
Palabras clave:GPT-5.2 Pro, DeepSeek V4, Agente Código Confucio, Problemas matemáticos de Erdős, Arquitectura mHC, Agente de memoria larga
🔥 Enfoque
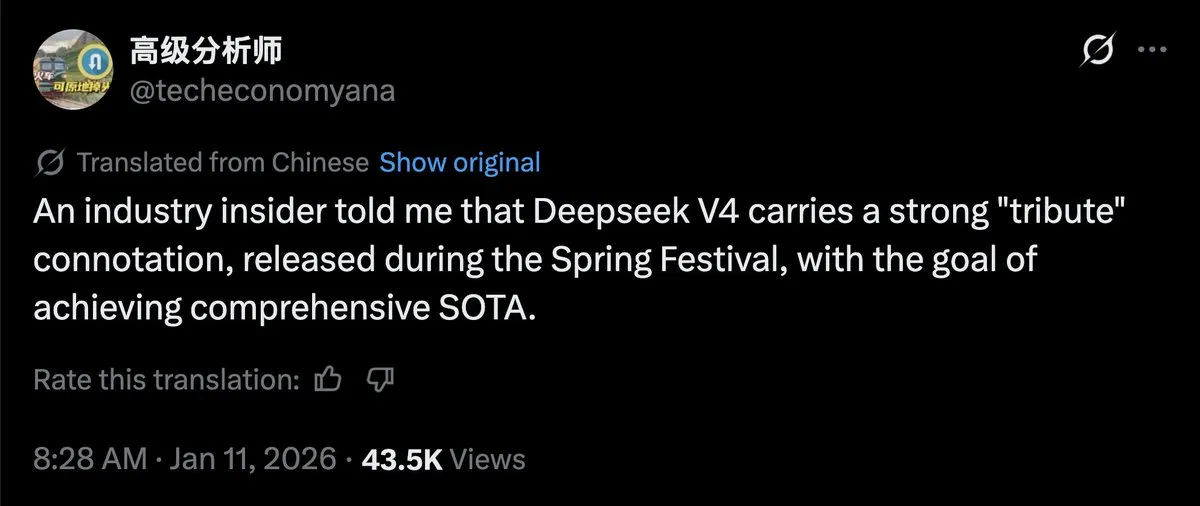
GPT-5.2 Pro resuelve de forma autónoma múltiples problemas matemáticos de Erdos : Las redes sociales han bullido recientemente con el avance disruptivo de GPT-5.2 Pro en el campo del descubrimiento científico. El modelo, en combinación con el sistema Aristotle, logró resolver de manera autónoma varios problemas matemáticos, incluidos los problemas de Erdos #729 y #397; la demostración del #397 ya ha sido reconocida por el matemático Terence Tao. Esto marca la evolución de la AI desde el simple aprendizaje de corpus hacia la capacidad de razonamiento para resolver problemas científicos nunca antes vistos. La comunidad considera que esto demuestra el enorme potencial de los modelos de razonamiento al manejar lógica abstracta de alto nivel, y que la obtención de una Fields Medal por parte de una AI podría ser solo cuestión de tiempo (Fuente: SebastienBubeck; kevinweil; halvarflake)
Predicción del lanzamiento de DeepSeek V4 y discusión profunda sobre la arquitectura mHC : Fuentes internas de la industria revelan que se espera el lanzamiento de DeepSeek V4 durante el Año Nuevo Chino, con el objetivo de alcanzar el SOTA global. Esta serie de modelos ha captado la atención recientemente debido a su arquitectura mHC (Multi-Head Connection), que asegura la estabilidad del producto de capas mediante las propiedades de la Doubly Stochastic Matrix, resolviendo eficazmente los problemas de desvanecimiento o explosión de gradiente en redes profundas. El análisis de la comunidad sugiere que la ruta tecnológica de DeepSeek está pasando de la simple acumulación de potencia de cómputo a la optimización de la arquitectura matemática subyacente, un enfoque de “lograr más con menos” que está cambiando el paradigma del desarrollo de grandes modelos (Fuente: teortaxesTex; Reddit r/MachineLearning)
