
Kata Kunci:AI inferensi, NVIDIA, OpenAI, Arsitektur Vera Rubin, Mesin Transformer, Jerry Tworek mengundurkan diri
🔥 Fokus
NVIDIA merilis arsitektur Vera Rubin: Memulai era superkomputer AI generasi berikutnya : Di CES 2026, Jensen Huang meluncurkan platform Vera Rubin terbaru, yang mencakup Vera CPU (dengan core Olympus kustom) dan Rubin GPU. Sistem ini memperkenalkan Transformer engine, dengan performa inferensi 5 kali lipat lebih tinggi dibandingkan Blackwell, serta mendukung Confidential Computing tingkat rak pertama. Sistem Rubin NVL72 meningkatkan efisiensi perakitan dan pemeliharaan hingga 18 kali lipat melalui desain 100% liquid cooling dan tanpa kabel. Selain itu, NVIDIA memperkenalkan platform penyimpanan memori konteks inferensi untuk mengatasi hambatan penyimpanan KV Cache dalam aplikasi teks panjang, dengan tujuan mengurangi biaya Token model MoE besar hingga 1/10 dari Blackwell, menandai evolusi infrastruktur AI dari “kekuatan komputasi titik tunggal” menuju “rekayasa sistem” yang komprehensif. (Sumber: NVIDIA, 智东西, TheTuringPost)

Kepala Penalaran OpenAI Jerry Tworek mengundurkan diri: Kehilangan otak inti terus berlanjut : Jerry Tworek, VP Research di OpenAI dan tokoh kunci di balik model penalaran o1/o3 serta model pemrograman Codex, mengumumkan pengunduran dirinya. Selama hampir tujuh tahun di OpenAI, ia memimpin pengembangan mulai dari Reinforcement Learning robotika awal hingga mekanisme penalaran GPT-4 dan GPT-5. Tworek menyatakan bahwa ia pergi untuk “mengeksplorasi penelitian yang sulit dilakukan di dalam OpenAI,” yang mengisyaratkan adanya ketegangan antara lingkungan penelitian idealis dan tekanan pengiriman produk di bawah komersialisasi tinggi. Sebagai pemimpin proyek o1, kepergiannya merupakan kehilangan besar lainnya bagi talenta teknis inti OpenAI setelah Ilya Sutskever dan John Schulman, yang memicu kekhawatiran mendalam di komunitas mengenai independensi penelitian OpenAI di masa depan. (Sumber: 36氪, 量子位, The Verge)
