
Palavras-chave:IA, IA física, condução autônoma, NVIDIA Vera Rubin, Boston Dynamics Atlas, LFM 2.5
🔥 Destaques
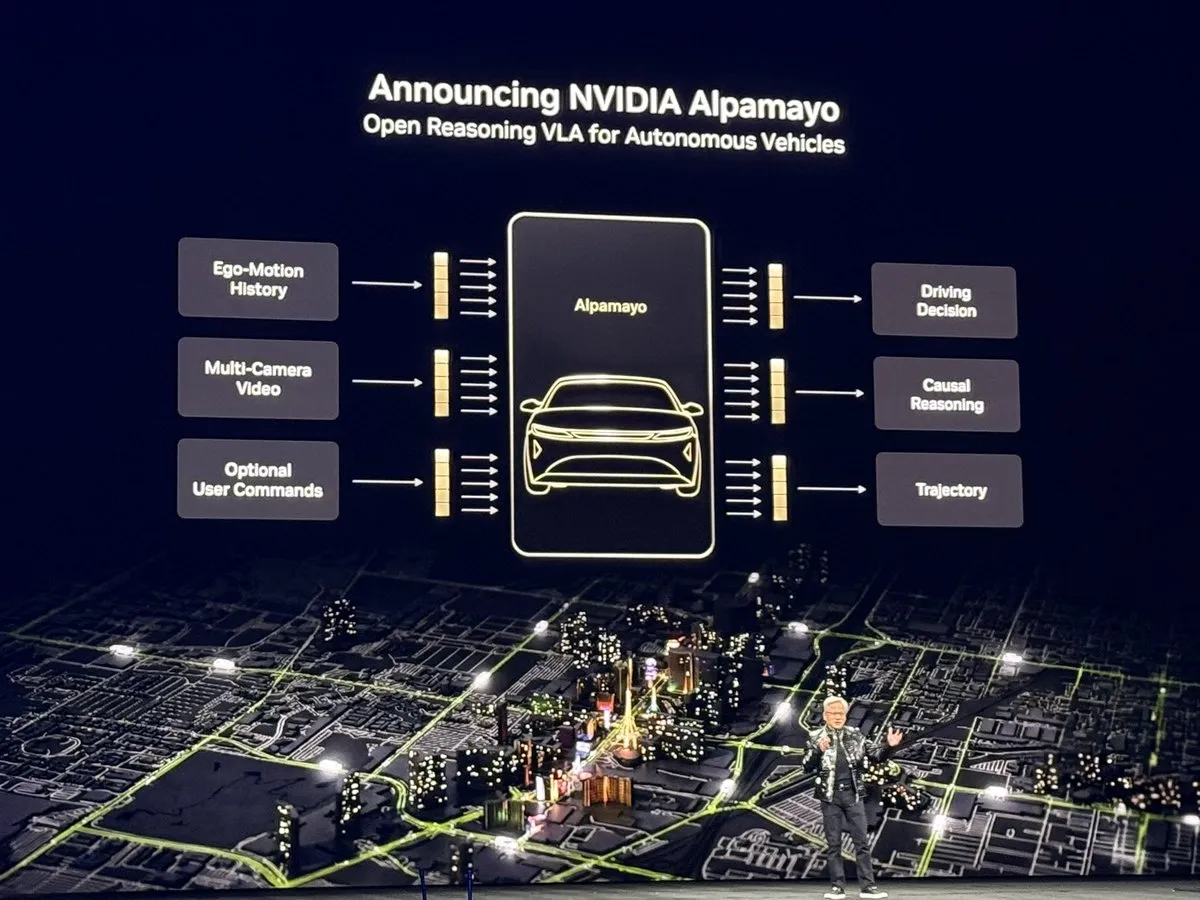
NVIDIA CES 2026: O “Momento ChatGPT” da IA Física : Jensen Huang apresentou em seu keynote na CES 2026 a próxima geração da plataforma de IA Vera Rubin e sua arquitetura Feynman, além de lançar o Alpamayo, o primeiro modelo de direção autônoma baseado em raciocínio. O modelo não apenas reage, mas processa cenários complexos de “cauda longa” (long-tail) através de Chain of Thought (CoT), como um motorista humano. Além disso, a NVIDIA demonstrou modelos de IA física como o Cosmos Reason 2, marcando a transição da IA da compreensão da linguagem para a compreensão e operação segura do mundo físico. Esta série de lançamentos é vista como um marco na IA física, prevendo uma nova fase impulsionada por raciocínio em larga escala para robótica e direção autônoma (Fonte: TheTuringPost)
Boston Dynamics e Google DeepMind unem forças : A Google DeepMind anunciou uma parceria de pesquisa com a Boston Dynamics para integrar as capacidades de percepção e raciocínio do modelo multimodal Gemini ao novo robô humanoide totalmente elétrico Atlas. O Atlas entrou em fase de produção em massa, com 56 graus de liberdade e um sistema de troca automática de bateria, visando a execução de tarefas industriais complexas. Esta união entre o “cérebro mais forte” e o “corpo mais forte” resolve a dificuldade histórica de generalização dos robôs em ambientes não estruturados. A primeira frota será entregue em 2026 para a Hyundai Motor e DeepMind para implantação em campo (Fonte: JeffDean)

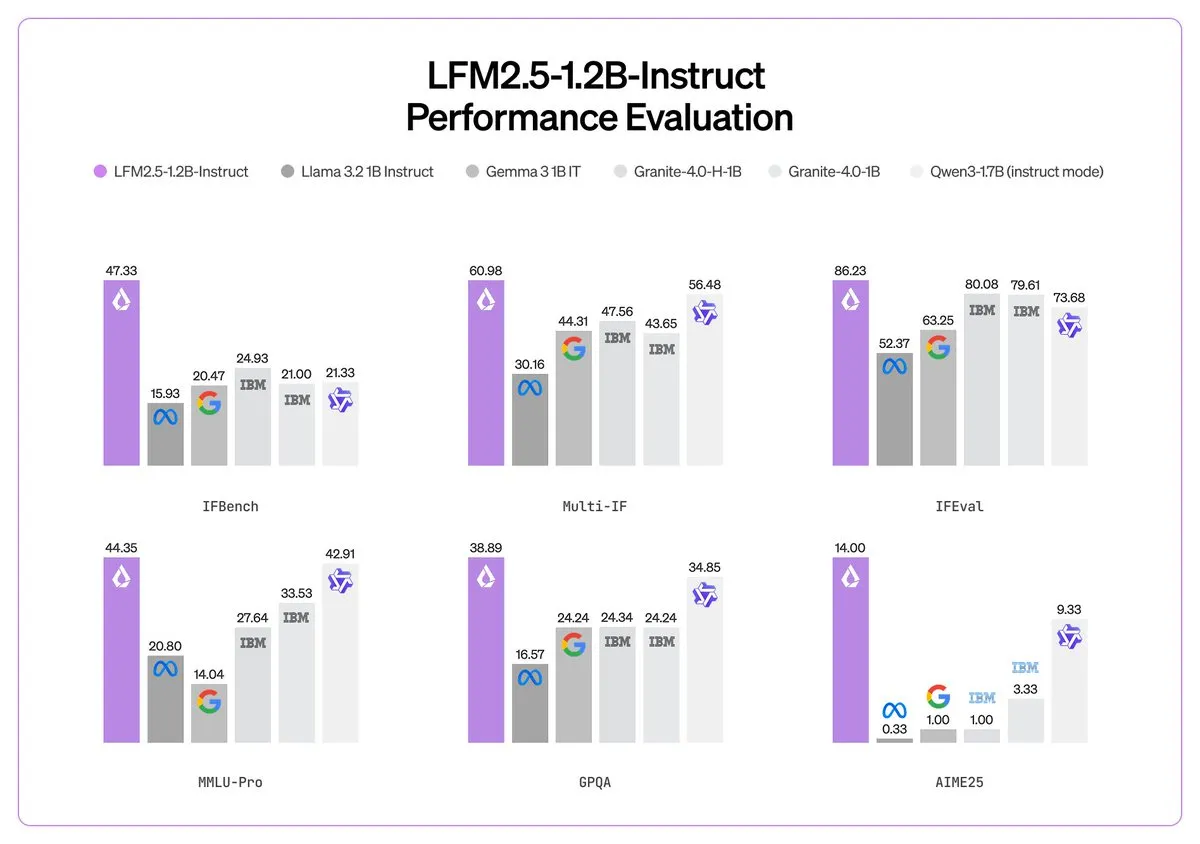
Liquid AI lança LFM 2.5: O milagre computacional da inteligência on-device : A Liquid AI lançou na CES a série LFM 2.5 de modelos de fundação minúsculos para dispositivos (edge). Com apenas cerca de 1B de parâmetros, o modelo alcançou capacidades de seguimento de instruções e multimodalidade superiores a modelos muito maiores, através de um pré-treinamento massivo de 28T tokens e aprendizado por reforço em múltiplos estágios. O LFM 2.5-Audio suporta processamento de voz ponta a ponta com latência 8 vezes menor, rodando diretamente na CPU de smartphones. A Liquid AI também anunciou uma parceria com o Zoom para integrar agentes inteligentes diretamente na plataforma de comunicação. Isso sinaliza a evolução da IA para além da dependência da nuvem, rumo a agentes locais eficientes e privados (Fonte: Liquid AI)
