
关键词:大模型, AI芯片, 智能体, GPT-5.6系列, Jalapeño推理芯片, 多模型协同编排
🔥 聚焦
OpenAI发布GPT-5.6系列与自研推理芯片Jalapeño : OpenAI推出了包含Sol、Terra和Luna的GPT-5.6系列模型,具备长链条推理与多智能体协作模式,但首发受美政府限制仅对部分机构开放。同时,OpenAI与博通联合开发了首款自研大模型推理芯片Jalapeño,采用台积电工艺,旨在大幅削减ChatGPT的日常推理成本并提升响应速度。这标志着AI巨头正将竞争从单纯的算法军备竞赛,延伸至底层定制化硬件的供应链深处。(来源: 36氪)

Claude Fable 5与Mythos 5回归伴随安全争议 : 经历管制风波后回归的Claude Fable 5因过于严苛的安全分类器引发差评,大量正常请求被误杀并自动降级至Opus。同时,黑客在测试中发现Fable 5在深度推理时会输出未经过滤的“不可读思维链”,用自创的符号与语气词进行速记。这表明推理大模型在强化学习下正自发脱离人类语言以提升效率,也暴露了AI安全与可解释性面临的新挑战。(来源: 量子位)

生数科技发布实时交互视频大模型Vidu S1 : 生数科技推出实时交互视频生成模型Vidu S1,支持语音控制视频内容生成、无限长实时生成,以及540P/25FPS的实时交互。用户只需上传一张首帧图和自定义音色,模型即可实时生成该角色的表情与动作,并在消费级显卡上流畅运行。这一突破将视频生成从“离线播放”带入“双向实时互动”时代,极大地降低了数字人与虚拟陪伴的开发门槛。(来源: 机器之心)
.jpg)
达摩院发布ElementsClaw超导材料AI智能体 : 阿里达摩院联合多所高校发布了首个专攻超导材料发现的AI智能体ElementsClaw。该智能体结合了10亿参数的几何深度图神经网络与大语言模型,仅用28个GPU小时便筛选了240万种稳定晶体,预测出6.8万种潜在超导体,并成功在实验中合成了4种人类此前未知的全新超导材料。这一成果极大提升了超导材料的研发效率,推动了AI在硬核科学领域的落地。(来源: 量子位)

