
Palavras-chave:GPT-5.2 Pro, DeepSeek V4, Agente do Código de Confúcio, Problemas Matemáticos de Erdős, Arquitetura mHC, Agente de Memória Longa
🔥 Destaques
GPT-5.2 Pro resolve autonomamente múltiplos problemas matemáticos de Erdos : As redes sociais fervilharam recentemente com o progresso disruptivo do GPT-5.2 Pro no campo das descobertas científicas. O modelo, em conjunto com o sistema Aristotle, resolveu com sucesso e de forma autônoma vários enigmas matemáticos, incluindo os problemas de Erdos #729 e #397, sendo que a prova do #397 já foi reconhecida pelo matemático Terence Tao. Isso marca a evolução da AI de um simples aprendizado de corpus para a posse de capacidade de raciocínio para resolver problemas científicos inéditos. A comunidade acredita que isso prova o enorme potencial dos modelos de raciocínio ao lidar com lógica altamente abstrata, e que a conquista de uma Fields Medal por uma AI pode ser apenas uma questão de tempo (Fonte: SebastienBubeck; kevinweil; halvarflake)
Previsão de lançamento do DeepSeek V4 e discussão profunda sobre a arquitetura mHC : Fontes internas da indústria revelaram que o DeepSeek V4 está previsto para ser lançado durante o Ano Novo Chinês, com o objetivo de atingir o estado da arte (SOTA) global. Esta série de modelos atraiu atenção recente devido à sua arquitetura mHC (Multi-Head Connection), que garante a estabilidade dos produtos de camada através das propriedades da Doubly Stochastic Matrix, resolvendo eficazmente os problemas de desaparecimento ou explosão de gradiente em redes profundas. Analistas da comunidade acreditam que a rota tecnológica do DeepSeek está mudando do simples empilhamento de poder computacional para a otimização da arquitetura matemática subjacente, uma abordagem de “fazer muito com pouco” que está transformando o paradigma de desenvolvimento de Large Language Models (Fonte: teortaxesTex; Reddit r/MachineLearning)
