Anahtar Kelimeler:Tesla Robotaxi, AMD MI350, OpenAI o3-pro, iFlytek AIUI, Yuanrong Qixing VLA, DeepSeek Nano-vLLM, Ant Group Ming Lite Omni, L2 seri üretim araçlarda L4 otonom sürüş, AMD MI350X ve B200 performans karşılaştırması, o3-pro modelinin uzun bağlam işleme yeteneği, AIUI tam çift yönlü etkileşim teknolojisi, Görsel-Dil-Eylem modeli VLA
🔥 Odak Noktaları
Tesla Robotaxi ilk kez halka açık yollarda, Musk L2 seri üretim araçların modifikasyona gerek kalmadan L4 seviyesinde otonom sürüşe ulaşabileceğini söyledi: Tesla’nın Robotaxi’si (yenilenmiş Model Y) Austin’de yol testlerine başladı; araç gövdesinde yeni Robotaxi logosu bulunuyor ancak direksiyon simidi korunuyor. Musk, tüm Tesla seri üretim araçlarının denetimsiz otonom sürüşü gerçekleştirebileceğini, şu anda test araçlarında mevcut FSD’nin 4.5 katı parametre sayısına sahip dahili test FSD sürümünün bulunduğunu ve yıl içinde optimize edilip yayınlanmasının beklendiğini belirtti. Robotaxi’nin 22 Haziran’da Austin’de başlayarak halka açılması planlanıyor. Bu hamle, Tesla’nın L2 seviyesindeki FSD’sinin L4/L5 seviyesindeki Robotaxi’ye yükseltilmesini işaret ediyor ve özellikle Waymo gibi L4 teknoloji rotasını izleyen oyuncular için rekabet ortamını hızlandırabilir ve bir meydan okuma oluşturabilir (Kaynak: 量子位)

AMD, en güçlü AI çipi MI350 serisini duyurdu, performansı Nvidia B200’ü aşıyor: AMD CEO’su Lisa Su ve OpenAI CEO’su Altman, MI350X ve MI355X GPU’larını birlikte duyurdu. Bu iki çip 3nm sürecini kullanıyor, 185 milyar transistöre ve 288GB HBM3E belleğe sahip; bellek kapasitesi Nvidia B200’ün 1.6 katı. Resmi verilere göre, MI350 serisi FP4 hassasiyetinde Llama 3.1 405B çalıştırma çıkarım hızı B200’den %30 daha hızlı ve FP64 hesaplama gücünde Nvidia’nın iki katı. AMD ayrıca OpenAI ile ortaklaşa geliştirilen MI400 serisinin gelecek yıl piyasaya sürüleceğini duyurdu, bu da AI çip pazarındaki rekabeti daha da kızıştıracak (Kaynak: 量子位)

OpenAI o3-pro modelinin akıl yürütme yeteneği dikkat çekiyor, gerçek performansı resmi testlerden biraz farklı: OpenAI’nin en son çıkarım modeli o3-pro, karmaşık metin oyunlarını (örneğin şarkıcı Sabrina Carpenter’ın şarkı adı özelliklerine göre belirli yanıtlar üretme) işlemede güçlü bir yetenek sergiledi ve OpenAI’nin eski AGI Readiness ekibi liderinin Apple’ın daha önce büyük modellerin akıl yürütme yeteneğine yönelik şüphelerine dair alaycı yorumlarına neden oldu. Ancak, LiveBench gibi yetkili sıralamalarda, o3-pro’nun kodlama ortalama puanı o3 ile neredeyse aynı seviyede ve agent kodlama puanı bile geride. Fiction.LiveBench testleri, o3-pro’nun kısa bağlamlarda üstün performans gösterdiğini ancak 192k ultra uzun bağlam işlemede Gemini 2.5 Pro’dan hala geride olduğunu gösteriyor. Apple ve SpaceX’in eski mühendisi Ben Hylak, o3-pro’nun gerçek yeteneğinin büyük ölçüde yeterli arka plan bilgisi girişine bağlı olduğunu, basit bir sohbet nesnesi yerine rapor oluşturucu olarak daha uygun olduğunu ve araç çağırma ve ortam anlama konularında önemli gelişmeler kaydettiğini belirtti (Kaynak: 量子位)

iFLYTEK, AIUI insan-makine etkileşim platformunu ve robot süper beyin platformunu yükselterek akıllı donanımların derin işbirliğini teşvik ediyor: iFLYTEK, insan-makine etkileşim platformu AIUI’nin önemli bir yükseltmesini duyurdu; tam çift yönlü etkileşim, duygu algılama ve ifade etme ile insan benzeri bellek sistemlerini geliştirmeye odaklandı. Özellikle çocuk senaryoları için, çocuk konuşmasını tanıma ve anlama yeteneğini geliştiren özel bir etkileşim çözümü sunuldu. Aynı zamanda, robot süper beyin platformu Spark büyük modeline dayanarak çok modlu etkileşim, anlamsal anlama ve bilgi uygulamasını güçlendirdi ve mevcut robotların donanım değişikliği yapmadan sesli etkileşim gerçekleştirmesini sağlayan “akıllı ses sırt çantası”nı piyasaya sürdü. Bu yükseltmeler, akıllı donanımları temel etkileşimden derin akıllı işbirliğine taşımayı ve araç içi sistemler, AI donanımları, robotlar gibi birçok alanı güçlendirmeyi amaçlıyor (Kaynak: 量子位)

🎯 Gelişmeler
DeepRoute.ai ve Volcengine, Doubao büyük modeline dayalı VLA fiziksel dünya Agent’ı geliştirmek için işbirliği yapıyor: DeepRoute.ai CEO’su Zhou Guang, Volcengine ile işbirliği yaparak Doubao büyük modelini kullanarak Vision-Language-Action (VLA) modeli gibi ileri teknolojileri ortaklaşa geliştireceklerini ve fiziksel dünya için bir Agent oluşturmayı hedeflediklerini duyurdu. DeepRoute.ai’nin VLA modeli 2025’in üçüncü çeyreğinde tüketici pazarına sunulacak ve mekansal anlamsal anlama, düzensiz engel tanıma, metin tabanlı yönlendirme levhası anlama ve sesle araç kontrolü olmak üzere dört temel işleve sahip olacak; bu da destekli sürüşün güvenliğini ve zekasını artırmayı amaçlıyor. VLA modeli şu anda yol testlerini tamamladı ve yıl içinde bu modeli kullanan 5’ten fazla AI otomobilin piyasaya sürülmesi bekleniyor (Kaynak: 量子位)

