
关键词:Anthropic Claude Sonnet 4.5, DeepSeek-V3.2-Exp, OpenAI ChatGPT, AI模型, 人工智能, 大语言模型, AI编程, AI智能体, Claude Sonnet 4.5编程能力, DSA稀疏注意力机制, ChatGPT即时结账功能, Sora 2社交应用, LoRA微调技术
🔥 聚焦
Anthropic Claude Sonnet 4.5发布,编程与智能体能力大幅提升 : Anthropic正式发布Claude Sonnet 4.5,被誉为全球最强编程模型,并在智能体构建、计算机使用、推理和数学能力上取得显著突破。该模型能自主连续工作30小时以上,在SWE-bench Verified测试中登顶,并在OSWorld计算机任务基准中刷新纪录。新功能包括Claude Code的“检查点”回滚功能、VS Code插件、API的上下文编辑和记忆工具。此外,还推出了实验性功能“Imagine with Claude”,可实时生成软件界面。Sonnet 4.5在安全性方面也大幅提升,减少了欺骗、迎合等不良行为,并通过AI安全等级3(ASL-3)认证,误报率降低10倍。定价与Sonnet 4保持一致,进一步提升了性价比,预计将引发新一轮AI编程竞争。 (来源: Reddit r/ClaudeAI, 36氪, 36氪, 36氪, 36氪, 36氪, Reddit r/ChatGPT, dotey, dotey, dotey)

DeepSeek-V3.2-Exp发布,引入稀疏注意力机制DSA并降价 : DeepSeek发布实验性模型V3.2-Exp,引入DeepSeek Sparse Attention (DSA) 稀疏注意力机制,大幅提升长上下文训练和推理效率,同时API价格降低50%以上。DSA通过“闪电索引器”高效识别关键Token进行精细计算,将注意力复杂度从O(L²)降至O(Lk)。华为昇腾、寒武纪、海光信息等国产AI芯片厂商已实现Day 0适配,进一步推动国产算力生态发展。该模型还开源了TileLang版本的GPU算子,对标NVIDIA CUDA,方便开发者进行原型开发和调试。尽管在某些能力上有所让步,但其架构创新和成本效益为大模型长文本处理指明了新方向。 (来源: 36氪, 36氪, 36氪, 量子位, 量子位, 量子位, Reddit r/LocalLLaMA, Twitter)

OpenAI推出ChatGPT即时结账功能,进军电商领域 : OpenAI在ChatGPT中推出“即时结账(Instant Checkout)”功能,用户可直接在对话中购买Etsy和Shopify平台上的商品,无需跳转外部网站。该功能基于OpenAI与Stripe合作开发的“代理式电商协议(Agentic Commerce Protocol)”,并已开源,旨在将ChatGPT的庞大流量转化为商业交易。初期支持美国市场,未来计划扩展至多商品购物车和更多区域。此举被视为OpenAI商业化的一大步,有望成为其重要收入来源,并对传统电商和广告行业产生深远影响。 (来源: 36氪, 36氪, Reddit r/artificial, Reddit r/artificial, Twitter, Twitter, Twitter, Twitter)
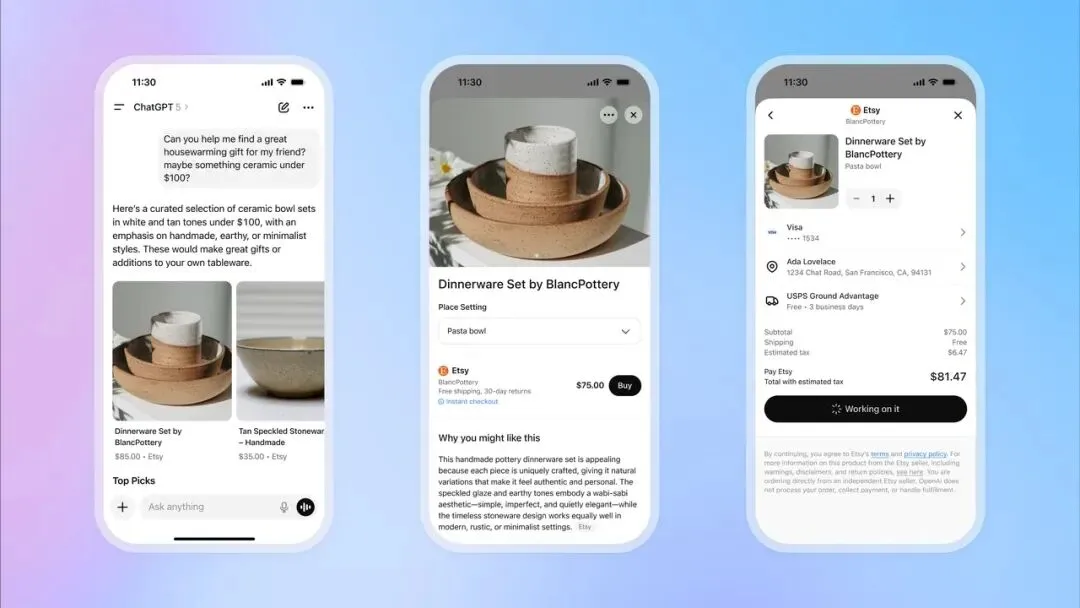
OpenAI筹备推出Sora 2社交应用,打造AI短视频平台 : OpenAI正准备推出一款由其最新视频模型Sora 2驱动的独立社交应用,该应用设计上与TikTok高度相似,采用垂直视频流和滑动浏览,但所有内容均由AI生成。用户可生成最长10秒的视频片段,并利用身份验证功能在视频中使用自己的肖像。此举旨在复制ChatGPT在文本领域的成功,让公众直观体验AI视频潜力,并直接进入与Meta和谷歌的竞争赛道。然而,OpenAI在版权处理上采取“默认使用版权内容,除非权利方主动退出”的策略,引发了内容创作者和影视公司的强烈担忧,预示着AI与知识产权的激烈博弈。 (来源: 36氪, Reddit r/artificial, Twitter, Twitter)

🎯 动向
华为盘古718B模型在SuperCLUE中文大模型榜单中位列开源第二 : 华为openPangu-Ultra-MoE-718B模型在SuperCLUE中文大模型通用基准测评中位列开源榜单第二。该模型采用“不靠堆数据,靠会思考”的训练哲学,通过“质量优先、多样性覆盖、复杂度适配”的数据构建原则,以及通用、推理、退火三阶段预训练策略,构建广泛世界知识并提升逻辑推理能力。为缓解幻觉问题,引入“批判内化”机制;为提升工具使用能力,采用升级版ToolACE合成框架。 (来源: 量子位)

FSDrive统一VLA和世界模型,推动自动驾驶迈向视觉推理 : FSDrive(FutureSightDrive)提出“时空视觉CoT”,通过统一的未来图像帧作为中间推理步骤,联合未来场景与感知结果进行可视化推理,从而推动自动驾驶从符号推理迈向视觉推理。该方法在不改动现有MLLM架构的前提下,通过词表扩展和自回归视觉生成激活图像生成能力,并以渐进式视觉CoT注入物理先验。模型既充当“世界模型”预测未来,又作为“逆动力学模型”进行轨迹规划。 (来源: 36氪)

GPT-5为量子计算提供关键思路,获大牛Scott Aaronson盛赞 : 量子计算理论大牛Scott Aaronson透露,GPT-5在不到半小时内为其量子复杂度理论研究提供了关键证明思路,解决了困扰团队的问题。Scott Aaronson表示,GPT-5在攻克最具人类特质的智力活动上取得了显著进展,这标志着人与AI协作进入“甜蜜时刻”,能够为研究者在关键时刻提供突破性启发。 (来源: 量子位, Twitter)

HuggingFace加速Qwen3-8B Agent模型在Intel Core Ultra上的推理 : HuggingFace与Intel合作,通过OpenVINO.GenAI和深度剪枝(depth-pruned)的Qwen3-0.6B草稿模型,成功将Qwen3-8B Agent模型在Intel Core Ultra集成GPU上的推理速度提升至1.4倍。这种优化使得Qwen3-8B在AI PC上运行Agent应用更加高效,尤其适用于需要多步推理和工具调用的复杂工作流,进一步推动了本地AI Agent的实用化。 (来源: HuggingFace Blog)

