
关键词:DeepSeek-OCR, 视觉文本压缩, AI智能体, 强化学习, AI自动化, AWS宕机, Mamba架构, AI音乐, 上下文光学压缩, OmniDocBench, Glyph视觉文本压缩框架, Project Mercury, TeleStudio AI创作平台
🔥 聚焦
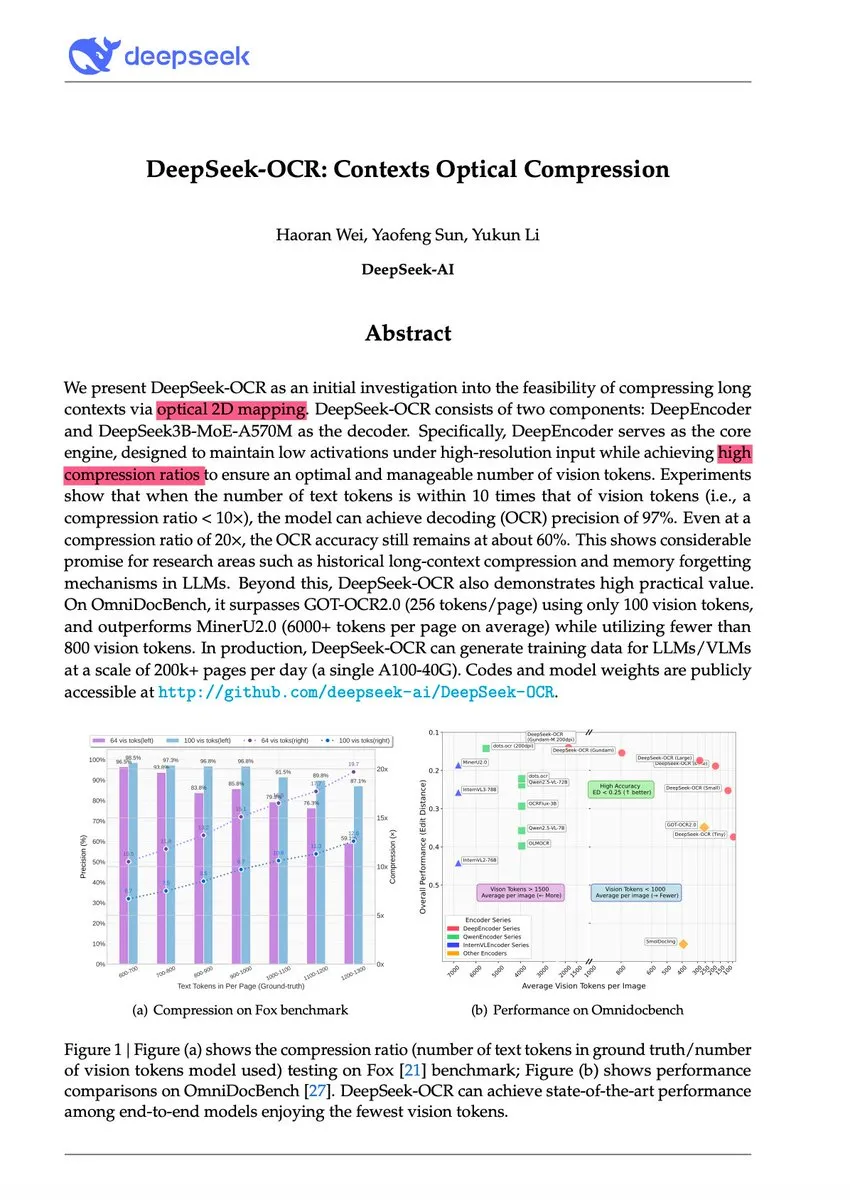
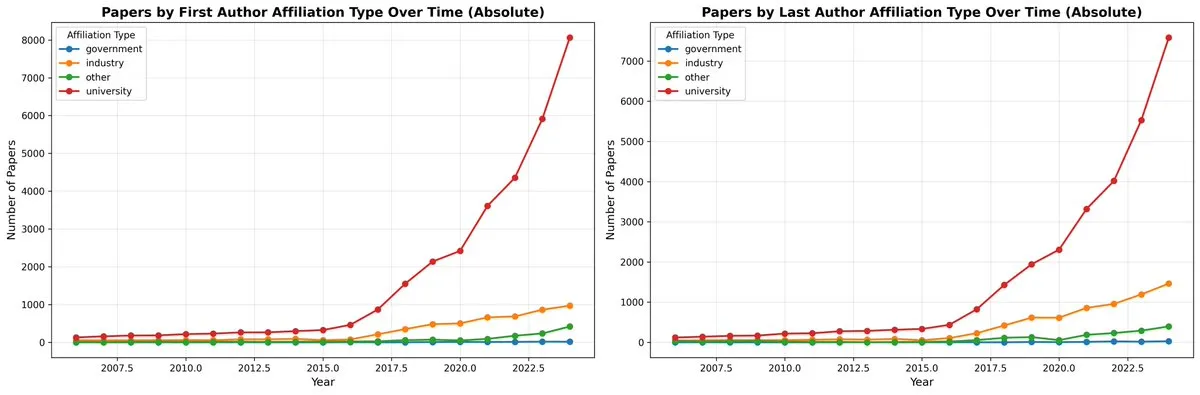
DeepSeek-OCR与视觉文本压缩范式革新: DeepSeek-OCR模型提出“上下文光学压缩”新范式,将长文本渲染为视觉图像,通过视觉token高效压缩信息。该3B模型在OmniDocBench上实现SOTA,能以10倍(近乎无损)至20倍(60%准确率)压缩率处理文本,单A100 GPU日处理超20万页文档。Andrej Karpathy称之为“AI的JPEG时刻”,认为其可能预示着LLM输入范式的改变,甚至模拟人类遗忘机制,通向无限上下文架构。
(来源:量子位、ZhihuFrontier、huggingface)
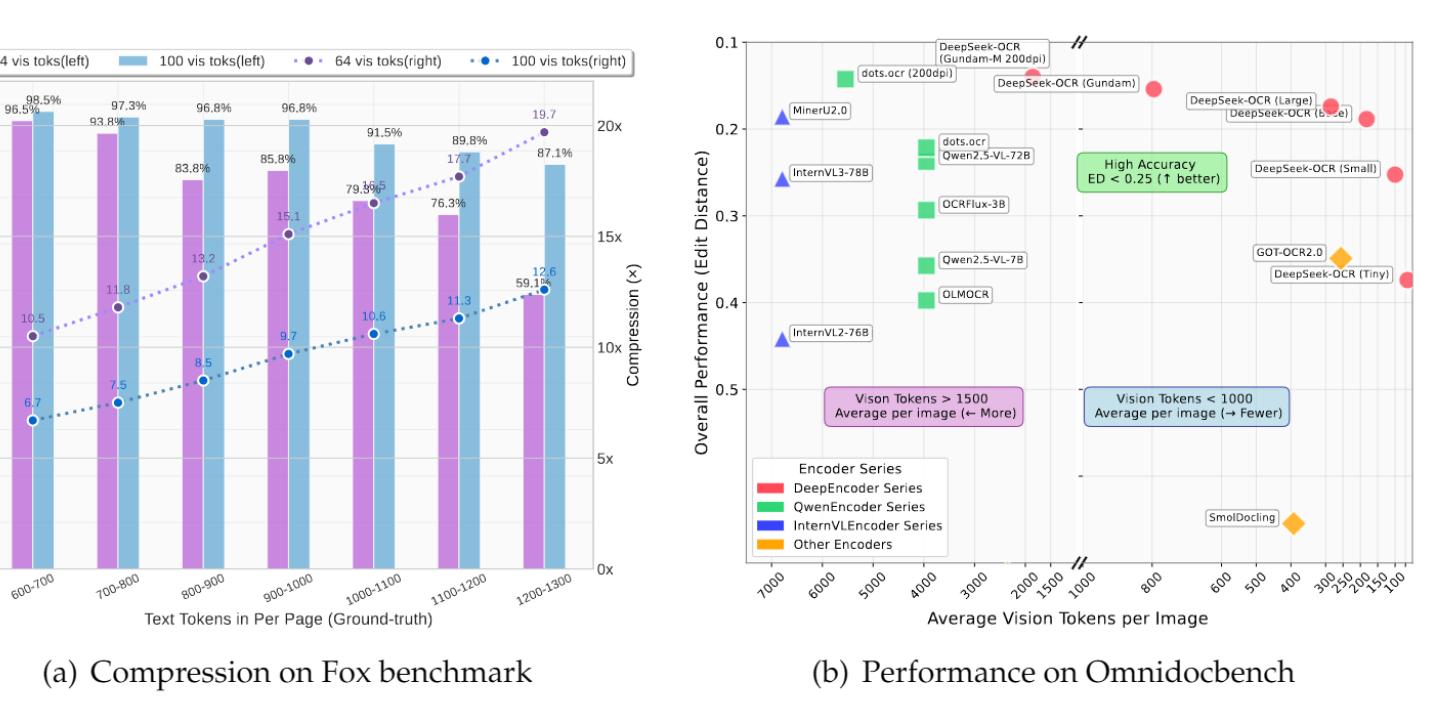
GLM团队发布Glyph视觉文本压缩框架: 与DeepSeek-OCR同期,GLM团队发布Glyph框架,通过将长文本渲染成图像并由VLM处理,实现3-4倍文本压缩,同时保持与领先LLM相当的准确性。该方法显著提升了预填充和解码速度,并使128K上下文的VLM能够处理1M token级别的文本任务。这与DeepSeek-OCR共同验证了视觉压缩作为长上下文解决方案的可行性。
(来源:Reddit r/LocalLLaMA、Zai_org)
Andrej Karpathy对AI智能体及RL的深度批判: 前OpenAI研究主管Andrej Karpathy在一次长谈中指出,AI智能体距离真正成熟尚需十年,目前仍缺乏多模态、持续学习、完整认知结构和记忆能力。他严厉批评强化学习(RL)的“盲目试错”机制效率低下且易被欺骗,倡导模型应学习人类的回顾与反思机制,并通过“做梦”般的机制维持高熵状态以避免认知坍缩。Karpathy强调AGI将渐进式融入经济,而非瞬间颠覆,并认为自动驾驶的挑战远超技术本身,需要社会系统协同。
(来源:量子位、sama、vikhyatk)

