Schlüsselwörter:Tesla Robotaxi, AMD MI350, OpenAI o3-pro, iFlytek AIUI, Yuanrong Qixing VLA, DeepSeek Nano-vLLM, Ant Group Ming Lite Omni, L2-Serienfahrzeuge mit L4-Autonomie, Leistungsvergleich zwischen AMD MI350X und B200, Langkontext-Verarbeitungsfähigkeit des o3-pro-Modells, AIUI Vollduplex-Interaktionstechnologie, Vision-Sprache-Handlung-Modell VLA
🔥 Fokus
Teslas Robotaxi erstmals öffentlich unterwegs, Musk sagt, L2-Serienfahrzeuge können autonomes Fahren Level 4 ohne Modifikationen erreichen: Teslas Robotaxi (überarbeitetes Model Y) wird bereits in Austin getestet, mit neuem Robotaxi-Logo, aber unter Beibehaltung des Lenkrads. Musk erklärte, dass alle Tesla-Serienfahrzeuge unüberwachtes autonomes Fahren erreichen können. Die aktuellen Testfahrzeuge sind mit einer internen Testversion von FSD ausgestattet, deren Parametermenge 4,5-mal so groß ist wie die des aktuellen FSD. Es wird erwartet, dass diese nach Optimierung noch in diesem Jahr ausgerollt wird. Der Robotaxi-Dienst soll am 22. Juni für die Öffentlichkeit zugänglich gemacht werden, beginnend in Austin. Dieser Schritt markiert die Weiterentwicklung von Teslas L2 FSD zu L4/L5 Robotaxi und könnte die Wettbewerbslandschaft in der autonomen Fahrindustrie beschleunigen, insbesondere eine Herausforderung für Akteure der L4-Technologieroute wie Waymo darstellen (Quelle: 量子位)

AMD veröffentlicht leistungsstärkste KI-Chips der MI350-Serie, übertrifft Nvidias B200: AMD CEO Lisa Su und OpenAI CEO Sam Altman stellten gemeinsam die MI350X und MI355X GPUs vor. Diese Chips verwenden einen 3nm-Fertigungsprozess, verfügen über 185 Milliarden Transistoren und 288 GB HBM3E-Speicher, was der 1,6-fachen Speicherkapazität von Nvidias B200 entspricht. Offiziellen Daten zufolge ist die MI350-Serie bei der Inferenz mit Llama 3.1 405B bei FP4-Genauigkeit 30 % schneller als der B200 und verfügt über die doppelte FP64-Rechenleistung von Nvidia. AMD kündigte außerdem die gemeinsam mit OpenAI entwickelte MI400-Serie für das nächste Jahr an, was den Wettbewerb auf dem KI-Chipmarkt weiter verschärfen wird (Quelle: 量子位)

Inferenzfähigkeiten des OpenAI o3-pro Modells erregen Aufmerksamkeit, tatsächliche Leistung weicht leicht von offiziellen Tests ab: Das neueste Inferenzmodell o3-pro von OpenAI zeigte bei der Verarbeitung komplexer Wortspiele (z. B. Generierung spezifischer Antworten basierend auf den Merkmalen der Songtitel der Sängerin Sabrina Carpenter) beeindruckende Fähigkeiten, was den ehemaligen Leiter des AGI Readiness Teams von OpenAI dazu veranlasste, Apples frühere Zweifel an den Inferenzfähigkeiten großer Modelle zu verspotten. Auf maßgeblichen Ranglisten wie LiveBench war die durchschnittliche Coding-Punktzahl von o3-pro jedoch fast identisch mit der von o3, und der Agent-Coding-Score war sogar niedriger. Fiction.LiveBench-Tests zeigten, dass o3-pro bei kurzem Kontext hervorragend abschneidet, bei der Verarbeitung von 192k ultralangem Kontext jedoch immer noch Gemini 2.5 Pro unterlegen ist. Ben Hylak, ehemaliger Ingenieur bei Apple und SpaceX, wies darauf hin, dass die tatsächliche Leistungsfähigkeit von o3-pro stark von ausreichender Eingabe von Hintergrundinformationen abhängt und es eher als Berichtsgenerator denn als einfacher Chatpartner geeignet ist, wobei es deutliche Verbesserungen bei Tool-Nutzung und Umgebungsverständnis aufweist (Quelle: 量子位)

iFlytek aktualisiert AIUI Mensch-Maschine-Interaktionsplattform und Roboter-Superhirn-Plattform und fördert die tiefe Zusammenarbeit intelligenter Hardware: iFlytek kündigte ein umfassendes Upgrade seiner Mensch-Maschine-Interaktionsplattform AIUI an, das sich auf die Verbesserung der Vollduplex-Interaktion, der Emotionserkennung und -ausdrucksfähigkeit sowie eines menschenähnlichen Gedächtnissystems konzentriert. Speziell für Kinderszenarien wurde eine eigene Interaktionslösung eingeführt, um die Erkennung und das Verständnis von Kindersprache zu verbessern. Gleichzeitig wurde die Roboter-Superhirn-Plattform, basierend auf dem Spark großen Modell, in Bezug auf multimodale Interaktion, semantisches Verständnis und Wissensanwendung gestärkt und ein „intelligenter Sprachrucksack“ eingeführt, der es bestehenden Robotern ermöglicht, ohne Hardware-Modifikationen Sprachinteraktion zu realisieren. Diese Upgrades zielen darauf ab, intelligente Hardware von grundlegender Interaktion zu tiefer intelligenter Kollaboration zu führen und verschiedene Bereiche wie Fahrzeuge, KI-Hardware und Robotik zu stärken (Quelle: 量子位)

🎯 Trends
DeepRoute.ai kooperiert mit Volcano Engine, um auf Basis des Doubao großen Modells einen Agent für die physische Welt (VLA) zu entwickeln: DeepRoute.ai CEO Zhou Guang kündigte eine Zusammenarbeit mit Volcano Engine an, um gemeinsam unter Nutzung des Doubao großen Modells zukunftsweisende Technologien wie das Vision-Language-Action (VLA) Modell zu entwickeln, mit dem Ziel, einen Agent für die physische Welt zu schaffen. Das VLA-Modell von DeepRoute.ai soll im dritten Quartal 2025 auf den Verbrauchermarkt kommen und über vier Kernfunktionen verfügen: räumliches semantisches Verständnis, Erkennung atypischer Hindernisse, Verständnis von textbasierten Wegweisern und Sprachsteuerung des Fahrzeugs. Ziel ist es, die Sicherheit und Intelligenz der Fahrerassistenz zu verbessern. Das VLA-Modell hat bereits Straßentests abgeschlossen, und es wird erwartet, dass noch in diesem Jahr mehr als fünf KI-Fahrzeugmodelle mit diesem Modell auf den Markt kommen werden (Quelle: 量子位)