Reachy Mini机器人集成GPT-4o,实现多模态交互 : Hugging Face / Pollen Robotics的Reachy Mini机器人已成功集成OpenAI的GPT-4o模型,实现了多模态交互能力的显著提升。新功能包括图像分析(机器人可描述和推理所拍照片)、面部追踪(保持眼神交流)、运动融合(头部摆动、面部追踪、情感/舞蹈同时运行)、本地面部识别及闲置时的自主行为。这些进展使得人机交互更加自然流畅,但仍面临记忆系统、语音识别和复杂人群策略等挑战。 (来源: Reddit r/ChatGPT, Twitter)

Intel发布新LLM Scaler Beta版,支持Battlemage GPU上的GenAI : Intel发布了新的LLM Scaler Beta版,旨在优化Battlemage GPU上的生成式AI(GenAI)性能。此举预示着Intel在AI硬件和软件生态方面的持续投入,以提升其GPU在大型语言模型推理和生成任务中的竞争力。 (来源: Reddit r/artificial)
Claude推出使用限制仪表盘,ChatGPT上线家长控制功能 : Anthropic为Claude Code和Claude App推出了实时使用限制仪表盘,允许用户跟踪其Token使用情况,以应对此前宣布的每周速率限制。同时,OpenAI在ChatGPT中推出了家长控制功能,允许父母关联青少年账户,自动提供更强的安全保护,并可调整功能和设置使用限制,但家长无法查看具体对话内容。 (来源: Reddit r/ClaudeAI, 36氪)
Minecraft中运行500万参数语言模型,展现AI创新应用 : Sammyuri在Minecraft中构建了一个复杂的红石系统,成功运行了一个约500万参数的语言模型,并赋予其基本的对话能力。这一突破性成果展示了在游戏环境中实现本地AI的可能性,也引发了社区对AI在非传统平台应用的广泛关注和讨论。 (来源: Reddit r/LocalLLaMA, Twitter)
浪潮信息AI服务器实现8.9ms推理速度,百万Token成本1元 : 浪潮信息发布超扩展AI服务器元脑HC1000和元脑SD200超节点,将AI推理速度提升至新纪录。元脑SD200在DeepSeek-R1模型上实现8.9ms的每Token输出时间(TPOT),领先此前SOTA近一倍,并支持万亿参数大模型推理和多智能体实时协作。元脑HC1000则将每百万Token输出成本降低至1元,单卡成本降低60%。这些突破旨在解决智能体产业化面临的速度和成本瓶颈,为多智能体协同与复杂任务推理的规模化落地提供高效、低成本的算力基础设施。 (来源: 量子位)

前馈3D高斯泼溅新方法:浙大团队提出“体素对齐” : 浙江大学团队提出“体素对齐”(voxel-aligned)的前馈3D Gaussian Splatting(3DGS)框架VolSplat,旨在解决现有“像素对齐”方法在多视角3D重建中的几何一致性与高斯密度分配瓶颈。VolSplat通过在三维空间中融合多视角2D信息,并利用稀疏3D U-Net细化特征,实现更高质量、更鲁棒、更高效的3D重建。该方法在公开数据集上表现优于多种基线,并在未见过的数据集上展现出强大的零样本泛化能力。 (来源: 量子位)

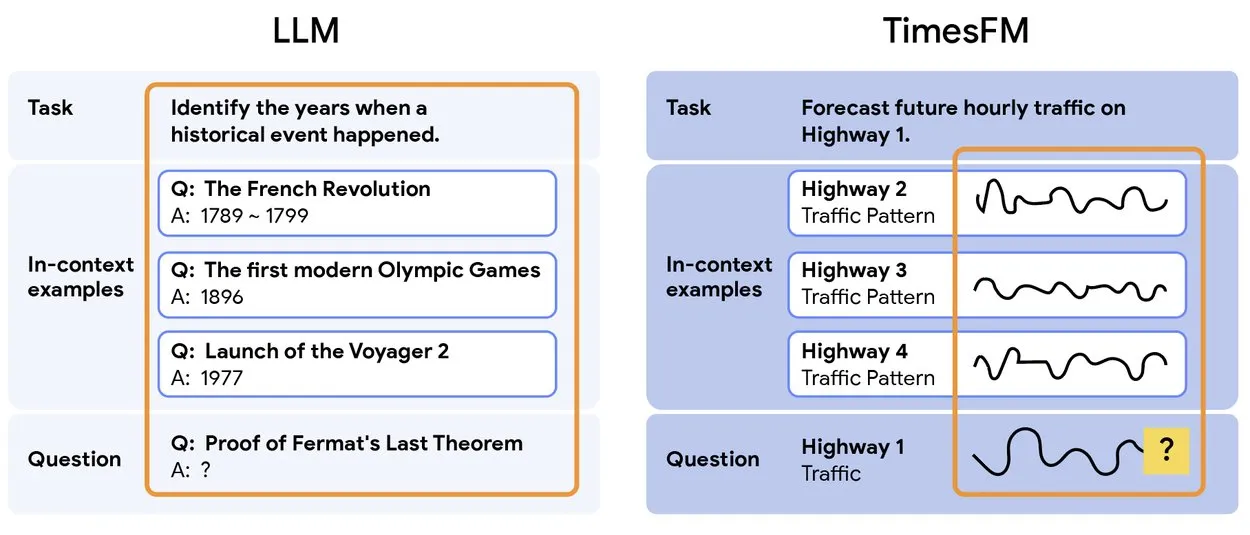
TimesFM 2.5:预训练时间序列预测模型发布 : TimesFM 2.5发布,这是一个用于时间序列预测的预训练模型,参数量从500M降至200M,上下文长度从2K增至16K,并在零样本设置下表现出色。该模型已在Hugging Face上可用并采用Apache 2.0许可,为时间序列预测任务提供了更高效、更强大的解决方案。 (来源: Twitter)
云澎科技发布AI+健康新品,推动AI在家庭健康领域应用 : 云澎科技与帅康、创维合作,发布“数智化未来厨房实验室”和搭载AI健康大模型的智能冰箱。其中,AI健康大模型优化厨房设计与运营,智能冰箱通过“健康助手小云”提供个性化健康管理。此次发布标志着AI在日常健康管理领域的突破,有望通过智能设备实现个性化健康服务,提升家庭健康科技水平。 (来源: 36氪)
阿里发布1万亿参数开源思维模型Ring-1T-preview : 阿里Ant Ling团队发布了首个1万亿参数的开源思维模型Ring-1T-preview,旨在实现“深度思考,无需等待”。该模型在自然语言处理任务上取得了早期优秀成果,包括AIME25、HMMT25、ARC-AGI-1、LCB和Codeforces等基准测试。此外,它还一次性解决了IMO25的Q3问题,并提供了Q1/Q2/Q4/Q5的部分解决方案,展现了其强大的推理和问题解决能力。 (来源: Twitter, Twitter, Twitter)