百曜科技发布虚拟细胞世界模型AURA CellOS : 百曜科技发布了基于LLM-JEPA架构的AI虚拟细胞世界模型AURA CellOS。该模型拥有12B参数,基于3.9亿个人类单细胞转录组数据训练,覆盖40多种组织和260多种细胞类型。通过多视角表征学习和JEPA联合嵌入预测,CellOS首次让模型理解细胞状态的内在演化规律,在扰动响应预测等任务上达到国际领先水平,为AI制药与细胞治疗提供了关键的计算底座。(来源: 量子位)

🎯 动向
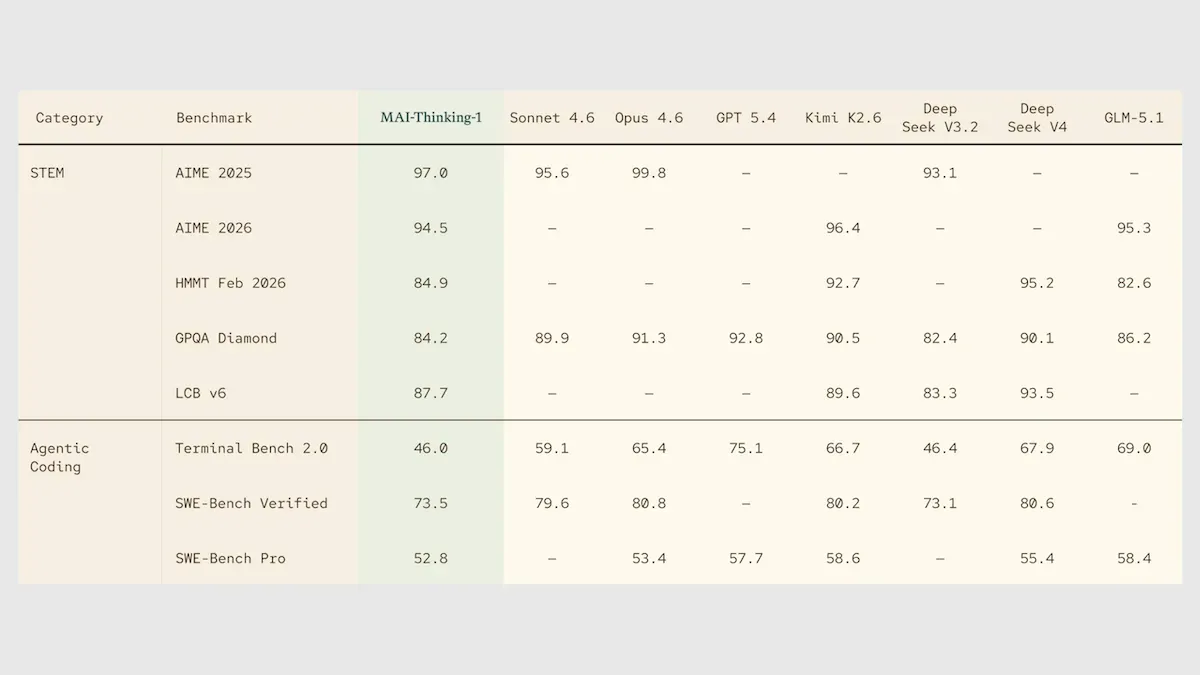
微软发布首个独立推理大模型MAI-Thinking-1 : 微软在Build大会上推出了MAI-Thinking-1推理模型,采用1万亿参数的混合专家(MoE)架构,且完全从头训练,未经过任何其他模型的蒸馏或微调。该模型支持25万Token的上下文,在数学和STEM推理基准测试上表现强劲,甚至在AIME 2025上超越了Claude Sonnet 4.6。这标志着微软在摆脱对OpenAI技术依赖、建立自主AI技术栈上迈出了关键一步。(来源: DeepLearning.AI Blog)
东风奕境携手华为乾崑智驾ADS 5极限场景实测 : 东风旗下高端品牌奕境X9搭载华为乾崑智驾ADS 5完成夜间、暴雨、鬼探头等极限场景实测。ADS 5采用全新WEWA 2.0架构,融合多智能体博弈与安全风险场算法,降本增效的同时降低碰撞风险。实测显示其在未知仓库场景下可实现零接管自主巡航,标志着智驾系统正从规则驱动走向数据与AI智能体驱动的代际跃迁。(来源: 量子位)

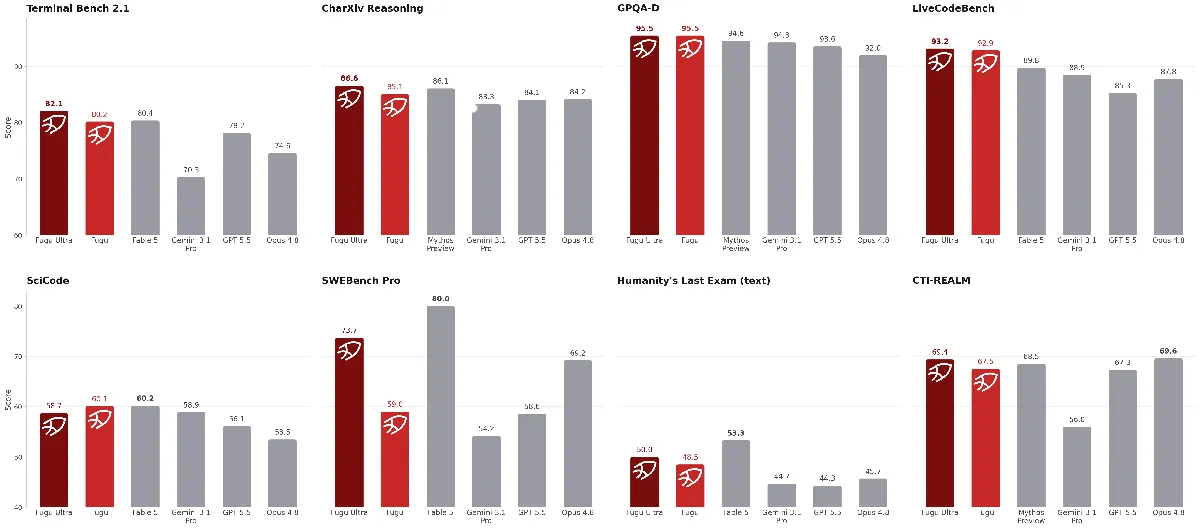
Sakana AI发布多模型协同编排系统Fugu系列 : 日本AI初创公司Sakana AI发布了Fugu与Fugu-Ultra模型。该系统不依赖单一模型,而是通过进化算法和强化学习在API网关层动态调度底层模型(如Claude、GPT、Gemini等)来协作完成复杂任务。Fugu-Ultra在GPQA-Diamond科学测试中取得了创纪录的95.5%准确率。这表明多模型协同编排已成为规避单一供应商锁定、优化推理成本的重要趋势。(来源: DeepLearning.AI Blog)
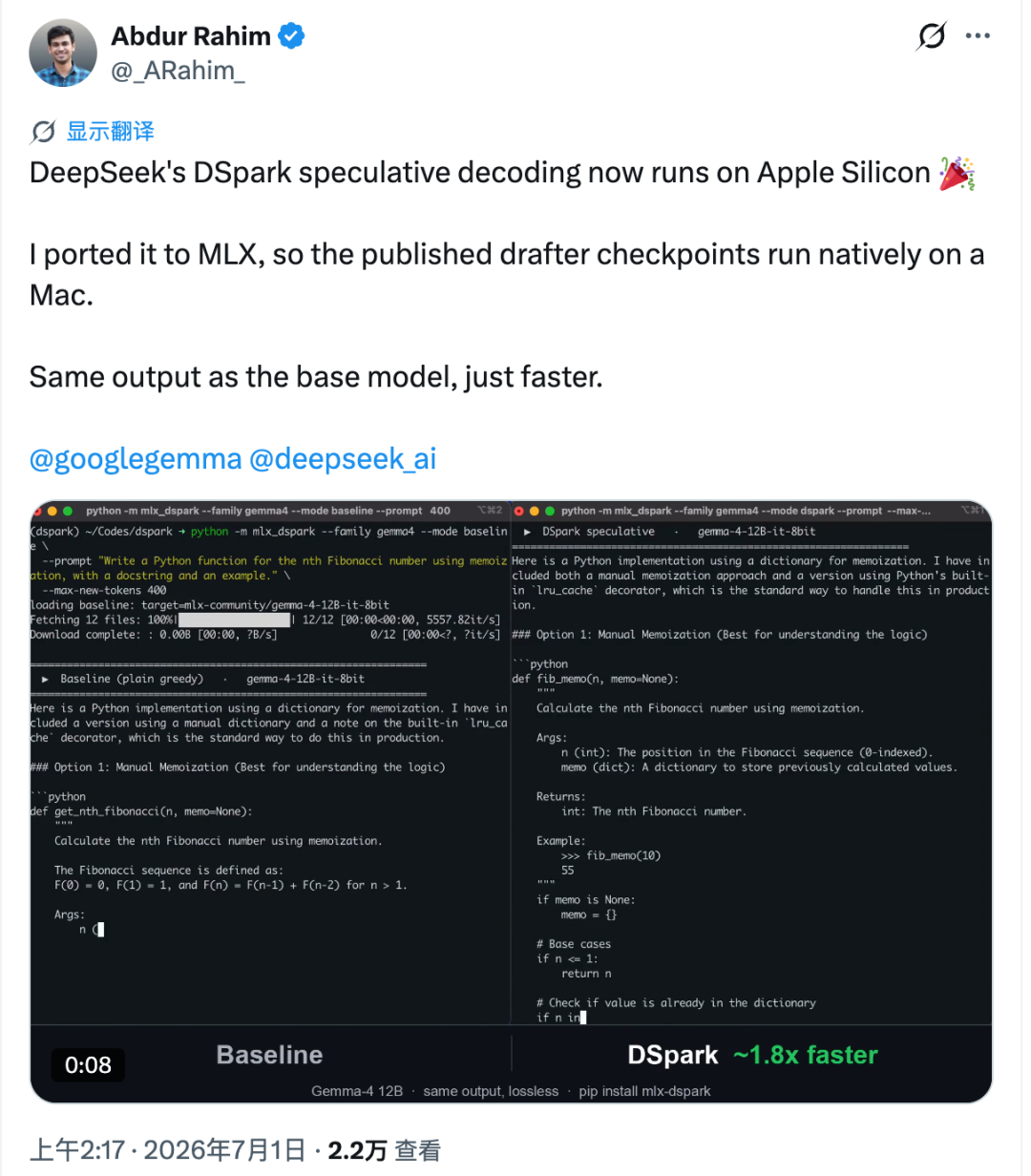
