
Schlüsselwörter:GPT-5.2 Pro, DeepSeek V4, Konfuzius Code Agent, Erdős-Mathematikprobleme, mHC-Architektur, Langzeitgedächtnis-Agent
🔥 Fokus
GPT-5.2 Pro löst eigenständig mehrere Erdos-Mathematikrätsel : In den sozialen Medien wird derzeit intensiv über die bahnbrechenden Fortschritte von GPT-5.2 Pro im Bereich wissenschaftlicher Entdeckungen diskutiert. Das Modell hat in Kombination mit dem Aristotle-System erfolgreich mehrere mathematische Probleme gelöst, darunter die Erdos-Probleme #729 und #397. Der Beweis für #397 wurde bereits vom Mathematiker Terence Tao anerkannt. Dies markiert die Entwicklung der AI vom reinen Lernen aus Korpora hin zur Fähigkeit, logische Schlussfolgerungen für bisher ungelöste wissenschaftliche Probleme zu ziehen. Die Community sieht darin ein Beweis für das enorme Potenzial von Reasoning-Modellen bei hochgradig abstrakter Logik; ein Fields Medal für eine AI scheint nur noch eine Frage der Zeit zu sein (Quelle: SebastienBubeck; kevinweil; halvarflake)
DeepSeek V4 Veröffentlichungsprognose und tiefgehende Diskussion der mHC-Architektur : Brancheninterne Quellen berichten, dass DeepSeek V4 voraussichtlich während des Frühlingsfestes veröffentlicht wird, mit dem Ziel, den vollständigen SOTA-Status zu erreichen. Die Modellreihe erregte kürzlich Aufmerksamkeit durch die mHC (Multi-Head Connection)-Architektur, die durch die Eigenschaften der Doubly Stochastic Matrix die Stabilität von Schichtprodukten gewährleistet und Probleme wie Gradient Vanishing oder Explosion in tiefen Netzwerken effektiv löst. Community-Analysen deuten darauf hin, dass sich der technologische Pfad von DeepSeek vom reinen Anhäufen von Rechenleistung hin zur Optimierung der zugrunde liegenden mathematischen Architektur verschiebt. Dieser „Efficiency-First“-Ansatz verändert das Paradigma der Large Model-Entwicklung (Quelle: teortaxesTex; Reddit r/MachineLearning)
