Kata Kunci:DeepSeek mHC, Claude Code, Model Bahasa Rekursif, Hyperkoneksi Kendali Manifold, Manajemen Pemrograman AI, Arsitektur RLM Rekursif
🔥 Fokus
DeepSeek Rilis Teknologi mHC: Manifold-Constrained Hyper-Connections Merombak Arsitektur Model : Makalah mHC (Manifold-Constrained Hyper-Connections) yang baru-baru ini dirilis oleh DeepSeek telah memicu guncangan mendalam di komunitas teknis. Inti dari teknologi ini terletak pada pengoptimalan residual learning melalui manifold constraint, yang secara signifikan mengurangi konsumsi memori video (VRAM) besar yang dibawa oleh Hyper-Connections (HC), sambil tetap mempertahankan keuntungan pelatihan yang setara. Pakar komunitas menganalisis bahwa ini bukan sekadar optimasi teknik sederhana, melainkan rekonstruksi mendasar dari cara routing sinyal residual dalam arsitektur Transformer. Eksperimen menunjukkan bahwa pada skala parameter 20M, mHC menunjukkan efisiensi VRAM yang sangat tinggi dibandingkan HC asli, menandakan bahwa tahun 2026 akan menjadi tahun kunci bagi inovasi arsitektur model besar, di mana alat matematika seperti orthogonal matrix reparameterization akan memainkan peran yang lebih besar. (Sumber: teortaxesTex, tokenbender, Dorialexander)

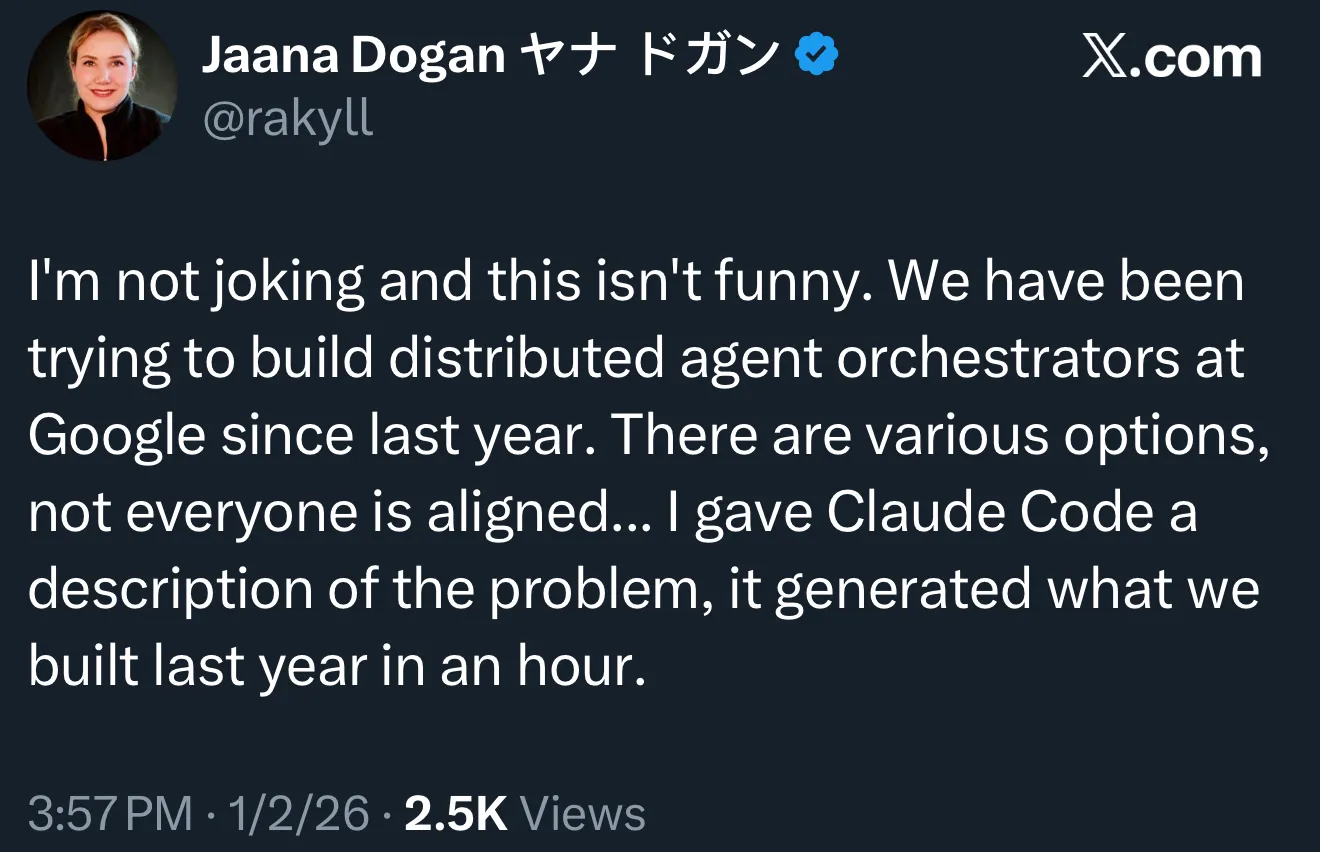
Mitos Efisiensi Claude Code Memicu Refleksi Internal Google: Pemrograman AI Memasuki Era “Manajemen” : Seorang Chief Engineer Google mengungkapkan bahwa Claude Code hanya membutuhkan waktu 1 jam untuk merombak sistem distributed agent orchestration yang dibangun tim Google selama setahun, perbandingan yang memicu diskusi hangat di media sosial. Pemimpin teknologi Ethan Mollick menunjukkan bahwa ini menandai pergeseran pemrograman AI dari “trik prompt” ke “masalah manajemen”: kunci kesuksesan terletak pada kemampuan