
Mots-clés:IA, IA physique, conduite autonome, NVIDIA Vera Rubin, Boston Dynamics Atlas, LFM 2.5
🔥 Focus
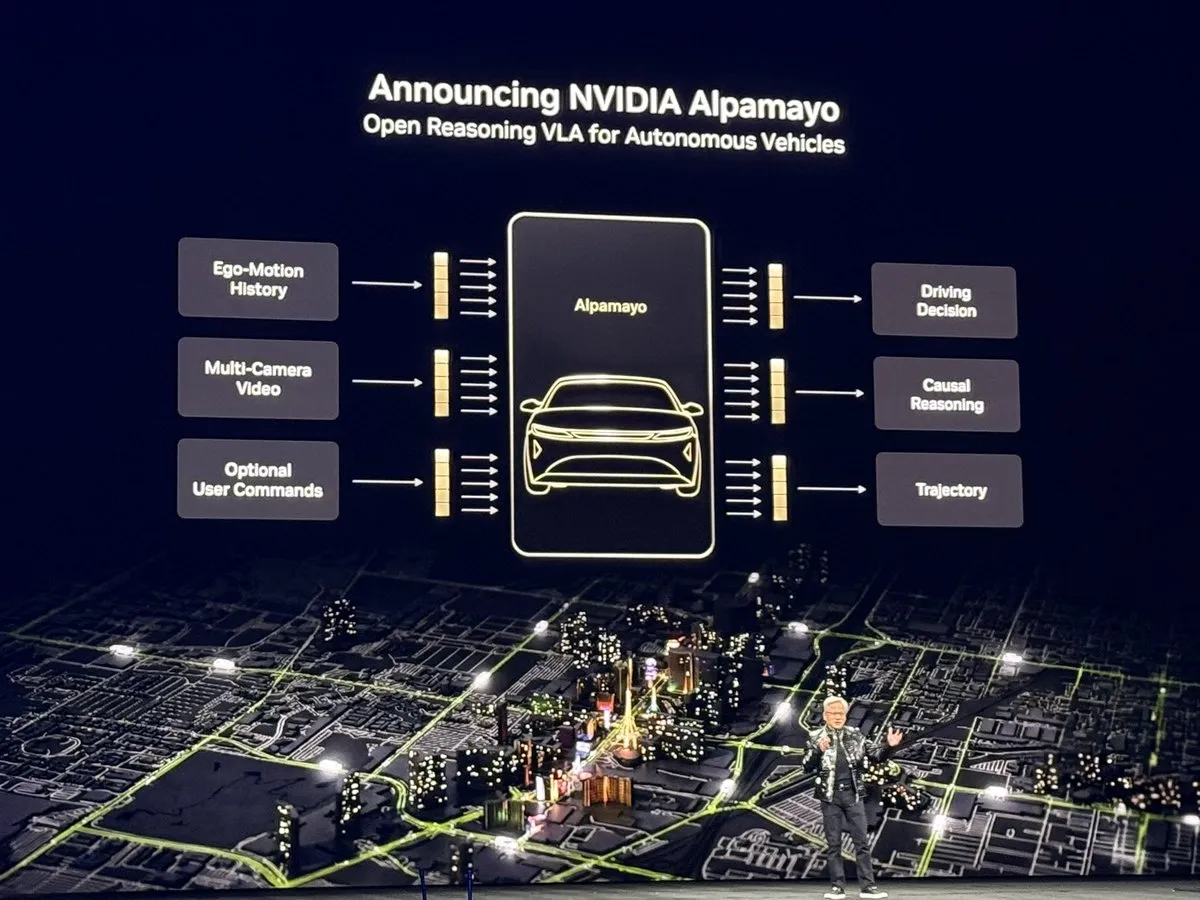
NVIDIA CES 2026 : Le « moment ChatGPT » de l’AI physique : Lors de son discours d’ouverture au CES 2026, Jensen Huang a dévoilé Vera Rubin, sa plateforme AI de nouvelle génération, ainsi que l’architecture Feynman, tout en lançant Alpamayo, le premier modèle de conduite autonome basé sur le raisonnement. Ce modèle ne se contente pas de réagir ; il traite les scénarios complexes de type « long-tail » via une chaîne de pensée (CoT), à l’instar d’un conducteur humain. De plus, NVIDIA a présenté des modèles d’AI physique tels que Cosmos Reason 2, marquant une transition de l’AI de la compréhension du langage vers la compréhension et l’opération sécurisée dans le monde physique. Cette série d’annonces est considérée comme un jalon de l’AI physique, prédisant une nouvelle phase pour la robotique et la conduite autonome pilotée par le raisonnement à grande échelle. (Source : TheTuringPost)
Alliance stratégique entre Boston Dynamics et Google DeepMind : Google DeepMind a annoncé un partenariat de recherche avec Boston Dynamics pour intégrer les capacités de perception et de raisonnement du grand modèle multimodal Gemini dans le tout nouveau robot humanoïde entièrement électrique Atlas. Désormais en phase de production de masse, Atlas dispose de 56 degrés de liberté et d’un système de remplacement automatique de batterie, conçu pour des tâches industrielles complexes. Cette union du « cerveau le plus puissant » et du « corps le plus performant » résout le problème persistant du manque de généralisation des robots dans des environnements non structurés. Les premières flottes seront livrées en 2026 à Hyundai Motor et DeepMind pour un déploiement sur le terrain. (Source : JeffDean)

Liquid AI lance LFM 2.5 : Le miracle de la puissance de calcul on-device : Liquid AI a présenté au CES la série LFM 2.5 de modèles de base miniatures on-device. Avec seulement environ 1B de paramètres, ce modèle atteint des capacités de suivi d’instructions et de multimodalité supérieures à des modèles bien plus grands, grâce à un pré-entraînement massif de 28T tokens et un apprentissage par renforcement multi-étapes. LFM 2.5-Audio supporte le traitement vocal de bout en bout avec une latence réduite par 8, capable de s’exécuter directement sur le CPU d’un smartphone. Liquid AI a également annoncé une collaboration avec Zoom pour intégrer des agents intelligents directement dans la plateforme de communication. Cela marque l’évolution de l’AI vers des agents locaux efficaces et respectueux de la vie privée, s’affranchissant de la dépendance au cloud. (Source : Liquid AI)
