
키워드:GPT-5.2 프로, 딥시크 V4, 공자 코드 에이전트, 에르되시 수학 난제, mHC 아키텍처, 장기 기억 에이전트
🔥 포커스
GPT-5.2 Pro 자율적으로 다수의 Erdos 수학 난제 해결 : 최근 소셜 미디어에서는 과학 발견 분야에서 GPT-5.2 Pro의 획기적인 진전이 화제가 되고 있습니다. 이 모델은 Aristotle 시스템과 협력하여 Erdos 문제 #729 및 #397을 포함한 여러 수학 난제를 자율적으로 해결했으며, 그중 #397의 증명은 수학자 Terence Tao의 인정을 받았습니다. 이는 AI가 단순한 코퍼스 학습에서 진화하여 본 적 없는 과학 난제를 해결할 수 있는 추론 능력을 갖추었음을 상징합니다. 커뮤니티에서는 이것이 고도의 추상적 논리를 처리하는 추론 모델의 거대한 잠재력을 증명한 것이며, AI가 Fields Medal을 수상하는 것은 시간 문제일 뿐이라고 보고 있습니다. (출처: SebastienBubeck; kevinweil; halvarflake)
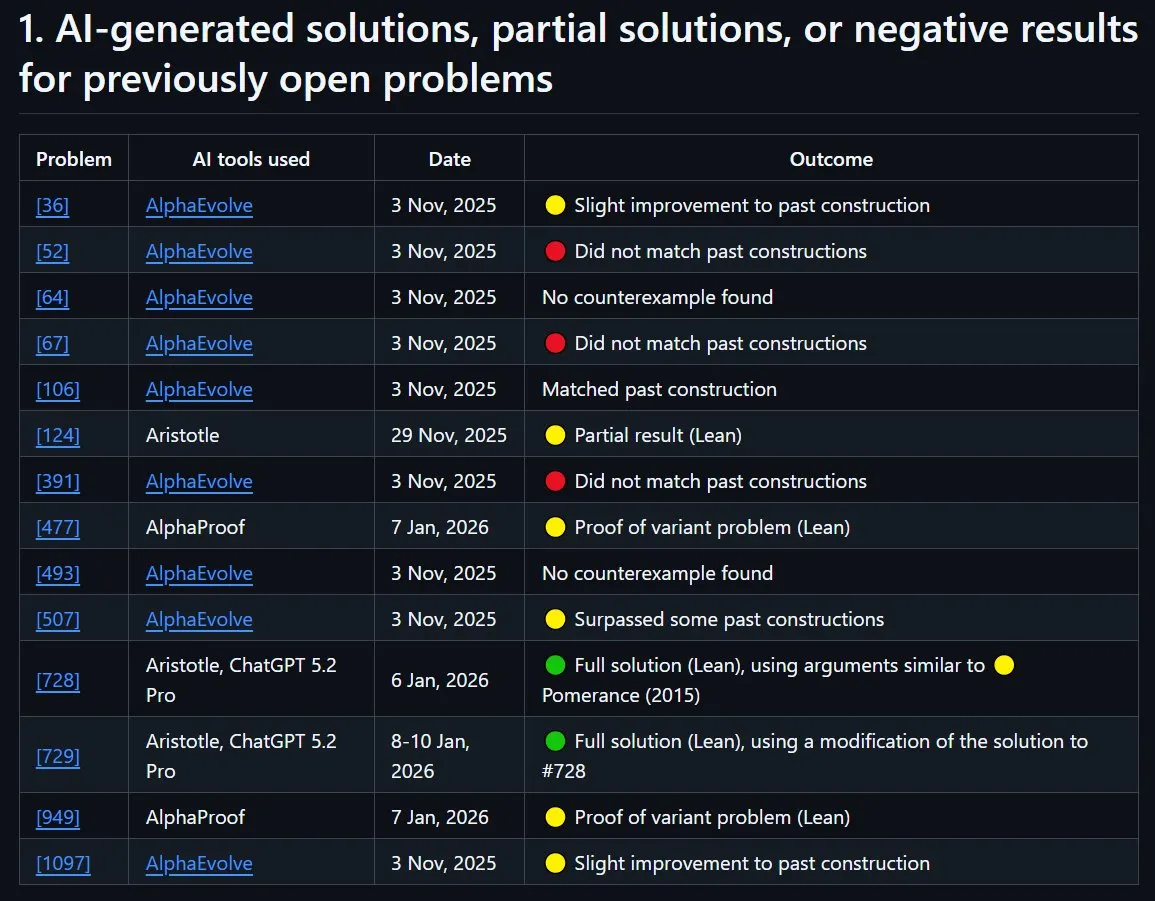
DeepSeek V4 출시 예측 및 mHC 아키텍처 심층 토론 : 업계 내부 소식에 따르면 DeepSeek V4가 설 연휴 기간에 출시될 예정이며, 목표는 전면적인 SOTA 달성입니다. 이 시리즈 모델은 최근 mHC(Multi-Head Connection) 아키텍처로 주목받고 있는데, 이 아키텍처는 Doubly Stochastic Matrix 특성을 통해 계층적 곱의 안정성을 확보하여 심층 네트워크에서의 그래디언트 소실 또는 폭주 문제를 효과적으로 해결했습니다. 커뮤니티 분석에 따르면 DeepSeek의 기술 경로는 단순한 컴퓨팅 파워 투입에서 더 근본적인 수학적 아키텍처 최적화로 전환되고 있으며, 이러한 “작은 것으로 큰 것을 얻는” 사고방식이 대형 모델 개발의 패러다임을 바꾸고 있습니다. (출처: teortaxesTex; Reddit r/MachineLearning)