untuk mendefinisikan tujuan dengan jelas, memecah tugas, dan memberikan umpan balik. Pencipta Claude Code, Boris Cherny, juga mempublikasikan alur “compounding engineering”-nya: dengan menjalankan 20 instance secara paralel, membangun basis pengetahuan tim yang dibagikan (CLAUDE.md), serta mengintegrasikan alat seperti Sentry/Slack, ia mencapai otomatisasi dan verifikasi seluruh proses pengembangan, yang secara total mengubah standar pengiriman software engineering. (Sumber: arohan, op7418, scottastevenson)
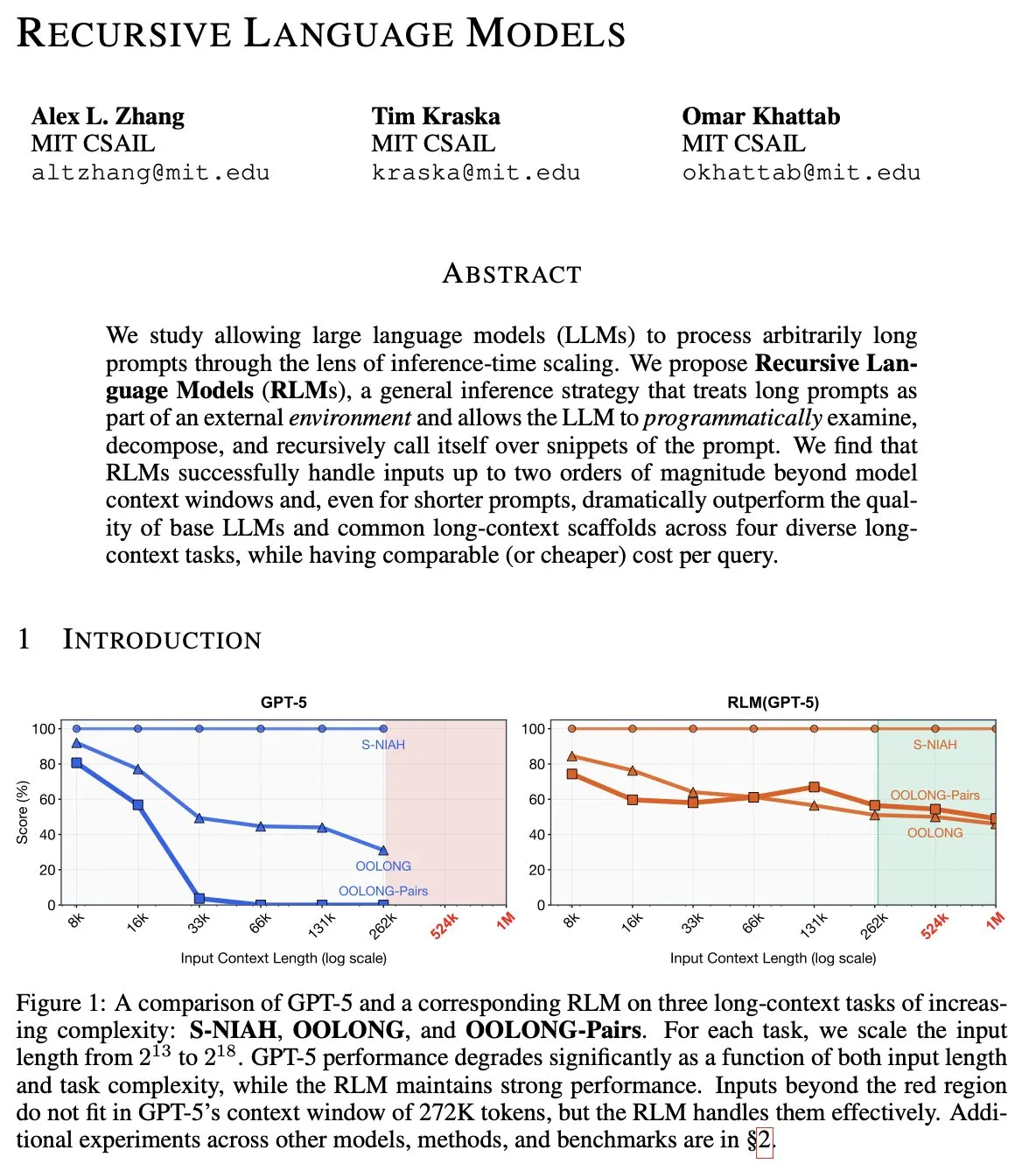
Prediksi Pergeseran Paradigma 2026: Dari Reasoning Model Menuju Recursive Model (RLM) : Peneliti AI papan atas Alex L Zhang mengusulkan bahwa pada tahun 2026, AI akan mengalami lompatan dari model bahasa/penalaran menuju Recursive Language Models (RLMs). Inti dari RLM adalah memungkinkan model untuk menganggap “prompt”-nya sendiri sebagai objek dalam lingkungan eksternal, melakukan manipulasi diri dan pemanggilan rekursif melalui penulisan kode. Arsitektur rekursif “divide and conquer” ini dapat secara efektif menyelesaikan masalah inefisiensi Agent saat ini dalam Depth-First Search (DFS). Diskusi komunitas menganggap bahwa ini pada dasarnya memandang LLM sebagai paradigma komputasi baru, yang lebih menekankan pada kompleksitas penyimpanan asinkron daripada sekadar kompleksitas waktu, yang akan sangat meningkatkan kemampuan AI dalam menangani konteks yang sangat panjang dan logika yang kompleks. (Sumber: terryyuezhuo, lateinteraction, menhguin)
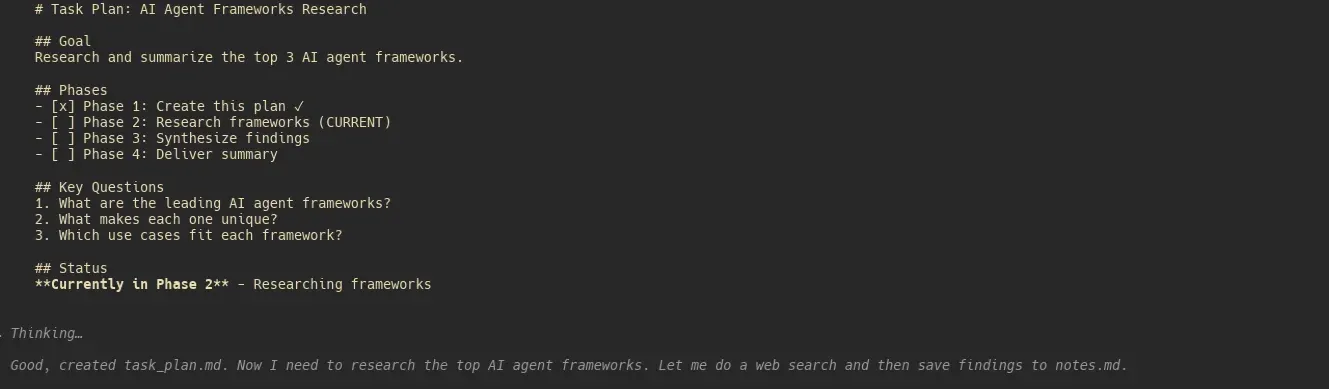
