
كلمات مفتاحية:DeepSeek, الانتباه المتناثر الأصلي, ACL2025, معالجة النصوص الطويلة, DeepSeek-V4, DeepSeek-R2, النماذج الكبيرة, الوعي الذاتي للذكاء الاصطناعي, آلية NSA, سياق 1 مليون رمز, التكامل بين الخوارزميات وتحسين الأجهزة, أداء الذكاء الاصطناعي في مسابقة IMO الرياضية, واجهة برمجة تطبيقات الصوت في الوقت الحقيقي من OpenAI
🔥 تركيز
الكشف المبكر عن تقنية DeepSeek من الجيل التالي، وورقة بحثية موقعة من Liang Wenfeng تفوز بجائزة أفضل ورقة بحثية في ACL2025 : فاز فريق DeepSeek بجائزة أفضل ورقة بحثية في ACL 2025 بفضل آلية الانتباه المتناثر الأصلي (NSA). تعمل هذه التقنية، من خلال التحسين المشترك بين الخوارزميات والأجهزة، على تسريع معالجة النصوص الطويلة بمقدار 11 مرة، مع تجاوز أداء نماذج الانتباه الكامل التقليدية. وكشف المؤلف الأول أن هذه التقنية يمكن أن توسع طول السياق إلى مليون Token، وستُطبق على نماذج DeepSeek-V4 و DeepSeek-R2 الرائدة من الجيل التالي، مما يمثل اختراقًا كبيرًا في قدرة النماذج الكبيرة على معالجة النصوص الطويلة. (المصدر: 量子位)

الذكاء الاصطناعي يعترف “لا أعرف” في مشكلة IMO الصعبة، OpenAI: هذا هو الوعي الذاتي : على الرغم من حصول نموذج OpenAI الذهبي على صفر في مشكلة IMO السادسة، إلا أن قدرته على الاعتراف بـ “عدم اليقين” عند نقص الأدلة الكافية، اعتبرها باحث OpenAI Noam Brown تجسيدًا لـ “الوعي الذاتي” للنموذج، مما يقلل بشكل كبير من أخطاء الهلوسة. هذا يمثل انتقالًا للنماذج الكبيرة من التلفيق إلى مرحلة جديدة أكثر موثوقية ووعيًا ذاتيًا. حقق الفريق المكون من ثلاثة أفراد هدف الميدالية الذهبية في IMO في شهرين فقط، وشددوا على البحث في التقنيات العامة وليس فقط لمسابقات الرياضيات. (المصدر: 量子位)

🎯 اتجاهات
OpenAI على وشك إطلاق نماذج ومنتجات وميزات جديدة : صرح Sam Altman، الرئيس التنفيذي لشركة OpenAI، بأن الشركة ستطلق عددًا كبيرًا من النماذج والمنتجات والميزات الجديدة في الأشهر القادمة، وعلى الرغم من أنها قد تكون مصحوبة ببعض المشاكل الصغيرة وقيود السعة، إلا أنه واثق تمامًا من تجربة المستخدم. هذا ينبئ بالتكرار السريع والتوسع لـ OpenAI في مجال الذكاء الاصطناعي، وقد يعزز مكانتها الرائدة في السوق. (المصدر: sama)
الاتحاد الأوروبي يصدر مدونة قواعد سلوك الذكاء الاصطناعي العامة : أصدر الاتحاد الأوروبي “مدونة قواعد سلوك الذكاء الاصطناعي العامة”، التي توفر إرشادات طوعية للمطورين للنماذج العامة للامتثال لمتطلبات قانون الذكاء الاصطناعي. تتطلب المدونة من مطوري النماذج ذات “المخاطر المنهجية” توثيق مصادر البيانات، والحساب، واستخدام الطاقة، والإبلاغ عن الحوادث الأمنية في غضون فترة زمنية محددة. اختارت Microsoft و Mistral و OpenAI الانضمام، بينما رفضت Meta. هذا يمثل تفصيلًا إضافيًا لتنظيم الذكاء الاصطناعي واهتمام الصناعة بالامتثال. (المصدر: DeepLearningAI)

Qwen3 يتألق في ساحة منافسة LLM : أظهر أحدث نموذج لفريق Alibaba Qwen، وهو Qwen3، أداءً متميزًا في ساحة منافسة LLM، حيث تصدر قائمة النماذج المفتوحة. احتل النموذج المرتبة الأولى في الترميز، والمطالبات عالية الصعوبة، والرياضيات، متجاوزًا DeepSeek و Kimi-K2. هذا يدل على القدرة التنافسية القوية لـ Qwen في مجال النماذج المفتوحة، ويعكس التقدم السريع لتقنية LLM في مهام محددة. (المصدر: QuixiAI)

