
Kata Kunci:DeepSeek, Perhatian Asli Jarang, ACL2025, Pemrosesan Teks Panjang, DeepSeek-V4, DeepSeek-R2, Model Besar, Kesadaran Diri AI, Mekanisme NSA, Konteks 1 Juta Token, Optimasi Kolaboratif Algoritma dan Perangkat Keras, Kinerja AI dalam Kompetisi Matematika IMO, API Suara Real-time OpenAI
🔥 Fokus
Teknologi Generasi Berikutnya DeepSeek Terungkap Lebih Awal, Makalah Bertanda Tangan Liang Wenfeng Raih Penghargaan Best Paper ACL 2025 : Tim DeepSeek meraih penghargaan Best Paper di ACL 2025 berkat mekanisme Native Sparse Attention (NSA). Teknologi ini, melalui optimasi kolaboratif algoritma dan perangkat keras, meningkatkan kecepatan pemrosesan teks panjang hingga 11 kali, sekaligus melampaui kinerja model Full Attention tradisional. Penulis utama mengungkapkan bahwa teknologi ini dapat memperluas panjang konteks hingga 1 juta Token dan akan diterapkan pada model mutakhir generasi berikutnya, DeepSeek-V4 dan DeepSeek-R2, menandai terobosan besar dalam kemampuan pemrosesan teks panjang model besar. (Sumber: 量子位)

AI Mengaku ‘Tidak Tahu’ Saat Menjawab Soal Sulit IMO, OpenAI: Ini Adalah Kesadaran Diri : Meskipun model unggulan OpenAI meraih nol poin pada soal ke-6 International Mathematical Olympiad (IMO), kemampuannya untuk mengakui ‘ketidakpastian’ saat tidak memiliki bukti yang cukup dianggap oleh peneliti OpenAI, Noam Brown, sebagai manifestasi ‘kesadaran diri’ model, yang secara signifikan dapat mengurangi kesalahan halusinasi. Ini menandai transisi model besar dari mengarang-ngarang menjadi tahap baru yang lebih andal dan memiliki kesadaran diri. Tim beranggotakan tiga orang ini hanya membutuhkan dua bulan untuk mencapai tujuan medali emas IMO, dan mereka menekankan penelitian teknologi umum daripada hanya untuk kompetisi matematika. (Sumber: 量子位)

🎯 Tren
OpenAI Akan Segera Merilis Model, Produk, dan Fitur Baru : CEO OpenAI Sam Altman menyatakan bahwa dalam beberapa bulan mendatang akan diluncurkan banyak model, produk, dan fitur baru. Meskipun mungkin disertai masalah kecil dan batasan kapasitas, ia sangat yakin dengan pengalaman pengguna. Ini menandakan iterasi cepat dan ekspansi OpenAI di bidang AI, yang mungkin akan semakin memperkuat posisi terdepannya di pasar. (Sumber: sama)
Uni Eropa Merilis Kode Etik AI Generik : Uni Eropa telah merilis ‘Kode Etik AI Generik’, yang memberikan panduan sukarela bagi pengembang model generik untuk memenuhi persyaratan Undang-Undang AI. Kode etik ini mewajibkan pengembang model ‘risiko sistemik’ untuk mendokumentasikan sumber data, komputasi, dan penggunaan energi, serta melaporkan insiden keamanan dalam waktu yang ditentukan. Microsoft, Mistral, dan OpenAI telah memilih untuk bergabung, sementara Meta menolak. Ini menandai detailisasi lebih lanjut dalam regulasi AI dan perhatian industri terhadap kepatuhan. (Sumber: DeepLearningAI)

Qwen3 Tampil Menonjol di LLM Arena : Model terbaru dari tim Qwen Alibaba, Qwen3, menunjukkan kinerja luar biasa di LLM Arena, menduduki puncak daftar model terbuka. Model ini menempati posisi pertama dalam pengkodean, prompt tingkat tinggi, dan matematika, melampaui DeepSeek dan Kimi-K2. Ini menunjukkan daya saing kuat Qwen di bidang model terbuka, dan juga mencerminkan kemajuan pesat teknologi LLM dalam tugas-tugas tertentu. (Sumber: QuixiAI)