Meta y Harvard lanzan Confucius Code Agent (CCA), un agente de memoria larga : Meta, en colaboración con la Universidad de Harvard, ha presentado Confucius Code Agent, diseñado para resolver problemas de operación de agentes en bases de código grandes y complejas. El núcleo de CCA reside en sus notas internas persistentes, memoria de tareas de largo alcance y cadenas de razonamiento trazables, además de contar con un bucle de retroalimentación para autoajustar las estrategias de uso de herramientas. Esta arquitectura permite que la AI mantenga la coherencia lógica en sistemas complejos del mundo real, en lugar de limitarse a procesar Prompts aislados. La comunidad señala que esto valida el nuevo consenso de la industria: “la inteligencia a gran escala depende de las estructuras de memoria más que del simple tamaño del modelo” (Fuente: Reddit r/artificial; Reddit r/ArtificialInteligence)

🎯 Tendencias
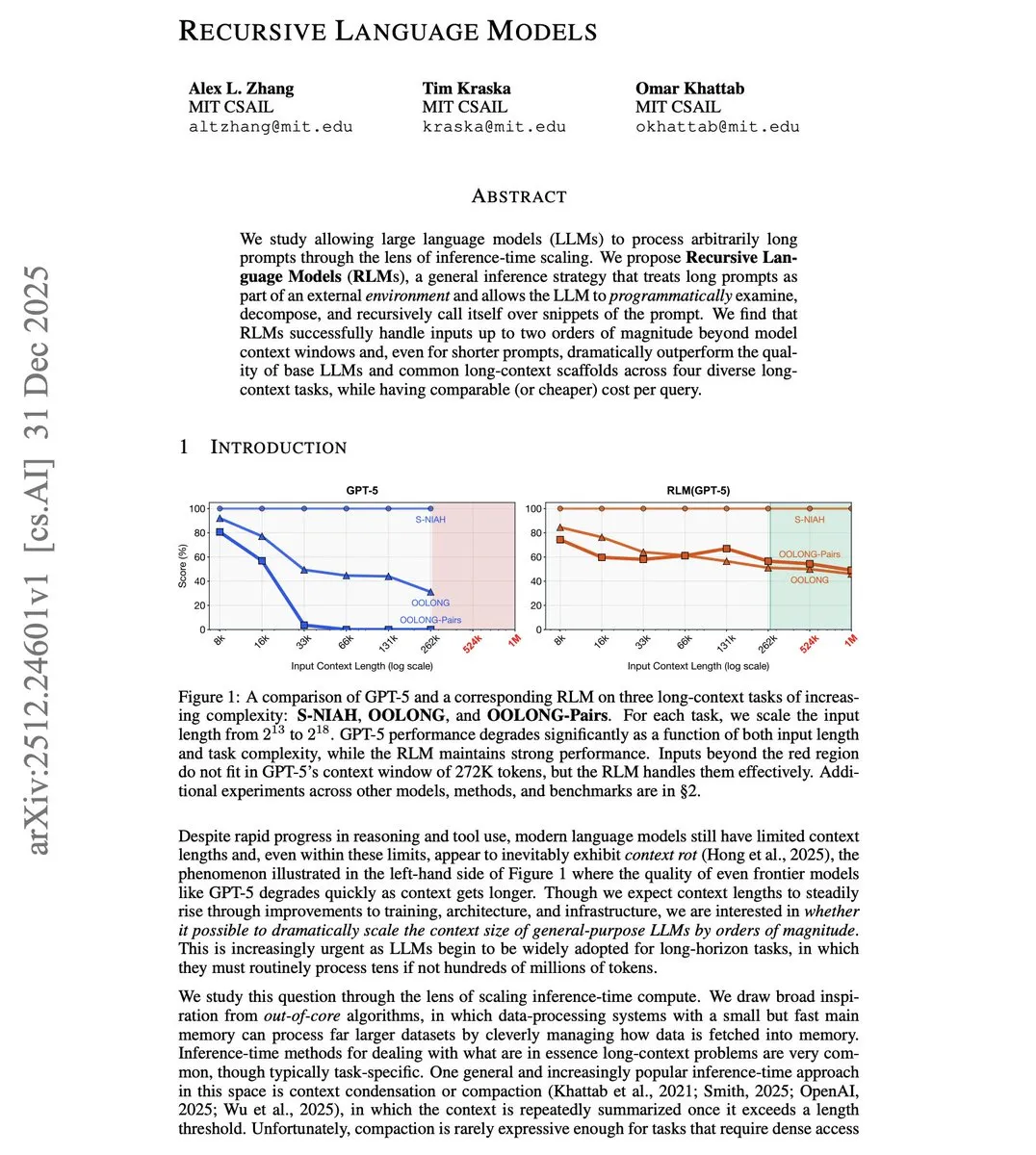
MIT propone el Recursive Language Model (RLM) para superar los límites de contexto : Investigadores del MIT han propuesto el RLM, que permite a los modelos procesar entradas que superan su ventana de contexto en 100 veces. Esta técnica no aumenta la ventana mediante cambios en la arquitectura, sino que trata programáticamente los prompts largos como un entorno externo, permitiendo que el modelo se llame a sí mismo de forma recursiva para procesar fragmentos. Las pruebas muestran que un modelo con una ventana de 8K puede procesar eficazmente 800K tokens, superando incluso a las soluciones tradicionales de contexto largo en tareas de prompts cortos, ofreciendo una ruta de bajo costo para que los Agents manejen bases de código completas o documentos extensos (Fuente: omarsar0)
