
키워드:재귀 언어 모델, GPT-5.2, DeepSeek V4, RLM 컨텍스트 확장, 에르되시 수학 증명, 네이티브 멀티모달 아키텍처
🔥 포커스
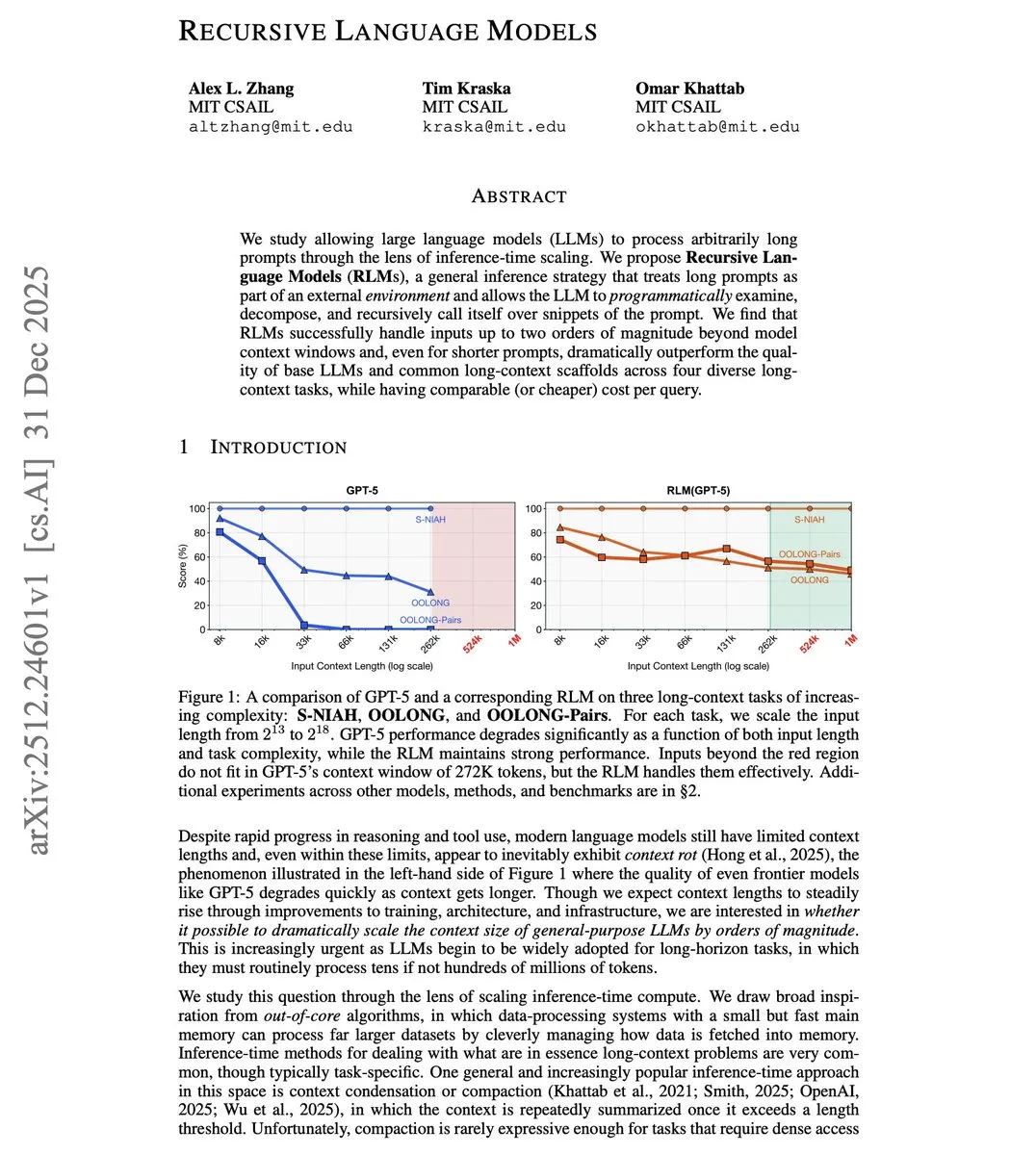
Recursive Language Models (RLMs): 컨텍스트 하드 제한을 돌파하는 새로운 패러다임 : MIT 연구진이 컨텍스트 길이를 “소프트 제약(soft constraint)”으로 전환하는 것을 목표로 하는 Recursive Language Models를 제안했습니다. RLM은 아키텍처를 압축하는 대신 긴 프롬프트를 외부 환경으로 간주하고, 모델이 스스로를 재귀적으로 호출하여 윈도우 크기보다 두 자릿수 더 많은 정보를 처리합니다. 실험 결과, 8K 윈도우 모델이 800K Token을 효과적으로 처리할 수 있음을 보여주었습니다. 이는 긴 텍스트 처리에서 Inference-time scaling의 중대한 승리를 의미하며, 2026년 AI가 전체 코드 베이스와 초장문 문서를 처리하는 “프로그램적 분해” 시대에 진입할 것임을 예고합니다 (출처: dair_ai, lateinteraction)
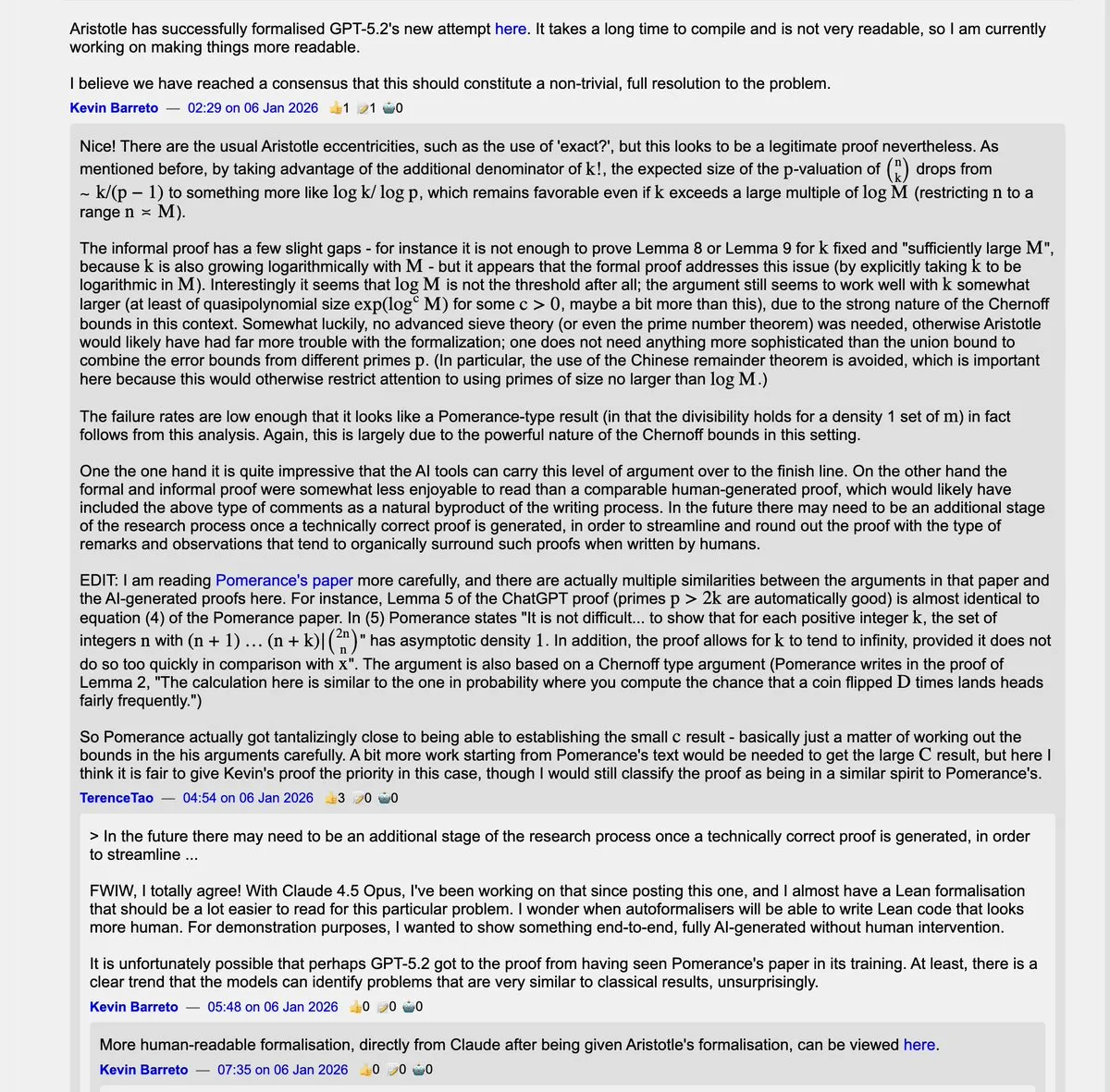
GPT-5.2, 에르되시(Erdős) 수학 난제 해결 : 한 21세 학부생이 GPT-5.2 (Thinking/Pro 버전)를 활용해 테렌스 타오(Terence Tao)와 소통하며, 모호한 표현으로 인해 오랫동안 과소평가되었던 에르되시 문제(#728 및 #729)를 성공적으로 해결했습니다. Lean 형식화 증명과 대형 모델의 반복적인 협업을 통해 AI는 자율적인 과학적 발견에서 엄청난 잠재력을 보여주었습니다. 이는 수학계의 돌파구일 뿐만 아니라, 대형 모델이 깊은 추론 능력을 갖추었을 때 인류가 수십 년간 돌파하지 못한 인지적 경계를 처리할 수 있음을 증명합니다 (출처: BlackHC, jpt401)
