
كلمات مفتاحية:أنثروبيك كلود سونيت 4.5, ديب سيك-V3.2-إكس بي, أوبن إيه آي تشات جي بي تي, نماذج الذكاء الاصطناعي, الذكاء الاصطناعي, نماذج اللغة الكبيرة, برمجة الذكاء الاصطناعي, وكلاء الذكاء الاصطناعي, قدرات برمجة كلود سونيت 4.5, آلية الانتباه المتفرق DSA, ميزة الدفع الفوري في تشات جي بي تي, تطبيق سورا 2 الاجتماعي, تقنية ضبط LoRA الدقيق
🔥 أبرز الأحداث
إطلاق Anthropic Claude Sonnet 4.5، مع تحسينات كبيرة في البرمجة وقدرات الوكيل : أطلقت Anthropic رسميًا Claude Sonnet 4.5، الذي يُوصف بأنه أقوى نموذج برمجة في العالم، وحقق اختراقات كبيرة في بناء الوكلاء، واستخدام الكمبيوتر، والاستدلال، والقدرات الرياضية. يمكن للنموذج العمل بشكل مستقل ومستمر لأكثر من 30 ساعة، وتصدر اختبار SWE-bench Verified، وحطم الأرقام القياسية في معيار مهام الكمبيوتر OSWorld. تشمل الميزات الجديدة وظيفة التراجع “检查点” (checkpoint) في Claude Code، ومكون VS Code الإضافي، وأدوات تحرير السياق والذاكرة في API. بالإضافة إلى ذلك، تم إطلاق ميزة تجريبية “Imagine with Claude” التي يمكنها إنشاء واجهات برمجية في الوقت الفعلي. تم تعزيز أمان Sonnet 4.5 بشكل كبير، مما قلل من السلوكيات غير المرغوبة مثل الخداع والتملق، وحصل على شهادة AI safety level 3 (ASL-3)، مع تقليل معدل الإنذارات الكاذبة بمقدار 10 أضعاف. ظل التسعير متوافقًا مع Sonnet 4، مما عزز القيمة مقابل السعر، ومن المتوقع أن يؤدي ذلك إلى جولة جديدة من المنافسة في برمجة الذكاء الاصطناعي. (المصدر: Reddit r/ClaudeAI, 36氪, 36氪, 36氪, 36氪, 36氪, Reddit r/ChatGPT, dotey, dotey, dotey)

إطلاق DeepSeek-V3.2-Exp، مع تقديم آلية الانتباه المتفرقة DSA وتخفيض الأسعار : أطلقت DeepSeek النموذج التجريبي V3.2-Exp، الذي يقدم آلية الانتباه المتفرقة DeepSeek Sparse Attention (DSA)، مما يعزز بشكل كبير كفاءة التدريب والاستدلال في السياقات الطويلة، بينما تم تخفيض أسعار API بأكثر من 50%. تحدد DSA بكفاءة الـ Token الرئيسية للحسابات الدقيقة من خلال “闪电索引器” (Lightning Indexer)، مما يقلل من تعقيد الانتباه من O(L²) إلى O(Lk). وقد حققت شركات شرائح الذكاء الاصطناعي المحلية مثل Huawei Ascend و Cambricon و Hygon التكيف في اليوم الأول، مما يعزز تطوير بيئة الحوسبة المحلية. كما قام النموذج بفتح مصدر عامل تشغيل GPU لإصدار TileLang، والذي يضاهي NVIDIA CUDA، لتسهيل تطوير النماذج الأولية وتصحيح الأخطاء للمطورين. على الرغم من بعض التنازلات في قدرات معينة، إلا أن ابتكاره المعماري وفعاليته من حيث التكلفة يشيران إلى اتجاه جديد لمعالجة النصوص الطويلة في النماذج الكبيرة. (المصدر: 36氪, 36氪, 36氪, 量子位, 量子位, 量子位, Reddit r/LocalLLaMA, Twitter)

OpenAI تطلق ميزة الدفع الفوري في ChatGPT، وتدخل مجال التجارة الإلكترونية : أطلقت OpenAI ميزة “Instant Checkout” في ChatGPT، مما يسمح للمستخدمين بشراء المنتجات مباشرة من منصتي Etsy و Shopify داخل المحادثة، دون الحاجة إلى الانتقال إلى مواقع خارجية. تعتمد هذه الميزة على “Agentic Commerce Protocol” الذي طورته OpenAI بالتعاون مع Stripe، وقد تم فتح مصدره، بهدف تحويل حركة المرور الهائلة لـ ChatGPT إلى معاملات تجارية. يدعم الإصدار الأولي السوق الأمريكي، مع خطط للتوسع ليشمل عربات التسوق متعددة المنتجات والمزيد من المناطق في المستقبل. تُعتبر هذه الخطوة بمثابة قفزة كبيرة في تسويق OpenAI، ومن المتوقع أن تصبح مصدر دخل مهمًا لها، وأن يكون لها تأثير عميق على التجارة الإلكترونية التقليدية وصناعة الإعلانات. (المصدر: 36氪, 36氪, Reddit r/artificial, Reddit r/artificial, Twitter, Twitter, Twitter, Twitter)
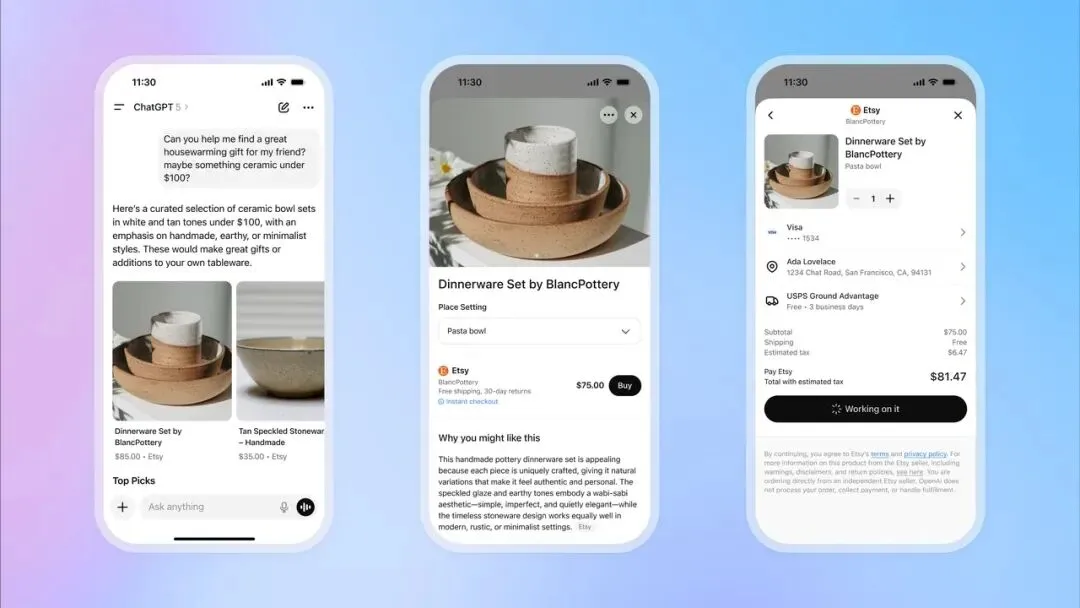
OpenAI تستعد لإطلاق تطبيق Sora 2 الاجتماعي، لإنشاء منصة فيديو قصيرة بالذكاء الاصطناعي : تستعد OpenAI لإطلاق تطبيق اجتماعي مستقل مدعوم بنموذج الفيديو الأخير Sora 2، والذي تم تصميمه ليكون مشابهًا جدًا لـ TikTok، مع تدفق فيديو عمودي وتصفح بالتمرير، ولكن جميع المحتوى يتم إنشاؤه بواسطة الذكاء الاصطناعي. يمكن للمستخدمين إنشاء مقاطع فيديو تصل مدتها إلى 10 ثوانٍ، واستخدام ميزات المصادقة لاستخدام صورهم الشخصية في الفيديو. تهدف هذه الخطوة إلى تكرار نجاح ChatGPT في مجال النصوص، والسماح للجمهور بتجربة إمكانات الفيديو بالذكاء الاصطناعي بشكل مباشر، والدخول في منافسة مباشرة مع Meta و Google. ومع ذلك، فإن استراتيجية OpenAI في التعامل مع حقوق الطبع والنشر، والتي تعتمد على “الاستخدام الافتراضي للمحتوى المحمي بحقوق الطبع والنشر، ما لم يقم صاحب الحقوق بالانسحاب طواعية”، أثارت مخاوف قوية من قبل منشئي المحتوى وشركات الأفلام، مما ينذر بصراع شرس بين الذكاء الاصطناعي والملكية الفكرية. (المصدر: 36氪, Reddit r/artificial, Twitter, Twitter)

🎯 التطورات
نموذج Huawei Pangu 718B يحتل المرتبة الثانية في قائمة SuperCLUE للنماذج اللغوية الكبيرة الصينية مفتوحة المصدر : احتل نموذج Huawei openPangu-Ultra-MoE-718B المرتبة الثانية في قائمة SuperCLUE للنماذج اللغوية الكبيرة الصينية مفتوحة المصدر. يعتمد النموذج فلسفة تدريب “لا يعتمد على تراكم البيانات، بل على القدرة على التفكير”، من خلال مبادئ بناء البيانات “الجودة أولاً، التغطية المتنوعة، التكيف مع التعقيد”، واستراتيجية التدريب المسبق ثلاثية المراحل (عام، استدلال، تلدين)، لبناء معرفة عالمية واسعة وتعزيز قدرات الاستدلال المنطقي. لمعالجة مشكلة الهلوسة، تم تقديم آلية “النقد الداخلي”؛ ولتعزيز قدرات استخدام الأدوات، تم استخدام إطار عمل ToolACE الاصطناعي المحدث. (المصدر: 量子位)

FSDrive يوحد VLA ونماذج العالم، ويدفع القيادة الذاتية نحو الاستدلال البصري : يقترح FSDrive (FutureSightDrive) “時空視覺CoT” (الاستدلال البصري الزماني المكاني CoT)، الذي يوحد إطارات الصور المستقبلية كخطوات استدلال وسيطة، ويجمع بين المشاهد المستقبلية ونتائج الإدراك للاستدلال البصري، وبالتالي يدفع القيادة الذاتية من الاستدلال الرمزي إلى الاستدلال البصري. لا يغير هذا الأسلوب بنية MLLM الحالية، ولكنه ينشط قدرة توليد الصور من خلال توسيع المفردات والتوليد البصري التراجعي، ويحقن الأولويات الفيزيائية من خلال الاستدلال البصري المتدرج CoT. يعمل النموذج كـ “نموذج عالم” للتنبؤ بالمستقبل، و”نموذج ديناميكي عكسي” لتخطيط المسار. (المصدر: 36氪)

GPT-5 يقدم أفكارًا رئيسية للحوسبة الكمومية، ويحظى بإشادة كبيرة من Scott Aaronson : كشف Scott Aaronson، الخبير البارز في نظرية الحوسبة الكمومية، أن GPT-5 قدم له أفكارًا رئيسية لإثبات نظريته في التعقيد الكمومي في أقل من نصف ساعة، مما حل مشكلة كانت تزعج فريقه. صرح Scott Aaronson أن GPT-5 حقق تقدمًا كبيرًا في التغلب على الأنشطة الفكرية الأكثر تميزًا للإنسان، مما يمثل “لحظة حلوة” في التعاون بين الإنسان والذكاء الاصطناعي، حيث يمكنه توفير إلهام اختراقي للباحثين في اللحظات الحاسمة. (المصدر: 量子位, Twitter)

HuggingFace يسرع استدلال نموذج Qwen3-8B Agent على Intel Core Ultra : تعاونت HuggingFace مع Intel لزيادة سرعة استدلال نموذج Qwen3-8B Agent على وحدة معالجة الرسوميات المدمجة Intel Core Ultra بمقدار 1.4 مرة، وذلك باستخدام OpenVINO.GenAI ونموذج Qwen3-0.6B المسودة ذو التقليم العميق (depth-pruned). هذا التحسين يجعل تشغيل تطبيقات Agent على أجهزة AI PC أكثر كفاءة، خاصة لمهام سير العمل المعقدة التي تتطلب استدلالًا متعدد الخطوات واستدعاء الأدوات، مما يدفع نحو التطبيق العملي لوكلاء الذكاء الاصطناعي المحليين. (المصدر: HuggingFace Blog)

