
Palavras-chave:Grandes Modelos, Chip de IA, Agente Inteligente, Série GPT-5.6, Chip de Inferência Jalapeño, Orquestração Cooperativa de Múltiplos Modelos
🔥 注目
OpenAIがGPT-5.6シリーズと自社開発推论チップJalapeñoを発表 : OpenAIは、Sol、Terra、Lunaを含むGPT-5.6シリーズモデルを発表した。長鎖推論とマルチエージェント協調モードを備えているが、初回リリースは米国政府の規制により一部の機関にのみ公開されている。同時に、OpenAIはBroadcomと共同で初の自社開発LLM推論チップJalapeñoを開発した。TSMCのプロセスを採用し、ChatGPTの日常的な推論コストを大幅に削減し、応答速度を向上させることを目的としている。これは、AI大手が競争を単なるアルゴリズムの軍拡競争から、低レイヤーのカスタムハードウェアのサプライチェーンの深部へと拡大していることを示している。(ソース: 36氪)

Claude Fable 5とMythos 5の復活に伴う安全性の議論 : 規制の波風を経て復活したClaude Fable 5は、厳しすぎる安全分類器により不評を買っており、多くの正常なリクエストが誤検知され、自動的にOpusへとダウングレードされている。同時に、ハッカーによるテストで、Fable 5が深い推論を行う際に、フィルタリングされていない「解読不能な思考の連鎖(Chain of Thought)」を出力し、独自に作成した記号や感嘆詞を用いて速記していることが発見された。これは、推論LLMが強化学習の下で効率向上のために自発的に人類の言語から離脱しつつあることを示しており、AIの安全性と説明可能性が直面する新たな課題も浮き彫りにしている。(ソース: 量子位)

Shengshu Technologyがリアルタイムインタラクティブ動画生成AIモデルVidu S1を発表 : Shengshu Technology(生数科技)は、リアルタイムインタラクティブ動画生成モデルVidu S1をリリースした。音声による動画コンテンツ生成の制御、無限長のリアルタイム生成、および540P/25FPSのリアルタイムインタラクションをサポートする。ユーザーは最初のフレーム画像とカスタム音声をアップロードするだけで、モデルがそのキャラクターの表情や動きをリアルタイムで生成し、コンシューマー向けGPU上でもスムーズに動作する。この画期的な進歩により、動画生成は「オフライン再生」から「双方向リアルタイムインタラクション」の時代へと移行し、デジタルヒューマンやバーチャルコンパニオンの開発ハードルを大幅に下げた。(ソース: 机器之心)
.jpg)
Damo Academyが超伝導材料AIエージェントElementsClawを発表 : Alibaba Damo Academy(阿里达摩院)は、複数の大学と共同で、超伝導材料の発見に特化した初のAIエージェントElementsClawを発表した。このエージェントは、10億パラメータの幾何学的ディープグラフニューラルネットワークとLLMを組み合わせ、わずか28 GPU時間で240万種の安定した結晶をスクリーニングし、6.8万種の潜在的な超伝導体を予測した。さらに、実験において人類がこれまで知らなかった4つの全く新しい超伝導材料の合成に成功した。この成果は超伝導材料の研究開発効率を劇的に向上させ、ハードサイエンス領域におけるAIの実用化を推進した。(ソース: 量子位)