Meta e Harvard lançam Confucius Code Agent (CCA), um agente de memória longa : A Meta, em colaboração com a Harvard University, lançou o Confucius Code Agent, visando resolver as dificuldades de operação de agentes em bases de código grandes e complexas. O núcleo do CCA reside em suas notas internas persistentes, memória de tarefas de longo alcance e cadeias de raciocínio rastreáveis, além de possuir um loop de feedback para autoajuste de estratégias de uso de ferramentas. Essa arquitetura permite que a AI mantenha a coerência lógica em sistemas complexos do mundo real, em vez de apenas processar Prompts isolados. A comunidade aponta que isso valida o novo consenso da indústria de que “a inteligência em larga escala depende de estruturas de memória e não apenas do tamanho do modelo” (Fonte: Reddit r/artificial; Reddit r/ArtificialInteligence)

🎯 Tendências
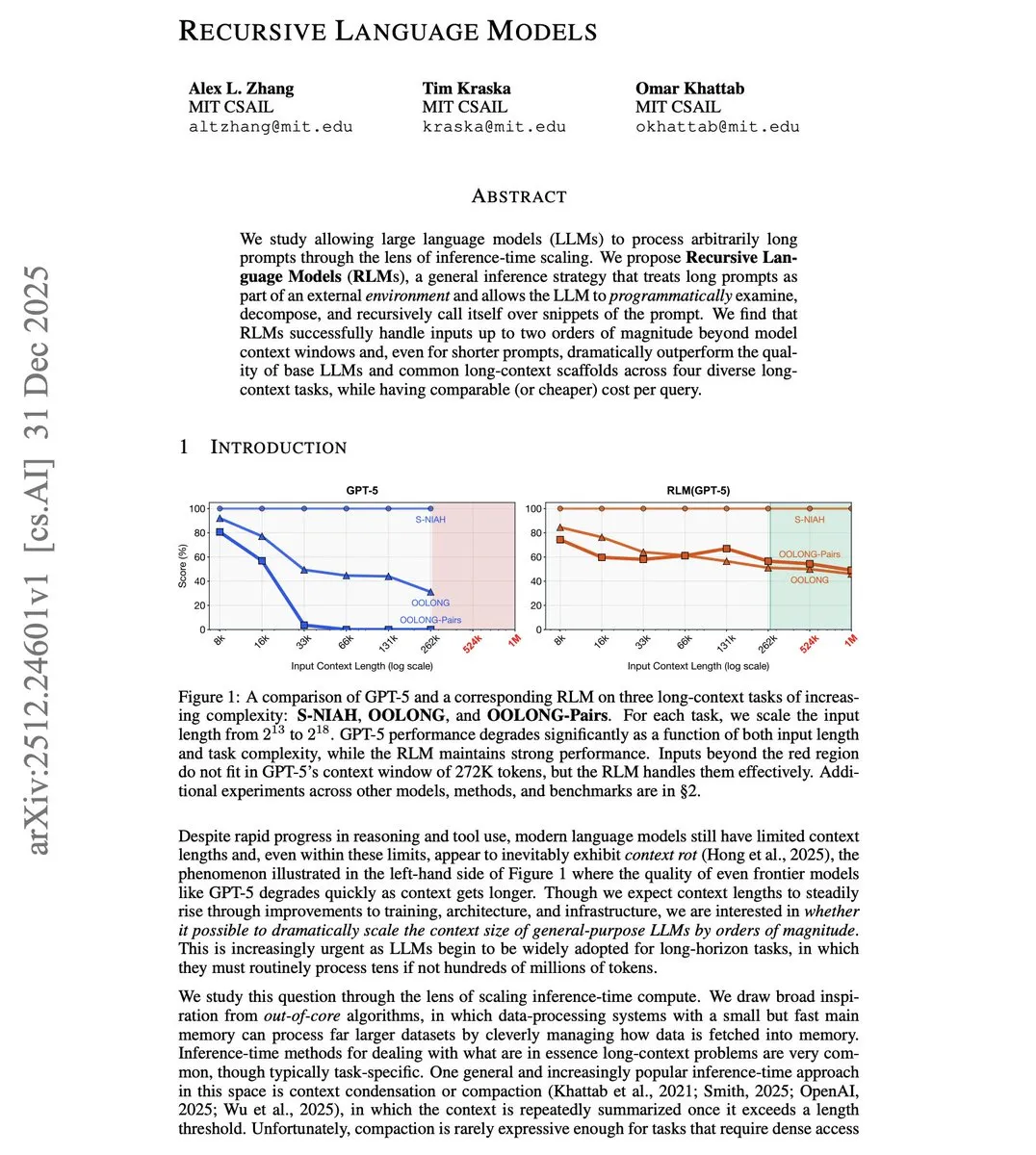
MIT propõe Recursive Language Model (RLM) para superar limites de contexto : Pesquisadores do MIT propuseram o RLM, que permite aos modelos processarem entradas que excedem sua janela de contexto em 100 vezes. A tecnologia não aumenta a janela por meio de mudanças na arquitetura, mas trata programaticamente prompts longos como um ambiente externo, permitindo que o modelo chame a si mesmo recursivamente para processar fragmentos. Testes mostram que um modelo com janela de 8K pode processar efetivamente 800K tokens e supera as soluções tradicionais de contexto longo mesmo em tarefas de prompt curto, oferecendo um caminho de baixo custo para que Agents processem repositórios inteiros de código ou documentos longos (Fonte: omarsar0)