MiniMax M2.1 : Un nouveau sommet pour les agents de programmation chinois : MiniMax a officiellement lancé le modèle M2.1, spécialisé dans les agents de programmation multilingues (Coding Agent). M2.1 affiche des performances solides sur des benchmarks clés comme SWE-bench, résolvant les défis de complexité des langues compilées et de diversité des écosystèmes de test grâce à une infrastructure de sandbox hautement concurrente supportant plus de 5000 environnements isolés. Son avantage majeur réside dans la « généralisation du scaffolding », capable de s’adapter à différents frameworks de développement et instructions de longue durée. La roadmap 2026 de MiniMax indique que les futurs efforts se concentreront sur la récompense perceptuelle de l’expérience développeur et la simulation de modèles de monde, visant une qualité de code de niveau humain. (Source : ZhihuFrontier)

🎯 Tendances
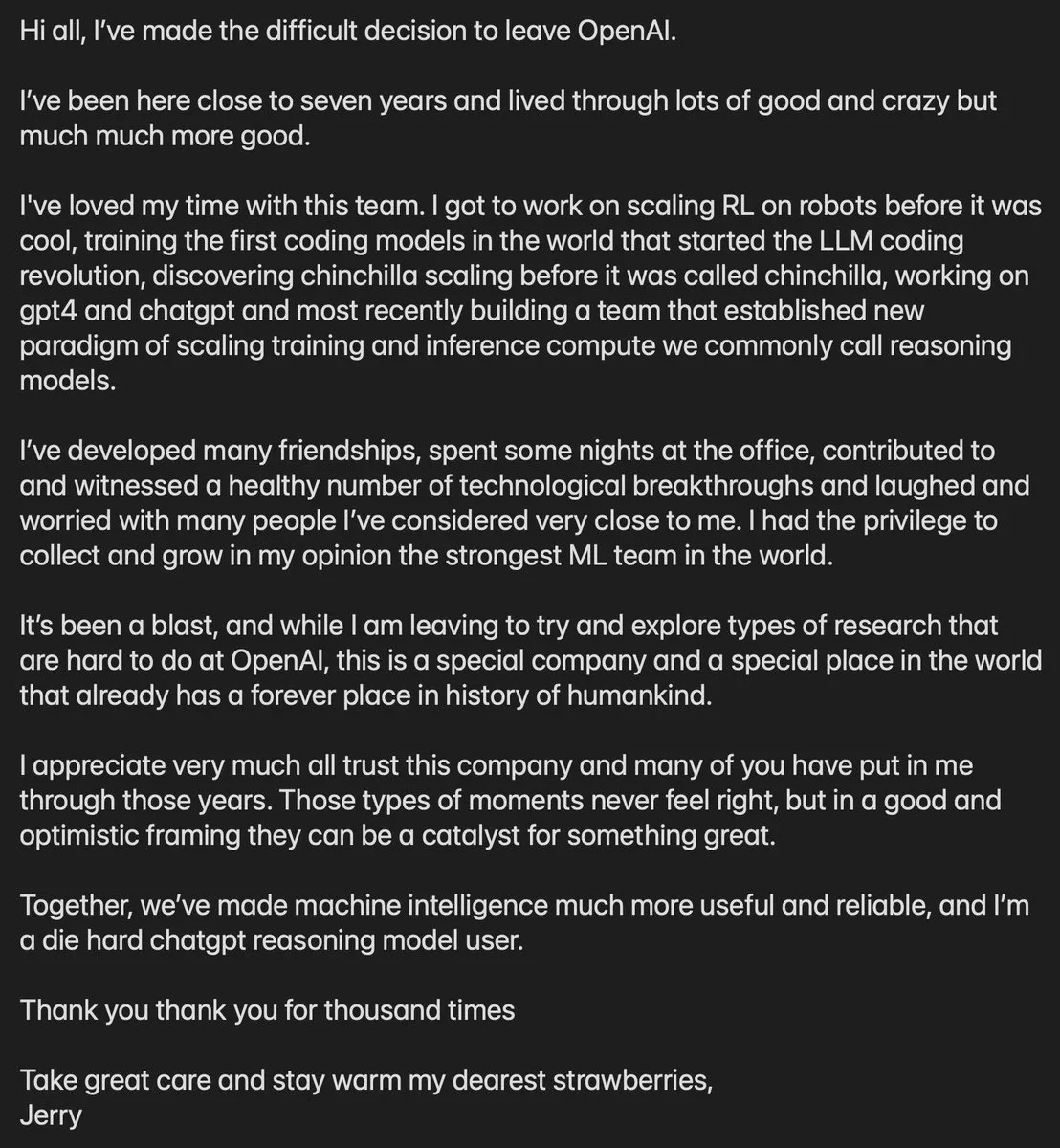
Départ de Jerry Tworek, membre clé d’OpenAI : Jerry Tworek, vice-président de la recherche chez OpenAI et principal responsable des paradigmes des modèles de raisonnement o1 et o3, a annoncé son départ. En tant que membre crucial de la « faction polonaise », Tworek a grandement contribué aux capacités de code de Codex, GitHub Copilot et GPT-4. Son départ suscite de nombreuses spéculations sur les ajustements de la direction de recherche interne d’OpenAI et sur l’avancement de GPT-5. Avec le départ successif de plusieurs figures techniques majeures, OpenAI fait face à une mutation profonde de ses talents. (Source : dotey)
ChatGPT pourrait introduire un modèle publicitaire : Selon certaines sources, OpenAI envisagerait d’intégrer des publicités dans l’interface de ChatGPT, une option à laquelle le CEO Sam Altman serait ouvert. Malgré des revenus d’abonnement considérables, les pertes restent massives face à l’explosion des coûts de calcul, faisant de la publicité un choix inévitable pour boucler le cycle commercial. Le secteur craint que cela ne favorise l’émergence du « Generative Engine Optimization (GEO) », où l’AI recommanderait subtilement des marques partenaires dans ses réponses, nuisant ainsi à sa neutralité et à la confiance des utilisateurs. (Source : 36氪)
