
Mots-clés:Inférence IA, NVIDIA, OpenAI, Architecture Vera Rubin, Moteur Transformer, Départ de Jerry Tworek
🔥 Focus
NVIDIA lance l’architecture Vera Rubin : l’ère du prochain supercalculateur AI : Lors du CES 2026, Jensen Huang a dévoilé la nouvelle plateforme Vera Rubin, comprenant le Vera CPU propriétaire (cœur Olympus personnalisé) et le Rubin GPU. Le système introduit le Transformer Engine, avec des performances d’inférence 5 fois supérieures à Blackwell, et supporte le premier Rack-scale Confidential Computing. Le système Rubin NVL72, grâce à un refroidissement liquide à 100 % et une conception sans câbles, améliore l’efficacité de l’assemblage et de la maintenance de 18 fois. De plus, NVIDIA a lancé une plateforme de stockage de mémoire contextuelle d’inférence pour résoudre les goulots d’étranglement du stockage KV Cache dans les applications à long texte, visant à réduire le coût des tokens des grands modèles MoE à 1/10 de celui de Blackwell, marquant l’évolution de l’infrastructure AI de la “puissance de calcul ponctuelle” vers l‘“ingénierie système”. (Source : NVIDIA, 智东西, TheTuringPost)

Départ de Jerry Tworek, responsable de l’inférence chez OpenAI : fuite continue des cerveaux clés : Jerry Tworek, vice-président de la recherche chez OpenAI et pilier des modèles de raisonnement o1/o3 et du modèle de programmation Codex, a annoncé son départ. Après près de sept ans chez OpenAI, il a dirigé la R&D depuis l’apprentissage par renforcement robotique précoce jusqu’aux mécanismes de raisonnement de GPT-4 et GPT-5. Tworek a déclaré partir pour “explorer des recherches difficiles à mener au sein d’OpenAI”, suggérant une fracture entre l’environnement de recherche idéaliste et la pression de livraison des produits sous une forte commercialisation. En tant que leader du projet o1, son départ est une nouvelle perte majeure de talents techniques après Ilya Sutskever et John Schulman, suscitant des inquiétudes quant à l’indépendance future de la recherche chez OpenAI. (Source : 36氪, 量子位, The Verge)