Meta와 하버드, Confucius Code Agent (CCA) 장기 기억 에이전트 발표 : Meta는 하버드 대학교와 공동으로 대규모의 복잡한 코드베이스 내 에이전트 작업 문제를 해결하기 위한 Confucius Code Agent를 출시했습니다. CCA의 핵심은 지속적인 내부 노트, 장기 작업 기억 및 추적 가능한 추론 체인에 있으며, 도구 사용 전략을 스스로 조정하는 피드백 루프를 갖추고 있습니다. 이러한 아키텍처를 통해 AI는 고립된 Prompt를 처리하는 데 그치지 않고 실제 세계의 복잡한 시스템에서 논리적 일관성을 유지할 수 있습니다. 커뮤니티에서는 이것이 “대규모 지능은 단순한 모델 규모가 아닌 기억 구조에 의존한다”는 업계의 새로운 합의를 검증한 것이라고 지적합니다. (출처: Reddit r/artificial; Reddit r/ArtificialInteligence)

🎯 동향
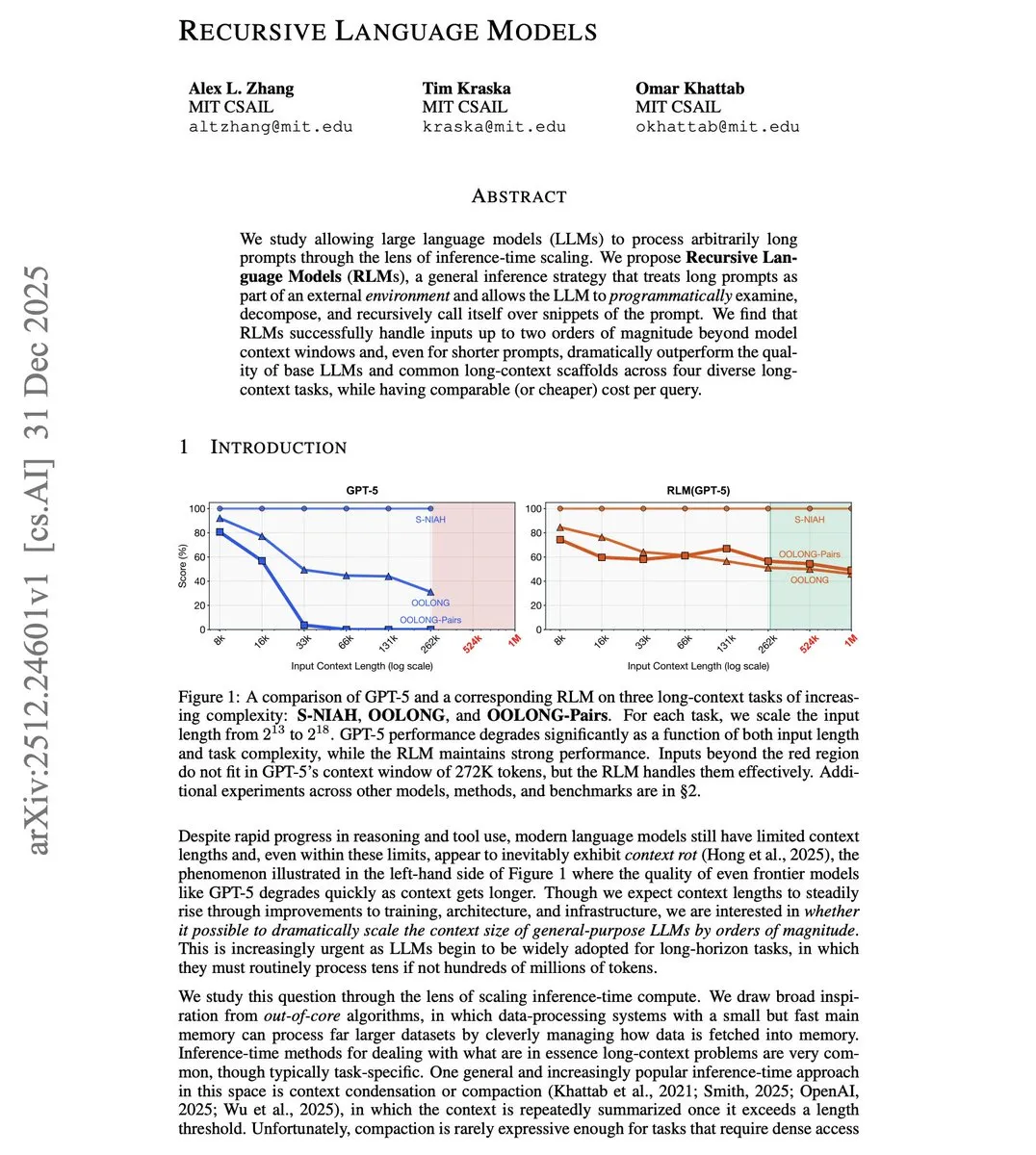
MIT, 컨텍스트 제한을 돌파하는 Recursive Language Model (RLM) 제안 : MIT 연구진이 제안한 RLM은 모델이 컨텍스트 윈도우의 100배를 초과하는 입력을 처리할 수 있게 합니다. 이 기술은 아키텍처 변경을 통해 윈도우를 늘리는 대신, 긴 프롬프트를 외부 환경으로 간주하고 모델이 자신을 재귀적으로 호출하여 조각들을 처리하도록 프로그래밍합니다. 테스트 결과, 8K 윈도우 모델이 800K Token을 효과적으로 처리했으며, 짧은 프롬프트 작업에서도 기존의 긴 컨텍스트 솔루션보다 우수한 성능을 보여 Agent가 전체 코드 라이브러리나 긴 문서를 저비용으로 처리할 수 있는 경로를 제시했습니다. (출처: omarsar0)
