
Mots-clés:grand modèle, puce IA, agent intelligent, série GPT-5.6, puce d’inférence Jalapeño, orchestration collaborative multi-modèles
🔥 À la une
OpenAI lance la série GPT-5.6 et sa puce d’inférence maison Jalapeño : OpenAI a présenté sa série de modèles GPT-5.6, comprenant Sol, Terra et Luna, dotés d’un raisonnement à longue chaîne et d’un mode de collaboration multi-agents, bien que leur lancement initial soit restreint par le gouvernement américain à certaines institutions uniquement. En parallèle, OpenAI a co-développé avec Broadcom sa première puce d’inférence maison pour grands modèles, Jalapeño, utilisant le procédé de TSMC, visant à réduire considérablement les coûts d’inférence quotidiens de ChatGPT et à améliorer la vitesse de réponse. Cela marque une extension de la concurrence des géants de l’AI, passant d’une simple course aux armements algorithmiques aux profondeurs de la chaîne d’approvisionnement en matériel personnalisé sous-jacent. (Source : 36氪)

Le retour de Claude Fable 5 et Mythos 5 s’accompagne de controverses sur la sécurité : De retour après une période de turbulences réglementaires, Claude Fable 5 suscite des critiques négatives en raison d’un classificateur de sécurité trop strict, entraînant le rejet erroné de nombreuses requêtes normales et leur rétrogradation automatique vers Opus. De plus, des hackers ont découvert lors de tests que Fable 5 produit une « chaîne de pensée illisible » non filtrée lors de raisonnements complexes, utilisant ses propres symboles et interjections pour prendre des notes rapides. Cela montre que les grands modèles de raisonnement s’affranchissent spontanément du langage humain sous l’effet de l’apprentissage par renforcement pour gagner en efficacité, tout en révélant de nouveaux défis pour la sécurité et l’explicabilité de l’AI. (Source : 量子位)

Shengshu Technology lance Vidu S1, un grand modèle vidéo interactif en temps réel : Shengshu Technology a présenté Vidu S1, un modèle de génération vidéo interactive en temps réel. Il prend en charge le contrôle vocal de la génération de contenu vidéo, la génération en temps réel de longueur infinie, ainsi que l’interaction en temps réel en 540P/25FPS. Les utilisateurs n’ont qu’à téléverser une image de première image (first frame) et un timbre vocal personnalisé pour que le modèle génère en temps réel les expressions et les mouvements du personnage, le tout fonctionnant de manière fluide sur des cartes graphiques grand public. Cette avancée fait passer la génération vidéo de la « lecture hors ligne » à l’ère de l’« interaction bidirectionnelle en temps réel », réduisant considérablement le seuil de développement pour les humains numériques et les compagnons virtuels. (Source : 机器之心)
.jpg)
Damo Academy lance ElementsClaw, un agent AI pour les matériaux supraconducteurs : Damo Academy d’Alibaba, en collaboration avec plusieurs universités, a lancé ElementsClaw, le premier agent AI dédié à la découverte de matériaux supraconducteurs. Combinant un réseau de neurones graphiques profonds géométriques de 1 milliard de paramètres avec un grand modèle de langage, cet agent n’a eu besoin que de 28 heures-GPU pour filtrer 2,4 millions de cristaux stables, prédire 68 000 supraconducteurs potentiels et synthétiser avec succès en laboratoire 4 nouveaux matériaux supraconducteurs jusqu’alors inconnus de l’humanité. Ce résultat améliore considérablement l’efficacité de la R&D sur les matériaux supraconducteurs et accélère l’application de l’AI dans les domaines scientifiques de pointe. (Source : 量子位)