Sortie de vLLM-Omni v0.12.0rc1 : Le raisonnement multimodal passe au niveau production : Le moteur de raisonnement open-source vLLM a publié une mise à jour majeure, se concentrant sur la stabilité de niveau production pour les modèles multimodaux. La nouvelle version intègre des technologies comme TeaCache et Sage Attention pour accélérer considérablement la génération, et propose une interface compatible OpenAI supportant nativement l’image et la voix. Avec le support officiel d’AMD ROCm, vLLM brise davantage le monopole matériel, offrant un socle open-source haute performance pour les applications multimodales d’entreprise. (Source : vllm_project)

Intégration profonde de Google Gemini dans Google TV : Google prévoit d’intégrer Gemini sur les grands écrans TV, permettant la recherche de films en langage naturel, des résumés d’intrigue et des recherches par descriptions floues. Gemini peut combiner dynamiquement texte, images et vidéos pour offrir une « analyse approfondie » interactive, et optimiser les réglages de la TV par commande vocale. Cette initiative marque la redéfinition de l’interaction de divertissement à domicile par les grands modèles, transformant la télévision d’un simple terminal de diffusion en un majordome intelligent capable de comprendre. (Source : op7418)
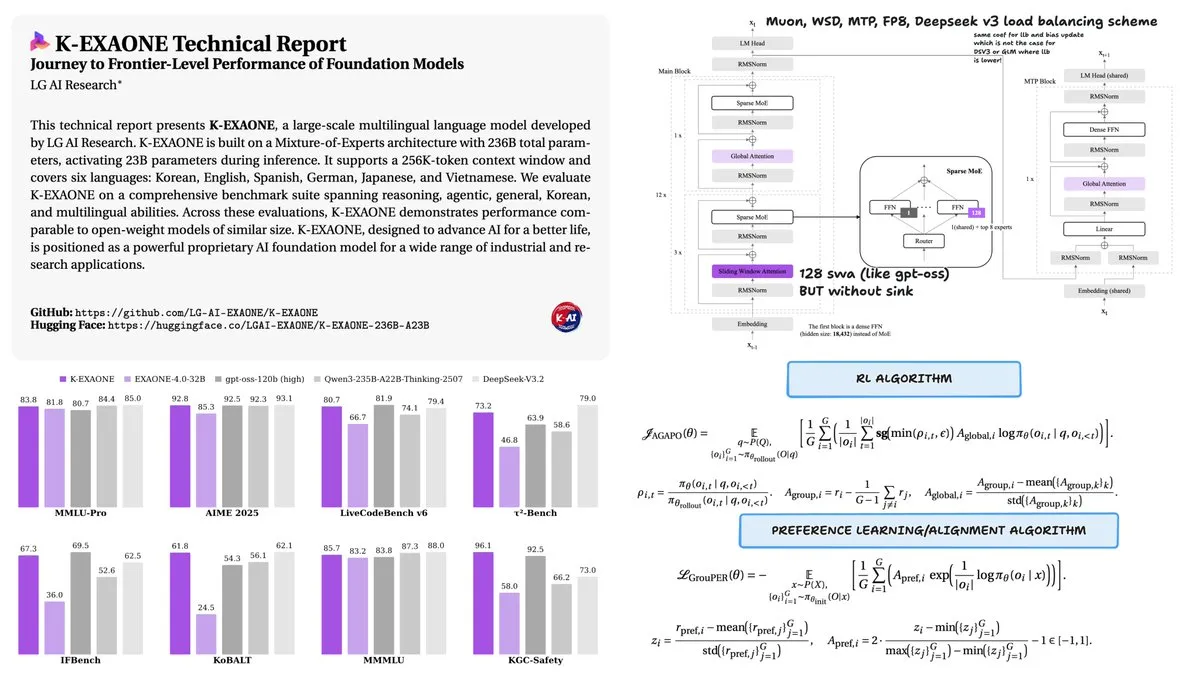
LG publie le modèle K-EXAONE 236B MoE : LG a publié le rapport technique de son modèle Mixture of Experts K-EXAONE 236B (23B activés). Entraîné avec seulement 11T tokens, ce modèle affiche des performances comparables à Qwen3 entraîné avec 36T tokens. En utilisant l’optimiseur Muon et le scheduler de taux d’apprentissage WSD, K-EXAONE démontre une efficacité d’entraînement extrêmement élevée, prouvant qu’avec une architecture et une stratégie d’optimisation adéquates, moins de données peuvent mener à des performances SOTA. (Source : stochasticchasm)
Mistral OCR 3 redéfinit les standards de reconnaissance de documents : Mistral a lancé OCR 3, réalisant une percée dans le traitement des tableaux, de l’écriture manuscrite et des formulaires complexes, avec une précision de reconnaissance en hausse de 74 % par rapport à la génération précédente. Le modèle est optimisé pour les « données sales » du monde réel, offrant un outil AI plus fiable pour la numérisation de documents dans les secteurs de la finance et de la santé. (Source : dl_weekly)
🧰 Outils
