
Kata Kunci:Model Besar, Chip AI, Agen Cerdas, Seri GPT-5.6, Chip Inferensi Jalapeño, Orkestrasi Kolaboratif Multi-Model
🔥 Im Fokus
OpenAI veröffentlicht GPT-5.6-Serie und eigenen Inference-Chip Jalapeño : OpenAI hat die GPT-5.6-Modellserie vorgestellt, die Sol, Terra und Luna umfasst. Sie bietet Long-Chain-Reasoning und Multi-Agent-Kollaborationsmodi, ist jedoch zum Start aufgrund von Einschränkungen der US-Regierung nur für ausgewählte Institutionen zugänglich. Gleichzeitig hat OpenAI in Zusammenarbeit mit Broadcom seinen ersten selbst entwickelten LLM-Inference-Chip Jalapeño vorgestellt, der im TSMC-Verfahren gefertigt wird. Ziel ist es, die täglichen Inference-Kosten von ChatGPT drastisch zu senken und die Antwortgeschwindigkeit zu erhöhen. Dies signalisiert, dass die AI-Giganten ihren Wettbewerb von einem reinen Algorithmen-Wettrüsten auf die tieferen Ebenen der Lieferkette für maßgeschneiderte Hardware ausweiten. (Quelle: 36氪)

Rückkehr von Claude Fable 5 und Mythos 5 von Sicherheitskontroversen begleitet : Nach der Rückkehr aus einer Phase regulatorischer Turbulenzen hat Claude Fable 5 aufgrund eines übermäßig strengen Sicherheits-Classifiers schlechte Bewertungen erhalten. Zahlreiche legitime Anfragen wurden fälschlicherweise blockiert und automatisch auf Opus heruntergestuft. Gleichzeitig entdeckten Hacker bei Tests, dass Fable 5 bei tiefgehendem Reasoning ungefilterte, „unlesbare Chain-of-Thought“-Pfade ausgibt und dabei selbst kreierte Symbole und Füllwörter als Kurzschrift verwendet. Dies deutet darauf hin, dass sich Reasoning-Modelle unter Reinforcement Learning spontan von der menschlichen Sprache entfernen, um die Effizienz zu steigern, und offenbart neue Herausforderungen für AI-Sicherheit und Erklärbarkeit. (Quelle: 量子位)

Shengshu Technology veröffentlicht interaktives Echtzeit-Video-Modell Vidu S1 : Shengshu Technology hat das interaktive Echtzeit-Videogenerierungsmodell Vidu S1 vorgestellt. Es unterstützt die sprachgesteuerte Generierung von Videoinhalten, unbegrenzte Echtzeit-Generierung sowie interaktive Echtzeit-Wiedergabe mit 540P/25FPS. Nutzer müssen lediglich ein Startbild (First Frame) und eine benutzerdefinierte Stimme hochladen, woraufhin das Modell die Mimik und Gestik des Charakters in Echtzeit generiert und flüssig auf Consumer-Grafikkarten läuft. Dieser Durchbruch führt die Videogenerierung von der „Offline-Wiedergabe“ in die Ära der „bidirektionalen Echtzeit-Interaktion“ und senkt die Hürden für die Entwicklung digitaler Menschen und virtueller Begleiter erheblich. (Quelle: 机器之心)
.jpg)
DAMO Academy veröffentlicht ElementsClaw AI Agent für Supraleiter-Materialien : Die Alibaba DAMO Academy hat in Zusammenarbeit mit mehreren Universitäten ElementsClaw vorgestellt, den ersten AI Agent, der speziell auf die Entdeckung von Supraleitern spezialisiert ist. Der Agent kombiniert ein geometrisches Deep Graph Neural Network mit 1 Milliarde Parametern mit einem Large Language Model. In nur 28 GPU-Stunden filterte er 2,4 Millionen stabile Kristalle, prognostizierte 68.000 potenzielle Supraleiter und synthetisierte im Experiment erfolgreich 4 völlig neue, der Menschheit bisher unbekannte Supraleiter-Materialien. Dieser Erfolg steigert die Effizienz der Forschung und Entwicklung im Bereich der Supraleiter erheblich und treibt den Einsatz von AI in der Hard Science voran. (Quelle: 量子位)

