
Mots-clés:GPT-5.2 Pro, DeepSeek V4, Agent Code Confucius, Problèmes mathématiques d’Erdős, Architecture mHC, Agent à mémoire longue
🔥 Focus
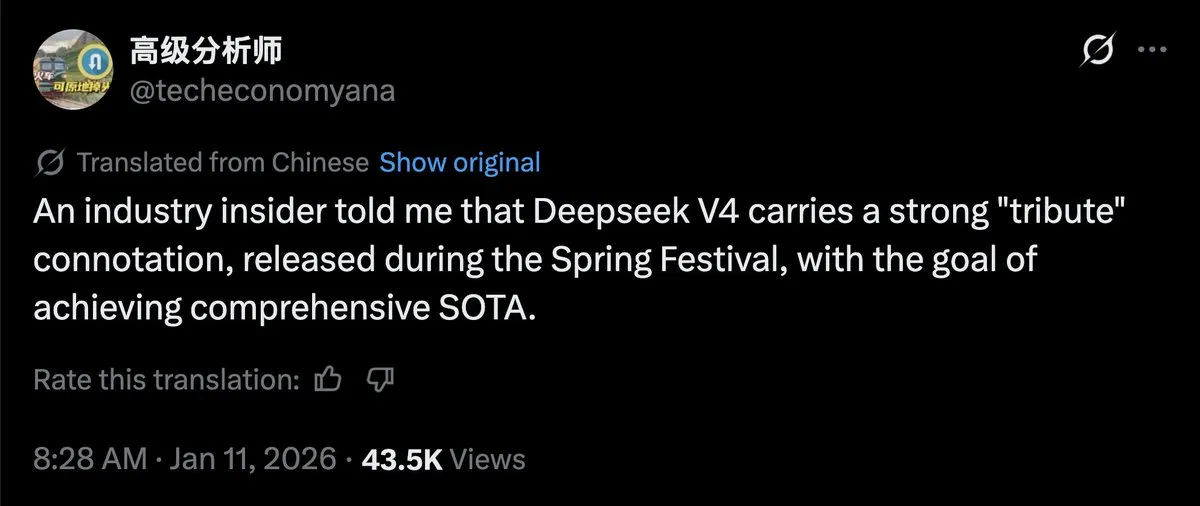
GPT-5.2 Pro résout de manière autonome plusieurs problèmes mathématiques d’Erdos : Les réseaux sociaux s’enflamment récemment pour les progrès révolutionnaires de GPT-5.2 Pro dans le domaine de la découverte scientifique. Couplé au système Aristotle, le modèle a réussi à résoudre de manière autonome plusieurs énigmes mathématiques, dont les problèmes d’Erdos #729 et #397. La preuve du #397 a déjà été validée par le mathématicien Terence Tao. Cela marque l’évolution de l’AI, passant d’un simple apprentissage sur corpus à une capacité de raisonnement capable de résoudre des problèmes scientifiques inédits. La communauté estime que cela prouve le potentiel immense des modèles de raisonnement pour traiter une logique hautement abstraite ; l’obtention d’une médaille Fields par une AI ne serait plus qu’une question de temps (Sources : SebastienBubeck ; kevinweil ; halvarflake)
Prédictions de sortie de DeepSeek V4 et discussions approfondies sur l’architecture mHC : Des sources internes à l’industrie révèlent que DeepSeek V4 devrait être publié pendant la période du Nouvel An chinois, avec pour objectif d’atteindre le plein SOTA. Cette série de modèles attire l’attention grâce à son architecture mHC (Multi-Head Connection), qui assure la stabilité du produit des couches via les propriétés de la Doubly Stochastic Matrix, résolvant efficacement les problèmes de disparition ou d’explosion de gradient dans les réseaux profonds. Les analyses de la communauté suggèrent que la trajectoire technologique de DeepSeek passe d’une simple accumulation de puissance de calcul à une optimisation de l’architecture mathématique fondamentale, changeant ainsi le paradigme du développement des grands modèles (Sources : teortaxesTex ; Reddit r/MachineLearning)