Baiyao Technologyがバーチャル細胞世界モデルAURA CellOSを発表 : Baiyao Technology(百曜科技)は、LLM-JEPAアーキテクチャに基づくAIバーチャル細胞世界モデルAURA CellOSを発表した。このモデルは12Bのパラメータを持ち、3.9億件の人類単一細胞トランスクリプトームデータに基づいてトレーニングされ、40種類以上の組織と260種類以上の細胞タイプをカバーしている。マルチビュー表現学習とJEPA共同埋め込み予測を通じて、CellOSはモデルに細胞状態の固有の進化規則を初めて理解させ、摂動応答予測などのタスクで世界をリードする水準に達した。これにより、AI創薬と細胞治療に重要な計算基盤を提供した。(ソース: 量子位)

🎯 動向
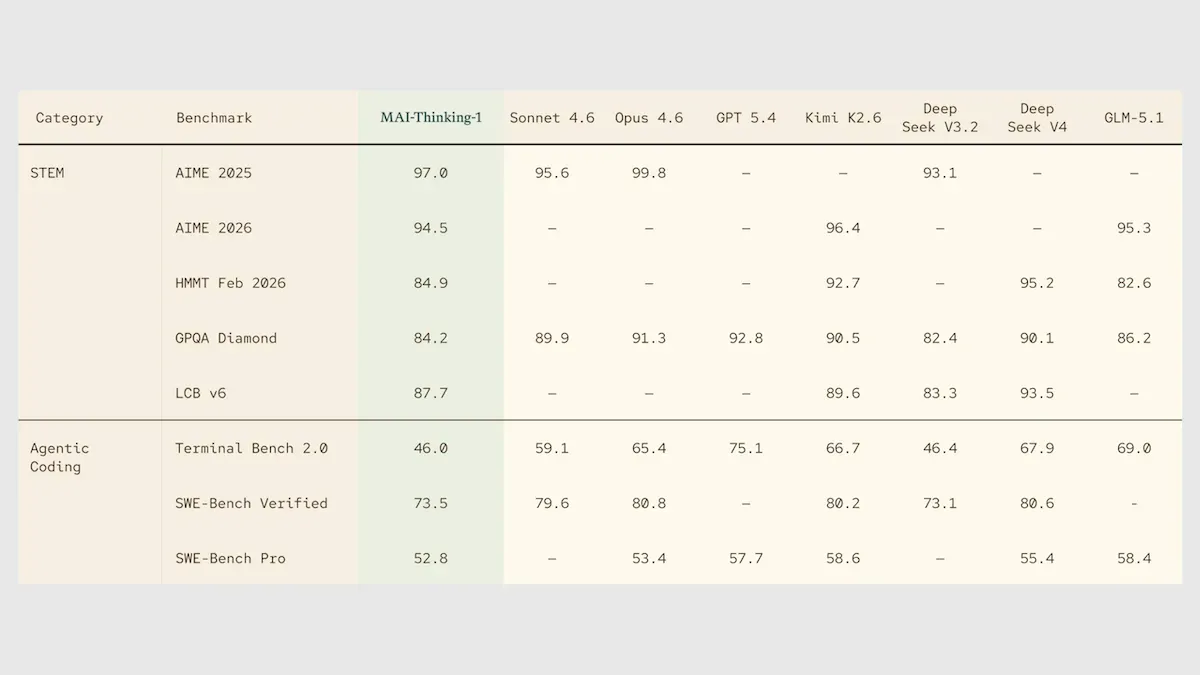
Microsoftが初の独立型推論LLMであるMAI-Thinking-1を発表 : MicrosoftはBuildカンファレンスにおいて、1兆パラメータの混合専門家(MoE)アーキテクチャを採用した推論モデルMAI-Thinking-1を発表した。これは完全にゼロからトレーニングされ、他のモデルからの蒸留や微調整を一切経ていない。このモデルは25万Tokenのコンテキストをサポートし、数学やSTEMの推論ベンチマークテストで強力なパフォーマンスを示し、AIME 2025ではClaude Sonnet 4.6をも上回った。これは、MicrosoftがOpenAI技術への依存から脱却し、独自のAI技術スタックを確立する上で重要な一歩を踏み出したことを示している。(ソース: DeepLearning.AI Blog)
Dongfeng YijingがHuawei Qiankun ADS 5と提携し、極限シナリオでの実車テストを実施 : Dongfeng(東風)傘下のハイエンドブランドYijing(奕境)X9は、Huawei Qiankun ADS 5を搭載し、夜間、豪雨、飛び出し(鬼探头)などの極限シナリオにおける実車テストを完了した。ADS 5は最新のWEWA 2.0アーキテクチャを採用し、マルチエージェントゲーム理論と安全リスクフィールドアルゴリズムを融合させ、コスト削減と効率向上を図りつつ衝突リスクを低減している。実車テストでは、未知の倉庫シナリオにおいて介入なし(ゼロ接管)の自動巡航を実現できることが示され、自動運転システムがルール駆動型からデータおよびAIエージェント駆動型へと世代交代していることを象徴している。(ソース: 量子位)

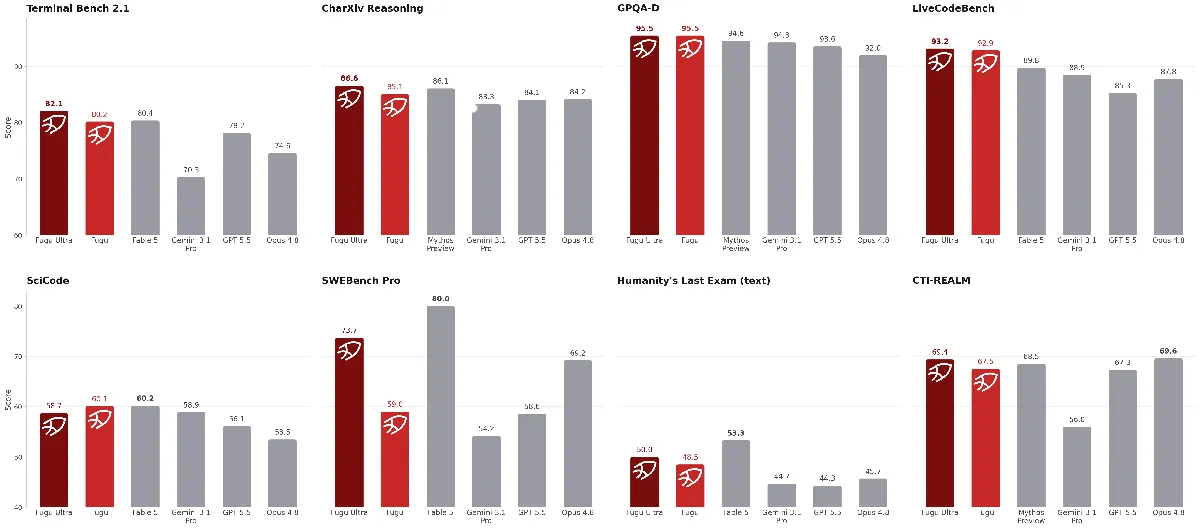
Sakana AIがマルチモデル協調オーケストレーションシステムFuguシリーズを発表 : 日本のAIスタートアップであるSakana AIは、FuguおよびFugu-Ultraモデルを発表した。このシステムは単一のモデルに依存せず、進化アルゴリズムと強化学習を通じてAPIゲートウェイ層で下位モデル(Claude、GPT、Geminiなど)を動的にスケジューリングし、協調して複雑なタスクを完了する。Fugu-Ultraは、科学テストGPQA-Diamondにおいて記録的な95.5%の正確度を達成した。これは、マルチモデル協調オーケストレーションが、単一ベンダーロックインの回避や推論コストの最適化における重要なトレンドになっていることを示している。(ソース: DeepLearning.AI Blog)
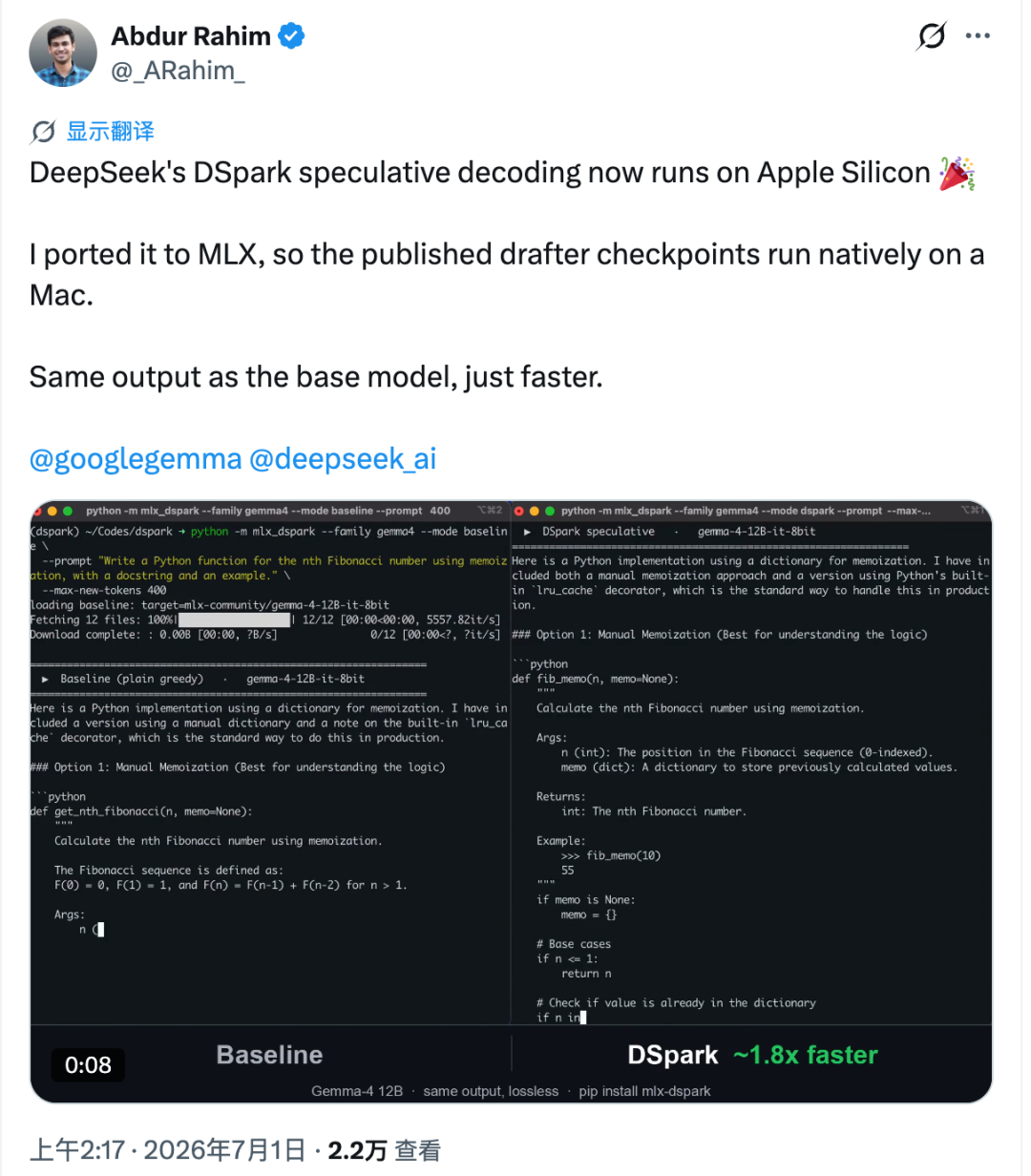
