
Ключевые слова:Anthropic Claude Sonnet 4.5, DeepSeek-V3.2-Exp, OpenAI ChatGPT, Искусственный интеллект, Большие языковые модели, AI модели, Программирование с ИИ, AI агенты, Программирование на Claude Sonnet 4.5, Механизм разреженного внимания (DSA), Функция мгновенного оформления заказа в ChatGPT, Социальное приложение Sora 2, Техника тонкой настройки LoRA
🔥 В центре внимания
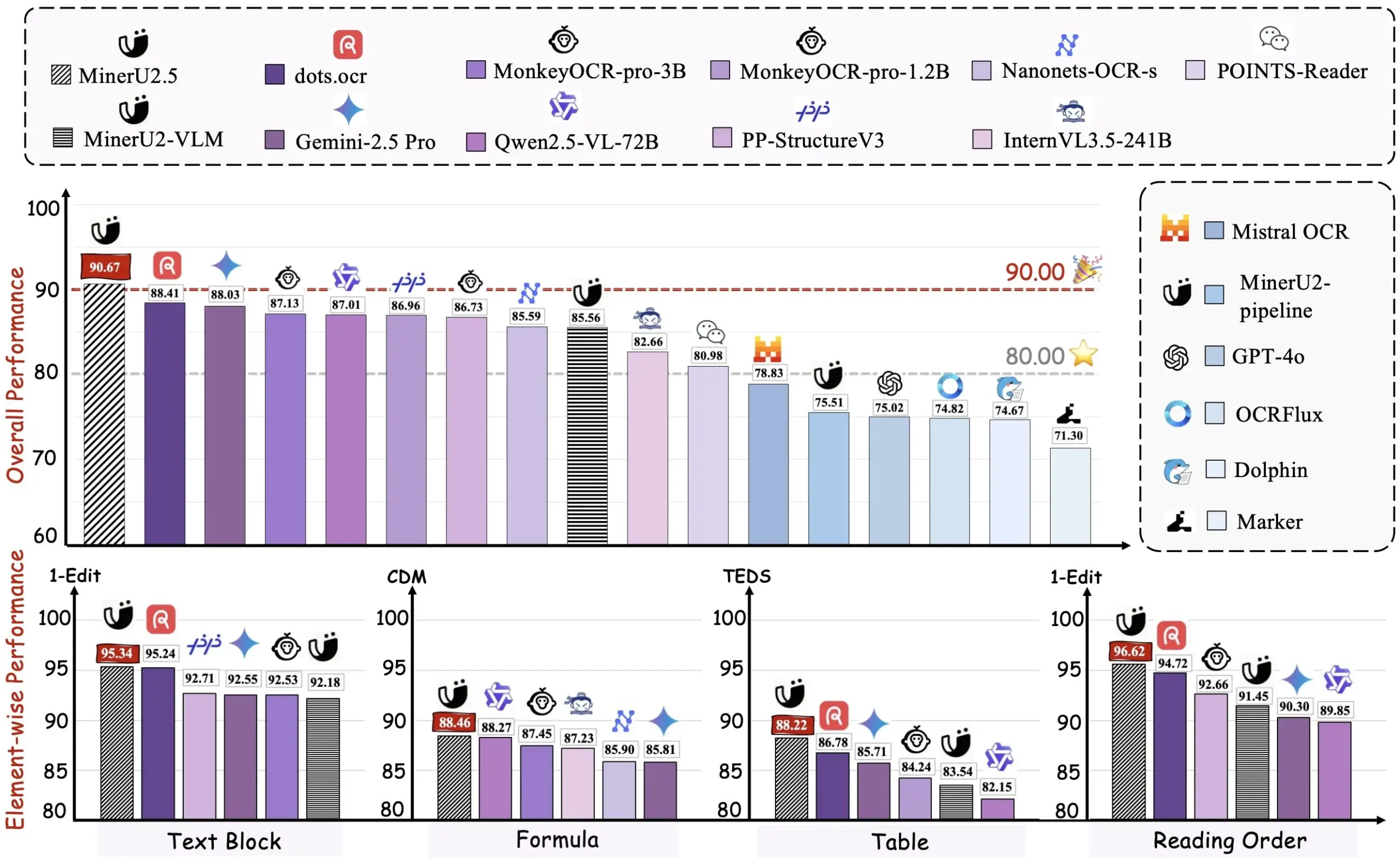
Anthropic выпустила Claude Sonnet 4.5: значительно улучшены возможности программирования и агентов : Anthropic официально выпустила Claude Sonnet 4.5, который считается самым мощным в мире моделью для программирования, добившись значительных прорывов в создании агентов, использовании компьютеров, рассуждениях и математических способностях. Модель может автономно работать более 30 часов подряд, заняла первое место в тесте SWE-bench Verified и установила новый рекорд в бенчмарке компьютерных задач OSWorld. Новые функции включают функцию отката “контрольных точек” в Claude Code, плагин VS Code, контекстное редактирование API и инструменты памяти. Кроме того, была представлена экспериментальная функция “Imagine with Claude”, позволяющая генерировать программные интерфейсы в реальном времени. Sonnet 4.5 также значительно улучшил безопасность, уменьшив нежелательное поведение, такое как обман и потворство, и получил сертификацию AI safety level 3 (ASL-3) с десятикратным снижением ложных срабатываний. Цена осталась такой же, как у Sonnet 4, что еще больше повышает соотношение цена/качество и, как ожидается, вызовет новый виток конкуренции в области AI-программирования. (Источник: Reddit r/ClaudeAI, 36氪, 36氪, 36氪, 36氪, 36氪, Reddit r/ChatGPT, dotey, dotey, dotey)

Выпущен DeepSeek-V3.2-Exp: представлена разреженная архитектура внимания DSA и снижены цены : DeepSeek выпустила экспериментальную модель V3.2-Exp, представив механизм разреженного внимания DeepSeek Sparse Attention (DSA), который значительно повышает эффективность обучения и инференса с длинным контекстом, при этом цены на API снижены более чем на 50%. DSA эффективно идентифицирует ключевые Token’ы для точных вычислений с помощью “молниеносного индексатора”, снижая сложность внимания с O(L²) до O(Lk). Китайские производители AI-чипов, такие как Huawei Ascend, Cambricon и Hygon Information, уже обеспечили адаптацию Day 0, что способствует дальнейшему развитию отечественной вычислительной экосистемы. Модель также открыла исходный код GPU-операторов версии TileLang, конкурирующих с NVIDIA CUDA, что облегчает разработчикам прототипирование и отладку. Несмотря на некоторые уступки в возможностях, архитектурные инновации и экономическая эффективность модели указывают новое направление для обработки длинных текстов в больших моделях. (Источник: 36氪, 36氪, 36氪, 量子位, 量子位, 量子位, Reddit r/LocalLLaMA, Twitter)

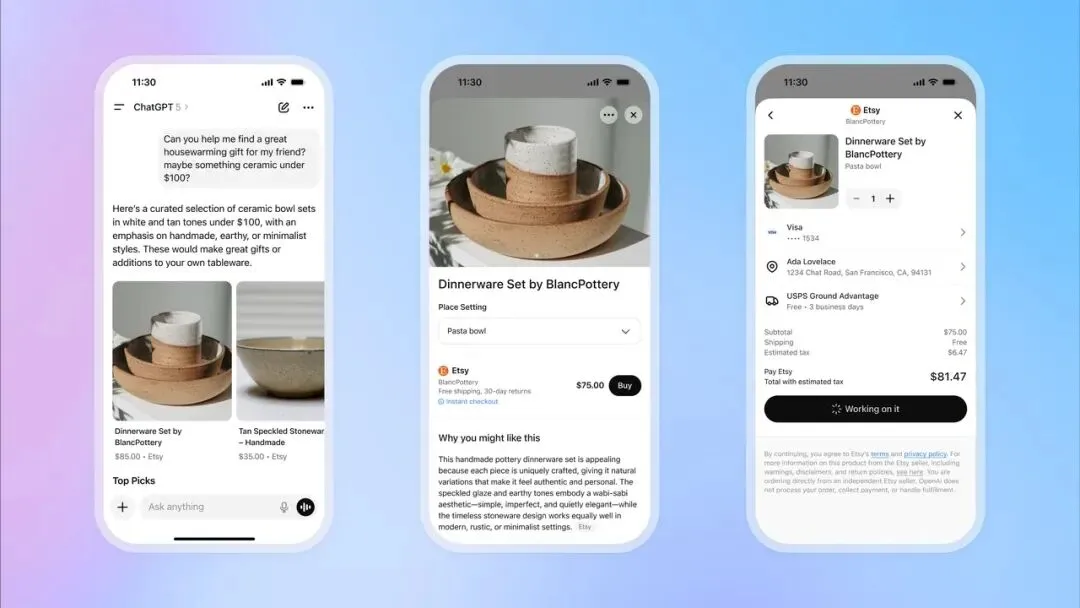
OpenAI запускает функцию мгновенной оплаты в ChatGPT, выходя на рынок электронной коммерции : OpenAI представила функцию “Instant Checkout” в ChatGPT, позволяющую пользователям напрямую приобретать товары на платформах Etsy и Shopify в ходе диалога, без перехода на внешние веб-сайты. Эта функция основана на “Agentic Commerce Protocol”, разработанном OpenAI в сотрудничестве со Stripe, и уже имеет открытый исходный код, призванный преобразовать огромный трафик ChatGPT в коммерческие транзакции. Изначально функция будет поддерживаться на рынке США, в будущем планируется расширение на корзины с несколькими товарами и другие регионы. Этот шаг рассматривается как важный этап в коммерциализации OpenAI, который может стать значительным источником дохода и оказать глубокое влияние на традиционную электронную коммерцию и рекламную индустрию. (Источник: 36氪, 36氪, Reddit r/artificial, Reddit r/artificial, Twitter, Twitter, Twitter, Twitter)
OpenAI готовится запустить социальное приложение Sora 2, создавая платформу для коротких AI-видео : OpenAI готовится запустить независимое социальное приложение, работающее на базе их новейшей видеомодели Sora 2. Приложение по дизайну очень похоже на TikTok, используя вертикальную видеоленту и прокрутку, но весь контент генерируется AI. Пользователи могут создавать видеоролики длиной до 10 секунд и использовать функцию аутентификации для использования своего портрета в видео. Этот шаг направлен на повторение успеха ChatGPT в текстовой области, чтобы дать публике интуитивно понять потенциал AI-видео и напрямую вступить в конкуренцию с Meta и Google. Однако OpenAI применяет стратегию обработки авторских прав, основанную на “использовании контента, защищенного авторским правом по умолчанию, если правообладатель не откажется от этого”, что вызывает серьезные опасения у создателей контента и кинокомпаний, предвещая ожесточенную борьбу между AI и интеллектуальной собственностью. (Источник: 36氪, Reddit r/artificial, Twitter, Twitter)