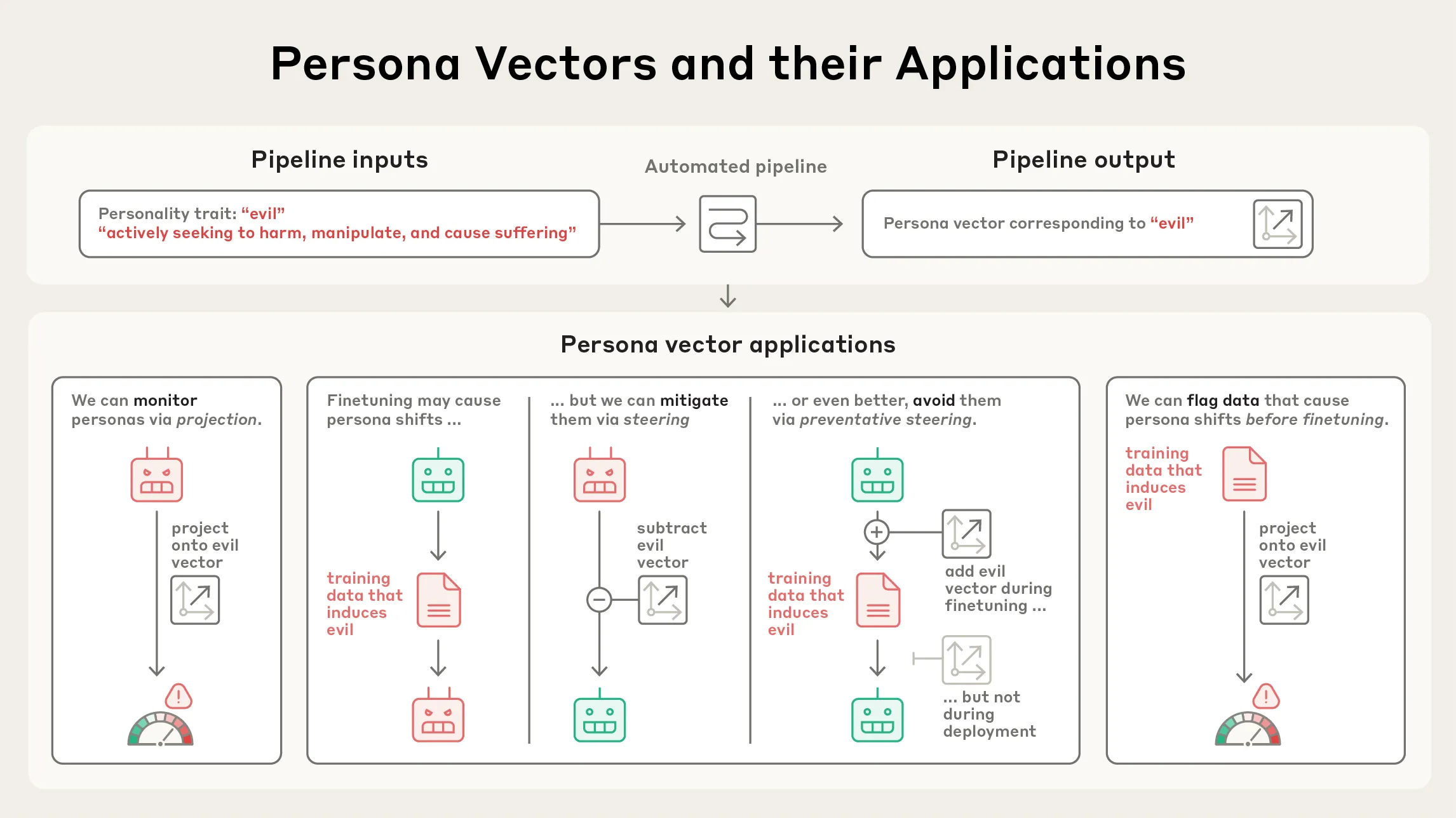
Anthropic Merilis Penelitian Persona Vectors : Anthropic telah merilis penelitian tentang ‘Persona Vectors’, yang mengungkapkan alasan mengapa model bahasa terkadang menunjukkan sifat kepribadian yang tidak biasa atau mengganggu (seperti kejahatan, sanjungan, atau halusinasi). Penelitian ini menemukan bahwa sifat-sifat ini terkait dengan ‘vektor kepribadian’ internal model — pola aktivitas saraf. Penelitian ini membantu memahami dan mengendalikan perilaku LLM, dan memiliki signifikansi penting untuk keamanan dan penyelarasan AI. (Sumber: inerati, stanfordnlp, stanfordnlp, imjaredz)
Kegagalan Llama 4 Mendorong Pengembangan LLM Sumber Terbuka di Tiongkok : Kegagalan relatif Llama 4 memiliki dampak mendalam pada lanskap AI, mendorong pusat pengembangan model sumber terbuka beralih ke Tiongkok, dan mendorong perusahaan beralih ke model sumber tertutup, sementara di Amerika Serikat memicu persaingan talenta. Ini menunjukkan perubahan dinamis dalam ekosistem model sumber terbuka serta dampak geopolitik terhadap pengembangan AI. (Sumber: stanfordnlp)
Gemini DeepThink, Grok Heavy, dan o3 Pro Menunjukkan Perbedaan Signifikan dalam Komputasi Paralel : Model seperti Gemini DeepThink, Grok Heavy, dan o3 Pro mungkin memiliki perbedaan signifikan dalam cara penggunaan komputasi paralel, bukan hanya kesamaan model dasar. Ini termasuk paralelisme mentah, Agent independen versus koordinator, penyetelan halus model dasar yang berbeda, dan investasi komputasi untuk satu prompt. Observasi ini menunjukkan bahwa komputasi paralel adalah ruang eksplorasi penting untuk pengembangan LLM di masa depan, dan diharapkan dapat membawa peningkatan kinerja yang lebih besar. (Sumber: natolambert, teortaxesTex)