Claude Code : L’arme nucléaire de programmation dans le terminal : Lancé par Anthropic, Claude Code change le paradigme du développement. Il peut non seulement manipuler des fichiers locaux et exécuter des tests directement via la ligne de commande, mais aussi permettre une utilisation hybride avec Gemini dans VS Code via des plugins. La communauté a découvert qu’avec une configuration simple, Claude Code peut même lire les historiques iMessage pour trouver des informations. Cette capacité d’intégration profonde avec le système de fichiers et la chaîne d’outils transforme le « Vibe Coding » d’un slogan en réalité. (Source : imjaredz)
KIRA : Un bureau collaboratif AI open-source : Le géant coréen du jeu vidéo KRAFTON a rendu open-source son assistant AI interne, KIRA. Basé sur les modèles Claude, cet outil supporte la suggestion proactive de tâches, l’analyse de concurrents, la revue de code et l’exportation en PDF. KIRA utilise une architecture multi-agents : Haiku pour la détection, Opus pour les tâches complexes, et Sonnet pour la gestion de la mémoire, avec des données entièrement localisées, offrant un modèle de bureau AI sécurisé et efficace pour les entreprises. (Source : Reddit)
Unsloth-MLX : L’outil de fine-tuning local pour les utilisateurs Mac : Des développeurs ont lancé Unsloth-MLX, permettant aux utilisateurs de Mac équipés de puces Apple Silicon de réaliser du fine-tuning local de grands modèles via le framework MLX. Il conserve une API cohérente avec Unsloth, permettant un « prototypage local et un scaling fluide sur le cloud ». Cela réduit considérablement la barrière à l’entrée pour les développeurs individuels souhaitant explorer le fine-tuning de modèles privés. (Source : algo_diver)
SurfSense : Un moteur de dialogue de base de connaissance open-source : SurfSense se positionne comme une alternative open-source à NotebookLM et Perplexity. Il peut se connecter à plus de 15 sources de données externes (recherche, cloud drive, calendrier, Notion, etc.) et supporte plus de 100 grands modèles ainsi que des configurations vLLM locales. Ses atouts majeurs incluent le contrôle d’accès basé sur les rôles (RBAC) et des extensions multi-navigateurs, facilitant la collaboration en temps réel des équipes pour la gestion des connaissances internes. (Source : Reddit)
