
Palabras clave:Infraestructura de IA, IA soberana, Agente, Modelo de pastel de cinco capas, Arquitectura Engram, Compresor cognitivo de Agente
🔥 Enfoque
Jensen Huang de NVIDIA en Davos: La teoría del “pastel de cinco capas” de la infraestructura AI : El CEO de NVIDIA, Jensen Huang, presentó en el Foro de Davos 2026 el modelo del “pastel de cinco capas” para la industria AI: energía, chips, servicios en la nube, modelos y aplicaciones. Señaló que las inversiones actuales de cientos de miles de millones son solo el comienzo, y que se avecina una ola de infraestructura de billones de dólares. Huang enfatizó que la AI debe considerarse como infraestructura nacional (AI soberana) y utilizó el ejemplo del aumento de radiólogos para argumentar que la AI automatiza “tareas” en lugar de reemplazar “propósitos”, creando nueva demanda al mejorar la eficiencia. Esta perspectiva ofrece un nuevo enfoque para abordar la ansiedad por el desempleo causado por la AI, presentándola como un amplificador de productividad en lugar de un rival humano (fuente: NVIDIA)

Anthropic lanza la “Constitución de Claude”: Definiendo la personalidad y valores independientes de la AI : Anthropic publicó oficialmente la nueva Constitución de Claude, detallando su visión de comportamiento y valores fundamentales. Este documento no solo guía el proceso de entrenamiento, sino que también busca moldear a Claude como una nueva “entidad mundial”, distinta de las concepciones previas de la ciencia ficción. La Constitución enfatiza la independencia de Claude más allá de los datos de entrenamiento, incluso incluyendo las obligaciones de Anthropic hacia la AI. La comunidad ha reaccionado intensamente, viendo esto como un paso hacia la transformación de la AI de herramienta a entidad con “personalidad digital”, generando debates sobre cómo equilibrar restricciones y autonomía (fuente: Anthropic)

DeepSeek presenta la arquitectura Engram: Superando limitaciones de potencia con DRAM en lugar de HBM : Un informe de Morgan Stanley elogió el módulo Engram (engrama) propuesto por DeepSeek en su último artículo. Esta arquitectura separa patrones estáticos del razonamiento dinámico mediante un mecanismo de “memoria condicional”, permitiendo descargar grandes cantidades de conocimiento en memoria de sistema de bajo costo (DRAM) y consultarlo solo cuando sea necesario. Este avance alivia el cuello de botella de la costosa memoria de alto ancho de banda (HBM), demostrando que la innovación algorítmica puede lograr “más con menos” en entornos con recursos limitados. Morgan Stanley predice que DeepSeek V4, utilizando esta arquitectura, podría ejecutarse en tarjetas gráficas de consumo (como la RTX 5090), reescribiendo las reglas de escalabilidad de la AI (fuente: Morgan Stanley)

