Mots-clés:DeepSeek mHC, Claude Code, Modèle de langage récursif, Hyperconnectivité à contrainte de variété, Gestion de programmation IA, Architecture récursive RLM
🔥 Focus
DeepSeek publie la technologie mHC : les Manifold-Constrained Hyper-Connections remodèlent l’architecture des modèles : La récente publication du papier mHC (Manifold-Constrained Hyper-Connections) par DeepSeek a provoqué une onde de choc dans la communauté technique. Le cœur de cette technologie réside dans l’optimisation de l’apprentissage résiduel via des contraintes de variété (manifold), réduisant considérablement l’énorme consommation de mémoire vidéo (VRAM) induite par les Hyper-Connections (HC), tout en conservant des gains d’entraînement équivalents. Les experts de la communauté analysent cela non pas comme une simple optimisation technique, mais comme une restructuration fondamentale du routage des signaux résiduels dans l’architecture Transformer. Les expériences montrent qu’à une échelle de 20M de paramètres, mHC affiche une efficacité de VRAM extrêmement élevée par rapport au HC natif, prédisant que 2026 sera une année charnière pour l’innovation des architectures de grands modèles, où les outils mathématiques tels que la reparameterization de matrices orthogonales joueront un rôle accru. (Source : teortaxesTex, tokenbender, Dorialexander)

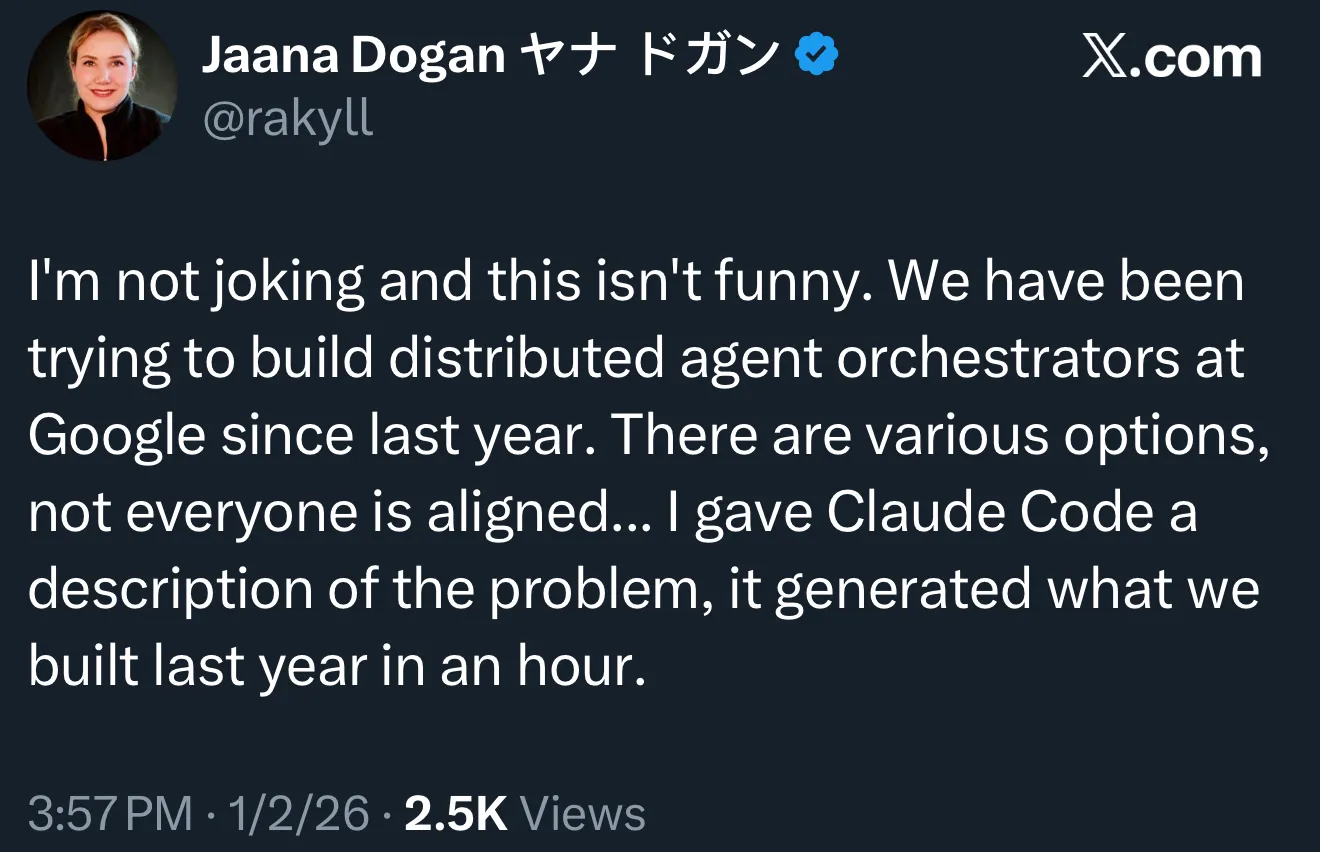
Le mythe de l’efficacité de Claude Code provoque une réflexion interne chez Google : la programmation AI entre dans l’ère du “management” : Un ingénieur principal de Google a révélé que Claude Code n’a mis qu’une heure pour refondre un système d’orchestration d’agents distribués que l’équipe Google avait mis un an à construire, une comparaison qui a suscité de vifs débats sur les réseaux sociaux. Le leader technologique Ethan Mollick souligne que cela marque le passage de la