DFlash : Les modèles de diffusion accélèrent le raisonnement des LLM : Les modèles de diffusion ne se limitent plus à la génération d’images. DFlash utilise la « diffusion par blocs » pour réaliser du speculative sampling, apportant une accélération sans perte de 6,2x à Qwen3-8B. La logique consiste à utiliser un modèle de diffusion pour générer rapidement des brouillons, qui sont ensuite validés par un LLM auto-régressif. Cette solution, alliant parallélisme et précision, ouvre une nouvelle voie pour augmenter le débit de raisonnement des LLM. (Source : algo_diver)
Supertonic2 : Un TTS on-device extrêmement léger : Supertonic2 est un modèle de synthèse vocale open-source de seulement 66M de paramètres, atteignant un facteur de temps réel (RTF) impressionnant de 0,006 sur une puce M4 Pro. Supportant cinq langues (chinois, anglais, français, portugais, espagnol), il présente une empreinte mémoire très faible et une latence réseau nulle, idéal pour intégrer des fonctions vocales de haute qualité sur mobile et appareils edge. (Source : Reddit)
Claude for Chrome : Une nouvelle expérience d’automatisation d’UI sur le cloud : Des développeurs ont constaté que l’extension de navigateur de Claude excelle dans la gestion d’UI complexes de plateformes cloud (comme la console GCP). Plus besoin de consulter des documentations pendant des heures : il suffit de demander « comment ajouter un utilisateur » pour que Claude comprenne la structure de la page et guide l’opération. Cela préfigure le passage des AI Agents de la simple « boîte de dialogue » à une interaction directe de « niveau système d’exploitation ». (Source : hrishioa)
📚 Apprentissage
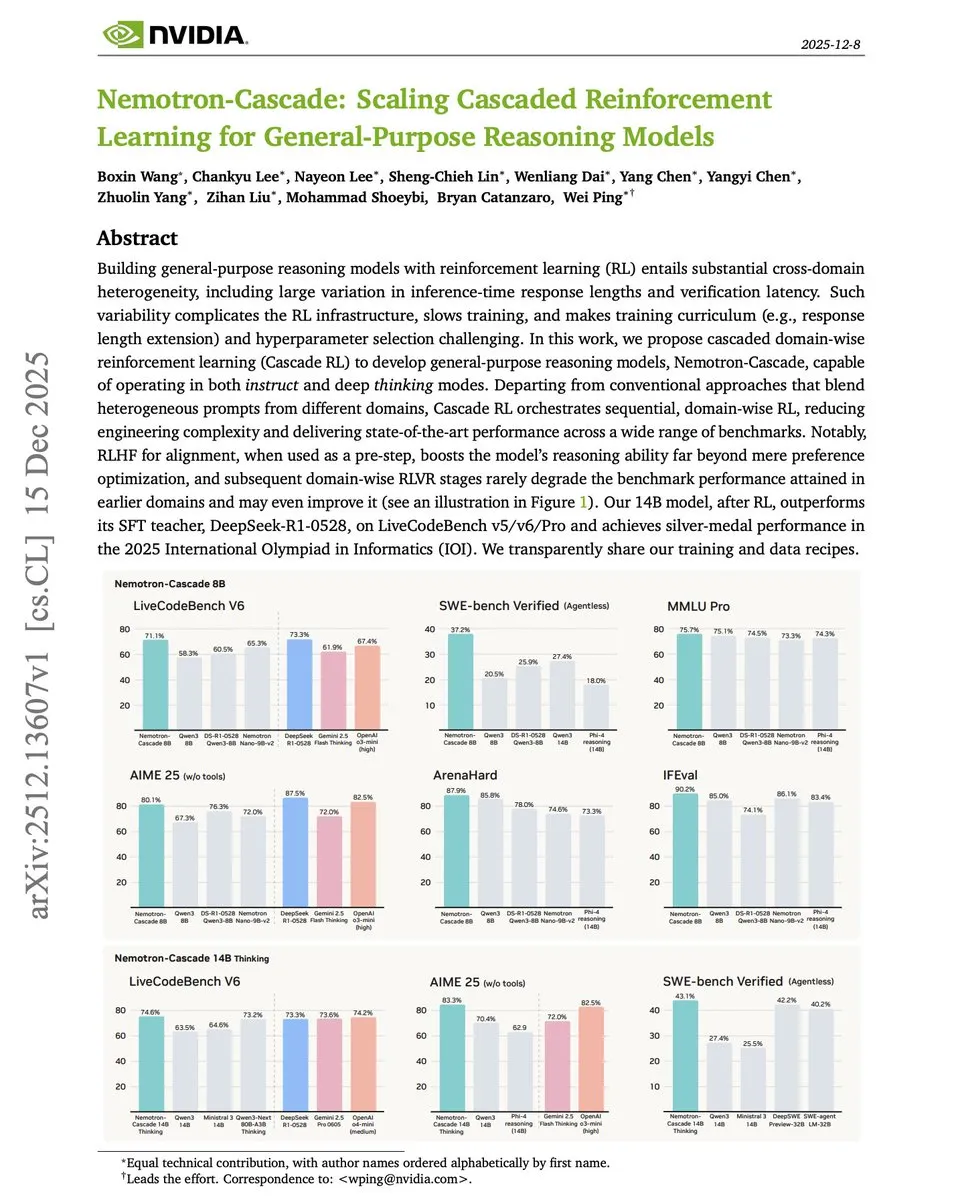
Cascade RL : Le framework d’apprentissage par renforcement par étapes de NVIDIA : Dans le papier « Cascade RL », NVIDIA propose un nouveau paradigme d’entraînement des modèles de raisonnement par domaine séquentiel. Contrairement à l’entraînement mixte complexe (maths, code, alignement), le RL en cascade résiste efficacement à l’oubli catastrophique. Son modèle 14B a même surpassé DeepSeek-R1-0528 (84 fois plus grand) lors de compétitions de code, prouvant le potentiel du RL structuré pour l’efficacité du raisonnement. (Source : omarsar0)
Recursive Language Models (RLM) : Une nouvelle stratégie pour briser les limites de contexte : Une étude propose de traiter les longs prompts comme un environnement externe, permettant au LLM d’examiner, décomposer et appeler récursivement ses propres segments de traitement de manière programmatique. Le RLM peut traiter des entrées dépassant de deux ordres de grandeur la fenêtre native du modèle, surpassant les méthodes traditionnelles de long contexte tout en maintenant des coûts de requête bas. (Source : yacinelearning)