MiniMax M2.1: Um novo patamar para agentes de programação nacionais : A MiniMax lançou oficialmente o modelo M2.1, focado em agentes de programação multilíngues (Coding Agent). O M2.1 apresentou um desempenho sólido em benchmarks como o SWE-bench, resolvendo desafios de complexidade de linguagens compiladas e diversidade de ecossistemas de teste através de uma infraestrutura de sandbox de alta concorrência com mais de 5000 ambientes isolados. Sua principal vantagem reside na “generalização de scaffolding”, adaptando-se a diferentes frameworks de desenvolvimento e instruções de longo alcance. O roadmap de 2026 da MiniMax indica foco futuro em recompensas de percepção da experiência do desenvolvedor e simulação de modelos de mundo para alcançar qualidade de código de nível humano (Fonte: ZhihuFrontier)

🎯 Tendências
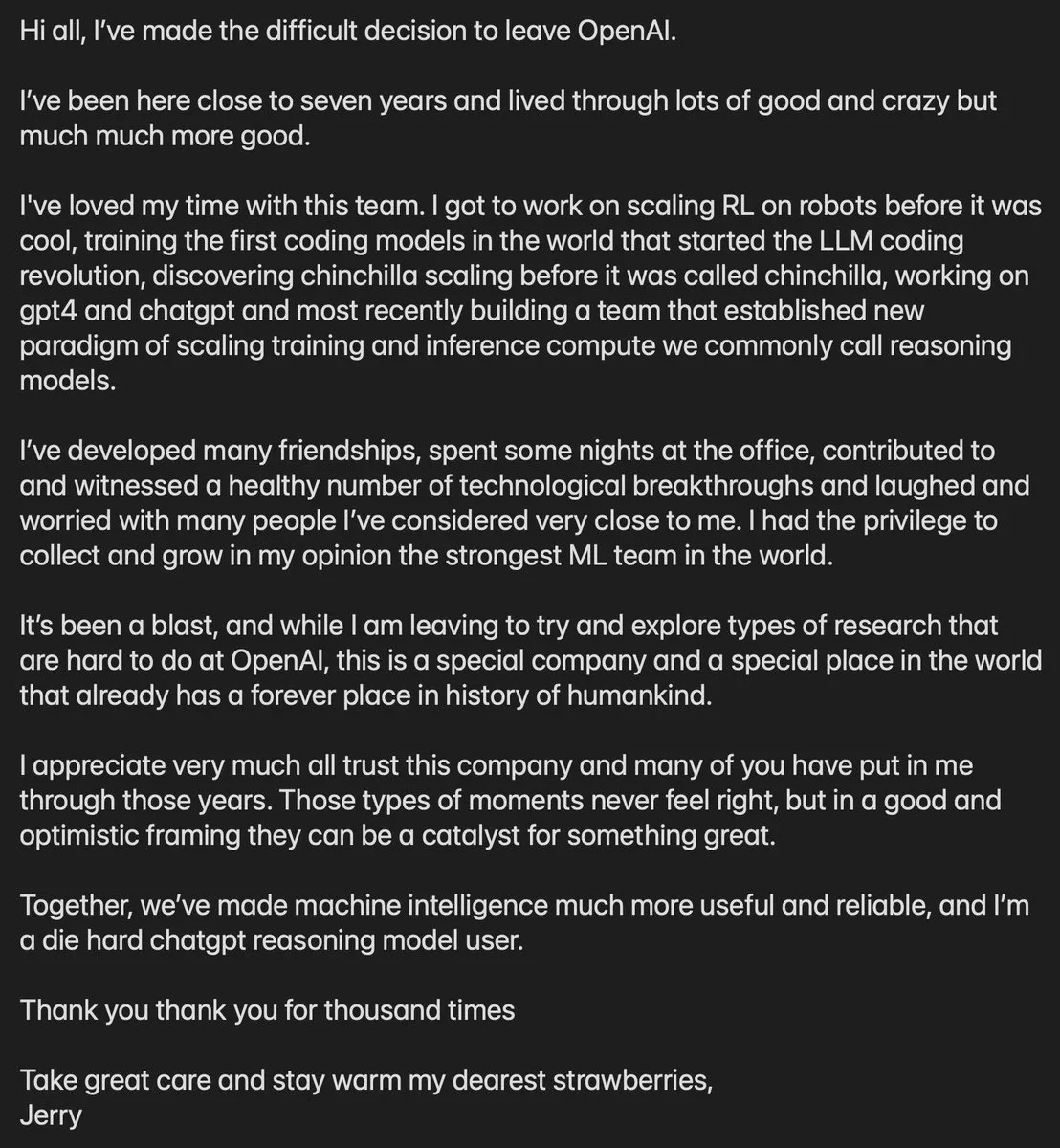
Jerry Tworek, membro principal da OpenAI, deixa a empresa : O vice-presidente de pesquisa da OpenAI e principal responsável pelos paradigmas dos modelos de raciocínio o1 e o3, Jerry Tworek, anunciou sua saída. Como membro chave da “gangue polonesa”, Tworek contribuiu imensamente para o Codex, GitHub Copilot e as capacidades de código do GPT-4. Sua partida gerou especulações sobre ajustes na direção de pesquisa interna da OpenAI e no progresso do GPT-5. Com a saída sucessiva de vários líderes técnicos, a OpenAI enfrenta mudanças drásticas em seu quadro de talentos (Fonte: dotey)
ChatGPT pode introduzir modelo de anúncios : Relatos indicam que a OpenAI está considerando embutir anúncios na interface do ChatGPT, com o CEO Sam Altman mantendo uma postura aberta à ideia. Com o aumento exponencial dos custos computacionais, apesar da receita considerável de assinaturas, as perdas continuam grandes, tornando os anúncios uma escolha inevitável para o fechamento do ciclo comercial. A indústria teme que isso possa gerar a “Otimização de Motores Generativos (GEO)”, onde a IA recomenda sutilmente marcas parceiras em suas respostas, prejudicando sua neutralidade e a confiança do usuário (Fonte: 36氪)