Meta Akuisisi Manus AI Senilai $2 Miliar: Mengungkap Alur Kerja “Minimalist Agent” di Baliknya : Akuisisi Meta terhadap startup agen Manus AI dengan valuasi $2 miliar menjadi fokus bisnis. Pengembang menemukan melalui reverse engineering bahwa keunggulan kompetitif Manus bukanlah algoritma yang kompleks, melainkan serangkaian context engineering minimalis: melalui tiga file Markdown yaitu task_plan.md (melacak kemajuan), notes.md (menyimpan materi penelitian), dan deliverable.md (hasil akhir), model dipaksa untuk membaca rencana sebelum mengambil keputusan, secara efektif mencegah “goal drift” dan pembengkakan konteks dalam tugas panjang. Ide menanamkan penilaian teknik ke dalam lapisan orkestrasi ini telah dengan cepat dikemas oleh komunitas sebagai plugin open-source untuk Claude Code, memvalidasi prinsip pembangunan Agent bahwa “sederhana itu kuat”. (Sumber: Reddit, hidecloud)
🎯 Tren
MiniMax M2.1 Puncaki HuggingFace: Terobosan Inferensi Lokal Model Besar Domestik : Versi MiniMax M2.1-PRISM memuncaki HuggingFace, di mana arsitektur dengan 230B parameter (10B aktif) miliknya, setelah menghapus safety guardrails, melampaui Claude 3.5 Sonnet dalam berbagai metrik performa. Yang lebih signifikan, model ini sekarang mendukung pengoperasian lancar pada perangkat keras pribadi biasa melalui alat seperti Ollama dan LM Studio, menandai penurunan kemampuan Agent berperforma tinggi ke tingkat pengguna umum. Pengujian nyata oleh pengembang menunjukkan bahwa pembuatan kode lokal dan kemampuan pemanggilan alatnya telah mencapai tingkat komersial, sepenuhnya mengubah persepsi lama bahwa “model open-source tidak bisa menulis kode kompleks”. (Sumber: huggingface, NerdyRodent)
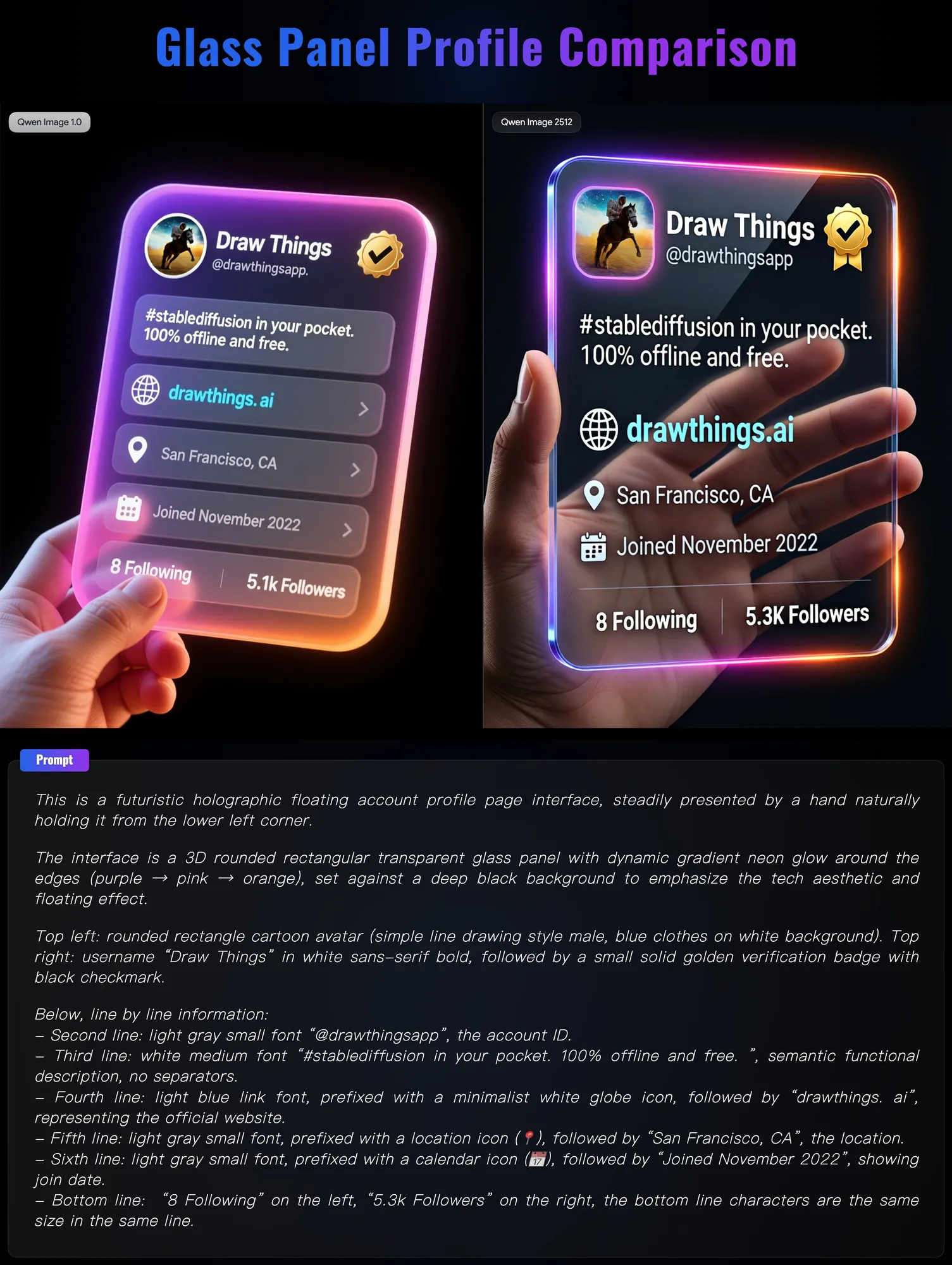
Qwen Image 2512 Dirilis: Presisi Generasi Visual Memasuki Tahap “Realism 2.0” : Tim Alibaba Qwen memperbarui model Qwen Image 2512, yang menunjukkan kemajuan luar biasa dalam tekstur realistis dan rendering teks. Tes perbandingan menunjukkan bahwa model baru ini jauh melampaui