Google DeepMind s’associe à Boston Dynamics : un cerveau AI pour le corps le plus puissant : Google DeepMind a annoncé un partenariat de recherche avec Boston Dynamics. Cette collaboration intègre les capacités de Vision-Language Model (VLM) de Gemini Robotics dans le tout nouveau robot humanoïde Atlas entièrement électrique. Cela signifie que les meilleurs algorithmes de raisonnement AI au monde s’allient au matériel robotique le plus avancé, propulsant l’Embodied AI d’une simple reconnaissance de formes vers une “Physical AI” capable de planification autonome de tâches complexes avec un bon sens physique. Cette alliance est vue comme une initiative clé contre l’écosystème Optimus de Tesla et Isaac de NVIDIA, annonçant un véritable “moment iPhone” pour les robots humanoïdes. (Source : GoogleDeepMind, HuggingFace)

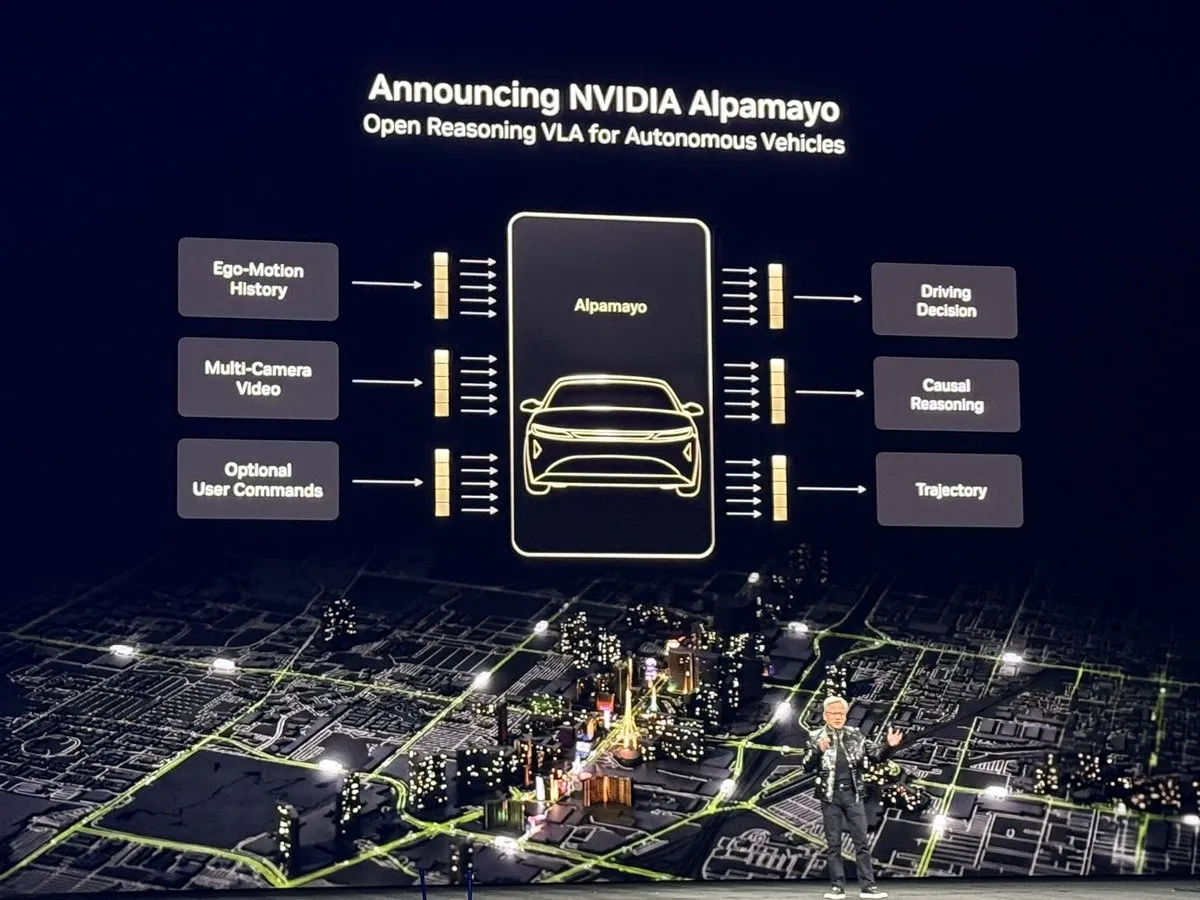
NVIDIA rend Alpamayo open source : le “moment ChatGPT” de la conduite autonome : NVIDIA a rendu open source Alpamayo (10B paramètres), le premier modèle de conduite autonome basé sur le raisonnement, lors du CES. Contrairement à la chaîne traditionnelle “perception-planification”, Alpamayo possède des capacités de Chain of Thought (CoT), lui permettant de comprendre des situations routières complexes et d’expliquer ses décisions comme un conducteur humain (ex: “ralentir car un piéton pourrait traverser”). Le modèle est accompagné du framework de simulation AlpaSim et de 1700 heures de données de conduite réelle. Jensen Huang l’a qualifié de “moment ChatGPT pour la Physical AI”, visant à briser le monopole des systèmes fermés comme le FSD de Tesla via un écosystème open source, permettant aux constructeurs mondiaux d’accélérer le déploiement de la conduite autonome L4. (Source : TheTuringPost, NVIDIA)
🎯 Tendances
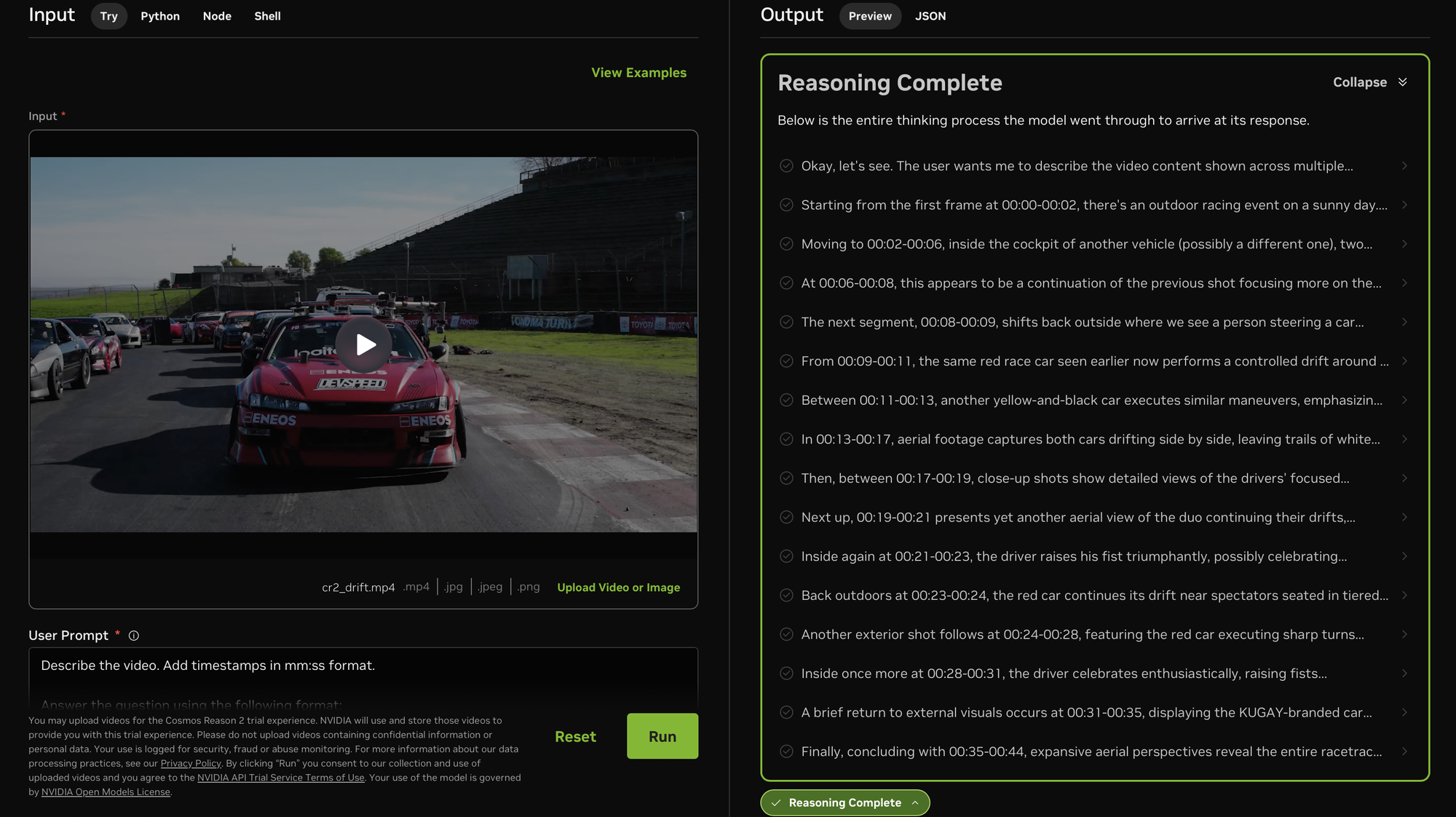
NVIDIA Cosmos Reason 2 : les performances de raisonnement en Physical AI au sommet : NVIDIA a publié Cosmos Reason 2, arrivant en tête de plusieurs classements comme le Physical AI Bench. Ce modèle améliore considérablement la compréhension spatio-temporelle et la précision des horodatages, supportant la localisation de points 2D/3D et la sortie de données de trajectoire. Sa fenêtre contextuelle passe de 16K à 256K, permettant une annotation précise et une analyse logique pour les vidéos longues. Salesforce l’a déjà intégré à Agentforce pour l’analyse de conformité sécuritaire des robots Cobalt, illustrant l’évolution de l’AI de la compréhension du langage à celle des lois du monde physique. (Source : HuggingFace)
