
Mots-clés:Infrastructure IA, IA souveraine, Agent, Modèle de gâteau à cinq couches, Architecture Engram, Compresseur cognitif d’Agent
🔥 À la Une
Jensen Huang de NVIDIA présente sa théorie du “gâteau à cinq étages” de l’infrastructure IA à Davos : Le PDG de NVIDIA, Jensen Huang, a exposé lors du Forum de Davos 2026 un modèle en “cinq couches” pour l’industrie de l’IA : énergie, puces, services cloud, modèles et applications. Il a souligné que les investissements actuels de plusieurs centaines de milliards de dollars ne sont qu’un début, et qu’une vague d’infrastructures de plusieurs milliers de milliards est à venir. Huang a insisté sur le fait que l’IA doit être considérée comme une infrastructure nationale (IA souveraine), illustrant son propos avec l’exemple du nombre croissant de radiologues pour démontrer que l’IA automatise des “tâches” plutôt qu’elle ne remplace des “métiers”, créant ainsi de nouvelles demandes grâce à des gains d’efficacité. Cette perspective offre une nouvelle vision pour répondre à l’anxiété mondiale sur les emplois, positionnant l’IA comme un amplificateur de productivité plutôt qu’un adversaire humain (Source : NVIDIA)

Anthropic publie la “Constitution de Claude” : définir la personnalité et les valeurs indépendantes de l’IA : Anthropic a officiellement dévoilé la nouvelle Constitution de Claude, détaillant sa vision comportementale et ses valeurs fondamentales. Ce document ne sert pas seulement de guide pour l’entraînement, mais tente de façonner Claude comme une nouvelle “entité mondiale”, distincte des conceptions de science-fiction traditionnelles. La Constitution souligne l’indépendance de Claude par rapport aux données d’entraînement, incluant même les obligations qu’Anthropic a envers l’IA. La communauté a réagi vivement, y voyant une transition de l’IA comme outil vers une entité dotée d’une “personnalité numérique”, tout en soulevant des débats profonds sur l’équilibre entre contraintes et autonomie de l’IA (Source : Anthropic)