روبوت Reachy Mini يدمج GPT-4o، ويحقق تفاعلاً متعدد الوسائط : نجح روبوت Reachy Mini من Hugging Face / Pollen Robotics في دمج نموذج OpenAI GPT-4o، مما أدى إلى تحسين كبير في قدرات التفاعل متعدد الوسائط. تشمل الميزات الجديدة تحليل الصور (يمكن للروبوت وصف الصور الملتقطة والاستدلال عليها)، وتتبع الوجه (للحفاظ على التواصل البصري)، ودمج الحركة (تحريك الرأس، تتبع الوجه، العواطف/الرقص تعمل في وقت واحد)، والتعرف المحلي على الوجه، والسلوكيات المستقلة في أوقات الخمول. هذه التطورات تجعل التفاعل بين الإنسان والروبوت أكثر طبيعية وسلاسة، ولكن لا تزال هناك تحديات تتعلق بأنظمة الذاكرة، والتعرف على الكلام، واستراتيجيات التعامل مع الحشود المعقدة. (المصدر: Reddit r/ChatGPT, Twitter)

Intel تطلق إصدارًا تجريبيًا جديدًا من LLM Scaler لدعم GenAI على Battlemage GPU : أطلقت Intel إصدارًا تجريبيًا جديدًا من LLM Scaler، يهدف إلى تحسين أداء الذكاء الاصطناعي التوليدي (GenAI) على Battlemage GPU. تشير هذه الخطوة إلى استمرار استثمار Intel في أجهزة وبرامج الذكاء الاصطناعي، لتعزيز قدرة وحدات معالجة الرسوميات الخاصة بها في مهام استدلال النماذج اللغوية الكبيرة والتوليد. (المصدر: Reddit r/artificial)
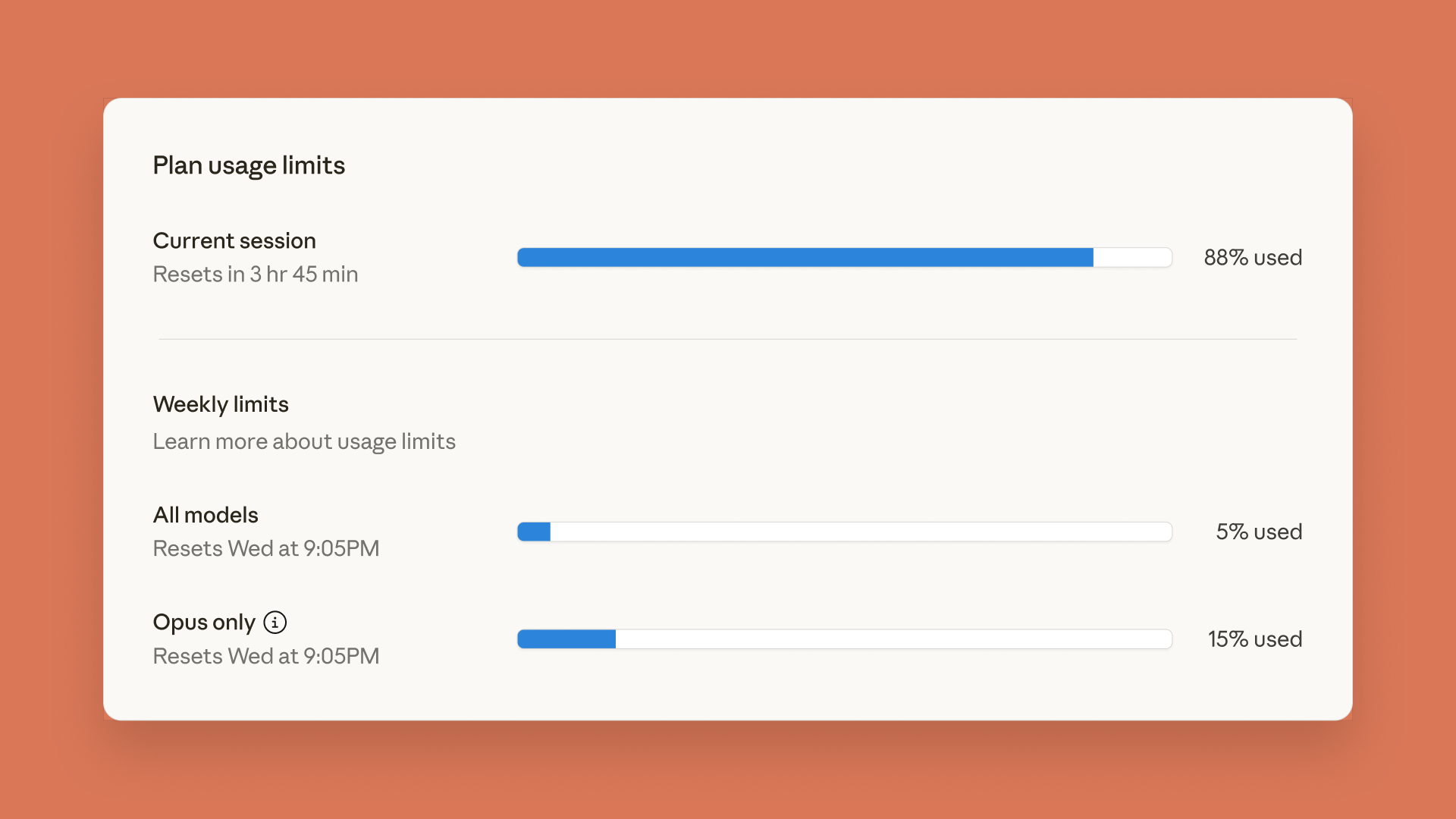
Claude تطلق لوحة تحكم لقيود الاستخدام، وChatGPT يطلق ميزة الرقابة الأبوية : أطلقت Anthropic لوحة تحكم في الوقت الفعلي لقيود الاستخدام لـ Claude Code و Claude App، مما يسمح للمستخدمين بتتبع استخدامهم للـ Token، استجابةً لقيود المعدل الأسبوعية المعلنة سابقًا. في الوقت نفسه، أطلقت OpenAI ميزة الرقابة الأبوية في ChatGPT، مما يسمح للآباء بربط حسابات المراهقين، وتوفير حماية أمنية أقوى تلقائيًا، ويمكنهم تعديل الوظائف وتعيين قيود الاستخدام، ولكن لا يمكن للآباء عرض محتوى المحادثات المحددة. (المصدر: Reddit r/ClaudeAI, 36氪)
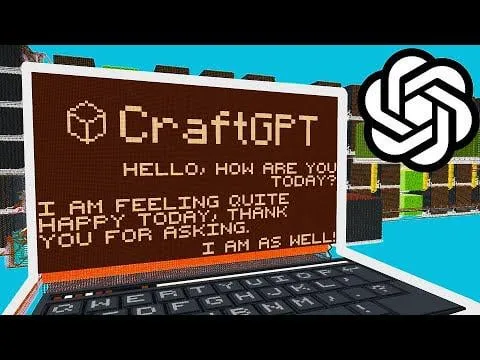
تشغيل نموذج لغوي بـ 5 ملايين معلمة في Minecraft، يظهر تطبيقات مبتكرة للذكاء الاصطناعي : قام Sammyuri ببناء نظام Redstone معقد في Minecraft، ونجح في تشغيل نموذج لغوي بحوالي 5 ملايين معلمة، ومنحه قدرات محادثة أساسية. يوضح هذا الإنجاز الرائد إمكانية تحقيق الذكاء الاصطناعي المحلي في بيئة الألعاب، وأثار نقاشًا واسعًا في المجتمع حول تطبيقات الذكاء الاصطناعي على المنصات غير التقليدية. (المصدر: Reddit r/LocalLLaMA, Twitter)
خوادم Inspur Information AI تحقق سرعة استدلال 8.9 مللي ثانية، وتكلفة مليون Token تبلغ 1 يوان : أطلقت Inspur Information خوادم AI فائقة التوسع Yuan Nao HC1000 و Yuan Nao SD200، مما رفع سرعة استدلال الذكاء الاصطناعي إلى رقم قياسي جديد. حقق Yuan Nao SD200 وقت إخراج لكل Token (TPOT) يبلغ 8.9 مللي ثانية على نموذج DeepSeek-R1، متفوقًا على SOTA السابق بما يقرب من الضعف، ويدعم استدلال النماذج الكبيرة ذات التريليون معلمة والتعاون في الوقت الفعلي بين الوكلاء المتعددين. بينما خفض Yuan Nao HC1000 تكلفة إخراج مليون Token إلى 1 يوان، وخفض تكلفة البطاقة الواحدة بنسبة 60%. تهدف هذه الاختراقات إلى حل اختناقات السرعة والتكلفة التي تواجه تصنيع الوكلاء، وتوفير بنية تحتية حاسوبية عالية الكفاءة ومنخفضة التكلفة للتطبيق على نطاق واسع للتعاون بين الوكلاء المتعددين والاستدلال على المهام المعقدة. (المصدر: 量子位)

طريقة جديدة لـ 3D Gaussian Splatting الأمامية: فريق جامعة Zhejiang يقترح “محاذاة الفوكسل” : اقترح فريق جامعة Zhejiang إطار عمل 3D Gaussian Splatting (3DGS) الأمامي “voxel-aligned” (VolSplat)، بهدف حل مشكلات الاتساق الهندسي واختناقات توزيع كثافة Gaussian في إعادة البناء ثلاثي الأبعاد متعدد الزوايا للطرق الحالية “pixel-aligned”. يدمج VolSplat معلومات ثنائية الأبعاد متعددة الزوايا في الفضاء ثلاثي الأبعاد، ويستخدم شبكة 3D U-Net متفرقة لتحسين الميزات، مما يحقق إعادة بناء ثلاثي الأبعاد بجودة أعلى وأكثر قوة وكفاءة. أظهرت هذه الطريقة أداءً أفضل من العديد من الخطوط الأساسية على مجموعات البيانات العامة، وأظهرت قدرة قوية على التعميم من الصفر على مجموعات البيانات غير المرئية. (المصدر: 量子位)