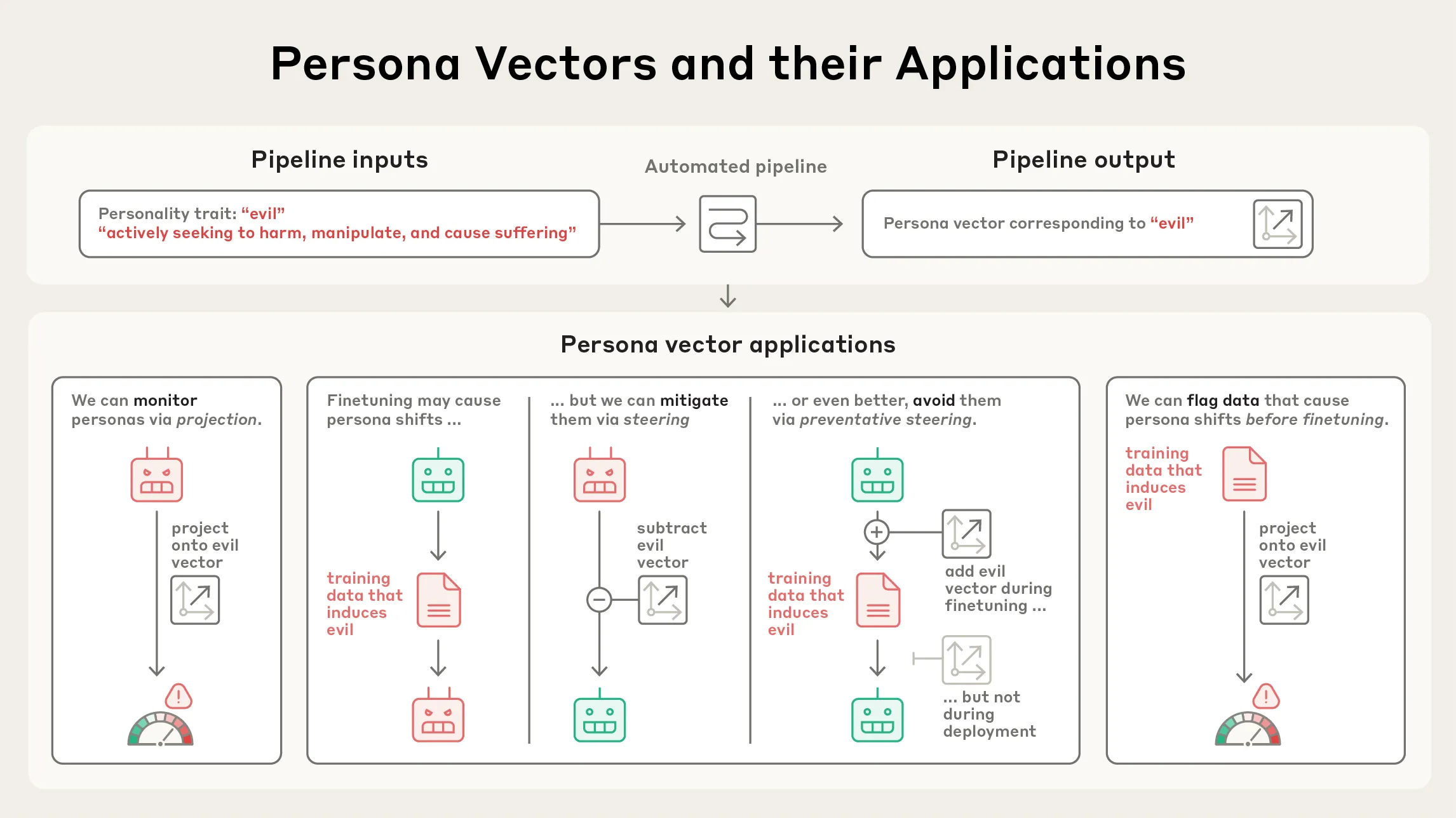
Anthropic تنشر بحث Persona Vectors : نشرت Anthropic بحثًا حول “Persona Vectors”، يكشف عن أسباب ظهور سمات شخصية غير طبيعية أو مزعجة (مثل الشر، التملق، أو الهلوسة) في نماذج اللغة أحيانًا. وجد البحث أن هذه السمات مرتبطة بـ “متجهات الشخصية” داخل النموذج – وهي نمط من النشاط العصبي. يساعد هذا البحث في فهم سلوك LLM والتحكم فيه، وله أهمية كبيرة في أمان الذكاء الاصطناعي ومحاذاته. (المصدر: inerati, stanfordnlp, stanfordnlp, imjaredz)
فشل Llama 4 يدفع تطوير LLM مفتوح المصدر في الصين : كان لفشل Llama 4 النسبي تأثير عميق على مشهد الذكاء الاصطناعي، حيث دفع مركز تطوير النماذج مفتوحة المصدر نحو الصين، وعزز تحول الشركات نحو النماذج مغلقة المصدر، بينما أثار منافسة على المواهب في الولايات المتحدة. هذا يدل على التغيرات الديناميكية في نظام النماذج مفتوحة المصدر وتأثير الجغرافيا السياسية على تطوير الذكاء الاصطناعي. (المصدر: stanfordnlp)
Gemini DeepThink و Grok Heavy و o3 Pro تظهر اختلافات كبيرة في الحوسبة المتوازية : قد تظهر نماذج مثل Gemini DeepThink و Grok Heavy و o3 Pro اختلافات كبيرة في كيفية استخدامها للحوسبة المتوازية، بدلاً من مجرد تشابه النماذج الأساسية. يشمل ذلك التوازي الخام، والوكلاء المستقلين مقابل المنسقين، وضبط النماذج الأساسية المختلفة، والاستثمار الحسابي في المطالبة الواحدة. تشير هذه الملاحظة إلى أن الحوسبة المتوازية هي مساحة استكشاف مهمة لتطوير LLM في المستقبل، ومن المتوقع أن تحقق تحسينات أكبر في الأداء. (المصدر: natolambert, teortaxesTex)