DeepSeek-Forscher repliziert vLLM mit 1200 Zeilen Code, übertrifft in einigen Szenarien die Leistung des Originals: DeepSeek-Forscher Yu Xingkai hat das Projekt Nano-vLLM als Open Source veröffentlicht, das die Kernfunktionen von vLLM, einschließlich Schlüsseltechnologien wie PagedAttention, mit weniger als 1200 Zeilen Python-Code implementiert. Das Projekt zielt darauf ab, eine minimierte und vollständig lesbare Version von vLLM zum Lernen und Verstehen bereitzustellen. Unter spezifischen Testbedingungen mit H800-Hardware und dem Qwen3-8B-Modell übertraf der Durchsatz von Nano-vLLM sogar den des ursprünglichen vLLM und demonstrierte seine Effizienz. vLLM ist ein von UC Berkeley entwickeltes Framework für LLM-Inferenz und -Serving, das durch seinen PagedAttention-Algorithmus den Durchsatz von LLM-Diensten erheblich verbessert (Quelle: 量子位)
Chinesische Unternehmen nutzen „fliegende Festplattenkoffer“, um US-Exportbeschränkungen für KI-Chips zu umgehen: Laut einem Bericht des Wall Street Journal verfolgen chinesische Unternehmen angesichts der US-Exportbeschränkungen für High-End-KI-Chips eine neue Strategie: Ingenieure transportieren Festplatten mit großen Mengen an Trainingsdaten (z. B. 80 TB) zu Rechenzentren in Übersee, etwa in Malaysia. Dort nutzen sie Server mit fortschrittlichen Chips von Nvidia und anderen Herstellern für das Training von KI-Modellen und bringen die Modellparameter anschließend zurück nach China. Dieser Schritt zielt darauf ab, die Schwierigkeiten beim direkten Import von Chips zu umgehen und hat den Aufstieg von KI-Rechenzentren in Südostasien und im Nahen Osten gefördert. Ehemalige Beamte des US-Handelsministeriums äußerten sich besorgt darüber (Quelle: dotey)

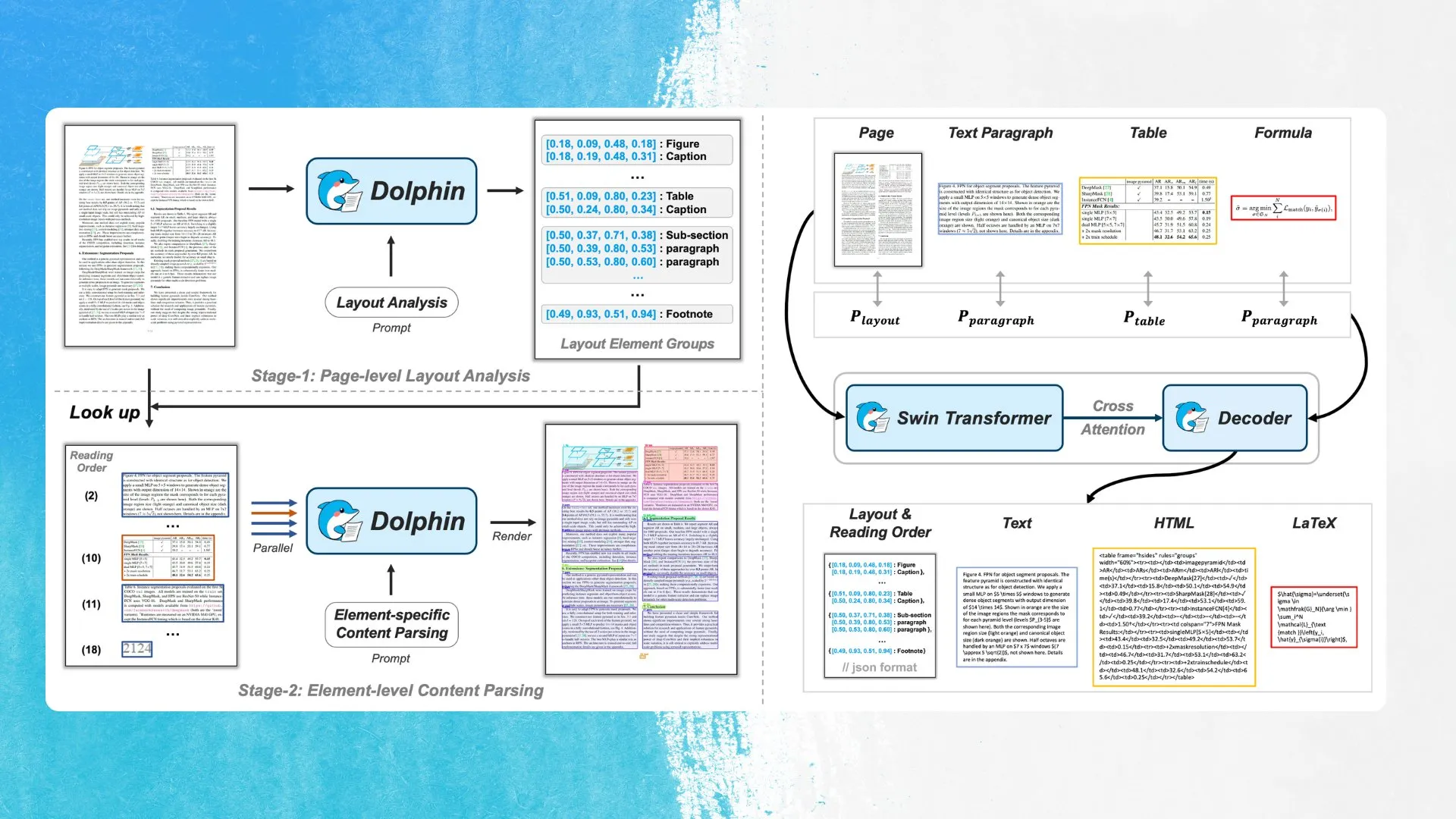
ByteDance stellt neues OCR-Modell Dolphin vor, das Layoutelementerkennung und parallele Analyse verwendet: ByteDance hat ein neues OCR-Modell namens Dolphin unter der MIT-Lizenz veröffentlicht. Das Modell erkennt zunächst Elemente im Dokumentenlayout (wie Tabellen, Formeln usw.) und analysiert dann jedes Element parallel, um den Inhalt zu generieren. Das Modell und eine Demo sind auf Hugging Face Hub verfügbar. Diese Methode zielt darauf ab, die Genauigkeit und Effizienz bei der Erkennung komplexer Dokumentstrukturen zu verbessern (Quelle: mervenoyann)
OpenAI ChatGPT Projektfunktion erweitert, unterstützt Tiefenrecherche, Sprachmodus und mobilen Dateiupload: OpenAI kündigte mehrere Verbesserungen für die „Projects“-Funktion in ChatGPT an, darunter erweiterte Unterstützung für Tiefenrecherche, Integration des Sprachmodus, verbesserte Speicherfunktion zum Zitieren vergangener Chats innerhalb eines Projekts sowie Unterstützung für Dateiuploads und Modellauswahl auf Mobilgeräten. Diese Updates zielen darauf ab, die Fähigkeit der Nutzer zu verbessern, konzentriertere und komplexere Arbeiten in ChatGPT durchzuführen (Quelle: kevinweil)
EuroLLM-Team veröffentlicht Vorschauversionen mehrerer neuer Modelle, darunter ein 22B-Modell und ein kleines MoE-Modell: Das EuroLLM-Team hat Vorschauversionen mehrerer neuer Modelle veröffentlicht, darunter eine Basisversion und eine instruktionsoptimierte Version eines 22B-Parameter-Modells, zwei visuelle Modelle (1,7B und 9B Parameter) basierend auf älteren EuroLLM-Versionen sowie ein kleines Mixture-of-Experts (MoE) Modell mit 0,6B aktiven Parametern und 2,6B Gesamtparametern. Alle diese Modelle stehen unter der Apache-2.0-Lizenz. Erste Tests zeigen, dass das kleine MoE-Modell für seine Größe überraschend gut abschneidet (Quelle: Reddit r/LocalLLaMA)

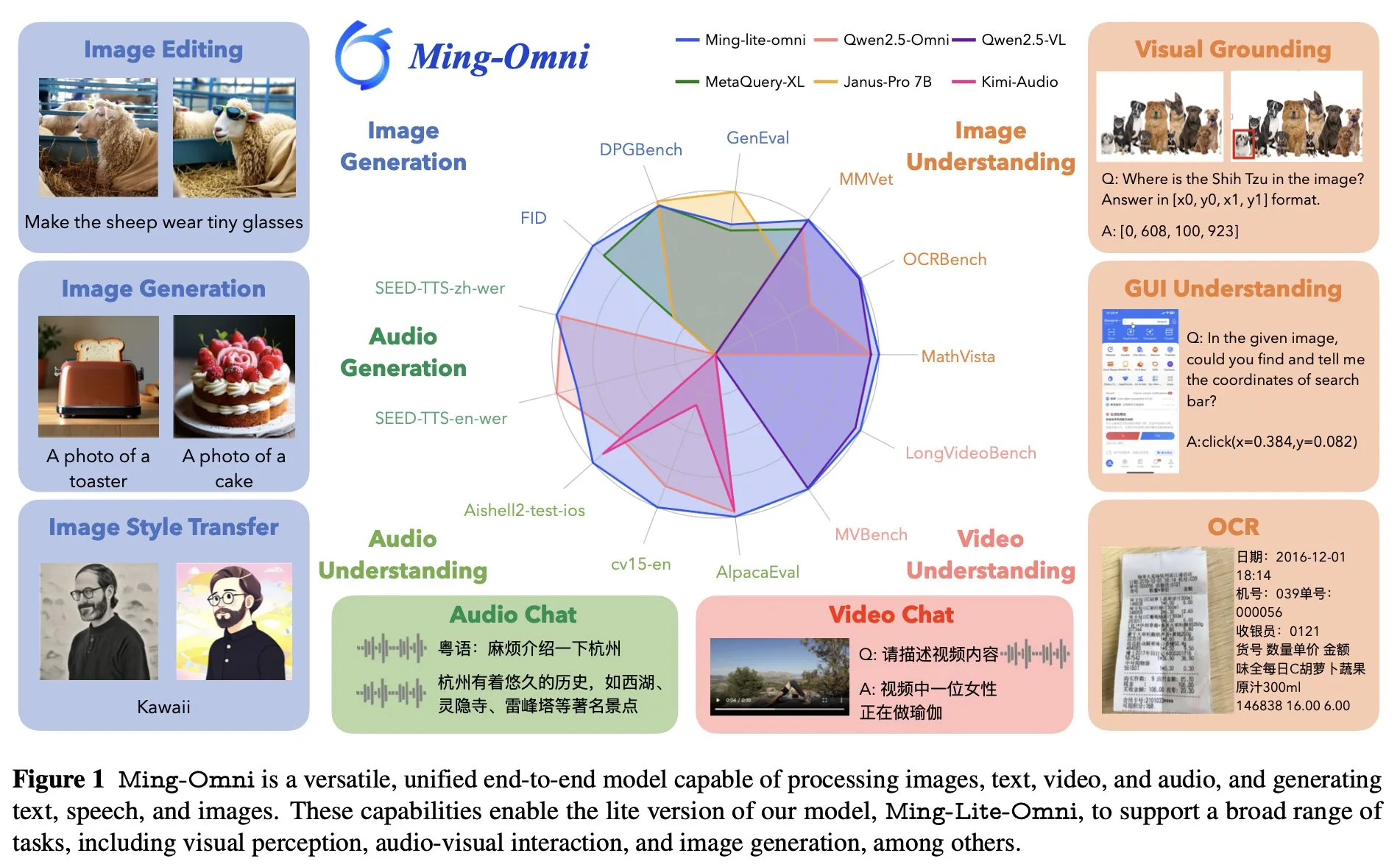
Ant Group veröffentlicht End-to-End Allround-Modell Ming Lite Omni, konkurriert mit GPT-4o: Die Ant Group hat das Modell Ming Lite Omni vorgestellt, das verschiedene Funktionen wie Hören, Sprechen und Bilderzeugung realisieren kann und leistungsmäßig mit GPT-4o konkurriert. Ming Lite Omni übertrifft Qwen2.5VL-7B bei GUI-Aufgaben, erreicht bei mehreren öffentlichen Benchmarks für Audioverständnis State-of-the-Art-Ergebnisse und zeigt auch eine hervorragende Leistung im Videoverständnis. Das Modell verwendet eine Mixture-of-Experts (MoE) Architektur mit nur 2,8B aktiven Parametern und wurde speziell für die Audio- und Bilderzeugung optimiert, z. B. durch die Verwendung von BPE zur Reduzierung der Audio-Token-Framerate und multiskalierbare lernbare Token zur Verbesserung der Bildgenerierungsqualität (Quelle: mervenoyann)
NVIDIA und Mistral AI kooperieren beim Aufbau der KI-Cloud-Plattform Mistral Compute: NVIDIA kündigte auf der GTC-Konferenz eine Zusammenarbeit mit Mistral AI an, um gemeinsam eine KI-Cloud-Plattform namens Mistral Compute aufzubauen. Dieser Schritt wird als bedeutender Vorteil für die USA und die Open-Source-Community angesehen, mit dem Ziel, durch von US-Chips unterstützte offene Modelle eine Vorlage für den globalen Aufbau von KI-Infrastruktur zu schaffen (Quelle: arthurmensch)