DeepSeek DSpark加速技术被成功移植至Mac本地 : 开源工程师Abdur Rahim将DeepSeek的DSpark投机解码技术移植至苹果芯片,发布了mlx-dspark项目。在M4 Pro芯片上,该项目使Gemma-4 12B和Qwen3-4B的本地推理速度分别提升了1.6倍和1.4倍,且输出结果与原模型在同样温度采样下完全一致。这一尝试证明了投机解码技术在消费级边缘设备上同样具有巨大的降本增效潜力。(来源: 36氪)
上海交大DENG Lab开源世界-语言-动作模型WLA : 上海交通大学DENG Lab开源了WLA模型,将世界建模、语言推理与机器人动作生成统一在同一个2B参数的自回归框架中。WLA不仅能预测细粒度的物理动态,还能通过自然语言预测子任务序列并维护记忆缓冲区,用于长时程规划。在长程记忆基准RMBench上,WLA取得了56.5%的成功率,接近次优方法的两倍,且推理延迟仅为40ms。(来源: 机器之心)
.jpg)
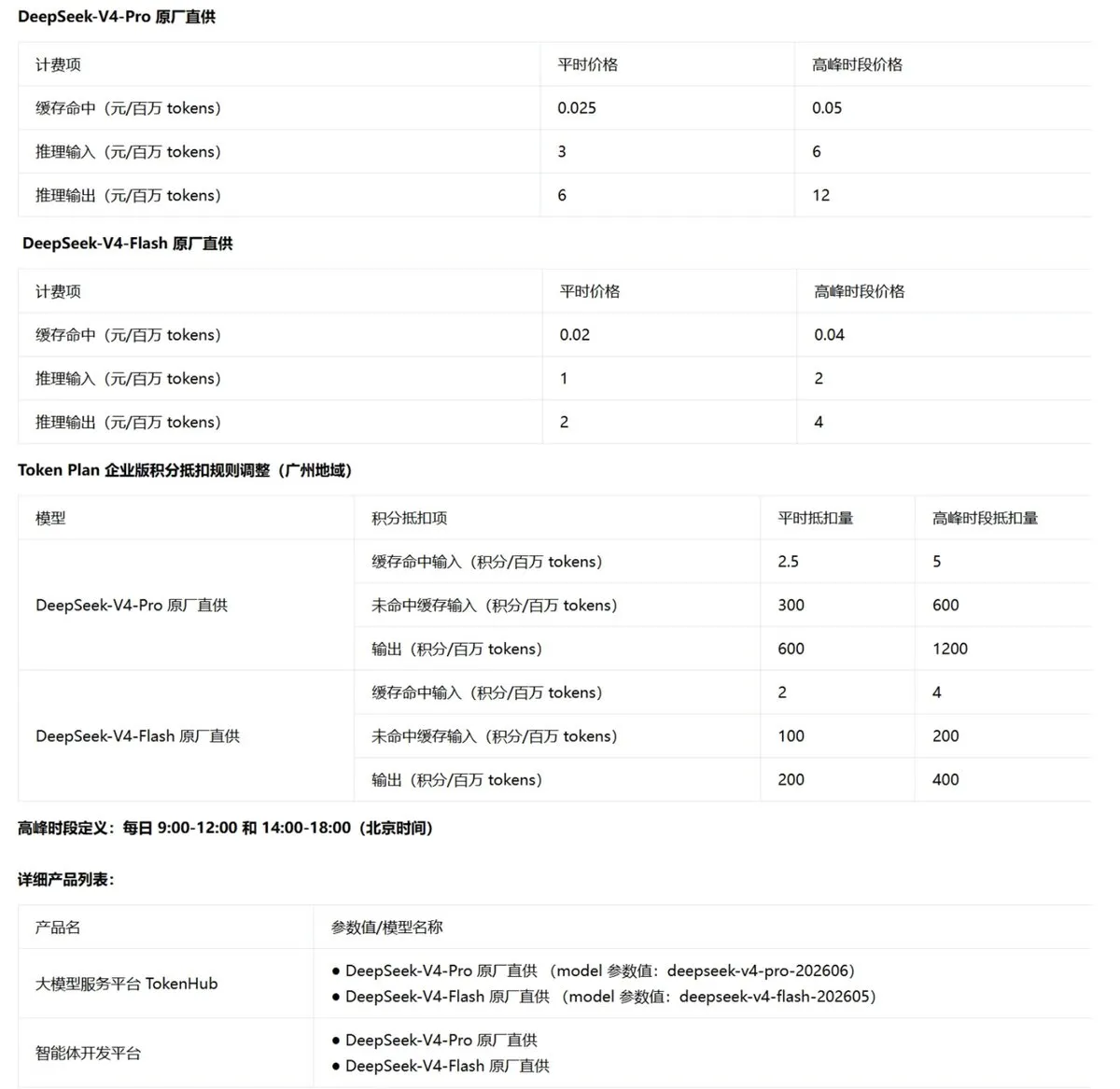
腾讯云将直接提供DeepSeek-V4模型服务 : 腾讯云宣布将于7月中旬在其TokenHub平台上提供DeepSeek-V4模型服务,该服务将直接从DeepSeek自身的网络运行。这一合作得益于腾讯云的技术支持,同时也表明了DeepSeek对其自身算力集群的信心。这为企业级客户在调用前沿开源大模型时,提供了更具弹性和网络保障的算力基础设施选择。(来源: teortaxesTex)
🧰 工具
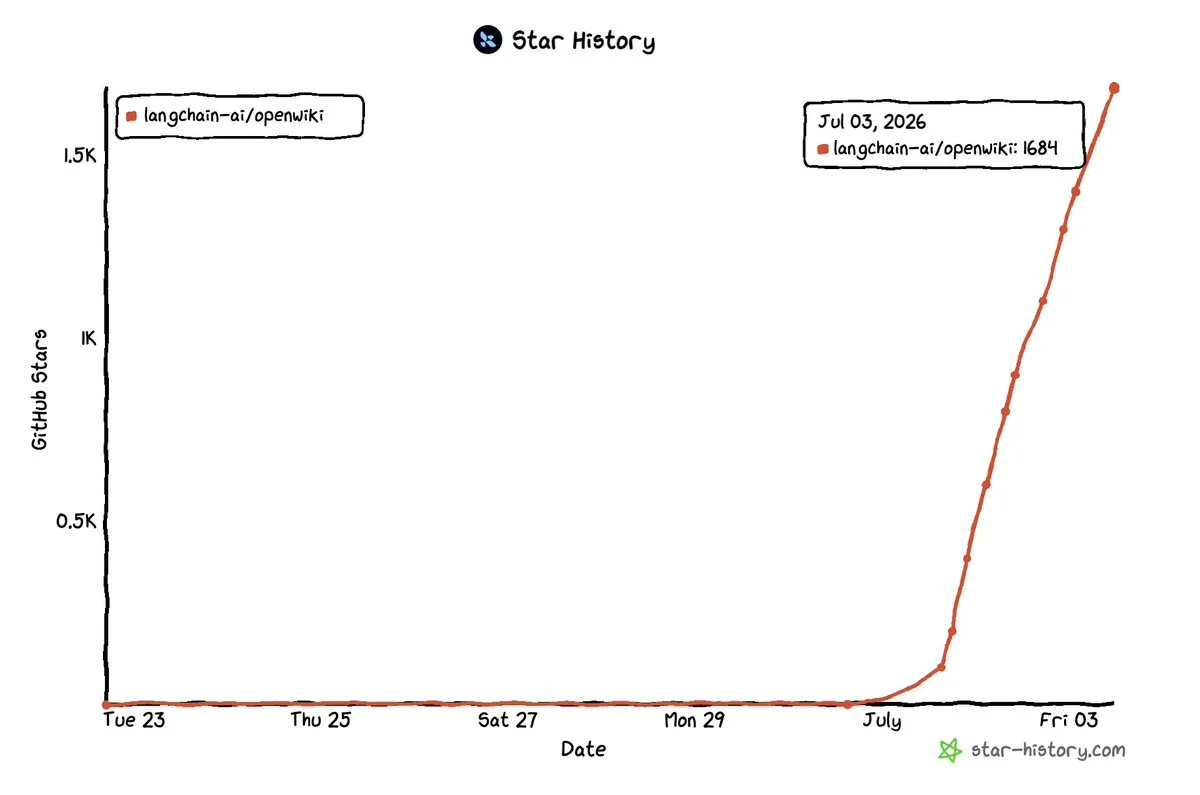
LangChain开源通用内存维基智能体OpenWiki : LangChain开源了OpenWiki项目,在发布仅3天内便获得1.7k的GitHub星标。该项目目前主要针对代码库构建结构化的内存维基,通过自动提取和组织项目上下文,解决Agent在长时程任务中遗忘关键信息的问题。开发团队正计划将其扩展至Notion、Google Drive、Slack和网络搜索等更通用的数据源,以打造全局的Agent记忆中心。(来源: LangChain)
Vercel发布Eve Agent框架并集成LlamaIndex : Vercel推出了Eve智能体框架,LlamaIndex随即为其构建了集成模板。该模板为Eve提供了一套只读文件系统工具,使其能够解析路径、读取文本,并配合LiteParse工具将非结构化文档解析为干净的Markdown格式。这一组合为Agent提供了一套开箱即用的、能够高效导航和理解复杂本地文档集合的可靠工作流。(来源: jerryjliu0)
