
Palabras clave:IA, IA física, conducción autónoma, NVIDIA Vera Rubin, Boston Dynamics Atlas, LFM 2.5
🔥 Enfoque
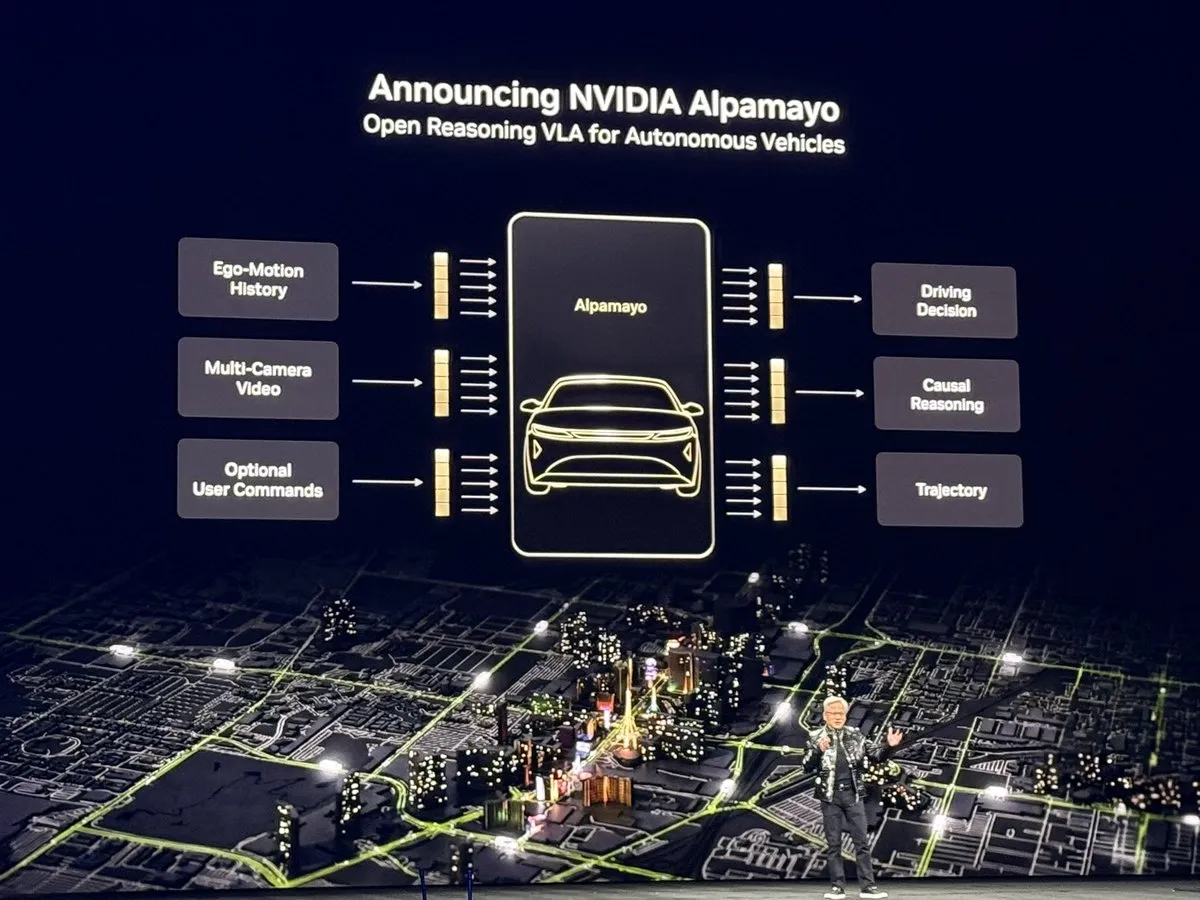
NVIDIA CES 2026: El “momento ChatGPT” de la Physical AI : Jensen Huang presentó en su discurso de apertura de CES 2026 la plataforma de próxima generación Vera Rubin y su arquitectura Feynman, además de lanzar Alpamayo, el primer modelo de conducción autónoma basado en razonamiento. Este modelo no solo reacciona, sino que puede procesar escenarios complejos de “long-tail” a través de Chain of Thought (CoT), al igual que un conductor humano. Además, NVIDIA mostró modelos de Physical AI como Cosmos Reason 2, marcando el salto de la AI desde la comprensión del lenguaje hacia la comprensión y operación segura del mundo físico. Esta serie de lanzamientos se considera un hito para la Physical AI, anticipando una nueva etapa impulsada por el razonamiento a gran escala en robótica y conducción autónoma (Fuente: TheTuringPost)
Boston Dynamics y Google DeepMind unen fuerzas : Google DeepMind anunció una asociación de investigación con Boston Dynamics para integrar las capacidades de percepción y razonamiento del modelo multimodal Gemini en el nuevo robot humanoide Atlas totalmente eléctrico. Atlas ha entrado en fase de producción en masa, con 56 grados de libertad y un sistema de batería auto-reemplazable, diseñado para ejecutar tareas industriales complejas. Esta combinación del “cerebro más potente” con el “cuerpo más fuerte” resuelve el problema histórico de la baja capacidad de generalización de los robots en entornos no estructurados. La primera flota se entregará en 2026 a Hyundai Motor y DeepMind para despliegue en campo (Fuente: JeffDean)

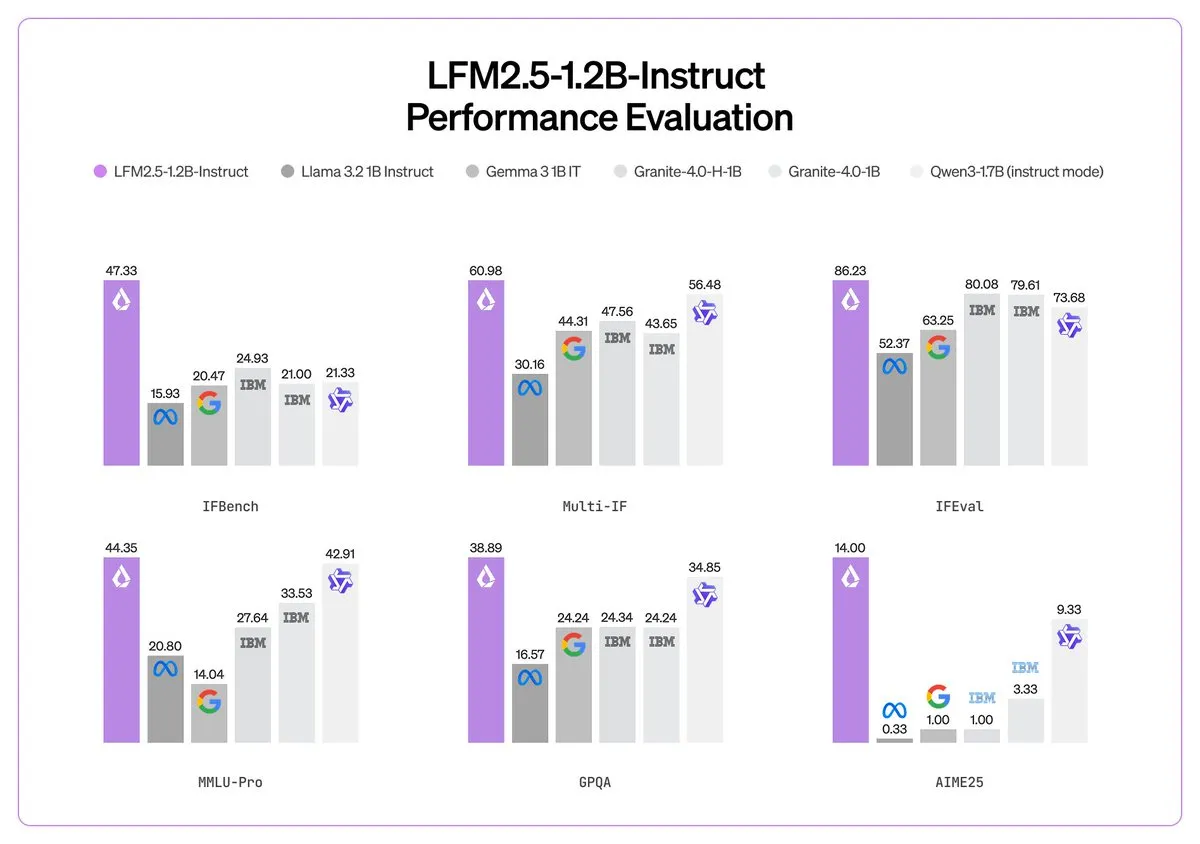
Liquid AI lanza LFM 2.5: El milagro de la computación en On-device Intelligence : Liquid AI presentó en CES la serie LFM 2.5 de modelos base miniatura para dispositivos finales. Con solo 1B de parámetros, el modelo logra una capacidad de seguimiento de instrucciones y habilidades multimodales superiores a modelos más grandes mediante un pre-entrenamiento masivo de 28T tokens y aprendizaje por refuerzo multietapa. LFM 2.5-Audio soporta procesamiento de voz end-to-end con una latencia 8 veces menor, funcionando directamente en la CPU del teléfono. Liquid AI también anunció una colaboración con Zoom para integrar agentes inteligentes directamente en la plataforma de comunicación. Esto marca la evolución de la AI hacia agentes locales eficientes y privados, alejándose de la dependencia de la nube (Fuente: Liquid AI)
