
Anahtar Kelimeler:GPT-5.2 Pro, DeepSeek V4, Konfüçyüs Kod Ajanı, Erdös Matematik Problemi, mHC Mimarisi, Uzun Hafıza Ajanı
🔥 Odak Noktası
GPT-5.2 Pro Birden Fazla Erdos Matematik Problemini Otonom Olarak Çözdü : Sosyal medya son günlerde GPT-5.2 Pro’nun bilimsel keşif alanındaki çığır açan ilerlemesini tartışıyor. Model, Aristotle sistemi ile birlikte çalışarak Erdos #729 ve #397 dahil olmak üzere birçok matematiksel problemi otonom olarak çözmeyi başardı; #397’nin kanıtı matematikçi Terence Tao tarafından onaylandı. Bu, AI’ın sadece külliyat öğreniminden, henüz görülmemiş bilimsel zorlukları çözebilen akıl yürütme (reasoning) yeteneğine evrildiğini gösteriyor. Topluluk, bunun akıl yürütme modellerinin yüksek derecede soyut mantığı işlemedeki devasa potansiyelini kanıtladığını ve AI’ın Fields Madalyası almasının sadece bir zaman meselesi olduğunu düşünüyor (Kaynak: SebastienBubeck; kevinweil; halvarflake)
DeepSeek V4 Yayınlanma Tahmini ve mHC Mimarisi Üzerine Derin Tartışma : Sektör içinden gelen bilgiler, DeepSeek V4’ün Bahar Bayramı civarında yayınlanacağını ve doğrudan tam SOTA hedeflediğini sızdırdı. Bu model serisi, son zamanlarda Doubly Stochastic Matrix özelliği sayesinde katmanlar arası çarpım kararlılığını sağlayan ve derin ağlardaki gradyan kaybolması veya patlaması sorununu etkili bir şekilde çözen mHC (Multi-Head Connection) mimarisi ile dikkat çekiyor. Topluluk analizlerine göre DeepSeek’in teknolojik yolu, sadece bilgi işlem gücü yığmaktan daha temel matematiksel mimari optimizasyonuna kayıyor; bu “küçükle büyük işler başarma” yaklaşımı büyük model geliştirme paradigmasını değiştiriyor (Kaynak: teortaxesTex; Reddit r/MachineLearning)