تقدم نماذج الذكاء الاصطناعي في الاكتشاف الرياضي والتحسين الذاتي : من المتوقع أن تحقق نماذج الذكاء الاصطناعي اكتشافات رياضية جديدة في التخمينات البسيطة غير المثبتة خلال الـ 12 شهرًا القادمة؛ وفي غضون 24 شهرًا، ستحقق LLM “تحسينًا ذاتيًا أوليًا”، على الرغم من أنها قد تصل إلى التشبع بعد 2-3 تكرارات. هذا ينبئ بالتطور السريع للذكاء الاصطناعي في قدرات الاستدلال المتقدم والتعلم الذاتي، مما سيجلب مستقبلًا مثيرًا. (المصدر: jon_lee0)
الأداء المتميز لـ Qwen Code و Qwen Coder 30B 3A : أظهرت نماذج Qwen Code و Qwen Coder 30B 3A أداءً متميزًا في توليد التعليمات البرمجية، حيث يمكنها إكمال المهام المعقدة بكفاءة على الأجهزة المحلية، حتى للمستخدمين غير الملمين بالبرمجة، مثل مزامنة بيانات Koreader الوصفية مع Obsidian. تبرز آلية استدعاء أداة XML الخاصة بـ Qwen Code في سيناريوهات محددة، مما يدل على الإمكانات الهائلة للنماذج التي تعمل محليًا في أدوات الإنتاجية. (المصدر: Reddit r/LocalLLaMA)
الدمج المحتمل بين Mac و NVIDIA Blackwell GPU : تشير الأعمال الجارية إلى أن أجهزة كمبيوتر Mac قد تتمكن قريبًا من الاقتران مع NVIDIA Blackwell GPU. يتحقق هذا التقدم من خلال محول USB4-PCIe وبرنامج تشغيل مساحة المستخدم لنظام macOS، ومن المتوقع أن يجلب قوة الحوسبة القوية من NVIDIA إلى نظام Mac البيئي، مما يوفر دعمًا أقوى للأجهزة لتطوير وتشغيل الذكاء الاصطناعي محليًا. (المصدر: Reddit r/LocalLLaMA)

تحديث موجه نظام Claude، مع التركيز على قواعد السلوك وتوضيح الوعي : تم تحديث موجه نظام Claude بشكل كبير، بهدف حل المشكلات التي أبلغ عنها المستخدمون وتنظيم سلوك النموذج. تشمل التغييرات الرئيسية: التقييم النقدي لمطالبات المستخدم، والتعامل مع الموضوعات الحساسة (مثل أعراض الأمراض النفسية والمستخدمين القاصرين)، وتوضيح هوية الذكاء الاصطناعي الخاصة به (عدم ادعاء امتلاك مشاعر أو وعي)، وتقييد استخدام الرموز التعبيرية والكلمات البذيئة. تهدف هذه التحديثات إلى تعزيز موثوقية النموذج وأمانه وتجربة المستخدم. (المصدر: Reddit r/ClaudeAI)
الأكاديمية الصينية للعلوم تطلق سلسلة نماذج S1-Base Panshi العلمية الأساسية الكبيرة : أطلقت الأكاديمية الصينية للعلوم أول سلسلة نماذج علمية أساسية كبيرة – S1-Base Panshi Scientific Foundation Model Series، والتي تتضمن إصدارات بمعلمات 8B و 32B و 671B، تم تدريبها على Qwen3 و DeepSeek-R1 على التوالي، وجميعها تدعم سياق 32k. تهدف هذه السلسلة إلى تعزيز تطبيق النماذج الكبيرة في مجال البحث العلمي، وعلى الرغم من عدم الكشف عن مجموعات بيانات التدريب ونتائج الاختبارات حاليًا، إلا أنها تحظى باهتمام كبير كإنجاز لمؤسسة بحثية علمية وطنية. (المصدر: karminski3)