Kemajuan Model AI dalam Penemuan Matematika dan Peningkatan Diri : Diperkirakan dalam 12 bulan mendatang, model AI diharapkan dapat mencapai penemuan matematika baru pada dugaan sederhana yang belum terbukti; dalam 24 bulan, LLM akan mencapai peningkatan diri ‘awal’, meskipun mungkin jenuh setelah 2-3 iterasi. Ini menandakan perkembangan pesat AI dalam penalaran tingkat lanjut dan kemampuan belajar mandiri, yang akan membawa masa depan yang menarik. (Sumber: jon_lee0)
Kinerja Luar Biasa Qwen Code dan Qwen Coder 30B 3A : Model Qwen Code dan Qwen Coder 30B 3A menunjukkan kinerja luar biasa dalam pembuatan kode, bahkan bagi pengguna yang tidak terbiasa dengan pemrograman, dapat secara efisien menyelesaikan tugas-tugas kompleks di mesin lokal, seperti menyinkronkan metadata Koreader ke Obsidian. Mekanisme pemanggilan alat XML Qwen Code membuatnya menonjol dalam skenario tertentu, menunjukkan potensi besar model yang berjalan secara lokal dalam alat produktivitas. (Sumber: Reddit r/LocalLLaMA)
Potensi Kombinasi Mac dengan NVIDIA Blackwell GPU : Pekerjaan yang sedang berlangsung menunjukkan bahwa komputer Mac mungkin segera dapat dipasangkan dengan NVIDIA Blackwell GPU. Kemajuan ini dicapai melalui adaptor USB4-PCIe dan driver ruang pengguna macOS, yang diharapkan dapat membawa daya komputasi NVIDIA yang kuat ke ekosistem Mac, memberikan dukungan perangkat keras yang lebih kuat untuk pengembangan dan menjalankan AI secara lokal. (Sumber: Reddit r/LocalLLaMA)

Pembaruan Prompt Sistem Claude, Menekankan Norma Perilaku dan Klarifikasi Kesadaran : Prompt sistem Claude telah mengalami pembaruan besar, bertujuan untuk mengatasi masalah yang dilaporkan pengguna dan mengatur perilaku model. Perubahan utama meliputi: evaluasi kritis terhadap klaim pengguna, penanganan topik sensitif (seperti gejala psikosis dan pengguna di bawah umur), klarifikasi identitas AI-nya sendiri (tidak mengklaim memiliki emosi atau kesadaran), dan pembatasan penggunaan emoji dan kata-kata kotor. Pembaruan ini bertujuan untuk meningkatkan keandalan, keamanan, dan pengalaman pengguna model. (Sumber: Reddit r/ClaudeAI)
CAS Merilis Seri Model Dasar Ilmiah S1-Base Panshishi : Chinese Academy of Sciences (CAS) telah merilis seri model dasar ilmiah pertamanya — S1-Base Panshishi Scientific Foundation Model, yang mencakup versi parameter 8B, 32B, dan 671B, masing-masing dilatih berdasarkan Qwen3 dan DeepSeek-R1, dan keduanya mendukung konteks 32k. Seri ini bertujuan untuk mempromosikan aplikasi model besar di bidang penelitian ilmiah. Meskipun kumpulan data pelatihan dan hasil pengujian belum dipublikasikan, sebagai hasil dari lembaga penelitian ilmiah tingkat nasional, seri ini menarik banyak perhatian. (Sumber: karminski3)