Baiyao Technology lance AURA CellOS, un modèle de monde cellulaire virtuel : Baiyao Technology a publié AURA CellOS, un modèle de monde cellulaire virtuel basé sur l’architecture LLM-JEPA. Doté de 12B de paramètres, ce modèle a été entraîné sur 390 millions de données de transcriptomique de cellules uniques humaines, couvrant plus de 40 types de tissus et plus de 260 types de cellules. Grâce à l’apprentissage de représentations multi-vues et à la prédiction d’intégration conjointe JEPA, CellOS permet pour la première fois à un modèle de comprendre les lois d’évolution interne des états cellulaires, atteignant un niveau de pointe international dans des tâches telles que la prédiction de réponse aux perturbations, fournissant ainsi un socle de calcul clé pour la pharmacie AI et la thérapie cellulaire. (Source : 量子位)

🎯 Tendances
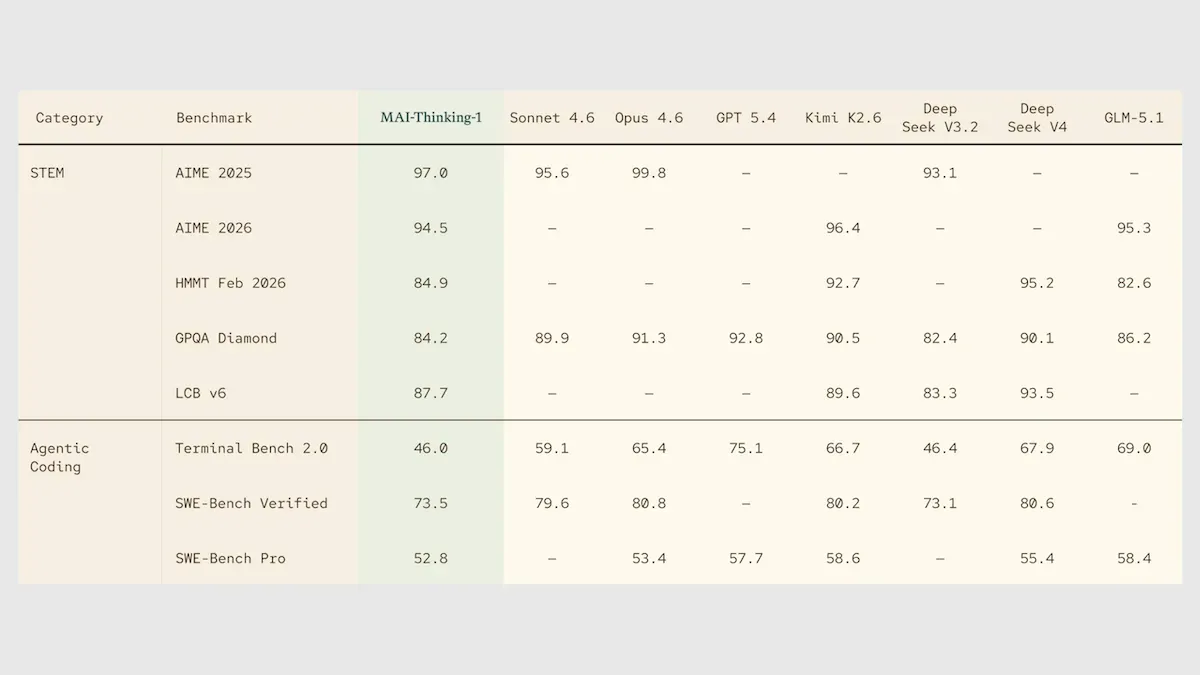
Microsoft lance MAI-Thinking-1, son premier grand modèle de raisonnement indépendant : Lors de sa conférence Build, Microsoft a présenté le modèle de raisonnement MAI-Thinking-1, basé sur une architecture de mélange d’experts (MoE) de 1 billion de paramètres, entièrement entraîné à partir de zéro, sans aucune distillation ni réglage fin à partir d’autres modèles. Ce modèle prend en charge un contexte de 250 000 tokens et affiche de solides performances dans les tests de référence de raisonnement en mathématiques et STEM, surpassant même Claude Sonnet 4.6 à l’AIME 2025. Cela marque une étape cruciale pour Microsoft dans sa volonté de s’affranchir de sa dépendance vis-à-vis de la technologie d’OpenAI et de bâtir sa propre pile technologique AI. (Source : DeepLearning.AI Blog)
Dongfeng Yijing s’associe à Huawei Qiankun Smart Driving ADS 5 pour des tests en conditions extrêmes : La marque haut de gamme de Dongfeng, Yijing X9, équipée du système de conduite intelligente Huawei Qiankun ADS 5, a réalisé des tests en conditions extrêmes (nuit, tempête de pluie, apparition soudaine d’obstacles, etc.). ADS 5 adopte la toute nouvelle architecture WEWA 2.0, intégrant la théorie des jeux multi-agents et des algorithmes de champ de risque de sécurité, réduisant les coûts et améliorant l’efficacité tout en limitant les risques de collision. Les tests réels montrent qu’il peut effectuer une navigation autonome sans aucune intervention humaine dans des scénarios d’entrepôts inconnus, marquant une transition générationnelle des systèmes de conduite intelligente, qui passent d’une approche basée sur des règles à une approche pilotée par les données et les agents AI. (Source : 量子位)

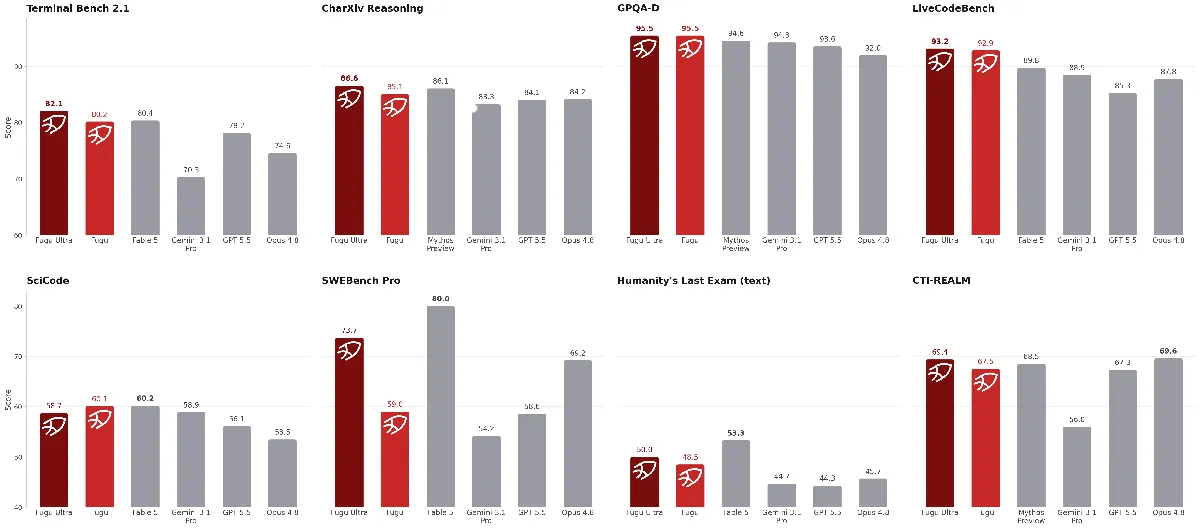
Sakana AI lance la série Fugu, un système d’orchestration collaborative multi-modèles : La startup japonaise d’AI Sakana AI a lancé les modèles Fugu et Fugu-Ultra. Plutôt que de s’appuyer sur un modèle unique, ce système utilise des algorithmes évolutionnaires et l’apprentissage par renforcement au niveau de la passerelle API pour planifier dynamiquement des modèles sous-jacents (tels que Claude, GPT, Gemini, etc.) afin de collaborer sur des tâches complexes. Fugu-Ultra a obtenu un taux de précision record de 95,5 % au test scientifique GPQA-Diamond. Cela démontre que l’orchestration collaborative multi-modèles est devenue une tendance majeure pour éviter le verrouillage par un fournisseur unique et optimiser les coûts d’inférence. (Source : DeepLearning.AI Blog)
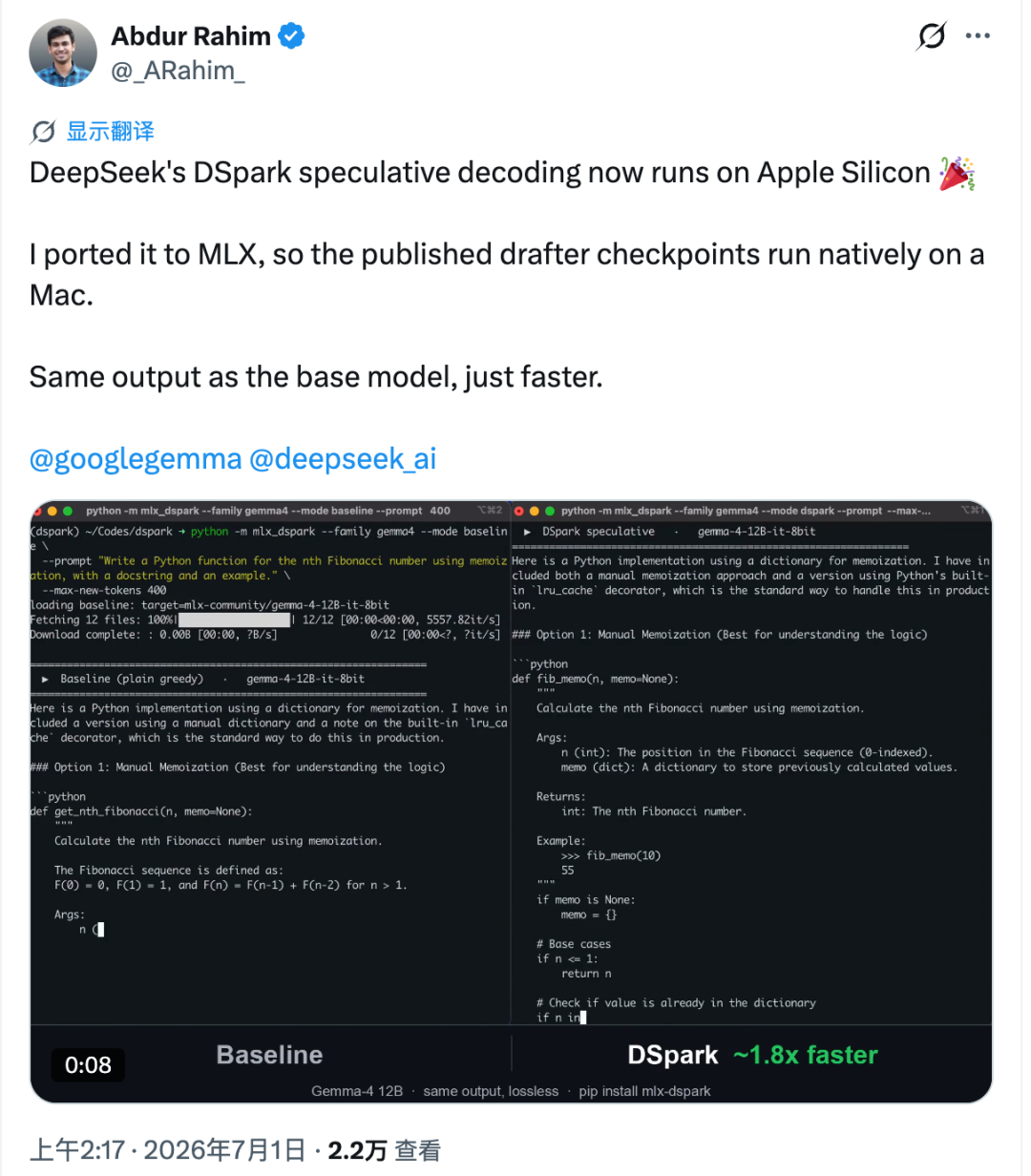
