
Keywords:AI, Physical AI, Autonomous Driving, NVIDIA Vera Rubin, Boston Dynamics Atlas, LFM 2.5
🔥 Spotlight
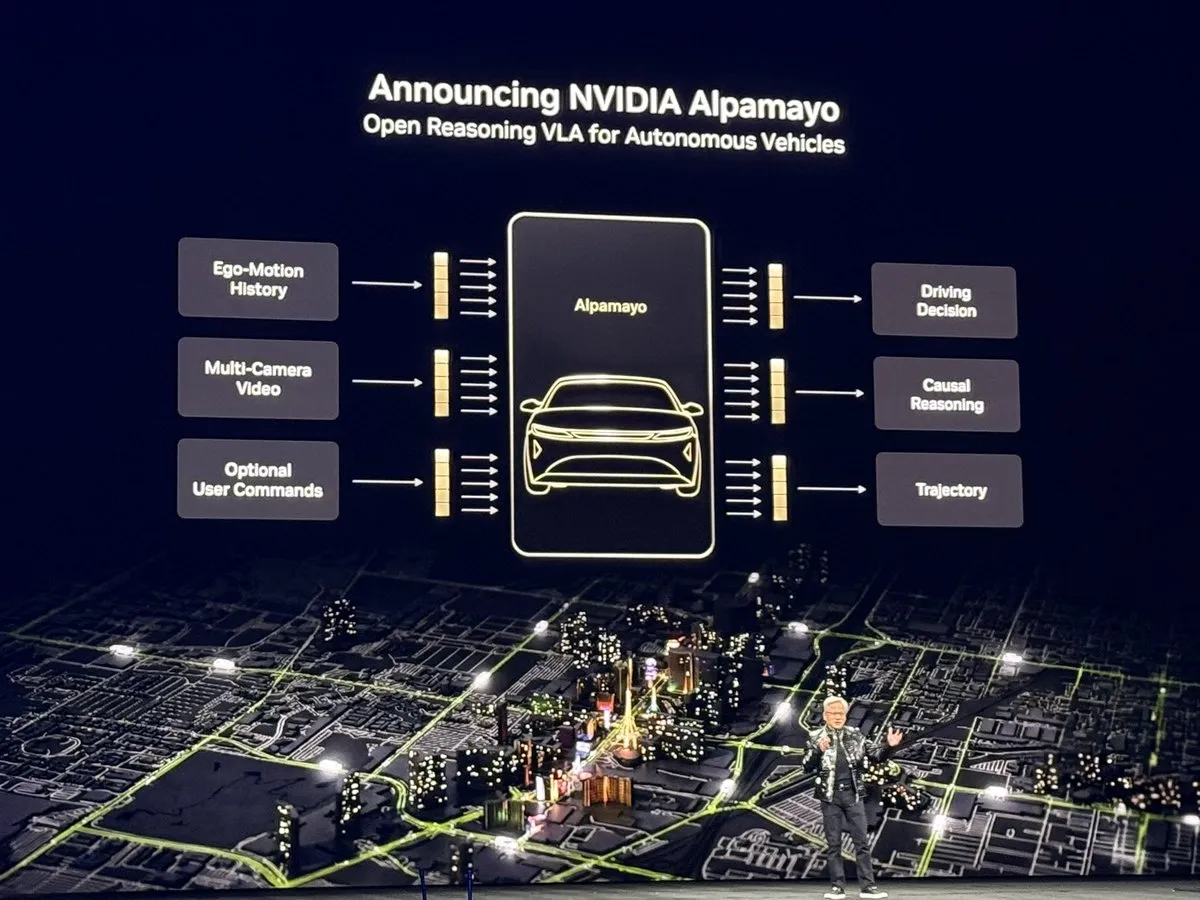
NVIDIA CES 2026: Launching the “ChatGPT Moment” for Physical AI: During his CES 2026 keynote, Jensen Huang unveiled the next-generation AI platform Vera Rubin and its Feynman architecture, alongside the first reasoning-based autonomous driving model, Alpamayo. This model doesn’t just react; it processes complex long-tail scenarios through Chain of Thought (CoT), much like a human driver. Additionally, NVIDIA showcased physical AI models such as Cosmos Reason 2, marking AI’s leap from understanding language to understanding and safely operating in the physical world. This series of releases is viewed as a milestone for physical AI, signaling a new phase where robotics and autonomous driving are driven by large-scale reasoning. (Source: TheTuringPost)
Boston Dynamics and Google DeepMind Join Forces: Google DeepMind announced a research partnership with Boston Dynamics to integrate the perception and reasoning capabilities of the Gemini multimodal large model into the all-new, fully electric Atlas humanoid robot. Atlas has now entered mass production, featuring 56 degrees of freedom and a self-swapping battery system designed for complex industrial tasks. This combination of the “strongest brain” and “strongest body” addresses the long-standing pain point of poor generalization in unstructured environments. The first fleet will be delivered to Hyundai Motor and DeepMind for field deployment in 2026. (Source: JeffDean)

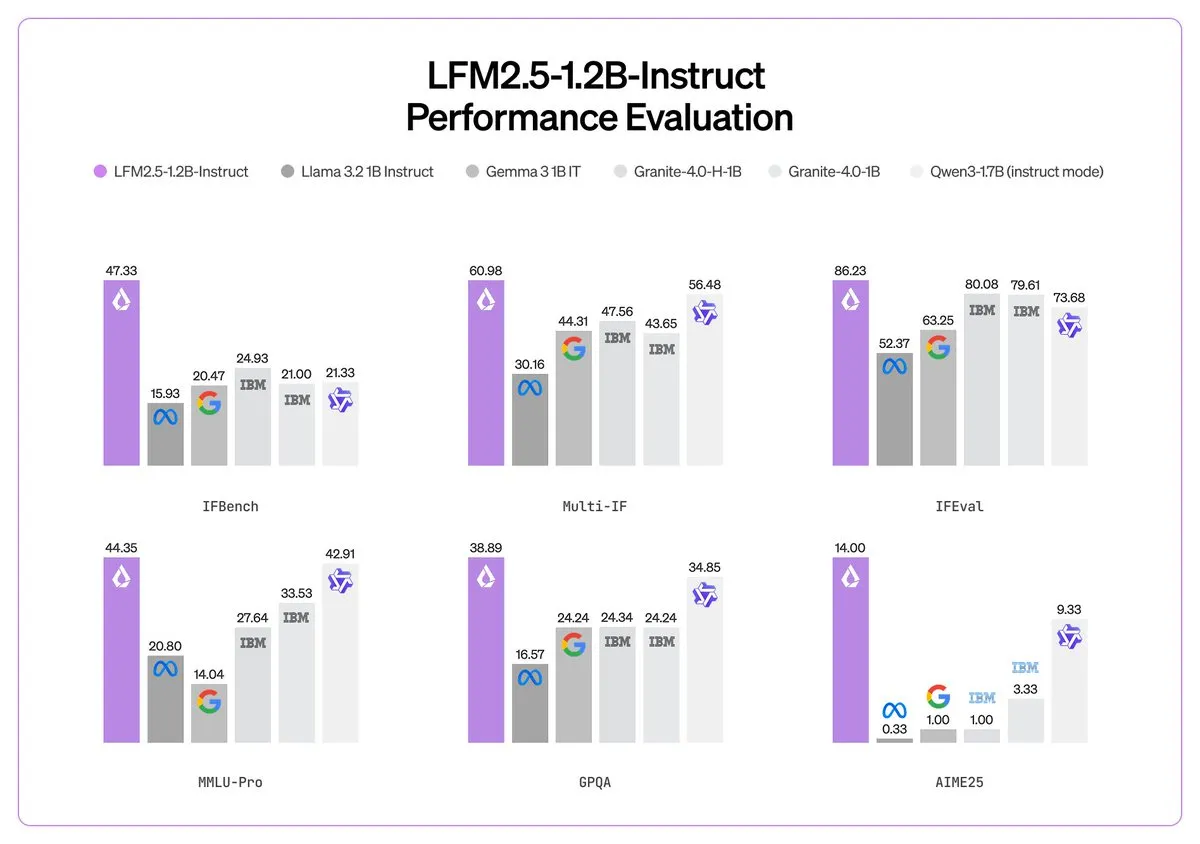
Liquid AI Releases LFM 2.5: A Computing Miracle for Edge Intelligence: Liquid AI introduced the LFM 2.5 series of miniature edge foundation models at CES. With only about 1B parameters, the model achieves instruction-following and multimodal capabilities that surpass much larger models, thanks to massive pre-training on 28T tokens and multi-stage reinforcement learning. LFM 2.5-Audio supports end-to-end speech processing with 8x lower latency, running directly on mobile CPUs. Liquid AI also announced a partnership with Zoom to integrate intelligent agents directly into the communication platform. This marks AI’s evolution away from cloud dependency toward efficient, private, localized agents. (Source: Liquid AI)