🎯 Тенденции
Модель Huawei Pangu 718B заняла второе место в рейтинге китайских больших моделей SuperCLUE : Модель Huawei openPangu-Ultra-MoE-718B заняла второе место в открытом рейтинге китайских больших моделей общего назначения SuperCLUE. Модель использует философию обучения “не полагаться на объем данных, а полагаться на способность мыслить”, применяя принципы построения данных “приоритет качества, охват разнообразия, адаптация сложности”, а также трехэтапную стратегию предварительного обучения (общее, рассуждение, отжиг) для формирования обширных мировых знаний и улучшения способностей к логическому рассуждению. Для смягчения проблемы галлюцинаций введен механизм “критической интернализации”; для улучшения способности использования инструментов применяется обновленная синтетическая платформа ToolACE. (Источник: 量子位)

FSDrive объединяет VLA и World Model, продвигая автономное вождение к визуальному рассуждению : FSDrive (FutureSightDrive) предлагает “пространственно-временной визуальный CoT”, который, используя унифицированные будущие кадры изображения в качестве промежуточных шагов рассуждения, объединяет будущие сценарии и результаты восприятия для визуального рассуждения, тем самым продвигая автономное вождение от символьного рассуждения к визуальному. Этот метод, не изменяя существующую архитектуру MLLM, активирует возможности генерации изображений за счет расширения словаря и авторегрессивной визуальной генерации, а также вводит физические априорные знания с помощью прогрессивного визуального CoT. Модель выступает как “World Model” для предсказания будущего, так и как “Inverse Dynamics Model” для планирования траектории. (Источник: 36氪)

GPT-5 предлагает ключевые идеи для квантовых вычислений, получив высокую оценку от Скотта Ааронсона : Выдающийся теоретик квантовых вычислений Скотт Ааронсон сообщил, что GPT-5 менее чем за полчаса предоставил ключевые идеи для доказательства в его исследовании теории квантовой сложности, решив проблему, которая беспокоила команду. Скотт Ааронсон заявил, что GPT-5 добился значительного прогресса в решении наиболее человеческих интеллектуальных задач, что знаменует собой “сладкий момент” в сотрудничестве человека и AI, способный предоставить исследователям прорывные озарения в критические моменты. (Источник: 量子位, Twitter)

HuggingFace ускоряет инференс модели Qwen3-8B Agent на Intel Core Ultra : HuggingFace в сотрудничестве с Intel успешно увеличила скорость инференса модели Qwen3-8B Agent на интегрированном GPU Intel Core Ultra в 1.4 раза, используя OpenVINO.GenAI и модель-черновик Qwen3-0.6B с глубоким отсечением (depth-pruned). Эта оптимизация делает запуск приложений Agent на Qwen3-8B на AI PC более эффективным, особенно для сложных рабочих процессов, требующих многошагового рассуждения и вызова инструментов, что способствует дальнейшей практической реализации локальных AI Agent’ов. (Источник: HuggingFace Blog)

Робот Reachy Mini интегрирован с GPT-4o для мультимодального взаимодействия : Робот Reachy Mini от Hugging Face / Pollen Robotics успешно интегрирован с моделью GPT-4o от OpenAI, что значительно улучшило его мультимодальные возможности взаимодействия. Новые функции включают анализ изображений (робот может описывать и рассуждать о сделанных фотографиях), отслеживание лица (поддержание зрительного контакта), слияние движений (одновременное движение головы, отслеживание лица, эмоции/танцы), локальное распознавание лиц и автономное поведение в режиме ожидания. Эти достижения делают взаимодействие человека и машины более естественным и плавным, но все еще существуют проблемы с системой памяти, распознаванием речи и стратегиями для сложных групп людей. (Источник: Reddit r/ChatGPT, Twitter)

Intel выпускает новую бета-версию LLM Scaler с поддержкой GenAI на Battlemage GPU : Intel выпустила новую бета-версию LLM Scaler, предназначенную для оптимизации производительности генеративного AI (GenAI) на Battlemage GPU. Этот шаг свидетельствует о постоянных инвестициях Intel в аппаратное и программное обеспечение AI-экосистемы для повышения конкурентоспособности своих GPU в задачах инференса и генерации больших языковых моделей. (Источник: Reddit r/artificial)
Claude запускает панель мониторинга использования, ChatGPT вводит функции родительского контроля : Anthropic представила панель мониторинга использования в реальном времени для Claude Code и Claude App, позволяющую пользователям отслеживать потребление Token’ов в ответ на ранее объявленные еженедельные ограничения скорости. В то же время OpenAI запустила функцию родительского контроля в ChatGPT, позволяющую родителям связывать учетные записи подростков, автоматически обеспечивая более надежную защиту и возможность регулировать функции и устанавливать ограничения использования, но родители не могут просматривать конкретное содержание диалогов. (Источник: Reddit r/ClaudeAI, 36氪)
Языковая модель с 5 миллионами параметров запущена в Minecraft, демонстрируя инновационное применение AI : Sammyuri построил сложную систему Redstone в Minecraft, успешно запустив языковую модель с примерно 5 миллионами параметров и наделив ее базовыми диалоговыми возможностями. Этот прорыв демонстрирует возможность реализации локального AI в игровой среде и вызвал широкий интерес и обсуждение в сообществе по поводу применения AI на нетрадиционных платформах. (Источник: Reddit r/LocalLLaMA, Twitter)
AI-серверы Inspur Information достигают скорости инференса 8.9 мс, стоимость миллиона Token’ов — 1 юань : Inspur Information выпустила сверхмасштабируемые AI-серверы Yuanbrain HC1000 и сверхузлы Yuanbrain SD200, установив новый рекорд скорости AI-инференса. Yuanbrain SD200 достигает времени вывода одного Token’а (TPOT) в 8.9 мс на модели DeepSeek-R1, что почти вдвое быстрее предыдущего SOTA, и поддерживает инференс моделей с триллионами параметров и совместную работу нескольких агентов в реальном времени. Yuanbrain HC1000 снижает стоимость вывода миллиона Token’ов до 1 юаня, а стоимость одной карты — на 60%. Эти прорывы направлены на решение проблем скорости и стоимости, с которыми сталкивается индустриализация агентов, предоставляя высокоэффективную и недорогую вычислительную инфраструктуру для масштабного внедрения многоагентного сотрудничества и рассуждений в сложных задачах. (Источник: 量子位)

Новый метод прямой 3D Gaussian Splatting: команда Чжэцзянского университета предлагает “выравнивание по вокселям” : Команда Чжэцзянского университета предложила фреймворк VolSplat для прямой 3D Gaussian Splatting (3DGS) с “выравниванием по вокселям” (voxel-aligned), направленный на решение проблем геометрической согласованности и распределения плотности Гаусса в существующих методах “выравнивания по пикселям” при многоракурсной 3D-реконструкции. VolSplat объединяет многоракурсную 2D-информацию в трехмерном пространстве и использует разреженную 3D U-Net для уточнения признаков, достигая более высокого качества, надежности и эффективности 3D-реконструкции. Метод превосходит различные базовые показатели на общедоступных наборах данных и демонстрирует мощную способность к обобщению с нулевым числом примеров на невиданных наборах данных. (Источник: 量子位)