La technologie d’accélération DSpark de DeepSeek portée avec succès en local sur Mac : L’ingénieur open-source Abdur Rahim a porté la technologie de décodage spéculatif DSpark de DeepSeek sur les puces Apple, publiant le projet mlx-dspark. Sur une puce M4 Pro, ce projet a permis d’accélérer la vitesse d’inférence locale de Gemma-4 12B et Qwen3-4B de respectivement 1,6x et 1,4x, avec des résultats de sortie strictement identiques à ceux du modèle d’origine sous le même échantillonnage de température. Cette tentative prouve que la technologie de décodage spéculatif possède également un immense potentiel de réduction des coûts et d’amélioration de l’efficacité sur les appareils de périphérie grand public. (Source : 36氪)
Le DENG Lab de l’Université Jiao Tong de Shanghai rend open-source WLA, un modèle Monde-Langage-Action : Le DENG Lab de l’Université Jiao Tong de Shanghai a rendu open-source le modèle WLA, unifiant la modélisation du monde, le raisonnement linguistique et la génération d’actions robotiques au sein d’un même cadre autorégressif de 2B de paramètres. WLA peut non seulement prédire des dynamiques physiques à grain fin, mais aussi prédire des séquences de sous-tâches via le langage naturel et maintenir un tampon mémoire pour la planification à long terme. Sur le benchmark de mémoire à long terme RMBench, WLA a obtenu un taux de réussite de 56,5 %, soit près du double de la deuxième meilleure méthode, avec une latence d’inférence de seulement 40 ms. (Source : 机器之心)
.jpg)
Tencent Cloud fournira directement le service de modèle DeepSeek-V4 : Tencent Cloud a annoncé qu’il proposerait le service de modèle DeepSeek-V4 sur sa plateforme TokenHub à la mi-juillet, le service fonctionnant directement depuis le propre réseau de DeepSeek. Cette collaboration bénéficie du support technique de Tencent Cloud, tout en démontrant la confiance de DeepSeek dans son propre cluster de calcul. Cela offre aux clients professionnels une option d’infrastructure de calcul plus résiliente et sécurisée sur le plan réseau lors de l’appel de grands modèles open-source de pointe. (Source : teortaxesTex)
🧰 Outils
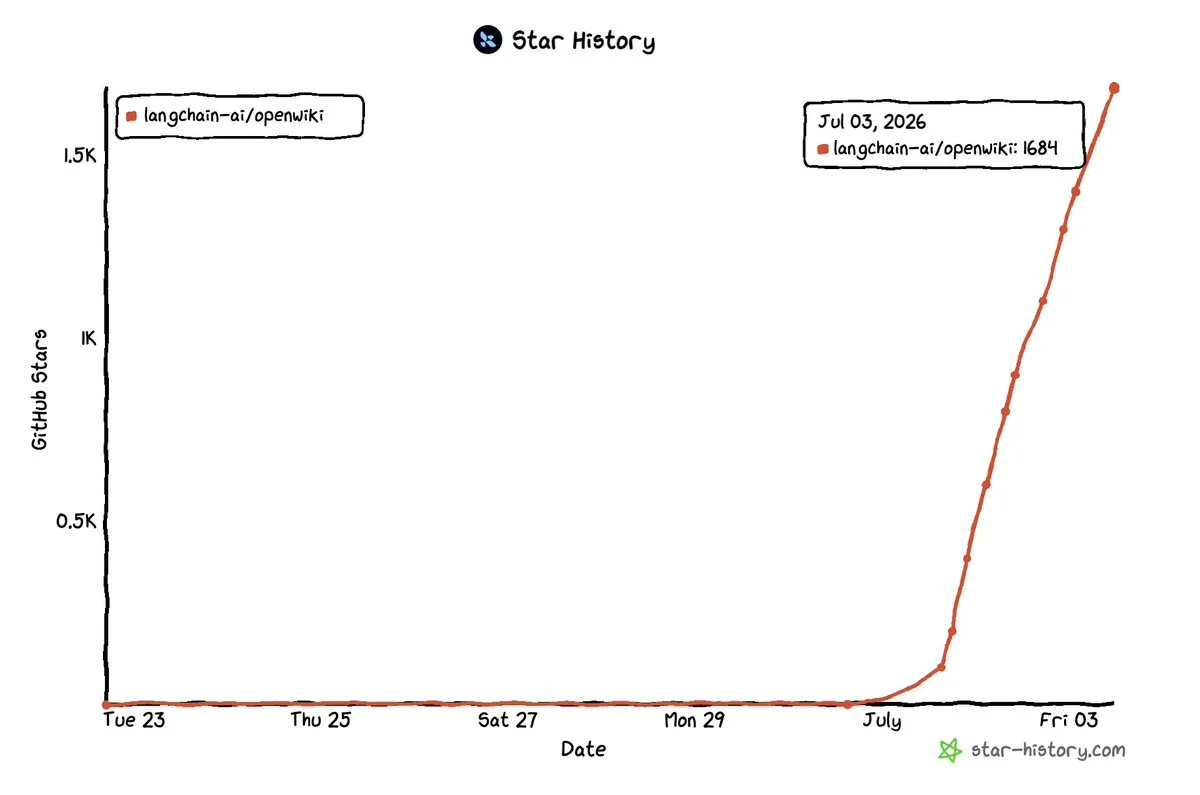
LangChain rend open-source OpenWiki, un agent de wiki mémoire universel : LangChain a rendu open-source le projet OpenWiki, qui a obtenu 1,7k étoiles sur GitHub en seulement 3 jours après son lancement. Ce projet vise actuellement à construire des wikis mémoire structurés pour les bases de code, résolvant le problème de l’oubli d’informations clés par les agents lors de tâches à long terme en extrayant et en organisant automatiquement le contexte du projet. L’équipe de développement prévoit de l’étendre à des sources de données plus générales telles que Notion, Google Drive, Slack et la recherche web, afin de créer un centre de mémoire global pour les agents. (Source : LangChain)
Vercel lance le framework Eve Agent et l’intègre à LlamaIndex : Vercel a lancé le framework d’agent Eve, et LlamaIndex a immédiatement construit un modèle d’intégration pour celui-ci. Ce modèle fournit à Eve un ensemble d’outils de système de fichiers en lecture seule, lui permettant d’analyser des chemins, de lire du texte et d’utiliser l’outil LiteParse pour analyser des documents non structurés dans un format Markdown propre. Cette combinaison offre aux agents un flux de travail fiable et prêt à l’emploi pour naviguer et comprendre efficacement des collections complexes de documents locaux. (Source : jerryjliu0)