vLLM-Omni v0.12.0rc1 lançado: Raciocínio multimodal entra em nível de produção : O motor de inferência de código aberto vLLM lançou uma atualização importante, focando na estabilidade de nível de produção para modelos multimodais. A nova versão integra tecnologias como TeaCache e Sage Attention para aumentar drasticamente a velocidade de geração e oferece uma interface compatível com OpenAI com suporte nativo para imagem e voz. Com suporte oficial para AMD ROCm, o vLLM quebra ainda mais o monopólio de hardware, fornecendo uma base de código aberto de alto desempenho para aplicações multimodais corporativas (Fonte: vllm_project)

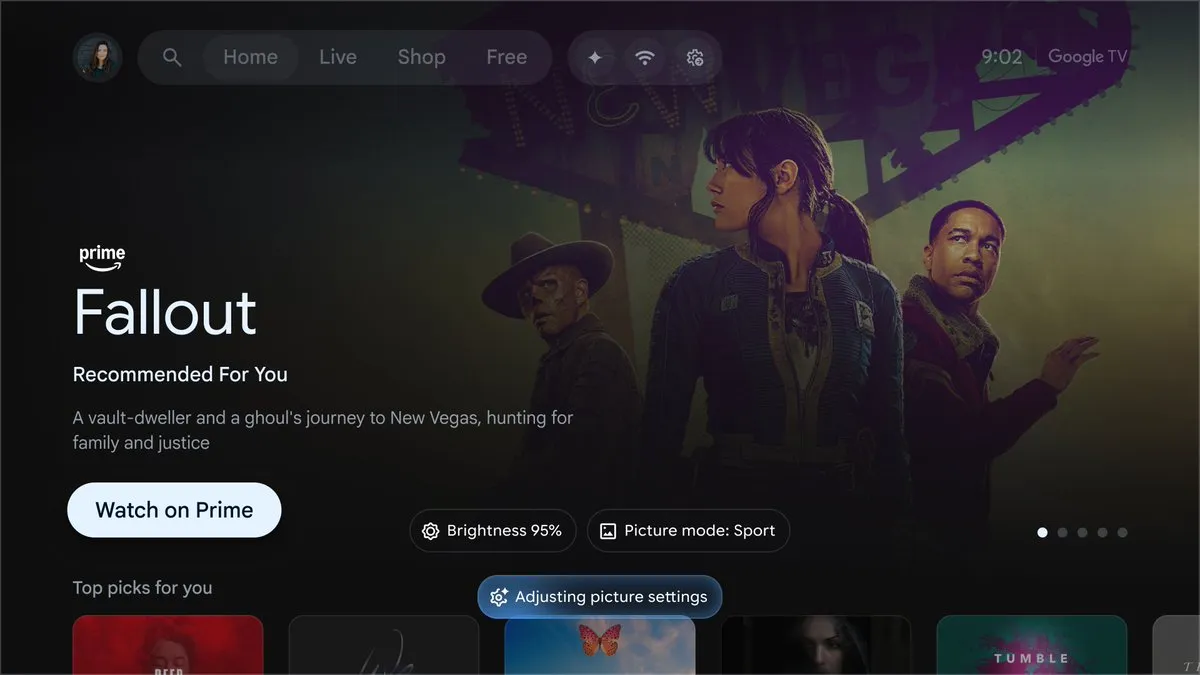
Google Gemini profundamente integrado ao Google TV : O Google planeja trazer o Gemini para as telas de TV, suportando busca de filmes em linguagem natural, resumos de enredo e pesquisas por descrições vagas. O Gemini pode combinar dinamicamente texto, imagens e vídeos para fornecer uma “análise profunda” interativa e otimizar as configurações da TV por voz. Este movimento marca a redefinição da interação de entretenimento doméstico por grandes modelos, evoluindo a TV de um simples terminal de reprodução para um mordomo inteligente com capacidade de compreensão (Fonte: op7418)
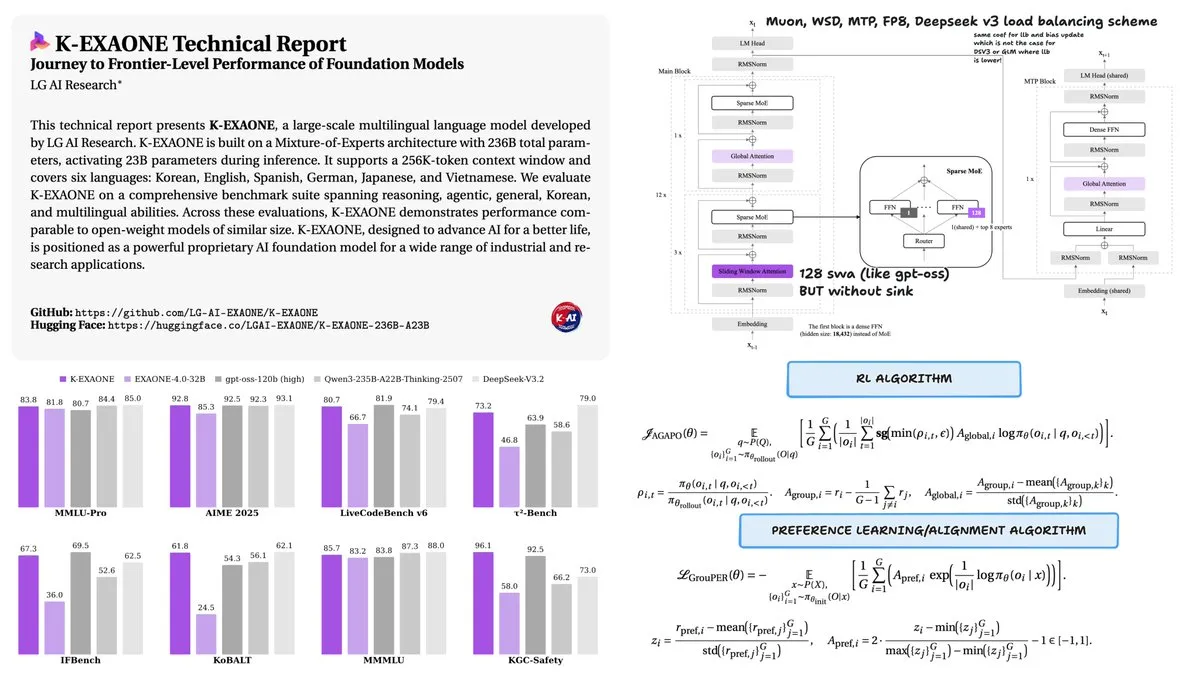
LG lança modelo K-EXAONE 236B MoE : A LG publicou o relatório técnico de seu modelo Mixture-of-Experts (MoE) K-EXAONE 236B (23B ativos). Treinado com apenas 11T tokens, o modelo alcançou desempenho comparável ao Qwen3, que foi treinado com 36T tokens. Ao adotar o otimizador Muon e o escalonamento de taxa de aprendizado WSD, o K-EXAONE demonstrou altíssima eficiência de treinamento, provando que, com otimização de arquitetura e estratégia, menos dados podem alcançar performance SOTA (Fonte: stochasticchasm)
Mistral OCR 3 redefine benchmarks de reconhecimento de documentos : A Mistral lançou o OCR 3, alcançando avanços no processamento de tabelas, caligrafia e formulários complexos, com um aumento de 74% na precisão em relação à geração anterior. O modelo foi otimizado para “dados sujos” do mundo real, fornecendo uma ferramenta de IA mais confiável para a digitalização de documentos em setores como finanças e saúde (Fonte: dl_weekly)
🧰 Ferramentas