KimiLinear-48B implementa soporte para MLA KV Cache : Desarrolladores han añadido con éxito soporte para MLA KV Cache independiente del backend para el modelo KimiLinear en llama.cpp. Esta optimización reduce drásticamente el uso de memoria de la caché KV F16 para 1M de Tokens de 140GB a solo 14.8GB, permitiendo la ejecución de modelos de contexto ultra largo en tarjetas gráficas de consumo con poca VRAM. KimiLinear ya había mostrado un excelente rendimiento en ContextArena, y esta optimización de memoria impulsará enormemente la popularización de aplicaciones de AI de texto largo de forma local (Fuente: Reddit r/LocalLLaMA)

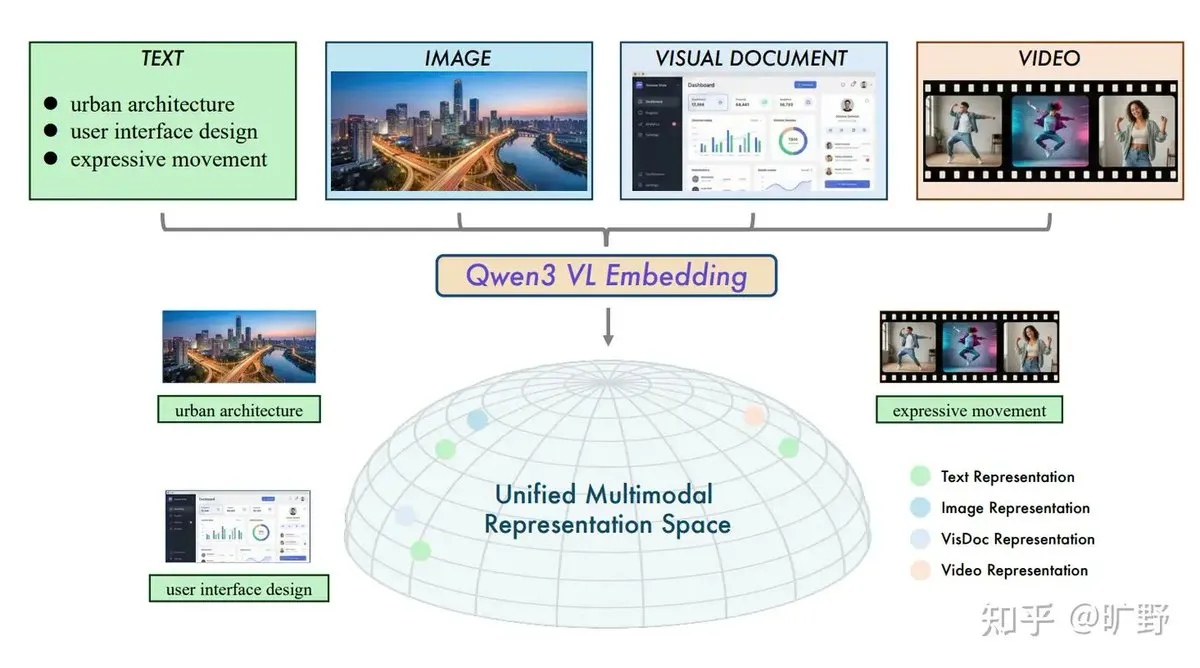
Alibaba lanza el sistema RAG cross-modal Qwen3-VL de código abierto : Alibaba ha lanzado los modelos Qwen3-VL-Embedding y Reranker, solucionando la excesiva dependencia del texto en los sistemas RAG tradicionales. El modelo permite incrustar texto, imágenes, vídeos y capturas de pantalla en un espacio vectorial unificado, logrando búsquedas de “texto a imagen” o “imagen a vídeo”. Su función única de “consciencia de instrucciones” permite a los usuarios definir la relevancia según tareas específicas (como búsqueda en e-commerce o comparativas legales), marcando una nueva etapa impulsada por tareas en el RAG multimodal (Fuente: ZhihuFrontier)
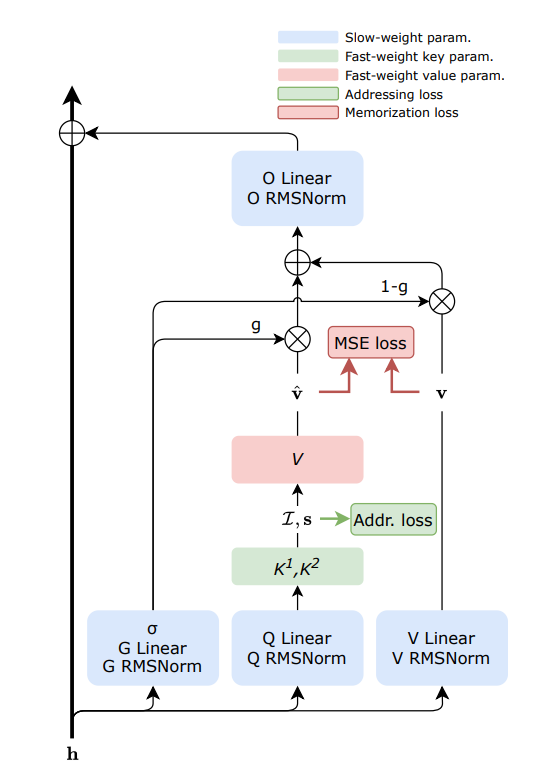
Sakana AI lanza la tecnología de memoria dinámica FwPKM : Sakana AI ha presentado Fast-weight Product Key Memory (FwPKM), diseñada para equilibrar una gran capacidad de memoria con bajos costos computacionales. Esta tecnología permite que la Product Key Memory (PKM) se actualice dinámicamente tanto durante el entrenamiento como en la inferencia, resolviendo el cuello de botella de la escalabilidad del mecanismo de atención. A medida que los modelos necesitan recordar más información y realizar razonamientos de largo alcance, este mecanismo de memoria de actualización dinámica se considera un paso clave hacia la AGI (Fuente: TheTuringPost)