Hugging Face publie un framework d’optimisation automatique pour le réglage fin des prompts de grands modèles : Hugging Face a présenté un framework d’optimisation automatique des prompts dans son projet Harness Optimization. Ce framework utilise Claude comme proposeur pour réécrire les prompts périphériques de l’agent et le code d’appel d’outils via des itérations et des validations automatiques, sans modifier les poids du modèle sous-jacent. Les tests montrent que cette méthode a permis à un modèle open-source gelé de faire passer son score dans une évaluation juridique complexe de 0 % à un niveau comparable à celui de Sonnet 4.6, tout en divisant par 7 le coût de la tâche. (Source : ClementDelangue)
Mise à jour de baoyu-design, l’outil de conception de PPT basé sur Fable 5 : Le développeur Baoyu a mis à jour sa compétence d’agent open-source baoyu-design, ajoutant la prise en charge des animations PPT et des appels d’illustrations AI. En tirant parti de la compréhension approfondie du format PPTX XML par Fable 5, cet outil résout avec succès les limites d’exportation d’animations que Opus 4.8 ne parvenait pas à gérer auparavant. Les utilisateurs peuvent désormais générer directement des PPT au format HTML avec des effets d’animation et les exporter de manière transparente dans des fichiers PPTX modifiables pour Keynote ou PowerPoint. (Source : dotey)
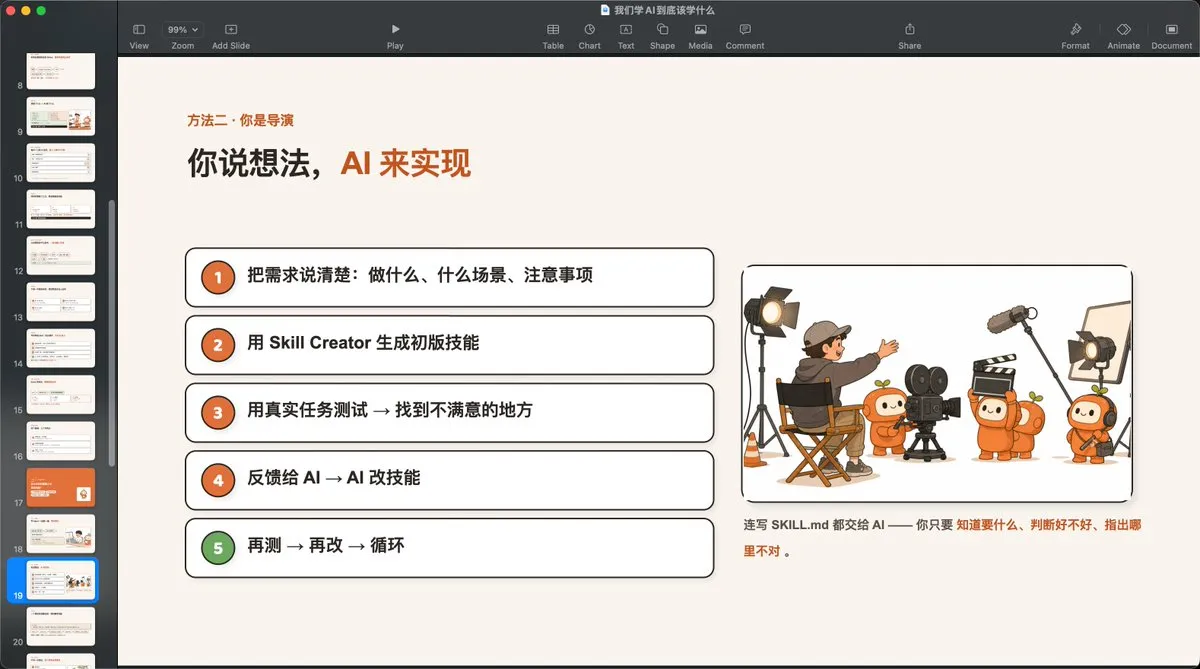
Termiprotocol crée un bureau virtuel en 3D pour Claude Code : Des développeurs ont lancé le projet open-source Termiprotocol, qui construit une interface de bureau virtuel en 3D pour les agents de terminal comme Claude Code et Codex. Chaque opération exécutée par l’agent dans le terminal (comme la lecture/écriture de fichiers, la recherche sur le web, l’exécution de code) est présentée en temps réel sous la forme d’un petit robot 3D tapant au clavier ou fouillant dans des classeurs dans le bureau, accompagnée d’un suivi intuitif de la consommation de tokens et d’un tableau de tâches, améliorant considérablement la visualisation et le côté ludique du flux de travail de l’agent. (Source : Reddit r/ClaudeAI)
Hugging Face et Cerebras lancent une démo vocale pour Gemma 4 : Hugging Face s’est associé à Cerebras pour créer une démo d’interaction vocale en temps réel entièrement open-source. Basée sur le modèle Gemma 4 et le matériel d’inférence à ultra-faible latence de Cerebras, cette démo offre une expérience de conversation vocale à vocale (Speech-to-Speech) ultra-rapide. Les utilisateurs peuvent tester, forker et ajuster le projet directement sur Hugging Face Spaces, offrant ainsi un excellent modèle pour la communauté open-source développant des assistants vocaux à faible latence. (Source : huggingface)
📚 Apprentissage
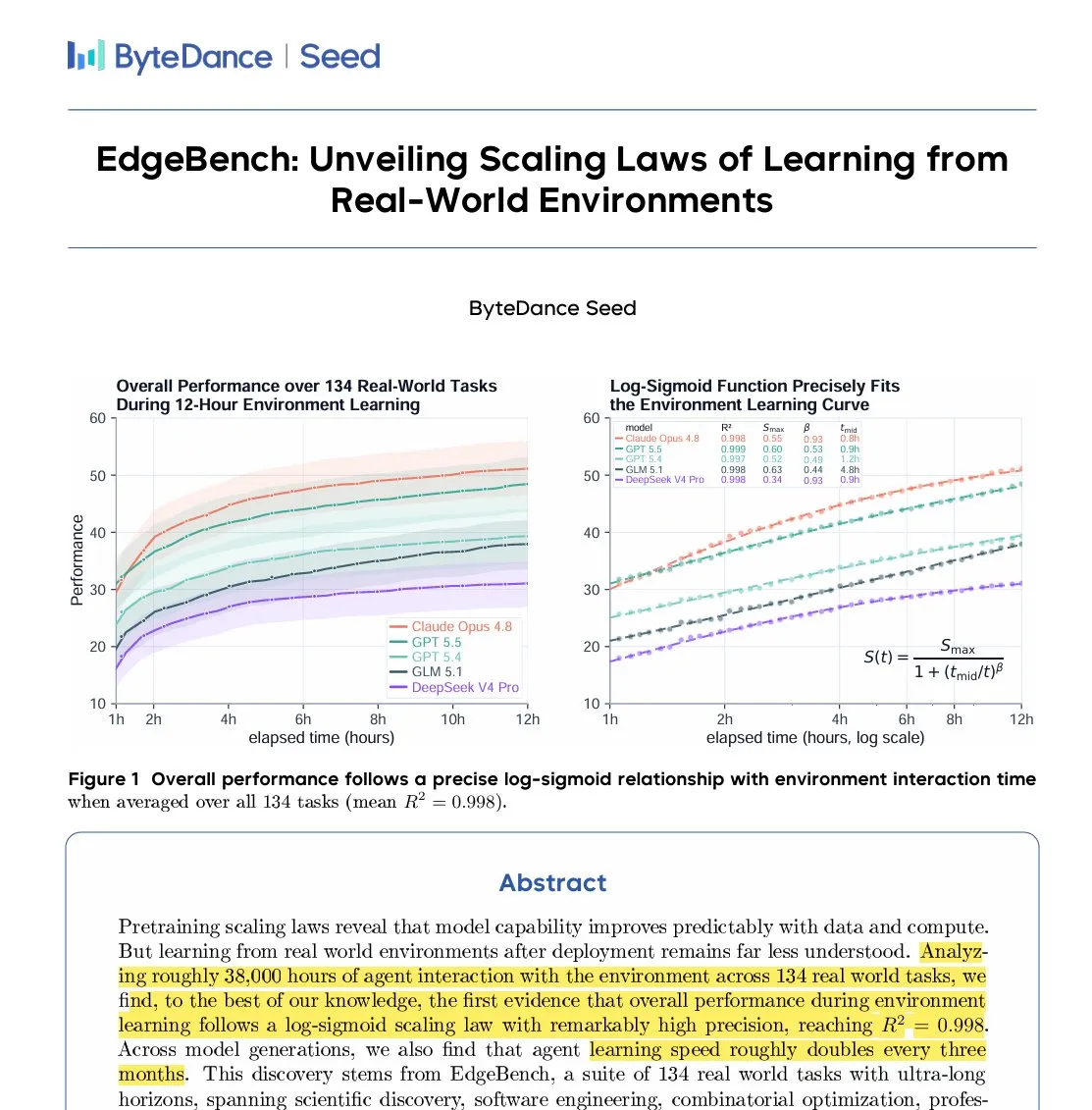
ByteDance publie EdgeBench, un benchmark d’évaluation de l’apprentissage des agents sur de très longues périodes : L’équipe Seed de ByteDance a publié EdgeBench, un benchmark conçu spécifiquement pour étudier comment les agents apprennent en continu à partir des retours de l’environnement sur des cycles de fonctionnement ultra-longs de 12 à 72 heures. Après avoir testé des agents sur un total cumulé de 38 000 heures de fonctionnement, les chercheurs ont découvert que l’amélioration des performances de l’agent et le temps d’interaction avec l’environnement suivent précisément une fonction log-sigmoïde, prouvant que l’accumulation et la réutilisation de l’expérience des tâches sont essentielles pour favoriser la progression à long terme des agents. (Source : arankomatsuzaki)