Meta et Harvard publient Confucius Code Agent (CCA), un agent à mémoire longue : Meta, en collaboration avec l’Université de Harvard, a lancé le Confucius Code Agent, conçu pour résoudre les difficultés opérationnelles des agents dans les bases de code larges et complexes. Le cœur de CCA réside dans ses notes internes persistantes, sa mémoire de tâches à long terme et ses chaînes de raisonnement traçables, avec une boucle de rétroaction pour l’auto-ajustement des stratégies d’utilisation des outils. Cette architecture permet à l’AI de maintenir une cohérence logique dans des systèmes complexes du monde réel, plutôt que de traiter des Prompt isolés. La communauté souligne que cela valide le nouveau consensus de l’industrie : « l’intelligence à grande échelle dépend de la structure de la mémoire plutôt que de la simple taille du modèle » (Sources : Reddit r/artificial ; Reddit r/ArtificialInteligence)

🎯 Tendances
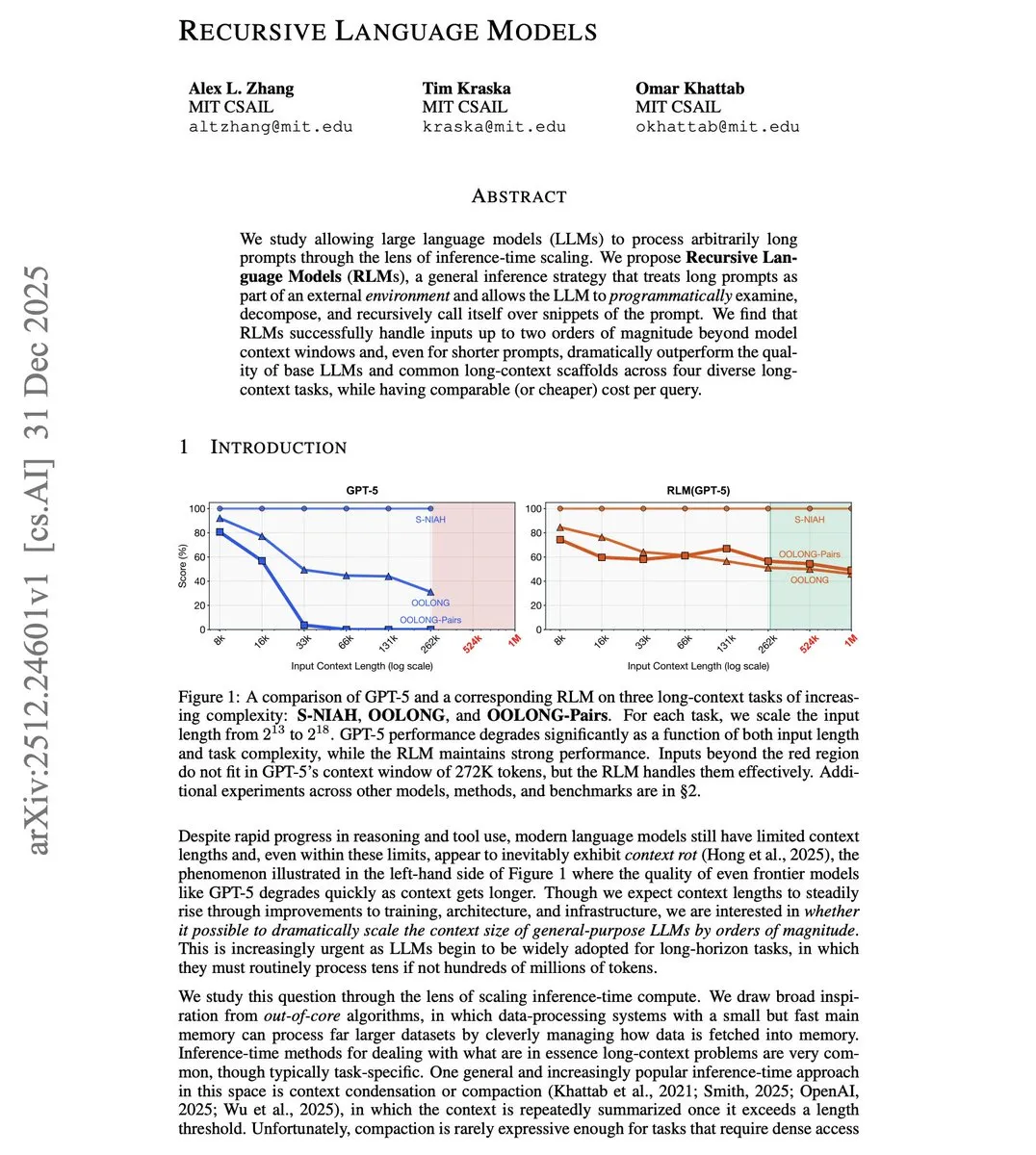
Le MIT propose le Recursive Language Model (RLM) pour briser les limites de contexte : Des chercheurs du MIT ont présenté le RLM, permettant aux modèles de traiter des entrées dépassant de 100 fois leur fenêtre de contexte. Cette technique n’augmente pas la fenêtre par des modifications architecturales, mais traite programmatiquement les longs prompts comme un environnement externe, permettant au modèle de s’appeler récursivement pour traiter des segments. Les tests montrent qu’un modèle avec une fenêtre de 8K peut traiter efficacement 800K tokens, surpassant les solutions traditionnelles de long contexte même sur des tâches à prompts courts, offrant une voie économique pour les Agents traitant des dépôts de code complets ou de longs documents (Source : omarsar0)