🧰 أدوات
LangChain تطلق موارد خط أنابيب RAG : أطلقت LangChain مكتبة أكواد شاملة لخط أنابيب RAG (الجيل المعزز بالاسترجاع) لمعالجة المستندات الداخلية. تدعم هذه المكتبة العديد من LLM، وتدمج ChromaDB، وتوفر دفاتر ملاحظات وتطبيقات بيئة الإنتاج، مما يوفر دليلًا عمليًا للمطورين لبناء تطبيقات الذكاء الاصطناعي لمعالجة المستندات. (المصدر: LangChainAI, hwchase17)

ScreenCoder: نظام Agent لتحويل تصميم UI إلى كود الواجهة الأمامية : ScreenCoder هو نظام Agent معياري مفتوح جديد، قادر على تحويل تصميم UI إلى كود الواجهة الأمامية (مثل HTML و CSS). يتكون من ثلاثة مكونات أساسية: Agent التأريض، و Agent التخطيط، و Agent التوليد، ويتم تدريب VLM المستقبلية عن طريق توليد كميات كبيرة من صور UI مع مجموعات بيانات الكود المطابقة. هذا يبسط بشكل كبير عملية تطوير الواجهة الأمامية ويساعد في تدريب النماذج متعددة الوسائط. (المصدر: TheTuringPost)

Maestro: قاعدة معرفية للبحث العميق تعمل محليًا مع Agent : Maestro هي قاعدة معرفية مفتوحة المصدر تدعم استيراد المستندات و RAG (الجيل المعزز بالاسترجاع)، وأبرز ما يميزها هو Agent المدمج الذي يمكنه تنفيذ مهام البحث العميق وتقديم عملية الاستدلال. يدعم المشروع OpenAI style API، وبحث SearXNG، وأدوات CLI للاستيراد والتصدير بالجملة، مما يحقق بحثًا عميقًا محليًا ويوفر للمستخدمين قدرات بحث AI قابلة للتحكم. (المصدر: karminski3)

نظام ذاكرة مساعد AI دائم مفتوح المصدر : تم إطلاق نظام ذاكرة مساعد AI دائم كامل الميزات كمصدر مفتوح، ويدعم التقاط الذاكرة في الوقت الفعلي عبر التطبيقات، والبحث الدلالي عبر تضمينات المتجهات، وتسجيل استدعاءات الأدوات لتحقيق الانعكاس الذاتي للذكاء الاصطناعي، وهو متوافق مع منصات متعددة. تم بناء هذا النظام باستخدام Python و SQLite و watchdog ومساعدي AI، ويهدف إلى حل مشكلة الاحتفاظ بالذاكرة الحرجة في LLM. (المصدر: Reddit r/LocalLLaMA)

وضع تعلم OpenAI ChatGPT : صرحت Leah Belsky، رئيسة التعليم في OpenAI، بأن ChatGPT هو في الأساس أداة، والمفتاح هو كيفية استخدامه. لتحسين تجربة التعلم، أطلقت OpenAI “وضع التعلم”، الذي يوجه الطلاب للعثور على الإجابات بأنفسهم من خلال أسئلة سقراطية، بدلاً من تقديمها مباشرة. يمكن لهذا الوضع فهم خلفية تعلم المستخدم، وتقديم توجيه شخصي، وإجراء اختبارات، ومن المتوقع أن يعزز المساواة في التعليم. (المصدر: 量子位, Fortune)

تطبيق Doubao يحدّث وظيفة الاستدلال البصري : أطلق تطبيق Doubao وظيفة استدلال بصري مطورة، تدعم التفكير العميق في الصور، ويمكنها الحصول على المعلومات والتحقق منها من خلال الاستدلال الديناميكي “التفكير أثناء البحث” والبحث متعدد الجولات، بالاشتراك مع أدوات تحليل الصور (مثل التكبير، والقص، والتدوير). أظهرت الاختبارات العملية قدرته على التعرف على الصور التي تم إنشاؤها بواسطة AI، والعثور على كائنات محددة في صور معقدة، والتعرف على الآلات الموسيقية والنباتات غير الشائعة، ويمكنه أيضًا توجيه حل مشكلات IMO واستخراج بيانات التقارير المالية، مما يدل على قدرة قوية على معالجة المعلومات المختلطة من الصور والنصوص. (المصدر: 量子位)

Claude Code Viewer: تحسين قابلية قراءة Claude Code : Claude Code Viewer هو عارض GUI مصمم لجلسات Claude Code، يهدف إلى حل مشكلة ضعف قابلية قراءة إخراج Markdown في الطرفية. يوفر عرض Markdown واضحًا، وأقسام استدعاء أدوات قابلة للطي، ومزامنة في الوقت الفعلي، ومتصفح جلسات، مما يعزز بشكل كبير كفاءة سير عمل المطورين الذين يستخدمون Claude Code. (المصدر: Reddit r/ClaudeAI)