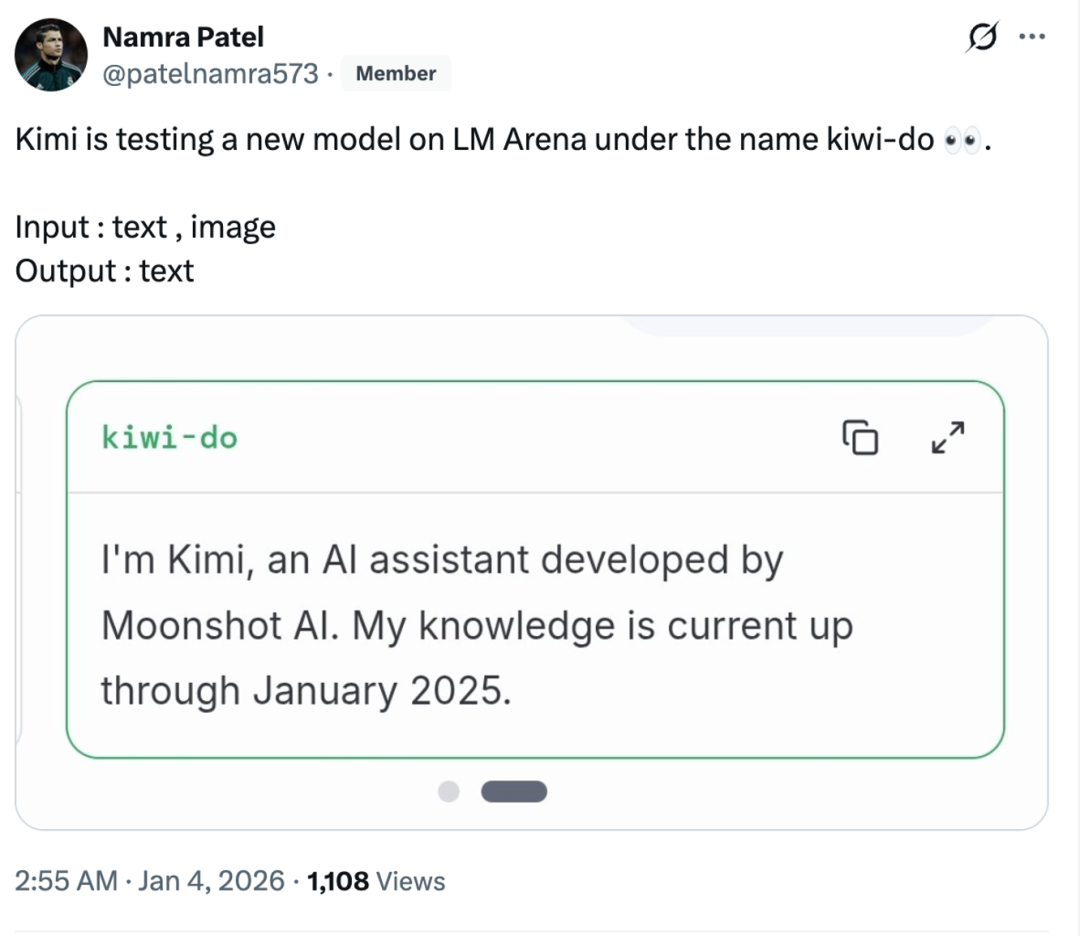
Le modèle mystérieux de Kimi “Kiwi-do” apparaît dans l’arène : des capacités multimodales impressionnantes : Un modèle mystérieux nommé “kiwi-do”, se présentant comme Kimi, est apparu dans la LMArena (Large Model Arena). Les tests des utilisateurs montrent d’excellentes performances en dessin SVG (ex: un pélican à vélo) et en compréhension physique visuelle (VPCT), capable de raisonner en intégrant des lois physiques. Il s’agirait du futur modèle multimodal K2-VL de Moonshot AI. Yang Zhilin a précédemment révélé que l’entreprise disposait de réserves de liquidités massives et prévoyait de lancer en 2026 une nouvelle génération d’Agent multimodal capable de “penser tout en collaborant”. (Source : 36氪)
GEO : nouveaux dividendes marketing et chaînes grises à l’ère de la recherche AI : Alors que les outils de recherche AI comme ChatGPT et Perplexity détournent le trafic des moteurs de recherche traditionnels, la Generative Engine Optimization (GEO) devient le nouveau champ de bataille des marques. En structurant le contenu pour guider les citations de l’AI, le marché de la GEO devrait atteindre 12 milliards de dollars d’ici 2025. Cependant, des dérives comme l‘“empoisonnement de données” apparaissent, utilisant des informations fallacieuses pour tromper l’indexation de l’AI. OpenAI a également signalé l’arrivée de publicités, envisageant d’afficher en priorité des contenus sponsorisés dans ses réponses, marquant un tournant vers la monétisation face aux pertes colossales. (Source : 36氪, Tech星球)
