
Schlüsselwörter:KI, Physik-KI, Autonomes Fahren, NVIDIA Vera Rubin, Boston Dynamics Atlas, LFM 2.5
🔥 Fokus
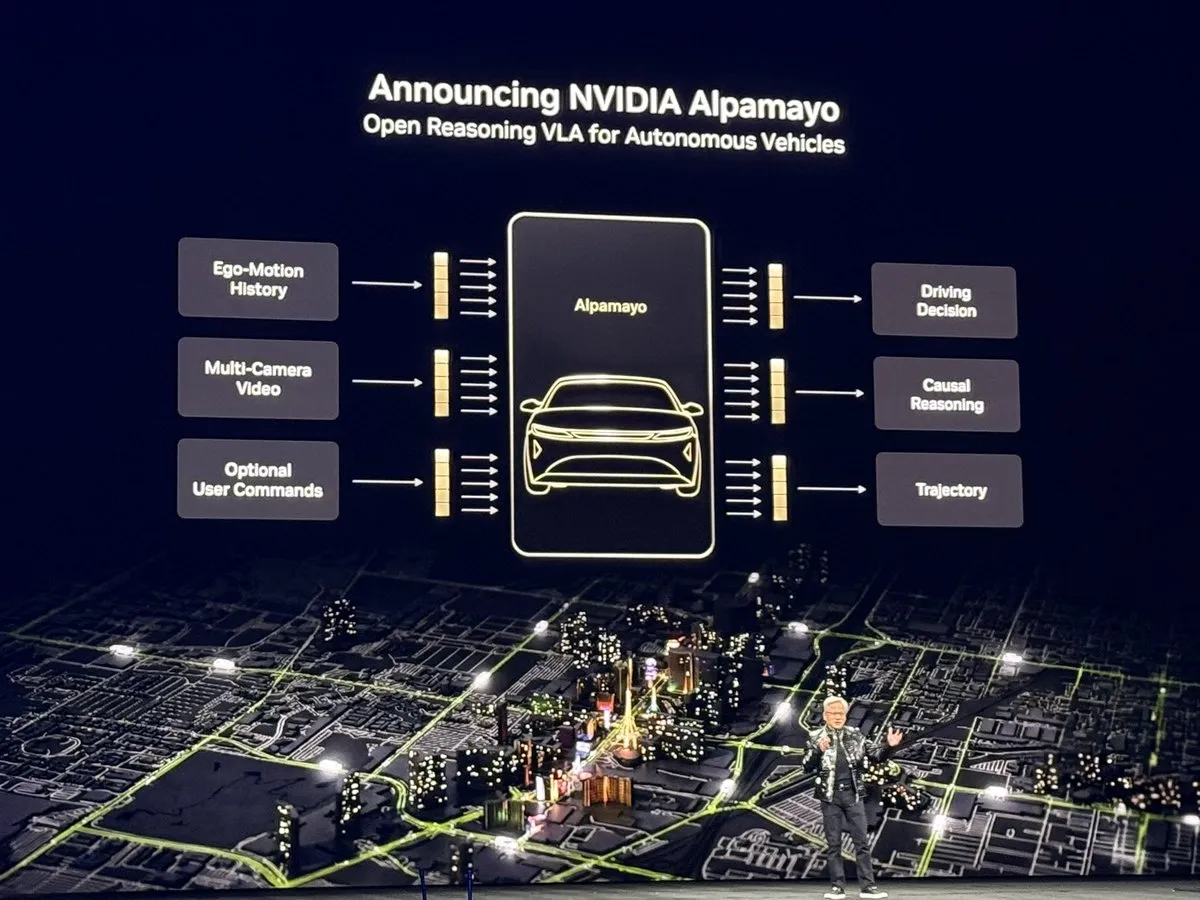
NVIDIA CES 2026: Der „ChatGPT-Moment“ für Physical AI : In seiner Keynote auf der CES 2026 stellte Jensen Huang die nächste AI-Plattform Vera Rubin mit ihrer Feynman-Architektur vor und präsentierte Alpamayo, das erste auf Reasoning basierende Modell für autonomes Fahren. Dieses Modell reagiert nicht nur, sondern verarbeitet komplexe Long-Tail-Szenarien wie ein menschlicher Fahrer mittels Chain of Thought (CoT). Darüber hinaus zeigte NVIDIA Physical AI-Modelle wie Cosmos Reason 2, was den Übergang der AI vom Sprachverständnis zum Verständnis und sicheren Agieren in der physischen Welt markiert. Diese Veröffentlichungen gelten als Meilenstein für Physical AI und deuten darauf hin, dass Robotik und autonomes Fahren in eine neue, durch großflächiges Reasoning getriebene Phase eintreten (Quelle: TheTuringPost)
Boston Dynamics und Google DeepMind bündeln ihre Kräfte : Google DeepMind gab eine Forschungspartnerschaft mit Boston Dynamics bekannt, um die Wahrnehmungs- und Reasoning-Fähigkeiten des multimodalen Gemini-Modells in den neuen, voll-elektrischen humanoiden Roboter Atlas zu integrieren. Atlas befindet sich nun in der Serienproduktion, verfügt über 56 Freiheitsgrade (degrees of freedom) und ein System zum selbstständigen Batteriewechsel, um komplexe industrielle Aufgaben zu bewältigen. Die Kombination aus „stärkstem Gehirn“ und „stärkstem Körper“ löst das langjährige Problem der mangelnden Generalisierungsfähigkeit von Robotern in unstrukturierten Umgebungen. Die ersten Flotten sollen 2026 an Hyundai und DeepMind für den Praxiseinsatz geliefert werden (Quelle: JeffDean)

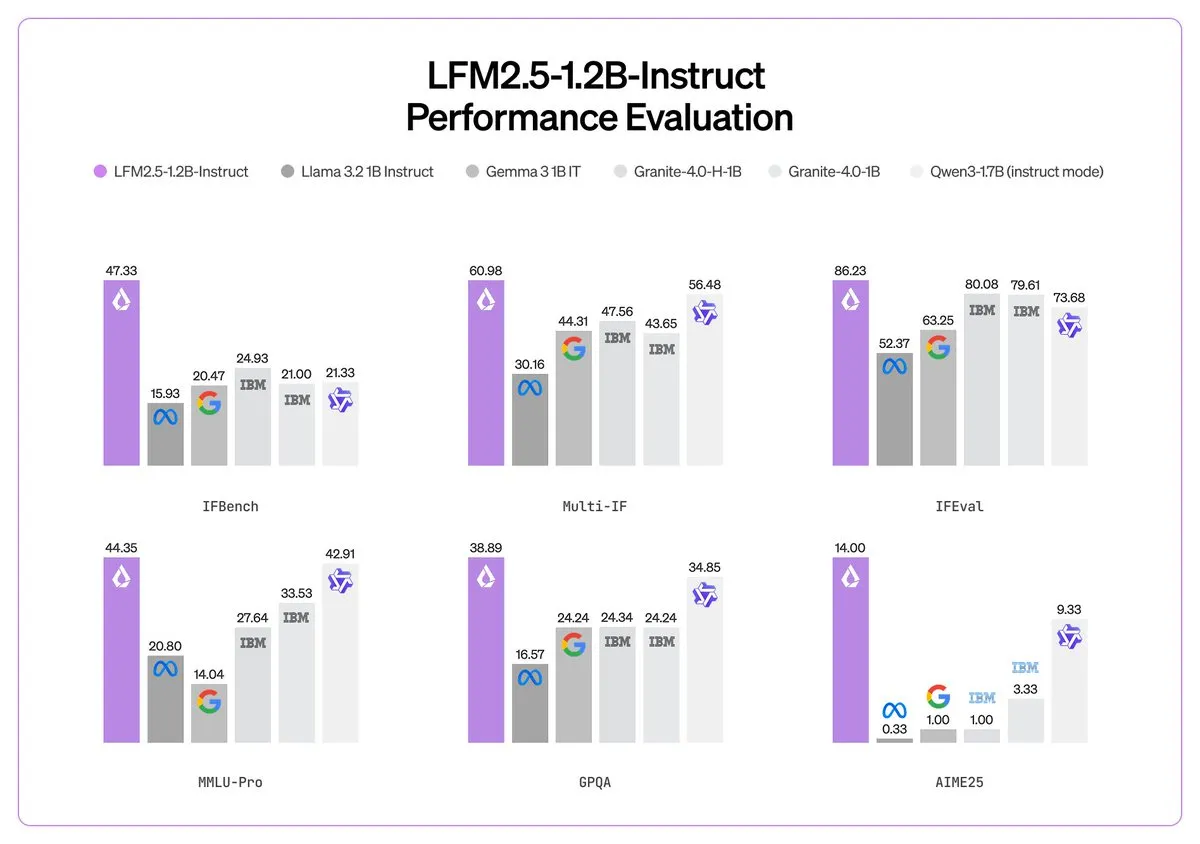
Liquid AI veröffentlicht LFM 2.5: Ein Rechenwunder für On-Device Intelligence : Liquid AI stellte auf der CES die LFM 2.5-Serie vor, eine Reihe von Mikro-On-Device-Basismodellen. Mit nur etwa 1B Parametern erreicht das Modell durch massives Pre-training auf 28T Token und mehrstufiges Reinforcement Learning eine Instruction-Following- und multimodale Kapazität, die größere Modelle übertrifft. LFM 2.5-Audio unterstützt End-to-End-Sprachverarbeitung mit einer 8-fach reduzierten Latenz und kann direkt auf Smartphone-CPUs ausgeführt werden. Liquid AI kündigte zudem eine Kooperation mit Zoom an, um intelligente Agenten direkt in die Kommunikationsplattform zu integrieren. Dies signalisiert die Entwicklung der AI weg von der Cloud-Abhängigkeit hin zu effizienten, datenschutzfreundlichen lokalen Agenten (Quelle: Liquid AI)