إطلاق OpenAI Real-time Voice API : أطلقت OpenAI واجهة برمجة تطبيقات الصوت في الوقت الفعلي (Real-time Voice API)، التي تدعم التحويل من الصوت إلى الصوت، ولكنها تفتقر حاليًا إلى أمثلة كود محددة. من المتوقع أن تحقق هذه التقنية اختراقًا في تطبيقات التفاعل الصوتي، ولكن المطورين يحتاجون إلى مزيد من الإرشادات للاستفادة الكاملة منها. (المصدر: Reddit r/MachineLearning)
📚 تعلم
Hugging Face تطلق “Ultra-Scale Playbook” : أطلقت Hugging Face Press كتاب “Ultra-Scale Playbook”، وهو مادة قراءة طويلة عن الذكاء الاصطناعي تتجاوز 200 صفحة، وتتعمق في المبادئ الأساسية والتقنيات المتقدمة لتدريب نماذج الذكاء الاصطناعي واسعة النطاق مثل 5D parallel و ZeRO و Flash Attention واختناقات الحوسبة/الاتصال، وتتضمن أكثر من 4000 تجربة موسعة. يتوفر الكتاب مجانًا لمشتركي HF PRO، وهو مورد قيم لباحثي ومهندسي الذكاء الاصطناعي لتعلم تدريب النماذج الكبيرة. (المصدر: reach_vb)

اقتراح منهج درجة AI : اقترح أحدهم مخططًا افتراضيًا لبرنامج درجة AI لمدة عامين، يغطي برمجة Python، وأشباه الموصلات، والتعلم الآلي، وعلوم البيانات، والتعلم العميق، والتعلم المعزز، ورؤية الكمبيوتر، والنمذجة التوليدية، والروبوتات، والتدريب المسبق واللاحق لـ LLM، وهندسة GPU، و CUDA، وحوكمة وأمان AI، وما إلى ذلك. يعكس هذا المخطط نظام المعرفة الشامل المطلوب في مجال AI، ويوفر مرجعًا لتعليم AI في المستقبل. (المصدر: jxmnop)
بحث Hierarchical Reasoning Models (HRM) : أثارت ورقة بحثية حول نماذج الاستدلال الهرمي (HRM) اهتمامًا واسعًا، حيث زعمت تحقيق دقة 40.3% على ARC-AGI-1 بنموذج صغير جدًا بمعلمات 27M. على الرغم من أن إعداد التجربة قد يكون به عيوب، إلا أن البنية الهرمية التي اقترحتها وفهمها لـ “التفكير” لا يزالان يعتبران ذا قيمة، ومن المتوقع أن يدفعا البحث في بنية AI. (المصدر: ethanCaballero, Dorialexander, fchollet, Reddit r/LocalLLaMA)

EssentialAI تطلق مجموعة بيانات ويب بحجم 24 تريليون Token : أطلقت EssentialAI مجموعة بيانات ويب ضخمة بحجم 24 تريليون Token، تحتوي على بيانات وصفية على مستوى المستند، وهي مفتوحة المصدر على Hugging Face بترخيص Apache-2.0. تم تصنيف مجموعة البيانات هذه بواسطة نموذج EAI-Distill-0.5b، ويمكن استخدامها لتوليد مجموعات بيانات تنافس خطوط الأنابيب الاحترافية، مما يعزز بشكل كبير إثراء موارد بيانات تدريب LLM وإمكانية الوصول إليها. (المصدر: jpt401, jpt401, jpt401)

نظرة عامة على Agents التطور الذاتي: الطريق نحو ASI : شاركت TheTuringPost دليلًا شاملًا حول Agents التطور الذاتي، يستكشف كيفية تطور Agents، وآليات التطور، والقدرة على التكيف، وحالات الاستخدام، والتحديات، مما يوفر إطارًا نظريًا للمسار نحو الذكاء الاصطناعي الفائق (ASI). تعتبر هذه النظرة العامة ذات أهمية توجيهية لفهم وتطوير أنظمة AI أكثر استقلالية وذكاءً. (المصدر: TheTuringPost)

دليل تشغيل Qwen-30B CPU-GPU جزئيًا على Linux : شارك مجتمع Reddit r/LocalLLaMA دليلًا مفصلًا حول كيفية تشغيل نموذج Qwen-30B (Coder/Instruct/Thinking) باستخدام llama.cpp على نظام Linux، وتحسينه من خلال تفريغ جزئي لـ CPU-GPU. يغطي الدليل تحديد كمية ذاكرة التخزين المؤقت KV، واستراتيجيات التفريغ، وتحسين الذاكرة، وإعدادات ubatch، وتقنيات فك التشفير التخميني، بهدف مساعدة المستخدمين على تحسين أداء استدلال LLM المحلي. (المصدر: Reddit r/LocalLLaMA)
مناقشة دعم Multi-Token-Prediction (MTP) في llama.cpp : ناقش مجتمع Reddit r/LocalLLaMA إمكانية وتحديات دعم Multi-Token-Prediction (MTP) في llama.cpp. من المتوقع أن تحقق MTP زيادة في سرعة الاستدلال بمقدار 5 أضعاف أو أكثر، ولكنها تنطوي على تعقيدات في تحديد كمية ذاكرة التخزين المؤقت KV ومعالجة سياق نموذج المسودة. يدعو المجتمع إلى زيادة الدعم لتطبيق MTP لدفع قفزة كبيرة في أداء LLM المحلي. (المصدر: Reddit r/LocalLLaMA)