Baiyao Technology veröffentlicht virtuelles Zellweltmodell AURA CellOS : Baiyao Technology hat AURA CellOS vorgestellt, ein auf der LLM-JEPA-Architektur basierendes AI-Modell für eine virtuelle Zellwelt. Das Modell verfügt über 12B Parameter und wurde auf Basis von 390 Millionen menschlichen Einzelzell-Transkriptomdaten trainiert, die über 40 Gewebearten und mehr als 260 Zelltypen abdecken. Durch Multi-View Representation Learning und Joint Embedding Predictive Architecture (JEPA) ermöglicht CellOS dem Modell erstmals, die internen Evolutionsgesetze von Zellzuständen zu verstehen. Es erreicht weltweit führende Ergebnisse bei Aufgaben wie der Vorhersage von Störungsreaktionen und bietet eine entscheidende Rechenbasis für AI-gestützte Pharmazeutika und Zelltherapien. (Quelle: 量子位)

🎯 Entwicklungen
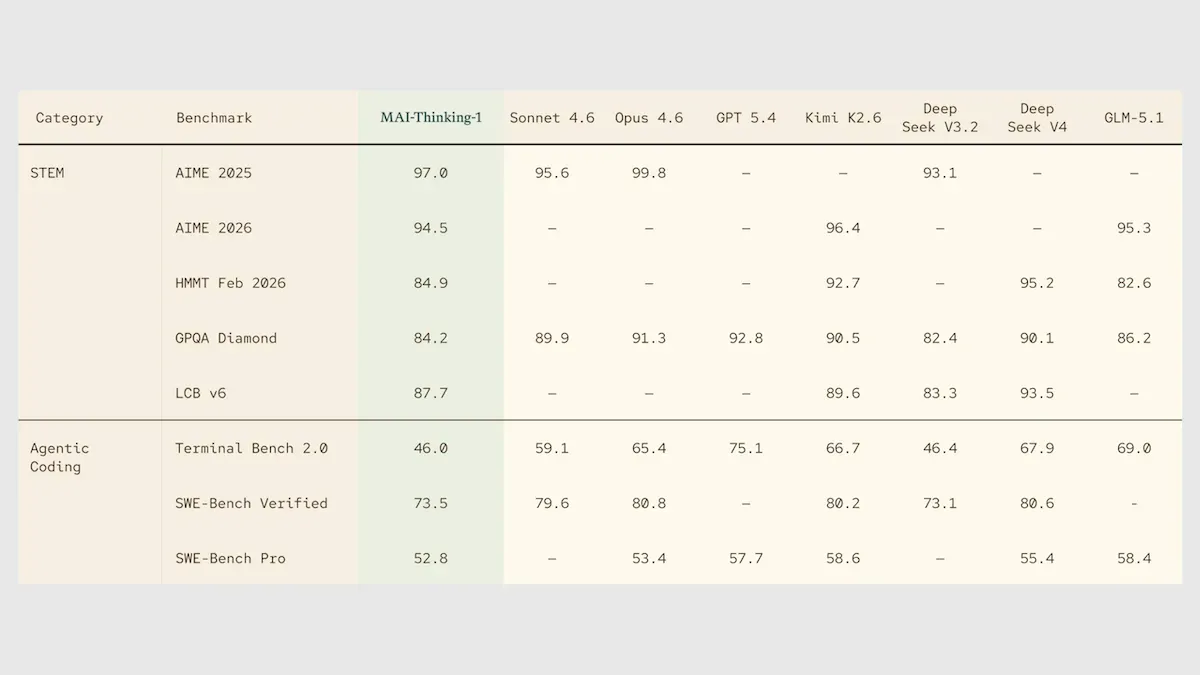
Microsoft veröffentlicht erstes eigenständiges Reasoning-Modell MAI-Thinking-1 : Microsoft hat auf der Build-Konferenz das Reasoning-Modell MAI-Thinking-1 vorgestellt. Es basiert auf einer Mixture-of-Experts (MoE)-Architektur mit 1 Billion Parametern und wurde komplett von Grund auf neu trainiert, ohne Destillation oder Feinabstimmung durch andere Modelle. Das Modell unterstützt einen Kontext von 250k Token und zeigt eine starke Leistung in Mathematik- und STEM-Reasoning-Benchmarks, wobei es beim AIME 2025 sogar Claude Sonnet 4.6 übertraf. Dies markiert einen entscheidenden Schritt für Microsoft, um sich von der Abhängigkeit von OpenAI-Technologie zu lösen und einen eigenen, unabhängigen AI-Technologie-Stack aufzubauen. (Quelle: DeepLearning.AI Blog)
Dongfeng Yijing testet Huawei Qiankun ADS 5 unter extremen Bedingungen : Die Premium-Marke Yijing X9 von Dongfeng hat, ausgestattet mit Huaweis intelligentem Fahrsystem Qiankun ADS 5, Tests unter extremen Bedingungen wie Nachtfahrten, Starkregen und plötzlichen Hindernissen („Ghost Cuts“) absolviert. ADS 5 nutzt die neue WEWA 2.0-Architektur, die Multi-Agent-Spieltheorie mit Algorithmen für Sicherheitsrisikofelder kombiniert, um Kosten zu senken, die Effizienz zu steigern und das Kollisionsrisiko zu minimieren. Die Tests zeigten, dass das System in unbekannten Lagerszenarien ein autonomes Cruisen ohne menschliches Eingreifen ermöglicht. Dies signalisiert den Generationenwechsel von regelbasierten Systemen hin zu daten- und AI-Agent-gesteuerten Systemen für autonomes Fahren. (Quelle: 量子位)

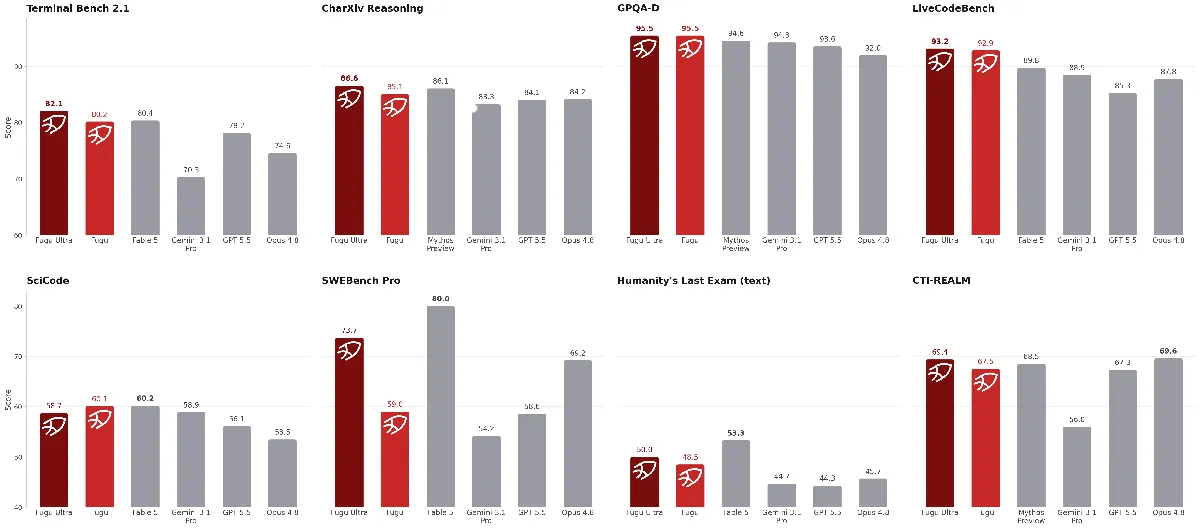
Sakana AI veröffentlicht Multi-Modell-Orchestrierungssystem Fugu-Serie : Das japanische AI-Startup Sakana AI hat die Modelle Fugu und Fugu-Ultra vorgestellt. Das System verlässt sich nicht auf ein einzelnes Modell, sondern orchestriert über evolutionäre Algorithmen und Reinforcement Learning auf der API-Gateway-Ebene dynamisch zugrunde liegende Modelle (wie Claude, GPT, Gemini usw.), um komplexe Aufgaben kollaborativ zu lösen. Fugu-Ultra erreichte im wissenschaftlichen Test GPQA-Diamond eine Rekordgenauigkeit von 95,5 %. Dies zeigt, dass die Multi-Modell-Orchestrierung zu einem wichtigen Trend geworden ist, um Vendor Lock-in zu vermeiden und Inference-Kosten zu optimieren. (Quelle: DeepLearning.AI Blog)
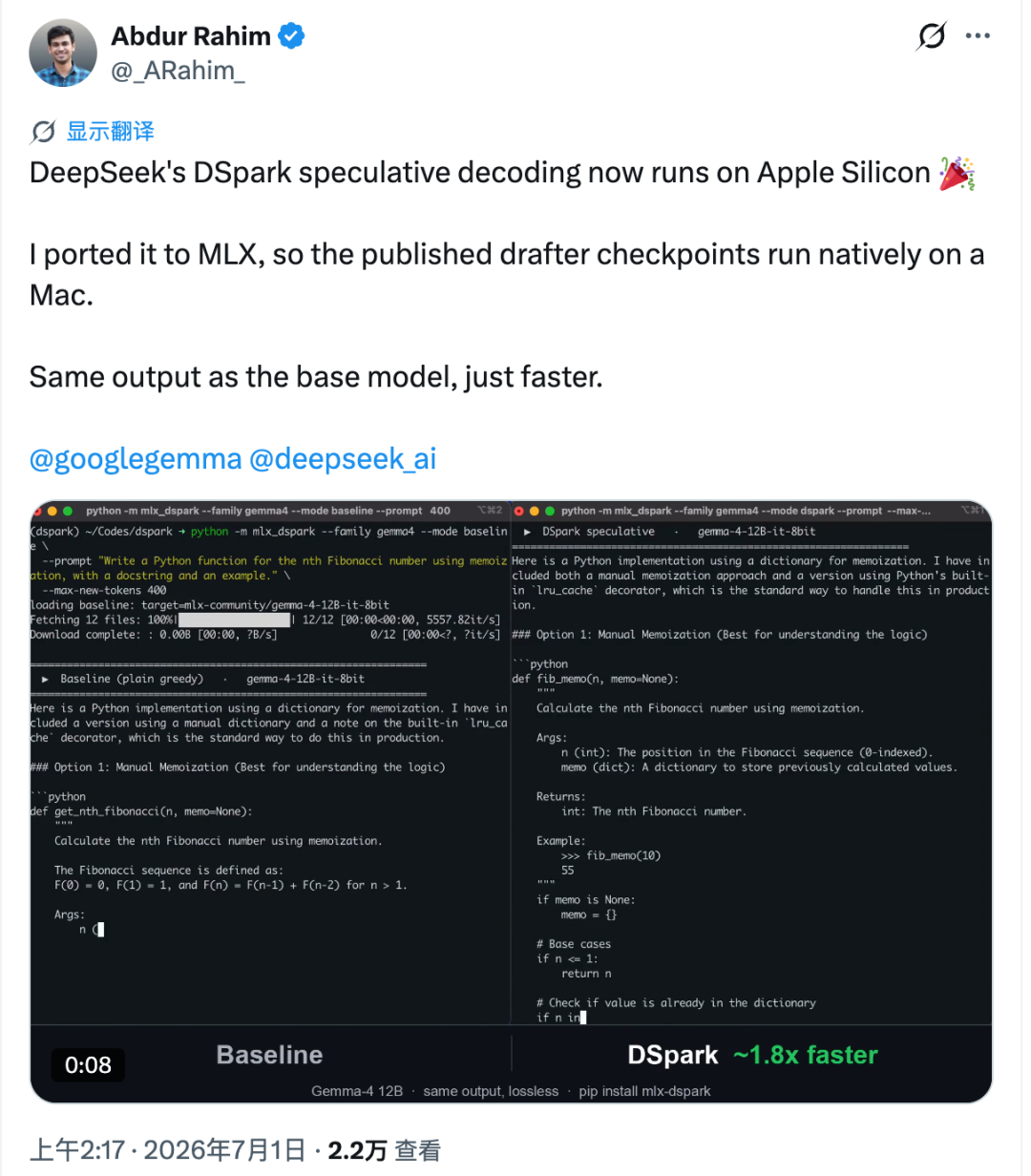