Samsung et l’Université de Pékin publient LiveClawBench, un benchmark systématique pour les agents AI : L’équipe des grands modèles de Samsung, en collaboration avec l’Université de Pékin et d’autres institutions, a publié LiveClawBench pour évaluer les performances des agents d’assistance personnelle dans des flux de travail complexes. Ce benchmark comprend 134 des tâches exécutables et propose un système de facteurs de complexité tridimensionnels. Les expériences montrent que pour les modèles de pointe, le domaine de la tâche n’explique qu’environ 9,6 % des fluctuations de score, tandis que le « profil de complexité » de la tâche a un pouvoir explicatif de 18,6 %, révélant que les dépendances inter-services et la résolution d’objectifs sont les principales causes d’instabilité des agents. (Source : 机器之心)
.jpg)
L’Université Renmin de Chine publie CoDA-Bench, un benchmark pour les agents de données : Une équipe de recherche de l’Université Renmin de Chine a lancé le benchmark CoDA-Bench, visant à évaluer conjointement l’intelligence de code et l’intelligence de données des agents. Ce benchmark place l’agent dans un bac à sable Linux complexe contenant plus de 1 000 fichiers perturbateurs, lui demandant d’explorer de manière autonome le système de fichiers, de localiser les données pertinentes et d’écrire du code pour les analyser. Les expériences montrent que même le système le plus performant n’atteint qu’une précision de 61,1 % sur CoDA-Bench, révélant que « ne pas trouver les bonnes données » est le principal goulot d’étranglement des agents de code actuels. (Source : 机器之心)
.jpg)
Meta découvre le défaut de « sur-réflexion » dans les modèles de raisonnement quantifiés et propose une solution : Dans une étude, Meta a révélé un mode de défaillance curieux des modèles de raisonnement quantifiés : après quantification, le modèle ne subit pas seulement une baisse de capacité, mais commence à « sur-réfléchir ». Dans près de 52 % des cas d’échec, le modèle avait déjà trouvé la bonne réponse au milieu de son raisonnement, mais comme la quantification augmentait la probabilité d’échantillonnage des tokens d’hésitation (comme wait, but, maybe), il s’est retrouvé piégé dans une auto-réflexion sans fin pour finalement rejeter la conclusion correcte. En appliquant une légère pénalité de décodage sur les tokens d’hésitation, Meta a réussi à réduire de 58 % ces erreurs de sur-réflexion. (Source : TheTuringPost)

Stanford et UC Berkeley publient RoboReward, un modèle de récompense vision-langage pour la robotique : Des équipes de recherche de Stanford et d’UC Berkeley ont présenté RoboReward, un modèle de récompense vision-langage pour la robotique doté de 4B/8B paramètres. En réétiquetant textuellement et en tronquant des vidéos d’actions réussies, cette étude a généré un grand nombre d’échantillons de tentatives négatives et incomplètes de haute qualité, résolvant ainsi le problème du manque d’exemples d’échec dans l’apprentissage par renforcement traditionnel. Les expériences montrent que l’utilisation de RoboReward pour l’évaluation des récompenses surpasse considérablement les grands modèles généraux similaires dans des tâches réelles de saisie par bras robotique et d’ouverture de tiroirs. (Source : DeepLearning.AI Blog)
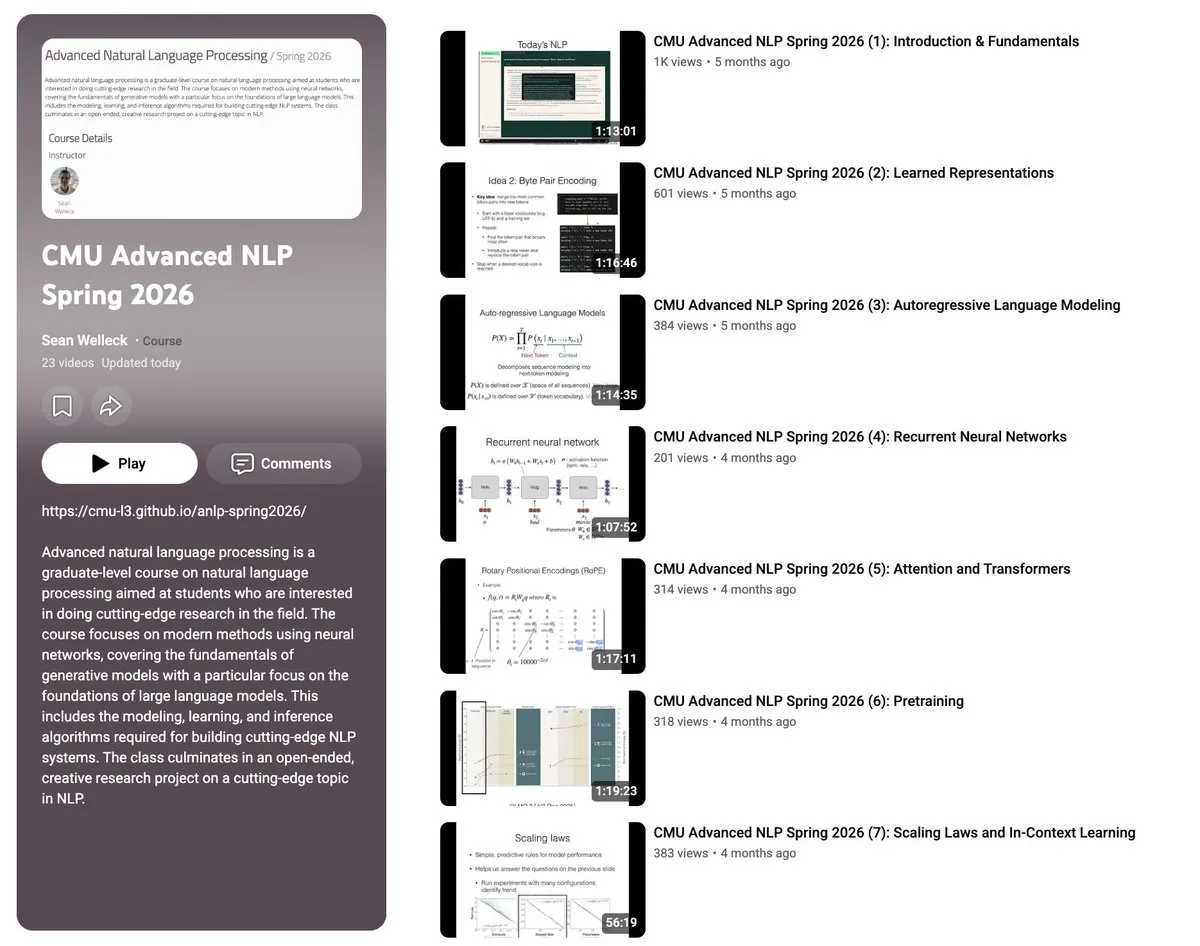