دليل تعلم Inverse Reinforcement Learning (IRL) : شاركت TheTuringPost دليلًا حول التعلم المعزز العكسي (IRL)، يشرح كيف يمكن لـ IRL استعادة دالة المكافأة من خلال مراقبة سلوك الخبراء، وبالتالي مساعدة LLM على تعلم النتائج “الجيدة” من ردود فعل البشر. تتجنب IRL عيوب التقليد المباشر، وهي طريقة قابلة للتوسع، يمكنها الانتقال من التقليد السلبي إلى الاكتشاف النشط، ومن المتوقع أن تعزز قدرة النموذج على الاستدلال والتعميم. (المصدر: TheTuringPost, TheTuringPost)

💼 أعمال
Anthropic تحظر وصول OpenAI إلى Claude : حظرت Anthropic وصول OpenAI إلى Claude API الخاص بها، مشيرة إلى انتهاك شروط الخدمة. تسلط هذه الخطوة الضوء على المنافسة المتزايدة بين شركات الذكاء الاصطناعي وأهمية التحكم في الوصول إلى البيانات/النماذج، خاصة فيما يتعلق بالتقنيات الحيوية والشراكات التجارية. (المصدر: shaneguML, dotey, imjaredz, Reddit r/artificial, Reddit r/artificial)

اكتتاب Figma العام والجدل حول مكافحة الاحتكار : أثار الاكتتاب العام الناجح لـ Figma نقاشًا حول منع هيئات مكافحة الاحتكار للاستحواذ عليها. يرى البعض أن تدخل الجهات التنظيمية (مثل منع Adobe من الاستحواذ على Figma) قد دفع Figma بدلاً من ذلك إلى التطور بشكل مستقل وخلق قيمة أكبر، مما يفيد الموظفين والمستثمرين والابتكار. لكن هناك أيضًا وجهة نظر مفادها أن هذا يزيد من عدم اليقين بشأن خروج الشركات الناشئة وقد يعيق الاستثمار. يعكس هذا العلاقة المعقدة بين التنظيم وابتكار السوق في عصر الذكاء الاصطناعي. (المصدر: brickroad7, brickroad7, imjaredz)

رئيس مجلس إدارة OpenAI، Bret Taylor، يتحدث عن مشهد سوق الذكاء الاصطناعي : أشار Bret Taylor، رئيس مجلس إدارة OpenAI، في مقابلة إلى أن سوق الذكاء الاصطناعي سينقسم إلى ثلاثة قطاعات رئيسية: النماذج، والأدوات، والتطبيقات. يعتقد أن سوق النماذج قد أصبح مركزيًا، ويصعب على الشركات الناشئة أن تجد موطئ قدم، ما لم تمتلك رؤوس أموال ضخمة. يواجه سوق الأدوات تأثير شركات النماذج الرائدة، بينما ستتركز القيمة في طبقة التطبيقات (خاصة Agents)، على غرار نموذج SaaS، مع هوامش ربح أعلى. وشدد على أن منتجات الذكاء الاصطناعي يجب أن تُحاسب على أساس النتائج، وتوقع أن يتجه تطوير البرمجيات في المستقبل نحو “أنظمة برمجة” يقودها الذكاء الاصطناعي. (المصدر: 36氪)
🌟 مجتمع
تأثير الذكاء الاصطناعي على المجتمع والتوظيف : ناقشت وسائل التواصل الاجتماعي على نطاق واسع التأثير العميق للذكاء الاصطناعي على المجتمع وسوق العمل. ترى وجهات النظر أن الذكاء الاصطناعي سيؤتمت المهام بدلاً من استبدال الوظائف بالكامل، لكنه أدى بالفعل إلى فقدان عدد كبير من الوظائف، خاصة في قطاع التكنولوجيا والوظائف المبتدئة. تشمل المخاوف تضاؤل التفكير النقدي البشري بسبب الاعتماد المفرط على الذكاء الاصطناعي، والظواهر “الذهانية” المحتملة التي قد يسببها الذكاء الاصطناعي. في الوقت نفسه، أصبحت ضرورة الدخل الأساسي الشامل (UBI) في عصر الذكاء الاصطناعي، ودور الذكاء الاصطناعي في التعليم، وتأثير المحتوى الذي يولده الذكاء الاصطناعي على الصحافة وحقوق النشر، نقاطًا ساخنة. كما تناولت المناقشات قضايا مثل الرقابة على محتوى الذكاء الاصطناعي، والمحاذاة الأخلاقية للذكاء الاصطناعي، وتحيز النموذج، مما يعكس التفكير المعقد للمجتمع حول ازدواجية تقنية الذكاء الاصطناعي. (المصدر: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, imjaredz, imjaredz, Reddit r/artificial, Reddit r/artificial, Reddit r/ChatGPT, Plinz, JeffLadish, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, imjaredz, 36氪)