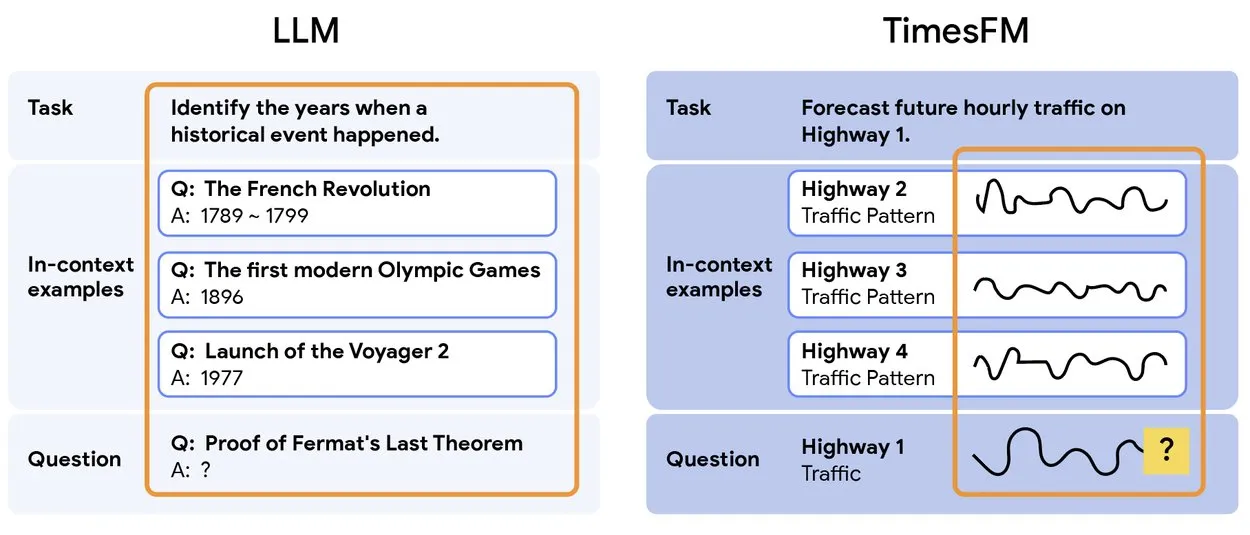
TimesFM 2.5: إطلاق نموذج تنبؤ السلاسل الزمنية المدرب مسبقًا : تم إطلاق TimesFM 2.5، وهو نموذج مدرب مسبقًا لتنبؤ السلاسل الزمنية، حيث تم تقليل عدد معلماته من 500 مليون إلى 200 مليون، وزيادة طول السياق من 2K إلى 16K، وأظهر أداءً ممتازًا في إعدادات التعلم من الصفر (zero-shot). النموذج متاح الآن على Hugging Face ويستخدم ترخيص Apache 2.0، مما يوفر حلاً أكثر كفاءة وقوة لمهام تنبؤ السلاسل الزمنية. (المصدر: Twitter)
Yunpeng Technology تطلق منتجات AI+health جديدة، لتعزيز تطبيق الذكاء الاصطناعي في مجال الصحة المنزلية : أطلقت Yunpeng Technology، بالتعاون مع Shuai Kang و Skyworth، “مختبر المطبخ الرقمي الذكي للمستقبل” وثلاجة ذكية مزودة بنموذج AI health large model. يعمل نموذج AI health large model على تحسين تصميم وتشغيل المطبخ، بينما توفر الثلاجة الذكية إدارة صحية شخصية من خلال “مساعد الصحة Xiao Yun”. يمثل هذا الإطلاق اختراقًا للذكاء الاصطناعي في مجال إدارة الصحة اليومية، ومن المتوقع أن يحقق خدمات صحية شخصية من خلال الأجهزة الذكية، ويرفع مستوى التكنولوجيا الصحية المنزلية. (المصدر: 36氪)
علي بابا تطلق نموذج التفكير مفتوح المصدر Ring-1T-preview بمليون معلمة : أطلق فريق Ant Ling من علي بابا أول نموذج تفكير مفتوح المصدر Ring-1T-preview بمليون معلمة، بهدف تحقيق “التفكير العميق، دون انتظار”. حقق النموذج نتائج ممتازة مبكرة في مهام معالجة اللغة الطبيعية، بما في ذلك اختبارات AIME25 و HMMT25 و ARC-AGI-1 و LCB و Codeforces. بالإضافة إلى ذلك، حل مشكلة Q3 في IMO25 دفعة واحدة، وقدم حلولًا جزئية لـ Q1/Q2/Q4/Q5، مما يدل على قدراته القوية في الاستدلال وحل المشكلات. (المصدر: Twitter, Twitter, Twitter)