🧰 Herramientas
Silicon-Studio: GUI para fine-tuning local en Mac serie M : Se trata de una herramienta de fine-tuning de LLM local de extremo a extremo diseñada específicamente para Macs con chips de la serie M. Encapsula el framework MLX de Apple y ofrece limpieza de datos, desensibilización de privacidad PII, ajuste de parámetros LoRA/QLoRA e interfaz de prueba de inferencia integrada. La herramienta reduce la barrera de entrada para que los usuarios comunes realicen entrenamiento personalizado de modelos en Mac mediante una operación gráfica completa (Fuente: Reddit r/LocalLLaMA)
Kreuzberg v4: Librería inteligente de documentos todoterreno reescrita en Rust : Kreuzberg v4 ha completado su reescritura subyacente de Python a Rust, soportando la extracción de datos estructurados de 56 formatos. Ha eliminado la dependencia de Pandoc y utiliza un analizador nativo en Rust, mejorando significativamente la velocidad y reduciendo el uso de memoria. La librería ofrece bindings para 10 lenguajes (como TS, Python, Go), soporta el cambio de backend OCR e incrustaciones ONNX, siendo una opción ideal para construir pipelines de RAG de alto rendimiento (Fuente: Reddit r/LocalLLaMA)

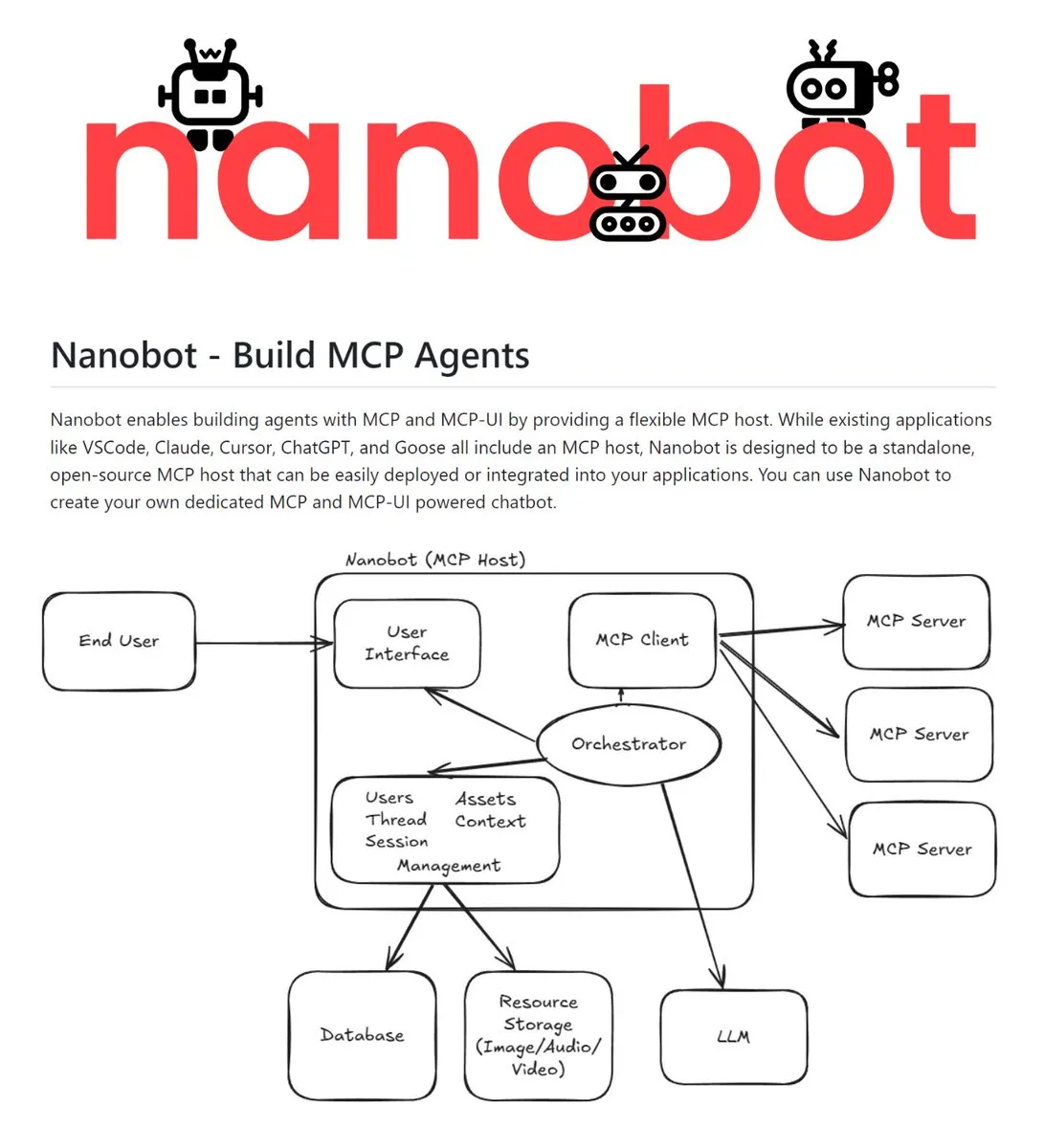
Nanobot: Host MCP independiente de código abierto : Nanobot es un host independiente de código abierto que soporta MCP (Model Context Protocol) y MCP-UI. Puede integrar servidores MCP, LLM y contexto en un único servicio, permitiendo construir experiencias de agentes a través de chatbots, voz, correo, Slack y otras interfaces. Su naturaleza de despliegue independiente lo convierte en un kit básico para que los desarrolladores construyan AI Agents multiplataforma (Fuente: TheTuringPost)