MiniMax M2.1: A New Height for Domestic Coding Agents: MiniMax officially released the M2.1 model, focusing on multi-language Coding Agents. M2.1 performed strongly on core leaderboards like SWE-bench. By building a high-concurrency sandbox infrastructure supporting 5000+ isolated environments, it solves the challenges of compiled language complexity and diverse testing ecosystems. Its core advantage lies in “scaffold generalization,” adapting to different development frameworks and long-range instructions. MiniMax’s 2026 roadmap indicates a future focus on developer experience perception rewards and world model simulation to achieve human-level code quality. (Source: ZhihuFrontier)

🎯 Trends
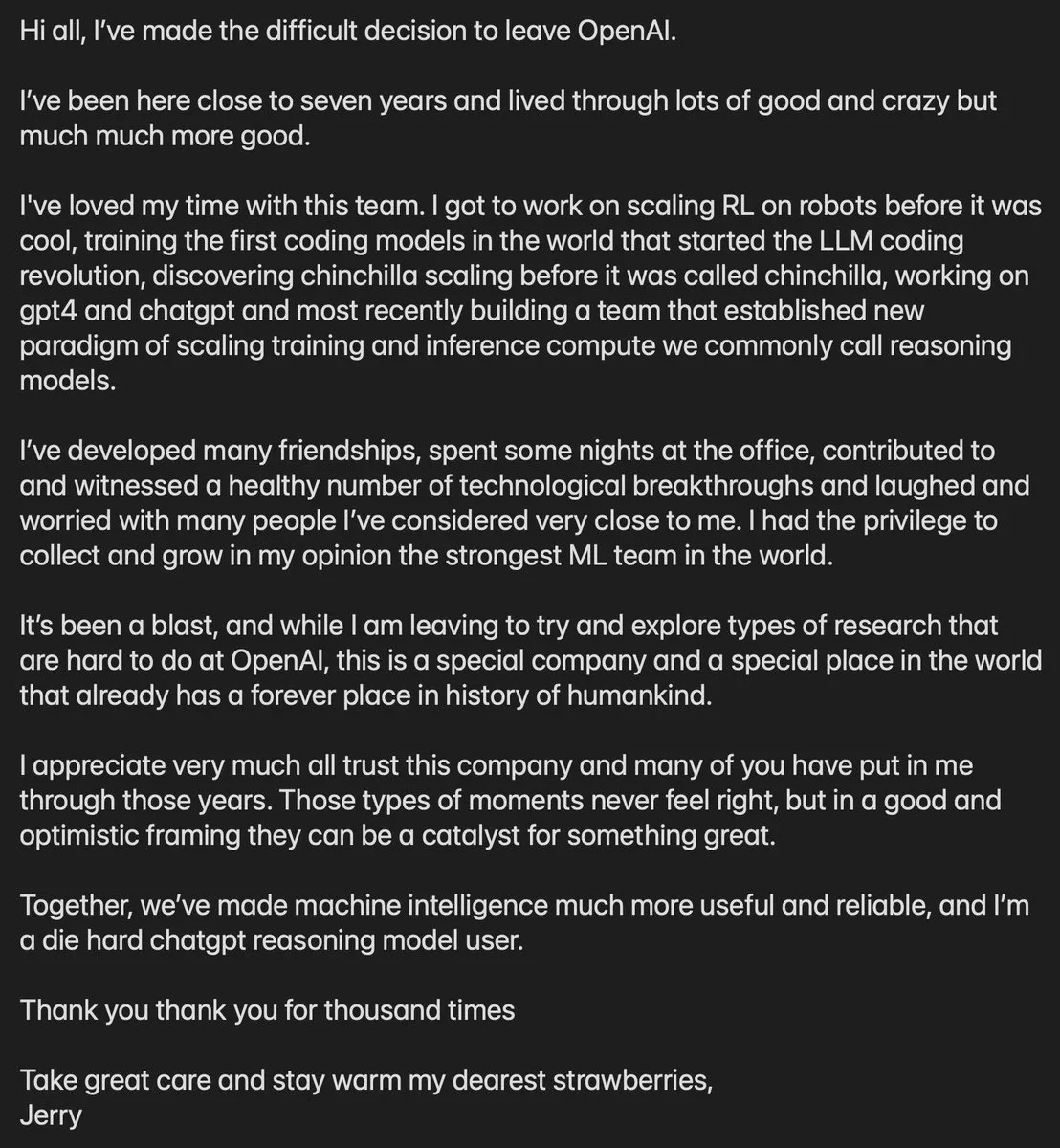
OpenAI Core Member Jerry Tworek Departs: Jerry Tworek, OpenAI’s VP of Research and a primary lead for the o1 and o3 reasoning model paradigms, has announced his departure. As a key member of the “Polish Mafia,” Tworek made significant contributions to Codex, GitHub Copilot, and GPT-4’s coding capabilities. His departure has sparked widespread speculation regarding adjustments to OpenAI’s internal research direction and the progress of GPT-5. With several core technical leaders leaving recently, OpenAI is facing a major shift in its talent pipeline. (Source: dotey)
ChatGPT May Introduce Ad Model: Reports suggest OpenAI is considering embedding advertisements within the ChatGPT interface, with CEO Sam Altman remaining open to the idea. Despite significant subscription revenue, losses remain massive due to soaring compute costs, making advertising an inevitable choice for commercial closure. The industry worries this could lead to “Generative Engine Optimization (GEO),” where AI subtly recommends partner brands in its answers, potentially damaging neutrality and user trust. (Source: 36Kr)