DeepSeek lance l’architecture Engram : une percée en calcul avec du DRAM remplaçant le HBM : Un rapport de Morgan Stanley salue le module Engram (Empreinte) proposé par DeepSeek dans son dernier article. Cette architecture sépare le stockage des motifs statiques du raisonnement dynamique via un mécanisme de “mémoire conditionnelle”, permettant de décharger des connaissances massives vers la mémoire système (DRAM) peu coûteuse, avec des consultations uniquement lorsque nécessaire. Cette innovation atténue efficacement le goulot d’étranglement de la mémoire à haute bande passante (HBM) coûteuse, prouvant qu’une innovation algorithmique peut permettre de “faire plus avec moins” dans des environnements limités en puissance. Morgan Stanley prédit que DeepSeek V4, utilisant cette architecture, pourrait fonctionner sur des cartes graphiques grand public (comme la RTX 5090), réécrivant les règles de l’expansion de l’IA (Source : Morgan Stanley)

Révélations sur le projet “Macrohard” de xAI : les ordinateurs de bord Tesla comme base pour des millions d’Agents : L’ancien ingénieur de xAI, Sulaiman Ghori, a divulgué des détails sur le projet interne “Macrohard” lors d’un podcast. Ce projet vise à construire un “simulateur humain” capable d’automatiser des tâches de cols blancs via des opérations clavier-souris accélérées 8 fois. La révélation la plus frappante est le plan de xAI d’utiliser les capacités de calcul de millions de voitures Tesla inactives (plateforme HW4) pour déployer ces Agents, évitant ainsi les cycles de construction traditionnels des centres de données. Ghori a été licencié pour cette divulgation, mais la culture “war room” et le calendrier agressif qu’il a décrits ont conduit à une réévaluation du potentiel concurrentiel de xAI (Source : The Information)
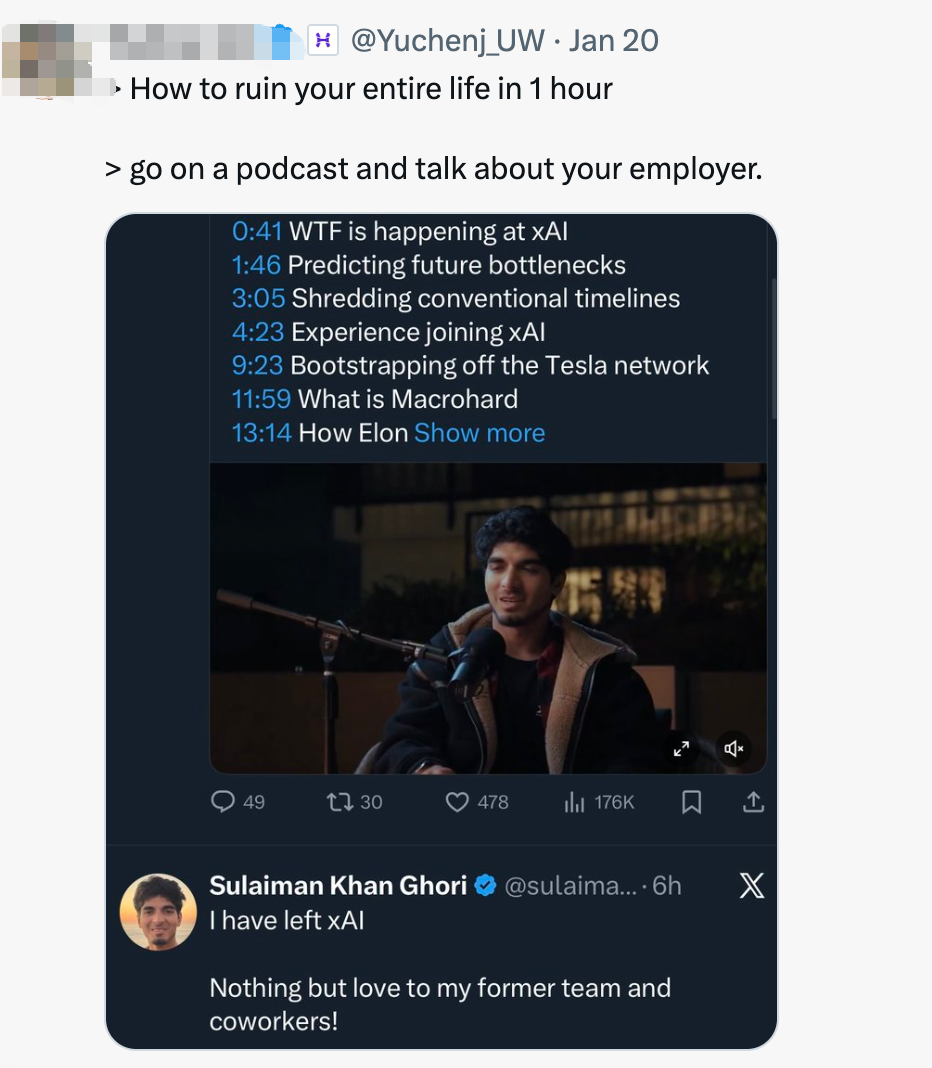
Google et Shopify s’allient pour l’IA dans le e-commerce : de la recherche à la transaction en boucle fermée : Google a annoncé le Universal Commerce Protocol (UCP), s’associant à Shopify, Walmart et d’autres géants pour faire de Gemini une plateforme complète d’achats. Les utilisateurs peuvent effectuer des comparaisons de prix, des analyses de paramètres et des paiements instantanés directement dans l’interface, sans quitter l’application. Gemini peut même appeler des magasins physiques pour vérifier les stocks. Cette initiative est perçue comme une contre-attaque à la fonction “paiement instantané” de ChatGPT, marquant une transition des modèles publicitaires vers le “commerce par agents intelligents”, où les fournisseurs de grands modèles deviennent des acteurs clés remodelant les canaux de vente au détail mondiaux (Source : Google)