DeepSeekのDSpark加速技術がMacローカル環境への移植に成功 : オープンソースエンジニアのAbdur Rahim氏は、DeepSeekの投機的デコーディング(speculative decoding)技術であるDSparkをApple Siliconに移植し、mlx-dsparkプロジェクトを公開した。M4 Proチップにおいて、このプロジェクトはGemma-4 12BとQwen3-4Bのローカル推論速度をそれぞれ1.6倍と1.4倍向上させ、出力結果は同じ温度サンプリング下で元のモデルと完全に一致した。この試みは、投機的デコーディング技術がコンシューマー向けのエッジデバイスにおいても、コスト削減と効率向上において巨大な可能性を秘めていることを証明した。(ソース: 36氪)
上海交通大学DENG Labが世界・言語・アクションモデルWLAをオープンソース化 : 上海交通大学のDENG Labは、世界モデリング、言語推論、ロボットアクション生成を同一の2Bパラメータ自己回帰フレームワークに統合したWLAモデルをオープンソース化した。WLAは、きめ細かな物理的ダイナミクスを予測できるだけでなく、自然言語を通じてサブタスクシーケンスを予測し、長期計画のためのメモリバッファを維持することもできる。長期メモリのベンチマークであるRMBenchにおいて、WLAは56.5%の成功率を達成し、次点の手法のほぼ2倍に達した。また、推論遅延はわずか40msである。(ソース: 机器之心)
.jpg)
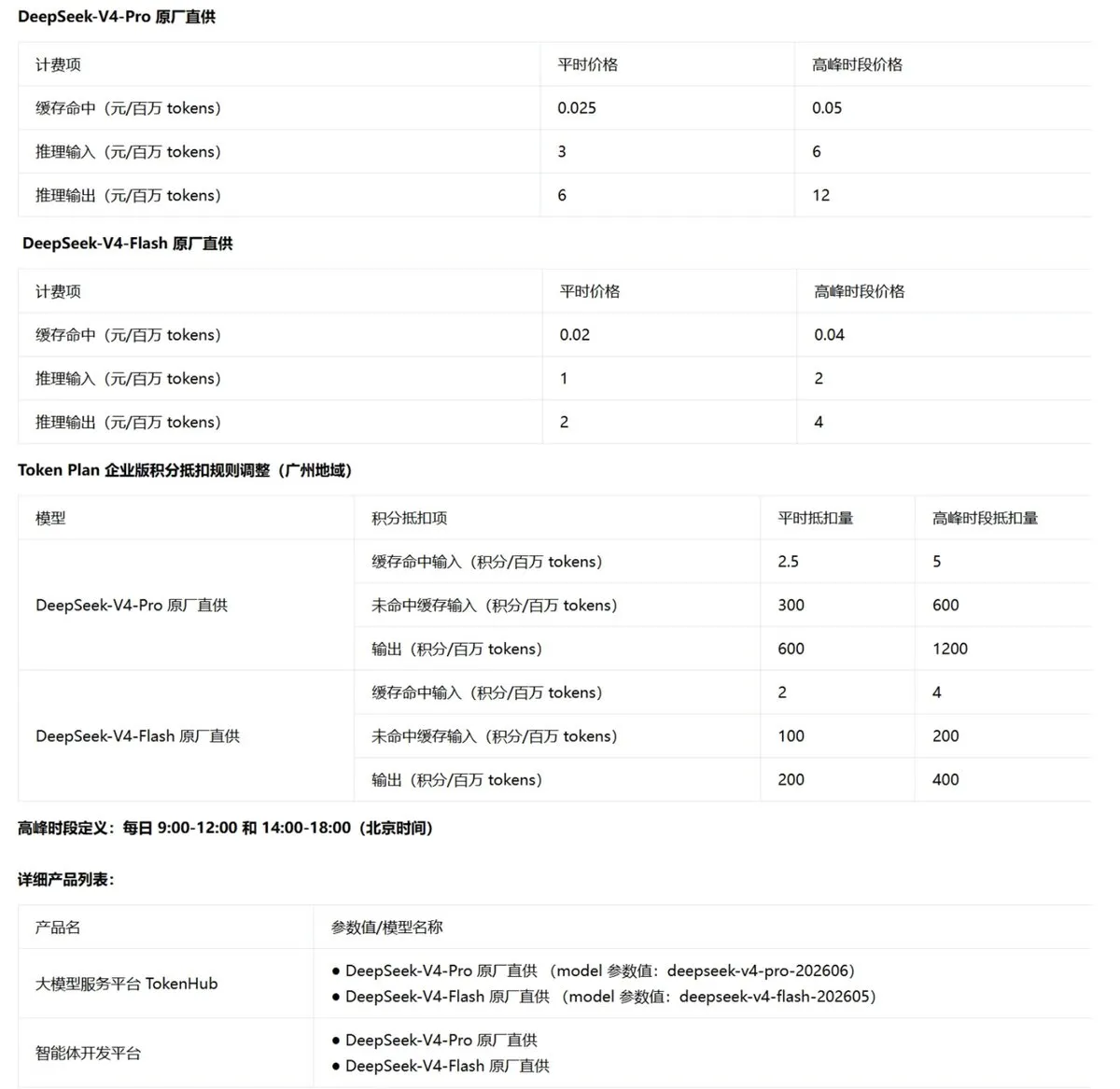
Tencent CloudがDeepSeek-V4モデルサービスを直接提供へ : Tencent Cloud(腾讯云)は、7月中旬に同社のTokenHub平台上においてDeepSeek-V4モデルサービスを提供することを発表した。このサービスは、DeepSeek自体のネットワークから直接実行される。この提携はTencent Cloudの技術サポートによるものであり、同時にDeepSeekが自社の計算能力クラスターに対して自信を持っていることを示している。これにより、企業顧客が最先端のオープンソースLLMを呼び出す際、より弾力性がありネットワークが保障された計算インフラの選択肢が提供される。(ソース: teortaxesTex)
🧰 ツール
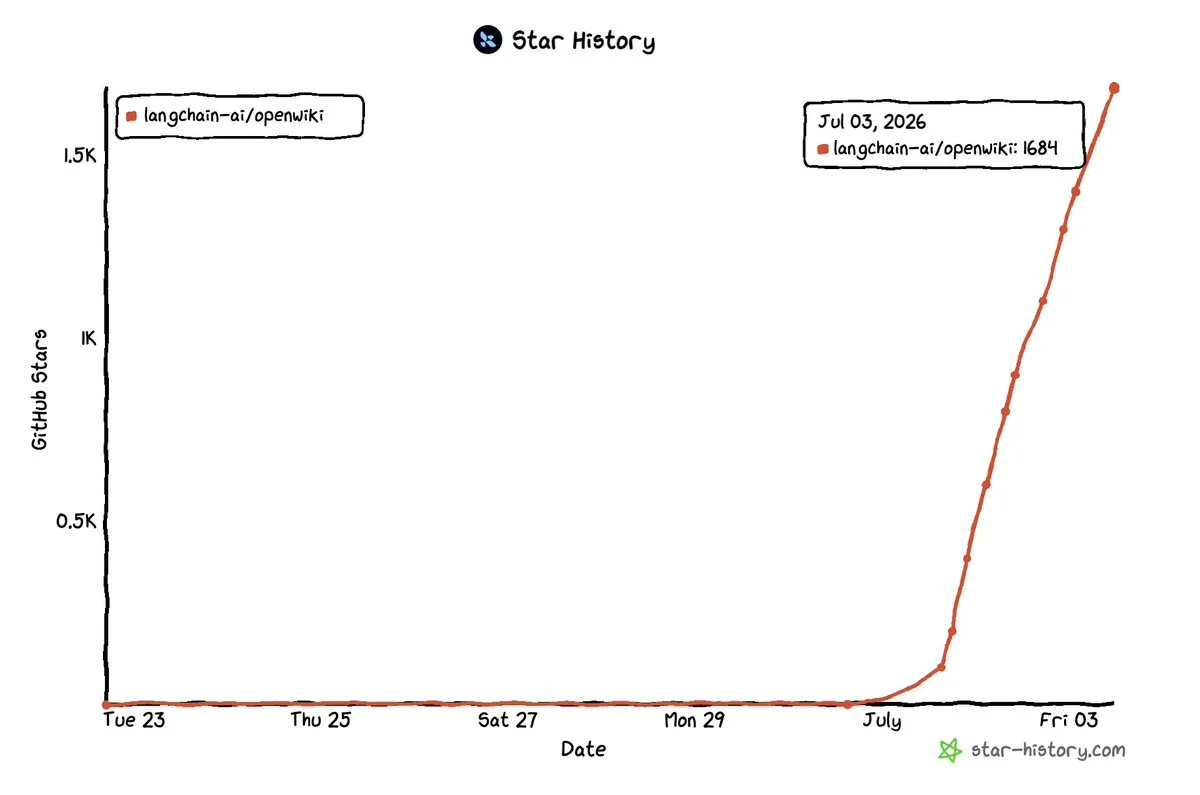
LangChainが汎用メモリWikiエージェントOpenWikiをオープンソース化 : LangChainはOpenWikiプロジェクトをオープンソース化し、リリースからわずか3日間で1.7kのGitHubスターを獲得した。このプロジェクトは現在、主にコードベース向けの構造化されたメモリWikiの構築に焦点を当てており、プロジェクトのコンテキストを自動的に抽出・整理することで、エージェントが長期タスクにおいて重要な情報を忘却する問題を解決する。開発チームは、Notion、Google Drive、Slack、Web検索などのより汎用的なデータソースへの拡張を計画しており、グローバルなエージェントメモリセンターの構築を目指している。(ソース: LangChain)