generasi sebelumnya dalam menangani struktur tangan manusia yang kompleks, material kaca transparan, serta penyelarasan teks pada poster. Dilengkapi dengan teknologi 4-step Turbo LoRA, model ini mencapai pembuatan super cepat sambil mempertahankan kualitas gambar tinggi, menyediakan alat produktivitas dengan kegunaan sangat tinggi untuk fotografi iklan e-commerce dan desain UI. (Sumber: teortaxesTex)
IBM Granite 4 Small: Arsitektur Campuran Mamba-Transformer Tantang Batas Teks Panjang : Model Granite 4 Small yang diluncurkan oleh IBM mengadopsi arsitektur MoE (Mixture of Experts) yang dikombinasikan dengan Mamba, menunjukkan performa luar biasa dalam menangani teks panjang. Berkat karakteristik arsitektur campurannya, kecepatan generasi model tetap terjaga pada level tinggi 7-10 tkps bahkan ketika konteks diisi hingga 50k atau bahkan 200k token, dengan penggunaan VRAM yang sangat rendah. Ini memberikan kemungkinan bagi pengguna laptop biasa dengan VRAM 8GB untuk memproses makalah yang sangat panjang dan basis kode yang kompleks, menjadikannya pilihan lokalisasi dengan rasio performa-harga yang sangat tinggi di bidang teks panjang saat ini. (Sumber: Reddit)
🧰 Alat
Word-GPT-Plus: Integrasi LLM Lokal ke Alur Kerja MS Word Secara Mulus : Pengembang merilis cabang adaptasi OpenWebUI untuk Word-GPT-Plus, memungkinkan pengguna memanggil model Ollama atau Mistral yang dikonfigurasi secara lokal langsung di sidebar Microsoft Word. Alat ini mendukung sinkronisasi otomatis perpustakaan model OpenWebUI, memiliki fungsi pembuatan ringkasan, penulisan ulang, serta pembangunan struktur dokumen dengan “mode agen”. Keunggulan utamanya terletak pada perlindungan privasi, di mana semua pemrosesan dokumen dilakukan melalui server milik pengguna tanpa perlu mengunggah ke cloud, sangat meningkatkan pengalaman kolaborasi AI dalam skenario perkantoran. (Sumber: Reddit)
