
Keywords:GPT-5.2 Pro, DeepSeek V4, Confucius Code Agent, Erdos Math Conjectures, mHC Architecture, Long Memory Agent
🔥 Focus
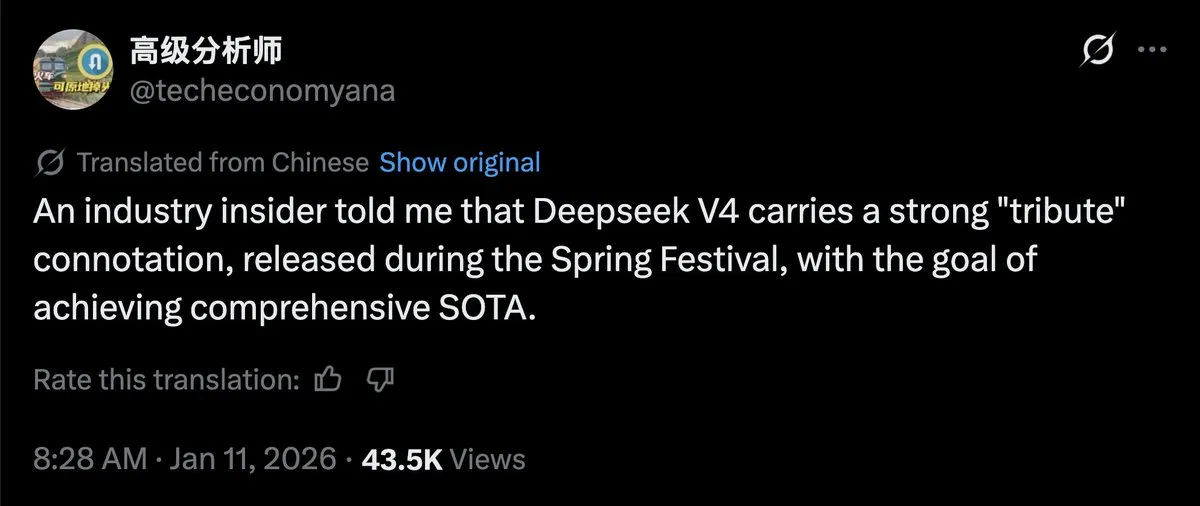
GPT-5.2 Pro Autonomously Solves Multiple Erdos Mathematical Problems: Social media has recently been abuzz with the breakthrough progress of GPT-5.2 Pro in the field of scientific discovery. Combined with the Aristotle system, the model successfully solved several mathematical puzzles autonomously, including Erdos problems #729 and #397. The proof for #397 has already been recognized by mathematician Terence Tao. This marks a shift for AI from simple corpus-based learning to possessing reasoning capabilities for unsolved scientific challenges. The community believes this proves the immense potential of reasoning models in handling highly abstract logic, suggesting that it may only be a matter of time before AI wins a Fields Medal (Source: SebastienBubeck; kevinweil; halvarflake)
DeepSeek V4 Release Prediction and Deep Discussion on mHC Architecture: Internal industry sources reveal that DeepSeek V4 is expected to be released during the Lunar New Year, aiming for full SOTA performance. This series of models has recently gained attention for its mHC (Multi-Head Connection) architecture, which ensures the stability of layer products through Doubly Stochastic Matrix properties, effectively solving gradient vanishing or explosion issues in deep networks. Community analysis suggests that DeepSeek’s technical path is shifting from pure compute stacking to lower-level mathematical architecture optimization. This “small-to-win-big” approach is changing the paradigm of large model development (Source: teortaxesTex; Reddit r/MachineLearning)