🧰 الأدوات
PopAi تطلق “Slide Agent”، الذكاء الاصطناعي لإنشاء العروض التقديمية بنقرة واحدة : أطلق فريق PopAi أداة “Slide Agent” التي تهدف إلى تبسيط عملية إنشاء العروض التقديمية. يمكن للمستخدمين ببساطة إدخال متطلباتهم عبر Prompt، ثم اختيار أكثر من 300 قالب، ليقوم الذكاء الاصطناعي بإنشاء مسودة تلقائيًا، وتعديل التخطيط والرسوم البيانية والصور والشعارات وغيرها من التنسيقات، وأخيرًا تنزيل الملف كملف .pptx قابل للتحرير. تجمع الأداة بين وظائف ChatGPT و Canva، مما يقلل بشكل كبير من عوائق وتكلفة الوقت لإنشاء العروض التقديمية. (المصدر: Twitter)
علي بابا تفتح مصدر أداة تحويل PDF إلى Markdown Miner U2.5 : أطلق فريق علي بابا أداة تحويل PDF إلى Markdown Miner U2.5 مفتوحة المصدر، وهي متاحة الآن كـ Demo على HuggingFace. يمكن للأداة تحويل مستندات PDF بكفاءة إلى تنسيق Markdown، مما يسهل على المستخدمين استخراج المحتوى وتحريره وإعادة استخدامه. تعد هذه الأداة مساعدة عملية للذكاء الاصطناعي للمطورين والباحثين الذين يحتاجون إلى معالجة كميات كبيرة من مستندات PDF. (المصدر: dotey)
إطلاق VEED Animate 2.2، يدعم إعادة تشكيل نمط الفيديو وتبديل الشخصيات : تم إطلاق الإصدار 2.2 من VEED Animate رسميًا، وهو مدعوم بتقنية WAN 2.2. تسمح هذه الأداة للمستخدمين بإعادة تشكيل نمط الفيديو بسهولة من خلال صورة واحدة، وتبديل الشخصيات في الفيديو على الفور، وإنشاء مقاطع فيديو بسرعة 10 أضعاف. تبسط هذه الميزات الجديدة بشكل كبير عملية إنشاء الفيديو، وتوفر لمنشئي المحتوى المزيد من الإمكانيات الإبداعية المدعومة بالذكاء الاصطناعي. (المصدر: TomLikesRobots)
LangChain تلتزم بتوحيد استجابات LLM، وتدعم الوظائف المعقدة : تركز LangChain في تطويرها للإصدار v1 على توحيد استجابات LLM كنقطة محورية، لمواجهة وظائف LLM المتزايدة التعقيد، مثل استدعاء الأدوات من جانب الخادم، والاستدلال، والاقتباس. يهدف هذا الإطار إلى حل مشكلة عدم توافق تنسيقات API بين موفري LLM المختلفين، وتوفير واجهة موحدة للمطورين، وبالتالي تبسيط بناء الوكلاء متعددي الوسائط وسير العمل المعقدة. (المصدر: LangChainAI, Twitter)
Hugging Face Transformers.js يدعم تشغيل نماذج الذكاء الاصطناعي دون اتصال بالإنترنت في المتصفح : تسمح مكتبة Transformers.js من Hugging Face للمستخدمين بتشغيل نماذج الذكاء الاصطناعي مثل Llama 3.2 دون اتصال بالإنترنت في المتصفح، باستخدام تقنيات ONNX و WebGPU. يتيح ذلك للمطورين تنفيذ مهام الذكاء الاصطناعي مثل روبوتات الدردشة، واكتشاف الكائنات، وإزالة الخلفية محليًا، دون الاعتماد على الخدمات السحابية، مما يعزز خصوصية البيانات وسرعة المعالجة. (المصدر: Twitter)
نظام ToolUniverse البيئي يدعم علماء الذكاء الاصطناعي في البناء والتكامل مع الأدوات : ToolUniverse هو نظام بيئي مصمم لبناء علماء الذكاء الاصطناعي، يوحد طريقة علماء الذكاء الاصطناعي في تحديد واستدعاء الأدوات، ويدمج أكثر من 600 نموذج تعلم آلي، ومجموعات بيانات، و APIs، وحزم برمجية علمية، لتحليل البيانات، واسترجاع المعرفة، وتصميم التجارب. تعمل المنصة على تحسين واجهات الأدوات تلقائيًا، وإنشاء أدوات جديدة من خلال وصف اللغة الطبيعية، وتحسين مواصفات الأدوات بشكل متكرر، ودمج الأدوات في سير عمل الوكلاء، وبالتالي تعزيز التعاون بين علماء الذكاء الاصطناعي في عملية الاكتشاف. (المصدر: HuggingFace Daily Papers)
إطار عمل EasySteer يعزز أداء LLM القابل للتحكم وقابليته للتوسع : EasySteer هو إطار عمل موحد يعتمد على vLLM، يهدف إلى تعزيز أداء LLM القابل للتحكم وقابليته للتوسع. من خلال بنية معيارية، وواجهات قابلة للتوصيل، وتحكم دقيق في المعلمات، ومتجهات توجيه محسوبة مسبقًا، حقق الإطار زيادة في السرعة تتراوح من 5.5 إلى 11.4 مرة، وقلل بشكل فعال من الإفراط في التفكير والهلوسة. يحول EasySteer التحكم في LLM من تقنية بحث إلى قدرة إنتاجية، ويوفر بنية تحتية أساسية لنماذج اللغة القابلة للنشر والتحكم. (المصدر: HuggingFace Daily Papers)
VibeGame: محرك ألعاب مدعوم بالذكاء الاصطناعي يعتمد على WebStack : VibeGame هو محرك ألعاب تعريفي متقدم يعتمد على three.js و rapier و bitecs، ومصمم خصيصًا لتطوير الألعاب بمساعدة الذكاء الاصطناعي. من خلال مستوى تجريد عالٍ، ووظائف فيزيائية وعرض مدمجة، وبنية Entity-Component-System (ECS)، يتيح للذكاء الاصطناعي فهم وإنشاء كود اللعبة بكفاءة أكبر. على الرغم من أنه مناسب حاليًا لألعاب المنصات البسيطة، إلا أن مصدره المفتوح وبنيته الصديقة للذكاء الاصطناعي يوفران حلاً واعدًا لتطوير الألعاب المدفوعة بالذكاء الاصطناعي. (المصدر: HuggingFace Blog)
أداة خريطة أبحاث الذكاء الاصطناعي، تدمج 900 ألف ورقة بحثية وتقدم إجابات مع مراجع : أداة ذكاء اصطناعي مبتكرة قادرة على تجميع وتصوير 900 ألف ورقة بحثية في مجال الذكاء الاصطناعي من العقد الماضي، لتشكيل خريطة بحثية مفصلة. يمكن للمستخدمين طرح الأسئلة على هذه الأداة والحصول على إجابات مع مراجع دقيقة، مما يبسط بشكل كبير عملية البحث وفهم الكم الهائل من الأدبيات الأكاديمية للباحثين، ويزيد من كفاءة البحث. (المصدر: Reddit r/ArtificialInteligence)
Kroko ASR: بديل سريع ومتدفق لـ Whisper : Kroko ASR هو نموذج جديد مفتوح المصدر لتحويل الكلام إلى نص، ويُعتبر بديلاً سريعًا ومتدفقًا لـ Whisper. يتميز بحجم نموذج أصغر، وسرعة استدلال أسرع على وحدة المعالجة المركزية (يدعم الأجهزة المحمولة والمتصفحات)، ويكاد لا يعاني من الهلوسة. يدعم Kroko ASR لغات متعددة، ويهدف إلى خفض عوائق الذكاء الاصطناعي الصوتي، مما يجعله أسهل في النشر والتدريب على الأجهزة الطرفية. (المصدر: Reddit r/LocalLLaMA)
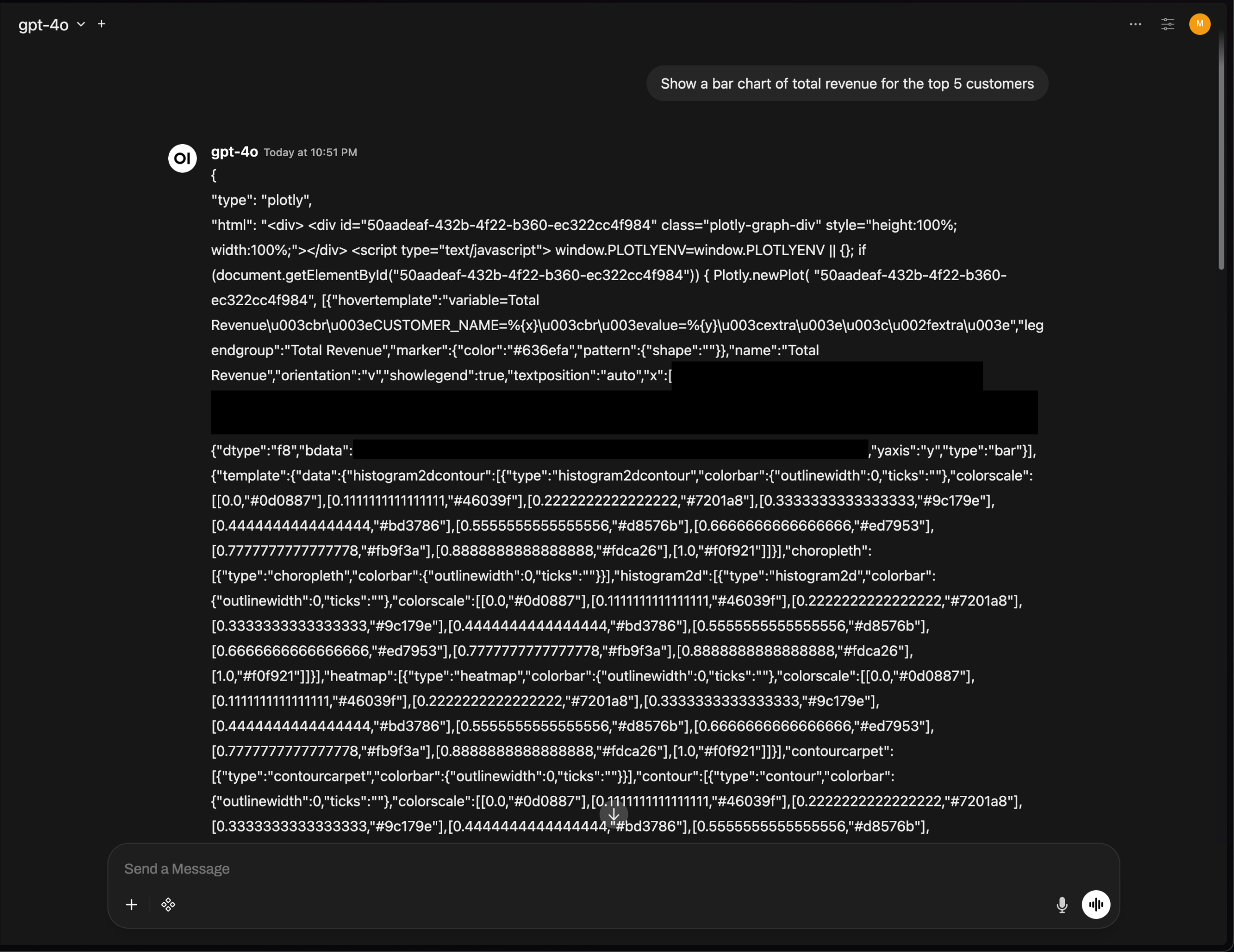
مشكلة عرض مخططات Plotly في OpenWebUI، تبرز تحديات تكامل واجهة المستخدم لأدوات الذكاء الاصطناعي : ظهرت مشكلة في الإصدار v0.6.32 من OpenWebUI حيث لا يتم عرض مخططات Plotly بشكل صحيح، بل يتم عرض JSON الأصلي مباشرة. أفاد المستخدمون أن الواجهة الخلفية تعيد JSON الصحيح، لكن الواجهة الأمامية لا تقوم بتشغيل العرض، مما يعكس أن أدوات الذكاء الاصطناعي لا تزال تواجه تحديات تقنية في تكامل واجهة المستخدم الأمامية وعرض النصوص الغنية، وتتطلب المزيد من التحسين من مجتمع المطورين. (المصدر: Reddit r/OpenWebUI)
📚 تعلم
دراسة مقارنة بين أداء LoRA finetuning و full finetuning : أظهرت أحدث الأبحاث من Thinking Machines (فريق John Schulman) أنه في التعلم المعزز، إذا تم تطبيق LoRA (Low-Rank Adaptation) بشكل صحيح، يمكن أن يتطابق أداؤها مع full finetuning، وتستهلك موارد أقل (حوالي ثلثي حجم الحوسبة)، وحتى عند rank=1 يمكن أن تؤدي بشكل ممتاز. تؤكد الدراسة على ضرورة تطبيق LoRA على جميع الطبقات (بما في ذلك MLP/MoE)، واستخدام معدل تعلم أعلى بـ 10 مرات من full finetuning. يقلل هذا الاكتشاف بشكل كبير من عوائق تدريب نماذج RL عالية الأداء، مما يتيح للمزيد من المطورين تحقيق نماذج عالية الجودة على وحدة معالجة رسوميات واحدة. (المصدر: Reddit r/LocalLLaMA, Twitter, Twitter)
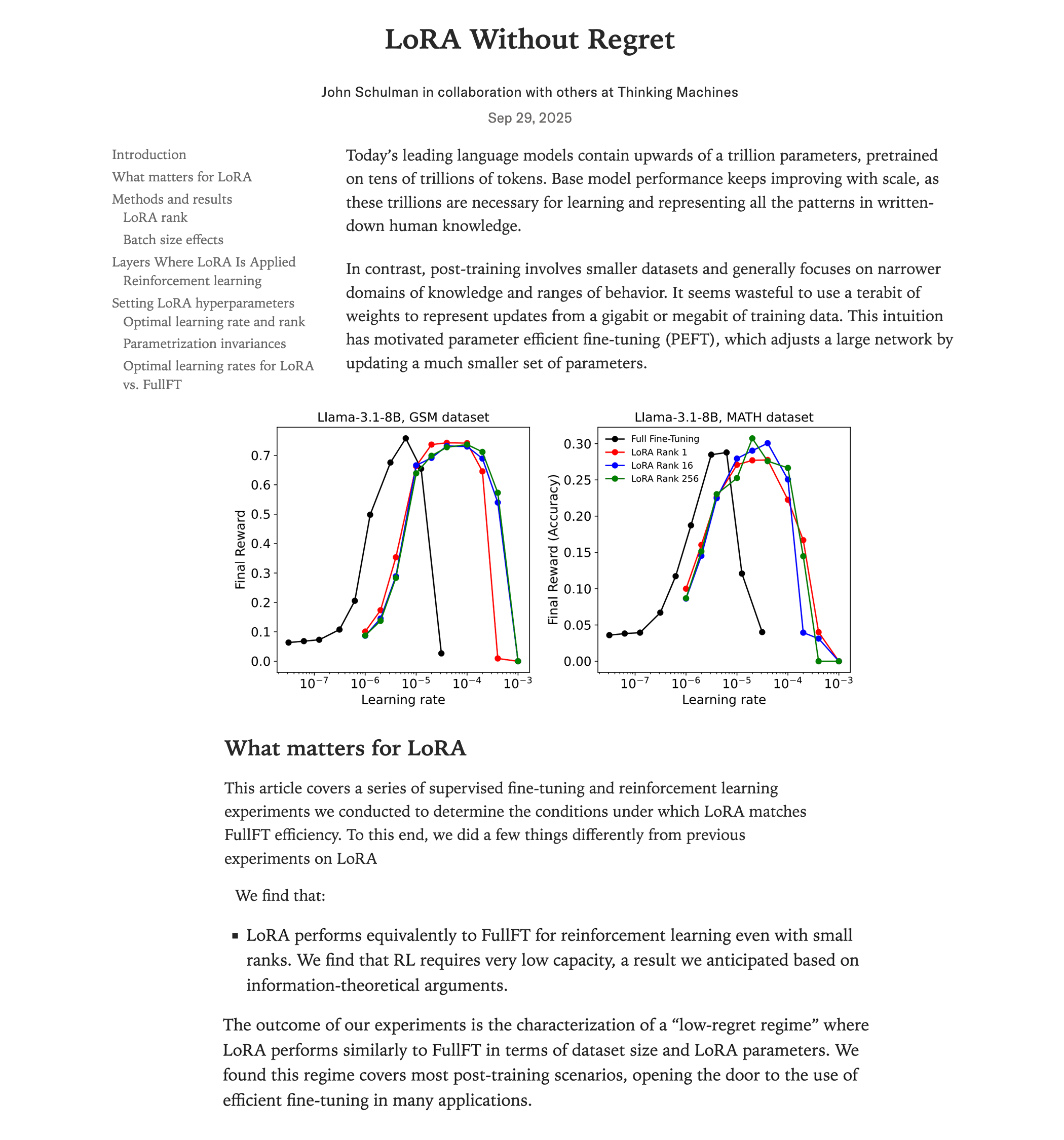
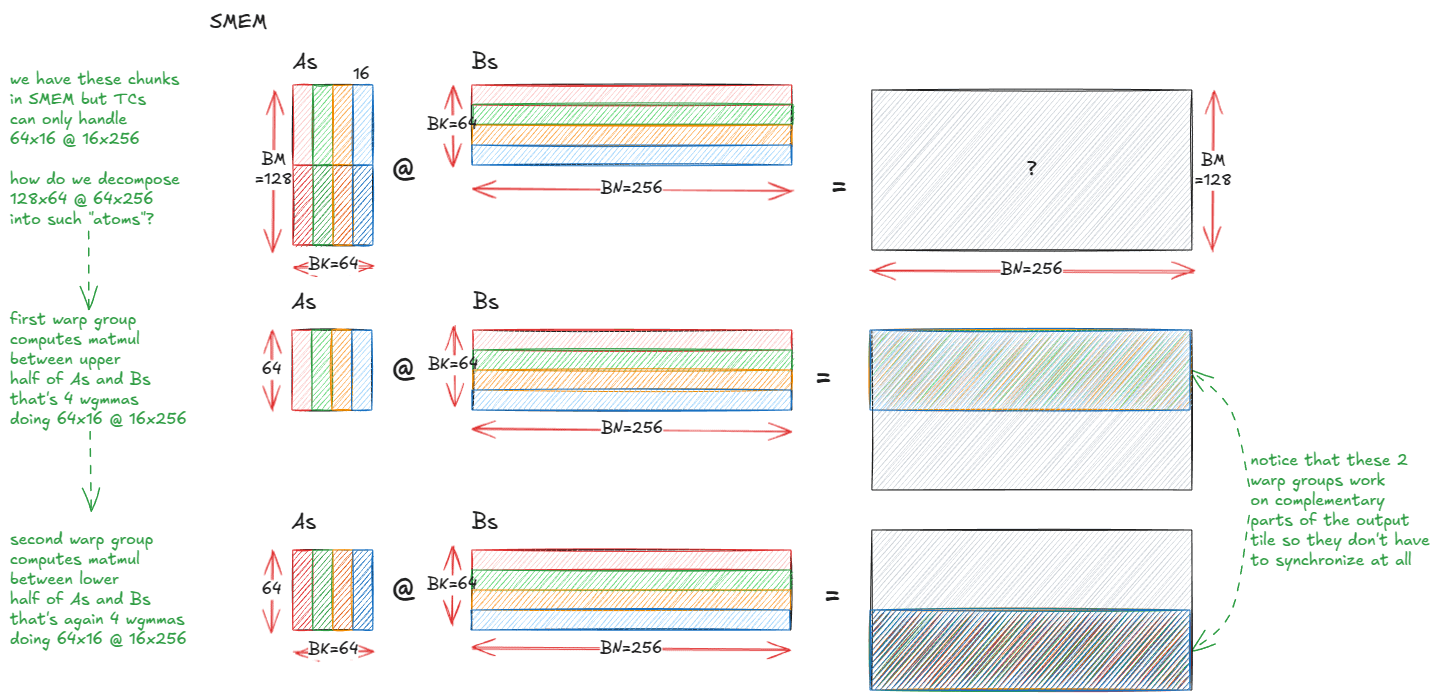
تشريح نواة ضرب المصفوفات عالية الأداء في NVIDIA GPU : تشرح مدونة تقنية متعمقة بالتفصيل آلية تنفيذ نواة ضرب المصفوفات عالية الأداء (matmul) داخل NVIDIA GPU. تغطي المقالة أساسيات بنية GPU، والتسلسل الهرمي للذاكرة (GMEM، SMEM، L1/L2)، وبرمجة PTX/SASS، والميزات المتقدمة لبنية Hopper (H100) مثل TMA، وتعليمات wgmma. يهدف هذا المورد إلى مساعدة المطورين على فهم برمجة CUDA وتحسين أداء GPU بعمق، وهو أمر بالغ الأهمية لتدريب واستدلال نماذج Transformer. (المصدر: Reddit r/deeplearning, Twitter)
محاضرات دورة Stanford CS231N للتعلم العميق والرؤية الحاسوبية متاحة الآن على YouTube : أصبحت محاضرات دورة Stanford CS231N (التعلم العميق للرؤية الحاسوبية) المشهورة متاحة الآن مجانًا على YouTube. يوفر هذا فرصة قيمة للمتعلمين في جميع أنحاء العالم للوصول إلى موارد تعليم الذكاء الاصطناعي عالية الجودة، والتي تغطي المعرفة بالتعلم العميق للرؤية الحاسوبية من المفاهيم الأساسية إلى التطبيقات المتطورة. (المصدر: Reddit r/deeplearning)