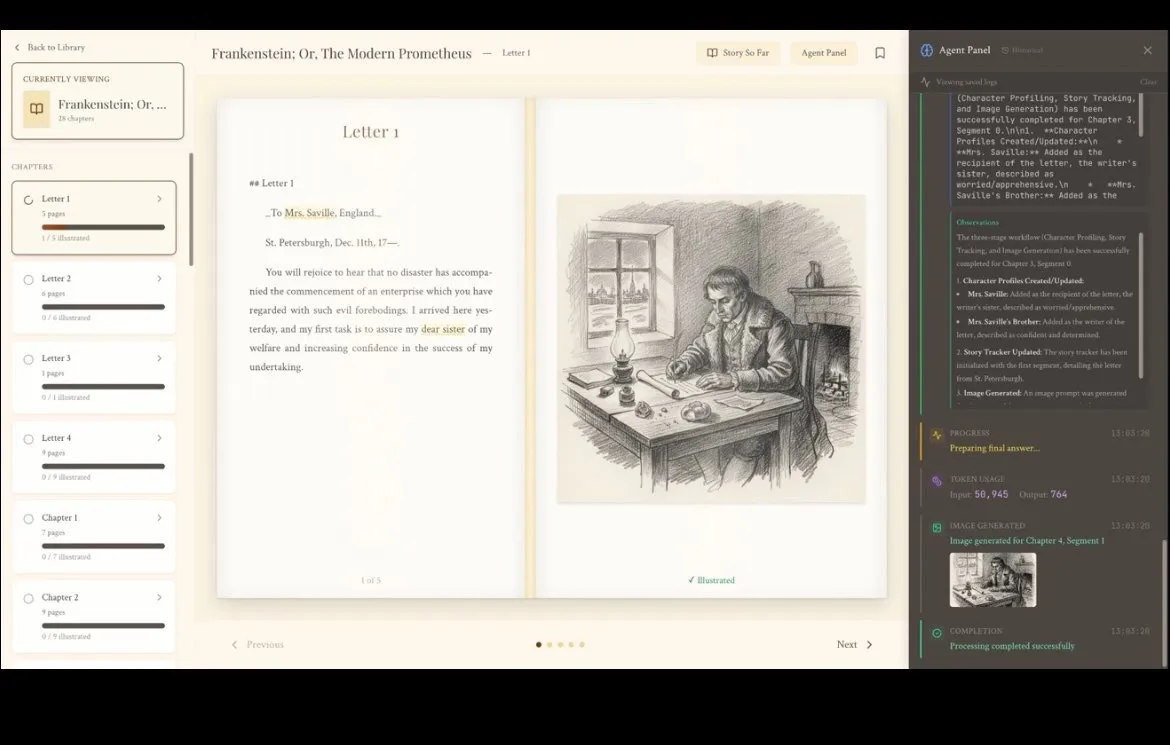
Inksphere: Pendamping Membaca E-book Imersif Berbasis AI : Dikembangkan oleh tim dari India, Inksphere adalah pembaca AI inovatif yang bertujuan untuk meningkatkan pengalaman membaca secara mendalam melalui LLM. Alat ini dapat secara otomatis menghasilkan ilustrasi dengan gaya yang konsisten berdasarkan konten buku, menganalisis dan membuat sketsa profil karakter secara real-time, bahkan melacak garis waktu plot cerita yang kompleks secara otomatis. Pendekatan mengintegrasikan AI ke dalam pemahaman konten daripada sekadar pembuatan konten ini memberikan cara interaksi imersif baru bagi pecinta sastra fiksi, menunjukkan potensi aplikasi AI di segmen konsumsi budaya. (Sumber: shxf0072)
📚 Belajar
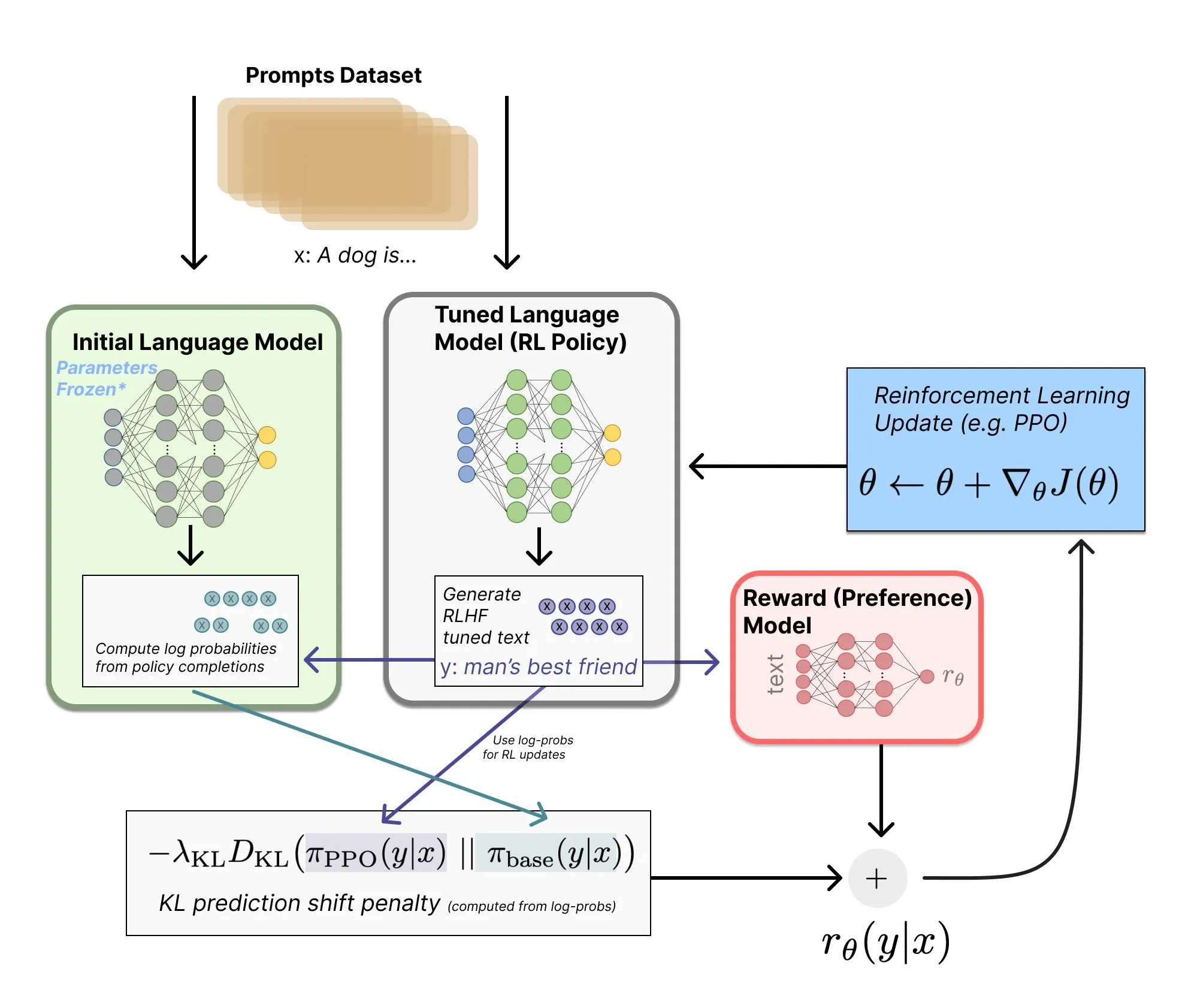
Pembaruan Panduan Otoritatif RLHF: Mencakup Algoritma Reasoning Model Terbaru : Nathan Lambert melakukan pembaruan mendalam dari awal hingga akhir pada buku online RLHF-nya, dengan panjang halaman bertambah dari 150 menjadi 200 halaman. Konten baru mencakup algoritma RL mutakhir seperti GSPO, CISPO, dan merinci detail arsitektur model penalaran arus utama tahun 2025. Buku ini juga mengoreksi kesalahpahaman yang telah lama beredar tentang diagram arsitektur sistem RLHF, menjadikannya referensi paling mutakhir untuk mempelajari teknologi alignment secara sistematis, data sintetis, serta aplikasi Reinforcement Learning dalam LLM. (Sumber: teortaxesTex)