Meta and Harvard Release Confucius Code Agent (CCA) Long-Memory Agent: Meta, in collaboration with Harvard University, has launched the Confucius Code Agent, designed to solve agent operation challenges in large, complex codebases. The core of CCA lies in its persistent internal notes, long-range task memory, and traceable reasoning chains, featuring a feedback loop for self-adjusting tool-use strategies. This architecture allows the AI to maintain logical consistency in real-world complex systems rather than just processing isolated prompts. The community noted that this validates a new industry consensus: “large-scale intelligence depends on memory structures rather than just model scale” (Source: Reddit r/artificial; Reddit r/ArtificialInteligence)

🎯 Trends
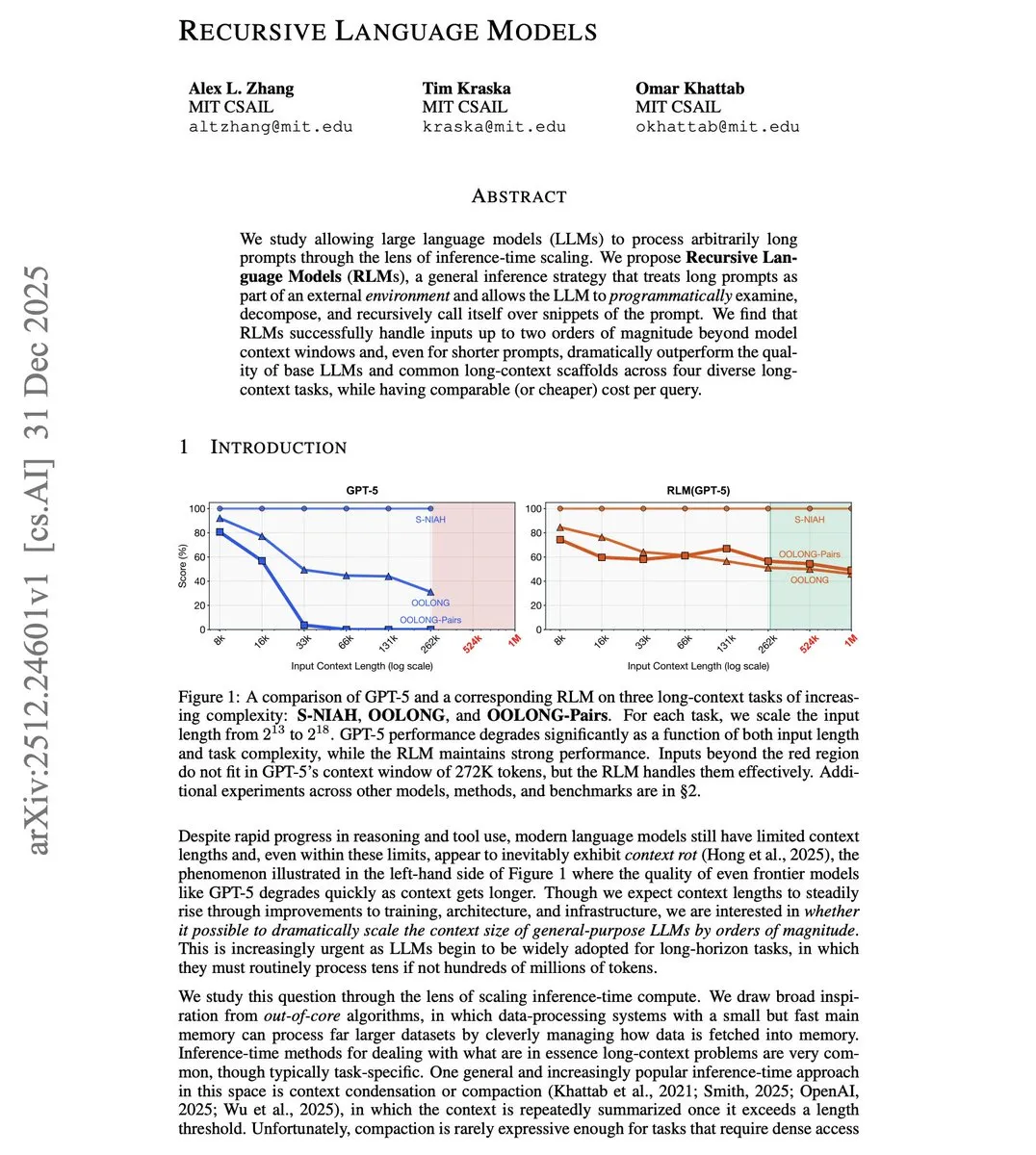
MIT Proposes Recursive Language Model (RLM) to Break Context Limits: MIT researchers have proposed RLM, which allows models to process inputs exceeding their context window by 100 times. Instead of increasing the window through architectural changes, this technique programmatically treats long prompts as an external environment, letting the model recursively call itself to process segments. Tests show that a model with an 8K window can effectively handle 800K tokens and outperforms traditional long-context solutions even in short-prompt tasks, providing a low-cost path for agents to handle entire code repositories or long documents (Source: omarsar0)