🧰 工具
PopAi发布“Slide Agent”,AI一键生成演示文稿 : PopAi团队推出了“Slide Agent”工具,旨在简化演示文稿的制作流程。用户只需通过Prompt输入需求,即可选择300+模板,由AI自动生成草稿,并进行布局、图表、图像、Logo等格式调整,最终下载为可编辑的.pptx文件。该工具集成了ChatGPT和Canva的功能,大幅降低了演示文稿制作的门槛和时间成本。 (来源: Twitter)
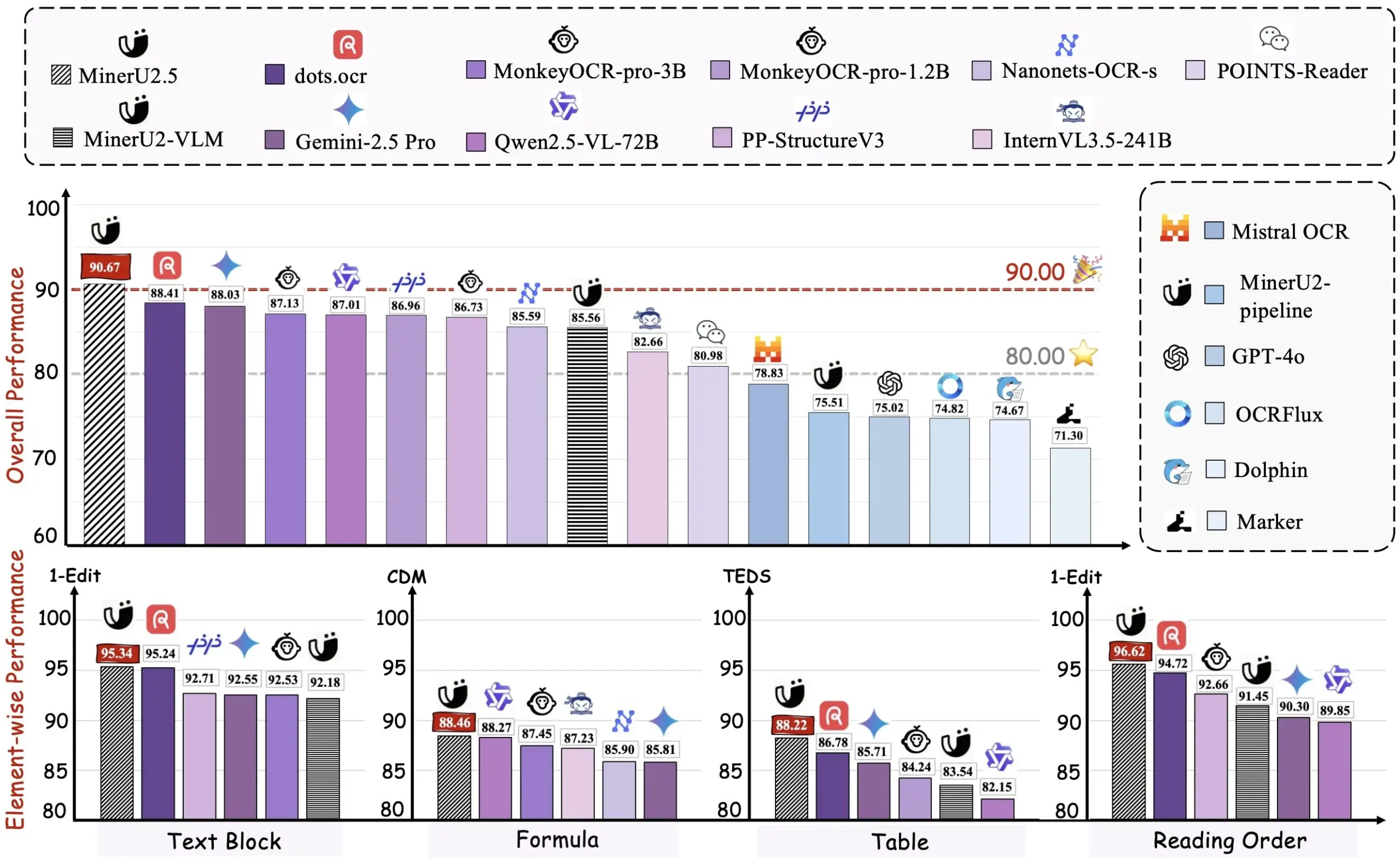
阿里开源PDF转Markdown工具Miner U2.5 : 阿里团队开源了PDF转Markdown工具Miner U2.5,并已在HuggingFace上线Demo。该工具能够高效地将PDF文档转换为Markdown格式,方便用户进行内容提取、编辑和再利用,对于需要处理大量PDF文档的开发者和研究人员来说,是一个实用的AI辅助工具。 (来源: dotey)
VEED Animate 2.2上线,支持视频风格重塑与角色互换 : VEED Animate 2.2版本已正式上线,由WAN 2.2技术提供支持。该工具允许用户通过一张图片轻松重塑视频风格、即时互换视频中的角色,并能以10倍的速度创建视频片段。这些新功能极大地简化了视频创作流程,为内容创作者提供了更多AI驱动的创意可能性。 (来源: TomLikesRobots)
LangChain致力于LLM响应标准化,支持复杂功能 : LangChain在其v1开发中,将标准化LLM响应作为核心关注点,以应对日益复杂的LLM功能,如服务器端工具调用、推理和引用。该框架旨在解决不同LLM提供商之间API格式不兼容的问题,为开发者提供统一的接口,从而简化多模态代理和复杂工作流的构建。 (来源: LangChainAI, Twitter)
Hugging Face Transformers.js支持浏览器离线运行AI模型 : Hugging Face的Transformers.js库允许用户在浏览器中利用ONNX和WebGPU技术离线运行AI模型,如Llama 3.2。这使得开发者可以在本地执行聊天机器人、对象检测和背景移除等AI任务,无需依赖云端服务,提升了数据隐私和处理速度。 (来源: Twitter)
ToolUniverse生态系统助力AI科学家构建与工具集成 : ToolUniverse是一个为构建AI科学家而设计的生态系统,它标准化了AI科学家识别和调用工具的方式,集成了600多个机器学习模型、数据集、API和科学软件包,用于数据分析、知识检索和实验设计。该平台自动优化工具接口,通过自然语言描述创建新工具,并迭代优化工具规范,将工具组合成代理工作流,从而推动AI科学家在发现过程中的协作。 (来源: HuggingFace Daily Papers)
EasySteer框架提升LLM操控性能与可扩展性 : EasySteer是一个基于vLLM的统一框架,旨在提升LLM的操控性能和可扩展性。它通过模块化架构、可插拔接口、细粒度参数控制和预计算的操控向量,实现了5.5-11.4倍的速度提升,并有效减少了过度思考和幻觉。EasySteer将LLM操控从研究技术转化为生产级能力,为可部署、可控的语言模型提供了关键基础设施。 (来源: HuggingFace Daily Papers)