Filtraciones del proyecto “Macrohard” de xAI: Las computadoras de Tesla como base para millones de Agent : El exingeniero de xAI Sulaiman Ghori reveló en un podcast detalles internos del proyecto con nombre en clave “Macrohard”. Este busca construir un “simulador humano” que opere a 8x la velocidad humana para automatizar trabajos de oficina. La revelación más impactante es que xAI planea utilizar la potencia de millones de autos Tesla inactivos (plataforma HW4) para desplegar estos Agent, evitando los ciclos tradicionales de construcción de centros de datos. Ghori fue despedido por la filtración, pero su descripción de la cultura “sala de guerra” y los plazos agresivos han llevado a reevaluar el potencial competitivo de xAI (fuente: The Information)
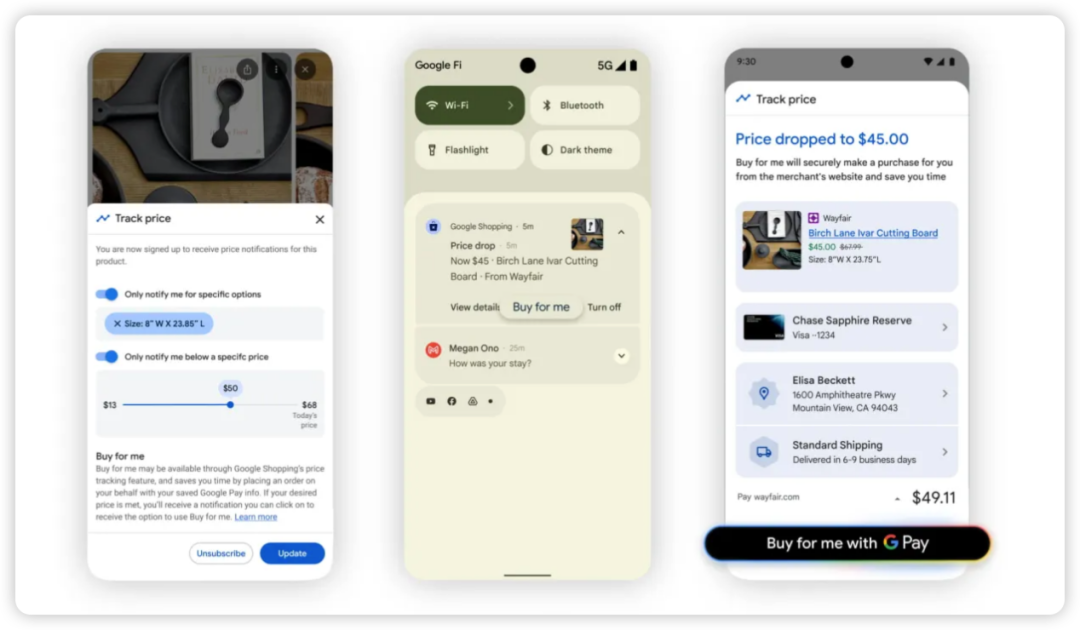
Google y Shopify entran en el comercio AI: Del buscador al circuito cerrado de transacciones : Google anunció el Protocolo de Comercio Universal (UCP), aliándose con Shopify, Walmart y otros gigantes para convertir a Gemini en una plataforma completa de compras. Los usuarios pueden comparar precios, especificaciones y pagar directamente en el chat, sin salir de la app. Gemini incluso puede llamar a tiendas físicas para confirmar inventarios. Esto se ve como una respuesta contundente a la función de “pago instantáneo” de ChatGPT, marcando una transición del modelo de anuncios de búsqueda al “comercio mediante agentes inteligentes”, donde los modelos de lenguaje están remodelando el panorama minorista global (fuente: Google)
🎯 Tendencias
Filtraciones del hardware AI de Apple y la actualización “Campos” de Siri : Según informes, Apple está desarrollando en secreto un dispositivo portátil AI similar a AirTag, con múltiples cámaras y sensores, programado para 2027. Paralelamente, la nueva Siri con nombre en clave “Campos” debutará en septiembre, integrando profundamente el modelo Gemini 3 de Google y con capacidad de “percibir pantallas” para manipular archivos y apps directamente. Apple busca contrarrestar a OpenAI y Meta en AI local, con una meta inicial de producción de 20 millones de unidades (fuente: The Information)