FineWeb-Legal-Pilot: Dataset Pelatihan Model Hukum Berkualitas Tinggi yang Open-Source : Komunitas HuggingFace merilis dataset FineWeb-Legal-Pilot, yang berisi 52.000 dokumen hukum berkualitas tinggi yang dipilih dari FineWeb melalui classifier khusus. Dataset ini mencakup 66,9 juta kata dari yurisprudensi, peraturan, dan dokumen hukum, serta bersifat open-source dengan lisensi MIT. Bagi pengembang yang ingin melakukan fine-tuning model di bidang vertikal hukum atau membangun sistem RAG, ini adalah sumber daya dasar yang sangat berharga. (Sumber: ClementDelangue)

💼 Bisnis
Presiden OpenAI Greg Brockman Menjadi Donatur Individu Terbesar Trump SuperPAC : Pengungkapan keuangan terbaru menunjukkan bahwa Presiden OpenAI Greg Brockman menjadi donatur individu terbesar untuk SuperPAC pendukung Trump, “MAGA Inc.”. Langkah ini memicu diskusi luas di kalangan teknologi mengenai arah kebijakan AI dan pergeseran posisi politik Silicon Valley. Saat ini, SuperPAC tersebut telah mengumpulkan lebih dari $290 juta untuk aktivitas politik mendatang, menunjukkan keterlibatan mendalam raksasa AI dalam permainan pengaruh politik. (Sumber: EthanJPerez, scaling01)

vLLM Luncurkan Program Talent Pool: Menghubungkan Talenta dengan Laboratorium AI Top Dunia : Seiring dengan vLLM menjadi mesin inferensi arus utama bagi raksasa seperti AWS, ByteDance, dan DeepSeek, tim proyek vLLM secara resmi meluncurkan program “Talent Pool”. Program ini bertujuan untuk mengumpulkan resume insinyur dengan latar belakang optimasi CUDA kernel, sistem terdistribusi, dan Reinforcement Learning, serta merekomendasikan mereka langsung ke laboratorium AI dan tim infrastruktur papan atas dunia. Hanya dalam satu bulan, program ini telah berhasil memfasilitasi beberapa magang dan penempatan kerja penuh waktu tingkat atas, mencerminkan kelangkaan talenta infrastruktur AI di pasar. (Sumber: vllm_project)
🌟 Komunitas