VibeGame:基于WebStack的AI辅助游戏引擎 : VibeGame是一个基于three.js、rapier和bitecs构建的高级声明式游戏引擎,专为AI辅助游戏开发设计。它通过高抽象层级、内置物理和渲染功能以及实体-组件-系统(ECS)架构,使AI能够更高效地理解和生成游戏代码。虽然目前主要适用于简单平台游戏,但其开放源代码和AI友好语法,为AI驱动的游戏开发提供了有前景的解决方案。 (来源: HuggingFace Blog)
AI研究地图工具,整合90万篇论文提供带引用的答案 : 一个创新的AI工具能够将过去十年间90万篇AI研究论文进行语义分组并可视化,形成一张详细的研究地图。用户可以向该工具提问,并获得带有精确引用的答案,这极大地简化了研究人员查找和理解海量学术文献的过程,提高了研究效率。 (来源: Reddit r/ArtificialInteligence)
Kroko ASR:Whisper的快速、流式替代方案 : Kroko ASR是一个新开源的语音转文本模型,被定位为Whisper的快速、流式替代方案。它拥有更小的模型尺寸、更快的CPU推理速度(支持移动和浏览器端),并且几乎没有幻觉。Kroko ASR支持多种语言,旨在降低语音AI的门槛,使其更易于在边缘设备上部署和训练。 (来源: Reddit r/LocalLLaMA)
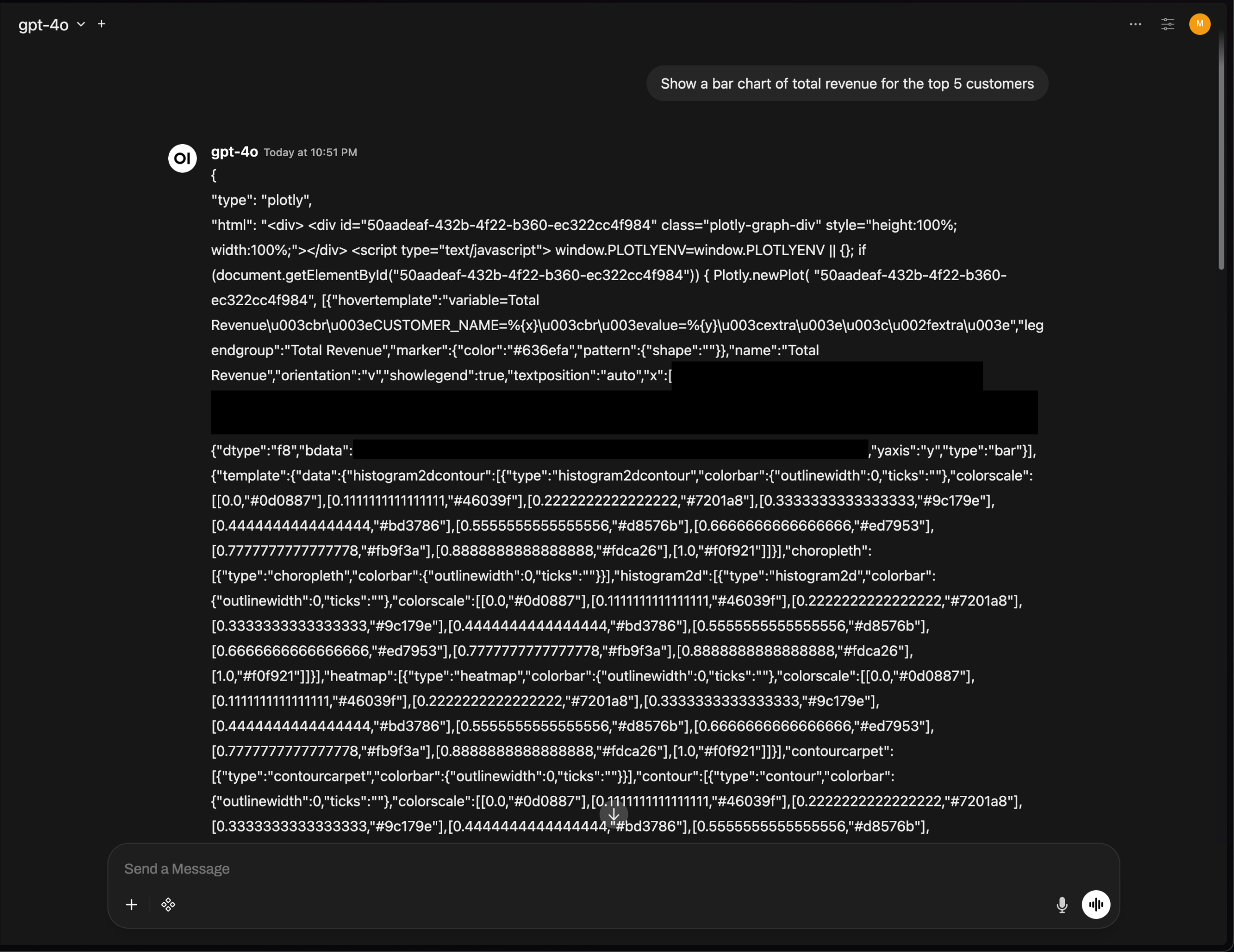
OpenWebUI Plotly图表渲染问题,凸显AI工具UI集成挑战 : OpenWebUI的v0.6.32版本出现Plotly图表无法正常渲染,而是直接显示原始JSON的问题。用户反馈后端返回正确JSON,但前端未能触发渲染,这反映了AI工具在前端UI集成和富文本渲染方面仍面临技术挑战,需要开发者社区进一步优化。 (来源: Reddit r/OpenWebUI)
📚 学习
LoRA微调与全量微调性能对比研究 : Thinking Machines(John Schulman团队)的最新研究表明,在强化学习中,若LoRA(Low-Rank Adaptation)应用得当,其性能可匹配全量微调,且资源消耗更少(约2/3计算量),即使在rank=1时也能表现出色。研究强调,LoRA应应用于所有层(包括MLP/MoE),并采用比全量微调高10倍的学习率。这一发现极大地降低了训练高性能RL模型的门槛,使更多开发者能在一块GPU上实现高质量模型。 (来源: Reddit r/LocalLLaMA, Twitter, Twitter)
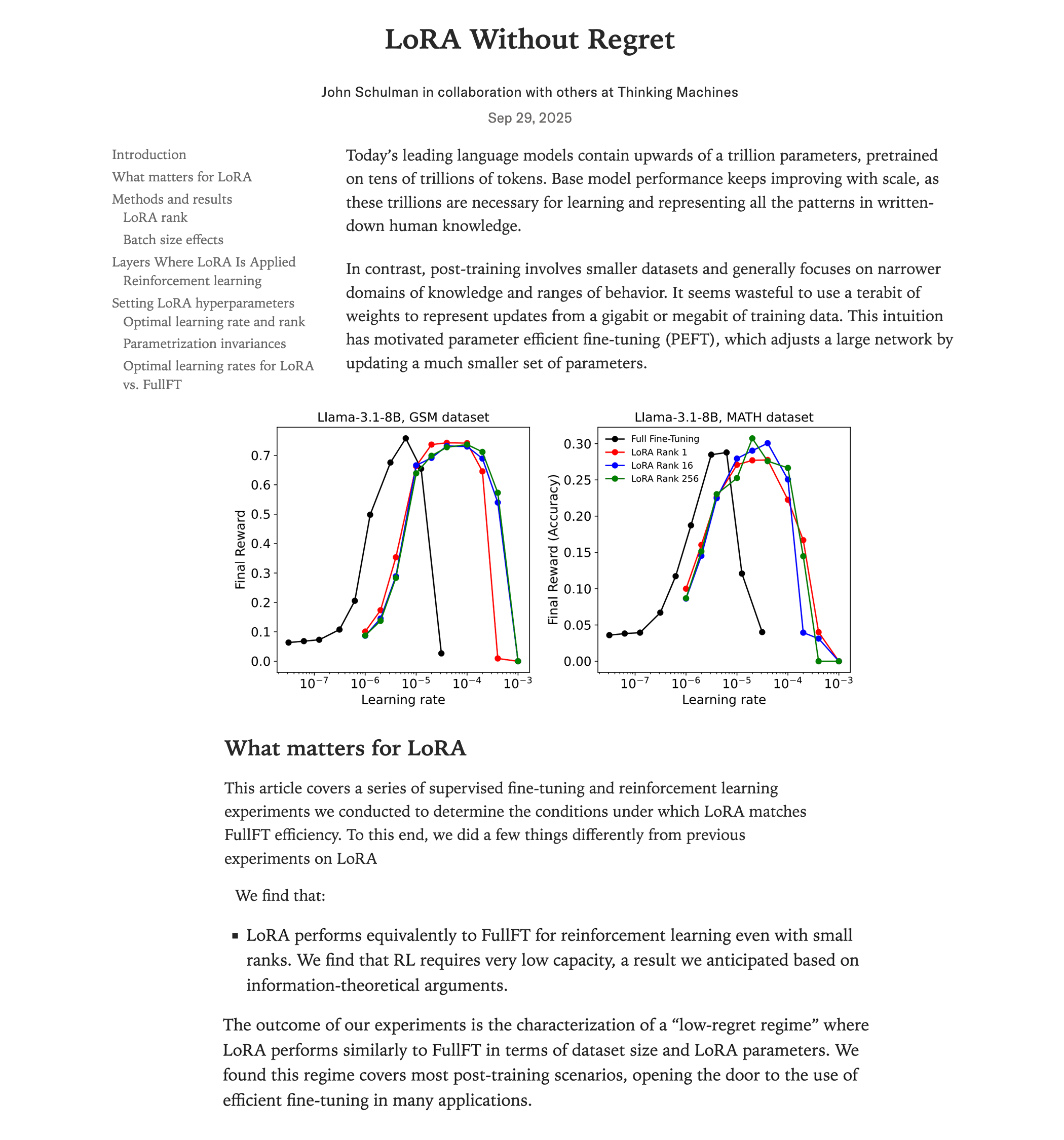
NVIDIA GPU高性能矩阵乘法内核解剖 : 一篇深度技术博客详细解剖了NVIDIA GPU内部高性能矩阵乘法(matmul)内核的实现机制。文章涵盖了GPU架构基础、内存层次结构(GMEM、SMEM、L1/L2)、PTX/SASS编程、Hopper(H100)架构的TMA、wgmma指令等高级特性。该资源旨在帮助开发者深入理解CUDA编程和GPU性能优化,对于训练和推理Transformer模型至关重要。 (来源: Reddit r/deeplearning, Twitter)
斯坦福CS231N深度学习计算机视觉课程讲座上线YouTube : 斯坦福大学备受赞誉的CS231N(计算机视觉深度学习)课程讲座现已在YouTube上免费提供。这为全球学习者提供了获取高质量AI教育资源的宝贵机会,涵盖了从基础概念到前沿应用的计算机视觉深度学习知识。 (来源: Reddit r/deeplearning)