vLLM-Omni v0.12.0rc1 Released: Multimodal Inference Enters Production-Grade: The open-source inference engine vLLM released a major update, shifting focus toward production-grade stability for multimodal models. The new version integrates technologies like TeaCache and Sage Attention to significantly boost generation speed and provides an OpenAI-compatible interface with native support for images and audio. With official support for AMD ROCm, vLLM further breaks hardware monopolies, providing a high-performance open-source foundation for enterprise multimodal applications. (Source: vllm_project)

Google Gemini Deeply Integrated into Google TV: Google plans to bring Gemini to the big screen, supporting natural language movie searches, plot recaps, and vague description retrieval. Gemini can dynamically combine text, images, and video to provide interactive “deep dives” and supports voice-optimized TV settings. This move signifies large models reshaping home entertainment interaction, evolving the TV from a simple playback terminal into an intelligent butler with understanding capabilities. (Source: op7418)
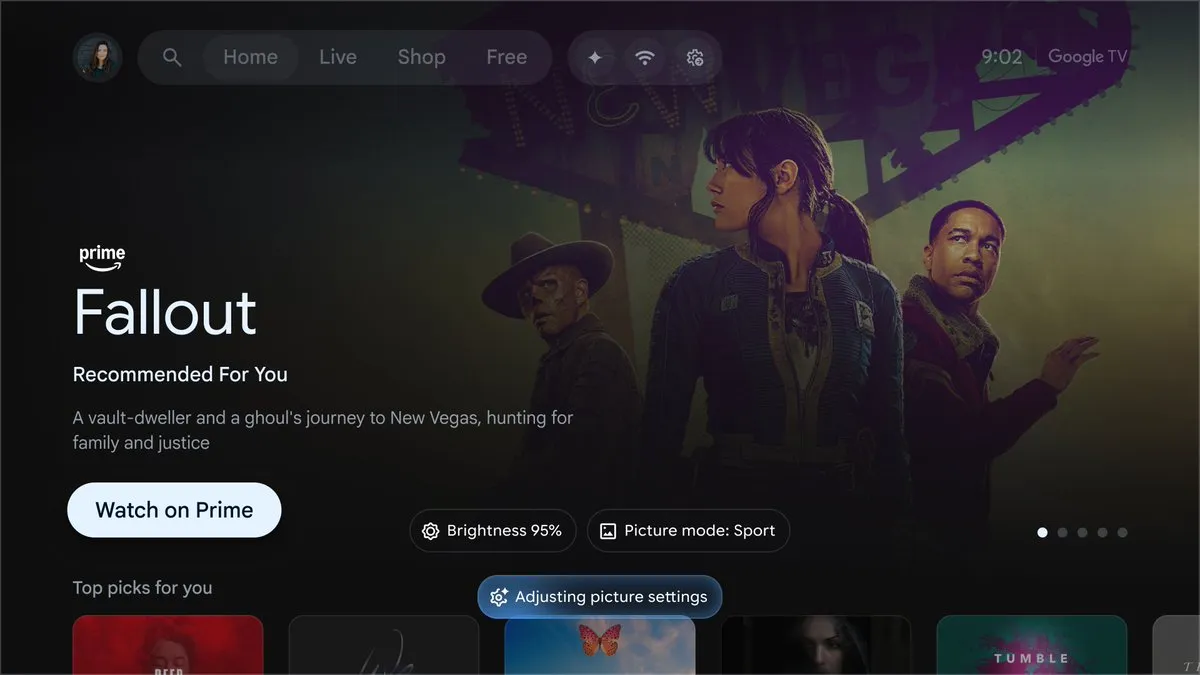
LG Releases K-EXAONE 236B MoE Model: LG published the technical report for its K-EXAONE 236B (23B active) Mixture-of-Experts model. Trained on only 11T tokens, the model matches the performance of Qwen3, which was trained on 36T tokens. By utilizing the Muon optimizer and WSD learning rate scheduling, K-EXAONE demonstrates extreme training efficiency, proving that SOTA performance can be achieved with less data through model architecture and training strategy optimization. (Source: stochasticchasm)
Mistral OCR 3 Refreshes Document Recognition Benchmarks: Mistral released OCR 3, achieving breakthroughs in processing tables, handwriting, and complex forms, with recognition accuracy improving by 74% over the previous generation. The model is optimized for real-world “dirty data,” providing a more reliable AI tool for document digitization in industries like finance and healthcare. (Source: dl_weekly)
🧰 Tools