KimiLinear-48B, MLA KV Cache 지원 구현 : 개발자들이 llama.cpp에서 KimiLinear 모델을 위한 백엔드 독립적인 MLA KV Cache 지원을 추가하는 데 성공했습니다. 이 최적화를 통해 1M Token의 F16 KV 캐시 점유 용량이 140GB에서 14.8GB로 급감하여, 낮은 VRAM의 소비자용 그래픽 카드에서도 초장문 컨텍스트 모델을 실행할 수 있게 되었습니다. KimiLinear는 이전에 ContextArena에서 우수한 성능을 보인 바 있으며, 이번 VRAM 최적화는 로컬 환경에서의 장문 텍스트 AI 애플리케이션 보급을 크게 촉진할 것입니다. (출처: Reddit r/LocalLLaMA)

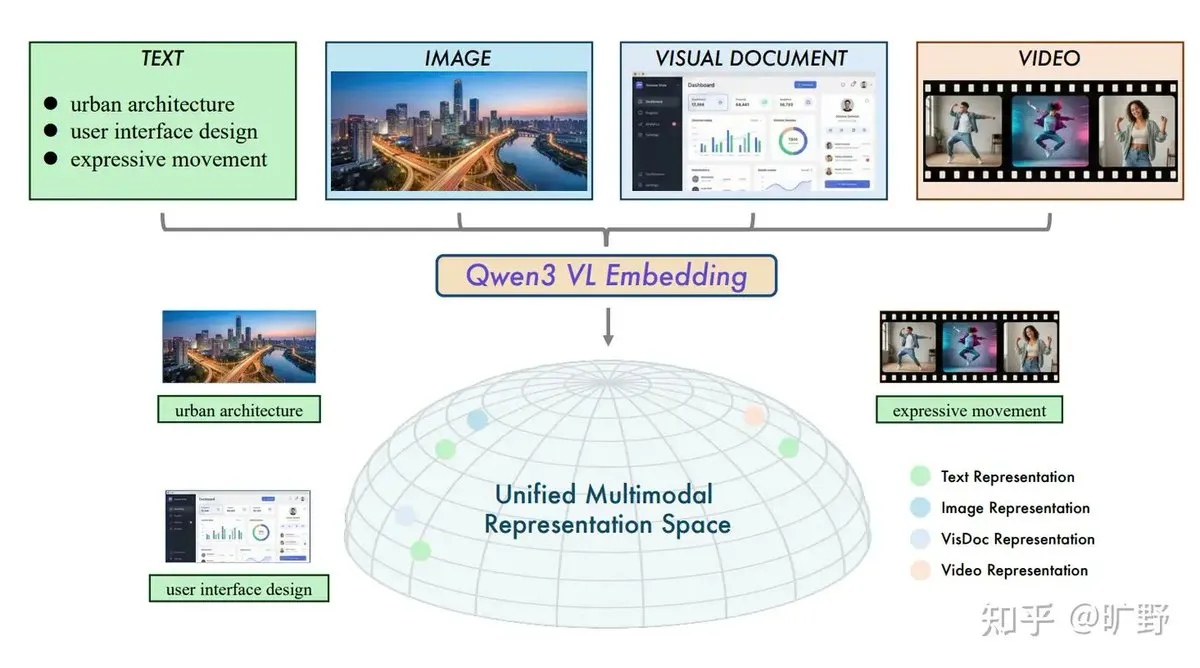
알리바바, Qwen3-VL 교차 모달 RAG 체계 오픈 소스 공개 : 알리바바가 Qwen3-VL-Embedding 및 Reranker 모델을 출시하여 과거 RAG가 텍스트에 지나치게 의존하던 문제를 해결했습니다. 이 모델은 텍스트, 이미지, 비디오 및 스크린샷을 통합 벡터 공간에 임베딩하여 “텍스트로 이미지 검색” 또는 “이미지로 영상 검색”을 가능하게 합니다. 독특한 “명령어 인식” 기능을 통해 사용자는 특정 작업(예: 이커머스 검색 또는 법률 비교)에 따라 관련성을 정의할 수 있으며, 이는 멀티모달 RAG가 작업 중심의 새로운 단계로 진입했음을 의미합니다. (출처: ZhihuFrontier)
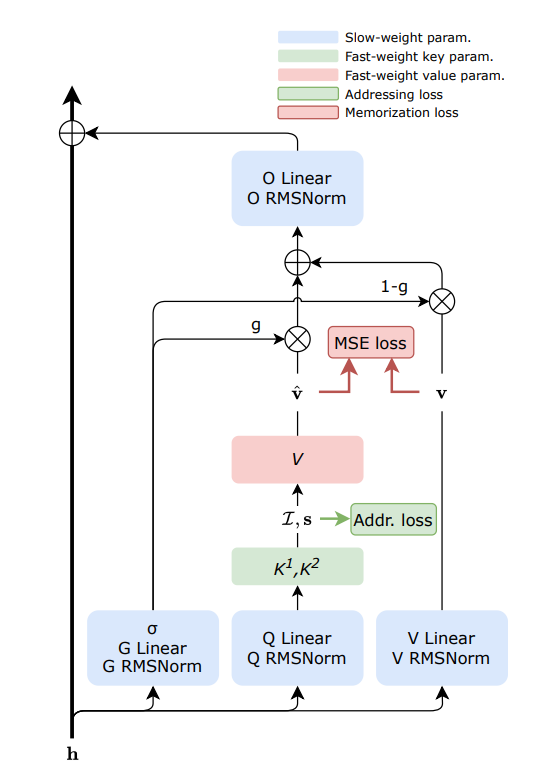