Meta ve Harvard, Confucius Code Agent (CCA) Uzun Bellekli Agent’ı Duyurdu : Meta, Harvard Üniversitesi ile birlikte büyük ve karmaşık kod tabanlarındaki agent operasyon zorluklarını çözmeyi amaçlayan Confucius Code Agent’ı tanıttı. CCA’nın merkezinde kalıcı dahili notlar, uzun vadeli görev belleği ve izlenebilir akıl yürütme zincirleri yer alıyor; ayrıca araç kullanım stratejilerini kendi kendine ayarlayan bir geri bildirim döngüsüne sahip. Bu mimari, AI’ın izole Prompt’lar yerine gerçek dünyadaki karmaşık sistemlerde mantıksal tutarlılığı korumasına olanak tanıyor. Topluluk, bunun “büyük ölçekli zekanın sadece model boyutuna değil, bellek yapısına dayandığı” yönündeki yeni sektör konsensüsünü doğruladığını belirtiyor (Kaynak: Reddit r/artificial; Reddit r/ArtificialInteligence)

🎯 Gelişmeler
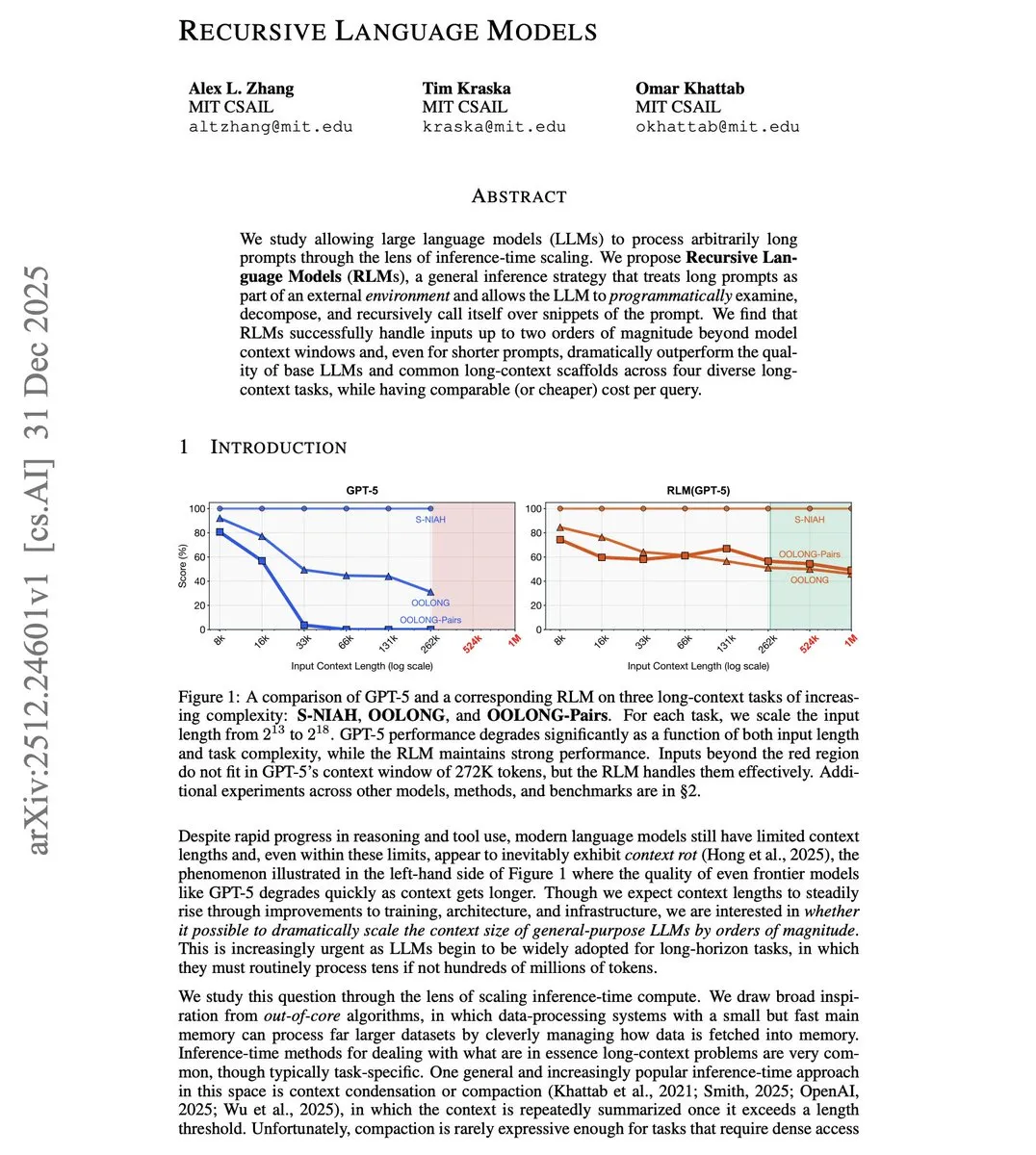
MIT, Context Limitlerini Aşan Recursive Language Model (RLM) Önerdi : MIT araştırmacıları tarafından önerilen RLM, modellerin context window kapasitelerinin 100 katı kadar girdiyi işlemesine olanak tanıyor. Bu teknoloji, mimari değişikliklerle pencereyi büyütmek yerine, uzun istemleri programlı olarak dış ortam gibi ele alıyor ve modelin parçaları işlemek için kendisini özyinelemeli (recursive) olarak çağırmasını sağlıyor. Testler, 8K pencereye sahip bir modelin 800K token’ı etkili bir şekilde işleyebildiğini ve kısa istemli görevlerde de geleneksel uzun context çözümlerinden daha iyi performans gösterdiğini ortaya koydu; bu da Agent’ların tüm kod depolarını veya uzun belgeleri işlemesi için düşük maliyetli bir yol sunuyor (Kaynak: omarsar0)