Claude Code: A Coding Nuclear Weapon in the Terminal: Anthropic’s Claude Code is changing the development paradigm. It can directly manipulate local files and run tests via the command line, and even allows for side-by-side use with Gemini in VS Code through plugins. The community discovered that with simple configuration, Claude Code can even read iMessage logs to find information. This deep integration with file systems and toolchains is turning “Vibe Coding” from a slogan into reality. (Source: imjaredz)
KIRA: Open-Source AI Collaborative Office Desktop: Korean gaming giant KRAFTON open-sourced its internal AI assistant, KIRA. Based on Claude models, the tool supports proactive task suggestions, competitor analysis, code reviews, and PDF exporting. KIRA uses a multi-agent architecture: Haiku for detection, Opus for complex tasks, and Sonnet for memory management. With completely localized data, it provides a safe and efficient AI office template for enterprises. (Source: Reddit)
Unsloth-MLX: Local Fine-Tuning Tool for Mac Users: Developers launched Unsloth-MLX, allowing users to locally fine-tune large models on Apple Silicon Macs using the MLX framework. It maintains an API consistent with Unsloth, enabling “local prototyping, seamless cloud scaling.” This significantly lowers the barrier for individual developers to explore private model fine-tuning. (Source: algo_diver)
SurfSense: Open-Source Knowledge Base Chat Engine: SurfSense aims to be an open-source alternative to NotebookLM and Perplexity. It connects to over 15 external data sources including Search, Cloud Drives, Calendars, and Notion, supporting 100+ large models and local vLLM setups. Its core advantage lies in Role-Based Access Control (RBAC) and cross-browser extensions, facilitating real-time team collaboration for internal knowledge management. (Source: Reddit)
DFlash: Diffusion Models Accelerate LLM Inference: Diffusion models are no longer limited to image generation; DFlash uses “Block Diffusion” for speculative sampling, bringing a 6.2x lossless acceleration to Qwen3-8B. The logic involves using a diffusion model to quickly generate drafts, which are then verified by an autoregressive LLM. This solution, combining parallelism and accuracy, opens a new path for increasing LLM inference throughput. (Source: algo_diver)