Crise de fiabilité des petits modèles : 50 à 69 % des bonnes réponses proviennent d’un raisonnement erroné : Une étude partagée par DAIR.AI révèle le phénomène “Right-for-Wrong-Reasons” : les petits modèles de 7-9B paramètres, bien que donnant la bonne réponse en mathématiques ou en Q&A, présentent souvent une chaîne de raisonnement logiquement brisée. Plus surprenant encore, les prompts d’auto-critique (Self-critique) nuisent aux performances, car les petits modèles tendent à générer des justifications plausibles mais fausses. L’étude suggère d’introduire des scores de vérification de processus (RIS) et le RAG pour renforcer l’intégrité du raisonnement plutôt que de se fier aveuglément au résultat final. (Source : dair_ai)

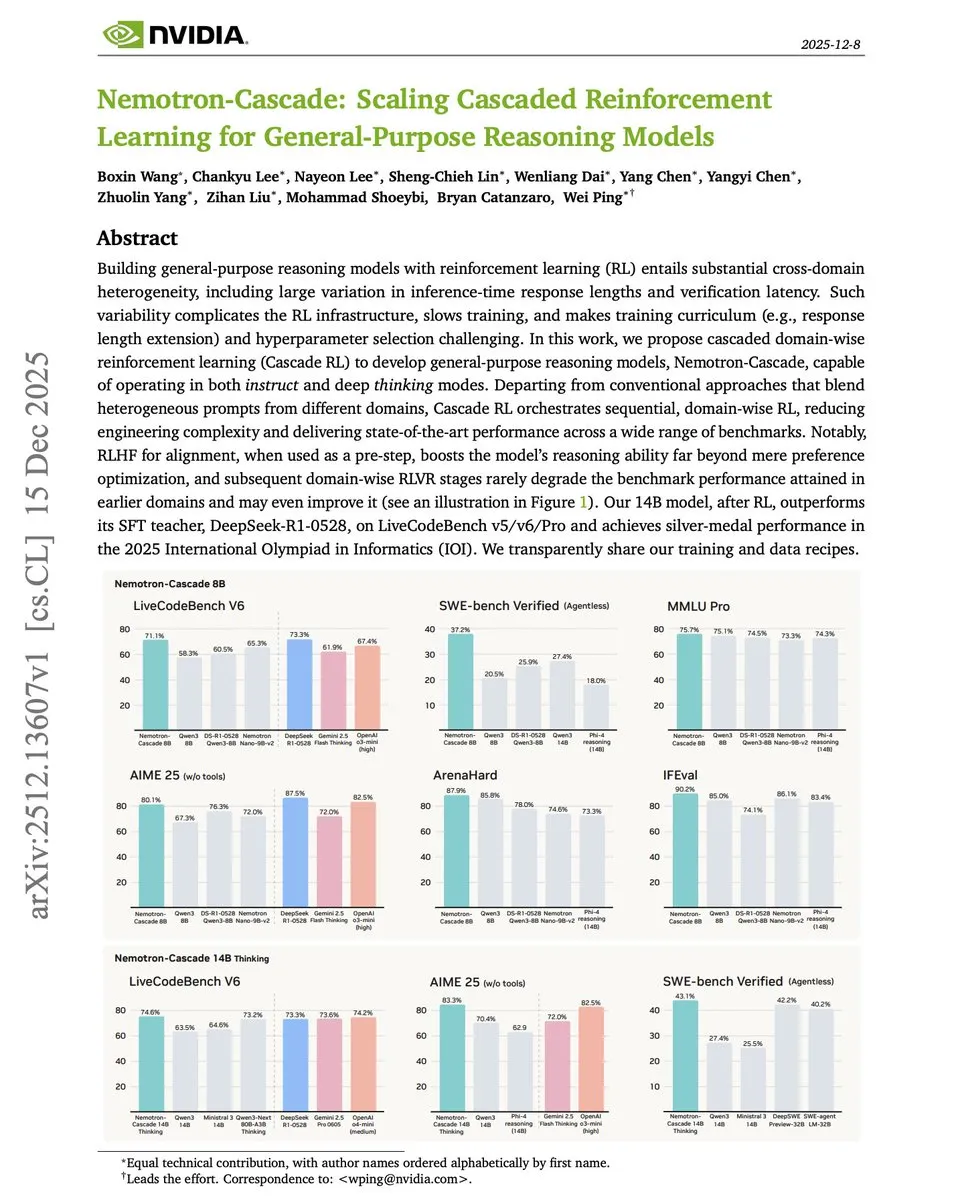
NVIDIA Cascade RL : résoudre les conflits d’entraînement au raisonnement multi-domaines : Pour répondre aux conflits d’objectifs d’entraînement entre les mathématiques, le code et l’alignement, NVIDIA propose le framework Cascade RL. Ce framework adopte un mode d’apprentissage par renforcement séquentiel : d’abord l’alignement RLHF, puis successivement le suivi d’instructions, les mathématiques, le code et l’ingénierie logicielle. Les expériences montrent que le modèle Nemotron-Cascade de 14B surpasse DeepSeek-R1-0528, pourtant 84 fois plus grand, dans les classements de code. Cette méthode prouve que l’entraînement séquentiel prévient l’oubli catastrophique et élève le plafond de raisonnement des tâches ultérieures. (Source : omarsar0)
L’ère post-Transformer : trois nouvelles architectures en compétition : L’un des inventeurs du Transformer souligne que cette architecture devient un obstacle au progrès de l’AI. En 2026, trois architectures lanceront un défi : 1. Les modèles de Text Diffusion, supportant le débruitage de phrases complètes pour améliorer la planification ; 2. Les Continuous Thought Machines, permettant au modèle de décider de sa durée de réflexion via la synchronisation neuronale ; 3. Le Nested Learning, simulant les circuits de pensée lente et rapide du cerveau humain. Ces architectures visent à résoudre les goulots d’étranglement du couplage entre raisonnement, mémoire et contrôle des Transformers. (Source : Reddit)

🧰 Outils
