
키워드:AI 모델, 오픈소스 대형 모델, AI 에이전트, 강화 학습, 구현형 지능 로봇, AI 하드웨어, AI 비즈니스 응용, K2 Think 오픈소스 AI 모델, 오라클과 OpenAI GPU 협약, Thinking Machines 배치 불변성 연구, Kimi 체크포인트 엔진, 구현형 지능 로봇 반도체 응용
🔥 포커스
K2 Think: 세계에서 가장 빠른 오픈소스 AI 모델 탄생 : 아랍에미리트 무함마드 빈 자이드 인공지능 대학(MBZUAI)과 G42 AI가 협력하여 K2 Think를 출시했다. 이 모델은 세계에서 가장 빠른 오픈소스 대규모 모델로 불리며, 초당 2000 tokens의 속도를 자랑하고 일반적인 GPU 배포보다 10배 이상 높은 처리량을 제공한다. Qwen 2.5-32B를 기반으로 구축되었으며, 주로 수학적 추론을 위해 개발되었고 AIME’24와 같은 수학 벤치마크 테스트에서 이상적인 점수를 획득했다. 기술 혁신에는 장기적 사고를 위한 지도 미세 조정, 검증 가능한 보상 기반 강화 학습, 추론 전 지능형 계획 등이 포함된다. (출처: 量子位)

Oracle과 OpenAI, 3000억 달러 규모 GPU 데이터센터 계약 체결 : Oracle 주가는 OpenAI와 3000억 달러 규모의 GPU 컴퓨팅 파워 구매 계약을 체결하면서 급등했다. 이 계약은 2027년에 발효될 예정이며, OpenAI는 약 5년 동안 분할 구매할 계획이며 연간 지불액은 600억 달러에 달한다. 이는 OpenAI의 “스타게이트” 데이터센터 프로젝트의 일환으로, 막대한 컴퓨팅 파워 수요를 해결하는 것을 목표로 한다. 하지만 이는 Oracle이 미래 수익의 상당 부분을 단일 고객에게 걸고 있음을 의미하며, 막대한 칩 구매로 인한 부채 압력에 직면할 수 있다. (출처: 量子位、Yuchenj_UW、TheRundownAI)

Thinking Machines, 첫 연구 발표: LLM 추론의 비결정성 극복 : OpenAI 전 CTO Mira Murati가 설립한 Thinking Machines가 첫 연구를 발표하며 LLM 추론 결과의 재현성 문제를 탐구했다. 연구는 부동 소수점 비결합성과 동시 실행이 유일한 원인이 아니며, 배치 불변성이 주범이라고 지적했다. 즉, 단일 요청의 출력은 동일 배치 내 요청 수에 영향을 받는다. 팀은 배치 불변성 커널(RMSNorm, 행렬 곱셈, 어텐션 메커니즘 대상) 설계를 통해 Qwen/Qwen3-235B-A22B-Instruct-2507 모델에서 1000개의 결과가 완전히 동일하게 나오는 데 성공했으며, 온라인 정책 강화 학습에서의 안정성을 검증했다. (출처: 量子位、Reddit r/ArtificialInteligence)

Kimi, 오픈소스 Checkpoint-Engine 공개: 20초 만에 조 단위 파라미터 LLM 업데이트 : Kimi 팀은 Checkpoint-Engine 미들웨어를 오픈소스화했다. 이는 추론 과정에서 대규모 언어 모델의 가중치를 효율적으로 업데이트하는 것을 목표로 한다. 이 엔진은 수천 개의 GPU에서 약 20초 만에 조 단위 파라미터 모델을 업데이트할 수 있으며, 두 단계 파이프라인 방식을 채택하여 메모리 사용량을 최소화한다. 모든 노드에 가중치를 한 번에 브로드캐스트하여 업데이트하는 것을 지원하며, 점대점 동적 업데이트도 구현할 수 있다. 또한 시작 시간을 최적화하여 모든 작업 노드가 체크포인트를 한 번에 읽도록 하여 디스크 IO 오버헤드를 최소화한다. (출처: 量子位、QuixiAI)

인간형 지능 로봇, 반도체 디스플레이 산업에 최초로 대규모 진출 : 선전 후이즈우롄(深圳慧智物联)과 즈핑팡(智平方)이 전략적 협력을 체결했다. 향후 3년 내에 BOE 글로벌 생산 기지에 1000대 이상의 인간형 지능 로봇을 배치할 예정이다. 이 로봇들은 엔드투엔드 VLA 대규모 모델에 의해 구동되며, 인지, 이해, 결정 및 실행의 높은 수준의 협업을 실현할 수 있고, 소량의 샘플로 새로운 작업을 빠르게 학습한다. 첫 시범 시나리오는 PCB 작업으로, 로봇은 기존 공장 환경에 적응할 수 있으며, 대규모 인프라 개조가 필요 없어 배포 비용을 크게 절감한다. 또한 OLED 진공 접합, 소모품 관리 등의 시나리오에서 역할을 수행할 예정이다. (출처: 量子位)