Sakana AI, FwPKM 동적 메모리 기술 발표 : Sakana AI는 대용량 메모리와 낮은 계산 비용의 균형을 맞추기 위해 Fast-weight Product Key Memory (FwPKM)를 출시했습니다. 이 기술은 Product Key Memory (PKM)가 학습 및 추론 과정에서 동적으로 업데이트될 수 있도록 하여 어텐션 메커니즘 확장의 병목 현상을 해결했습니다. 모델이 더 많은 정보를 기억하고 장기 추론을 수행해야 함에 따라, 이러한 동적 업데이트 메모리 메커니즘은 AGI로 가는 핵심 단계로 간주됩니다. (출처: TheTuringPost)
🧰 도구
Silicon-Studio: M 시리즈 Mac용 로컬 미세 조정 GUI : M 시리즈 칩 Mac을 위해 설계된 엔드 투 엔드 로컬 LLM 미세 조정 도구입니다. Apple의 MLX 프레임워크를 캡슐화하여 데이터 정제, PII 개인정보 비식별화, LoRA/QLoRA 파라미터 조정 및 내장 추론 테스트 인터페이스를 제공합니다. 이 도구는 일반 사용자가 Mac에서 개인화된 모델 학습을 수행할 수 있는 문턱을 낮추었으며, 전 과정을 그래픽 작업으로 구현했습니다. (출처: Reddit r/LocalLLaMA)
Kreuzberg v4: Rust로 재작성된 만능 문서 지능 라이브러리 : Kreuzberg v4가 Python에서 Rust로 바닥부터 재작성되어 56가지 형식의 구조화된 데이터 추출을 지원합니다. Pandoc 의존성을 제거하고 네이티브 Rust 파서를 채택하여 속도를 크게 향상시키고 메모리 점유를 줄였습니다. 이 라이브러리는 10가지 언어 바인딩(예: TS, Python, Go)을 제공하며 OCR 백엔드 전환 및 ONNX 임베딩을 지원하여 고성능 RAG 파이프라인 구축에 이상적인 선택입니다. (출처: Reddit r/LocalLLaMA)

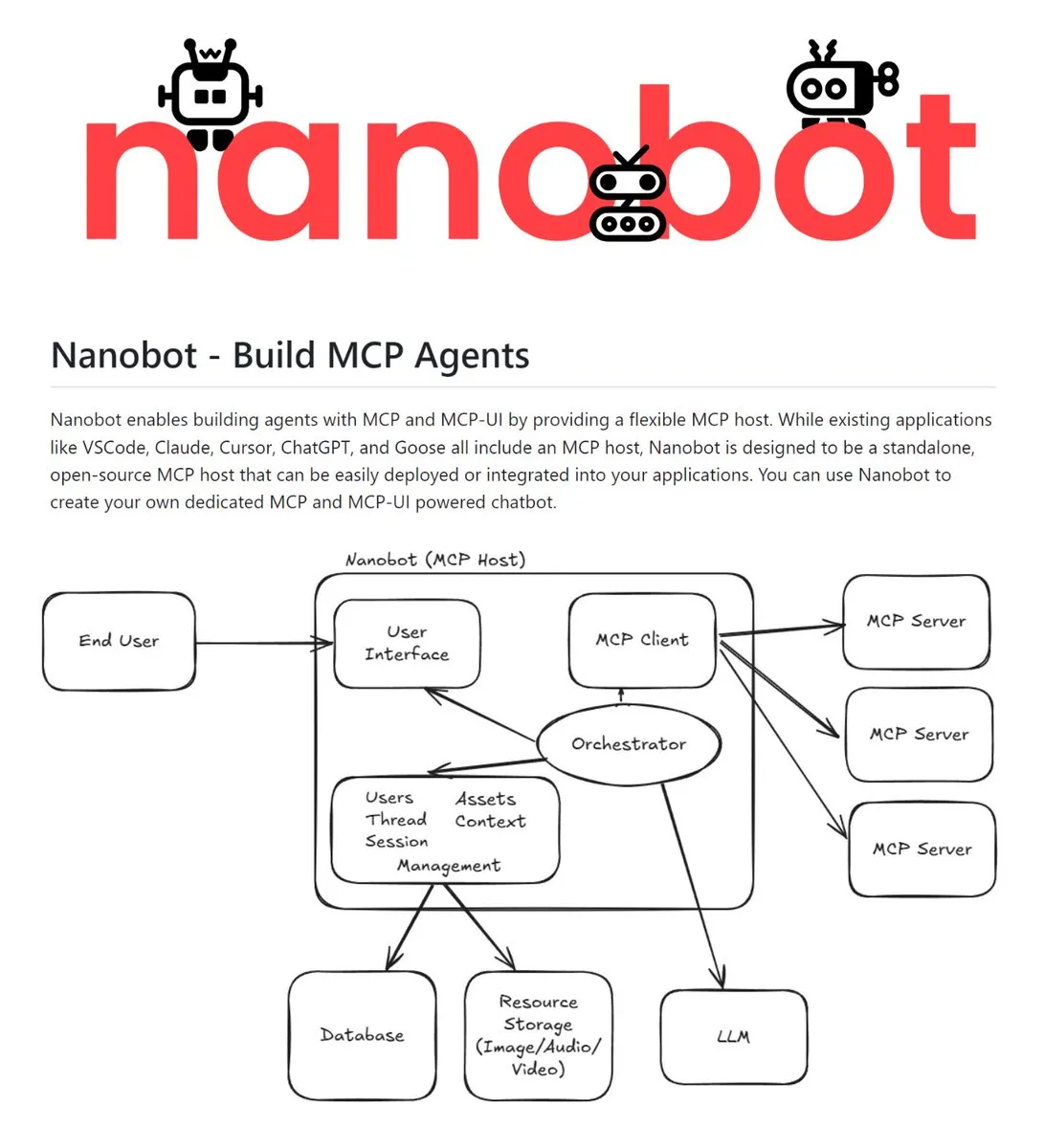