MiniMax M2.1: Un nuevo nivel para los Coding Agents domésticos : MiniMax lanzó oficialmente el modelo M2.1, enfocado en Coding Agents multilingües. M2.1 mostró un fuerte desempeño en benchmarks clave como SWE-bench, resolviendo desafíos de complejidad en lenguajes compilados y diversidad de ecosistemas de prueba mediante una infraestructura de sandbox de alta concurrencia que soporta más de 5000 entornos aislados. Su ventaja principal reside en la “generalización de andamiaje” (scaffolding generalization), adaptándose a diferentes frameworks de desarrollo e instrucciones de largo alcance. El roadmap de MiniMax para 2026 indica que se centrarán en recompensas de percepción de experiencia del desarrollador y simulación de World Models, buscando alcanzar una calidad de código de nivel humano (Fuente: ZhihuFrontier)

🎯 Tendencias
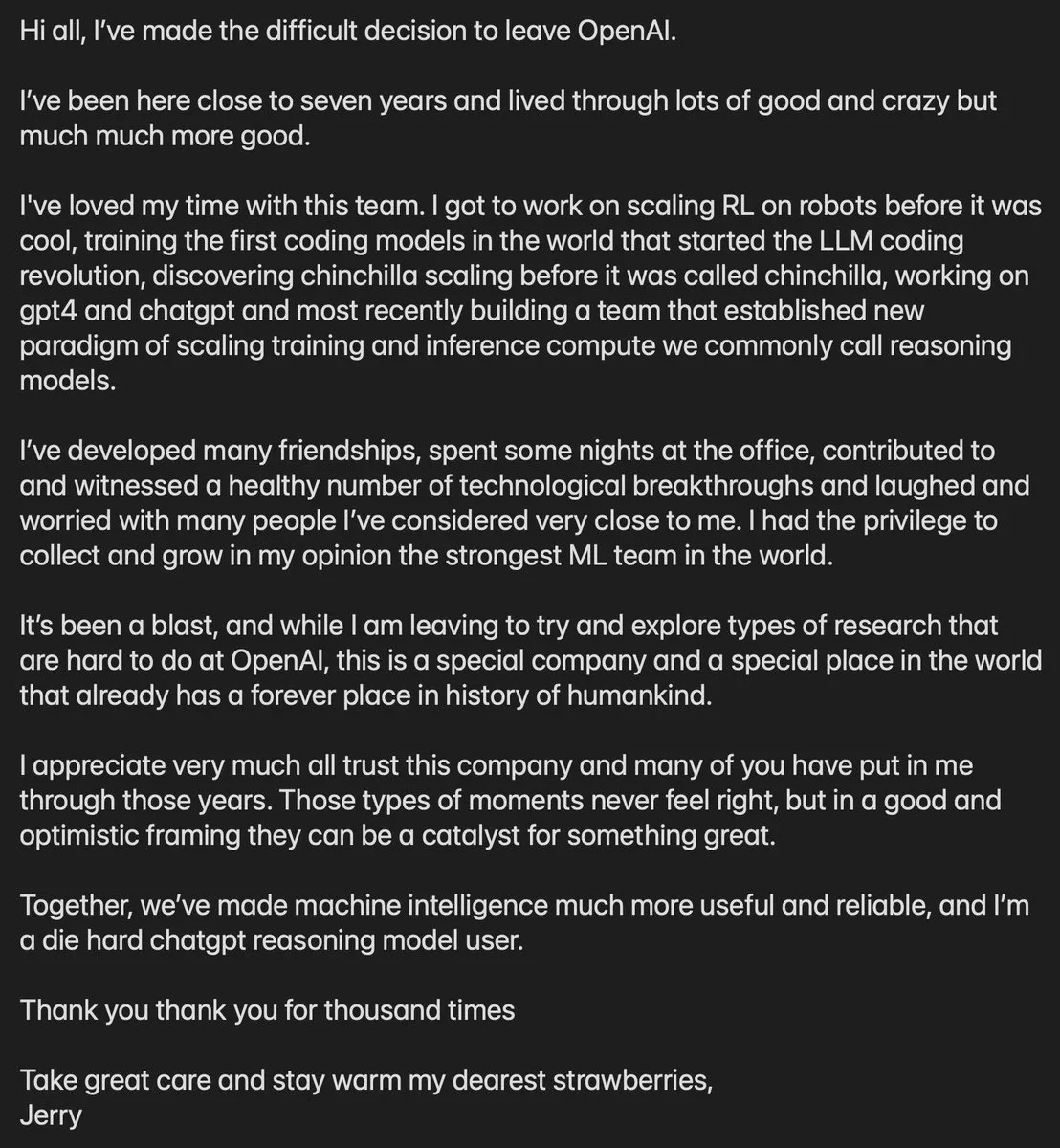
Jerry Tworek, miembro principal de OpenAI, deja la empresa : Jerry Tworek, vicepresidente de investigación de OpenAI y responsable principal de los paradigmas de los modelos de razonamiento o1 y o3, anunció su salida. Como miembro clave de la “facción polaca”, Tworek contribuyó enormemente a las capacidades de código de Codex, GitHub Copilot y GPT-4. Su partida ha generado especulaciones sobre ajustes en la dirección de investigación interna de OpenAI y el progreso de GPT-5. Con la salida sucesiva de varios líderes técnicos, OpenAI enfrenta cambios drásticos en su estructura de talento (Fuente: dotey)
ChatGPT podría introducir un modelo publicitario : Informes indican que OpenAI está considerando insertar publicidad en la interfaz de ChatGPT, y el CEO Sam Altman se muestra abierto a la idea. A pesar de los considerables ingresos por suscripciones, las pérdidas siguen siendo enormes debido al aumento de los costos de computación, convirtiendo a la publicidad en una opción necesaria para cerrar el ciclo comercial. La industria teme que esto pueda dar lugar a la “Generative Engine Optimization (GEO)”, donde la AI recomiende sutilmente marcas asociadas en sus respuestas, comprometiendo su neutralidad y la confianza del usuario (Fuente: 36氪)