KimiLinear-48B implémente le support MLA KV Cache : Des développeurs ont réussi à ajouter un support MLA KV Cache indépendant du back-end pour le modèle KimiLinear dans llama.cpp. Cette optimisation réduit l’occupation du cache KV F16 pour 1M de tokens de 140 Go à seulement 14,8 Go, rendant possible l’exécution de modèles à contexte ultra-long sur des cartes graphiques grand public à faible mémoire vidéo. KimiLinear ayant déjà excellé dans ContextArena, cette optimisation de mémoire boostera considérablement la popularité des applications AI à texte long en local (Source : Reddit r/LocalLLaMA)

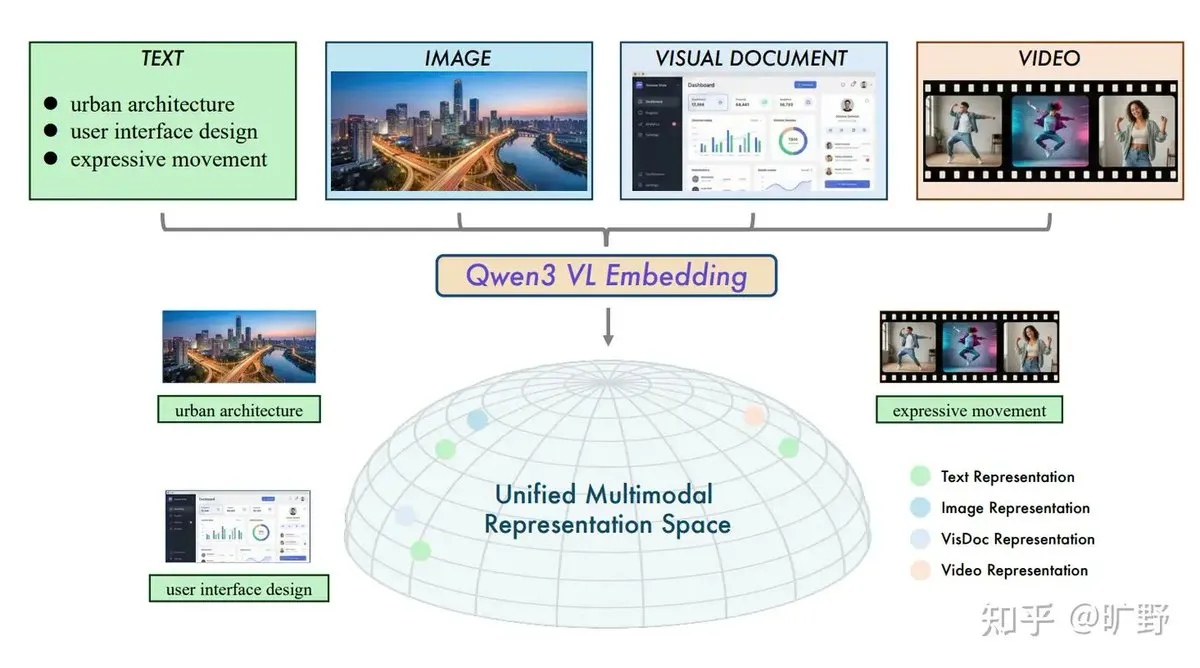
Alibaba open-source le système RAG cross-modal Qwen3-VL : Alibaba a publié les modèles Qwen3-VL-Embedding et Reranker, résolvant le problème de la dépendance excessive au texte du RAG par le passé. Ce modèle permet d’intégrer du texte, des images, des vidéos et des captures d’écran dans un espace vectoriel unifié, réalisant la « recherche d’images par texte » ou la « recherche de vidéos par image ». Sa fonction unique « instruction-aware » permet aux utilisateurs de définir la pertinence selon des tâches spécifiques (comme la recherche e-commerce ou la comparaison juridique), marquant une nouvelle étape du RAG multi-modal piloté par les tâches (Source : ZhihuFrontier)
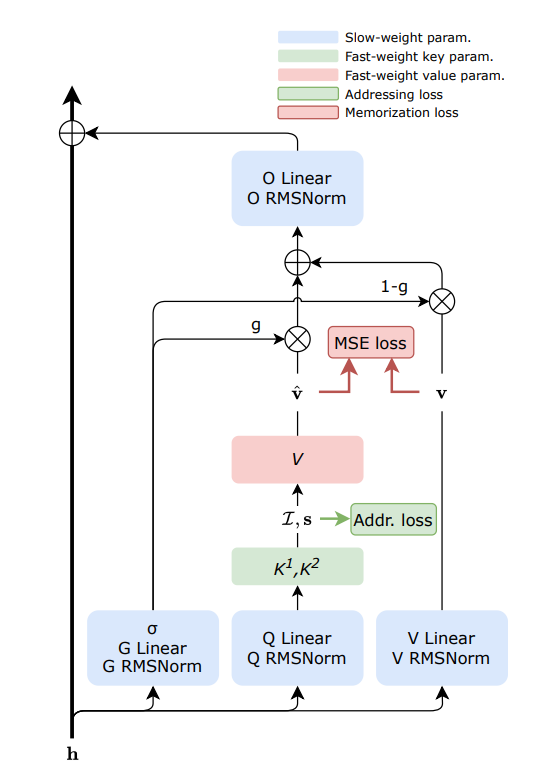