🎯 Tendances
Fuites sur les plans d’Apple pour le matériel IA et la mise à niveau de Siri “Campos” : Selon des sources, Apple développerait secrètement un appareil portable IA en forme d’AirTag, doté de multiples caméras et capteurs, avec une sortie prévue en 2027. Parallèlement, la nouvelle version de Siri, nom de code “Campos”, intégrant profondément le modèle Google Gemini 3, sera dévoilée en septembre. Elle disposera d’une “conscience de l’écran”, capable d’interagir directement avec les fichiers et applications affichés. Apple vise ainsi à contrer OpenAI et Meta grâce à ses avantages matériels et logiciels intégrés, avec un objectif de production initial de 20 millions d’unités (Source : The Information)

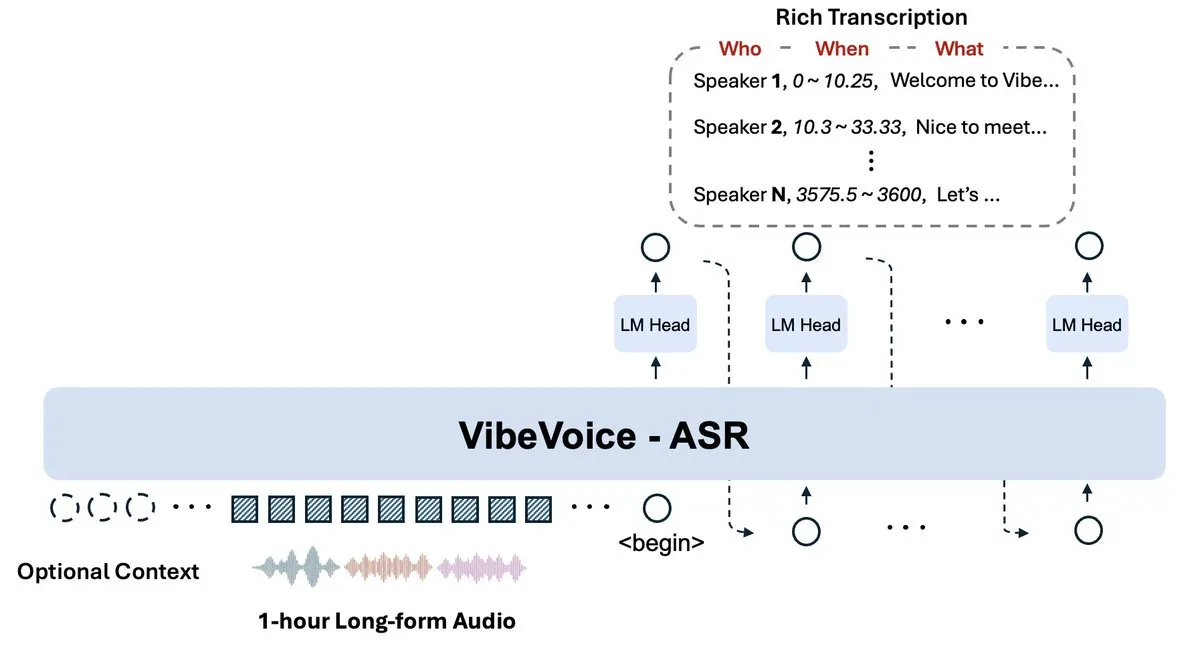
Microsoft publie VibeVoice-ASR : traitement d’audios d’une heure en une seule passe : Microsoft a open-sourcé sur Hugging Face le modèle de reconnaissance vocale VibeVoice-ASR de 9B paramètres. Ce modèle rompt avec la pratique traditionnelle de découpage audio, supportant des fenêtres de 64K tokens pour traiter 60 minutes d’audio en une seule fois, évitant ainsi la perte de contexte global et la confusion dans le suivi des locuteurs. Les tests montrent des performances robustes dans des environnements complexes (comme isoler des voix dans de la musique) et pour de longs textes (comme des lectures de romans), avec une précision moyenne de 91,9% et la possibilité de configurer des mots-clés pour corriger la reconnaissance de termes spécifiques (Source : Microsoft)
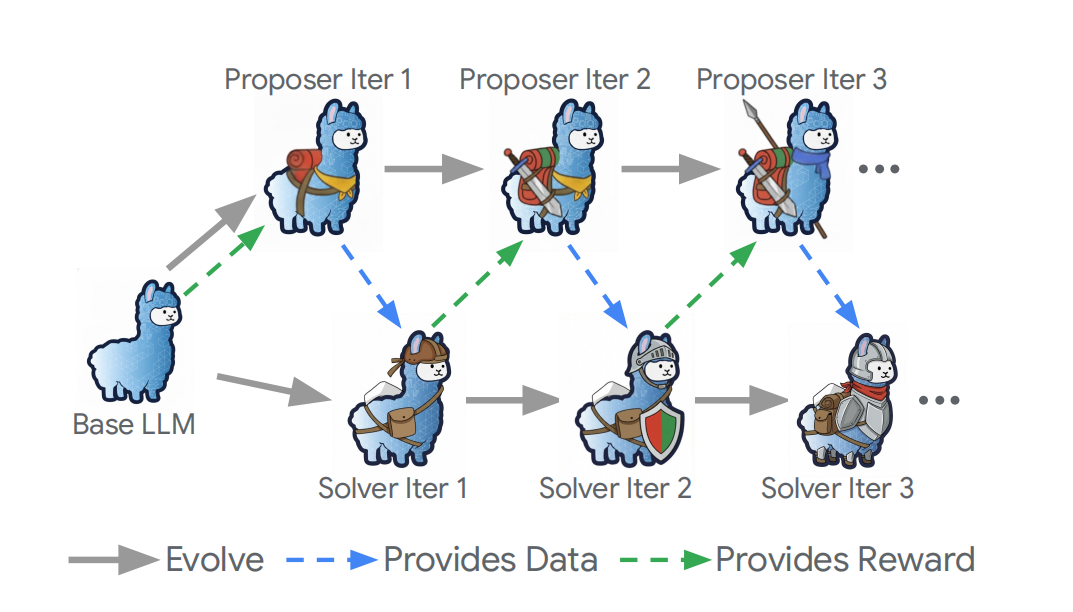