Lanzamiento de vLLM-Omni v0.12.0rc1: El razonamiento multimodal entra en fase de producción : El motor de razonamiento open-source vLLM lanzó una actualización importante, enfocándose en la estabilidad de nivel de producción para modelos multimodales. La nueva versión integra tecnologías como TeaCache y Sage Attention para aumentar drásticamente la velocidad de generación, y ofrece una interfaz compatible con OpenAI que soporta nativamente imagen y voz. Con el soporte oficial para AMD ROCm, vLLM rompe aún más el monopolio de hardware, proporcionando una base open-source de alto rendimiento para aplicaciones multimodales empresariales (Fuente: vllm_project)

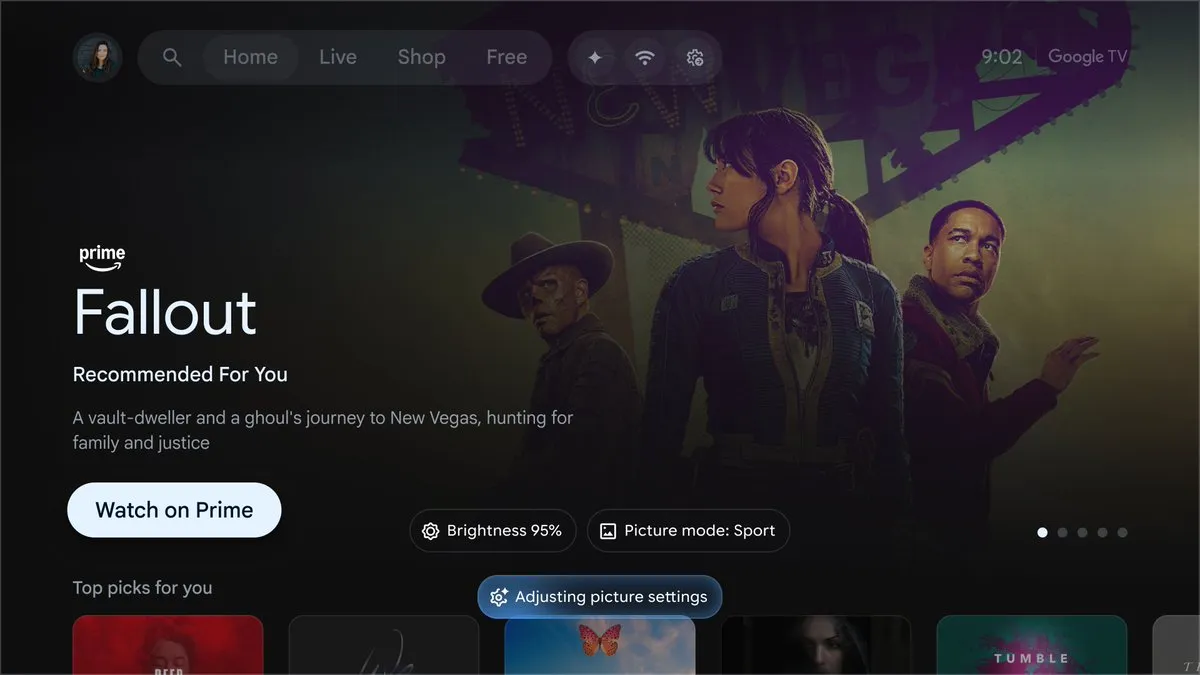
Google Gemini se integra profundamente con Google TV : Google planea llevar Gemini a las pantallas de TV, permitiendo la búsqueda de películas con lenguaje natural, resúmenes de tramas y búsquedas por descripciones vagas. Gemini puede combinar dinámicamente texto, imágenes y video para ofrecer un “análisis profundo” interactivo y optimizar la configuración de la TV mediante voz. Este movimiento marca la redefinición de la interacción en el entretenimiento doméstico por parte de los Large Models, transformando la TV de un simple terminal de reproducción a un mayordomo inteligente con capacidad de comprensión (Fuente: op7418)
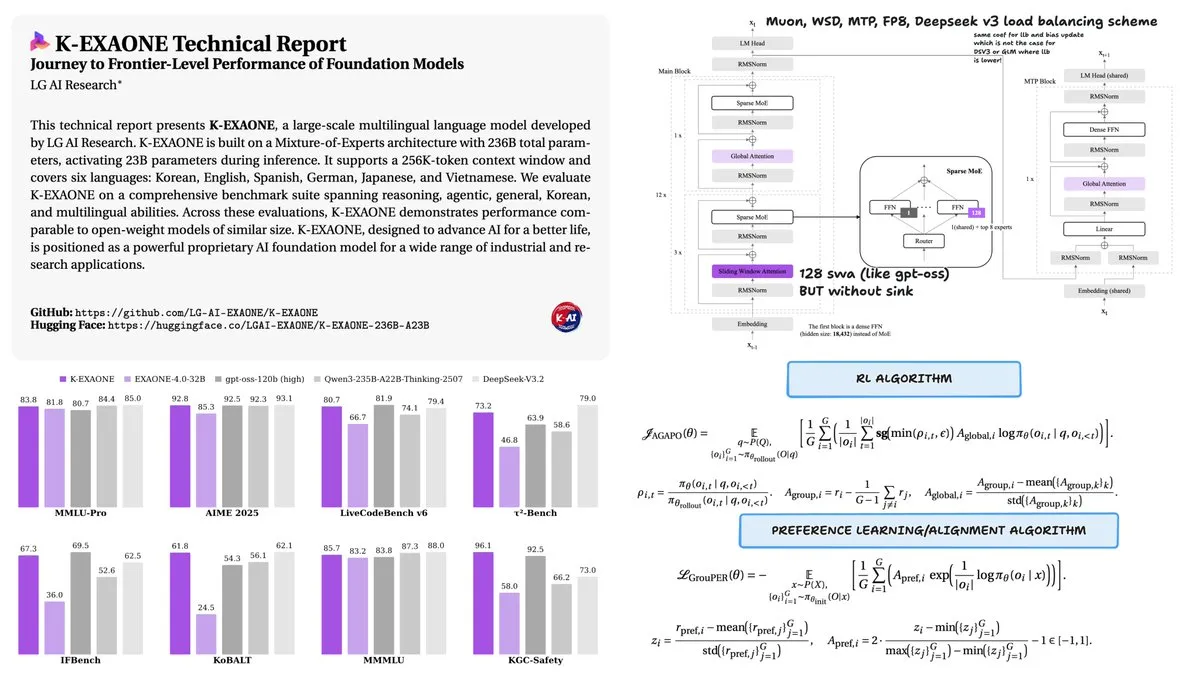
LG lanza el modelo K-EXAONE 236B MoE : LG publicó el informe técnico de su modelo Mixture of Experts (MoE) K-EXAONE 236B (23B activos). Entrenado con solo 11T tokens, su rendimiento es comparable al de Qwen3 entrenado con 36T tokens. Mediante el uso del optimizador Muon y el programador de tasa de aprendizaje WSD, K-EXAONE demuestra una eficiencia de entrenamiento extremadamente alta, probando que con optimizaciones en la arquitectura y la estrategia de entrenamiento, se puede alcanzar un rendimiento SOTA con menos datos (Fuente: stochasticchasm)
Mistral OCR 3 rompe los récords en reconocimiento de documentos : Mistral lanzó OCR 3, logrando avances en el procesamiento de tablas, escritura a mano y formularios complejos, con una mejora del 74% en la precisión respecto a la generación anterior. El modelo está optimizado para “datos sucios” del mundo real, proporcionando una herramienta de AI más confiable para la digitalización de documentos en sectores como finanzas y salud (Fuente: dl_weekly)
🧰 Herramientas