Hugging Face kündigt vollständige Umarmung von PyTorch an, vereinfacht Transformers-Bibliothek: Lysandre Jik, Chief Open Source Officer bei Hugging Face, erklärte, dass angesichts des Konsenses der Nutzerbasis für PyTorch zukünftig alle Anstrengungen auf PyTorch konzentriert werden, um die Transformers-Bibliothek zu verschlanken und ein schlankeres Toolkit anzubieten. PyTorch begrüßte dies offiziell und betonte, dass dieser Schritt zur Aufrechterhaltung der Code-Schlankheit beiträgt (Quelle: reach_vb)

ByteDance stellt Echtzeit-Interaktive Videogenerierungstechnologie APT2 vor: ByteDance präsentierte seine neueste Technologie zur interaktiven Videogenerierung in Echtzeit, APT2 (Autoregressive Adversarial Post-Training). Diese Technologie zielt durch autoregressives adversariales Post-Training darauf ab, qualitativ hochwertige, interaktive Videoinhalte in Echtzeit zu generieren und treibt damit die Entwicklung im Bereich der Videogenerierung weiter voran (Quelle: NerdyRodent)
🧰 Tools
Llama-Server Launcher: Ein llama.cpp Server-Starter mit GUI, fokussiert auf CUDA-Leistungsoptimierung: Ein Entwickler teilte seinen persönlich genutzten Llama-Server-Starter, geschrieben in Python und mit einer grafischen Benutzeroberfläche (GUI). Das Tool zielt darauf ab, die Konfiguration und den Start von llama.cpp-Diensten zu vereinfachen, mit besonderem Augenmerk auf die CUDA-Leistungsoptimierung. Zu den Funktionen gehören Modellauswahl, Pfadeinstellungen, Anpassung der Kontext- und Batch-Größe, GPU-Offloading, FlashAttention, Tensor-Splitting und andere erweiterte Leistungseinstellungen sowie die Auswahl von Chat-Vorlagen und die Verwaltung von Umgebungskonfigurationen. Es unterstützt die automatische Erfassung von GPU- und Systeminformationen, die Analyse von GGUF-Modellmetadaten und kann plattformübergreifende Startskripte (.ps1/.sh) generieren (Quelle: Reddit r/LocalLLaMA)
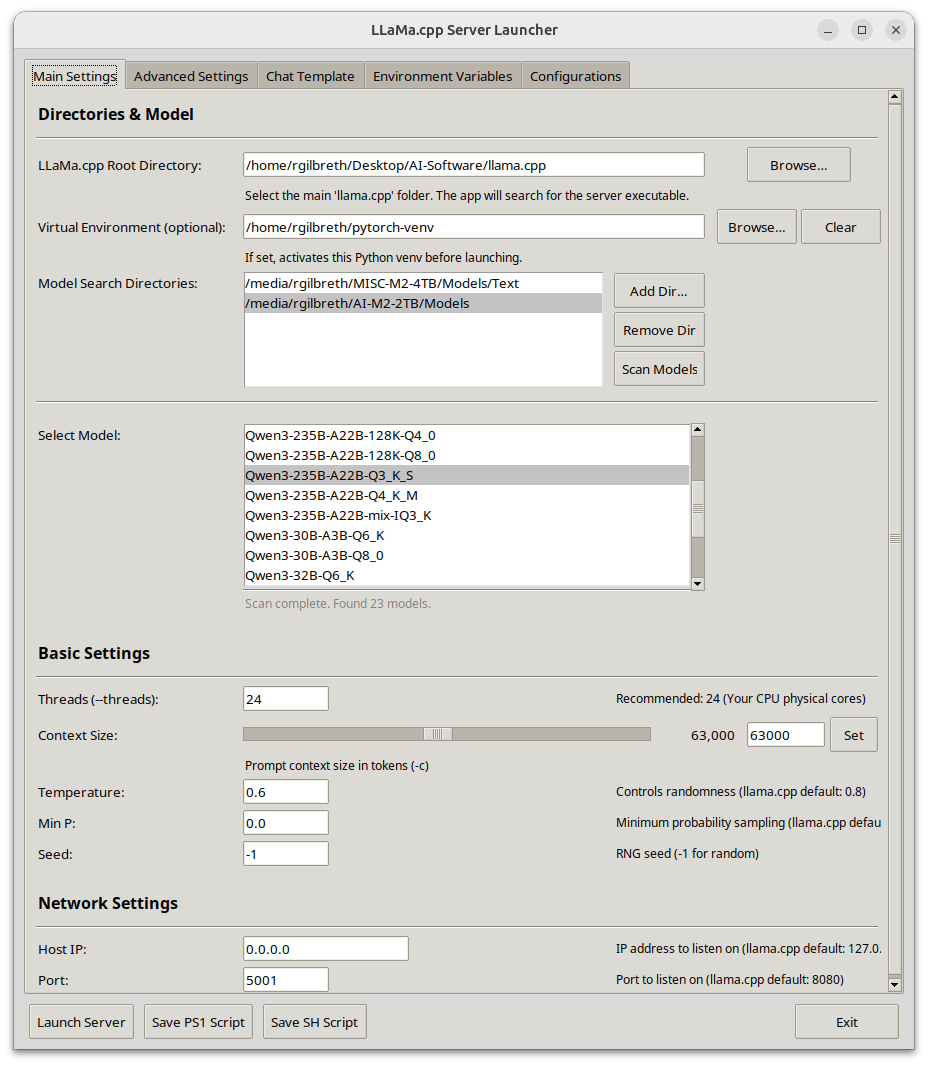
Together AI veröffentlicht Open-Source Data Scientist Agent: Together AI hat einen Open-Source-KI-Agenten entwickelt, der wie ein Datenwissenschaftler schlussfolgern kann. Der Agent kann Daten laden, Python-Code schreiben, bei Modellversagen neu trainieren und reale Kaggle- und DABStep-Aufgaben lösen. Dieser Schritt zielt darauf ab, die Automatisierung und Demokratisierung von KI im Bereich Data Science voranzutreiben (Quelle: percyliang)
AutoMind: Ein adaptives, wissensbasiertes Agenten-Framework für die Automatisierung von Data Science: AutoMind ist ein neues LLM-Agenten-Framework, das darauf abzielt, die Grenzen bestehender Data-Science-Agenten bei der Bewältigung komplexer und innovativer Aufgaben zu überwinden, indem es Expertenwissensdatenbanken integriert, einen Agenten-Wissensbaum-Suchalgorithmus verwendet und adaptive Codierungsstrategien einsetzt, um so die reale Wirksamkeit automatisierter maschineller Lernprozesse zu verbessern (Quelle: HuggingFace Daily Papers)
LlamaParse veröffentlicht „Presets“-Funktion zur Vereinfachung der Dokumentenanalyse-Konfiguration: LlamaParse führt die Funktion „Presets“ (Voreinstellungen) ein, die eine Reihe leicht verständlicher, vorkonfigurierter Modi bietet, um Einstellungen für verschiedene Anwendungsfälle zu optimieren. Dazu gehören schnelle, ausgewogene und erweiterte Modi für allgemeine Szenarien sowie optimierte Modi für häufige Anwendungsfälle wie Rechnungen, wissenschaftliche Arbeiten, technische Dokumentationen und Formulare. Ziel ist es, den Nutzern eine bequemere Wahl zwischen Geschwindigkeit und Genauigkeit zu ermöglichen (Quelle: jerryjliu0)
OpenWebUI fügt o3-pro-Unterstützungsfunktion hinzu und erweitert die Modellkompatibilität: Ein Community-Entwickler hat eine neue Funktion für OpenWebUI erstellt, die die Unterstützung für das o3-pro-Modell durch Hinzufügen von Response-API-Unterstützung, Kostenverfolgung, Multi-Key-Unterstützung und Websuche erweitert. Dies ermöglicht es Benutzern, o3-pro in OpenWebUI zu verwenden, ohne das offizielle Premium-Abonnement abschließen zu müssen (Quelle: Reddit r/OpenWebUI)
📚 Lernen
Studie untersucht die Zerlegung von MLP-Aktivierungen in interpretierbare Merkmale mittels Semi-Nonnegative Matrix Factorization (SNMF): Diese Forschung schlägt vor, SNMF zur direkten Zerlegung der Aktivierungen von Multilayer Perceptrons (MLP) zu verwenden, um dünnbesetzte Merkmale zu lernen, die aus linearen Kombinationen gemeinsam aktivierter Neuronen bestehen. Diese Merkmale werden dann auf ihre aktivierenden Eingaben abgebildet, wodurch sie direkt interpretierbar werden. Experimente zeigen, dass SNMF-abgeleitete Merkmale bei der kausalen Lenkung Sparse Autoencoder (SAE) überlegen sind und mit von Menschen interpretierbaren Konzepten übereinstimmen, was hierarchische Strukturen im MLP-Aktivierungsraum aufdeckt (Quelle: HuggingFace Daily Papers)