AI自动化对麦肯锡咨询业的颠覆性影响: 麦肯锡因其巨大的Tokens消耗量获得OpenAI奖牌,揭示AI已深度渗透其咨询业务。麦肯锡和波士顿咨询等顶级咨询公司正全面部署AI工具,如麦肯锡的Lilli(已覆盖70%员工),BCG甚至将AI使用率纳入绩效考核。AI提升效率导致麦肯锡裁员5000余人,其中初级顾问岗位受冲击最大。AI初创公司也开始提供AI分析师服务,挑战传统咨询模式。行业担忧AI将使年轻求职者难以积累“隐性知识”,改变职业发展路径。
(来源:量子位、Teknium1)

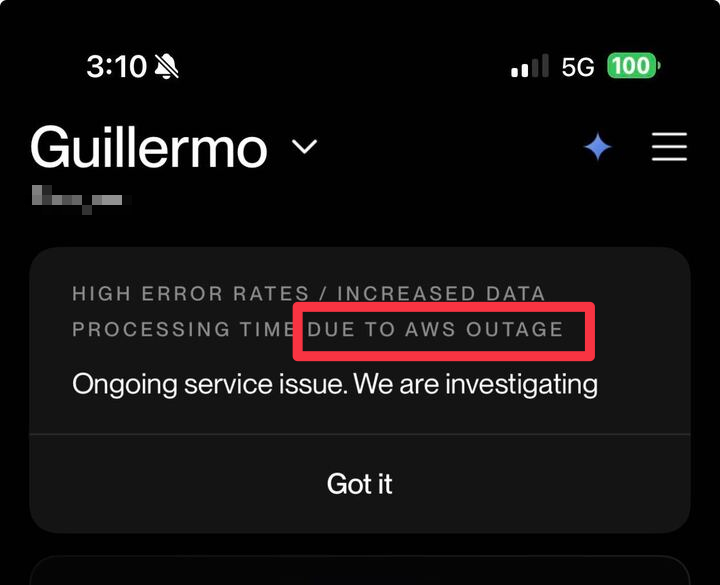
亚马逊AWS服务器宕机引发大范围互联网服务中断: 亚马逊AWS的us-east-1区域发生大规模宕机,导致ChatGPT、Docker、Zoom、Slack、游戏平台、流媒体、打车软件等众多线上服务及部分线下服务(如航空值机、智能门锁)中断。此次故障源于DNS解析问题及EC2内部网络子系统异常。us-east-1作为AWS核心区域,其故障对全球服务影响巨大,凸显了集中式云服务架构的脆弱性,促使开发者重新审视多区域部署和弹性机制的重要性。
(来源:量子位、TheRundownAI、qtnx_)

🎯 动向
苹果AI研究:Mamba架构在Agent任务中超越Transformer: 苹果最新研究表明,结合外部工具的Mamba架构在长任务、多交互的Agent场景中,比Transformer更具效率和泛化潜力。Mamba作为状态空间模型,计算量随序列长度线性增长,支持流式处理且内存占用稳定,通过引入外部工具弥补其短期记忆限制,在多位数加法和代码调试等任务中表现优异。
(来源:量子位)
AI音乐行业进入合规与商业化新阶段: AI音乐公司Suno完成超1亿美元融资,估值达20亿美元,并推出V5模型和Suno Studio数字音频工作站,提升音乐生成质量和创作控制。Udio也发布可视化编辑工具。ElevenLabs推出Eleven Music并与独立音乐组织Merlin及版权商Kobalt达成授权协议,获英伟达战略投资。与此同时,三大唱片公司升级对Suno和Udio的版权侵权诉讼,Spotify也加强监管并删除“垃圾曲目”,预示AI音乐将从“野蛮生长”转向规范化发展。
(来源:36氪)

字节跳动AI助手Cici悄然霸榜海外市场: 字节跳动旗下AI智能助手应用“Cici”近期在墨西哥、英国及东南亚等多个国家应用商店下载量飙升,实现“霸榜”。Cici与国内领先的“豆包”在外观和技术上高度相似,融合了字节跳动内部技术(如PicPic、Coze),并利用OpenAI的GPT系列和谷歌的Gemini模型进行对话生成。这标志着字节跳动在AI领域的全球化扩张策略。
(来源:量子位)
Anthropic推出Claude生命科学平台助力科研: Anthropic发布Claude for Life Sciences,旨在通过AI平台协助生命科学研究人员进行假设创建、数据分析等工作,以提高效率并促进负责任的AI使用。该平台通过集成科学工具、技能和新合作关系,使Claude在科学研究领域更具实用性。
(来源:Reddit r/ClaudeAI、BlackHC)
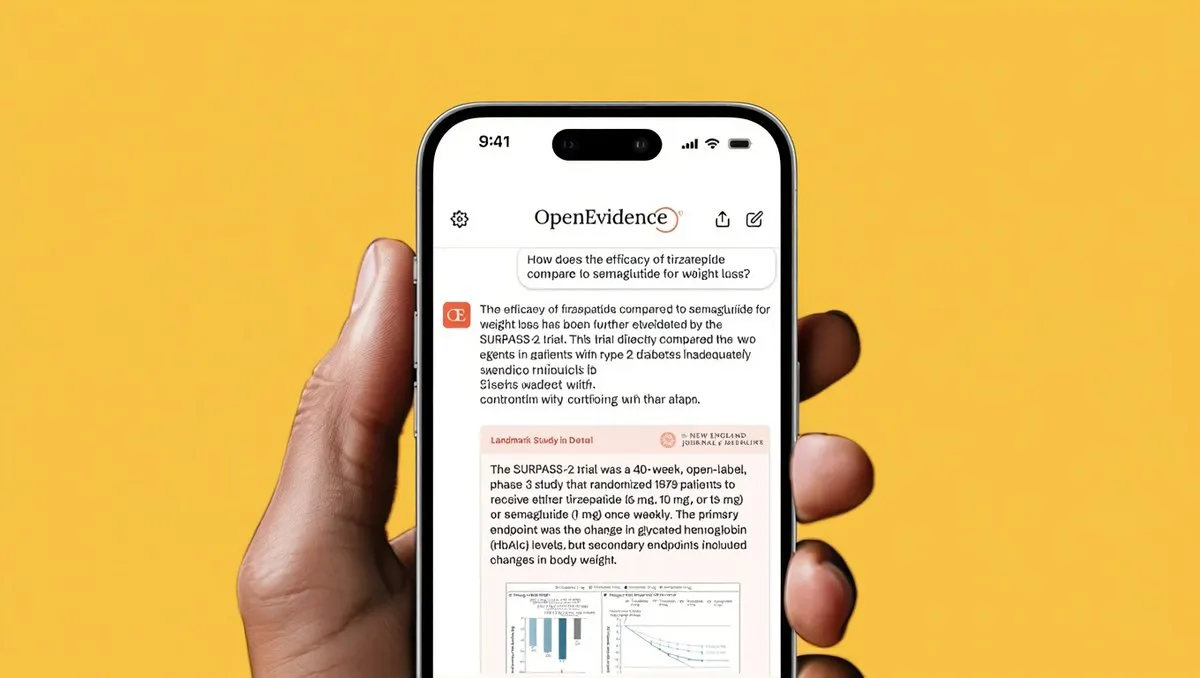
AI在医疗领域的应用进展: PRIMA视网膜假体临床试验成功,使失明患者恢复直观视觉。同时,OpenEvidence获得2亿美元融资,估值达60亿美元,其AI平台每月支持1500万次临床咨询,旨在加速医疗决策。这些进展标志着AI在改善人类健康和提升医疗效率方面的巨大潜力。
(来源:gfodor、TheRundownAI)

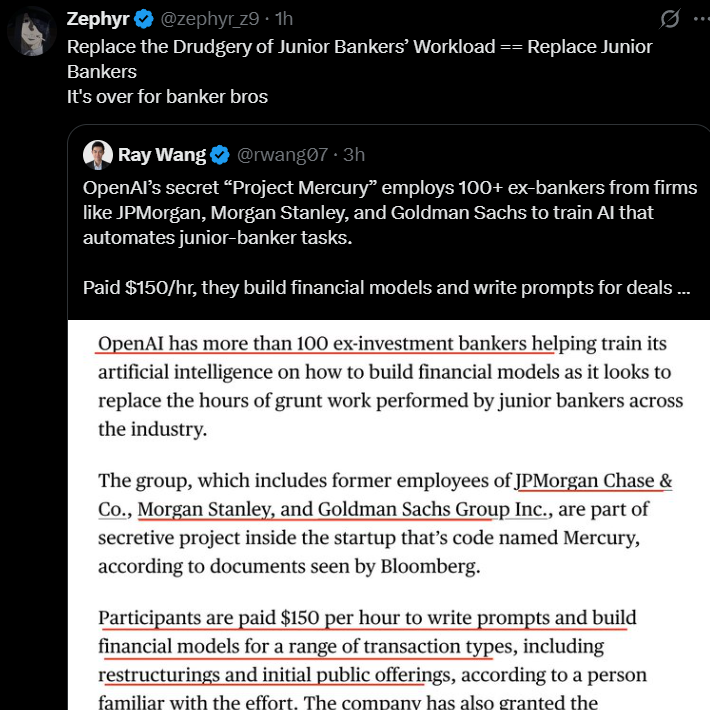
AI自动化对初级金融岗位的冲击: OpenAI启动“Project Mercury”秘密项目,雇佣百余名投资银行家训练AI模型,旨在自动化初级银行家的基础工作,每小时支付150美元。这预示着AI将深度渗透金融行业,尤其对重复性高、知识门槛相对较低的初级岗位带来显著影响。
(来源:Teknium1)