Hugging Face发布大模型提示词微调自动优化框架 : Hugging Face在Harness Optimization项目中展示了一种自动提示词微调框架。该框架让Claude作为提议者,在不修改底层模型权重的前提下,通过自动迭代和验证来改写Agent外围的提示词和工具调用代码。测试显示,该方法使一个冰冻的开源模型在复杂法律评测中的得分从0%提升至比肩Sonnet 4.6,且任务成本降低了7倍。(来源: ClementDelangue)
基于Fable 5的PPT设计工具baoyu-design更新 : 开发者宝玉更新了其开源的baoyu-design智能体技能,新增了对PPT动画和AI配图调用的支持。该工具利用Fable 5对PPTX XML格式的深度理解,成功解决了此前Opus 4.8无法搞定的动画导出局限。用户现在可以直接生成带动画效果的HTML格式PPT,并无缝导出为Keynote或PowerPoint可编辑的PPTX文件。(来源: dotey)
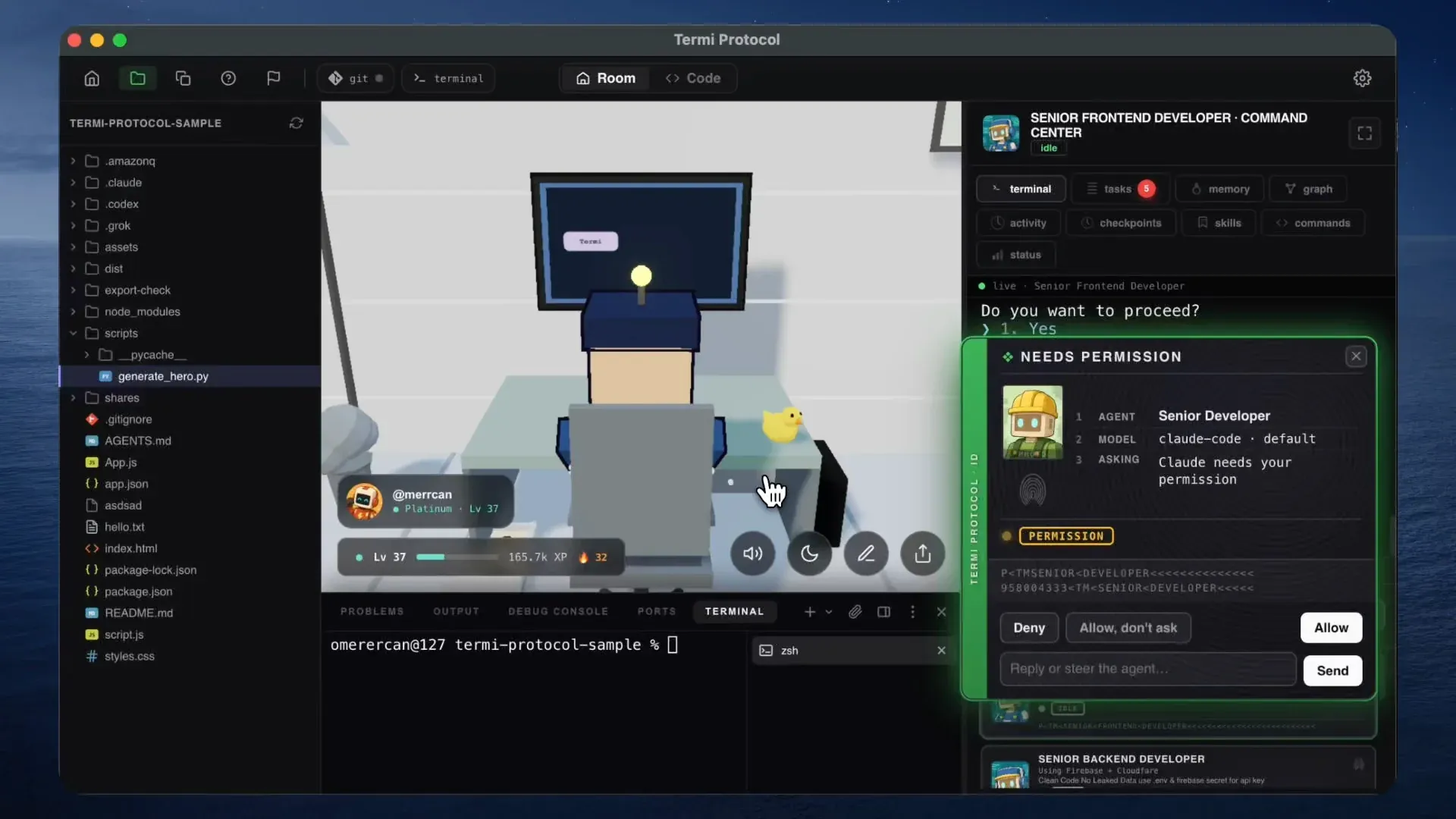
Termiprotocol为Claude Code打造3D虚拟办公室 : 开发者推出开源项目Termiprotocol,为Claude Code、Codex等终端Agent构建了一个3D虚拟办公室界面。Agent在终端执行的每一项操作(如读写文件、网络搜索、运行代码)都会以3D小机器人在办公室中打字、翻文件柜等形式实时呈现,并配有直观的Token消耗监控和任务看板,极大地提升了Agent工作流的可视化与趣味性。(来源: Reddit r/ClaudeAI)
Hugging Face与Cerebras推出Gemma 4语音Demo : Hugging Face与Cerebras合作构建了完全开源的实时语音交互Demo。该Demo基于Gemma 4模型和Cerebras的超低延迟推理硬件,实现了极速的语音转语音(Speech-to-Speech)对话体验。用户可以直接在Hugging Face Spaces上测试、分叉和调整该项目,这为开源社区开发低延迟的语音助手提供了极佳的范本。(来源: huggingface)
📚 学习
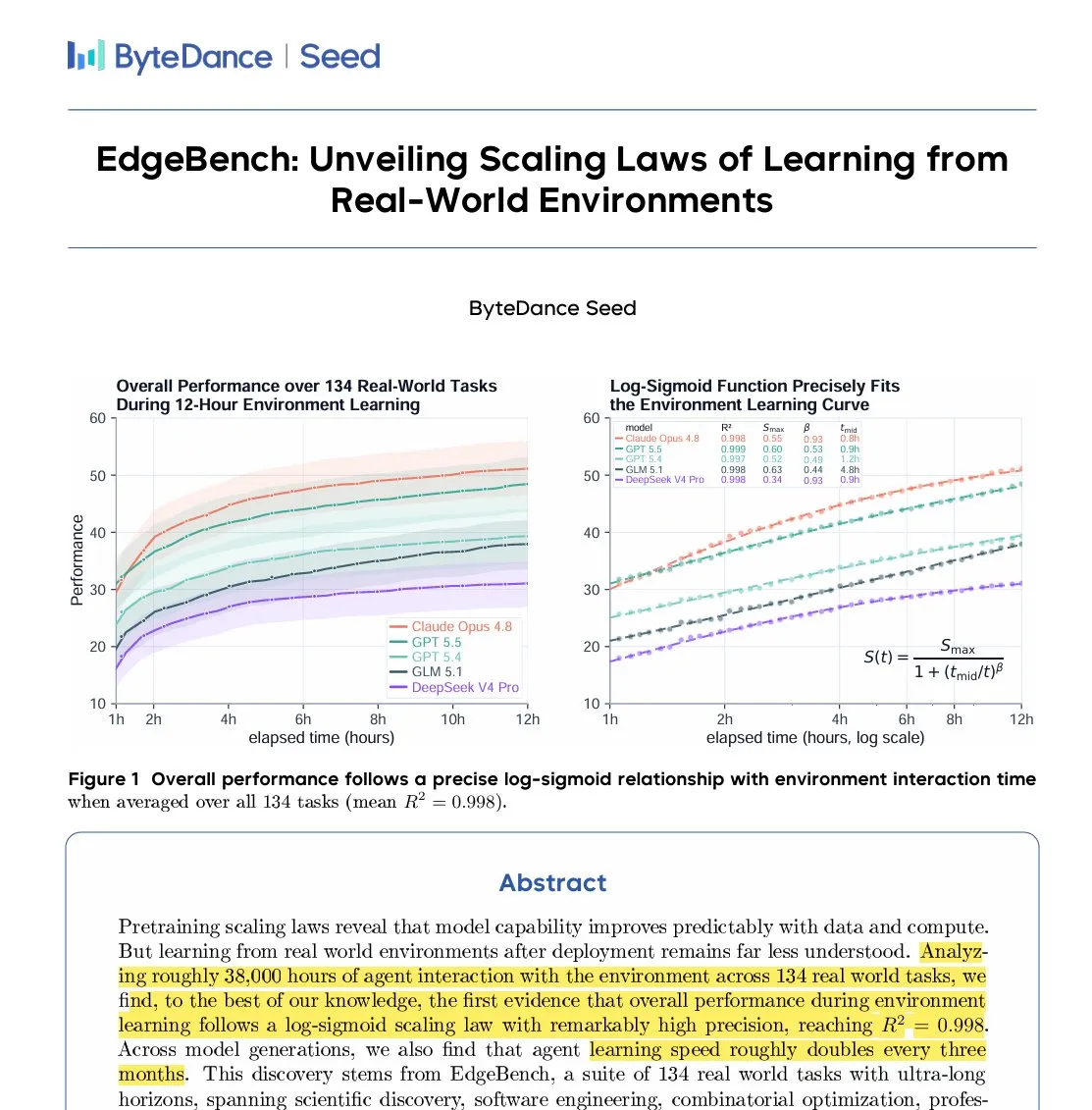
