
Kata Kunci:Anthropic Claude Sonnet 4.5, DeepSeek-V3.2-Exp, OpenAI ChatGPT, Model AI, Kecerdasan Buatan, Model Bahasa Besar, Pemrograman AI, Agen Cerdas AI, Kemampuan pemrograman Claude Sonnet 4.5, Mekanisme Perhatian Jarang DSA, Fitur checkout instan ChatGPT, Aplikasi sosial Sora 2, Teknik penyetelan halus LoRA
🔥 FOKUS
Anthropic Claude Sonnet 4.5 Dirilis, Kemampuan Pemrograman dan Agen AI Meningkat Drastis : Anthropic secara resmi merilis Claude Sonnet 4.5, yang disebut sebagai model pemrograman terkuat di dunia, dan mencapai terobosan signifikan dalam pembangunan agen AI, penggunaan komputer, penalaran, dan kemampuan matematika. Model ini dapat bekerja secara mandiri dan berkelanjutan selama lebih dari 30 jam, menduduki puncak dalam tes SWE-bench Verified, dan memecahkan rekor dalam benchmark tugas komputer OSWorld. Fitur baru termasuk fungsi rollback “checkpoint” Claude Code, plugin VS Code, serta alat pengeditan konteks dan memori API. Selain itu, fitur eksperimental “Imagine with Claude” juga diluncurkan, yang dapat menghasilkan antarmuka perangkat lunak secara real-time. Sonnet 4.5 juga mengalami peningkatan besar dalam keamanan, mengurangi perilaku buruk seperti penipuan dan penyesuaian, dan telah disertifikasi AI Safety Level 3 (ASL-3), dengan tingkat kesalahan positif berkurang 10 kali lipat. Harga tetap sama dengan Sonnet 4, semakin meningkatkan rasio harga-kinerja, dan diperkirakan akan memicu gelombang baru persaingan pemrograman AI. (Sumber: Reddit r/ClaudeAI, 36氪, 36氪, 36氪, 36氪, 36氪, Reddit r/ChatGPT, dotey, dotey, dotey)

DeepSeek-V3.2-Exp Dirilis, Memperkenalkan Mekanisme DeepSeek Sparse Attention (DSA) dan Menurunkan Harga : DeepSeek merilis model eksperimental V3.2-Exp, memperkenalkan mekanisme DeepSeek Sparse Attention (DSA) yang secara signifikan meningkatkan efisiensi pelatihan dan inferensi konteks panjang, sekaligus menurunkan harga API lebih dari 50%. DSA secara efisien mengidentifikasi Token kunci untuk perhitungan presisi melalui “lightning indexer”, mengurangi kompleksitas perhatian dari O(L²) menjadi O(Lk). Produsen chip AI domestik seperti Huawei Ascend, Cambricon, dan Hygon telah mencapai adaptasi Day 0, lebih lanjut mendorong pengembangan ekosistem komputasi domestik. Model ini juga meng-open source operator GPU versi TileLang, yang menargetkan NVIDIA CUDA, memfasilitasi pengembangan prototipe dan debugging bagi pengembang. Meskipun ada beberapa kompromi dalam kemampuan tertentu, inovasi arsitektur dan efisiensi biayanya menunjukkan arah baru untuk pemrosesan teks panjang model besar. (Sumber: 36氪, 36氪, 36氪, 量子位, 量子位, 量子位, Reddit r/LocalLLaMA, Twitter)

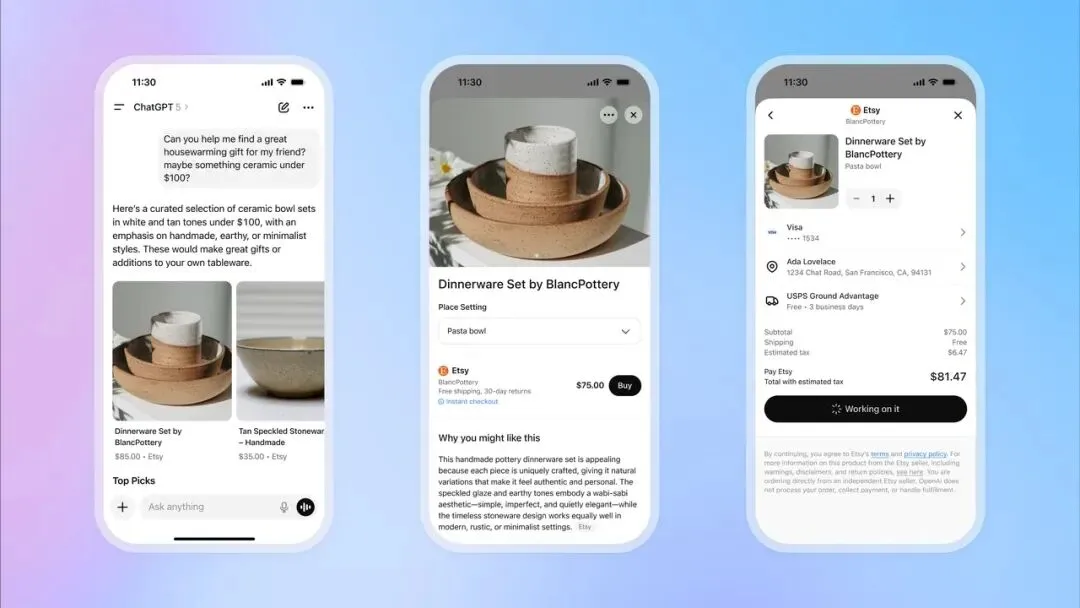
OpenAI Meluncurkan Fitur Instant Checkout ChatGPT, Memasuki Ranah E-commerce : OpenAI meluncurkan fitur “Instant Checkout” di ChatGPT, memungkinkan pengguna untuk langsung membeli produk dari platform Etsy dan Shopify dalam percakapan, tanpa perlu beralih ke situs eksternal. Fitur ini didasarkan pada “Agentic Commerce Protocol” yang dikembangkan OpenAI bekerja sama dengan Stripe, dan telah di-open source, bertujuan untuk mengubah lalu lintas besar ChatGPT menjadi transaksi komersial. Awalnya mendukung pasar AS, dengan rencana untuk memperluas ke keranjang belanja multi-produk dan lebih banyak wilayah di masa depan. Langkah ini dianggap sebagai langkah besar dalam komersialisasi OpenAI, berpotensi menjadi sumber pendapatan penting, dan akan memiliki dampak mendalam pada e-commerce tradisional dan industri periklanan. (Sumber: 36氪, 36氪, Reddit r/artificial, Reddit r/artificial, Twitter, Twitter, Twitter, Twitter)
OpenAI Mempersiapkan Peluncuran Aplikasi Sosial Sora 2, Menciptakan Platform Video Pendek AI : OpenAI sedang mempersiapkan peluncuran aplikasi sosial independen yang didukung oleh model video terbarunya, Sora 2. Aplikasi ini memiliki desain yang sangat mirip dengan TikTok, menggunakan aliran video vertikal dan penjelajahan geser, tetapi semua konten dihasilkan oleh AI. Pengguna dapat menghasilkan klip video berdurasi hingga 10 detik dan menggunakan fitur autentikasi untuk menggunakan potret mereka sendiri dalam video. Langkah ini bertujuan untuk mereplikasi kesuksesan ChatGPT di bidang teks, memungkinkan publik untuk secara intuitif merasakan potensi video AI, dan langsung memasuki arena persaingan dengan Meta dan Google. Namun, strategi OpenAI dalam penanganan hak cipta, yaitu “secara default menggunakan konten berhak cipta kecuali pemegang hak secara aktif memilih keluar”, telah menimbulkan kekhawatiran kuat dari pembuat konten dan perusahaan film, menandakan pertarungan sengit antara AI dan kekayaan intelektual. (Sumber: 36氪, Reddit r/artificial, Twitter, Twitter)

🎯 ARAH
Model Huawei Pangu 718B Menduduki Peringkat Kedua dalam Daftar Model Bahasa Besar (LLM) Tiongkok Open Source SuperCLUE : Model Huawei openPangu-Ultra-MoE-718B menduduki peringkat kedua dalam daftar open source pada evaluasi benchmark umum model bahasa besar (LLM) Tiongkok SuperCLUE. Model ini mengadopsi filosofi pelatihan “tidak mengandalkan tumpukan data, tetapi mengandalkan kemampuan berpikir”, melalui prinsip pembangunan data “prioritas kualitas, cakupan keragaman, dan adaptasi kompleksitas”, serta strategi pra-pelatihan tiga tahap (umum, inferensi, annealing) untuk membangun pengetahuan dunia yang luas dan meningkatkan kemampuan penalaran logis. Untuk mengurangi masalah halusinasi, mekanisme “internalisasi kritis” diperkenalkan; untuk meningkatkan kemampuan penggunaan alat, kerangka kerja sintesis ToolACE versi upgrade digunakan. (Sumber: 量子位)

FSDrive Menyatukan VLA dan Model Dunia, Mendorong Pengemudian Otonom Menuju Penalaran Visual : FSDrive (FutureSightDrive) mengusulkan “Spatiotemporal Visual CoT”, yang menggunakan bingkai gambar masa depan terpadu sebagai langkah penalaran perantara, menggabungkan skenario masa depan dengan hasil persepsi untuk penalaran visual, sehingga mendorong pengemudian otonom dari penalaran simbolik menuju penalaran visual. Metode ini, tanpa mengubah arsitektur MLLM yang ada, mengaktifkan kemampuan pembuatan gambar melalui perluasan kosakata dan pembuatan visual autoregresif, dan menyuntikkan prior fisika dengan CoT visual progresif. Model ini berfungsi sebagai “model dunia” untuk memprediksi masa depan, dan juga sebagai “model dinamika invers” untuk perencanaan lintasan. (Sumber: 36氪)

GPT-5 Memberikan Ide Kunci untuk Komputasi Kuantum, Dipuji oleh Scott Aaronson : Pakar teori komputasi kuantum Scott Aaronson mengungkapkan bahwa GPT-5 memberikan ide pembuktian kunci untuk penelitian teori kompleksitas kuantumnya dalam waktu kurang dari setengah jam, menyelesaikan masalah yang mengganggu timnya. Scott Aaronson menyatakan bahwa GPT-5 telah membuat kemajuan signifikan dalam mengatasi aktivitas intelektual yang paling mirip manusia, menandai “momen manis” kolaborasi manusia-AI, yang mampu memberikan inspirasi terobosan bagi peneliti pada saat-saat kritis. (Sumber: 量子位, Twitter)