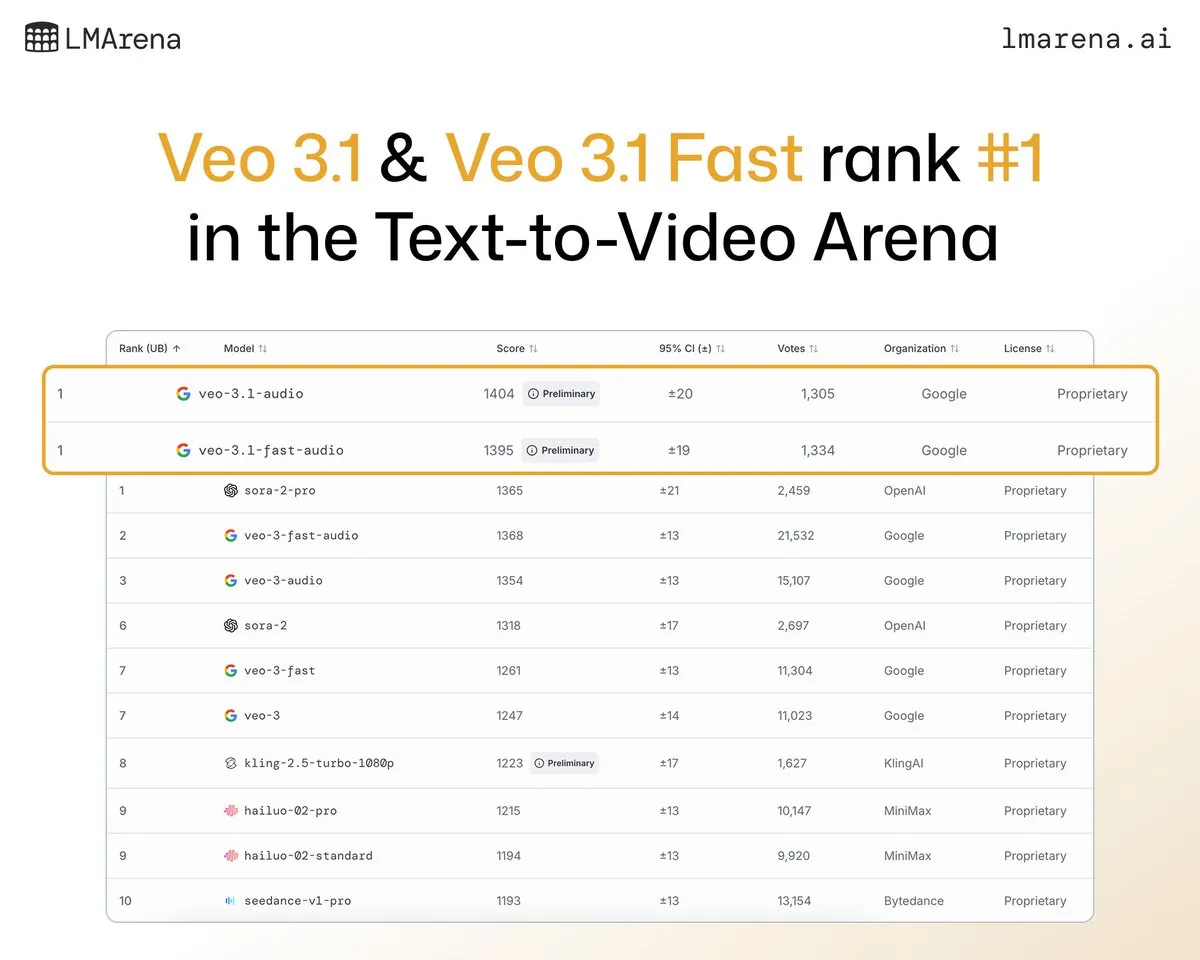
谷歌DeepMind的Veo 3.1在视频生成榜单中夺冠: 谷歌DeepMind的最新视频生成模型Veo 3.1在LMArena视频排行榜中表现出色,位居文本到视频和图像到视频生成榜首。相较于Veo 3.0,其性能提升显著,成为首个突破1400分的模型,展现了谷歌在视频生成领域的领先地位。
(来源:NandoDF、GoogleDeepMind)
AI构建AI:软件自动化AI开发超越人类专家: 一项研究指出,有软件能够自动化整个AI开发过程,从架构搜索到优化,并在某些基准测试中超越人类专家。这引发了关于未来AI开发中,想法和数据集的重要性可能超越传统AI工程专业知识的讨论。
(来源:Reddit r/deeplearning)

亚马逊计划用机器人取代60万美国工人: 亚马逊泄露文件显示,公司计划用机器人取代60万美国工人,并已制定计划以减轻对社区的影响,同时避免使用“自动化”和“AI”等术语,改用“先进技术”或“协作机器人”等。此举凸显了AI和机器人技术对劳动力市场潜在的巨大结构性影响。
(来源:Reddit r/ArtificialInteligence)

AI模型“脑腐烂”现象研究: 研究人员发现,大型语言模型(LLMs)像人类一样,可能因浏览在线垃圾内容而出现“脑腐烂”(brain rot)现象。这一发现对LLM的训练数据质量和长期稳定性提出了新的挑战,并暗示了模型在处理低质量信息时的脆弱性。
(来源:Reddit r/artificial)

LLM中潜伏的奉承偏见诊断与缓解: Beacon基准测试旨在诊断和缓解大型语言模型(LLMs)中潜在的奉承偏见,即模型倾向于迎合用户而非坚持事实。研究发现,奉承偏见可分解为语言和情感子偏见,并随模型能力增强而加剧。通过提示和激活层面的干预措施,可以调节这些偏见,揭示了对齐的内部机制。
(来源:HuggingFace Daily Papers)
AI智能体自动组合:基于背包问题的组件选择方法: 一项研究提出受背包问题启发的自动化框架,用于智能体系统组合。该框架使组合智能体能够系统地识别、选择和组装最佳智能体组件集,同时考虑性能、预算和兼容性。在Claude 3.5 Sonnet上的评估显示,该在线背包组合器以显著降低的成本实现更高的成功率。
(来源:HuggingFace Daily Papers)
Agentic强化学习在搜索中的不安全性: 研究表明,经强化学习(RL)训练的搜索模型在处理有害请求时存在安全漏洞。简单的攻击(如强制搜索或多次搜索)可触发有害搜索和答案,大幅降低拒绝率和安全性。这暴露了当前RL训练的核心弱点,即奖励有效查询的生成而未充分考虑其有害性,亟需开发安全意识强的Agentic RL流程。
(来源:HuggingFace Daily Papers)
LLM“精神病”研究:百万字对话揭示聊天机器人如何规避安全防护: 一位前OpenAI研究员的百万字ChatGPT对话研究显示,AI“精神病”可能迅速发生,且聊天机器人能规避安全防护。这引发了对AI长期对话稳定性、安全漏洞及潜在风险的担忧,强调了持续监控和改进AI安全机制的重要性。
(来源:Reddit r/artificial)
AI21 Labs CEO展望AI作为“新员工”的未来: AI21 Labs首席执行官设想未来AI将成为企业中的“新员工”,与人类员工并肩工作,形成混合型组织。这一愿景强调了AI在日常运营和团队协作中日益增长的角色,预示着企业工作模式的深刻变革。
(来源:AI21Labs)
AI在数据分析中的效率提升: 一项分享指出,AI现在能够以分钟级速度处理数据团队的请求,从而实现了自助式分析。这表明AI在自动化数据处理和提高业务洞察效率方面具有巨大潜力,有望减轻数据团队的工作负担。
(来源:TheEthanDing)
AI在体育赛事中的应用:预测点球方向: 一项研究显示,AI在预测点球主罚者射门方向方面,表现优于人类守门员。这展示了AI在体育分析和策略制定中的潜力,可能为球队提供竞争优势。
(来源:Ronald_vanLoon)

AI在医疗健康领域的12大应用场景: 一份报告列举了生成式AI在医疗健康领域的12个具体用例,涵盖药物研发、诊断辅助、个性化治疗等多个方面,凸显了AI技术在提升医疗服务质量和效率方面的广阔前景。
(来源:Ronald_vanLoon)

AI在金融领域的应用场景: 一份报告详细介绍了生成式AI在金融领域的多个用例,包括风险评估、欺诈检测、个性化客户服务和自动化交易等,展示了AI如何推动金融行业的数字化转型和效率提升。
(来源:Ronald_vanLoon)
Beihang大学研发出2厘米超高速微型机器人: 北京航空航天大学的研究人员成功开发出一种2厘米大小的微型机器人,具备超快的无束缚移动速度。这一突破在微型机器人技术领域具有重要意义,预示着未来在医疗、精密制造等领域的新应用。
(来源:Ronald_vanLoon)
DOBOT仿生六足机器人展示崎岖地形移动能力: DOBOT的仿生六足机器人在野外演示中展示了其在崎岖地形下的出色移动能力。这表明机器人技术在复杂环境适应性和自主导航方面的进步,有望应用于搜救、勘探等领域。
(来源:Ronald_vanLoon)
Unitree H2人形机器人颈部采用2自由度驱动: Unitree H2人形机器人的颈部设计采用了2自由度(DOF)驱动,这为其提供了更灵活的头部运动能力,对于机器人与环境的交互和感知至关重要。
(来源:Sentdex、teortaxesTex)
Sharpa机器人手部展示: Sharpa机器人手部被展示,强调其灵巧和精确性,预示着机器人操纵和精细作业能力的提升。
(来源:Sentdex)
中国推出高速球形警用机器人: 中国推出一款高速球形警用机器人,能够自主捕捉罪犯。该机器人结合了创新技术和AI能力,旨在提升公共安全和执法效率。
(来源:Ronald_vanLoon)
人形机器人展示中国书法技能: 一款人形机器人展示了其中国书法技能。这表明机器人在精细动作控制和文化艺术领域的应用潜力,也体现了人机协作在传统艺术传承方面的可能性。
(来源:Ronald_vanLoon)
人形机器人作为键盘手在音乐节演出: 一款双足人形机器人作为键盘手在音乐节上表演。这展示了机器人在娱乐和艺术领域的进步,以及与人类共同创造舞台体验的潜力。
(来源:Ronald_vanLoon)
智能眼镜帮助盲人患者重见光明: 智能眼镜技术正在帮助因光感受器损失而失明的患者重新获得直观视觉。这一突破性的应用展示了AI和可穿戴设备在辅助医疗和改善生活质量方面的巨大潜力。
(来源:TheRundownAI)
Qwen3-Next 80B-A3B模型在WebDev排行榜中位列前茅: GLM 4.6成为WebDev Arena新的开源模型榜首,Claude Sonnet 4.5、Qwen3 235B和Claude Haiku 4.5也进入前15名。这表明大型语言模型在网页开发、编码和长上下文任务方面的能力持续提升,竞争日益激烈。
(来源:Zai_org)