Meta und Harvard veröffentlichen Confucius Code Agent (CCA) Long-Memory Agent : Meta hat in Zusammenarbeit mit der Harvard University den Confucius Code Agent vorgestellt, um Herausforderungen bei Agent-Operationen in großen, komplexen Codebasen zu bewältigen. Der Kern von CCA liegt in seinen persistenten internen Notizen, dem Langzeit-Aufgabengedächtnis und rückverfolgbaren Reasoning-Ketten, ergänzt durch einen Feedback-Loop zur Selbstanpassung der Tool-Nutzungsstrategien. Diese Architektur ermöglicht es der AI, in komplexen realen Systemen logische Konsistenz zu wahren, anstatt nur isolierte Prompts zu verarbeiten. Die Community betont, dass dies den neuen Branchenkonsens bestätigt: „Großskalige Intelligenz hängt von Gedächtnisstrukturen ab, nicht nur von der Modellgröße“ (Quelle: Reddit r/artificial; Reddit r/ArtificialInteligence)

🎯 Trends
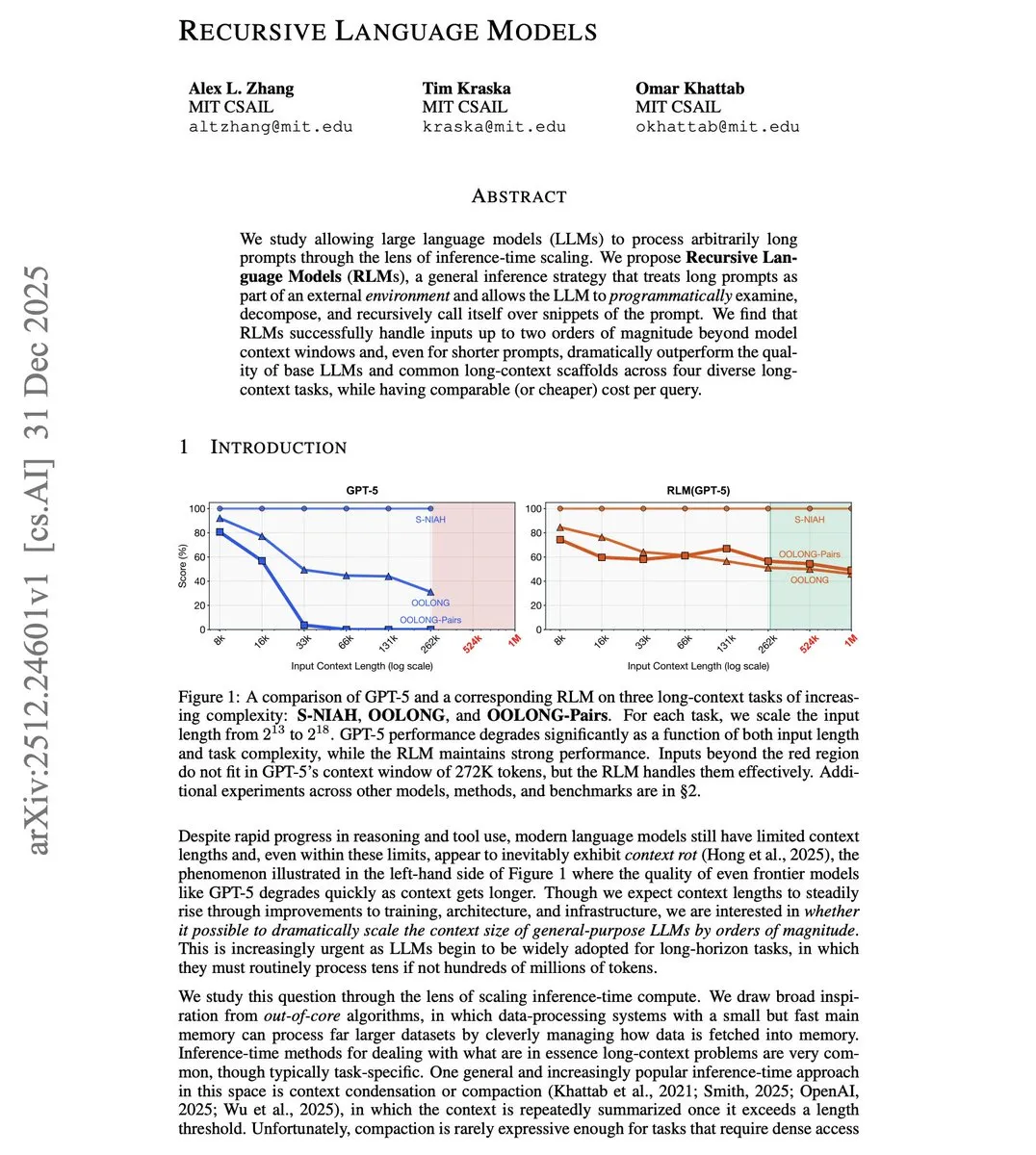
MIT schlägt Recursive Language Model (RLM) vor, um Context-Limits zu durchbrechen : Forscher des MIT haben RLM vorgestellt, das es Modellen ermöglicht, Eingaben zu verarbeiten, die das 100-fache ihres Context Window überschreiten. Diese Technik erhöht das Fenster nicht durch Architekturänderungen, sondern betrachtet lange Prompts programmatisch als externe Umgebung, wobei das Modell sich selbst rekursiv aufruft, um Segmente zu verarbeiten. Tests zeigen, dass ein Modell mit einem 8K-Fenster effektiv 800K Tokens verarbeiten kann und dabei auch bei Aufgaben mit kurzen Prompts herkömmliche Long-Context-Lösungen übertrifft. Dies bietet einen kostengünstigen Pfad für Agents zur Verarbeitung vollständiger Code-Repositorys oder langer Dokumente (Quelle: omarsar0)
KimiLinear-48B implementiert MLA KV Cache Support : Entwickler haben in llama.cpp erfolgreich einen Backend-unabhängigen MLA KV Cache Support für das KimiLinear-Modell hinzugefügt. Diese Optimierung reduziert den Speicherbedarf für den F16 KV Cache von 1M Tokens von 140 GB auf 14,8 GB, wodurch der Betrieb von Long-Context-Modellen auf Consumer-Grafikkarten mit geringem VRAM möglich wird. KimiLinear zeigte bereits in der ContextArena eine hervorragende Leistung; diese Speicheroptimierung wird die Verbreitung von Long-Text AI-Anwendungen auf lokaler Ebene massiv vorantreiben (Quelle: Reddit r/LocalLLaMA)