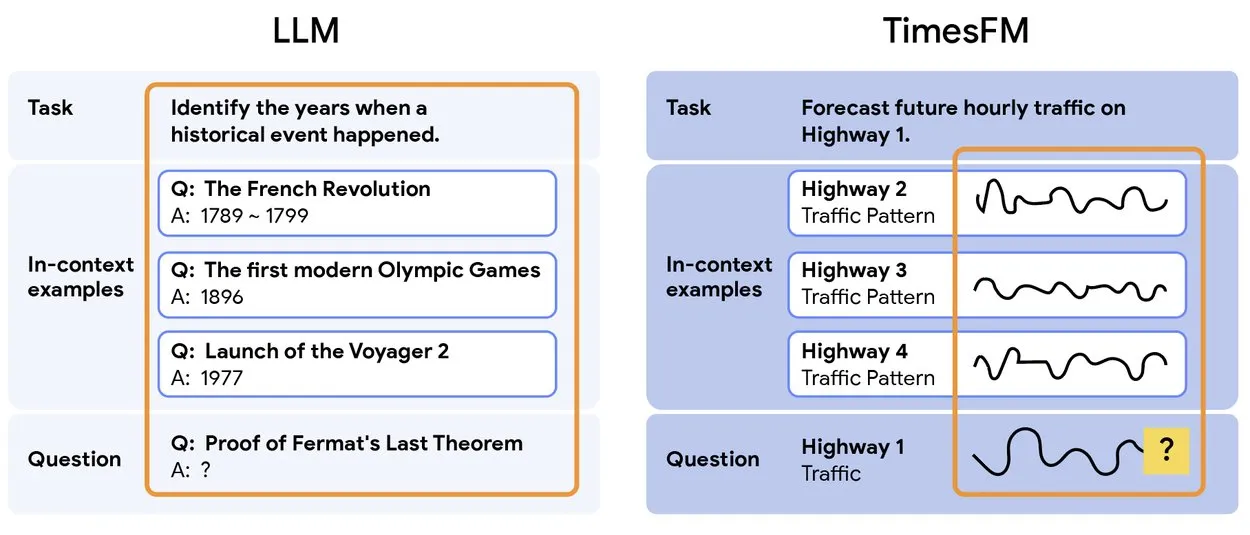
TimesFM 2.5: выпущена предварительно обученная модель для прогнозирования временных рядов : Выпущена TimesFM 2.5, предварительно обученная модель для прогнозирования временных рядов, количество параметров которой уменьшено с 500M до 200M, длина контекста увеличена с 2K до 16K, и она демонстрирует отличные результаты в условиях нулевого числа примеров. Модель доступна на Hugging Face и распространяется под лицензией Apache 2.0, предоставляя более эффективное и мощное решение для задач прогнозирования временных рядов. (Источник: Twitter)
Yunpeng Technology выпускает новые продукты AI+Health, продвигая применение AI в области домашнего здоровья : Yunpeng Technology в сотрудничестве с Shuaikang и Skyworth представила “Лабораторию цифрового интеллектуального будущего кухни” и умный холодильник, оснащенный большой AI-моделью для здоровья. Большая AI-модель для здоровья оптимизирует дизайн и эксплуатацию кухни, а умный холодильник предоставляет персонализированное управление здоровьем через “помощника по здоровью Сяоюнь”. Этот запуск знаменует прорыв AI в области повседневного управления здоровьем, обещая персонализированные медицинские услуги через умные устройства и повышение уровня технологий домашнего здоровья. (Источник: 36氪)
Alibaba выпускает открытую модель мышления Ring-1T-preview с 1 триллионом параметров : Команда Ant Ling из Alibaba выпустила первую открытую модель мышления Ring-1T-preview с 1 триллионом параметров, призванную обеспечить “глубокое мышление без ожидания”. Модель достигла ранних выдающихся результатов в задачах обработки естественного языка, включая бенчмарки AIME25, HMMT25, ARC-AGI-1, LCB и Codeforces. Кроме того, она решила проблему Q3 IMO25 с первой попытки и предоставила частичные решения для Q1/Q2/Q4/Q5, демонстрируя свои мощные способности к рассуждению и решению проблем. (Источник: Twitter, Twitter, Twitter)