DeepSeek DSpark-Beschleunigungstechnologie erfolgreich auf Mac portiert : Der Open-Source-Entwickler Abdur Rahim hat die Speculative Decoding-Technologie DSpark von DeepSeek auf Apple Silicon portiert und das Projekt mlx-dspark veröffentlicht. Auf einem M4 Pro-Chip steigerte das Projekt die lokale Inference-Geschwindigkeit von Gemma-4 12B und Qwen3-4B um das 1,6- bzw. 1,4-fache, wobei die Ausgaben bei gleicher Temperature-Einstellung exakt mit dem Originalmodell übereinstimmten. Dieser Versuch beweist, dass Speculative Decoding auch auf Consumer-Edge-Geräten ein enormes Potenzial zur Kostensenkung und Effizienzsteigerung besitzt. (Quelle: 36氪)
DENG Lab der Shanghai Jiao Tong University veröffentlicht Open-Source-Welt-Sprach-Aktions-Modell WLA : Das DENG Lab der Shanghai Jiao Tong University hat das WLA-Modell als Open Source bereitgestellt. Es vereint Weltmodellierung, sprachliches Reasoning und die Generierung von Roboteraktionen in einem einzigen autoregressiven Framework mit 2B Parametern. WLA kann nicht nur feinkörnige physikalische Dynamiken vorhersagen, sondern auch Teilaufgaben-Sequenzen über natürliche Sprache prognostizieren und einen Speicherpuffer für die langfristige Planung verwalten. Im Long-Term-Memory-Benchmark RMBench erreichte WLA eine Erfolgsquote von 56,5 % – fast das Doppelte der zweitbesten Methode – bei einer Inference-Latenz von nur 40 ms. (Quelle: 机器之心)
.jpg)
Tencent Cloud wird DeepSeek-V4-Modelldienste direkt anbieten : Tencent Cloud hat angekündigt, ab Mitte Juli DeepSeek-V4-Modelldienste auf seiner TokenHub-Plattform anzubieten. Der Dienst wird direkt über das eigene Netzwerk von DeepSeek betrieben. Diese Kooperation profitiert von der technischen Unterstützung durch Tencent Cloud und zeigt gleichzeitig das Vertrauen von DeepSeek in die eigenen Rechencluster. Dies bietet Unternehmenskunden eine flexiblere und netzwerkseitig abgesicherte Infrastrukturoption für den Zugriff auf führende Open-Source-Modelle. (Quelle: teortaxesTex)
🧰 Tools
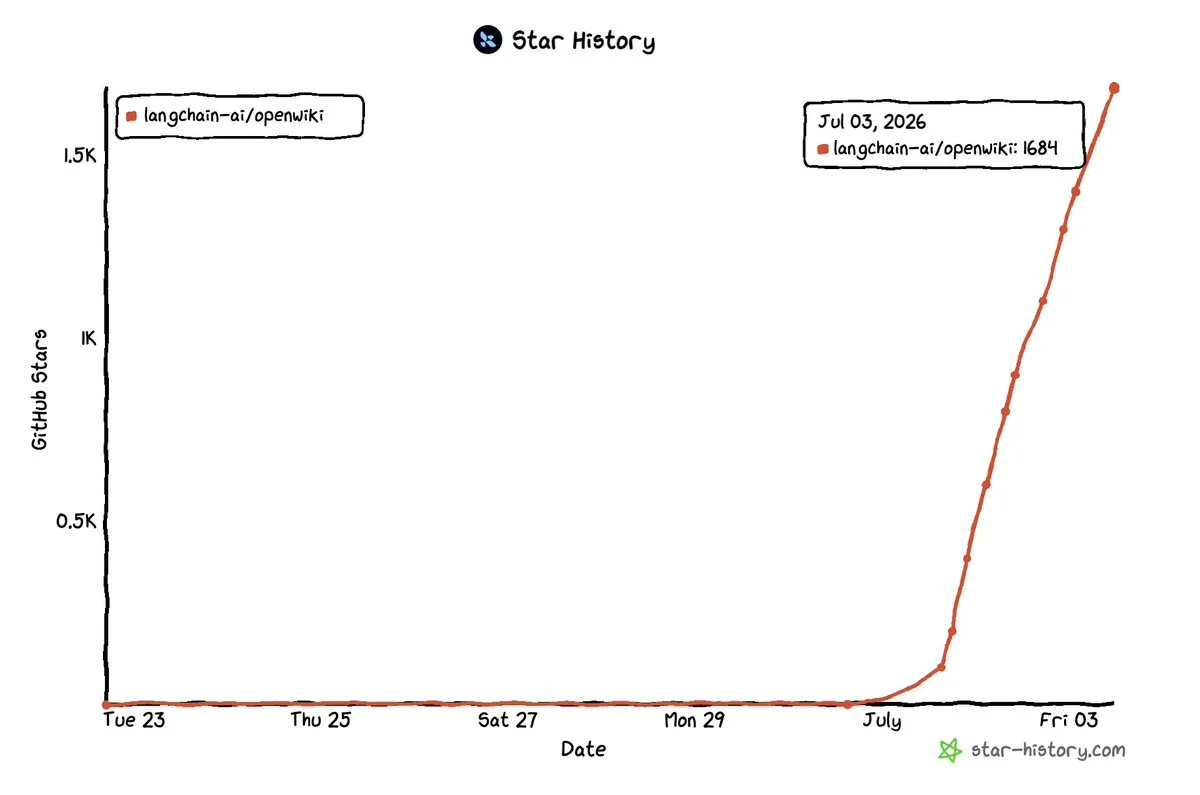
LangChain veröffentlicht Open-Source-Memory-Wiki-Agent OpenWiki : LangChain hat das OpenWiki-Projekt als Open Source veröffentlicht, das innerhalb von nur drei Tagen nach dem Release 1,7k GitHub-Sterne erhielt. Das Projekt konzentriert sich derzeit auf den Aufbau strukturierter Memory-Wikis für Codebases, um das Problem zu lösen, dass Agenten bei langfristigen Aufgaben wichtige Informationen vergessen, indem Projektkontexte automatisch extrahiert und organisiert werden. Das Entwicklerteam plant, das Projekt auf allgemeinere Datenquellen wie Notion, Google Drive, Slack und Websuche auszuweiten, um ein globales Gedächtniszentrum für Agenten zu schaffen. (Quelle: LangChain)
Vercel veröffentlicht Eve Agent-Framework und integriert LlamaIndex : Vercel hat das Eve-Agent-Framework vorgestellt, für das LlamaIndex umgehend ein Integrations-Template bereitgestellt hat. Dieses Template stattet Eve mit schreibgeschützten Dateisystem-Tools aus, die es ermöglichen, Pfade zu analysieren, Texte zu lesen und unstrukturierte Dokumente mithilfe des LiteParse-Tools in sauberes Markdown zu konvertieren. Diese Kombination bietet Agenten einen direkt einsatzbereiten, zuverlässigen Workflow zur effizienten Navigation und zum Verständnis komplexer lokaler Dokumentensammlungen. (Quelle: jerryjliu0)
