
Ключевые слова:OpenAI Codex, Разработка ПО с ИИ, Мультимодальные модели ИИ, Генерация голоса ИИ, Фильтрация данных, Исследовательская версия Codex, MiniMax Speech-02, Мультимодальная модель BLIP3-o, Система фильтрации PreSelect, Серия моделей SWE-1
🔥 聚焦
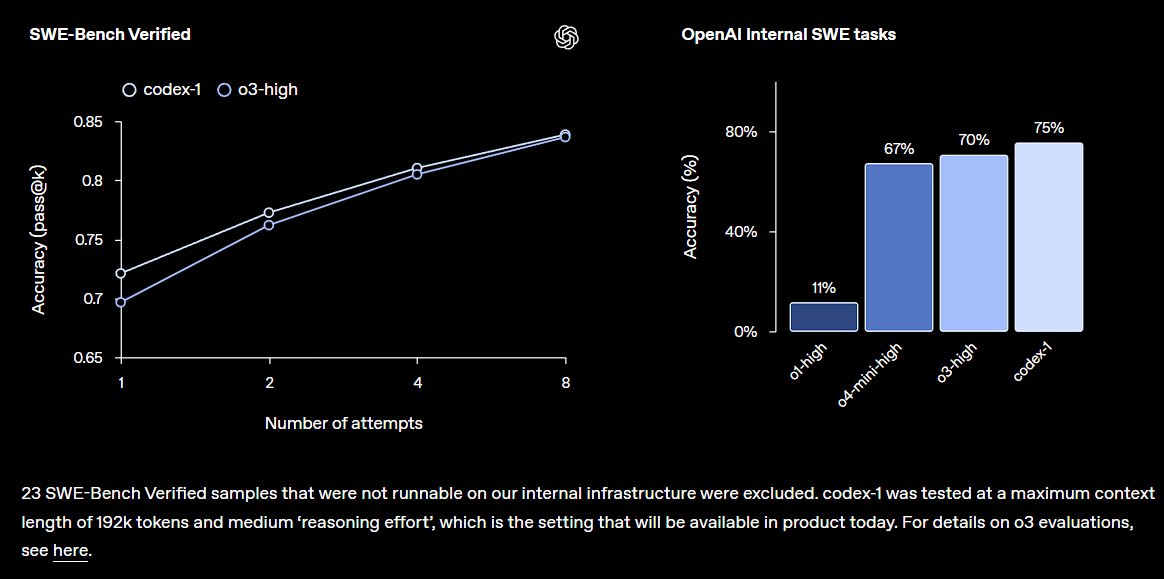
OpenAI выпустила предварительную исследовательскую версию Codex, интегрированную в ChatGPT: OpenAI представила Codex, облачный интеллектуальный агент для разработки программного обеспечения, способный понимать большие кодовые базы, писать новые функции, исправлять ошибки и обрабатывать несколько задач параллельно. Codex основан на модели codex-1, дообученной на o3, и показал отличные результаты на SWE-bench. Эта функция будет постепенно доступна пользователям ChatGPT Pro, Team и Enterprise и призвана значительно повысить производительность разработчиков, предвещая более центральную роль AI в разработке программного обеспечения. Сообщество отреагировало положительно, но также обеспокоено его практической эффективностью и потенциальными ошибками (источник: OpenAI, OpenAI Developers, scaling01, dotey)
Массовые увольнения в Microsoft вызвали потрясение в отрасли, организационные изменения, вызванные AI, ускоряются: Microsoft объявила о сокращении около 6000 сотрудников по всему миру с целью упрощения уровней управления и увеличения доли программистов. Среди уволенных есть ветераны с 25-летним стажем и значительным вкладом, а также ключевые разработчики TypeScript. Считается, что эти увольнения связаны с повышением эффективности за счет технологий AI и автоматизацией некоторых рабочих задач, что отражает тенденцию технологических гигантов к контролю затрат и оптимизации кадровой структуры в эпоху AI. Это событие вызвало широкие дискуссии о влиянии AI на рынок труда, лояльности компаний и будущих моделях работы (источник: WeChat, NeelNanda5)
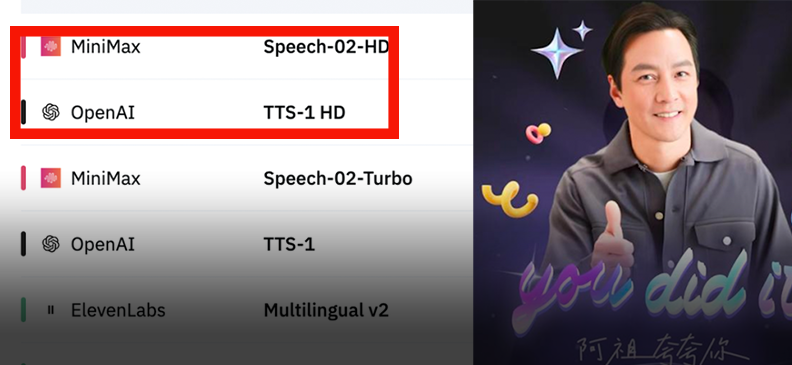
MiniMax выпустила модель синтеза речи Speech-02, возглавившую мировые рейтинги: MiniMax представила модель синтеза речи нового поколения Speech-02, которая заняла первое место в двух авторитетных рейтингах оценки речи — Artificial Analysis Speech Arena и Hugging Face TTS Arena, превзойдя OpenAI и ElevenLabs. Модель отличается сверхреалистичностью, персонализированной настройкой тембра голоса (поддерживает 32 языка и акцента, копирование за несколько секунд по образцу) и разнообразием, а также инновационно использует технологию Flow-VAE для улучшения детализации клонирования. Ее технология уже применяется в таких сценариях, как «AI Азу учит английский» и AI-гид по Запретному городу, демонстрируя лидирующие позиции отечественных больших моделей в области генерации речи с помощью AI (источник: WeChat, WeChat)
Salesforce и другие учреждения выпустили унифицированную мультимодальную модель BLIP3-o: Salesforce Research совместно с несколькими университетами выпустили полностью открытую унифицированную мультимодальную модель BLIP3-o, использующую стратегию «сначала понимание, затем генерация» и сочетающую авторегрессионную и диффузионную архитектуры. Модель инновационно использует признаки CLIP и Flow Matching для обучения, значительно улучшая качество, разнообразие и соответствие подсказкам генерируемых изображений. BLIP3-o показала отличные результаты в нескольких бенчмарках и расширяется на сложные мультимодальные задачи, такие как редактирование изображений и визуальный диалог, способствуя развитию мультимодальных технологий AI (источник: 36氪)