🧰 Инструменты
PopAi выпускает “Slide Agent”, AI-инструмент для создания презентаций в один клик : Команда PopAi представила инструмент “Slide Agent”, призванный упростить процесс создания презентаций. Пользователям достаточно ввести запрос через Prompt, выбрать один из 300+ шаблонов, и AI автоматически сгенерирует черновик, а также выполнит настройку макета, графиков, изображений, Logo и других элементов форматирования, после чего можно будет скачать редактируемый файл .pptx. Инструмент объединяет функции ChatGPT и Canva, значительно снижая порог и временные затраты на создание презентаций. (Источник: Twitter)
Alibaba открывает исходный код инструмента Miner U2.5 для преобразования PDF в Markdown : Команда Alibaba открыла исходный код инструмента Miner U2.5 для преобразования PDF в Markdown, и его демо-версия уже доступна на HuggingFace. Этот инструмент позволяет эффективно преобразовывать PDF-документы в формат Markdown, что удобно для извлечения, редактирования и повторного использования контента. Для разработчиков и исследователей, которым приходится обрабатывать большое количество PDF-документов, это практичный AI-инструмент. (Источник: dotey)
VEED Animate 2.2 запущен с поддержкой изменения стиля видео и замены персонажей : Версия VEED Animate 2.2 официально запущена, поддерживаемая технологией WAN 2.2. Этот инструмент позволяет пользователям легко изменять стиль видео с помощью одного изображения, мгновенно менять персонажей в видео и создавать видеоклипы в 10 раз быстрее. Эти новые функции значительно упрощают процесс создания видео, предоставляя создателям контента больше AI-управляемых творческих возможностей. (Источник: TomLikesRobots)
LangChain стремится к стандартизации ответов LLM для поддержки сложных функций : В разработке версии v1 LangChain сосредоточилась на стандартизации ответов LLM, чтобы справиться с постоянно усложняющимися функциями LLM, такими как вызов инструментов на стороне сервера, рассуждения и ссылки. Цель фреймворка — решить проблему несовместимости форматов API между различными поставщиками LLM, предоставив разработчикам унифицированный интерфейс, тем самым упрощая создание мультимодальных агентов и сложных рабочих процессов. (Источник: LangChainAI, Twitter)
Hugging Face Transformers.js поддерживает автономный запуск AI-моделей в браузере : Библиотека Transformers.js от Hugging Face позволяет пользователям запускать AI-модели, такие как Llama 3.2, в браузере в автономном режиме, используя технологии ONNX и WebGPU. Это дает разработчикам возможность выполнять AI-задачи, такие как чат-боты, обнаружение объектов и удаление фона, локально, без зависимости от облачных сервисов, что повышает конфиденциальность данных и скорость обработки. (Источник: Twitter)
Экосистема ToolUniverse помогает AI-ученым создавать и интегрировать инструменты : ToolUniverse — это экосистема, разработанная для создания AI-ученых, которая стандартизирует способы идентификации и вызова инструментов AI-учеными, интегрируя более 600 моделей машинного обучения, наборов данных, API и научных пакетов для анализа данных, извлечения знаний и проектирования экспериментов. Платформа автоматически оптимизирует интерфейсы инструментов, создает новые инструменты с помощью описаний на естественном языке и итеративно оптимизирует спецификации инструментов, объединяя их в рабочие процессы агентов, тем самым способствуя сотрудничеству AI-ученых в процессе открытий. (Источник: HuggingFace Daily Papers)
Фреймворк EasySteer повышает управляемость и масштабируемость LLM : EasySteer — это унифицированный фреймворк на базе vLLM, разработанный для повышения управляемости и масштабируемости LLM. Благодаря модульной архитектуре, подключаемым интерфейсам, тонкой настройке параметров и предварительно вычисленным векторам управления, он обеспечивает ускорение в 5.5-11.4 раза и эффективно снижает чрезмерное обдумывание и галлюцинации. EasySteer превращает управление LLM из исследовательской технологии в производственную возможность, предоставляя ключевую инфраструктуру для развертываемых и управляемых языковых моделей. (Источник: HuggingFace Daily Papers)
VibeGame: AI-помогающий игровой движок на базе WebStack : VibeGame — это высокоуровневый декларативный игровой движок, построенный на three.js, rapier и bitecs, разработанный специально для AI-попомогающей разработки игр. Благодаря высокому уровню абстракции, встроенным функциям физики и рендеринга, а также архитектуре сущность-компонент-система (ECS), он позволяет AI более эффективно понимать и генерировать игровой код. Хотя в настоящее время он в основном подходит для простых платформеров, его открытый исходный код и AI-дружественный синтаксис предлагают многообещающее решение для разработки игр, управляемых AI. (Источник: HuggingFace Blog)
Инструмент “Карта AI-исследований” объединяет 900 тысяч статей и предоставляет ответы со ссылками : Инновационный AI-инструмент способен семантически группировать и визуализировать 900 тысяч AI-исследовательских статей за последнее десятилетие, формируя подробную карту исследований. Пользователи могут задавать вопросы этому инструменту и получать ответы с точными ссылками, что значительно упрощает процесс поиска и понимания огромного объема академической литературы для исследователей и повышает эффективность исследований. (Источник: Reddit r/ArtificialInteligence)
Kroko ASR: быстрая потоковая альтернатива Whisper : Kroko ASR — это новая модель преобразования речи в текст с открытым исходным кодом, позиционируемая как быстрая потоковая альтернатива Whisper. Она имеет меньший размер модели, более высокую скорость инференса на CPU (поддерживает мобильные устройства и браузеры) и практически не имеет галлюцинаций. Kroko ASR поддерживает несколько языков и призвана снизить порог входа в голосовой AI, делая его более доступным для развертывания и обучения на периферийных устройствах. (Источник: Reddit r/LocalLLaMA)
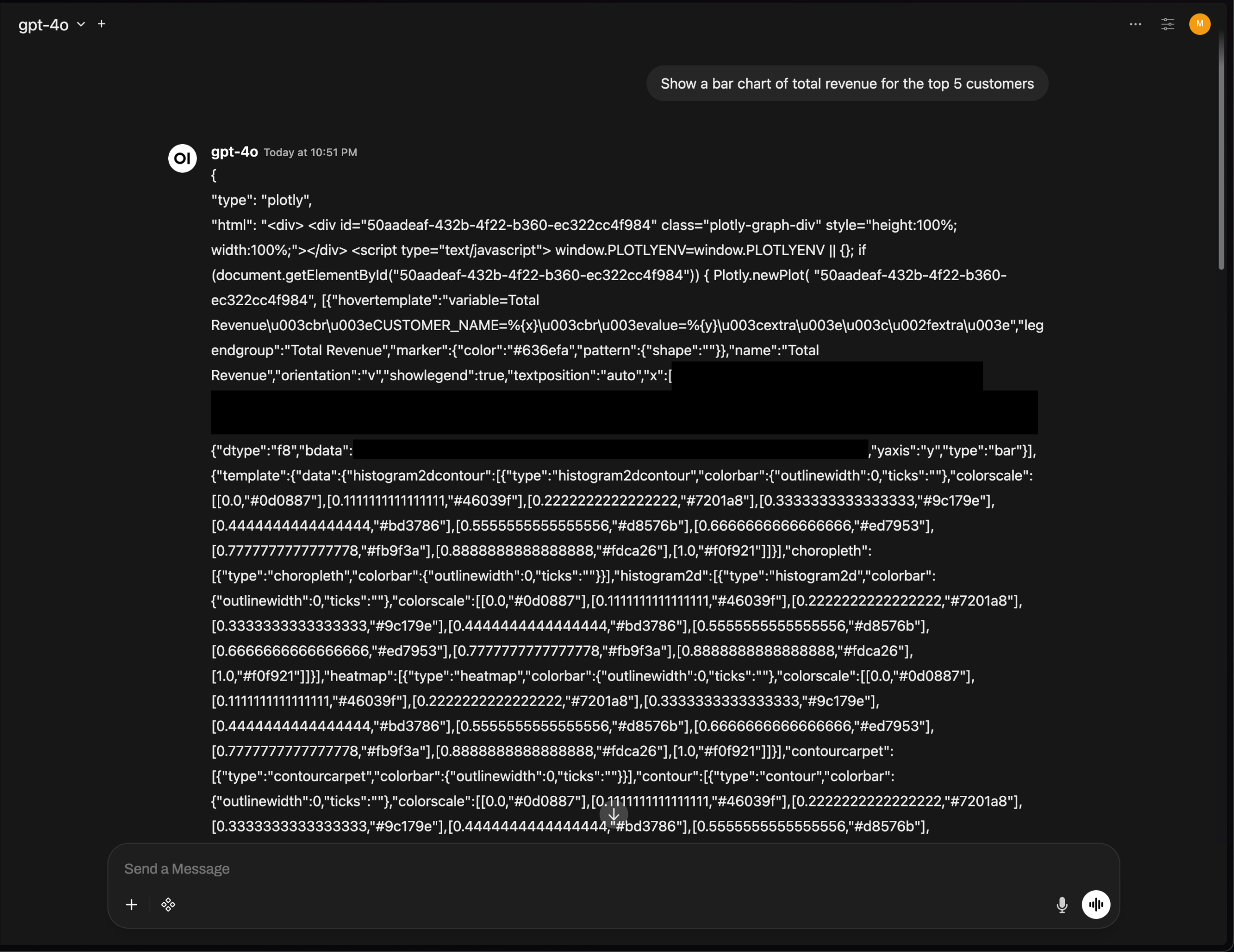
Проблема с рендерингом графиков Plotly в OpenWebUI подчеркивает проблемы интеграции UI AI-инструментов : В версии OpenWebUI v0.6.32 возникла проблема, при которой графики Plotly не отображаются должным образом, а вместо этого напрямую показывается исходный JSON. Пользователи сообщают, что бэкенд возвращает правильный JSON, но фронтенд не запускает рендеринг, что отражает технические проблемы, с которыми все еще сталкиваются AI-инструменты в интеграции фронтенд-UI и рендеринге форматированного текста, требующие дальнейшей оптимизации со стороны сообщества разработчиков. (Источник: Reddit r/OpenWebUI)
📚 Обучение
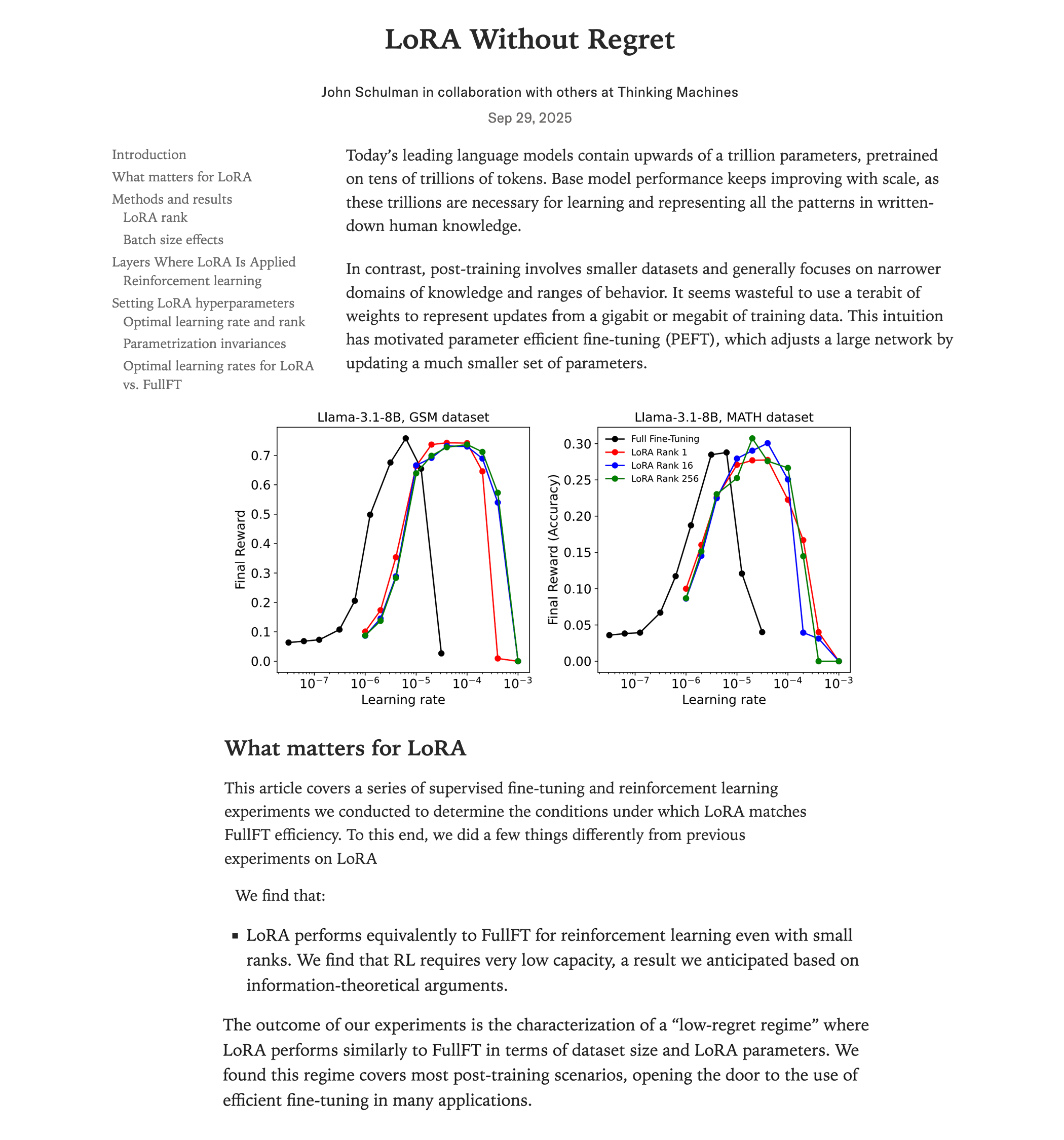
Сравнительное исследование производительности LoRA-дообучения и полного дообучения : Новейшее исследование Thinking Machines (команда Джона Шульмана) показывает, что в обучении с подкреплением, при правильном применении LoRA (Low-Rank Adaptation), ее производительность может соответствовать полному дообучению, при этом потребляя меньше ресурсов (около 2/3 вычислительных затрат), и демонстрировать отличные результаты даже при rank=1. Исследование подчеркивает, что LoRA следует применять ко всем слоям (включая MLP/MoE) и использовать скорость обучения в 10 раз выше, чем при полном дообучении. Это открытие значительно снижает порог для обучения высокопроизводительных RL-моделей, позволяя большему числу разработчиков создавать высококачественные модели на одном GPU. (Источник: Reddit r/LocalLLaMA, Twitter, Twitter)
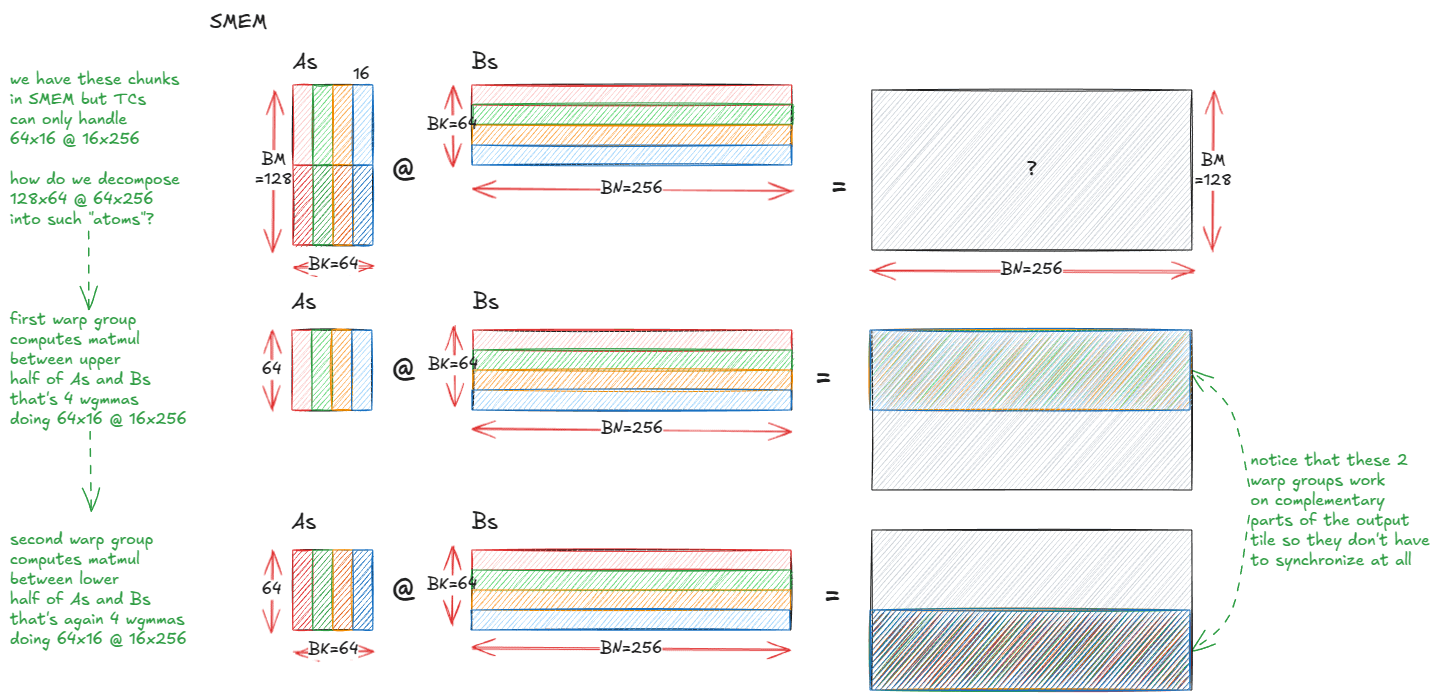
Анатомия высокопроизводительных ядер умножения матриц на NVIDIA GPU : Глубокий технический блог подробно анализирует механизм реализации высокопроизводительных ядер умножения матриц (matmul) внутри NVIDIA GPU. Статья охватывает основы архитектуры GPU, иерархию памяти (GMEM, SMEM, L1/L2), программирование PTX/SASS, а также расширенные функции архитектуры Hopper (H100), такие как TMA и инструкции wgmma. Этот ресурс предназначен для помощи разработчикам в глубоком понимании программирования CUDA и оптимизации производительности GPU, что крайне важно для обучения и инференса моделей Transformer. (Источник: Reddit r/deeplearning, Twitter)
Лекции по курсу глубокого обучения компьютерного зрения CS231N Стэнфордского университета доступны на YouTube : Высоко оцененные лекции по курсу CS231N (Глубокое обучение компьютерного зрения) Стэнфордского университета теперь доступны бесплатно на YouTube. Это предоставляет ценную возможность для учащихся по всему миру получить доступ к высококачественным образовательным ресурсам по AI, охватывающим знания в области глубокого обучения компьютерного зрения от базовых концепций до передовых приложений. (Источник: Reddit r/deeplearning)