DeepSeek araştırmacısı 1200 satır kodla vLLM’i yeniden oluşturdu, bazı senaryolarda performansı orijinalini geçti: DeepSeek araştırmacısı Yu Xingkai, vLLM’in PagedAttention gibi temel işlevlerini 1200 satırdan az Python koduyla gerçekleştiren Nano-vLLM projesini açık kaynak olarak yayınladı. Proje, öğrenme ve anlama kolaylığı için vLLM’in minimize edilmiş ve tamamen okunabilir bir sürümünü sunmayı amaçlıyor. H800 donanımı ve Qwen3-8B modelinin belirli test koşullarında, Nano-vLLM’in verimi orijinal vLLM’i bile aştı ve verimliliğini gösterdi. vLLM, UC Berkeley tarafından geliştirilen ve PagedAttention algoritmasıyla LLM hizmetlerinin verimini önemli ölçüde artıran bir LLM çıkarım ve hizmet çerçevesidir (Kaynak: 量子位)
Çinli şirketler, ABD’nin AI çip ihracat kısıtlamalarını aşmak için “uçan sabit disk kutuları” kullanıyor: Wall Street Journal’ın haberine göre, ABD’nin üst düzey AI çipleri üzerindeki ihracat kısıtlamalarıyla karşı karşıya kalan Çinli şirketler yeni bir strateji benimsiyor: Büyük miktarda eğitim verisi içeren sabit diskleri (örneğin 80TB) mühendisler aracılığıyla Malezya gibi denizaşırı veri merkezlerine taşıyor, burada Nvidia gibi gelişmiş çiplere sahip yerel sunucuları kullanarak AI modellerini eğitiyor ve tamamlandıktan sonra model parametrelerini Çin’e geri getiriyorlar. Bu hamle, doğrudan çip ithalatındaki zorlukları aşmayı ve Güneydoğu Asya ile Orta Doğu’daki AI veri merkezlerinin yükselişini teşvik etmeyi amaçlıyor. Eski bir ABD Ticaret Bakanlığı yetkilisi bu durumdan endişe duyduğunu belirtti (Kaynak: dotey)

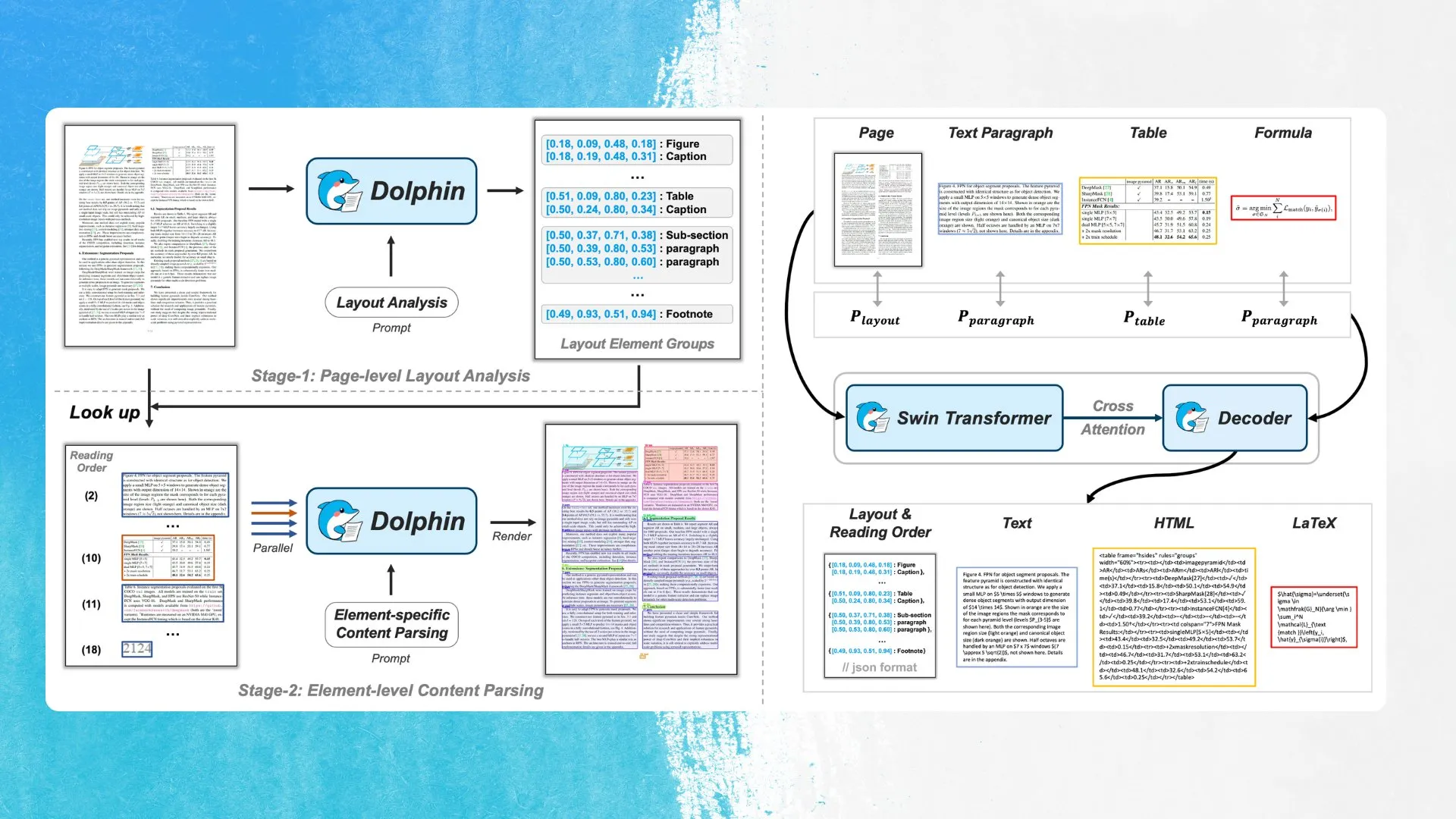
ByteDance, düzen öğesi tespiti ve paralel ayrıştırma kullanan yeni OCR modeli Dolphin’i tanıttı: ByteDance, MIT lisansına dayalı yeni OCR modeli Dolphin’i yayınladı. Model önce belge düzenindeki öğeleri (tablolar, formüller vb.) tespit ediyor, ardından içeriği oluşturmak için her öğeyi paralel olarak ayrıştırıyor. Model ve demo Hugging Face Hub’da kullanıma sunuldu. Bu yöntem, karmaşık belge yapısı tanımanın doğruluğunu ve verimliliğini artırmayı amaçlıyor (Kaynak: mervenoyann)
OpenAI ChatGPT proje işlevselliğini geliştiriyor; derinlemesine araştırma, ses modu ve mobil dosya yükleme desteği ekleniyor: OpenAI, ChatGPT’deki “Projeler” (Projects) özelliği için geliştirilmiş derinlemesine araştırma desteği, ses modunun entegrasyonu, proje içindeki geçmiş sohbetlere atıfta bulunmak için geliştirilmiş bellek işlevi ve mobil cihazlarda dosya yükleme ve model seçici desteği dahil olmak üzere birçok iyileştirme duyurdu. Bu güncellemeler, kullanıcıların ChatGPT’de daha odaklı ve karmaşık işler yapma yeteneğini artırmayı amaçlıyor (Kaynak: kevinweil)
EuroLLM ekibi, 22B model ve küçük MoE modeli dahil olmak üzere birçok yeni modelin önizleme sürümünü yayınladı: EuroLLM ekibi, 22B parametreli bir temel sürüm ve talimatlarla ince ayarlanmış bir model, eski EuroLLM tabanlı iki görsel model (1.7B ve 9B parametre) ve 0.6B aktif parametreye ve 2.6B toplam parametreye sahip küçük bir Uzmanlar Karışımı (MoE) modeli dahil olmak üzere birçok yeni modelin önizleme sürümlerini yayınladı. Bu modellerin tümü Apache-2.0 lisansını kullanıyor ve ilk testler, bu küçük MoE modelinin kendi ölçeğinde beklenmedik derecede iyi performans gösterdiğini ortaya koyuyor (Kaynak: Reddit r/LocalLLaMA)

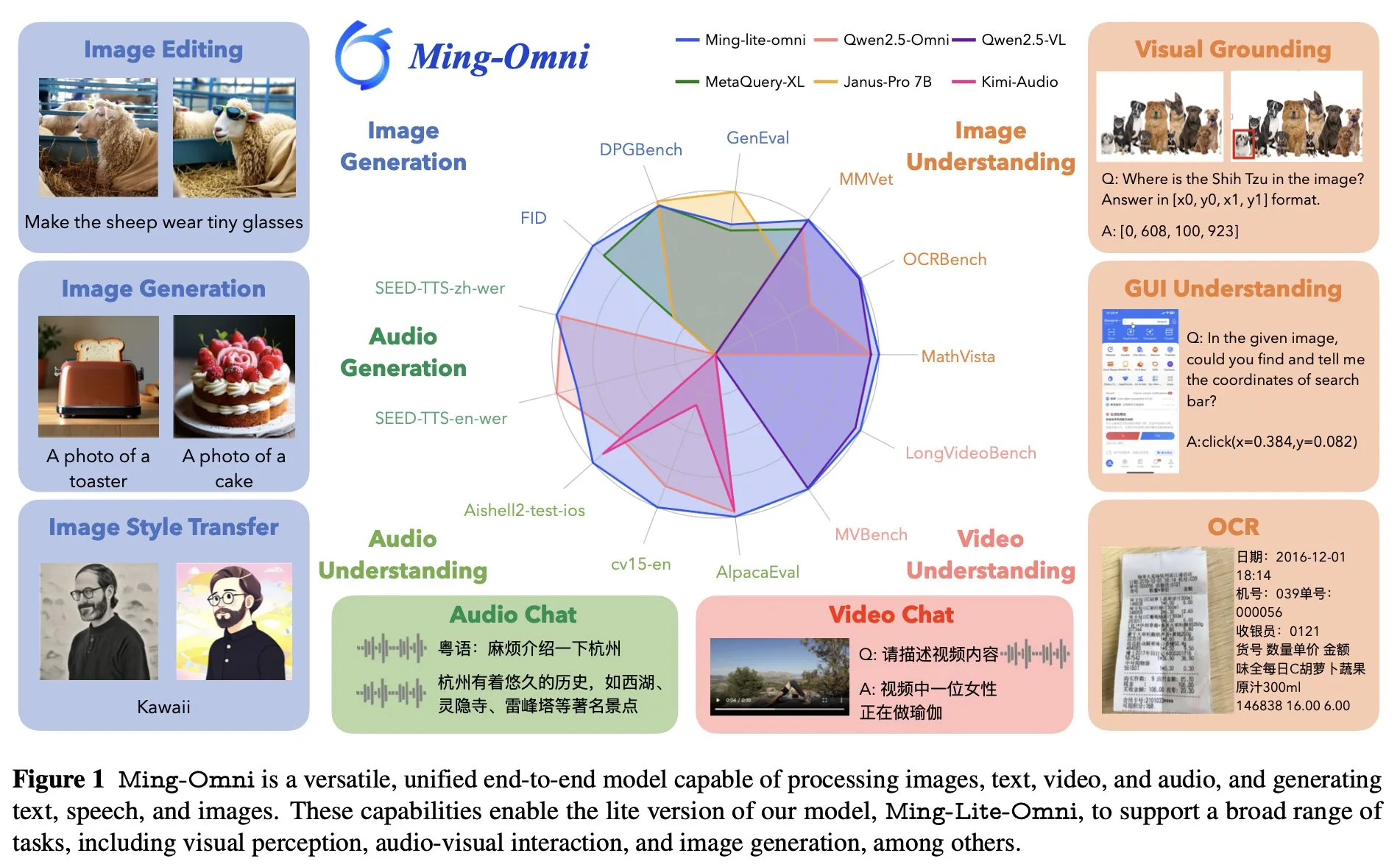
Ant Group, GPT-4o’ya rakip olarak uçtan uca çok yönlü model Ming Lite Omni’yi yayınladı: Ant Group, dinleme, konuşma, görüntü oluşturma gibi birçok işlevi gerçekleştirebilen ve performans açısından GPT-4o ile rekabet eden Ming Lite Omni modelini tanıttı. Ming Lite Omni, GUI görevlerinde Qwen2.5VL-7B’yi geride bırakıyor, ses anlama konusunda birçok halka açık benchmark’ta SOTA seviyesine ulaşıyor ve video anlama yeteneği de üstün performans sergiliyor. Model, Uzmanlar Karışımı (MoE) mimarisini kullanıyor, aktif parametre sayısı sadece 2.8B ve ses ile görüntü oluşturma için BPE kullanarak ses token kare hızını azaltma ve çok ölçekli öğrenilebilir token’lar ile görüntü oluşturma kalitesini artırma gibi özel optimizasyonlar içeriyor (Kaynak: mervenoyann)
NVIDIA ve Mistral AI, AI bulut platformu Mistral Compute’u birlikte kurmak için işbirliği yapıyor: NVIDIA, GTC konferansında Mistral AI ile işbirliği yaparak Mistral Compute adlı bir AI bulut platformu oluşturacağını duyurdu. Bu hamle, ABD çipleriyle desteklenen açık modeller aracılığıyla küresel AI altyapı inşaatı için bir şablon sağlamayı amaçlayan, ABD ve açık kaynak topluluğu için önemli bir gelişme olarak görülüyor (Kaynak: arthurmensch)
Hugging Face, Transformers kütüphanesini basitleştirmek için tamamen PyTorch’u benimseyeceğini duyurdu: Hugging Face Baş Açık Kaynak Sorumlusu Lysandre Jik, kullanıcı tabanının PyTorch üzerinde bir fikir birliğine varması nedeniyle gelecekte tüm çabalarını PyTorch’a odaklayacaklarını, böylece Transformers kütüphanesindeki şişkinliği azaltacaklarını ve daha sade bir araç seti sunmaya çalışacaklarını belirtti. PyTorch yetkilileri bu adımı memnuniyetle karşıladı ve bunun kod sadeliğini korumaya yardımcı olacağını vurguladı (Kaynak: reach_vb)