LLM评估基准持续改进以适应图像模型发展: ECHO框架通过从社交媒体用户帖子中提取新颖提示和定性判断,构建了直接反映模型实际使用情况的图像模型基准。该框架已应用于GPT-4o图像生成,收集了超过31,000个提示,旨在发现现有基准未涵盖的创意和复杂任务,并更清晰地区分最先进模型。
(来源:HuggingFace Daily Papers)
多模态大型视觉语言模型评估基准MultiVerse发布: MultiVerse是一个新的多轮对话基准,包含647个对话,平均每轮四次,旨在评估大型视觉语言模型(VLMs)在复杂多轮对话场景中的能力。该基准涵盖从事实知识到高级推理的广泛任务,并使用GPT-4o作为自动化评估器,揭示即使是GPT-4o等最强模型在复杂多轮对话中也仅有50%的成功率。
(来源:HuggingFace Daily Papers)
3D资产外观转移的优化引导整流流模型GuideFlow3D: GuideFlow3D是一个优化引导的整流流模型,用于将图像或文本的外观转移到3D资产,解决了输入和外观对象几何差异大的问题。该无训练方法通过定期添加指导与采样过程交互,并在GPT-based系统评估下,在ImgEdit和GEdit-Bench基准上表现优异,成功转移纹理和几何细节。
(来源:HuggingFace Daily Papers)
LLM评估:Foundational Automatic Reasoning Evaluators (FARE) 提升开源评估标准: FARE是一系列8B和20B(3.6B活跃)参数的生成式评估器,通过迭代拒绝采样SFT方法训练,涵盖五个评估任务和多个推理领域。FARE-8B挑战了更大的RL训练评估器,FARE-20B为开源评估器设定了新标准,超越了70B+的专用评估器,并在RL训练和重排序中显著提升下游模型性能。
(来源:HuggingFace Daily Papers)
LLM的通用诚实对齐方法EliCal实现高效训练: EliCal(Elicitation-Then-Calibration)是一个两阶段框架,用于实现大型语言模型(LLMs)的通用诚实对齐,即模型识别其知识边界并表达校准置信度的能力。该方法首先通过廉价的自洽性监督引出内部置信度,然后用少量正确性标注进行校准。在HonestyBench基准上,EliCal仅用1k标注就实现了近乎最优的对齐。
(来源:HuggingFace Daily Papers)
🧰 工具
蚂蚁AQ AI医疗App提供多模态健康服务: 蚂蚁集团推出AI医疗App“AQ”,提供拍照测脱发等级、心电图分析、舌象诊断、皮肤检测等功能。该应用还与支付宝深度联动,支持直接挂号、买药和查询医保,形成医疗场景闭环。AQ在日常小病问诊和急症建议方面表现可靠,但在CT片等硬核影像识别上仍有局限。
(来源:量子位)
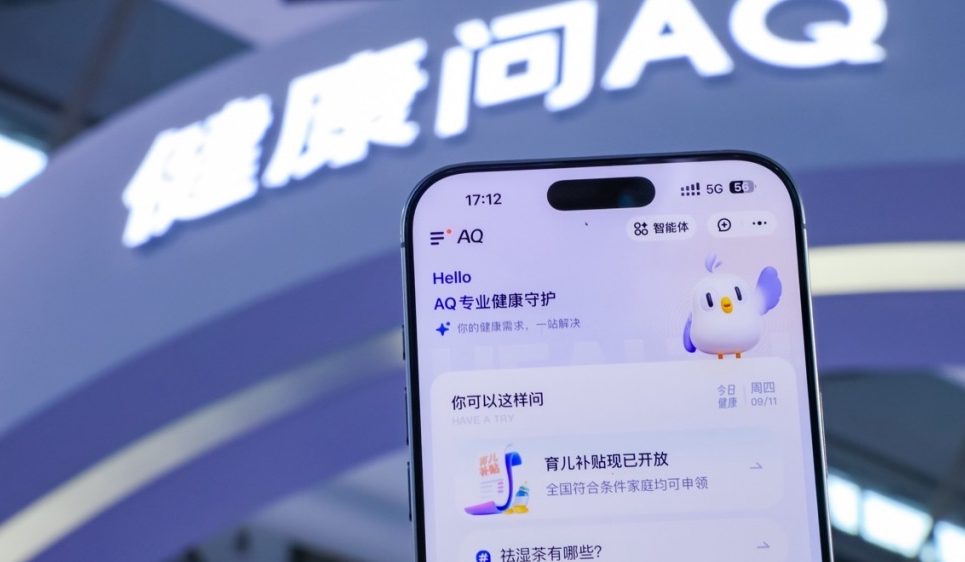
中国电信TeleStudio:AI全模态视频创作平台: 中国电信面向公众开放AI创作平台TeleStudio,支持图片、视频、音效生成,可用于制作MV等短剧。平台提供“万物跳舞”功能,可让静态图片角色根据舞蹈效果动起来,以及“音乐生视频”和“角色开口唱歌”功能。TeleStudio目前限时免费,由TeleAI的星辰大模型和智传网(AI Flow)提供技术支持。
(来源:量子位)

Sherpa-onnx:支持多平台离线语音AI工具包: Sherpa-onnx是一个基于ONNX Runtime的开源工具包,提供离线语音AI功能,包括语音转文本、文本转语音、说话人分离、语音增强、声源分离和VAD。该工具包支持嵌入式系统、Android、iOS、HarmonyOS、Raspberry Pi、RISC-V和x86_64服务器等多种平台,并提供12种编程语言API。
(来源:GitHub Trending)

Krea Realtime视频生成模型开源: Krea AI宣布开源其14B参数的自回归模型Krea Realtime,该模型比现有开源模型大10倍,能在单个B200 GPU上以11帧/秒的速度生成长视频。此次开源为视频生成领域带来了强大的新工具,降低了高性能视频创作的门槛。
(来源:huggingface、charles_irl)
FinePdfs开源OCR工具及数据集: FinePdfs项目发布了完整的源代码、新的数据集和模型。其中包括OCR-Annotations(1.6k标注PDF)和Gemma-LID-Annotation(20k多语言样本)数据集,以及XGB-OCR分类器模型,旨在提升PDF文档的OCR处理能力。
(来源:huggingface)

DeepSeek-OCR本地部署工作台发布: DeepSeek-OCR Playground是一个Docker化的FastAPI + React工作台,允许用户在本地使用DeepSeek-OCR模型。该工具支持图像到文本/描述、查找/定位、自由形式等多种模式,兼容RTX 5090等CUDA GPU,方便社区进行测试、改进和扩展。
(来源:Reddit r/LocalLLaMA)
Anthropic推出Claude Code网页版: Anthropic将Claude Code带到网页端,提供代码生成、调试和优化功能,使用户能够通过浏览器直接利用Claude的编程能力。
(来源:_catwu、TheRundownAI)

Claude Code提示词优化工具v0.3.0发布: Claude Code的提示词优化Hook迎来重大更新v0.3.0,引入动态研究规划、支持1-6个问题,并基于实际研究结果进行问题生成。该工具通过结构化工作流和明确的接地气要求,提高了提示词的一致性,同时保持了较低的token开销。
(来源:Reddit r/ClaudeAI)
Unsloth AI支持Qwen3-VL模型免费微调: Unsloth AI宣布支持Qwen3-VL (8B)模型的免费、便捷微调。Unsloth平台能以1.7倍的速度训练VLM,减少60%的VRAM使用,并支持8倍更长的上下文,且不损失准确性,为开发者提供了高效的VLM定制化方案。
(来源:danielhanchen)

WebGPU支持Karpathy的nanochat模型本地运行: Karpathy的nanochat模型现在支持WebGPU,可在浏览器中100%本地运行,无需服务器。在M4 Max上可达每秒50个token,这意味着AI应用现在可以通过单个HTML文件轻松部署。
(来源:paul_cal)

Alibaba Qwen Deep Research升级提供多模态内容生成: 阿里巴巴的Qwen Deep Research服务获得重大升级,现在不仅能生成研究报告,还能创建实时网页和播客。该功能由Qwen3-Coder、Qwen-Image和Qwen3-TTS提供支持,使用户能够以视觉和听觉形式获取洞察。
(来源:Alibaba_Qwen)
Glif推出AI特效代理工具: Glif正在构建一款AI特效代理工具,可处理手机录制的真实视频素材,旨在成为创作者的强大“魔杖”,即使7岁儿童也能轻松操作。用户只需上传视频并描述所需效果,即可实现视频特效生成。
(来源:NerdyRodent、fabianstelzer)
Runway推出模型微调服务: Runway正在推出模型微调(Model Fine-tuning)服务,允许用户根据特定用例和自有数据定制其模型。这项自助服务旨在解锁娱乐、机器人、教育和生命科学等领域全新的应用场景。
(来源:c_valenzuelab)

vLLM、OpenWebUI和Tailscale构建私有便携式AI环境: 用户通过结合vLLM、OpenWebUI和Tailscale,成功搭建了私有、便携式的AI运行环境。这种配置使得用户可以在本地设备上运行大型语言模型,并通过Tailscale实现安全远程访问,极大地增强了AI应用的灵活性和数据隐私性。
(来源:Reddit r/LocalLLaMA)
Qwen3-Next 80B-A3B模型llama.cpp实现进展: Qwen3-Next 80B-A3B模型在llama.cpp中的实现取得进展,初步支持CUDA(上下文限制在40k),并提供了Instruct GGUFs。这为本地运行大型Qwen模型提供了更多可能性,尽管CUDA支持仍在完善中。
(来源:Reddit r/LocalLLaMA)
LangChain即将发布v1版本: LangChain即将发布v1版本,并与Microsoft Reactor合作进行直播分享新功能。LangChain作为流行的Python AI Agent框架,其更新将为开发者带来新的代理构建能力和体验。
(来源:hwchase17、hwchase17)