🎯 동향
Qwen3-Next 시리즈 모델 곧 출시 예정 : 알리바바 통이치엔원(通义千问) 팀은 Qwen3-Next 시리즈 기반 모델을 곧 출시할 것이라고 발표했다. 이 새로운 모델들은 극대화된 컨텍스트 길이와 대규모 파라미터 효율성을 위해 최적화될 것이며, 일련의 아키텍처 혁신을 도입하여 성능을 최대화하면서 계산 비용을 최소화하는 것을 목표로 한다. Hugging Face에는 이미 관련 병합 요청이 있어, 새로운 모델이 곧 커뮤니티에 공개될 수 있음을 시사한다. (출처: Alibaba_Qwen、Reddit r/LocalLLaMA)
OpenAI Evals, 오디오 입력 및 평가 기능 추가 : OpenAI 개발자들은 평가 도구 Evals가 이제 네이티브 오디오 입력 및 오디오 평가기를 전면 지원한다고 발표했다. 이는 사용자가 모델의 오디오 응답을 텍스트 전사 없이 직접 평가할 수 있음을 의미하며, 음성 생성 또는 이해 모델과 관련된 테스트 프로세스를 간소화하고 평가 효율성과 정확성을 향상시킨다. (출처: gdb)
Microsoft Copilot, 새로운 스크립트 오디오 모드 출시 : Microsoft Copilot의 오디오 표현 기능이 업데이트되어, Microsoft 내부 AI 모델 MAI-Voice-1 기반의 스크립트 오디오 모드를 도입했다. 사용자는 텍스트를 입력하고 다양한 스타일로 낭독을 선택할 수 있으며, 예를 들어 할로윈 테마의 뱀파이어 스타일을 선택할 수 있다. 이 업데이트는 Copilot의 음성 상호작용 및 콘텐츠 제작 측면에서 유연성과 재미를 높였다. (출처: The Verge)
Google Gemini CLI, v0.4.0 업데이트 발표 : Gemini CLI가 v0.4.0의 주요 업데이트를 맞이했다. 여러 기능이 추가되었는데, CloudRun 및 Security Integrations를 포함하여 애플리케이션 배포 및 보안 분석 자동화를 실현한다. 새로운 Edit Tool 및 Prompt Completion 기능을 도입하여 개발 경험을 향상시키고, Footer Visibility 설정 및 Citations 표시를 강화했다. 2.5 Flash Lite 모델을 지원하며, @{path} 구문을 사용하여 로컬 파일 내용을 사용자 정의 명령에 삽입할 수 있도록 한다. (출처: algo_diver)

Hugging Face TRL v0.23 출시: 임의의 컨텍스트 길이 미세 조정 지원 : Hugging Face의 TRL(Transformer Reinforcement Learning) 라이브러리가 v0.23 버전을 출시했다. 핵심 하이라이트는 컨텍스트 병렬 처리(Context Parallelism) 기능 도입으로, 사용자가 임의의 컨텍스트 길이로 모델을 훈련할 수 있도록 한다. 또한, 새 버전에는 후처리(post-training)에 대한 여러 중요한 개선 사항이 포함되어 LLM 미세 조정의 유연성과 효율성을 향상시켰다. (출처: _lewtun)
Hugging Face Transformers 라이브러리, OpenAI GPT-OSS 모델 최적화 : Hugging Face는 블로그를 통해 transformers 라이브러리가 OpenAI GPT-OSS 모델을 지원하기 위해 수행한 여러 중요한 업그레이드를 자세히 소개했다. 이러한 최적화에는 제로 빌드 커널(Hub에서 사전 컴파일된 바이너리 다운로드), MXFP4 양자화(메모리 사용량 대폭 감소), 텐서 병렬 처리, 전문가 병렬 처리, 동적 슬라이딩 윈도우 레이어 및 캐시(KV 캐시 메모리 감소), 그리고 연속 배치 처리 및 페이지드 어텐션이 포함된다. 이러한 개선 사항은 GPT-OSS의 로딩, 실행 및 미세 조정 효율성을 향상시킬 뿐만 아니라 transformers 라이브러리의 다른 모델에도 일반적으로 적용된다. (출처: HuggingFace Blog)
AI Agent, 사무실에 혁신적으로 침투 : AI Agent의 사무실 적용은 보조 도구에서 비즈니스 프로세스에 깊이 통합된 “디지털 직원”으로 진화하고 있다. ChatGPT 시대의 Copilot 보조 기능부터 2024년 중반 AI Agent가 다단계 작업을 수행하기 시작했으며, WAIC에서 전시된 AI 아바타 “디지털 직원”이 비즈니스에 깊이 통합되었다. 사례로는 차이냐오(菜鸟) AI 비서가 HR 문의의 80%를 처리하고, 스자이(实在) Agent가 허베이 통신 재무 시나리오를 처리하며, 융성(永升) 부동산 AI가 아침 회의 내용을 분석하는 것 등이 있다. 기술적으로는 LLM+RPA+로우코드의 융합, 화면 의미 분석 기술, MCP(도구 프로토콜 계층)의 적용이 핵심 추진력이며, 이는 사무실의 생산 관계를 재편하고 있다. (출처: 36氪)
🧰 도구
콰이쇼우 AIGC 슈퍼 직원 Kwali: 한 문장으로 완전한 짧은 동영상 생성 : 콰이쇼우(快手)는 AIGC 슈퍼 직원 Kwali를 출시했다. 이는 한 문장 명령으로 스크립트 기획, 소재 매칭, 편집 합성, 배경 음악 및 자막을 포함한 완전한 짧은 동영상을 생성하고 원클릭 게시를 지원한다. 이 시스템은 의도 분석, 스크립트 생성, 장면 매칭, 편집 합성 등 여러 Agent를 통합했으며, 치엔쉰(千寻) 소재 라이브러리와 디지털 휴먼 모델 라이브러리에 연결되어 비디오 제작 진입 장벽을 크게 낮추고 아이디어부터 게시까지의 완전한 프로세스를 실현한다. (출처: 量子位)
알리페이, 전국 최초 스마트 에이전트 결제 서비스 ‘AI페이’ 출시 : 알리페이(支付宝)는 2025 Inclusion·와이탄(外滩) 컨퍼런스에서 국내 최초의 “AI페이” 서비스를 출시한다고 발표했다. 이는 AI 시대를 맞아 스마트 에이전트에게 결제 서비스를 제공한다. 이 서비스는 이미 루이싱 커피(瑞幸咖啡)의 AI 주문 도우미 “Lucky AI”에 먼저 적용되었으며, 사용자는 음성으로 주문 및 결제를 완료할 수 있고 AI 대화 인터페이스를 벗어나지 않아도 된다. 알리페이는 또한 “결제 MCP Server”, “AI 팁”, “AI 구독 결제” 등 새로운 결제 인프라를 출시하여 AI 산업 생태계를 활성화하는 것을 목표로 한다. (출처: 量子位)

