah AI dapat benar-benar “bernalar” terus berlanjut, paper Apple memicu kontroversi: Paper terbaru Apple yang menyatakan bahwa Large Language Models (LLM) dalam tugas kompleks (seperti Menara Hanoi) kinerjanya bukanlah penalaran sejati, melainkan lebih seperti pencocokan pola, pandangan ini menjadi diskusi luas di komunitas. Mantan karyawan OpenAI Miles Brundage, ketika mengomentari o3-pro yang memecahkan permainan kata kompleks, secara sarkastis bertanya “jika ini bukan penalaran, lalu apa?”. Penelitian lanjutan menunjukkan bahwa fenomena “keruntuhan penalaran” dalam paper Apple mungkin disebabkan oleh keterbatasan desain eksperimental (seperti batasan token, evaluasi yang salah terhadap masalah yang tidak dapat dipecahkan) daripada kurangnya kemampuan penalaran model itu sendiri. Setelah menyesuaikan metode pengujian, model berkinerja baik pada tugas-tugas yang sebelumnya gagal, ini menunjukkan bahwa evaluasi kemampuan penalaran AI memerlukan desain eksperimental yang lebih cermat (Sumber: o3-pro menjawab permainan kata sulit menarik perhatian, mantan karyawan OpenAI menyindir Apple:Jika ini bukan penalaran lalu apa yang disebut penalaran, Reddit r/LocalLLaMA)
CEO Nvidia Jensen Huang dan CEO Anthropic Dario Amodei memiliki perbedaan pandangan yang signifikan tentang masa depan AI: Fortune melaporkan bahwa CEO Nvidia Jensen Huang menyatakan bahwa ia hampir tidak setuju dengan hampir semua pandangan CEO Anthropic Dario Amodei tentang AI. Amodei sering menekankan potensi risiko AI dan dampak besar pada pekerjaan, serta menganjurkan kontrol yang lebih ketat terhadap pengembangan AI dan dipimpin oleh beberapa organisasi yang “bertanggung jawab”. Huang, di sisi lain, skeptis terhadap pandangan semacam itu dan lebih cenderung mendorong aplikasi dan pengembangan teknologi AI secara luas. Komentar komunitas berpendapat bahwa posisi Huang mungkin terkait dengan kepentingan bisnisnya, karena Nvidia adalah pemasok utama perangkat keras AI (Sumber: Reddit r/ArtificialInteligence, Reddit r/ClaudeAI)