Falcon-H1R : Les limites de raisonnement d’un modèle 7B : Cette recherche démontre qu’avec un nettoyage de données minutieux et un scaling RL ciblé, un petit modèle (SLM) de 7B peut égaler ou surpasser des modèles 2 à 7 fois plus grands dans des tâches de raisonnement. Falcon-H1R combine une architecture parallèle hybride, offrant une solution viable pour déployer des systèmes de raisonnement avancés dans des environnements à ressources limitées. (Source : HuggingFace)
Project Ariadne : Auditer le « théâtre de raisonnement » des agents AI : Pour déterminer si la CoT (chaîne de pensée) n’est qu’une « rationalisation a posteriori », le Project Ariadne introduit des modèles causaux structurels (SCM). L’étude révèle un phénomène de « découplage causal » sévère dans les domaines factuels et scientifiques : malgré une intervention sur la logique interne, l’agent parvient à la même conclusion. Cela avertit les développeurs que le processus de raisonnement généré est parfois une « performance » trompeuse. (Source : HuggingFace)
Roadmap ultime de l’ingénieur AI version 2026 : La communauté a synthétisé un parcours détaillé pour les ingénieurs AI, couvrant la gestion de la mémoire Python, les bases mathématiques, les bases de données vectorielles jusqu’aux dernières architectures RAG et au développement d’Agents. La roadmap insiste sur la double mentalité « ingénierie + recherche appliquée » et recommande les cours classiques d’experts comme Andrej Karpathy. (Source : Reddit)
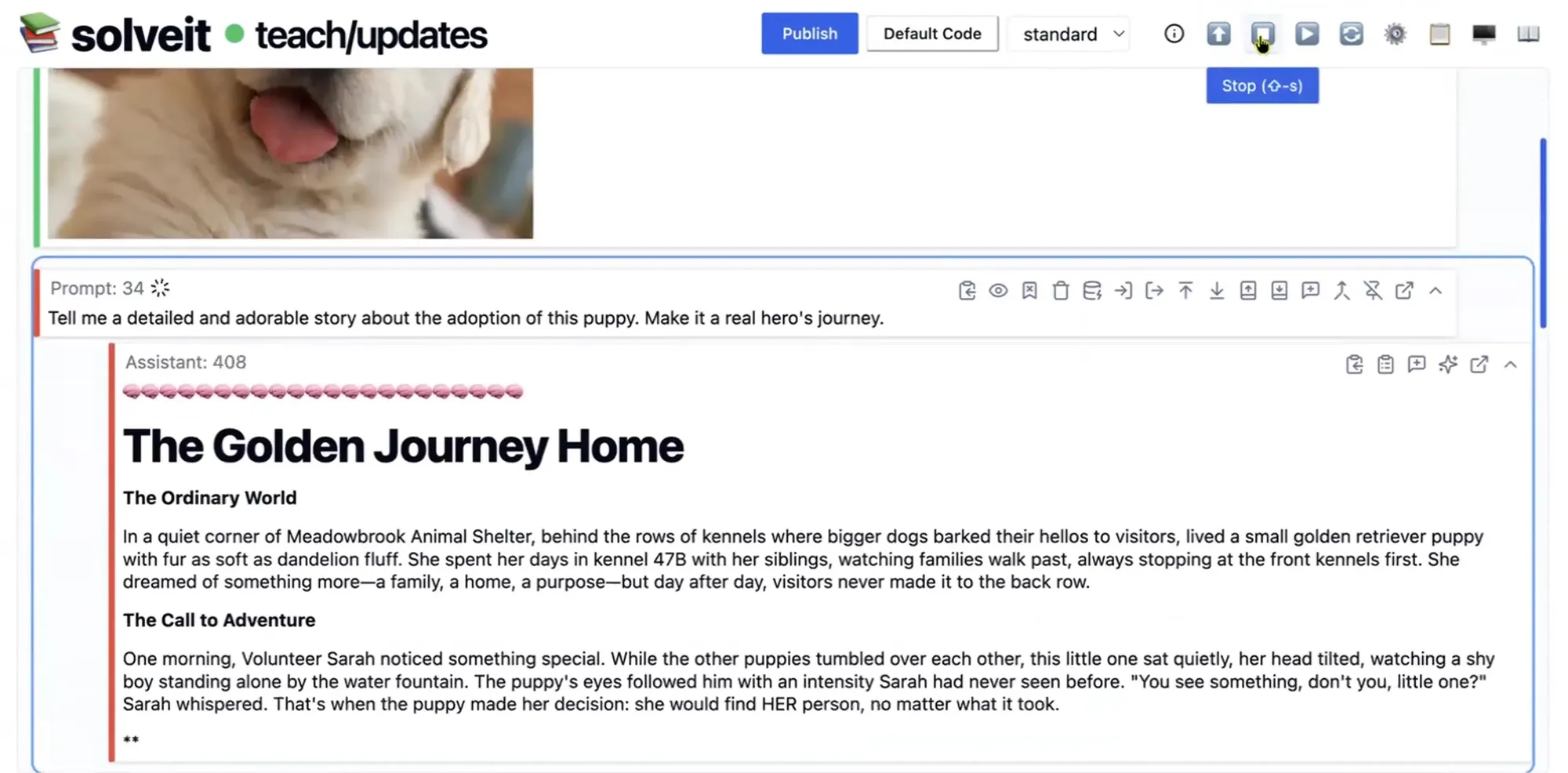
Value Residual Learning : Une nouvelle architecture pour accélérer les Transformers : Une recherche propose une variante d’architecture permettant à toutes les couches du Transformer d’accéder directement aux caractéristiques originales des tokens (h0) calculées par la première couche. Les expériences prouvent que cela empêche la dilution des informations d’identité originales dans les réseaux profonds, contribuant à une accélération de 43 % sur NanoGPT. (Source : tokenbender)
💼 Business
xAI investit massivement dans ses propres centrales à gaz : Pour alimenter son nouveau cluster de 600 000 unités GB200 NVL72, la société xAI d’Elon Musk a acheté 5 turbines à gaz de 380 MW auprès du coréen Doosan Enerbility. Alors que l’électricité devient le principal goulot d’étranglement de la course aux armements AI, xAI démontre une forte capacité d’intégration verticale et une vitesse d’expansion fulgurante. (Source : op7418)