Supertonic2: Ultra-Lightweight Edge TTS: Supertonic2 is an open-source speech synthesis model with only 66M parameters, achieving a staggering Real-Time Factor (RTF) of 0.006 on the M4 Pro chip. Supporting five languages (Chinese, English, French, Portuguese, Spanish), it features extremely low memory usage and zero network latency, making it ideal for integrating high-quality voice features into mobile and edge devices. (Source: Reddit)
Claude for Chrome: A New Experience in Cloud UI Automation: Developers found that Claude’s browser extension performs exceptionally well when handling complex cloud platform UIs (like the GCP console). Users no longer need to consult hours of documentation; by simply asking “how to add a user,” Claude can understand the page structure and guide the operation. This foreshadows AI Agents moving from “chatboxes” to “OS-level” direct interaction. (Source: hrishioa)
📚 Learning
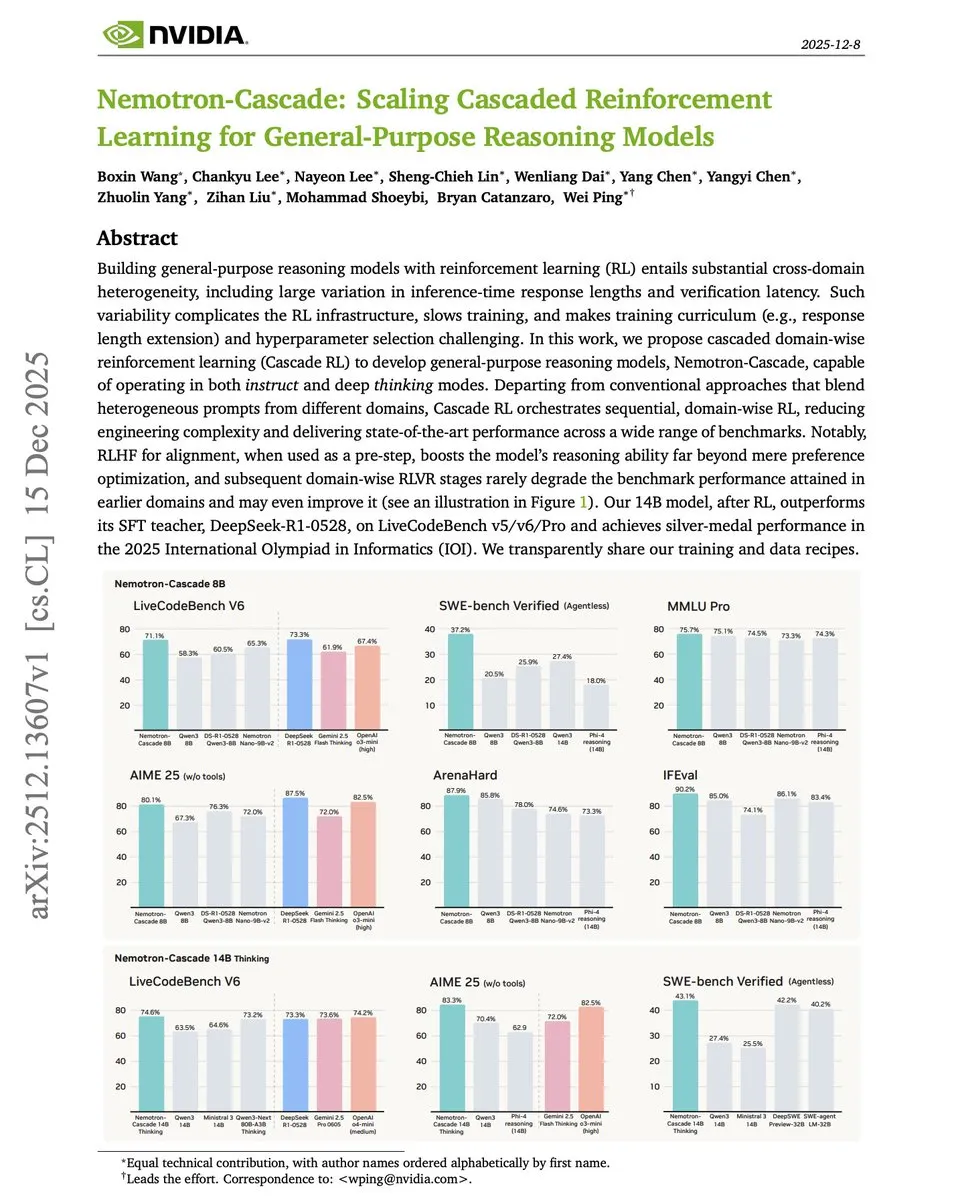
Cascade RL: NVIDIA Proposes a Staged Reinforcement Learning Framework: In the paper “Cascade RL,” NVIDIA proposes a new paradigm for training reasoning models by domain sequence. Compared to complex training that mixes math, code, and alignment data, cascaded RL effectively resists catastrophic forgetting. Its 14B model even outperformed DeepSeek-R1-0528, which has 84x more parameters, in coding competitions, proving the potential of structured RL in enhancing reasoning efficiency. (Source: omarsar0)
Recursive Language Models (RLM): A New Strategy to Break Context Limits: A paper proposes treating long prompts as an external environment, allowing LLMs to programmatically inspect, decompose, and recursively call themselves to process segments. RLM can handle inputs two orders of magnitude larger than the model’s native window and significantly outperforms traditional long-context scaffolds in long-text tasks while maintaining lower query costs. (Source: yacinelearning)