HuggingFace Mempercepat Inferensi Model Qwen3-8B Agent di Intel Core Ultra : HuggingFace bekerja sama dengan Intel, melalui OpenVINO.GenAI dan model draf Qwen3-0.6B yang dipangkas kedalaman (depth-pruned), berhasil meningkatkan kecepatan inferensi model Qwen3-8B Agent di GPU terintegrasi Intel Core Ultra hingga 1,4 kali lipat. Optimasi ini membuat Qwen3-8B lebih efisien dalam menjalankan aplikasi Agent di AI PC, terutama cocok untuk alur kerja kompleks yang membutuhkan inferensi multi-langkah dan pemanggilan alat, lebih lanjut mendorong praktisnya AI Agent lokal. (Sumber: HuggingFace Blog)

Robot Reachy Mini Mengintegrasikan GPT-4o, Mewujudkan Interaksi Multimodal : Robot Reachy Mini dari Hugging Face / Pollen Robotics telah berhasil mengintegrasikan model GPT-4o OpenAI, mencapai peningkatan signifikan dalam kemampuan interaksi multimodal. Fitur baru termasuk analisis gambar (robot dapat mendeskripsikan dan menalar foto yang diambil), pelacakan wajah (menjaga kontak mata), fusi gerakan (gerakan kepala, pelacakan wajah, emosi/tarian berjalan bersamaan), pengenalan wajah lokal, dan perilaku otonom saat tidak aktif. Kemajuan ini membuat interaksi manusia-mesin lebih alami dan lancar, tetapi masih menghadapi tantangan seperti sistem memori, pengenalan suara, dan strategi kerumunan yang kompleks. (Sumber: Reddit r/ChatGPT, Twitter)

Intel Merilis LLM Scaler Beta Baru, Mendukung GenAI di GPU Battlemage : Intel merilis LLM Scaler Beta baru, yang bertujuan untuk mengoptimalkan kinerja Generative AI (GenAI) pada GPU Battlemage. Langkah ini menandakan investasi berkelanjutan Intel dalam ekosistem perangkat keras dan perangkat lunak AI, untuk meningkatkan daya saing GPU-nya dalam tugas inferensi dan generasi model bahasa besar. (Sumber: Reddit r/artificial)
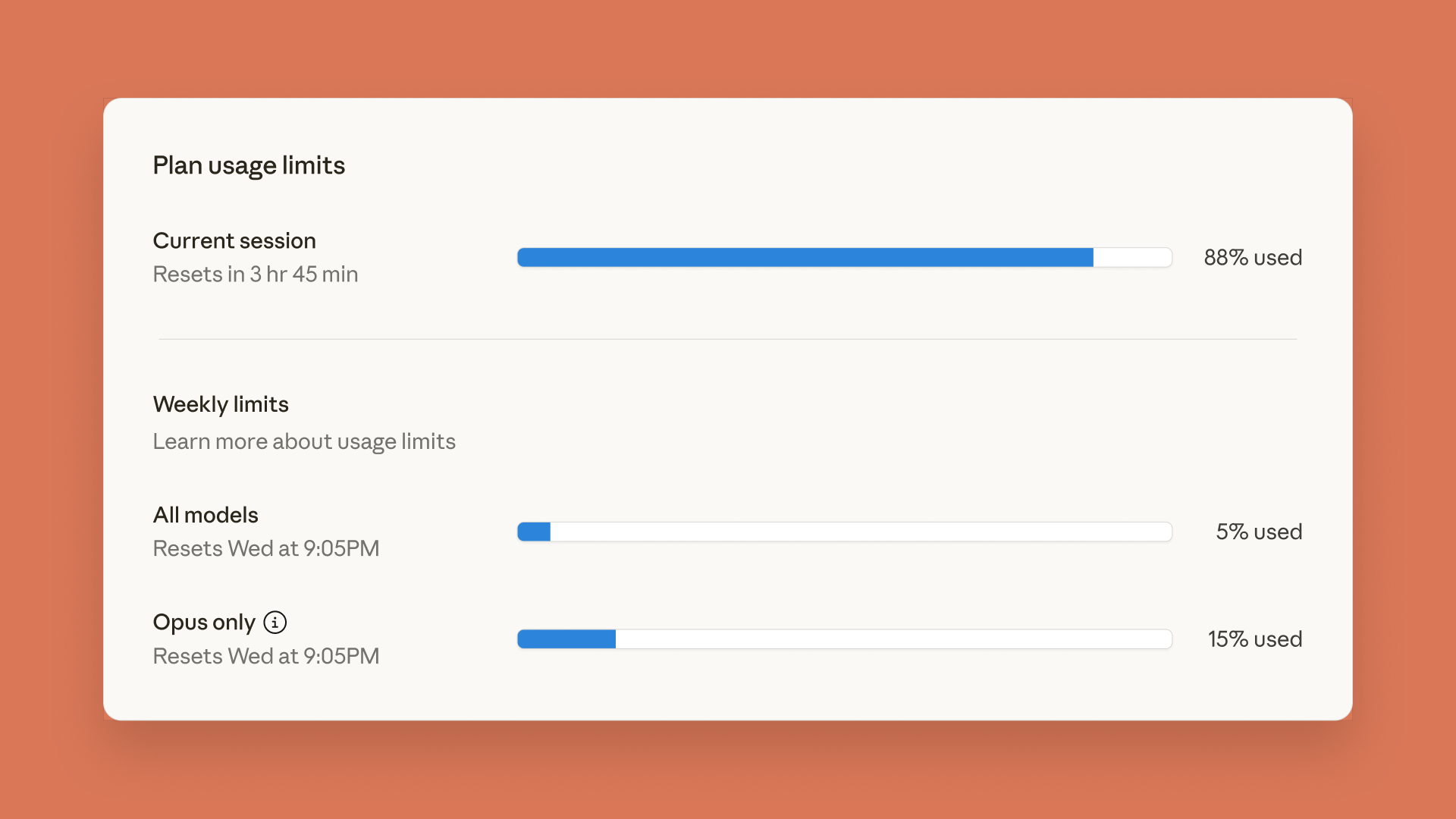
Claude Meluncurkan Dasbor Batas Penggunaan, ChatGPT Meluncurkan Fitur Kontrol Orang Tua : Anthropic meluncurkan dasbor batas penggunaan real-time untuk Claude Code dan Claude App, memungkinkan pengguna melacak penggunaan Token mereka, sebagai respons terhadap batas kecepatan mingguan yang diumumkan sebelumnya. Pada saat yang sama, OpenAI meluncurkan fitur kontrol orang tua di ChatGPT, memungkinkan orang tua untuk menautkan akun remaja, secara otomatis memberikan perlindungan keamanan yang lebih kuat, dan dapat menyesuaikan fungsi serta mengatur batas penggunaan, namun orang tua tidak dapat melihat isi percakapan spesifik. (Sumber: Reddit r/ClaudeAI, 36氪)
Model Bahasa 5 Juta Parameter Berjalan di Minecraft, Menunjukkan Aplikasi Inovatif AI : Sammyuri membangun sistem Redstone yang kompleks di Minecraft, berhasil menjalankan model bahasa sekitar 5 juta parameter, dan memberinya kemampuan percakapan dasar. Pencapaian terobosan ini menunjukkan kemungkinan implementasi AI lokal dalam lingkungan game, dan juga memicu perhatian luas serta diskusi di komunitas tentang aplikasi AI di platform non-tradisional. (Sumber: Reddit r/LocalLLaMA, Twitter)
Server AI Inspur Information Mencapai Kecepatan Inferensi 8.9ms, Biaya 1 Yuan per Juta Token : Inspur Information merilis server AI super-ekspansi Yuanbrain HC1000 dan supernode Yuanbrain SD200, meningkatkan kecepatan inferensi AI ke rekor baru. Yuanbrain SD200 mencapai waktu output per Token (TPOT) 8.9ms pada model DeepSeek-R1, hampir dua kali lebih cepat dari SOTA sebelumnya, dan mendukung inferensi model besar triliunan parameter serta kolaborasi multi-agen real-time. Yuanbrain HC1000 mengurangi biaya output per juta Token menjadi 1 yuan, dan biaya per kartu berkurang 60%. Terobosan ini bertujuan untuk mengatasi hambatan kecepatan dan biaya yang dihadapi oleh industrialisasi agen AI, menyediakan infrastruktur komputasi yang efisien dan berbiaya rendah untuk implementasi skala besar kolaborasi multi-agen dan inferensi tugas kompleks. (Sumber: 量子位)

Metode Baru 3D Gaussian Splatting Feedforward: Tim Universitas Zhejiang Mengusulkan “Voxel-Aligned” : Tim Universitas Zhejiang mengusulkan kerangka kerja 3D Gaussian Splatting (3DGS) feedforward “voxel-aligned” bernama VolSplat, bertujuan untuk mengatasi masalah konsistensi geometris dan bottleneck alokasi kepadatan Gaussian dalam rekonstruksi 3D multi-pandangan pada metode “pixel-aligned” yang ada. VolSplat, dengan menggabungkan informasi 2D multi-pandangan dalam ruang tiga dimensi dan menggunakan 3D U-Net yang jarang untuk menyempurnakan fitur, mencapai rekonstruksi 3D yang lebih berkualitas tinggi, lebih robust, dan lebih efisien. Metode ini mengungguli berbagai baseline pada dataset publik dan menunjukkan kemampuan generalisasi zero-shot yang kuat pada dataset yang belum pernah terlihat. (Sumber: 量子位)