KimiLinear-48B Implements MLA KV Cache Support: Developers have successfully added backend-agnostic MLA KV Cache support for the KimiLinear model in llama.cpp. This optimization slashes the F16 KV cache footprint for 1M tokens from 140GB to 14.8GB, making it possible to run ultra-long context models on consumer-grade GPUs with low VRAM. KimiLinear previously performed excellently in ContextArena, and this VRAM optimization will greatly drive the localization of long-text AI applications (Source: Reddit r/LocalLLaMA)

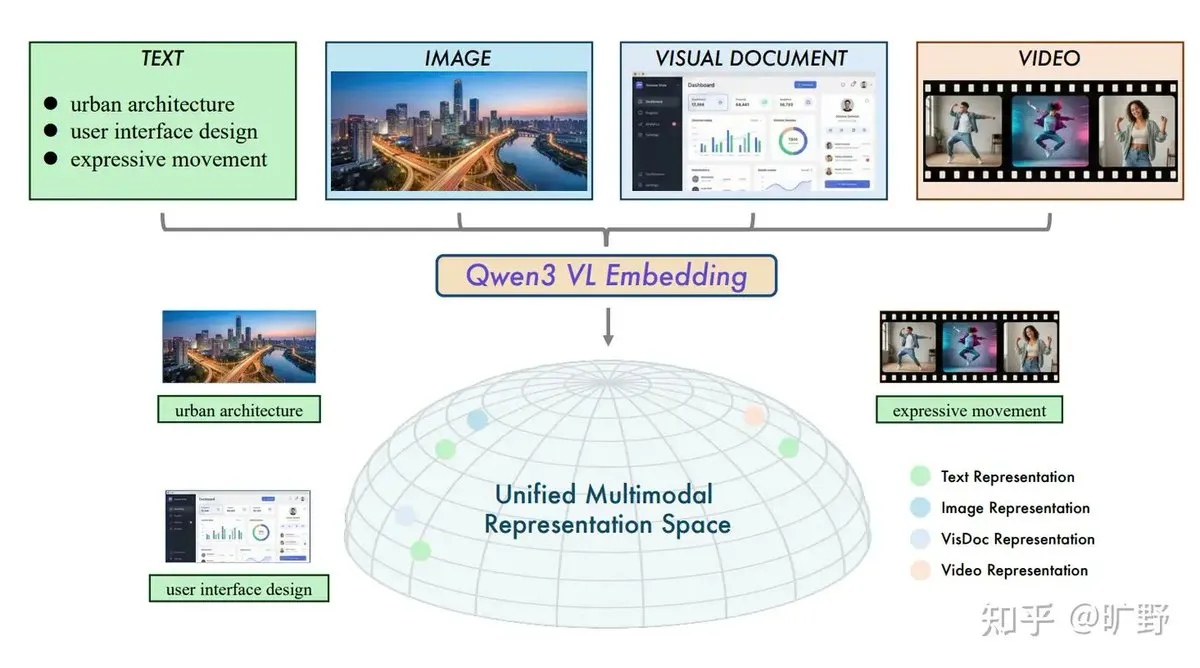
Alibaba Open-Sources Qwen3-VL Cross-Modal RAG System: Alibaba has released the Qwen3-VL-Embedding and Reranker models, addressing the pain point of RAG’s over-reliance on text. The model supports embedding text, images, videos, and screenshots into a unified vector space, enabling “text-to-image” or “image-to-video” searches. Its unique “instruction-aware” feature allows users to define relevance based on specific tasks (such as e-commerce search or legal comparison), marking a new task-driven stage for multimodal RAG (Source: ZhihuFrontier)
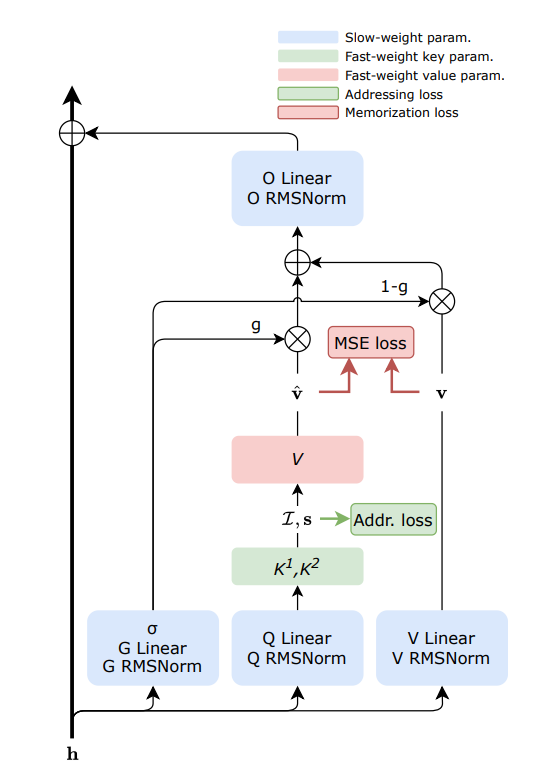
Sakana AI Releases FwPKM Dynamic Memory Technology: Sakana AI has introduced Fast-weight Product Key Memory (FwPKM), aimed at balancing large memory capacity with low computational costs. This technology allows Product Key Memory (PKM) to be dynamically updated during both training and inference, solving bottlenecks in scaling attention mechanisms. As models need to remember more information and perform long-range reasoning, this dynamically updated memory mechanism is seen as a key step toward AGI (Source: TheTuringPost)