KimiLinear-48B İçin MLA KV Cache Desteği Sağlandı : Geliştiriciler, llama.cpp içerisinde KimiLinear modeli için backend bağımsız MLA KV Cache desteğini başarıyla ekledi. Bu optimizasyon, 1M Token için F16 KV önbellek kullanımını 140GB’tan 14.8GB’a düşürerek, ultra uzun context modellerinin düşük VRAM’li tüketici sınıfı ekran kartlarında çalışmasını mümkün kılıyor. KimiLinear daha önce ContextArena’da üstün performans göstermişti; bu bellek optimizasyonu, uzun metin AI uygulamalarının yerel cihazlarda yaygınlaşmasını büyük ölçüde hızlandıracak (Kaynak: Reddit r/LocalLLaMA)

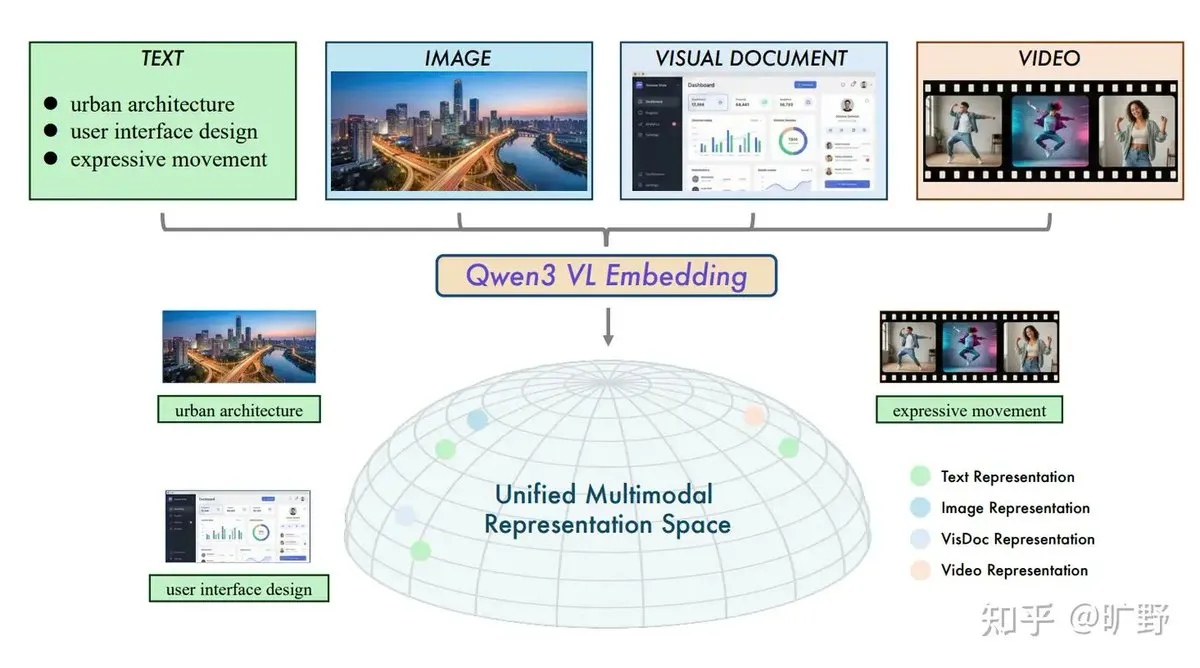
Alibaba, Qwen3-VL Çapraz Modallı RAG Sistemini Açık Kaynak Olarak Sundu : Alibaba, RAG’in geçmişte metne aşırı bağımlı olma sorununu çözen Qwen3-VL-Embedding ve Reranker modellerini yayınladı. Bu model; metin, görüntü, video ve ekran görüntülerini birleşik bir vektör uzayına yerleştirerek “metinle görsel arama” veya “görselle video arama” imkanı tanıyor. Benzersiz “instruction-aware” özelliği, kullanıcıların belirli görevlere (e-ticaret araması veya hukuki karşılaştırma gibi) göre alaka düzeyini tanımlamasına olanak tanıyarak çok modallı RAG’in görev odaklı yeni bir aşamaya geçtiğini simgeliyor (Kaynak: ZhihuFrontier)
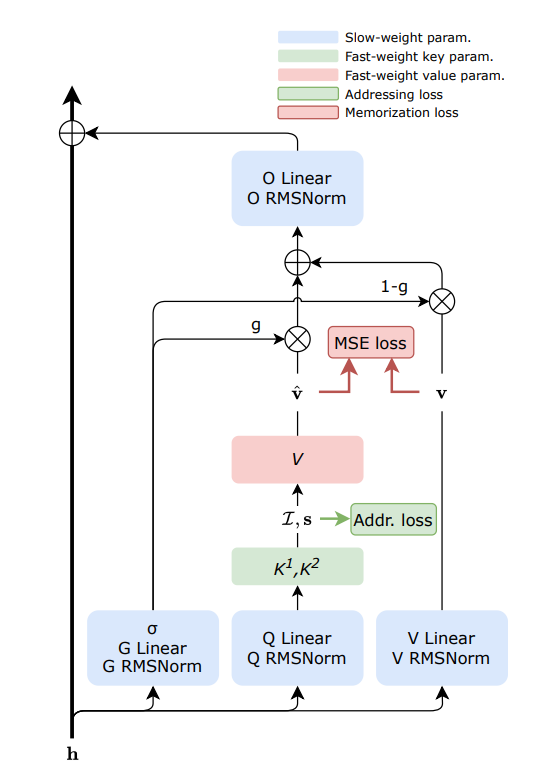
Sakana AI, FwPKM Dinamik Bellek Teknolojisini Duyurdu : Sakana AI, büyük bellek kapasitesi ile düşük hesaplama maliyetini dengelemeyi amaçlayan Fast-weight Product Key Memory (FwPKM) teknolojisini tanıttı. Bu teknoloji, Product Key Memory (PKM) yapısının hem eğitim hem de çıkarım (inference) sırasında dinamik olarak güncellenmesini sağlayarak attention mekanizmasının ölçeklenme darboğazını çözüyor. Modellerin daha fazla bilgi hatırlaması ve uzun vadeli akıl yürütme yapması gerektikçe, bu dinamik güncellenen bellek mekanizması AGI’ye giden yolda kritik bir adım olarak görülüyor (Kaynak: TheTuringPost)