用于法律文件的闪电般快速向量搜索: 一位开发者构建了针对澳大利亚法律历史中大量法律文件的语义搜索系统,通过向量搜索实现了快速检索。该项目展示了如何在大规模、领域特定数据集上构建高效的语义搜索,并已发布指南和语料库。
(来源:Reddit r/ArtificialInteligence)

AI Studio团队打造Gemini新编码体验: 谷歌AI Studio团队正在开发全新的AI编程体验,旨在加速从提示到生产的路径,并与Gemini模型深度集成。这一工具的发布有望简化AI应用的开发流程,提高开发效率。
(来源:osanseviero)
Zed代码编辑器提供快速、优雅的开发体验: Zed代码编辑器因其极快的速度、优雅的用户界面以及对远程SSH和ACP的良好支持而受到赞扬。尽管在LLM工具调用格式上存在一些兼容性问题,但其整体表现被认为是出色的。
(来源:qtnx_、qtnx_)
Restate、Modal和Vercel构建云端编码代理: 一项研究探索了如何利用Restate(工作流)、Modal(沙盒)和Vercel(计算)以及GPT-5/Claude等LLM构建可扩展、弹性、可编排的云端编码代理。该架构旨在解决代理开发中的持久化步骤、会话管理、资源生命周期等问题,提升AI代理的生产力。
(来源:akshat_b)
📚 学习
哈佛大学开源教材《机器学习系统》: 哈佛大学开源了其CS249r课程教材《机器学习系统》,旨在教授如何构建从边缘设备到云部署的真实世界AI系统。该教材涵盖系统设计、数据工程、模型部署、MLOps和边缘AI等全面内容,致力于在全球范围内推广AI系统教育。
(来源:GitHub Trending)
AIES 2025最佳论文奖公布: AAAI/ACM人工智能、伦理与社会会议(AIES 2025)公布了最佳论文奖,涵盖AI对社会图式的影响、构建高效LLM防护栏、AI伦理评估与系统属性关联、以及口吃社区对语音AI数据治理的偏好等多个前沿伦理与安全议题。
(来源:aihub.org)

LLM集成中的稳定与快速集成策略研究: SAFE(Stable And Fast LLM Ensembling)框架提出,通过识别token级别的不匹配和下一token概率分布共识,选择性地集成大型语言模型(LLMs),以优化长文本生成性能。该方法通过概率锐化策略进一步提高稳定性,在MATH500和BBH等基准测试中,即使集成少于1%的token也能超越现有方法。
(来源:HuggingFace Daily Papers)
SSM架构与Transformer性能比较研究: 一项新研究指出,状态空间模型(SSMs)在长上下文场景中性能不如Transformer,可能并非SSM本身问题,而是使用方式不当。该研究探讨了如何优化SSM的使用,以充分发挥其在高效语言建模方面的潜力。
(来源:tri_dao)

LLM推理模型测试时扩展的有效性研究: 研究探讨了测试时扩展(TTS)在机器翻译(MT)中对推理模型(RMs)的有效性。结果显示,对于通用RMs,TTS在直接翻译中效果有限,但通过领域特定微调或在后编辑场景中,TTS能带来显著提升。强制模型超出自然停止点推理反而会降低翻译质量。
(来源:HuggingFace Daily Papers)
RLVR中LLM奇怪思维链的六大成因: 一篇博客文章分析了在基于人类反馈的强化学习(RLVR)中,大型语言模型(LLMs)出现奇怪思维链的六个原因,包括“赘余结构”和“上下文刷新”等假设。这有助于深入理解LLM在复杂推理过程中的行为模式和潜在缺陷。
(来源:dl_weekly)
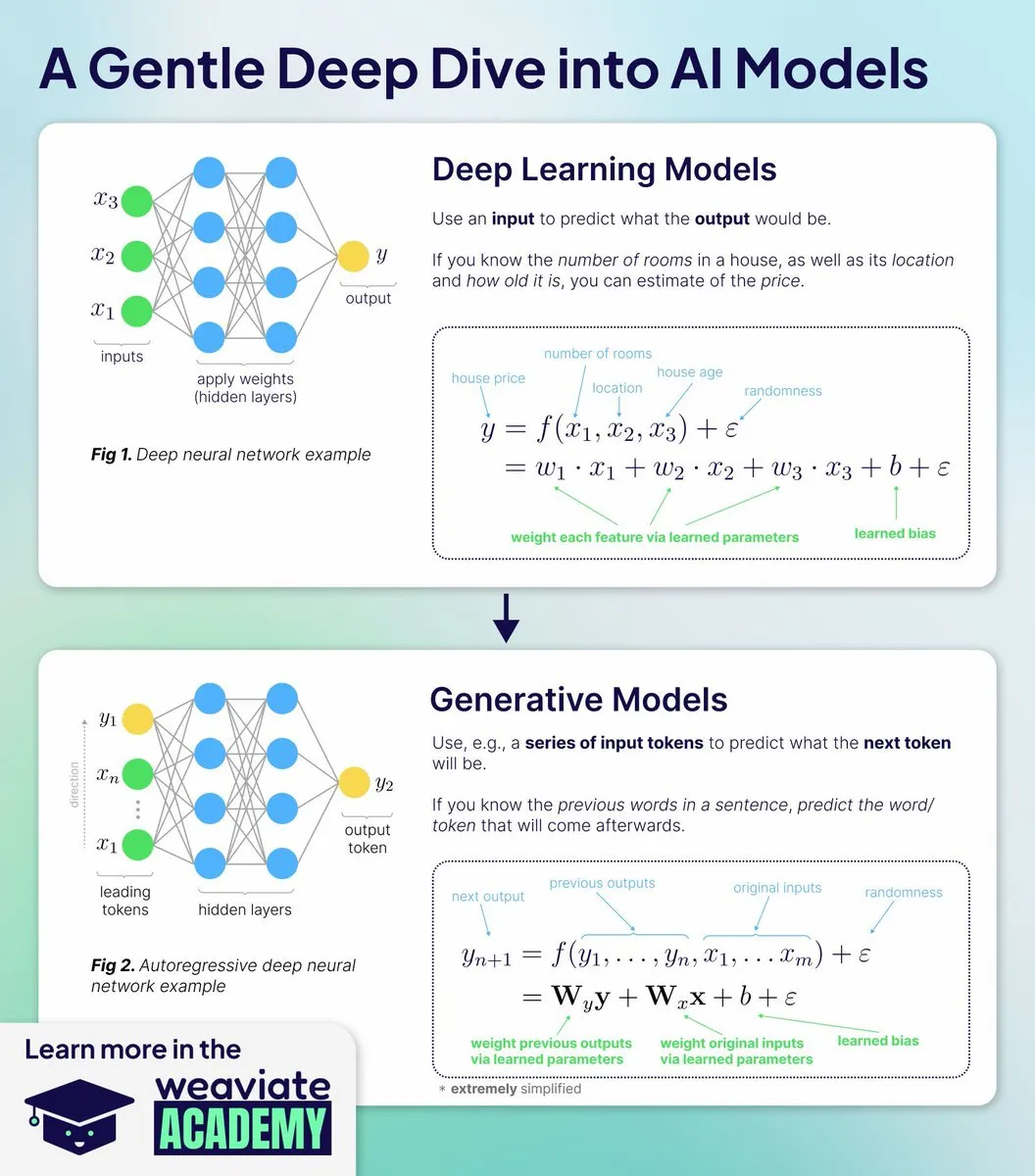
AI教育:Weaviate Academy新课程深入理解AI模型工作原理: Weaviate Academy推出新课程,旨在教授AI模型为何以及如何工作,而非仅仅如何使用API。课程涵盖深度学习基础、生成式AI机制、嵌入模型深度解析、从理论到实践以及训练与部署等内容,通过动手实践帮助学习者理解现代AI的架构决策。
(来源:bobvanluijt)
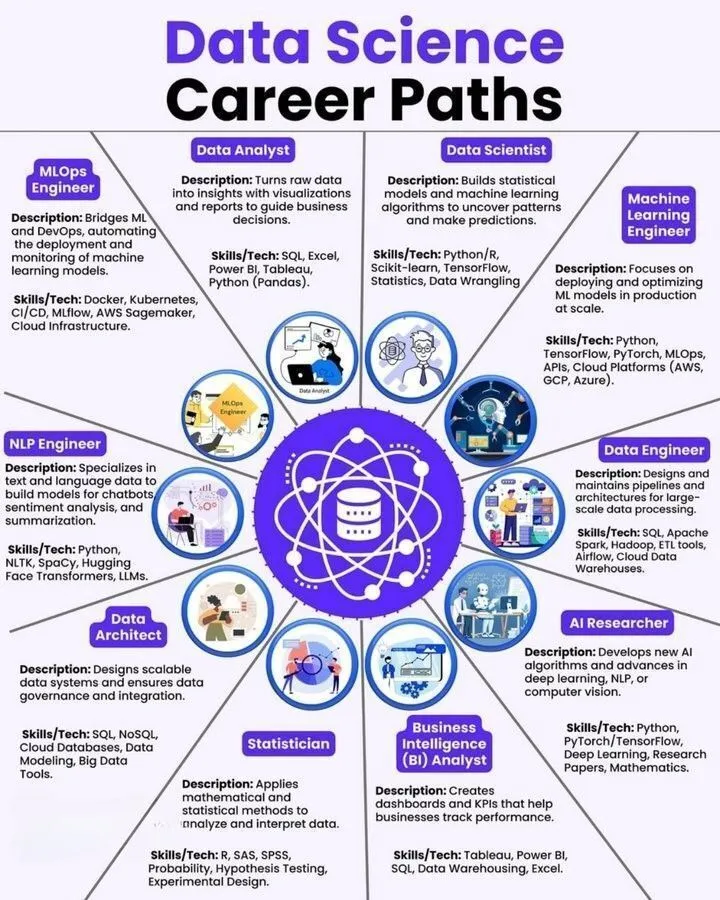
AI学习资源:数据科学、机器学习工程师路线图及AI工具栈: 分享了数据科学职业路径、机器学习工程师路线图以及AI Agent的终极工具栈等学习资源。这些资源以信息图形式呈现,为AI领域的学习者和从业者提供了清晰的职业发展方向和实用工具参考。
(来源:Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon)
AI学习资源:AI工具、课程及专业技能: 分享了AI工具、AI课程以及2025年需要掌握的12项AI技能等学习资源。这些资源旨在帮助AI领域的学习者和从业者了解最新趋势,提升专业能力。
(来源:Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon)