RL-ZVP: تعزيز قدرة الاستدلال في التعلم المعزز للنماذج اللغوية الكبيرة باستخدام Zero-Variance Prompt : تقترح دراسة حديثة طريقة “RL with Zero-Variance Prompts (RL-ZVP)”، بهدف تعزيز قدرة الاستدلال في التعلم المعزز للنماذج اللغوية الكبيرة (LLM). لا تتجاهل هذه الطريقة بعد الآن “Zero-Variance Prompt” (أي الحالات التي تحصل فيها جميع استجابات النموذج على نفس المكافأة)، بل تستخلص منها إشارات تعلم قيمة، وتكافئ الصواب مباشرة وتعاقب الخطأ، وتستخدم انتروبيا على مستوى الـ Token لتوجيه تشكيل الميزة. أظهرت النتائج التجريبية أن RL-ZVP يحقق زيادة كبيرة في الدقة ومعدل النجاح في اختبارات الاستدلال الرياضي، مقارنة بالطرق التقليدية. (المصدر: Reddit r/MachineLearning)
التعلم الموجه بالمستقبل: نهج تنبؤي لتعزيز تنبؤ السلاسل الزمنية : تقترح دراسة “Future-Guided Learning” (التعلم الموجه بالمستقبل)، لتعزيز تنبؤ أحداث السلاسل الزمنية من خلال آلية ردود فعل ديناميكية. تتضمن هذه الطريقة نموذج اكتشاف يحلل البيانات المستقبلية، ونموذج تنبؤ يتنبأ بناءً على البيانات الحالية. عندما يختلف نموذج التنبؤ عن نموذج الاكتشاف، يقوم نموذج التنبؤ بتحديثات أكثر أهمية لتقليل “المفاجأة”، وبالتالي يضبط المعلمات ديناميكيًا، مما يعزز بشكل فعال دقة تنبؤ السلاسل الزمنية. (المصدر: Reddit r/MachineLearning)
مستقبل الذكاء الاصطناعي في الأبعاد المنخفضة: Yann Lecun حول تعلم التمثيل التجريدي : طرح رائد الذكاء الاصطناعي Yann Lecun في مقابلة مع Lex Fridman أن القفزة التالية في الذكاء الاصطناعي ستأتي من التعلم في مساحات كامنة منخفضة الأبعاد، بدلاً من المعالجة المباشرة للبيانات الخام عالية الأبعاد مثل البكسلات. يعتقد أن أنظمة الذكاء الحقيقية تحتاج إلى تعلم التمثيل التجريدي للهيكل السببي وديناميكيات العالم الفيزيائية، مما يمكنها من إجراء تنبؤات دقيقة حتى مع تغير التفاصيل. ستجعل هذه الطريقة النماذج أكثر مرونة وقوة، وتقلل من الاعتماد على كميات هائلة من البيانات، وتخفض تكاليف الحوسبة. (المصدر: Reddit r/ArtificialInteligence)
SIRI: توسيع التعلم المعزز التكراري بضغط متداخل : SIRI (Scaling Iterative Reinforcement Learning with Interleaved Compression) هي طريقة تعلم معزز بسيطة وفعالة، تقوم بتعديل طول الـ rollout الأقصى ديناميكيًا أثناء التدريب من خلال ضغط وتوسيع ميزانية الاستدلال بشكل متكرر. تجبر آلية التدريب هذه النموذج على اتخاذ قرارات دقيقة في سياق محدود، وتقليل الـ Token الزائدة، مع توفير مساحة للاستكشاف والتخطيط، وبالتالي تحسين كفاءة ودقة نماذج الاستدلال الكبيرة بشكل مطرد في مفاضلة الأداء والكفاءة. (المصدر: HuggingFace Daily Papers)
نموذج توليد متعدد الوكلاء MultiCrafter: انتباه مفصول مكانيًا وتعلم معزز حساس للهوية : MultiCrafter هو إطار عمل يهدف إلى تحقيق توليد صور متعددة الوكلاء عالية الدقة ومتوافقة مع التفضيلات. يقدم الإطار إشرافًا صريحًا على الموقع لفصل مناطق الانتباه بين الوكلاء المختلفين، مما يخفف بشكل فعال من مشكلة تسرب السمات. في الوقت نفسه، يستخدم الإطار بنية Mixture-of-Experts (MoE) لتعزيز سعة النموذج، ويصمم إطار عمل تعلم معزز جديد عبر الإنترنت، يجمع بين آلية التسجيل واستراتيجية تدريب مستقرة، لضمان دقة الوكيل في الصور المولدة وتوافقها العالي مع التفضيلات الجمالية البشرية. (المصدر: HuggingFace Daily Papers)
Visual Jigsaw: تعزيز الفهم البصري لـ MLLMs من خلال التدريب اللاحق ذاتي الإشراف : Visual Jigsaw هو إطار عمل عام للتدريب اللاحق ذاتي الإشراف، يهدف إلى تعزيز قدرات الفهم البصري لنماذج اللغة الكبيرة متعددة الوسائط (MLLMs). تقسم هذه الطريقة المدخلات البصرية، وتخلطها، وتطلب من النموذج إعادة بناء الترتيب الصحيح باستخدام اللغة الطبيعية. تعمل طريقة التعلم المعزز القائمة على المكافآت القابلة للتحقق (RLVR) هذه على تحسين أداء MLLMs بشكل كبير في الإدراك الدقيق، والاستدلال الزماني، والفهم المكاني ثلاثي الأبعاد، دون الحاجة إلى مكونات توليد بصري إضافية أو تسميات يدوية. (المصدر: HuggingFace Daily Papers)
MGM-Omni: توسيع Omni LLMs لتوليد الكلام الطويل المخصص : MGM-Omni هو نموذج Omni LLM موحد، يحقق فهمًا متعدد الوسائط وتوليد كلام طويل معبر من خلال بنيته الفريدة “الدماغ-الفم” ثنائية المسار للـ Tokenization. يفصل هذا التصميم الاستدلال متعدد الوسائط عن توليد الكلام في الوقت الفعلي، ويدعم التفاعل الفعال عبر الوسائط واستنساخ الكلام المتدفق بزمن انتقال منخفض، ويظهر كفاءة ممتازة في البيانات. أثبتت التجارب أن MGM-Omni يتفوق على النماذج مفتوحة المصدر الحالية في الحفاظ على اتساق النبرة، وتوليد كلام طبيعي حساس للسياق، وفهم الصوت الطويل ومتعدد الوسائط. (المصدر: HuggingFace Daily Papers)
SID: تعلم التنقل اللغوي الموجه بالهدف من خلال عروض التحسين الذاتي : SID (Self-Improving Demonstrations) هي طريقة لتعلم التنقل اللغوي الموجه بالهدف، تعزز بشكل كبير قدرة وكلاء التنقل على الاستكشاف والتعميم في البيئات غير المعروفة من خلال عروض التحسين الذاتي المتكررة. تقوم هذه الطريقة أولاً بتدريب وكيل مبدئي باستخدام بيانات أقصر مسار، ثم يستخدم هذا الوكيل لإنشاء مسارات استكشاف جديدة، توفر استراتيجيات استكشاف أقوى لتدريب وكلاء أفضل، وبالتالي تحقيق تحسين مستمر في الأداء. أظهرت التجارب أن SID حقق أداء SOTA في مهام مثل REVERIE و SOON، خاصة في مجموعة التحقق غير المرئية لـ SOON حيث بلغ معدل النجاح 50.9%، متجاوزًا الطرق السابقة بنسبة 13.9%. (المصدر: HuggingFace Daily Papers)
LOVE-R1: تعزيز فهم الفيديو الطويل من خلال آلية التوسع التكيفي : يهدف نموذج LOVE-R1 إلى حل التناقض بين الفهم الزمني الطويل والإدراك المكاني الدقيق في فهم الفيديو الطويل. يقدم هذا النموذج آلية التوسع التكيفي، حيث يقوم أولاً بأخذ عينات مكثفة للإطارات بدقة منخفضة، وعند الحاجة إلى تفاصيل مكانية، يمكن للنموذج توسيع مقاطع الفيديو المهتمة بدقة عالية بناءً على الاستدلال، حتى الحصول على المعلومات البصرية الرئيسية. تتم العملية بأكملها من خلال استدلال متعدد الخطوات، وتجمع بين الضبط الدقيق لبيانات CoT والضبط الدقيق المعزز المفصول، مما يحقق تحسينًا كبيرًا في اختبارات فهم الفيديو الطويل. (المصدر: HuggingFace Daily Papers)
Euclid’s Gift: تعزيز الاستدلال المكاني لنماذج اللغة البصرية من خلال مهام الوكيل الهندسي : Euclid’s Gift هو بحث يهدف إلى تعزيز الإدراك المكاني وقدرات الاستدلال لنماذج اللغة البصرية (VLM) من خلال مهام الوكيل الهندسي. أنشأ هذا المشروع مجموعة بيانات متعددة الوسائط Euclid30K تحتوي على 30 ألف مشكلة هندسية مستوية ومجسمة، وقام بضبط نماذج Qwen2.5VL وسلسلة RoboBrain2.0 باستخدام Group Relative Policy Optimization (GRPO). أثبتت التجارب أن النماذج المدربة حققت تحسينات كبيرة من الصفر في أربعة معايير استدلال مكاني، بما في ذلك Super-CLEVR و Omni3DBench، حيث حقق RoboBrain2.0-Euclid-7B دقة 49.6%، متجاوزًا نماذج SOTA السابقة. (المصدر: HuggingFace Daily Papers)
SphereAR: تحسين توليد الـ Token المتسلسل التراجعي من خلال الفضاء الكامن فوق الكروي : يهدف SphereAR إلى حل المشكلات الناجمة عن التباين غير المتجانس في الفضاء الكامن لـ VAE في نماذج توليد الصور التراجعية المتسلسلة (AR). التصميم الأساسي هو تقييد جميع مدخلات ومخرجات AR (بما في ذلك بعد CFG) على كرة فائقة ثابتة نصف القطر، باستخدام VAE فوق كروي. يظهر التحليل النظري أن القيد فوق الكروي يزيل السبب الرئيسي لانهيار التباين، وبالتالي يثبت فك تشفير AR. أثبتت التجارب أن SphereAR حقق أداء SOTA في مهام توليد ImageNet، متجاوزًا نماذج الانتشار ونماذج التوليد المقنعة ذات الحجم المعلمي المماثل. (المصدر: HuggingFace Daily Papers)
AceSearcher: توجيه استدلال LLM والبحث من خلال اللعب الذاتي المعزز : AceSearcher هو إطار عمل للعب الذاتي التعاوني، يهدف إلى تعزيز قدرات LLM المدعومة بالبحث في مهام الاستدلال المعقدة. يدرب هذا الإطار LLM واحدًا على التناوب بين تحليل الاستعلامات المعقدة ودمج سياق الاسترجاع، ويحسن دقة الإجابة النهائية من خلال الضبط الدقيق الخاضع للإشراف والضبط الدقيق المعزز، دون الحاجة إلى تسميات وسيطة. أظهرت التجارب أن AceSearcher يتفوق بشكل كبير على خطوط الأساس SOTA في العديد من مهام الاستدلال المكثفة، وفي مهام الاستدلال المالي على مستوى المستندات، طابق AceSearcher-32B أداء DeepSeek-V3 بأقل من 5% من عدد المعلمات. (المصدر: HuggingFace Daily Papers)
SparseD: آلية الانتباه المتفرقة لنماذج لغة الانتشار : SparseD هي طريقة انتباه متفرقة لنماذج لغة الانتشار (DLMs)، تهدف إلى حل اختناق تعقيد الانتباه التربيعي في أطوال السياق الطويلة. تحقق هذه الطريقة تسريعًا بدون فقدان من خلال حساب أنماط التفرقة الخاصة بالرأس مسبقًا وإعادة استخدامها في جميع خطوات إزالة الضوضاء، مع استخدام الانتباه الكامل في خطوات إزالة الضوضاء المبكرة، ثم التبديل إلى الانتباه المتفرق. أظهرت النتائج التجريبية أن SparseD يمكن أن يحقق سرعة تصل إلى 1.5 مرة مقارنة بـ FlashAttention عند طول سياق 64k، مما يحسن بشكل فعال كفاءة الاستدلال لـ DLMs في تطبيقات السياق الطويل. (المصدر: HuggingFace Daily Papers)
SLA: تسريع Diffusion Transformer من خلال الانتباه الخطي المتفرق القابل للضبط : SLA (Sparse-Linear Attention) هي طريقة انتباه قابلة للتدريب، تهدف إلى تسريع نماذج Diffusion Transformer (DiT)، خاصة حساب الانتباه في توليد الفيديو. تقسم هذه الطريقة أوزان الانتباه إلى ثلاث فئات: رئيسية، وحافة، ومهملة، وتطبق انتباه O(N²) و O(N) على التوالي، وتتخطى الأجزاء المهملة. من خلال دمج هذه الحسابات في نواة GPU واحدة، وبعد عدد قليل من خطوات الضبط الدقيق، تقلل SLA حساب الانتباه في نماذج DiT بمقدار 20 مرة، وتسرع توليد الفيديو من البداية إلى النهاية بمقدار 2.2 مرة، دون فقدان جودة التوليد. (المصدر: HuggingFace Daily Papers)
OpenGPT-4o-Image: مجموعة بيانات شاملة لتوليد وتحرير الصور المتقدمة : OpenGPT-4o-Image هي مجموعة بيانات واسعة النطاق، تم بناؤها من خلال الجمع بين تصنيف المهام الهرمي وطرق توليد البيانات الآلية لـ GPT-4o، بهدف تحسين أداء النماذج متعددة الوسائط الموحدة في توليد الصور وتحريرها. تحتوي مجموعة البيانات هذه على 80 ألف زوج من التعليمات والصور عالية الجودة، وتغطي 11 مجالًا رئيسيًا و 51 مهمة فرعية، بما في ذلك عرض النصوص، والتحكم في النمط، والصور العلمية، وتحرير التعليمات المعقدة. حققت النماذج التي تم ضبطها بدقة على OpenGPT-4o-Image تحسينات كبيرة في الأداء في العديد من المعايير، مما يثبت الدور الحاسم لبناء البيانات المنهجي في تطوير قدرات الذكاء الاصطناعي متعدد الوسائط. (المصدر: HuggingFace Daily Papers)
SANA-Video: نموذج انتشار صغير لتوليد فيديو بدقة 720p وطول دقيقة بكفاءة : SANA-Video هو نموذج انتشار صغير قادر على توليد فيديو بدقة تصل إلى 720×1280 وطول دقيقة بكفاءة. يحقق توليد فيديو عالي الدقة والجودة وطويل من خلال بنية DiT الخطية وذاكرة التخزين المؤقت KV الثابتة، مع الحفاظ على توافق قوي بين النص والفيديو. تبلغ تكلفة تدريب SANA-Video 1% فقط من MovieGen، وعند نشره على وحدة معالجة الرسوميات RTX 5090، يمكن أن تصل سرعة الاستدلال لتوليد فيديو بدقة 720p لمدة 5 ثوانٍ إلى 29 ثانية، مما يحقق توليد فيديو عالي الجودة بتكلفة منخفضة. (المصدر: HuggingFace Daily Papers)
AdvChain: تعزيز محاذاة أمان نماذج الاستدلال الكبيرة من خلال ضبط CoT العدائي : AdvChain هو نموذج محاذاة جديد، يعلم نماذج الاستدلال الكبيرة (LRMs) قدرة التصحيح الذاتي الديناميكي من خلال ضبط Chain-of-Thought (CoT) العدائي. يبني هذا الأسلوب مجموعة بيانات تحتوي على عينات “إغراء-تصحيح” و “تردد-تصحيح”، مما يمكن النموذج من التعافي من الانحرافات الاستدلالية الضارة والحذر غير الضروري. أظهرت التجارب أن AdvChain يعزز بشكل كبير مقاومة النموذج لهجمات الهروب من السجن واختطاف CoT، بينما يقلل بشكل كبير من الرفض المفرط للـ Prompt الحميدة، مما يحقق توازنًا ممتازًا بين الأمان والمنفعة. (المصدر: HuggingFace Daily Papers)
SDLM: توسيع التعلم المعزز التكراري من خلال الضغط المتداخل : يقترح Sequential Diffusion Language Model (SDLM) طريقة موحدة للتنبؤ بالـ next-token والـ next-block، مما يمكن النموذج من تحديد طول التوليد في كل خطوة بشكل تكيفي. يمكن لـ SDLM تحويل نماذج اللغة التراجعية المدربة مسبقًا بأقل تكلفة، وإجراء استدلال الانتشار داخل كتل مقنعة ذات حجم ثابت، بينما يقوم بفك تشفير تسلسلات فرعية متتالية ديناميكيًا. أظهرت التجارب أن SDLM يحقق إنتاجية أعلى مع مطابقة أو تجاوز خطوط الأساس التراجعية القوية، مما يدل على إمكاناته القوية للتوسع. (المصدر: HuggingFace Daily Papers)
Insight-to-Solve (I2S): تحويل عروض الاستدلال في السياق إلى أصول لنماذج الاستدلال اللغوية : Insight-to-Solve (I2S) هو برنامج وقت الاختبار يهدف إلى تحويل عروض الاستدلال في السياق عالية الجودة إلى أصول فعالة لنماذج الاستدلال اللغوية الكبيرة (RLMs). وجدت الأبحاث أن إضافة أمثلة العروض التوضيحية مباشرة قد يقلل من دقة RLMs. يقوم I2S بتحويل العروض التوضيحية إلى رؤى واضحة قابلة لإعادة الاستخدام، ويولد مسارات استدلال خاصة بالهدف، مع إمكانية التحسين الذاتي لزيادة الاتساق والصحة. أظهرت التجارب أن I2S و I2S+ يتفوقان باستمرار على الإجابات المباشرة وخطوط الأساس للتوسع في وقت الاختبار في مختلف المعايير، وحتى بالنسبة لنماذج GPT يمكن أن يؤدي إلى تحسينات كبيرة. (المصدر: HuggingFace Daily Papers)
UniMIC: ترميز تفاعلي متعدد الوسائط قائم على الـ Token لتحقيق التعاون بين الإنسان والآلة : UniMIC (Unified token-based Multimodal Interactive Coding) هو إطار عمل يهدف إلى تحقيق تفاعل فعال ومنخفض معدل البتات متعدد الوسائط بين الأجهزة الطرفية ووكلاء الذكاء الاصطناعي السحابيين من خلال تمثيل قائم على الـ Token. يستخدم UniMIC تمثيلًا مضغوطًا قائمًا على الـ Token كوسيط اتصال، ويجمع بين نموذج انتروبيا Transformer، لتقليل التكرار بين الـ Token بشكل فعال. أثبتت التجارب أن UniMIC يحقق توفيرًا كبيرًا في معدل البتات في مهام مثل توليد النص إلى الصورة، وإصلاح الصور، والإجابة على الأسئلة البصرية، ويحافظ على القوة عند معدلات بتات منخفضة جدًا، مما يوفر نموذجًا عمليًا للجيل القادم من الاتصالات التفاعلية متعددة الوسائط. (المصدر: HuggingFace Daily Papers)
RLBFF: ردود فعل ثنائية مرنة تربط بين ردود الفعل البشرية والمكافآت القابلة للتحقق : RLBFF (Reinforcement Learning with Binary Flexible Feedback) هو نموذج تعلم معزز يجمع بين تنوع التفضيلات البشرية ودقة التحقق من القواعد. يستخلص مبادئ يمكن الإجابة عليها بنعم/لا من ردود الفعل باللغة الطبيعية (مثل دقة المعلومات: نعم/لا، قابلية قراءة الكود: نعم/لا)، ويستخدمها لتدريب نموذج المكافأة. أظهر RLBFF أداءً ممتازًا على RM-Bench و JudgeBench، ويسمح للمستخدمين بتخصيص تركيز المبادئ أثناء الاستدلال. بالإضافة إلى ذلك، يوفر حلاً مفتوح المصدر بالكامل لمحاذاة Qwen3-32B باستخدام RLBFF، مما يجعله يطابق أو يتجاوز أداء o3-mini و DeepSeek R1 في معايير المحاذاة العامة. (المصدر: HuggingFace Daily Papers)
MetaAPO: تحسين المحاذاة من خلال أخذ العينات الموزونة ميتا عبر الإنترنت : MetaAPO (Meta-Weighted Adaptive Preference Optimization) هو إطار عمل جديد، يحسن محاذاة النماذج اللغوية الكبيرة (LLMs) مع التفضيلات البشرية من خلال ربط توليد البيانات وتدريب النموذج ديناميكيًا. يستخدم MetaAPO متعلمًا ميتا خفيف الوزن كـ “مقدر فجوة المحاذاة”، لتقييم الفوائد المحتملة لأخذ العينات عبر الإنترنت مقارنة بالبيانات غير المتصلة، وتوجيه التوليد المستهدف عبر الإنترنت وتخصيص أوزان ميتا على مستوى العينة، لتحقيق توازن ديناميكي بين جودة وتوزيع البيانات عبر الإنترنت وغير المتصلة. أظهرت التجارب أن MetaAPO يتفوق باستمرار على طرق تحسين التفضيلات الحالية في AlpacaEval 2 و Arena-Hard و MT-Bench، بينما يقلل تكلفة التسمية عبر الإنترنت بنسبة 42%. (المصدر: HuggingFace Daily Papers)
Tool-Light: استدلال فعال لتكامل الأدوات من خلال تعلم التفضيلات ذاتية التطور : Tool-Light هو إطار عمل يهدف إلى تشجيع النماذج اللغوية الكبيرة (LLMs) على تنفيذ مهام الاستدلال المتكاملة مع الأدوات (TIR) بكفاءة ودقة. وجدت الأبحاث أن نتائج استدعاء الأدوات يمكن أن تؤدي إلى تغييرات كبيرة في انتروبيا المعلومات للاستدلال اللاحق. يحقق Tool-Light ذلك من خلال الجمع بين بناء مجموعة البيانات والضبط الدقيق متعدد المراحل، حيث يستخدم بناء مجموعة البيانات أخذ العينات ذاتية التطور المستمرة، ويدمج أخذ العينات العادي وأخذ العينات الموجه بالانتروبيا، ويضع معايير صارمة لاختيار الأزواج الإيجابية والسلبية. تتضمن عملية التدريب SFT وتحسين التفضيلات المباشر ذاتي التطور (DPO). أثبتت التجارب أن Tool-Light يحسن بشكل كبير كفاءة النموذج في تنفيذ مهام TIR. (المصدر: HuggingFace Daily Papers)
ChatInject: هجمات حقن Prompt على وكلاء LLM باستخدام قوالب الدردشة : ChatInject هي طريقة لهجمات حقن Prompt غير المباشرة تستغل اعتماد LLM على قوالب الدردشة المنظمة والتلاعب بالسياق في المحادثات متعددة الأدوار. يقوم المهاجمون بتنسيق الحمولة الضارة من خلال محاكاة تنسيق قالب الدردشة الأصلي، مما يدفع الوكيل إلى تنفيذ عمليات مشبوهة. أظهرت التجارب أن ChatInject يحقق معدل نجاح أعلى للهجوم مقارنة بطرق حقن Prompt التقليدية، خاصة في المحادثات متعددة الأدوار، ولديه قابلية نقل قوية بين النماذج المختلفة، بينما معظم إجراءات الدفاع القائمة على Prompt الحالية غير فعالة ضد هذه الأنواع من الهجمات. (المصدر: HuggingFace Daily Papers)
💼 أعمال
Modal تكمل جولة تمويل B بقيمة 87 مليون دولار، وتقدر قيمتها بـ 1.1 مليار دولار : أعلنت شركة Modal للبنية التحتية للذكاء الاصطناعي عن إكمال جولة تمويل B بقيمة 87 مليون دولار، مما رفع قيمتها إلى 1.1 مليار دولار. تهدف هذه الجولة من التمويل إلى تسريع الابتكار وتطوير البنية التحتية للذكاء الاصطناعي، لمواجهة التحديات التي تواجه البنية التحتية الحاسوبية التقليدية في عصر الذكاء الاصطناعي. من خلال توفير خدمات حوسبة سحابية عالية الكفاءة، تساعد Modal الباحثين والمطورين على تحسين عمليات تدريب ونشر نماذج الذكاء الاصطناعي الخاصة بهم. (المصدر: Twitter, Twitter, Twitter)
إيرادات OpenAI في النصف الأول 4.3 مليار دولار، وخسائر 13.5 مليار دولار، وتواجه تحديات الربحية : أعلنت OpenAI عن إيرادات بلغت 4.3 مليار دولار في النصف الأول من عام 2025، ومن المتوقع أن تتجاوز الإيرادات السنوية 13 مليار دولار، ويرجع الفضل في ذلك أساسًا إلى اشتراكات ChatGPT Plus وخدمات API على مستوى المؤسسات. ومع ذلك، بلغت الخسارة الصافية في نفس الفترة 13.5 مليار دولار، وكانت التكاليف الهيكلية ونفقات البحث والتطوير (مثل GPT-5) هي العوامل الرئيسية، حيث بلغت رسوم استئجار الخوادم السنوية 16 مليار دولار. على الرغم من أن OpenAI تمتلك احتياطيًا نقديًا قدره 17.5 مليار دولار وتدفع خطة تمويل بقيمة 30 مليار دولار، إلا أن الاستهلاك المستمر للنقد والفجوة في الكفاءة مع المنافسين مثل Anthropic، يجعلها تواجه تحديات ربحية خطيرة. (المصدر: 36氪)
صراع رأس المال الخفي في قطاع الروبوتات البشرية: Zhiyuan و Galaxy Universal وغيرهما يخططون بنشاط لسلسلة الصناعة : دخل قطاع الروبوتات البشرية مرحلة صراع رأس المال الخفي، حيث تقوم الشركات الرائدة مثل Zhiyuan Robot و Galaxy Universal بتوسيع “دائرة أصدقائها” بنشاط من خلال إنشاء صناديق، والاستثمار في الشركات المنافسة، والتعاون الاستراتيجي. استثمرت Zhiyuan Robot ما يقرب من 20 استثمارًا خارجيًا، تغطي المحركات، وأجهزة الاستشعار، والتطبيقات النهائية، وتعاونت مع Fulin Precision و Softcom Power وغيرهما لتطبيق سيناريوهات تجارية. بينما أنشأت Galaxy Universal شركة مشتركة مع Bosch China، لتعزيز تطبيق embodied intelligence في صناعة السيارات. تهدف هذه الإجراءات إلى الحصول على الطلبات، وسد الثغرات، وإنشاء شبكة توريد مستقرة للشحنات الكبيرة في المستقبل، ولكن مسارات التكنولوجيا في الصناعة تختلف اختلافًا كبيرًا، والمنافسة شرسة. (المصدر: 36氪)