Nanobot: 오픈 소스 독립형 MCP 호스트 : Nanobot은 MCP (Model Context Protocol) 및 MCP-UI를 지원하는 오픈 소스 독립형 호스트입니다. MCP 서버, LLM 및 컨텍스트를 단일 서비스로 통합할 수 있으며 챗봇, 음성, 이메일, Slack 등 다양한 인터페이스를 통해 에이전트 경험을 구축할 수 있도록 지원합니다. 독립적인 배포 특성 덕분에 개발자가 크로스 플랫폼 AI Agent를 구축하기 위한 기초 키트가 됩니다. (출처: TheTuringPost)
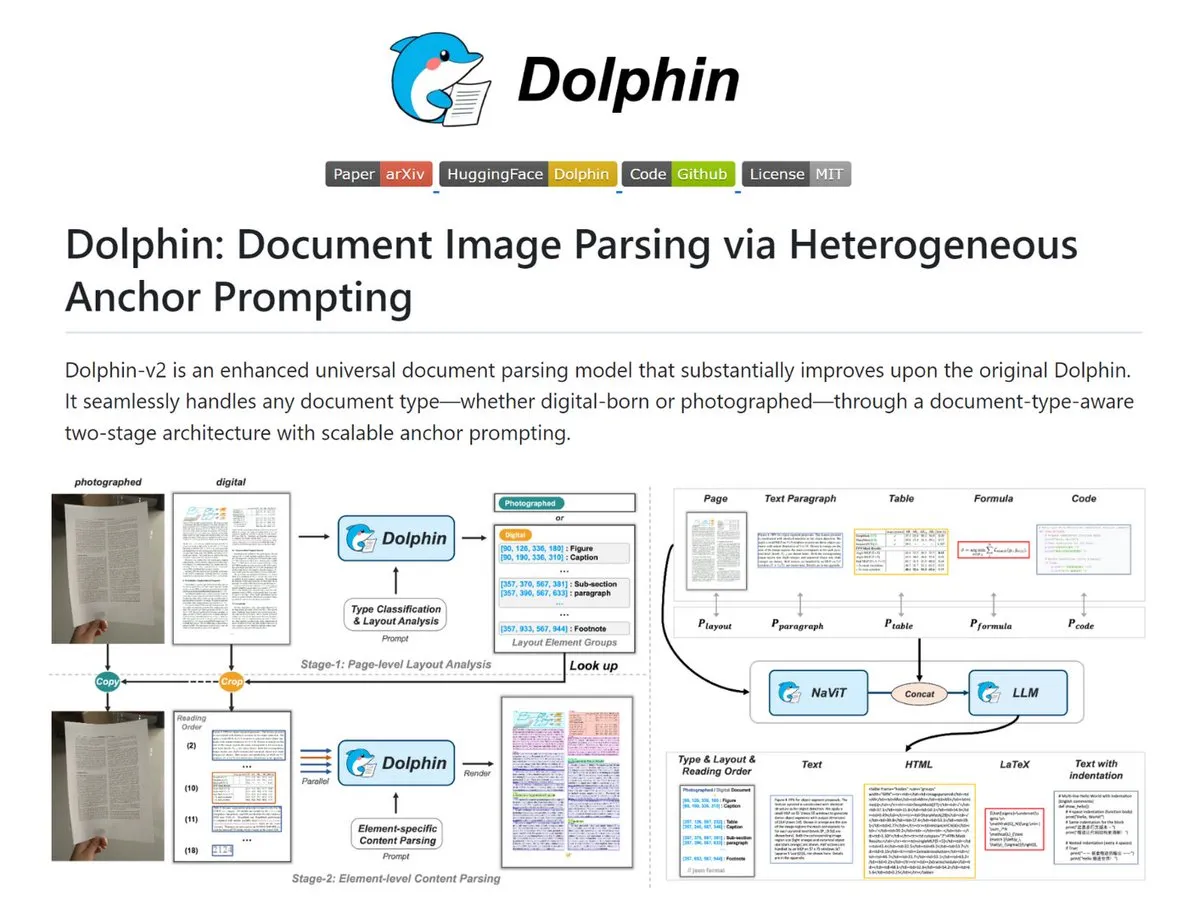
Dolphin: 복잡한 문서 파싱 도구 : Dolphin은 문서 이미지와 PDF를 구조화된 Markdown/JSON으로 변환하는 도구입니다. 스캔본과 디지털본을 자동으로 식별하고 레이아웃 읽기 순서를 복구하며 텍스트, 표, 수식을 병렬로 파싱합니다. 이 도구는 0.3B에서 3B까지의 모델 범위를 가지며 OmniDocBench에서 우수한 성능을 보여 고정밀 문서 디지털화가 필요한 시나리오에 적합합니다. (출처: TheTuringPost)
📚 학습
AI Agents A-Z: 전 과정 Agent 개발 튜토리얼 : 이 GitHub 저장소는 《AI Agents A-Z》 시리즈 영상의 n8n 템플릿을 요약한 것으로, 처방약 관리 에이전트, 일일 요약 에이전트부터 LinkedIn 자동화, YouTube 영상 생성 등 40개 이상의 실전 사례를 포함합니다. 노코드 도구와 LLM을 결합하여 복잡한 자동화 워크플로우를 구축하는 방법을 보여주며, 초보자가 Agent 활용 시나리오를 이해하는 데 훌륭한 리소스입니다. (출처: GitHub Trending)
LLM 기반 지식 그래프 구축 리뷰 : 논문 《LLM-empowered knowledge graph construction》은 LLM을 활용하여 전통적인 지식 그래프(KG) 방법을 강화하는 방법을 체계적으로 정리했습니다. 온톨로지 추출, 스키마 기반 및 비스키마 추출, 지식 융합 및 미래의 동적 메모리 추론 등의 방향을 다룹니다. 구조화된 지식과 대형 모델의 추론 능력을 결합하고자 하는 개발자에게 중요한 참고 가치가 있습니다. (출처: TheTuringPost)