Google DeepMind bermitra dengan Boston Dynamics: Otak AI menggerakkan tubuh terkuat : Google DeepMind mengumumkan kemitraan penelitian dengan Boston Dynamics. Kolaborasi ini akan mengintegrasikan kemampuan Vision-Language Model (VLM) dari Gemini Robotics ke dalam robot humanoid Atlas elektrik terbaru. Ini berarti algoritma penalaran AI top dunia akan digabungkan dengan perangkat keras robotika tercanggih, mendorong Embodied AI dari pencocokan pola sederhana menuju “Physical AI” yang memiliki pemahaman fisik dan mampu merencanakan tugas kompleks secara mandiri. Aliansi ini dipandang sebagai langkah kunci untuk menyaingi ekosistem Tesla Optimus dan NVIDIA Isaac, menandakan bahwa robot humanoid akan segera menghadapi “momen iPhone” yang sesungguhnya. (Sumber: GoogleDeepMind, HuggingFace)

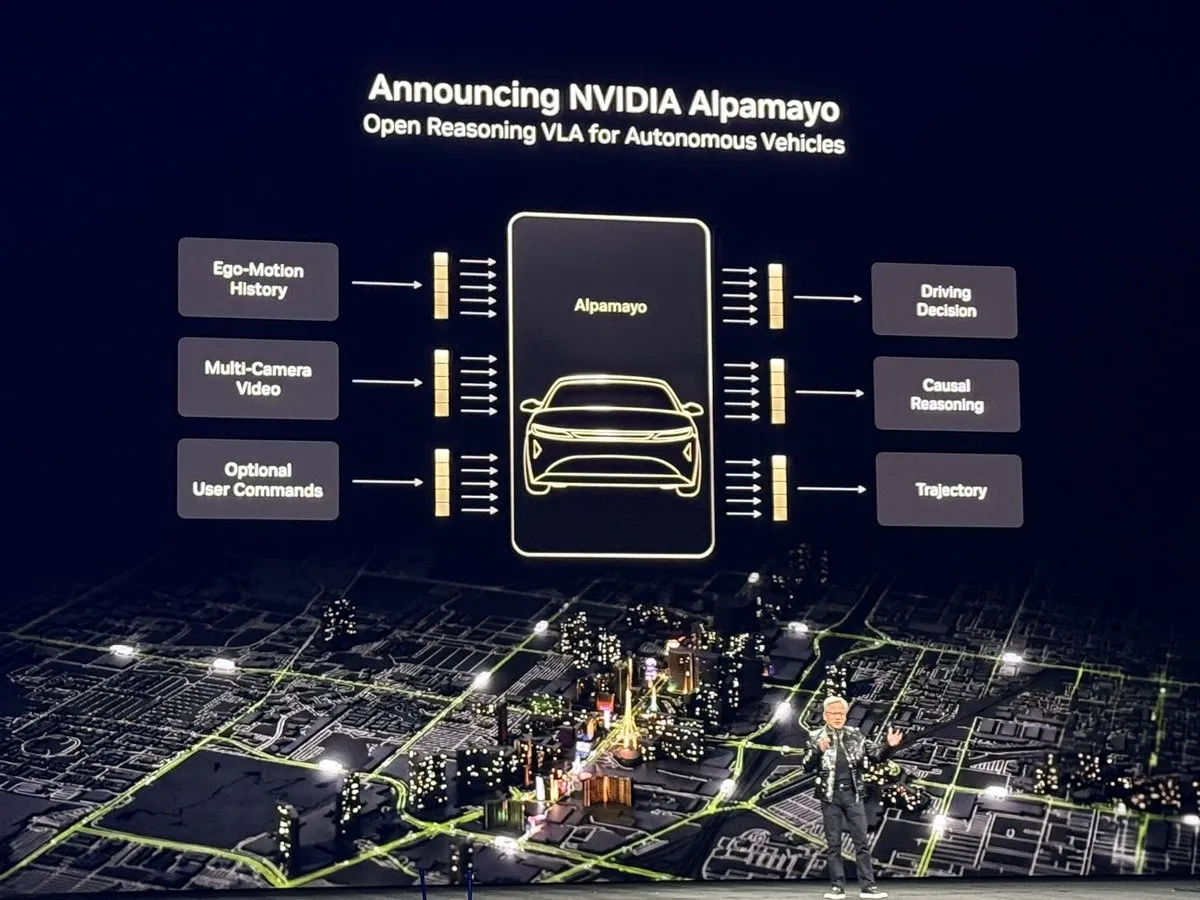
NVIDIA open-source Alpamayo: “Momen ChatGPT” untuk mengemudi otonom : NVIDIA merilis model mengemudi otonom berbasis penalaran pertama, Alpamayo (10B parameter), secara open-source di CES. Berbeda dengan rantai “persepsi-perencanaan” tradisional, Alpamayo memiliki kemampuan Chain of Thought (CoT), yang memungkinkannya memahami kondisi jalan yang kompleks dan menjelaskan logika keputusan seperti pengemudi manusia (misalnya, “melambat karena pejalan kaki mungkin menyeberang”). Model ini dilengkapi dengan framework simulasi AlpaSim dan 1700 jam data mengemudi nyata yang juga open-source. Jensen Huang menyebutnya sebagai “momen ChatGPT untuk Physical AI,” yang bertujuan memecahkan monopoli sistem tertutup seperti Tesla FSD melalui ekosistem open-source, sehingga produsen mobil global dapat mempercepat implementasi mengemudi otonom L4 berdasarkan framework penalaran yang seragam. (Sumber: TheTuringPost, NVIDIA)
🎯 Tren
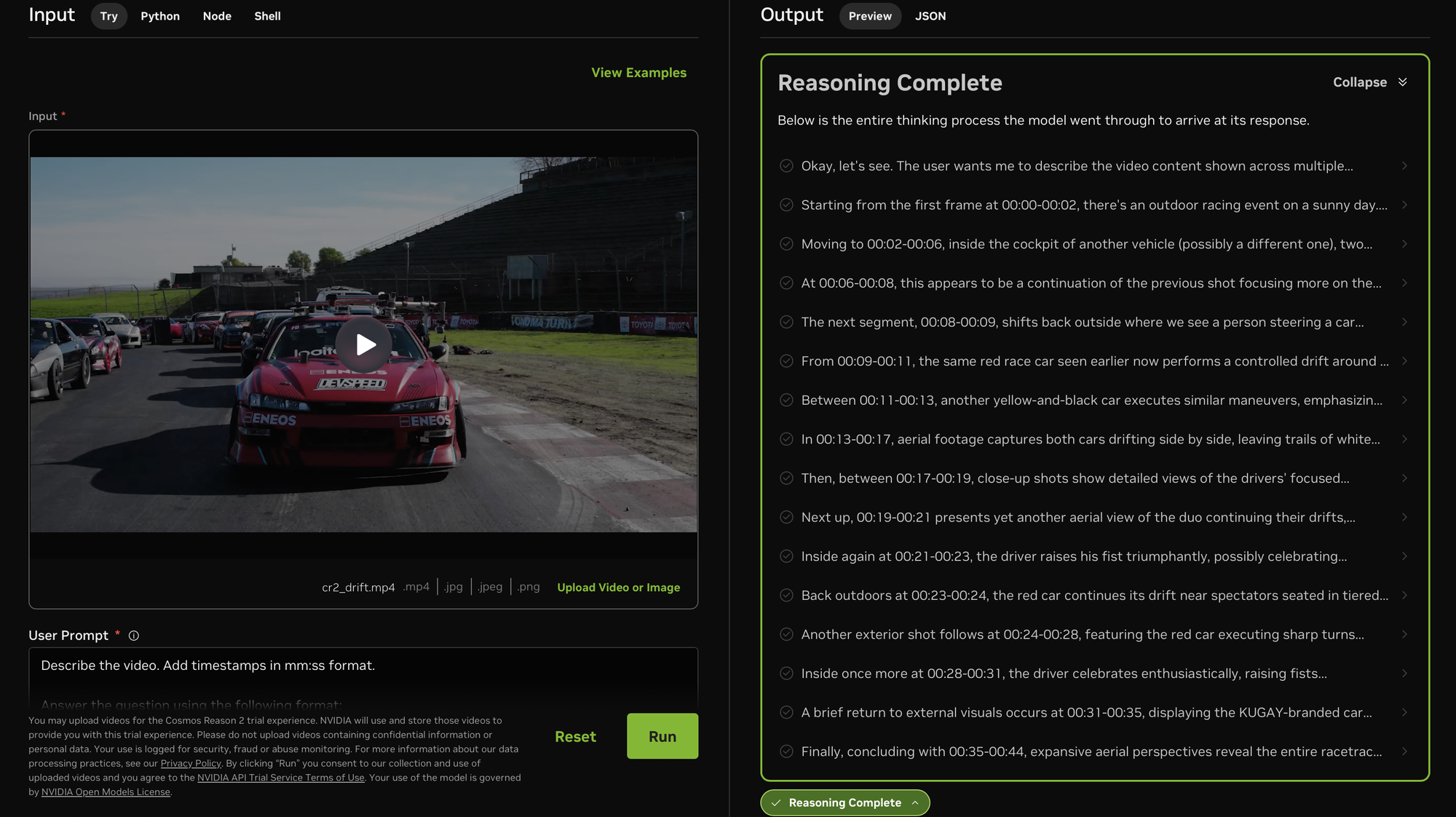
NVIDIA Cosmos Reason 2: Performa penalaran Physical AI mencapai puncak : NVIDIA merilis Cosmos Reason 2, yang menempati posisi pertama di berbagai papan peringkat termasuk Physical AI Bench. Model ini secara signifikan meningkatkan pemahaman ruang-waktu dan akurasi timestamp, mendukung lokalisasi titik 2D/3D serta output data lintasan. Context window-nya melonjak dari 16K menjadi 256K, mampu memberikan anotasi dan analisis logika yang presisi untuk video panjang. Salesforce telah mengintegrasikannya ke dalam Agentforce untuk analisis kepatuhan keselamatan robot Cobalt, menunjukkan evolusi AI dari memahami bahasa menjadi memahami hukum operasi dunia fisik. (Sumber: HuggingFace)
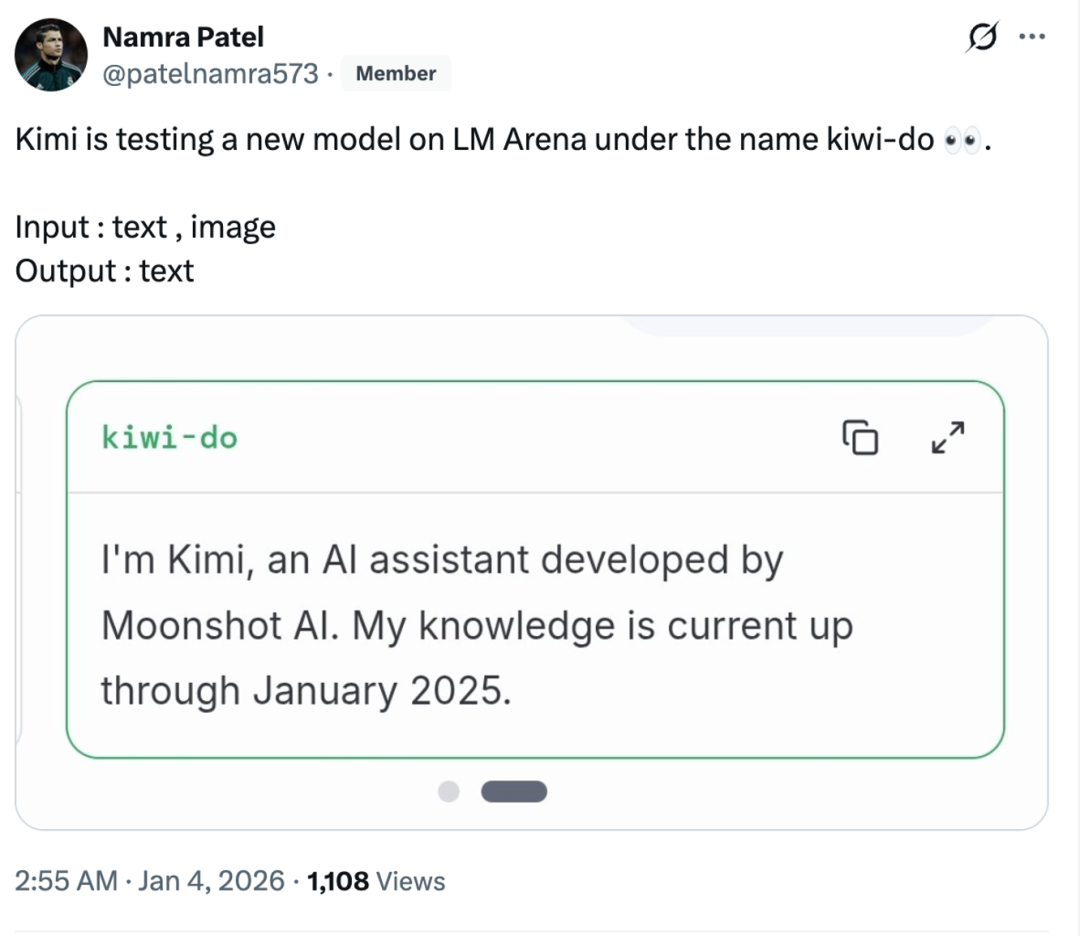