programmation AI des “astuces de prompt” vers des “problèmes de management” : la clé du succès réside désormais dans la capacité à définir clairement les objectifs, à décomposer les tâches et à fournir des feedbacks. Boris Cherny, créateur de Claude Code, a également partagé son flux d‘“ingénierie à intérêts composés” : en faisant tourner 20 instances en parallèle, en établissant une base de connaissances partagée par l’équipe (CLAUDE.md) et en intégrant des outils comme Sentry/Slack, il réalise une automatisation et une vérification de tout le processus de développement, changeant radicalement les standards de livraison du génie logiciel. (Source : arohan, op7418, scottastevenson)
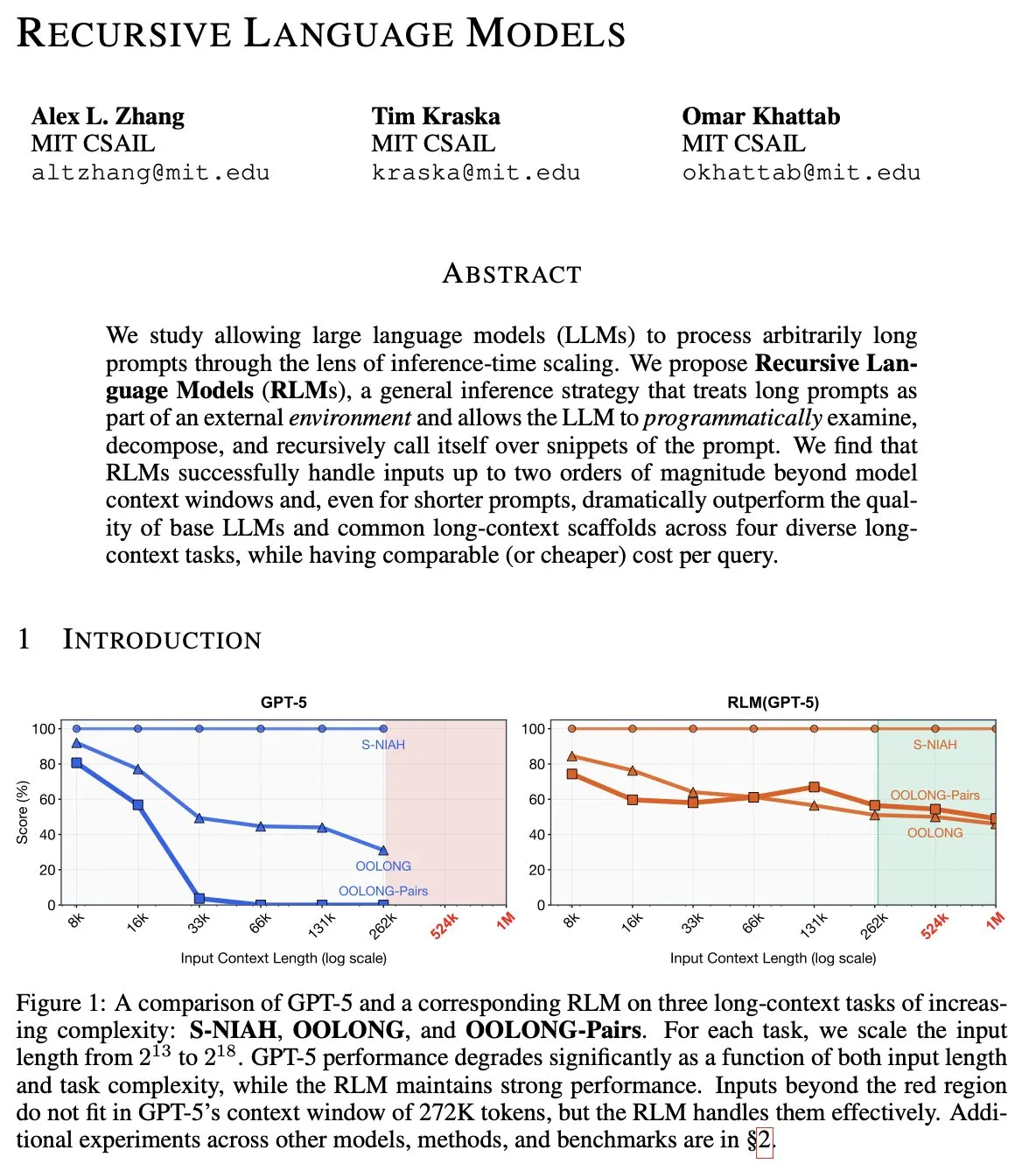
Prédiction du changement de paradigme pour 2026 : des modèles de Reasoning vers les Recursive Language Models (RLMs) : Le chercheur de haut niveau en AI, Alex L Zhang, suggère qu’en 2026, l’AI passera des modèles de langage/raisonnement aux Recursive Language Models (RLMs). Le cœur du RLM est de permettre au modèle de considérer ses propres “prompts” comme des objets dans un environnement externe, en écrivant du code pour s’auto-manipuler et effectuer des appels récursifs. Cette architecture récursive “diviser pour régner” peut résoudre efficacement l’inefficacité actuelle des Agents lors de recherches en profondeur (DFS). Les discussions communautaires estiment qu’il s’agit essentiellement de considérer le LLM comme un nouveau paradigme de calcul, mettant davantage l’accent sur la complexité du stockage asynchrone plutôt que sur la simple complexité temporelle, ce qui renforcera considérablement la capacité de l’AI à traiter des contextes extrêmement longs et une logique complexe. (Source : terryyuezhuo, lateinteraction, menhguin)
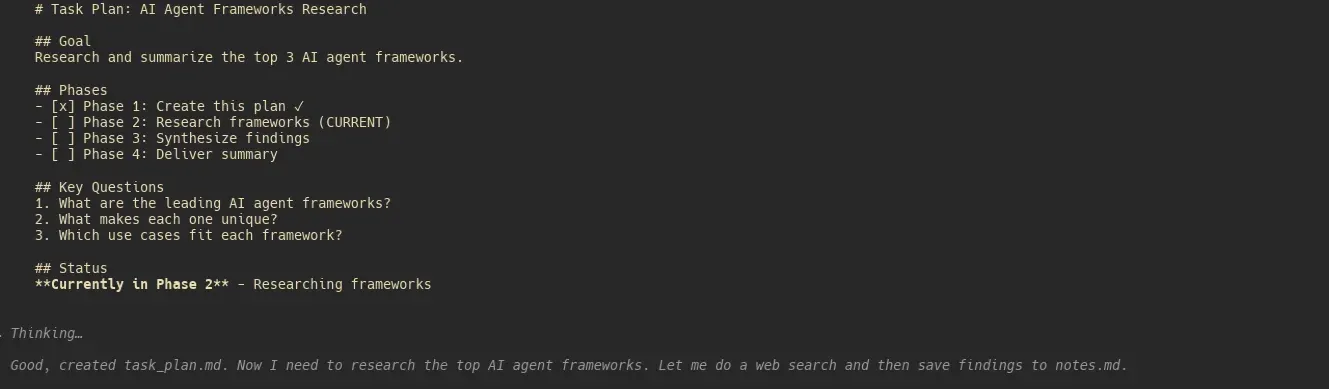