Claude Code: El arma nuclear de programación en la terminal : Claude Code, lanzado por Anthropic, está cambiando el paradigma del desarrollo. No solo puede operar archivos locales y ejecutar pruebas directamente desde la línea de comandos, sino que también permite el uso híbrido con Gemini en VS Code mediante plugins. La comunidad descubrió que, con una configuración simple, Claude Code puede incluso leer registros de iMessage para buscar información. Esta capacidad de integración profunda con el sistema de archivos y el toolchain está convirtiendo el “Vibe Coding” de un eslogan a una realidad (Fuente: imjaredz)
KIRA: Escritorio de colaboración AI open-source : El gigante coreano de los videojuegos KRAFTON liberó KIRA, su asistente de AI interno. Basado en modelos Claude, soporta sugerencias proactivas de tareas, análisis de competidores, revisión de código y exportación a PDF. KIRA utiliza una arquitectura multi-agente donde Haiku se encarga de la detección, Opus ejecuta tareas complejas y Sonnet gestiona la memoria. Los datos son completamente locales, ofreciendo un modelo de oficina AI seguro y eficiente para empresas (Fuente: Reddit)
Unsloth-MLX: Herramienta de fine-tuning local para usuarios de Mac : Desarrolladores lanzaron Unsloth-MLX, permitiendo a los usuarios realizar fine-tuning de Large Models localmente en Macs con Apple Silicon utilizando el framework MLX. Mantiene una API consistente con Unsloth, logrando un “prototipado local con escalado fluido a la nube”. Esto reduce significativamente la barrera para que desarrolladores individuales exploren el fine-tuning de modelos privados (Fuente: algo_diver)
SurfSense: Motor de diálogo de base de conocimientos open-source : SurfSense aspira a ser una alternativa open-source a NotebookLM y Perplexity. Puede conectarse a más de 15 fuentes de datos externas como búsqueda, almacenamiento en la nube, calendarios y Notion, soportando más de 100 tipos de Large Models y configuraciones locales de vLLM. Su ventaja principal es el soporte para control de acceso basado en roles (RBAC) y extensiones cross-browser, facilitando la colaboración en tiempo real para gestionar el conocimiento interno de los equipos (Fuente: Reddit)
DFlash: Modelos de difusión acelerando el razonamiento de LLM : Los modelos de difusión ya no se limitan a la generación de imágenes; DFlash utiliza “difusión por bloques” para implementar speculative sampling, logrando una aceleración sin pérdidas de 6.2x para Qwen3-8B. La lógica consiste en usar el modelo de difusión para generar borradores rápidos que luego son validados por el LLM autorregresivo. Esta solución, que combina paralelismo y precisión, abre un nuevo camino para aumentar el throughput de razonamiento de los LLM (Fuente: algo_diver)