Model misterius Kimi “Kiwi-do” muncul di arena: Kemampuan multimodal yang luar biasa : Model misterius dengan nama kode “kiwi-do” muncul di Large Model Arena (LMArena) dan mengaku sebagai Kimi. Tes pengguna menunjukkan bahwa model ini berkinerja sangat baik dalam tugas menggambar SVG (seperti pelikan mengendarai sepeda) dan pemahaman fisik visual (VPCT), serta mampu melakukan penalaran yang akurat berdasarkan hukum fisika. Ini diyakini sebagai model multimodal K2-VL yang akan segera dirilis oleh Moonshot AI. Yang Zhilin sebelumnya mengungkapkan bahwa perusahaan memiliki cadangan kas miliaran dan berencana meluncurkan generasi baru multimodal Agent yang mendukung “berpikir sambil berkolaborasi” pada tahun 2026. (Sumber: 36氪)
GEO: Bonus pemasaran baru dan rantai industri abu-abu di era pencarian AI : Seiring dengan alat pencarian AI seperti ChatGPT dan Perplexity yang mengalihkan lalu lintas dari mesin pencari tradisional, Generative Engine Optimization (GEO) menjadi medan tempur baru bagi merek. Dengan menyusun konten terstruktur untuk memandu kutipan AI, ukuran pasar GEO diperkirakan mencapai 12 miliar USD pada tahun 2025. Namun, bidang ini telah melahirkan rantai industri abu-abu seperti “data poisoning,” yang menipu AI untuk mengambil informasi melalui tutorial berbiaya rendah dan informasi otoritas palsu. OpenAI juga secara jelas memberikan sinyal iklan, meneliti tampilan konten bersponsor secara prioritas dalam jawaban, yang menandai tunduknya model besar pada model monetisasi nyata di bawah tekanan kerugian besar. (Sumber: 36氪, Tech星球)
Krisis keandalan model kecil: 50-69% jawaban benar berasal dari penalaran yang salah : Penelitian yang dibagikan oleh DAIR.AI mengungkapkan fenomena “Right-for-Wrong-Reasons”: model kecil dengan parameter 7-9B dalam tugas matematika dan tanya jawab seringkali memberikan jawaban yang benar, tetapi rantai penalarannya secara logis rusak. Yang lebih mengejutkan, prompt Self-critique justru merusak performa karena model kecil cenderung menghasilkan pembelaan yang tampak masuk akal padahal palsu. Penelitian menyarankan pengenalan Process-based Verification Scores (RIS) dan RAG untuk memperkuat integritas penalaran, daripada mempercayai output akhir secara buta. (Sumber: dair_ai)

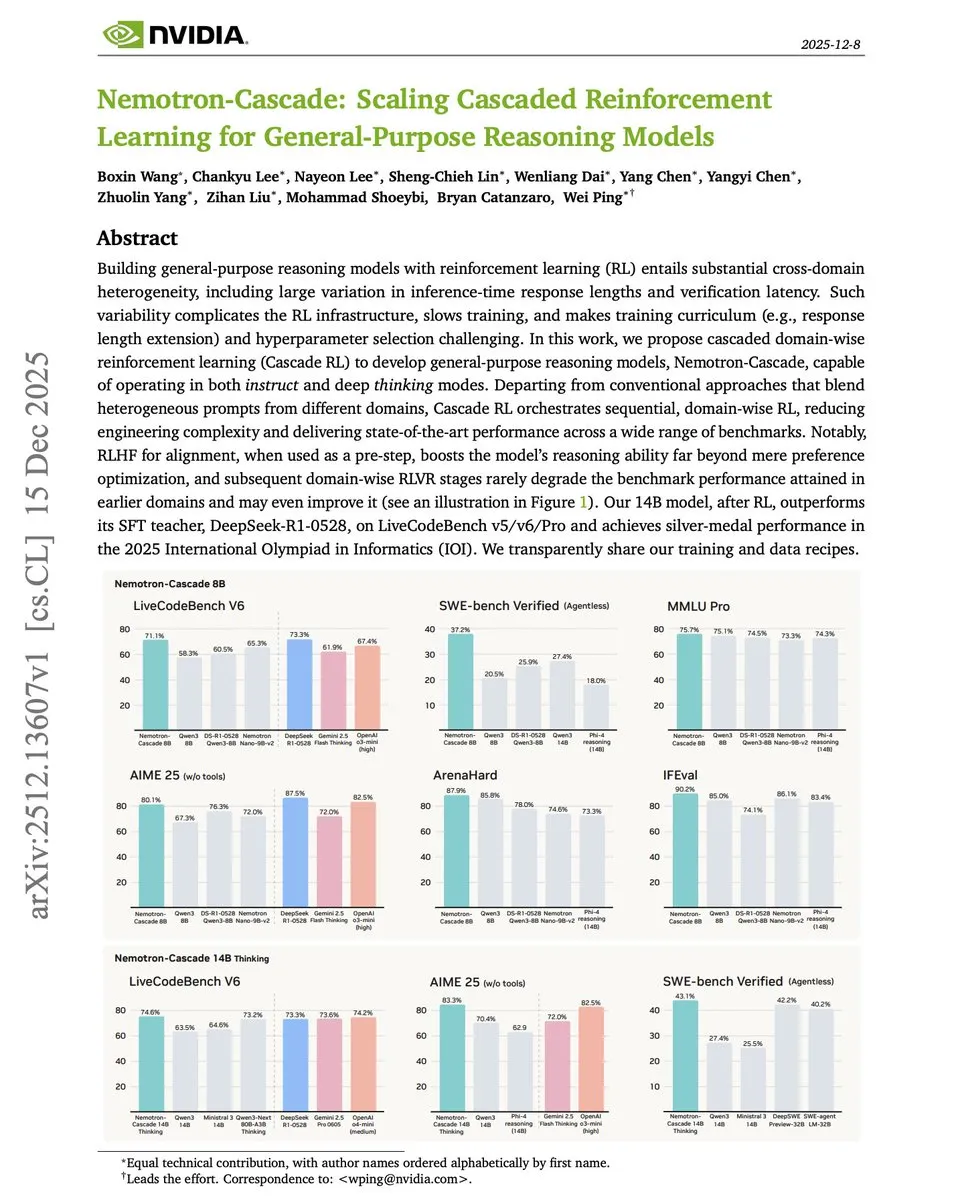