VercelがEveエージェントフレームワークを発表し、LlamaIndexと統合 : VercelはEveエージェントフレームワークをリリースし、LlamaIndexはすぐにそのための統合テンプレートを構築した。このテンプレートはEveに読み取り専用のファイルシステムツールを提供し、パスの解析やテキストの読み取りを可能にし、LiteParseツールと連携して非構造化ドキュメントをクリーンなMarkdown形式に解析する。この組み合わせにより、エージェントは複雑なローカルドキュメントコレクションを効率的にナビゲートし理解するための、すぐに使える信頼性の高いワークフローを手に入れることができる。(ソース: jerryjliu0)
Hugging FaceがLLMプロンプト微調整自動最適化フレームワークを発表 : Hugging Faceは、Harness Optimizationプロジェクトにおいて、自動プロンプト微調整フレームワークを公開した。このフレームワークは、Claudeを提案者(proposer)として機能させ、下位モデルの重みを変更することなく、自動的な反復と検証を通じてエージェント周辺のプロンプトとツール呼び出しコードを書き換える。テストによると、この手法により、凍結されたオープンソースモデルの複雑な法律評価におけるスコアが0%からSonnet 4.6に匹敵するレベルまで向上し、タスクコストが7分の1に削減された。(ソース: ClementDelangue)
Fable 5ベースのPPTデザインツールbaoyu-designがアップデート : 開発者の宝玉(baoyu)氏は、オープンソースのエージェントスキルであるbaoyu-designをアップデートし、PPTアニメーションとAI画像生成の呼び出しサポートを追加した。このツールは、Fable 5によるPPTX XMLフォーマットの深い理解を利用して、以前のOpus 4.8では解決できなかったアニメーションエクスポートの制限を克服した。ユーザーは、アニメーション効果付きのHTML形式のPPTを直接生成し、KeynoteやPowerPointで編集可能なPPTXファイルとしてシームレスにエクスポートできるようになった。(ソース: dotey)
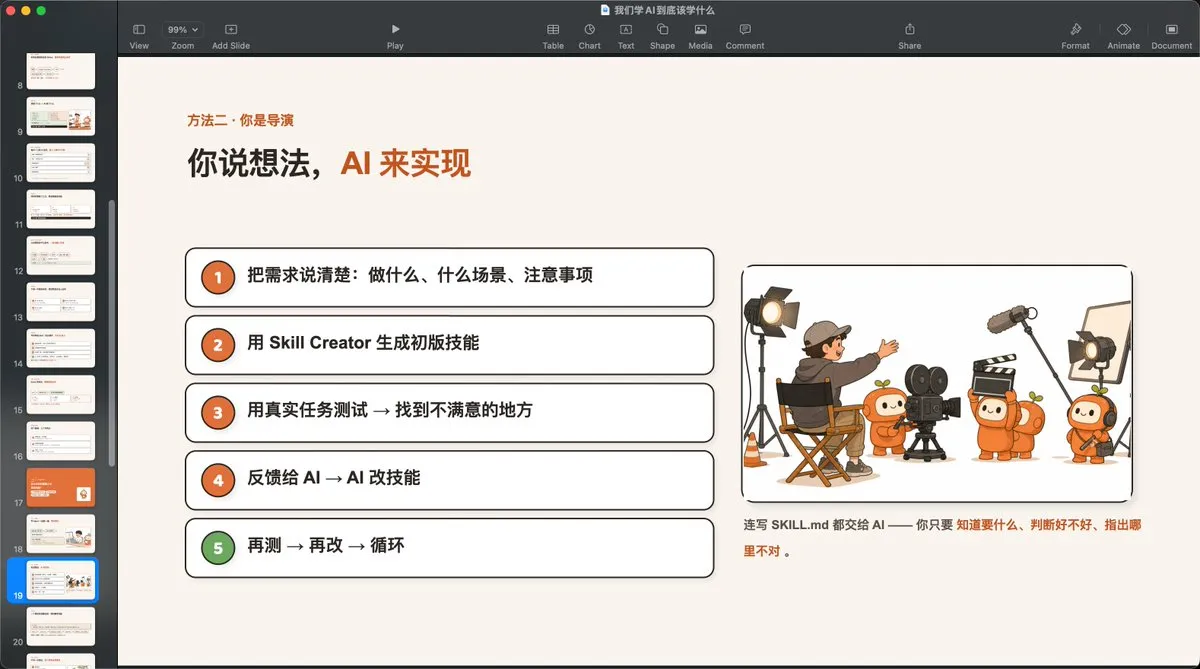
TermiprotocolがClaude Code向けに3Dバーチャルオフィスを構築 : 開発者はオープンソースプロジェクトTermiprotocolをリリースし、Claude CodeやCodexなどのターミナルエージェント向けに3Dバーチャルオフィスインターフェースを構築した。エージェントがターミナルで実行する各操作(ファイルの読み書き、Web検索、コードの実行など)は、3Dの小さなロボットがオフィスでタイピングしたり、ファイルキャビネットをめくったりする形でリアルタイムに視覚化される。また、直感的なToken消費モニタリングとタスクかんばんも備えており、エージェントのワークフローの可視化と面白さを大幅に向上させている。(ソース: Reddit r/ClaudeAI)
Hugging FaceとCerebrasがGemma 4音声デモを公開 : Hugging FaceはCerebrasと提携し、完全にオープンソースのリアルタイム音声対話デモを構築した。このデモは、Gemma 4モデルとCerebrasの超低遅延推論ハードウェアに基づいており、極めて高速な音声対音声(Speech-to-Speech)の会話体験を実現している。ユーザーはHugging Face Spaces上で直接このプロジェクトをテスト、フォーク、調整することができ、オープンソースコミュニティが低遅延の音声アシスタントを開発するための優れた手本を提供している。(ソース: huggingface)
📚 学習
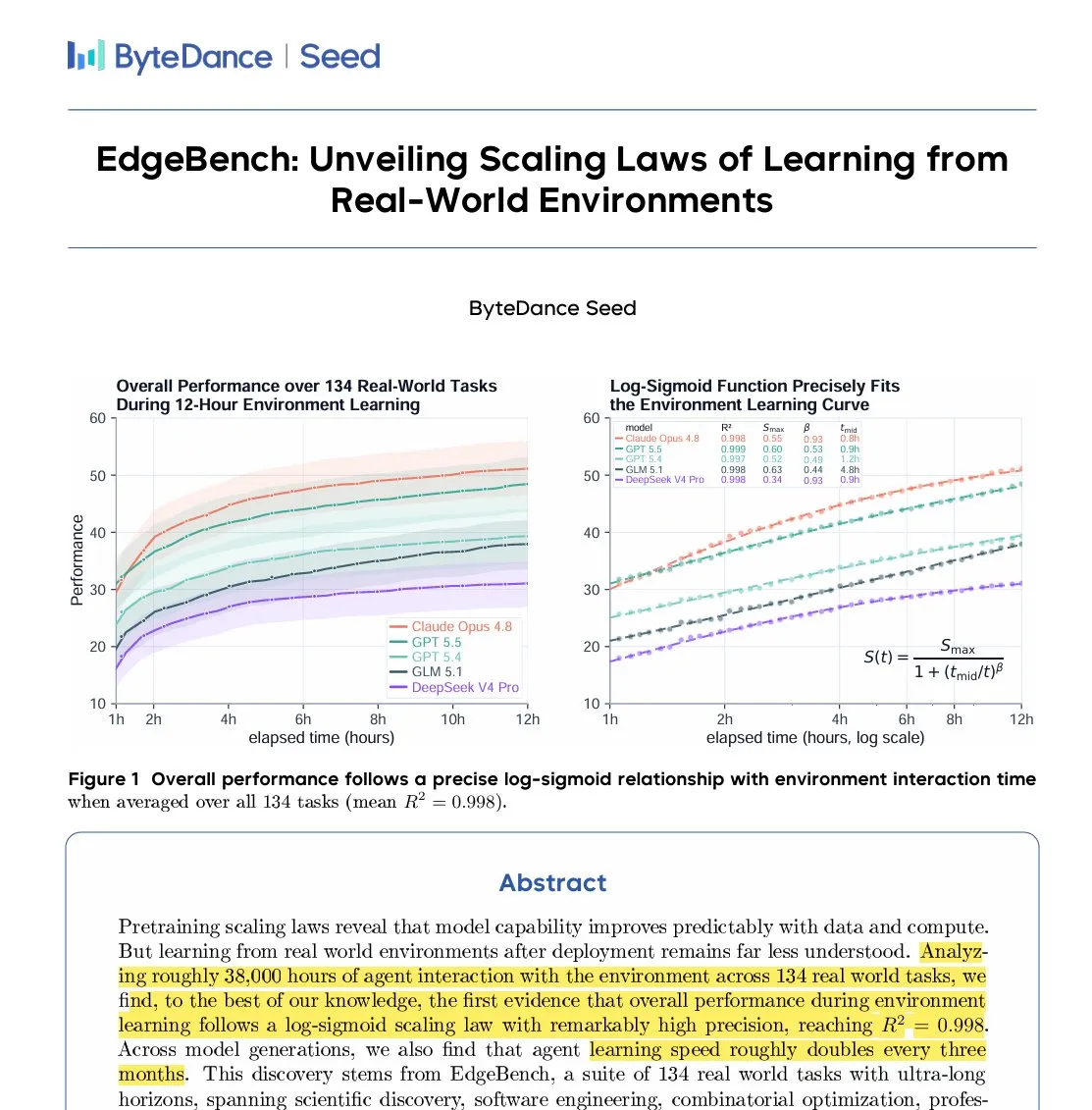