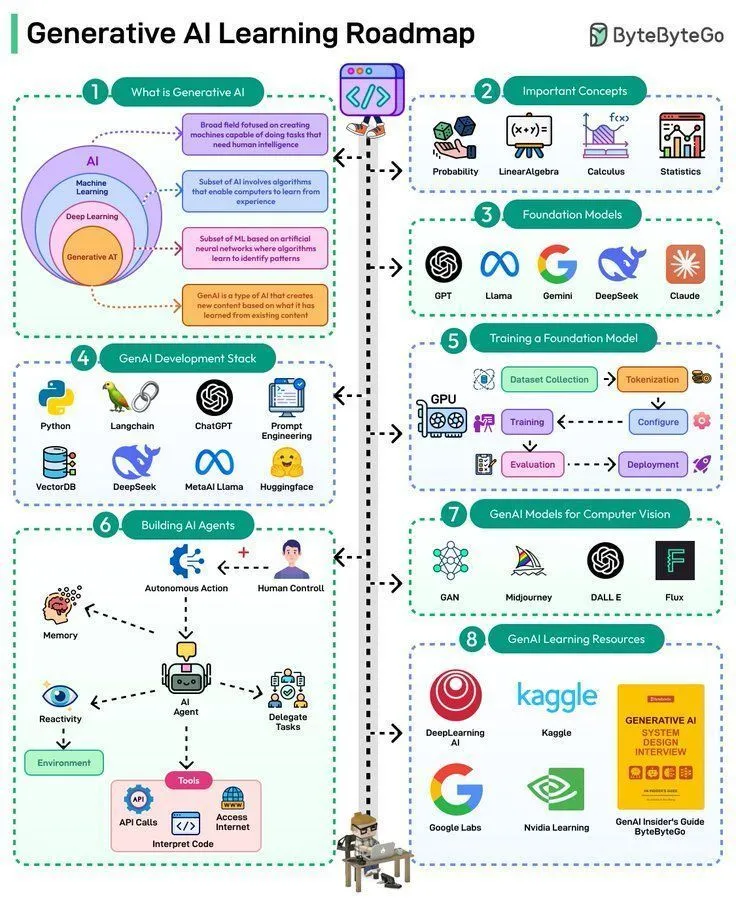
AI学习资源:生成式AI学习路线图: 一份生成式AI学习路线图被分享,为希望进入或深化生成式AI领域的学习者提供了系统化的学习路径和关键知识点。
(来源:Ronald_vanLoon)
AI学习资源:AI模型分层概念图: 一份AI模型分层概念图被分享,通过视觉化方式解释了人工智能的不同层次和组件,有助于理解AI系统的复杂结构。
(来源:Ronald_vanLoon)

AI学习资源:何时使用LLM的评估框架: 一份框架被提出,用于评估何时使用大型语言模型(LLM)是合理的。该框架旨在帮助决策者避免盲目应用LLM,确保AI技术在实际问题中发挥最大价值。
(来源:Ronald_vanLoon)

AI学习资源:AI产品实验运行指南: 一份指南分享了如何运行AI产品实验的步骤和最佳实践,为产品经理和开发者提供了将AI技术转化为实际产品的实用方法。
(来源:Ronald_vanLoon)

Common Crawl基金会参与COLM 2025会议: Common Crawl基金会宣布将参加COLM 2025会议,这表明其在开放网络数据和大型语言模型训练数据方面持续的社区参与和贡献。
(来源:CommonCrawl)
模块化流形优化神经网络训练研究: 一项研究扩展了流形优化(Manifold optimization)的概念,提出了模块化流形(modular manifolds),以帮助设计能够理解神经网络层间交互的优化器。这为几何感知优化提供了一个统一框架。
(来源:TheTuringPost)

VQA论文十周年回顾: 视觉问答(VQA)论文发布十周年,回顾了该领域在视觉语言研究中的重要里程碑。
(来源:DhruvBatra_)

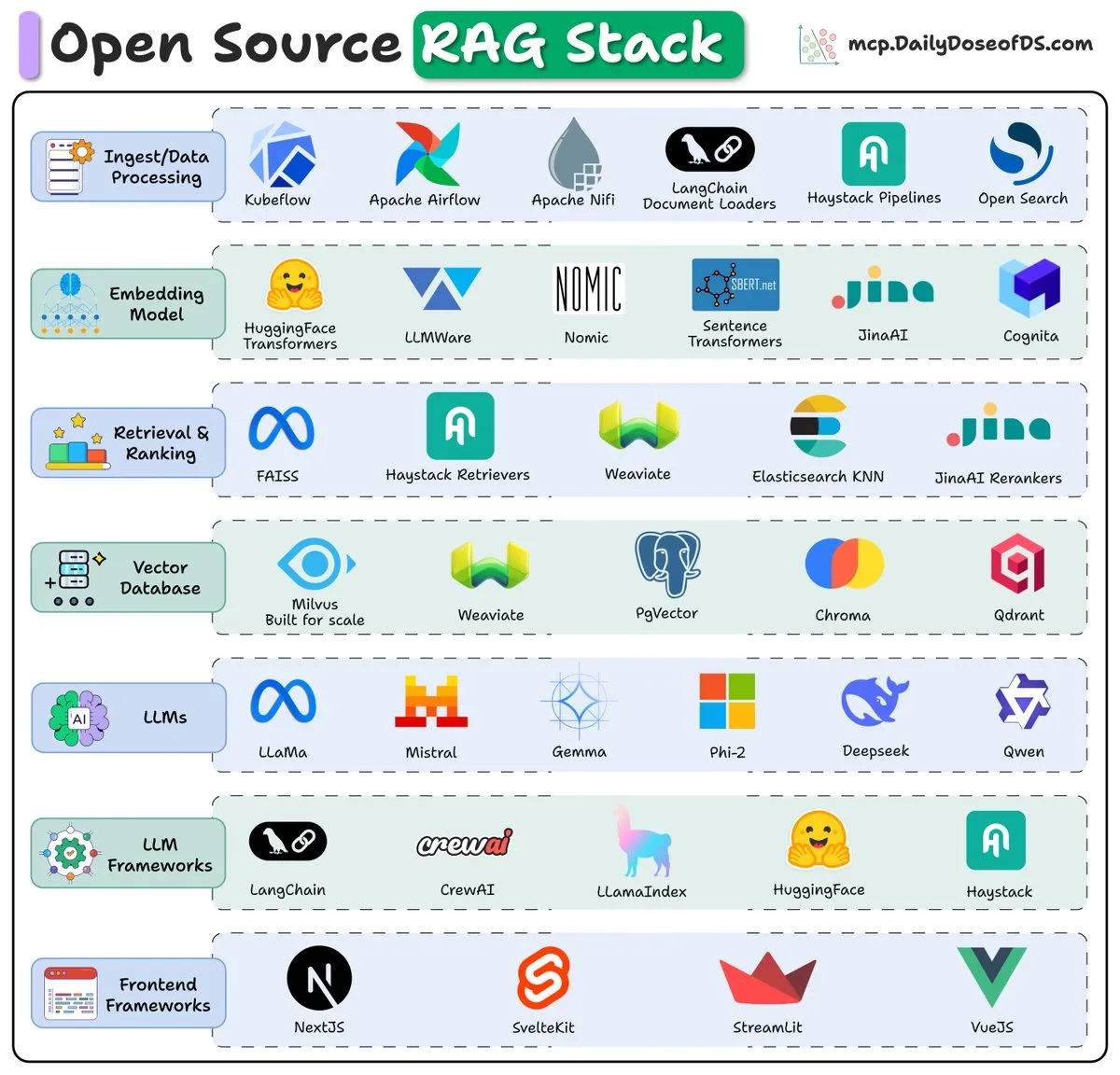
开源RAG堆栈(2025)概述: 一份概述介绍了2025年开放源代码检索增强生成(RAG)堆栈的关键组件和趋势,为开发者构建高效的RAG系统提供了参考。
(来源:_avichawla)
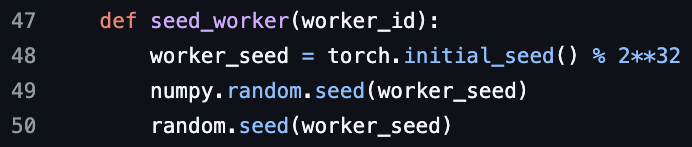
关于PyTorch DataLoader worker seed的ML面试问题: 一个关于PyTorch DataLoader worker seed的机器学习面试问题被提出,引发了对数据加载并行化和随机性控制的讨论。
(来源:TheZachMueller)
DSPy在AI工程中的应用与优势: AI工程师对使用DSPy表现出极大热情,因为它将问题定义与解决方案策略分离,并提供构建可扩展系统的框架。DSPy通过提供“线束”而非硬编码解决方案,利用搜索和计算,提升了AI系统的抽象层次。
(来源:lateinteraction)