NVIDIA Cascade RL: Menyelesaikan masalah pelatihan penalaran multi-domain : Untuk mengatasi konflik target pelatihan di berbagai bidang seperti matematika, kode, dan penyelarasan, NVIDIA mengusulkan framework Cascade RL. Framework ini menggunakan mode Reinforcement Learning berurutan, dimulai dengan penyelarasan RLHF, diikuti secara berurutan oleh instruction following, matematika, kode, dan software engineering RL. Eksperimen menunjukkan bahwa model Nemotron-Cascade 14B mengalahkan DeepSeek-R1-0528 yang 84 kali lebih besar di papan peringkat kode. Metode ini membuktikan bahwa pelatihan berurutan tidak hanya mencegah catastrophic forgetting, tetapi juga meningkatkan batas atas penalaran tugas berikutnya melalui langkah-langkah awal. (Sumber: omarsar0)
Era pasca-Transformer: Tiga arsitektur baru bersaing untuk posisi tersebut : Salah satu penemu Transformer menyatakan bahwa arsitektur tersebut mulai menjadi penghambat kemajuan AI. Pada tahun 2026, tiga arsitektur besar akan menantang: 1. Text Diffusion, mendukung denoising seluruh kalimat untuk meningkatkan kemampuan perencanaan; 2. Continuous Thought Machines, memungkinkan model memutuskan durasi berpikir secara mandiri melalui sinkronisasi saraf; 3. Nested Learning, mensimulasikan sirkuit berpikir cepat dan lambat pada otak manusia. Arsitektur ini bertujuan untuk menyelesaikan hambatan kopling pada penalaran, memori, dan kontrol dalam Transformer. (Sumber: Reddit)

🧰 Alat
Claude Agent SDK: Memulai pengembangan Agent cerdas tingkat lanjut : Komunitas pengembang sedang mendiskusikan Claude Agent SDK (sebelumnya Claude Code SDK), yang dianggap jauh melampaui sekadar bantuan pemrograman. SDK ini memungkinkan pembangunan Agent kompleks dengan kemampuan penalaran multi-langkah, pemanggilan alat, dan operasi lingkungan otonom. Di konferensi AI Engineer, Thariq mendemonstrasikan cara menggunakan SDK ini untuk membangun orkestrator Agent masa depan. Dibandingkan dengan IDE seperti Cursor, SDK memberikan kontrol tingkat rendah yang lebih besar kepada pengembang, mendukung pembangunan alur kerja otomatisasi yang sangat terkustomisasi. (Sumber: omarsar0, swyx)
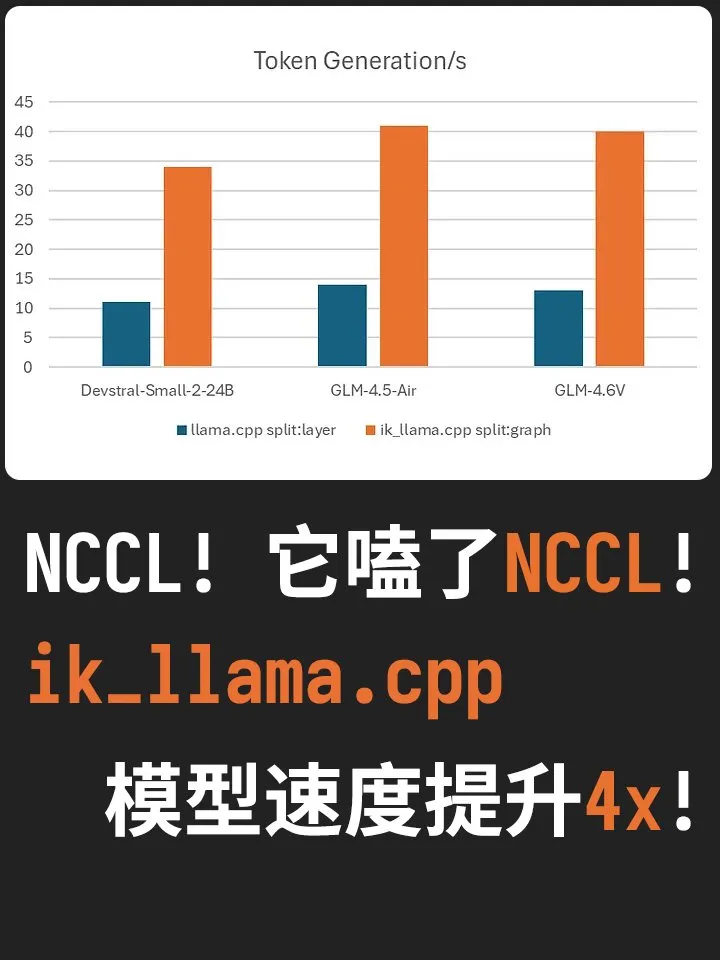