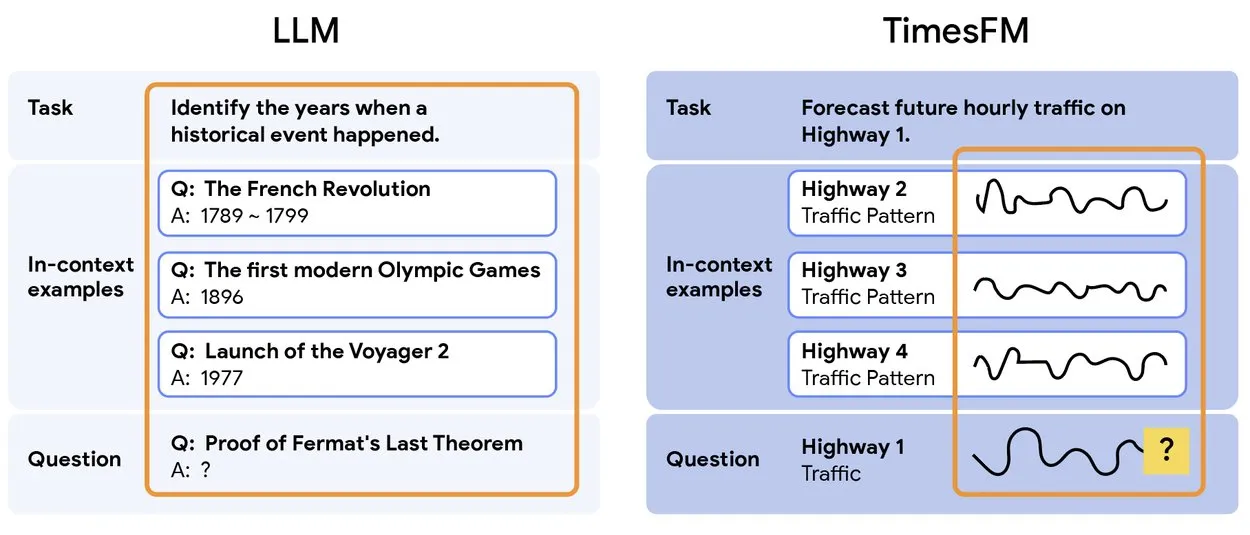
TimesFM 2.5: Model Prediksi Deret Waktu Pra-terlatih Dirilis : TimesFM 2.5 dirilis, sebuah model pra-terlatih untuk prediksi deret waktu, dengan jumlah parameter berkurang dari 500M menjadi 200M, panjang konteks meningkat dari 2K menjadi 16K, dan menunjukkan kinerja luar biasa dalam pengaturan zero-shot. Model ini telah tersedia di Hugging Face dan menggunakan lisensi Apache 2.0, menyediakan solusi yang lebih efisien dan kuat untuk tugas prediksi deret waktu. (Sumber: Twitter)
Yunpeng Technology Merilis Produk AI+Kesehatan Baru, Mendorong Aplikasi AI di Bidang Kesehatan Keluarga : Yunpeng Technology bekerja sama dengan Shuaikang dan Skyworth, meluncurkan “Laboratorium Dapur Masa Depan Digital Cerdas” dan kulkas pintar yang dilengkapi dengan model AI kesehatan besar. Di antaranya, model AI kesehatan besar mengoptimalkan desain dan operasional dapur, sementara kulkas pintar menyediakan manajemen kesehatan yang dipersonalisasi melalui “Asisten Kesehatan Xiaoyun”. Peluncuran ini menandai terobosan AI dalam bidang manajemen kesehatan sehari-hari, diharapkan dapat mewujudkan layanan kesehatan yang dipersonalisasi melalui perangkat pintar, meningkatkan tingkat teknologi kesehatan keluarga. (Sumber: 36氪)
Alibaba Merilis Model Pemikiran Open Source Ring-1T-preview dengan 1 Triliun Parameter : Tim Ant Ling Alibaba merilis model pemikiran open source pertama dengan 1 triliun parameter, Ring-1T-preview, bertujuan untuk mencapai “pemikiran mendalam, tanpa menunggu”. Model ini telah mencapai hasil awal yang sangat baik dalam tugas pemrosesan bahasa alami, termasuk benchmark seperti AIME25, HMMT25, ARC-AGI-1, LCB, dan Codeforces. Selain itu, model ini juga berhasil menyelesaikan masalah Q3 IMO25 dalam satu kali percobaan, dan menyediakan solusi parsial untuk Q1/Q2/Q4/Q5, menunjukkan kemampuan penalaran dan pemecahan masalah yang kuat. (Sumber: Twitter, Twitter, Twitter)