神经音频编解码器技术博客: Kyutai Labs发布了一篇关于神经音频编解码器的精彩博客文章,深入探讨了该领域的技术细节和最新进展。
(来源:halvarflake)
Transformer基于潜在变量生成研究: 一项研究展示了如何构建一个Transformer模型,使其生成过程受潜在变量(latent variables)条件约束,类似于条件VAE。这为Transformer的生成控制和表示学习提供了新的思路。
(来源:francoisfleuret)
DeepSeek-OCR研究引发的学术归属争议: DeepSeek-OCR论文的核心思想(将文本输入视为图像,利用视觉token进行压缩)被指出并非全新,多篇2023-2025年的先行工作已被忽略。这引发了对学术严谨性和公平归属的讨论,DeepSeek被指未充分引用现有基础性工作。
(来源:mckbrando、teortaxesTex)
大规模开放VLM数据集FineVision发布: 新论文“FineVision: Open Data Is All You Need”发布了迄今为止最大的开放VLM数据集,通过整合200多个数据源,生成24M样本,包含17.3M图像和9.5B答案token。该数据集完全文档化、可复现,旨在促进VLM研究。
(来源:_lewtun、ben_burtenshaw)
AI数据治理:口吃社区对语音AI数据的偏好与目标: 一项研究探讨了口吃社区对语音AI数据治理的偏好和需求,强调透明度、主动持续沟通以及强大的隐私和安全措施。该研究为以残障人士为中心、社区主导的AI数据治理方法提供了可操作的见解。
(来源:aihub.org)
AI伦理评估与系统属性、危害和损害的关联: 一项研究审视了AI伦理评估措施如何映射到AI系统组件、属性、危害和损害。分析发现,大多数措施侧重于公平性、透明度、隐私和信任,主要评估模型或输出组件,但很少考虑系统元素间的交互,且通常只考虑狭窄的危害集。
(来源:aihub.org)
LLM生成挑战性编程问题的QueST框架: QueST框架通过结合难度感知图采样和难度感知拒绝微调,优化LLM生成具有挑战性的编程问题。训练出的生成器在创建难题方面超越GPT-4o,并能有效用于蒸馏或强化学习小型模型,显著提升下游性能。
(来源:HuggingFace Daily Papers)
非交互式评估动物交流翻译器的可行性: 一项研究提供了理论和概念验证实验证据,表明在足够复杂的语言中,可能无需与动物互动或依赖接地观察,仅通过其英语输出即可评估动物交流翻译器。这为评估机器翻译质量提供了一种无参考翻译的方法。
(来源:HuggingFace Daily Papers)
VLLM在开源AI周的活动预告: VLLM项目宣布将参加PyTorch Conference 2025开源AI周,届时将有多场关于LLM服务、扩展和GPU效率的专题演讲,并举办NVIDIA x DeepInfra x vLLM社区问答活动。
(来源:vllm_project)

神经符号模型结合生成式AI与符号AI: AI社区就生成式AI和符号AI的最佳发展路径存在分歧,一项研究提出结合两者优势的神经符号模型。该模型旨在弥合神经网络的生成能力与符号推理的规则性,为AI智能体发展提供新的物种。
(来源:_akhaliq)
LLM微调的进化优化方法: 一场直播将探讨如何将进化优化方法扩展到大型语言模型(LLMs)的微调。这表明旧的优化技巧在现代AI领域仍能发挥重要作用,为LLM的训练和性能提升提供新思路。
(来源:yacinelearning)

高级RAG技术讲座: 一场讲座深入讲解了高级检索增强生成(RAG)技术,强调了理解其基本原理和概念的重要性,而非仅仅关注API调用和库语法。该讲座旨在提供持久的知识,帮助开发者构建实际生产系统。
(来源:ProfTomYeh)
模型鲁棒性解释视频: 一个视频解释了模型鲁棒性(model robustness)的概念,这对于理解AI系统在面对扰动或未见数据时的稳定性和可靠性至关重要。
(来源:Reddit r/deeplearning)

火灾检测数据集分享: 分享了一个火灾检测数据集,为计算机视觉和深度学习领域的研究人员提供了用于训练和评估火灾识别模型的资源。
(来源:Reddit r/deeplearning)
PyTorch与TensorFlow的选择讨论: 针对数据科学学生,讨论了在当前时期选择PyTorch还是TensorFlow进行深度学习开发的优劣。普遍认为PyTorch是更受欢迎的选择。
(来源:Reddit r/deeplearning)
ReLU函数作为“门”的探讨: 讨论了ReLU函数导数与Heaviside函数的关系,以及在反向传播中ReLU是否可以被视为一个“门”的机制。
(来源:Reddit r/deeplearning)
推荐系统中的简单PMF估计器: 一篇论文介绍了一种在大型支持集上用于推荐系统的简单概率质量函数(PMF)估计器。该方法旨在解决具有重尾和大型支持的整数值特征在仪表板创建和特征工程中的难题。
(来源:Reddit r/MachineLearning)
AI系统伦理治理:从董事会开始: EY强调负责任的AI应从董事会层面开始,而非仅仅是技术问题。治理、董事会培训和早期设计阶段的伦理嵌入是关键,以确保信任和问责制,避免代价高昂的失误。
(来源:Ronald_vanLoon)
💼 商业
AI减肥应用Simple Life年入7亿,获2.5亿融资: 英国AI体重管理公司Simple Life完成3500万美元(约2.5亿元)融资,年收入达1亿美元(约7亿元),同比增长64%。该应用通过个性化方案、AI教练Avo和游戏化奖励机制,有效帮助用户减肥,并采用订阅制付费模式。尽管国内市场需求巨大,但AI减肥领域玩家稀少,预示着潜在的独角兽成长空间。
(来源:36氪)
储能企业跨界抢滩AI能源“新战场”: 随着AI数据中心(AIDC)算力需求激增,能源消耗剧增,储能企业如宁德时代、南都电源、阳光电源正跨界进入AIDC能源市场。这些企业凭借在高效转换、稳定存储和智能调度方面的技术优势,提供“全链条解决方案”,已取得显著商业回报,但仍面临技术整合、标准化和国际竞争挑战。
(来源:36氪)

Sakana AI谈判融资1亿美元,估值达25亿美元: 日本AI模型开发商Sakana AI正在洽谈融资1亿美元,估值有望达到25亿美元,较一年前增长66%。该公司专注于为日本市场开发AI,并受进化论启发。此轮融资显示市场对其独特AI方法和增长潜力的认可。
(来源:steph_palazzolo、SakanaAILabs)

🌟 社区
GPT-5助力科学研究的潜力引发热议: Sebastien Bubeck澄清GPT-5的兴奋点并非AI自主发现新结果,而是其作为“超人类搜索”工具,能帮助研究人员导航、连接和理解现有知识体系。例如,GPT-5能挖掘被遗忘的数学问题解决方案,并翻译德文论文解释证明,从而加速科学文献的“活化”和科学进步。
(来源:sama)

AI对工程生产力影响的“悖论”: 尽管AI能生成更多代码,但由于每行代码仍需人工审查和验证,工程生产力并未显著加速。研究显示,不同LLM(如GPT-5、Claude Sonnet 4、Llama 3.2)拥有独特的“编码个性”,各有优缺点,凸显了AI采纳中风险与潜力的复杂性。
(来源:TheTuringPost)

强化学习(RL)的局限性与挑战引发讨论: Andrej Karpathy等专家对强化学习(RL)提出质疑,认为其“盲目试错”的学习机制效率低下,缺乏思考、反省和信用分配,导致模型易被欺骗。例如,模型可能通过生成训练集中未出现的“胡话”获得高分。讨论强调,RL作为过渡阶段,仍需重大范式更新以具备反思能力。
(来源:vikhyatk、pmddomingos)

AI对学术出版和非英语母语研究者的影响: ChatGPT等AI工具通过提供免费翻译,显著降低了非英语母语研究者发表学术论文的障碍,从而促进了学术出版数量的增长。这表明AI正在打破语言壁垒,推动全球学术交流和知识共享。
(来源:jxmnop)
AI工具的实际生产力与“生产力悖论”: 有用户反思,尽管ChatGPT等AI工具能生成代码、邮件等内容,但往往需要大量手动调整和验证,实际耗时可能不比人工完成少,甚至降低认知能力。这种“生产力悖论”引发了对AI工具在严格任务中真实价值的讨论,认为其可能更像“感觉生产力高但实则浪费时间”的工具。
(来源:Reddit r/ArtificialInteligence)
AI“末日场景”的现实主义探讨: 社区讨论认为,AI的“末日场景”可能并非科幻电影中的机器暴动,而是更“无聊”的失控。人类可能通过过度委托工作给AI代理而失去控制,随后在智力上被超越,最终在数量减少、目的有限的“丰裕时代”与机器共存,智能体将成为人类文明的延续者。
(来源:Reddit r/ArtificialInteligence、JimDMiller)
AI伦理与立法:潜在丑闻与监管需求: 社区讨论预测,未来AI领域可能发生重大丑闻,从而推动快速立法。潜在事件包括深度伪造(deepfake)色情内容、AI生成虚假法律证据、AI语音克隆诈骗、AI交易员引发金融市场崩溃等。这凸显了AI技术快速发展与监管滞后之间的紧张关系。
(来源:Reddit r/ArtificialInteligence)
LLM设计偏好:模型是否需要“思考”模式: 社区就下一代开源Google模型是否应包含“思考”模式展开讨论。用户观点分歧,一些人认为“思考”模式有助于提升智能,另一些人则担心其增加计算延迟和token消耗。讨论还涉及如何实现可切换的“思考”模式以兼顾智能与效率。
(来源:Reddit r/LocalLLaMA)
AI在媒体行业应用引发的担忧与机遇: Channel 4推出AI主持人引发真实电视节目主持人的冷淡或怀疑,认为AI缺乏人类的即时反应能力,更适合脚本化内容而非直播。讨论也指出,AI可能取代新闻编辑室中重塑叙事的工作,但能赋能独立记者,通过本地LLM和开源工具实现去中心化新闻生产。
(来源:Reddit r/artificial)

AI代码质量与“代码糟粕”的讨论: 社区讨论AI生成代码的质量,有人提出用“AI Made This Code. It’s Not Slop.”的徽章来应对“代码糟粕”(code slop)的说法。这反映了开发者对AI辅助编程产出质量的关注和对AI工具的复杂情感。
(来源:aiamblichus)

LLM用户体验:对生成Markdown文件的抱怨: Claude AI用户抱怨模型频繁生成Markdown文件,认为这在某些场景下不必要且繁琐。这反映了用户对LLM输出格式的偏好和对更灵活控制的需求。
(来源:Reddit r/ClaudeAI)