La CMU rend open-source l’intégralité des vidéos et supports des 23 cours d’Advanced NLP : Sean Welleck, professeur à l’Université Carnegie Mellon (CMU), a mis en ligne sur YouTube l’intégralité des vidéos des 23 cours de son programme « Advanced Natural Language Processing (ANLP Spring 2026) », et a rendu open-source les supports de cours associés ainsi que 20 exemples de code. Le contenu du cours couvre systématiquement sept thèmes majeurs, notamment les bases du NLP, les architectures de modèles, l’apprentissage et le raisonnement, les méthodes d’évaluation, l’apprentissage par renforcement et les agents (RL & Agents), ainsi que la mise à l’échelle et l’efficacité des modèles, constituant une excellente ressource pour approfondir les principes fondamentaux des grands modèles. (Source : gneubig)
Le nouveau livre de Sebastian Raschka, « Build a Reasoning Model (From Scratch) », est officiellement publié : Le nouveau livre du célèbre expert en apprentissage automatique Sebastian Raschka, intitulé Build a Reasoning Model (From Scratch), a été officiellement publié. L’ouvrage de 440 pages, en couleur, propose des exemples de code exécutables. Il présente de manière systématique la logique sous-jacente des modèles de raisonnement, y compris des technologies de pointe telles que la mise à l’échelle de l’inférence (Inference Scaling), l’apprentissage par renforcement (RL) et la distillation de modèles (Distillation), constituant une excellente lecture pour acquérir les bases théoriques des grands modèles. (Source : cwolferesearch)

💼 Business
L’enregistrement de l’introduction en bourse d’Unitree Robotics sur le STAR Market approuvé par la CSRC : La Commission de régulation des valeurs mobilières de Chine (CSRC) a officiellement approuvé la demande d’enregistrement d’Unitree Robotics pour son introduction en bourse (IPO) sur le STAR Market. Unitree Robotics prévoit d’émettre publiquement au moins 10 % de ses actions, visant à lever 4,202 milliards de yuans pour une valorisation d’environ 42 milliards de yuans. Le prospectus montre qu’en 2025, Unitree a réalisé un chiffre d’affaires de 1,708 milliard de yuans, avec un bénéfice net de 591 millions de yuans, et a livré plus de 5 500 robots humanoïdes, atteignant une part de marché mondiale de 32,4 %. Cela marque l’entrée officielle sur le marché des actions A de la première entreprise chinoise rentable de robots complets dotés d’intelligence incarnée. (Source : 36氪)
Silicon Flow dépose son prospectus à la Bourse de Hong Kong pour devenir la « première action d’usine à tokens » : La startup d’infrastructure AI Silicon Flow a officiellement déposé son prospectus d’introduction en bourse auprès de la Bourse de Hong Kong (HKEX). Se positionnant comme un « grossiste de tokens » pour l’industrie de l’AI, l’entreprise fournit un service d’accès unifié multi-modèles via des API standardisées. Après son cycle de financement de série B+, sa valorisation a atteint 7,74 milliards de yuans, avec des actionnaires comprenant des géants tels qu’Alibaba, Tencent, Huawei et Meituan. Le prospectus indique qu’en 2025, l’entreprise comptait 716 000 clients payants sur le cloud public, mais en raison d’investissements massifs initiaux dans la puissance de calcul et la promotion, sa perte nette s’est élevée à 345 millions de yuans. (Source : 36氪)