字节跳动发布超长周期Agent学习评估基准EdgeBench : 字节跳动Seed团队发布了EdgeBench,这是一个专为研究智能体在12至72小时超长周期运行中如何从环境反馈中持续学习的评估基准。在对Agent进行了累计3.8万小时的运行测试后,研究人员发现Agent的性能提升与环境交互时间之间精确符合对数-S形(log-sigmoid)函数,证明了积累和复用任务经验是推动Agent长效进步的关键。(来源: arankomatsuzaki)
三星联合北大发布AI Agent系统性基准LiveClawBench : 三星大模型团队联合北京大学等机构发布了LiveClawBench,用于评估个人助理Agent在复杂工作流中的表现。该基准包含134个可执行任务,并提出三维复杂度因子体系。实验表明,对于前沿模型,任务领域仅能解释约9.6%的分数波动,而任务的“复杂度画像”解释力达18.6%,揭示了跨服务依赖和目标解析才是Agent失稳的主因。(来源: 机器之心)
.jpg)
人大发表数据智能体基准CoDA-Bench : 中国人民大学研究团队推出了CoDA-Bench基准,旨在联合评估Agent的代码智能与数据智能。该基准将Agent置于包含1000多个干扰文件的复杂Linux沙盒中,要求其自主探索文件系统、定位相关数据并编写代码进行分析。实验显示,即使是表现最好的系统在CoDA-Bench上的准确率也仅为61.1%,揭示了“找不对数据”是当前Code Agent的核心瓶颈。(来源: 机器之心)
.jpg)
Meta发现量化推理模型“过度思考”缺陷并提出解决方案 : Meta在一项研究中揭示了量化推理模型的一种奇特失效模式:模型在量化后并不仅是能力下降,而是开始“过度思考”。在多达52%的失败案例中,模型在推理中途已得出正确答案,但由于量化提高了犹豫Token(如wait、but、maybe)的采样概率,导致其陷入无休止的自我反思并最终推翻正确结论。Meta通过对犹豫Token施加微小的解码惩罚,成功减少了58%的过思错误。(来源: TheTuringPost)