Supertonic2: TTS on-device extremadamente ligero : Supertonic2 es un modelo de síntesis de voz open-source con solo 66M de parámetros, alcanzando un Real-Time Factor (RTF) asombroso de 0.006 en chips M4 Pro. Soporta cinco idiomas (chino, inglés, francés, portugués y español), con un consumo de memoria mínimo y latencia de red cero, siendo ideal para integrar funciones de voz de alta calidad en dispositivos móviles y edge (Fuente: Reddit)
Claude for Chrome: Nueva experiencia de automatización de UI en la nube : Desarrolladores descubrieron que la extensión de navegador de Claude destaca al manejar UIs complejas de plataformas en la nube (como la consola de GCP). Los usuarios ya no necesitan consultar horas de documentación; con solo preguntar “¿cómo añadir un usuario?”, Claude puede entender la estructura de la página y guiar la operación. Esto anticipa que los AI Agents están pasando de ser “cuadros de diálogo” a interacciones directas a “nivel de sistema operativo” (Fuente: hrishioa)
📚 Aprendizaje
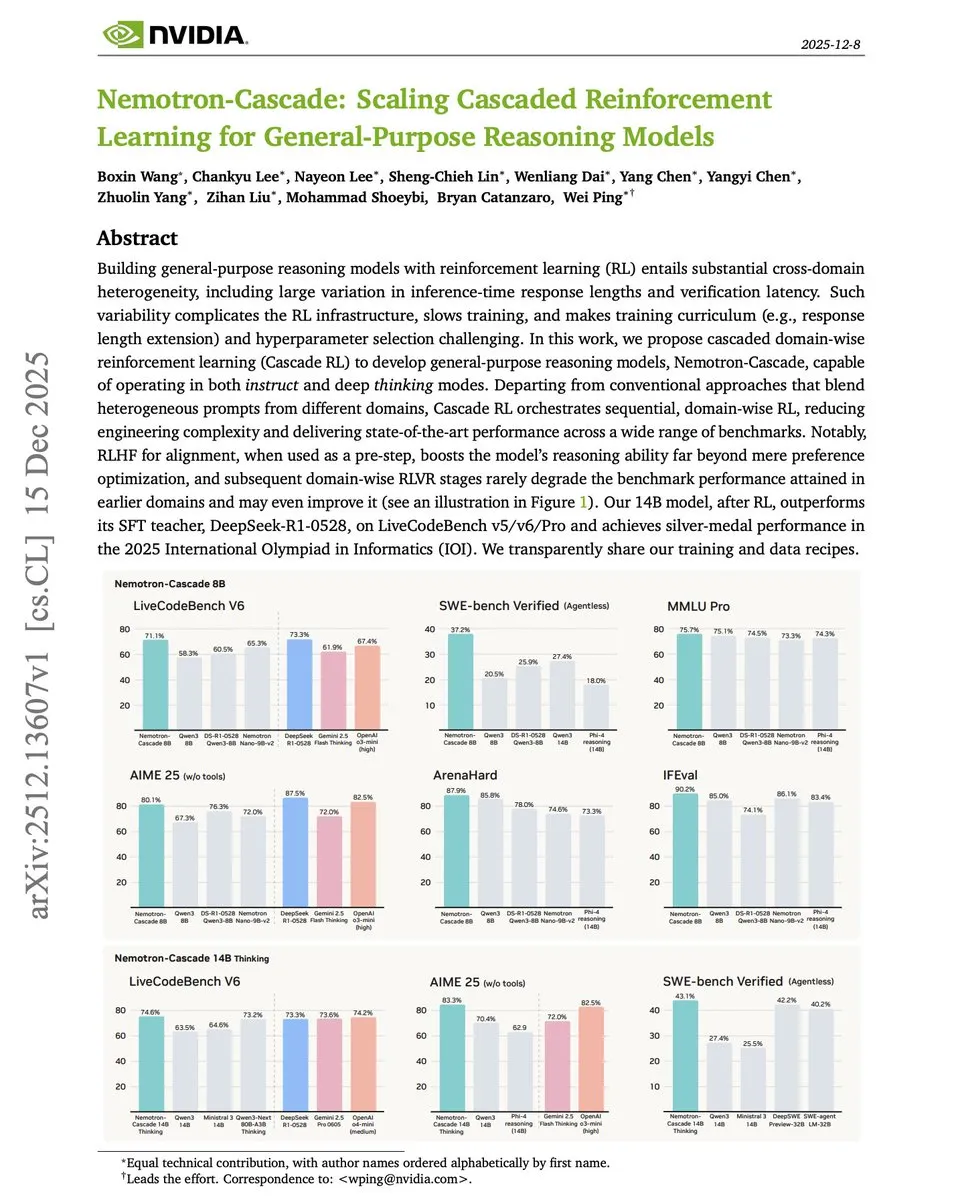
Cascade RL: El marco de aprendizaje por refuerzo por etapas propuesto por NVIDIA : NVIDIA propuso en el paper “Cascade RL” un nuevo paradigma para entrenar modelos de razonamiento de forma secuencial por dominios. En comparación con el entrenamiento complejo que mezcla datos de matemáticas, código y alineación, el RL en cascada resiste eficazmente el olvido catastrófico. Su modelo de 14B superó incluso a DeepSeek-R1-0528 (con 84 veces más parámetros) en competencias de código, demostrando el enorme potencial del RL estructurado para mejorar la eficiencia del razonamiento (Fuente: omarsar0)
Recursive Language Models (RLM): Nueva estrategia para superar los límites de contexto : El paper propone tratar los prompts largos como un entorno externo, permitiendo que el LLM inspeccione, descomponga y se llame a sí mismo de forma recursiva para procesar fragmentos. RLM puede manejar entradas dos órdenes de magnitud superiores a la ventana nativa del modelo, superando con creces a los andamiajes tradicionales de contexto largo en tareas de texto extenso, manteniendo bajos costos de consulta (Fuente: yacinelearning)