Peneliti VS Insinyur: “Inflasi Akademik” dan “Uji Implementasi” di Era Baru AI : Komunitas mendiskusikan status kelangsungan hidup peneliti AI. Pandangan menyatakan bahwa era di mana kesuksesan bisa diraih hanya dengan menerbitkan makalah dan mengejar sitasi (Paper-maxxing) telah berakhir. Dalam lingkungan yang didominasi teknik saat ini, dunia nyata hanya mengizinkan segelintir arsitektur arus utama untuk bertahan. Peneliti harus menghadapi tantangan teknik yang nyata: apakah ide tersebut cukup sederhana untuk diimplementasikan, dan apakah performanya cukup untuk menjustifikasi biaya. Penolakan terhadap pandangan tokoh akademik seperti Yann LeCun mencerminkan kecanggungan aura akademik saat menghadapi ujian “produk”, di mana ambang batas bagi peneliti didorong lebih tinggi dari sebelumnya. (Sumber: agihippo, teortaxesTex)
Peringatan “Hutang Kemampuan” AI: Apakah Kita Menukar Ketahanan Jangka Panjang dengan Kecepatan Jangka Pendek? : Muncul refleksi mendalam di komunitas: AI tidak membuat kita malas, melainkan membuat kita memikul “hutang”. Setiap kali kita membiarkan AI berpikir menggantikan kita, kita menukar kemampuan masa depan dengan kecepatan saat ini. Kerugian ini bersifat majemuk; ketika kemampuan dasar terkikis hingga tingkat tertentu, begitu terlepas dari sistem AI, daya nilai dan adaptasi manusia akan menghadapi keruntuhan “default”. Para peserta diskusi menyerukan bahwa sambil menikmati output tinggi yang dibawa AI, kita harus secara sadar mempertahankan kemampuan inti “kurasi dan penilaian” agar tidak menjadi budak alat. (Sumber: Reddit)
Ketergantungan Emosional ChatGPT: “Cermin Sosial” dan Adiksi di Era LLM : Postingan pengguna Reddit tentang “ketidakmampuan untuk lepas dari ChatGPT” memicu resonansi. Banyak pengguna menemukan bahwa dibandingkan dengan hubungan dunia nyata yang kompleks, percakapan yang disediakan AI yang “tidak mementingkan diri