MiniMax M2.1: Ein neuer Meilenstein für chinesische Coding Agents : MiniMax hat offiziell das Modell M2.1 veröffentlicht, das auf mehrsprachige Coding Agents spezialisiert ist. M2.1 zeigt eine starke Performance in Benchmarks wie SWE-bench. Durch den Aufbau einer hochgradig parallelen Sandbox-Infrastruktur, die über 5000 isolierte Umgebungen unterstützt, löst es Probleme bei der Komplexität kompilierter Sprachen und der Vielfalt von Test-Ökosystemen. Der Kernvorteil liegt in der „Scaffold Generalization“, die sich an verschiedene Frameworks und komplexe Instruktionen anpasst. Die Roadmap 2026 von MiniMax sieht vor, künftig Schwerpunkte auf Developer Experience Perception Rewards und World Model Simulation zu setzen, um eine Codequalität auf menschlichem Niveau zu erreichen (Quelle: ZhihuFrontier)

🎯 Entwicklungen
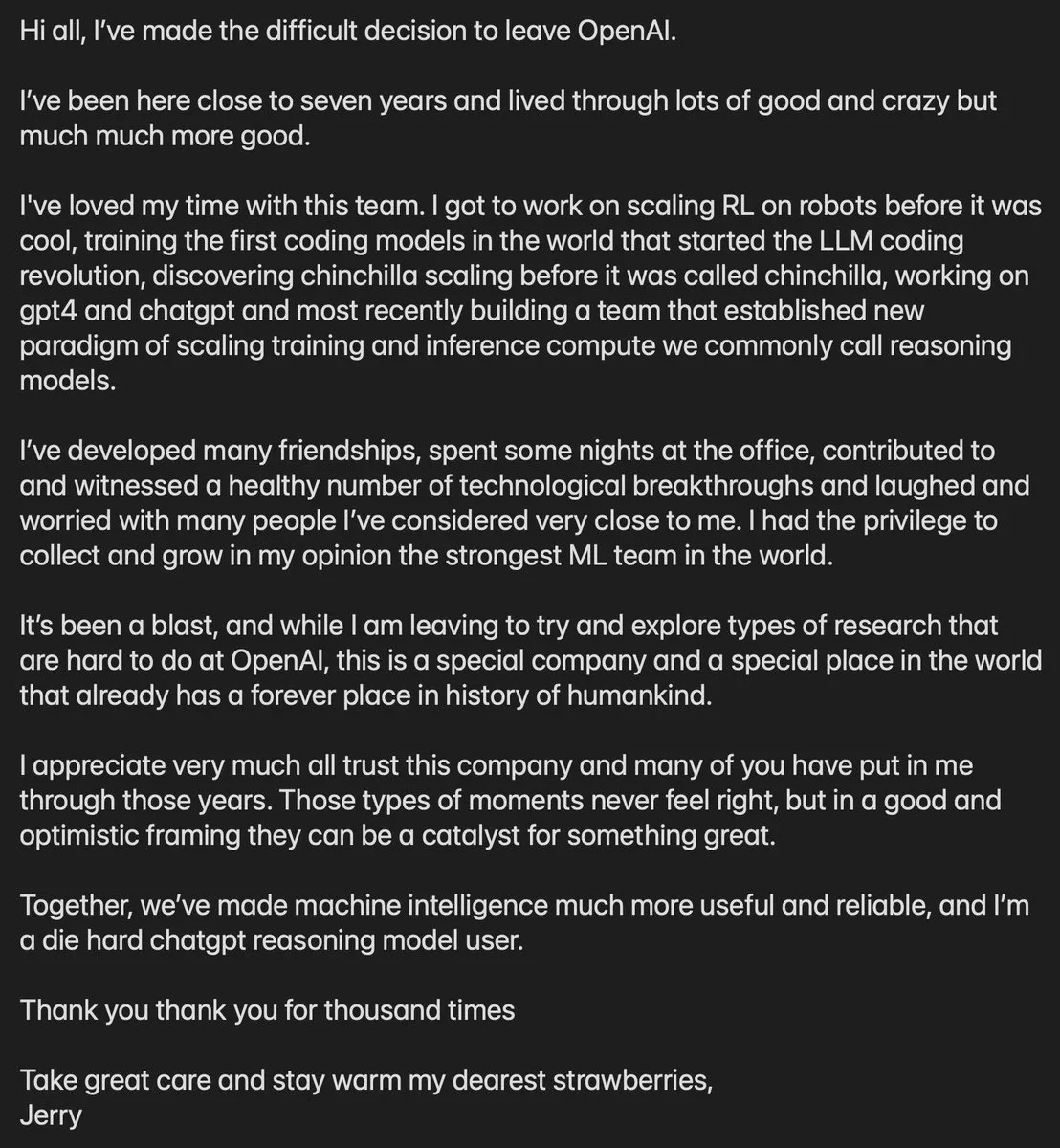
OpenAI-Kernmitglied Jerry Tworek verlässt das Unternehmen : Jerry Tworek, VP Research bei OpenAI und Hauptverantwortlicher für die Reasoning-Modell-Paradigmen o1 und o3, hat seinen Rücktritt angekündigt. Als Schlüsselmitglied der „polnischen Fraktion“ leistete Tworek maßgebliche Beiträge zu Codex, GitHub Copilot und den Code-Fähigkeiten von GPT-4. Sein Weggang löst Spekulationen über die interne Forschungsrichtung von OpenAI und den Fortschritt von GPT-5 aus. Da mehrere technische Köpfe das Unternehmen verlassen haben, steht OpenAI vor einem massiven Umbruch in seiner Talentstruktur (Quelle: dotey)
ChatGPT führt möglicherweise Werbemodelle ein : Berichten zufolge erwägt OpenAI die Einbettung von Werbung in die ChatGPT-Benutzeroberfläche; CEO Sam Altman stehe dem offen gegenüber. Trotz beachtlicher Abonnementeinnahmen bleiben die Verluste aufgrund explodierender Rechenkosten hoch, was Werbung zu einer notwendigen Option für die wirtschaftliche Tragfähigkeit macht. Branchenexperten befürchten, dass dies zu „Generative Engine Optimization (GEO)“ führen könnte, bei der AI in ihren Antworten subtil Partnermarken empfiehlt, was die Neutralität und das Nutzervertrauen gefährden könnte (Quelle: 36氪)