Neue Studie stellt LoRMA vor: Ein neues Paradigma zur Feinabstimmung von LLMs durch Low-Rank Multiplicative Adaptation: Traditionelles LLM-Finetuning aktualisiert Gewichte typischerweise additiv, während LoRMA multiplikative Updates untersucht. Um das Problem der „Rangunterdrückung“ durch niedrigrangige Matrizen zu lösen, führt die Studie neuartige Rangerweiterungsoperationen basierend auf Permutation und Addition ein und stellt durch effiziente Umsortierungsoperationen die Recheneffizienz sicher. Experimente zeigen, dass LoRMA wettbewerbsfähig ist und neue Ansätze für die LLM-Anpassung bietet (Quelle: Reddit r/deeplearning)
Studie schlägt TaxoAdapt-Framework vor, um von LLMs erstellte mehrdimensionale Taxonomien an sich entwickelnde Forschungskorpora anzupassen: Angesichts der Herausforderung, wissenschaftliche Literatur zu organisieren, kann das TaxoAdapt-Framework von LLMs generierte Klassifikationssysteme dynamisch an spezifische Korpora anpassen und unterstützt mehrere Dimensionen (wie Methodik, Aufgabe, Bewertungsmetriken). Das Framework erweitert durch iterative hierarchische Klassifikation die Breite und Tiefe der Klassifikation entsprechend der thematischen Verteilung des Korpus, um wissenschaftliche Bereiche besser zu organisieren und deren Entwicklung zu erfassen (Quelle: HuggingFace Daily Papers)
Studie stellt MOSAIC-Framework vor, das kollaboratives Lernen in Agentensystemen ermöglicht: MOSAIC ist ein Framework für autonomes, agentenbasiertes KI-Systemlernen in dezentralen, dynamischen Umgebungen. Agenten teilen und verwenden selektiv modulares Wissen (in Form von neuronalen Netzwerkmasken), ohne Synchronisation oder zentrale Kontrolle. Experimente zeigen, dass MOSAIC in Geschwindigkeit und Leistung isolierten Lernern überlegen ist, manchmal Aufgaben lösen kann, die isolierte Agenten nicht lösen können, und die kollektive Effizienz und Anpassungsfähigkeit fördert (Quelle: Reddit r/MachineLearning)
Studie schlägt ClaimSpect-Framework für retrieval-augmentierte hierarchische Analyse komplexer Behauptungen vor: Viele Behauptungen (z. B. wissenschaftliche, politische) sind nicht einfach wahr oder falsch. Das ClaimSpect-Framework erstellt durch retrieval-augmentierte Generierung automatisch eine hierarchische Struktur von Aspekten, die mit einer Behauptung zusammenhängen, und reichert diese Aspekte mit Perspektiven aus einem spezifischen Korpus an. Diese Methode zielt darauf ab, komplexe Behauptungen zu dekonstruieren und unterschiedliche Sichtweisen auf verschiedene Aspekte sowie deren Verbreitung im Korpus darzustellen (Quelle: HuggingFace Daily Papers)
Studie schlägt feingranulare Perturbationslenkung durch Auswahl von Attention Heads vor: Diese Forschung fand heraus, dass spezifische Attention Heads in Diffusionsmodellen unterschiedliche visuelle Konzepte (wie Struktur, Stil, Texturqualität) steuern. Darauf basierend schlägt die Studie das “HeadHunter”-Framework vor, das systematisch Attention Heads auswählt, die mit den Zielen des Benutzers übereinstimmen, um eine feingranulare Kontrolle über die Generierungsqualität und visuelle Attribute zu erreichen, und führt SoftPAG zur Anpassung der Perturbationsintensität ein. Diese Methode wurde an Modellen wie Stable Diffusion 3 und FLUX.1 validiert und zeigte ihre Überlegenheit bei der Verbesserung der Qualität und der Stilführung (Quelle: HuggingFace Daily Papers)
Studie untersucht, dass LLM-Unlearning formunabhängig sein sollte: Die Forschung weist darauf hin, dass die Wirksamkeit aktueller LLM-Unlearning-Methoden stark von der Form der Trainingsbeispiele abhängt und sich nur schwer auf unterschiedliche Darstellungen desselben Wissens verallgemeinern lässt. Die Studie definiert dieses Problem als „Form-Dependent Bias“ und führt den ORT-Benchmark zur Bewertung ein. Um dieses Problem zu lösen, schlägt die Studie die ROCR-Methode (Rank-one Concept Redirection) vor, die Unlearning durch Umleitung der Wahrnehmung spezifischer Konzepte durch das Modell erreicht. Experimente zeigen, dass ROCR die Unlearning-Effektivität signifikant verbessert und natürliche Ausgaben generieren kann (Quelle: HuggingFace Daily Papers)
Studie schlägt UniPre3D vor: Eine einheitliche Vortrainingsmethode für 3D-Punktwolkenmodelle basierend auf crossmodalem Gaussian Splatting: UniPre3D zielt darauf ab, die Herausforderungen der vielfältigen Skalen von Punktwolkendaten in der 3D-Vision zu bewältigen und schlägt die erste einheitliche Vortrainingsmethode vor, die nahtlos auf Punktwolken jeder Skala und jede Architektur von 3D-Modellen angewendet werden kann. Die Methode prognostiziert Gaußsche Primitive als Vortrainingsaufgabe und nutzt differenzierbares Gaussian Splatting zur Bildwiedergabe, um eine präzise pixelweise Überwachung und End-to-End-Optimierung zu erreichen, während gleichzeitig Merkmale von 2D-vortrainierten Modellen integriert werden, um Texturwissen einzuführen (Quelle: HuggingFace Daily Papers)
Studie schlägt StreamSplat vor: Online-dynamische 3D-Rekonstruktion für unkalibrierte Videoströme: StreamSplat ist ein vollständig Feedforward-Framework, das unkalibrierte Videoströme beliebiger Länge online in eine dynamische 3D Gaussian Splatting (3DGS) Darstellung umwandeln kann. Es erreicht eine robuste und effiziente dynamische Modellierung durch einen probabilistischen Abtastmechanismus im statischen Encoder zur Vorhersage von 3DGS-Positionen sowie ein bidirektionales Deformationsfeld im dynamischen Decoder. Ziel ist es, die Herausforderungen der Kalibrierung, dynamischen Modellierung und Effizienzstabilität bei der Echtzeit-Rekonstruktion dynamischer Szenen zu lösen (Quelle: HuggingFace Daily Papers)