🧰 Tools
Silicon-Studio: Local Fine-tuning GUI for M-series Macs: This is an end-to-end local LLM fine-tuning tool specifically designed for M-series chip Macs. It encapsulates Apple’s MLX framework, providing data cleaning, PII privacy de-identification, LoRA/QLoRA parameter adjustment, and a built-in inference testing interface. The tool lowers the barrier for average users to perform personalized model training on Mac, achieving a full-process graphical operation (Source: Reddit r/LocalLLaMA)
Kreuzberg v4: Universal Document Intelligence Library Rewritten in Rust: Kreuzberg v4 has completed a low-level rewrite from Python to Rust, supporting structured data extraction for 56 formats. It removes the Pandoc dependency and uses native Rust parsers, significantly increasing speed and reducing memory usage. The library provides bindings for 10 languages (e.g., TS, Python, Go) and supports OCR backend switching and ONNX embeddings, making it an ideal choice for building high-performance RAG pipelines (Source: Reddit r/LocalLLaMA)

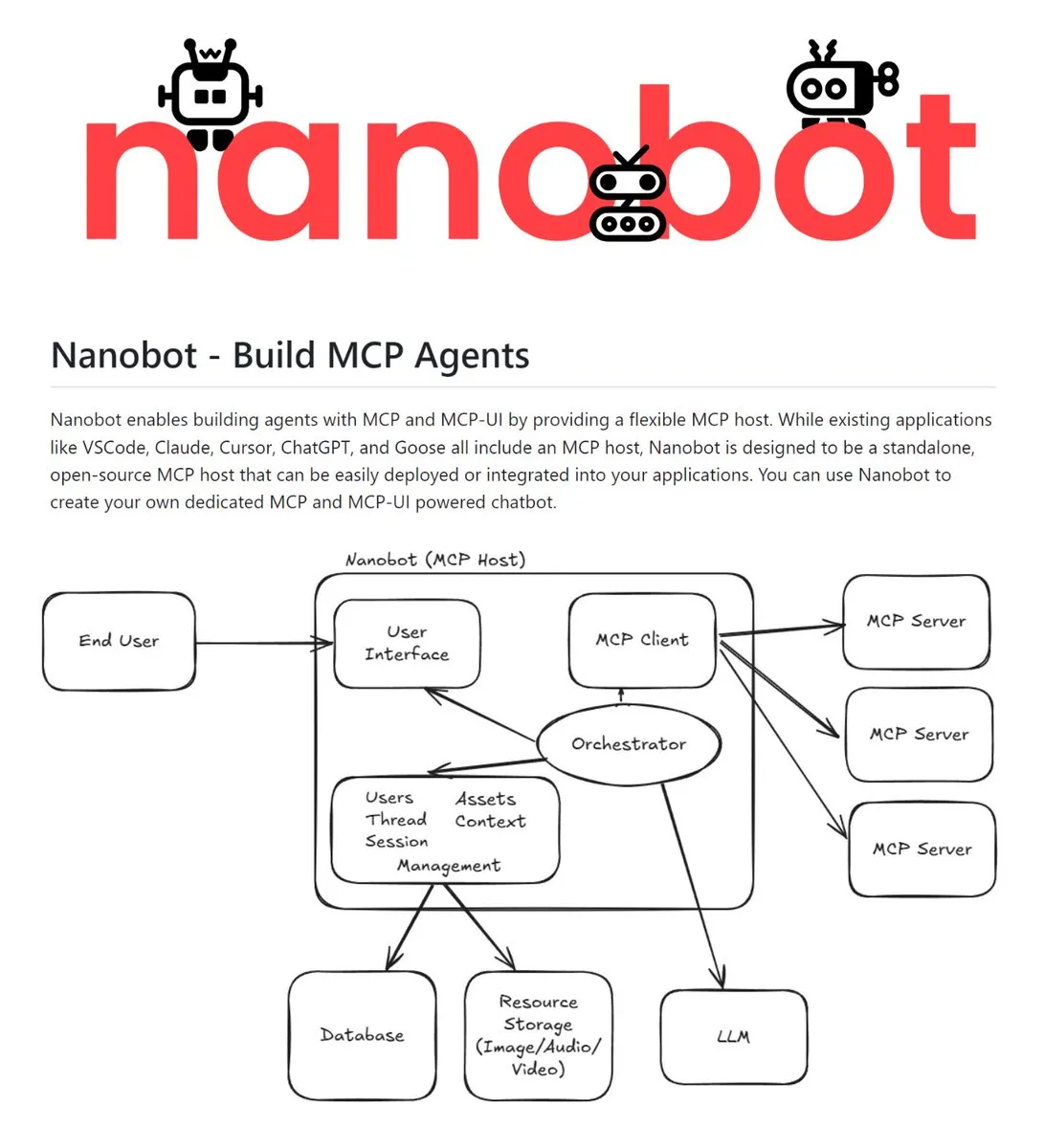
Nanobot: Open-Source Independent MCP Host: Nanobot is an open-source independent host that supports MCP (Model Context Protocol) and MCP-UI. It can integrate MCP servers, LLMs, and context into a single service, supporting the construction of agent experiences through various interfaces such as chatbots, voice, email, and Slack. Its independent deployment nature makes it a foundational suite for developers building cross-platform AI Agents (Source: TheTuringPost)