💼 비즈니스
NVIDIA 그래픽 카드 지연 루머와 AI 우선 전략 : 소셜 미디어에서는 NVIDIA가 메모리 부족과 수익성이 더 높은 AI 칩 공급 우선순위 때문에 RTX 50 Super 시리즈 그래픽 카드 출시를 무기한 연기할 수 있다는 루머가 돌고 있습니다. 비록 루머에 불과하지만, NVIDIA 매출에서 게임 사업 비중이 8%로 감소한 상황에서 컴퓨팅 파워 수요가 급증함에 따라 소비자용 그래픽 카드가 ‘전략적으로 희생’되는 것이 논리적으로 타당하다는 것이 커뮤니티의 중론입니다. (출처: Reddit r/LocalLLaMA)

Meta, AI 슈퍼컴퓨팅 전력 확보를 위한 원자력 협정 체결 : Meta가 자사의 Prometheus AI 슈퍼컴퓨터 클러스터를 위해 원자력 협정을 체결했습니다. AI 경쟁이 치열해짐에 따라 에너지가 컴퓨팅 파워 확장의 병목 현상이 되었습니다. Meta의 이번 행보는 마이크로소프트 등 거대 기업들을 벤치마킹한 것으로, 안정적이고 깨끗한 원자력 자원을 확보함으로써 향후 몇 년간 지속적인 컴퓨팅 파워 확장 능력을 보장받기 위함입니다. (출처: Reddit r/artificial)
Zhipu AI IPO 동향 주목 : 업계 분석에서 Zhipu AI가 중국 내 첫 번째 대형 모델 상장사가 될 가능성이 언급되었습니다. 중국 내 대형 모델 분야의 선두 주자로서 Zhipu의 상업화 과정과 자본 시장 성과는 업계의 풍향계로 간주되며, 특히 현재 글로벌 AI 투자 환경이 복잡해진 상황에서 그 상장 진행 상황은 높은 대표성을 가집니다. (출처: ZhihuFrontier)
🌟 커뮤니티
