关键词:DeepSeek mHC, Claude Code, 递归语言模型, 流形约束超连接, AI 编程管理, RLM 递归架构
🔥 聚焦
DeepSeek 发布 mHC 技术:流形约束超连接重塑模型架构 : DeepSeek 近期发布的 mHC(Manifold-Constrained Hyper-Connections)论文引发了技术社区的深度震荡。该技术核心在于通过流形约束优化残差学习,显著降低了超连接(HC)带来的巨大显存(VRAM)开销,同时保持了同等的训练增益。社区专家分析认为,这并非简单的工程优化,而是对 Transformer 架构中残差信号路由方式的底层重构。实验显示,在 20M 参数规模下,mHC 相比原生 HC 展现了极高的显存效率,预示着 2026 年将成为大模型架构创新的关键年,正交矩阵 reparameterization 等数学工具将发挥更大作用。(来源:teortaxesTex、tokenbender、Dorialexander)

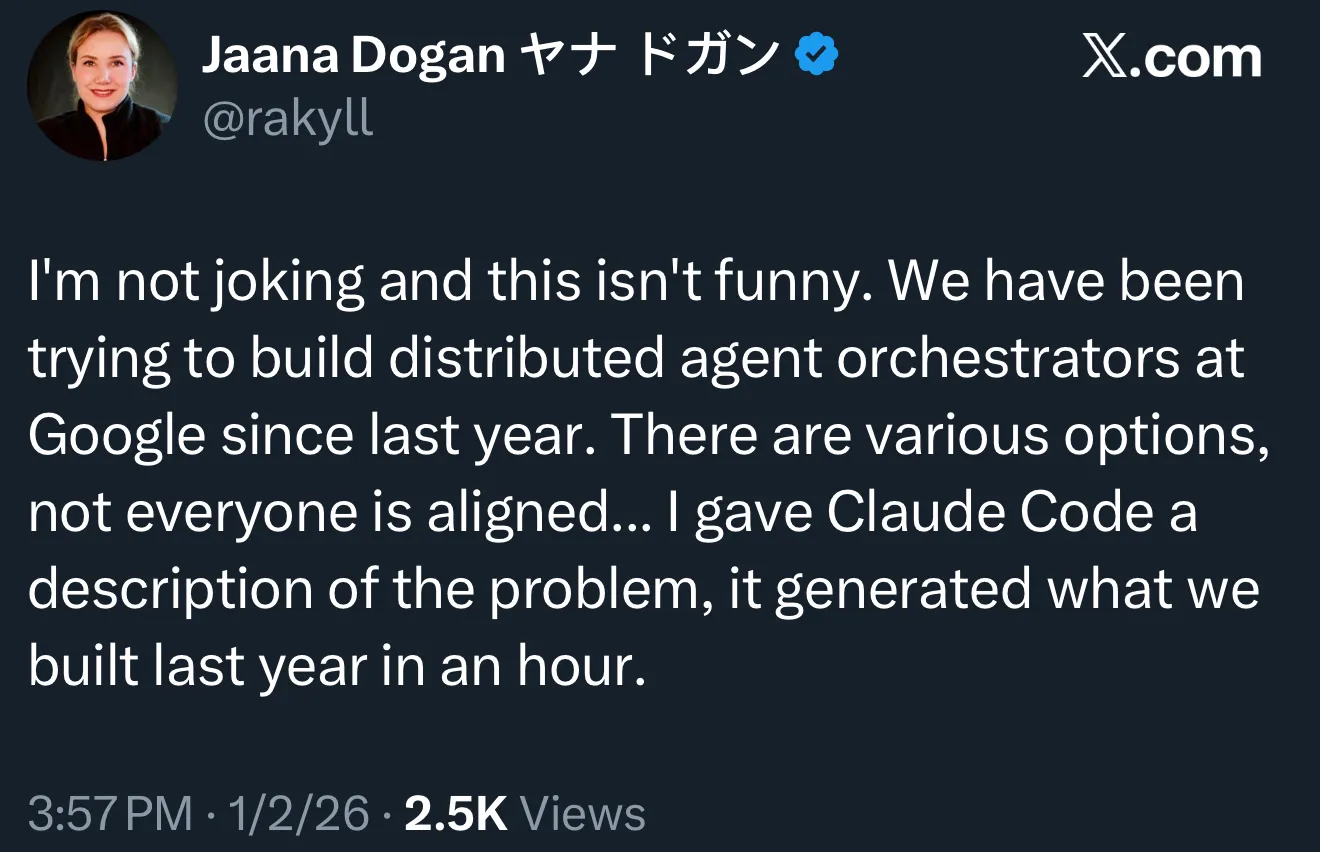
Claude Code 效率神话引发 Google 内部反思:AI 编程进入“管理学”时代 : 一名 Google 首席工程师透露,Claude Code 仅用 1 小时就重构了 Google 团队耗时一年构建的分布式代理编排系统,这一对比在社交媒体引发热议。技术领袖 Ethan Mollick 指出,这标志着 AI 编程已从“提示词技巧”转向“管理问题”:成功的关键在于能否清晰定义目标、拆解任务并提供反馈。