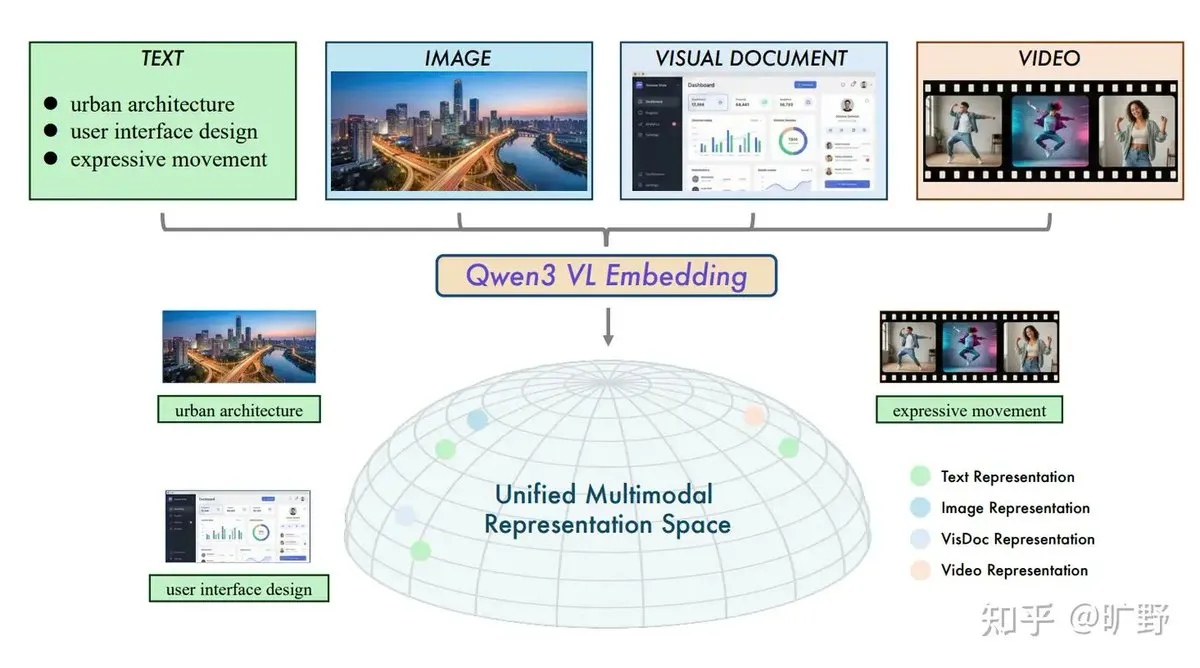
Alibaba veröffentlicht Open-Source Qwen3-VL Cross-Modal RAG System : Alibaba hat die Modelle Qwen3-VL-Embedding und Reranker veröffentlicht, die das bisherige Problem der zu starken Textabhängigkeit von RAG lösen. Das Modell unterstützt das Embedding von Text, Bildern, Videos und Screenshots in einen einheitlichen Vektorraum und ermöglicht Suchen wie „Text-zu-Bild“ oder „Bild-zu-Video“. Die einzigartige „Instruction-aware“-Funktion erlaubt es Nutzern, Relevanz basierend auf spezifischen Aufgaben (wie E-Commerce-Suche oder Rechtsvergleichung) zu definieren, was den Eintritt von multimodalem RAG in eine aufgabenorientierte Phase markiert (Quelle: ZhihuFrontier)
Sakana AI veröffentlicht FwPKM Dynamic Memory Technologie : Sakana AI hat Fast-weight Product Key Memory (FwPKM) vorgestellt, um eine hohe Speicherkapazität mit niedrigen Rechenkosten in Einklang zu bringen. Diese Technologie ermöglicht es dem Product Key Memory (PKM), sich sowohl während des Trainings als auch während der Inference dynamisch zu aktualisieren, wodurch Engpässe bei der Skalierung des Attention-Mechanismus gelöst werden. Da Modelle immer mehr Informationen speichern und Long-Range Reasoning durchführen müssen, wird dieser dynamische Speichermechanismus als entscheidender Schritt in Richtung AGI angesehen (Quelle: TheTuringPost)
🧰 Tools
Silicon-Studio: Lokales Fine-Tuning GUI für M-Serie Macs : Dies ist ein End-to-End-Tool für das lokale Fine-Tuning von LLMs, das speziell für Macs mit Chips der M-Serie entwickelt wurde. Es kapselt Apples MLX-Framework ein und bietet Datenbereinigung, PII-Anonymisierung, LoRA/QLoRA-Parameteranpassung sowie ein integriertes Interface für Inference-Tests. Das Tool senkt die Hürde für normale Nutzer, personalisiertes Modelltraining auf dem Mac durchzuführen, und bietet eine vollständig grafische Bedienung (Quelle: Reddit r/LocalLLaMA)