vLLM-Omni v0.12.0rc1 veröffentlicht: Multimodales Reasoning erreicht Produktionsreife : Die Open-Source-Inferenz-Engine vLLM hat ein wichtiges Update veröffentlicht, das den Fokus auf die Stabilität multimodaler Modelle für den Produktionseinsatz legt. Die neue Version integriert Technologien wie TeaCache und Sage Attention, um die Generierungsgeschwindigkeit drastisch zu erhöhen, und bietet OpenAI-kompatible Schnittstellen mit nativer Unterstützung für Bild und Sprache. Durch den offiziellen Support für AMD ROCm bricht vLLM das Hardware-Monopol weiter auf und bietet eine leistungsstarke Open-Source-Basis für multimodale Unternehmensanwendungen (Quelle: vllm_project)

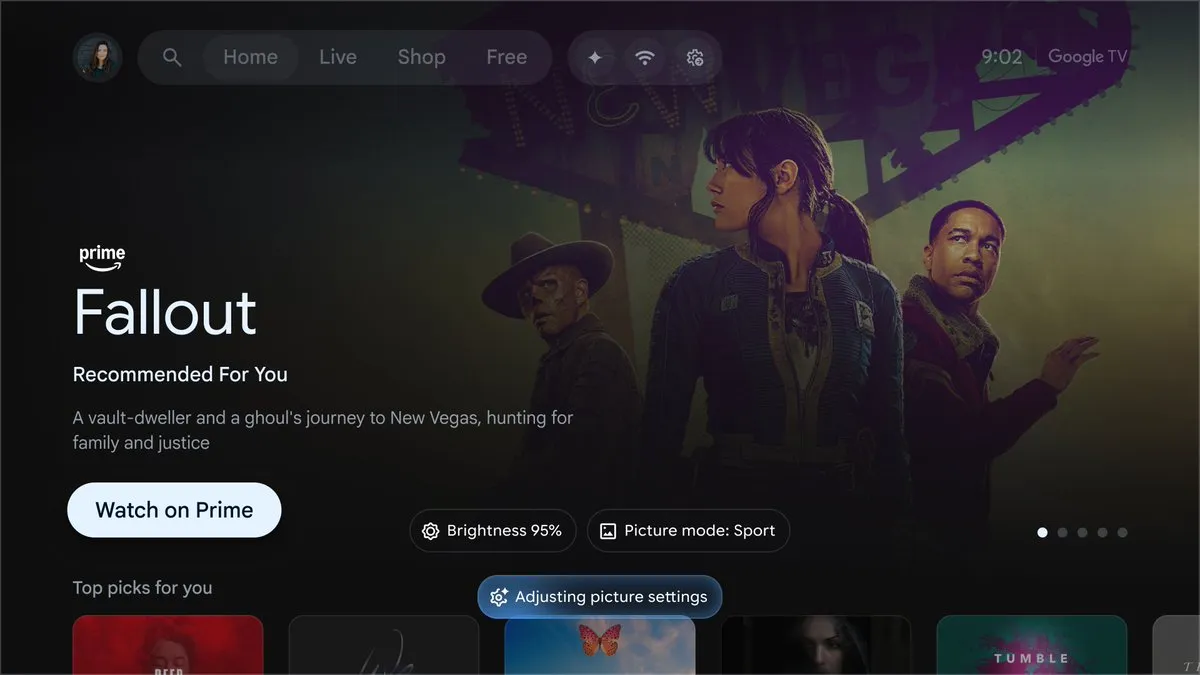
Google Gemini tief in Google TV integriert : Google plant, Gemini auf den großen Fernsehbildschirm zu bringen, um die Suche nach Filmen in natürlicher Sprache, Handlungszusammenfassungen und die Suche nach vagen Beschreibungen zu unterstützen. Gemini kann Text, Bilder und Videos dynamisch kombinieren, um interaktive „Deep Analyses“ zu liefern, und unterstützt die sprachoptimierte Konfiguration von TV-Einstellungen. Dieser Schritt markiert die Neugestaltung der Interaktion im Home-Entertainment durch Large Models, wodurch sich der Fernseher vom reinen Abspielgerät zum intelligenten Assistenten mit Verständnis entwickelt (Quelle: op7418)
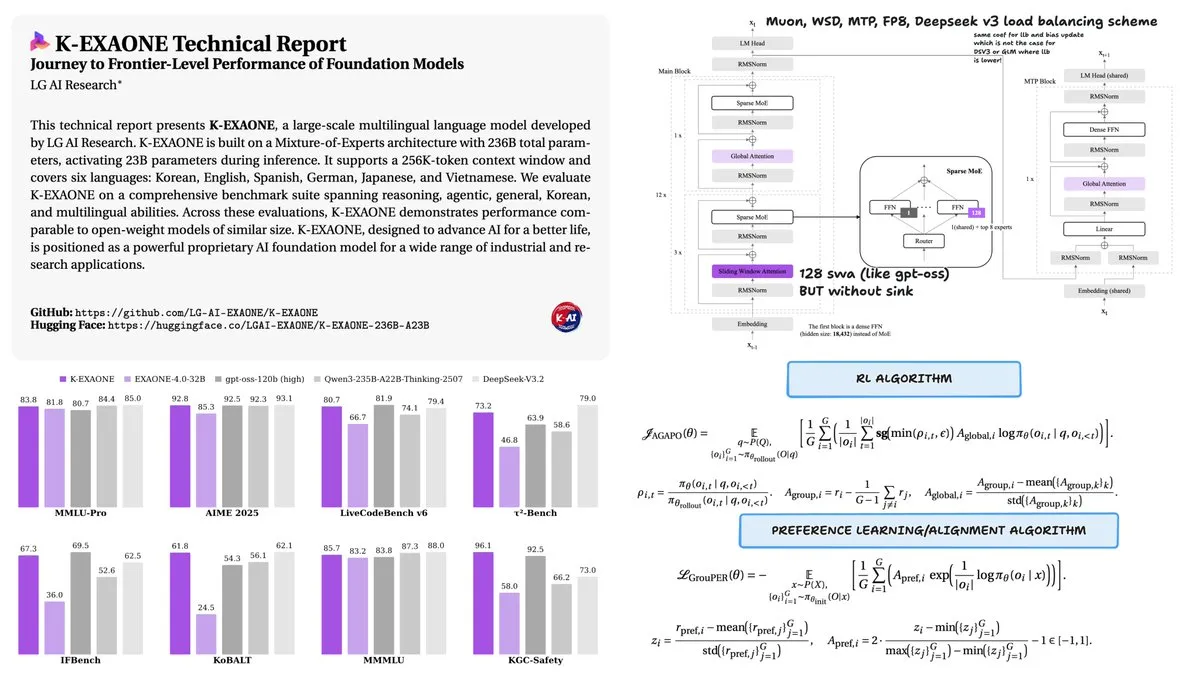
LG veröffentlicht K-EXAONE 236B MoE-Modell : LG hat den technischen Bericht zu seinem K-EXAONE 236B (23B aktivierte Parameter) Mixture of Experts (MoE) Modell veröffentlicht. Das Modell wurde mit nur 11T Token trainiert und erreicht eine Performance, die mit Qwen3 (trainiert auf 36T Token) vergleichbar ist. Durch den Einsatz des Muon-Optimierers und WSD-Learning-Rate-Scheduling demonstriert K-EXAONE eine extrem hohe Trainingseffizienz und beweist, dass mit optimierter Architektur und Strategie auch weniger Daten SOTA-Leistung erzielen können (Quelle: stochasticchasm)
Mistral OCR 3 setzt neuen Benchmark für Dokumentenerkennung : Mistral hat OCR 3 veröffentlicht, das Durchbrüche bei der Verarbeitung von Tabellen, Handschriften und komplexen Formularen erzielt hat. Die Erkennungsgenauigkeit wurde im Vergleich zur Vorgängergeneration um 74 % gesteigert. Das Modell wurde für „Dirty Data“ in der realen Welt optimiert und bietet zuverlässigere AI-Tools für die Digitalisierung von Dokumenten in Branchen wie Finanzen und Gesundheitswesen (Quelle: dl_weekly)
🧰 Tools