Sakana AI publie la technologie de mémoire dynamique FwPKM : Sakana AI a lancé Fast-weight Product Key Memory (FwPKM), visant à équilibrer une grande capacité de mémoire avec de faibles coûts de calcul. Cette technologie permet à la Product Key Memory (PKM) d’être mise à jour dynamiquement pendant l’entraînement et l’inférence, résolvant les goulots d’étranglement de l’extension du mécanisme d’attention. Alors que les modèles doivent mémoriser plus d’informations et effectuer des raisonnements à long terme, ce mécanisme de mémoire dynamique est considéré comme une étape clé vers l’AGI (Source : TheTuringPost)
🧰 Outils
Silicon-Studio : GUI de fine-tuning local pour Mac série M : Il s’agit d’un outil de fine-tuning LLM local de bout en bout conçu spécifiquement pour les puces Mac série M. Il encapsule le framework MLX d’Apple, offrant le nettoyage des données, l’anonymisation PII, l’ajustement des paramètres LoRA/QLoRA et une interface de test d’inférence intégrée. Cet outil abaisse la barrière à l’entrée pour l’entraînement personnalisé de modèles sur Mac grâce à une interface graphique complète (Source : Reddit r/LocalLLaMA)
Kreuzberg v4 : Bibliothèque d’intelligence documentaire polyvalente réécrite en Rust : Kreuzberg v4 a achevé sa réécriture de Python vers Rust, supportant l’extraction de données structurées pour 56 formats. Il supprime la dépendance à Pandoc au profit de parseurs Rust natifs, augmentant considérablement la vitesse et réduisant l’empreinte mémoire. La bibliothèque propose des bindings pour 10 langages (ex: TS, Python, Go), supporte le changement de back-end OCR et les embeddings ONNX, ce qui en fait un choix idéal pour construire des pipelines RAG haute performance (Source : Reddit r/LocalLLaMA)

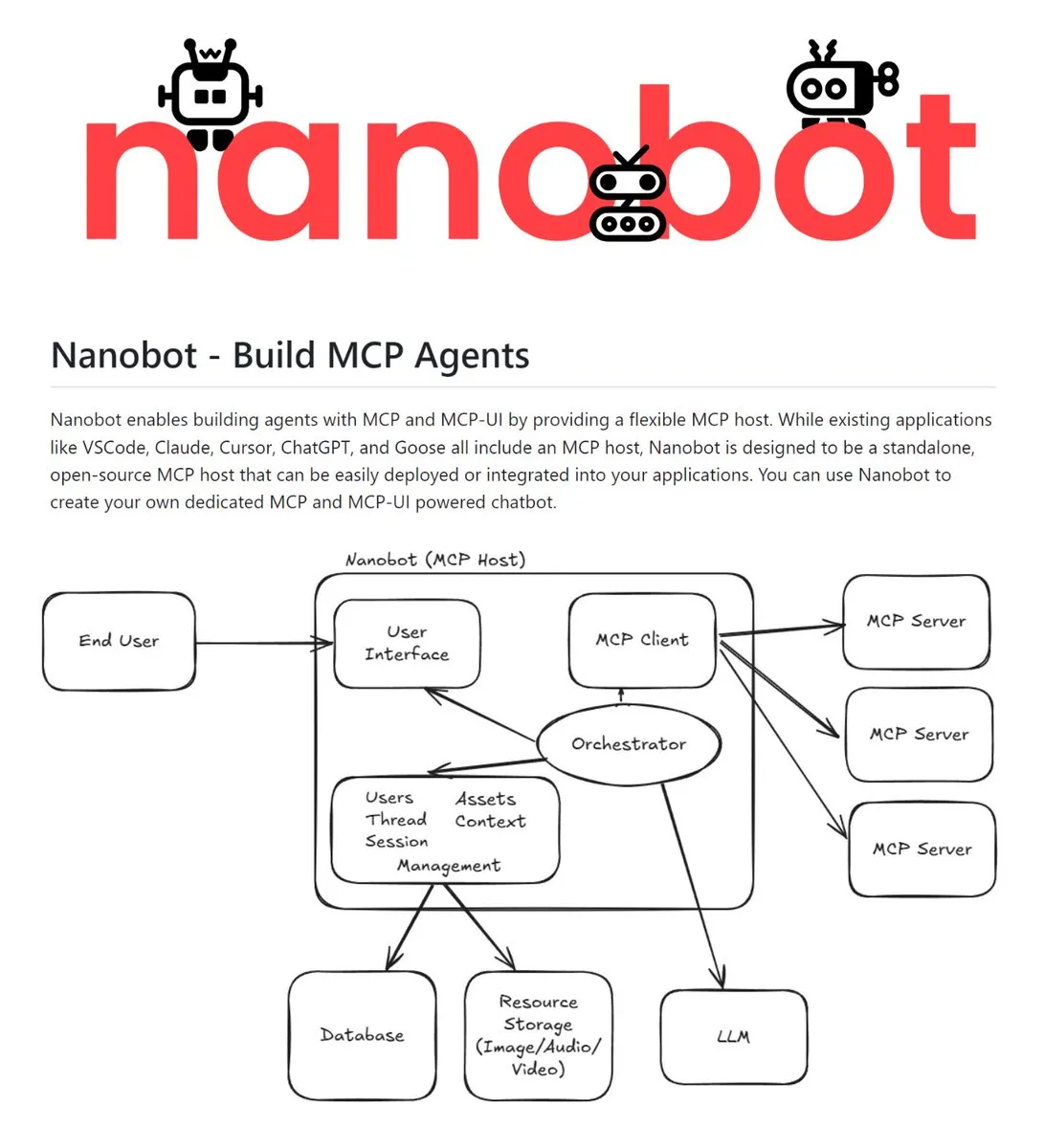