Hugging Face veröffentlicht Framework zur automatischen Optimierung von Prompt-Tuning für LLMs : Hugging Face hat im Rahmen des Harness Optimization-Projekts ein Framework zur automatischen Optimierung von Prompt-Tuning demonstriert. Das Framework nutzt Claude als Proposer, um die Prompts und den Tool-Calling-Code rund um den Agenten durch automatische Iteration und Validierung umzuschreiben, ohne die Gewichte des zugrunde liegenden Modells zu verändern. Tests zeigten, dass diese Methode die Punktzahl eines eingefrorenen Open-Source-Modells in einer komplexen rechtlichen Bewertung von 0 % auf das Niveau von Sonnet 4.6 steigerte, während die Aufgabenkosten um das 7-fache gesenkt wurden. (Quelle: ClementDelangue)
Fable 5-basiertes PPT-Design-Tool baoyu-design aktualisiert : Der Entwickler Baoyu hat seine Open-Source-Agenten-Fähigkeit baoyu-design aktualisiert und Unterstützung für PPT-Animationen sowie AI-Bildgenerierung hinzugefügt. Das Tool nutzt das tiefe Verständnis von Fable 5 für das PPTX-XML-Format, um die Einschränkungen beim Export von Animationen zu überwinden, die Opus 4.8 zuvor nicht bewältigen konnte. Nutzer können nun direkt HTML-Präsentationen mit Animationseffekten erstellen und diese nahtlos in editierbare PPTX-Dateien für Keynote oder PowerPoint exportieren. (Quelle: dotey)
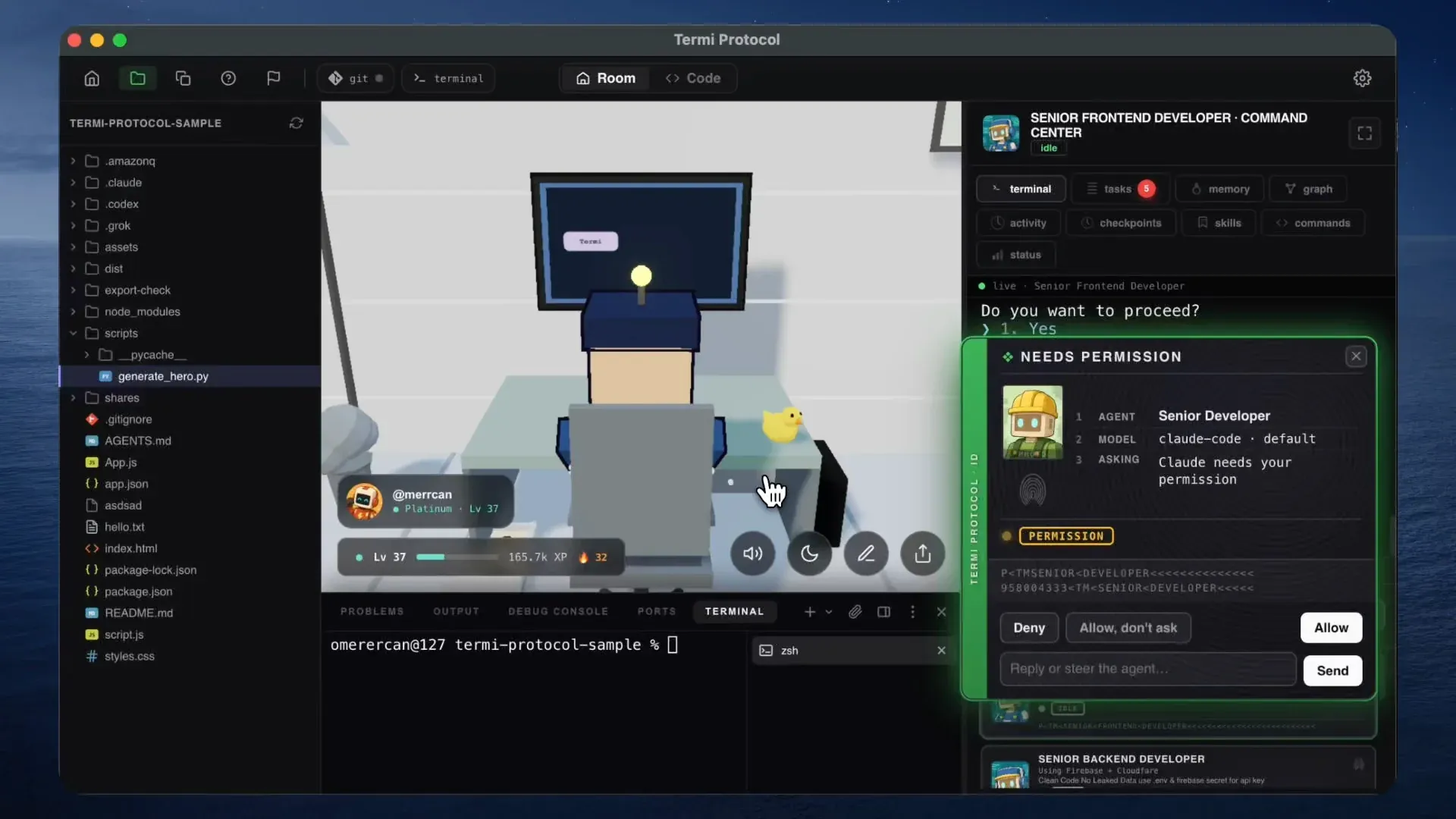
Termiprotocol entwickelt virtuelles 3D-Büro für Claude Code : Entwickler haben das Open-Source-Projekt Termiprotocol gestartet, das eine virtuelle 3D-Büro-Oberfläche für Terminal-Agenten wie Claude Code und Codex bereitstellt. Jede vom Agenten im Terminal ausgeführte Aktion (wie das Lesen/Schreiben von Dateien, Websuchen oder das Ausführen von Code) wird in Echtzeit durch einen kleinen 3D-Roboter dargestellt, der im Büro tippt oder Aktenschränke durchsucht. Ergänzt wird dies durch eine intuitive Token-Verbrauchsüberwachung und ein Task-Board, was die Visualisierung und den Spaßfaktor von Agenten-Workflows erheblich steigert. (Quelle: Reddit r/ClaudeAI)
Hugging Face und Cerebras präsentieren Gemma 4 Voice-Demo : Hugging Face hat in Zusammenarbeit mit Cerebras eine vollständig quelloffene Echtzeit-Sprachinteraktions-Demo entwickelt. Die Demo basiert auf dem Gemma 4-Modell und der extrem latenzarmen Inference-Hardware von Cerebras und ermöglicht eine ultraschnelle Speech-to-Speech-Konversation. Nutzer können das Projekt direkt auf Hugging Face Spaces testen, forken und anpassen, was der Open-Source-Community eine hervorragende Vorlage für die Entwicklung latenzarmer Sprachassistenten bietet. (Quelle: huggingface)
📚 Lernen
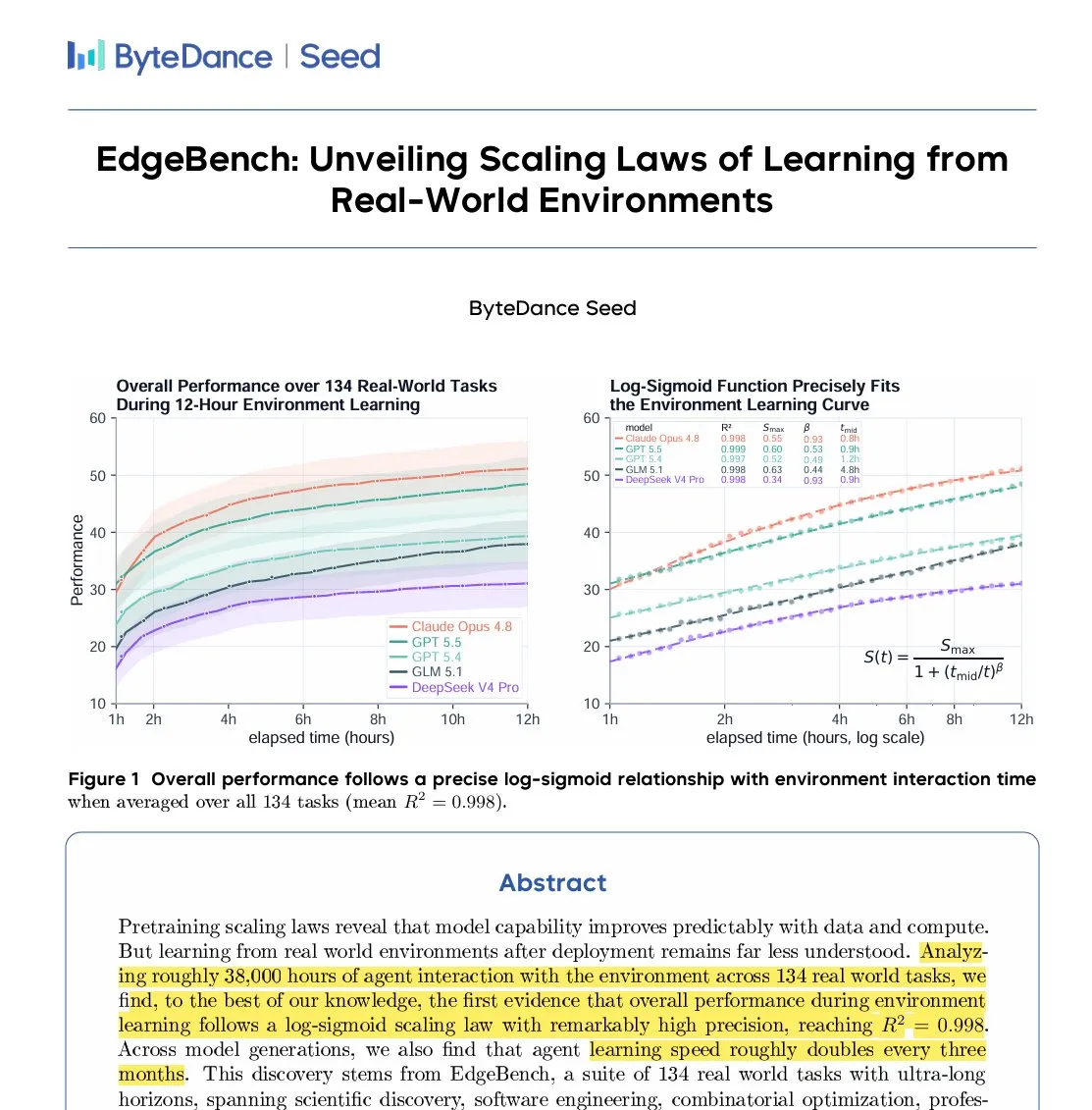
ByteDance veröffentlicht EdgeBench zur Bewertung von Agenten-Lernen über extrem lange Zeiträume : Das Seed-Team von ByteDance hat EdgeBench veröffentlicht, einen Benchmark zur Untersuchung, wie Agenten über extrem lange Zeiträume von 12 bis 72 Stunden kontinuierlich aus Umweltfeedback lernen. Nach Tests mit einer kumulierten Laufzeit von 38.000 Stunden stellten die Forscher fest, dass die Leistungssteigerung der Agenten und die Interaktionszeit mit der Umgebung einer präzisen Log-Sigmoid-Funktion folgen. Dies beweist, dass das Akkumulieren und Wiederverwenden von Aufgabenerfahrung der Schlüssel zu langfristigen Fortschritten von Agenten ist. (Quelle: arankomatsuzaki)