RL-ZVP:利用零方差Prompt提升LLM强化学习推理能力 : 一项最新研究提出“RL with Zero-Variance Prompts (RL-ZVP)”方法,旨在提升大型语言模型(LLM)的强化学习推理能力。该方法不再忽略“零方差Prompt”(即所有模型响应获得相同奖励的情况),而是从中提取有价值的学习信号,直接奖励正确性并惩罚错误,并利用Token级熵引导优势塑造。实验结果显示,RL-ZVP在数学推理基准测试中,相较于传统方法,准确率和通过率显著提升。 (来源: Reddit r/MachineLearning)
未来引导学习:增强时间序列预测的预测性方法 : 一项研究提出“未来引导学习”(Future-Guided Learning),通过动态反馈机制增强时间序列事件预测。该方法包含一个检测模型分析未来数据,以及一个预测模型基于当前数据进行预测。当预测模型与检测模型出现差异时,预测模型会进行更显著的更新以最小化“惊喜”,从而动态调整参数,有效提升时间序列预测的准确性。 (来源: Reddit r/MachineLearning)
AI未来在低维度:Yann Lecun论抽象表示学习 : AI先驱Yann Lecun在Lex Fridman访谈中提出,AI的下一个飞跃将来自在低维度潜在空间中学习,而非直接处理像素等高维原始数据。他认为,真正的智能系统需要学习世界的因果结构和物理动态的抽象表示,从而在细节变化时仍能做出准确预测。这种方法将使模型更灵活、鲁棒,减少对海量数据的依赖,并降低计算成本。 (来源: Reddit r/ArtificialInteligence)
SIRI:通过交错压缩扩展迭代强化学习 : SIRI(Scaling Iterative Reinforcement Learning with Interleaved Compression)是一种简单而有效的强化学习方法,通过迭代地压缩和扩展推理预算,动态调整训练中的最大rollout长度。这种训练机制迫使模型在有限上下文中做出精确决策,减少冗余Token,同时提供探索和规划的空间,从而在性能-效率权衡中稳步提升大型推理模型的效率和准确性。 (来源: HuggingFace Daily Papers)
多主体生成模型MultiCrafter:空间解耦注意力与身份感知强化学习 : MultiCrafter是一个旨在实现高保真、偏好对齐的多主体图像生成的框架。它通过引入显式位置监督来分离不同主体之间的注意力区域,有效缓解属性泄漏问题。同时,该框架采用混合专家(MoE)架构增强模型容量,并设计了新颖的在线强化学习框架,结合评分机制和稳定训练策略,确保生成图像的主体保真度与人类审美偏好高度一致。 (来源: HuggingFace Daily Papers)
Visual Jigsaw:通过自监督后训练提升MLLMs视觉理解 : Visual Jigsaw是一个通用的自监督后训练框架,旨在增强多模态大语言模型(MLLMs)的视觉理解能力。该方法将视觉输入分区、打乱,并要求模型通过自然语言重建正确的排列顺序。这种基于可验证奖励的强化学习(RLVR)方法无需额外的视觉生成组件或人工标注,即可显著提升MLLMs在细粒度感知、时间推理和3D空间理解方面的表现。 (来源: HuggingFace Daily Papers)
MGM-Omni:将Omni LLMs扩展到个性化长时语音生成 : MGM-Omni是一个统一的Omni LLM,通过其独特的“大脑-嘴巴”双轨Token化架构,实现多模态理解和富有表现力的长时语音生成。该设计将多模态推理与实时语音生成解耦,支持高效的跨模态交互和低延迟流式语音克隆,并在数据效率上表现出色。实验证明,MGM-Omni在保持音色一致性、生成自然上下文感知语音以及长时音频和多模态理解方面均优于现有开源模型。 (来源: HuggingFace Daily Papers)
SID:通过自改进演示学习目标导向语言导航 : SID(Self-Improving Demonstrations)是一种目标导向语言导航学习方法,通过迭代自改进演示显著提升导航智能体在未知环境中的探索能力和泛化性。该方法首先利用最短路径数据训练初始智能体,然后通过该智能体生成新的探索轨迹,这些轨迹提供了更强的探索策略来训练更好的智能体,从而实现性能的持续提升。实验表明,SID在REVERIE和SOON等任务上取得了SOTA性能,特别是在SOON的未见验证集上成功率达到50.9%,超越此前方法13.9%。 (来源: HuggingFace Daily Papers)
LOVE-R1:通过自适应缩放机制提升长视频理解 : LOVE-R1模型旨在解决长视频理解中长时序理解与细节空间感知之间的冲突。该模型引入自适应缩放机制,首先以低分辨率密集采样帧,当需要空间细节时,模型可根据推理对感兴趣的视频片段进行高分辨率缩放,直至获取关键视觉信息。整个过程通过多步推理实现,并结合CoT数据微调和解耦强化微调,在长视频理解基准测试中取得显著提升。 (来源: HuggingFace Daily Papers)
Euclid’s Gift:通过几何代理任务增强视觉语言模型空间推理 : Euclid’s Gift是一项通过几何代理任务提升视觉语言模型(VLM)空间感知和推理能力的研究。该项目构建了包含30K平面和立体几何问题的多模态数据集Euclid30K,并使用Group Relative Policy Optimization(GRPO)微调Qwen2.5VL和RoboBrain2.0系列模型。实验证明,训练后的模型在Super-CLEVR、Omni3DBench等四个空间推理基准测试中取得了显著的零样本提升,其中RoboBrain2.0-Euclid-7B达到了49.6%的准确率,超越了此前的SOTA模型。 (来源: HuggingFace Daily Papers)
SphereAR:通过超球面潜在空间改进连续Token自回归生成 : SphereAR旨在解决连续Token自回归(AR)图像生成模型中VAE潜在空间异质方差导致的问题。该核心设计是将所有AR输入和输出(包括CFG后)约束在固定半径超球面上,利用超球面VAE。理论分析表明,超球面约束消除了方差崩溃的主要原因,从而稳定了AR解码。实验证明,SphereAR在ImageNet生成任务上取得了SOTA性能,超越了同等参数规模下的扩散模型和掩码生成模型。 (来源: HuggingFace Daily Papers)
AceSearcher:通过强化自博弈引导LLM推理与搜索 : AceSearcher是一个合作自博弈框架,旨在提升LLM在复杂推理任务中的搜索增强能力。该框架训练单个LLM在分解复杂查询和整合检索上下文之间交替,通过监督微调和强化微调优化最终答案准确性,无需中间标注。实验表明,AceSearcher在多项推理密集型任务中显著优于SOTA基线,在文档级金融推理任务上,AceSearcher-32B以不到5%的参数量匹配了DeepSeek-V3的性能。 (来源: HuggingFace Daily Papers)
SparseD:扩散语言模型的稀疏注意力机制 : SparseD是一种针对扩散语言模型(DLMs)的稀疏注意力方法,旨在解决长上下文长度下注意力计算的二次方复杂度瓶颈。该方法通过预计算头特定稀疏模式并在所有去噪步骤中重用,同时在早期去噪步骤使用全注意力,随后切换到稀疏注意力,从而实现无损加速。实验结果表明,SparseD在64k上下文长度下,相较于FlashAttention可实现高达1.5倍的速度提升,有效提升了DLMs在长上下文应用中的推理效率。 (来源: HuggingFace Daily Papers)
SLA:通过可微调稀疏线性注意力加速扩散Transformer : SLA(Sparse-Linear Attention)是一种可训练的注意力方法,旨在加速Diffusion Transformer (DiT) 模型,特别是视频生成中的注意力计算。该方法将注意力权重分为关键、边缘和可忽略三类,分别应用O(N²)和O(N)注意力,并跳过可忽略部分。SLA通过在单个GPU内核中融合这些计算,并在少量微调步骤后,使DiT模型在注意力计算上实现20倍的减少,在视频生成中端到端加速2.2倍,且不损失生成质量。 (来源: HuggingFace Daily Papers)