🧰 Araçlar
Silicon-Studio: M Serisi Mac İçin Yerel Fine-tuning GUI : M serisi çipli Mac’ler için özel olarak tasarlanmış uçtan uca yerel bir LLM fine-tuning aracıdır. Apple’ın MLX framework yapısını kapsayan araç; veri temizleme, PII gizlilik maskeleme, LoRA/QLoRA parametre ayarları ve yerleşik çıkarım test arayüzü sunuyor. Bu araç, sıradan kullanıcıların Mac üzerinde model kişiselleştirme eğitimi yapma eşiğini düşürerek tüm süreci grafiksel bir operasyona dönüştürüyor (Kaynak: Reddit r/LocalLLaMA)
Kreuzberg v4: Rust ile Yeniden Yazılan Çok Yönlü Belge Zekası Kütüphanesi : Kreuzberg v4, Python’dan Rust’a temel bir yeniden yazım sürecini tamamlayarak 56 farklı formatta yapılandırılmış veri çıkarımını destekler hale geldi. Pandoc bağımlılığını kaldırarak yerel Rust ayrıştırıcılarını kullanan kütüphane, hızı önemli ölçüde artırırken bellek kullanımını azalttı. 10 dilde binding (TS, Python, Go gibi) sunan, OCR backend değişimi ve ONNX embedding desteği sağlayan bu kütüphane, yüksek performanslı RAG boru hatları oluşturmak için ideal bir seçimdir (Kaynak: Reddit r/LocalLLaMA)

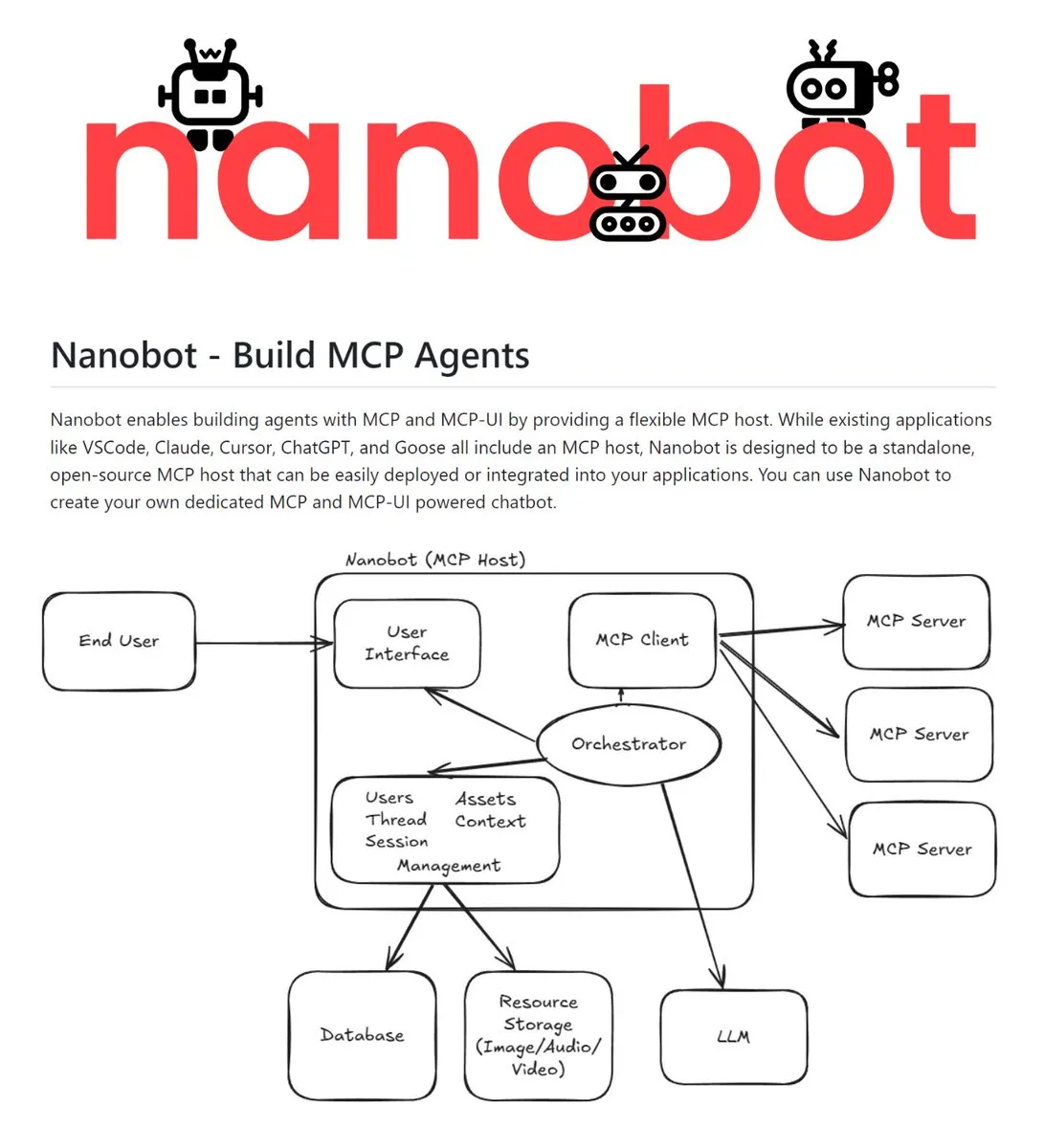
Nanobot: Açık Kaynaklı Bağımsız MCP Host : Nanobot, MCP (Model Context Protocol) ve MCP-UI desteği sunan açık kaynaklı bağımsız bir host’tur. MCP sunucularını, LLM’leri ve bağlamı tek bir hizmette birleştirerek chatbot, ses, e-posta, Slack gibi çeşitli arayüzler üzerinden agent deneyimleri oluşturulmasını sağlar. Bağımsız dağıtım özelliği, onu geliştiriciler için platformlar arası AI Agent’lar oluşturmada temel bir kit haline getiriyor (Kaynak: TheTuringPost)