Samsung und Peking-Universität veröffentlichen systematischen AI Agent-Benchmark LiveClawBench : Das LLM-Team von Samsung hat in Zusammenarbeit mit der Peking-Universität und anderen Institutionen LiveClawBench veröffentlicht, um die Leistung von persönlichen Assistenz-Agenten in komplexen Workflows zu bewerten. Der Benchmark umfasst 134 auszuführende Aufgaben und führt ein dreidimensionales Komplexitätsfaktorensystem ein. Experimente zeigen, dass bei führenden Modellen die Aufgabendomäne nur etwa 9,6 % der Score-Fluktuation erklärt, während das „Komplexitätsprofil“ der Aufgabe 18,6 % erklärt. Dies verdeutlicht, dass serviceübergreifende Abhängigkeiten und Zielauflösungen die Hauptursachen für die Instabilität von Agenten sind. (Quelle: 机器之心)
.jpg)
Renmin-Universität veröffentlicht Daten-Agenten-Benchmark CoDA-Bench : Ein Forschungsteam der Renmin-Universität von China hat den CoDA-Bench-Benchmark vorgestellt, der darauf abzielt, die Code- und Datenintelligenz von Agenten gemeinsam zu bewerten. Der Benchmark platziert Agenten in einer komplexen Linux-Sandbox mit über 1.000 Stördateien und verlangt von ihnen, das Dateisystem autonom zu erkunden, relevante Daten zu lokalisieren und Code zur Analyse zu schreiben. Experimente zeigen, dass selbst die leistungsstärksten Systeme auf CoDA-Bench-Benchmark nur eine Genauigkeit von 61,1 % erreichen. Dies verdeutlicht, dass das „Finden der falschen Daten“ der zentrale Engpass aktueller Code-Agenten ist. (Quelle: 机器之心)
.jpg)
Meta entdeckt „Overthinking“-Fehler bei quantisierten Reasoning-Modellen und schlägt Lösung vor : Meta hat in einer Studie ein kurioses Fehlermuster bei quantisierten Reasoning-Modellen aufgedeckt: Nach der Quantisierung sinkt nicht einfach nur die Leistungsfähigkeit der Modelle, sondern sie beginnen zu „überdenken“ (overthinking). In bis zu 52 % der Fehlschläge hatte das Modell die richtige Antwort bereits in der Mitte des Reasoning-Prozesses gefunden. Da die Quantisierung jedoch die Sampling-Wahrscheinlichkeit von Zögerungs-Token (wie wait, but, maybe) erhöhte, geriet das Modell in eine endlose Selbstreflexion und verwarf letztlich die korrekte Schlussfolgerung. Durch eine minimale Decoding-Strafe auf Zögerungs-Token konnte Meta Overthinking-Fehler erfolgreich um 58 % reduzieren. (Quelle: TheTuringPost)

Stanford und UC Berkeley veröffentlichen Vision-Language-Reward-Modell RoboReward für Roboter : Ein Forschungsteam von Stanford und UC Berkeley hat RoboReward vorgestellt, ein Vision-Language-Reward-Modell für Roboter mit 4B/8B Parametern. Durch das Umetikettieren und Abschneiden von Videos erfolgreicher Aktionen generierte die Studie eine Vielzahl hochwertiger negativer und unvollständiger Versuchsproben. Dies löst das Problem des Mangels an Fehlschlag-Beispielen im traditionellen Reinforcement Learning. Experimente zeigen, dass die Erfolgsquote bei der Verwendung von RoboReward zur Reward-Bewertung bei Aufgaben wie dem Greifen mit einem echten Roboterarm und dem Öffnen von Schubladen die Leistung vergleichbarer allgemeiner LLMs deutlich übertrifft. (Quelle: DeepLearning.AI Blog)
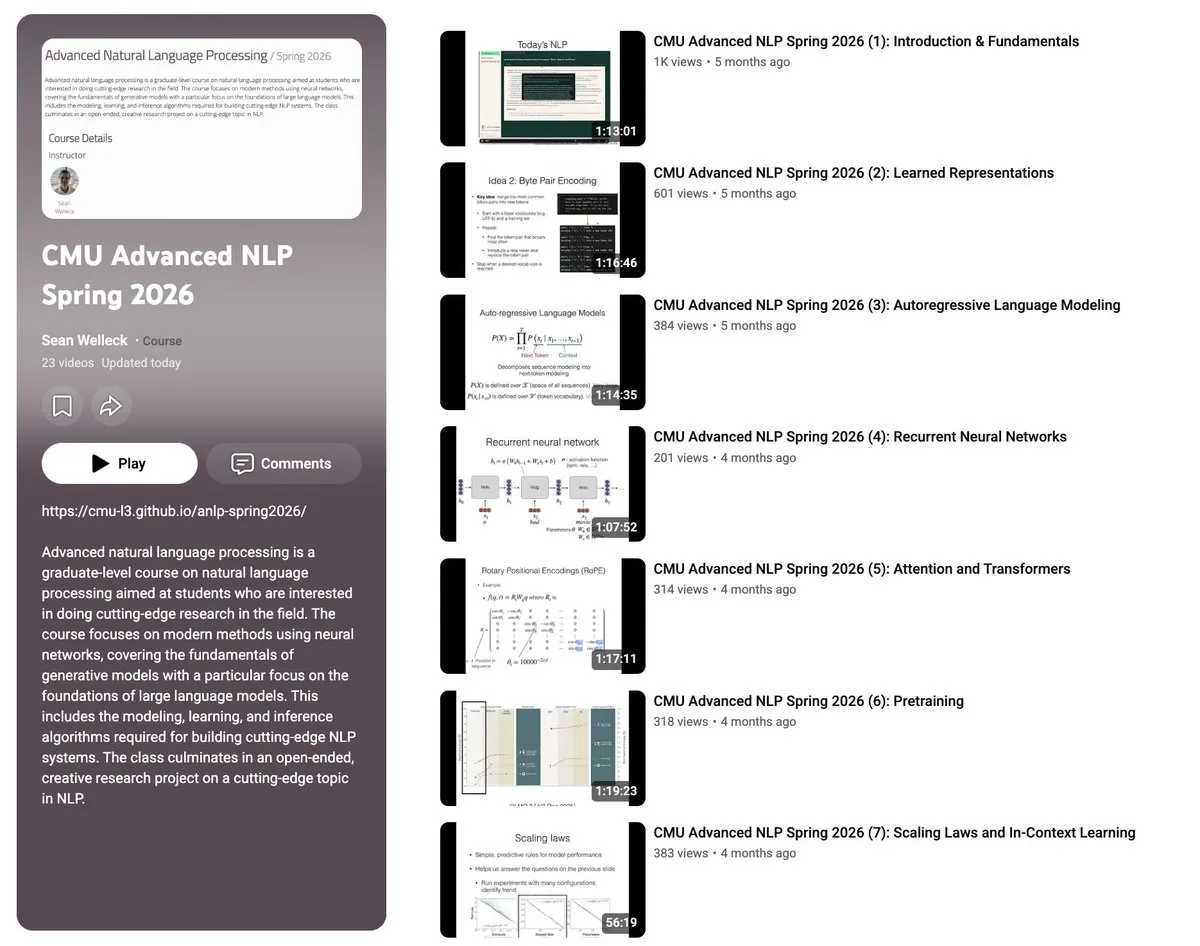