ByteDance, gerçek zamanlı etkileşimli video oluşturma teknolojisi APT2’yi tanıttı: ByteDance, en son gerçek zamanlı etkileşimli video oluşturma teknolojisi olan APT2’yi (Autoregressive Adversarial Post-Training) sergiledi. Bu teknoloji, otoregresif karşıtlık sonrası eğitim yoluyla yüksek kaliteli, gerçek zamanlı etkileşimli video içeriği oluşturmayı amaçlıyor ve video oluşturma alanındaki gelişmeleri daha da ileri taşıyor (Kaynak: NerdyRodent)
🧰 Araçlar
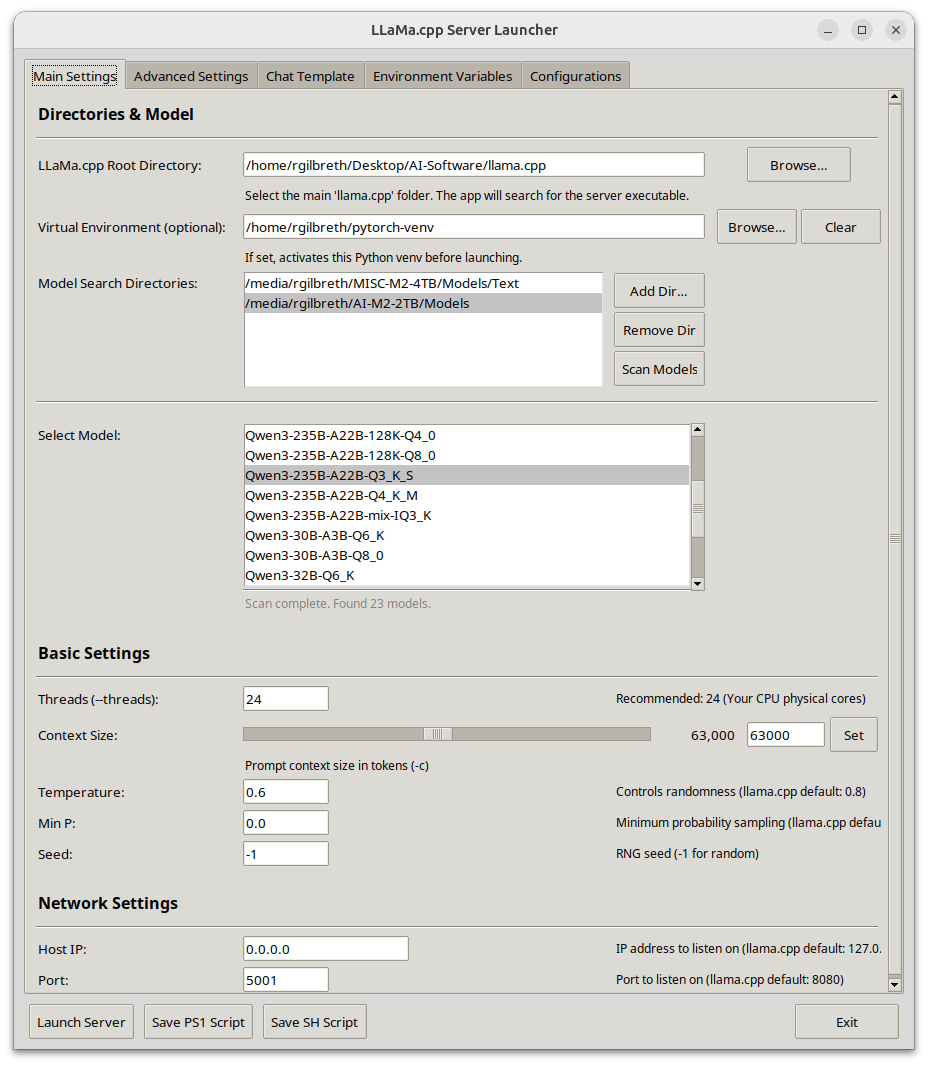
Llama-Server Launcher: GUI’li bir llama.cpp sunucu başlatıcısı, CUDA performans optimizasyonuna odaklanıyor: Bir geliştirici, Python ile yazılmış ve grafik kullanıcı arayüzü (GUI) sunan kişisel llama-server başlatıcısını paylaştı. Bu araç, llama.cpp hizmetlerinin yapılandırılmasını ve başlatılmasını basitleştirmeyi amaçlıyor ve özellikle CUDA performans ayarlarına odaklanıyor. İşlevler arasında model seçimi, yol ayarları, bağlam ve toplu iş boyutu ayarlaması, GPU boşaltma, FlashAttention, tensör bölme gibi gelişmiş performans ayarları ile sohbet şablonu seçimi ve ortam yapılandırma yönetimi bulunuyor. GPU ve sistem bilgilerini otomatik olarak almayı, GGUF model meta verilerini analiz etmeyi ve platformlar arası başlatma komut dosyaları (.ps1/.sh) oluşturmayı destekliyor (Kaynak: Reddit r/LocalLLaMA)
Together AI, açık kaynaklı veri bilimcisi agent’ını yayınladı: Together AI, bir veri bilimcisi gibi akıl yürütebilen açık kaynaklı bir AI agent’ı oluşturdu. Bu agent, veri yükleyebilir, Python kodu yazabilir, model başarısız olduğunda yeniden eğitim yapabilir ve gerçek Kaggle ve DABStep görevlerini çözebilir. Bu hamle, AI’ın veri bilimi alanındaki otomasyonunu ve yaygınlaşmasını teşvik etmeyi amaçlıyor (Kaynak: percyliang)
AutoMind: Otomatikleştirilmiş veri bilimi için uyarlanabilir bilgi tabanlı agent çerçevesi: AutoMind, uzman bilgi tabanlarını entegre ederek, agent bilgi ağacı arama algoritmasını benimseyerek ve uyarlanabilir kodlama stratejileri kullanarak mevcut veri bilimi agent’larının karmaşık ve yenilikçi görevleri işlemedeki sınırlamalarını aşmayı ve böylece otomatikleştirilmiş makine öğrenimi süreçlerinin gerçek dünya etkinliğini artırmayı amaçlayan yeni bir LLM agent çerçevesidir (Kaynak: HuggingFace Daily Papers)
LlamaParse, belge ayrıştırma yapılandırmasını basitleştirmek için “Ön Ayarlar” (Presets) özelliğini yayınladı: LlamaParse, farklı kullanım durumları için ayarları optimize eden, anlaşılması kolay bir dizi önceden yapılandırılmış mod sunan “Ön Ayarlar” (Presets) özelliğini tanıttı. Genel senaryolar için hızlı, dengeli ve gelişmiş modların yanı sıra faturalar, bilimsel makaleler, teknik belgeler ve formlar gibi yaygın kullanım durumları için optimize edilmiş modları içerir; bu da kullanıcıların hız ve doğruluk arasında daha kolay seçim yapmasını sağlamayı amaçlar (Kaynak: jerryjliu0)
OpenWebUI, o3-pro destek işlevini ekleyerek model uyumluluğunu genişletiyor: Topluluk geliştiricileri, yanıt API desteği, maliyet takibi, çoklu anahtar desteği ve web araması gibi özellikler ekleyerek o3-pro modelleri için desteği genişleten Open WebUI için yeni bir işlev oluşturdu. Bu, kullanıcıların resmi premium pakete abone olmadan Open WebUI’de o3-pro’yu kullanmalarını sağlar (Kaynak: Reddit r/OpenWebUI)
📚 Araştırmalar
Makale, MLP aktivasyonlarını yorumlanabilir özelliklere ayrıştırmak için yarı-negatif olmayan matris ayrıştırmasını (SNMF) kullanmayı tartışıyor: Bu çalışma, seyrek, ortaklaşa aktive olan nöronların doğrusal birleşimlerinden oluşan özellikleri öğrenmek ve bu özellikleri aktive eden girdilere eşleyerek doğrudan yorumlanabilir hale getirmek için çok katmanlı algılayıcı (MLP) aktivasyonlarını doğrudan ayrıştırmak üzere SNMF kullanmayı önermektedir. Deneyler, SNMF türevli özelliklerin nedensel yönlendirmede seyrek otomatik kodlayıcılardan (SAE) daha iyi performans gösterdiğini ve insan tarafından yorumlanabilir kavramlarla tutarlı olduğunu ve MLP aktivasyon uzayındaki hiyerarşik yapıyı ortaya çıkardığını göstermektedir (Kaynak: HuggingFace Daily Papers)
Yeni makale LoRMA’yı öneriyor: LLM’leri Düşük Ranklı Çarpımsal Adaptasyon (Low-Rank Multiplicative Adaptation) yoluyla ince ayarlamak için yeni bir paradigma: Geleneksel LLM ince ayarı genellikle ağırlıkları toplamsal güncellemelerle yapar, LoRMA ise çarpımsal güncellemeleri araştırır. Düşük ranklı matrislerin neden olduğu “rank çökmesi” sorununu çözmek için makale, permütasyon ve toplamaya dayalı yeni rank genişletme işlemleri sunar ve etkili yeniden sıralama işlemleriyle hesaplama verimliliğini sağlar. Deneyler LoRMA’nın rekabetçi olduğunu göstermekte ve LLM adaptasyonu için yeni fikirler sunmaktadır (Kaynak: Reddit r/deeplearning)