Claude Agent SDK : ouvrir le développement d’agents intelligents avancés : La communauté des développeurs s’enthousiasme pour le Claude Agent SDK (anciennement Claude Code SDK), jugé bien supérieur à une simple aide à la programmation. Ce SDK permet de construire des Agents complexes dotés de raisonnement multi-étapes, d’appels d’outils et de capacités d’opération autonome dans l’environnement. Lors de la conférence AI Engineer, Thariq a montré comment utiliser ce SDK pour bâtir des orchestrateurs d’Agents futuristes. Comparé aux IDE comme Cursor, le SDK offre un contrôle de plus bas niveau pour des flux de travail automatisés hautement personnalisés. (Source : omarsar0, swyx)
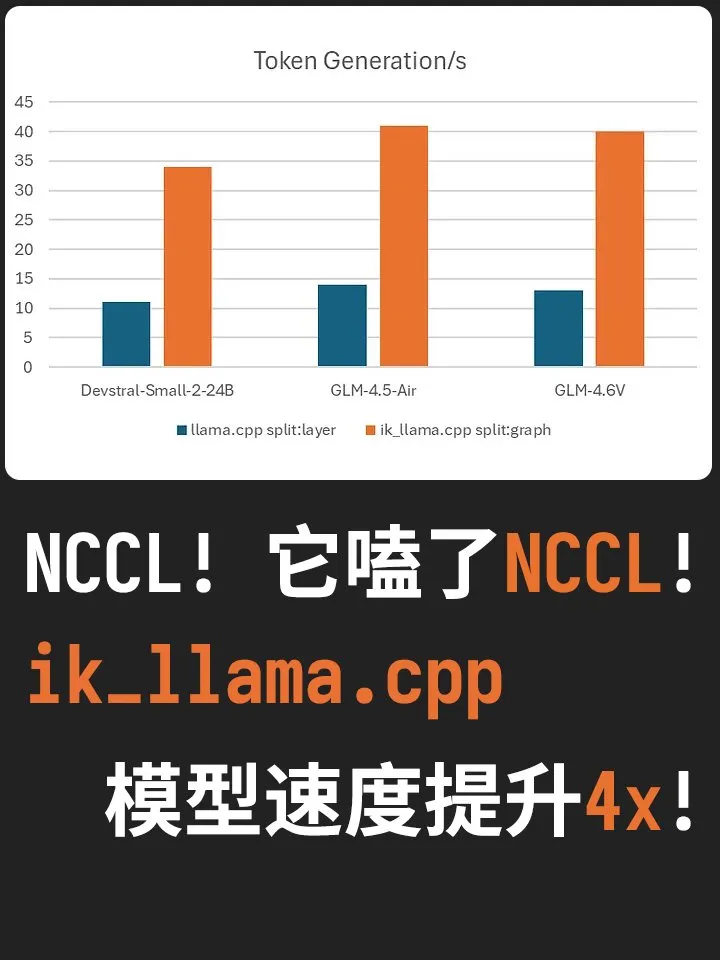
ik_llama.cpp : bond de performance pour l’inférence multi-GPU locale : La branche haute performance ik_llama.cpp de llama.cpp a fusionné une mise à jour majeure, intégrant la bibliothèque NVIDIA NCCL pour réaliser un véritable parallélisme de tenseurs (Tensor Parallelism). Dans un environnement multi-GPU, cet outil multiplie par 3 ou 4 la vitesse de génération des modèles locaux, éliminant les attentes de pipeline. Cette percée permet aux développeurs de faire tourner des modèles de l’ordre du trillion de paramètres sur du matériel grand public avec une efficacité extrême, abaissant considérablement le seuil de déploiement local de l’AI. (Source : karminski3, Reddit)
Memvid v2 : remplacer les piles RAG complexes par un seul fichier : Le projet open source viral Memvid a publié sa version v2, introduisant le concept de “Smart Frames” qui stocke les embeddings de texte dans les images vidéo, rendant la mémoire 100 % portable. Il peut compresser 50 000 documents dans un fichier de 200 Mo avec une latence de recherche inférieure à 17 ms. Memvid vise à remplacer totalement les bases de données vectorielles complexes et les pipelines RAG, permettant aux Agents de transporter une mémoire à long terme comme une clé USB, compatible avec GPT, Claude, Llama, etc. (Source : Reddit)
hf-mem : estimer en un clic les besoins en mémoire vidéo des modèles HuggingFace : Le développeur Alvaro Bartolome a lancé hf-mem, un outil Python léger. S’appuyant uniquement sur les métadonnées Safetensors, il prédit précisément la VRAM nécessaire à l’inférence sans télécharger le modèle complet. Via la commande uvx hf-mem --model-id, les utilisateurs peuvent rapidement juger si leur matériel supporte un modèle spécifique, évitant ainsi le gaspillage de ressources à l’heure de l’explosion des paramètres. (Source : huggingface)