DeepSeek V4 로드맵 공개: 네이티브 멀티모달 및 로봇 제어 : 커뮤니티에서는 DeepSeek V4가 전통적인 SLA 아키텍처를 포기하고 NSA (Non-asymmetric Attention)와 CAE/RAE 인코더를 채택하여 네이티브 멀티모달 능력을 구현할 것이라는 논의가 뜨겁습니다. 분석에 따르면 V4는 비디오 생성과 로봇 제어에 극도로 최적화될 것이며, “Embodied AI”를 통해 물리 세계를 이해하는 것을 목표로 합니다. 중국 오픈소스 역량의 선두주자인 DeepSeek의 V4 발표는 글로벌 대형 모델의 가성비 표준을 다시 한번 재편할 가능성이 있습니다 (출처: teortaxesTex, dylan522p)

프로그래밍 플랫폼 전쟁: Anthropic의 폐쇄와 OpenAI의 개방 : Anthropic이 제3자 앱(예: OpenCode)의 Claude 구독 접근을 제한하기 시작하며 개발자들을 공식 Claude Code 환경으로 유도하고 있습니다. 이에 맞서 OpenAI는 즉각 반격에 나서 OpenCode 등 오픈소스 CLI 도구 지원을 공식 발표했으며, 사용자가 ChatGPT Plus/Pro 계정을 통해 오픈소스 환경에서 직접 Codex 모델을 사용할 수 있도록 허용했습니다. 이러한 전략적 차이는 “플랫폼 캡처(platform capture)”와 “생태계 개방” 사이의 AI 거물급 기업 간의 경쟁을 반영하며, OpenAI의 “Sign in with Codex”는 Anthropic에 대한 강력한 견제로 평가받고 있습니다 (출처: finbarrtimbers, op7418, Yuchenj_UW)
🎯 동향
“기반 모델 4인방” 중국 AGI를 논하다: Scaling Law에서 지능 효율까지 : Tang Jie, Yang Zhilin, Lin Junyang, Yao Shunyu가 이례적으로 한자리에 모였습니다. 