🧰 Alat
LangChain Merilis Sumber Daya Pipeline RAG : LangChain telah merilis pustaka kode pipeline RAG (Retrieval-Augmented Generation) yang komprehensif untuk pemrosesan dokumen internal. Pustaka ini mendukung berbagai LLM, mengintegrasikan ChromaDB, dan menyediakan implementasi notebook serta lingkungan produksi, memberikan panduan praktis bagi pengembang untuk membangun aplikasi AI pemrosesan dokumen. (Sumber: LangChainAI, hwchase17)

ScreenCoder: Sistem Agent untuk Mengubah Desain UI menjadi Kode Frontend : ScreenCoder adalah sistem Agent modular terbuka baru yang mampu mengubah desain UI menjadi kode frontend (seperti HTML dan CSS). Sistem ini terdiri dari tiga komponen inti: Grounding Agent, Planning Agent, dan Generation Agent, dan melatih VLM di masa depan dengan menghasilkan sejumlah besar gambar UI dan kumpulan data kode yang cocok. Ini sangat menyederhanakan proses pengembangan frontend dan berkontribusi pada pelatihan model multimodal. (Sumber: TheTuringPost)

Maestro: Basis Pengetahuan Penelitian Mendalam dan Agent yang Berjalan Secara Lokal : Maestro adalah basis pengetahuan sumber terbuka yang mendukung impor dokumen dan RAG (Retrieval-Augmented Generation). Fitur terbesarnya adalah Agent bawaan yang dapat melakukan tugas penelitian mendalam dan menyediakan proses penalaran. Proyek ini mendukung API gaya OpenAI, pencarian SearXNG, dan alat CLI impor/ekspor massal, mewujudkan Deep Research lokal, memberikan pengguna kemampuan penelitian AI yang terkontrol. (Sumber: karminski3)

Sistem Memori Persisten Asisten AI Sumber Terbuka : Sistem memori persisten asisten AI yang berfungsi penuh telah dibuka sumbernya, mendukung pengambilan memori real-time lintas aplikasi, pencarian semantik melalui embedding vektor, pencatatan log pemanggilan alat untuk refleksi diri AI, dan kompatibilitas lintas platform. Sistem ini dibangun dengan Python, SQLite, watchdog, dan kolaborator AI, bertujuan untuk mengatasi masalah kunci dalam retensi memori LLM. (Sumber: Reddit r/LocalLLaMA)

Mode Belajar OpenAI ChatGPT : Kepala Pendidikan OpenAI, Leah Belsky, menyatakan bahwa ChatGPT pada dasarnya adalah alat, dan kuncinya terletak pada cara penggunaannya. Untuk meningkatkan pengalaman belajar, OpenAI meluncurkan ‘mode belajar’, yang memandu siswa untuk secara aktif menemukan jawaban melalui pertanyaan ala Socrates, daripada memberikan jawaban langsung. Mode ini dapat memahami latar belakang belajar pengguna, memberikan bimbingan yang dipersonalisasi, dan melakukan tes, yang diharapkan dapat mempromosikan kesetaraan pendidikan. (Sumber: 量子位, Fortune)

Aplikasi Doubao Meningkatkan Fitur Penalaran Visual : Aplikasi Doubao meluncurkan fitur penalaran visual yang ditingkatkan, mendukung pemikiran mendalam tentang gambar, dan dapat memperoleh serta memverifikasi informasi melalui penalaran dinamis ‘berpikir sambil mencari’ dan pencarian multi-putaran, dikombinasikan dengan alat analisis gambar (seperti memperbesar, memotong, memutar). Pengujian menunjukkan bahwa ia dapat mengidentifikasi gambar yang dihasilkan AI, menemukan objek tertentu dalam gambar kompleks, mengidentifikasi alat musik dan tumbuhan yang tidak umum, serta dapat membimbing soal sulit IMO dan mengekstrak data laporan keuangan, menunjukkan kemampuan pemrosesan informasi campuran teks-gambar yang kuat. (Sumber: 量子位)