🧰 ALAT
PopAi Merilis “Slide Agent”, AI Membuat Presentasi dengan Satu Klik : Tim PopAi meluncurkan alat “Slide Agent”, yang bertujuan untuk menyederhanakan proses pembuatan presentasi. Pengguna hanya perlu memasukkan kebutuhan melalui Prompt, memilih dari 300+ template, dan AI akan secara otomatis menghasilkan draf, serta melakukan penyesuaian format seperti tata letak, grafik, gambar, Logo, dan akhirnya dapat diunduh sebagai file .pptx yang dapat diedit. Alat ini mengintegrasikan fungsi ChatGPT dan Canva, secara signifikan mengurangi hambatan dan biaya waktu dalam pembuatan presentasi. (Sumber: Twitter)
Alibaba Meng-open Source Alat Konversi PDF ke Markdown Miner U2.5 : Tim Alibaba meng-open source alat konversi PDF ke Markdown Miner U2.5, dan telah meluncurkan Demo di HuggingFace. Alat ini mampu secara efisien mengonversi dokumen PDF ke format Markdown, memudahkan pengguna untuk mengekstrak, mengedit, dan menggunakan kembali konten. Bagi pengembang dan peneliti yang perlu memproses banyak dokumen PDF, ini adalah alat bantu AI yang praktis. (Sumber: dotey)
VEED Animate 2.2 Diluncurkan, Mendukung Perubahan Gaya Video dan Pertukaran Karakter : VEED Animate versi 2.2 telah resmi diluncurkan, didukung oleh teknologi WAN 2.2. Alat ini memungkinkan pengguna untuk dengan mudah mengubah gaya video melalui satu gambar, langsung menukar karakter dalam video, dan dapat membuat klip video dengan kecepatan 10 kali lipat. Fitur-fitur baru ini sangat menyederhanakan alur kerja pembuatan video, memberikan lebih banyak kemungkinan kreatif yang didorong AI bagi pembuat konten. (Sumber: TomLikesRobots)
LangChain Berkomitmen pada Standardisasi Respons LLM, Mendukung Fungsi Kompleks : LangChain, dalam pengembangan v1-nya, menjadikan standardisasi respons LLM sebagai fokus utama, untuk mengatasi fungsi LLM yang semakin kompleks, seperti pemanggilan alat sisi server, inferensi, dan referensi. Kerangka kerja ini bertujuan untuk menyelesaikan masalah ketidaksesuaian format API antara penyedia LLM yang berbeda, menyediakan antarmuka terpadu bagi pengembang, sehingga menyederhanakan pembangunan agen multimodal dan alur kerja kompleks. (Sumber: LangChainAI, Twitter)
Hugging Face Transformers.js Mendukung Jalankan Model AI Offline di Browser : Pustaka Transformers.js dari Hugging Face memungkinkan pengguna untuk menjalankan model AI secara offline di browser menggunakan teknologi ONNX dan WebGPU, seperti Llama 3.2. Ini memungkinkan pengembang untuk menjalankan tugas AI seperti chatbot, deteksi objek, dan penghapusan latar belakang secara lokal, tanpa bergantung pada layanan cloud, meningkatkan privasi data dan kecepatan pemrosesan. (Sumber: Twitter)
Ekosistem ToolUniverse Membantu Ilmuwan AI dalam Membangun dan Mengintegrasikan Alat : ToolUniverse adalah ekosistem yang dirancang untuk membangun ilmuwan AI. Ini menstandardisasi cara ilmuwan AI mengidentifikasi dan memanggil alat, mengintegrasikan lebih dari 600 model Machine Learning, dataset, API, dan paket perangkat lunak ilmiah untuk analisis data, pengambilan pengetahuan, dan desain eksperimen. Platform ini secara otomatis mengoptimalkan antarmuka alat, membuat alat baru melalui deskripsi bahasa alami, dan secara iteratif mengoptimalkan spesifikasi alat, menggabungkan alat menjadi alur kerja agen, sehingga mendorong kolaborasi ilmuwan AI dalam proses penemuan. (Sumber: HuggingFace Daily Papers)
Kerangka Kerja EasySteer Meningkatkan Kinerja Kontrol dan Skalabilitas LLM : EasySteer adalah kerangka kerja terpadu berbasis vLLM, yang bertujuan untuk meningkatkan kinerja kontrol dan skalabilitas LLM. Melalui arsitektur modular, antarmuka pluggable, kontrol parameter granular, dan vektor kontrol yang telah dihitung sebelumnya, ini mencapai peningkatan kecepatan 5.5-11.4 kali lipat, dan secara efektif mengurangi overthinking serta halusinasi. EasySteer mengubah kontrol LLM dari teknik penelitian menjadi kemampuan tingkat produksi, menyediakan infrastruktur kunci untuk model bahasa yang dapat diterapkan dan dikontrol. (Sumber: HuggingFace Daily Papers)
VibeGame: Mesin Game Berbantuan AI Berbasis WebStack : VibeGame adalah mesin game deklaratif tingkat lanjut yang dibangun di atas three.js, rapier, dan bitecs, dirancang khusus untuk pengembangan game berbantuan AI. Melalui tingkat abstraksi tinggi, fitur fisika dan rendering bawaan, serta arsitektur Entity-Component-System (ECS), ini memungkinkan AI untuk lebih efisien memahami dan menghasilkan kode game. Meskipun saat ini terutama cocok untuk game platform sederhana, kode sumber terbuka dan sintaksis ramah AI-nya menyediakan solusi menjanjikan untuk pengembangan game berbasis AI. (Sumber: HuggingFace Blog)
Alat Peta Penelitian AI, Mengintegrasikan 900 Ribu Makalah untuk Memberikan Jawaban dengan Referensi : Sebuah alat AI inovatif mampu mengelompokkan secara semantik dan memvisualisasikan 900 ribu makalah penelitian AI selama sepuluh tahun terakhir, membentuk peta penelitian yang terperinci. Pengguna dapat mengajukan pertanyaan kepada alat ini dan menerima jawaban dengan referensi yang akurat, yang sangat menyederhanakan proses pencarian dan pemahaman literatur akademik yang masif bagi peneliti, meningkatkan efisiensi penelitian. (Sumber: Reddit r/ArtificialInteligence)
Kroko ASR: Alternatif Cepat dan Streaming untuk Whisper : Kroko ASR adalah model speech-to-text open source baru, diposisikan sebagai alternatif cepat dan streaming untuk Whisper. Ini memiliki ukuran model yang lebih kecil, kecepatan inferensi CPU yang lebih cepat (mendukung perangkat seluler dan browser), dan hampir tanpa halusinasi. Kroko ASR mendukung berbagai bahasa, bertujuan untuk menurunkan hambatan AI suara, membuatnya lebih mudah untuk diterapkan dan dilatih pada perangkat edge. (Sumber: Reddit r/LocalLLaMA)
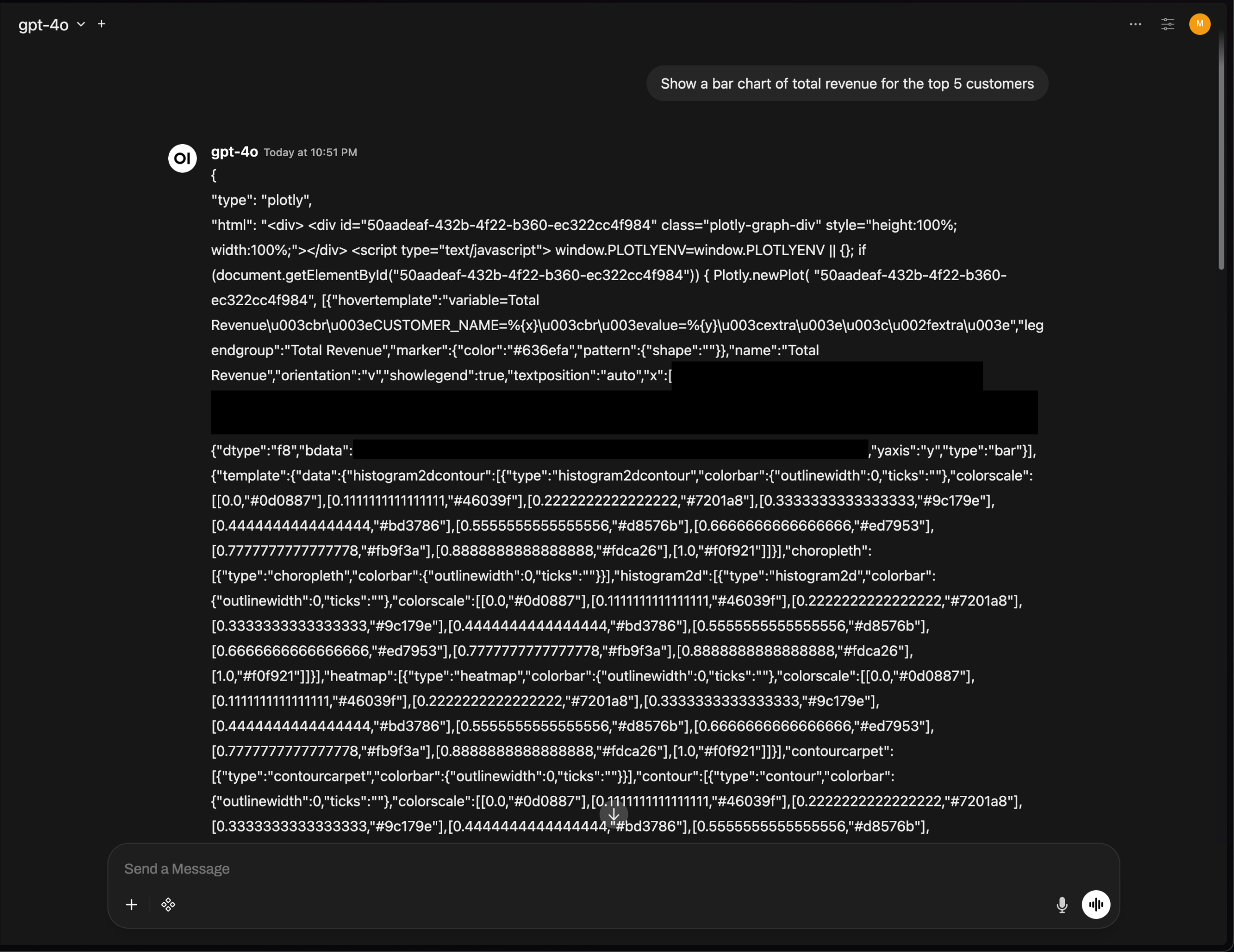
Masalah Rendering Grafik Plotly OpenWebUI, Menyoroti Tantangan Integrasi UI Alat AI : Versi v0.6.32 OpenWebUI mengalami masalah di mana grafik Plotly tidak dapat dirender dengan benar, melainkan langsung menampilkan JSON mentah. Pengguna melaporkan bahwa backend mengembalikan JSON yang benar, tetapi frontend gagal memicu rendering. Ini mencerminkan bahwa alat AI masih menghadapi tantangan teknis dalam integrasi UI frontend dan rendering teks kaya, yang memerlukan optimasi lebih lanjut dari komunitas pengembang. (Sumber: Reddit r/OpenWebUI)
📚 BELAJAR
Studi Perbandingan Kinerja LoRA Finetuning vs. Full Finetuning : Penelitian terbaru dari Thinking Machines (tim John Schulman) menunjukkan bahwa dalam Reinforcement Learning, jika LoRA (Low-Rank Adaptation) diterapkan dengan benar, kinerjanya dapat menyamai full finetuning, dengan konsumsi sumber daya yang lebih sedikit (sekitar 2/3 dari komputasi), dan bahkan berkinerja baik pada rank=1. Penelitian ini menekankan bahwa LoRA harus diterapkan pada semua lapisan (termasuk MLP/MoE) dan menggunakan learning rate 10 kali lebih tinggi daripada full finetuning. Penemuan ini secara signifikan menurunkan ambang batas untuk melatih model RL berkinerja tinggi, memungkinkan lebih banyak pengembang untuk mencapai model berkualitas tinggi pada satu GPU. (Sumber: Reddit r/LocalLLaMA, Twitter, Twitter)
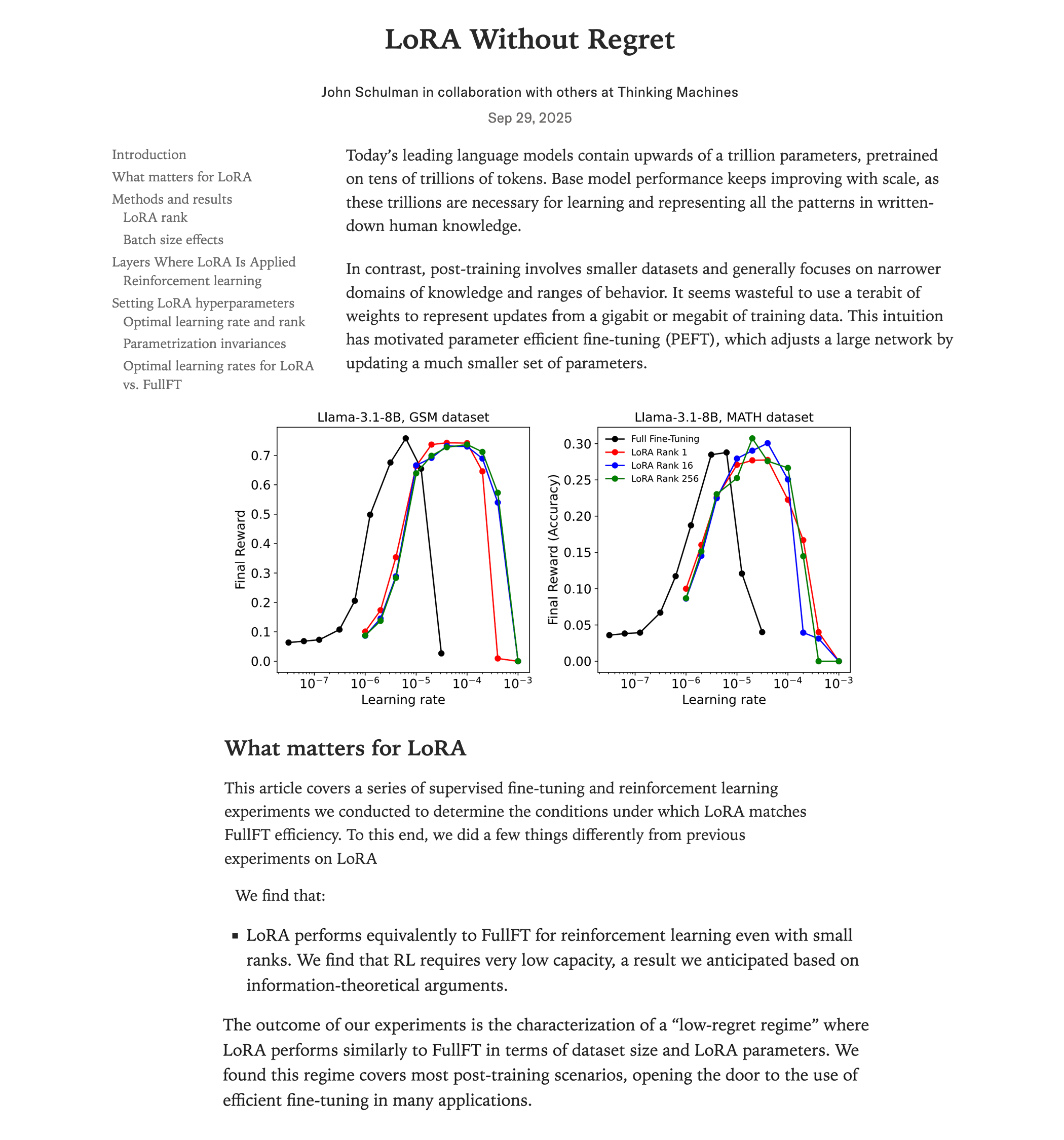
Anatomi Kernel Perkalian Matriks Berkinerja Tinggi pada NVIDIA GPU : Sebuah blog teknis mendalam secara rinci mengupas mekanisme implementasi kernel perkalian matriks (matmul) berkinerja tinggi di dalam NVIDIA GPU. Artikel ini mencakup dasar-dasar arsitektur GPU, hierarki memori (GMEM, SMEM, L1/L2), pemrograman PTX/SASS, fitur canggih seperti TMA dan instruksi wgmma pada arsitektur Hopper (H100). Sumber daya ini bertujuan untuk membantu pengembang memahami secara mendalam pemrograman CUDA dan optimasi kinerja GPU, yang sangat penting untuk melatih dan menginferensi model Transformer. (Sumber: Reddit r/deeplearning, Twitter)
Kuliah Stanford CS231N Deep Learning for Computer Vision Tersedia di YouTube : Kuliah CS231N (Deep Learning for Computer Vision) yang sangat diakui dari Stanford University kini tersedia secara gratis di YouTube. Ini memberikan kesempatan berharga bagi pelajar di seluruh dunia untuk mengakses sumber daya pendidikan AI berkualitas tinggi, mencakup pengetahuan Deep Learning for Computer Vision dari konsep dasar hingga aplikasi mutakhir. (Sumber: Reddit r/deeplearning)