Meta introduit le cadre Dr. Zero : auto-évolution des Agents sans données annotées : Le laboratoire Super Intelligence de Meta propose le cadre Dr. Zero, permettant aux agents intelligents d’évoluer efficacement sans données étiquetées. Ce mécanisme de “proposeur-résolveur” utilise des moteurs de recherche pour explorer et générer des questions complexes. La technologie HRPO (Optimisation de Politique Relative par Groupes à Sauts) regroupe des questions similaires pour créer des benchmarks, évitant un échantillonnage imbriqué coûteux. Sur des tâches de questions-réponses complexes, cette méthode surpasse les approches supervisées de 14,1%, offrant une nouvelle voie pour résoudre l’épuisement des données d’entraînement IA (Source : Meta)
L’industrie se tourne vers l’évaluation des tâches longues : publication de benchmarks réalistes : L’évaluation IA se concentre désormais sur les tâches longues plutôt que sur les tests mathématiques ou de code. Le nouveau benchmark APEX-Agents teste la capacité des Agents à collaborer professionnellement dans Google Workspace ; DSAEval couvre 641 problèmes réels de science des données. Les tests montrent que GPT-5.2 mène en efficacité, tandis que Claude-Sonnet-4.5 excelle en performance globale. Ces benchmarks reflètent un consensus : ce qui limite les Agents n’est plus leur capacité de raisonnement, mais leur cohérence logique et leur contrôle de la mémoire sur le long terme (Source : Mercor, DSAEval)
Compresseur Cognitif d’Agent (ACC) : contrôle de mémoire inspiré de la biologie : Des chercheurs proposent l’Agent Cognitive Compressor pour résoudre la “dégradation contextuelle” dans les dialogues multi-tours. L’ACC ne rejoue pas simplement l’historique, mais maintient un “état cognitif compressé” avec des variables clés comme les objectifs, entités et relations. Les tests montrent un taux quasi nul d’hallucinations et de dérives sur des workflows complexes de 50+ tours, surpassant les méthodes traditionnelles de récupération augmentée (RAG) (Source : DAIR.AI)

🧰 Outils
Prefect Horizon : plateforme de gestion et gouvernance pour serveurs MCP : Face à la popularité du Model Context Protocol (MCP), Prefect lance Horizon. Cette plateforme résout les problèmes de déploiement en entreprise des serveurs MCP, offrant hébergement, contrôle d’accès basé sur les rôles (RBAC), journaux d’audit et découverte d’outils. Horizon permet aux entreprises d’exposer en toute sécurité des données et workflows privés aux Agents IA, transformant le MCP d’un simple protocole en une plateforme de productivité gouvernable à grande échelle (Source : Prefect)