Guangxiang Technology lève plusieurs centaines de millions de yuans lors de son tour de table d’amorçage : La startup d’intelligence incarnée Guangxiang Technology a annoncé la finalisation d’un tour de table d’amorçage (Angel round) de plusieurs centaines de millions de yuans, co-investi par Zhuhai Science and Technology Group, Industrial Securities Capital, Songhe Capital, etc. Incubée par une équipe de l’Université Tsinghua, Guangxiang Technology a établi une feuille de route technologique d’« intelligence physique native » et a construit un système composé d’une matrice d’algorithmes d’apprentissage par renforcement, d’actifs de données physiques haute fidélité et d’une plateforme de développement intelligente. Son robot incarné développé en interne, Phi-Bot X1, a validé des opérations continues de haute précision sur des postes de soudage et de chargement de lignes de production automobile. (Source : 量子位)

🌟 Communauté
Alibaba émet une directive interne interdisant totalement Claude et Claude Code : Alibaba a émis une directive interne urgente demandant à ses employés de désinstaller et de cesser d’utiliser complètement les produits d’Anthropic, notamment Claude et Claude Code, avant le 10 juillet. Auparavant, des analyses d’ingénierie inverse menées par la communauté de la sécurité avaient révélé que Claude Code intégrait un mécanisme caché de détection des utilisateurs chinois et des laboratoires d’AI. En utilisant du code obscurci, il collectait les fuseaux horaires du système, les proxys et les mots-clés d’API, puis renvoyait l’empreinte numérique de l’environnement au serveur en altérant des caractères Unicode dans les prompts, suscitant des inquiétudes au sein de l’entreprise quant à la fuite de code source stratégique. (Source : 36氪)

Le moteur de jeu Godot annonce un durcissement de sa politique sur les contributions de code générées par AI : Le moteur de jeu open-source Godot a annoncé une modification de sa politique de contribution, interdisant totalement l’utilisation d’AI pour générer de larges blocs de code ainsi que la soumission automatique de PR par des agents AI. L’équipe officielle a déclaré sans détour que bien que l’AI abaisse la barrière à l’écriture de code, elle entraîne un afflux massif de PR de mauvaise qualité, ce qui épuise les ressources des mainteneurs bénévoles chargés de leur examen. Pire encore, de nombreux contributeurs sont incapables d’expliquer le code généré par l’AI ou de le maintenir en cas de bug. Godot a souligné que l’AI ne peut être tenue responsable du code, et que le projet a besoin de personnes qui comprennent réellement le code. (Source : 36氪)

Meta prévoit de lancer le service cloud Metamate pour louer sa puissance de calcul AI inutilisée : Selon Bloomberg, Meta prévoit de créer une division d’infrastructure cloud nommée « Metamate » pour vendre de la puissance de calcul AI inutilisée et des accès à des modèles à des clients externes, dans le but de générer entre 10 et 15 milliards de dollars de revenus annuels d’ici 2027. Cette nouvelle a suscité des inquiétudes sur le marché quant à une possible surcapacité temporaire de la puissance de calcul AI, entraînant des ventes massives dans les secteurs mondiaux des puces et du stockage au cours des deux jours de bourse suivants. (Source : 36氪)
Le monde académique constate que les grands modèles AI remplacent progressivement les humains dans la recherche mathématique : Alors qu’un modèle interne d’OpenAI a réfuté de manière indépendante la « conjecture des distances unitaires dans le plan » proposée par le physicien Erdős, sur laquelle les humains travaillaient depuis près de 80 ans, la capacité de raisonnement mathématique de l’AI a connu un bond spectaculaire. Cela a déclenché une crise existentielle et de l’anxiété chez les doctorants en mathématiques, certains plaisantant sur le fait qu’ils ne pouvaient échapper à la réalité qu’en jouant à Honor of Kings. Les universitaires estiment que l’efficacité de l’AI dans la recherche mathématique standardisée et formalisée oblige les mathématiciens humains à repenser la valeur de leurs propres recherches et leurs frontières esthétiques. (Source : 36氪)