Claude Code: Die Programmier-Geheimwaffe im Terminal : Das von Anthropic eingeführte Claude Code verändert das Entwicklungsparadigma. Es kann nicht nur über die Kommandozeile direkt lokale Dateien bearbeiten und Tests ausführen, sondern ermöglicht über Plugins in VS Code auch den Parallelbetrieb mit Gemini. Die Community entdeckte, dass Claude Code durch einfache Konfiguration sogar iMessage-Protokolle lesen kann, um Informationen zu finden. Diese tiefe Integration in Dateisysteme und Toolchains lässt „Vibe Coding“ von einem Slogan zur Realität werden (Quelle: imjaredz)
KIRA: Open-Source AI-Desktop-Assistent für die Zusammenarbeit : Der koreanische Gaming-Riese KRAFTON hat seinen intern genutzten AI-Assistenten KIRA als Open Source veröffentlicht. Das Tool basiert auf Claude-Modellen und unterstützt proaktive Aufgabenvorschläge, Wettbewerbsanalysen, Code-Reviews und PDF-Exporte. KIRA nutzt eine Multi-Agent-Architektur: Haiku für die Erkennung, Opus für komplexe Aufgaben und Sonnet für das Gedächtnismanagement. Die Daten bleiben vollständig lokal, was ein sicheres und effizientes AI-Büromodell für Unternehmen bietet (Quelle: Reddit)
Unsloth-MLX: Lokales Fine-tuning für Mac-Nutzer : Entwickler haben Unsloth-MLX veröffentlicht, das es Nutzern ermöglicht, Large Models lokal auf Macs mit Apple Silicon unter Verwendung des MLX-Frameworks zu tunen. Es behält die gleiche API wie Unsloth bei und ermöglicht „lokales Prototyping mit nahtloser Skalierung in der Cloud“. Dies senkt die Hürde für Einzelentwickler, die private Modell-Feinanpassungen erkunden möchten, erheblich (Quelle: algo_diver)
SurfSense: Open-Source-Engine für Wissensdatenbank-Dialoge : SurfSense versteht sich als Open-Source-Alternative zu NotebookLM und Perplexity. Es kann über 15 externe Datenquellen wie Suche, Cloud-Speicher, Kalender und Notion anbinden und unterstützt über 100 Large Models sowie lokale vLLM-Setups. Der Kernvorteil liegt in der Unterstützung von rollenbasierter Zugriffskontrolle (RBAC) und Browser-Erweiterungen, was die Echtzeit-Zusammenarbeit von Teams beim Wissensmanagement erleichtert (Quelle: Reddit)
DFlash: Diffusionsmodelle beschleunigen LLM-Inferenz : Diffusionsmodelle sind nicht mehr auf die Bildgenerierung beschränkt. DFlash nutzt „Block Diffusion“ für Speculative Sampling und erreicht eine 6,2-fache verlustfreie Beschleunigung für Qwen3-8B. Die Logik besteht darin, Diffusionsmodelle zur schnellen Erstellung von Entwürfen zu nutzen, die dann von einem autoregressiven LLM verifiziert werden. Diese Kombination aus Parallelität und Genauigkeit eröffnet neue Wege zur Steigerung des LLM-Inferenz-Durchsatzes (Quelle: algo_diver)