CopilotKit + LangChain : solution frontale pour Agents profonds : CopilotKit supporte désormais l’architecture Deep Agents de LangChain, permettant aux développeurs de créer des UI interactives pour Agents planificateurs en quelques lignes de code. L’outil gère les sorties en flux, les compétences personnalisées et l’orchestration de sous-agents, résolvant les goulots d’étranglement UI/UX dans la construction d’applications complexes, accélérant ainsi la transformation d’Agents “orientés planification” en produits finaux (Source : CopilotKit)

Devin Review : outil IA repensant l’expérience de revue de code : Cognition lance Devin Review pour résoudre le goulot d’étranglement humain dans la revue de code généré par IA. L’outil ne cherche pas seulement des bugs, mais aide à comprendre rapidement la logique complexe des PR via une interface repensée. Utilisable directement depuis les liens GitHub, il peut détecter des erreurs liées au-delà des Diff. Son principe : le code généré par IA doit être revu par des outils IA plus efficaces, plutôt que de noyer les programmeurs dans du “code garbage” (Source : Cognition)
Optimisation locale de GLM-4.7 Flash : 200K contextes sur une seule carte : La communauté a corrigé le support du cache KV de vLLM pour GLM-4.7-Flash en une ligne de code, activant le mécanisme MLA (Multi-Head Latent Attention). Ainsi, l’empreinte mémoire de ce modèle 30B passe de 180GB à 10GB pour des contextes de 200K. Une seule RTX 5090 (32GB VRAM) peut désormais exécuter ce modèle hautement performant, marquant l’avènement des Agents locaux puissants (Source : Zai_org)

📚 Apprentissage
Cours pratique Gemini CLI : construire des workflows automatisés multi-étapes : DeepLearning.AI et Google proposent un cours gratuit pour développer des agents open-source avec Gemini CLI. Le cours couvre des opérations sur fichiers locaux, l’intégration d’outils de développement jusqu’aux appels de services cloud, montrant comment utiliser des Agents pour automatiser du code, créer des tableaux de bord et planifier des tâches complexes. Idéal pour les développeurs souhaitant passer de simples appels API à la construction d’outils productifs réels (Source : DeepLearningAI)