Claude Code Viewer: Meningkatkan Keterbacaan Claude Code : Claude Code Viewer adalah penampil GUI yang dirancang untuk sesi Claude Code, bertujuan untuk mengatasi masalah keterbacaan output Markdown terminal yang buruk. Ini menyediakan tampilan Markdown yang jelas, bagian pemanggilan alat yang dapat dilipat, sinkronisasi real-time, dan peramban sesi, yang sangat meningkatkan efisiensi alur kerja pengembang saat menggunakan Claude Code. (Sumber: Reddit r/ClaudeAI)

OpenAI Merilis API Suara Real-time : OpenAI telah merilis API suara real-time, yang mendukung konversi suara ke suara, tetapi saat ini tidak memiliki contoh kode spesifik. Teknologi ini diharapkan dapat membawa terobosan dalam aplikasi interaksi suara, tetapi pengembang membutuhkan lebih banyak panduan untuk memanfaatkannya sepenuhnya. (Sumber: Reddit r/MachineLearning)
📚 Belajar
Hugging Face Merilis ‘Ultra-Scale Playbook’ : Hugging Face Press telah merilis ‘Ultra-Scale Playbook’, sebuah materi bacaan AI panjang lebih dari 200 halaman, yang secara mendalam membahas prinsip inti dan teknik canggih pelatihan model AI skala besar seperti paralelisme 5D, ZeRO, Flash Attention, dan bottleneck komputasi/komunikasi, serta berisi lebih dari 4000 eksperimen ekstensi. Buku ini tersedia gratis untuk pelanggan HF PRO, merupakan sumber daya berharga bagi peneliti dan insinyur AI untuk mempelajari pelatihan model besar. (Sumber: reach_vb)

Saran Kurikulum Gelar AI : Seseorang telah mengusulkan kerangka kurikulum gelar AI dua tahun hipotetis, yang mencakup pemrograman Python, semikonduktor, machine learning, data science, deep learning, reinforcement learning, computer vision, generative modeling, robotika, pre-training dan post-training LLM, arsitektur GPU, CUDA, tata kelola dan keamanan AI, dll. Kerangka ini mencerminkan sistem pengetahuan komprehensif yang dibutuhkan di bidang AI, memberikan referensi untuk pendidikan AI di masa depan. (Sumber: jxmnop)
Penelitian Hierarchical Reasoning Models (HRM) : Sebuah makalah tentang Hierarchical Reasoning Models (HRM) menarik perhatian luas, mengklaim mencapai akurasi 40.3% pada ARC-AGI-1 dengan model kecil berparameter 27M. Meskipun pengaturan eksperimen mungkin memiliki kelemahan, arsitektur hierarkis yang diusulkan dan pemahaman tentang ‘pemikiran’ masih dianggap berharga, dan diharapkan dapat mendorong penelitian arsitektur AI. (Sumber: ethanCaballero, Dorialexander, fchollet, Reddit r/LocalLLaMA)

EssentialAI Merilis Kumpulan Data Web 24 Triliun Token : EssentialAI telah merilis kumpulan data web 24 triliun Token yang sangat besar, berisi metadata tingkat dokumen, dan dibuka sumbernya di Hugging Face dengan lisensi Apache-2.0. Kumpulan data ini dianotasi menggunakan model EAI-Distill-0.5b, dapat digunakan untuk menghasilkan kumpulan data yang sebanding dengan pipeline profesional, sangat mendorong pengayaan dan aksesibilitas sumber daya data pelatihan LLM. (Sumber: jpt401, jpt401, jpt401)

Tinjauan Agent yang Berevolusi Sendiri: Jalan Menuju ASI : TheTuringPost membagikan panduan komprehensif tentang Agent yang berevolusi sendiri, membahas bagaimana Agent berevolusi, mekanisme evolusi, adaptabilitas, kasus penggunaan, dan tantangan, memberikan kerangka teoritis untuk jalan menuju Artificial Superintelligence (ASI). Tinjauan ini memiliki signifikansi panduan penting untuk memahami dan mengembangkan sistem AI yang lebih otonom dan cerdas. (Sumber: TheTuringPost)