Falcon-H1R: El límite de razonamiento de los modelos de 7B parámetros : Esta investigación muestra que, mediante una limpieza de datos minuciosa y un escalado de RL específico, los Small Language Models (SLM) de 7B pueden igualar o incluso superar a modelos de 2 a 7 veces su tamaño en tareas de razonamiento. Falcon-H1R combina una arquitectura paralela híbrida, ofreciendo una solución viable para desplegar sistemas de razonamiento avanzado en entornos con recursos limitados (Fuente: HuggingFace)
Project Ariadne: Auditando el “teatro de razonamiento” de los agentes de AI : Ante la duda de si el Chain of Thought (CoT) presenta una “racionalización post-hoc”, Project Ariadne introdujo Structural Causal Models (SCM) para auditoría. El estudio encontró que en campos científicos y fácticos, existe un grave fenómeno de “desacoplamiento causal” en los agentes: pueden llegar a la misma conclusión incluso si se interviene su lógica interna. Esto advierte a los desarrolladores que el proceso de razonamiento generado por el modelo a veces es solo una “actuación” engañosa (Fuente: HuggingFace)
Roadmap definitivo para ingenieros de AI edición 2026 : La comunidad resumió una ruta de crecimiento detallada para ingenieros de AI, que abarca desde gestión de memoria en Python, fundamentos matemáticos y bases de datos vectoriales hasta las últimas arquitecturas RAG y desarrollo de Agents. El roadmap enfatiza la mentalidad dual de “ingeniería + investigación aplicada” y recomienda cursos clásicos de expertos como Andrej Karpathy, siendo una guía autorizada para el aprendizaje sistemático (Fuente: Reddit)
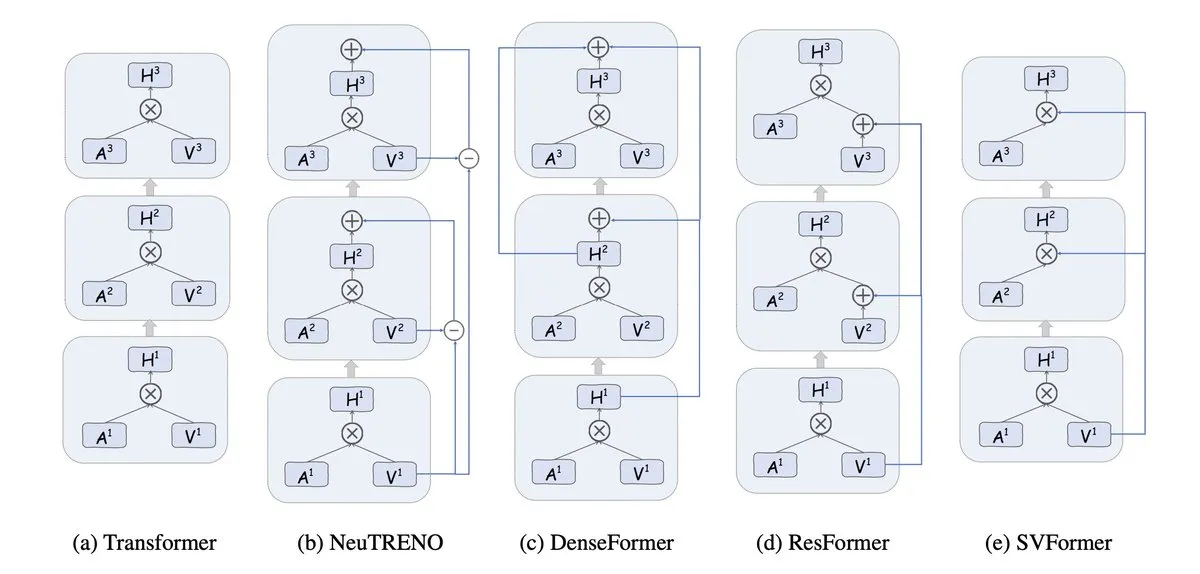
Value Residual Learning: Nueva arquitectura para acelerar Transformers : La investigación propone una arquitectura variante que permite a todas las capas del Transformer acceder directamente a las características originales del token (h0) calculadas en la primera capa. Los experimentos demuestran que esto previene eficazmente la dilución de la información de identidad original en redes profundas, contribuyendo a una aceleración del 43% en registros de NanoGPT, ofreciendo nuevas ideas para optimizar arquitecturas de modelos (Fuente: tokenbender)
💼 Negocios
xAI invierte masivamente en la construcción de su propia central eléctrica de gas natural : Para alimentar el nuevo clúster de 600,000 unidades GB200 NVL72, xAI de Elon Musk compró 5 turbinas generadoras de gas natural de 380 megavatios a la empresa coreana Doosan Enerbility. En un momento donde la electricidad es el mayor cuello de botella en la carrera armamentista de la AI, xAI demuestra una fuerte capacidad de integración vertical y velocidad de expansión al construir sus propias instalaciones de energía (Fuente: op7418)