RL-ZVP: повышение способности LLM к рассуждению в обучении с подкреплением с помощью Prompt’ов с нулевой дисперсией : Новейшее исследование предлагает метод “RL with Zero-Variance Prompts (RL-ZVP)”, направленный на повышение способности больших языковых моделей (LLM) к рассуждению в обучении с подкреплением. Этот метод больше не игнорирует “Prompt’ы с нулевой дисперсией” (т.е. ситуации, когда все ответы модели получают одинаковую награду), а извлекает из них ценные обучающие сигналы, напрямую вознаграждая за правильность и наказывая за ошибки, а также используя энтропию на уровне Token’ов для формирования преимуществ. Результаты экспериментов показывают, что RL-ZVP значительно повышает точность и процент прохождения в бенчмарках математического рассуждения по сравнению с традиционными методами. (Источник: Reddit r/MachineLearning)
Обучение, управляемое будущим: предиктивный подход к улучшению прогнозирования временных рядов : Исследование предлагает “обучение, управляемое будущим” (Future-Guided Learning), которое улучшает прогнозирование событий временных рядов с помощью динамического механизма обратной связи. Этот метод включает модель обнаружения, анализирующую будущие данные, и модель прогнозирования, делающую прогнозы на основе текущих данных. Когда между моделью прогнозирования и моделью обнаружения возникают расхождения, модель прогнозирования выполняет более значительные обновления, чтобы минимизировать “сюрпризы”, тем самым динамически корректируя параметры и эффективно повышая точность прогнозирования временных рядов. (Источник: Reddit r/MachineLearning)
Будущее AI в низких измерениях: Ян Лекун об обучении абстрактным представлениям : Пионер AI Ян Лекун в интервью с Лексом Фридманом предположил, что следующий скачок в AI произойдет благодаря обучению в низкоразмерных латентных пространствах, а не прямой обработке высокоразмерных необработанных данных, таких как пиксели. Он считает, что истинно интеллектуальные системы должны изучать абстрактные представления причинно-следственной структуры и физической динамики мира, чтобы делать точные прогнозы даже при изменении деталей. Этот подход сделает модели более гибкими, надежными, уменьшит зависимость от огромных объемов данных и снизит вычислительные затраты. (Источник: Reddit r/ArtificialInteligence)
SIRI: Масштабирование итеративного обучения с подкреплением с чередующимся сжатием : SIRI (Scaling Iterative Reinforcement Learning with Interleaved Compression) — это простой и эффективный метод обучения с подкреплением, который динамически регулирует максимальную длину rollout’а во время обучения путем итеративного сжатия и расширения бюджета инференса. Этот механизм обучения заставляет модель принимать точные решения в ограниченном контексте, уменьшая избыточные Token’ы, одновременно предоставляя пространство для исследования и планирования, тем самым неуклонно повышая эффективность и точность больших моделей инференса в компромиссе между производительностью и эффективностью. (Источник: HuggingFace Daily Papers)
Мультиагентная генеративная модель MultiCrafter: пространственно-разделенное внимание и обучение с подкреплением, чувствительное к идентичности : MultiCrafter — это фреймворк, предназначенный для создания высококачественных, согласованных с предпочтениями мультиагентных изображений. Он эффективно смягчает проблему утечки атрибутов, вводя явный позиционный надзор для разделения областей внимания между различными агентами. В то же время фреймворк использует архитектуру Mixture of Experts (MoE) для увеличения емкости модели и разработал новый онлайн-фреймворк обучения с подкреплением, который в сочетании с механизмом оценки и стабильными стратегиями обучения обеспечивает высокую точность изображения агента и его соответствие человеческим эстетическим предпочтениям. (Источник: HuggingFace Daily Papers)
Visual Jigsaw: улучшение визуального понимания MLLM через самоконтролируемое пост-обучение : Visual Jigsaw — это универсальный фреймворк самоконтролируемого пост-обучения, разработанный для улучшения способностей мультимодальных больших языковых моделей (MLLM) к визуальному пониманию. Этот метод разделяет и перемешивает визуальные входы, а затем требует от модели восстановить правильный порядок расположения с помощью естественного языка. Этот метод обучения с подкреплением на основе проверяемых вознаграждений (RLVR) значительно улучшает производительность MLLM в задачах детального восприятия, временного рассуждения и понимания 3D-пространства без необходимости в дополнительных компонентах визуальной генерации или ручной аннотации. (Источник: HuggingFace Daily Papers)
MGM-Omni: расширение Omni LLM для персонализированной генерации длительной речи : MGM-Omni — это унифицированная Omni LLM, которая, благодаря своей уникальной двухканальной Token-архитектуре “мозг-рот”, обеспечивает мультимодальное понимание и выразительную генерацию длительной речи. Эта конструкция разделяет мультимодальное рассуждение и генерацию речи в реальном времени, поддерживая эффективное кросс-модальное взаимодействие и клонирование речи с низкой задержкой, а также демонстрирует выдающуюся эффективность данных. Эксперименты показывают, что MGM-Omni превосходит существующие открытые модели по сохранению тембра, генерации естественной контекстно-зависимой речи, а также по длительному аудио- и мультимодальному пониманию. (Источник: HuggingFace Daily Papers)
SID: Обучение языковой навигации, ориентированной на цель, с помощью самосовершенствующихся демонстраций : SID (Self-Improving Demonstrations) — это метод обучения языковой навигации, ориентированной на цель, который значительно улучшает исследовательские способности и обобщаемость навигационных агентов в неизвестных средах за счет итеративных самосовершенствующихся демонстраций. Этот метод сначала использует данные кратчайшего пути для обучения исходного агента, а затем генерирует новые траектории исследования с помощью этого агента. Эти траектории предоставляют более сильные стратегии исследования для обучения лучшего агента, что приводит к постоянному улучшению производительности. Эксперименты показывают, что SID достигает SOTA-производительности в задачах REVERIE и SOON, в частности, достигая 50.9% успешности на невиданном наборе данных SOON, превосходя предыдущие методы на 13.9%. (Источник: HuggingFace Daily Papers)
LOVE-R1: Улучшение понимания длинных видео с помощью адаптивного механизма масштабирования : Модель LOVE-R1 призвана решить конфликт между пониманием длительных временных последовательностей и детальным пространственным восприятием в задачах понимания длинных видео. Модель вводит адаптивный механизм масштабирования, который сначала плотно сэмплирует кадры с низким разрешением, а затем, при необходимости пространственных деталей, модель может масштабировать интересующие видеофрагменты до высокого разрешения на основе рассуждений, пока не получит ключевую визуальную информацию. Весь процесс реализуется с помощью многошагового рассуждения и сочетает CoT-дообучение данных с декомпозированным усиленным дообучением, что приводит к значительному улучшению в бенчмарках понимания длинных видео. (Источник: HuggingFace Daily Papers)
Euclid’s Gift: Улучшение пространственного рассуждения визуально-языковых моделей с помощью геометрических агентских задач : Euclid’s Gift — это исследование, направленное на повышение пространственного восприятия и способности к рассуждению визуально-языковых моделей (VLM) с помощью геометрических агентских задач. В рамках проекта был создан мультимодальный набор данных Euclid30K, содержащий 30 тысяч задач по планиметрии и стереометрии, а также выполнено дообучение моделей Qwen2.5VL и серии RoboBrain2.0 с использованием Group Relative Policy Optimization (GRPO). Эксперименты показали, что обученные модели достигли значительного улучшения в условиях нулевого числа примеров на четырех бенчмарках пространственного рассуждения, включая Super-CLEVR и Omni3DBench, при этом RoboBrain2.0-Euclid-7B достиг точности 49.6%, превзойдя предыдущие SOTA-модели. (Источник: HuggingFace Daily Papers)
SphereAR: Улучшение авторегрессивной генерации непрерывных Token’ов через гиперсферическое латентное пространство : SphereAR направлен на решение проблем, вызванных гетерогенной дисперсией в латентном пространстве VAE в моделях авторегрессивной (AR) генерации изображений с непрерывными Token’ами. Основная идея заключается в ограничении всех AR-входов и выходов (включая после CFG) на гиперсфере фиксированного радиуса, используя гиперсферический VAE. Теоретический анализ показывает, что гиперсферическое ограничение устраняет основную причину коллапса дисперсии, тем самым стабилизируя AR-декодирование. Эксперименты доказывают, что SphereAR достигает SOTA-производительности в задачах генерации ImageNet, превосходя диффузионные модели и модели генерации масок с аналогичным количеством параметров. (Источник: HuggingFace Daily Papers)
AceSearcher: Управление рассуждениями и поиском LLM через усиленную самоигру : AceSearcher — это совместный фреймворк самоигры, разработанный для повышения способности LLM к поисковому усилению в сложных задачах рассуждения. Фреймворк обучает одну LLM чередовать декомпозицию сложных запросов и интеграцию контекста поиска, оптимизируя точность окончательного ответа с помощью контролируемого и усиленного дообучения, без необходимости промежуточной аннотации. Эксперименты показывают, что AceSearcher значительно превосходит SOTA-базовые показатели в нескольких задачах, требующих интенсивного рассуждения; в задачах финансового рассуждения на уровне документов AceSearcher-32B соответствует производительности DeepSeek-V3 с менее чем 5% параметров. (Источник: HuggingFace Daily Papers)
SparseD: Механизм разреженного внимания для диффузионных языковых моделей : SparseD — это метод разреженного внимания для диффузионных языковых моделей (DLM), разработанный для решения проблемы квадратичной сложности вычислений внимания при большой длине контекста. Метод предварительно вычисляет разреженные паттерны для каждой головы и повторно использует их на всех шагах денойзинга, при этом на ранних шагах денойзинга используется полное внимание, а затем переключается на разреженное внимание, что обеспечивает ускорение без потерь. Результаты экспериментов показывают, что SparseD может достигать ускорения до 1.5 раз по сравнению с FlashAttention при длине контекста 64k, эффективно повышая эффективность инференса DLM в приложениях с длинным контекстом. (Источник: HuggingFace Daily Papers)
SLA: Ускорение Diffusion Transformer с помощью настраиваемого разреженного линейного внимания : SLA (Sparse-Linear Attention) — это обучаемый метод внимания, разработанный для ускорения моделей Diffusion Transformer (DiT), особенно для вычислений внимания при генерации видео. Этот метод делит веса внимания на три категории: ключевые, граничные и незначительные, применяя O(N²) и O(N) внимание соответственно, и пропуская незначительные части. SLA объединяет эти вычисления в одном ядре GPU и после нескольких шагов дообучения позволяет моделям DiT достичь 20-кратного сокращения вычислений внимания и 2.2-кратного сквозного ускорения в генерации видео без потери качества генерации. (Источник: HuggingFace Daily Papers)