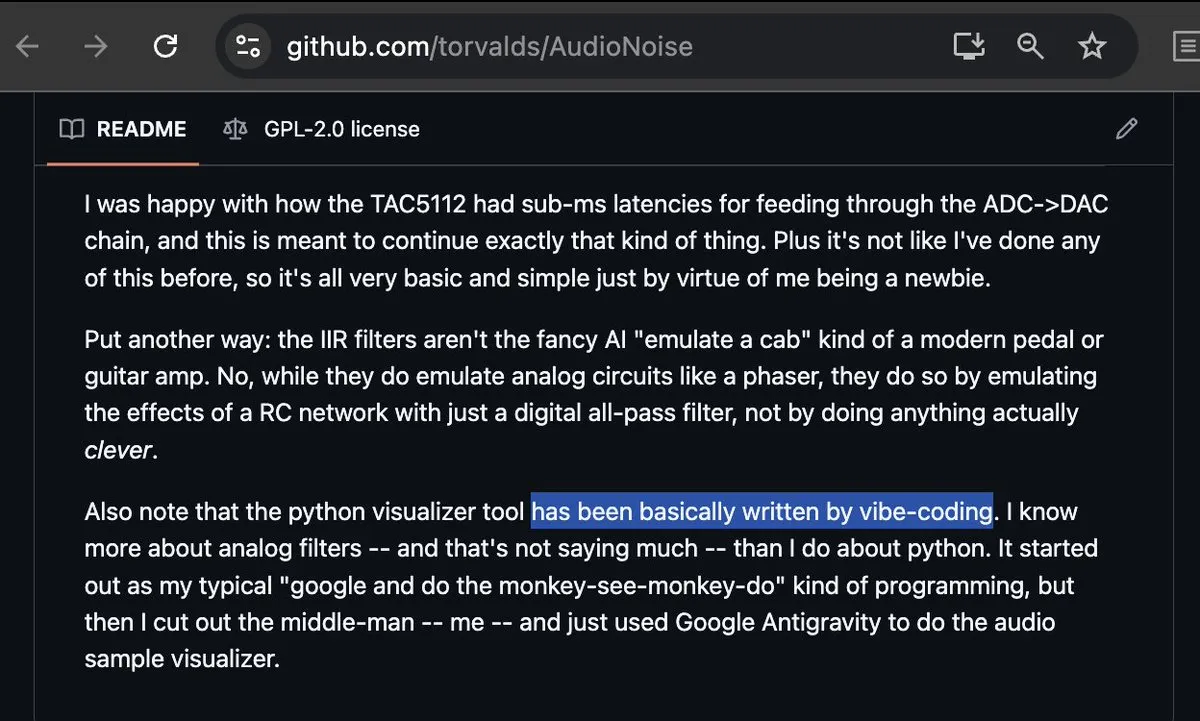
Linus Torvalds의 Vibe-coding 참여로 화제 : 평소 엄격하기로 유명한 Linux의 아버지 Linus Torvalds조차 Google Antigravity를 사용해 Vibe-coding(분위기 코딩)을 시작하고 오디오 시각화 도구를 성공적으로 구현했습니다. 이 사건은 커뮤니티에 큰 파장을 일으켰으며, AI 프로그래밍 도구가 성숙해졌음을 알리는 이정표로 간주됩니다. 프로그래머들은 핵심 개발자들조차 ‘분위기’ 코딩을 받아들이기 시작하면서 전통적인 코드 감사 및 작성 방식이 근본적으로 흔들리고 있다고 감탄하고 있습니다. (출처: dotey; cto_junior; osanseviero)
베테랑 프로그래머들의 AI 프로그래밍에 대한 인식 급변 : 과거 AI 코드를 “쓰레기(slop)”라며 무시했던 하드코어 프로그래머들(컴파일러, CUDA 커널 연구자 등)이 빠르게 견해를 바꾸고 있다는 점이 커뮤니티에서 관찰되고 있습니다. GPT-5.2 등 모델이 복잡한 논리와 저수준 코드에서 보여주는 성능이 정교해짐에 따라 AI 능력을 부정할 수 있는 시간적 여유가 사라졌습니다. 이러한 거부에서 충격, 그리고 수용으로 이어지는 심리적 변화는 AI 생산성 도구의 세대적 도약을 반영합니다. (출처: Yuchenj_UW; timsoret)
Agent 디버깅의 새로운 패러다임: 코드가 아닌 Trace를 보라 : Harrison Chase가 제안한 “Agent를 디버깅할 때 코드를 보여주지 말고 Trace를 보여달라”는 관점이 폭넓은 공감을 얻고 있습니다. Agentic 워크플로우에서는 LLM의 의사 결정 과정이 정적 코드보다 더 중요합니다. 실행 궤적(Trace) 분석을 통해 개발자는 모델이 어느 추론 단계에서 오류를 일으켰는지 더 명확하게 파악할 수 있으며, 이러한 “행동학”적 디버깅이 전통적인 “논리학”적 디버깅을 대체하고 있습니다. (출처: Hacubu; _philschmid)