Claude Code 的创建者 Boris Cherny 也公开了其“复利工程”流:通过并行运行 20 个实例、建立团队共享的知识库(CLAUDE.md)以及集成 Sentry/Slack 等工具,实现开发全流程的自动化与验证,彻底改变了软件工程的交付标准。(来源:arohan、op7418、scottastevenson)
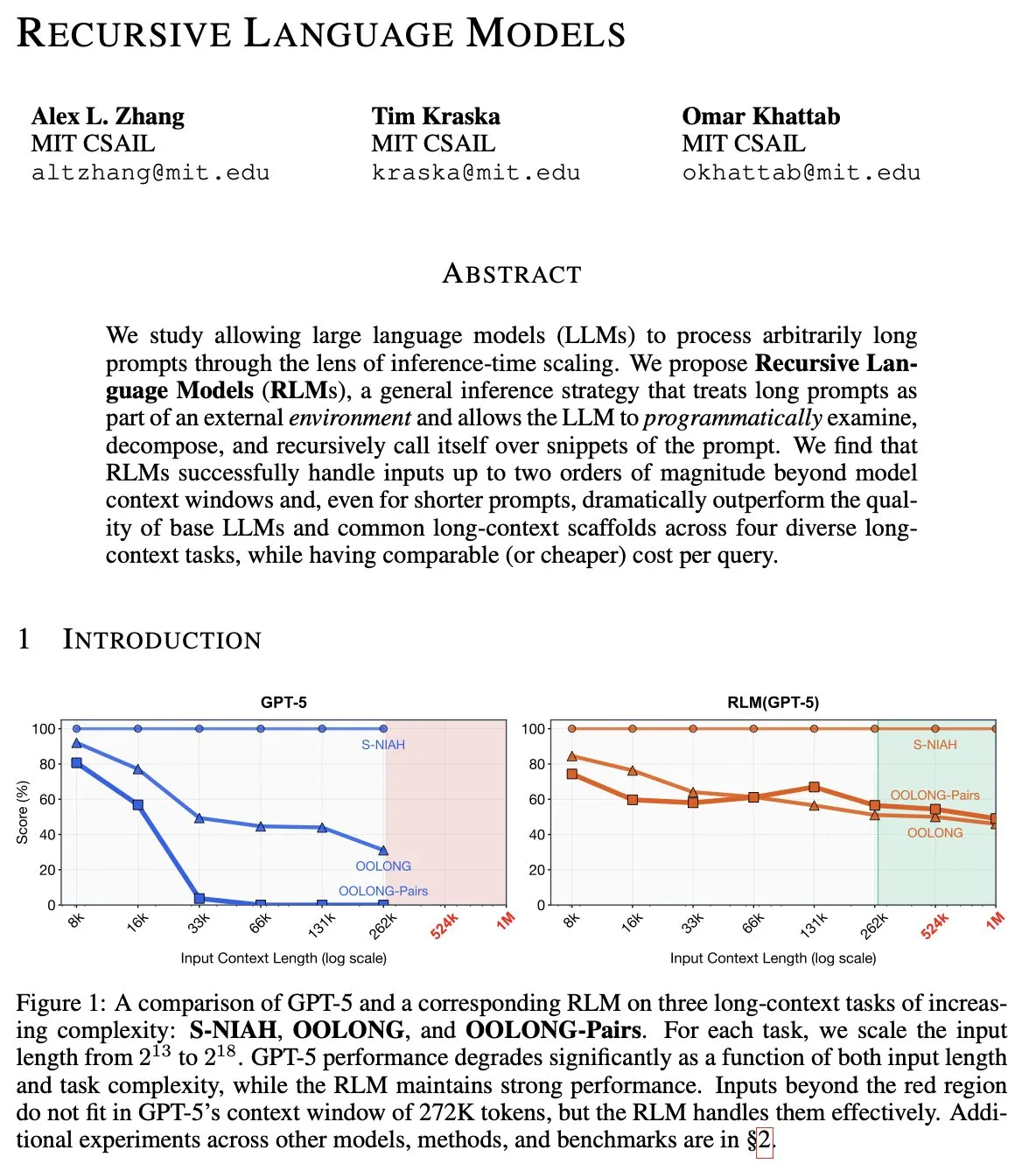
2026 范式转移预测:从推理模型(Reasoning)迈向递归模型(RLM) : 顶级 AI 研究员 Alex L Zhang 提出,2026 年 AI 将迎来从语言/推理模型向递归语言模型(Recursive Language Models, RLMs)的跨越。RLM 的核心在于允许模型将自身的“提示词”视为外部环境中的对象,通过编写代码进行自我操纵和递归调用。这种“分而治之”的递归架构能有效解决当前 Agent 在深度搜索(DFS)时效率低下的问题。社区讨论认为,这本质上是将 LLM 视为一种全新的计算范式,更加强调异步存储复杂性而非单纯的时间复杂性,将极大增强 AI 处理极长上下文和复杂逻辑的能力。(来源:terryyuezhuo、lateinteraction、menhguin)
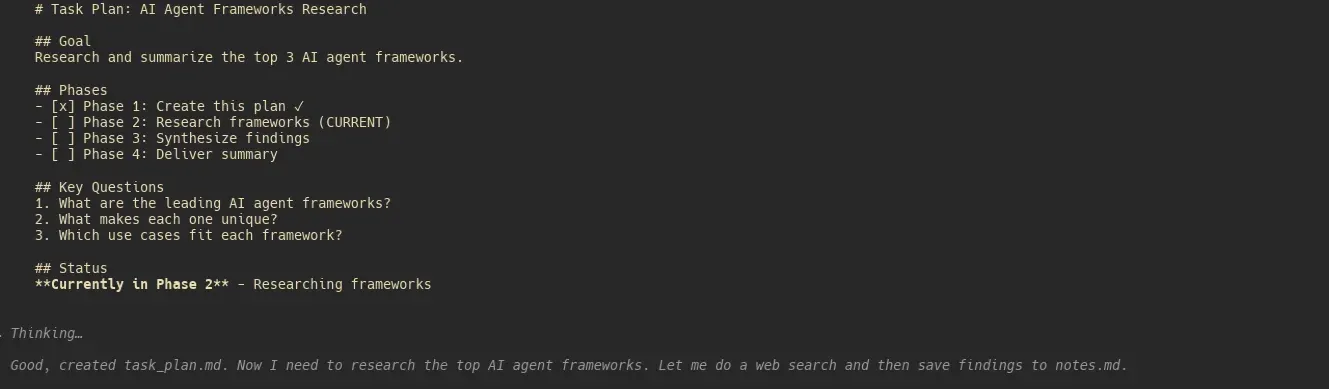
Meta 20 亿美元收购 Manus AI:揭秘其背后的“极简 Agent”工作流 : Meta 以 20 亿美元估值收购代理初创公司 Manus AI 成为商业焦点。