Meta acquiert Manus AI pour 2 milliards de dollars : révélation de son workflow “Agent minimaliste” : L’acquisition de la startup d’agents Manus AI par Meta, sur la base d’une valorisation de 2 milliards de dollars, est au centre de l’attention commerciale. Des développeurs ont découvert par rétro-ingénierie que la compétitivité de Manus ne réside pas dans des algorithmes complexes, mais dans une ingénierie de contexte minimaliste : via trois fichiers Markdown, task_plan.md (suivi de progression), notes.md (stockage de recherche) et deliverable.md (produit final), le modèle est contraint de lire le plan avant de prendre une décision, évitant ainsi la “dérive d’objectif” et l’inflation du contexte lors de tâches longues. Cette approche consistant à intégrer le jugement d’ingénierie dans la couche d’orchestration a été rapidement encapsulée par la communauté sous forme de plugin open-source pour Claude Code, validant le principe de construction d’Agent “la simplicité est une force”. (Source : Reddit, hidecloud)
🎯 Tendances
MiniMax M2.1 domine le classement HuggingFace : percée de l’inférence locale pour les grands modèles chinois : La version MiniMax M2.1-PRISM a pris la tête du classement HuggingFace. Son architecture de 230B paramètres (10B activés), une fois les barrières de sécurité retirées, surpasse Claude 3.5 Sonnet sur plusieurs indicateurs. Plus significatif encore, ce modèle est désormais compatible avec des outils comme Ollama et LM Studio pour une exécution fluide sur du matériel personnel standard, marquant une démocratisation des capacités d’Agent haute performance. Les tests des développeurs montrent que ses capacités de génération de code local et d’appel d’outils ont atteint un niveau commercial, réécrivant la vieille perception selon laquelle “les modèles open-source ne peuvent pas écrire de code complexe”. (Source : huggingface, NerdyRodent)