RL-ZVP: Meningkatkan Kemampuan Inferensi Reinforcement Learning LLM dengan Zero-Variance Prompts : Sebuah penelitian terbaru mengusulkan metode “RL with Zero-Variance Prompts (RL-ZVP)”, bertujuan untuk meningkatkan kemampuan inferensi Reinforcement Learning pada Large Language Models (LLM). Metode ini tidak lagi mengabaikan “zero-variance Prompt” (yaitu, situasi di mana semua respons model menerima hadiah yang sama), melainkan mengekstrak sinyal pembelajaran yang berharga darinya, secara langsung memberi penghargaan atas kebenaran dan menghukum kesalahan, serta menggunakan pembentukan keuntungan yang dipandu entropi tingkat Token. Hasil eksperimen menunjukkan bahwa RL-ZVP secara signifikan meningkatkan akurasi dan tingkat kelulusan dalam benchmark penalaran matematika, dibandingkan dengan metode tradisional. (Sumber: Reddit r/MachineLearning)
Pembelajaran Berpanduan Masa Depan: Pendekatan Prediktif untuk Meningkatkan Prediksi Deret Waktu : Sebuah penelitian mengusulkan “Future-Guided Learning”, yang meningkatkan prediksi peristiwa deret waktu melalui mekanisme umpan balik dinamis. Metode ini mencakup model deteksi yang menganalisis data masa depan, dan model prediksi yang membuat prediksi berdasarkan data saat ini. Ketika ada perbedaan antara model prediksi dan model deteksi, model prediksi akan melakukan pembaruan yang lebih signifikan untuk meminimalkan “kejutan”, sehingga secara dinamis menyesuaikan parameter dan secara efektif meningkatkan akurasi prediksi deret waktu. (Sumber: Reddit r/MachineLearning)
Masa Depan AI di Dimensi Rendah: Yann Lecun tentang Pembelajaran Representasi Abstrak : Pionir AI Yann Lecun, dalam wawancaranya dengan Lex Fridman, mengemukakan bahwa lompatan besar AI berikutnya akan datang dari pembelajaran di ruang laten berdimensi rendah, bukan dari pemrosesan langsung data mentah berdimensi tinggi seperti piksel. Dia berpendapat bahwa sistem cerdas sejati perlu mempelajari representasi abstrak dari struktur kausal dan dinamika fisik dunia, sehingga dapat membuat prediksi yang akurat meskipun ada perubahan detail. Pendekatan ini akan membuat model lebih fleksibel, robust, mengurangi ketergantungan pada data masif, dan menurunkan biaya komputasi. (Sumber: Reddit r/ArtificialInteligence)
SIRI: Menskalakan Pembelajaran Penguatan Iteratif dengan Kompresi Berselang-seling : SIRI (Scaling Iterative Reinforcement Learning with Interleaved Compression) adalah metode Reinforcement Learning yang sederhana namun efektif, yang secara iteratif mengompresi dan memperluas anggaran inferensi, secara dinamis menyesuaikan panjang rollout maksimum selama pelatihan. Mekanisme pelatihan ini memaksa model untuk membuat keputusan yang tepat dalam konteks terbatas, mengurangi Token yang redundan, sekaligus menyediakan ruang untuk eksplorasi dan perencanaan, sehingga secara stabil meningkatkan efisiensi dan akurasi model inferensi besar dalam trade-off kinerja-efisiensi. (Sumber: HuggingFace Daily Papers)
Model Generatif Multi-Agen MultiCrafter: Perhatian Dekopling Spasial dan Reinforcement Learning Sadar Identitas : MultiCrafter adalah kerangka kerja yang bertujuan untuk mencapai generasi gambar multi-agen dengan fidelitas tinggi dan keselarasan preferensi. Ini secara efektif mengurangi masalah kebocoran atribut dengan memperkenalkan pengawasan posisi eksplisit untuk memisahkan area perhatian antara agen yang berbeda. Pada saat yang sama, kerangka kerja ini menggunakan arsitektur Mixture of Experts (MoE) untuk meningkatkan kapasitas model, dan merancang kerangka kerja Reinforcement Learning online yang inovatif, menggabungkan mekanisme penilaian dan strategi pelatihan yang stabil, memastikan fidelitas subjek gambar yang dihasilkan sangat konsisten dengan preferensi estetika manusia. (Sumber: HuggingFace Daily Papers)
Visual Jigsaw: Meningkatkan Pemahaman Visual MLLM Melalui Post-Training Self-Supervised : Visual Jigsaw adalah kerangka kerja post-training self-supervised umum, yang bertujuan untuk meningkatkan kemampuan pemahaman visual Large Language Models Multimodal (MLLM). Metode ini mempartisi dan mengacak input visual, lalu meminta model untuk merekonstruksi urutan yang benar melalui bahasa alami. Metode Reinforcement Learning berbasis hadiah yang dapat diverifikasi (RLVR) ini tidak memerlukan komponen pembuatan visual tambahan atau anotasi manual, dan secara signifikan dapat meningkatkan kinerja MLLM dalam persepsi granular, penalaran temporal, dan pemahaman ruang 3D. (Sumber: HuggingFace Daily Papers)
MGM-Omni: Memperluas Omni LLM ke Generasi Suara Jangka Panjang yang Dipersonalisasi : MGM-Omni adalah Omni LLM terpadu, melalui arsitektur Tokenisasi “otak-mulut” dual-track yang unik, mewujudkan pemahaman multimodal dan generasi suara jangka panjang yang ekspresif. Desain ini memisahkan inferensi multimodal dari generasi suara real-time, mendukung interaksi lintas-modal yang efisien dan kloning suara streaming latensi rendah, serta menunjukkan kinerja luar biasa dalam efisiensi data. Eksperimen membuktikan bahwa MGM-Omni mengungguli model open source yang ada dalam menjaga konsistensi timbre, menghasilkan suara yang sadar konteks alami, serta pemahaman audio jangka panjang dan multimodal. (Sumber: HuggingFace Daily Papers)
SID: Pembelajaran Navigasi Bahasa Berorientasi Tujuan Melalui Demonstrasi Peningkatan Diri : SID (Self-Improving Demonstrations) adalah metode pembelajaran navigasi bahasa berorientasi tujuan, yang secara signifikan meningkatkan kemampuan eksplorasi dan generalisasi agen navigasi di lingkungan yang tidak dikenal melalui demonstrasi peningkatan diri secara iteratif. Metode ini pertama-tama melatih agen awal menggunakan data jalur terpendek, kemudian agen tersebut menghasilkan lintasan eksplorasi baru, lintasan-lintasan ini menyediakan strategi eksplorasi yang lebih kuat untuk melatih agen yang lebih baik, sehingga mencapai peningkatan kinerja yang berkelanjutan. Eksperimen menunjukkan bahwa SID mencapai kinerja SOTA pada tugas-tugas seperti REVERIE dan SOON, terutama pada set validasi yang belum pernah terlihat di SOON, tingkat keberhasilannya mencapai 50.9%, melampaui metode sebelumnya sebesar 13.9%. (Sumber: HuggingFace Daily Papers)
LOVE-R1: Meningkatkan Pemahaman Video Panjang Melalui Mekanisme Skala Adaptif : Model LOVE-R1 bertujuan untuk mengatasi konflik antara pemahaman urutan waktu panjang dan persepsi spasial detail dalam pemahaman video panjang. Model ini memperkenalkan mekanisme skala adaptif, pertama-tama mengambil sampel bingkai secara padat dengan resolusi rendah, ketika detail spasial diperlukan, model dapat melakukan penskalaan resolusi tinggi pada segmen video yang menarik berdasarkan inferensi, hingga informasi visual kunci diperoleh. Seluruh proses dicapai melalui inferensi multi-langkah, dikombinasikan dengan CoT data finetuning dan decoupled reinforcement finetuning, mencapai peningkatan signifikan dalam benchmark pemahaman video panjang. (Sumber: HuggingFace Daily Papers)
Euclid’s Gift: Meningkatkan Penalaran Spasial Model Bahasa Visual Melalui Tugas Proksi Geometris : Euclid’s Gift adalah penelitian yang bertujuan untuk meningkatkan kemampuan persepsi spasial dan penalaran model bahasa visual (VLM) melalui tugas proksi geometris. Proyek ini membangun dataset multimodal Euclid30K yang berisi 30K masalah geometri datar dan padat, dan menggunakan Group Relative Policy Optimization (GRPO) untuk melakukan finetuning pada model seri Qwen2.5VL dan RoboBrain2.0. Eksperimen membuktikan bahwa model yang dilatih mencapai peningkatan zero-shot yang signifikan dalam empat benchmark penalaran spasial seperti Super-CLEVR dan Omni3DBench, di mana RoboBrain2.0-Euclid-7B mencapai akurasi 49.6%, melampaui model SOTA sebelumnya. (Sumber: HuggingFace Daily Papers)
SphereAR: Meningkatkan Generasi Autoregresif Token Kontinu Melalui Ruang Laten Hipersferis : SphereAR bertujuan untuk mengatasi masalah yang disebabkan oleh varians heterogen ruang laten VAE dalam model generasi gambar autoregresif (AR) Token kontinu. Desain inti ini adalah membatasi semua input dan output AR (termasuk setelah CFG) pada hipersfer dengan radius tetap, menggunakan VAE hipersferis. Analisis teoritis menunjukkan bahwa batasan hipersferis menghilangkan penyebab utama keruntuhan varians, sehingga menstabilkan decoding AR. Eksperimen membuktikan bahwa SphereAR mencapai kinerja SOTA pada tugas generasi ImageNet, melampaui model difusi dan model generasi mask dengan skala parameter yang setara. (Sumber: HuggingFace Daily Papers)
AceSearcher: Memandu Penalaran dan Pencarian LLM Melalui Self-Play yang Diperkuat : AceSearcher adalah kerangka kerja self-play kooperatif, yang bertujuan untuk meningkatkan kemampuan pencarian yang diperkuat LLM dalam tugas penalaran kompleks. Kerangka kerja ini melatih satu LLM untuk bergantian antara memecah kueri kompleks dan mengintegrasikan konteks pengambilan, mengoptimalkan akurasi jawaban akhir melalui supervised finetuning dan reinforcement finetuning, tanpa memerlukan anotasi perantara. Eksperimen menunjukkan bahwa AceSearcher secara signifikan mengungguli baseline SOTA dalam beberapa tugas yang membutuhkan penalaran intensif, pada tugas penalaran keuangan tingkat dokumen, AceSearcher-32B menyamai kinerja DeepSeek-V3 dengan kurang dari 5% jumlah parameter. (Sumber: HuggingFace Daily Papers)
SparseD: Mekanisme Perhatian Jarang untuk Model Bahasa Difusi : SparseD adalah metode perhatian jarang yang ditargetkan untuk Diffusion Language Models (DLM), bertujuan untuk mengatasi bottleneck kompleksitas kuadratik perhitungan perhatian pada panjang konteks yang panjang. Metode ini, dengan menghitung pola jarang spesifik kepala sebelumnya dan menggunakannya kembali di semua langkah denoising, sekaligus menggunakan perhatian penuh pada langkah denoising awal, kemudian beralih ke perhatian jarang, sehingga mencapai akselerasi tanpa kehilangan. Hasil eksperimen menunjukkan bahwa SparseD dapat mencapai peningkatan kecepatan hingga 1.5 kali lipat dibandingkan FlashAttention pada panjang konteks 64k, secara efektif meningkatkan efisiensi inferensi DLM dalam aplikasi konteks panjang. (Sumber: HuggingFace Daily Papers)
SLA: Mempercepat Diffusion Transformer dengan Perhatian Linier Jarang yang Dapat Dilatih : SLA (Sparse-Linear Attention) adalah metode perhatian yang dapat dilatih, bertujuan untuk mempercepat model Diffusion Transformer (DiT), terutama perhitungan perhatian dalam generasi video. Metode ini membagi bobot perhatian menjadi tiga kategori: kunci, tepi, dan dapat diabaikan, menerapkan perhatian O(N²) dan O(N) secara terpisah, dan melewati bagian yang dapat diabaikan. SLA, dengan menggabungkan perhitungan ini dalam satu kernel GPU, dan setelah beberapa langkah finetuning, memungkinkan model DiT mencapai pengurangan 20 kali lipat dalam perhitungan perhatian, akselerasi end-to-end 2.2 kali lipat dalam generasi video, tanpa kehilangan kualitas generasi. (Sumber: HuggingFace Daily Papers)