Replit, Agent 3 출시: 애플리케이션 개발 ‘완전 자율 주행’ 실현 : Replit은 Agent 3를 출시했다. 이는 엔드투엔드로 완전한 애플리케이션을 자율적으로 프로토타이핑, 테스트, 디버깅 및 리팩토링할 수 있는 AI 에이전트이다. 이 도구는 소프트웨어 개발의 “완전 자율 주행” 순간으로 불리며, 인간처럼 애플리케이션을 사용하고 클릭하여 반복 작업을 수행하고 로그를 분석하여 소프트웨어 개발 효율성과 자동화 수준을 크게 향상시킨다. (출처: amasad)
Bilibili, IndexTTS-2.0 오픈소스 공개: TTS 길이 및 감정 제어 병목 현상 돌파 : Bilibili Index 팀은 IndexTTS-2.0을 공식 오픈소스화했다. 이는 감정 제어가 가능하고 길이가 조절 가능한 자기회귀 제로샷 텍스트-음성 변환(TTS) 시스템이다. 이 시스템은 시간 인코딩 메커니즘을 도입하여 길이 제어 정확도 문제를 해결하고, 음색과 감정의 디커플링 모델링을 실현하며, 다양한 방식으로 합성 음성의 감정 표현을 정밀하게 조절하는 것을 지원한다. IndexTTS-2.0은 AI 더빙, 오디오북, 비디오 번역 등 다양한 시나리오에 널리 적용될 수 있으며, 글로벌 콘텐츠 해외 진출을 위한 기술 지원을 제공한다. (출처: 量子位)