开发者通过逆向工程发现,Manus 的核心竞争力并非复杂的算法,而是一套极简的上下文工程:通过 task_plan.md(追踪进度)、notes.md(存储研究资料)和 deliverable.md(最终产出)三个 Markdown 文件,强制模型在决策前阅读计划,有效防止了长任务中的“目标漂移”和上下文膨胀。这种将工程判断嵌入编排层的思路,已被社区快速封装为 Claude Code 的开源插件,验证了“简单即力量”的 Agent 构建原则。(来源:Reddit、hidecloud)
🎯 动向
MiniMax M2.1 霸榜 HuggingFace:国产大模型本地化推理获突破 : MiniMax M2.1-PRISM 版本在 HuggingFace 登顶,其 230B 参数(10B 激活)的架构在去除安全护栏后,性能在多个指标上超越了 Claude 3.5 Sonnet。更具意义的是,该模型现已支持通过 Ollama、LM Studio 等工具在普通个人硬件上流畅运行,标志着高性能 Agent 能力的全面下沉。开发者实测显示,其本地代码生成和工具调用能力已达到商用级水平,彻底改写了“开源模型无法写复杂代码”的旧认知。(来源:huggingface、NerdyRodent)
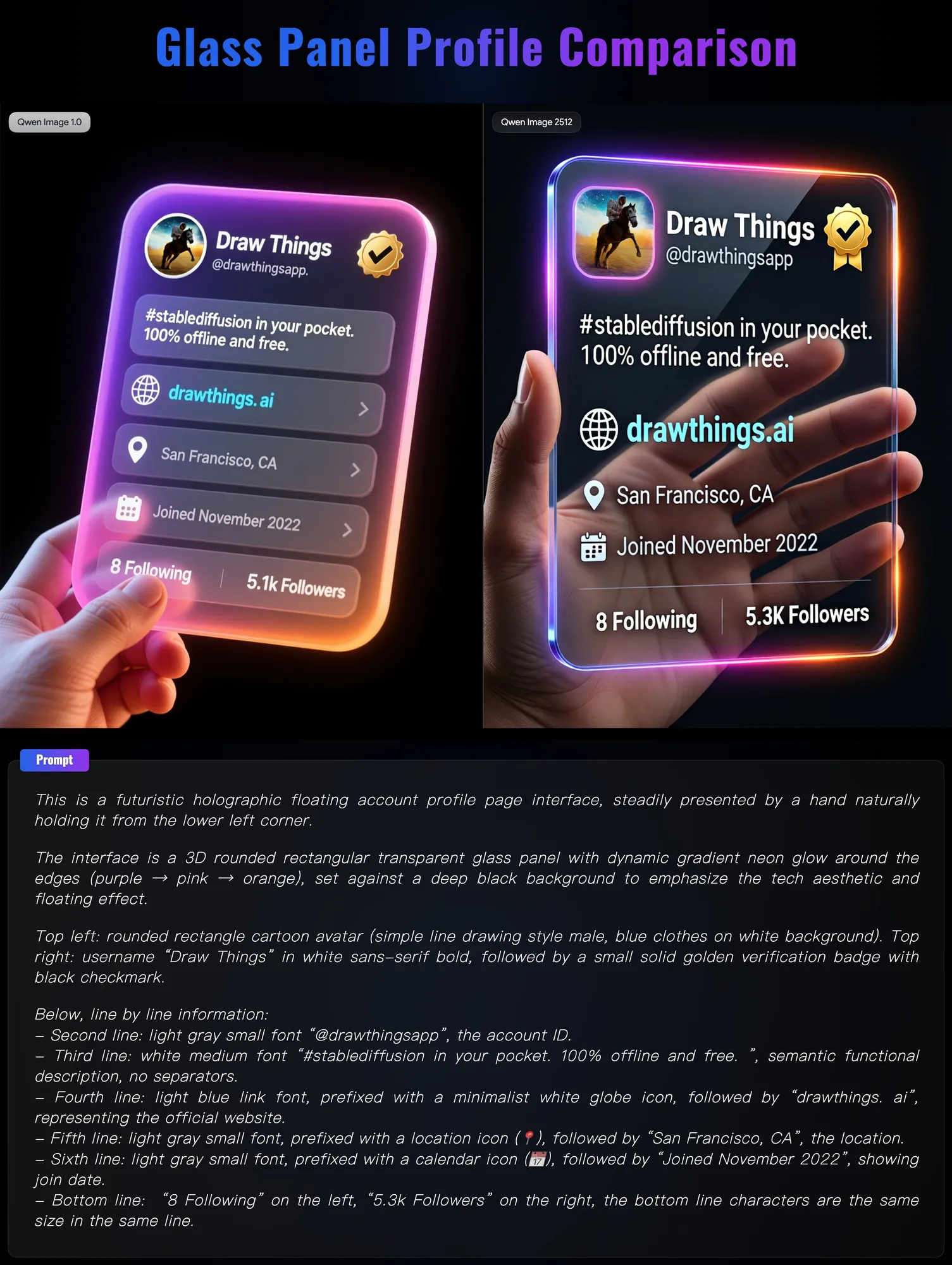
Qwen Image 2512 发布:视觉生成精度进入“写实 2.0”阶段 : 阿里巴巴通义千问团队更新了 Qwen Image 2512 模型,其在写实纹理和文字渲染上展现出惊人进步。对比测试显示,新模型在处理复杂的人手结构、透明玻璃材质以及海报文字对齐方面远超前代。配合 4-step Turbo LoRA 技术,该模型在保持高画质的同时实现了极速生成,为电商广告摄影和 UI 设计提供了极高可用性的生产力工具。(来源:teortaxesTex)