KimiLinear-48B implementa suporte para MLA KV Cache : Desenvolvedores adicionaram com sucesso o suporte a MLA KV Cache independente de backend para o modelo KimiLinear no llama.cpp. Esta otimização reduziu drasticamente a ocupação de cache KV F16 para 1M de tokens de 140GB para 14,8GB, tornando possível rodar modelos de contexto ultra-longo em placas de vídeo de nível de consumidor com baixa memória de vídeo. O KimiLinear teve um desempenho excelente no ContextArena, e esta otimização de memória impulsionará significativamente a popularização de aplicações de AI de texto longo no lado local (Fonte: Reddit r/LocalLLaMA)

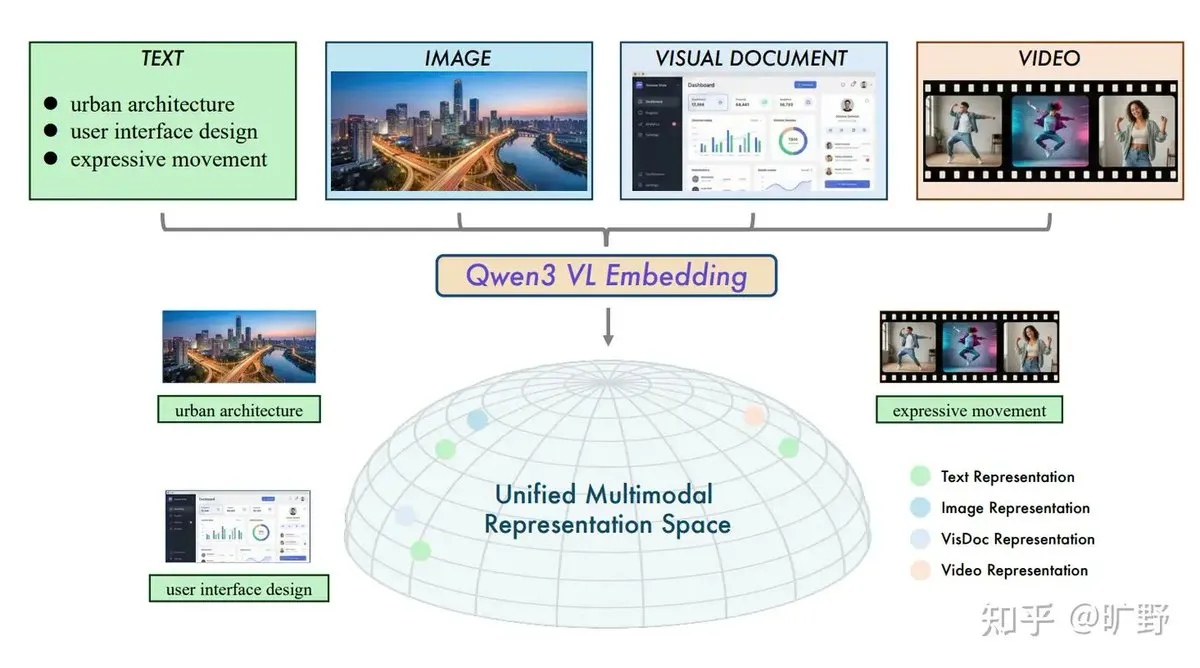
Alibaba lança sistema RAG cross-modal Qwen3-VL em open-source : A Alibaba lançou os modelos Qwen3-VL-Embedding e Reranker, resolvendo a dor latente do RAG que dependia excessivamente de texto no passado. O modelo suporta a incorporação de texto, imagens, vídeos e capturas de tela em um espaço vetorial unificado, permitindo “busca de imagem por texto” ou “busca de vídeo por imagem”. Sua função única de “percepção de instrução” permite que os usuários definam a relevância com base em tarefas específicas (como busca em e-commerce ou comparação jurídica), marcando uma nova fase orientada a tarefas para o RAG multimodal (Fonte: ZhihuFrontier)
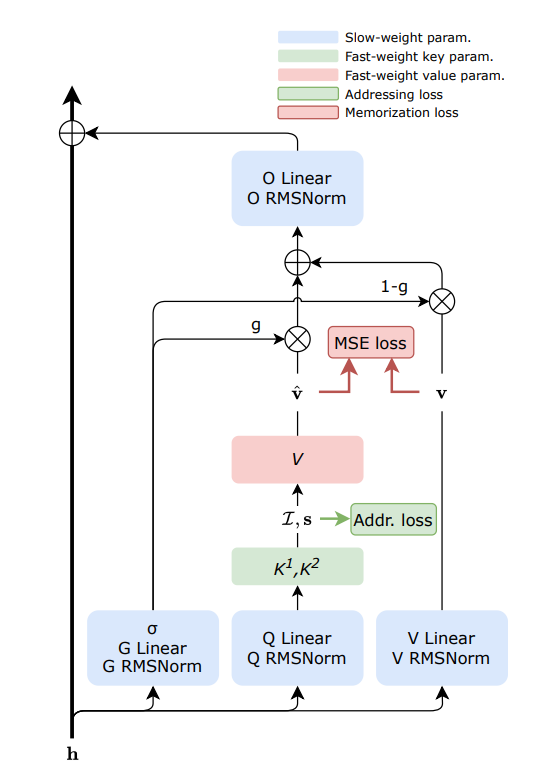
Sakana AI lança tecnologia de memória dinâmica FwPKM : A Sakana AI apresentou o Fast-weight Product Key Memory (FwPKM), visando equilibrar grande capacidade de memória com baixo custo computacional. Esta tecnologia permite que a Product Key Memory (PKM) seja atualizada dinamicamente durante o treinamento e a inferência, resolvendo o gargalo de expansão do mecanismo de atenção. À medida que os modelos precisam memorizar mais informações e realizar raciocínios de longo alcance, esse mecanismo de memória de atualização dinâmica é visto como um passo crucial em direção à AGI (Fonte: TheTuringPost)