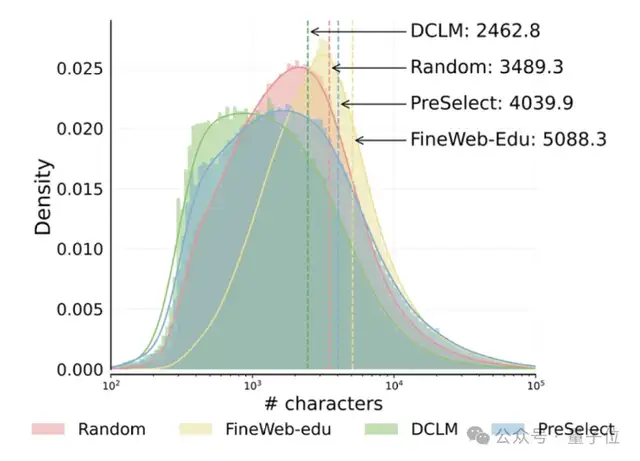
Гонконгский университет науки и технологий и vivo предложили схему отбора данных PreSelect, повышающую эффективность предварительного обучения в 10 раз: Гонконгский университет науки и технологий (HKUST) в сотрудничестве с vivo AI Lab предложили легковесный и эффективный метод отбора данных PreSelect, который был принят на ICML 2025. Этот метод количественно оценивает вклад данных в конкретные возможности модели с помощью показателя «интенсивности прогнозирования» и использует классификатор fastText для отбора полного набора обучающих данных, позволяя улучшить результаты модели в среднем на 3% при одновременном снижении вычислительных потребностей в 10 раз. PreSelect нацелен на более объективный и обобщенный отбор высококачественных и разнообразных данных, преодолевая ограничения традиционных методов отбора на основе правил или моделей (источник: 量子位)
🎯 Движение
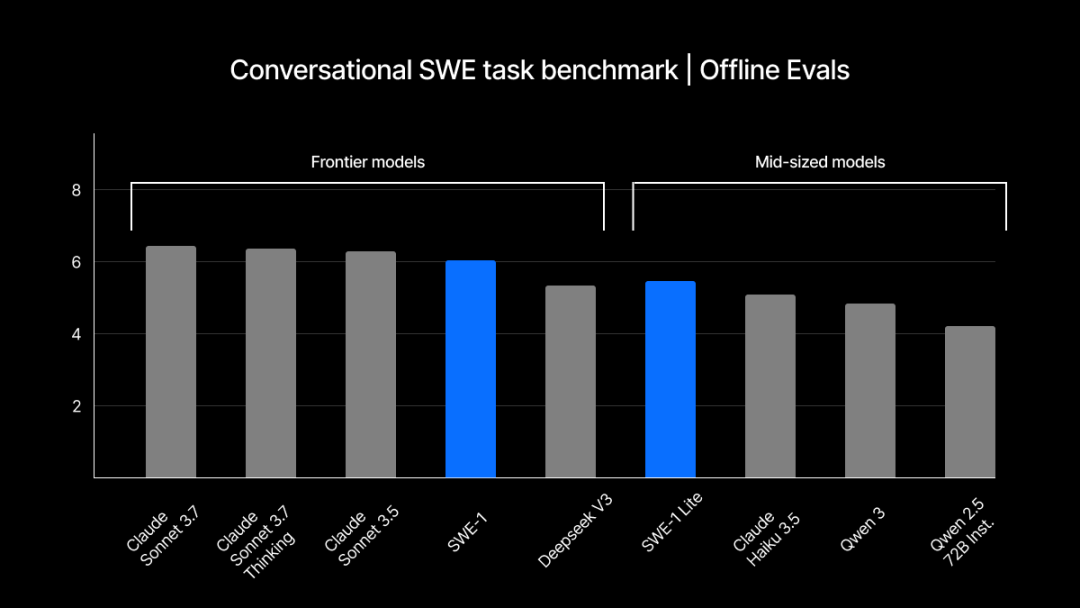
Windsurf выпустила собственную серию моделей SWE-1 для оптимизации процессов разработки программного обеспечения: Windsurf представила первую серию моделей SWE-1, специально оптимизированных для разработки программного обеспечения, с целью повышения эффективности разработки на 99%. Серия включает SWE-1 (возможности вызова инструментов близки к Claude 3.5 Sonnet, но с меньшими затратами), SWE-1-lite (высокое качество, замена Cascade Base) и SWE-1-mini (маленькая и быстрая, для сценариев с низкой задержкой). Ключевой инновацией является система «Flow Awareness» (осведомленность о потоке), то есть AI и пользователь совместно используют временную шкалу операций, обеспечивая эффективное сотрудничество и понимание незавершенных состояний (источник: WeChat, WeChat)
Механизм памяти ChatGPT подвергся обратному инжинирингу, раскрыты три подсистемы памяти: Функция памяти «истории чатов», представленная OpenAI для ChatGPT, была проанализирована энтузиастами технологий, которые выявили, что она может включать три подсистемы: текущую историю диалога, историю диалогов (на основе резюме и поиска контента) и пользовательские инсайты (генерируемые на основе анализа нескольких диалогов, с уровнем достоверности). Эти механизмы предназначены для обеспечения более персонализированного и эффективного взаимодействия с использованием таких технологий, как RAG и векторные пространства. Хотя официальные лица утверждают, что это улучшает пользовательский опыт, отзывы сообщества неоднозначны, некоторые пользователи сообщают о нестабильной работе функции или наличии ошибок (источник: WeChat, 量子位)
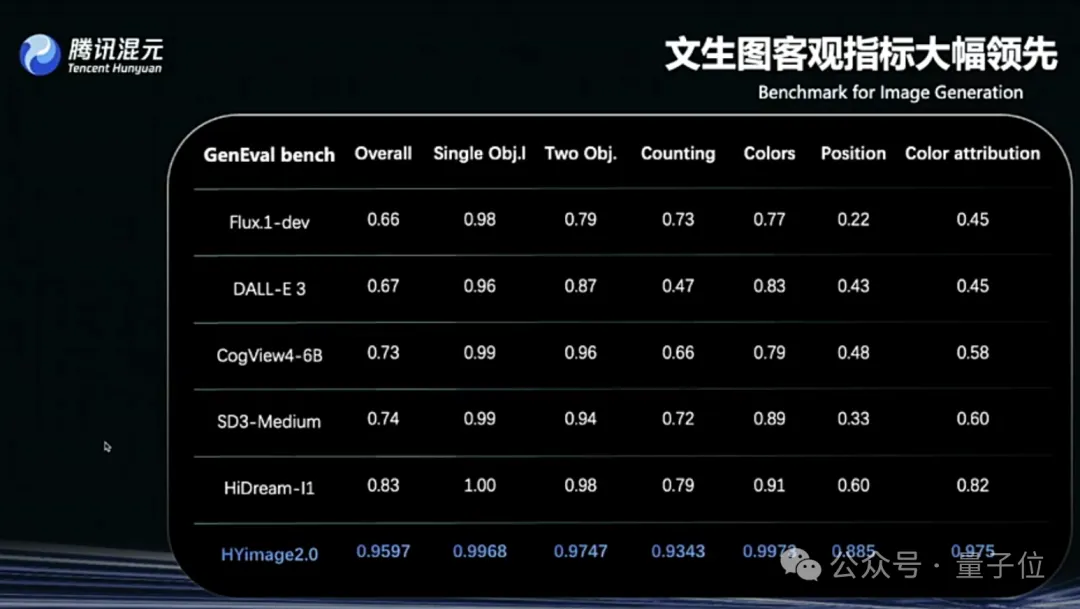
Tencent Hunyuan Image 2.0 выпущен, поддерживает функцию «рисуй, пока говоришь» в реальном времени: Tencent Hunyuan представила модель Hunyuan Image 2.0, которая реализует функцию генерации изображений из текста в реальном времени с откликом на уровне миллисекунд. Когда пользователь вводит текст или голосовое описание, изображение генерируется и корректируется в реальном времени. Новая модель также поддерживает доску для рисования в реальном времени, где пользователи могут создавать изображения, рисуя эскизы вручную и добавляя текстовые описания. Модель значительно улучшена в плане реалистичности, семантического соответствия (адаптирована для использования мультимодальных больших языковых моделей в качестве текстовых кодировщиков) и коэффициента сжатия кодеков изображений, а также оптимизирована с помощью обучения с подкреплением (источник: 量子位)
TII выпустила серию моделей BitNet Falcon-Edge и библиотеку для дообучения onebitllms: TII представила Falcon-Edge, серию компактных языковых моделей с 1B и 3B параметрами, размером всего 600 МБ и 900 МБ соответственно. Эти модели используют архитектуру BitNet и могут быть восстановлены до bfloat16 практически без потери производительности. Предварительные результаты показывают, что их производительность превосходит другие небольшие модели и сравнима с Qwen3-1.7B, но занимают в 4 раза меньше памяти. Одновременно выпущена библиотека onebitllms, специально предназначенная для дообучения моделей BitNet (источник: Reddit r/LocalLLaMA, winglian)