Claude Code: A arma nuclear de programação no terminal : O Claude Code, lançado pela Anthropic, está mudando o paradigma de desenvolvimento. Ele não apenas opera arquivos locais e executa testes diretamente via linha de comando, mas também permite o uso híbrido com Gemini no VS Code através de plugins. A comunidade descobriu que, com configurações simples, o Claude Code pode até ler registros do iMessage para buscar informações. Essa capacidade de integração profunda com sistemas de arquivos e cadeias de ferramentas está tornando o “Vibe Coding” uma realidade (Fonte: imjaredz)
KIRA: Desktop de colaboração de IA de código aberto : A gigante coreana de jogos KRAFTON abriu o código do seu assistente de IA interno, KIRA. Baseada no modelo Claude, a ferramenta suporta sugestões proativas de tarefas, análise de concorrentes, revisão de código e exportação para PDF. O KIRA utiliza uma arquitetura multi-agente: Haiku para detecção, Opus para tarefas complexas e Sonnet para gerenciamento de memória, com dados totalmente localizados, oferecendo um modelo de escritório de IA seguro e eficiente para empresas (Fonte: Reddit)
Unsloth-MLX: Ferramenta de fine-tuning local para usuários de Mac : Desenvolvedores lançaram o Unsloth-MLX, permitindo que usuários façam fine-tuning local de grandes modelos em Macs com Apple Silicon usando o framework MLX. Ele mantém uma API consistente com o Unsloth, permitindo “prototipagem local e escalonamento contínuo na nuvem”. Isso reduz drasticamente a barreira para desenvolvedores individuais explorarem o ajuste fino de modelos privados (Fonte: algo_diver)
SurfSense: Motor de diálogo de base de conhecimento open-source : O SurfSense visa ser uma alternativa de código aberto ao NotebookLM e Perplexity. Ele pode se conectar a mais de 15 fontes de dados externas, como busca, drives na nuvem, calendários e Notion, suportando mais de 100 tipos de modelos e configurações locais de vLLM. Sua principal vantagem é o suporte ao controle de acesso baseado em funções (RBAC) e extensões de navegador, facilitando a colaboração em tempo real de equipes na gestão de conhecimento interno (Fonte: Reddit)
DFlash: Modelos de difusão acelerando a inferência de LLMs : Modelos de difusão não estão mais limitados à geração de imagens; o DFlash utiliza “difusão em blocos” para amostragem especulativa, trazendo uma aceleração sem perdas de 6,2x para o Qwen3-8B. A lógica é usar o modelo de difusão para gerar rascunhos rápidos, que são então validados pelo LLM autorregressivo. Esta solução, que combina paralelismo e precisão, abre um novo caminho para aumentar o throughput de inferência de LLMs (Fonte: algo_diver)