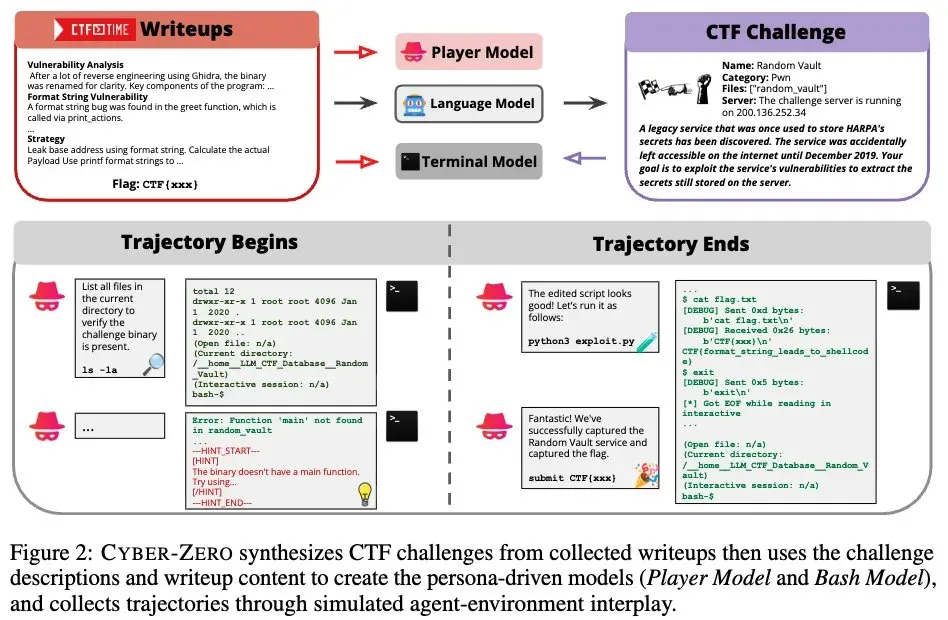
LLM Agent, 화이트햇 해커로 훈련 가능 : Amazon AWS AI의 Q Developer 팀은 Cyber-Zero와 CTF-Dojo를 출시했다. 이는 LLM Agent를 사이버 보안 작업에 훈련시키는 새로운 방법이다. 이러한 연구는 LLM Agent가 일반적인 작업에서 사이버 보안 최전선으로 전환하고 있음을 보여주며, 화이트햇 해커 작업을 수행할 수 있어 AI가 보안 분야에서 전문화된 응용 잠재력을 가지고 있음을 시사한다. (출처: terryyuezhuo)
Reka Research: 더 스마트한 AI 애플리케이션 구축 도구 : Reka AI는 Reka Research를 출시했다. 이는 API 우선 도구로, 개발자들이 능동적으로 다중 소스 정보를 연구, 분석하고 검증된 구조화된 데이터를 반환할 수 있는 스마트 AI 애플리케이션을 구축하도록 돕는 것을 목표로 한다. 이 도구는 완전한 추론 투명성, 위치 인식 검색 기능 및 출처에 대한 정밀한 제어를 제공하여, 신뢰할 수 있고 검증 가능한 정보가 필요한 AI 애플리케이션 개발에 이상적인 선택이 되게 한다. (출처: RekaAILabs)
AI 모델 품질 드리프트 감지 도구: aistupidlevel.info : 한 개발자가 aistupidlevel.info를 만들었다. 이는 Claude Sonnet 4를 핵심으로 활용하여 20분마다 Claude, GPT, Gemini, Grok 등 모델에 대해 140개 이상의 코딩/디버깅 작업을 실행하고, 정확성, 복잡성, 거부율, 안정성, 지연 시간 등 7가지 차원에 따라 점수를 매겨 AI 모델 품질의 드리프트를 정량적으로 감지한다. 이 도구는 오픈소스화되었으며, “Test Your Keys” 기능을 제공하여 사용자가 자신의 Claude API 키를 테스트하고 공개 순위표와 비교할 수 있도록 한다. (출처: Reddit r/ClaudeAI)
📚 학습
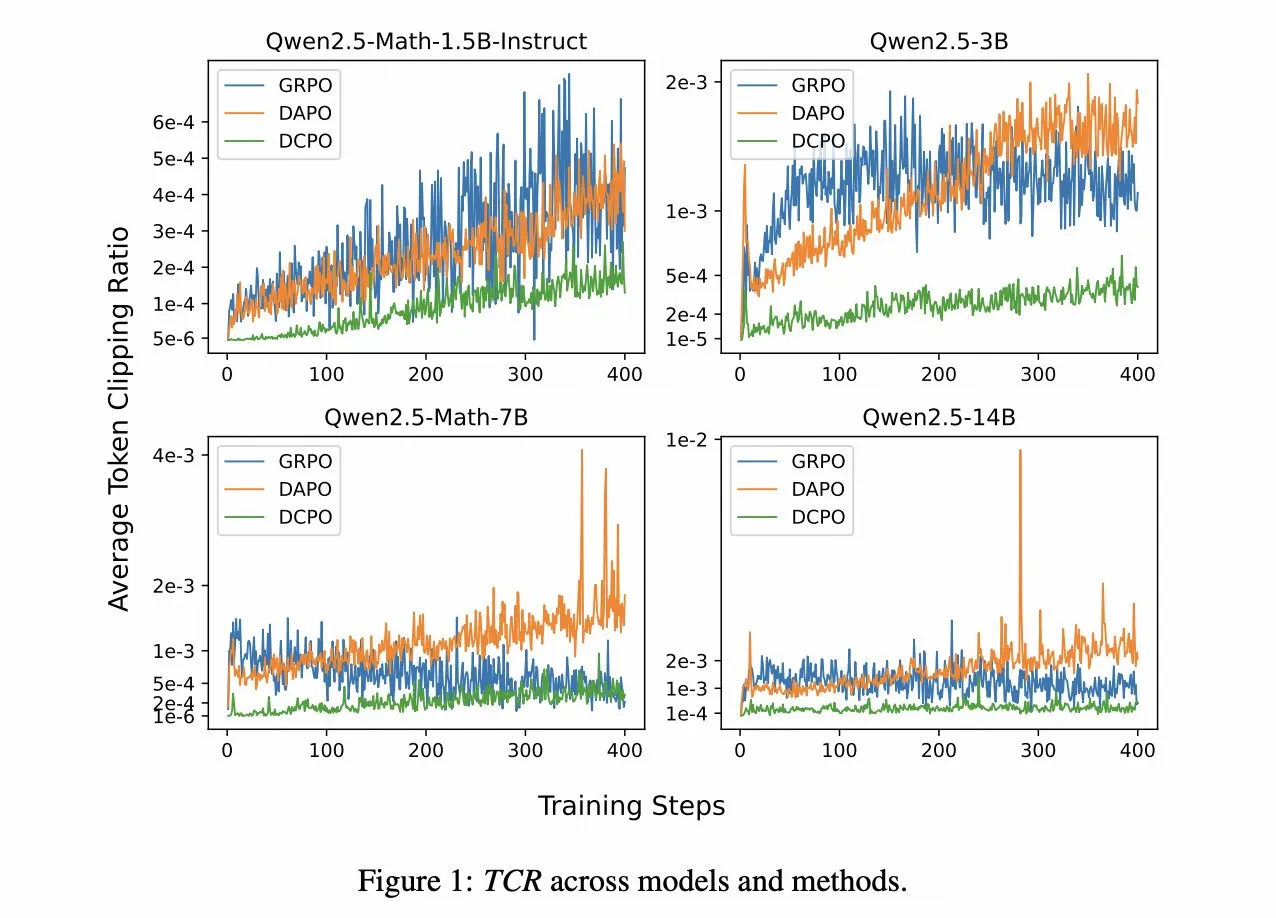
DCPO: 강화 학습의 동적 클리핑 정책 최적화 : 바이촨 AI(BaichuanAI)는 논문 “DCPO: Dynamic Clipping Policy Optimization”을 발표했다. 이는 RLHF(인간 피드백 기반 강화 학습) 보상 모델링의 중요한 업그레이드를 제안한다. DCPO는 동적 적응형 클리핑과 부드러운 이점 표준화를 통해 동일한 보상으로 인한 기울기 소실과 정적 클리핑으로 인한 탐색 제한 문제를 해결하여 데이터 효율성과 훈련 속도를 향상시켰으며, MATH500, AIME 등 수학 벤치마크 테스트에서 뛰어난 성능을 보였다. (출처: ZhihuFrontier)
최초의 Data Agent 벤치마크 FDABench 출시 : 난양 기술 대학, 싱가포르 국립 대학 및 화웨이가 공동으로 FDABench를 오픈소스화했다. 이는 데이터 에이전트(Data Agents)의 이기종 혼합 데이터 분석을 위한 최초의 종합 벤치마크이다. 이 벤치마크는 2007개의 테스트 작업을 포함하며, 50개 이상의 데이터 영역과 다양한 난이도를 다룬다. 추론 데이터 소스에는 데이터베이스, PDF, 비디오, 오디오 등이 포함된다. FDABench는 Agent-Expert 협업 프레임워크를 독창적으로 개발하여 다양한 Data Agent 워크플로우 모드를 지원하며, 다중 소스 분석 작업에서 데이터 에이전트의 능력을 종합적으로 평가하는 것을 목표로 한다. (출처: 量子位)