OpenGPT-4o-Image:高级图像生成与编辑综合数据集 : OpenGPT-4o-Image是一个大规模数据集,通过结合分层任务分类和GPT-4o自动化数据生成方法构建,旨在提升统一多模态模型在图像生成和编辑方面的性能。该数据集包含80k高质量指令-图像对,涵盖11个主要领域和51个子任务,包括文本渲染、风格控制、科学图像和复杂指令编辑。在OpenGPT-4o-Image上进行微调的模型在多个基准测试中取得了显著性能提升,证明了系统化数据构建对推进多模态AI能力的关键作用。 (来源: HuggingFace Daily Papers)
SANA-Video:高效生成720p分钟级视频的小型扩散模型 : SANA-Video是一个小型扩散模型,能够高效生成高达720×1280分辨率和分钟级时长的视频。它通过线性DiT架构和恒定内存KV缓存实现高分辨率、高质量、长视频生成,同时保持文本-视频强对齐。SANA-Video的训练成本仅为MovieGen的1%,且在RTX 5090 GPU上部署时,生成5秒720p视频的推理速度可达29秒,实现低成本、高质量视频生成。 (来源: HuggingFace Daily Papers)
AdvChain:对抗性CoT调优增强大推理模型安全对齐 : AdvChain是一种新的对齐范式,通过对抗性Chain-of-Thought (CoT) 调优,教授大型推理模型(LRMs)动态自校正能力。该方法构建包含“诱惑-纠正”和“犹豫-纠正”样本的数据集,使模型学习从有害推理漂移和不必要谨慎中恢复。实验表明,AdvChain显著增强了模型对越狱攻击和CoT劫持的鲁棒性,同时大幅减少对良性Prompt的过度拒绝,实现了卓越的安全-效用平衡。 (来源: HuggingFace Daily Papers)
SDLM:通过交错压缩扩展迭代强化学习 : Sequential Diffusion Language Model (SDLM) 提出了一种统一next-token和next-block预测的方法,使模型能够自适应地确定每一步的生成长度。SDLM可以在最小成本下改造预训练自回归语言模型,并在固定大小的掩码块内执行扩散推理,同时动态解码连续子序列。实验表明,SDLM在匹配或超越强自回归基线的同时,实现了更高的吞吐量,展示了其强大的可扩展性潜力。 (来源: HuggingFace Daily Papers)
Insight-to-Solve (I2S):将推理In-Context演示转化为推理LMs资产 : Insight-to-Solve (I2S) 是一种测试时程序,旨在将高质量的推理In-Context演示转化为大型推理模型(RLMs)的有效资产。研究发现,直接添加演示示例可能降低RLMs的准确性。I2S通过将演示转化为明确可重用的见解,并生成目标特定的推理轨迹,可选地进行自精炼以提高连贯性和正确性。实验表明,I2S和I2S+在各种基准测试中持续优于直接回答和测试时缩放基线,即使对于GPT模型也能带来显著提升。 (来源: HuggingFace Daily Papers)
UniMIC:基于Token的多模态交互式编码实现人机协作 : UniMIC(Unified token-based Multimodal Interactive Coding)是一个框架,旨在通过基于Token的表示实现边缘设备与云AI智能体之间高效、低比特率的多模态交互。UniMIC采用紧凑的Token化表示作为通信介质,并结合Transformer熵模型,有效减少Token间冗余。实验证明,UniMIC在文本到图像生成、图像修复和视觉问答等任务中实现了显著的比特率节省,并在超低比特率下保持鲁棒性,为下一代多模态交互通信提供了实用范式。 (来源: HuggingFace Daily Papers)
RLBFF: 二进制灵活反馈桥接人类反馈与可验证奖励 : RLBFF (Reinforcement Learning with Binary Flexible Feedback) 是一种结合了人类偏好多样性与规则验证精确性的强化学习范式。它从自然语言反馈中提取可二元回答的原则(如信息准确性:是/否,代码可读性:是/否),并以此训练奖励模型。RLBFF在RM-Bench和JudgeBench上表现出色,并允许用户在推理时自定义原则焦点。此外,它提供了一个完全开源的方案,以RLBFF对Qwen3-32B进行对齐,使其在通用对齐基准上匹配或超越o3-mini和DeepSeek R1的性能。 (来源: HuggingFace Daily Papers)
MetaAPO: 通过元加权在线采样实现对齐优化 : MetaAPO(Meta-Weighted Adaptive Preference Optimization)是一个新颖的框架,通过动态耦合数据生成与模型训练来优化大型语言模型(LLMs)与人类偏好的对齐。MetaAPO利用轻量级元学习器作为“对齐差距估计器”,评估在线采样相对于离线数据的潜在收益,指导目标在线生成并分配样本级元权重,动态平衡在线和离线数据的质量与分布。实验表明,MetaAPO在AlpacaEval 2、Arena-Hard和MT-Bench上持续优于现有偏好优化方法,同时将在线标注成本降低42%。 (来源: HuggingFace Daily Papers)
Tool-Light: 通过自进化偏好学习实现高效工具集成推理 : Tool-Light是一个旨在鼓励大型语言模型(LLMs)高效准确执行工具集成推理(TIR)任务的框架。研究发现工具调用结果会导致后续推理信息熵的显著变化。Tool-Light通过结合数据集构建和多阶段微调实现,其中数据集构建采用连续自进化采样,整合了香草采样和熵引导采样,并建立严格的正负对选择标准。训练过程包括SFT和自进化直接偏好优化(DPO)。实验证明Tool-Light显著提升了模型执行TIR任务的效率。 (来源: HuggingFace Daily Papers)
ChatInject: 利用聊天模板对LLM代理进行Prompt注入攻击 : ChatInject是一种利用LLM对结构化聊天模板的依赖和多轮对话的上下文操纵,进行间接Prompt注入攻击的方法。攻击者通过模仿原生聊天模板格式化恶意负载,诱导代理执行可疑操作。实验表明,ChatInject比传统Prompt注入方法具有更高的攻击成功率,尤其是在多轮对话中,且对不同模型具有很强的可迁移性,而现有基于Prompt的防御措施对此类攻击大多无效。 (来源: HuggingFace Daily Papers)
💼 商业
Modal完成8700万美元B轮融资,估值达11亿美元 : AI基础设施公司Modal宣布完成8700万美元B轮融资,估值达到11亿美元。此轮融资旨在加速AI基础设施的创新和发展,以应对传统计算基础设施在AI时代面临的挑战。Modal通过提供高效的云端计算服务,帮助研究人员和开发者优化其AI模型训练和部署流程。 (来源: Twitter, Twitter, Twitter)
OpenAI上半年营收43亿美元,亏损135亿美元,面临盈利挑战 : OpenAI公布2025年上半年营收达到43亿美元,预计全年营收将突破130亿美元,主要得益于ChatGPT Plus订阅和企业级API服务。然而,同期净亏损高达135亿美元,其中结构性成本和研发投入(如GPT-5)是主要因素,服务器租赁年费用高达160亿美元。尽管OpenAI拥有175亿美元现金储备并推进300亿美元融资计划,但持续的现金消耗和与Anthropic等竞争对手在效率上的差距,使其面临严峻的盈利挑战。 (来源: 36氪)
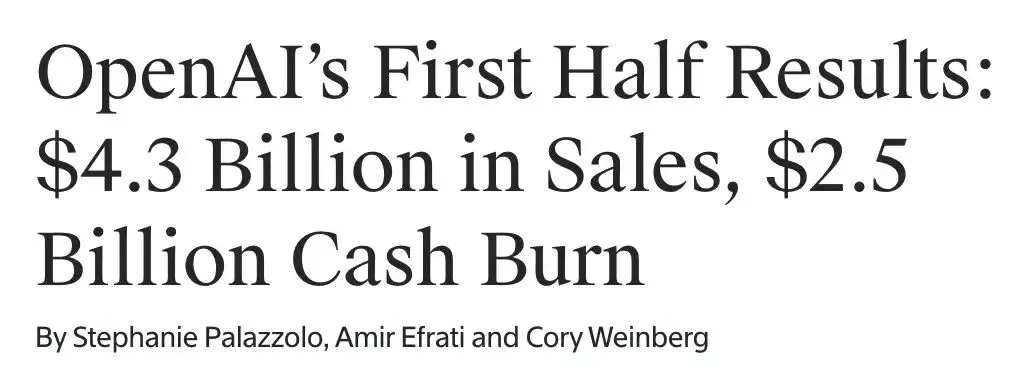
人形机器人赛道资本暗战:智元、银河通用等积极布局产业链 : 人形机器人赛道进入资本暗战阶段,智元机器人、银河通用等头部企业通过成立基金、参投同行、战略合作等方式,积极拓展“朋友圈”。智元机器人已对外投资近20笔,涵盖电机、传感器及下游应用,并与富临精工、软通动力等合作落地商业场景。银河通用则与博世中国成立合资公司,推动具身智能在汽车制造领域的应用。这些举措旨在获取订单、补齐短板,并为未来规模出货建立稳定的供应链网络,但行业技术路线差异大,竞争激烈。 (来源: 36氪)