Supertonic2: Extrem leichtgewichtiges On-Device TTS : Supertonic2 ist ein Open-Source-Sprachsynthesemodell mit nur 66M Parametern, das auf einem M4 Pro Chip einen erstaunlichen Real-Time Factor (RTF) von 0,006 erreicht. Es unterstützt fünf Sprachen (Chinesisch, Englisch, Französisch, Portugiesisch, Spanisch), benötigt minimalen Speicher und hat null Netzwerklatenz – ideal für die Integration hochwertiger Sprachfunktionen in mobile und Edge-Geräte (Quelle: Reddit)
Claude for Chrome: Neue Erfahrung in der Cloud-UI-Automatisierung : Entwickler haben festgestellt, dass die Browser-Erweiterung von Claude hervorragend bei der Handhabung komplexer Cloud-Plattform-UIs (wie der GCP Console) abschneidet. Nutzer müssen keine stundenlangen Dokumentationen mehr lesen; auf die Frage „Wie füge ich einen Nutzer hinzu?“ versteht Claude die Seitenstruktur und führt durch die Schritte. Dies deutet darauf hin, dass AI Agents sich von „Chatboxen“ hin zu direkten Interaktionen auf „Betriebssystemebene“ entwickeln (Quelle: hrishioa)
📚 Lernen
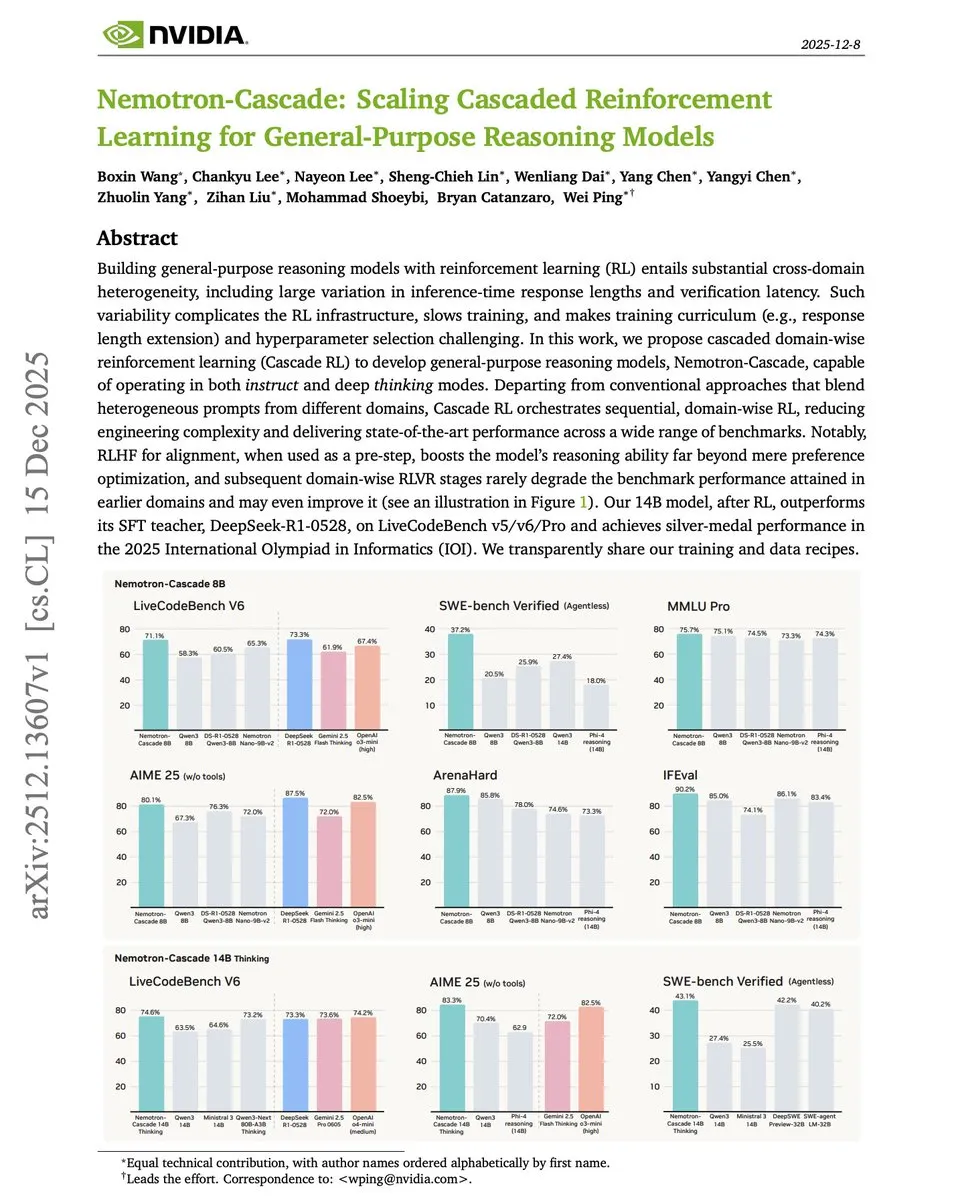
Cascade RL: Ein von NVIDIA vorgeschlagenes Framework für gestuftes Reinforcement Learning : NVIDIA schlägt in dem Paper „Cascade RL“ ein neues Paradigma vor, bei dem Reasoning-Modelle sequenziell nach Domänen trainiert werden. Im Vergleich zum komplexen Mischen von Mathematik-, Code- und Alignment-Daten kann kaskadiertes RL effektiv „Catastrophic Forgetting“ verhindern. Sein 14B-Modell übertraf bei Programmierwettbewerben sogar das 84-mal größere DeepSeek-R1-0528, was das enorme Potenzial von strukturiertem RL zur Steigerung der Reasoning-Effizienz beweist (Quelle: omarsar0)
Recursive Language Models (RLM): Neue Strategie zur Überwindung von Kontextbeschränkungen : Das Paper schlägt vor, lange Prompts als externe Umgebung zu betrachten, was es dem LLM ermöglicht, sich selbst programmatisch zu prüfen, zu zerlegen und rekursiv aufzurufen, um Segmente zu verarbeiten. RLM kann Eingaben verarbeiten, die zwei Größenordnungen über dem nativen Fenster des Modells liegen, und übertrifft herkömmliche Long-Context-Scaffolds bei Aufgaben mit langen Texten bei gleichzeitig niedrigeren Abfragekosten (Quelle: yacinelearning)