Nanobot : Hôte MCP indépendant open-source : Nanobot est un hôte indépendant open-source supportant le MCP (Model Context Protocol) et MCP-UI. Il peut intégrer des serveurs MCP, des LLM et du contexte dans un service unique, permettant de construire des expériences d’agents via diverses interfaces comme les chatbots, la voix, l’e-mail, Slack, etc. Sa nature de déploiement indépendant en fait un kit de base pour les développeurs créant des AI Agents multiplateformes (Source : TheTuringPost)
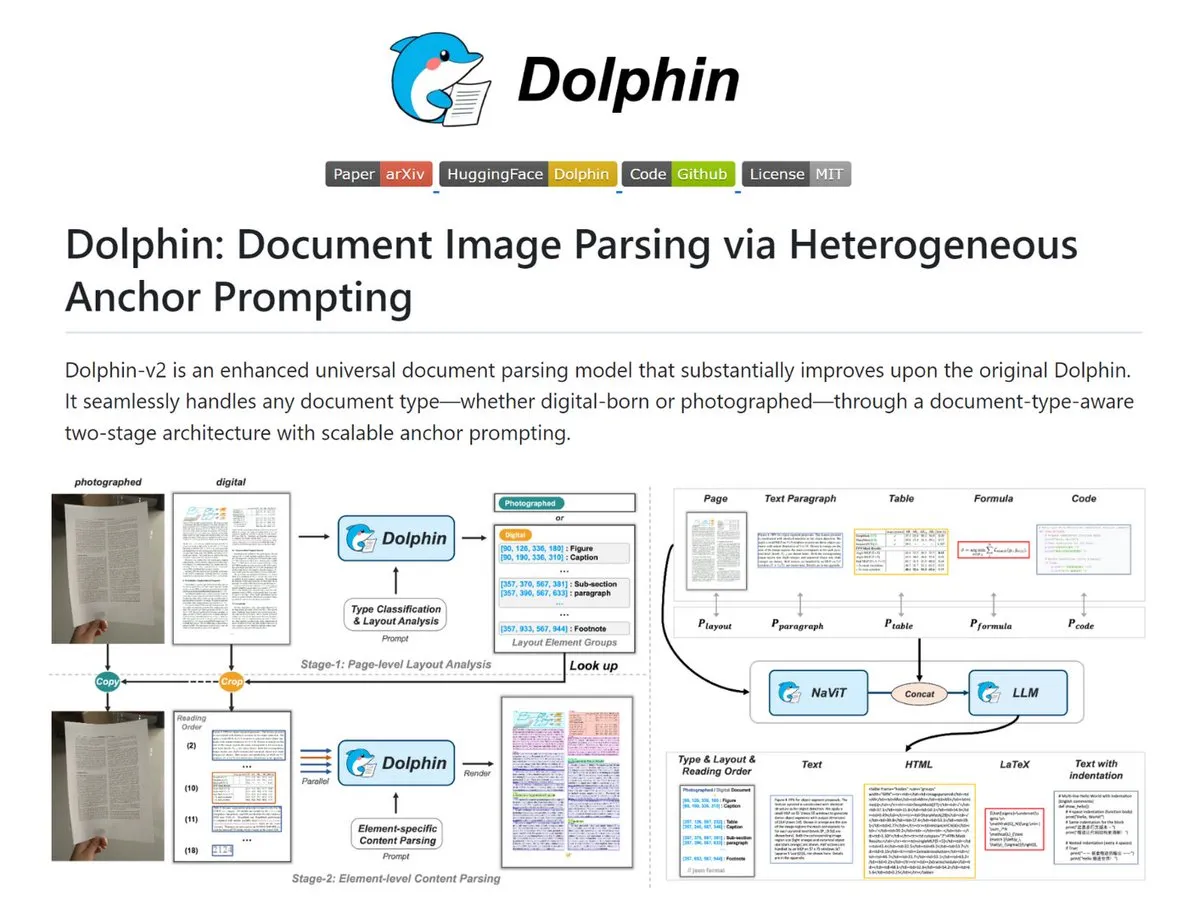
Dolphin : Un outil puissant pour l’analyse de documents complexes : Dolphin est un outil capable de convertir des images de documents et des PDF en Markdown/JSON structuré. Il reconnaît automatiquement les documents scannés et numériques, restaure l’ordre de lecture de la mise en page et analyse en parallèle le texte, les tableaux et les formules. Les modèles vont de 0.3B à 3B, avec d’excellentes performances sur OmniDocBench, idéal pour les scénarios nécessitant une numérisation de documents de haute précision (Source : TheTuringPost)
📚 Apprentissage
AI Agents A-Z : Tutoriel complet de développement d’Agents : Ce dépôt GitHub regroupe les modèles n8n de la série de vidéos « AI Agents A-Z », couvrant plus de 40 cas pratiques allant de l’agent de gestion de médicaments sur ordonnance à l’automatisation LinkedIn et la génération de vidéos YouTube. Il montre comment utiliser des outils no-code combinés aux LLM pour construire des workflows d’automatisation complexes (Source : GitHub Trending)
Revue sur la construction de graphes de connaissances assistée par LLM : L’article « LLM-empowered knowledge graph construction » analyse systématiquement comment utiliser les LLM pour renforcer les méthodes traditionnelles de graphes de connaissances (KG). Le contenu couvre l’extraction d’ontologies, l’extraction avec ou sans schéma, la fusion de connaissances et le raisonnement futur par mémoire dynamique (Source : TheTuringPost)