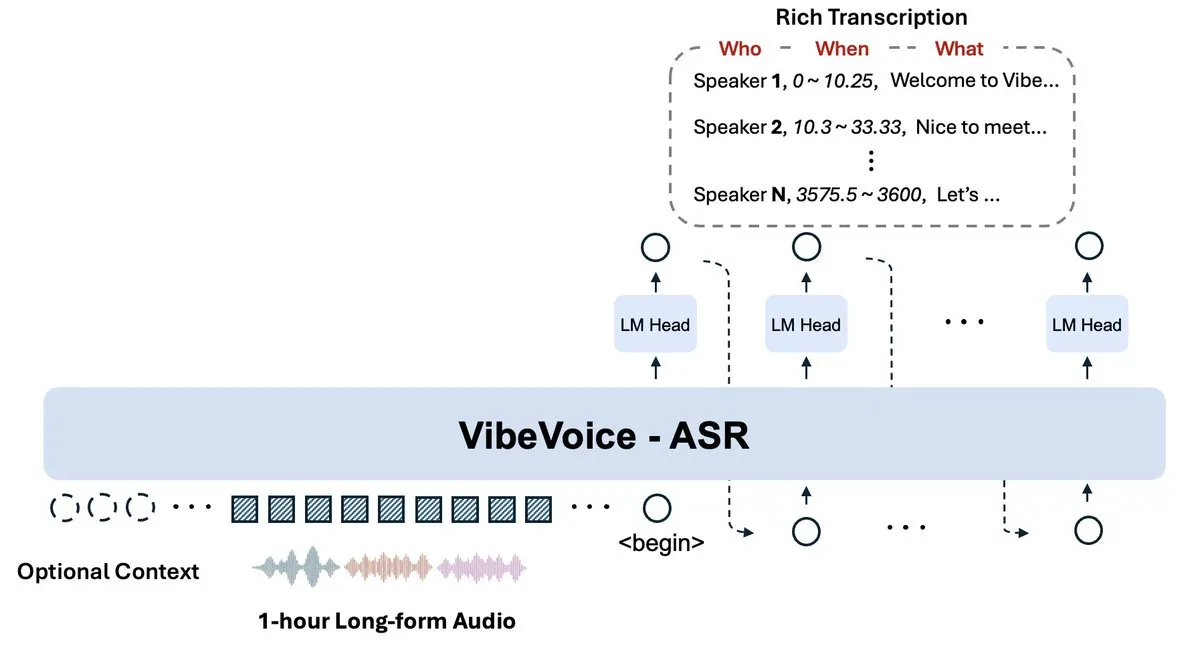
Microsoft lanza VibeVoice-ASR: Procesamiento de audio de una hora en una sola pasada : Microsoft liberó en Hugging Face el modelo de reconocimiento de voz VibeVoice-ASR de 9B de parámetros. Rompiendo con el enfoque tradicional de segmentar audio, este modelo maneja ventanas de 64K tokens para procesar 60 minutos de audio continuo, preservando el contexto global y evitando confusiones al rastrear hablantes. Las pruebas muestran un 91.9% de precisión en entornos complejos (como voces sobre música) y textos largos (como audiolibros), admitiendo palabras clave para corregir nombres propios (fuente: Microsoft)
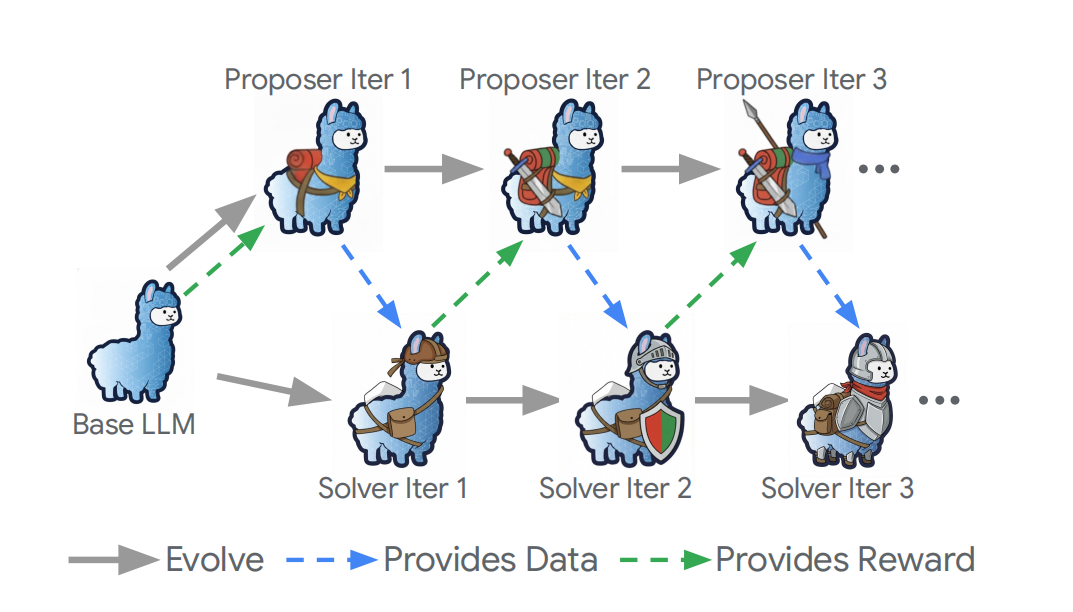
Meta presenta el marco Dr. Zero: Auto-evolución de Agent sin datos : El Laboratorio de Superinteligencia de Meta propuso el marco Dr. Zero, que permite a los Agent evolucionar eficientemente sin datos etiquetados. Mediante un mecanismo de “proponente-resolvedor”, utiliza motores de búsqueda para generar preguntas complejas. La técnica HRPO (Optimización de Política Relativa por Saltos Agrupados) agrupa preguntas similares como referencia, evitando muestreo anidado costoso. En tareas de QA complejas, superó en un 14.1% a modelos supervisados, ofreciendo una nueva solución a la escasez de datos de entrenamiento (fuente: Meta)
El sector se enfoca en evaluaciones de tareas prolongadas: Nuevos benchmarks de escenarios reales : La evaluación de AI está pasando de pruebas matemáticas/código a tareas extendidas. APEX-Agents mide la colaboración profesional en Google Workspace; DSAEval cubre 641 problemas reales de ciencia de datos. Las pruebas muestran que GPT-5.2 lidera en eficiencia, mientras Claude-Sonnet-4.5 destaca en rendimiento integral. Estos benchmarks reflejan un consenso: el límite para los Agent ya no es el razonamiento, sino mantener coherencia lógica y control de memoria a largo plazo (fuente: Mercor, DSAEval)
Compresor Cognitivo para Agent (ACC): Control de memoria inspirado en la biología : Investigadores propusieron el Agent Cognitive Compressor para resolver la “degradación de contexto” en diálogos multilarga. En lugar de repetir historiales, ACC mantiene un “estado cognitivo comprimido” con variables clave como objetivos, entidades y relaciones. En flujos de trabajo complejos de 50+ iteraciones, ACC logró tasas cercanas a cero en alucinaciones y desviaciones, superando ampliamente los métodos tradicionales de recuperación aumentada (RAG) (fuente: DAIR.AI)