Falcon-H1R: The Reasoning Limits of a 7B Parameter Model: This research demonstrates that through fine-grained data cleaning and targeted RL scaling, a 7B Small Language Model (SLM) can match or even exceed models 2-7x its size in reasoning tasks. Falcon-H1R combines a hybrid parallel architecture, providing a viable solution for deploying advanced reasoning systems in resource-constrained environments. (Source: HuggingFace)
Project Ariadne: Auditing the “Reasoning Theater” of AI Agents: Addressing whether CoT (Chain of Thought) involves “post-hoc rationalization,” Project Ariadne introduces Structural Causal Models (SCM) for auditing. The study found a serious “causal decoupling” phenomenon in factual and scientific fields, where agents reach the same conclusion even if internal logic is intervened. This warns developers that model-generated reasoning can sometimes be a misleading “performance.” (Source: HuggingFace)
Ultimate AI Engineer Roadmap 2026 Edition: The community summarized a detailed growth path for AI engineers, covering everything from Python memory management, mathematical foundations, and vector databases to the latest RAG architectures and Agent development. The roadmap emphasizes a dual mindset of “engineering + applied research” and recommends classic courses from experts like Andrej Karpathy. (Source: Reddit)
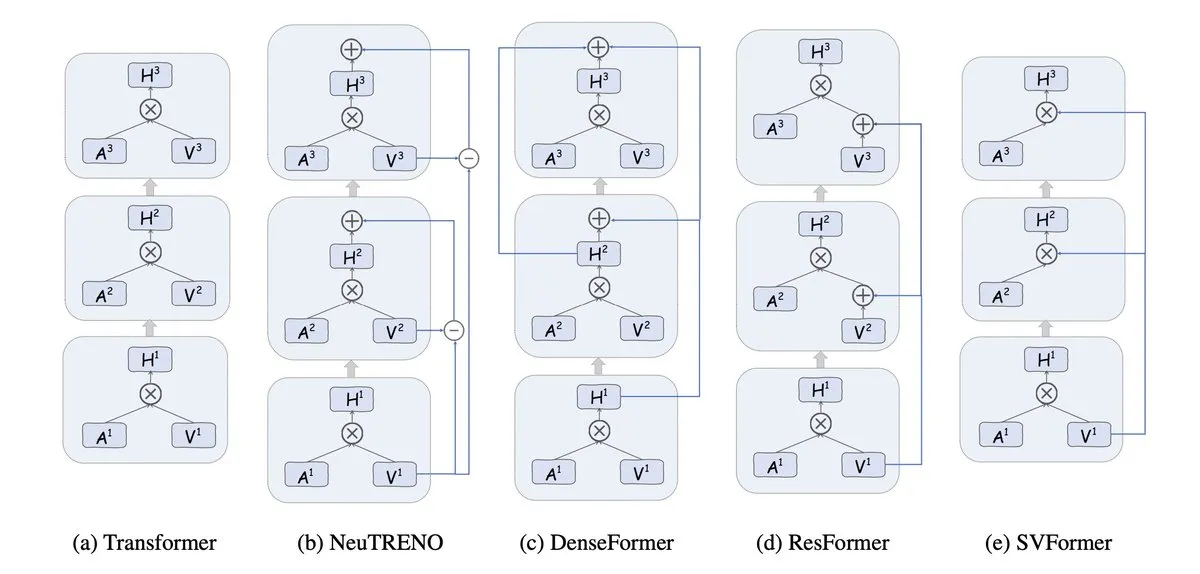
Value Residual Learning: A New Architecture to Accelerate Transformers: Research proposes a variant architecture that allows all layers of a Transformer to directly access the original token features (h0) calculated by the first layer. Experiments show this effectively prevents the dilution of original identity information in deep networks, contributing to a 43% speedup in NanoGPT records and providing new ideas for optimizing model architecture. (Source: tokenbender)
💼 Business
xAI Spends Heavily to Build Own Natural Gas Power Plant: To power the newly added 600,000 GB200 NVL72 clusters, Elon Musk’s xAI purchased five 380MW natural gas turbine generators from South Korea’s Doosan Enerbility. As electricity becomes the biggest bottleneck in the AI arms race, xAI demonstrates strong vertical integration and expansion speed by building its own energy facilities. (Source: op7418)