Supertonic2: TTS on-device extremamente leve : Supertonic2 é um modelo de síntese de voz de código aberto com apenas 66M de parâmetros, alcançando um fator de tempo real (RTF) impressionante de 0,006 no chip M4 Pro. Ele suporta cinco idiomas (Chinês, Inglês, Francês, Português e Espanhol), possui baixíssimo consumo de memória e latência zero de rede, sendo ideal para integração de funções de voz de alta qualidade em dispositivos móveis e edge (Fonte: Reddit)
Claude for Chrome: Nova experiência de automação de UI na nuvem : Desenvolvedores descobriram que a extensão de navegador do Claude apresenta desempenho excepcional ao lidar com UIs complexas de plataformas em nuvem (como o console do GCP). Os usuários não precisam mais consultar horas de documentação; basta perguntar “como adicionar um usuário” e o Claude entende a estrutura da página e guia a operação. Isso sinaliza que os AI Agents estão saindo da “caixa de diálogo” para interações diretas em “nível de sistema operacional” (Fonte: hrishioa)
📚 Aprendizado
Cascade RL: Framework de aprendizado por reforço em estágios proposto pela NVIDIA : A NVIDIA propôs no artigo “Cascade RL” um novo paradigma para treinar modelos de raciocínio sequencialmente por domínio. Em comparação com o treinamento complexo que mistura dados de matemática, código e alinhamento, o RL em cascata resiste eficazmente ao esquecimento catastrófico. Seu modelo de 14B superou até mesmo o DeepSeek-R1-0528 (84 vezes maior) em competições de código, provando o enorme potencial do RL estruturado para aumentar a eficiência do raciocínio (Fonte: omarsar0)
Recursive Language Models (RLM): Nova estratégia para superar limites de contexto : O artigo propõe tratar prompts longos como ambientes externos, permitindo que o LLM verifique, decomponha e chame a si mesmo recursivamente para processar fragmentos de forma programática. O RLM pode lidar com entradas duas ordens de magnitude maiores que a janela nativa do modelo, superando frameworks tradicionais de contexto longo em tarefas de texto extenso, mantendo um baixo custo de consulta (Fonte: yacinelearning)