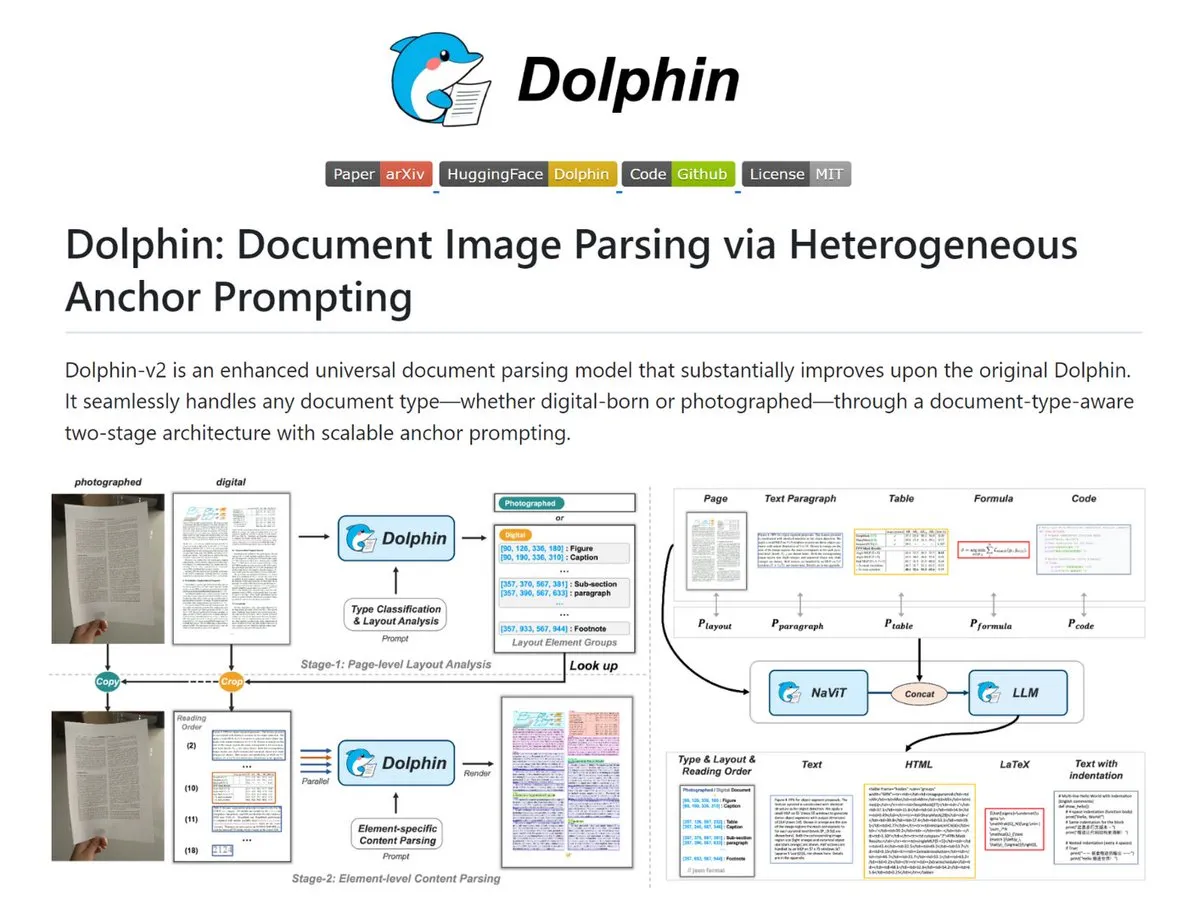
Dolphin: Karmaşık Belge Ayrıştırma Aracı : Dolphin, belge görüntülerini ve PDF’leri yapılandırılmış Markdown/JSON formatına dönüştürebilen bir araçtır. Taranmış ve dijital belgeleri otomatik olarak tanır, sayfa düzeni okuma sırasını geri yükler ve metin, tablo ve formülleri paralel olarak ayrıştırır. Model boyutu 0.3B ile 3B arasında değişen araç, OmniDocBench üzerinde üstün performans sergileyerek yüksek hassasiyetli belge dijitalleştirme senaryoları için uygun bir çözüm sunuyor (Kaynak: TheTuringPost)
📚 Öğrenme
AI Agents A-Z: Uçtan Uca Agent Geliştirme Eğitimi : Bu GitHub deposu, “AI Agents A-Z” video serisindeki n8n şablonlarını bir araya getiriyor. Reçeteli ilaç yönetim agent’larından günlük özet agent’larına, LinkedIn otomasyonundan YouTube video üretimine kadar 40’tan fazla pratik vakayı kapsıyor. Kodsuz araçların LLM’ler ile birleştirilerek nasıl karmaşık otomasyon iş akışları oluşturulabileceğini gösteren bu kaynak, yeni başlayanlar için Agent kullanım senaryolarını anlamada mükemmel bir kaynaktır (Kaynak: GitHub Trending)
LLM Destekli Bilgi Grafiği Oluşturma İncelemesi : “LLM-empowered knowledge graph construction” başlıklı makale, geleneksel Bilgi Grafiği (KG) yöntemlerini geliştirmek için LLM’lerin nasıl kullanılacağını sistematik olarak ele alıyor. İçerik; ontoloji çıkarımı, şema odaklı ve şemasız çıkarım, bilgi füzyonu ve gelecekteki dinamik bellek akıl yürütmesi gibi konuları kapsıyor. Yapılandırılmış bilgi ile büyük model akıl yürütme yeteneklerini birleştirmek isteyen geliştiriciler için önemli bir referans değerindedir (Kaynak: TheTuringPost)