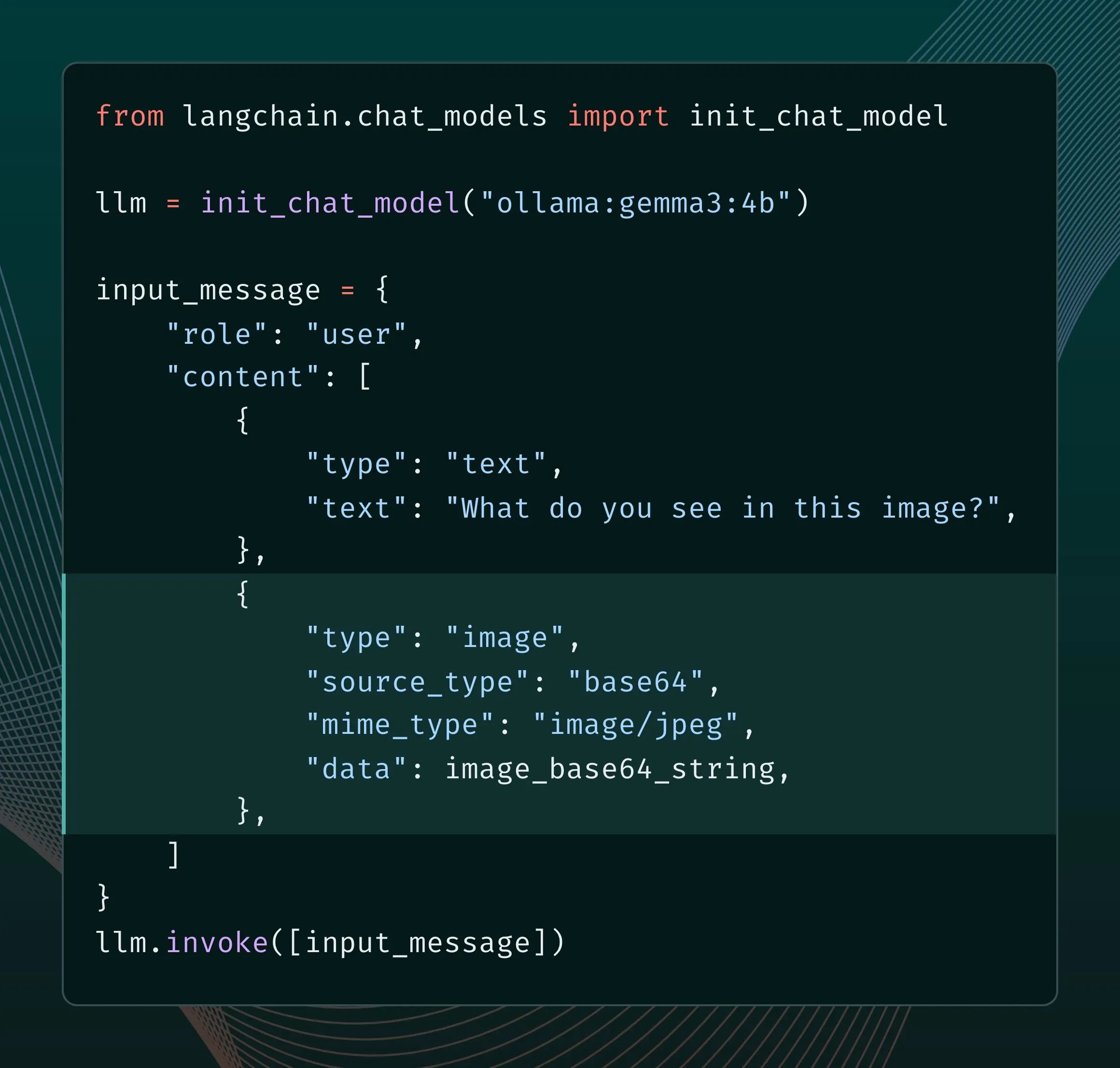
Новый движок Ollama улучшает поддержку мультимодальности: Ollama обновила свой движок, обеспечив нативную поддержку мультимодальных моделей, что позволяет проводить специфические для моделей оптимизации и улучшать управление памятью. Пользователи могут попробовать мультимодальные модели, такие как Llama 4, Gemma 3, через интеграцию с LangChain. Разработчики Google AI также опубликовали руководство по использованию Ollama и Gemma 3 для вызова функций, чтобы реализовать такие возможности, как поиск в реальном времени (источник: LangChainAI, ollama)
Grok добавил функцию контроля соотношения сторон при генерации изображений: Модель Grok от xAI теперь позволяет пользователям указывать желаемое соотношение сторон при генерации изображений, предоставляя большую гибкость и контроль над созданием изображений (источник: grok)
Обновления Google AI Studio: новая страница генерации медиа и панель использования: Платформа ai.studio от Google получила ряд обновлений, включая новый дизайн целевой страницы, встроенную панель мониторинга использования и новую страницу генерации медиа (gen media), что предвещает возможные новые анонсы на предстоящей конференции I/O (источник: matvelloso)
LatitudeGames выпустила новую модель Harbinger-24B (New Wayfarer): LatitudeGames опубликовала на Hugging Face новую модель под названием Harbinger-24B, кодовое имя New Wayfarer. Сообщество проявило интерес и обсуждает, почему не были выбраны для дообучения другие модели, такие как Qwen3 32B или Llama 4 Scout (источник: Reddit r/LocalLLaMA)