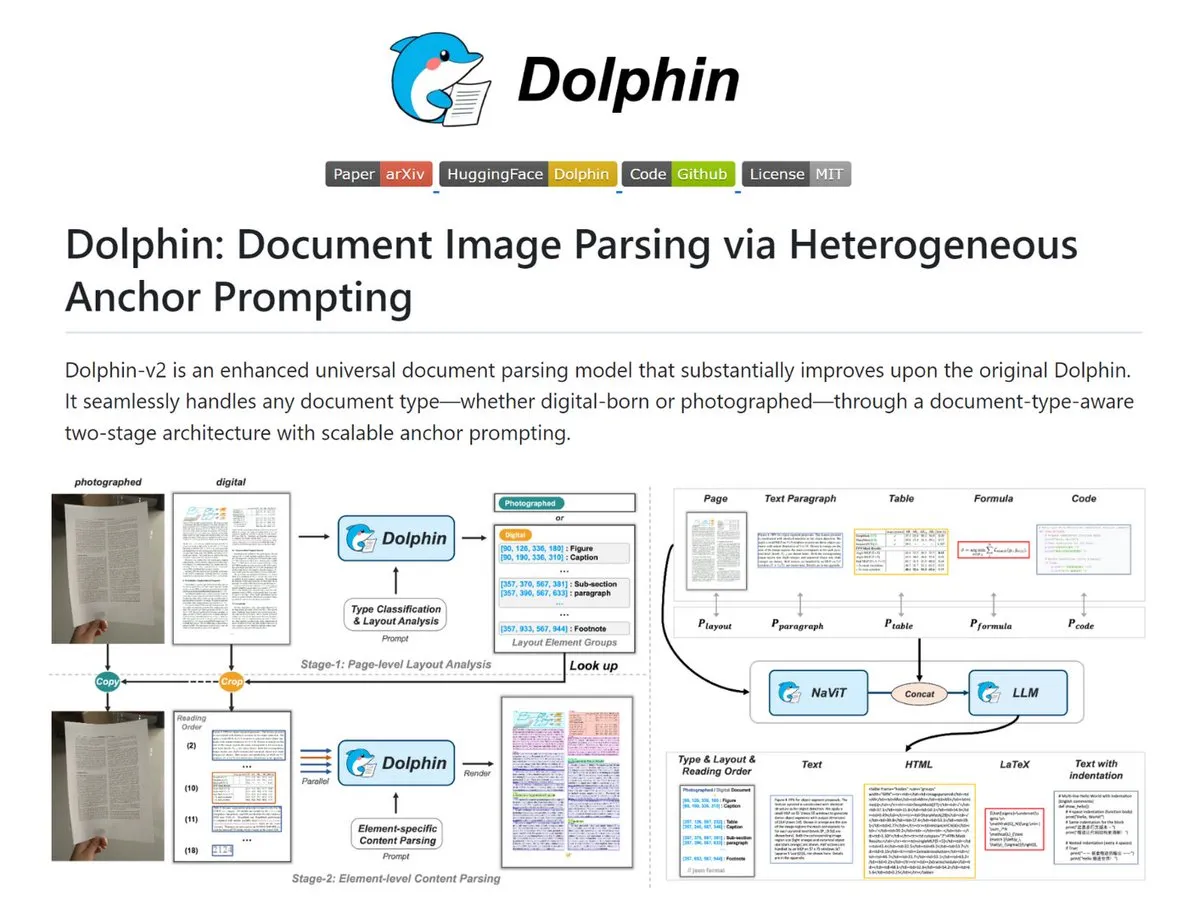
Dolphin: Herramienta potente para el análisis de documentos complejos : Dolphin es una herramienta capaz de convertir imágenes de documentos y PDFs en Markdown/JSON estructurado. Reconoce automáticamente documentos escaneados y digitales, restaura el orden de lectura del diseño y analiza en paralelo texto, tablas y fórmulas. El modelo varía de 0.3B a 3B y ha mostrado un rendimiento excelente en OmniDocBench, siendo adecuado para escenarios que requieren digitalización de documentos de alta precisión (Fuente: TheTuringPost)
📚 Aprendizaje
AI Agents A-Z: Tutorial completo de desarrollo de agentes : Este repositorio de GitHub reúne las plantillas de n8n de la serie de vídeos “AI Agents A-Z”, cubriendo más de 40 casos prácticos que van desde agentes de gestión de medicamentos recetados y resúmenes diarios hasta automatización de LinkedIn y generación de vídeos para YouTube. Muestra cómo utilizar herramientas no-code combinadas con LLM para construir flujos de trabajo automatizados complejos, siendo un recurso excelente para que los principiantes entiendan los escenarios de aplicación de los Agents (Fuente: GitHub Trending)
Revisión sobre la construcción de grafos de conocimiento potenciados por LLM : El artículo “LLM-empowered knowledge graph construction” analiza sistemáticamente cómo utilizar LLM para mejorar los métodos tradicionales de grafos de conocimiento (KG). El contenido abarca la extracción de ontologías, extracción impulsada por esquemas y sin esquemas, fusión de conocimientos y razonamiento futuro con memoria dinámica. Tiene un valor de referencia importante para desarrolladores que deseen combinar el conocimiento estructurado con la capacidad de razonamiento de los grandes modelos (Fuente: TheTuringPost)

💼 Negocios