Paket langganan Claude Code seharga $20 mendapat pujian dari pengembang karena hemat biaya: Banyak pengembang di media sosial membagikan pengalaman positif mereka menggunakan paket langganan bulanan Anthropic Claude Code seharga $20, menyebutnya sangat hemat biaya dan dapat dengan cepat menutup biaya dalam proyek. Pengguna menyebutkan bahwa meskipun ada batasan kecepatan tertentu, Claude Code berkinerja sangat baik dalam membantu pengkodean, mempelajari bahasa baru (seperti beralih dari C# ke SwiftUI), dan mengoptimalkan instruksi proyek (seperti file CLAUDE.md), yang secara signifikan meningkatkan efisiensi kerja. Beberapa pengguna bahkan mempertimbangkan untuk membatalkan langganan alat bantu pemrograman AI lainnya (Sumber: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Komunitas membahas aplikasi masa depan dan tantangan etika AI di bidang psikologi: Seiring dengan perkembangan teknologi seperti LLM yang menyusun petunjuk terapi dan aplikasi yang melacak emosi melalui sensor ponsel, AI secara bertahap merambah bidang psikologi. Diskusi komunitas berfokus pada apakah AI dalam praktik klinis akan meningkatkan kemampuan terapis atau pada akhirnya menggantikan sebagian pekerjaan, kredibilitas AI dalam evaluasi dan penelitian, dampak pada pelatihan profesional dan pasar kerja psikologi, serta masalah etika dan regulasi aplikasi AI, terutama bias data, privasi, dan keterbatasan “terapis robot”. Kekhawatiran utama adalah bagaimana memanfaatkan AI untuk meningkatkan efisiensi dan layanan yang dipersonalisasi sambil menjaga keselamatan pasien dan mempertahankan nilai terapeutik dari hubungan antarmanusia (Sumber: Reddit r/artificial)
Model DeepSeek-R1-0528 terkuantisasi 3.53bit dari Unsloth berkinerja baik pada benchmark pengkodean Aider Polyglot: Tim Unsloth melakukan kuantisasi 3.53bit (UD-Q3_K_XL) pada model DeepSeek-R1-0528, dan mencapai tingkat kelulusan 68% dalam pengujian benchmark pengkodean Aider Polyglot. Pengujian menggunakan ukuran konteks 40960 dan Flash Attention, membutuhkan RAM/VRAM sekitar 300GB. Hasil ini berada di antara Claude Sonnet 3.7 dan Claude Opus 4, menunjukkan potensi model terkuantisasi dalam mempertahankan kemampuan pengkodean yang tinggi. Anggota komunitas terkesan dengan kinerja menjalankan model semacam itu secara lokal dan menantikan hasil pengujian versi terkuantisasi lainnya (Sumber: Reddit r/LocalLLaMA)
💡 Lainnya