ik_llama.cpp: Lompatan performa inferensi multi-GPU lokal : Cabang performa tinggi dari llama.cpp, ik_llama.cpp, menggabungkan pembaruan besar dengan mengintegrasikan perpustakaan NVIDIA NCCL untuk mencapai Tensor Parallelism yang sesungguhnya. Dalam lingkungan multi-GPU, alat ini dapat meningkatkan kecepatan generasi model besar lokal hingga 3-4 kali lipat, secara efektif menghilangkan waktu tunggu pipeline. Terobosan ini memungkinkan pengembang untuk menjalankan model dengan parameter tingkat Trillion pada perangkat keras kelas konsumen dengan efisiensi sangat tinggi, sangat menurunkan ambang batas penyebaran AI lokal. (Sumber: karminski3, Reddit)
Memvid v2: Menggantikan tumpukan RAG yang kompleks dengan satu file : Proyek open-source viral Memvid merilis versi v2, memperkenalkan konsep “Smart Frames” yang menyimpan text embedding di dalam frame video, mencapai portabilitas memori 100%. Ini dapat mengompresi 50.000 dokumen ke dalam file 200MB dengan latensi pengambilan di bawah 17ms. Memvid bertujuan untuk sepenuhnya menggantikan database vektor dan pipeline RAG yang kompleks, memungkinkan Agent membawa memori jangka panjang seperti membawa USB drive, dan mendukung peralihan mulus antara model yang berbeda seperti GPT, Claude, dan Llama. (Sumber: Reddit)
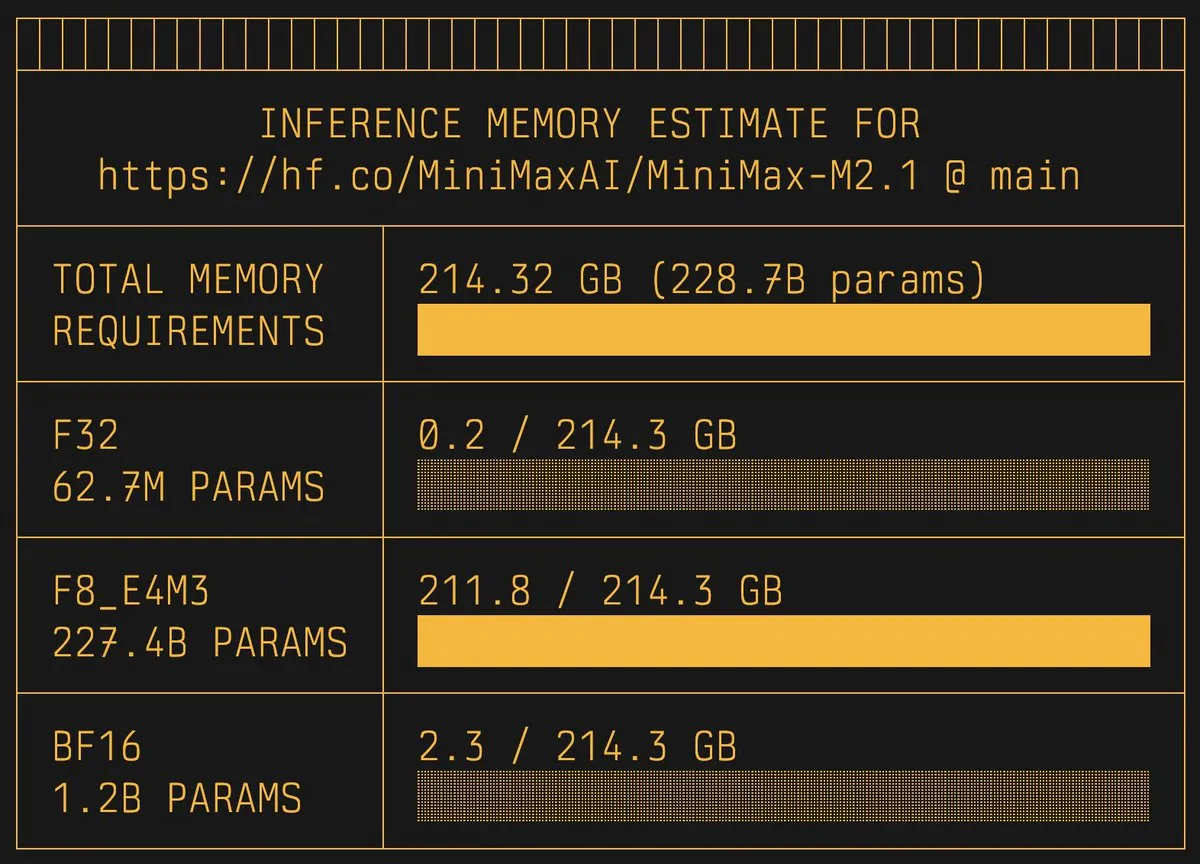
hf-mem: Estimasi kebutuhan memori video model HuggingFace dalam satu klik : Pengembang Alvaro Bartolome meluncurkan alat Python ringan hf-mem. Alat ini hanya mengandalkan metadata Safetensors untuk memprediksi VRAM yang dibutuhkan untuk inferensi secara akurat tanpa perlu mengunduh model lengkap. Melalui perintah uvx hf-mem --model-id, pengguna dapat dengan cepat menentukan apakah perangkat keras mereka mendukung model tertentu. Di tengah ledakan parameter model saat ini, alat ini memberikan kenyamanan besar untuk penyebaran lokal, menghindari pemborosan sumber daya akibat pengunduhan buta. (Sumber: huggingface)
Unsloth-MLX: Alat fine-tuning lokal yang ampuh untuk Mac : Pengembang Abdur Rahim merilis Unsloth-MLX, yang memungkinkan pengguna melakukan fine-tuning model besar menggunakan framework MLX pada Mac dengan Apple Silicon. Alat ini mempertahankan API yang konsisten dengan Unsloth, mendukung migrasi mulus dari desain prototipe lokal ke GPU cloud. Ini adalah kabar baik bagi pengguna Mac yang ingin melakukan pelatihan data privasi secara lokal namun terbatas oleh biaya komputasi cloud yang mahal, yang lebih lanjut mendorong demokratisasi teknologi fine-tuning. (Sumber: awnihannun)