🌟 社区
AI生成内容真伪难辨,引发社会信任危机 : 随着AI技术飞速发展,AI生成视频(如《进击的巨人》真人版、印尼主播“换脸”日本网红)的逼真度已达到令人难以置信的程度,引发了社会对内容真实性的深刻担忧。社交媒体上,用户普遍表示越来越难以辨别真实与AI生成内容,这不仅损害了合法内容创作者的公信力,也可能被用于传播虚假信息。专家指出,除非强制性AI内容标签化,否则这种“超现实引擎”将持续侵蚀现实感,最终可能“终结互联网”。 (来源: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ArtificialInteligence, Twitter, Twitter)

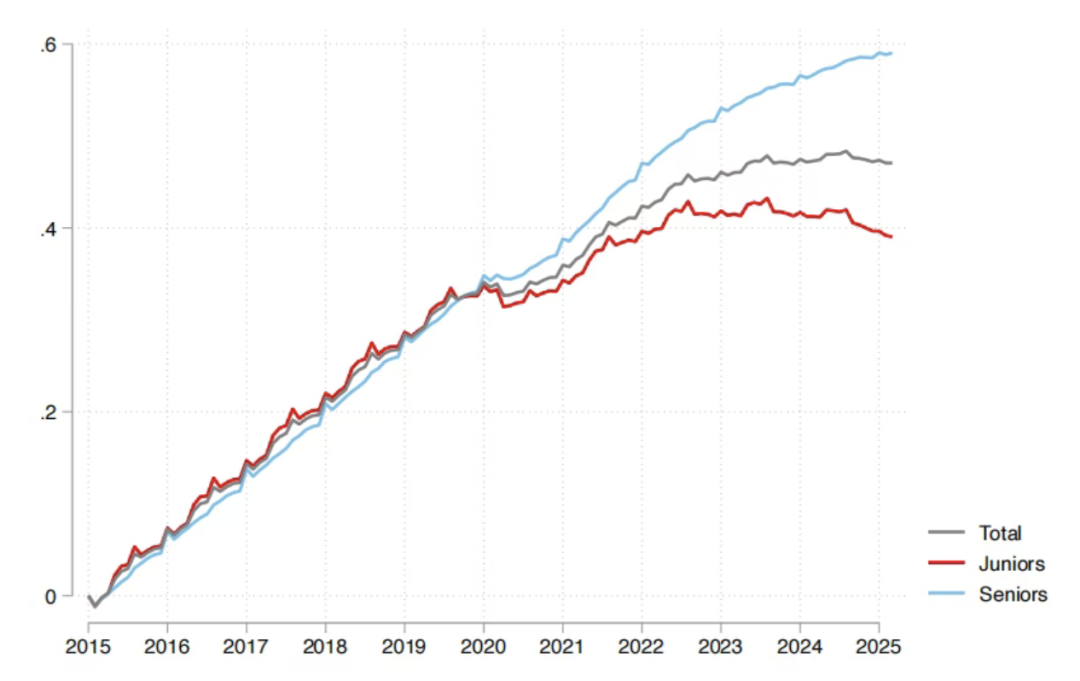
AI对就业市场影响:红杉报告称95%AI投入无效,毕业生受冲击最大 : 红杉资本分享MIT和哈佛大学研究报告指出,企业95%的AI投入未产生实际价值,真正的生产力提升源于员工“偷偷”使用个人AI工具形成的“影子AI经济”。报告还揭示,AI对就业市场的冲击主要集中在刚毕业的年轻人,尤其在批发零售业,初级岗位招聘数量显著下滑,名校学历也非完全护身符。这表明AI正改变任务分配,人类价值转向经验和独特判断。 (来源: 36氪, Reddit r/ArtificialInteligence)
OpenAI模型调整引发用户强烈不满,呼吁透明沟通 : OpenAI近期未经通知将GPT-4o/GPT-5模型“降级”至低算力版本,导致模型性能下降,引发用户强烈不满。许多用户抱怨模型“变笨”,失去了原有的洞察力和“朋友”般的交流体验,甚至有人称之为“精神打击”。OpenAI高管回应称此为“安全路由测试”,旨在处理敏感话题,但用户普遍呼吁OpenAI应加强与用户的沟通和透明度,避免单方面更改产品协议,以重建用户信任。 (来源: Reddit r/artificial, Reddit r/ChatGPT, Reddit r/ChatGPT, Twitter)
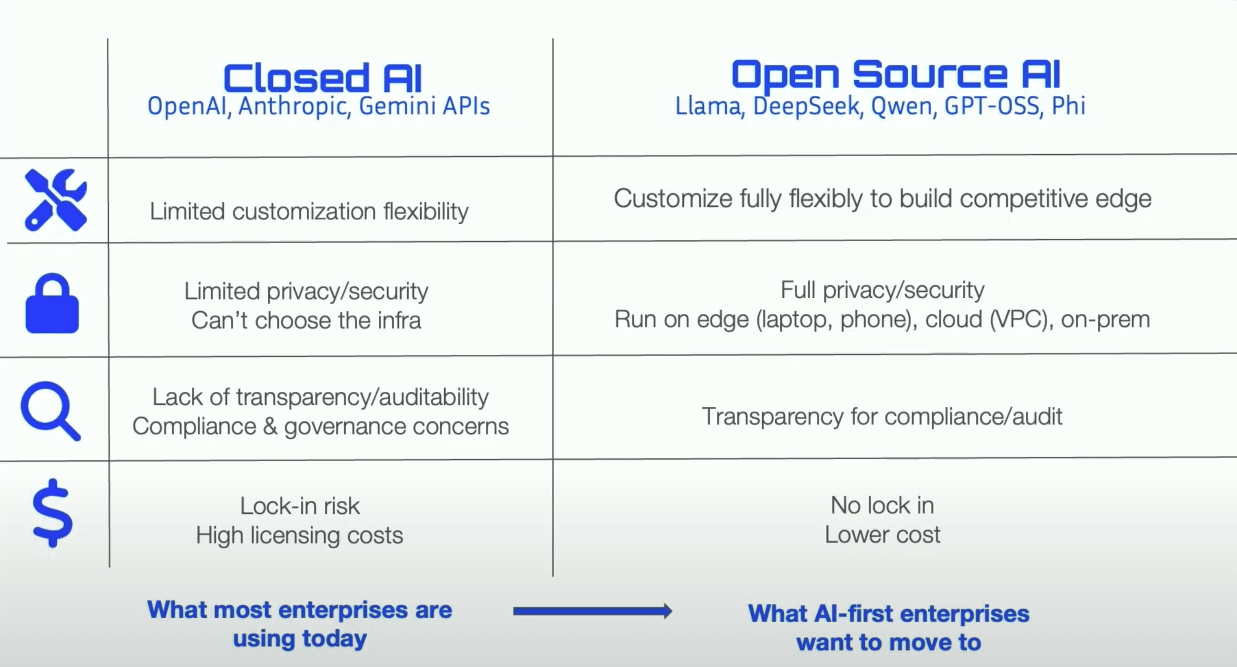
机器人征税:技术进步与社会公平的讨论 : 随着AI和机器人技术的发展,关于向机器人“征税”的讨论日益增多,旨在平衡机器人替代人类劳动力可能引发的就业问题和社会不平等。支持者认为,机器人税可为失业者提供社会福利和再就业支持,纠正资本与劳动之间的议价失衡。然而,机器人行业从业者普遍认为目前征税为时尚早,可能阻碍新兴产业发展。韩国已通过减少自动化企业税收优惠来间接增加机器人使用成本。 (来源: 36氪)
人形机器人未来走向:著名机器人专家Rodney Brooks认为未来不像人 : 著名机器人专家Rodney Brooks撰文指出,尽管投入巨资,当前人形机器人仍无法实现人类级别的灵巧性,且双足行走存在安全隐患。他预测,未来15年人形机器人将不再模仿人类形态,而是演变为轮式移动、多臂(配备夹爪或吸盘)、多传感器(主动光成像、非可见光感知)的专用机器人,以适应特定任务。他认为,目前对“类人”形态的追求投入巨大但终将付诸东流。 (来源: 36氪)