Laporan insiden pemadaman global GCP mengungkap: kebijakan kuota ilegal menyebabkan gangguan layanan: Laporan insiden pemadaman global Google Cloud Platform (GCP) baru-baru ini menunjukkan bahwa penyebabnya adalah penerapan kebijakan kuota yang salah ke sistem manajemen API global (seperti membatasi hanya 1 permintaan per jam), yang menyebabkan permintaan eksternal ditolak karena melebihi kuota (kesalahan 403). Setelah insinyur menemukannya, mereka melewati pemeriksaan kuota untuk API yang terpengaruh. Namun, di wilayah us-central1, ketika mencoba menghapus kebijakan lama dan menulis kebijakan baru, masalah cache menyebabkan database kelebihan beban, sehingga waktu pemulihan lebih lama. Wilayah lain menggunakan metode pembersihan cache secara bertahap untuk pulih, dan seluruh proses memakan waktu sekitar 2 jam (Sumber: karminski3)

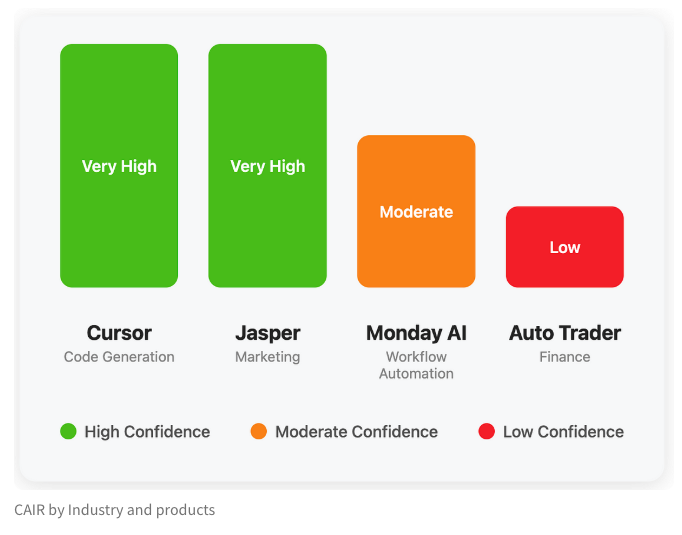
Tim LangChain mengusulkan metrik CAIR untuk mengevaluasi potensi keberhasilan produk AI: Harrison Chase dari LangChain bersama Assaf Elovic menulis artikel yang membahas mengapa beberapa produk AI dapat dengan cepat populer sementara yang lain kesulitan. Mereka berpendapat bahwa kemampuan model bukanlah satu-satunya faktor penentu, pengalaman pengguna (UX) sangat penting, dan mengusulkan metrik “CAIR” (Confidence in AI Results, keyakinan pada hasil AI). Semakin tinggi CAIR, semakin tinggi tingkat adopsi produk. Kerangka kerja ini bertujuan untuk membantu pengembang mengidentifikasi dan meningkatkan berbagai komponen yang memengaruhi kepercayaan pengguna, sehingga meningkatkan tingkat keberhasilan produk (Sumber: hwchase17, swyx, hwchase17, Hacubu)
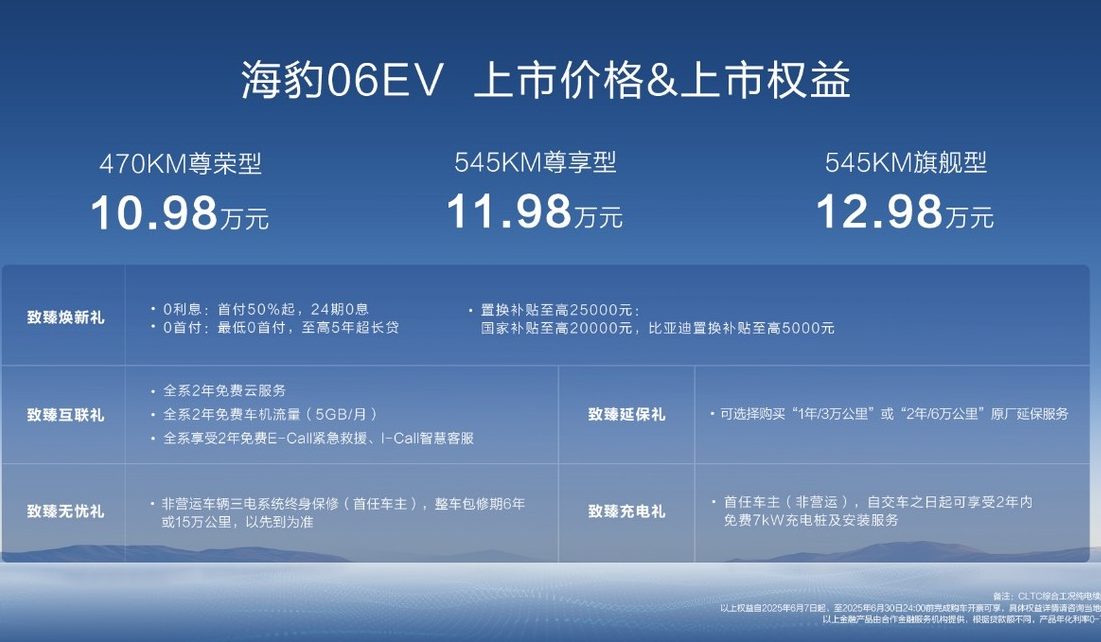
BYD merilis sedan sport listrik murni untuk keluarga, Seal 06EV, harga mulai dari 109.800 yuan: BYD Ocean Network meluncurkan Seal 06EV di Chongqing Auto Show, diposisikan sebagai sedan sport pilihan berkualitas yang trendi, dengan total 3 konfigurasi, rentang harga 109.800-129.800 yuan. Mobil ini dibangun di atas platform BYD e-platform 3.0 Evo, dilengkapi dengan penggerak listrik cerdas delapan-dalam-satu dan sistem pompa panas efisien rentang suhu lebar generasi baru, menawarkan dua pilihan jangkauan CLTC 470KM dan 545KM. Kendaraan ini menggunakan tata letak penggerak roda belakang, dilengkapi dengan sistem kontrol bodi peredam cerdas YunLian-C, dan dilengkapi dengan versi tiga mata bantuan mengemudi cerdas “Eye of the Gods C”, mendukung fungsi seperti navigasi cepat di jalan raya dan parkir otomatis (Sumber: 量子位)