📚 Pembelajaran
Ensiklopedia Deep Learning: Deep Learning Book edisi 2025 dirilis : University of Notre Dame merilis manual kuliah “Deep Learning Book 2025” setebal ratusan halaman. Buku ini mencakup segalanya mulai dari dasar perceptron hingga model difusi terbaru, varian Transformer, dan teknologi mutakhir Reinforcement Learning. Isinya sangat detail dan dilengkapi dengan banyak derivasi matematika serta diagram intuitif, menjadikannya sumber daya gratis yang sangat baik bagi praktisi AI untuk melengkapi kekurangan teknis secara sistematis pada tahun 2026. (Sumber: Reddit)

Buku Panduan Rekayasa GRPO + LoRA: Membangun siklus RL tingkat industri dari nol : Menanggapi tren Reinforcement Learning yang dipicu oleh DeepSeek-R1, Maxime Labonne membagikan “Buku Panduan Rekayasa GRPO + LoRA dengan Verl”. Panduan ini menjelaskan secara rinci cara membangun pipeline RLVR yang stabil di lingkungan multi-GPU, termasuk pelacakan eksperimen, teknik debugging, dan pengalaman praktis dalam memaksimalkan kekuatan komputasi A100. Ini adalah tutorial praktik terbaik saat ini untuk membawa kemampuan penalaran gaya DeepSeek ke dalam model privat. (Sumber: maximelabonne)

9 Buku untuk Memahami AI: Daftar bacaan wajib 2025/2026 : TheTuringPost merekomendasikan 9 buku untuk membantu pemahaman mendalam tentang tren AI, termasuk “Apple in China” (perspektif rantai pasokan), “The Thinking Machine” (biografi Jensen Huang dan NVIDIA), “The Path to AGI,” serta “Source Code” karya Bill Gates. Daftar ini mencakup perspektif menyeluruh mulai dari persaingan chip tingkat bawah hingga dampak sosial tingkat tinggi, cocok bagi pembaca yang ingin tetap berpikir jernih di tengah antusiasme teknologi. (Sumber: TheTuringPost)

💼 Bisnis
Meta mengakuisisi Manus AI: Taruhan besar pada Agent cerdas umum : Meta mengumumkan akuisisi startup AI Agent, Manus AI, dengan tujuan mengintegrasikan kemampuan Agent terkemukanya ke dalam produk konsumen dan bisnis Meta. Manus sebelumnya memiliki valuasi sekitar 500 juta USD dengan tingkat pertumbuhan pendapatan yang sangat tinggi. Langkah ini menunjukkan bahwa setelah Mark Zuckerberg melewatkan peluang awal dalam “Physical AI,” ia kini secara agresif melengkapi kekurangannya di bidang Agent operasi otonom melalui akuisisi. (Sumber: Reddit)