🧰 Ferramentas
Silicon-Studio: GUI para fine-tuning local em Macs série M : Esta é uma ferramenta de fine-tuning de LLM local de ponta a ponta projetada especificamente para Macs com chips da série M. Ela encapsula o framework MLX da Apple, oferecendo limpeza de dados, anonimização de privacidade PII, ajuste de parâmetros LoRA/QLoRA e uma interface de teste de inferência integrada. A ferramenta reduz a barreira para usuários comuns realizarem treinamento personalizado de modelos no Mac, permitindo operações gráficas em todo o processo (Fonte: Reddit r/LocalLLaMA)
Kreuzberg v4: Biblioteca de inteligência documental reescrita em Rust : O Kreuzberg v4 completou sua reescrita de baixo nível de Python para Rust, suportando a extração de dados estruturados de 56 formatos. Ele removeu a dependência do Pandoc, adotando um parser nativo em Rust, o que aumentou significativamente a velocidade e reduziu o consumo de memória. A biblioteca oferece bindings para 10 linguagens (como TS, Python, Go), suporta troca de backend de OCR e embeddings ONNX, sendo a escolha ideal para construir pipelines de RAG de alto desempenho (Fonte: Reddit r/LocalLLaMA)

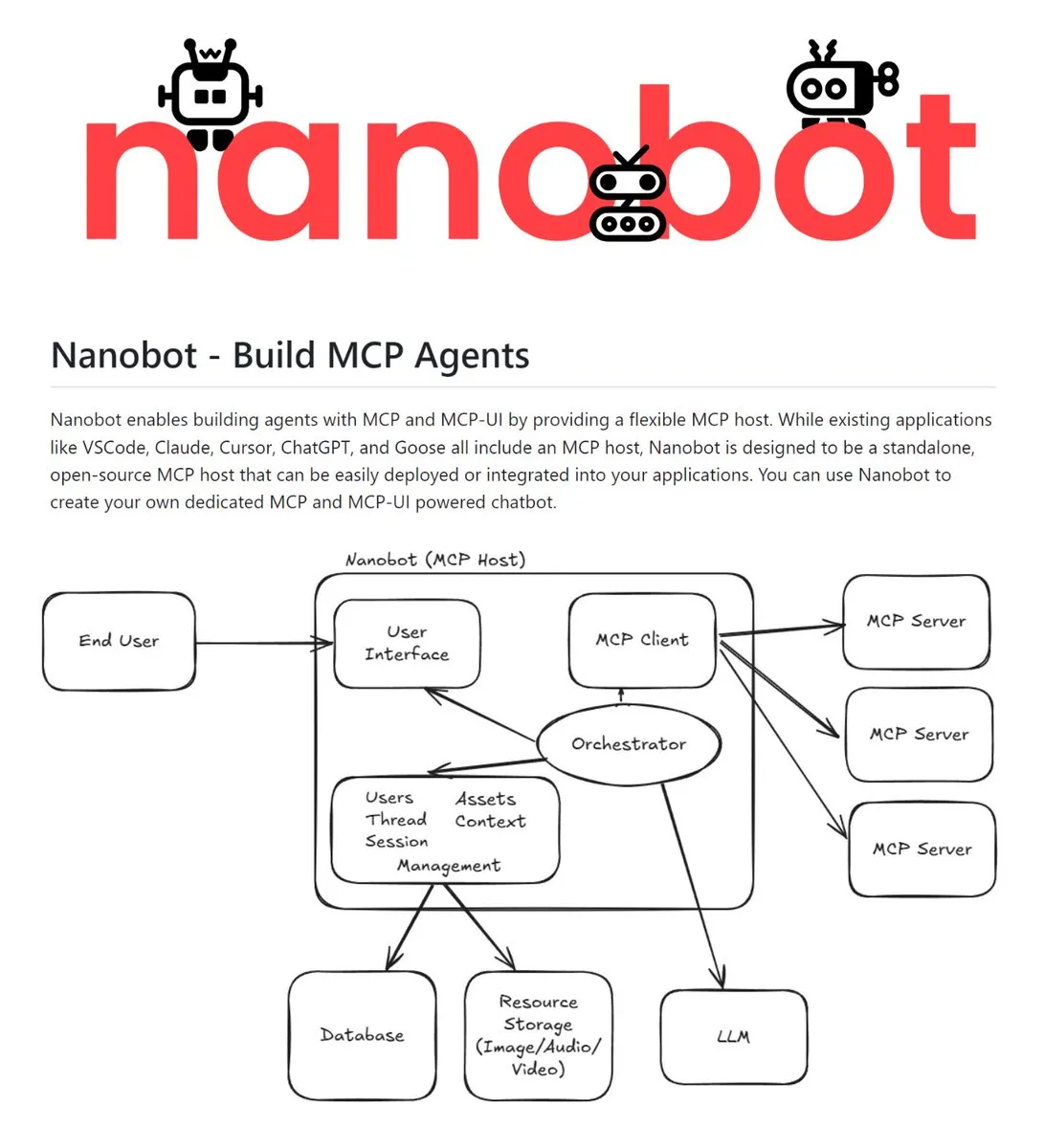
Nanobot: Host MCP independente de código aberto : O Nanobot é um host independente de código aberto que suporta o MCP (Model Context Protocol) e MCP-UI. Ele pode integrar servidores MCP, LLMs e contexto em um único serviço, permitindo a construção de experiências de agentes através de chatbots, voz, e-mail, Slack e outras interfaces. Sua característica de implantação independente o torna um kit básico para desenvolvedores construírem AI Agents multiplataforma (Fonte: TheTuringPost)