🌟 المجتمع
صعوبة تمييز المحتوى الذي يولده الذكاء الاصطناعي، تثير أزمة ثقة اجتماعية : مع التطور السريع لتقنيات الذكاء الاصطناعي، وصلت واقعية مقاطع الفيديو التي يولدها الذكاء الاصطناعي (مثل فيلم “Attack on Titan” الواقعي، ومذيعة إندونيسية “تغير وجهها” لمؤثرة يابانية) إلى مستوى لا يصدق، مما أثار مخاوف اجتماعية عميقة بشأن أصالة المحتوى. على وسائل التواصل الاجتماعي، أعرب المستخدمون بشكل عام عن صعوبة متزايدة في التمييز بين المحتوى الحقيقي والمحتوى الذي يولده الذكاء الاصطناعي، وهذا لا يضر فقط بمصداقية منشئي المحتوى الشرعيين، بل يمكن استخدامه أيضًا لنشر معلومات مضللة. يشير الخبراء إلى أنه ما لم يتم فرض وضع علامات إلزامية على محتوى الذكاء الاصطناعي، فإن هذا “المحرك فائق الواقعية” سيستمر في تآكل الإحساس بالواقع، وقد “ينهي الإنترنت” في النهاية. (المصدر: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ArtificialInteligence, Twitter, Twitter)