RayNeo memperoleh pendanaan 1 miliar Yuan: China Mobile dan China Unicom bertaruh pada “ponsel generasi berikutnya” : Pemimpin kacamata AR, RayNeo (雷鸟创新), menyelesaikan putaran pendanaan baru senilai lebih dari 1 miliar Yuan, yang diinvestasikan bersama oleh dana di bawah China Mobile dan China Unicom. Ini adalah pertama kalinya operator telekomunikasi secara kolektif bertaruh besar pada jalur kacamata pintar, dengan tujuan menata pembawa terbaik untuk implementasi model besar AI. RayNeo akan memamerkan kacamata AR eSIM pertama di CES, menggunakan kekuatan komputasi tepi operator untuk menutupi kekurangan latensi terminal, mempercepat proses kacamata pintar menggantikan smartphone. (Sumber: 36氪)
Zhipu AI menuju IPO di Hong Kong: Berusaha menjadi “saham model besar AI pertama di dunia” : Zhipu AI secara resmi memulai penawaran umum di Hong Kong, dengan rencana pencatatan pada 8 Januari. Sebagai pemimpin dari “Enam Harimau Kecil” di China, Zhipu menyelesaikan beberapa putaran pendanaan pada tahun 2025 dengan valuasi pasca-investasi lebih dari 20 miliar Yuan. Raksasa seperti Alibaba, Tencent, dan Meituan termasuk di antara para pemegang sahamnya. IPO Zhipu dianggap sebagai batu ujian bagi valuasi industri AI dan akan secara langsung mempengaruhi arah komersialisasi perusahaan rintisan model besar di dalam negeri. (Sumber: 36氪)
🌟 Komunitas
Vibe Coding vs. Rekayasa Abstrak: Perdebatan filosofis pemrograman AI : Komunitas sedang berdebat sengit tentang “Vibe Coding”. Andre Karpathy dan lainnya berpendapat bahwa AI membuat kode menjadi murah, dan pemrograman berevolusi menjadi seni yang mirip dengan memainkan alat musik. Namun, para akademisi seperti Omar Khattab memperingatkan bahwa jika hanya mengandalkan dialog untuk menghasilkan 100.000 baris kode tingkat rendah tanpa abstraksi tingkat tinggi, itu akan menyebabkan banjir “Slop Code” (kode sampah) yang sulit dipelihara. Masa depan yang sebenarnya seharusnya adalah mengembangkan bahasa pemrograman tingkat lebih tinggi, di mana AI bertindak sebagai compiler, bukan sekadar generator kode sederhana. (Sumber: lateinteraction, gfodor)