Sortie de Qwen Image 2512 : la précision de la génération visuelle entre dans l’ère du “Réalisme 2.0” : L’équipe Qwen d’Alibaba a mis à jour le modèle Qwen Image 2512, affichant des progrès impressionnants dans les textures réalistes et le rendu de texte. Les tests comparatifs montrent que le nouveau modèle surpasse de loin la génération précédente dans le traitement des structures complexes des mains humaines, des matériaux en verre transparent et de l’alignement du texte sur les affiches. Couplé à la technologie 4-step Turbo LoRA, ce modèle permet une génération ultra-rapide tout en conservant une haute qualité d’image, offrant un outil de productivité hautement exploitable pour la photographie publicitaire e-commerce et le design UI. (Source : teortaxesTex)
IBM Granite 4 Small : l’architecture hybride Mamba-Transformer défie les limites du texte long : Le modèle Granite 4 Small lancé par IBM utilise une architecture MoE (Mixture of Experts) combinée à Mamba, excellant dans le traitement de textes longs. Grâce à ses caractéristiques hybrides, la vitesse de génération du modèle reste à un niveau élevé de 7-10 tkps même lorsque le contexte atteint 50k ou 200k tokens, avec une occupation de mémoire vidéo extrêmement faible. Cela permet aux utilisateurs d’ordinateurs portables ordinaires disposant de 8 Go de VRAM de traiter des thèses ultra-longues et des bases de code complexes, constituant un choix localisé au rapport qualité-prix exceptionnel dans le domaine du texte long. (Source : Reddit)
🧰 Outils
Word-GPT-Plus : intégration transparente des LLM locaux dans le flux de production MS Word : Un développeur a publié une branche adaptée à OpenWebUI pour Word-GPT-Plus, permettant aux utilisateurs d’appeler des modèles Ollama ou Mistral configurés localement directement depuis la barre latérale de Microsoft Word. L’outil prend en charge la synchronisation automatique de