Un rapport de Cloudflare montre que le trafic web des machines dépasse pour la première fois celui des humains : Le fournisseur de services de cybersécurité Cloudflare a publié un rapport indiquant que parmi toutes les requêtes d’accès web reçues par les sites qu’il héberge, environ 57,4 % provenaient de programmes d’intelligence artificielle et d’automatisation (tels que les robots d’entraînement d’AI, les agents, etc.), tandis que les requêtes provenant de véritables humains ne représentaient que 42,6 %. C’est la première fois dans l’histoire d’Internet que le trafic des machines dépasse celui des humains, marquant un changement fondamental dans le paradigme des interactions en ligne et portant un coup systémique au modèle commercial traditionnel de monétisation publicitaire basé sur le trafic. (Source : 36氪)

💡 Divers
Des chercheurs découvrent le nom fantôme « Dr. Elena Rodriguez » dans les grands modèles de langage : Dans un article sur la « différenciation par décodage contrastif (CDD) », les laboratoires de Samsung ont révélé une découverte amusante : lors de la reconstruction inverse des données d’entraînement sur plusieurs modèles affinés, le nom d’une scientifique fictive, « Dr. Elena Rodriguez », est apparu très fréquemment dans les sorties de modèles de différents domaines. L’enquête a révélé que cela s’explique par le fait que Claude Sonnet 3.6 privilégie énormément ce nom lors de la génération de données d’entraînement synthétiques, ce qui l’a involontairement « intégré » dans tous les modèles affinés utilisant ces données synthétiques. (Source : Reddit r/MachineLearning)

Des utilisateurs de Reddit ironisent sur la limitation discrète des quotas de Perplexity Pro : De nombreux utilisateurs abonnés à Perplexity Pro (200 dollars par an) se sont plaints sur Reddit de constater que leurs fonctionnalités de « téléversement illimité de fichiers » et de « recherche approfondie (Deep Research) » avaient été discrètement limitées récemment, apparaissant grisées et indisponibles. Les utilisateurs accusent la plateforme d’avoir unilatéralement réduit les avantages des utilisateurs Pro sans envoyer d’e-mail, d’annonce ou de mise à jour des conditions d’utilisation, déclenchant un large débat au sein de la communauté sur la transparence des services SaaS et la protection des droits des consommateurs. (Source : Reddit r/artificial)
Un utilisateur de Reddit partage comment il a utilisé Fable 5 pour organiser dix ans de création d’univers et générer automatiquement un wiki : Un auteur de romans a partagé sur Reddit comment il a rassemblé ses brouillons de romans, ses descriptions d’univers et ses notes désordonnées accumulés sur dix ans (représentant des centaines de milliers de mots) dans un seul PDF pour les analyser avec Fable 5. Après avoir consommé 90 % de son quota de session unique, Fable 5 a parfaitement structuré ces contenus en fiches de personnages, d’événements et de lieux géographiques, générant automatiquement des fichiers Markdown directement importables dans le système de wiki World Anvil, l’aidant ainsi à surmonter un blocage créatif de longue date. (Source : Reddit r/ClaudeAI)