LLM 독성 텍스트 생성 및 해독 모델 훈련의 교훈 : 한 연구는 LLM이 생성한 합성 독성 데이터를 사용하여 해독 모델을 훈련할 가능성을 탐구했다. 연구 결과, Llama 3 및 Qwen 모델이 생성한 합성 데이터로 훈련된 모델은 인간이 생성한 데이터로 훈련된 모델보다 성능이 항상 떨어지며, 종합 지표에서 성능이 최대 30% 감소했다. 주요 원인은 어휘 다양성 격차이다. LLM이 생성한 독성 콘텐츠는 적고 반복적인 모욕적인 단어를 사용하며, 인간의 독성 표현의 미묘한 차이와 다양성을 포착하지 못했다. (출처: HuggingFace Daily Papers)
강화 학습을 통한 LLM 솔루션 통합: AggLM 모델 : 한 연구는 AggLM 모델을 제안했다. 이는 강화 학습을 통해 복잡한 추론 작업에서 대규모 언어 모델(LLM)이 생성한 여러 솔루션을 통합한다. AggLM은 통합기 모델을 훈련시켜 검증 가능한 보상에 따라 최종 정답을 검토, 조정 및 합성한다. 이 방법은 쉽고 어려운 훈련 예제를 균형 있게 사용하여 모델이 소수이지만 정확한 답을 복구할 수 있도록 하며, 여러 벤치마크 테스트에서 규칙 기반 및 보상 모델 기반 방법보다 우수하다. (출처: HuggingFace Daily Papers)
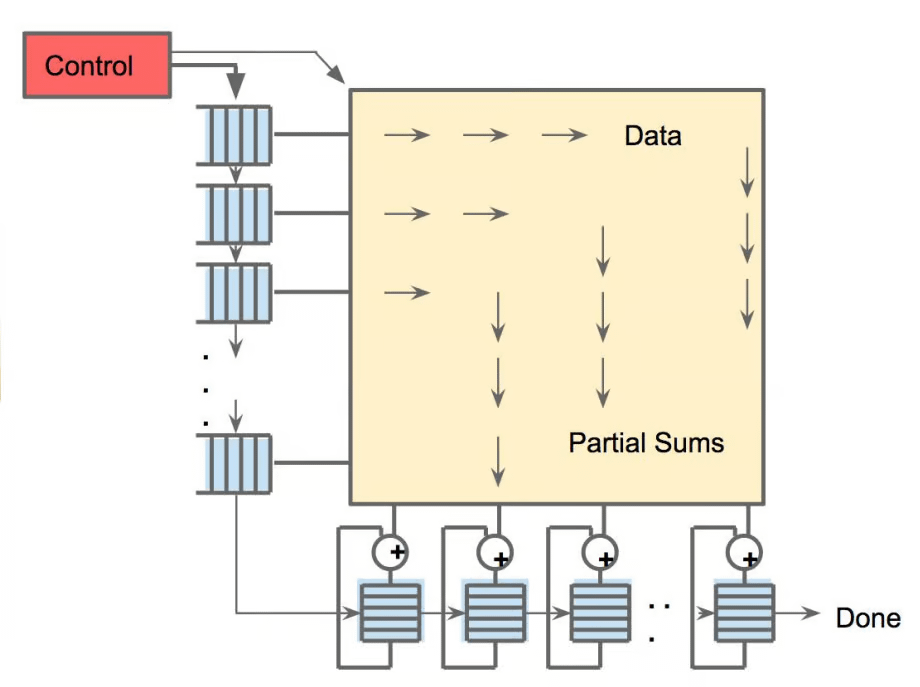
AI 하드웨어 구성 가이드 : 포괄적인 가이드가 AI를 구동하는 다양한 하드웨어 구성 요소를 자세히 소개한다. 여기에는 GPU(그래픽 처리 장치), TPU(텐서 처리 장치), CPU(중앙 처리 장치), ASIC(주문형 반도체), NPU(신경망 처리 장치), APU(가속 처리 장치), IPU(지능형 처리 장치), RPU(저항성 처리 장치), FPGA(필드 프로그래머블 게이트 어레이), 양자 프로세서, PIM(메모리 내 처리) 및 MRAM 기반 칩, 그리고 뉴로모픽 칩이 포함된다. (출처: TheTuringPost)
오픈 비디오 생성 모델 현황 강연 : 오픈 비디오 생성 모델 현황에 대한 가벼운 강연이 YouTube에 게시되었다. 이는 사람들이 이 주제를 빠르게 이해하도록 돕는 것을 목표로 한다. 강연 슬라이드는 연사의 개인 웹사이트에서 찾을 수 있으며, 관심 있는 학습자에게 편리한 입문 자료를 제공한다. (출처: RisingSayak)
대규모 추론 모델에서 강화 학습 적용에 대한 개요 : 100페이지가 넘는 개요 보고서가 대규모 추론 모델에서 강화 학습의 적용을 심층적으로 탐구한다. 보고서는 기본 구성 요소, 핵심 문제, 훈련 자원 및 실제 적용 등 여러 측면을 다루며, 연구원과 개발자에게 LLM 분야에서 RL의 최신 발전을 포괄적으로 이해할 수 있는 귀중한 자료를 제공한다. (출처: Dorialexander)