AI 보안과 직원 습관 사이의 “줄다리기” : 많은 기업 관리자들이 직원이 기밀 데이터를 ChatGPT에 입력하는 것에 대해 우려하고 있습니다. 보안 교육에도 불구하고 AI가 주는 편리함 때문에 직원들은 종종 규정 위반 행위를 반복합니다. 커뮤니티 토론에 따르면 단순한 금지는 효과가 없으며, 동일하게 편리한 로컬 보안 AI 대안을 제공하고 실제 유출 사례인 “공포 이야기”를 통해 의식을 강화해야 한다고 보고 있습니다. (출처: Reddit r/ArtificialInteligence)
💡 기타
중미 로봇 후방 공중제비 기술 비교 : 소셜 미디어에서 Boston Dynamics Atlas와 Unitree 로봇의 후방 공중제비 성능을 비교했습니다. Unitree는 더 완벽한 균형과 착지를 보여준 반면, Atlas는 회복 동작에서 더 진보된 비인간 형태의 관절 전략을 보여주었습니다. 이러한 경쟁은 중국 로봇이 하드웨어 제조와 균형 제어에서 미국을 따라잡거나 부분적으로 추월했음을 보여주며, 미국은 여전히 복잡한 전략 알고리즘에서 우위를 점하고 있음을 나타냅니다. (출처: teortaxesTex)
광자 AI 칩, 100배 속도 향상 주장 : 새로운 유형의 광 구동 AI 칩이 최고 사양의 NVIDIA GPU보다 100배 빠르다고 주장하고 있습니다. 이 기술은 전자 신호 대신 광 신호 처리를 활용하여 전통적인 반도체가 컴퓨팅 파워 확장 시 겪는 전력 소모와 지연 시간 병목 현상을 해결하는 것을 목표로 합니다. 비록 아직 연구 개발 단계에 있지만, 이는 하드웨어 계층에서 NVIDIA의 독점에 대항하는 또 다른 공격적인 기술 노선을 상징합니다. (출처: Ronald_vanLoon)