Rumores sobre el retraso de las tarjetas gráficas NVIDIA y estrategia de prioridad de AI : Circulan rumores en redes sociales de que NVIDIA podría retrasar indefinidamente el lanzamiento de la serie RTX 50 Super debido a la escasez de memoria y a que la empresa prioriza el suministro de chips de AI, que son más rentables. Aunque son solo rumores, la comunidad coincide en que el negocio de gaming ha caído al 8% de los ingresos de NVIDIA; en un contexto de sed de potencia de cómputo, el “sacrificio estratégico” de las tarjetas gráficas de consumo tiene lógica (Fuente: Reddit r/LocalLLaMA)

Meta firma un acuerdo de energía nuclear para asegurar el suministro de supercomputación de AI : Meta ha firmado un acuerdo de energía nuclear para su clúster de supercomputación Prometheus AI. A medida que la carrera de la AI se intensifica, la energía se ha convertido en un cuello de botella para la expansión de la potencia de cómputo. Meta sigue los pasos de gigantes como Microsoft, asegurando recursos de energía nuclear estables y limpios para garantizar su capacidad de expansión de cómputo en los próximos años (Fuente: Reddit r/artificial)
Atención a los movimientos de la IPO de Zhipu AI : Los informes de la industria mencionan los movimientos potenciales de Zhipu AI como la primera empresa de grandes modelos en salir a bolsa en China. Como actor principal de los modelos nacionales chinos, el proceso de comercialización y el desempeño en el mercado de capitales de Zhipu se consideran un barómetro del sector, especialmente dada la complejidad actual del entorno de financiación global de AI (Fuente: ZhihuFrontier)
🌟 Comunidad
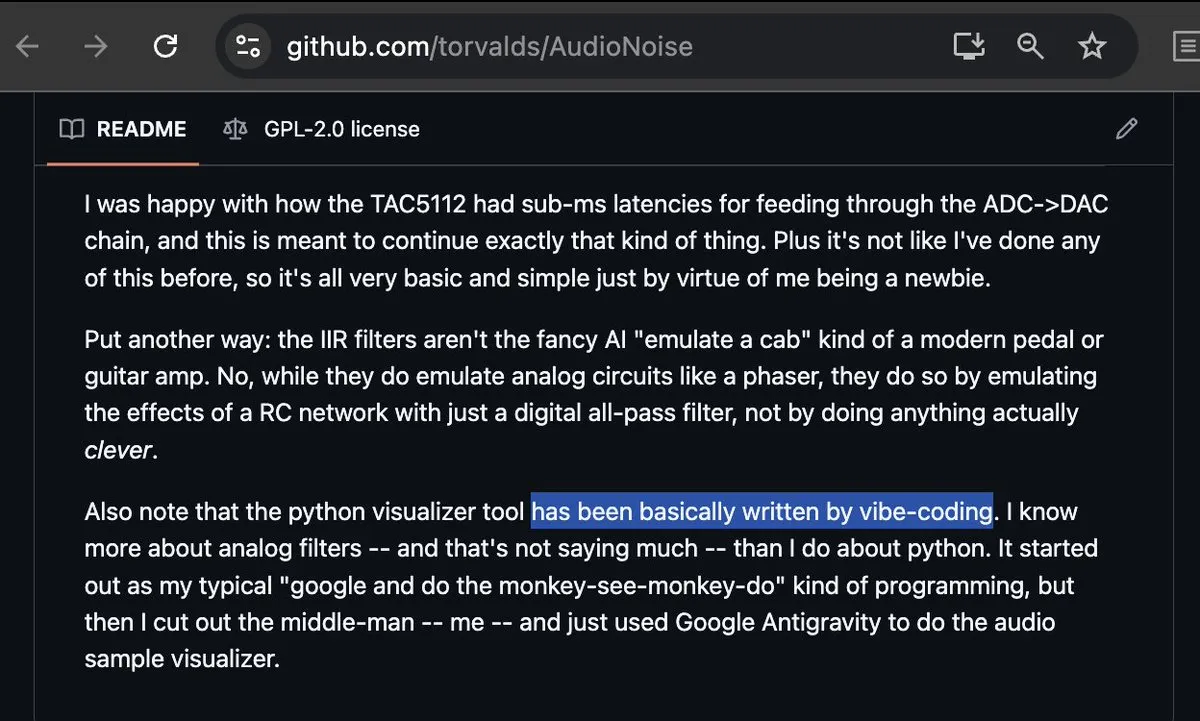