OpenAI, LLM 환각 연구: 보상 메커니즘이 핵심 : OpenAI는 논문 및 관련 논의를 통해 대규모 언어 모델(LLM)이 환각을 생성하는 주된 원인은 훈련 및 평가 메커니즘이 “추측”에 보상하고 “불확실성 인정”에는 보상하지 않기 때문이라고 지적했다. 연구는 통계학적 방법을 통해 시험과 유사한 인센티브 메커니즘을 활용하여 자신감 있고 정확한 답변에 보상함으로써 모델 환각을 줄이고 신뢰성을 높이는 것을 목표로 한다. (출처: YejinChoinka)

💼 비즈니스
AI 투자, 수익 실현 단계 진입: 기술 거대 기업과 수직 시장 플레이어의 수익 모델 부상 : 3년간의 막대한 투자 끝에 구글, Meta, 알리클라우드, 텐센트 등 미중 기술 거대 기업들은 AI 사업에서 규모화된 수익을 실현하기 시작하며 매출과 이익의 동반 성장을 견인하고 있다. 구글과 Meta의 2분기 순이익은 각각 19.4%와 36% 급증했으며, 알리클라우드 매출은 635억 위안을 넘어섰다. 동시에 Figma, C3.ai 등 AI 스타 기업들의 실적 “폭락”은 시장의 관심이 “투자”에서 “산출”로 전환되고 있음을 시사한다. 산업은 세 가지 주요 경로를 형성하고 있다: 기술 거대 기업은 “인프라 구축, 생태계 조성”에 중점을 두고, 수직 시장 플레이어는 “강력한 시나리오”에 집중하며, 전통 기업은 “제품 업그레이드, 비즈니스 모델 확장”을 추구한다. (출처: 36氪)
AI 로봇 스타트업 Medra, 1100만 달러 투자 유치 : 33세의 첫 창업 CEO Michelle Lee는 AI 로봇 스타트업 Medra를 공식적으로 출범했다. 이 회사는 시드 및 프리시드 라운드에서 1100만 달러를 유치했으며, 이미 첫 고객을 확보하고 실험실 프로세스 자동화에 전념하고 있다. 이는 AI 로봇 기술이 특정 산업 응용 분야에서 상업화되고 있음을 나타낸다. (출처: kchonyc)
AI21 Labs, 금융 기관의 워크플로우 자동화 지원 : AI21 Labs는 금융 기관이 복잡한 워크플로우를 자동화하도록 돕고 있다. 이는 비용 상승, 이윤 감소 및 규제 강화의 도전에 대응하기 위함이다. 그 솔루션에는 재무 기록을 구조화된 데이터로 변환하고, 규정 준수를 실시간으로 모니터링하며, M&A 실사 속도를 높이고, 거시적 추세 신호를 전략과 결합하는 것이 포함된다. 이는 금융 분야에서 AI가 효율성과 위험 관리 능력을 향상시키는 것을 보여준다. (출처: AI21Labs)
🌟 커뮤니티
LLM의 물리 세계 이해 한계, 뜨거운 논쟁 불러일으켜 : 리페이페이(李飞飞)가 1년 전 대규모 언어 모델(LLM)의 한계에 대해 제시한 견해가 다시 커뮤니티에서 뜨거운 논쟁을 불러일으켰다. 그녀는 언어가 순수하게 생성되는 신호인 반면, 물리 세계는 객관적으로 존재한다고 주장했다. LLM은 1차원 언어 신호 기반의 훈련으로 인해 3차원 물리 세계의 상식을 이해하는 데 본질적인 차이가 있다. Animal-AI, ABench-Physics와 같은 여러 실험은 LLM이 물리적 추론 및 시각적 인지 작업에서 인간 어린이 또는 특수 설계된 로봇에 훨씬 못 미치는 성능을 보임을 보여주며, 물리 세계 이해에 대한 한계를 검증했다. (출처: 量子位、dzhng、torchcompiled)