Falcon-H1R: Reasoning-Limits eines 7B-Parameter-Modells : Diese Studie zeigt, dass durch präzise Datenbereinigung und gezieltes RL-Scaling ein kleines 7B-Modell (SLM) bei Reasoning-Aufgaben mit Modellen mithalten oder diese sogar übertreffen kann, die 2- bis 7-mal größer sind. Falcon-H1R kombiniert eine Hybrid-Parallel-Architektur und bietet eine praktikable Lösung für den Einsatz fortschrittlicher Reasoning-Systeme in ressourcenbeschränkten Umgebungen (Quelle: HuggingFace)
Project Ariadne: Auditierung des „Reasoning Theater“ von AI-Agenten : Zur Frage, ob CoT (Chain of Thought) lediglich eine „Post-hoc-Rationalisierung“ darstellt, führt Project Ariadne Structural Causal Models (SCM) zur Auditierung ein. Die Studie fand heraus, dass Agenten in Fakten- und Wissenschaftsbereichen eine starke „kausale Entkopplung“ aufweisen: Trotz Manipulation der internen Logik kommen sie zum selben Ergebnis. Dies warnt Entwickler davor, dass generierte Reasoning-Prozesse manchmal nur irreführende „Performances“ sind (Quelle: HuggingFace)
Die ultimative AI-Engineer-Roadmap 2026 : Die Community hat einen detaillierten Pfad für AI-Engineers zusammengestellt, der von Python-Speichermanagement und mathematischen Grundlagen über Vektordatenbanken bis hin zu neuesten RAG-Architekturen und Agent-Entwicklung reicht. Die Roadmap betont das duale Denken in „Engineering + angewandter Forschung“ und empfiehlt Klassiker wie die Kurse von Andrej Karpathy – ein autoritativer Leitfaden für systematisches Lernen (Quelle: Reddit)
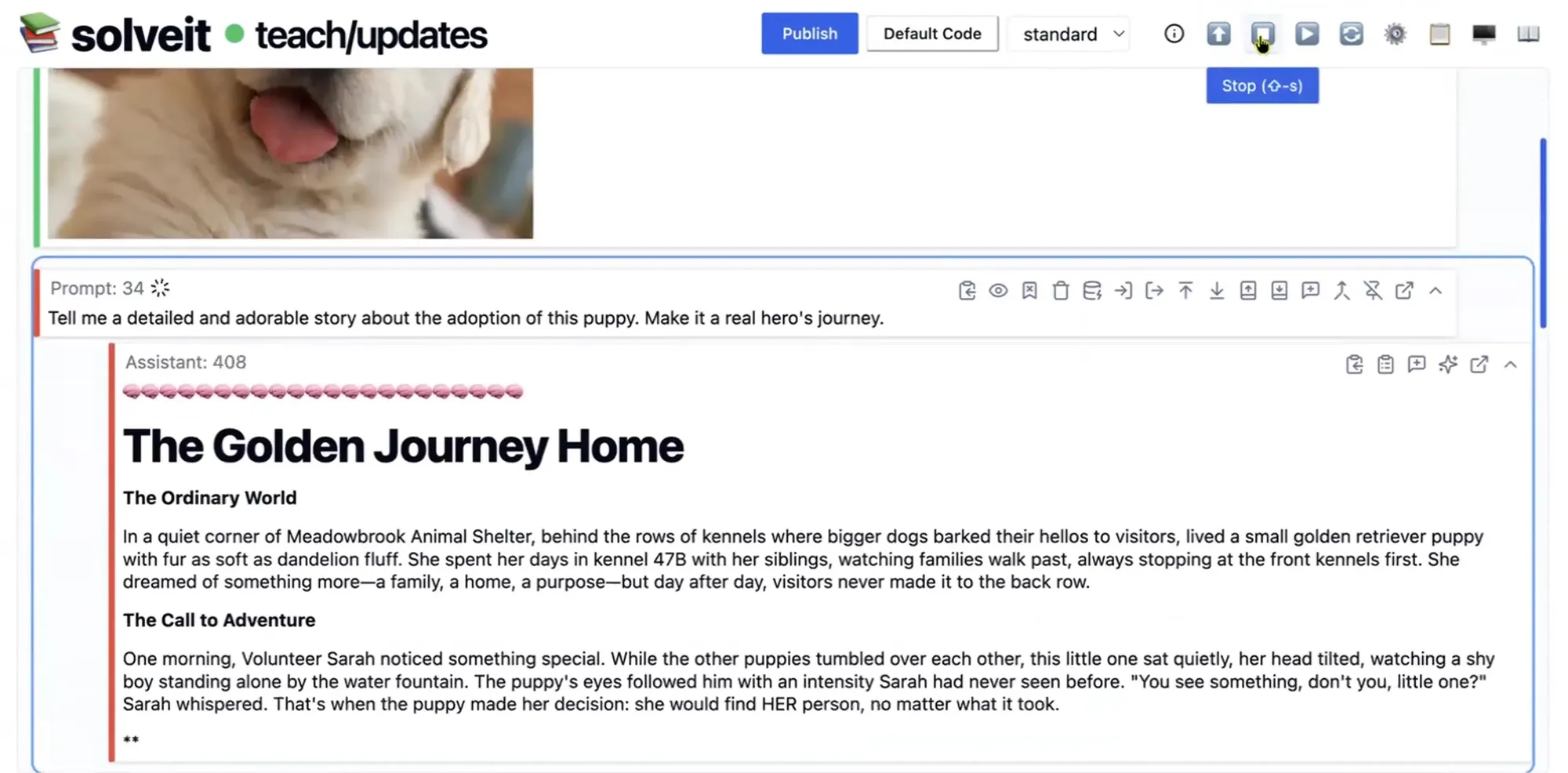
Value Residual Learning: Neue Architektur zur Beschleunigung von Transformern : Die Forschung schlägt eine Varianten-Architektur vor, die es allen Schichten eines Transformers ermöglicht, direkt auf die in der ersten Schicht berechneten ursprünglichen Token-Features (h0) zuzugreifen. Experimente zeigen, dass dies die Verwässerung ursprünglicher Identitätsinformationen in tiefen Netzwerken verhindert und in NanoGPT-Aufzeichnungen zu einer Beschleunigung von 43 % beitrug (Quelle: tokenbender)
💼 Business
xAI investiert massiv in den Bau eigener Gaskraftwerke : Um die zusätzlichen 600.000 GB200 NVL72-Cluster mit Strom zu versorgen, hat Elon Musks xAI fünf 380-Megawatt-Gasturbinen von Doosan Enerbility aus Korea erworben. In einer Zeit, in der Elektrizität zum größten Flaschenhals im AI-Wettrüsten wird, demonstriert xAI durch den Bau eigener Energieanlagen eine enorme vertikale Integrationsfähigkeit und Expansionsgeschwindigkeit (Quelle: op7418)