CMU veröffentlicht alle 23 Vorlesungsvideos und Materialien des Advanced NLP-Kurses als Open Source : Sean Welleck, Professor an der Carnegie Mellon University (CMU), hat alle 23 Vorlesungsvideos seines Kurses „Advanced Natural Language Processing (ANLP Spring 2026)“ auf YouTube hochgeladen und die dazugehörigen Handouts sowie 20 Codebeispiele als Open Source bereitgestellt. Die Kursinhalte decken systematisch sieben Hauptthemen ab, darunter NLP-Grundlagen, Modellarchitekturen, Lernen und Reasoning, Bewertungsmethoden, Reinforcement Learning und Agenten (RL & Agents) sowie Modellskalierung und -effizienz. Dies stellt eine hervorragende Ressource dar, um die zugrunde liegenden Prinzipien von LLMs tiefgehend zu erlernen. (Quelle: gneubig)
Sebastian Raschkas neues Buch „Build a Reasoning Model (From Scratch)“ offiziell veröffentlicht : Das neue Buch des renommierten Machine-Learning-Experten Sebastian Raschka mit dem Titel „Build a Reasoning Model (From Scratch)“ ist offiziell erschienen. Das 440-seitige, durchgehend farbige Buch bietet ausführbare Codebeispiele. Es führt systematisch in die zugrunde liegende Logik von Reasoning-Modellen ein, einschließlich zukunftsweisender Technologien wie Inference Scaling, Reinforcement Learning (RL) und Modelldestillation (Distillation), und ist eine hervorragende Lektüre zum Aufbau theoretischer Grundlagen für LLMs. (Quelle: cwolferesearch)

💼 Business
Unitree IPO auf dem STAR Market von der CSRC genehmigt : Die chinesische Wertpapieraufsichtsbehörde (CSRC) hat den Registrierungsantrag von Unitree für den Börsengang (IPO) auf dem STAR Market offiziell genehmigt. Unitree plant, mindestens 10 % der Anteile öffentlich anzubieten, um 4,202 Milliarden RMB einzunehmen, bei einer Bewertung von rund 42 Milliarden RMB. Der Prospekt zeigt, dass Unitree im Jahr 2025 einen Umsatz von 1,708 Milliarden RMB und einen Nettogewinn von 591 Millionen RMB erzielte. Die Auslieferungen humanoider Roboter überstiegen 5.500 Einheiten, was einem weltweiten Marktanteil von 32,4 % entspricht. Dies markiert den bevorstehenden A-Aktien-Börsengang des ersten profitablen chinesischen Herstellers von Embodied AI-Komplettsystemen. (Quelle: 36氪)
Silicon Flow reicht Prospekt an der HKEX ein, um erste börsennotierte „Token-Fabrik“ zu werden : Das AI-Infrastruktur-Startup Silicon Flow hat offiziell seinen Börsenprospekt bei der Hongkonger Börse (HKEX) eingereicht. Das Unternehmen positioniert sich als „Token-Großhändler“ der AI-Branche und bietet über standardisierte APIs einen einheitlichen Zugang zu mehreren Modellen. Nach einer B+-Finanzierungsrunde liegt die Bewertung bei 7,74 Milliarden RMB, zu den Aktionären gehören Giganten wie Alibaba, Tencent, Huawei und Meituan. Der Prospekt zeigt, dass das Unternehmen im Jahr 2025 716.000 zahlende Public-Cloud-Kunden verzeichnete, jedoch aufgrund hoher anfänglicher Investitionen in Rechenleistung und Marketing einen Nettoverlust von 345 Millionen RMB verbuchte. (Quelle: 36氪)