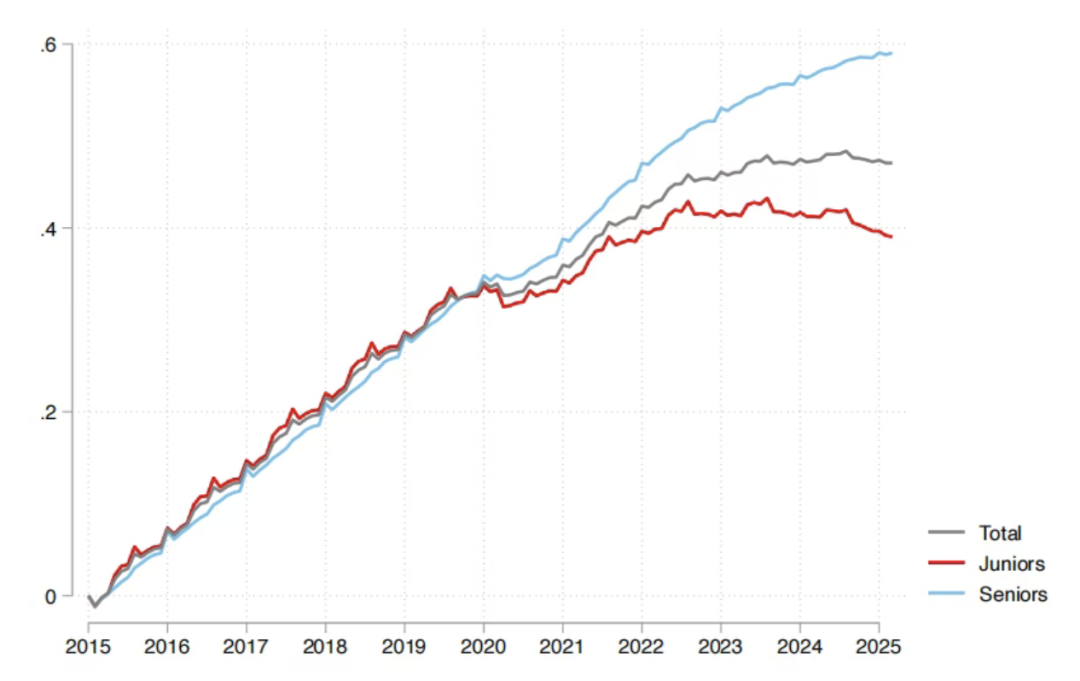
تأثير الذكاء الاصطناعي على سوق العمل: تقرير Sequoia يشير إلى أن 95% من استثمارات الذكاء الاصطناعي غير فعالة، والخريجون هم الأكثر تضررًا : شاركت Sequoia Capital تقريرًا بحثيًا من MIT و Harvard University يشير إلى أن 95% من استثمارات الشركات في الذكاء الاصطناعي لم تحقق قيمة فعلية، وأن الزيادة الحقيقية في الإنتاجية تنبع من “اقتصاد الذكاء الاصطناعي الخفي” الذي يتكون من الموظفين الذين يستخدمون أدوات الذكاء الاصطناعي الشخصية “سرًا”. كشف التقرير أيضًا أن تأثير الذكاء الاصطناعي على سوق العمل يتركز بشكل أساسي على الشباب حديثي التخرج، خاصة في قطاع البيع بالجملة والتجزئة، حيث انخفض عدد الوظائف للمبتدئين بشكل كبير، ولم تعد الشهادات الجامعية المرموقة حصنًا منيعًا بالكامل. يشير هذا إلى أن الذكاء الاصطناعي يغير توزيع المهام، وتتحول قيمة الإنسان نحو الخبرة والحكم الفريد. (المصدر: 36氪, Reddit r/ArtificialInteligence)
تعديلات نموذج OpenAI تثير استياء المستخدمين، ودعوات للتواصل الشفاف : أدت التعديلات الأخيرة التي أجرتها OpenAI على نماذج GPT-4o/GPT-5، دون إشعار مسبق، إلى “تخفيض” هذه النماذج إلى إصدارات ذات قدرة حاسوبية أقل، مما أدى إلى تدهور أداء النموذج، وأثار استياءً شديدًا بين المستخدمين. اشتكى العديد من المستخدمين من أن النموذج “أصبح غبيًا”، وفقد بصيرته الأصلية وتجربة التواصل “الودية”، حتى أن البعض وصف ذلك بأنه “ضربة نفسية”. رد مسؤولون تنفيذيون في OpenAI بأن هذا كان “اختبار توجيه أمني”، يهدف إلى التعامل مع الموضوعات الحساسة، لكن المستخدمين طالبوا OpenAI بشكل عام بتعزيز التواصل والشفافية مع المستخدمين، وتجنب تغيير اتفاقيات المنتج من جانب واحد، لإعادة بناء ثقة المستخدمين. (المصدر: Reddit r/artificial, Reddit r/ChatGPT, Reddit r/ChatGPT, Twitter)
فرض الضرائب على الروبوتات: نقاش حول التقدم التكنولوجي والعدالة الاجتماعية : مع تطور تقنيات الذكاء الاصطناعي والروبوتات، تتزايد النقاشات حول فرض “ضرائب” على الروبوتات، بهدف تحقيق التوازن بين مشكلات البطالة المحتملة وعدم المساواة الاجتماعية التي قد تنجم عن استبدال الروبوتات للعمالة البشرية. يرى المؤيدون أن ضريبة الروبوتات يمكن أن توفر الرعاية الاجتماعية ودعم إعادة التوظيف للعاطلين عن العمل، وتصحيح اختلال توازن المساومة بين رأس المال والعمل. ومع ذلك، يرى العاملون في صناعة الروبوتات بشكل عام أن فرض الضرائب مبكر جدًا، وقد يعيق تطور الصناعات الناشئة. وقد قامت كوريا الجنوبية بالفعل بزيادة تكلفة استخدام الروبوتات بشكل غير مباشر من خلال تقليل الإعفاءات الضريبية للشركات الآلية. (المصدر: 36氪)
مستقبل الروبوتات البشرية: خبير الروبوتات الشهير Rodney Brooks يرى أن المستقبل لن يكون شبيهًا بالبشر : كتب خبير الروبوتات الشهير Rodney Brooks مقالًا يشير فيه إلى أنه على الرغم من الاستثمارات الضخمة، لا تزال الروبوتات البشرية الحالية غير قادرة على تحقيق مستوى براعة البشر، وأن المشي على قدمين ينطوي على مخاطر أمنية. يتوقع أن الروبوتات البشرية في الـ 15 عامًا القادمة لن تحاكي الشكل البشري، بل ستتطور إلى روبوتات متخصصة ذات عجلات، وأذرع متعددة (مجهزة بمقابض أو أكواب شفط)، وأجهزة استشعار متعددة (تصوير ضوئي نشط، استشعار الضوء غير المرئي)، للتكيف مع مهام محددة. يعتقد أن السعي الحالي وراء الشكل “الشبيه بالبشر” ينطوي على استثمارات ضخمة ولكنه سيذهب سدى في النهاية. (المصدر: 36氪)

جودة الكود الذي يولده الذكاء الاصطناعي وتجربة المطور: جدل : على وسائل التواصل الاجتماعي، أجرى المطورون نقاشًا حارًا حول جودة وفائدة الكود الذي يولده الذكاء الاصطناعي. أشاد البعض بـ Claude Sonnet 4.5 لقدرته على إعادة هيكلة قاعدة بيانات كاملة، لكن الكود الذي يولده لم يعمل؛ بينما اشتكى آخرون من أن الكود الذي يولده الذكاء الاصطناعي “لا يتم تجميعه”، مما أدى إلى انخفاض كفاءة التطوير. تعكس هذه المناقشات أن البرمجة بمساعدة الذكاء الاصطناعي لا تزال تواجه تحديات بين الكفاءة والدقة، بالإضافة إلى حاجة المطورين إلى تصحيح الأخطاء والتحقق عند التعامل مع النتائج التي يولدها الذكاء الاصطناعي. (المصدر: Twitter, Twitter, Twitter)