AI Agent 네트워크의 소셜 미디어 조작, 우려 증폭 : 소셜 미디어에서는 AI Agent 네트워크가 온라인 토론을 대규모로 조작하고 있다는 우려가 많이 제기되고 있다. 이 Agent들은 실제 사용자 행동을 모방하도록 프로그래밍되어 있으며, 블랙리스트를 피하기 위해 IP 주소와 하드웨어 주소를 위조할 수 있다. 이에 따라, 일부에서는 사용자들이 온라인에서 검증되지 않은 소셜 미디어 의견에 대해 “제로 트러스트” 모델을 채택할 것을 제안하며, 소셜 플랫폼이 조작될 수 있는 위험에 대응해야 한다고 강조한다. (출처: Reddit r/ArtificialInteligence、zacharynado)

AI가 노동력과 국가 부채에 미치는 영향 : 이노베이션 웍스 CEO 카이푸 리(李开复)는 AI Agent의 진화가 미국 노동 시장에 더욱 현저한 영향을 미칠 것이라고 예측했다. 동시에 일론 머스크는 AI와 로봇이 국가 부채 문제를 해결할 수 없다면, 인류는 곤경에 처할 것이라고 주장하며 AI가 경제 및 사회적 도전에서 핵심적인 역할을 수행함을 강조했다. (출처: kaifulee、brickroad7)
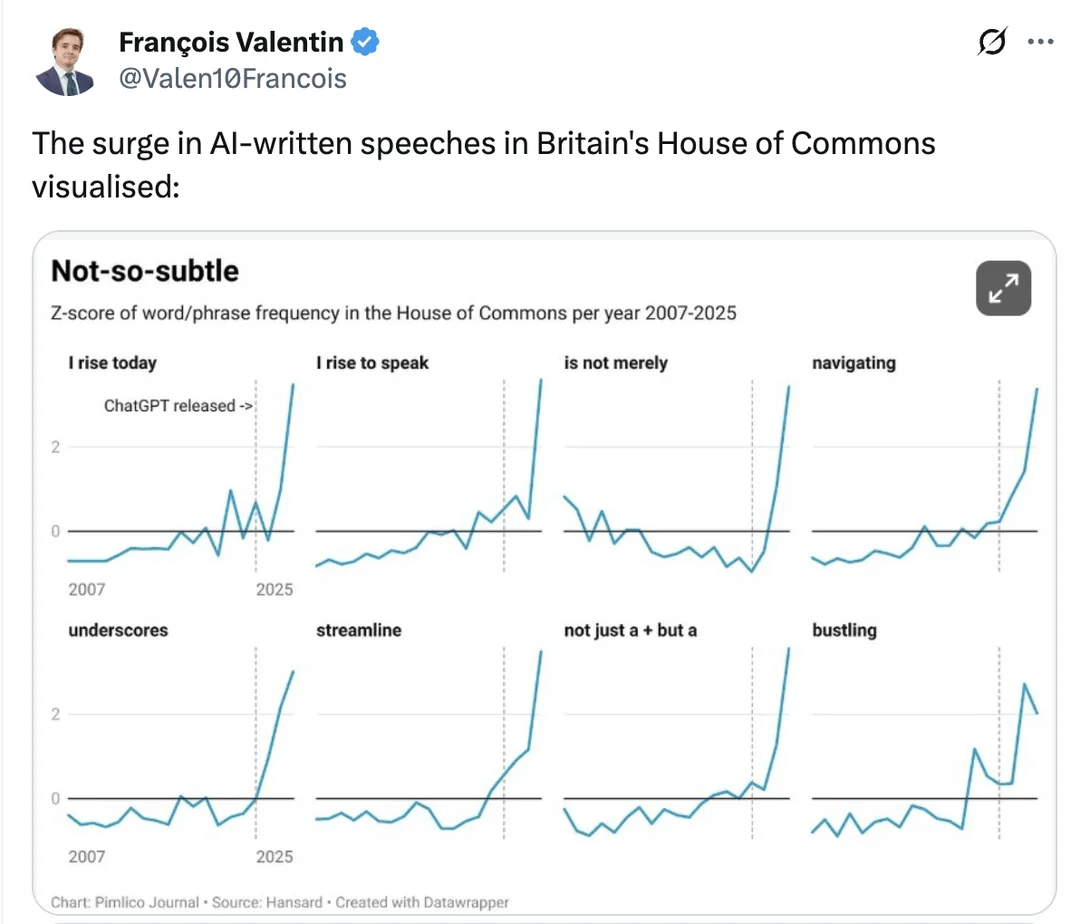
영국 정부 내 AI 적용, 관심 집중 : 소셜 미디어 논의에 따르면, AI가 영국 정부에 조용히 침투하고 있다. 의회 연설에서 단어 빈도 변화를 분석하여 특정 AI 관련 문구 사용량이 급증했음을 발견했다. 이는 공공 거버넌스에서 AI의 역할, 정책 수립 및 언어 표현에 미치는 영향에 대한 논의를 촉발했으며, AI 도구가 가져올 수 있는 “정형화” 위험에 대한 고찰도 불러일으켰다. (출처: Reddit r/artificial、Reddit r/ChatGPT)
ChatGPT, 의료 진단에서의 잠재적 역할 : 여러 사용자가 ChatGPT가 의료 건강 분야에서 보조 역할을 한 경험을 공유했다. 한 사용자는 ChatGPT가 질문을 통해 맹장염 증상을 정확히 식별하여 생명을 구했을 수 있다고 말했다. 다른 사용자는 자녀 입원 시 ChatGPT가 맹장염 외의 대체 진단 옵션을 제공하고 자신의 의료 상태를 정확하게 설명했다고 밝혔다. 이러한 사례들은 ChatGPT가 의료 전문가가 아님에도 불구하고, 그 깊은 의학 지식 기반이 보조 진단 및 건강 정보 제공에 실용적인 가치를 지님을 보여준다. (출처: Reddit r/ChatGPT)
GPT-OSS 20B, 엔지니어링 작업에서 GPT-5 무료 버전보다 우수 : Reddit 사용자들은 OpenAI의 오픈소스 모델 GPT-OSS 20B가 엔지니어링 작업을 처리할 때 GPT-5의 무료 계층(아마도 GPT-5-thinking-mini)보다 항상 우수한 성능을 보였다고 보고했다. 사용자들은 이는 오픈소스 모델이 컴퓨팅 자원에서 더 큰 자유도와 더 나은 최적화를 누리기 때문일 수 있다고 생각한다. GPT-OSS는 문제를 해결할 때 더 오래 생각하며, 평균적으로 문제당 20-30k tokens를 소비하는데, 이는 더 높은 정확도로 이어질 수 있다. (출처: Reddit r/LocalLLaMA)
AI Agent, 소프트웨어 개발의 ‘완전 자율 주행’ 순간 : 소셜 미디어에서는 AI Agent가 소프트웨어 개발 분야에서 이룬 돌파구가 뜨겁게 논의되고 있으며, “완전 자율 주행” 순간으로 묘사된다. Replit의 Agent 3는 완전한 애플리케이션을 자율적으로 테스트, 디버깅 및 리팩토링할 수 있어 효율성을 크게 향상시킨다. 그러나 일부 개발자들은 여러 코딩 Agent를 동시에 관리하면 “혼란스러운 코딩”이 발생할 수 있다고 지적하며, 즉 Agent들이 서로의 작업을 덮어쓰게 되어 더 효율적인 조직 관리 방식이 필요하다고 말한다. (출처: amasad、HamelHusain)
NVIDIA의 AI 해자(垓子)와 미래 하드웨어 경쟁 : 커뮤니티에서는 NVIDIA가 AI 하드웨어 분야에서 독점적인 지위를 가지고 있으며, 그 해자(垓子)의 견고성에 대해 논의했다. 일부 견해는 미래 AI 하드웨어가 현재 NVIDIA 하드웨어와 완전히 다를 수 있으며, 비용/에너지 효율성에 더 중점을 두어 NVIDIA의 강점을 약화시킬 수 있다고 본다. 그러나 다른 이들은 NVIDIA가 4.3조 달러 규모의 거대 기업으로서 혁신과 실행력에서 뛰어난 성과를 보이고 있어, 단기간에 그 지위를 흔들기 어렵다고 지적했다. (출처: teortaxesTex、TheTuringPost)
AI Agent의 한계와 상상력 부족 : AI Agent에 대한 논의는 많은 AI 노력이 충분한 상상력을 결여하고 있으며, 진정한 AI Agent는 개방형 세계 환상이 아닌 경계가 있는 문제를 해결해야 한다고 지적한다. 일부 평론은 Copilot과 같은 “무료하지만 쓸모없는” 솔루션과 비교하며, 맞춤형 Agent가 워크플로우를 더 정확하게 자동화하고 구체적인 가치를 제공할 수 있다고 강조한다. 이는 AI의 실용성과 심층적인 응용에 대한 기대를 반영하며, 막연한 홍보가 아님을 보여준다. (출처: Ronald_vanLoon、RichardSocher)