Makale, LLM tarafından oluşturulan çok boyutlu sınıflandırma sistemlerini gelişen araştırma külliyatlarına uyarlamak için TaxoAdapt çerçevesini öneriyor: Bilimsel literatürün düzenlenmesindeki zorluklara yönelik olarak TaxoAdapt çerçevesi, LLM tarafından oluşturulan sınıflandırma sistemlerini belirli bir külliyata dinamik olarak uyarlayabilir ve çoklu boyutları (metodoloji, görev, değerlendirme metrikleri gibi) destekleyebilir. Bu çerçeve, külliyatın konu dağılımına göre sınıflandırmanın genişliğini ve derinliğini genişletmek için yinelemeli hiyerarşik sınıflandırma yoluyla bilimsel alanların evrimini daha iyi organize etmeyi ve yakalamayı amaçlamaktadır (Kaynak: HuggingFace Daily Papers)
Makale, agent sistemlerinde işbirlikçi öğrenmeyi sağlayan MOSAIC çerçevesini tanıtıyor: MOSAIC, merkezi olmayan, dinamik ortamlarda otonom, agent’lı AI sistemleri için işbirlikçi öğrenmeye yönelik bir çerçevedir. Agent’lar, senkronizasyon veya merkezi kontrol olmaksızın modüler bilgiyi (sinir ağı maskeleri şeklinde) seçici olarak paylaşır ve yeniden kullanır. Deneyler, MOSAIC’in hız ve performans açısından izole öğrenicilerden daha iyi olduğunu, bazen izole agent’ların çözemediği görevleri çözebildiğini ve kolektif verimlilik ile uyarlanabilirliğin artırılmasına katkıda bulunduğunu göstermektedir (Kaynak: Reddit r/MachineLearning)
Makale, karmaşık iddiaların geri getirme ile zenginleştirilmiş hiyerarşik analizi için ClaimSpect çerçevesini öneriyor: Birçok iddia (bilimsel, politik iddialar gibi) basitçe doğru veya yanlış değildir. ClaimSpect çerçevesi, geri getirme ile zenginleştirilmiş üretim yoluyla iddiayla ilgili yönlerin hiyerarşik bir yapısını otomatik olarak oluşturur ve bu yönleri belirli bir külliyatın bakış açılarıyla zenginleştirir. Bu yöntem, karmaşık iddiaları yapılandırmayı ve külliyattaki çeşitli yönlere ilişkin farklı görüşleri ve bunların yaygınlığını sunmayı amaçlamaktadır (Kaynak: HuggingFace Daily Papers)
Makale, dikkat başlığı seçimi yoluyla İnce Taneli Pertürbasyon Yönlendirmesi (Fine-Grained Perturbation Guidance) gerçekleştirmeyi öneriyor: Bu çalışma, difüzyon modellerindeki belirli dikkat başlıklarının farklı görsel kavramları (yapı, stil, doku kalitesi gibi) kontrol ettiğini bulmuştur. Buna dayanarak makale, kullanıcı hedefleriyle tutarlı dikkat başlıklarını sistematik olarak seçmek, üretilen kalite ve görsel özellikler üzerinde ince taneli kontrol sağlamak ve pertürbasyon yoğunluğunu ayarlamak için SoftPAG’ı tanıtmak üzere “HeadHunter” çerçevesini önermektedir. Bu yöntem, Stable Diffusion 3 ve FLUX.1 gibi modellerde kaliteyi artırma ve stil yönlendirmesi konularındaki üstünlüğünü doğrulamıştır (Kaynak: HuggingFace Daily Papers)
Makale, LLM unutmasının biçimden bağımsız (Form-Independent) olması gerektiğini tartışıyor: Araştırma, mevcut LLM unutma (unlearning) yöntemlerinin etkinliğinin büyük ölçüde eğitim örneklerinin biçimine bağlı olduğunu ve aynı bilginin farklı ifadelerine genelleştirilmesinin zor olduğunu belirtiyor. Makale bu sorunu “biçime bağlı yanlılık” (Form-Dependent Bias) olarak tanımlıyor ve değerlendirme için ORT benchmark’ını sunuyor. Bu sorunu çözmek için makale, modelin belirli kavramlara yönelik algısını yeniden yönlendirerek unutmayı gerçekleştiren ROCR (Rank-one Concept Redirection) yöntemini öneriyor; deneyler ROCR’ın unutma etkisini önemli ölçüde artırdığını ve doğal çıktılar üretebildiğini kanıtlıyor (Kaynak: HuggingFace Daily Papers)
Makale, UniPre3D’yi öneriyor: Çapraz modal Gaussian Splatting tabanlı 3D nokta bulutu modelleri için birleşik bir ön eğitim yöntemi: UniPre3D, 3D görüntülemede nokta bulutu verilerinin ölçek çeşitliliğinden kaynaklanan zorlukları çözmeyi amaçlar ve herhangi bir ölçekteki nokta bulutuna ve herhangi bir mimarideki 3D modele sorunsuz bir şekilde uygulanabilen ilk birleşik ön eğitim yöntemini önerir. Bu yöntem, ön eğitim görevi olarak Gaussian ilkellerini tahmin ederek ve görüntüleri işlemek için türevlenebilir Gaussian Splatting kullanarak hassas piksel düzeyinde denetim ve uçtan uca optimizasyon sağlar; aynı zamanda doku bilgisini dahil etmek için 2D ön eğitimli modellerin özelliklerini entegre eder (Kaynak: HuggingFace Daily Papers)
Makale, StreamSplat’ı öneriyor: Kalibre edilmemiş video akışları için çevrimiçi dinamik 3D yeniden yapılandırma: StreamSplat, herhangi bir uzunluktaki kalibre edilmemiş video akışını çevrimiçi olarak dinamik 3D Gaussian Splatting (3DGS) temsiline dönüştürebilen tamamen ileri beslemeli bir çerçevedir. Statik kodlayıcıdaki olasılıksal örnekleme mekanizması aracılığıyla 3DGS konumlarını tahmin ederek ve dinamik kod çözücüdeki çift yönlü deformasyon alanı aracılığıyla sağlam ve verimli dinamik modelleme gerçekleştirir; gerçek zamanlı dinamik sahne yeniden yapılandırmasındaki kalibrasyon, dinamik modelleme ve verimlilik kararlılığı zorluklarını çözmeyi amaçlar (Kaynak: HuggingFace Daily Papers)