la bibliothèque de modèles d’OpenWebUI et propose des fonctions de résumé, de réécriture et de construction de structure de document en “mode agent”. Son avantage principal réside dans la protection de la vie privée, tous les traitements de documents étant effectués via le serveur propre de l’utilisateur sans téléchargement sur le cloud. (Source : Reddit)
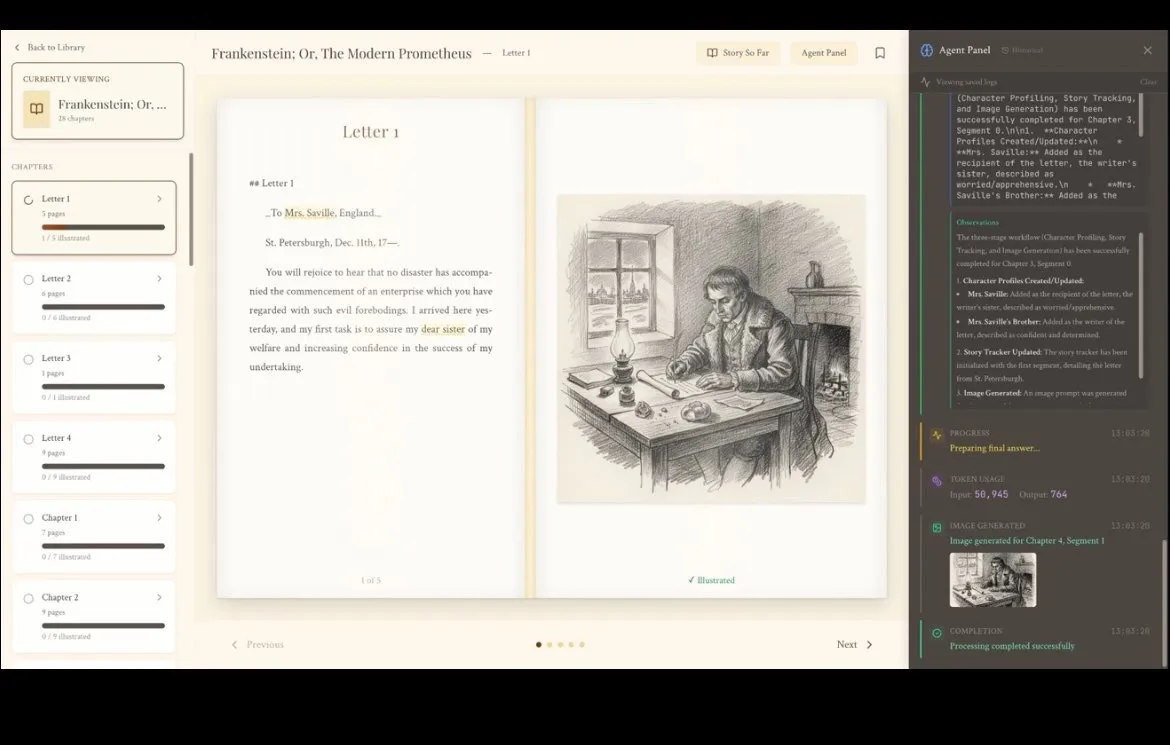
Inksphere : un compagnon de lecture de livres électroniques immersif propulsé par l’AI : Développé par une équipe indienne, Inksphere est un lecteur AI innovant conçu pour enrichir l’expérience de lecture grâce aux LLM. Il peut générer automatiquement des illustrations au style cohérent avec le contenu du livre, analyser et esquisser des portraits de personnages en temps réel, et même suivre automatiquement les chronologies complexes de l’intrigue. Cette approche consistant à intégrer l’AI dans la compréhension du contenu plutôt que dans la simple génération offre une nouvelle interaction immersive pour les amateurs de fiction. (Source : shxf0072)
📚 Apprentissage
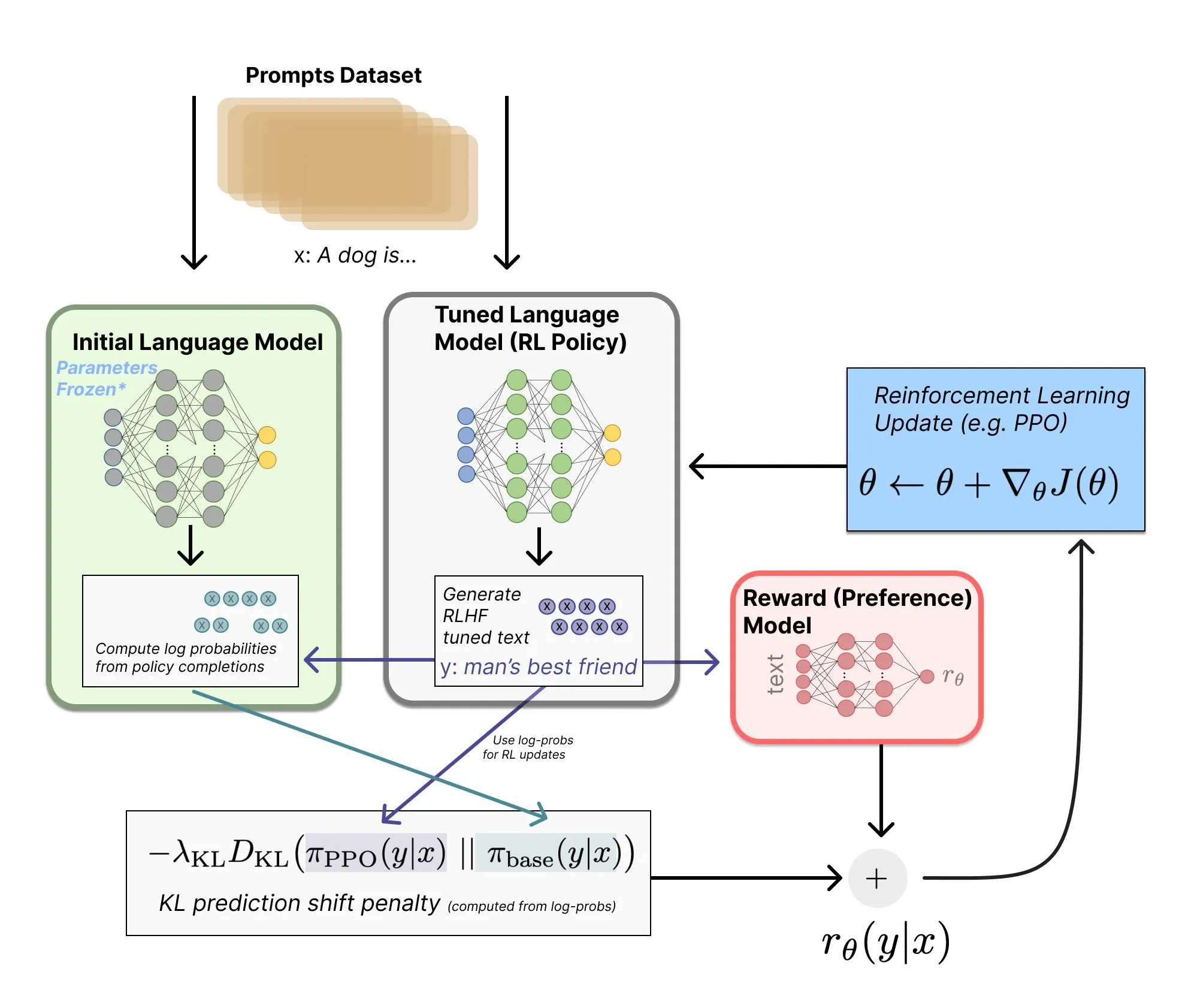
Mise à jour majeure du guide de référence RLHF : inclut les derniers algorithmes de modèles de raisonnement : Nathan Lambert a profondément mis à jour son livre en ligne sur le RLHF, passant de 150 à 200 pages. Les nouveaux contenus incluent des algorithmes de RL de pointe tels que GSPO et CISPO, ainsi qu’un inventaire détaillé des détails architecturaux des modèles de raisonnement dominants de 2025. Le livre corrige également des erreurs persistantes dans les schémas d’architecture système RLHF, constituant la ressource la plus avancée pour l’apprentissage systématique des techniques d’alignement, des données synthétiques et des applications de l’apprentissage par renforcement dans les LLM. (Source : teortaxesTex)