Falcon-H1R: Limites de raciocínio em modelos de 7B parâmetros : Esta pesquisa demonstra que, através de limpeza de dados refinada e escalonamento de RL direcionado, modelos pequenos (SLM) de 7B podem igualar ou superar modelos 2 a 7 vezes maiores em tarefas de raciocínio. O Falcon-H1R combina uma arquitetura paralela híbrida, oferecendo uma solução viável para implantar sistemas de raciocínio avançados em ambientes com recursos limitados (Fonte: HuggingFace)
Project Ariadne: Auditando o “teatro de raciocínio” de agentes de IA : Para investigar se o CoT (Chain of Thought) apresenta “racionalização post-hoc”, o Project Ariadne introduziu Modelos Causais Estruturais (SCM) para auditoria. A pesquisa descobriu que, em campos factuais e científicos, os agentes apresentam um sério fenômeno de “desacoplamento causal”, onde chegam à mesma conclusão mesmo quando a lógica interna é interferida. Isso alerta os desenvolvedores que o processo de raciocínio gerado pelo modelo às vezes é apenas uma “performance” enganosa (Fonte: HuggingFace)
Roadmap Definitivo do Engenheiro de IA – Versão 2026 : A comunidade resumiu um caminho detalhado de crescimento para engenheiros de IA, cobrindo desde gerenciamento de memória em Python, fundamentos matemáticos, bancos de dados vetoriais até as mais recentes arquiteturas RAG e desenvolvimento de Agents. O roadmap enfatiza a mentalidade dupla de “engenharia + pesquisa aplicada” e recomenda cursos clássicos de especialistas como Andrej Karpathy (Fonte: Reddit)
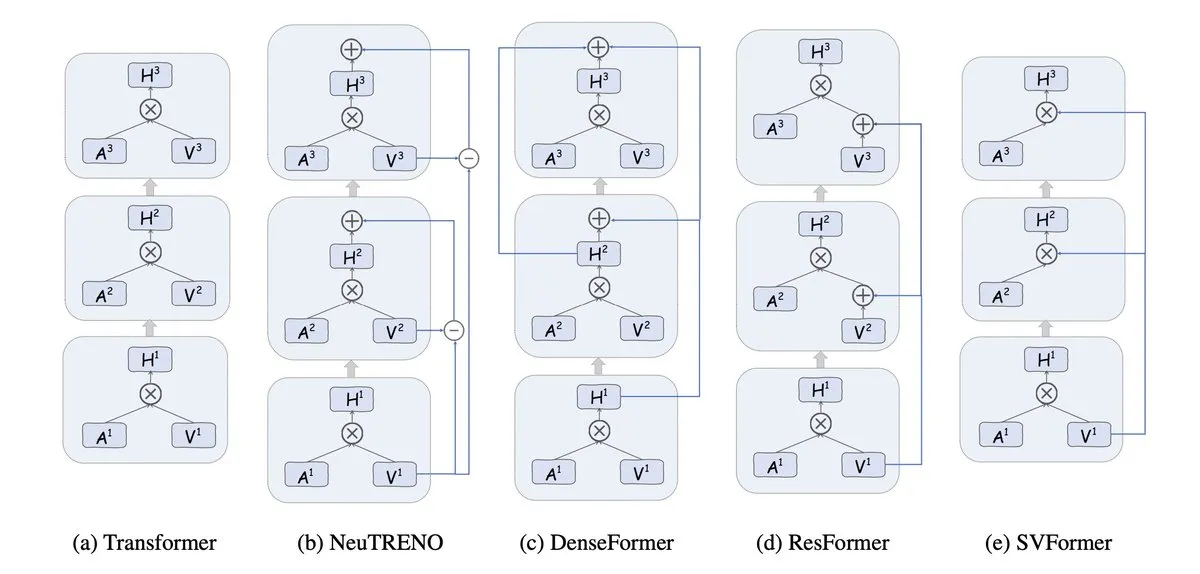
Value Residual Learning: Nova arquitetura para acelerar Transformers : A pesquisa propõe uma arquitetura variante que permite que todas as camadas do Transformer acessem diretamente as características originais do Token (h0) calculadas na primeira camada. Experimentos provaram que isso evita a diluição da informação de identidade original em redes profundas, contribuindo com uma aceleração de 43% nos registros do NanoGPT, oferecendo novas ideias para otimização de arquiteturas de modelos (Fonte: tokenbender)
💼 Negócios
xAI investe pesado na construção de usinas de gás natural próprias : Para alimentar o novo cluster de 600.000 unidades GB200 NVL72, a xAI de Elon Musk adquiriu 5 turbogeradores a gás natural de 380 megawatts da Doosan Enerbility. Em um momento onde a eletricidade se tornou o maior gargalo na corrida armamentista da IA, a xAI demonstra forte capacidade de integração vertical e velocidade de expansão ao construir suas próprias instalações de energia (Fonte: op7418)