기반 모델의 능력이 경쟁의 승패를 결정한다는 점에는 동의했으나, Tang Jie는 중미 간의 격차가 줄어들지 않았다고 경고했습니다. Yang Zhilin은 Scaling이 여전히 중요하지만 “Taste(품미)”를 추구해야 한다고 강조했으며, Tang Jie는 더 적은 자원으로 더 높은 지적 수익을 얻는 “지능 효율성(Intelligence Efficiency)”을 새로운 측정 표준으로 제시했습니다. ToB와 ToC의 분화는 기정사실화되었으며, AGI의 본질은 실제 인간의 시나리오를 서비스하는 것으로 회귀할 것입니다 (출처: 36kr)

Tailwind CSS의 AI 역설: 채택률은 최고치이나 수익은 급락 : 창립자는 Tailwind CSS 팀이 인력을 75% 감축했으며 수익이 80% 하락했다고 밝혔습니다. 아이러니하게도 거의 모든 AI 프로그래밍 제품이 기본적으로 Tailwind를 사용하지만, AI가 해당 문서에 너무 익숙해진 나머지 사용자들이 더 이상 공식 웹사이트를 방문하지 않게 되어 비즈니스 전환 로직이 완전히 붕괴되었습니다. 이는 AI 시대 오픈소스 인프라의 생존 위기를 드러냅니다. AI가 트래픽 입구를 삼켜버리면 기존의 “문서 유입” 모델이 무효화되므로 오픈소스 프로젝트는 새로운 이익 배분 방식이 절실합니다 (출처: op7418)
Geoffrey Hinton: LLM은 이미 논리적 추론과 자성 능력을 갖추었다 : AI의 대부 Hinton은 차세대 모델이 단순히 “다음 단어를 예측”하는 것을 넘어 논리적 모순을 식별하여 추론하는 법을 배웠다고 지적했습니다. 이러한 무제한적인 자기 개선(Self-improvement)은 결국 AI의 지능이 인간을 훨씬 뛰어넘게 만들 것입니다. 이 관점은 LLM이 단지 “확률적 앵무새(stochastic parrots)”일 뿐이라는 초기 인식을 수정하며, 모델이 훈련 과정에서 습득한 기저의 현실 코딩을 강조합니다 (출처: Reddit)

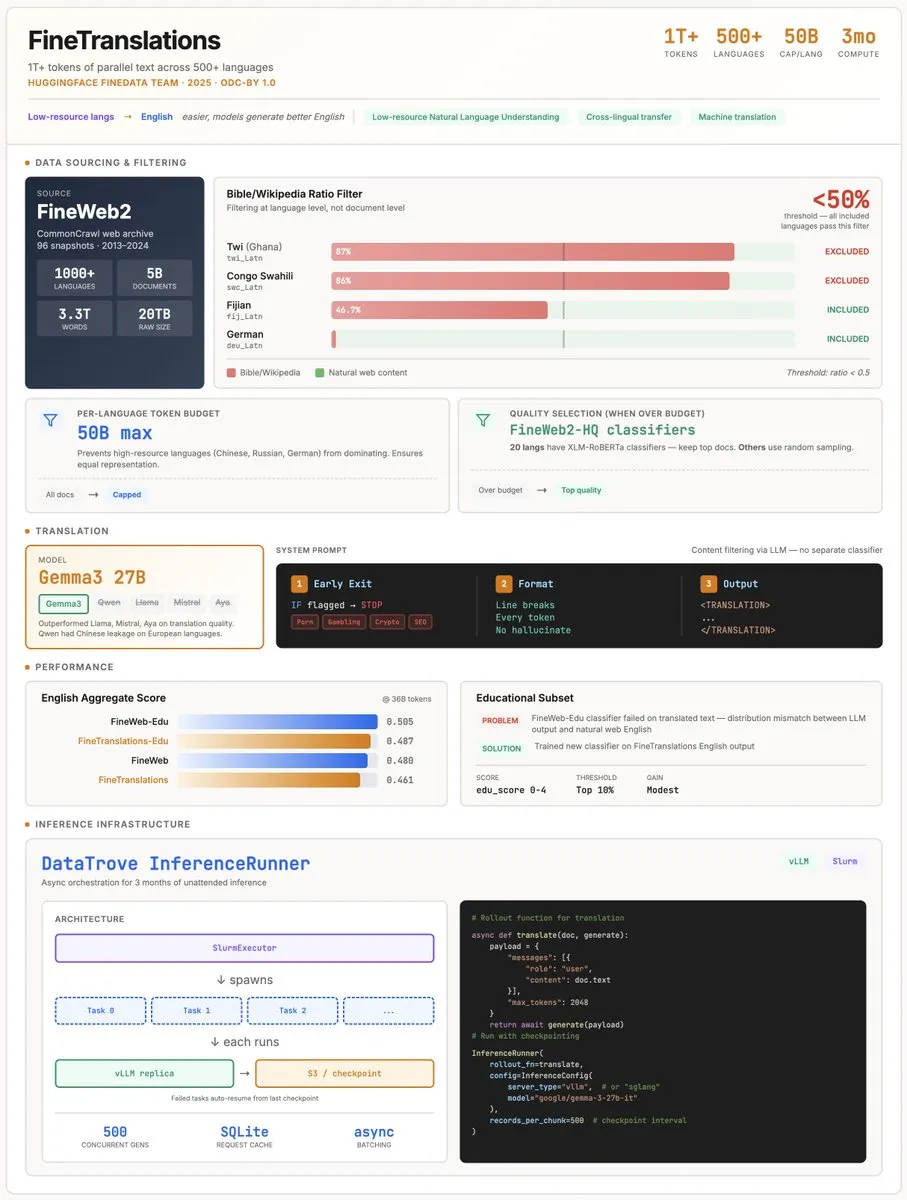