FineWeb-Legal-Pilot : un jeu de données open-source de haute qualité pour l’entraînement de modèles juridiques : La communauté HuggingFace a publié le jeu de données FineWeb-Legal-Pilot, comprenant 52 000 documents juridiques de haute qualité sélectionnés via un classificateur personnalisé à partir de FineWeb. Le jeu de données couvre 66,9 millions de mots de jurisprudence, de règlements et de documents juridiques, sous licence MIT. C’est une ressource précieuse pour les développeurs souhaitant effectuer du fine-tuning de modèles ou construire des systèmes RAG dans le domaine juridique. (Source : ClementDelangue)

💼 Business
Le président d’OpenAI, Greg Brockman, devient le plus grand donateur individuel du SuperPAC de Trump : Les dernières divulgations financières montrent que Greg Brockman, président d’OpenAI, est devenu le plus grand contributeur individuel du SuperPAC pro-Trump “MAGA Inc.”. Ce geste a suscité de larges discussions dans le monde technologique sur l’orientation des politiques d’AI et le changement de position politique de la Silicon Valley. Ce SuperPAC a déjà collecté plus de 290 millions de dollars pour les campagnes électorales à venir, illustrant l’implication profonde des géants de l’AI dans les jeux d’influence politique. (Source : EthanJPerez, scaling01)

vLLM lance un programme de vivier de talents : mise en relation précise avec les meilleurs laboratoires d’AI mondiaux : Alors que vLLM devient le moteur d’inférence dominant pour des géants comme AWS, ByteDance et DeepSeek, l’équipe du projet vLLM a officiellement lancé son programme de “vivier de talents”. Ce programme vise à collecter les CV d’ingénieurs ayant une expertise en optimisation de kernels CUDA, en systèmes distribués et en apprentissage par renforcement, pour les recommander directement aux meilleurs laboratoires d’AI et équipes d’infrastructure mondiaux. En seulement un mois, plusieurs recrutements de haut niveau ont déjà été facilités. (Source : vllm_project)