تحول في مفهوم المواهب في عصر الذكاء الاصطناعي: من “البحث عن المواهب” إلى “زراعة المحاصيل” : على وسائل التواصل الاجتماعي، يدور نقاش حار حول ضرورة تحويل مفهوم المواهب في عصر الذكاء الاصطناعي من “البحث عن المواهب في كل مكان” إلى “زراعة المحاصيل”. نظرًا لندرة المواهب في مجال الذكاء الاصطناعي والتطور السريع للتكنولوجيا، يجب على الشركات التركيز بشكل أكبر على تدريب الموظفين الذين يمتلكون المهارات التقنية الأساسية، بدلاً من السعي الأعمى وراء المواهب “الجاهزة” باهظة الثمن في السوق. يؤكد هذا الرأي على أهمية التعلم المستمر والتطوير الداخلي للتكيف مع الاحتياجات المتغيرة بسرعة في مجال الذكاء الاصطناعي. (المصدر: dotey)
استهلاك الطاقة للبنية التحتية للذكاء الاصطناعي ومتطلبات Sam Altman للطاقة : أثار Sam Altman اهتمامًا ونقاشًا اجتماعيًا حول استهلاك الطاقة الهائل للبنية التحتية للذكاء الاصطناعي، حيث اقترح أن تطوير الذكاء الاصطناعي يتطلب 250 جيجاوات من الكهرباء. يتجاوز هذا الطلب بكثير قدرة إمدادات الطاقة الحالية، مما يدفع الناس إلى التفكير في كيفية الموازنة بين التطور السريع للذكاء الاصطناعي وإمدادات الطاقة المستدامة. تتناول المناقشات ذات الصلة أيضًا القضايا البيئية في تصنيع أشباه الموصلات، مثل استخدام PFAS والمخاطر المحتملة للبدائل. (المصدر: Twitter, Twitter)

نظرية نهاية الذكاء الاصطناعي والمتفائلون: مخاوف ودحض : تدور نقاشات واسعة على وسائل التواصل الاجتماعي حول “نظرية نهاية الذكاء الاصطناعي” والمخاطر المحتملة للذكاء الاصطناعي، لكن الكثيرين يرون أن هذه المخاوف مبالغ فيها. يرى المتفائلون أن المشكلات الفعلية التي يسببها الذكاء الاصطناعي (مثل التأثير المناخي، استغلال الشركات، المراقبة العسكرية) أكثر إلحاحًا من “الذكاء الخارق الذي يدمر البشرية” البعيد، ويجب التركيز على التحديات التي يمكن حلها حاليًا. يرى البعض أن نظرية نهاية الذكاء الاصطناعي “هراء”، وهي علامة على الكسل وعدم الاستقرار، بينما يعتقد آخرون أن الذكاء الاصطناعي سيتجه في النهاية نحو الإبداع والتنمية. (المصدر: Reddit r/ArtificialInteligence, Twitter, Twitter)
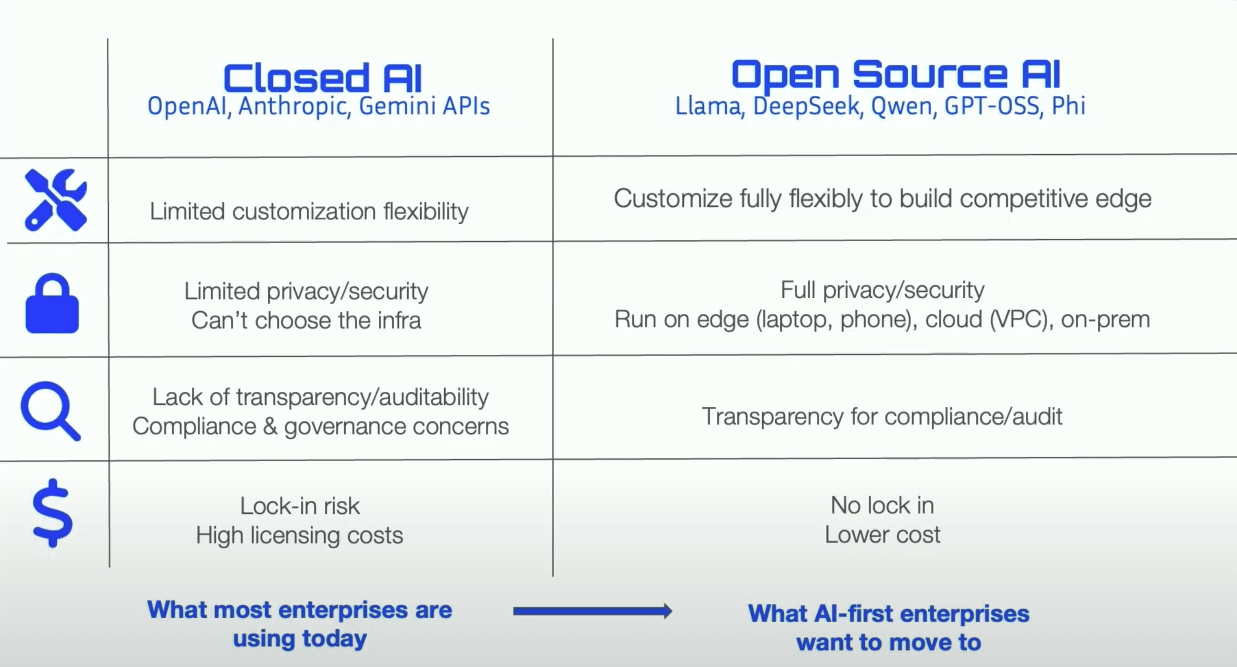
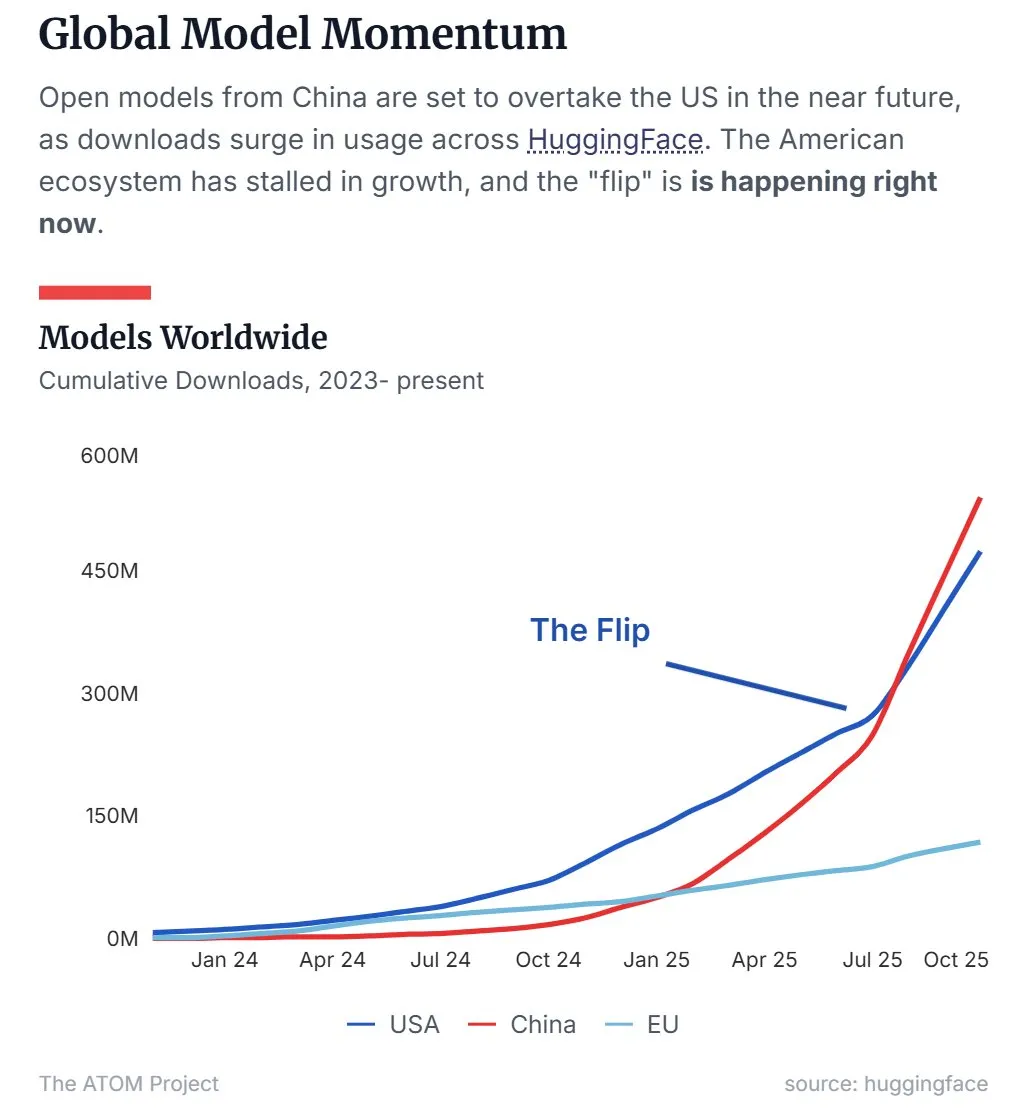
حصة السوق الصينية من LLM مفتوحة المصدر تتجاوز الولايات المتحدة : تظهر أحدث البيانات أن النماذج اللغوية الكبيرة (LLM) الصينية مفتوحة المصدر، ممثلة بـ Qwen، قد تجاوزت الولايات المتحدة في حصة السوق، لتصبح القوة المهيمنة في مجال LLM مفتوحة المصدر. يشير هذا الاتجاه إلى أن الصين تتسارع في البحث والتطوير وتطبيق تقنيات الذكاء الاصطناعي مفتوحة المصدر، مما يؤثر بشكل كبير على المشهد العالمي للذكاء الاصطناعي. (المصدر: Twitter, Twitter)
فريق من 10 أشخاص ينتج مسلسل رسوم متحركة بالذكاء الاصطناعي “明日周一” (غدًا الاثنين) في 45 يومًا، ويحقق عشرات الملايين من المشاهدات : أكمل فريق مكون من 10 أشخاص فقط إنتاج 50 حلقة من مسلسل الرسوم المتحركة بالذكاء الاصطناعي “明日周一” (غدًا الاثنين) في 45 يومًا، وحقق أكثر من عشرة ملايين مشاهدة عبر الإنترنت دون أي ترويج مدفوع، وغطت إيرادات الدفع على Douyin جميع التكاليف. اعتمد المشروع المفهوم الأساسي “شخصيات أصلية + توليد بالذكاء الاصطناعي”، وحل مشكلة ملكية حقوق الطبع والنشر لمحتوى الذكاء الاصطناعي، واستكشف مسار تطوير تجاري شامل للملكية الفكرية. تم تقسيم عملية الإنتاج بشكل كبير، حيث عمل رسامو الرسوم الأصلية، والمهندسون، ومحررو ما بعد الإنتاج، والمخرجون بشكل وثيق، مما أظهر الإمكانات الهائلة لتقنية الذكاء الاصطناعي في خفض التكاليف وزيادة الكفاءة في إنتاج المحتوى. (المصدر: 36氪)

💡 أخرى
استبيان حول الحاجة إلى محاذاة دقيقة للنص الصوتي : أظهر مستخدمو وسائل التواصل الاجتماعي اهتمامًا كبيرًا بتقنية محاذاة النص الصوتي الدقيقة، ونشروا استبيانًا يهدف إلى جمع متطلبات المستخدمين المحددة بشأن الوظائف وسيناريوهات التطبيق لهذه التقنية، على أمل دفع تطوير وتحسين التقنيات ذات الصلة. (المصدر: dotey)
DeepMind تعرض Nano Banana Demo : عرضت Google DeepMind عرضًا توضيحيًا باسم “Nano Banana”، مما أثار اهتمام وسائل التواصل الاجتماعي. على الرغم من عدم الكشف عن التفاصيل الكاملة، إلا أنه قد يكون مرتبطًا بتوليد الفيديو بالذكاء الاصطناعي أو تقنيات الذكاء الاصطناعي متعددة الوسائط، مما يشير إلى تطورات جديدة لـ DeepMind في مجال الذكاء الاصطناعي البصري. (المصدر: GoogleDeepMind)
نقاش أكاديمي حول أولوية اختراع Highway Net و ResNet : أعاد الباحث الشهير في الذكاء الاصطناعي Jürgen Schmidhuber نشر تغريدة، مما أثار مرة أخرى نقاشًا أكاديميًا حول أولوية اختراع Highway Net و ResNet في التعلم العميق المتبقي. أشار إلى أن وصف ورقة Microsoft لـ ResNet بأنها عمل “معاصر” لـ Highway Net غير دقيق، وأكد أن Highway Net نُشرت قبل ResNet بسبعة أشهر، وقد حددت وقدمت بالفعل حلولًا للاتصالات المتبقية. (المصدر: SchmidhuberAI)