Kreuzberg v4: In Rust neu geschriebene All-in-One Document Intelligence Library : Kreuzberg v4 wurde von Python auf Rust umgeschrieben und unterstützt die strukturierte Datenextraktion aus 56 Formaten. Es entfernt die Abhängigkeit von Pandoc und nutzt native Rust-Parser, was die Geschwindigkeit signifikant erhöht und den Speicherverbrauch senkt. Die Library bietet Bindings für 10 Sprachen (z. B. TS, Python, Go), unterstützt den Wechsel von OCR-Backends und ONNX-Embeddings und ist die ideale Wahl für den Aufbau von Hochleistungs-RAG-Pipelines (Quelle: Reddit r/LocalLLaMA)

Nanobot: Open-Source Standalone MCP Host : Nanobot ist ein Open-Source Standalone-Host, der MCP (Model Context Protocol) und MCP-UI unterstützt. Er kann MCP-Server, LLMs und Kontext in einem einzigen Dienst integrieren und unterstützt den Aufbau von Agent-Erlebnissen über verschiedene Schnittstellen wie Chatbots, Voice, E-Mail und Slack. Seine unabhängige Bereitstellung macht ihn zu einem Basis-Kit für Entwickler, die plattformübergreifende AI Agents erstellen (Quelle: TheTuringPost)
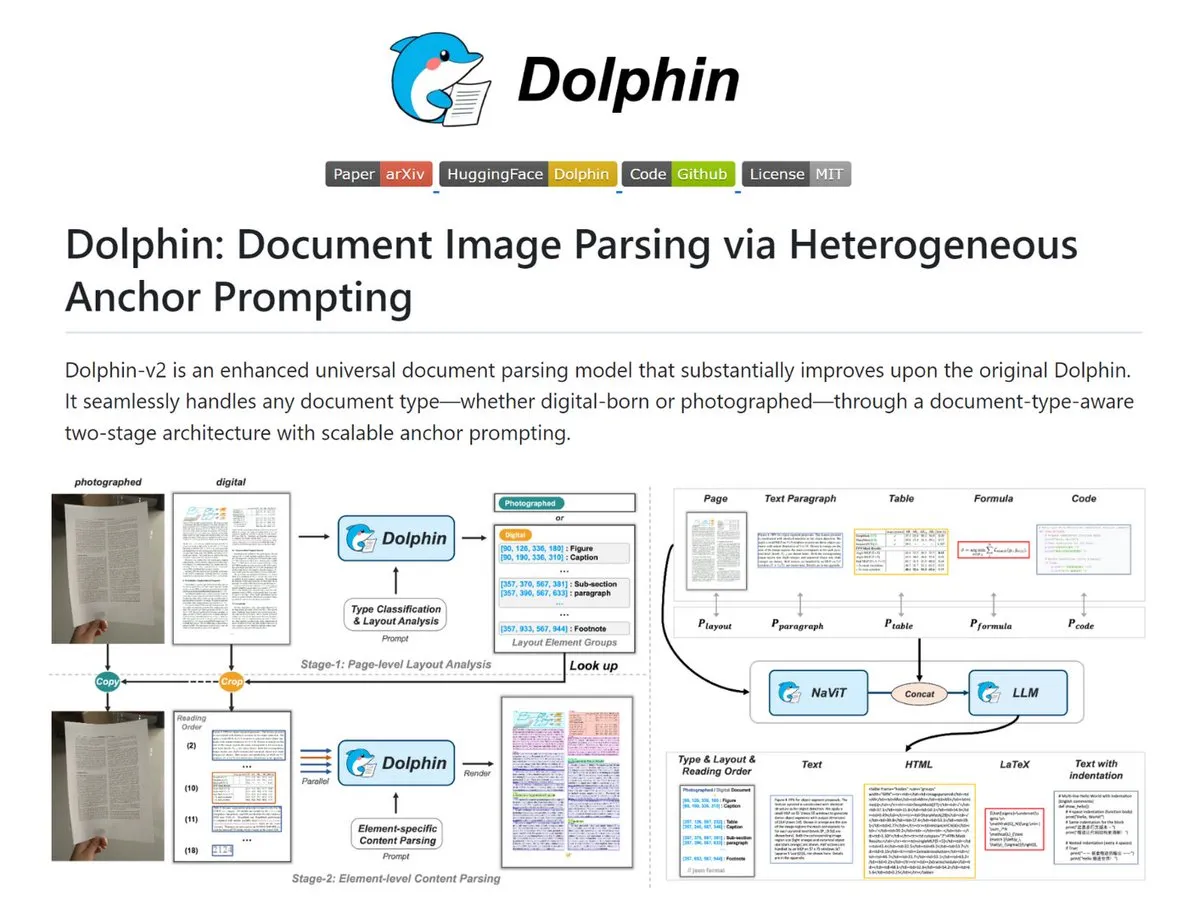
Dolphin: Tool für komplexe Dokumentenanalyse : Dolphin ist ein Tool, das Dokumentenbilder und PDFs in strukturiertes Markdown/JSON umwandelt. Es erkennt automatisch Scans und digitale Dokumente, stellt die Layout-Reihenfolge wieder her und analysiert Text, Tabellen und Formeln parallel. Die Modellgrößen reichen von 0.3B bis 3B. Dolphin zeigt eine hervorragende Leistung auf OmniDocBench und eignet sich für Szenarien, die eine hochpräzise Digitalisierung von Dokumenten erfordern (Quelle: TheTuringPost)
📚 Lernen
AI Agents A-Z: Tutorial für den gesamten Agent-Entwicklungsprozess : Dieses GitHub-Repository fasst die n8n-Templates der Videoserie „AI Agents A-Z“ zusammen. Es deckt über 40 Praxisbeispiele ab, von Agents für das Management verschreibungspflichtiger Medikamente über Daily-Summary-Agents bis hin zu LinkedIn-Automatisierung und YouTube-Video-Generierung. Es zeigt, wie man No-Code-Tools in Kombination mit LLMs nutzt, um komplexe automatisierte Workflows aufzubauen – eine exzellente Ressource für Anfänger (Quelle: GitHub Trending)