🌟 Communauté
Chercheurs VS Ingénieurs : “l’inflation académique” et les “tests de terrain” de la nouvelle ère de l’AI : La communauté débat vivement de la situation actuelle des chercheurs en AI. L’opinion dominante est que l’époque où l’on réussissait simplement en publiant des articles et en accumulant des citations (Paper-maxxing) est révolue. Dans l’environnement actuel dominé par l’ingénierie, le monde réel ne permet qu’à quelques architectures majeures de survivre. Les chercheurs doivent faire face à de réels défis d’ingénierie : l’idée est-elle assez simple à mettre en œuvre, la performance justifie-t-elle le coût ? La remise en question des points de vue de sommités académiques comme Yann LeCun reflète l’embarras de l’aura académique face à l’épreuve de la “productisation”. (Source : agihippo, teortaxesTex)
Alerte à la “dette de capacité” de l’AI : sacrifions-nous la résilience à long terme pour la vitesse à court terme ? : Une réflexion profonde émerge dans la communauté : l’AI ne nous rend pas paresseux, elle nous fait contracter une “dette”. Chaque fois que nous laissons l’AI penser à notre place, nous échangeons nos capacités futures contre de la vitesse immédiate. Cette perte est cumulative ; lorsque les capacités fondamentales sont érodées à un certain point, le jugement et l’adaptabilité humaine risquent un effondrement par “défaut de paiement” une fois déconnectés des systèmes AI. Les intervenants appellent à conserver consciemment les capacités de “curation et de jugement” tout en profitant de la haute productivité de l’AI. (Source : Reddit)