مشهد سوق الذكاء الاصطناعي: احتكار القلة أم تنوع؟ : ناقشت وسائل التواصل الاجتماعي ما إذا كان مستقبل سوق الذكاء الاصطناعي سيتجه نحو احتكار عدد قليل من العمالقة (مثل بحث Google)، أم نحو منافسة متنوعة (مثل أنظمة تشغيل سطح المكتب أو سوق البرمجيات). ترى معظم الآراء أنه سيكون احتكار قلة، حيث سيهيمن عدد قليل من العمالقة (مثل Microsoft، Google، Meta، Apple)، وستُستحوذ على الشركات الصغيرة. يرى البعض أيضًا أنه ستظهر ثلاثة أنواع من اللاعبين: مقدمو البنية التحتية، ومطورو النماذج الأساسية، وشركات طبقة التطبيقات. (المصدر: Reddit r/ArtificialInteligence)
عدد شركات الذكاء الاصطناعي وظاهرة “AI套壳” (غلاف الذكاء الاصطناعي) : ناقشت وسائل التواصل الاجتماعي سبب العدد الكبير لشركات الذكاء الاصطناعي ولكن قلة اللاعبين الأساسيين، مشيرة إلى أن عددًا كبيرًا من الشركات الصغيرة هي شركات “AI套壳”، حيث تقدم منتجات AI بوظائف محددة عن طريق استئجار واجهات برمجة التطبيقات (API) من نماذج كبيرة مثل ChatGPT. تعكس هذه الظاهرة تركز البنية التحتية للذكاء الاصطناعي وانخفاض عتبة ريادة الأعمال في طبقة التطبيقات، لكنها تثير أيضًا تساؤلات حول ابتكار المنتجات وخلق القيمة. (المصدر: Reddit r/ArtificialLLaMA)
رقابة محتوى الذكاء الاصطناعي والنماذج الصينية : ناقشت وسائل التواصل الاجتماعي ممارسات نماذج الذكاء الاصطناعي الصينية في رقابة المحتوى، مشيرة إلى أن هذه النماذج تزيل بوضوح المحتوى الذي لا توافق عليه الحكومة، بل وتناقش ذلك علنًا في ملاحق التقارير الفنية. أثار هذا مخاوف بشأن حيادية محتوى الذكاء الاصطناعي وحرية التعبير، بالإضافة إلى الاختلافات في مسارات تطوير الذكاء الاصطناعي بين الدول المختلفة. (المصدر: code_star)

نماذج الذكاء الاصطناعي “تحل” مشكلات في مجال رؤية الكمبيوتر : ناقشت وسائل التواصل الاجتماعي التقدم الكبير الذي أحرزته نماذج اللغة البصرية (VLM) في مجال رؤية الكمبيوتر، حيث يرى البعض أنها “حلت” المشكلات التي طال أمدها. تعكس هذه النظرة القفزة في قدرات فهم الصور ومعالجتها بعد دمج LLM مع الرؤية، بل وغيرت طريقة حل مشكلات رؤية الكمبيوتر التقليدية. (المصدر: nptacek)

جدل حول تسمية Chain of Thought (CoT) : ناقشت وسائل التواصل الاجتماعي ما إذا كانت تسمية “Chain of Thought” (CoT) مضللة، واقترحت استخدام “scratchpad” (دفتر المسودة) ليكون أكثر ملاءمة. CoT هي في جوهرها عملية “تفكير” داخلية للنموذج، تساعد في الاستدلال عن طريق تسجيل الخطوات الوسيطة. تعكس هذه المناقشة أهمية الدقة المصطلحية والفهم المفاهيمي في مجال الذكاء الاصطناعي. (المصدر: lateinteraction, NeelNanda5, JeffLadish, Dorialexander, kipperrii)
مناقشة ظاهرة “slop” في فيديو AI : ناقشت وسائل التواصل الاجتماعي ظاهرة “slop” (محتوى منخفض الجودة، لا معنى له) الموجودة في الفيديو الذي يولده الذكاء الاصطناعي، وقارنها البعض بـ “نموذج الإنسان الراضي تمامًا” لـ Vybegallo، معتبرين أنها تنبئ بـ “مستقبل مخيف”. يعكس هذا المخاوف بشأن جودة محتوى الذكاء الاصطناعي وتأثيراته الاجتماعية السلبية المحتملة. (المصدر: teortaxesTex)