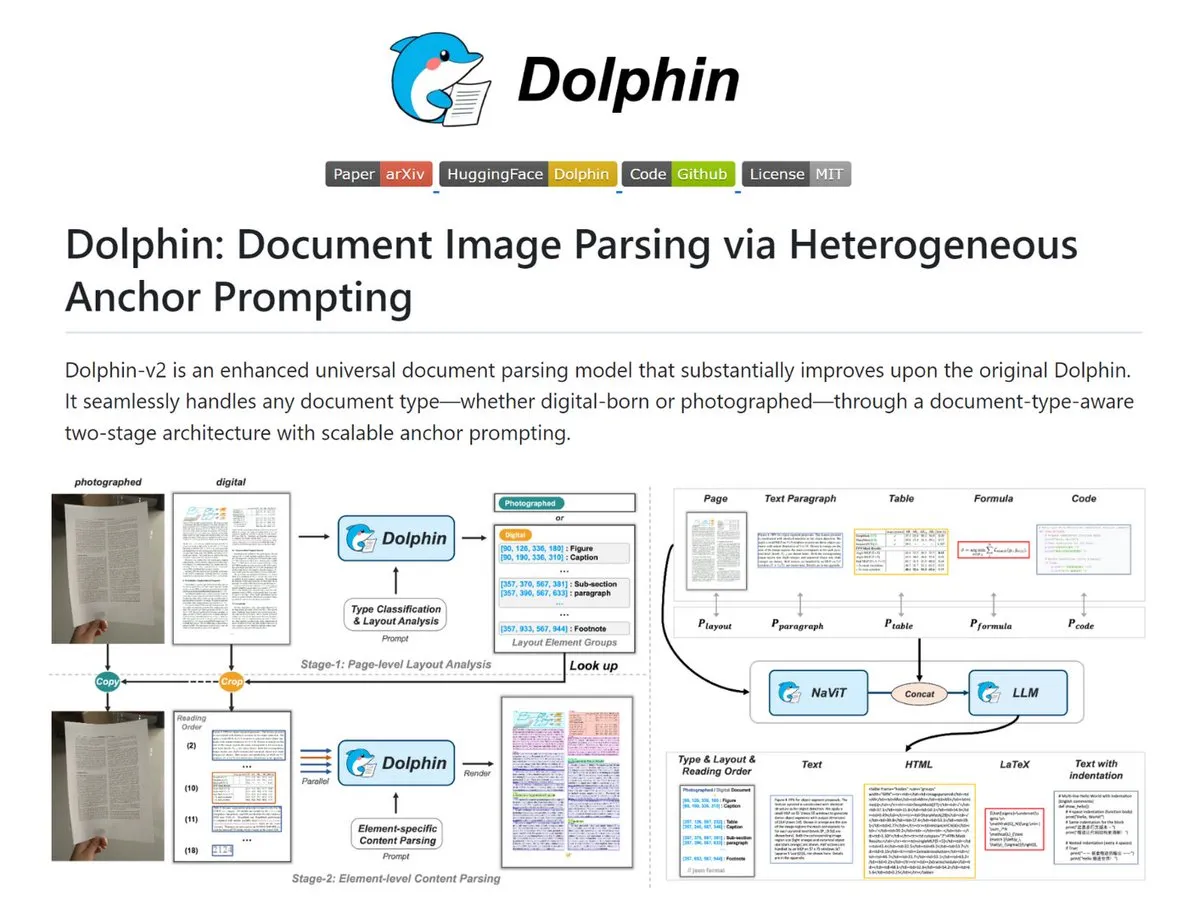
Dolphin: Ferramenta poderosa para análise de documentos complexos : O Dolphin é uma ferramenta capaz de converter imagens de documentos e PDFs em Markdown/JSON estruturado. Ele reconhece automaticamente documentos escaneados e digitais, restaura a ordem de leitura do layout e analisa paralelamente texto, tabelas e fórmulas. O modelo da ferramenta varia de 0.3B a 3B, com excelente desempenho no OmniDocBench, sendo adequado para cenários que exigem digitalização de documentos de alta precisão (Fonte: TheTuringPost)
📚 Aprendizado
AI Agents A-Z: Tutorial completo de desenvolvimento de agentes : Este repositório no GitHub reúne os templates n8n da série de vídeos “AI Agents A-Z”, cobrindo mais de 40 casos práticos, desde agentes de gerenciamento de medicamentos prescritos e resumos diários até automação do LinkedIn e geração de vídeos para o YouTube. Ele demonstra como utilizar ferramentas no-code combinadas com LLMs para construir fluxos de trabalho automatizados complexos, sendo um excelente recurso para iniciantes entenderem cenários de aplicação de Agents (Fonte: GitHub Trending)
Review sobre construção de grafos de conhecimento potencializados por LLM : O artigo “LLM-empowered knowledge graph construction” sistematiza como utilizar LLMs para aprimorar os métodos tradicionais de Knowledge Graph (KG). O conteúdo abrange extração de ontologia, extração orientada por esquema e sem esquema, fusão de conhecimento e futuras direções de raciocínio de memória dinâmica. Possui valor de referência importante para desenvolvedores que desejam combinar conhecimento estruturado com as capacidades de raciocínio de grandes modelos (Fonte: TheTuringPost)

💼 Negócios