🧰 Herramientas
Prefect Horizon: Plataforma de gestión para servidores MCP : Ante la adopción del Model Context Protocol (MCP), Prefect lanzó Horizon, abordando los desafíos empresariales en despliegue de servidores MCP. Ofrece alojamiento, control de acceso basado en roles (RBAC), registros de auditoría y descubrimiento de herramientas. Horizon permite exponer datos y flujos de trabajo privados a Agent AI de forma segura, elevando el MCP de protocolo simple a plataforma productiva escalable (fuente: Prefect)

CopilotKit + LangChain: Solución frontend para Agent profundos : CopilotKit ahora soporta la arquitectura Deep Agents de LangChain, permitiendo a desarrolladores crear UIs interactivas para Agent con planificación avanzada en pocas líneas de código. La herramienta soporta salida en flujo, personalización de Skills y orquestación de sub-Agent, resolviendo cuellos de botella en UI/UX para aplicaciones complejas y acelerando la conversión de Agent “centrados en planificación” en productos finales (fuente: CopilotKit)

Devin Review: Herramienta AI para revisión de código reinventada : Cognition presentó Devin Review, enfocada en el cuello de botella humano al revisar código generado por AI. Más que buscar bugs, su interfaz rediseñada ayuda a comprender lógicas complejas en PRs. Funciona directamente en enlaces GitHub con reemplazo de dominio, detectando errores relacionados más allá del diff. Su premisa es clara: el código generado por AI debe ser revisado por herramientas AI eficientes, no por humanos abrumados por “basura de código” (fuente: Cognition)
Optimización local de GLM-4.7 Flash: 200K de contexto en una sola GPU : La comunidad corrigió con una línea de código el soporte de vLLM para la caché KV de GLM-4.7-Flash, activando el mecanismo MLA (atención latente multi-cabeza). Esto redujo el uso de memoria para contexto de 200K de 180GB a solo 10GB. Ahora, una RTX 5090 (32GB VRAM) puede ejecutar este modelo de 30B con capacidad de razonamiento de élite, marcando el inicio de la era de Agent locales de alto rendimiento (fuente: Zai_org)