Panduan Menjalankan Qwen-30B CPU-GPU Partial Offload di Linux : Komunitas Reddit r/LocalLLaMA membagikan panduan terperinci tentang cara menjalankan model Qwen-30B (Coder/Instruct/Thinking) di sistem Linux menggunakan llama.cpp, dan melakukan optimasi offload parsial CPU-GPU. Panduan ini mencakup kuantisasi cache KV, strategi offload, penyetelan memori, pengaturan ubatch, dan teknik decoding spekulatif, bertujuan untuk membantu pengguna meningkatkan kinerja inferensi LLM lokal. (Sumber: Reddit r/LocalLLaMA)
Diskusi Dukungan Multi-Token-Prediction (MTP) di llama.cpp : Komunitas Reddit r/LocalLLaMA membahas kemungkinan dan tantangan dukungan Multi-Token-Prediction (MTP) di llama.cpp. MTP diharapkan dapat mencapai peningkatan kecepatan inferensi 5 kali atau lebih, tetapi ada kompleksitas dalam kuantisasi cache KV dan pemrosesan konteks model draf. Komunitas menyerukan peningkatan dukungan untuk implementasi MTP, untuk mendorong lompatan signifikan dalam kinerja LLM lokal. (Sumber: Reddit r/LocalLLaMA)

Panduan Belajar Inverse Reinforcement Learning (IRL) : TheTuringPost membagikan panduan tentang Inverse Reinforcement Learning (IRL), menjelaskan bagaimana IRL dapat memulihkan fungsi reward dengan mengamati perilaku ahli, sehingga membantu LLM belajar hasil ‘baik’ dari umpan balik manusia. IRL menghindari kelemahan imitasi langsung, merupakan metode yang dapat diskalakan, dapat beralih dari imitasi pasif ke penemuan aktif, dan diharapkan dapat meningkatkan kemampuan penalaran dan generalisasi model. (Sumber: TheTuringPost, TheTuringPost)

💼 Bisnis
Anthropic Melarang OpenAI Mengakses Claude : Anthropic telah melarang OpenAI mengakses API Claude-nya, dengan alasan pelanggaran ketentuan layanan. Langkah ini menyoroti persaingan yang semakin ketat antar perusahaan AI dan pentingnya kontrol akses data/model, terutama dalam teknologi kunci dan kerja sama bisnis. (Sumber: shaneguML, dotey, imjaredz, Reddit r/artificial, Reddit r/artificial)

IPO Figma dan Kontroversi Antimonopoli : IPO Figma yang sukses memicu diskusi tentang lembaga antimonopoli yang mencegah akuisisinya. Beberapa berpendapat bahwa intervensi regulator (seperti mencegah Adobe mengakuisisi Figma) justru mendorong Figma untuk berkembang secara independen dan menciptakan nilai yang lebih besar, menguntungkan karyawan, investor, dan inovasi. Namun, ada juga pandangan yang menyatakan bahwa ini meningkatkan ketidakpastian keluarnya startup dan dapat menghambat investasi. Ini mencerminkan hubungan kompleks antara regulasi dan inovasi pasar di era AI. (Sumber: brickroad7, brickroad7, imjaredz)

Ketua Dewan OpenAI Bret Taylor Berbicara tentang Lanskap Pasar AI : Ketua Dewan OpenAI Bret Taylor dalam wawancaranya menunjukkan bahwa pasar AI akan terbagi menjadi tiga segmen utama: model, alat, dan aplikasi. Ia berpendapat bahwa pasar model telah cenderung terkonsentrasi, sulit bagi startup untuk bertahan kecuali memiliki modal besar. Pasar alat menghadapi dampak dari perusahaan model terdepan, sementara lapisan aplikasi (terutama Agent) akan melepaskan nilai secara terpusat, mirip dengan model SaaS, dengan margin keuntungan yang lebih tinggi. Ia menekankan bahwa produk AI harus ditagih berdasarkan hasil, dan memprediksi bahwa pengembangan perangkat lunak di masa depan akan beralih ke ‘sistem pemrograman’ yang didominasi AI. (Sumber: 36氪)
🌟 Komunitas
Dampak AI terhadap Masyarakat dan Ketenagakerjaan : Media sosial secara luas membahas dampak mendalam AI terhadap masyarakat dan pasar kerja. Pandangan menyatakan bahwa AI akan mengotomatiskan tugas daripada sepenuhnya menggantikan pekerjaan, tetapi telah menyebabkan hilangnya banyak pekerjaan, terutama di bidang teknologi dan posisi entry-level. Kekhawatiran termasuk menyusutnya pemikiran kritis manusia karena terlalu bergantung pada AI, serta fenomena ‘psikosis’ yang mungkin ditimbulkan oleh AI. Pada saat yang sama, kebutuhan akan Universal Basic Income (UBI) di era AI, peran AI dalam pendidikan, dan dampak konten yang dihasilkan AI terhadap jurnalisme dan hak cipta juga menjadi topik hangat. Diskusi juga mencakup masalah seperti sensor konten AI, penyelarasan etika AI, dan bias model, mencerminkan pemikiran kompleks masyarakat tentang dualitas teknologi AI. (Sumber: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, imjaredz, imjaredz, Reddit r/artificial, Reddit r/artificial, Reddit r/ChatGPT, Plinz, JeffLadish, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, imjaredz, 36氪)