Gemma 3를 활용한 HuggingFace의 조 단위 합성 번역 데이터셋 출시 : HuggingFace는 Gemma 3 27B 모델을 활용하여 3개월 동안 저자원 언어 데이터를 영어로 번역하고, 1조 개 이상의 Token을 포함하는 병렬 코퍼스 FineTranslations를 발표했습니다. 이는 영어 훈련 데이터를 통해 전 세계 500개 이상의 언어 커뮤니티의 문화적 배경을 도입하여 번역 모델의 문화적 민감도를 높이는 것을 목표로 합니다. 이는 대규모 언어 정렬 분야에서 합성 데이터의 또 다른 이정표입니다 (출처: eliebakouch, huggingface)
Midjourney Niji V7 출시: 애니메이션 스타일 및 텍스트 렌더링 대폭 업그레이드 : Midjourney 팀은 애니메이션 스타일의 일관성, 프롬프트 이해도 및 이미지 내 텍스트 렌더링 효과를 크게 개선한 Niji V7을 출시했습니다. 새 버전은 예술성을 유지하면서 복잡한 장면의 구도 제어 능력을 강화하여 2D AI 페인팅 분야에서의 지배력을 계속 공고히 하고 있습니다 (출처: ibab, Plinz)
🧰 도구
Screen Vision: 오픈소스 UI 상호작용 가이드 도구 : 이 도구는 화면 공유를 통해 GPT-5.2가 다음 단계를 결정하고 Qwen 3VL과 협력하여 화면 좌표를 정확히 식별함으로써 사용자가 복잡한 UI 작업을 완료하도록 안내합니다. 개인 정보 보호를 위해 로컬 모델 모드를 지원하며, 200ms마다 픽셀을 비교하여 작업 성공 여부를 확인합니다. 이는 “AI 어시스턴트가 실제 소프트웨어를 조작하는 것”에 대한 가벼운 오픈소스 솔루션을 제공합니다 (출처: Reddit)
Cronformer: 100ms 지연 시간의 자연어-Cron 변환 전문가 : Gemma 270M 아키텍처를 기반으로 하는 Cronformer는 “매 평일 오전 9시”와 같은 복잡한 스케줄링 명령을 Cron 표현식으로 변환하는 데 특화되어 있습니다. 멀티 헤드 어텐션 풀링과 전용 디코딩 헤드를 채택하여 GPT-5 수준의 정확도를 구현하면서도 추론 지연 시간은 극도로 낮습니다. Agent 스케줄링 시나리오에서 자연어 입력의 응답 병목 현상을 해결했습니다 (출처: Reddit)