Studie blickt zurück auf Attentive Probing im Masked Image Modeling (MIM): Da groß angelegtes Finetuning unpraktisch wird, ist Probing zur bevorzugten Methode für die Bewertung von Self-Supervised Learning (SSL) geworden. Standardmäßiges Linear Probing (LP) spiegelt das Potenzial von im Masked Image Modeling (MIM) trainierten Modellen nicht ausreichend wider. Dieser Artikel überprüft Attentive Probing erneut und führt Efficient Probing (EP) ein, einen Multi-Query-Cross-Attention-Mechanismus, der die Anzahl trainierbarer Parameter reduziert und die Geschwindigkeit erhöht. In mehreren Benchmarks übertrifft EP sowohl LP als auch frühere Attentive-Probing-Methoden (Quelle: HuggingFace Daily Papers)
Studie schlägt PosterCraft vor: Neuer Ansatz zur Generierung hochwertiger ästhetischer Poster in einem einheitlichen Framework: PosterCraft zielt darauf ab, die Herausforderung der Generierung ästhetischer Poster zu lösen, die nicht nur präzises Text-Rendering erfordert, sondern auch die nahtlose Integration von abstrakten künstlerischen Inhalten, ansprechendem Layout und harmonischem Gesamtstil. PosterCraft verwendet einen kaskadierten Workflow zur Optimierung der Generierung, einschließlich Optimierung des großflächigen Text-Renderings, regionenbewusstem überwachtem Finetuning, ästhetischem Text-Reinforcement-Learning und gemeinsamer visuell-sprachlicher Feedback-Verfeinerung. In mehreren Experimenten übertrifft es Open-Source-Baselines signifikant (Quelle: HuggingFace Daily Papers)
Studie schlägt Verbesserung von Diffusionsmodellen durch Token Perturbation Guidance (TPG) vor: Um die Einschränkungen der Classifier-Free Guidance (CFG) zu beheben, die einen spezifischen Trainingsprozess erfordert und nur auf konditionale Generierung beschränkt ist, wendet die TPG-Methode Perturbationsmatrizen direkt auf intermediäre Token-Repräsentationen innerhalb des Diffusionsnetzwerks an. TPG verwendet eine normerhaltende Shuffling-Operation, um effektive Lenkungssignale zu liefern, die Generierungsqualität ohne Architekturänderungen zu verbessern und ist sowohl für konditionale als auch für unkonditionale Generierung geeignet. Experimente zeigen, dass TPG bei der unkonditionalen Generierung eine fast zweifache Verbesserung des FID gegenüber der SDXL-Baseline erzielt (Quelle: HuggingFace Daily Papers)
Studie stellt DreamActor-H1 vor: Generierung hochrealistischer Mensch-Produkt-Demonstrationsvideos durch Diffusion Transformers mit Bewegungsdesign: DreamActor-H1 ist ein auf Diffusion Transformer (DiT) basierendes Framework, das darauf abzielt, qualitativ hochwertige Videos von Interaktionen zwischen Menschen und Produkten zu generieren. Die Methode injiziert paarweise Mensch-Produkt-Referenzinformationen und einen zusätzlichen maskierten Cross-Attention-Mechanismus, während gleichzeitig Identitätsdetails von Mensch und Produkt (wie Logos, Texturen) erhalten bleiben. Es nutzt 3D-Mensch-Mesh-Vorlagen und Produkt-Bounding-Boxes für eine präzise Bewegungsführung und verbessert die 3D-Konsistenz durch strukturierte Textcodierung (Quelle: HuggingFace Daily Papers)
Studie stellt EmbodiedGen vor: Eine generative 3D-Welt-Engine für Embodied AI: EmbodiedGen ist eine grundlegende Plattform für die interaktive Generierung von 3D-Welten, die darauf abzielt, kostengünstig und skalierbar qualitativ hochwertige, kontrollierbare, fotorealistische 3D-Assets mit genauen physikalischen Eigenschaften und realen Maßstäben zu generieren, die das Unified Robot Description Format (URDF) verwenden. Diese Assets können direkt in verschiedene Physik-Simulationsengines importiert werden und unterstützen Trainings- und Bewertungsaufgaben für Embodied AI, wodurch die Probleme hoher Kosten und begrenzter Realitätsnähe traditioneller 3D-Computergrafik-Assets gelöst werden (Quelle: HuggingFace Daily Papers)
Neue Studie widerlegt Apples „Illusion des Denkens“-Paper und argumentiert, dass LLMs neue komplexe Probleme lösen können: Als Reaktion auf Apples kürzlich veröffentlichtes Paper „Illusion des Denkens“, das besagt, dass große Inferenzmodelle (LRMs) bei komplexen Planungsrätseln (wie den Türmen von Hanoi) einen „Genauigkeitskollaps“ erleiden, weist eine nachfolgende kommentierende Studie darauf hin, dass Apples Schlussfolgerungen hauptsächlich die Grenzen des experimentellen Designs widerspiegeln und nicht ein Versagen der grundlegenden Inferenzfähigkeiten der Modelle. Die neue Studie argumentiert, dass im ursprünglichen Experiment überschrittene Token-Budgets, die falsche Bewertung absichtlich abgeschnittener Ausgaben und die Einbeziehung mathematisch unlösbarer Rätselinstanzen gemeinsam zu einer Fehleinschätzung der Modellfähigkeiten führten. Bei Anpassung der experimentellen Methode, z. B. indem das Modell aufgefordert wird, eine kompakte Lua-Funktion zur Generierung der Lösung für die Türme von Hanoi anstelle einer detaillierten Schrittliste auszugeben, zeigten die Modelle in Fällen, die zuvor als vollständige Fehlschläge gemeldet wurden, eine hohe Genauigkeit. Dies deutet darauf hin, dass die Modelle nicht unfähig zum Schlussfolgern sind, sondern durch Ausgabeformate und Token-Beschränkungen limitiert werden (Quelle: Reddit r/LocalLLaMA)