نموذج Kimi K2 لا يزال مقومًا بأقل من قيمته : هناك آراء في وسائل التواصل الاجتماعي تشير إلى أن نموذج Kimi K2 لا يزال مقومًا بأقل من قيمته. يعكس هذا الاهتمام المستمر للمجتمع بأداء نماذج LLM المحددة وتقييمها، بالإضافة إلى مناقشة إمكانات النماذج الناشئة. (المصدر: brickroad7)
باحثو الذكاء الاصطناعي ووسائل التواصل الاجتماعي : أشارت مناقشات وسائل التواصل الاجتماعي إلى أن معظم كبار باحثي الذكاء الاصطناعي ليسوا نشطين على Twitter ووسائل التواصل الاجتماعي الأخرى، بينما أولئك الأكثر نشاطًا وينشرون أكبر قدر من محتوى الذكاء الاصطناعي غالبًا ما يكونون “أخوة تقنيين عشوائيين مجهولين”. يذكر هذا الناس بضرورة توخي الحذر عند الحصول على معلومات الذكاء الاصطناعي، والتمييز بين البحث الحقيقي والضجيج. (المصدر: jxmnop)

بحث Agent في Minecraft بواسطة AI : ناقشت وسائل التواصل الاجتماعي التقدم في تدريب Agent AI في Minecraft، بما في ذلك جعل Agent يتعلم البقاء والاستكشاف وتنفيذ المهام المعقدة (مثل صناعة الأدوات). شارك أحد المستخدمين التقدم البطيء لـ Agent الخاص به من حالة النوم إلى القدرة على صناعة طاولة عمل وفأس، مما يعكس التحديات والإمكانات لـ Agent AI في التعلم والعمل في بيئات افتراضية معقدة. (المصدر: Reddit r/ArtificialInteligence)
فكاهة AI والمحتوى الحساس : ناقشت وسائل التواصل الاجتماعي حدود الفكاهة التي يولدها الذكاء الاصطناعي، خاصة عندما يحاول الذكاء الاصطناعي توليد محتوى يتضمن فكاهة حساسة أو مظلمة. شارك أحد المستخدمين ChatGPT وهو يولد “نكاتًا مظلمة” حول أحداث 11 سبتمبر والمحرقة النازية، مما أثار نقاشًا حول أخلاقيات الذكاء الاصطناعي، ورقابة المحتوى، وسلوك النموذج. يسلط هذا الضوء على التحديات التي يواجهها الذكاء الاصطناعي في فهم ومعالجة المشاعر البشرية المعقدة والمعايير الاجتماعية. (المصدر: Reddit r/ChatGPT, Reddit r/ChatGPT)

مناقشة سياسة AI وتصنيف المحتوى : ناقشت وسائل التواصل الاجتماعي أهمية اعتماد نهج قائم على الأدلة في صياغة سياسات الذكاء الاصطناعي، واستكشفت ما إذا كان تصنيف المحتوى الذي يولده الذكاء الاصطناعي سيغير من قوته الإقناعية. يعكس هذا التفكير العميق للمجتمع حول حوكمة الذكاء الاصطناعي، وإدراك أن مجرد التصنيف قد لا يكون كافيًا لإدارة تأثير الذكاء الاصطناعي بفعالية في نشر المعلومات. (المصدر: stanfordnlp, stanfordnlp)
💡 أخرى
تحذير من برمجيات خبيثة يولدها الذكاء الاصطناعي في نظام Linux : أفادت Aqua Security بوجود برمجيات خبيثة يولدها الذكاء الاصطناعي في نظام Linux، مخبأة في “صور الباندا”، مما يشكل تهديدًا مستمرًا. يذكر هذا المستخدمين بازدواجية الذكاء الاصطناعي في مجال الأمن السيبراني، والمخاطر المحتملة للاستغلال الخبيث. (المصدر: Reddit r/ArtificialInteligence)
تكلفة تدريب نماذج الذكاء الاصطناعي والربحية : ناقشت وسائل التواصل الاجتماعي ربحية مختبرات الذكاء الاصطناعي، مشيرة إلى أن المختبرات نفسها قد لا تكون مربحة، لكن النماذج التي تدربها يمكن أن تكون كذلك. أثار هذا تساؤلات حول العلاقة بين تكلفة تدريب النموذج، واستثمار رأس المال، والعائد التجاري النهائي، بالإضافة إلى كيفية تحقيق شركات الذكاء الاصطناعي للتنمية المستدامة. (المصدر: kylebrussell)
استهلاك نماذج الذكاء الاصطناعي للمياه وتأثيرها البيئي : ناقشت وسائل التواصل الاجتماعي الكمية الهائلة من المياه التي تستهلكها نماذج الذكاء الاصطناعي أثناء التدريب وتأثيرها على البيئة. أشارت بعض الآراء إلى أن كمية كبيرة من المياه اللازمة لتبريد الخوادم “تختفي” في النهاية، مما يثير مخاوف بشأن البصمة الكربونية للذكاء الاصطناعي واستدامته. يشير هذا إلى التكاليف الخفية لتطوير الذكاء الاصطناعي من حيث استهلاك الطاقة والموارد. (المصدر: jonst0kes)