Unsloth-MLX : l’outil de fine-tuning local sur Mac : Le développeur Abdur Rahim a publié Unsloth-MLX, permettant aux utilisateurs de Mac équipés d’Apple Silicon de fine-tuner des modèles via le framework MLX. L’outil conserve une API cohérente avec Unsloth, facilitant la migration du prototypage local vers les GPU cloud. C’est une aubaine pour les utilisateurs de Mac souhaitant s’entraîner sur des données privées tout en évitant les coûts élevés du cloud, démocratisant davantage les technologies de fine-tuning. (Source : awnihannun)
📚 Apprentissage
Encyclopédie du Deep Learning : publication du Deep Learning Book 2025 : L’Université de Notre Dame a publié le manuel “Deep Learning Book 2025”, fort de plusieurs centaines de pages. L’ouvrage couvre tout, du perceptron de base aux derniers modèles de diffusion, variantes de Transformer et frontières de l’apprentissage par renforcement. Riche en démonstrations mathématiques et graphiques intuitifs, c’est une ressource gratuite incontournable pour les professionnels de l’AI en 2026. (Source : Reddit)

Manuel d’ingénierie GRPO + LoRA : construire un cycle RL industriel de zéro : Face à l’engouement pour l’apprentissage par renforcement suscité par DeepSeek-R1, Maxime Labonne a partagé le “Manuel d’ingénierie GRPO + LoRA avec Verl”. Ce guide explique en détail comment construire un pipeline RLVR stable en environnement multi-GPU, incluant le suivi d’expériences, les astuces de débogage et l’optimisation de la puissance de calcul des A100. (Source : maximelabonne)

Comprendre l’AI en 9 livres : la liste de lecture indispensable 2025/2026 : TheTuringPost recommande 9 ouvrages pour approfondir sa compréhension des tendances AI, dont “Apple in China” (perspective supply chain), “The Thinking Machine” (biographie de Jensen Huang et NVIDIA), “The Path to AGI” et “Source Code” de Bill Gates. La liste offre une vision complète, de la compétition des puces aux impacts sociétaux. (Source : TheTuringPost)