🧰 Инструменты
Adopt AI привлек $6 млн финансирования для реорганизации взаимодействия с ПО с помощью AI Agent: Стартап Adopt AI привлек $6 млн в рамках посевного раунда финансирования. Компания стремится с помощью двух основных функций, Agent Builder и Agent Experience, предоставить традиционному корпоративному программному обеспечению возможность быстрой интеграции взаимодействия на естественном языке без написания кода. Ее технология способна автоматически изучать структуру приложений и API, генерируя операции, которые можно вызывать на естественном языке, и обеспечивая безопасность данных за счет архитектуры Pass-through. Цель — повысить уровень внедрения и эффективность программного обеспечения, а также снизить затраты предприятий (источник: WeChat)

Volcano Engine от ByteDance представил демо-версию мини-аппаратного AI-устройства с высокой степенью кастомизации: Volcano Engine выпустил демо-версию мини-аппаратного AI-устройства и открыл исходный код его клиентской/серверной части. Устройство поддерживает высокую степень кастомизации и может подключаться к большим моделям Volcano, интеллектуальным агентам Coze, а также к сторонним большим моделям, совместимым с OpenAI API (например, FastGPT), и различным TTS-голосам (включая MiniMax). Пользователи могут самостоятельно реализовывать диалоги с определенными персонажами (например, молодым Джеем Чоу, Хэ Цзюном) или создавать AI-голосовых помощников для обслуживания клиентов, что обеспечивает богатый опыт взаимодействия с AI (источник: WeChat)

Runway выпустила Gen-4 References API, предоставляя разработчикам возможность создавать приложения для генерации изображений: Runway открыла доступ разработчикам к своей популярной модели генерации изображений Gen-4 References через API. Эта модель известна своей универсальностью и гибкостью, способностью генерировать новые, стилистически согласованные изображения на основе эталонных изображений. Выпуск API позволит разработчикам интегрировать эту мощную возможность генерации изображений в свои приложения и рабочие процессы (источник: c_valenzuelab)

Zencoder представила платформу интеллектуальных агентов AI для оптимизации кодирования Zen Agents: AI-стартап Zencoder (официальное название For Good AI Inc.) выпустил облачную платформу под названием Zen Agents. Платформа предназначена для создания AI-агентов, оптимизированных для задач кодирования, с целью повышения эффективности и качества разработки программного обеспечения (источник: dl_weekly)
llmbasedos: минималистичный дистрибутив Linux на базе MCP, специально оптимизированный для локальных LLM: Разработчик создал llmbasedos, минималистичный дистрибутив на базе Arch Linux, предназначенный для превращения локальной среды в первоклассного гражданина для LLM-фронтендов (таких как Claude Desktop, VS Code). Он предоставляет локальные возможности (файлы, почта, прокси и т.д.) через протокол MCP (Model Context Protocol), поддерживает автономный режим (включая llama.cpp) или подключение к облачным моделям, таким как GPT-4o, Claude, что позволяет разработчикам быстро добавлять новые функции (источник: Reddit r/LocalLLaMA)
Возможность запуска LLM и ОС Linux в PDF-файлах привлекает внимание: Энтузиаст технологий Айден Бай продемонстрировал проект «llm.pdf», позволяющий запускать небольшие языковые модели (такие как TinyStories, Pythia, TinyLLM) в PDF-файлах путем компиляции моделей в JavaScript и использования поддержки JS в PDF. В комментариях также отметили, что ранее уже существовал прецедент запуска ОС Linux в PDF (через эмулятор RISC-V). Это раскрывает потенциал PDF как контейнера для динамического контента, но также вызывает дискуссии о безопасности и практичности (источник: WeChat)

Обновление инструмента OpenAI Codex CLI: поддержка входа через ChatGPT и новая модель mini: Команда разработчиков OpenAI объявила об улучшениях в инструменте Codex CLI, включая поддержку входа через учетную запись ChatGPT для быстрого подключения к API-организациям, а также добавление новой модели codex-mini, оптимизированной для задач вопросно-ответной системы по коду и редактирования с низкой задержкой (источник: openai, dotey)
Интегрированная машина для больших моделей от SenseTime получила рекомендацию IDC, поддерживает модели Rì Rì Xīn, DeepSeek и другие: В отчете IDC «Анализ рынка интегрированных машин для больших AI-моделей в Китае и рекомендации брендов, 2025» была отмечена интегрированная машина для больших моделей от SenseTime. Эта машина основана на AI-инфраструктуре SenseTime Large Model Device, оснащена высокопроизводительными вычислительными чипами и движком ускорения логического вывода, поддерживает «Rì Rì Xīn SenseNova V6» от SenseTime и основные большие модели, такие как DeepSeek, предоставляя полностью автономное и контролируемое решение, оптимизирующее общую стоимость владения (TCO), и уже внедрена в таких отраслях, как медицина и финансы (источник: 量子位)