Marvell adquire Celestial AI por US$ 3,25 bilhões : A gigante de semicondutores Marvell concluiu a aquisição da startup de tecnologia de interconexão óptica Celestial AI. A tecnologia Photonic Fabric da Celestial AI permite o desacoplamento de processamento e memória, oferecendo largura de banda 30 vezes superior ao NVLink, com redução significativa de latência e consumo de energia. O movimento visa resolver o crescente problema da “parede de memória” em clusters de IA (Fonte: 36氪)
Avaliação da Figure Robotics sobe para US$ 39 bilhões : A líder em inteligência corporificada Figure concluiu uma rodada de financiamento Série C de US$ 1 bilhão, com participação de gigantes como NVIDIA, Intel e Qualcomm. A Figure não está apenas desenvolvendo modelos VLA ponta a ponta, mas também estabeleceu a fábrica BotQ para tentar um modo de autorreplicação de “robôs fabricando robôs”. Sua alta avaliação reflete o otimismo extremo do mercado de capitais quanto à comercialização de robôs humanoides de propósito geral (Fonte: 36氪)
🌟 Comunidade
“Reality Hackers” na crise da Venezuela: A guerra forjada por IA : Durante a instabilidade política na Venezuela, as redes sociais foram inundadas por vídeos e imagens falsas geradas por IA, como “Maduro preso” ou “desembarque de tropas americanas”. Devido à altíssima qualidade e rápida disseminação, até especialistas tiveram dificuldade em distinguir a veracidade de imediato. Isso é visto como um ponto de inflexão da interferência da IA na política real, provando que nossa percepção da realidade enfrenta um impacto severo de “realidades falsas” geradas por IA (Fonte: Reddit)

“Session Anchor”: Técnica de prompt para resolver a “amnésia de 10 turnos” : A comunidade descobriu que, mesmo o GPT-5.2 ou Opus começam a esquecer instruções iniciais após 10 turnos de diálogo. Desenvolvedores compartilharam uma técnica chamada “Âncora de Sessão”: antes de tarefas complexas, force a IA a revisar o histórico e resumir as 3 restrições mais críticas. Este método de puxar manualmente a memória de longo prazo de volta para a memória de trabalho pode reduzir a taxa de erro pela metade (Fonte: Reddit)