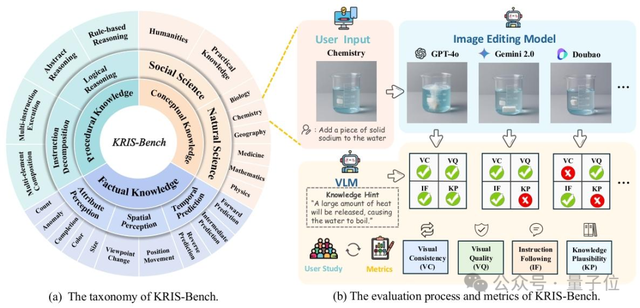
KRIS-Bench: Neuer Benchmark zur umfassenden Bewertung der Inferenzfähigkeiten von Bildbearbeitungsmodellen aus der Perspektive von Wissenstypen: Die Southeast University und andere Institutionen haben gemeinsam KRIS-Bench veröffentlicht, einen wissensbasierten Benchmark für die Inferenzfähigkeiten von Bildbearbeitungssystemen. Er unterteilt 22 Bearbeitungsaufgaben in drei Ebenen: faktisches Wissen (z. B. Farbe, Anzahl), konzeptionelles Wissen (z. B. physikalischer Hausverstand) und prozedurales Wissen (z. B. mehrstufige Operationen) und bewertet damit 10 gängige Bildbearbeitungsmodelle (einschließlich GPT-Image-1, Gemini 2.0 Flash usw.). Die Ergebnisse zeigen, dass das Closed-Source-Modell GPT-Image-1 am besten abschneidet, aber alle Modelle bei prozeduralem Schlussfolgern, Naturwissenschaften und mehrstufiger Synthese – also tiefergehenden Inferenzaufgaben – generell schlecht abschneiden. Dies deckt die Defizite aktueller Modelle bei fortgeschrittenen kognitiven Fähigkeiten auf (Quelle: 量子位)
Neue Studie schlägt Finetune-RAG-Methode vor, um Sprachmodelle gegen Halluzinationen in RAG zu optimieren: Große Sprachmodelle neigen in der Retrieval Augmented Generation (RAG) zu Halluzinationen, wenn der Abruf unvollkommen ist (z. B. bei störenden Dokumentfragmenten). Finetune-RAG trainiert Modelle mit Eingabebeispielen, die sowohl korrekten als auch falschen Kontext enthalten, damit sie die Fakten besser einhalten können. Das Forschungsteam veröffentlichte einen Datensatz mit über 1600 Dual-Kontext-Beispielen, einen optimierten Checkpoint von LLaMA 3.1-8B-Instruct und ein GPT-4o-Evaluierungsframework namens Bench-RAG. Die Evaluierung zeigte, dass diese Methode die Genauigkeit von 77 % auf 98 % steigerte und auch Verbesserungen in Bezug auf Nützlichkeit, Relevanz und Tiefe erzielte (Quelle: Reddit r/MachineLearning)
TeleMath: Erster LLM-Benchmark für die Fähigkeit zur Lösung mathematischer Probleme im Telekommunikationsbereich veröffentlicht: Um die Fähigkeit großer Sprachmodelle zur Lösung spezifischer, mathematisch intensiver Aufgaben im Telekommunikationsbereich zu bewerten, haben Forscher den TeleMath-Benchmark eingeführt. Dieser Benchmark enthält 500 Frage-Antwort-Paare, die Telekommunikationsthemen wie Signalverarbeitung, Netzwerkoptimierung und Leistungsanalyse abdecken. Die Bewertung verschiedener Open-Source-LLMs zeigte, dass Modelle, die speziell für mathematisches oder logisches Denken entwickelt wurden, bei TeleMath besser abschnitten, während universelle Modelle mit vielen Parametern häufig auf Schwierigkeiten stießen. Der Datensatz und der Evaluierungscode wurden veröffentlicht (Quelle: HuggingFace Daily Papers)
ChineseHarm-Bench: Benchmark zur Erkennung schädlicher Inhalte in chinesischer Sprache veröffentlicht: Angesichts der Tatsache, dass bestehende Ressourcen zur Erkennung schädlicher Inhalte hauptsächlich auf Englisch sind, haben Forscher ChineseHarm-Bench veröffentlicht, einen umfassenden, professionell annotierten Benchmark zur Erkennung von Inhaltsgefahren in chinesischer Sprache. Dieser Benchmark deckt sechs repräsentative Kategorien ab, wobei die Daten vollständig aus der realen Welt stammen. Der Annotationsprozess erzeugte auch eine Wissensregelbasis, die LLMs explizites Expertenwissen liefert. Darüber hinaus schlugen die Forscher eine wissensgestützte Basismethode vor, die manuell annotierte Regeln mit dem impliziten Wissen von LLMs kombiniert, sodass kleinere Modelle die Leistung von SOTA LLMs erreichen können (Quelle: HuggingFace Daily Papers)
Neue Studie entdeckt hierarchische Struktur latenter Fähigkeiten von Sprachmodellen durch kausales Repräsentationslernen: Um die Fähigkeiten von Sprachmodellen zuverlässig zu bewerten und Störeffekte sowie hohe Rechenkosten zu überwinden, schlägt diese Studie ein Framework für kausales Repräsentationslernen vor. Dieses Framework modelliert die beobachtete Benchmark-Leistung als lineare Transformation einiger weniger latenter Fähigkeitsfaktoren und identifiziert nach Kontrolle des Basismodells als gemeinsamen Störfaktor die kausalen Beziehungen zwischen diesen latenten Faktoren. Angewendet auf Daten von über 1500 Modellen aus dem Open LLM Leaderboard, fand die Studie eine prägnante lineare kausale Struktur mit drei Knoten, die einen klaren kausalen Pfad von allgemeinen Problemlösungsfähigkeiten über die Beherrschung von Anweisungen bis hin zu mathematischen Denkfähigkeiten aufdeckt (Quelle: HuggingFace Daily Papers)
DeepLearning.AI startet neuen Kurs „Orchestrierung von Workflows für GenAI-Anwendungen“: Andrew Ng kündigte in Zusammenarbeit mit Astronomer einen neuen Kurzkurs an, der lehrt, wie man mit dem beliebten Open-Source-Tool Airflow 3.0 zuverlässige generative KI-Pipelines erstellt und bereitstellt. Die Kursinhalte umfassen die Aufteilung von Workflows in diskrete Aufgaben, Aufgabenplanung, parallele Ausführung, Fehlerbehebung und Beobachtbarkeit und sollen Lernenden helfen, Prototypen aus Jupyter-Notebooks oder Python-Skripten in produktionsreife Workflows umzuwandeln (Quelle: DeepLearningAI)