AI代码生成质量与开发者体验的争议 : 社交媒体上,开发者对AI生成代码的质量和实用性展开热议。有人称赞Claude Sonnet 4.5能重构整个代码库,但生成代码却无法运行;也有人抱怨AI生成的代码“不编译”,导致开发效率下降。这些讨论反映了AI辅助编程在效率与准确性之间仍存在挑战,以及开发者在面对AI生成结果时,对调试和验证的需求。 (来源: Twitter, Twitter, Twitter)

AI时代人才观转变:从“挖人”到“种庄稼” : 社交媒体上热议AI时代的人才观应从传统的“四处挖人”转变为“种庄稼”。鉴于AI领域人才稀缺且技术迭代迅速,企业应更注重培养具备基础技术栈的员工,而非盲目追逐市场上高价的“成品”人才。这种观点强调持续学习和内部培养的重要性,以适应AI赛道快速变化的需求。 (来源: dotey)
AI基础设施能耗与Sam Altman的能源需求 : Sam Altman提出AI发展需要250GW的电力,引发了社会对AI基础设施巨大能耗的关注和讨论。这一需求远超现有能源供应能力,促使人们思考如何平衡AI的快速发展与可持续能源供给。相关讨论也涉及半导体制造中的环境问题,如PFAS的使用及其替代方案的潜在风险。 (来源: Twitter, Twitter)

AI末日论与乐观派:担忧与反驳 : 社交媒体上存在对AI“末日论”和AI潜在风险的广泛讨论,但也有许多人认为这些担忧被夸大。乐观派认为,AI带来的实际问题(如气候影响、企业剥削、军事监控)比遥远的“超级智能毁灭人类”更紧迫,应关注当下可解决的挑战。一些人认为AI末日论是“无稽之谈”,是懒惰和不稳定的表现,而另一些人则相信AI最终会走向创造和培育。 (来源: Reddit r/ArtificialInteligence, Twitter, Twitter)
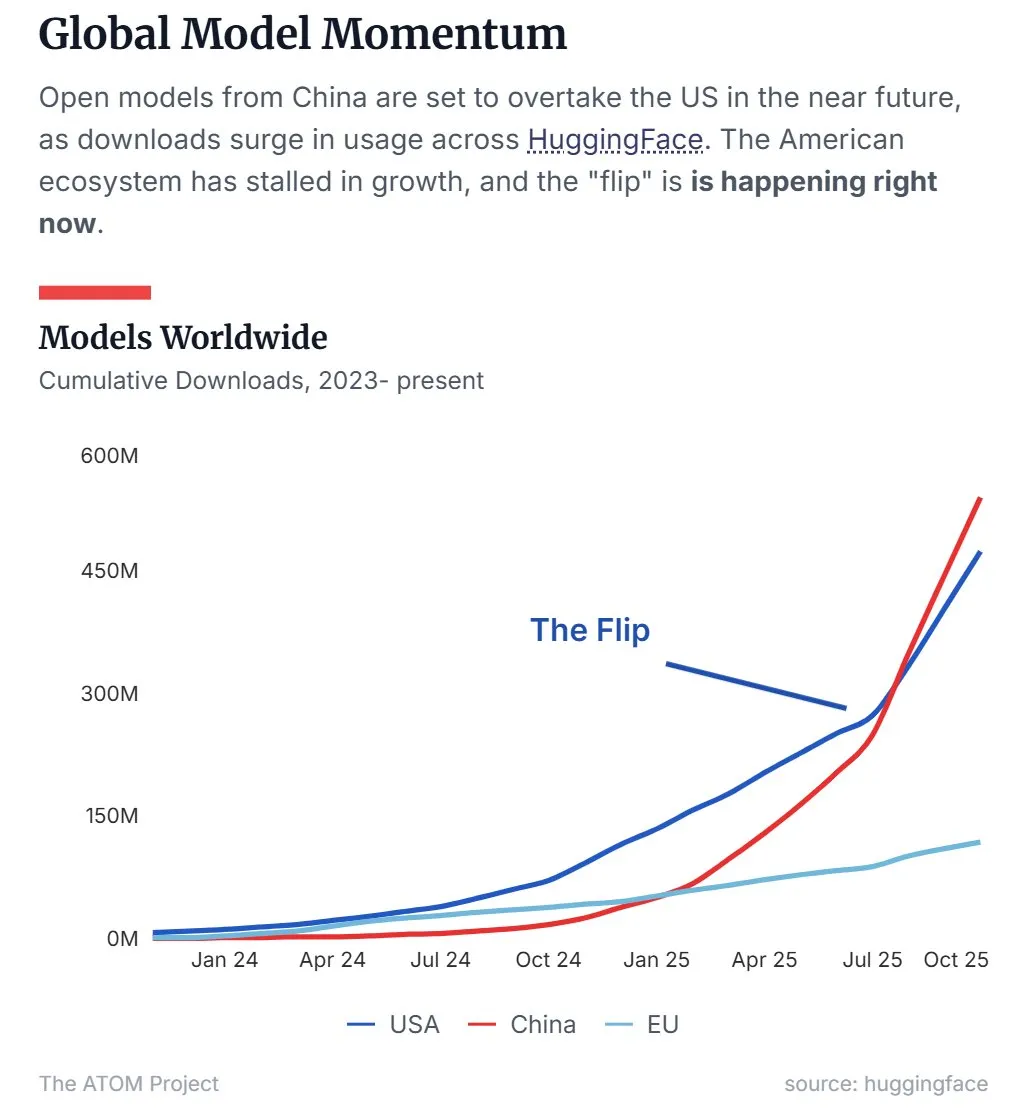
中国开源LLM市场份额超越美国 : 最新数据显示,以Qwen为代表的中国开源大型语言模型(LLM)在市场份额上已超越美国,成为开源LLM领域的主导力量。这一趋势表明中国在开源AI技术研发和应用方面正在加速崛起,对全球AI格局产生重要影响。 (来源: Twitter, Twitter)
45天团队制作AI漫剧《明日周一》实现千万播放量 : 一个仅10人的团队在45天内完成了50集AI漫剧《明日周一》的制作,并在没有任何投流的情况下,全网播放量突破千万,抖音付费收入已覆盖所有成本。该项目采用“原创形象+AI生成”的核心理念,解决了AI内容版权归属问题,并探索出IP全品类商业开发路径。制作流程高度分工,原画师、工程师、后期剪辑和导演紧密协作,展现了AI技术在内容生产中降本增效的巨大潜力。 (来源: 36氪)

💡 其他
音频文本精准对齐需求问卷 : 有社交媒体用户对音频文本精准对齐技术表现出浓厚兴趣,并发布了一份需求问卷,旨在收集用户对该技术在功能和应用场景上的具体需求,以期推动相关技术的发展和优化。 (来源: dotey)
DeepMind展示Nano Banana Demo : Google DeepMind展示了名为“Nano Banana”的演示,引发了社交媒体的关注。虽然具体细节未完全披露,但可能与AI视频生成或多模态AI技术相关,暗示了DeepMind在视觉AI领域的新进展。 (来源: GoogleDeepMind)
关于Highway Net和ResNet发明优先权的学术讨论 : 著名AI研究者Jürgen Schmidhuber转发推文,再次引发了关于Highway Net和ResNet在深度残差学习发明优先权上的学术讨论。他指出,微软的ResNet论文将Highway Net称为“同期”工作是不准确的,并强调Highway Net早于ResNet七个月发表,且已识别并提出了残差连接的解决方案。 (来源: SchmidhuberAI)