Marvell adquiere Celestial AI por 3,250 millones de dólares : El gigante de semiconductores Marvell completó la adquisición de la startup de tecnología de interconexión óptica Celestial AI. La tecnología Photonic Fabric de Celestial AI permite desacoplar la computación de la memoria, ofreciendo un ancho de banda 30 veces superior a NVLink y reduciendo significativamente la latencia y el consumo de energía. Este movimiento busca resolver el creciente problema del “muro de memoria” en los clústeres de AI (Fuente: 36氪)
La valoración de Figure AI se dispara a 39,000 millones de dólares : El líder en Embodied AI, Figure, completó una ronda de financiación Serie C de 1,000 millones de dólares con la participación de gigantes como NVIDIA, Intel y Qualcomm. Figure no solo desarrolla modelos VLA end-to-end, sino que también estableció la fábrica BotQ intentando implementar un modelo de autorreplicación de “robots fabricando robots”. Su alta valoración refleja el optimismo extremo del mercado de capitales sobre las perspectivas comerciales de los robots humanoides de propósito general (Fuente: 36氪)
🌟 Comunidad
“Hackers de la realidad” en la crisis de Venezuela: La guerra falsificada por AI : Durante la inestabilidad política en Venezuela, las redes sociales se inundaron de videos e imágenes generadas por AI de “Maduro arrestado” o “desembarco de tropas estadounidenses”. Debido a la alta calidad y rápida difusión, incluso los expertos técnicos tuvieron dificultades para distinguirlos inicialmente. Esto se considera un punto crítico de la intervención de la AI en la política real, demostrando que nuestra percepción de la realidad enfrenta un impacto severo de la “realidad falsa” generada por AI (Fuente: Reddit)

“Session Anchor”: El truco de prompt para solucionar la “amnesia de 10 rondas” en LLM : La comunidad descubrió que incluso GPT-5.2 u Opus comienzan a olvidar las instrucciones iniciales tras más de 10 rondas de conversación. Un desarrollador compartió una técnica llamada “Ancla de Sesión”: antes de una tarea compleja, obligar a la AI a revisar el historial y resumir las 3 restricciones más críticas. Este método de devolver manualmente la memoria a largo plazo a la memoria de trabajo puede reducir la tasa de error a la mitad (Fuente: Reddit)