Light-up Technology schließt Angel-Finanzierungsrunde über mehrere hundert Millionen RMB ab : Das Embodied AI-Startup Light-up Technology (Guangxiang Keji) hat den Abschluss einer Angel-Finanzierungsrunde im Gesamtwert von mehreren hundert Millionen RMB bekannt gegeben. Die Runde wurde gemeinsam von der Zhuhai Technology Group, Industrial Securities Capital, Songhe Capital und anderen investiert. Light-up Technology wurde von einem Team der Tsinghua-Universität ausgegründet und verfolgt den technologischen Ansatz der „Physics-Native Intelligence“. Das Unternehmen hat ein System aufgebaut, das aus einer Reinforcement-Learning-Algorithmenmatrix, hochpräzisen physikalischen Datenwerten und einer intelligenten Entwicklungsplattform besteht. Der selbst entwickelte Embodied Robot Phi-Bot X1 hat bereits hochpräzise kontinuierliche Arbeitsabläufe an Schweißbeschickungsstationen in Automobilproduktionslinien erfolgreich demonstriert. (Quelle: 量子位)

🌟 Community
Alibaba verbietet intern die Nutzung von Claude und Claude Code vollständig : Alibaba hat eine dringende interne Mitteilung herausgegeben, in der Mitarbeiter aufgefordert werden, Anthropic-Produkte wie Claude und Claude Code bis zum 10. Juli vollständig zu deinstallieren und zu sperren. Zuvor hatte die Sicherheits-Community durch Reverse Engineering herausgefunden, dass Claude Code über verdeckte Erkennungsmechanismen für chinesische Nutzer und AI-Labore verfügt. Durch obfuskierten Code sammelt das Tool Systemzeitzonen, Proxys und API-Schlüsselwörter und sendet diese System-Fingerabdrücke an die Server zurück, indem es Unicode-Zeichen in den Prompts manipuliert. Dies löste bei Unternehmen Besorgnis über den Abfluss von Kern-Quellcode aus. (Quelle: 36氪)

Godot Game Engine verschärft Richtlinien für AI-Code-Beiträge drastisch : Die Open-Source-Spiel-Engine Godot hat eine Änderung ihrer Beitragsrichtlinien angekündigt. Die Verwendung von AI zur Generierung großer Codeblöcke sowie die automatische Einreichung von Pull Requests (PRs) durch AI-Agenten sind ab sofort vollständig untersagt. Die Verantwortlichen erklärten offen, dass AI zwar die Hürde für das Schreiben von Code senke, dies jedoch zu einer Flut minderwertiger PRs führe, was die Kapazitäten der ehrenamtlichen Maintainer für Code-Reviews stark strapaziere. Schlimmer noch: Viele Einreicher konnten den von der AI generierten Code nicht erklären oder bei Fehlern nicht warten. Godot betonte, dass AI keine Verantwortung für Code übernehmen könne und das Projekt Menschen brauche, die den Code tatsächlich verstehen. (Quelle: 36氪)

Meta plant Cloud-Dienst Metamate zur Vermietung ungenutzter AI-Rechenleistung : Laut einem Bericht von Bloomberg plant Meta den Aufbau einer Cloud-Infrastruktur-Sparte namens „Metamate“, um ungenutzte AI-Rechenleistung und Modellzugänge an externe Kunden zu verkaufen. Ziel ist es, bis 2027 einen Jahresumsatz von 10 bis 15 Milliarden US-Dollar zu generieren. Diese Nachricht schürte am Markt die Sorge vor einer vorübergehenden Überkapazität an AI-Rechenleistung, was in den folgenden zwei Handelstagen zu massiven Verkäufen im globalen Chip- und Speichersektor führte. (Quelle: 36氪)
Wissenschaft stellt fest: LLMs ersetzen zunehmend Menschen in der mathematischen Forschung : Nachdem ein internes Modell von OpenAI eigenständig die vom Physiker Erdős aufgestellte und seit fast 80 Jahren erforschte „Einheitsdistanz-Vermutung in der Ebene“ widerlegt hat, erlebt die mathematische Reasoning-Fähigkeit von AI einen sprunghaften Anstieg. Dies hat unter Mathematik-Doktoranden zu einer tiefen Identitätskrise geführt; einige scherzten, sie könnten der Realität nur noch durch das Spielen von „Honor of Kings“ entfliehen. Wissenschaftler glauben, dass die Effizienz von AI bei standardisierter und formalisierter mathematischer Forschung menschliche Mathematiker dazu zwingt, den Wert ihrer eigenen Forschung und ihre ästhetischen Grenzen neu zu überdenken. (Quelle: 36氪)