💼 Business
Rumeurs de retard des GPU NVIDIA et stratégie de priorité AI : Des rumeurs circulent sur les réseaux sociaux selon lesquelles NVIDIA pourrait retarder indéfiniment le lancement des cartes graphiques RTX 50 Super, en raison d’une pénurie de mémoire et de la priorité donnée par l’entreprise aux puces AI plus rentables. Bien qu’il ne s’agisse que de rumeurs, la communauté estime que le jeu ne représentant plus que 8 % des revenus de NVIDIA, le « sacrifice stratégique » des cartes grand public est logiquement plausible dans un contexte de soif de puissance de calcul (Source : Reddit r/LocalLLaMA)

Meta signe un accord sur l’énergie nucléaire pour ses supercalculateurs AI : Meta a signé un accord nucléaire pour son cluster de supercalculateurs Prometheus AI. Alors que la course à l’AI s’intensifie, l’énergie est devenue un goulot d’étranglement pour l’expansion de la puissance de calcul. Meta suit l’exemple de géants comme Microsoft en sécurisant des ressources nucléaires stables et propres pour garantir sa capacité d’expansion future (Source : Reddit r/artificial)
L’actualité de l’IPO de Zhipu AI attire l’attention : Les analyses du secteur mentionnent les mouvements potentiels de Zhipu AI en tant que première entreprise de grands modèles à entrer en bourse en Chine. En tant qu’acteur majeur des modèles nationaux, le processus de commercialisation et la performance boursière de Zhipu sont considérés comme un baromètre pour l’industrie, particulièrement dans le contexte actuel complexe du financement mondial de l’AI (Source : ZhihuFrontier)
🌟 Communauté
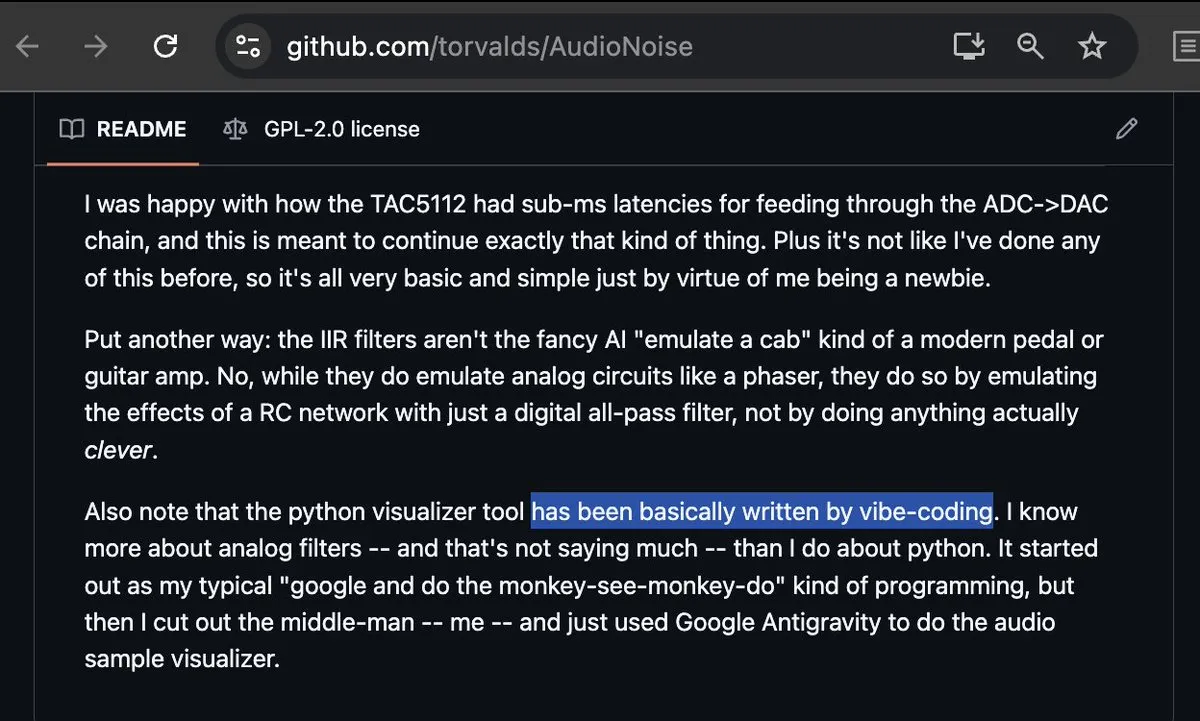