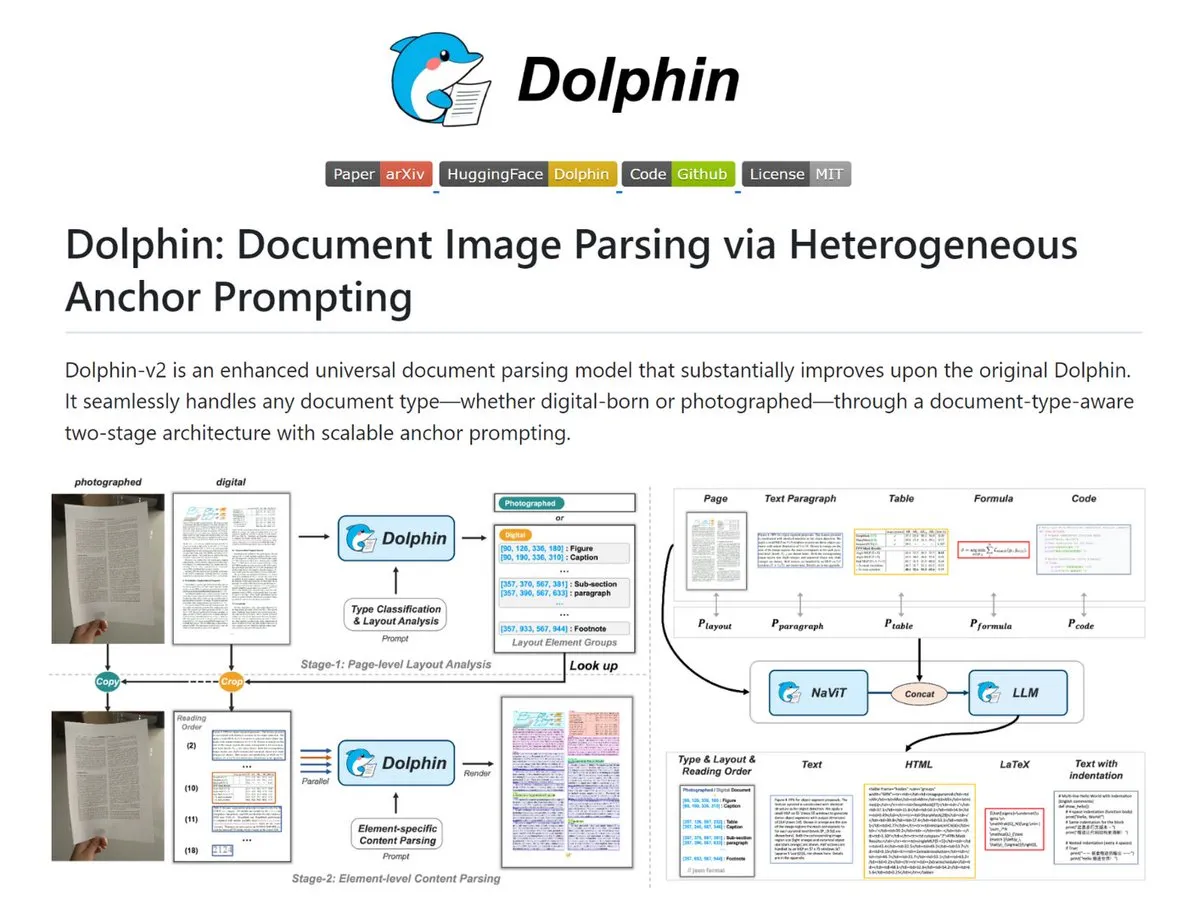
Dolphin: A Powerful Tool for Complex Document Parsing: Dolphin is a tool that converts document images and PDFs into structured Markdown/JSON. It automatically identifies scanned and digital documents, restores layout reading order, and parses text, tables, and formulas in parallel. The tool’s models range from 0.3B to 3B and perform excellently on OmniDocBench, making it suitable for scenarios requiring high-precision document digitization (Source: TheTuringPost)
📚 Learning
AI Agents A-Z: Full-Process Agent Development Tutorial: This GitHub repository aggregates n8n templates from the “AI Agents A-Z” video series, covering over 40 practical cases ranging from prescription drug management agents and daily summary agents to LinkedIn automation and YouTube video generation. It demonstrates how to use no-code tools combined with LLMs to build complex automated workflows, serving as an excellent resource for beginners to understand agent implementation scenarios (Source: GitHub Trending)
Review of LLM-Empowered Knowledge Graph Construction: The paper “LLM-empowered knowledge graph construction” systematically reviews how to use LLMs to enhance traditional Knowledge Graph (KG) methods. Content covers ontology extraction, schema-driven vs. schema-free extraction, knowledge fusion, and future dynamic memory reasoning. It holds significant reference value for developers looking to combine structured knowledge with large model reasoning capabilities (Source: TheTuringPost)