Studie untersucht Optimierungsmethoden, Herausforderungen und zukünftige Richtungen für Komposit-KI-Systeme: Mit der Entwicklung von LLMs und KI-Systemen werden Komposit-KI-Systeme, die mehrere Komponenten integrieren, bei der Ausführung komplexer Aufgaben immer ausgereifter. Dieser Artikel gibt einen systematischen Überblick über die neuesten Fortschritte bei der Optimierung von Komposit-KI-Systemen, einschließlich numerischer und sprachbasierter Techniken. Die Studie formalisiert das Konzept der Optimierung von Komposit-KI-Systemen, klassifiziert bestehende Methoden und hebt offene Forschungsherausforderungen und zukünftige Richtungen in diesem Bereich hervor (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
Disney und Universal Studios verklagen Bildgenerator Midjourney wegen Urheberrechtsverletzung: Disney und Universal Studios werfen Midjourney vor, ohne Genehmigung ihre kreativen Archive (einschließlich Charakteren aus Star Wars, Die Eiskönigin, Minions usw.) zum Trainieren von Modellen genutzt und eine große Anzahl abgeleiteter Werke generiert und verbreitet zu haben, und bezeichnen dies als „bodenlose Kopiergrube“. Dieser Fall entfacht erneut die Diskussion über die Grenzen zwischen KI-generierten Inhalten und geistigem Eigentum (Quelle: Reddit r/ArtificialInteligence)
NVIDIA und Deutsche Telekom kooperieren, um bis 2026 die erste industrielle KI-Cloud für europäische Hersteller aufzubauen: Bundeskanzler Friedrich Merz traf sich mit NVIDIA CEO Jensen Huang, um weitere strategische Kooperationen zur Stärkung Deutschlands als globalen KI-Führer zu diskutieren. Als Teil dieser Vision kündigten die Deutsche Telekom und NVIDIA eine neue Partnerschaft an, um bis 2026 die weltweit erste industrielle KI-Cloud für europäische Hersteller aufzubauen. Diese sichere und europakonforme Infrastruktur wird Spitzeninnovationen unterstützen und gleichzeitig volle Datensouveränität gewährleisten (Quelle: nvidia)

Gerüchten zufolge könnte Sam Altman die gemeinnützige Kontrolle über OpenAI durch reine Aktienübernahmen verwässern: Die jüngsten reinen Aktienübernahmen von io (6,5 Mrd. USD) und Windsurf (3 Mrd. USD) durch OpenAI haben Spekulationen ausgelöst. Auf Hacker News gibt es die Theorie, dass Sam Altman diese Transaktionen nutzen könnte, um schrittweise die Kontrolle der gemeinnützigen Organisation OpenAI Inc. über die gewinnorientierte Einheit OpenAI Global LLC (jetzt OpenAI PBC) zu verwässern und so möglicherweise rechtliche Beschränkungen für eine Umwandlung in ein vollständig gewinnorientiertes Unternehmen zu umgehen. Dieser Schritt wird von einigen mit Altmans Vorgehen bei Reddit im Jahr 2014 in Verbindung gebracht, es gibt aber auch Stimmen, die diese Übernahmen als normale geschäftsstrategische Maßnahmen betrachten (Quelle: Reddit r/ArtificialInteligence)
🌟 Community
Diskussion über die Fähigkeit von KI zum echten „Schlussfolgern“ hält an, Apple-Paper löst Kontroverse aus: Ein kürzlich veröffentlichtes Paper von Apple, das besagt, dass die Leistung großer Sprachmodelle (LLM) bei komplexen Aufgaben (wie den Türmen von Hanoi) kein echtes Schlussfolgern, sondern eher Mustererkennung sei, wird in der Community breit diskutiert. Miles Brundage, ehemaliger Mitarbeiter von OpenAI, fragte bei der Kommentierung der Lösung komplexer Wortspiele durch o3-pro sarkastisch: „Wenn das kein Schlussfolgern ist, was ist es dann?“. Nachfolgende Forschungen deuten darauf hin, dass das im Apple-Paper beschriebene Phänomen des „Inferenzkollaps“ möglicherweise auf Einschränkungen im experimentellen Design (wie Token-Limits, falsche Bewertung unlösbarer Probleme) und nicht auf einen Mangel an Inferenzfähigkeiten der Modelle selbst zurückzuführen ist. Nach Anpassung der Testmethoden zeigten die Modelle bei zuvor gescheiterten Aufgaben gute Leistungen, was darauf hindeutet, dass die Bewertung der Inferenzfähigkeiten von KI ein sorgfältigeres experimentelles Design erfordert (Quelle: o3-pro答高难题文字游戏引围观,OpenAI前员工讽刺苹果:这都不叫推理那什么叫推理, Reddit r/LocalLLaMA)
Nvidia CEO Jensen Huang und Anthropic CEO Dario Amodei vertreten deutlich unterschiedliche Ansichten zur Zukunft der KI: Fortune berichtet, dass Nvidia CEO Jensen Huang erklärte, er stimme mit fast keiner der Ansichten von Anthropic CEO Dario Amodei über KI überein. Amodei betont häufig die potenziellen Risiken von KI und die massiven Auswirkungen auf Arbeitsplätze und plädiert für eine strengere Kontrolle der KI-Entwicklung, die von einigen wenigen „verantwortungsbewussten“ Organisationen geleitet werden sollte. Huang steht solchen Ansichten skeptisch gegenüber und neigt eher dazu, die breite Anwendung und Entwicklung von KI-Technologien zu fördern. Kommentare aus der Community deuten darauf hin, dass Huangs Haltung möglicherweise mit seinen Geschäftsinteressen zusammenhängt, da Nvidia der Hauptlieferant von KI-Hardware ist (Quelle: Reddit r/ArtificialInteligence, Reddit r/ClaudeAI)