Review zu LLM-gestütztem Knowledge Graph Aufbau : Das Paper „LLM-empowered knowledge graph construction“ gibt einen systematischen Überblick darüber, wie LLMs traditionelle Knowledge Graph (KG)-Methoden verbessern können. Die Inhalte umfassen Ontologie-Extraktion, Schema-gesteuerte vs. schema-lose Extraktion, Wissensfusion sowie zukünftiges Dynamic Memory Reasoning. Dies ist eine wichtige Referenz für Entwickler, die strukturiertes Wissen mit den Reasoning-Fähigkeiten großer Modelle kombinieren möchten (Quelle: TheTuringPost)

💼 Business
Gerüchte über NVIDIA GPU-Verzögerungen und AI-Prioritätsstrategie : In den sozialen Medien kursieren Gerüchte, dass NVIDIA die Veröffentlichung der RTX 50 Super-Serie auf unbestimmte Zeit verschieben könnte. Grund sei ein Mangel an Speicherchips und die Priorisierung der profitableren AI-Chips. Obwohl es sich nur um Gerüchte handelt, ist die Community der Meinung, dass dies logisch konsistent ist, da der Anteil des Gaming-Geschäfts am Umsatz von NVIDIA auf 8 % gesunken ist und Consumer-Grafikkarten angesichts des enormen Bedarfs an Rechenleistung „strategisch geopfert“ werden könnten (Quelle: Reddit r/LocalLLaMA)

Meta unterzeichnet Atomkraft-Abkommen zur Sicherung der Stromversorgung für AI-Supercomputer : Meta hat ein Atomkraft-Abkommen für seine Prometheus AI-Supercomputer-Cluster unterzeichnet. Da das AI-Wettrüsten in eine heiße Phase eintritt, ist Energie zum Engpass für die Skalierung von Rechenleistung geworden. Meta folgt damit dem Beispiel von Giganten wie Microsoft, um durch die Sicherung stabiler, sauberer Kernenergiekapazitäten die Expansion der Rechenleistung in den kommenden Jahren zu gewährleisten (Quelle: Reddit r/artificial)