💼 Business
Meta acquiert Manus AI : pari massif sur les Agents universels : Meta a annoncé l’acquisition de la startup d’AI Agent Manus AI, afin d’intégrer ses capacités d’Agent de pointe dans les produits grand public et commerciaux de Meta. Manus était précédemment valorisée à environ 500 millions de dollars avec une croissance rapide. Ce mouvement montre que Mark Zuckerberg, après avoir manqué le coche de la “Physical AI”, comble agressivement son retard dans le domaine des Agents opérationnels autonomes. (Source : Reddit)
RayNeo lève 1 milliard de yuans : China Mobile et China Unicom parient sur le “prochain smartphone” : Le leader des lunettes AR, RayNeo (雷鸟创新), a bouclé un nouveau tour de table de plus d’un milliard de yuans, mené par des fonds affiliés à China Mobile et China Unicom. C’est la première fois que les opérateurs investissent massivement et collectivement dans les lunettes intelligentes, y voyant le meilleur support pour les grands modèles AI. RayNeo présentera au CES ses premières lunettes AR eSIM, utilisant le edge computing des opérateurs pour réduire la latence. (Source : 36氪)
Zhipu AI vers une IPO à Hong Kong : en route pour être la “première action mondiale des grands modèles” : Zhipu AI a officiellement lancé son processus d’introduction en bourse à Hong Kong, avec une cotation prévue pour le 8 janvier. Leader des “Six Petits Tigres” chinois, Zhipu a réalisé plusieurs levées de fonds en 2025 pour une valorisation dépassant les 20 milliards de yuans. Alibaba, Tencent et Meituan figurent parmi les actionnaires. Cette IPO est vue comme un test pour la valorisation du secteur AI. (Source : 36氪)
🌟 Communauté
Vibe Coding vs. Ingénierie Abstraite : débat philosophique sur la programmation AI : La communauté débat vivement du “Vibe Coding” (programmation à l’instinct). Andrej Karpathy estime que l’AI rend le code bon marché, transformant la programmation en un art proche de la pratique d’un instrument. Cependant, des chercheurs comme Omar Khattab préviennent que générer 100 000 lignes de code sans abstraction de haut niveau mènera à une prolifération de “Slop Code” (code déchet) inmaintenable. Le futur résiderait dans des langages de programmation de plus haut niveau où l’AI agirait comme compilateur. (Source : lateinteraction, gfodor)