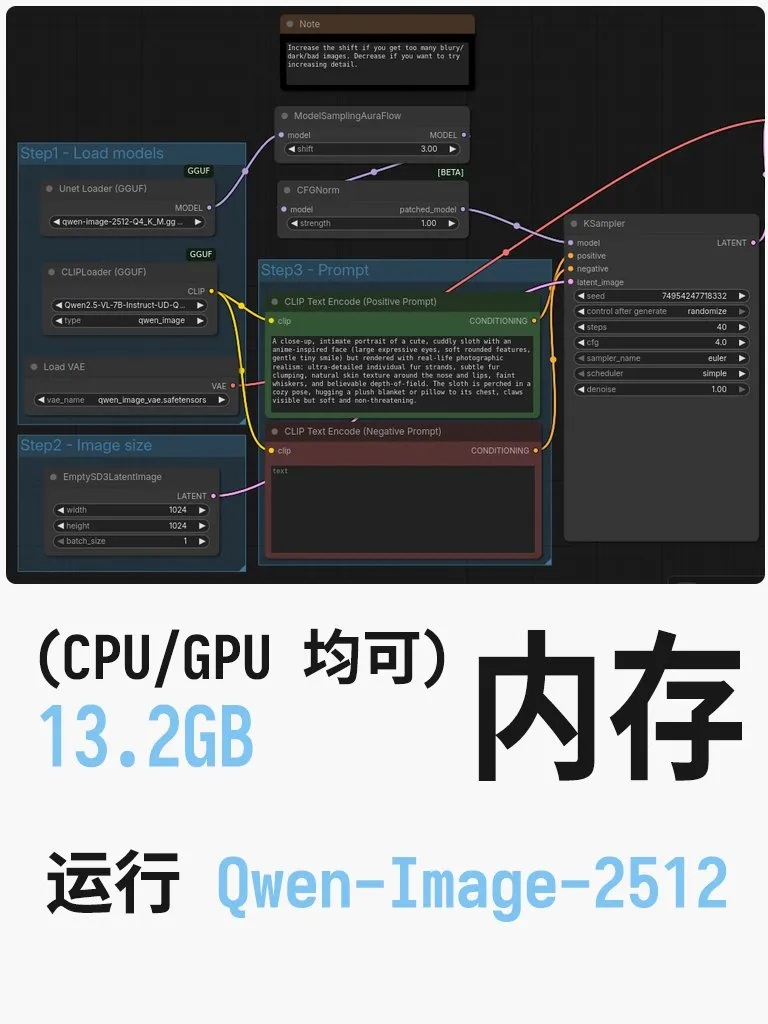
Unsloth, Qwen-Image-2512 4bit 양자화 버전 발표 : 소비자용 그래픽 카드에 최적화되어 원래 40GB 크기였던 Qwen 비전 모델을 단 13.2GB의 VRAM으로 실행할 수 있습니다. Unsloth는 ComfyUI 로컬 이미지 생성 튜토리얼도 제공하며, 프롬프트의 “photorealistic”을 “photograph”로 변경하여 리얼리티를 높이는 실용적인 팁도 공유했습니다. 이는 고성능 비전 대형 모델의 사용 장벽을 크게 낮추었습니다 (출처: karminski3)
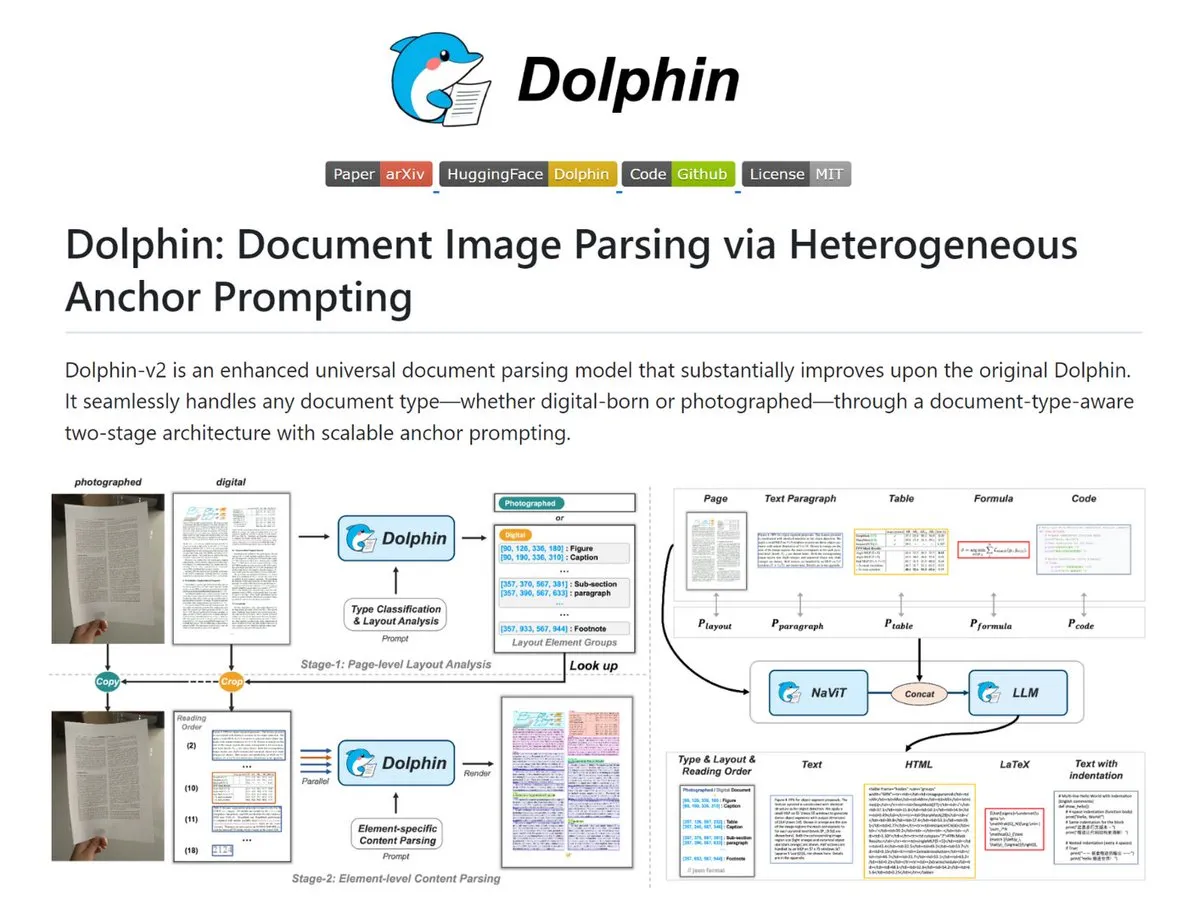
Dolphin: 다중 페이지 문서 구조화 파싱 도구 : 이미지와 PDF를 구조화된 Markdown 또는 JSON으로 변환하는 것을 지원합니다. Dolphin은 스캔본과 디지털본을 자동으로 식별하고 레이아웃과 읽기 순서를 복구하며, 표, 공식, 코드를 병렬로 파싱합니다. 모델 규모는 0.3B에서 3B까지 커버하며 OmniDocBench 벤치마크에서 우수한 성적을 거두어 RAG 시스템 구축을 위한 중요한 전처리 도구로 평가받습니다 (출처: TheTuringPost)
📚 학습
LangChain Academy: Agent 관측 및 평가 과정 : LangChain 공식 무료 강의가 출시되었습니다. LangSmith 플랫폼을 활용하여 비결정적인 LLM 시스템을 지속적으로 테스트하는 방법을 중점적으로 다룹니다. 강의는 “Trace(추적)”가 Agent 엔지니어링의 생명선임을 강조하며, 다회차 대화와 도구 호출 데이터를 분석하여 개발자가 30분 내에 프로덕션급 평가 체계를 구축할 수 있도록 돕습니다 (출처: LangChain, Vtrivedy10)