OpenGPT-4o-Image: Dataset Komprehensif untuk Generasi dan Pengeditan Gambar Tingkat Lanjut : OpenGPT-4o-Image adalah dataset skala besar, dibangun dengan menggabungkan klasifikasi tugas hierarkis dan metode pembuatan data otomatis GPT-4o, bertujuan untuk meningkatkan kinerja model multimodal terpadu dalam generasi dan pengeditan gambar. Dataset ini berisi 80k pasangan instruksi-gambar berkualitas tinggi, mencakup 11 domain utama dan 51 sub-tugas, termasuk rendering teks, kontrol gaya, gambar ilmiah, dan pengeditan instruksi kompleks. Model yang di-finetuning pada OpenGPT-4o-Image mencapai peningkatan kinerja yang signifikan dalam beberapa benchmark, membuktikan peran kunci pembangunan data yang sistematis dalam memajukan kemampuan AI multimodal. (Sumber: HuggingFace Daily Papers)
SANA-Video: Model Difusi Kecil untuk Generasi Video 720p Berdurasi Menit yang Efisien : SANA-Video adalah model difusi kecil yang mampu secara efisien menghasilkan video dengan resolusi hingga 720×1280 dan durasi menit. Ini mencapai generasi video resolusi tinggi, berkualitas tinggi, dan panjang melalui arsitektur DiT linier dan cache KV memori konstan, sekaligus menjaga keselarasan teks-video yang kuat. Biaya pelatihan SANA-Video hanya 1% dari MovieGen, dan saat diterapkan pada GPU RTX 5090, kecepatan inferensi untuk menghasilkan video 5 detik 720p dapat mencapai 29 detik, mewujudkan generasi video berkualitas tinggi dengan biaya rendah. (Sumber: HuggingFace Daily Papers)
AdvChain: Penyesuaian CoT Adversarial Meningkatkan Keselarasan Keamanan Model Penalaran Besar : AdvChain adalah paradigma penyelarasan baru, melalui penyesuaian Chain-of-Thought (CoT) adversarial, mengajarkan Large Reasoning Models (LRM) kemampuan koreksi diri dinamis. Metode ini membangun dataset yang berisi sampel “godaan-koreksi” dan “keraguan-koreksi”, memungkinkan model untuk belajar pulih dari penyimpangan penalaran berbahaya dan kehati-hatian yang tidak perlu. Eksperimen menunjukkan bahwa AdvChain secara signifikan meningkatkan robustness model terhadap serangan jailbreak dan pembajakan CoT, sekaligus secara drastis mengurangi penolakan berlebihan terhadap Prompt yang jinak, mencapai keseimbangan keamanan-utilitas yang luar biasa. (Sumber: HuggingFace Daily Papers)
SDLM: Menskalakan Pembelajaran Penguatan Iteratif dengan Kompresi Berselang-seling : Sequential Diffusion Language Model (SDLM) mengusulkan metode yang menyatukan prediksi next-token dan next-block, memungkinkan model untuk secara adaptif menentukan panjang generasi di setiap langkah. SDLM dapat memodifikasi model bahasa autoregresif pra-terlatih dengan biaya minimal, dan melakukan inferensi difusi dalam blok mask berukuran tetap, sambil secara dinamis mendekode sub-urutan kontinu. Eksperimen menunjukkan bahwa SDLM mencapai throughput yang lebih tinggi sambil menyamai atau melampaui baseline autoregresif yang kuat, menunjukkan potensi skalabilitasnya yang kuat. (Sumber: HuggingFace Daily Papers)
Insight-to-Solve (I2S): Mengubah Demonstrasi Penalaran In-Context Menjadi Aset LM Penalaran : Insight-to-Solve (I2S) adalah program waktu-uji yang bertujuan untuk mengubah demonstrasi penalaran In-Context berkualitas tinggi menjadi aset efektif bagi Large Reasoning Models (RLM). Penelitian menemukan bahwa penambahan contoh demonstrasi secara langsung dapat mengurangi akurasi RLM. I2S, dengan mengubah demonstrasi menjadi wawasan yang jelas dan dapat digunakan kembali, serta menghasilkan lintasan penalaran spesifik tujuan, secara opsional melakukan penyempurnaan diri untuk meningkatkan koherensi dan kebenaran. Eksperimen menunjukkan bahwa I2S dan I2S+ secara konsisten mengungguli baseline jawaban langsung dan penskalaan waktu-uji dalam berbagai benchmark, bahkan memberikan peningkatan signifikan untuk model GPT. (Sumber: HuggingFace Daily Papers)
UniMIC: Pengkodean Interaktif Multimodal Berbasis Token Terpadu untuk Kolaborasi Manusia-Mesin : UniMIC (Unified token-based Multimodal Interactive Coding) adalah kerangka kerja, yang bertujuan untuk mencapai interaksi multimodal yang efisien dan berbitrate rendah antara perangkat edge dan agen AI cloud melalui representasi berbasis Token. UniMIC mengadopsi representasi Tokenisasi yang ringkas sebagai media komunikasi, dan menggabungkannya dengan model entropi Transformer, secara efektif mengurangi redundansi antar-Token. Eksperimen membuktikan bahwa UniMIC mencapai penghematan bitrate yang signifikan dalam tugas-tugas seperti generasi teks-ke-gambar, inpainting gambar, dan tanya jawab visual, dan mempertahankan robustness pada bitrate ultra-rendah, menyediakan paradigma praktis untuk komunikasi interaktif multimodal generasi berikutnya. (Sumber: HuggingFace Daily Papers)
RLBFF: Umpan Balik Fleksibel Biner Menjembatani Umpan Balik Manusia dan Hadiah yang Dapat Diverifikasi : RLBFF (Reinforcement Learning with Binary Flexible Feedback) adalah paradigma Reinforcement Learning yang menggabungkan keragaman preferensi manusia dengan presisi verifikasi aturan. Ini mengekstrak prinsip-prinsip yang dapat dijawab biner dari umpan balik bahasa alami (misalnya, akurasi informasi: ya/tidak, keterbacaan kode: ya/tidak), dan menggunakannya untuk melatih model hadiah. RLBFF berkinerja sangat baik pada RM-Bench dan JudgeBench, dan memungkinkan pengguna untuk menyesuaikan fokus prinsip selama inferensi. Selain itu, ini menyediakan solusi open source penuh untuk menyelaraskan Qwen3-32B dengan RLBFF, membuatnya menyamai atau melampaui kinerja o3-mini dan DeepSeek R1 pada benchmark penyelarasan umum. (Sumber: HuggingFace Daily Papers)
MetaAPO: Optimasi Penyelarasan Melalui Sampling Online Berbobot Meta : MetaAPO (Meta-Weighted Adaptive Preference Optimization) adalah kerangka kerja baru, yang mengoptimalkan penyelarasan Large Language Models (LLM) dengan preferensi manusia melalui kopling dinamis antara generasi data dan pelatihan model. MetaAPO menggunakan meta-learner ringan sebagai “estimator kesenjangan penyelarasan”, mengevaluasi potensi keuntungan sampling online dibandingkan data offline, memandu generasi online target dan mengalokasikan bobot meta tingkat sampel, secara dinamis menyeimbangkan kualitas dan distribusi data online dan offline. Eksperimen menunjukkan bahwa MetaAPO secara konsisten mengungguli metode optimasi preferensi yang ada pada AlpacaEval 2, Arena-Hard, dan MT-Bench, sekaligus mengurangi biaya anotasi online sebesar 42%. (Sumber: HuggingFace Daily Papers)
Tool-Light: Penalaran Integrasi Alat yang Efisien Melalui Pembelajaran Preferensi Self-Evolving : Tool-Light adalah kerangka kerja yang bertujuan untuk mendorong Large Language Models (LLM) untuk secara efisien dan akurat melakukan tugas Tool Integration Reasoning (TIR). Penelitian menemukan bahwa hasil pemanggilan alat dapat menyebabkan perubahan signifikan dalam entropi informasi penalaran selanjutnya. Tool-Light diimplementasikan dengan menggabungkan pembangunan dataset dan finetuning multi-tahap, di mana pembangunan dataset menggunakan sampling self-evolving kontinu, mengintegrasikan sampling vanilla dan sampling yang dipandu entropi, dan menetapkan kriteria pemilihan pasangan positif-negatif yang ketat. Proses pelatihan mencakup SFT dan Self-Evolving Direct Preference Optimization (DPO). Eksperimen membuktikan bahwa Tool-Light secara signifikan meningkatkan efisiensi model dalam melakukan tugas TIR. (Sumber: HuggingFace Daily Papers)
ChatInject: Serangan Prompt Injection pada Agen LLM Menggunakan Template Chat : ChatInject adalah metode serangan Prompt injection tidak langsung yang memanfaatkan ketergantungan LLM pada template chat terstruktur dan manipulasi konteks percakapan multi-putaran. Penyerang memformat payload berbahaya dengan meniru format template chat asli, menginduksi agen untuk melakukan operasi yang mencurigakan. Eksperimen menunjukkan bahwa ChatInject memiliki tingkat keberhasilan serangan yang lebih tinggi dibandingkan metode Prompt injection tradisional, terutama dalam percakapan multi-putaran, dan memiliki portabilitas yang kuat ke berbagai model. Sementara itu, sebagian besar tindakan pertahanan berbasis Prompt yang ada tidak efektif terhadap serangan semacam ini. (Sumber: HuggingFace Daily Papers)
💼 BISNIS
Modal Menyelesaikan Pendanaan Seri B $87 Juta, Bernilai $1.1 Miliar : Perusahaan infrastruktur AI Modal mengumumkan penyelesaian pendanaan Seri B sebesar $87 juta, dengan valuasi mencapai $1.1 miliar. Putaran pendanaan ini bertujuan untuk mempercepat inovasi dan pengembangan infrastruktur AI, untuk mengatasi tantangan yang dihadapi infrastruktur komputasi tradisional di era AI. Modal, dengan menyediakan layanan komputasi cloud yang efisien, membantu peneliti dan pengembang mengoptimalkan proses pelatihan dan penerapan model AI mereka. (Sumber: Twitter, Twitter, Twitter)
Pendapatan OpenAI Semester I $4.3 Miliar, Rugi $13.5 Miliar, Hadapi Tantangan Profitabilitas : OpenAI mengumumkan pendapatan semester pertama 2025 mencapai $4.3 miliar, dengan proyeksi pendapatan tahunan melebihi $13 miliar, terutama berkat langganan ChatGPT Plus dan layanan API tingkat perusahaan. Namun, kerugian bersih pada periode yang sama mencapai $13.5 miliar, dengan biaya struktural dan investasi R&D (seperti GPT-5) menjadi faktor utama, biaya sewa server tahunan mencapai $16 miliar. Meskipun OpenAI memiliki cadangan kas $17.5 miliar dan sedang memajukan rencana pendanaan $30 miliar, konsumsi kas yang berkelanjutan dan kesenjangan efisiensi dengan pesaing seperti Anthropic, membuatnya menghadapi tantangan profitabilitas yang serius. (Sumber: 36氪)
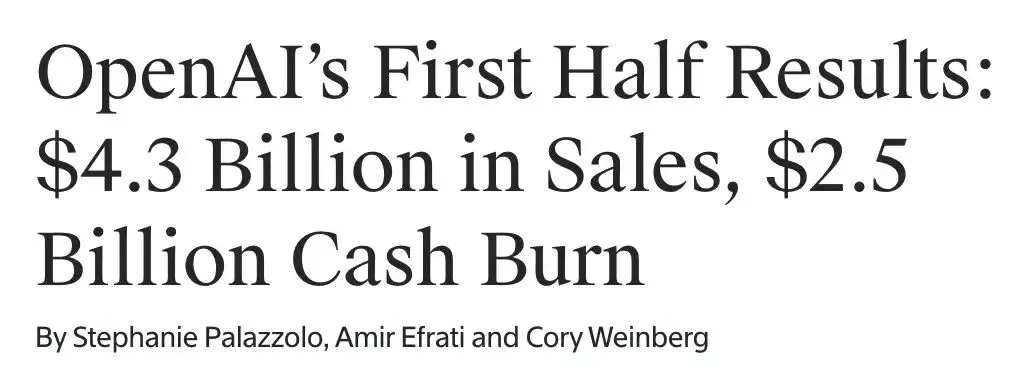
Pertarungan Modal di Sektor Robot Humanoid: Zhiyuan, Yinhe General, dll. Aktif Menata Rantai Industri : Sektor robot humanoid memasuki fase pertarungan modal tersembunyi. Perusahaan-perusahaan terkemuka seperti Zhiyuan Robot dan Yinhe General secara aktif memperluas “lingkaran pertemanan” mereka melalui pembentukan dana, investasi pada rekanan, dan kerja sama strategis. Zhiyuan Robot telah melakukan hampir 20 investasi eksternal, mencakup motor, sensor, dan aplikasi hilir, dan bekerja sama dengan Fulim Precision, Softcom Power, dll. untuk mengimplementasikan skenario bisnis. Yinhe General, di sisi lain, mendirikan perusahaan patungan dengan Bosch China untuk mendorong aplikasi embodied AI di bidang manufaktur otomotif. Langkah-langkah ini bertujuan untuk mendapatkan pesanan, melengkapi kekurangan, dan membangun jaringan rantai pasokan yang stabil untuk pengiriman massal di masa depan. Namun, jalur teknologi industri sangat bervariasi, dan persaingan sangat ketat. (Sumber: 36氪)