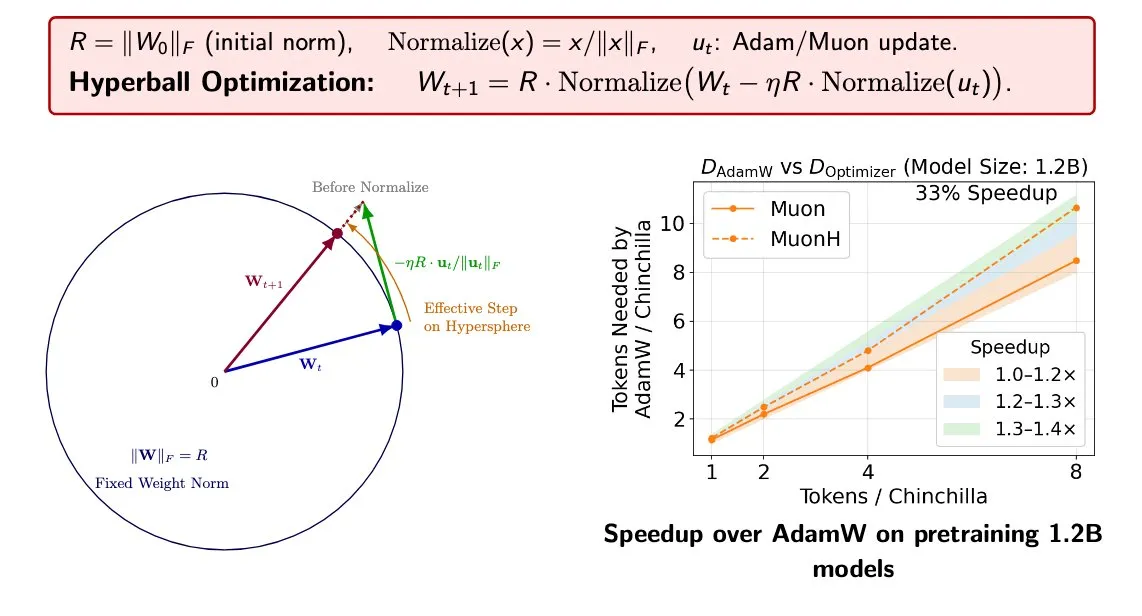
Optimiseur Hyperball : accélération de 33% de l’entraînement via normalisation : Des chercheurs de Stanford proposent l’optimiseur Hyperball. Cette méthode maintient constante la norme des poids et des mises à jour, permettant un contrôle direct de la taille effective des pas, remplaçant la décroissance de poids traditionnelle. Les tests montrent une accélération de 33% de l’entraînement avec Hyperball sur des optimiseurs comme Muon, avec une meilleure transférabilité des hyperparamètres, offrant un cadre mathématique plus stable pour l’entraînement de grands modèles (Source : Kaiyue Wen)
NVIDIA Motive : méthode d’attribution pour la génération vidéo : Les chercheurs de NVIDIA présentent Motive, une méthode d’attribution basée sur le gradient centrée sur le mouvement. En isolant la dynamique temporelle de l’apparence statique, Motive identifie quelles vidéos d’entraînement influencent positivement ou négativement les mouvements générés. Cela a une valeur importante pour optimiser la qualité des modèles de génération vidéo et comprendre les causes des dégradations de mouvement (Source : NVIDIA Research)
InT (Intervention Training) : résoudre l’attribution du crédit dans le raisonnement : Un article propose l’Intervention Training, où le modèle localise sa première erreur dans un chemin de raisonnement et suggère une intervention en une étape pour initialiser efficacement l’apprentissage par renforcement. Contrairement au RL standard qui ne récompense que la réponse finale, InT corrige précisément les étapes intermédiaires. Sur le benchmark IMO-AnswerBench, cette méthode améliore la précision d’un modèle 4B de 14%, surpassant même des modèles 20B (Source : HuggingFace)
💼 Business
OpenAI prévoit une levée de 50 milliards à une valorisation de 830 milliards : Sam Altman rencontrerait des investisseurs aux Émirats pour discuter d’un nouveau tour de table géant. L’objectif est de lever 50 milliards à une valorisation entre 750 et 830 milliards, finançant les dépenses estimées à 2000 milliards d’OpenAI en calcul d’ici