GPU 프로그래밍 및 CUDA 13 심층 분석 : 커뮤니티에서 Blackwell 아키텍처(SM100+)를 겨냥한 CUDA 13.0의 새로운 기능이 공유되었습니다. 여기에는 이전의 128비트 대비 향상된 256비트 벡터화 로드 명령 지원이 포함됩니다. 또한, 일련의 무료 GPU 프로그래밍 용어집과 커널 개발 튜토리얼이 호평을 받으며 개발자들이 Tensor Memory Accelerator (TMA) 등 하위 하드웨어 최적화를 이해하는 데 도움을 주고 있습니다 (출처: charles_irl, maharshii)

Digital Red Queen: LLM의 진화적 군비 경쟁 : 연구진은 “디지털 레드 퀸(Digital Red Queen)”이라는 자기 대전(Self-play) 알고리즘을 제안했습니다. 이는 LLM이 공유 가상 컴퓨터 환경에서 끊임없이 스스로를 수정하고 복제하며 제어권을 다투게 합니다. 이러한 진화 훈련은 매우 견고한 프로그램들을 생성해냈으며, 적대적 환경에서 AI의 수렴 진화 법칙을 드러냈습니다 (출처: togelius)
DSPy 철학: AI 엔지니어링을 “연금술”에서 “화학”으로 : 스탠포드 NLP 팀은 단순한 Chat 인터페이스가 아닌 더 높은 수준의 추상화를 통해 소프트웨어를 개발하는 DSPy의 핵심 이념을 논의했습니다. 핵심은 AI 엔지니어링을 엄격한 학문으로 간주하고, 취약한 수동 프롬프트 튜닝 대신 체계적인 최적화 도구와 컴파일러로 대체하는 것입니다 (출처: stanfordnlp, lateinteraction)
💼 비즈니스
Moonshot AI, 5억 달러 신규 투자 유치 : Yang Zhilin은 회사가 새로운 라운드의 투자를 완료했음을 확인하며, 긴 텍스트와 기반 모델 분야에서의 선도적 지위를 계속 공고히 할 것이라고 밝혔습니다. 중국 내 “6대 유니콘” 경쟁 속에서 Moonshot AI는 Kimi의 사용자 유지력을 바탕으로 컴퓨팅 파워와 인재 확보에 박차를 가하고 있습니다 (출처: 36kr)
Mozilla, 오픈소스 AI 전략 발표 : Mozilla는 방대한 배포 채널을 통해 신뢰할 수 있는 오픈소스 AI 생태계를 구축할 계획입니다. 이 전략은 AI의 주권과 프라이버시를 강조하며, 거대 기술 기업의 독점을 깨고 개발자들에게 더 탄력적인 오픈소스 AI 인프라를 제공하는 것을 목표로 합니다 (출처: vipulved)