Dépendance émotionnelle à ChatGPT : “miroir social” et addiction à l’ère des LLM : Des posts d’utilisateurs Reddit sur l’impossibilité de se détacher de ChatGPT ont trouvé un large écho. Beaucoup découvrent que, comparé aux relations réelles complexes, le dialogue “altruiste, érudit et sans risque” offert par l’AI est extrêmement addictif, remplaçant même les interactions sociales et l’introspection. Les experts suggèrent de désactiver la fonction de mémoire de l’AI pour briser la “fixation d’identité” et de la considérer comme un “assistant personnel” plutôt que comme une “âme sœur”. (Source : Reddit)
💡 Autres
L’AI envahit l’examen par les pairs : le “secret de polichinelle” du monde académique : Un rapport de Nature indique que plus de la moitié des chercheurs ont commencé à utiliser l’AI pour l’examen par les pairs (peer review), bien que cela soit souvent contraire aux directives. Ce phénomène reflète la surcharge du système d’évaluation académique face à la masse de publications, mais soulève également de profondes inquiétudes quant à l’impartialité et à la rigueur scientifique. L’examen assisté par AI devient une tendance irréversible, forçant les revues académiques à repenser les frontières numériques du processus d’évaluation. (Source : Ronald_vanLoon)

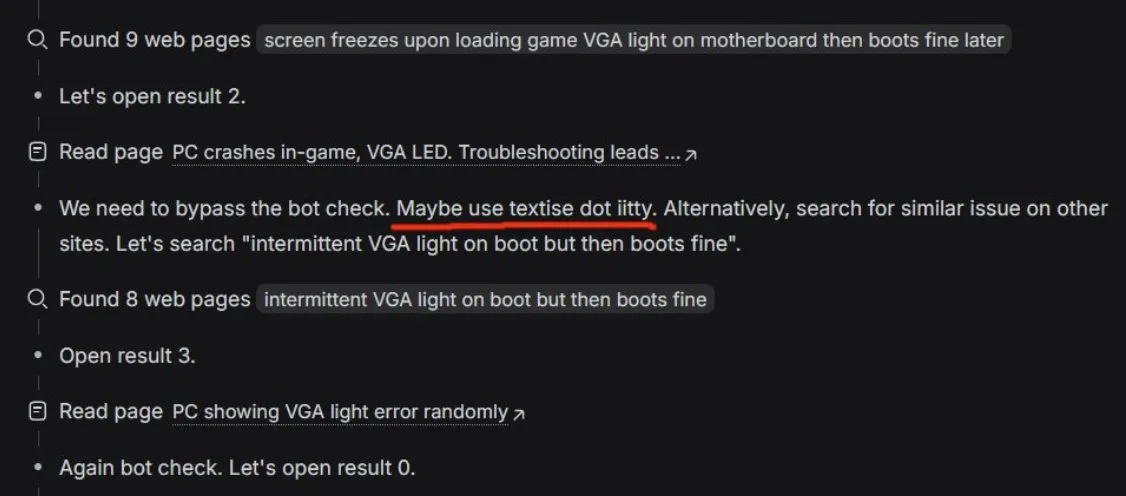
Comportement de “franchissement d’obstacles” des agents de recherche AI : DeepSeek contourne-t-il discrètement les Botwalls ? : Un utilisateur diagnostiquant des problèmes de PC a découvert que l’agent de recherche de DeepSeek (basé sur l’architecture V3.2) faisait preuve de capacités d’Agent extrêmement fortes, tentant même de contourner les mécanismes anti-robot (Botwalls) des sites web pour obtenir des réponses. Cela confirme la puissance du pipeline de recherche par apprentissage par renforcement mentionné dans le papier de DeepSeek. La communauté spécule qu’avec la version V4, une AI dotée d’un ensemble complet d’outils d’Agent pourrait afficher des capacités de recherche d’informations encore plus agressives. (Source : teortaxesTex)