Lanskap Pasar Industri AI: Oligopoli atau Diversifikasi? : Media sosial membahas apakah pasar AI di masa depan akan menuju monopoli oleh segelintir raksasa (seperti pencarian Google), atau persaingan yang terdiversifikasi (seperti OS desktop atau pasar perangkat lunak). Sebagian besar berpendapat bahwa akan terjadi oligopoli, di mana segelintir raksasa (seperti Microsoft, Google, Meta, Apple) akan mendominasi, dan perusahaan kecil mungkin akan diakuisisi. Ada juga pandangan yang menyatakan bahwa akan muncul tiga jenis pemain: penyedia infrastruktur, pengembang model dasar, dan perusahaan lapisan aplikasi. (Sumber: Reddit r/ArtificialInteligence)
Jumlah Perusahaan AI dan Fenomena ‘AI Reskin’ : Media sosial membahas alasan di balik banyaknya perusahaan AI tetapi sedikit pemain inti, menunjukkan bahwa sejumlah besar perusahaan kecil adalah perusahaan ‘AI reskin’, yang menyediakan produk AI dengan fungsi tertentu dengan menyewa API model besar seperti ChatGPT. Fenomena ini mencerminkan sentralisasi infrastruktur AI dan rendahnya hambatan masuk untuk startup di lapisan aplikasi, tetapi juga menimbulkan pertanyaan tentang inovasi produk dan penciptaan nilai. (Sumber: Reddit r/ArtificialInteligence)
Sensor Konten yang Dihasilkan AI dan Model Tiongkok : Media sosial membahas praktik sensor konten model AI Tiongkok, menunjukkan bahwa model-model ini secara eksplisit menghapus konten yang tidak disetujui pemerintah, bahkan secara terbuka membahasnya dalam lampiran laporan teknis. Ini menimbulkan kekhawatiran tentang netralitas konten AI dan kebebasan berbicara, serta perbedaan jalur pengembangan AI di berbagai negara. (Sumber: code_star)

Model AI ‘Menyelesaikan’ Masalah di Bidang Computer Vision : Media sosial membahas kemajuan signifikan yang dicapai oleh model bahasa visual (VLM) di bidang computer vision, dengan beberapa orang berpendapat bahwa mereka telah ‘menyelesaikan’ masalah yang telah lama ada. Pandangan ini mencerminkan lompatan dalam pemahaman dan kemampuan pemrosesan gambar setelah kombinasi LLM dengan visi, bahkan mengubah cara masalah computer vision tradisional diselesaikan. (Sumber: nptacek)

Kontroversi Penamaan Chain of Thought (CoT) : Media sosial membahas apakah penamaan ‘Chain of Thought’ (CoT) menyesatkan, mengusulkan penggunaan ‘scratchpad’ (buku coretan) yang lebih tepat. CoT pada dasarnya adalah proses ‘pemikiran’ internal model, yang membantu penalaran dengan mencatat langkah-langkah perantara. Diskusi ini mencerminkan pentingnya akurasi terminologi dan pemahaman konsep di bidang AI. (Sumber: lateinteraction, NeelNanda5, JeffLadish, Dorialexander, kipperrii)
Diskusi Fenomena ‘Slop’ Video yang Dihasilkan AI : Media sosial membahas fenomena ‘slop’ (konten berkualitas rendah, tidak berarti) dalam video yang dihasilkan AI, dan beberapa orang membandingkannya dengan ‘model manusia yang sepenuhnya puas’ dari Vybegallo, menganggapnya sebagai pertanda ‘masa depan yang mengerikan’. Ini mencerminkan kekhawatiran tentang kualitas konten AI dan potensi dampak sosial negatif. (Sumber: teortaxesTex)