Zhipu AI IPO-Dynamik im Fokus : Branchenanalysen erwähnen die potenziellen Schritte von Zhipu AI als erstes börsennotiertes Large-Model-Unternehmen in China. Als führender Akteur im Bereich der heimischen Modelle gelten der Kommerzialisierungsprozess und die Performance von Zhipu am Kapitalmarkt als Indikator für die Branche, insbesondere angesichts des komplexer werdenden globalen AI-Finanzierungsumfelds (Quelle: ZhihuFrontier)
🌟 Community
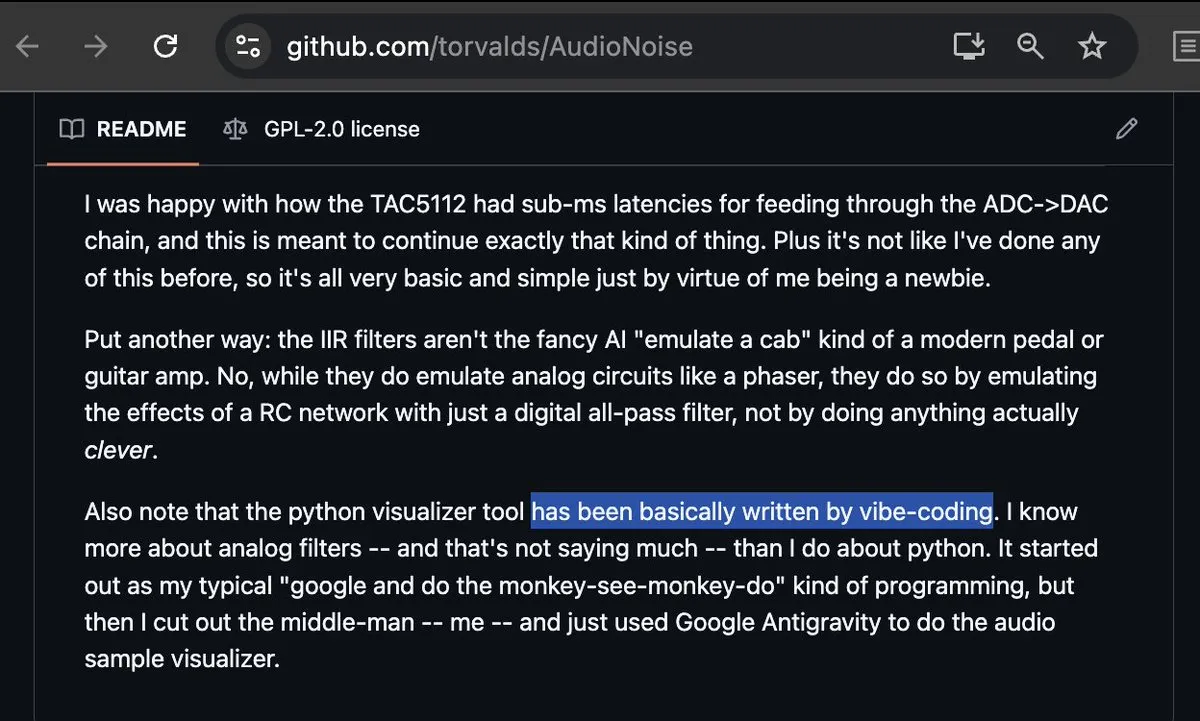
Linus Torvalds nimmt an Vibe-coding teil und sorgt für Diskussionen : Selbst der stets strenge Linux-Vater Linus Torvalds hat begonnen, Google Antigravity für „Vibe-coding“ zu nutzen, und damit erfolgreich ein Audio-Visualisierungstool implementiert. Dieses Ereignis sorgte in der Community für Aufsehen und wird als Meilenstein für die Reife von AI-Programmiertools gewertet. Programmierer stellen fest, dass sich traditionelle Code-Audit- und Schreibmuster grundlegend ändern, wenn selbst Core-Entwickler beginnen, das Programmieren nach „Vibe“ zu akzeptieren (Quelle: dotey; cto_junior; osanseviero)
Drastischer Sinneswandel erfahrener Programmierer gegenüber AI-Programmierung : Die Community beobachtet, dass Hardcore-Programmierer (die an Compilern, CUDA-Kernen usw. arbeiten), die AI-Code früher als „Slop“ (Abfall) abgetan haben, ihre Meinung rapide ändern. Da Modelle wie GPT-5.2 bei komplexer Logik und Low-Level-Code immer besser abschneiden, hat sich das Zeitfenster für das Leugnen von AI-Fähigkeiten geschlossen. Dieser psychologische Wandel von Widerstand über Schock bis hin zur Akzeptanz spiegelt den Generationensprung bei AI-Produktivitätstools wider (Quelle: Yuchenj_UW; timsoret)
Neues Paradigma für Agent-Debugging: Trace statt Code betrachten : Harrison Chases Ansicht „Zeig mir beim Debuggen eines Agents nicht den Code, zeig mir den Trace“ findet breite Zustimmung. In Agentic-Workflows ist der Entscheidungsprozess des LLM wichtiger als statischer Code. Durch die Analyse der Ausführungsspuren (Trace) können Entwickler klarer lokalisieren, an welcher Stelle des Reasoning-Prozesses das Modell einen Fehler gemacht hat. Dieses „verhaltensbasierte“ Debugging ersetzt zunehmend das traditionelle „logikbasierte“ Debugging (Quelle: Hacubu; _philschmid)