Rumores de atraso nas placas de vídeo NVIDIA e estratégia de prioridade para AI : Circulam rumores nas redes sociais de que a NVIDIA pode atrasar indefinidamente o lançamento da série de placas RTX 50 Super, devido à escassez de memória e à prioridade da empresa em garantir o fornecimento de chips de AI com margens de lucro mais altas. Embora sejam apenas rumores, a comunidade acredita amplamente que, como a participação do negócio de jogos na receita da NVIDIA caiu para 8%, o “sacrifício estratégico” das placas de vídeo de consumo faz sentido lógico no contexto da sede por poder computacional (Fonte: Reddit r/LocalLLaMA)

Meta assina acordo de energia nuclear para garantir eletricidade para supercomputação de AI : A Meta assinou um acordo de energia nuclear para seu cluster de supercomputação Prometheus AI. À medida que a corrida pela AI se intensifica, a energia tornou-se um gargalo que restringe a expansão do poder computacional. A Meta segue o exemplo de gigantes como a Microsoft, garantindo recursos de energia nuclear estáveis e limpos para assegurar sua capacidade de expansão contínua de poder computacional nos próximos anos (Fonte: Reddit r/artificial)
Movimentações de IPO da Zhipu AI sob atenção : Um levantamento da indústria mencionou as potenciais movimentações da Zhipu AI como a primeira empresa de grandes modelos da China a abrir capital. Como um dos principais players de modelos nacionais, o processo de comercialização e o desempenho no mercado de capitais da Zhipu são vistos como um termômetro para a indústria, especialmente no atual ambiente complexo de financiamento global de AI (Fonte: ZhihuFrontier)
🌟 Comunidade
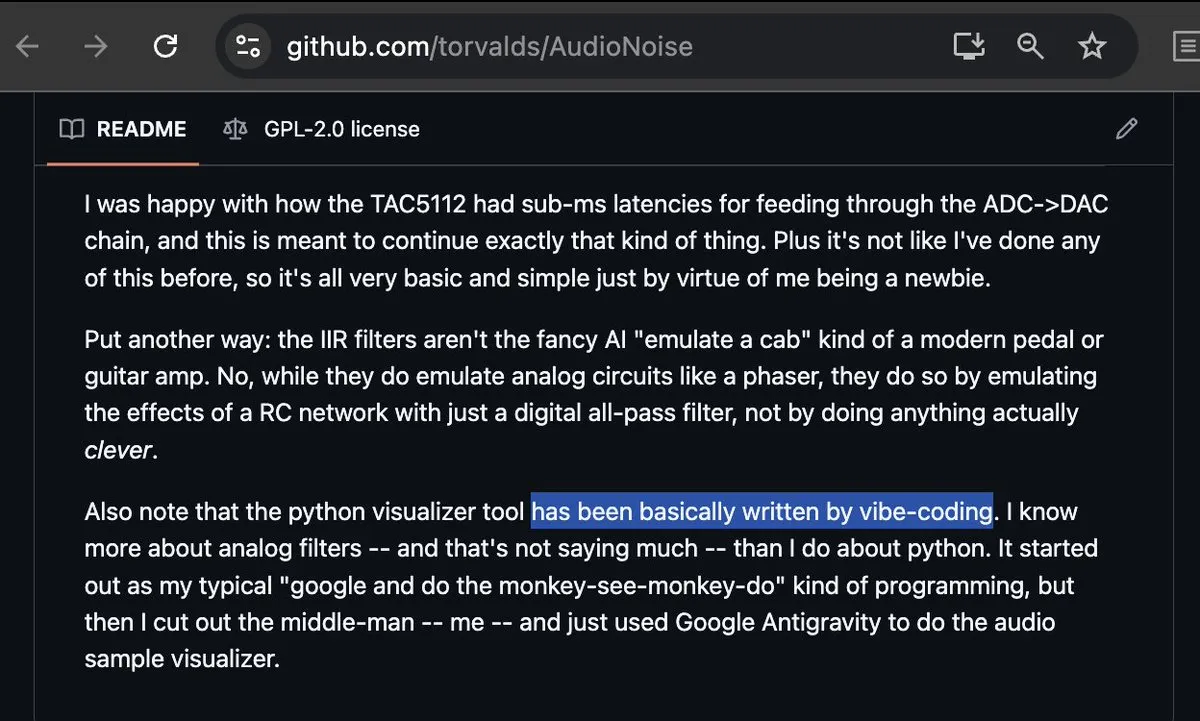