Étude de Harvard : l’efficacité d’apprentissage doublée avec les tuteurs AI : Un essai contrôlé randomisé de l’Université de Harvard montre que les étudiants utilisant des tuteurs AI pour apprendre la physique progressent deux fois plus vite que dans une classe traditionnelle, en deux fois moins de temps. Les tuteurs AI offrent une “patience infinie” et un “feedback personnalisé immédiat”. La communauté souligne que si c’est une chance pour la démocratisation de l’éducation, cela pourrait aussi creuser la fracture numérique. (Source : Reddit)
Miracle juridique AI : Claude aide à gagner un procès de 8 000 $ : Un internaute vivant dans une zone reculée a partagé comment il a utilisé Claude Opus 4.5 pour apprendre le droit et rédiger une plainte, gagnant finalement un procès civil de 8 000 $. Il affirme que la jurisprudence et les lois trouvées par Claude étaient “solides comme le roc”, sans aucune hallucination. Ce cas alimente la réflexion sur la fin de l‘“hégémonie de l’information” dans le secteur juridique grâce à l’AI. (Source : Reddit)
💡 Autres
Lego lance les “Smart Bricks” : la plus grande évolution en 50 ans : Lego a annoncé des briques intelligentes 2×4 intégrant un micro-ordinateur pour “donner vie” aux modèles. Grâce à des capteurs et à l’AI, les modèles Lego peuvent réagir par la lumière, le son ou le mouvement, comme un sabre laser qui vrombit lorsqu’on l’agite. Cela marque l’adoption massive de l’AI par l’industrie du jouet traditionnel. (Source : robrombach)
Production de masse des batteries sodium-ion en 2026 : fin de l’anxiété liée à l’autonomie : CATL a confirmé que les batteries sodium-ion entreront sur le marché à grande échelle en 2026. Avec une densité énergétique de 175 Wh/kg, elles supportent des températures de -40°C et sont extrêmement peu coûteuses. La communauté estime que cela accélérera la chute de la demande de pétrole et propulsera les flottes de véhicules autonomes abordables. (Source : teortaxesTex)