💼 İş Dünyası
NVIDIA Ekran Kartı Gecikme Söylentileri ve AI Öncelikli Strateji : Sosyal medyada NVIDIA’nın, bellek kıtlığı ve şirketin daha yüksek kârlı AI çiplerine öncelik vermesi nedeniyle RTX 50 Super serisi ekran kartlarının çıkışını süresiz olarak erteleyebileceği konuşuluyor. Sadece bir söylenti olsa da topluluk, oyun işinin NVIDIA gelirlerindeki payının %8’e düştüğü ve bilgi işlem gücü açlığının olduğu bir ortamda, tüketici sınıfı kartların “stratejik olarak feda edilmesinin” mantıklı olduğunu düşünüyor (Kaynak: Reddit r/LocalLLaMA)

Meta, AI Süper Bilgisayarları İçin Nükleer Enerji Anlaşması İmzaladı : Meta, Prometheus AI süper bilgisayar kümeleri için nükleer enerji anlaşması imzaladı. AI yarışı kızıştıkça, enerji bilgi işlem gücünü artırmanın önündeki en büyük engel haline geldi. Meta, Microsoft gibi devleri takip ederek istikrarlı ve temiz nükleer enerji kaynaklarını güvence altına alıyor ve önümüzdeki yıllarda sürekli bilgi işlem gücü genişletme kapasitesine sahip olmayı hedefliyor (Kaynak: Reddit r/artificial)
Zhipu AI IPO Dinamikleri Dikkat Çekiyor : Sektör analizleri, Zhipu AI’ın Çin’in ilk halka açık büyük model şirketi olma potansiyeline odaklanıyor. Yerli büyük modellerin lider oyuncularından biri olan Zhipu’nun ticarileşme süreci ve sermaye piyasası performansı, özellikle küresel AI finansman ortamının karmaşıklaştığı bu dönemde sektör için bir gösterge olarak kabul ediliyor (Kaynak: ZhihuFrontier)
🌟 Topluluk
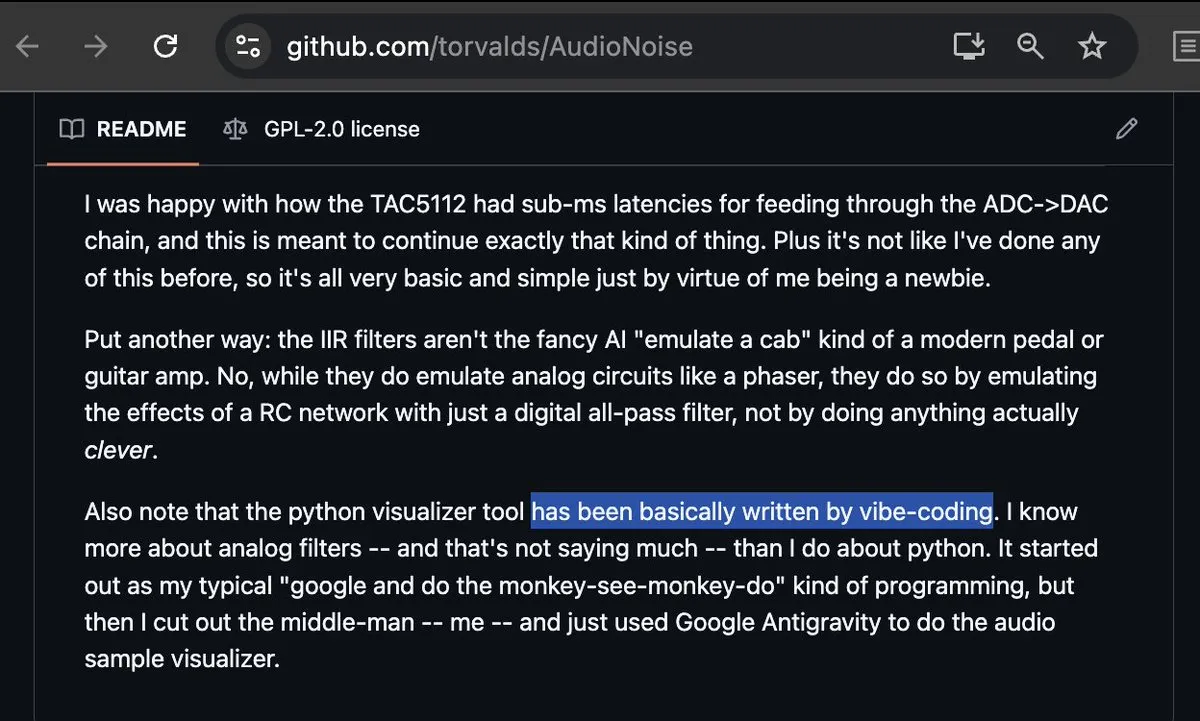