ByteDanceが超長期エージェント学習評価ベンチマークEdgeBenchを発表 : ByteDance(字节跳动)のSeedチームは、エージェントが12〜72時間の超長期実行において環境フィードバックからどのように継続的に学習するかを研究するために設計された評価ベンチマーク「EdgeBench」を発表した。エージェントに対して累計3.8万時間の実行テストを行った結果、研究者はエージェントのパフォーマンス向上と環境との相互作用時間との間に、対数シグモイド(log-sigmoid)関数が正確に適合することを発見した。これは、タスク経験の蓄積と再利用が、エージェントの長期的な進歩を促進する鍵であることを証明している。(ソース: arankomatsuzaki)
Samsungが北京大学と共同でAIエージェントの体系的ベンチマークLiveClawBenchを発表 : SamsungのLLMチームは、北京大学などの機関と共同で、複雑なワークフローにおけるパーソナルアシスタントエージェントのパフォーマンスを評価するためのLiveClawBenchを発表した。このベンチマークは134の実行可能なタスクを含み、3次元の複雑さ因子体系を提案している。実験によると、最先端のモデルにおいて、タスクのドメインはスコア変動の約9.6%しか説明できないのに対し、タスクの「複雑さプロファイル」の説明力は18.6%に達し、サービス間の依存関係と目標の解析こそがエージェントの不安定化の主な原因であることを明らかにした。(ソース: 机器之心)
.jpg)
中国人民大学がデータエージェントベンチマークCoDA-Benchを発表 : 中国人民大学の研究チームは、エージェントのコードインテリジェンスとデータインテリジェンスを共同で評価することを目的としたCoDA-Benchベンチマークを公開した。このベンチマークは、エージェントを1000以上のノイズファイルが含まれる複雑なLinuxサンドボックス環境に配置し、ファイルシステムを自律的に探索し、関連データを特定し、分析のためのコードを作成することを要求する。実験によると、最も優れたパフォーマンスを示したシステムであっても、CoDA-Benchでの正確度はわずか61.1%にとどまり、「適切なデータを見つけられない」ことが現在のCode Agentの核心的なボトルネックであることを明らかにした。(ソース: 机器之心)
.jpg)
Metaが量子化推論モデルの「過剰思考」欠陥を発見し、解決策を提案 : Metaは研究において、量子化された推論モデルの奇妙な失敗モードを明らかにした。モデルは量子化後に能力が低下するだけでなく、「過剰思考(overthinking)」を始めるという。失敗事例の最大52%において、モデルは推論の途中で正しい答えに達していたが、量子化によってためらいを示すToken(wait、but、maybeなど)のサンプリング確率が高まったため、終わりのない自己反省に陥り、最終的に正しい結論を覆してしまった。Metaは、ためらいTokenにわずかなデコーディングペナルティを課すことで、過剰思考によるエラーを58%削減することに成功した。(ソース: TheTuringPost)

スタンフォード大とUCバークレーがロボット視覚・言語報酬モデルRoboRewardを発表 : スタンフォード大学とカリフォルニア大学バークレー校の研究チームは、4B/8Bパラメータのロボット視覚・言語報酬モデルであるRoboRewardを発表した。この研究では、成功したアクションの動画をテキストで再ラベル付けおよび切り取ることで、高品質なネガティブサンプルや不完全な試行サンプルを大量に生成し、従来の強化学習における失敗事例の不足という課題を解決した。実験では、RoboRewardを使用して報酬評価を行うことで、実際のロボットアームによる把持や引き出しを開けるタスクにおける成功率が、同クラスの汎用LLMを大幅に上回ることが示された。(ソース: DeepLearning.AI Blog)