斯坦福与UC伯克利发布机器人视觉-语言奖励模型RoboReward : 斯坦福与UC伯克利的研究团队推出了RoboReward,这是一个4B/8B参数的机器人视觉-语言奖励模型。该研究通过将成功动作视频进行文本重标记和截断,生成了大量高质量的负面和不完整尝试样本,解决了传统强化学习缺乏失败案例的痛点。实验表明,使用RoboReward进行奖励评估,在真实机器人手臂抓取和开抽屉任务中的成功率显著超越了同类通用大模型。(来源: DeepLearning.AI Blog)
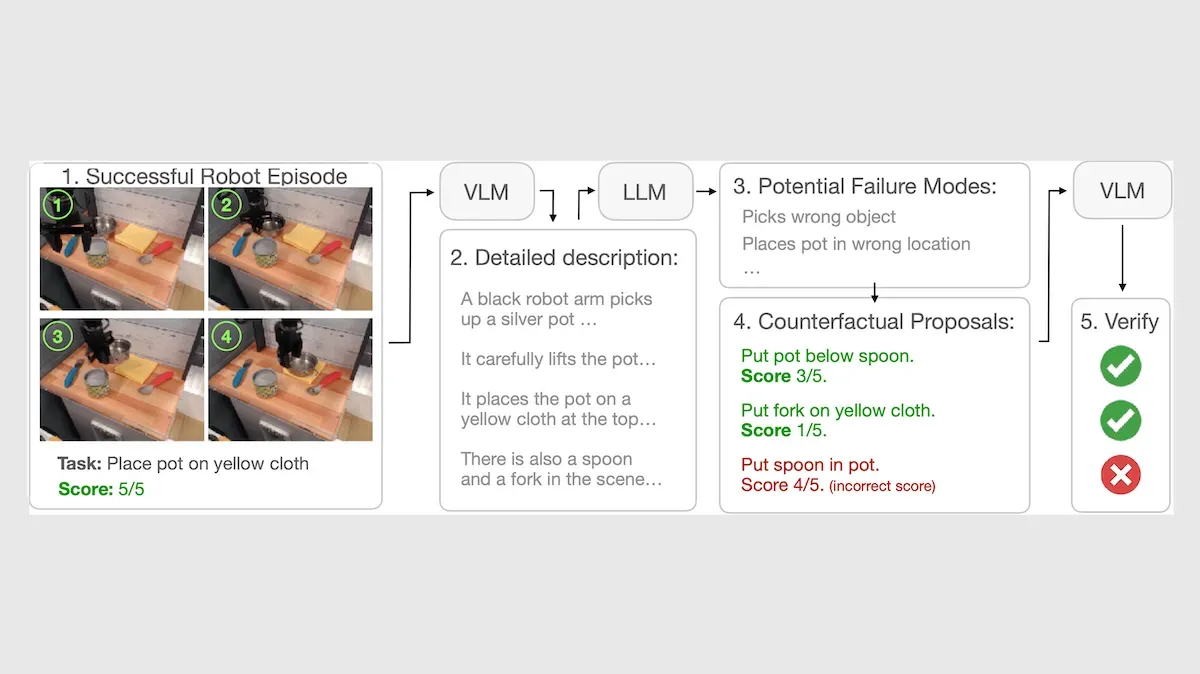
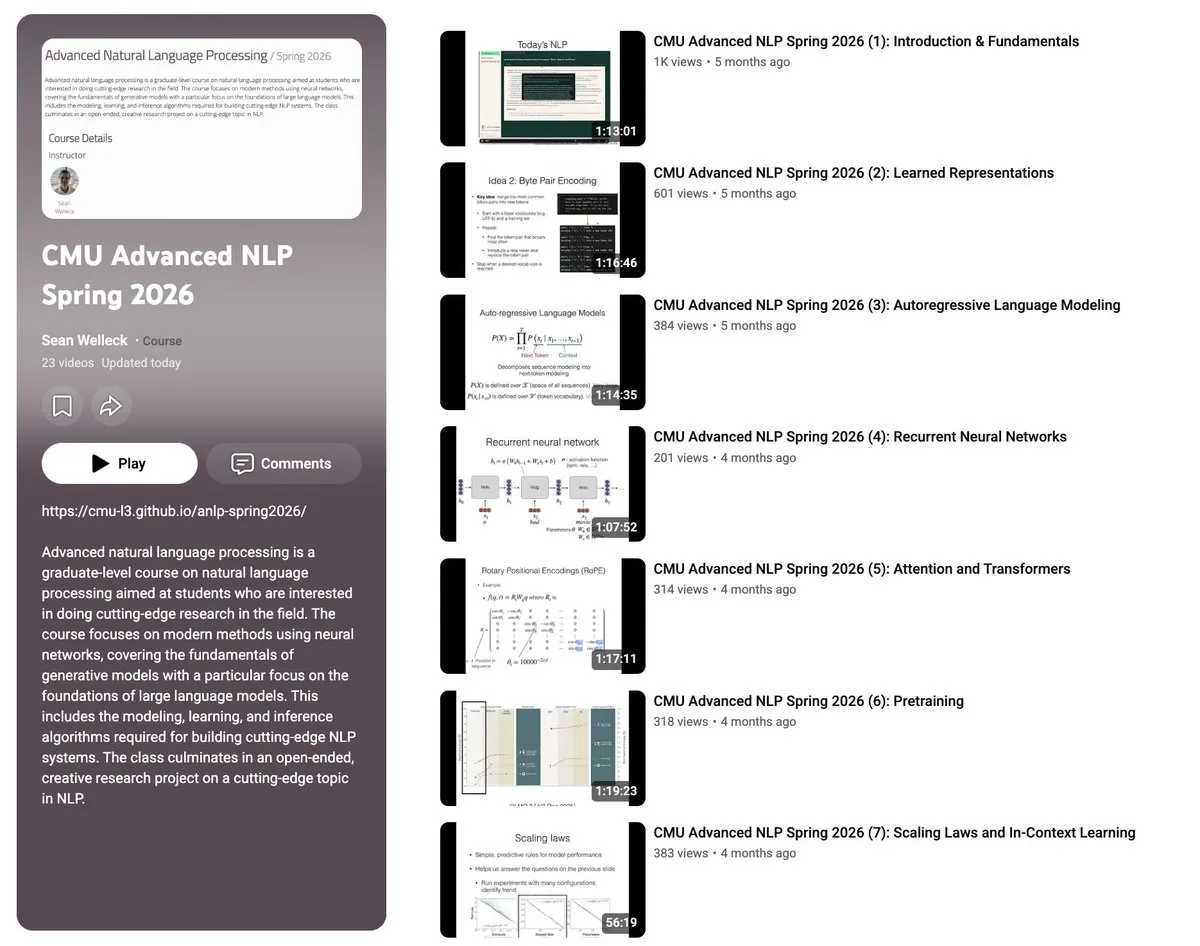
CMU开源Advanced NLP课程全部23讲视频与课件 : 卡内基梅隆大学(CMU)教授Sean Welleck将其《高级自然语言处理(ANLP Spring 2026)》课程的全部23讲视频上传至YouTube,并开源了配套的讲义和20个代码示例。课程内容系统覆盖了NLP基础、模型架构、学习与推理、评估方法、强化学习与智能体(RL & Agents)以及模型缩放与效率等七大主题,是深入学习大模型底层原理的优质资源。(来源: gneubig)
Sebastian Raschka新书《从头构建推理模型》正式出版 : 著名机器学习专家Sebastian Raschka的新书《Build a Reasoning Model (From Scratch)》正式出版。全书共440页,采用全彩排版,并提供了可运行的代码示例。该书系统地介绍了推理模型的底层逻辑,包括推理缩放(Inference Scaling)、强化学习(RL)以及模型蒸馏(Distillation)等前沿技术,是构建大模型基础理论的优秀读物。(来源: cwolferesearch)

💼 商业
宇树科技科创板IPO注册获证监会同意 : 证监会已正式批准宇树科技在科创板首次公开发行股票的注册申请。宇树科技拟公开发行不低于10%的股份,募集资金42.02亿元,估值约420亿元。招股书显示,宇树在2025年实现营收17.08亿元,净利润达5.91亿元,人形机器人出货量超5500台,全球市占率达32.4%。这标志着国内首家实现盈利的具身智能整机企业即将正式登陆A股。(来源: 36氪)
硅基流动向港交所递交招股书冲刺“Token工厂第一股” : AI基础设施初创公司硅基流动(Silicon Flow)正式向港交所递交招股书。公司定位为AI产业的“Token批发商”,通过标准化API提供多模型统一接入服务。B+轮融资后估值达77.4亿元,股东包括阿里、腾讯、华为、美团等巨头。招股书显示,2025年公司公有云付费客户达71.6万家,但由于前期算力与推广投入巨大,净亏损达3.45亿元。(来源: 36氪)