Linus Torvalds’ın Vibe-coding’e Katılması Heyecan Yarattı : Her zaman titizliğiyle bilinen Linux’un babası Linus Torvalds bile Google Antigravity kullanarak Vibe-coding (atmosferik programlama) yapmaya başladı ve başarıyla bir ses görselleştirme aracı geliştirdi. Bu olay toplulukta büyük yankı uyandırdı ve AI programlama araçlarının olgunlaştığının bir dönüm noktası olarak görüldü. Yazılımcılar, en çekirdek geliştiricilerin bile “vibe” odaklı programlamayı kabul etmeye başlamasıyla, geleneksel kod denetimi ve yazım modellerinin temelinden sarsıldığını belirtiyor (Kaynak: dotey; cto_junior; osanseviero)
Kıdemli Programcıların AI Kodlama Algısındaki Keskin Değişim : Topluluk, bir zamanlar AI kodlarını küçümseyen ve onları tamamen “çöp (slop)” olarak gören hardcore programcıların (derleyici, CUDA çekirdeği vb. çalışanlar) fikirlerini hızla değiştirdiğini gözlemliyor. GPT-5.2 gibi modellerin karmaşık mantık ve alt seviye kodlardaki performansı arttıkça, AI yeteneklerini inkar etme penceresi kapandı. Direnişten şaşkınlığa ve ardından kabule uzanan bu psikolojik değişim, AI üretkenlik araçlarındaki nesilsel sıçramayı yansıtıyor (Kaynak: Yuchenj_UW; timsoret)
Agent Hata Ayıklamada Yeni Paradigma: Koda Değil, Trace’e Bakmak : Harrison Chase tarafından ortaya atılan “Agent hata ayıklarken bana kod göstermeyin, Trace gösterin” görüşü geniş kabul gördü. Agentic iş akışlarında, LLM’in karar verme süreci statik koddan daha önemlidir. Yürütme izlerini (Trace) analiz ederek, geliştiriciler modelin hangi akıl yürütme aşamasında hata yaptığını daha net belirleyebiliyor; bu “davranışsal” hata ayıklama yöntemi, geleneksel “mantıksal” hata ayıklamanın yerini alıyor (Kaynak: Hacubu; _philschmid)