CMUがAdvanced NLP講義の全23回動画と教材をオープンソース化 : カーネギーメロン大学(CMU)のSean Welleck教授は、自身の「Advanced Natural Language Processing (ANLP Spring 2026)」講義の全23回の動画をYouTubeにアップロードし、付随する講義資料と20個のコード例をオープンソース化した。講義内容は、NLPの基礎、モデルアーキテクチャ、学習と推論、評価方法、強化学習とエージェント(RL & Agents)、モデルのスケーリングと効率性など、7つの主要テーマを体系的にカバーしており、LLMの基礎原理を深く学習するための優れたリソースとなっている。(ソース: gneubig)
Sebastian Raschkaの新著『Build a Reasoning Model (From Scratch)』が正式出版 : 著名な機械学習エキスパートであるSebastian Raschka氏の新著『Build a Reasoning Model (From Scratch)』が正式に出版された。全440ページで、フルカラーのレイアウトを採用し、実行可能なコード例を提供している。本書は、推論スケーリング(Inference Scaling)、強化学習(RL)、モデル蒸留(Distillation)などの最先端技術を含む、推論モデルの基礎となるロジックを体系的に紹介しており、LLMの基礎理論を構築するための優れた読本である。(ソース: cwolferesearch)

💼 ビジネス
Unitree Roboticsの科創板IPO登録が証監会により承認 : 中国証券監督管理委員会(証監会)は、Unitree Robotics(宇树科技)の科創板(STAR Market)における新規公開株(IPO)登録申請を正式に承認した。Unitree Roboticsは10%以上の株式を公募し、42.02億元を調達する予定で、評価額は約420億元に達する。目論見書によると、同社は2025年に売上高17.08億元、純利益5.91億元を達成し、ヒューマノイドロボットの出荷台数は5500台を超え、世界市場シェアは32.4%に達した。これは、中国国内で初めて黒字化を達成したエンボディドAI(具身智能)完成品企業が、正式にA株市場に上場することを意味している。(ソース: 36氪)
Silicon Flowが香港取引所に目論見書を提出、「Token工場第1号銘柄」の上場を目指す : AIインフラスタートアップであるSilicon Flow(硅基流动)は、香港取引所(HKEX)に正式に目論見書を提出した。同社はAI業界の「Token卸売業者」と位置づけられ、標準化されたAPIを通じてマルチモデルの統一アクセスサービスを提供している。シリーズB+の資金調達後の評価額は77.4億元に達し、株主にはAlibaba、Tencent、Huawei、Meituanなどの巨頭が名を連ねる。目論見書によると、2025年に同社のパブリッククラウド有料顧客は71.6万社に達したが、初期の計算能力とプロモーションへの巨額の投資により、純損失は3.45億元に達した。(ソース: 36氪)