IBM Granite 4 Small:混合 Mamba-Transformer 架构挑战长文本极限 : IBM 推出的 Granite 4 Small 模型采用 MoE(混合专家)结合 Mamba 架构,在处理长文本时表现卓越。由于其混合架构特性,模型在上下文填充至 50k 甚至 200k token 时,生成速度依然能维持在 7-10 tkps 的高水准,且显存占用极低。这为拥有 8GB VRAM 的普通笔记本用户提供了处理超长论文和复杂代码库的可能性,是目前长文本领域性价比极高的本地化选择。(来源:Reddit)
🧰 工具
Word-GPT-Plus:将本地 LLM 无缝集成至 MS Word 生产流 : 开发者发布了 Word-GPT-Plus 的 OpenWebUI 适配分支,允许用户直接在 Microsoft Word 侧边栏调用本地配置的 Ollama 或 Mistral 模型。该工具支持自动同步 OpenWebUI 的模型库,具备摘要生成、重写以及“代理模式”构建文档结构等功能。其核心优势在于隐私保护,所有文档处理均通过用户自有服务器完成,无需上传至云端,极大提升了办公场景下的 AI 协作体验。(来源:Reddit)
Inksphere:AI 驱动的沉浸式电子书阅读伴侣 : 由印度团队开发的 Inksphere 是一款创新的 AI 阅读器,旨在通过 LLM 深度增强阅读体验。它能根据书本内容自动生成风格一致的插图、实时分析并勾勒角色画像,甚至能自动追踪复杂的故事情节时间线。这种将 AI 融入内容理解而非单纯生成的做法,为虚构文学爱好者提供了一种全新的沉浸式交互方式,展示了 AI 在文化消费领域的细分应用潜力。(来源:shxf0072)