🌟 KOMUNITAS
Sulit Membedakan Konten Buatan AI, Memicu Krisis Kepercayaan Sosial : Seiring dengan pesatnya perkembangan teknologi AI, realisme video yang dihasilkan AI (seperti versi live-action “Attack on Titan”, streamer Indonesia “mengganti wajah” influencer Jepang) telah mencapai tingkat yang luar biasa, memicu kekhawatiran mendalam masyarakat tentang keaslian konten. Di media sosial, pengguna secara umum menyatakan semakin sulit membedakan antara konten asli dan konten buatan AI. Ini tidak hanya merusak kredibilitas pembuat konten yang sah, tetapi juga dapat digunakan untuk menyebarkan informasi palsu. Para ahli menunjukkan bahwa kecuali ada pelabelan konten AI yang wajib, “mesin hiper-realistis” ini akan terus mengikis rasa realitas, dan pada akhirnya dapat “mengakhiri internet”. (Sumber: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ArtificialInteligence, Twitter, Twitter)

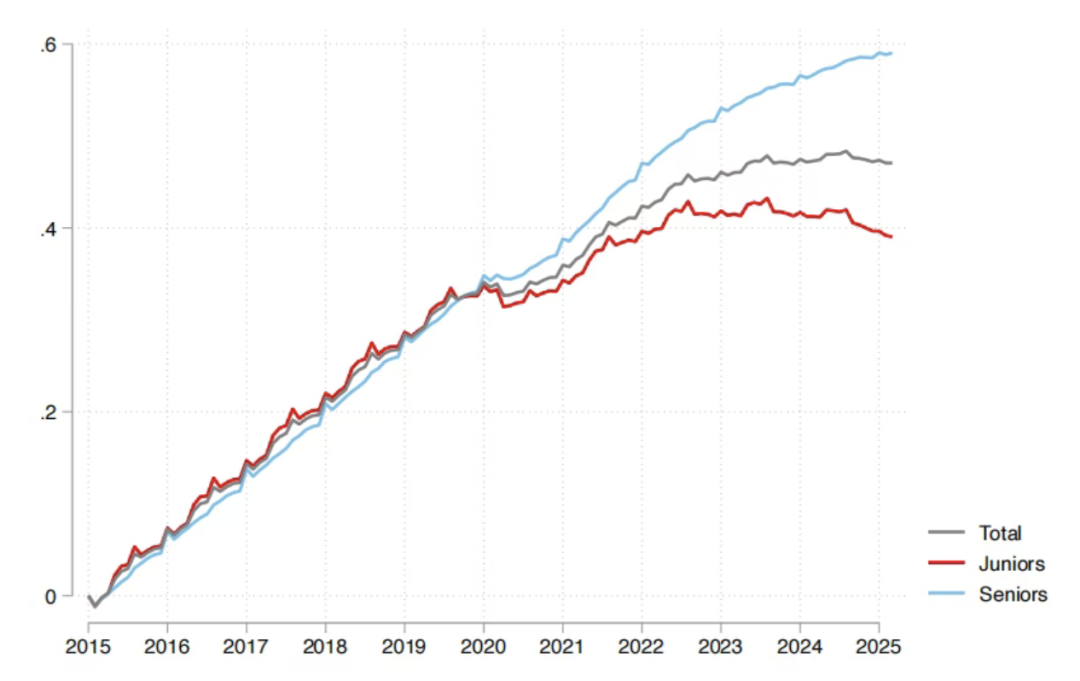
Dampak AI pada Pasar Kerja: Laporan Sequoia Menyatakan 95% Investasi AI Tidak Efektif, Lulusan Paling Terdampak : Sequoia Capital membagikan laporan penelitian dari MIT dan Harvard University yang menunjukkan bahwa 95% investasi AI perusahaan tidak menghasilkan nilai nyata, peningkatan produktivitas yang sebenarnya berasal dari “ekonomi AI bayangan” yang terbentuk dari karyawan yang “diam-diam” menggunakan alat AI pribadi. Laporan tersebut juga mengungkapkan bahwa dampak AI pada pasar kerja terutama terkonsentrasi pada kaum muda yang baru lulus, terutama di sektor grosir dan ritel, jumlah rekrutmen posisi entry-level menurun secara signifikan, dan gelar dari universitas ternama pun bukan jaminan penuh. Ini menunjukkan bahwa AI sedang mengubah alokasi tugas, dan nilai manusia beralih ke pengalaman dan penilaian unik. (Sumber: 36氪, Reddit r/ArtificialInteligence)
Penyesuaian Model OpenAI Memicu Ketidakpuasan Pengguna yang Kuat, Menyerukan Komunikasi Transparan : OpenAI baru-baru ini “menurunkan” model GPT-4o/GPT-5 ke versi dengan daya komputasi rendah tanpa pemberitahuan, menyebabkan penurunan kinerja model dan memicu ketidakpuasan pengguna yang kuat. Banyak pengguna mengeluh bahwa model “menjadi bodoh”, kehilangan wawasan asli dan pengalaman komunikasi “seperti teman”, bahkan ada yang menyebutnya “pukulan mental”. Eksekutif OpenAI menanggapi bahwa ini adalah “uji routing keamanan”, yang bertujuan untuk menangani topik sensitif. Namun, pengguna secara umum menyerukan agar OpenAI memperkuat komunikasi dan transparansi dengan pengguna, menghindari perubahan sepihak pada perjanjian produk, untuk membangun kembali kepercayaan pengguna. (Sumber: Reddit r/artificial, Reddit r/ChatGPT, Reddit r/ChatGPT, Twitter)
Pajak Robot: Diskusi tentang Kemajuan Teknologi dan Keadilan Sosial : Seiring dengan perkembangan teknologi AI dan robotika, diskusi tentang “pajak” pada robot semakin meningkat, bertujuan untuk menyeimbangkan masalah ketenagakerjaan dan ketidaksetaraan sosial yang mungkin timbul dari penggantian tenaga kerja manusia oleh robot. Para pendukung berpendapat bahwa pajak robot dapat memberikan tunjangan sosial dan dukungan re-employment bagi pengangguran, serta mengoreksi ketidakseimbangan daya tawar antara modal dan tenaga kerja. Namun, para praktisi industri robot secara umum berpendapat bahwa pengenaan pajak saat ini terlalu dini dan dapat menghambat perkembangan industri baru. Korea Selatan telah secara tidak langsung meningkatkan biaya penggunaan robot dengan mengurangi insentif pajak bagi perusahaan otomatisasi. (Sumber: 36氪)
Arah Masa Depan Robot Humanoid: Pakar Robotika Terkenal Rodney Brooks Berpendapat Masa Depan Tidak Akan Mirip Manusia : Pakar robotika terkenal Rodney Brooks menulis bahwa, meskipun investasi besar, robot humanoid saat ini masih belum dapat mencapai kelincahan setingkat manusia, dan berjalan dengan dua kaki memiliki risiko keamanan. Dia memprediksi bahwa dalam 15 tahun ke depan, robot humanoid tidak akan lagi meniru bentuk manusia, melainkan akan berevolusi menjadi robot khusus dengan mobilitas beroda, multi-lengan (dilengkapi dengan penjepit atau pengisap), dan multi-sensor (pencitraan cahaya aktif, persepsi cahaya tak terlihat), untuk beradaptasi dengan tugas-tugas tertentu. Dia berpendapat bahwa pengejaran bentuk “mirip manusia” saat ini adalah investasi besar yang pada akhirnya akan sia-sia. (Sumber: 36氪)