Makale, maskeli görüntü modellemesinde Dikkatli Sonda (Attentive Probing) yöntemini gözden geçiriyor: Büyük ölçekli ince ayarın pratik olmaktan çıkmasıyla birlikte, sonda (probing) yöntemi öz-denetimli öğrenme (SSL) değerlendirmesi için tercih edilen yöntem haline geldi. Standart doğrusal sonda (LP), maskeli görüntü modellemesi (MIM) ile eğitilmiş modellerin potansiyelini yeterince yansıtamadı. Bu makale, dikkatli sondayı yeniden ele alıyor ve eğitilebilir parametreleri azaltıp hızı artıran çoklu sorgulu çapraz dikkat mekanizması olan Verimli Sonda’yı (EP) tanıtıyor; EP, birçok benchmark testinde LP ve önceki dikkatli sonda yöntemlerinden daha iyi performans gösteriyor (Kaynak: HuggingFace Daily Papers)
Makale, PosterCraft’ı öneriyor: Birleşik bir çerçeve altında yüksek kaliteli estetik poster üretimi için yeni bir yaklaşım: PosterCraft, sadece hassas metin oluşturmayı değil, aynı zamanda soyut sanatsal içerik, dikkat çekici düzen ve genel stil uyumunun sorunsuz entegrasyonunu gerektiren estetik posterler üretme zorluğunu çözmeyi amaçlamaktadır. PosterCraft, üretimi optimize etmek için basamaklı bir iş akışı benimser; bu, büyük ölçekli metin oluşturma optimizasyonu, bölgeye duyarlı denetimli ince ayar, estetik metin için pekiştirmeli öğrenme ve ortak görsel-dil geri bildirim iyileştirmesini içerir ve birçok deneyde açık kaynaklı temel çizgilerden önemli ölçüde daha iyi performans gösterir (Kaynak: HuggingFace Daily Papers)
Makale, Token Pertürbasyon Yönlendirmesi (Token Perturbation Guidance) yoluyla difüzyon modellerini iyileştirmeyi öneriyor: Sınıflandırıcıdan bağımsız yönlendirmenin (CFG) belirli bir eğitim süreci gerektirmesi ve yalnızca koşullu üretimle sınırlı olması sorununu çözmek için TPG yöntemi, doğrudan difüzyon ağı içindeki ara token temsillerine pertürbasyon matrisleri uygular. TPG, üretim kalitesini mimari değişiklikler gerektirmeden artırmak için etkili bir yönlendirme sinyali sağlayan norm koruyucu bir karıştırma işlemi kullanır ve hem koşullu hem de koşulsuz üretim için uygundur. Deneyler, TPG’nin koşulsuz üretimde SDXL temel çizgisine göre FID’de yaklaşık 2 kat iyileşme sağladığını göstermektedir (Kaynak: HuggingFace Daily Papers)
Makale, DreamActor-H1’i öneriyor: Hareket tasarımı yoluyla Diffusion Transformers kullanarak yüksek sadakatli insan-ürün tanıtım videoları üretme: DreamActor-H1, yüksek kaliteli insan-ürün etkileşimi tanıtım videoları üretmeyi amaçlayan Diffusion Transformer (DiT) tabanlı bir çerçevedir. Bu yöntem, eşleştirilmiş insan-ürün referans bilgilerini ve ek maskeli çapraz dikkat mekanizmalarını enjekte ederek insan ve ürün kimlik ayrıntılarını (logo, doku gibi) korur. Hassas hareket yönlendirmesi sağlamak için 3D insan ağı şablonlarını ve ürün sınırlayıcı kutularını kullanır ve yapılandırılmış metin kodlamasıyla 3D tutarlılığını artırır (Kaynak: HuggingFace Daily Papers)
Makale, EmbodiedGen’i öneriyor: Somutlaşmış zeka için üretken bir 3D dünya motoru: EmbodiedGen, etkileşimli 3D dünya üretimi için temel bir platformdur ve doğru fiziksel özelliklere ve gerçek dünya ölçeğine sahip, Birleşik Robot Tanımlama Formatı (URDF) kullanan yüksek kaliteli, kontrol edilebilir, fotogerçekçi 3D varlıkları düşük maliyetle ölçeklenebilir bir şekilde üretmeyi amaçlar. Bu varlıklar, çeşitli fizik simülasyon motorlarına doğrudan aktarılabilir ve somutlaşmış zekanın eğitim ve değerlendirme görevlerini destekleyerek geleneksel 3D bilgisayar grafikleri varlıklarının yüksek maliyet ve sınırlı gerçekçilik sorunlarını çözer (Kaynak: HuggingFace Daily Papers)
Yeni araştırma, Apple’ın “Düşünme Yanılsaması” makalesini çürütüyor ve LLM’lerin yeni karmaşık sorunları çözebileceğini savunuyor: Apple şirketinin yakın zamanda yayınladığı ve büyük çıkarım modellerinin (LRM) karmaşık planlama bulmacalarında (Hanoi Kulesi gibi) “doğruluk çöküşü” yaşadığını iddia eden “Düşünme Yanılsaması” (Illusion of Thinking) makalesine karşılık, bir sonraki yorumlayıcı araştırma, Apple’ın sonuçlarının modelin temel akıl yürütme yeteneklerinin başarısızlığından ziyade esas olarak deney tasarımının sınırlamalarını yansıttığını belirtti. Yeni araştırma, orijinal deneydeki token bütçesinin aşılması, kasıtlı olarak kesilmiş çıktıların yanlış değerlendirilmesi ve matematiksel olarak çözülemeyen bulmaca örneklerinin dahil edilmesinin, modelin yeteneklerinin yanlış değerlendirilmesine ortaklaşa yol açtığını savunuyor. Deney yöntemleri ayarlandığında, örneğin modelden ayrıntılı adım listeleri yerine Hanoi Kulesi çözümünü üreten kompakt bir Lua fonksiyonu çıktısı vermesi istendiğinde, model daha önce tamamen başarısız olduğu bildirilen durumlarda yüksek doğruluk gösterdi; bu da modelin akıl yürütemediğini değil, çıktı formatı ve token sınırlamalarıyla kısıtlandığını gösteriyor (Kaynak: Reddit r/LocalLLaMA)

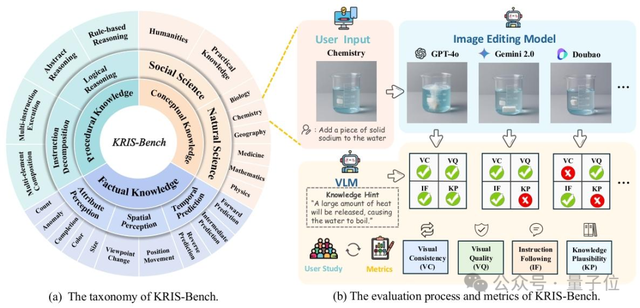