Studi Harvard: Efisiensi belajar tutor AI meningkat dua kali lipat : Sebuah uji coba terkontrol acak oleh Universitas Harvard menunjukkan bahwa siswa yang menggunakan tutor AI untuk belajar fisika memperoleh hasil belajar dua kali lipat dibandingkan kelas tradisional, dengan waktu yang dihabiskan berkurang setengahnya. Tutor AI dapat mencapai “kesabaran tanpa batas” dan “umpan balik yang dipersonalisasi secara instan” yang sulit dilakukan oleh guru manusia. Diskusi komunitas menunjukkan bahwa ini adalah peluang bagi demokratisasi pendidikan, namun juga dapat memperburuk kesenjangan digital: 87% siswa di negara berpenghasilan tinggi memiliki akses internet, sementara di negara berpenghasilan rendah hanya 6%. (Sumber: Reddit)
Keajaiban Hukum AI: Claude membantu memenangkan gugatan 8.000 USD : Seorang pengguna internet di daerah terpencil berbagi pengalamannya menggunakan Claude Opus 4.5 untuk belajar hukum secara mandiri dan menyusun gugatan, yang akhirnya memenangkan kasus perdata senilai 8.000 USD di pengadilan. Ia menyatakan bahwa hukum kasus dan hukum tertulis yang ditemukan oleh Claude “sangat kokoh” dan sama sekali tidak ada halusinasi. Kasus ini memicu diskusi hangat, di mana orang-orang mulai berpikir apakah AI akan mengakhiri “hegemoni informasi” dalam industri hukum, sehingga orang biasa juga bisa mendapatkan keadilan dengan biaya rendah. (Sumber: Reddit)
💡 Lainnya
LEGO merilis “Smart Bricks”: Evolusi terbesar dalam 50 tahun : LEGO mengumumkan peluncuran Smart Bricks 2×4 dengan komputer mikro internal yang dapat membuat model balok “menjadi hidup”. Melalui sensor dan penggerak AI, model LEGO dapat memancarkan cahaya, suara, dan merespons gerakan, seperti lightsaber yang mengeluarkan suara dengungan saat diayunkan. Ini menandai industri mainan tradisional yang sepenuhnya merangkul perangkat keras AI. (Sumber: robrombach)
Produksi massal baterai natrium-ion 2026: Menghilangkan kecemasan jarak tempuh : CATL mengonfirmasi bahwa baterai natrium-ion akan memasuki pasar secara besar-besaran pada tahun 2026. Baterai ini memiliki kepadatan energi 175 Wh/kg, mendukung pengoperasian di suhu dingin ekstrem -40°C, dan harganya sangat murah. Komunitas percaya ini akan mempercepat keruntuhan permintaan minyak dan menyediakan tenaga inti bagi armada mengemudi otonom murah yang digerakkan oleh AI. (Sumber: teortaxesTex)