OpenGPT-4o-Image: комплексный набор данных для продвинутой генерации и редактирования изображений : OpenGPT-4o-Image — это крупномасштабный набор данных, созданный путем сочетания иерархической классификации задач и метода автоматической генерации данных GPT-4o, предназначенный для повышения производительности унифицированных мультимодальных моделей в области генерации и редактирования изображений. Набор данных содержит 80 тысяч высококачественных пар инструкция-изображение, охватывающих 11 основных областей и 51 подзадачу, включая рендеринг текста, управление стилем, научные изображения и редактирование сложных инструкций. Модели, дообученные на OpenGPT-4o-Image, продемонстрировали значительное улучшение производительности в нескольких бенчмарках, что доказывает ключевую роль систематического построения данных в развитии мультимодальных AI-возможностей. (Источник: HuggingFace Daily Papers)
SANA-Video: небольшая диффузионная модель для эффективной генерации минутного видео в разрешении 720p : SANA-Video — это небольшая диффузионная модель, способная эффективно генерировать видео с разрешением до 720×1280 и продолжительностью до нескольких минут. Она обеспечивает генерацию высококачественного видео высокого разрешения и большой длительности, сохраняя при этом сильное текстово-видео выравнивание, благодаря линейной архитектуре DiT и KV-кэшу с постоянной памятью. Стоимость обучения SANA-Video составляет всего 1% от MovieGen, а при развертывании на GPU RTX 5090 скорость инференса для генерации 5-секундного видео в разрешении 720p достигает 29 секунд, что обеспечивает низкую стоимость и высокое качество генерации видео. (Источник: HuggingFace Daily Papers)
AdvChain: Настройка adversarial CoT для повышения безопасности и согласованности больших моделей рассуждения : AdvChain — это новая парадигма согласования, которая обучает большие модели рассуждения (LRM) способности к динамической самокоррекции с помощью настройки adversarial Chain-of-Thought (CoT). Этот метод создает набор данных, содержащий образцы “искушение-коррекция” и “колебание-коррекция”, позволяя модели учиться восстанавливаться после вредоносных отклонений в рассуждениях и излишней осторожности. Эксперименты показывают, что AdvChain значительно повышает устойчивость модели к атакам “jailbreak” и перехвату CoT, при этом значительно сокращая чрезмерный отказ от доброкачественных Prompt’ов, достигая превосходного баланса безопасности и полезности. (Источник: HuggingFace Daily Papers)
SDLM: Расширение итеративного обучения с подкреплением через чередующееся сжатие : Sequential Diffusion Language Model (SDLM) предлагает унифицированный метод предсказания следующего Token’а и следующего блока, позволяющий модели адаптивно определять длину генерации на каждом шаге. SDLM может модифицировать предварительно обученные авторегрессивные языковые модели с минимальными затратами и выполнять диффузионный инференс внутри блоков фиксированного размера с маской, одновременно динамически декодируя непрерывные подпоследовательности. Эксперименты показывают, что SDLM достигает более высокой пропускной способности, соответствуя или превосходя сильные авторегрессивные базовые показатели, демонстрируя свой мощный потенциал масштабируемости. (Источник: HuggingFace Daily Papers)
Insight-to-Solve (I2S): Преобразование In-Context демонстраций рассуждений в активы для моделей рассуждений (RLM) : Insight-to-Solve (I2S) — это программа для времени тестирования, разработанная для преобразования высококачественных In-Context демонстраций рассуждений в эффективные активы для больших моделей рассуждений (RLM). Исследования показали, что прямое добавление демонстрационных примеров может снизить точность RLM. I2S преобразует демонстрации в четкие, многократно используемые идеи и генерирует целевые траектории рассуждений, опционально проводя самоочистку для повышения связности и правильности. Эксперименты показывают, что I2S и I2S+ постоянно превосходят прямые ответы и базовые показатели масштабирования во время тестирования на различных бенчмарках, принося значительные улучшения даже для моделей GPT. (Источник: HuggingFace Daily Papers)
UniMIC: Унифицированное Token-основанное мультимодальное интерактивное кодирование для человеко-машинного сотрудничества : UniMIC (Unified token-based Multimodal Interactive Coding) — это фреймворк, разработанный для обеспечения эффективного мультимодального взаимодействия с низкой скоростью передачи данных между периферийными устройствами и облачными AI-агентами с помощью Token-основанных представлений. UniMIC использует компактное Token-представление в качестве среды связи и сочетает его с энтропийной моделью Transformer, эффективно уменьшая избыточность между Token’ами. Эксперименты показывают, что UniMIC достигает значительной экономии битрейта в задачах генерации текста в изображение, восстановления изображений и визуальных вопросов-ответов, сохраняя при этом надежность при сверхнизких битрейтах, предоставляя практическую парадигму для мультимодальной интерактивной связи следующего поколения. (Источник: HuggingFace Daily Papers)
RLBFF: Бинарная гибкая обратная связь, связывающая человеческую обратную связь с проверяемыми наградами : RLBFF (Reinforcement Learning with Binary Flexible Feedback) — это парадигма обучения с подкреплением, которая сочетает разнообразие человеческих предпочтений с точностью проверки правил. Она извлекает принципы, на которые можно ответить бинарно (например, точность информации: да/нет, читаемость кода: да/нет), из обратной связи на естественном языке и использует их для обучения модели вознаграждения. RLBFF демонстрирует отличные результаты на RM-Bench и JudgeBench и позволяет пользователям настраивать фокус принципов во время инференса. Кроме того, она предлагает полностью открытое решение для согласования Qwen3-32B с RLBFF, что позволяет ей соответствовать или превосходить производительность o3-mini и DeepSeek R1 на общих бенчмарках согласования. (Источник: HuggingFace Daily Papers)
MetaAPO: Оптимизация согласования через мета-взвешенную онлайн-выборку : MetaAPO (Meta-Weighted Adaptive Preference Optimization) — это новый фреймворк, который оптимизирует согласование больших языковых моделей (LLM) с человеческими предпочтениями путем динамического связывания генерации данных и обучения модели. MetaAPO использует легкий мета-обучатель в качестве “оценщика разрыва согласования” для оценки потенциальной выгоды онлайн-выборки по сравнению с офлайн-данными, направляя целевую онлайн-генерацию и распределяя мета-веса на уровне образцов, динамически балансируя качество и распределение онлайн- и офлайн-данных. Эксперименты показывают, что MetaAPO постоянно превосходит существующие методы оптимизации предпочтений на AlpacaEval 2, Arena-Hard и MT-Bench, при этом снижая затраты на онлайн-аннотацию на 42%. (Источник: HuggingFace Daily Papers)
Tool-Light: Эффективное рассуждение с интеграцией инструментов через саморазвивающееся обучение предпочтениям : Tool-Light — это фреймворк, разработанный для поощрения больших языковых моделей (LLM) к эффективному и точному выполнению задач рассуждения с интеграцией инструментов (TIR). Исследование показало, что результаты вызова инструментов приводят к значительному изменению информационной энтропии последующих рассуждений. Tool-Light реализуется путем сочетания построения набора данных и многоэтапного дообучения, где построение набора данных использует непрерывную саморазвивающуюся выборку, интегрирующую обычную выборку и выборку, управляемую энтропией, а также устанавливает строгие критерии выбора положительных и отрицательных пар. Процесс обучения включает SFT и саморазвивающуюся прямую оптимизацию предпочтений (DPO). Эксперименты доказывают, что Tool-Light значительно повышает эффективность выполнения моделью задач TIR. (Источник: HuggingFace Daily Papers)
ChatInject: Атака Prompt-инъекцией на LLM-агентов с использованием шаблонов чата : ChatInject — это метод косвенной атаки Prompt-инъекцией, который использует зависимость LLM от структурированных шаблонов чата и манипуляции контекстом многораундовых диалогов. Злоумышленник форматирует вредоносную нагрузку, имитируя формат нативного шаблона чата, чтобы побудить агента выполнить подозрительные операции. Эксперименты показывают, что ChatInject имеет более высокую успешность атаки, чем традиционные методы Prompt-инъекции, особенно в многораундовых диалогах, и обладает сильной переносимостью на разные модели, в то время как существующие защиты на основе Prompt’ов в основном неэффективны против таких атак. (Источник: HuggingFace Daily Papers)
💼 Бизнес
Modal завершила раунд финансирования серии B на $87 млн, оценка достигла $1.1 млрд : Компания Modal, занимающаяся AI-инфраструктурой, объявила о завершении раунда финансирования серии B на сумму $87 млн, при этом ее оценка достигла $1.1 млрд. Этот раунд финансирования направлен на ускорение инноваций и развития AI-инфраструктуры для решения проблем, с которыми сталкивается традиционная вычислительная инфраструктура в эпоху AI. Modal предоставляет эффективные облачные вычислительные услуги, помогая исследователям и разработчикам оптимизировать процессы обучения и развертывания своих AI-моделей. (Источник: Twitter, Twitter, Twitter)
OpenAI: выручка за первое полугодие $4.3 млрд, убыток $13.5 млрд, сталкивается с проблемами прибыльности : OpenAI объявила, что выручка за первое полугодие 2025 года достигла $4.3 млрд, а ожидаемая годовая выручка превысит $13 млрд, в основном благодаря подписке ChatGPT Plus и корпоративным услугам API. Однако чистый убыток за тот же период составил $13.5 млрд, причем основными факторами являются структурные затраты и инвестиции в R&D (например, GPT-5), а годовая стоимость аренды серверов достигает $16 млрд. Несмотря на то, что OpenAI располагает $17.5 млрд наличных средств и продвигает план финансирования на $30 млрд, постоянное расходование денежных средств и отставание в эффективности от конкурентов, таких как Anthropic, ставят компанию перед серьезными проблемами прибыльности. (Источник: 36氪)
Капитальная битва в сфере человекоподобных роботов: Zhiyuan, Galaxy General и другие активно развивают цепочку поставок : Сфера человекоподобных роботов вступила в фазу скрытой капитальной борьбы. Ведущие компании, такие как Zhiyuan Robot и Galaxy General, активно расширяют свои “круги общения” путем создания фондов, инвестирования в конкурентов и стратегического сотрудничества. Zhiyuan Robot уже осуществила около 20 внешних инвестиций, охватывающих двигатели, датчики и downstream-приложения, а также сотрудничает с Fulin Precision и iSoftStone для реализации коммерческих сценариев. Galaxy General, в свою очередь, создала совместное предприятие с Bosch China для продвижения воплощенного интеллекта в автомобилестроении. Эти шаги направлены на получение заказов, устранение недостатков и создание стабильной сети поставок для будущих массовых поставок, но технологические маршруты в отрасли сильно различаются, и конкуренция ожесточена. (Источник: 36氪)