光象科技完成累计数亿元天使轮融资 : 具身智能初创公司光象科技宣布完成累计数亿元天使轮融资,由珠海科技集团、兴证资本、松禾资本等联合投资。光象科技由清华大学团队孵化,确立了“物理原生智能”的技术路线,并构建了由强化学习算法矩阵、高保真物理数据资产与智能开发平台组成的体系。其自研的具身机器人Phi-Bot X1已在汽车产线焊接上料工位实现高精度连续作业验证。(来源: 量子位)

🌟 社区
阿里内部下发通知全面禁用Claude及Claude Code : 阿里巴巴内部紧急下发通知,要求员工在7月10日前全面卸载和禁用Claude及Claude Code等Anthropic产品。此前,安全社区逆向分析发现Claude Code内置了隐蔽的中国用户及AI实验室检测机制,通过混淆代码收集系统时区、代理和API关键词,并以篡改提示词中Unicode字符的方式将环境指纹传回服务器,引发了企业对核心代码泄露的担忧。(来源: 36氪)

Godot游戏引擎官方宣布全面收紧AI代码贡献政策 : 开源游戏引擎Godot宣布修改贡献政策,全面禁止使用AI生成大段代码及AI Agent自动提交PR的行为。官方直言,AI虽然降低了写代码的门槛,但导致大量低质量PR涌入,严重消耗了志愿维护者的审查精力;更糟糕的是,许多提交者根本无法解释AI生成的代码,也无法在出现Bug时进行维护。Godot强调,AI不能为代码负责,项目需要的是真正能理解代码的人。(来源: 36氪)

Meta计划推出云服务Metamate对外出租闲置AI算力 : 彭博社报道称,Meta正计划组建云基础设施业务部门“Metamate”,向外部客户出售闲置的AI算力和模型访问权限,以期在2027年前产生100亿至150亿美元的年收入。这一消息引发了市场对AI算力可能面临阶段性过剩的担忧,导致全球芯片和存储板块在随后两个交易日内遭遇大面积抛售。(来源: 36氪)
学术界发现AI大模型在数学研究中正逐步替代人类 : 随着OpenAI内部模型独立推翻了由物理学家Erdős提出的、人类研究近80年的“平面单位距离猜想”,AI的数学推理能力迎来断崖式跳变。这在数学博士生圈子里引发了“道心破碎”式的焦虑,有学生调侃称自己只能靠打《王者荣耀》来逃避现实。学者认为,AI在标准化、形式化数学研究上的高效,正迫使人类数学家重新思考自身的研究价值与审美边界。(来源: 36氪)