Guangxiang Technologyが累計数億元のエンジェルラウンド資金調達を完了 : エンボディドAIスタートアップであるGuangxiang Technology(光象科技)は、Zhuhai Technology Group(珠海科技集团)、Industrial Securities Capital(兴证资本)、Green Pine Capital(松禾资本)などから共同投資を受け、累計数億元のエンジェルラウンド資金調達を完了したと発表した。Guangxiang Technologyは清華大学のチームによってインキュベートされ、「物理ネイティブインテリジェンス(物理原生智能)」の技術路線を確立し、強化学習アルゴリズムマトリクス、高忠実度物理データアセット、インテリジェント開発プラットフォームからなる体系を構築した。自社開発のエンボディドロボット「Phi-Bot X1」は、自動車生産ラインの溶接供給工程において、高精度な連続作業の検証を完了している。(ソース: 量子位)

🌟 コミュニティ
Alibabaが社内通知を出し、ClaudeおよびClaude Codeの全面使用禁止を指示 : Alibaba(阿里巴巴)は社内に緊急通知を出し、従業員に対して7月10日までにClaudeやClaude CodeなどのAnthropic製品を完全にアンインストールし、使用を禁止するよう求めた。これに先立ち、セキュリティコミュニティによるリバースエンジニアリング分析で、Claude Codeに中国のユーザーおよびAIラボを検出する隠蔽されたメカニズムが組み込まれていることが判明した。難読化されたコードを通じてシステムのタイムゾーン、プロキシ、APIキーワードを収集し、プロンプト内のUnicode文字を改ざんする方法で環境フィンガープリントをサーバーに送り返していたため、企業側でコアコード漏洩への懸念が高まった。(ソース: 36氪)

Godotゲームエンジン公式がAIコード貢献ポリシーの全面的な厳格化を発表 : オープンソースのゲームエンジンGodotは、貢献ポリシーを改定し、AIによって生成された大規模なコードブロックの使用や、AIエージェントによるプルリクエスト(PR)の自動送信を全面的に禁止することを発表した。公式は、AIがコード記述のハードルを下げた一方で、低品質なPRが大量に流入し、ボランティアメンテナーのレビューリソースを深刻に消耗させていると率直に指摘した。さらに悪いことに、多くの投稿者はAIが生成したコードを説明できず、バグが発生した際にもメンテナンスができない。Godotは、AIはコードに対して責任を負うことはできず、プロジェクトが必要としているのはコードを真に理解できる人材であると強調した。(ソース: 36氪)

Metaが余剰AI計算能力を外部に貸し出すクラウドサービス「Metamate」の立ち上げを計画 : Bloombergの報道によると、Metaはクラウドインフラ事業部門「Metamate」を設立し、外部顧客に余剰のAI計算能力とモデルアクセス権を販売することで、2027年までに年間100億〜150億ドルの収益を上げることを計画している。このニュースは、AI計算能力が一時的な過剰に直面する可能性があるという市場の懸念を引き起こし、その後の2取引日で世界の半導体およびメモリセクターが大幅に売られる結果となった。(ソース: 36氪)