KRIS-Bench: Görüntü düzenleme modellerinin çıkarım yeteneklerini bilgi türü perspektifinden kapsamlı bir şekilde değerlendiren yeni bir benchmark: Güneydoğu Üniversitesi ve diğer kurumlar, bilgi tabanlı görüntü düzenleme sistemlerinin çıkarım yetenekleri için bir benchmark olan KRIS-Bench’i ortaklaşa yayınladı. Olguya dayalı bilgi (renk, miktar gibi), kavramsal bilgi (fiziksel sağduyu gibi) ve prosedürel bilgi (çok adımlı işlemler gibi) olmak üzere üç düzeyden 22 düzenleme görevini alt bölümlere ayırarak 10 ana akım görüntü düzenleme modelini (GPT-Image-1, Gemini 2.0 Flash dahil) değerlendiriyor. Sonuçlar, kapalı kaynaklı model GPT-Image-1’in en iyi performansı gösterdiğini, ancak tüm modellerin prosedürel çıkarım, doğa bilimleri ve çok adımlı sentez gibi derin çıkarım görevlerinde genel olarak zayıf performans gösterdiğini ortaya koyuyor; bu da mevcut modellerin ileri düzey bilişsel yeteneklerindeki eksiklikleri gözler önüne seriyor (Kaynak: 量子位)
Yeni araştırma, RAG’deki halüsinasyonlara direnmek için dil modellerini ince ayarlayan Finetune-RAG yöntemini öneriyor: Büyük dil modelleri, geri getirme ile zenginleştirilmiş üretimde (RAG), geri getirme kusurlu olduğunda (örneğin, dikkat dağıtıcı belge parçacıkları mevcut olduğunda) halüsinasyon üretmeye eğilimlidir. Finetune-RAG, doğru ve yanlış bağlamlar içeren girdi örnekleri üzerinde modeli eğiterek gerçekliğe daha iyi bağlı kalmasını sağlar. Araştırma ekibi, 1600’den fazla çift bağlamlı örnek içeren bir veri kümesi, LLaMA 3.1-8B-Instruct’in ince ayarlanmış bir kontrol noktası ve Bench-RAG adlı bir GPT-4o değerlendirme çerçevesi yayınladı. Değerlendirme, bu yöntemin doğruluğu %77’den %98’e çıkardığını ve kullanışlılık, alaka düzeyi ve derinlik açısından da iyileşmeler sağladığını gösteriyor (Kaynak: Reddit r/MachineLearning)
TeleMath: Telekomünikasyon alanında matematiksel problem çözme yeteneği için ilk LLM benchmark’ı yayınlandı: Büyük dil modellerinin telekomünikasyon alanına özgü, matematiksel açıdan yoğun görevleri çözme yeteneğini değerlendirmek için araştırmacılar TeleMath benchmark’ını tanıttı. Bu benchmark, sinyal işleme, ağ optimizasyonu ve performans analizi gibi telekomünikasyon konularını kapsayan 500 soru-cevap çifti içeriyor. Çeşitli açık kaynaklı LLM’lerin değerlendirilmesi, matematiksel veya mantıksal akıl yürütme için özel olarak tasarlanmış modellerin TeleMath’ta daha iyi performans gösterdiğini, genel amaçlı büyük parametreli modellerin ise genellikle zorluklarla karşılaştığını gösterdi. Veri kümesi ve değerlendirme kodu kullanıma açıldı (Kaynak: HuggingFace Daily Papers)
ChineseHarm-Bench: Çince zararlı içerik tespiti için benchmark yayınlandı: Mevcut zararlı içerik tespit kaynaklarının çoğunlukla İngilizce olması durumuna karşılık, araştırmacılar kapsamlı, profesyonelce etiketlenmiş bir Çince içerik zararı tespit benchmark’ı olan ChineseHarm-Bench’i yayınladı. Bu benchmark, altı temsili kategoriyi kapsıyor ve veriler tamamen gerçek dünyadan geliyor. Etiketleme süreci ayrıca LLM’lere açık uzman bilgisi sağlayan bir bilgi kural tabanı da üretti. Ek olarak, araştırmacılar, küçük modellerin SOTA LLM performansına ulaşmasını sağlayan, yapay olarak etiketlenmiş kuralları ve LLM örtük bilgisini birleştiren bilgiyle zenginleştirilmiş bir temel yöntem önerdiler (Kaynak: HuggingFace Daily Papers)
Yeni araştırma, nedensel temsil öğrenimi yoluyla dil modellerinin potansiyel yeteneklerinin hiyerarşik yapısını keşfediyor: Dil modellerinin yeteneklerini sadık bir şekilde değerlendirmek ve karıştırıcı etkiler ile yüksek hesaplama maliyetlerinin üstesinden gelmek için bu çalışma, nedensel bir temsil öğrenimi çerçevesi önermektedir. Bu çerçeve, gözlemlenen benchmark performansını az sayıda potansiyel yetenek faktörünün doğrusal bir dönüşümü olarak modeller ve temel modeli ortak bir karıştırıcı faktör olarak kontrol ettikten sonra bu potansiyel faktörler arasındaki nedensel ilişkileri tanımlar. Open LLM Leaderboard’daki 1500’den fazla model verisine uygulanan araştırma, genel problem çözme yeteneğinden talimat takip etme yeterliliğine ve ardından matematiksel akıl yürütme yeteneğine kadar net bir nedensel yolu ortaya koyan özlü, üç düğümlü bir doğrusal nedensel yapı bulmuştur (Kaynak: HuggingFace Daily Papers)
DeepLearning.AI, “GenAI Uygulamaları için İş Akışlarını Düzenleme” adlı yeni bir kurs başlattı: Andrew Ng, popüler açık kaynak aracı Airflow 3.0 kullanarak güvenilir üretken AI boru hatları oluşturmayı ve dağıtmayı öğreten yeni bir kısa kurs için Astronomer ile işbirliği yaptığını duyurdu. Kurs içeriği, iş akışlarını ayrı görevlere ayırma, görev zamanlama, paralel yürütme, hata kurtarma ve gözlemlenebilirlik gibi konuları içeriyor ve öğrencilerin prototip Jupyter not defterlerini veya Python komut dosyalarını üretime hazır iş akışlarına dönüştürmelerine yardımcı olmayı amaçlıyor (Kaynak: DeepLearningAI)