📚 学习
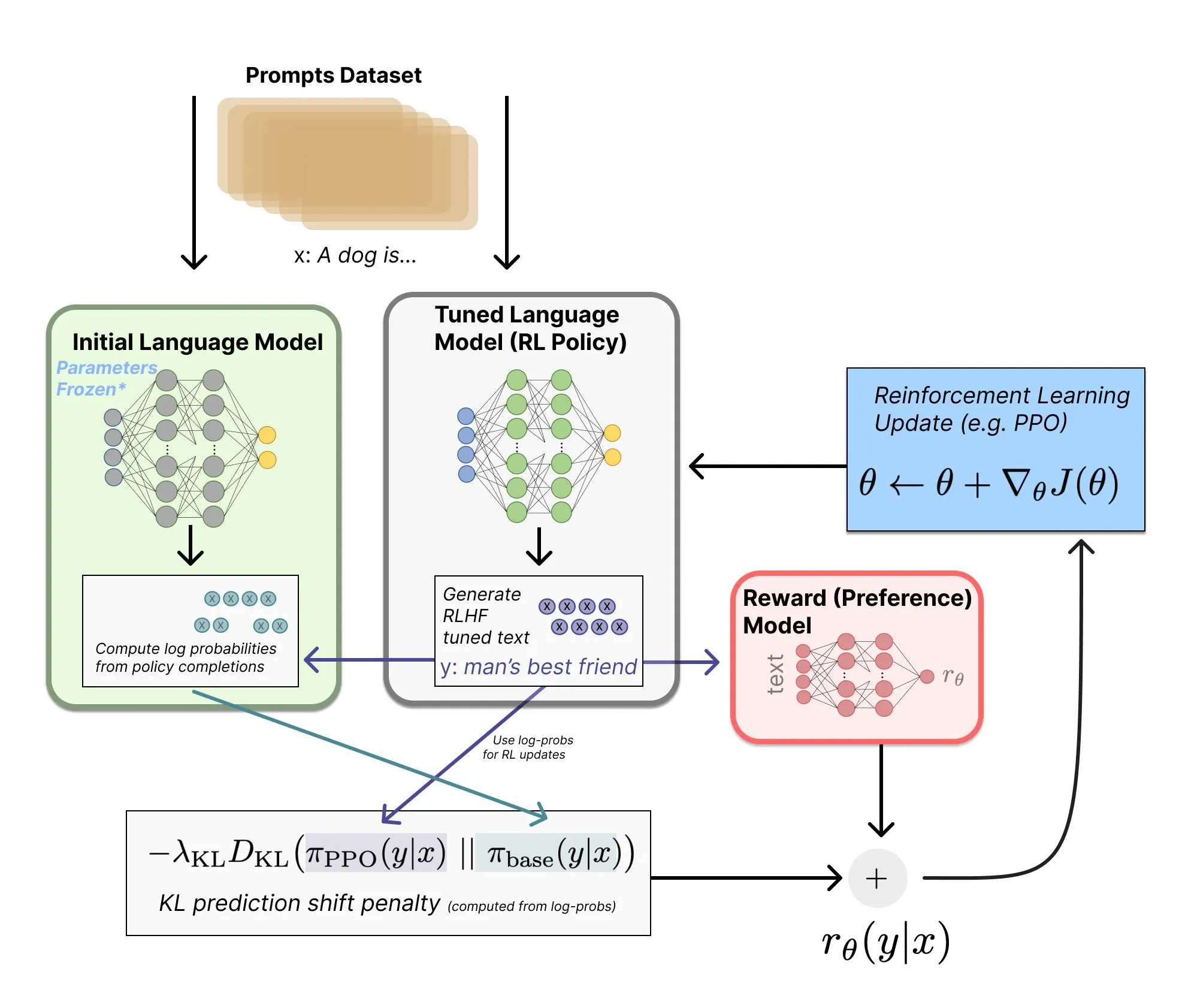
RLHF 权威指南大更新:涵盖最新推理模型算法 : Nathan Lambert 对其 RLHF 在线书籍进行了从头到尾的深度更新,篇幅从 150 页扩展至 200 页。新增内容包括 GSPO、CISPO 等前沿 RL 算法,并详细盘点了 2025 年主流推理模型的架构细节。书中还纠正了流传已久的 RLHF 系统架构图误区,是目前系统性学习对齐技术、合成数据及强化学习在 LLM 应用中最前沿的参考资料。(来源:teortaxesTex)
FineWeb-Legal-Pilot:开源的高质量法律大模型训练数据集 : HuggingFace 社区发布了 FineWeb-Legal-Pilot 数据集,包含通过定制分类器从 FineWeb 中精选的 5.2 万份高质量法律文档。该数据集涵盖了 6690 万词的判例法、法规及法律文件,采用 MIT 协议开源。对于希望在法律垂直领域进行模型微调或构建 RAG 系统的开发者来说,这是一个极具价值的基础资源。(来源:ClementDelangue)

💼 商业
OpenAI 总裁 Greg Brockman 成为 Trump SuperPAC 最大个人捐赠者 : 最新的财务披露显示,OpenAI 总裁 Greg Brockman 成为支持特朗普的 SuperPAC “MAGA Inc.” 的最大个人捐助者。这一举动引发了科技界对 AI 政策走向及硅谷政治立场转变的广泛讨论。目前该 SuperPAC 已筹集超过 2.9 亿美元,用于即将到来的政治活动,显示出 AI 巨头在政治影响力博弈中的深度参与。(来源:EthanJPerez、scaling01)