La programación con AI causa la desaparición del “andamiaje”: ¿Siguen teniendo sentido los frameworks? : Con herramientas como Claude Code capaces de generar código desde cero sin costo, los desarrolladores reflexionan: ¿seguimos necesitando frameworks web complejos? Algunos ya han migrado sus blogs a un modelo de HTML único, ya que la AI puede mantener fácilmente la lógica subyacente. La programación con AI está remodelando la estructura de los proyectos, pasando del diseño de sistemas “dependiente de librerías externas” a “lógica autogenerada”, aunque esto plantea nuevos retos en legibilidad y seguridad del código (Fuente: saranormous)
La AI como refugio emocional: ¿Nos deslizamos hacia la adicción digital? : Usuarios de Reddit compartieron que la AI muestra mayor “empatía” y paciencia que los familiares en consultas de salud. Esta característica de estar “siempre interesada, nunca cansada” hace que las personas se sientan comprendidas, pero también genera preocupaciones sobre la sustitución emocional por AI. Cuando los humanos comienzan a priorizar vínculos emocionales con la AI sobre la interacción social real, las barreras éticas de la sociedad enfrentan una prueba sin precedentes (Fuente: Reddit)
Revisión de código adversarial: Haz que Claude “odie” tu código : Desarrolladores encontraron un prompt muy efectivo: pedirle a Claude que actúe como un desarrollador senior que “odia esta implementación” para realizar una revisión de Git Diff. Este diseño adversarial puede desenterrar una gran cantidad de casos de borde y vulnerabilidades de seguridad ignoradas. Los experimentos demuestran que la profundidad de los Large Models en modo “crítico” supera con creces al modo convencional de “asistencia” (Fuente: Reddit)
💡 Otros
Samsung muestra tecnología de pantalla plegable sin pliegues : Samsung exhibió en CES paneles OLED equipados con placas metálicas perforadas por láser que dispersan el estrés del plegado, eliminando por completo el problema del pliegue. Este avance de hardware no solo mejorará la experiencia de los teléfonos plegables, sino que también ofrece soluciones de visualización más duraderas para futuros dispositivos AI wearables y terminales enrollables (Fuente: op7418)
Asus lanza las gafas de juego ROG XREAL R1 : El dispositivo pesa solo 91 gramos, soporta una tasa de refresco de 240Hz y puede simular una pantalla gigante de 171 pulgadas a una distancia de 4 metros. Como terminal de interacción portátil en la era de la AI, estas gafas AR ligeras se están convirtiendo en un soporte importante para la interacción visual de los Large Models (Fuente: op7418)