Makale, bileşik AI sistem optimizasyon yöntemlerini, zorluklarını ve gelecekteki yönlerini tartışıyor: LLM’ler ve AI sistemleri geliştikçe, birden fazla bileşeni entegre eden bileşik AI sistemleri karmaşık görevleri yerine getirme konusunda giderek daha olgunlaşıyor. Bu makale, sayısal ve dil tabanlı teknikler de dahil olmak üzere bileşik AI sistem optimizasyonundaki en son gelişmeleri sistematik olarak gözden geçirmektedir. Makale, bileşik AI sistem optimizasyonu kavramını biçimlendirmekte, mevcut yöntemleri sınıflandırmakta ve bu alandaki açık araştırma zorluklarını ve gelecekteki yönlerini vurgulamaktadır (Kaynak: HuggingFace Daily Papers)
💼 İş Dünyası
Disney ve Universal Studios, görüntü oluşturucu Midjourney’e telif hakkı ihlali davası açtı: Disney ve Universal Studios, Midjourney’i, Star Wars, Frozen, Minyonlar gibi karakterleri içeren yaratıcı kütüphanelerini izinsiz olarak modelini eğitmek için kullanmakla ve büyük miktarda türev eser üretip dağıtmakla suçlayarak “dipsiz bir intihal kuyusu” olarak nitelendirdi. Bu dava, AI tarafından üretilen içerik ile fikri mülkiyet sınırları hakkındaki tartışmaları yeniden alevlendirdi (Kaynak: Reddit r/ArtificialInteligence)
NVIDIA ve Deutsche Telekom, 2026’ya kadar Avrupa’daki üreticiler için ilk endüstriyel AI bulutunu kurmak üzere işbirliği yapıyor: Almanya Federal Şansölyesi Friedrich Merz ve NVIDIA CEO’su Jensen Huang, Almanya’nın küresel bir AI lideri olarak konumunu sağlamlaştırmak için daha fazla stratejik işbirliğini görüşmek üzere bir araya geldi. Bu vizyonun bir parçası olarak Deutsche Telekom ve NVIDIA, 2026 yılına kadar Avrupa’daki üreticiler için dünyanın ilk endüstriyel AI bulutunu kurmayı planladıkları yeni bir işbirliği duyurdu. Bu güvenli ve Avrupa normlarına uygun altyapı, tam veri egemenliği sağlarken en son yenilikleri destekleyecektir (Kaynak: nvidia)

Söylentiye göre Sam Altman, tamamen hisse senediyle satın almalar yoluyla OpenAI’nin kar amacı gütmeyen kontrolünü sulandırabilir: OpenAI’nin yakın zamanda io’yu (6.5 milyar $) ve Windsurf’ü (3 milyar $) tamamen hisse senediyle satın alması spekülasyonlara yol açtı. Hacker News’te yer alan bir teoriye göre, Sam Altman bu işlemleri kullanarak kar amacı gütmeyen OpenAI Inc.’in kar amacı güden OpenAI Global LLC (şimdiki OpenAI PBC) üzerindeki kontrolünü kademeli olarak sulandırabilir ve böylece tamamen kar amacı güden bir şirkete dönüşümün yasal kısıtlamalarından kaçınabilir. Bu hamle bazıları tarafından Altman’ın 2014’te Reddit’e yaptığı operasyonla ilişkilendiriliyor, ancak bazı görüşler bu satın almaların normal ticari strateji hamleleri olduğunu savunuyor (Kaynak: Reddit r/ArtificialInteligence)
🌟 Topluluk
AI’nin gerçekten “akıl yürütüp yürütemeyeceği” tartışması devam ediyor, Apple makalesi tartışma yarattı: Apple şirketinin yakın tarihli makalesinde büyük dil modellerinin (LLM) karmaşık görevlerdeki (Hanoi Kulesi gibi) performansının gerçek akıl yürütme olmadığı, daha çok örüntü eşleştirme olduğu iddiası toplulukta geniş çapta tartışıldı. OpenAI’nin eski çalışanı Miles Brundage, o3-pro’nun karmaşık metin oyunlarını çözmesini yorumlarken alaycı bir şekilde “Eğer bu akıl yürütme değilse ne akıl yürütmedir?” diye sordu. Sonraki bir araştırma, Apple makalesindeki “akıl yürütme çöküşü” olgusunun, modelin kendisinin akıl yürütme yeteneğinin eksikliğinden ziyade deney tasarımının sınırlamalarından (token sınırlaması, çözülemeyen sorunların yanlış değerlendirilmesi gibi) kaynaklanabileceğini belirtti. Test yöntemleri ayarlandığında, model daha önce başarısız olduğu görevlerde iyi performans gösterdi; bu da AI akıl yürütme yeteneklerinin değerlendirilmesinin daha dikkatli bir deney tasarımı gerektirdiğini gösteriyor (Kaynak: o3-pro’nun zorlu metin oyunlarına verdiği yanıtlar ilgiyle izleniyor, OpenAI eski çalışanı Apple ile dalga geçiyor: Bu akıl yürütme değilse ne akıl yürütmedir, Reddit r/LocalLLaMA)
Nvidia CEO’su Jensen Huang ile Anthropic CEO’su Dario Amodei’nin AI’nin geleceği konusundaki görüşleri arasında önemli farklılıklar bulunuyor: Fortune’un haberine göre, Nvidia CEO’su Jensen Huang, Anthropic CEO’su Dario Amodei’nin AI hakkındaki neredeyse tüm görüşlerine katılmadığını belirtti. Amodei sık sık AI’nin potansiyel risklerini ve istihdam üzerindeki büyük etkisini vurguluyor ve AI gelişiminin daha sıkı kontrol edilmesi ve az sayıda “sorumlu” kuruluş tarafından yönetilmesi gerektiğini savunuyor. Huang ise bu tür görüşlere şüpheyle yaklaşıyor ve AI teknolojilerinin yaygın uygulamasını ve gelişimini desteklemeye daha eğilimli. Topluluk yorumları, Huang’ın duruşunun ticari çıkarlarıyla ilgili olabileceğini, çünkü Nvidia’nın AI donanımının ana tedarikçisi olduğunu öne sürüyor (Kaynak: Reddit r/ArtificialInteligence, Reddit r/ClaudeAI)