🌟 Сообщество
Трудно отличить AI-генерированный контент от реального, что вызывает кризис доверия в обществе : С стремительным развитием AI-технологий, реалистичность AI-генерированных видео (таких как живая версия “Атаки на Титанов”, индонезийский стример, “меняющий лица” с японской интернет-знаменитостью) достигла невероятного уровня, что вызывает глубокую обеспокоенность общества по поводу подлинности контента. В социальных сетях пользователи повсеместно отмечают, что становится все труднее отличить реальный контент от AI-генерированного, что не только подрывает доверие к законным создателям контента, но и может быть использовано для распространения ложной информации. Эксперты указывают, что без обязательной маркировки AI-контента этот “гиперреалистичный движок” будет продолжать подрывать чувство реальности и в конечном итоге может “положить конец интернету”. (Источник: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ArtificialInteligence, Twitter, Twitter)

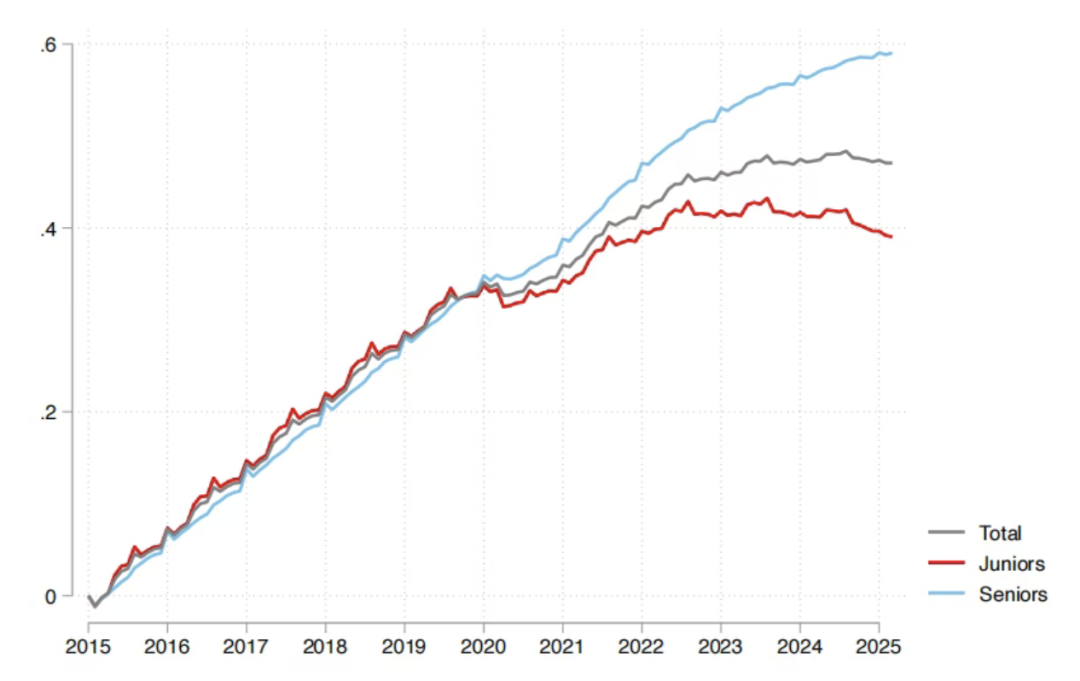
Влияние AI на рынок труда: отчет Sequoia Capital утверждает, что 95% инвестиций в AI неэффективны, выпускники страдают больше всего : Sequoia Capital поделилась отчетом, основанным на исследованиях MIT и Гарвардского университета, в котором говорится, что 95% инвестиций компаний в AI не принесли реальной ценности, а истинный рост производительности обусловлен “теневой AI-экономикой”, сформированной сотрудниками, “тайно” использующими личные AI-инструменты. Отчет также показывает, что влияние AI на рынок труда в основном сосредоточено на недавних выпускниках, особенно в оптовой и розничной торговле, где количество вакансий начального уровня значительно сократилось, и диплом престижного университета не является полной защитой. Это указывает на то, что AI меняет распределение задач, а человеческая ценность смещается в сторону опыта и уникальных суждений. (Источник: 36氪, Reddit r/ArtificialInteligence)
Корректировки моделей OpenAI вызывают сильное недовольство пользователей, призывы к прозрачному общению : Недавнее “понижение” моделей GPT-4o/GPT-5 до версий с низкой вычислительной мощностью без предварительного уведомления со стороны OpenAI привело к снижению производительности моделей и вызвало сильное недовольство пользователей. Многие пользователи жалуются, что модели “поглупели”, потеряли свою первоначальную проницательность и “дружелюбный” опыт общения, а некоторые даже называют это “психологическим ударом”. Руководство OpenAI ответило, что это “тест безопасной маршрутизации”, предназначенный для обработки деликатных тем, но пользователи повсеместно призывают OpenAI усилить общение и прозрачность с пользователями, избегать односторонних изменений в продуктовых соглашениях, чтобы восстановить доверие пользователей. (Источник: Reddit r/artificial, Reddit r/ChatGPT, Reddit r/ChatGPT, Twitter)
Налогообложение роботов: дискуссия о технологическом прогрессе и социальной справедливости : С развитием технологий AI и робототехники все чаще обсуждается вопрос о “налогообложении” роботов, направленный на балансирование проблем занятости и социального неравенства, которые могут возникнуть в результате замены роботами человеческого труда. Сторонники считают, что налог на роботов может обеспечить социальные льготы и поддержку переквалификации для безработных, а также скорректировать дисбаланс в переговорной силе между капиталом и трудом. Однако специалисты в области робототехники в целом считают, что введение налога пока преждевременно и может препятствовать развитию новых отраслей. Южная Корея уже косвенно увеличила стоимость использования роботов, сократив налоговые льготы для компаний-автоматизаторов. (Источник: 36氪)
Будущее человекоподобных роботов: известный эксперт по робототехнике Родни Брукс считает, что будущее не будет человекоподобным : Известный эксперт по робототехнике Родни Брукс написал статью, в которой указывает, что, несмотря на огромные инвестиции, современные человекоподобные роботы все еще не могут достичь человеческого уровня ловкости, а двуногое хождение сопряжено с угрозами безопасности. Он предсказывает, что в ближайшие 15 лет человекоподобные роботы перестанут имитировать человеческую форму и превратятся в специализированных роботов с колесным движением, несколькими манипуляторами (оснащенными захватами или присосками) и множеством датчиков (активное оптическое изображение, невидимое световое восприятие), чтобы адаптироваться к конкретным задачам. Он считает, что нынешние огромные инвестиции в стремление к “человекоподобной” форме в конечном итоге будут потрачены впустую. (Источник: 36氪)