学術界でAI LLMが数学研究において人間を徐々に代替しつつあることが判明 : OpenAIの内部モデルが、物理学者Erdősが提唱し、人類が約80年間研究してきた「平面単位距離予想」を独自に覆したことで、AIの数学的推論能力は劇的な飛躍を迎えた。これは数学の博士課程の学生たちの間で「心が折れる(道心破碎)」ような不安を引き起こし、一部の学生は現実逃避のために『王者栄耀(Honor of Kings)』をプレイするしかないと自嘲している。学者は、標準化・形式化された数学研究におけるAIの効率性の高さが、人間の数学者に自身の研究価値や審美的境界を再考することを迫っていると考えている。(ソース: 36氪)
CloudflareのレポートでマシンのWebトラフィックが初めて人間を上回ったことが判明 : サイバーセキュリティサービスプロバイダーのCloudflareが発表したレポートによると、同社がホストするWebサイトが受信した全アクセスリクエストのうち、約57.4%がAIや自動化プログラム(AIトレーニングクローラー、エージェントなど)によるものであり、本物の人間からのリクエストはわずか42.6%にとどまった。インターネットの歴史上、マシンのトラフィックが人間のトラフィックを上回ったのはこれが初めてであり、Webインタラクションのパラダイムが根本的に変化したことを示している。また、従来のトラフィック広告による収益化ビジネスモデルにもシステム的な打撃を与えている。(ソース: 36氪)

💡 その他
研究者がLLM内に存在する「Dr. Elena Rodriguez」というゴーストネームを発見 : Samsungの研究所は、「対照的デコーディング差異(Contrastive Decoding Diffing: CDD)」に関する論文の中で、興味深い発見を明らかにした。複数の微調整モデルに対してトレーニングデータの逆方向復元を行ったところ、異なるドメインのモデル出力において、架空の科学者の名前「Dr. Elena Rodriguez」が高頻度で出現した。調査の結果、これはClaude Sonnet 3.6が合成トレーニングデータを生成する際にこの名前を極端に好んだためであり、その結果、この合成データを使用したすべての微調整モデルに意図せず「焼き付けられて(baked in)」しまったことが判明した。(ソース: Reddit r/MachineLearning)

RedditユーザーがPerplexity Proが密かに利用制限を設けたと皮肉る : Perplexity Pro(年会費200ドル)を購読している多くのユーザーがReddit上で、最近「無制限のファイルアップロード」と「ディープリサーチ(Deep Research)」機能が密かに制限され、グレーアウトして利用できない状態になっていると不満を漏らしている。ユーザーは、プラットフォームがメールや告知、利用規約の更新を一切行わずに、Proユーザーの権利を一方的に削減したと訴えており、SaaSサービスの透明性と消費者権利保護に関する広範な議論がコミュニティで巻き起こっている。(ソース: Reddit r/artificial)
RedditユーザーがFable 5を使って10年分の世界観設定を整理しWikiを自動生成した体験を共有 : ある小説のクリエイターがRedditで、自身が10年間にわたって蓄積してきた、数十万字に及ぶ小説の下書き、世界観の設定、雑多なメモを1つのPDFにまとめ、Fable 5を利用して分析した体験を共有した。Fable 5は1回のセッション制限の90%を消費したものの、これらの内容を構造化されたキャラクター、イベント、地理の項目へと完璧に整理し、World AnvilのWikiシステムに直接インポートできるMarkdownファイルを自動生成した。これにより、長年の創作のボトルネックから脱却することができたという。(ソース: Reddit r/ClaudeAI)