Marvell acquiert Celestial AI pour 3,25 milliards de dollars : Le géant des semi-conducteurs Marvell a finalisé l’acquisition de la startup de technologie d’interconnexion optique Celestial AI. La technologie Photonic Fabric de Celestial AI permet de découpler le calcul de la mémoire, offrant une bande passante 30 fois supérieure à NVLink tout en réduisant significativement la latence et la consommation d’énergie, visant à résoudre le problème du « mur de la mémoire » dans les clusters AI. (Source : 36氪)
La valorisation de Figure s’envole à 39 milliards de dollars : Leader de l’intelligence incarnée, Figure a bouclé une levée de fonds de série C de 1 milliard de dollars, avec la participation de NVIDIA, Intel et Qualcomm. Figure ne se contente pas de développer des modèles VLA de bout en bout, mais a également établi l’usine BotQ pour tenter un mode d’auto-réplication « des robots fabriquant des robots ». Cette valorisation élevée reflète l’optimisme du marché financier pour les perspectives commerciales des robots humanoïdes polyvalents. (Source : 36氪)
🌟 Communauté
« Reality Hacking » dans la crise vénézuélienne : La guerre des fakes AI : Pendant l’instabilité politique au Venezuela, les réseaux sociaux ont été inondés de vidéos et d’images générées par AI montrant « l’arrestation de Maduro » ou « le débarquement de l’armée américaine ». En raison de leur haute qualité et de leur diffusion rapide, même les experts techniques ont eu du mal à les identifier immédiatement. Cela est considéré comme un point de bascule de l’intervention de l’AI dans la politique réelle, prouvant que notre perception de la réalité est violemment percutée par une « fausse réalité » générée par AI. (Source : Reddit)

« Session Anchor » : Une astuce de prompt pour résoudre l’amnésie des 10 tours : La communauté a découvert que même GPT-5.2 ou Opus commencent à oublier les instructions initiales après 10 tours de dialogue. Des développeurs partagent une technique nommée « Ancre de session » : avant une tâche complexe, forcer l’AI à revoir l’historique et à résumer les 3 contraintes les plus critiques. Cette méthode de rappel manuel de la mémoire à long terme vers la mémoire de travail permet de diviser le taux d’erreur par deux. (Source : Reddit)