Инструмент автоматизации рабочих процессов с открытым исходным кодом n8n добавил поддержку китайского языка: Популярный инструмент автоматизации рабочих процессов с открытым исходным кодом n8n теперь поддерживает китайский интерфейс благодаря вкладу сообщества в виде пакета локализации. Пользователи могут загрузить файл локализации для соответствующей версии и, внеся простые изменения в конфигурацию Docker, использовать n8n на китайском языке, что снижает порог входа для китайских пользователей (источник: WeChat)

git-bug: распределенный офлайн-трекер ошибок, встроенный в Git: git-bug — это инструмент с открытым исходным кодом, который встраивает задачи, комментарии и т. д. в виде объектов в репозиторий Git (а не обычных файлов), реализуя распределенный, офлайн-ориентированный трекинг ошибок. Он поддерживает синхронизацию задач с платформами, такими как GitHub, GitLab, через мосты и предоставляет интерфейсы CLI, TUI и веб-интерфейс (источник: GitHub Trending)
PyLate интегрировал индекс PLAID для повышения эффективности бенчмаркинга моделей на больших наборах данных: Антуан Шаффен объявил, что PyLate (экосистема для обучения и инференса моделей ColBERT) объединила индекс PLAID. Эта интеграция позволяет пользователям эффективно проводить бенчмаркинг лучших моделей на своих очень больших наборах данных, обеспечивая удобство для достижения SOTA в различных рейтингах поиска (источник: lateinteraction, tonywu_71)

Neon: бессерверная база данных PostgreSQL с открытым исходным кодом: Neon — это альтернатива PostgreSQL с открытым исходным кодом и бессерверной архитектурой, которая разделяет хранение и вычисления для автоматического масштабирования, ветвления баз данных в стиле кода и масштабирования до нуля. Проект привлек внимание на GitHub, предлагая новый выбор разработчикам AI и других приложений, нуждающихся в эластичных, масштабируемых решениях для баз данных (источник: GitHub Trending)

Unmute.sh: новый инструмент для AI-голосового чата с настраиваемыми подсказками и голосами: Unmute.sh — это недавно запущенный инструмент для AI-голосового чата, особенностью которого является возможность для пользователей настраивать подсказки (prompt) и выбирать различные голоса, предоставляя пользователям более персонализированный и гибкий опыт голосового взаимодействия (источник: Reddit r/artificial)
📚 Обучение
Опубликованы первая в мире система оценки мультимодальных моделей-универсалов General-Level и бенчмарк General-Bench: Исследование, принятое на ICML‘25 (Spotlight), представляет новую систему оценки мультимодальных больших моделей (MLLM) General-Level и сопутствующий набор данных General-Bench. Система вводит пятиуровневую систему рангов, основной акцент которой делается на «эффекте синергетической генерализации» (Synergy) модели, то есть способности к переносу и улучшению знаний между различными модальностями или задачами. General-Bench является на данный момент крупнейшим и наиболее полным бенчмарком для оценки MLLM, включающим более 700 задач, более 320 000 тестовых данных, охватывающих пять основных модальностей (изображение, видео, аудио, 3D и язык) и 29 областей. Рейтинг показывает, что модели, такие как GPT-4V, в настоящее время достигают только Уровня-2 (без синергии), и ни одна модель еще не достигла Уровня-5 (полная синергия всех модальностей) (источник: WeChat)

Статья J1 предлагает стимулировать мышление в LLM-as-a-Judge с помощью обучения с подкреплением: Новая статья под названием “J1: Incentivizing Thinking in LLM-as-a-Judge via RL” (arxiv:2505.10320) исследует, как использовать обучение с подкреплением (RL) для стимулирования больших языковых моделей, выступающих в роли оценщиков (LLM-as-a-Judge), к более глубокому «мышлению», а не просто к вынесению поверхностных суждений. Этот подход может повысить точность и надежность LLM при оценке сложных задач (источник: jaseweston)

Новая структура TREQA использует LLM для оценки качества перевода сложных текстов: В связи с недостатками существующих метрик машинного перевода (MT) при оценке сложных текстов, исследователи предложили структуру TREQA. Эта структура использует большие языковые модели (LLM) для генерации вопросов по исходному тексту и переведенному тексту, а затем сравнивает ответы на эти вопросы, чтобы оценить, сохранена ли ключевая информация в переводе. Этот метод направлен на более всестороннюю оценку качества перевода длинных текстов (источник: gneubig)

Исследование обнаружило эффективный метод вычисления произведения матрицы на ее транспонированную: Дмитрий Рыбин и др. обнаружили более быстрый алгоритм для вычисления произведения матрицы на ее транспонированную (arxiv:2505.09814). Этот фундаментальный прорыв имеет далеко идущие последствия для многих областей, таких как анализ данных, проектирование микросхем, беспроводная связь и обучение LLM, поскольку такие вычисления являются распространенными операциями в этих областях. Это еще раз доказывает, что даже в зрелой области вычислительной линейной алгебры все еще есть место для улучшений (источник: teortaxesTex, Ar_Douillard)