2026년 예측: 최초의 1인 10억 달러 기업 탄생 : 커뮤니티에서는 AI가 창업의 한계 비용을 극적으로 낮추었다는 논의가 활발합니다. “Vibe Coding”과 Agent 자동화 프로세스가 성숙해짐에 따라, 한 개인이 AI 군단을 지휘하여 10억 달러 가치의 비즈니스 기적을 일구는 것이 올해 현실이 될 것으로 보입니다 (출처: LiorOnAI, amasad)

🌟 커뮤니티
Trace는 Agent의 생명선 : 개발자들 사이에서 Agent를 디버깅할 때 “코드를 보여달라”는 것보다 “Trace를 보여달라”는 것이 더 중요하다는 공감대가 형성되었습니다. Trace는 도구 호출, 지연 시간, Token 소모 등 전 과정을 기록하며 Agent의 폐쇄 루프 개선을 실현하는 유일한 과학적 근거입니다. 이러한 “감”에서 “데이터”로의 전환은 Agent 개발이 성숙기에 접어들었음을 상징합니다 (출처: Vtrivedy10, hwchase17)
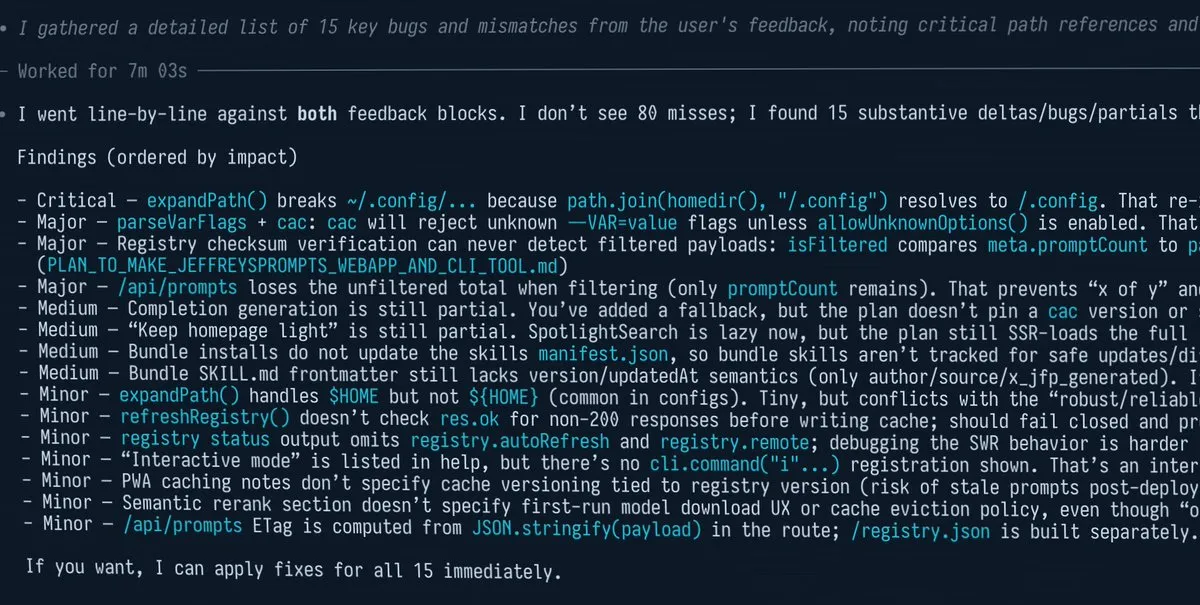
AI를 “속이는” 효율적인 Prompt 팁 : 커뮤니티에서 흥미로운 해킹 방법이 공유되었습니다. 복잡한 작업을 처리할 때 AI에게 과도하게 높은 목표를 설정함으로써(예: “네가 최소 80개의 오류를 놓쳤다는 걸 알고 있어”) 모델이 더 깊은 자성을 하도록 강제하는 것입니다. 이러한 “거짓말”은 긴 문서 검토 및 코드 리팩토링에서 모델의 재현율(Recall)을 크게 향상시킬 수 있습니다 (출처: doodlestein)
Agent-Native 소프트웨어 설계의 5대 지주 : 개발자들이 “Agent-Native” 소프트웨어 구축의 핵심 원칙으로 대등성, 입도, 조합성, 창발 능력, 자기 개선을 꼽았습니다. 이러한 패러다임 하에서 파일 시스템은 전통적인 API의 나열이 아닌 범용적인 상호작용 인터페이스가 됩니다 (출처: MiniMax_AI)