Linus Torvalds participe au Vibe-coding et suscite un vif débat : Même le créateur de Linux, Linus Torvalds, d’habitude si rigoureux, a commencé à utiliser Google Antigravity pour du Vibe-coding (programmation au feeling), réussissant à créer un outil de visualisation audio. Cet événement a fait sensation dans la communauté, considéré comme un jalon de la maturité des outils de programmation AI. Les développeurs constatent que lorsque les codeurs les plus puristes acceptent cette approche, les modes traditionnels d’audit et d’écriture de code sont fondamentalement ébranlés (Sources : dotey ; cto_junior ; osanseviero)
Changement radical de perception des programmeurs seniors vis-à-vis du codage AI : La communauté observe que les programmeurs « hardcore » (travaillant sur les compilateurs, les noyaux CUDA, etc.), qui méprisaient autrefois le code généré par AI le qualifiant de « déchets (slop) », changent rapidement d’avis. Avec les performances de modèles comme GPT-5.2 sur la logique complexe et le code de bas niveau, la fenêtre de déni des capacités de l’AI s’est refermée. Ce passage de la résistance au choc, puis à l’acceptation, reflète un saut générationnel des outils de productivité AI (Sources : Yuchenj_UW ; timsoret)
Nouveau paradigme de débogage d’Agents : regarder les Traces plutôt que le code : L’idée de Harrison Chase, « pour déboguer un Agent, ne me montrez pas le code, montrez-moi la Trace », fait consensus. Dans les workflows Agentic, le processus de décision du LLM est plus important que le code statique. En analysant les traces d’exécution (Trace), les développeurs peuvent localiser plus clairement à quelle étape du raisonnement le modèle a échoué ; ce débogage de type « comportemental » remplace le débogage « logique » traditionnel (Sources : Hacubu ; _philschmid)