Linus Torvalds participa en Vibe-coding y genera un gran debate : Incluso el siempre riguroso padre de Linux, Linus Torvalds, ha comenzado a usar Google Antigravity para hacer Vibe-coding (programación por “vibras”), logrando implementar con éxito una herramienta de visualización de audio. Este evento ha causado sensación en la comunidad y se considera un hito en la madurez de las herramientas de programación con AI. Los programadores comentan que cuando incluso los desarrolladores más puristas aceptan la programación por “vibras”, los modelos tradicionales de auditoría y escritura de código se están tambaleando (Fuente: dotey; cto_junior; osanseviero)
Cambio drástico en la percepción de los programadores experimentados sobre la programación con AI : La comunidad observa que programadores “hardcore” (que investigan compiladores, kernels de CUDA, etc.), quienes antes despreciaban el código generado por AI calificándolo de “basura (slop)”, están cambiando de opinión rápidamente. Con modelos como GPT-5.2 demostrando un rendimiento cada vez más refinado en lógica compleja y código de bajo nivel, la ventana de tiempo para negar las capacidades de la AI se ha cerrado. Este cambio psicológico, de la resistencia al asombro y luego a la aceptación, refleja el salto generacional de las herramientas de productividad de AI (Fuente: Yuchenj_UW; timsoret)
Nuevo paradigma de depuración de agentes: mirar el Trace en lugar del código : El punto de vista propuesto por Harrison Chase, “al depurar un Agent, no me muestres el código, muéstrame el Trace”, ha ganado un amplio consenso. En los flujos de trabajo Agentic, el proceso de toma de decisiones del LLM es más importante que el código estático. Al analizar la trayectoria de ejecución (Trace), los desarrolladores pueden localizar con mayor claridad en qué paso del razonamiento falló el modelo; esta depuración de estilo “conductista” está reemplazando a la depuración tradicional de “lógica” (Fuente: Hacubu; _philschmid)