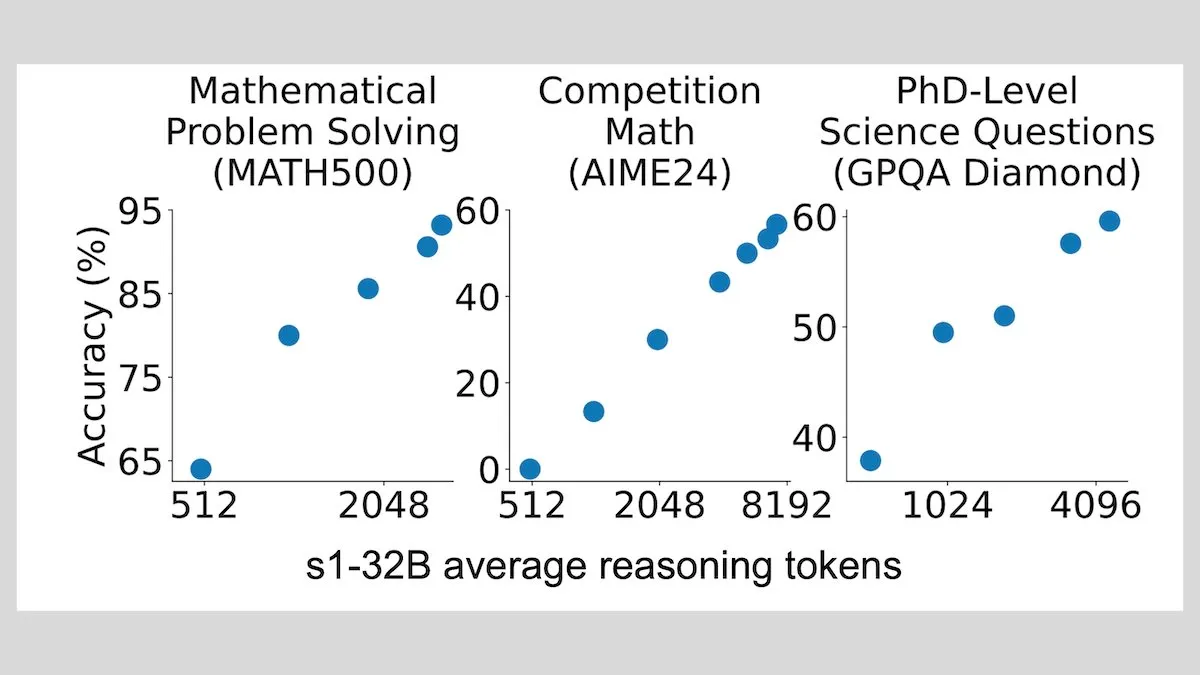
DeepLearningAI: дообучение на небольшом количестве примеров может значительно улучшить способности LLM к рассуждению: Исследования показывают, что дообучение большой языковой модели всего на 1000 примерах может значительно улучшить ее способности к рассуждению. Экспериментальная модель s1 расширяет процесс рассуждения, добавляя слово «Wait» во время рассуждения, и достигла хороших результатов в бенчмарках, таких как AIME и MATH 500. Этот низкоресурсный метод показывает, что можно обучить продвинутому рассуждению с небольшим количеством данных без необходимости обучения с подкреплением (источник: DeepLearningAI)
Hugging Face запускает бесплатный курс по MCP для создания AI-приложений с богатым контекстом: Hugging Face в сотрудничестве с Anthropic запустила бесплатный курс под названием «MCP: Build Rich-Context AI Apps with Anthropic». Курс призван помочь разработчикам понять архитектуру MCP (Model Context Protocol), научиться создавать и развертывать MCP-серверы и совместимые приложения, тем самым упрощая интеграцию AI-приложений с инструментами и источниками данных. На данный момент зарегистрировалось более 3000 студентов (источник: DeepLearningAI, huggingface, ClementDelangue)
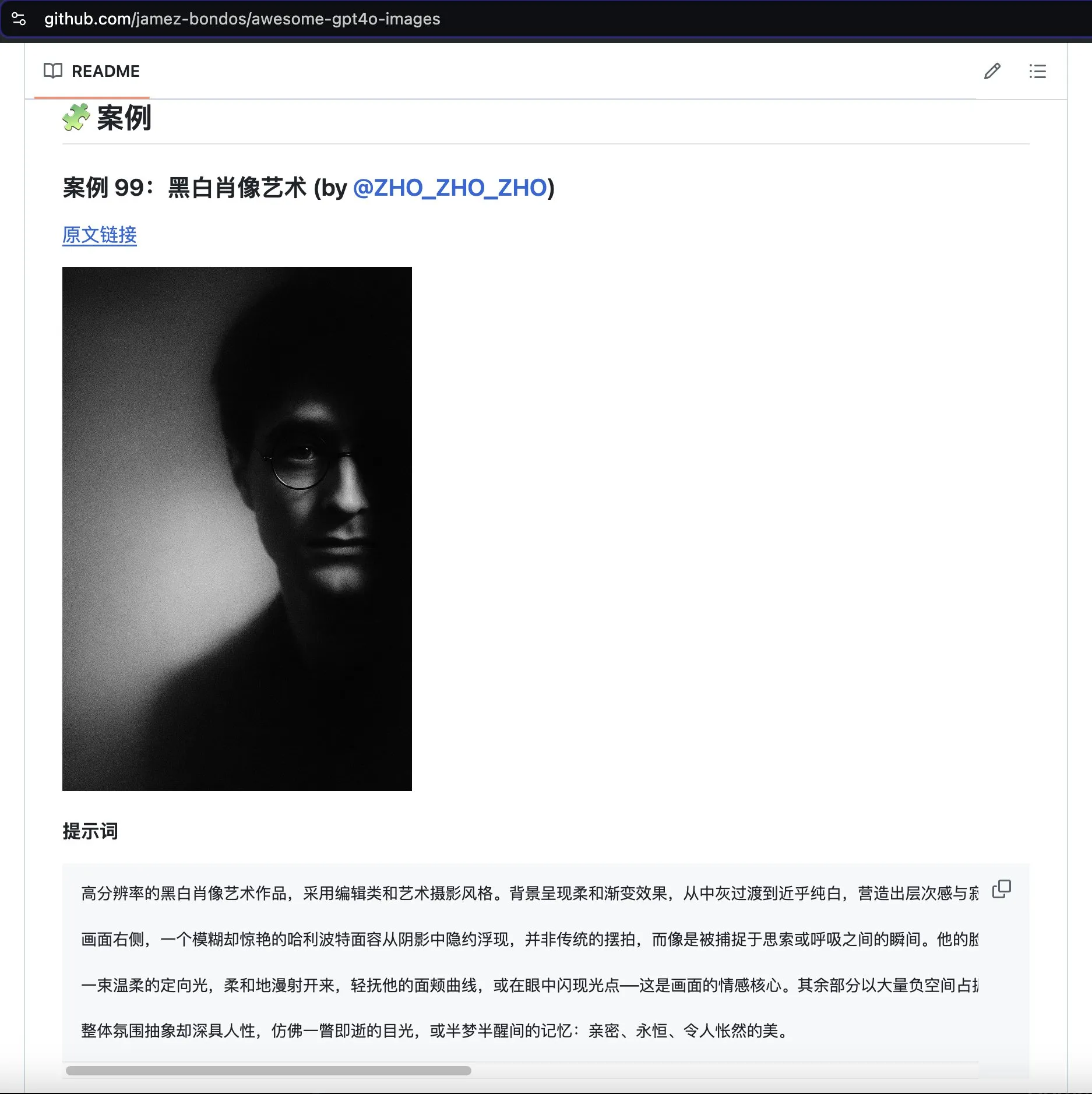
Проект awesome-gpt4o-images собирает яркие примеры генерации изображений с помощью GPT-4o: Проект Jamez Bondos на GitHub awesome-gpt4o-images за 33 дня набрал более 5700 звезд. Проект собирает и демонстрирует отличные примеры изображений, сгенерированных с помощью GPT-4o, а также соответствующие подсказки. В настоящее время насчитывается около ста примеров, и планируется постоянное обновление после сортировки и проверки, предоставляя ценный творческий ресурс для сообщества AIGC (источник: dotey)
Yann LeCun поделился презентацией о самообучении (SSL): Yann LeCun поделился содержанием своей презентации о самообучении (Self-Supervised Learning, SSL). SSL, как важная парадигма машинного обучения, направлена на то, чтобы модели учились эффективным представлениям из неразмеченных данных, что имеет большое значение для снижения зависимости от крупномасштабных размеченных данных и повышения способности моделей к обобщению (источник: ylecun)
Форум статей Hugging Face становится качественным ресурсом для отбора AI-статей: Дваркеш Патель рекомендует форум статей Hugging Face, считая его отличным ресурсом для отбора лучших AI-статей за последний месяц. Эта платформа предоставляет исследователям удобный канал для обнаружения и обсуждения последних достижений в области AI-исследований (источник: dwarkesh_sp, huggingface)
Объявлены результаты приема на ACL 2025, несколько статей команды Alibaba International AIB приняты: Объявлены результаты приема на ведущую конференцию по обработке естественного языка ACL 2025. В этом году количество поданных заявок достигло исторического максимума, конкуренция была жесткой. Несколько статей команды Alibaba International AI Business были приняты, некоторые результаты, такие как Marco-o1 V2, Marco-Bench-IF и HD-NDEs (нейронные дифференциальные уравнения для обнаружения галлюцинаций), получили высокую оценку и были приняты в основную программу конференции. Это отражает постоянные инвестиции Alibaba International в область AI и первые успехи в подготовке кадров (источник: 量子位)