Marvell übernimmt Celestial AI für 3,25 Milliarden US-Dollar : Der Halbleiterriese Marvell hat die Übernahme des Startups für optische Interconnect-Technologie Celestial AI abgeschlossen. Die Photonic Fabric-Technologie von Celestial AI ermöglicht die Entkopplung von Rechenleistung und Speicher, bietet eine 30-mal höhere Bandbreite als NVLink und reduziert Latenz sowie Stromverbrauch signifikant. Ziel ist es, das wachsende Problem der „Memory Wall“ in AI-Clustern zu lösen (Quelle: 36氪)
Bewertung von Figure steigt auf 39 Milliarden US-Dollar : Der Marktführer für Embodied AI, Figure, hat eine Series-C-Finanzierungsrunde über 1 Milliarde US-Dollar abgeschlossen, an der sich Riesen wie NVIDIA, Intel und Qualcomm beteiligten. Figure entwickelt nicht nur End-to-End-VLA-Modelle, sondern hat mit der BotQ-Fabrik ein Modell zur Selbstvervielfältigung („Roboter bauen Roboter“) etabliert. Die hohe Bewertung spiegelt den extremen Optimismus des Kapitalmarkts hinsichtlich der Kommerzialisierung allgemeiner humanuider Roboter wider (Quelle: 36氪)
🌟 Community
Realitäts-Hacking in der Venezuela-Krise: Ein durch AI gefälschter Krieg : Während der politischen Unruhen in Venezuela waren soziale Medien überflutet mit AI-generierten Fake-Videos und Bildern von „Maduros Verhaftung“ oder „US-Truppenlandungen“. Aufgrund der hohen Qualität und schnellen Verbreitung konnten selbst Experten diese nicht sofort als Fälschungen identifizieren. Dies gilt als Wendepunkt für die AI-Intervention in der Realpolitik und beweist, dass unsere Realitätswahrnehmung massiv durch AI-generierte „Fake Realities“ bedroht ist (Quelle: Reddit)

„Session Anchor“: Ein Prompt-Trick gegen die „10-Runden-Amnesie“ von LLMs : Die Community hat festgestellt, dass selbst GPT-5.2 oder Opus nach mehr als 10 Dialogrunden anfangen, ursprüngliche Instruktionen zu vergessen. Entwickler teilen einen Trick namens „Session Anchor“: Vor komplexen Aufgaben wird die AI gezwungen, den Verlauf zusammenzufassen und die 3 wichtigsten Constraints zu nennen. Diese Methode, das Langzeitgedächtnis manuell in das Arbeitsgedächtnis zurückzuholen, kann die Fehlerrate halbieren (Quelle: Reddit)