Le bras de fer entre sécurité AI et habitudes des employés : De nombreux dirigeants s’inquiètent de voir leurs employés fournir des données confidentielles à ChatGPT. Malgré les formations à la sécurité, la commodité de l’AI pousse souvent les employés à « rechuter ». Les discussions communautaires suggèrent que l’interdiction pure et simple est inefficace ; il faut proposer des alternatives AI locales sécurisées tout aussi pratiques, complétées par des « histoires d’horreur » de fuites réelles pour renforcer la vigilance (Source : Reddit r/ArtificialInteligence)
💡 Autres
Comparaison de la technologie de salto arrière des robots sino-américains : Les réseaux sociaux comparent les performances de salto arrière de l’Atlas de Boston Dynamics et des robots de Unitree. Unitree a montré un équilibre et un atterrissage plus parfaits, tandis qu’Atlas a fait preuve de stratégies d’articulation non-humaines plus avancées lors de la récupération. Cette compétition montre que les robots chinois ont rattrapé, voire localement dépassé les États-Unis en fabrication matérielle et contrôle d’équilibre, tandis que les États-Unis conservent un avantage sur les algorithmes de stratégie complexe (Source : teortaxesTex)
Une puce AI photonique revendique une accélération de 100 fois : Une nouvelle puce AI pilotée par la lumière serait 100 fois plus rapide que les meilleurs GPU NVIDIA. Cette technologie utilise le traitement des signaux optiques pour remplacer les signaux électroniques, visant à résoudre les goulots d’étranglement de consommation d’énergie et de latence des semi-conducteurs traditionnels. Bien qu’encore au stade de la R&D, cela représente une voie technologique radicale pour contrer le monopole de NVIDIA au niveau matériel (Source : Ronald_vanLoon)