Linus Torvalds participa do Vibe-coding e gera discussões : Até mesmo o criador do Linux, Linus Torvalds, conhecido por seu rigor, começou a usar o Google Antigravity para Vibe-coding (programação por “vibe”), implementando com sucesso uma ferramenta de visualização de áudio. Este evento causou sensação na comunidade, sendo visto como um marco na maturidade das ferramentas de programação com AI. Programadores comentaram que, quando até os desenvolvedores mais puristas começam a aceitar a programação baseada em “vibe”, os modelos tradicionais de auditoria e escrita de código estão sendo fundamentalmente abalados (Fonte: dotey; cto_junior; osanseviero)
Mudança drástica na percepção de programadores seniores sobre programação com AI : A comunidade observou que programadores “hardcore” (que pesquisam compiladores, kernels CUDA, etc.), que antes desprezavam o código gerado por AI como sendo apenas “lixo (slop)”, estão mudando rapidamente de opinião. Com o desempenho de modelos como o GPT-5.2 em lógica complexa e código de baixo nível se tornando cada vez mais refinado, a janela de tempo para negar as capacidades da AI se fechou. Essa mudança psicológica, da resistência ao choque e depois à aceitação, reflete o salto geracional das ferramentas de produtividade de AI (Fonte: Yuchenj_UW; timsoret)
Novo paradigma de depuração de agentes: olhar para o Trace em vez do código : O ponto de vista proposto por Harrison Chase, “ao depurar um Agent, não me mostre o código, mostre-me o Trace”, obteve amplo consenso. Em fluxos de trabalho Agentic, o processo de decisão do LLM é mais importante do que o código estático. Ao analisar a trajetória de execução (Trace), os desenvolvedores podem localizar com mais clareza em qual etapa de raciocínio o modelo errou; essa depuração de estilo “comportamental” está substituindo a depuração tradicional de estilo “lógico” (Fonte: Hacubu; _philschmid)