dstack опубликовал руководство по быстрой настройке межсоединений для распределенного обучения: dstack предоставил краткое руководство для пользователей, проводящих распределенное обучение на кластерах NVIDIA или AMD, о том, как настроить быстрые межсоединения с помощью dstack. Руководство призвано помочь пользователям оптимизировать производительность сети при масштабировании рабочих нагрузок AI в облаке или локально (источник: algo_diver)
AssemblyAI поделилась 10 видео-советами по улучшению подсказок для LLM: AssemblyAI через YouTube-видео поделилась 10 советами по улучшению эффективности подсказок (prompting) для больших языковых моделей (LLM), чтобы помочь пользователям более эффективно взаимодействовать с LLM для получения желаемых результатов (источник: AssemblyAI)
Коллекция учебных ресурсов по LangGraph.js «awesome-langgraphjs» привлекает внимание: Брейс создал и поддерживает репозиторий на GitHub под названием «awesome-langgraphjs», в котором собраны проекты с открытым исходным кодом, созданные с использованием LangGraph.js, и видеоуроки на YouTube. Этот ресурс предоставляет удобство для разработчиков, желающих изучить и использовать LangGraph.js для создания различных приложений, от мультиагентных систем до полностековых чат-приложений (источник: LangChainAI)
💼 Бизнес
Трансформация AI-стратегии Alibaba приносит результаты, доходы от облачного бизнеса и AI-продуктов значительно выросли: Финансовый отчет Alibaba за 4 квартал 2025 года показывает, что после исключения определенных направлений бизнеса общий доход вырос на 10% в годовом исчислении, доход от облачного интеллектуального бизнеса вырос на 18%, из которых доход от AI-продуктов сохраняет трехзначный рост в годовом исчислении седьмой квартал подряд. Alibaba рассматривает AI как ключевую стратегию и планирует в ближайшие три года инвестировать более 380 миллиардов юаней в модернизацию облачных вычислений и AI-инфраструктуры. Ее модель с открытым исходным кодом Qwen-3 от Tongyi Qianwen возглавила несколько мировых рейтингов, породив более 100 000 производных моделей, что демонстрирует ее технологическую мощь и жизнеспособность экосистемы открытого исходного кода. Alibaba ускоряет внедрение AI в автомобильной, телекоммуникационной, финансовой и других отраслях (источник: 36氪)
Приложение для редактирования видео Mojo приобретено Dailymotion: Приложение для редактирования видео Mojo (@mojo_video_app) было приобретено Dailymotion. Технологии редактирования видео Mojo будут интегрированы в социальное приложение Dailymotion и его B2B-продукты. Стороны стремятся совместно создать европейскую социальную видеоплатформу следующего поколения (источник: ClementDelangue)
Cohere приобретает Ottogrid для усиления корпоративных AI-возможностей: AI-компания Cohere объявила о приобретении стартапа Ottogrid. Ожидается, что это приобретение усилит возможности Cohere в области корпоративных AI-решений, однако конкретные детали сделки и технологическое направление Ottogrid не были подробно раскрыты (источник: aidangomez, nickfrosst)

🌟 Сообщество
AI Agent вызывает дискуссии об изменении методов работы, будущее может напоминать стратегические игры в реальном времени: Уилл Депью предположил, что будущая работа может превратиться в нечто похожее на Starcraft или Age of Empires, где люди будут командовать примерно 200 микро-интеллектуальными агентами для выполнения задач, сбора информации, проектирования систем и т.д. Сэм Альтман ретвитнул, выразив согласие. Фабиан Штельцер в шутку назвал это «кодированием в стиле Zerg rush». Эта точка зрения отражает размышления и обсуждения в сообществе о том, как AI Agent изменит рабочие процессы и модели взаимодействия человека и машины (источник: willdepue, sama, fabianstelzer)
Ответы робота Grok от xAI вызвали споры, утверждается о несанкционированном изменении промптов: xAI признала, что промпты ее робота-ответчика Grok на платформе X были несанкционированно изменены рано утром 14 мая, что привело к тому, что его анализ некоторых событий (например, связанных с Трампом) выглядел необычно или не соответствовал основной информации. Сообщество пристально следит за этим событием, Клеман Деланж и другие призывают Grok открыть исходный код для повышения прозрачности. Колин Фрейзер и другие пользователи, сравнивая ответы Grok в разное время, пытаются реконструировать историю изменений его системных промптов (источник: ClementDelangue, menhguin, colin_fraser)

Слухи о массовом уходе сотрудников из команды Meta Llama4 вызывают обеспокоенность в сообществе относительно перспектив открытого AI: По сообщениям из сообщества, около 80% членов команды Meta Llama4 (11 из 14 человек первоначальной команды) уволились, а выпуск их флагманской модели Behemoth отложен. Это событие вызвало широкий резонанс, инсайдеры отрасли, такие как Нэт Ламберт, выразили сожаление. Scaling01 прокомментировал, что Meta, возможно, понадобится новый директор по маркетингу Llama. TeortaxesTex и другие пользователи обеспокоены тем, что это может негативно сказаться на развитии открытого AI, и даже обсуждают, станет ли Китай последней надеждой для открытого исходного кода (источник: teortaxesTex, Dorialexander, scaling01)