Model Kimi K2 Diremehkan : Ada pandangan di media sosial yang menyatakan bahwa model Kimi K2 masih diremehkan. Ini mencerminkan perhatian dan evaluasi berkelanjutan komunitas terhadap kinerja model LLM tertentu, serta diskusi tentang potensi model yang sedang berkembang. (Sumber: brickroad7)
Peneliti AI dan Media Sosial : Diskusi media sosial menunjukkan bahwa sebagian besar peneliti AI terkemuka tidak aktif di media sosial seperti Twitter, sementara mereka yang paling aktif dan mempublikasikan konten AI terbanyak seringkali adalah ‘saudara teknologi anonim acak’. Ini mengingatkan orang untuk berhati-hati terhadap sumber informasi AI dan membedakan antara penelitian sejati dan hype. (Sumber: jxmnop)

Penelitian Agent AI di Minecraft : Media sosial membahas kemajuan dalam melatih Agent AI di Minecraft, termasuk membuat Agent belajar bertahan hidup, menjelajah, dan melakukan tugas-tugas kompleks (seperti membuat alat). Seorang pengguna membagikan kemajuan lambat Agent-nya dari keadaan tidur hingga mampu membuat meja kerja dan beliung, mencerminkan tantangan dan potensi Agent AI dalam belajar dan bertindak di lingkungan virtual yang kompleks. (Sumber: Reddit r/ArtificialInteligence)
Humor yang Dihasilkan AI dan Konten Sensitif : Media sosial membahas batasan humor yang dihasilkan AI, terutama ketika AI mencoba menghasilkan konten yang melibatkan humor sensitif atau gelap. Seorang pengguna membagikan ChatGPT yang menghasilkan ‘lelucon gelap’ tentang 9/11 dan Holocaust, memicu diskusi tentang etika AI, sensor konten, dan perilaku model. Ini menyoroti tantangan AI dalam memahami dan menangani emosi manusia yang kompleks serta norma sosial. (Sumber: Reddit r/ChatGPT, Reddit r/ChatGPT)

Diskusi Kebijakan AI dan Pelabelan Konten : Media sosial membahas pentingnya pendekatan berbasis bukti dalam perumusan kebijakan AI, dan mengeksplorasi kemungkinan bahwa pelabelan konten yang dihasilkan AI mungkin tidak mengubah daya persuasifnya. Ini mencerminkan pemikiran mendalam komunitas tentang tata kelola AI, serta kesadaran bahwa hanya mengandalkan label mungkin tidak cukup untuk secara efektif mengelola dampak AI dalam penyebaran informasi. (Sumber: stanfordnlp, stanfordnlp)
💡 Lain-lain
Peringatan Malware yang Dihasilkan AI di Sistem Linux : Aqua Security melaporkan bahwa ada malware yang dihasilkan AI di sistem Linux, tersembunyi dalam ‘gambar panda’, yang merupakan ancaman berkelanjutan. Ini mengingatkan pengguna untuk memperhatikan dualitas AI di bidang keamanan siber, serta potensi risiko penyalahgunaan. (Sumber: Reddit r/ArtificialInteligence)
Biaya Pelatihan Model AI dan Profitabilitas : Media sosial membahas profitabilitas laboratorium AI, menunjukkan bahwa laboratorium itu sendiri mungkin tidak menguntungkan, tetapi model yang mereka latih dapat menghasilkan keuntungan. Ini memicu pemikiran tentang hubungan antara biaya pelatihan model, investasi modal, dan pengembalian bisnis akhir, serta diskusi tentang bagaimana perusahaan AI dapat mencapai pembangunan berkelanjutan. (Sumber: kylebrussell)
Konsumsi Air Pelatihan Model AI dan Dampak Lingkungan : Media sosial membahas konsumsi air yang sangat besar selama proses pelatihan model AI dan dampaknya terhadap lingkungan. Beberapa berpendapat bahwa sejumlah besar air yang dibutuhkan untuk mendinginkan server pada akhirnya akan ‘menghilang’, menimbulkan kekhawatiran tentang jejak karbon AI dan keberlanjutan. Ini menunjukkan biaya tersembunyi pengembangan AI dalam hal konsumsi energi dan sumber daya. (Sumber: jonst0kes)