Claude Codes 20-Dollar-Abonnementplan wird von Entwicklern wegen seines guten Preis-Leistungs-Verhältnisses gelobt: Viele Entwickler haben in sozialen Medien ihre positiven Erfahrungen mit dem monatlichen 20-Dollar-Abonnementplan von Anthropic Claude Code geteilt und ihn als äußerst kostengünstig bezeichnet, da er sich schnell in Projekten amortisiert. Benutzer erwähnten, dass Claude Code trotz gewisser Ratenbegrenzungen bei der Unterstützung der Codierung, dem Erlernen neuer Sprachen (z. B. von C# zu SwiftUI) und der Optimierung von Projektanweisungen (z. B. CLAUDE.md-Dateien) hervorragend abschneidet und die Arbeitseffizienz erheblich steigert. Einige Benutzer erwägen sogar, ihre Abonnements für andere KI-Programmierhilfswerkzeuge zu kündigen (Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Community diskutiert zukünftige Anwendungen und ethische Herausforderungen von KI im Bereich Psychologie: Mit der Entwicklung von Technologien wie LLMs, die Therapieanregungen entwerfen, und Anwendungen, die Emotionen über Handy-Sensoren verfolgen, dringt KI allmählich in die Psychologie ein. Die Community-Diskussion konzentriert sich darauf, ob KI in der klinischen Praxis die Fähigkeiten von Therapeuten erweitert oder letztendlich einige Arbeitsplätze ersetzt, auf die Glaubwürdigkeit von KI in Bewertung und Forschung, auf die Auswirkungen auf die psychologische Fachausbildung und den Arbeitsmarkt sowie auf ethische und regulatorische Fragen von KI-Anwendungen, insbesondere Datenbias, Datenschutz und die Grenzen von „Roboter-Therapeuten“. Die Kernsorge besteht darin, wie man die Effizienz und personalisierte Dienste durch KI steigern kann, während gleichzeitig die Patientensicherheit gewährleistet und der therapeutische Wert menschlicher Verbindungen erhalten bleibt (Quelle: Reddit r/artificial)
Unsloths 3,53-Bit quantisiertes DeepSeek-R1-0528 Modell zeigt gute Leistung im Aider Polyglot Coding-Benchmark: Das Unsloth-Team hat das DeepSeek-R1-0528 Modell mit 3,53 Bit quantisiert (UD-Q3_K_XL) und im Aider Polyglot Coding-Benchmark eine Erfolgsquote von 68 % erzielt. Der Test verwendete eine Kontextgröße von 40960 und Flash Attention, wobei etwa 300 GB RAM/VRAM benötigt wurden. Dieses Ergebnis liegt zwischen Claude Sonnet 3.7 und Claude Opus 4 und zeigt das Potenzial quantisierter Modelle, eine hohe Codierungsfähigkeit beizubehalten. Community-Mitglieder zeigten sich beeindruckt von der Leistung solcher Modelle im lokalen Betrieb und erwarten mit Spannung weitere Testergebnisse quantisierter Versionen (Quelle: Reddit r/LocalLLaMA)
💡 Sonstiges
Bericht über weltweiten GCP-Ausfall enthüllt: Fehlerhafte Kontingentrichtlinie verursachte Dienstunterbrechung: Der Bericht über den jüngsten weltweiten Ausfall von Google Cloud Platform (GCP) zeigt, dass die Ursache die Verteilung einer fehlerhaften Kontingentrichtlinie (z. B. Beschränkung auf nur 1 Anfrage pro Stunde) an das globale API-Managementsystem war. Dies führte dazu, dass externe Anfragen aufgrund von Kontingentüberschreitungen abgelehnt wurden (Fehler 403). Nachdem Ingenieure dies entdeckt hatten, umgingen sie die Kontingentprüfung für die betroffenen APIs. In der Region us-central1 führte jedoch der Versuch, die alte Richtlinie zu löschen und eine neue zu schreiben, aufgrund von Cache-Problemen zu einer Überlastung der Datenbank, was die Wiederherstellungszeit verlängerte. Andere Regionen stellten den Dienst durch schrittweises Leeren des Caches wieder her, der gesamte Vorgang dauerte etwa 2 Stunden (Quelle: karminski3)

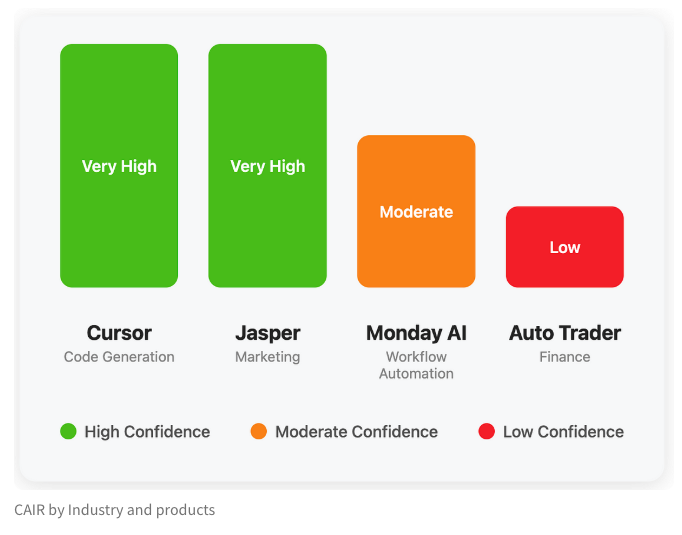
LangChain-Team schlägt CAIR-Metrik zur Bewertung des Erfolgspotenzials von KI-Produkten vor: Harrison Chase von LangChain und Assaf Elovic erörtern in einem gemeinsamen Artikel, warum einige KI-Produkte schnell Verbreitung finden, während andere Schwierigkeiten haben. Sie argumentieren, dass die Modellfähigkeit nicht der einzige entscheidende Faktor ist, sondern die Benutzererfahrung (UX) von entscheidender Bedeutung ist, und schlagen die Metrik „CAIR“ (Confidence in AI Results, Vertrauen in KI-Ergebnisse) vor. Je höher CAIR, desto höher die Produktakzeptanz. Dieses Framework soll Entwicklern helfen, die verschiedenen Komponenten, die das Nutzervertrauen beeinflussen, zu identifizieren und zu verbessern, um so die Erfolgsquote von Produkten zu steigern (Quelle: hwchase17, swyx, hwchase17, Hacubu)
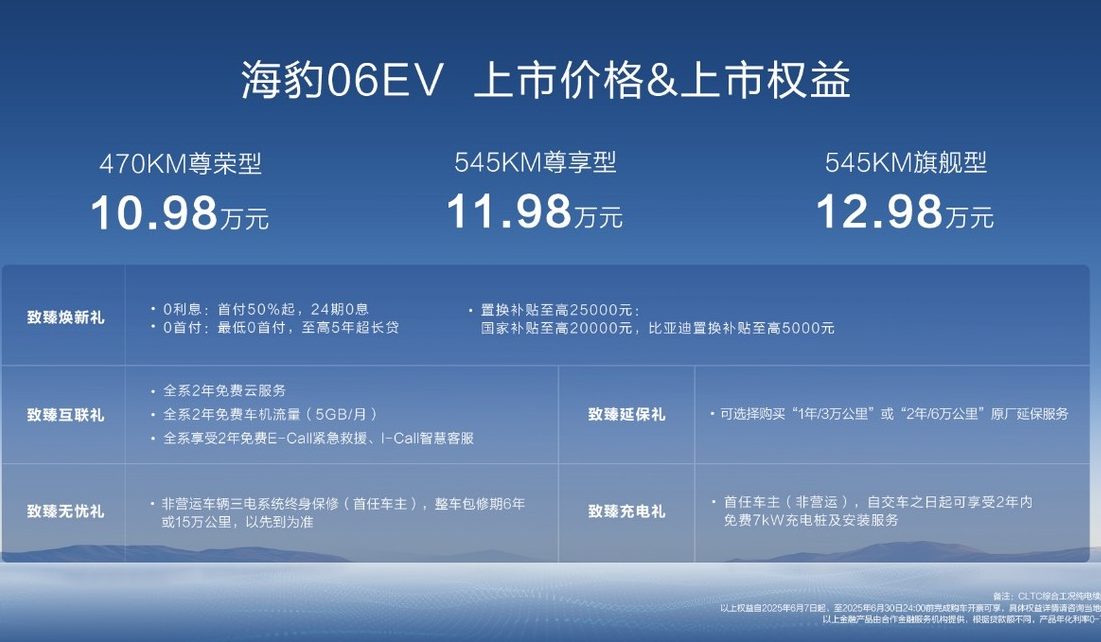
BYD stellt neues rein elektrisches Familien-Coupé Seal 06EV vor, Preis ab 109.800 Yuan: BYD Ocean Net präsentierte auf der Chongqing Auto Show den Seal 06EV, positioniert als trendiges und hochwertiges Coupé, in 3 Ausstattungsvarianten zu Preisen zwischen 109.800 und 129.800 Yuan. Das Fahrzeug basiert auf der BYD e-Plattform 3.0 Evo, ist mit einem intelligenten Acht-in-Eins-Elektroantrieb und einem hocheffizienten Wärmepumpensystem der neuen Generation für breite Temperaturbereiche ausgestattet und bietet zwei Reichweiten von 470 km und 545 km nach CLTC-Norm. Das Fahrzeug verfügt über einen Heckantrieb, ist mit dem intelligenten Dämpferregelsystem Cloud Chariot-C ausgestattet und verfügt über das intelligente Fahrassistenzsystem „Eye of the Gods C“ (Dreikamera-Version), das Funktionen wie Autobahnpilot und automatisches Einparken unterstützt (Quelle: 量子位)