AI Güvenliği ve Çalışan Alışkanlıkları Arasındaki Çekişme : Birçok işletme yöneticisi, çalışanların gizli verileri ChatGPT’ye beslemesinden endişe duyuyor. Güvenlik eğitimlerine rağmen, AI’ın sağladığı kolaylık nedeniyle çalışanlar genellikle kural ihlallerine geri dönüyor. Topluluk tartışmaları, sadece yasaklamanın etkisiz olduğunu, aynı derecede kullanışlı yerel ve güvenli AI alternatiflerinin sunulması ve farkındalığı artırmak için gerçek sızıntı “korku hikayeleri” ile desteklenmesi gerektiğini savunuyor (Kaynak: Reddit r/ArtificialInteligence)
💡 Diğer
Çin-ABD Robot Ters Takla Teknolojisi Karşılaştırması : Sosyal medyada Boston Dynamics Atlas ile Unitree robotlarının ters takla performansları karşılaştırıldı. Unitree daha mükemmel bir denge ve iniş sergilerken, Atlas toparlanma hareketlerinde daha gelişmiş insan dışı formda eklem stratejileri gösterdi. Bu rekabet, Çinli robotların donanım üretimi ve denge kontrolünde ABD’yi yakaladığını hatta yer yer geçtiğini, ABD’nin ise karmaşık strateji algoritmalarında hala avantajlı olduğunu gösteriyor (Kaynak: teortaxesTex)
Fotonik AI Çipi 100 Kat Hız Artışı İddia Ediyor : Yeni bir ışık tahrikli AI çipinin, en üst düzey NVIDIA GPU’lardan 100 kat daha hızlı olduğu iddia ediliyor. Bu teknoloji, geleneksel yarı iletkenlerin bilgi işlem gücü genişlemesindeki güç tüketimi ve gecikme darboğazlarını çözmek için elektronik sinyaller yerine ışık sinyallerini kullanıyor. Henüz Ar-Ge aşamasında olsa da bu, donanım düzeyinde NVIDIA monopolüne karşı bir başka radikal teknolojik rotayı temsil ediyor (Kaynak: Ronald_vanLoon)