El “tira y afloja” entre la seguridad de AI y los hábitos de los empleados : Muchos directivos de empresas están preocupados por el hecho de que los empleados introduzcan datos confidenciales en ChatGPT. A pesar de la formación en seguridad, debido a la conveniencia que aporta la AI, los empleados suelen “reincidir” en comportamientos infractores. Las discusiones en la comunidad sugieren que la simple prohibición es ineficaz; es necesario ofrecer alternativas de AI seguras y locales igualmente convenientes, complementadas con “historias de terror” reales sobre filtraciones para reforzar la concienciación (Fuente: Reddit r/ArtificialInteligence)
💡 Otros
Comparativa de la tecnología de volteretas hacia atrás entre robots de China y EE. UU. : Las redes sociales compararon el desempeño en volteretas hacia atrás del Atlas de Boston Dynamics con los robots de Unitree. Unitree mostró un equilibrio y aterrizaje más perfectos, mientras que Atlas demostró una estrategia de articulaciones de forma no humana más avanzada en sus movimientos de recuperación. Esta competencia muestra que los robots chinos han igualado o incluso superado parcialmente a los estadounidenses en fabricación de hardware y control de equilibrio, mientras que EE. UU. mantiene la ventaja en algoritmos de estrategia complejos (Fuente: teortaxesTex)
Chip de AI fotónico afirma una velocidad 100 veces mayor : Un nuevo tipo de chip de AI impulsado por luz afirma ser 100 veces más rápido que las GPUs de gama alta de NVIDIA. Esta tecnología utiliza el procesamiento de señales ópticas en lugar de señales electrónicas, con el objetivo de resolver los cuellos de botella de consumo de energía y latencia de los semiconductores tradicionales en la expansión de la potencia de cómputo. Aunque todavía está en fase de investigación y desarrollo, representa otra ruta tecnológica radical para combatir el monopolio de NVIDIA desde el nivel de hardware (Fuente: Ronald_vanLoon)