💼 Business
NVIDIA GPU Delay Rumors and AI Priority Strategy: Rumors are circulating on social media that NVIDIA may indefinitely delay the release of RTX 50 Super series GPUs due to memory shortages and the company’s priority on supplying higher-margin AI chips. Although only a rumor, the community generally believes that since the gaming business has dropped to 8% of NVIDIA’s revenue, the “strategic sacrifice” of consumer GPUs is logically plausible in the context of compute hunger (Source: Reddit r/LocalLLaMA)

Meta Signs Nuclear Power Deal to Secure AI Supercomputing Electricity: Meta has signed a nuclear power agreement for its Prometheus AI supercomputing cluster. As the AI race intensifies, energy has become a bottleneck for scaling compute. Meta’s move follows giants like Microsoft, aiming to ensure continuous compute expansion capacity in the coming years by locking in stable, clean nuclear power resources (Source: Reddit r/artificial)
Zhipu AI IPO Dynamics Gain Attention: Industry reviews have mentioned the potential move of Zhipu AI as the first domestic large-model company to go public. As a leading player in domestic large models, Zhipu’s commercialization process and capital market performance are seen as industry bellwethers, especially given the current complexity of the global AI financing environment (Source: ZhihuFrontier)
🌟 Community
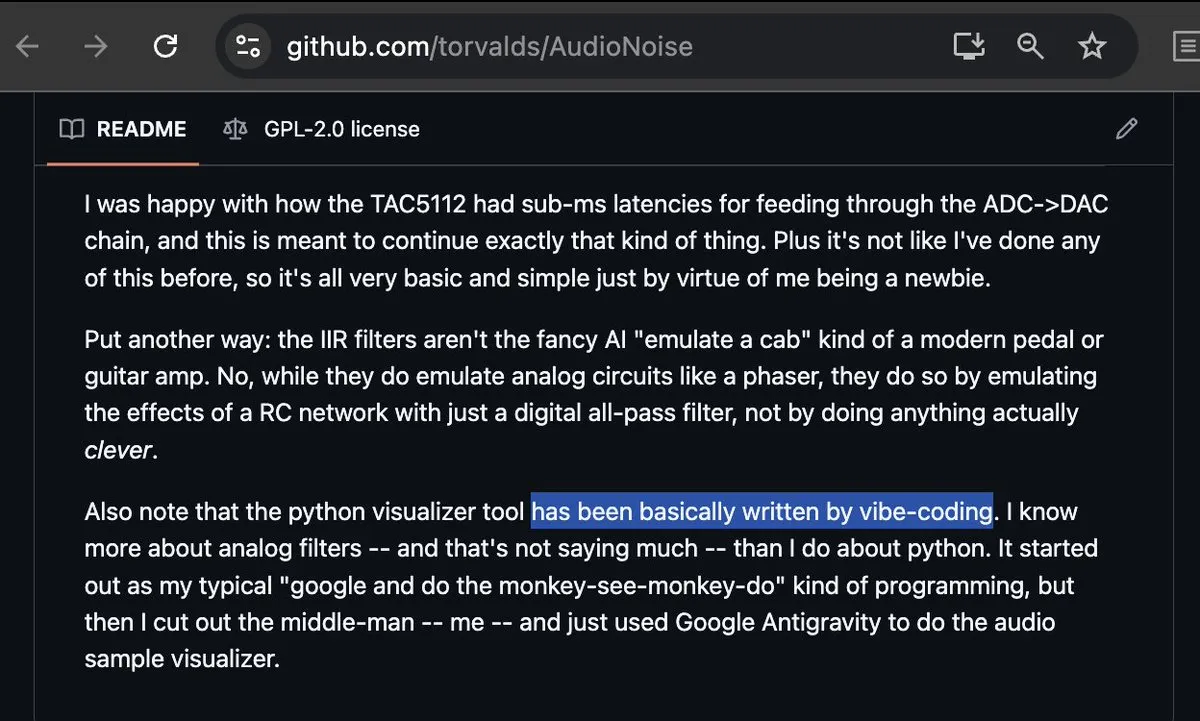
Linus Torvalds Participates in Vibe-coding, Sparking Heated Discussion: Even the usually rigorous father of Linux, Linus Torvalds, has started using Google Antigravity for “Vibe-coding,” successfully implementing an audio visualization tool. This event caused a sensation in the community and is seen as a milestone in the maturity of AI programming tools. Programmers remarked that when even the most hardcore developers start accepting “vibe-based” programming, traditional code auditing and writing patterns are being fundamentally shaken (Source: dotey; cto_junior; osanseviero)
Sharp Shift in Senior Programmers’ Perception of AI Programming: The community has observed that hardcore programmers (those researching compilers, CUDA kernels, etc.), who once scoffed at AI code as “slop,” are rapidly changing their views. As models like GPT-5.2 improve in handling complex logic and low-level code, the window for denying AI’s capability has closed. This psychological shift from resistance to shock and then acceptance reflects a generational leap in AI productivity tools (Source: Yuchenj_UW; timsoret)
New Paradigm for Agent Debugging: Look at Trace, Not Code: Harrison Chase’s view that “when debugging an Agent, don’t show me the code, show me the Trace” has gained wide consensus. In agentic workflows, the LLM’s decision-making process is more important than static code. By analyzing execution traces, developers can more clearly locate which reasoning step the model failed at; this “ethological” debugging is replacing traditional “logical” debugging (Source: Hacubu; _philschmid)