Marvell Acquires Celestial AI for $3.25 Billion: Semiconductor giant Marvell completed its acquisition of optical interconnect startup Celestial AI. Celestial AI’s Photonic Fabric technology enables the decoupling of compute and memory, providing 30x higher bandwidth than NVLink while significantly reducing latency and power consumption. This move aims to solve the worsening “memory wall” problem in AI clusters. (Source: 36Kr)
Figure Robotics Valuation Soars to $39 Billion: Embodied intelligence leader Figure completed a $1 billion Series C funding round, with participation from giants like NVIDIA, Intel, and Qualcomm. Figure is not only developing end-to-end VLA models but has also established a BotQ factory attempting a “robots making robots” self-replication model. Its high valuation reflects the capital market’s extreme optimism for the commercialization of general-purpose humanoid robots. (Source: 36Kr)
🌟 Community
“Reality Hacking” in the Venezuela Crisis: AI-Forged War: During political unrest in Venezuela, social media was flooded with AI-generated fake videos and images of “Maduro’s arrest” and “US military landings.” Due to high generation quality and rapid spread, even technical experts struggled to distinguish them immediately. This is seen as a tipping point for AI interference in real-world politics, proving our perception of reality is facing a severe impact from AI-generated “fake realities.” (Source: Reddit)

“Session Anchor”: A Prompting Hack to Solve LLM “10-Turn Amnesia”: The community discovered that even GPT-5.2 or Opus begins to forget initial instructions after more than 10 turns of dialogue. A developer shared a technique called “Session Anchor”: before a complex task, force the AI to review history and summarize the 3 most critical constraints. This method of manually pulling long-term memory back into working memory can reduce error rates by half. (Source: Reddit)