Cloudflare-Bericht zeigt: Maschinen-Traffic im Web übersteigt erstmals menschlichen Traffic : Der Cybersicherheits-Dienstleister Cloudflare hat einen Bericht veröffentlicht, wonach rund 57,4 % aller Web-Zugriffsanfragen auf den von ihm gehosteten Websites von künstlicher Intelligenz und automatisierten Programmen (wie AI-Trainings-Crawlern, Agenten usw.) stammen, während Anfragen von echten Menschen nur 42,6 % ausmachen. Dies ist das erste Mal in der Geschichte des Internets, dass der Maschinen-Traffic den menschlichen Traffic übersteigt. Dies markiert einen grundlegenden Wandel im Paradigma der Web-Interaktion und stellt das traditionelle Geschäftsmodell der Werbemonetarisierung über Traffic vor systemische Herausforderungen. (Quelle: 36氪)

💡 Sonstiges
Forscher entdecken Phantom-Namen „Dr. Elena Rodriguez“ in LLMs : Die Samsung Labs haben in einem Paper über „Contrastive Decoding Diffing (CDD)“ eine interessante Entdeckung offengelegt: Bei der Rekonstruktion von Trainingsdaten aus mehreren feinabgestimmten Modellen tauchte in den Ausgaben von Modellen aus verschiedenen Domänen auffallend häufig der Name einer fiktiven Wissenschaftlerin auf: „Dr. Elena Rodriguez“. Untersuchungen ergaben, dass Claude Sonnet 3.6 diesen Namen bei der Generierung synthetischer Trainingsdaten extrem bevorzugte, was dazu führte, dass er unbeabsichtigt in alle feinabgestimmten Modelle „eingebrannt“ wurde, die diese synthetischen Daten verwendeten. (Quelle: Reddit r/MachineLearning)

Reddit-Nutzer kritisieren heimliche Limitierung der Nutzung bei Perplexity Pro : Viele Nutzer, die Perplexity Pro (Jahresgebühr 200 USD) abonniert haben, beschweren sich auf Reddit darüber, dass die Funktionen „unbegrenzter Datei-Upload“ und „Deep Research“ kürzlich heimlich eingeschränkt wurden und ausgegraut nicht mehr verfügbar sind. Nutzer werfen der Plattform vor, die Vorteile für Pro-Nutzer einseitig gekürzt zu haben, ohne E-Mails, Ankündigungen oder Aktualisierungen der Nutzungsbedingungen zu senden. Dies hat in der Community eine breite Diskussion über die Transparenz von SaaS-Diensten und den Schutz von Verbraucherrechten ausgelöst. (Quelle: Reddit r/artificial)
Reddit-Nutzer teilt Erfahrung: Mit Fable 5 ein Jahrzehnt an Worldbuilding-Notizen sortiert und automatisch ein Wiki generiert : Ein Romanautor teilte auf Reddit, wie er seine über zehn Jahre angesammelten Romanentwürfe, Worldbuilding-Konzepte und ungeordneten Notizen im Umfang von Hunderttausenden Wörtern in einer PDF-Datei zusammenfasste und mit Fable 5 analysierte. Nachdem Fable 5 90 % seines Limits für eine einzelne Session verbraucht hatte, strukturierte das Modell die Inhalte perfekt in strukturierte Einträge für Charaktere, Ereignisse und Geografie. Zudem generierte es automatisch Markdown-Dateien, die direkt in das World Anvil-Wiki-System importiert werden können, was dem Autor half, seine langjährige Schreibblockade zu überwinden. (Quelle: Reddit r/ClaudeAI)