Claude Code’un 20 dolarlık abonelik planı, yüksek fiyat/performans oranı nedeniyle geliştiricilerden övgü alıyor: Birçok geliştirici, Anthropic Claude Code’un aylık 20 dolarlık abonelik planını kullanma konusundaki olumlu deneyimlerini sosyal medyada paylaştı ve bunun son derece uygun maliyetli olduğunu, projelerde maliyetini hızla çıkardığını belirtti. Kullanıcılar, belirli bir hız sınırlaması olmasına rağmen, Claude Code’un kodlamaya yardımcı olma, yeni diller öğrenme (C#’tan SwiftUI’ye geçiş gibi) ve proje talimatlarını optimize etme (CLAUDE.md dosyası gibi) konularında mükemmel performans gösterdiğini ve iş verimliliğini önemli ölçüde artırdığını belirtti. Bazı kullanıcılar diğer AI programlama yardımcı araçlarının aboneliklerini iptal etmeyi bile düşünüyor (Kaynak: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Topluluk, AI’nin psikoloji alanındaki gelecekteki uygulamalarını ve etik zorluklarını tartışıyor: LLM’lerin terapi ipuçları tasarlaması, uygulamaların telefon sensörleri aracılığıyla duyguları izlemesi gibi teknolojik gelişmelerle birlikte AI, psikolojiye giderek daha fazla nüfuz ediyor. Topluluk tartışmaları, AI’nin klinik pratikte terapistlerin yeteneklerini artırıp artırmayacağı veya sonunda bazı işlerin yerini alıp almayacağı, AI’nin değerlendirme ve araştırmadaki güvenilirliği, psikoloji mesleki eğitimi ve istihdam piyasası üzerindeki etkisi ile veri yanlılığı, gizlilik ve “robot terapistlerin” sınırlamaları başta olmak üzere AI uygulamalarının etik ve düzenleyici sorunlarına odaklanıyor. Temel endişe, AI’nin verimliliği ve kişiselleştirilmiş hizmetleri artırma potansiyelinden yararlanırken hasta güvenliğini nasıl sağlayacağı ve kişilerarası bağlantının tedavi edici değerini nasıl koruyacağıdır (Kaynak: Reddit r/artificial)
Unsloth’un 3.53bit nicelenmiş DeepSeek-R1-0528 modeli, Aider Polyglot kodlama benchmark’ında iyi performans gösteriyor: Unsloth ekibi, DeepSeek-R1-0528 modelini 3.53bit niceledikten (UD-Q3_K_XL) sonra, Aider Polyglot kodlama benchmark testinde %68 geçme oranı elde etti. Testte 40960 bağlam boyutu ve Flash Attention kullanıldı ve yaklaşık 300GB RAM/VRAM gerekti. Bu sonuç, Claude Sonnet 3.7 ve Claude Opus 4 arasında yer alıyor ve nicelenmiş modellerin yüksek kodlama yeteneğini koruma potansiyelini gösteriyor. Topluluk üyeleri, bu tür modellerin yerel olarak çalıştırılmasındaki performanstan etkilendiklerini belirttiler ve daha fazla nicelenmiş sürümün test sonuçlarını bekliyorlar (Kaynak: Reddit r/LocalLLaMA)
💡 Diğer
GCP küresel kesinti kazası raporu açıklandı: Yasadışı kota politikası hizmet kesintisine neden oldu: Google Cloud Platform (GCP) yakın tarihli küresel kesinti kazasının raporu, nedenin küresel API yönetim sistemine yanlış bir kota politikası (örneğin saatte yalnızca 1 istek gibi) gönderilmesi olduğunu gösteriyor; bu da harici isteklerin kota aşımı nedeniyle reddedilmesine (403 hatası) yol açtı. Mühendisler durumu fark ettikten sonra etkilenen API’lerin kota kontrolünü devre dışı bıraktı. Ancak us-central1 bölgesinde, eski politikayı temizleyip yeni bir politika yazmaya çalışırken önbellekleme sorunları nedeniyle veritabanı aşırı yüklendi ve kurtarma süresi daha uzun sürdü. Diğer bölgeler ise önbelleği kademeli olarak temizleyerek kurtarıldı ve tüm süreç yaklaşık 2 saat sürdü (Kaynak: karminski3)

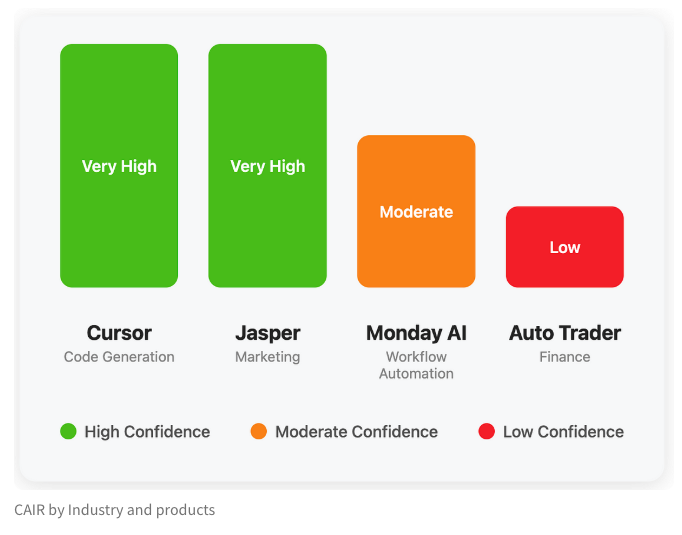
LangChain ekibi, AI ürünlerinin başarı potansiyelini değerlendirmek için CAIR metriğini önerdi: LangChain’den Harrison Chase, Assaf Elovic ile birlikte yazdığı bir makalede, bazı AI ürünlerinin neden hızla yaygınlaşırken diğerlerinin zorlandığını tartıştı. Model yeteneğinin tek belirleyici faktör olmadığını, kullanıcı deneyiminin (UX) hayati önem taşıdığını savundular ve “CAIR” (Confidence in AI Results, AI Sonuçlarına Güven) metriğini önerdiler. CAIR ne kadar yüksekse, ürün benimsenme oranı o kadar yüksek olur. Bu çerçeve, geliştiricilerin kullanıcı güvenini etkileyen çeşitli bileşenleri belirleyip iyileştirmelerine ve böylece ürün başarı oranını artırmalarına yardımcı olmayı amaçlıyor (Kaynak: hwchase17, swyx, hwchase17, Hacubu)
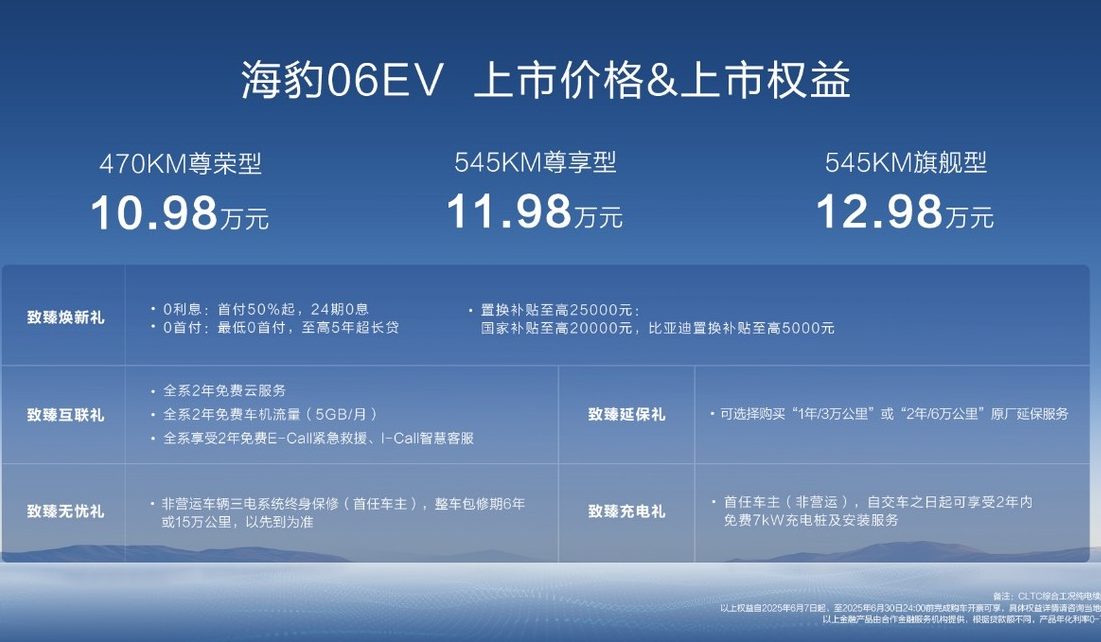
BYD, yeni tamamen elektrikli aile coupe’si Seal 06EV’yi tanıttı, başlangıç fiyatı 109.800 yuan: BYD Ocean Network, Chongqing Otomobil Fuarı’nda Seal 06EV’yi tanıttı; şık ve kaliteli bir coupe olarak konumlandırılan aracın 3 farklı donanım seçeneği bulunuyor ve fiyat aralığı 109.800 yuan ile 129.800 yuan arasında değişiyor. Araç, BYD e-platform 3.0 Evo üzerine inşa edilmiş olup, sekiz-bir-arada akıllı elektrikli tahrik sistemi ve yeni nesil geniş sıcaklık aralıklı yüksek verimli ısı pompası sistemi ile donatılmıştır; CLTC çalışma koşullarında 470KM ve 545KM olmak üzere iki farklı menzil sunmaktadır. Araç, arkadan itişli bir güç aktarma düzenine, DiSus-C akıllı sönümleme gövde kontrol sistemine ve yüksek hızlı otoyol navigasyonu, otomatik park etme gibi işlevleri destekleyen “Eye of the Gods C” akıllı sürüş destek sisteminin üç gözlü versiyonuna sahiptir (Kaynak: 量子位)