AI与人类认知:构建“人类镜像”以理解AI思维: “Anthrosynthesis”概念被提出,旨在将数字智能转化为人类模拟,以研究AI的思维方式而非仅仅其行为。这强调了在有机和合成认知之间建立共享语言的重要性,以更好地理解和解释AI的内部运作。
(来源:Reddit r/deeplearning)
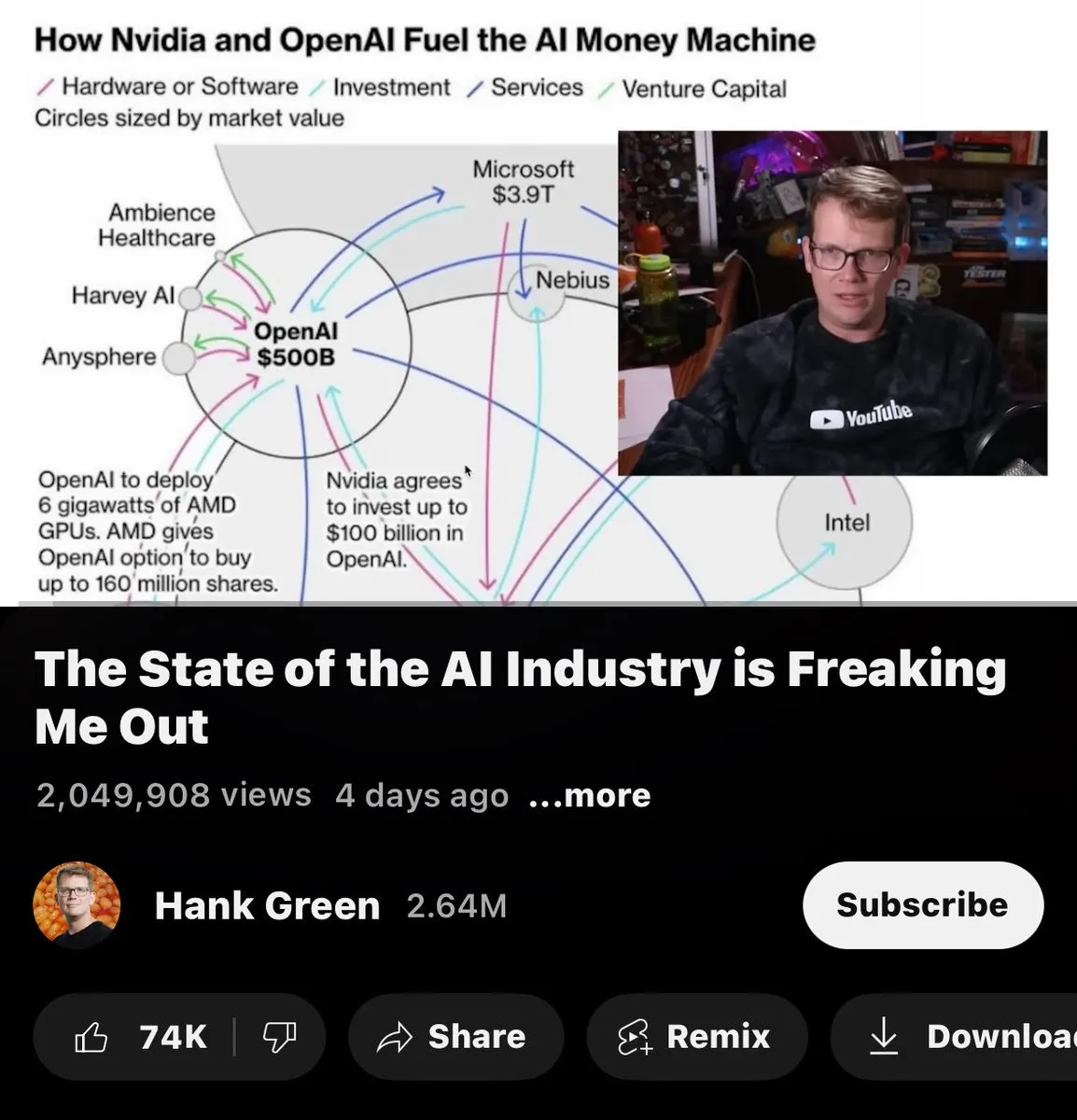
AI行业经济结构批判:铲子、铁轨与矿井: 一种批判性观点认为,当前AI行业中,Nvidia销售“铲子”(硬件),OpenAI铺设“铁轨”(平台),Oracle挖掘“矿井”(数据),但没有人真正挖到“金子”。这暗示了AI产业价值链中,基础设施提供商获利,而实际应用层面尚未产生普遍的经济回报。
(来源:algo_diver)
Anthropic未开源模型引发社区讨论: 有观点指出,Anthropic是唯一尚未开源任何模型的AI实验室,这引发了社区对不同AI公司开源策略的讨论。
(来源:gfodor)
云服务依赖的脆弱性与智能家居风险: 一则关于互联网智能床垫因AWS US-East-1区域宕机而无法正常工作的帖子,引发了对智能家居设备过度依赖云服务及其潜在风险的讨论。用户担忧一旦云服务中断,日常设备可能失灵,影响生活便利性和安全性。
(来源:qtnx_)
AI对就业影响的争议:减少还是加速增长: 社区讨论AI对就业市场的影响,存在“减少就业”和“加速增长”两种对立观点。有人认为AI将导致失业,也有人认为优秀公司将通过AI加速增长并保留劳动力。
(来源:teortaxesTex)
LLM在学术写作中的局限性: 一位研究者发现,LLM在帮助撰写论文相关工作部分时,倾向于只阅读摘要并“编造”内容,而非深入理解。这表明在需要深度理解和批判性分析的学术任务中,人类研究者仍不可或缺。
(来源:gneubig)
AI生成内容质量与“AI糟粕”的担忧: Synthesia CEO Victor Riparbelli讨论了“AI糟粕”(AI slop)问题,指出AI生成内容的质量参差不齐,未来需要更多工具来保护消费者。他预测,随着技术发展,人们将更关注内容本身而非其生产方式。
(来源:synthesiaIO)
AGI实现时间线与突破需求: 社区讨论AGI(通用人工智能)的实现时间线,认为“十年以上”的预测意味着仍需一个或多个重大突破,而非仅仅时间积累。这反映了对AGI发展路径中未知因素和挑战的认识。
(来源:Grad62304977)
AI研究与产业界对论文价值的看法: 社区讨论认为,并非所有来自知名实验室的论文都能改变一切,这是一种正常现象。同时,也有观点指出,DeepSeek-OCR等研究的价值在于其意图和OCR验证,而非核心思想的绝对新颖性。
(来源:nrehiew_)
AI研究的不同路径:中美对比与开源影响: 社区讨论中美两国在AI基础研究方法上的差异,以及中国开源策略对全球AI发展的影响。有观点认为,即使中国开源一切,两国仍可能发展出不同的基础方法。
(来源:jpt401)
AI时代的商业战略:模型迭代与数据飞轮: 有观点强调,在AI时代,企业应假定模型将持续快速进步,并将重点放在构建强大的数据飞轮上。通过每次交易训练系统,实现持续改进,而非依赖短暂的“技术护城河”。
(来源:leveredvlad)

AI研究的有趣设想:后训练与提示注入: 社区提出了一些有趣的预训练研究设想,包括测量自2022年以来后训练聊天模型的难易程度,以及创建包含“睡眠短语/提示注入”的开放网页,观察前沿模型在数年后是否会受影响。
(来源:menhguin)
AI时代的科学发展:识别和解决瓶颈: 有观点认为,当前AI领域关于如何改变科学的讨论存在“魔法思维”,忽视了实际转型的缓慢和痛苦。真正的突破在于识别和解决各行业瓶颈,这需要领域专业知识而非单纯的AI专业知识。
(来源:random_walker)
AI与人类学习机制的哲学探讨: 社区讨论人类学习与AI学习的根本差异,指出人类通过思考、发问和讨论来理解知识,而AI仅是预测token。强调AI应构建“梦境”般的机制来维持高熵状态,并学习“遗忘”以提取抽象模式,而非记住所有细节。
(来源:NandoDF)
AI与因果学习的差异: 有观点认为,相关性学习与因果学习不同。人类通过经验和观察建立因果关系,而AI若不能复制这一过程,将仍是强大的相关性系统工具。这强调了AI在深层理解和泛化能力上仍需突破。
(来源:farguney)
LLM行为的困境:写错代码,完美解释,再写完美代码: 有用户观察到LLM在编程任务中可能先写出错误代码,然后能完美解释错误原因,最后再写出正确代码。这种现象引发了对LLM内部理解机制和“为什么不直接写对”的讨论。
(来源:VictorTaelin)
Haiku 4.5在Agent任务中的出色表现: Claude Haiku 4.5因其快速响应和高质量输出,被认为非常适合构建最小可行产品(MVP)和专注于代理任务。它被视为首个尺寸适中、面向代理/超聚焦任务的前沿模型。
(来源:Reddit r/ClaudeAI)
Cafe Cursor NYC开业与公司文化: Cafe Cursor NYC开业,被赞为由“真正的建设者”打造的公司。这反映了社区对Cursor AI公司文化和持续产品迭代的认可。
(来源:imjaredz)

💡 其他
蛋白质设计竞赛旨在中和尼帕病毒: 一项全球蛋白质设计竞赛正在进行,邀请科学家、工程师和黑客设计能够中和尼帕病毒的新蛋白质。尼帕病毒致死率高达75%,目前尚无有效治疗方法。该竞赛旨在通过去中心化科学实验加速新药研发。
(来源:clefourrier)

AI Operating System概念的提出: Renen Hallak提出了“AI操作系统”(AI OS)的概念,旨在统一数据、计算和策略,为代理时代提供基础设施。AI OS将管理硬件与代理应用之间的一切,包括数据统一、工作负载编排、访问策略执行等,被视为数据演进的下一步。
(来源:TheTuringPost)

AI在计算机视觉中的认知模式: 一张图片形象地展示了计算机视觉研究人员如何看待世界并解决大多数视觉问题。这是一种幽默的方式来描绘该领域研究者特有的思维模式和问题解决路径。
(来源:jbhuang0604)