AI 이미지 생성, ‘손가락’ 디테일에서 진보 : 오랫동안 AI 이미지 생성 모델은 인간의 손과 손가락 디테일을 처리하는 데 어려움을 겪었다. 그러나 최신 발전은 AI 모델이 이제 사실적인 손가락을 정확하게 렌더링할 수 있게 되어, 이러한 일반적인 한계를 극복했음을 보여준다. 이러한 진보는 AI 이미지 생성 기술이 디테일 표현력에서 새로운 수준에 도달했음을 의미한다. (출처: fabianstelzer)

💡 기타
AI와 양자 컴퓨팅의 교차점 도전과 기회 : 논의는 인공지능과 양자 컴퓨팅이라는 두 가지 첨단 기술 분야 사이에 중첩되는 도전과 기회가 존재한다고 지적한다. 두 기술의 발전과 함께, 두 기술의 장점을 효과적으로 통합하고 각자가 직면한 복잡한 문제를 해결하는 방법이 미래 기술 발전의 중요한 방향이 될 것이다. (출처: Ronald_vanLoon)

AI, 창의 분야 재편: 음악, 글쓰기, 예술 : 논의는 인공지능이 음악, 글쓰기, 예술 등 창의 분야를 어떻게 재편하고 있는지 탐구한다. 알고리즘 시대에 AI는 창작 효율성을 높이는 보조 도구일 뿐만 아니라, 공동 창작자로서 예술 표현의 경계를 확장하며 창의 산업에 새로운 가능성과 도전을 가져온다. (출처: Ronald_vanLoon)

인간형 지능 로봇, 호텔 및 요양 산업 서비스 제공 : 보도에 따르면, 인간형 로봇 제조업체들은 15개 언어 능력을 갖춘 서비스 로봇을 개발하고 있다. 이는 호텔 및 요양 산업의 수요를 충족시키기 위함이다. 이 다국어 로봇들은 고객 서비스, 일상 지원 및 동반자 역할에서 활약할 것으로 기대되며, 서비스 품질을 향상시키고 노동력 부족 문제를 완화할 것이다. (출처: Ronald_vanLoon)