Tauziehen zwischen AI-Sicherheit und Mitarbeitergewohnheiten : Viele Unternehmensleiter sind besorgt darüber, dass Mitarbeiter vertrauliche Daten in ChatGPT einspeisen. Trotz Sicherheitsschulungen neigen Mitarbeiter aufgrund der Bequemlichkeit der AI oft dazu, in regelwidriges Verhalten „rückfällig“ zu werden. Die Community-Diskussion legt nahe, dass reine Verbote wirkungslos sind; es müssen ebenso bequeme, lokale und sichere AI-Alternativen angeboten werden, ergänzt durch reale „Horrorgeschichten“ über Datenlecks zur Bewusstseinsstärkung (Quelle: Reddit r/ArtificialInteligence)
💡 Sonstiges
Vergleich der Backflip-Technologie zwischen chinesischen und US-Robotern : In den sozialen Medien wurde die Backflip-Performance von Boston Dynamics Atlas mit der von Unitree-Robotern verglichen. Unitree zeigte eine perfektere Balance und Landung, während Atlas bei der Erholungsbewegung eine fortschrittlichere Gelenkstrategie in nicht-menschlicher Form demonstrierte. Dieser Wettbewerb zeigt, dass chinesische Roboter bei der Hardware-Fertigung und Balancesteuerung aufgeholt oder die USA teilweise sogar überholt haben, während die USA bei komplexen Strategie-Algorithmen weiterhin Vorteile haben (Quelle: teortaxesTex)
Photonischer AI-Chip verspricht hundertfache Geschwindigkeitssteigerung : Ein neuartiger lichtbetriebener AI-Chip soll angeblich 100-mal schneller sein als Top-GPUs von NVIDIA. Die Technologie nutzt optische Signalverarbeitung anstelle von elektronischen Signalen, um Engpässe bei Stromverbrauch und Latenz herkömmlicher Halbleiter bei der Skalierung von Rechenleistung zu lösen. Obwohl er sich noch in der Forschungsphase befindet, stellt dies eine radikale technologische Alternative dar, um das NVIDIA-Monopol auf Hardware-Ebene herauszufordern (Quelle: Ronald_vanLoon)