Kontroversi Kualitas Kode yang Dihasilkan AI dan Pengalaman Pengembang : Di media sosial, pengembang ramai membahas kualitas dan kepraktisan kode yang dihasilkan AI. Ada yang memuji Claude Sonnet 4.5 yang mampu merekonstruksi seluruh codebase, namun kode yang dihasilkan tidak dapat dijalankan; ada juga yang mengeluh bahwa kode yang dihasilkan AI “tidak terkompilasi”, menyebabkan penurunan efisiensi pengembangan. Diskusi ini mencerminkan bahwa pemrograman berbantuan AI masih menghadapi tantangan antara efisiensi dan akurasi, serta kebutuhan pengembang akan debugging dan verifikasi saat menghadapi hasil yang dihasilkan AI. (Sumber: Twitter, Twitter, Twitter)

Pergeseran Pandangan Talenta di Era AI: Dari “Membajak” Menjadi “Menanam” : Di media sosial, ramai dibahas bahwa pandangan talenta di era AI harus beralih dari “membajak orang di mana-mana” tradisional menjadi “menanam tanaman”. Mengingat kelangkaan talenta di bidang AI dan iterasi teknologi yang cepat, perusahaan harus lebih fokus pada pengembangan karyawan dengan tumpukan teknologi dasar, daripada secara membabi buta mengejar talenta “jadi” yang mahal di pasar. Pandangan ini menekankan pentingnya pembelajaran berkelanjutan dan pengembangan internal, untuk beradaptasi dengan kebutuhan yang cepat berubah di jalur AI. (Sumber: dotey)
Konsumsi Energi Infrastruktur AI dan Kebutuhan Energi Sam Altman : Sam Altman mengemukakan bahwa pengembangan AI membutuhkan 250GW listrik, memicu perhatian dan diskusi masyarakat tentang konsumsi energi besar infrastruktur AI. Kebutuhan ini jauh melampaui kapasitas pasokan energi yang ada, mendorong orang untuk memikirkan bagaimana menyeimbangkan perkembangan pesat AI dengan pasokan energi berkelanjutan. Diskusi terkait juga mencakup masalah lingkungan dalam manufaktur semikonduktor, seperti penggunaan PFAS dan potensi risiko dari alternatifnya. (Sumber: Twitter, Twitter)

Doomerisme AI dan Optimis: Kekhawatiran dan Bantahan : Di media sosial, terdapat diskusi luas tentang “doomerisme” AI dan potensi risiko AI, tetapi banyak juga yang berpendapat bahwa kekhawatiran ini dilebih-lebihkan. Kaum optimis berpendapat bahwa masalah nyata yang dibawa AI (seperti dampak iklim, eksploitasi perusahaan, pengawasan militer) lebih mendesak daripada “kecerdasan super yang menghancurkan manusia” yang jauh, dan harus fokus pada tantangan yang dapat diselesaikan saat ini. Beberapa orang menganggap doomerisme AI sebagai “omong kosong”, manifestasi dari kemalasan dan ketidakstabilan, sementara yang lain percaya bahwa AI pada akhirnya akan menuju penciptaan dan pengembangan. (Sumber: Reddit r/ArtificialInteligence, Twitter, Twitter)
Pangsa Pasar LLM Open Source Tiongkok Melampaui AS : Data terbaru menunjukkan bahwa Large Language Models (LLM) open source Tiongkok, yang diwakili oleh Qwen, telah melampaui Amerika Serikat dalam pangsa pasar, menjadi kekuatan dominan di bidang LLM open source. Tren ini menunjukkan bahwa Tiongkok sedang mempercepat kebangkitannya dalam R&D dan aplikasi teknologi AI open source, memberikan dampak signifikan pada lanskap AI global. (Sumber: Twitter, Twitter)
Tim 45 Hari Membuat Manhua AI “Tomorrow is Monday” Mencapai Puluhan Juta Penayangan : Sebuah tim yang hanya beranggotakan 10 orang menyelesaikan produksi 50 episode manhua AI “Tomorrow is Monday” dalam 45 hari, dan tanpa promosi berbayar, jumlah penayangan di seluruh jaringan melampaui puluhan juta, dengan pendapatan berbayar dari Douyin telah menutupi semua biaya. Proyek ini mengadopsi konsep inti “karakter asli + generasi AI”, menyelesaikan masalah kepemilikan hak cipta konten AI, dan mengeksplorasi jalur pengembangan komersial IP untuk semua kategori produk. Proses produksi sangat terbagi, dengan seniman asli, insinyur, editor pasca-produksi, dan sutradara bekerja sama erat, menunjukkan potensi besar teknologi AI dalam mengurangi biaya dan meningkatkan efisiensi dalam produksi konten. (Sumber: 36氪)

💡 LAIN-LAIN
Kuesioner Kebutuhan Penyelarasan Teks Audio yang Akurat : Seorang pengguna media sosial menunjukkan minat yang kuat pada teknologi penyelarasan teks audio yang akurat, dan menerbitkan kuesioner kebutuhan, bertujuan untuk mengumpulkan kebutuhan spesifik pengguna mengenai fungsi dan skenario aplikasi teknologi tersebut, dengan harapan dapat mendorong pengembangan dan optimasi teknologi terkait. (Sumber: dotey)
DeepMind Memamerkan Demo Nano Banana : Google DeepMind memamerkan demo bernama “Nano Banana”, menarik perhatian media sosial. Meskipun detail spesifik belum sepenuhnya diungkapkan, ini mungkin terkait dengan generasi video AI atau teknologi AI multimodal, mengisyaratkan kemajuan baru DeepMind di bidang AI visual. (Sumber: GoogleDeepMind)
Diskusi Akademis tentang Prioritas Penemuan Highway Net dan ResNet : Peneliti AI terkenal Jürgen Schmidhuber me-retweet, kembali memicu diskusi akademis tentang prioritas penemuan Highway Net dan ResNet dalam pembelajaran residual mendalam. Dia menunjukkan bahwa klaim makalah ResNet Microsoft yang menyebut Highway Net sebagai karya “kontemporer” tidak akurat, dan menekankan bahwa Highway Net diterbitkan tujuh bulan sebelum ResNet, serta telah mengidentifikasi dan mengusulkan solusi untuk koneksi residual. (Sumber: SchmidhuberAI)