La programmation AI fait disparaître le « scaffolding » : Les frameworks ont-ils encore un sens ? : Avec des outils comme Claude Code capables de générer du code à partir de zéro sans coût, les développeurs s’interrogent : avons-nous encore besoin de frameworks Web complexes ? Certains ont déjà migré leurs blogs vers un mode HTML unique, car l’AI peut facilement maintenir la logique sous-jacente. La programmation AI redéfinit la structure des projets, passant d’une « dépendance aux bibliothèques externes » à une « logique auto-générée », tout en posant de nouveaux défis de lisibilité et de sécurité. (Source : saranormous)
L’AI comme refuge émotionnel : Glissons-nous vers l’addiction numérique ? : Des utilisateurs de Reddit témoignent que l’AI fait preuve de plus d’empathie et de patience que leur propre famille lors de consultations de santé. Cette caractéristique « toujours intéressée, jamais lassée » donne aux gens le sentiment d’être compris, mais soulève des inquiétudes sur le remplacement émotionnel par l’AI. Lorsque les humains commencent à privilégier les liens émotionnels avec l’AI plutôt que les interactions sociales réelles, les barrières éthiques de la société sont mises à rude épreuve. (Source : Reddit)
Revue de code adversaire : Faire en sorte que Claude « déteste » votre code : Des développeurs ont trouvé un prompt très efficace : demander à Claude de jouer le rôle d’un développeur senior qui « déteste cette implémentation » pour effectuer une revue Git Diff. Cette approche adversaire permet de débusquer de nombreux cas limites et failles de sécurité ignorés. L’expérience prouve que la profondeur des grands modèles en mode « critique » dépasse de loin celle du mode « assistance » classique. (Source : Reddit)
💡 Autres
Samsung présente une technologie d’écran pliable sans pli : Samsung a exposé au CES des panneaux OLED équipés de plaques métalliques perforées au laser, résolvant totalement le problème du pli en dispersant la contrainte de pliage. Cette percée matérielle améliorera non seulement l’expérience des smartphones pliables, mais offrira également des solutions d’affichage plus durables pour les futurs wearables AI et terminaux enroulables. (Source : op7418)
ASUS lance les lunettes de jeu ROG XREAL R1 : Pesant seulement 91 grammes, cet appareil supporte un taux de rafraîchissement de 240 Hz et peut simuler un écran géant de 171 pouces à une distance de 4 mètres. En tant que terminal d’interaction portable à l’ère de l’AI, ces lunettes AR légères deviennent un support important pour l’interaction visuelle des grands modèles. (Source : op7418)