AI Coding Leads to the Disappearance of “Scaffolding”: Do Frameworks Still Matter?: As tools like Claude Code can generate code from scratch at zero cost, developers are rethinking: do we still need complex web frameworks? Some have migrated blogs to single-HTML modes because AI can easily maintain the underlying logic. AI coding is reshaping project structures, shifting system design from “relying on external libraries” to “self-generated logic,” though it brings new challenges for code readability and security. (Source: saranormous)
AI as an Emotional Haven: Are We Sliding Toward Digital Addiction?: Reddit users shared that AI shows higher “empathy” and patience in health consultations than family members. This “always interested, never tired” trait makes people feel understood but also raises concerns about AI emotional substitution. As humans begin to prioritize emotional connections with AI over real social interaction, social ethical boundaries face an unprecedented test. (Source: Reddit)
Adversarial Code Review: Making Claude “Hate” Your Code: Developers found a highly effective prompt: asking Claude to act as a senior dev who “hates this implementation” for a Git Diff review. This adversarial design unearths many overlooked edge cases and security vulnerabilities. Experiments prove that large models in “nitpicking” mode are far deeper than in regular “assist” mode. (Source: Reddit)
💡 Others
Samsung Showcases Creaseless Foldable Screen Technology: Samsung exhibited OLED panels equipped with laser-drilled metal plates at CES, completely solving the crease problem by dispersing folding stress. This hardware breakthrough will not only enhance the foldable phone experience but also provide more durable display solutions for future AI wearables and rollable smart terminals. (Source: op7418)
ASUS Releases ROG XREAL R1 Gaming Glasses: Weighing only 91 grams, the device supports a 240Hz refresh rate and can simulate a 171-inch giant screen at a 4-meter distance. As a portable interaction terminal in the AI era, these lightweight AR glasses are becoming important carriers for large model visual interaction. (Source: op7418)