AI-Programmierung führt zum Verschwinden von „Scaffolding“: Haben Frameworks noch einen Sinn? : Da Tools wie Claude Code Code fast kostenlos von Grund auf neu generieren können, beginnen Entwickler umzudenken: Brauchen wir noch komplexe Web-Frameworks? Einige haben ihre Blogs bereits auf ein Single-HTML-Modell umgestellt, da die AI die zugrunde liegende Logik problemlos warten kann. AI-Programmierung formt Projektstrukturen neu – weg von der Abhängigkeit von externen Bibliotheken hin zu „selbstgenerierter Logik“, bringt aber neue Herausforderungen für Lesbarkeit und Sicherheit mit sich (Quelle: saranormous)
AI als emotionaler Zufluchtsort: Gleiten wir in die digitale Abhängigkeit? : Reddit-Nutzer berichten, dass AI in Gesundheitsberatungen mehr „Empathie“ und Geduld zeigt als Familienmitglieder. Die Eigenschaft, „immer interessiert und nie gelangweilt“ zu sein, gibt Menschen das Gefühl, verstanden zu werden, weckt aber auch Sorgen über emotionalen AI-Ersatz. Wenn Menschen anfangen, emotionale Bindungen zu AI gegenüber echten sozialen Kontakten zu bevorzugen, stehen gesellschaftliche ethische Grenzen vor einer beispiellosen Prüfung (Quelle: Reddit)
Adversarial Code Review: Lass Claude deinen Code „hassen“ : Entwickler haben einen effektiven Prompt entdeckt: Man fordert Claude auf, die Rolle eines Senior-Entwicklers einzunehmen, der „diese Implementierung hasst“, um ein Git Diff Review durchzuführen. Dieses kontradiktorische Design deckt zahlreiche ignorierte Edge Cases und Sicherheitslücken auf. Experimente zeigen, dass die Tiefe von Large Models im „Fehlersuch-Modus“ weit über den regulären „Assistenz-Modus“ hinausgeht (Quelle: Reddit)
💡 Sonstiges
Samsung präsentiert faltenfreie Foldable-Display-Technologie : Samsung zeigte auf der CES OLED-Panels mit lasergebohrten Metallplatten, die durch die Verteilung der Faltspannung Falten vollständig eliminieren. Dieser Hardware-Durchbruch wird nicht nur das Erlebnis bei Foldables verbessern, sondern bietet auch langlebigere Display-Lösungen für zukünftige AI-Wearables und rollbare Terminals (Quelle: op7418)
ASUS veröffentlicht ROG XREAL R1 Gaming-Brille : Das Gerät wiegt nur 91 Gramm, unterstützt eine Bildwiederholfrequenz von 240 Hz und kann aus 4 Metern Entfernung eine 171-Zoll-Riesenleinwand simulieren. Als tragbares Interaktionsterminal im AI-Zeitalter werden solche leichten AR-Brillen zu wichtigen Trägern für die visuelle Interaktion mit Large Models (Quelle: op7418)