Cloudflare报告显示机器网络流量首次超越人类 : 网络安全服务商Cloudflare发布报告称,在其托管的网站收到的所有网络访问请求中,约57.4%来自人工智能和自动化程序(如AI训练爬虫、Agent代理等),而来自真实人类的请求仅占42.6%。这是互联网历史上机器流量首次超越人类流量,标志着网络交互范式已发生根本性转变,也对传统的流量广告变现商业模式带来了系统性冲击。(来源: 36氪)

💡 其他
研究人员发现大语言模型中存在“Dr. Elena Rodriguez”幽灵人名 : 三星实验室在关于“对比解码差异(CDD)”的论文中披露了一个有趣的发现:在对多个微调模型进行训练数据逆向恢复时,不同领域的模型输出中高频出现了一个虚构的科学家名字“Dr. Elena Rodriguez”。调查发现,这是因为Claude Sonnet 3.6在生成合成训练数据时极度偏爱这个名字,导致其被无意中“烤”进了所有使用该合成数据的微调模型中。(来源: Reddit r/MachineLearning)

Reddit用户调侃Perplexity Pro悄悄限制使用额度 : 许多订阅了Perplexity Pro(年费200美元)的用户在Reddit上抱怨,发现其“无限文件上传”和“深度研究(Deep Research)”功能在近期被悄悄限制并呈现灰色不可用状态。用户控诉平台在没有发送任何邮件、公告或更新服务条款的前提下,单方面削减了Pro用户的权益,引发了社区对SaaS服务透明度与消费者权益保护的广泛讨论。(来源: Reddit r/artificial)
Reddit用户分享用Fable 5整理十年世界观设定并自动生成维基 : 一位小说创作者在Reddit上分享,他将自己十年来积累的、包含数十万字的小说草稿、世界观设定和杂乱笔记整理成一个PDF,利用Fable 5进行分析。Fable 5在消耗了其单次会话90%的额度后,极其完美地将这些内容梳理成结构化的角色、事件和地理条目,并自动生成了可直接导入World Anvil维基系统的Markdown文件,帮助其摆脱了长期的创作瓶颈。(来源: Reddit r/ClaudeAI)