Queda de braço entre segurança de AI e hábitos dos funcionários : Muitos gestores de empresas estão preocupados com funcionários alimentando o ChatGPT com dados confidenciais. Apesar dos treinamentos de segurança, devido à conveniência trazida pela AI, os funcionários tendem a “reincidir” em comportamentos irregulares. Discussões na comunidade sugerem que a simples proibição é ineficaz; é necessário fornecer alternativas de AI seguras locais igualmente convenientes, complementadas por “histórias de terror” reais de vazamentos para reforçar a conscientização (Fonte: Reddit r/ArtificialInteligence)
💡 Outros
Comparação da tecnologia de backflip entre robôs da China e dos EUA : As redes sociais compararam o desempenho de backflip do Atlas da Boston Dynamics com os robôs da Unitree. A Unitree demonstrou um equilíbrio e aterrissagem mais perfeitos, enquanto o Atlas mostrou estratégias de articulação de forma não humana mais avançadas em seus movimentos de recuperação. Essa competição mostra que os robôs chineses já alcançaram ou até superaram parcialmente os EUA em fabricação de hardware e controle de equilíbrio, enquanto os EUA ainda mantêm vantagem em algoritmos de estratégia complexos (Fonte: teortaxesTex)
Chip de AI fotônico promete aumento de velocidade de 100 vezes : Um novo tipo de chip de AI movido a luz afirma ser 100 vezes mais rápido que as GPUs top de linha da NVIDIA. A tecnologia utiliza processamento de sinais ópticos em substituição aos sinais eletrônicos, visando resolver os gargalos de consumo de energia e latência dos semicondutores tradicionais na expansão do poder computacional. Embora ainda esteja em fase de pesquisa e desenvolvimento, isso representa outra rota tecnológica radical no nível de hardware para combater o monopólio da NVIDIA (Fonte: Ronald_vanLoon)