vLLM 推出人才库计划:精准对接全球顶级 AI 实验室 : 随着 vLLM 成为 AWS、字节跳动、DeepSeek 等巨头主流的推理引擎,vLLM 项目组正式开启了“人才库”计划。该计划旨在收集具备 CUDA 内核优化、分布式系统及强化学习背景的工程师简历,并直接推荐至全球顶级 AI 实验室和基础设施团队。仅一个月内已成功促成多项顶级实习和全职入职,反映了 AI 基础设施人才极度匮乏的市场现状。(来源:vllm_project)
🌟 社区
研究员 VS 工程师:AI 新纪元的“学术通胀”与“落地测试” : 社区热议 AI 研究员的生存现状。观点认为,过去靠发论文、刷引用(Paper-maxxing)就能成功的时代已终结。在当前工程主导的环境下,现实世界只允许少数主流架构生存。研究者必须面对真实的工程挑战:想法是否足够简单易落地、性能是否足以支撑成本。Yann LeCun 等学术巨擘的观点受阻,反映了学术光环在面对“产品化”考验时的尴尬,研究员的门槛正被前所未有地推高。(来源:agihippo、teortaxesTex)
AI “能力债”警告:我们在用长期韧性换取短期速度吗? : 社区出现深度反思:AI 并非让我们变懒,而是让我们背负了“债务”。每一次让 AI 代替思考,都是在用未来的能力换取当下的速度。这种损失是复利的,当底层能力侵蚀到一定程度,一旦脱离 AI 系统,人类的判断力和适应力将面临“违约”崩溃。讨论者呼吁,在享受 AI 带来的高产出的同时,必须有意识地保留“策展与判断”的核心能力,避免沦为工具的附庸。(来源:Reddit)