📚 Aprendizaje
Curso práctico de Gemini CLI: Construyendo flujos de trabajo automatizados : DeepLearning.AI y Google lanzaron un curso gratuito para desarrollar Agent de código abierto con Gemini CLI. Cubre desde operaciones locales, integración de herramientas hasta llamadas a la nube, mostrando cómo usar Agent para automatización de código, creación de dashboards y planificación de tareas complejas. Ideal para desarrolladores que buscan pasar de simples APIs a herramientas productivas reales (fuente: DeepLearningAI)
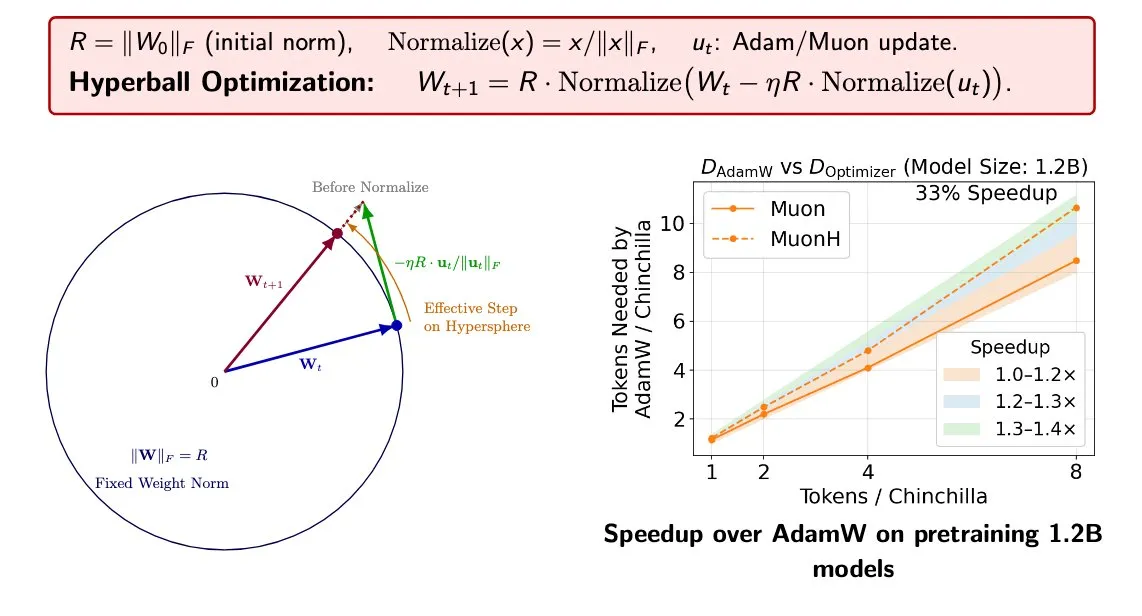
Optimizador Hyperball: Aceleración del 33% en entrenamiento mediante normalización : Investigadores de Stanford crearon el envoltorio Hyperball para optimizadores. Al mantener constantes las normas de pesos y actualizaciones, permite controlar directamente el tamaño de paso efectivo, reemplazando el decaimiento de pesos tradicional. Las pruebas muestran que Hyperball acelera el entrenamiento un 33% sobre optimizadores como Muon, con mejor transferencia de hiperparámetros, ofreciendo un marco matemático más estable para entrenamiento a gran escala (fuente: Kaiyue Wen)
NVIDIA Motive: Método de atribución para generación de video : Investigadores de NVIDIA presentaron Motive, un enfoque basado en gradientes para atribución de datos centrado en movimiento. Al aislar dinámicas temporales de apariencias estáticas, Motive identifica qué videos en los datos de entrenamiento afectan positivamente o negativamente el movimiento generado. Esto es valioso para optimizar calidad en modelos de generación de video y entender causas de degradación en movimiento (fuente: NVIDIA Research)
InT (Entrenamiento por Intervención): Solucionando asignación de crédito en razonamiento : Un artículo propuso Intervention Training, donde los modelos localizan su primer error en trayectorias de razonamiento y sugieren intervenciones de un paso para mejorar inicialización en aprendizaje reforzado. A diferencia del RL estándar que solo premia respuestas finales, InT corrige pasos intermedios con precisión. En el benchmark IMO-AnswerBench, mejoró la precisión de modelos de 4B en un 14%, superando incluso a modelos de 20B (fuente: HuggingFace)
💼 Negocios
OpenAI planea recaudar $50 mil millones con valoración de $830 mil millones : Fuentes indican que Sam Altman se reunió con inversionistas en Emiratos Árabes para discutir una nueva ronda de financiamiento masivo. El objetivo es recaudar $50 mil millones con una valoración entre $750-830 mil millones, destinados a cubrir los $200 mil millones estimados en costos de computación para 2030. Esto ocurre mientras OpenAI enfrenta una costosa demanda de Musk por “desviarse de su propósito sin fines de lucro” (fuente: Bloomberg)

T-Head de Alibaba inicia proceso de IPO: Completando el ecosistema de chips AI : Alibaba decidió respaldar la salida a bolsa independiente de su subsidiaria de chips T-Head. En 8 años, T-Head ha lanzado chips líderes en computación, almacenamiento y redes, con su PPU (GPU) autónoma rivalizando con la H20 de NVIDIA en rendimiento, convirtiéndose en pieza clave para la expansión de capacidad AI en China. Esta IPO redefinirá la valoración de chips AI locales y marcará la culminación de la estrategia de Alibaba en modelos, infraestructura en la nube y ahora, chips (fuente: 36Kr) ![IPO de T-Head](https://img.36krcdn.com/hsossms/20260122/v2