Споры о качестве AI-генерированного кода и опыте разработчиков : В социальных сетях разработчики активно обсуждают качество и практичность AI-генерированного кода. Некоторые хвалят Claude Sonnet 4.5 за возможность рефакторинга всей кодовой базы, но при этом сгенерированный код не работает; другие жалуются, что AI-генерированный код “не компилируется”, что приводит к снижению эффективности разработки. Эти дискуссии отражают сохраняющиеся проблемы в AI-помогающем программировании между эффективностью и точностью, а также потребность разработчиков в отладке и проверке результатов, сгенерированных AI. (Источник: Twitter, Twitter, Twitter)

Изменение подхода к талантам в эпоху AI: от “охоты за головами” к “выращиванию урожая” : В социальных сетях активно обсуждается, что в эпоху AI подход к талантам должен измениться с традиционного “поиска людей повсюду” на “выращивание урожая”. Учитывая дефицит талантов в области AI и быструю итерацию технологий, компаниям следует уделять больше внимания обучению сотрудников с базовым технологическим стеком, а не слепо гнаться за дорогими “готовыми” талантами на рынке. Эта точка зрения подчеркивает важность непрерывного обучения и внутреннего развития для адаптации к быстро меняющимся требованиям AI-индустрии. (Источник: dotey)
Энергопотребление AI-инфраструктуры и энергетические потребности Сэма Альтмана : Заявление Сэма Альтмана о том, что для развития AI потребуется 250 ГВт электроэнергии, вызвало общественное внимание и дискуссии о колоссальном энергопотреблении AI-инфраструктуры. Эта потребность значительно превышает существующие возможности энергоснабжения, что заставляет задуматься о том, как сбалансировать быстрое развитие AI и устойчивое энергоснабжение. Соответствующие дискуссии также затрагивают экологические проблемы в производстве полупроводников, такие как использование PFAS и потенциальные риски его альтернатив. (Источник: Twitter, Twitter)

AI-думеризм и оптимизм: опасения и опровержения : В социальных сетях широко обсуждаются “AI-думеризм” и потенциальные риски AI, но многие также считают эти опасения преувеличенными. Оптимисты полагают, что реальные проблемы, вызванные AI (такие как влияние на климат, корпоративная эксплуатация, военное наблюдение), более актуальны, чем далекое “уничтожение человечества сверхинтеллектом”, и следует сосредоточиться на текущих решаемых задачах. Некоторые считают AI-думеризм “бессмыслицей”, проявлением лени и нестабильности, в то время как другие верят, что AI в конечном итоге приведет к созиданию и развитию. (Источник: Reddit r/ArtificialInteligence, Twitter, Twitter)
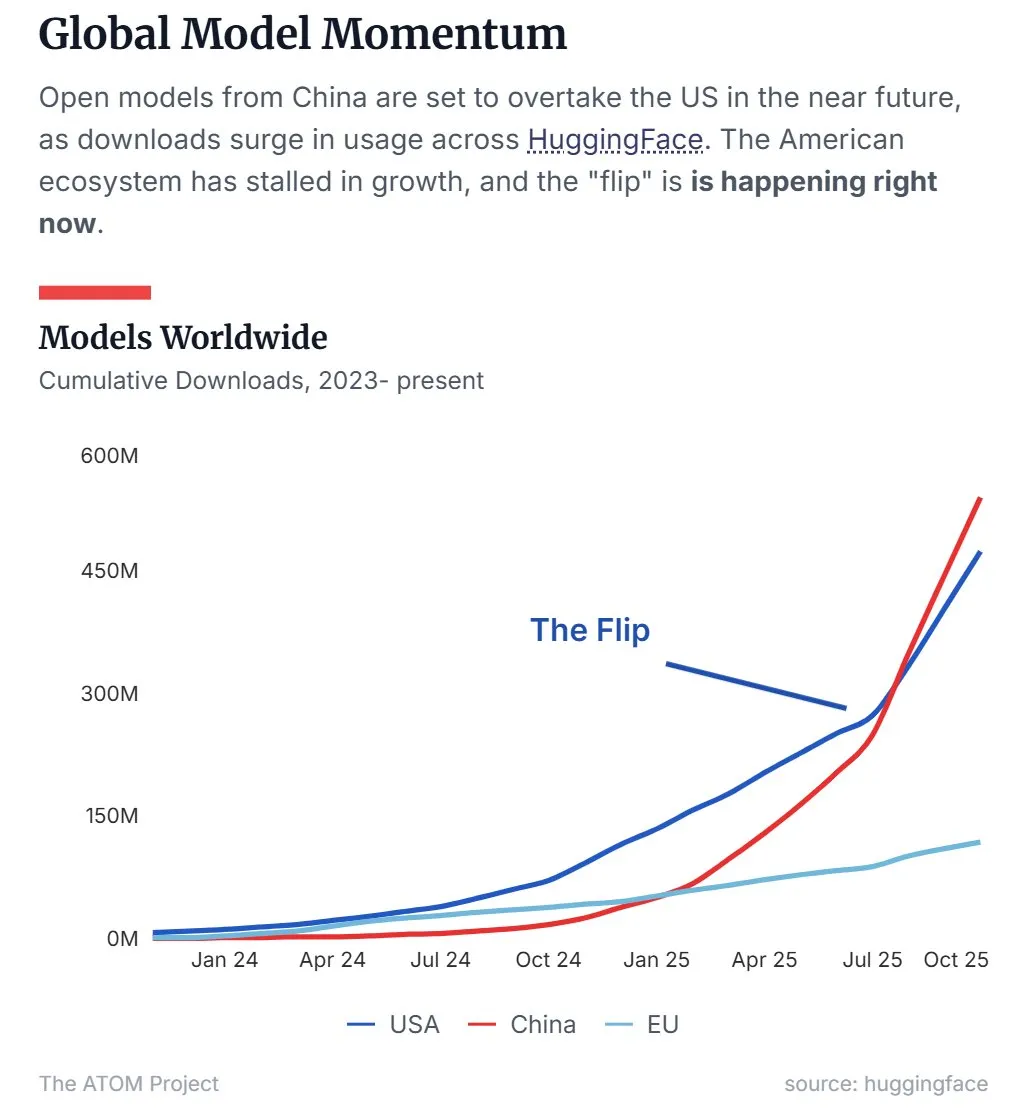
Доля китайских открытых LLM на рынке превзошла США : Последние данные показывают, что китайские открытые большие языковые модели (LLM), представленные Qwen, превзошли США по доле рынка, став доминирующей силой в области открытых LLM. Эта тенденция указывает на ускоренный подъем Китая в разработке и применении открытых AI-технологий, что оказывает значительное влияние на глобальный AI-ландшафт. (Источник: Twitter, Twitter)
Команда из 10 человек за 45 дней создала AI-манхуа “Завтра понедельник”, набравшую десятки миллионов просмотров : Команда из всего 10 человек за 45 дней завершила производство 50-серийной AI-манхуа “Завтра понедельник”, и без каких-либо рекламных вложений общее количество просмотров в сети превысило десять миллионов, а платные доходы на Douyin уже покрыли все затраты. Проект использует основную концепцию “оригинальный образ + AI-генерация”, что решило проблему принадлежности авторских прав на AI-контент и открыло путь для коммерческой разработки IP во всех категориях. Производственный процесс высоко разделен, художники, инженеры, монтажеры и режиссеры тесно сотрудничают, демонстрируя огромный потенциал AI-технологий в снижении затрат и повышении эффективности в производстве контента. (Источник: 36氪)

💡 Прочее
Опрос о потребностях в точной синхронизации аудио и текста : Пользователи социальных сетей проявили большой интерес к технологии точной синхронизации аудио и текста и опубликовали опрос, направленный на сбор конкретных требований пользователей к функциям и сценариям применения этой технологии, чтобы способствовать ее развитию и оптимизации. (Источник: dotey)
DeepMind демонстрирует демо Nano Banana : Google DeepMind представила демонстрацию под названием “Nano Banana”, которая привлекла внимание в социальных сетях. Хотя конкретные детали не были полностью раскрыты, это может быть связано с генерацией AI-видео или мультимодальными AI-технологиями, что намекает на новые достижения DeepMind в области визуального AI. (Источник: GoogleDeepMind)
Академическая дискуссия о приоритете изобретения Highway Net и ResNet : Известный AI-исследователь Юрген Шмидхубер ретвитнул сообщение, вновь вызвав академическую дискуссию о приоритете изобретения Highway Net и ResNet в глубоком остаточном обучении. Он отметил, что утверждение в статье Microsoft о ResNet, что Highway Net является “одновременной” работой, неточно, и подчеркнул, что Highway Net была опубликована на семь месяцев раньше ResNet и уже идентифицировала и предложила решение для остаточных связей. (Источник: SchmidhuberAI)