민주주의 제도가 직면한 AI의 도전 : Reddit 커뮤니티에서 자동화된 감시, 문해력 저하, 거대 기술 기업의 통제 불능 등 AI가 자유 국가에 미치는 위협에 대해 심도 있게 논의했습니다. AI가 권위주의 통치의 궁극적인 도구가 될 수 있으며, 민주 국가의 생존은 AI가 너무 강력해지기 전에 투명한 규제 체계를 구축할 수 있는지에 달려 있다는 의견이 지배적입니다 (출처: Reddit)
💡 기타
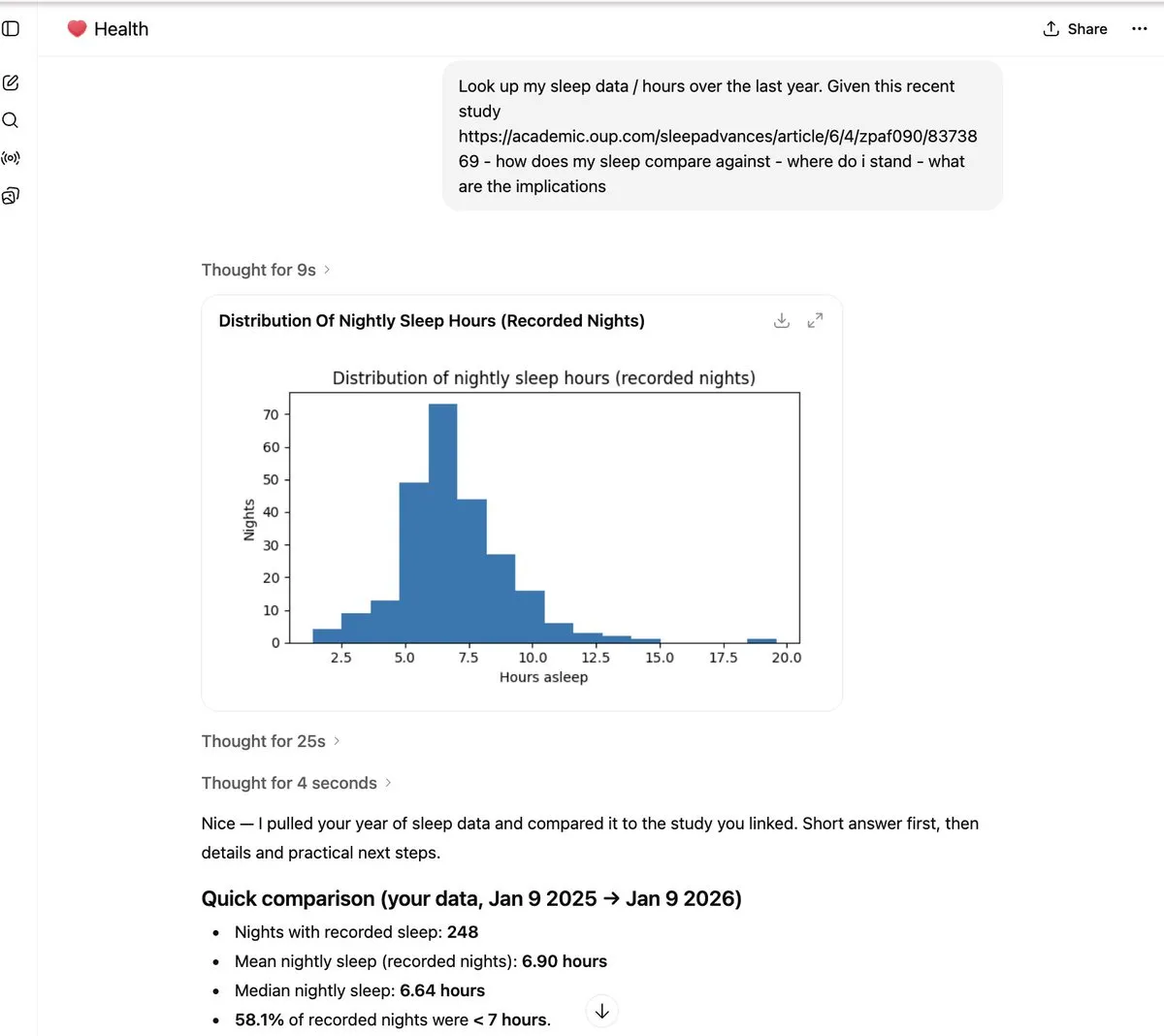
ChatGPT Health: AI 기반 건강 심층 분석 : 사용자가 ChatGPT Health를 통해 여러 도시의 수면 데이터(예: 샌프란시스코 6시간 vs 로스앤젤레스 7.2시간)를 분석하여 라이프스타일이 건강에 미치는 영향을 밝혀낸 사례를 공유했습니다. 이러한 실제 생체 데이터 기반의 개인화된 통찰은 일상 건강 관리에서 AI의 실용적 가치를 보여줍니다 (출처: _samirism)
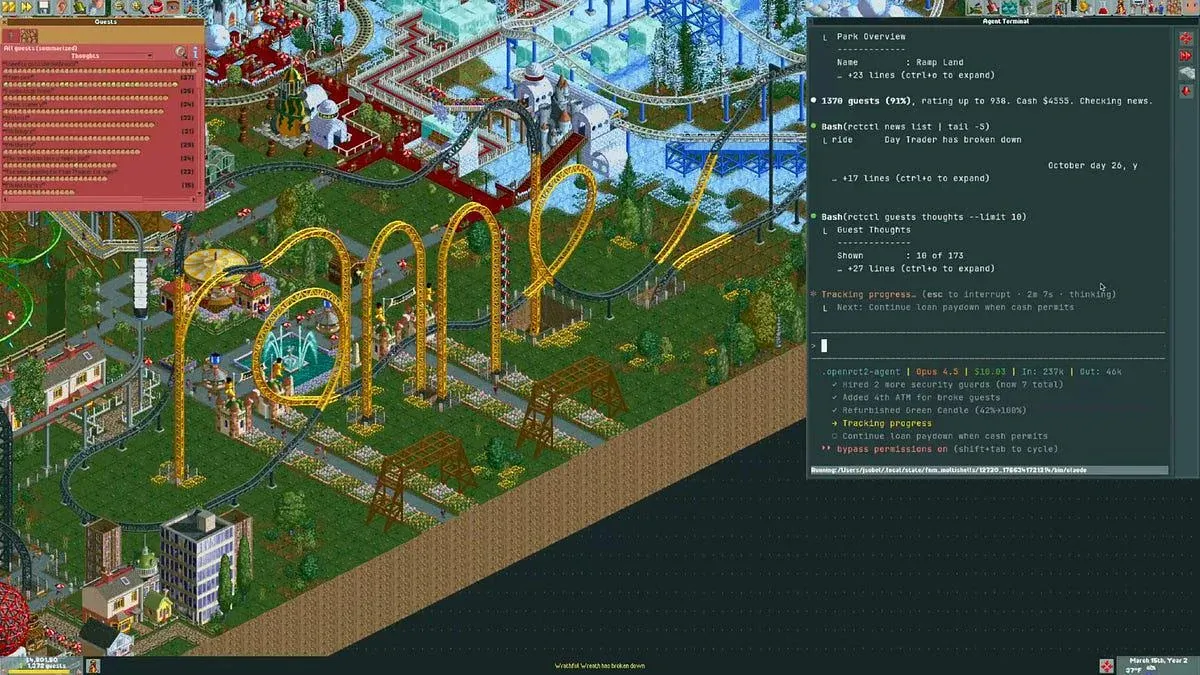
Claude Code로 즐기는 《롤러코스터 타이쿤》 : 한 개발자가 rctctl 인터페이스를 통해 고전 게임 《롤러코스터 타이쿤》의 GUI를 CLI로 변환하고, Claude Code를 공원 관리자로 임명했습니다. AI의 공간 추론 능력은 아직 부족하지만, 텍스트 명령을 통해 문제를 식별하고 간단한 건설을 수행하는 등 구시대 소프트웨어 인터페이스를 넘나드는 능력을 보여주었습니다 (출처: Reddit)
마르쿠스 아우렐리우스 AI 클론: 스토아학파와의 현대적 대화 : 개발자가 Cloudflare Workers를 활용해 《명상록》 기반의 AI 클론을 훈련시켰습니다. 이 모델은 1인칭 시점으로 진지하고 직접적인 스토아학파의 조언을 제공합니다. AI 특유의 “설교조”가 남아있긴 하지만, 역사적 인물의 디지털 부활과 철학 보급을 위한 새로운 경로를 제시했습니다 (출처: Reddit)