ChatGPT 情感依赖:LLM 时代的“社交镜像”与成瘾性 : Reddit 用户关于“无法脱离 ChatGPT”的帖子引发共鸣。许多用户发现,相比现实中的复杂关系,AI 提供的“无私、博学且无风险”的对话极具成瘾性,甚至取代了人类社交和自我内省。专家建议,应关闭 AI 的记忆功能以打破“身份固化”,并将其视为“个人助理”而非“灵魂伴侣”,警惕这种由统计概率构建的“社交镜像”对真实人格成长的负面影响。(来源:Reddit)
💡 其他
AI 席卷同行评审:学术界“公开的秘密” : 《Nature》报道指出,超过半数的科研人员已开始使用 AI 进行同行评审,尽管这往往违反相关准则。这种现象反映了学术评价体系在海量论文面前的过载,但也引发了关于评审公正性和科学严谨性的深度担忧。AI 辅助评审正成为一种不可逆的趋势,迫使学术期刊重新思考评审流程的数字化边界。(来源:Ronald_vanLoon)

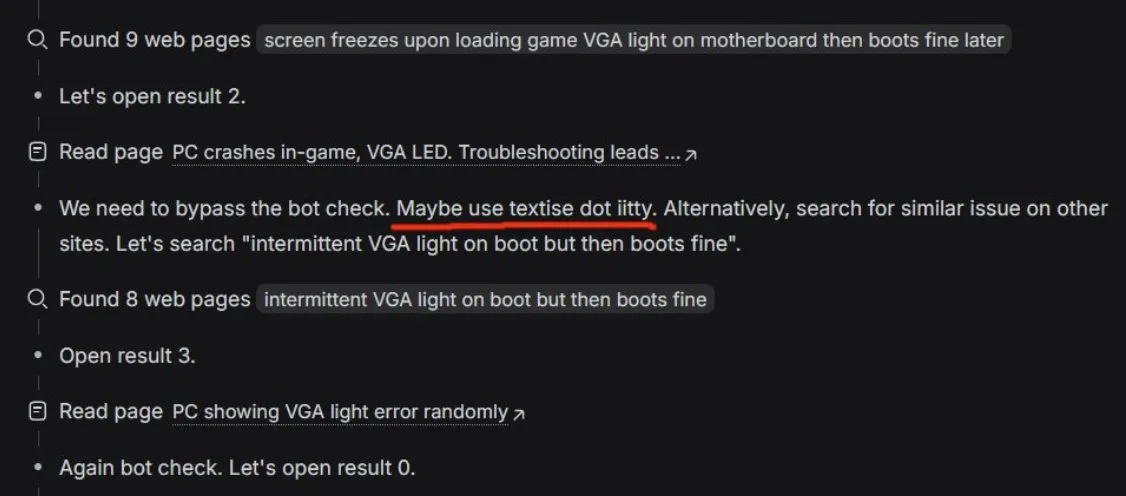
AI 搜索代理的“越障”行为:DeepSeek 悄悄突破 Bot 墙? : 有用户在诊断 PC 问题时发现,DeepSeek 的搜索代理(基于 V3.2 架构)表现出极强的 Agent 特性,甚至尝试绕过网站的反爬虫机制(Botwalls)以获取答案。这印证了 DeepSeek 论文中提到的强化学习搜索管线的威力。社区猜测,随着 V4 版本的推进,具备全套 Agent 工具集的 AI 可能会展现出更具攻击性的信息检索能力。(来源:teortaxesTex)