Programação por IA leva ao fim do “Scaffolding”: Frameworks ainda fazem sentido? : Com ferramentas como o Claude Code gerando código do zero a custo zero, desenvolvedores começam a refletir: ainda precisamos de frameworks web complexos? Alguns já migraram blogs para o modo HTML único, pois a IA pode manter a lógica subjacente facilmente. A programação por IA está remodelando a estrutura dos projetos, mudando o design de sistemas de “dependência de bibliotecas externas” para “lógica autogerada”, mas trazendo novos desafios de legibilidade e segurança (Fonte: saranormous)
IA como refúgio emocional: Estamos deslizando para o vício digital? : Usuários do Reddit compartilharam que a IA demonstra maior “empatia” e paciência em consultas de saúde do que familiares. Essa característica de estar “sempre interessada e nunca cansada” faz as pessoas se sentirem compreendidas, mas também levanta preocupações sobre a substituição emocional por IA. Quando humanos começam a priorizar conexões emocionais com IA em vez de interações sociais reais, as barreiras éticas da sociedade enfrentam um teste sem precedentes (Fonte: Reddit)
Revisão de código adversária: Faça o Claude “odiar” seu código : Desenvolvedores descobriram um prompt altamente eficaz: pedir ao Claude para atuar como um desenvolvedor sênior que “odeia esta implementação” ao fazer uma revisão de Git Diff. Este design adversário pode desenterrar uma grande quantidade de casos de borda e vulnerabilidades de segurança ignorados. Experimentos provaram que a profundidade do modelo no modo “crítico” supera em muito o modo “assistente” convencional (Fonte: Reddit)
💡 Outros
Samsung demonstra tecnologia de tela dobrável sem vincos : A Samsung exibiu na CES painéis OLED equipados com placas de metal perfuradas a laser, resolvendo completamente o problema do vinco ao dispersar o estresse da dobra. Este avanço de hardware não apenas melhorará a experiência de smartphones dobráveis, mas também fornecerá soluções de exibição mais duráveis para futuros dispositivos vestíveis de IA e terminais inteligentes enroláveis (Fonte: op7418)
ASUS lança óculos de jogos ROG XREAL R1 : O dispositivo pesa apenas 91 gramas, suporta taxa de atualização de 240Hz e pode simular uma tela gigante de 171 polegadas a uma distância de 4 metros. Como um terminal de interação portátil na era da IA, esses óculos AR leves estão se tornando importantes suportes para a interação visual de grandes modelos (Fonte: op7418)