The “Tug-of-War” Between AI Security and Employee Habits: Many corporate managers are concerned about employees feeding confidential data into ChatGPT. Despite security training, the convenience of AI often leads employees to “relapse” into non-compliant behavior. Community discussions suggest that simple bans are ineffective; companies must provide equally convenient local secure AI alternatives, supplemented by real “horror stories” of leaks to reinforce awareness (Source: Reddit r/ArtificialInteligence)
💡 Others
Comparison of US and Chinese Robot Backflip Technology: Social media compared the backflip performance of Boston Dynamics’ Atlas and Unitree’s robots. Unitree demonstrated more perfect balance and landing, while Atlas showed more advanced non-humanoid joint strategies during recovery. This competition shows that Chinese robots have caught up or even partially surpassed the US in hardware manufacturing and balance control, while the US still holds an advantage in complex strategic algorithms (Source: teortaxesTex)
Photonic AI Chip Claims 100x Speedup: A new light-driven AI chip reportedly runs 100 times faster than top-tier NVIDIA GPUs. The technology uses optical signal processing instead of electronic signals, aiming to solve power consumption and latency bottlenecks in traditional semiconductor scaling. Although still in the R&D stage, this represents another radical technical route to challenge NVIDIA’s monopoly at the hardware level (Source: Ronald_vanLoon)