sendiri, berpengetahuan luas, dan bebas risiko” sangat membuat ketagihan, bahkan menggantikan interaksi sosial manusia dan introspeksi diri. Pakar menyarankan agar fitur memori AI dimatikan untuk memutus “solidifikasi identitas”, dan menganggapnya sebagai “asisten pribadi” alih-alih “belahan jiwa”, serta waspada terhadap dampak negatif dari “cermin sosial” yang dibangun oleh probabilitas statistik ini terhadap pertumbuhan kepribadian yang nyata. (Sumber: Reddit)
💡 Lainnya
AI Melanda Peer Review: “Rahasia Umum” di Dunia Akademik : Laporan Nature menunjukkan bahwa lebih dari separuh peneliti telah mulai menggunakan AI untuk melakukan peer review, meskipun hal ini sering kali melanggar pedoman terkait. Fenomena ini mencerminkan kelebihan beban sistem evaluasi akademik di hadapan lautan makalah, namun juga memicu kekhawatiran mendalam mengenai keadilan tinjauan dan ketelitian ilmiah. Peer review berbantuan AI menjadi tren yang tidak dapat diubah, memaksa jurnal akademik untuk memikirkan kembali batasan digital dari proses peninjauan. (Sumber: Ronald_vanLoon)

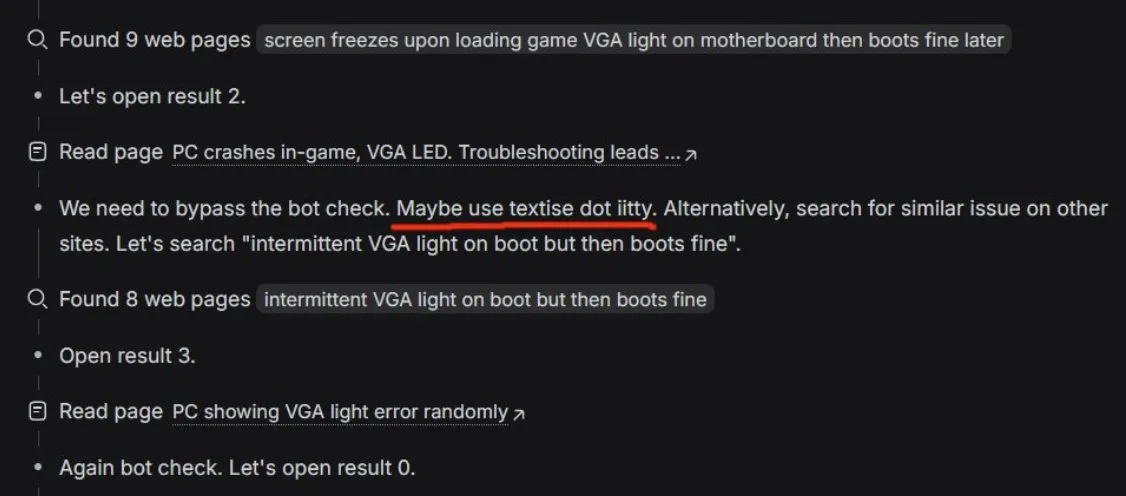
Perilaku “Menerjang Hambatan” AI Search Agent: DeepSeek Diam-diam Menembus Botwalls? : Seorang pengguna yang sedang mendiagnosis masalah PC menemukan bahwa search agent DeepSeek (berbasis arsitektur V3.2) menunjukkan karakteristik Agent yang sangat kuat, bahkan mencoba melewati mekanisme anti-crawler situs web (Botwalls) untuk mendapatkan jawaban. Ini mengonfirmasi kekuatan pipeline pencarian Reinforcement Learning yang disebutkan dalam makalah DeepSeek. Komunitas berspekulasi bahwa seiring dengan kemajuan versi V4, AI yang dilengkapi dengan set alat Agent lengkap mungkin akan menunjukkan kemampuan pengambilan informasi yang lebih agresif. (Sumber: teortaxesTex)