Применение AI в военных действиях и этические вопросы вызывают озабоченность: Сообщество Reddit обсуждает применение AI в военных действиях, отмечая, что он уже используется для наблюдения и определения местоположения комбатантов путем анализа информации для предоставления военной разведки. В обсуждении упоминается, что американские военные используют AI-инструменты, такие как DART, с 1991 года. Пользователи обеспокоены смертельными рисками, которые может нести вооружение AI, и потенциальной угрозой для человечества, а также следят за разработкой соответствующих международных договоров и мер. В руководстве по использованию OpenAI также был удален пункт о запрете военного использования, что вызвало дальнейшие размышления (источник: Reddit r/ArtificialInteligence)
Большие языковые модели показали плохие результаты на соревнованиях по программированию CCPC, выявив текущие ограничения: На финале десятого Китайского студенческого чемпионата по программированию (CCPC) несколько известных больших языковых моделей, включая Seed-Thinking от ByteDance (а также o3/o4, Gemini 2.5 pro, DeepSeek R1), показали плохие результаты, большинство из них решили только простейшую задачу или получили ноль баллов. Официальные лица объяснили, что модели работали полностью автономно, без вмешательства человека. Сообщество анализирует, что это выявило недостатки текущих больших моделей в решении высокоинновационных и сложных алгоритмических задач, особенно в неагентном режиме (т.е. без вспомогательных инструментов для выполнения и отладки). Это контрастирует с OpenAI o3, который получил золотую медаль на соревнованиях IOI благодаря агентному обучению (источник: WeChat)

Обсуждение фреймворка DSPy и «горьких уроков», подчеркивается важность规范ного проектирования и автоматизации промптов: Обсуждения, связанные с DSPy, подчеркивают, что хотя масштабирование AI (Scaling) может обойти многие инженерные трудности («горькие уроки»), оно не может заменить тщательное проектирование основной спецификации проблемы (требований и потоков информации). Однако масштабирование может повысить уровень абстракции при определении проблем. Автоматизация промптов (например, prompt optimizers) рассматривается как метод использования вычислительных мощностей, соответствующий «горьким урокам», в то время как ручное создание промптов может противоречить этому, поскольку оно привносит человеческую интуицию, а не позволяет модели учиться (источник: lateinteraction, lateinteraction)
Вычислительные затраты на самопроверку/исследование инструментов AI Agent во время логического вывода вызывают интерес: Пол Калкрафт задает вопрос о практике выделения значительных вычислительных ресурсов (например, более 200 долларов на решение одной проблемы) на этапе логического вывода для активной самопроверки, использования инструментов и исследовательских рабочих процессов AI Agent. Он отмечает, что такие проекты, как Devin и его конкуренты, могут делать это для PR-демонстраций, но для сценариев поиска новых решений (аналогично FunSearch, но с меньшими ограничениями) это неясно (источник: paul_cal)
AI-ассистированное «программирование по наитию» (Vibe Coding) вызывает дискуссии: Инструменты, такие как GitHub Copilot, делают возможным «программирование по наитию» (Vibe Coding, означающее программирование, которое больше полагается на интуицию и помощь AI, чем на строгое планирование), и даже 16-летние студенты используют Copilot для выполнения школьных проектов. Мнения сообщества по этому явлению разделились: одни считают это новой парадигмой программирования, другие подчеркивают важность основ и规范 (источник: Reddit r/ArtificialInteligence, nrehiew_)
Библиотека Transformers от Hugging Face запускает новую доску сообщества: Hugging Face открыла новую доску сообщества для своей основной библиотеки Transformers для публикации объявлений, представления новых функций, обновлений дорожной карты, а также приглашает пользователей задавать вопросы и обсуждать использование библиотеки или проблемы с моделями, с целью укрепления взаимодействия и поддержки разработчиков (источник: TheZachMueller, ClementDelangue)
Разработчики AI призывают ведущие конференции добавить трек статей “Findings”: Учитывая резкий рост числа заявок на ведущие AI-конференции, такие как NeurIPS (например, NeurIPS достигла 25 000 заявок), Дэн Рой и другие призывают последовать примеру конференций, таких как ACL, и учредить трек статей типа “Findings”. Это направлено на предоставление возможности публикации для тех исследований, которые, хотя и не достигли стандартов основной конференции, все же имеют ценность, снижение нагрузки на рецензентов и содействие более широкому академическому обмену. Предложения включают облегченное рецензирование, сосредоточенное на повышении ясности статей и т.д. (источник: AndrewLampinen)
💡 Другое
Экзоскелет с AI-приводом помогает пользователям инвалидных колясок стоять и ходить: Экзоскелет с AI-приводом продемонстрировал свою способность помогать пользователям инвалидных колясок снова стоять и ходить. Такие технологии сочетают в себе робототехнику, датчики и AI-алгоритмы, воспринимая намерения пользователя и обеспечивая силовую поддержку, что дает надежду на реабилитацию и улучшение качества жизни людям с ограниченными возможностями передвижения (источник: Ronald_vanLoon)
Использование AI для визуализации творческих идей на основе имен пользователей: В сообществах Reddit и X возник небольшой ажиотаж: пользователи массово используют инструменты генерации изображений AI (например, встроенный в ChatGPT DALL-E 3) для создания концептуальных изображений на основе своих имен пользователей в социальных сетях и делятся этими полными воображения работами, демонстрируя забавное применение AI в персонализированном творческом самовыражении (источник: Reddit r/ChatGPT, Reddit r/ChatGPT)

Реклама Amazon использует AI для повышения эффективности маркетинга брендов при выходе на международный рынок: Реклама Amazon представила концепцию «Лаборатории мирового экрана», демонстрируя, как она использует технологии AI для расширения возможностей китайских брендов при выходе на международный рынок. За счет медиа-матрицы, такой как Prime Video, расширяется охват бренда, использование AI-креативных студий (например, инструментов для генерации видео) снижает порог создания контента, а инструменты, такие как Amazon DSP и Performance+, оптимизируют размещение рекламы и конверсию. AI играет роль на всех этапах, от генерации идей до измерения эффективности, с целью помочь владельцам брендов, особенно малым и средним предприятиям, более эффективно осуществлять глобальное брендирование (источник: 36氪)
