
Mots-clés:DeepSeek, Attention Native Sparse, ACL2025, Traitement de texte long, DeepSeek-V4, DeepSeek-R2, Grand modèle, Conscience de soi de l’IA, Mécanisme NSA, Contexte de 1 million de tokens, Optimisation conjointe algorithme et matériel, Performance de l’IA aux Olympiades mathématiques IMO, API vocale en temps réel d’OpenAI, DeepSeek, Attention Native Sparse, ACL2025, Traitement de texte long, DeepSeek-V4, DeepSeek-R2, Grand modèle, Conscience de soi de l’IA, Mécanisme NSA, Contexte de 1 million de tokens, Optimisation conjointe algorithme et matériel, Performance de l’IA aux Olympiades mathématiques IMO, API vocale en temps réel d’OpenAI
🔥 À la Une
DeepSeek: la prochaine génération de technologie dévoilée en avance, un article co-écrit par Liang Wenfeng remporte le prix du meilleur article à l’ACL 2025 : L’équipe DeepSeek a remporté le prix du meilleur article à l’ACL 2025 grâce à son mécanisme d’attention nativement clairsemée (NSA). Cette technologie, qui optimise la collaboration entre l’algorithme et le matériel, accélère le traitement des textes longs de 11 fois tout en surpassant les performances des modèles d’attention complets traditionnels. L’auteur principal a révélé que cette technologie peut étendre la longueur du contexte jusqu’à 1 million de Token et sera appliquée aux modèles de pointe de prochaine génération, DeepSeek-V4 et DeepSeek-R2, marquant une avancée majeure dans la capacité de traitement des textes longs des grands modèles. (Source: 量子位)

L’IA admet “ne pas savoir” répondre à un problème de l’IMO, OpenAI : c’est de la conscience de soi : Bien que le modèle vedette d’OpenAI ait obtenu un score de zéro au problème 6 de l’Olympiade Internationale de Mathématiques (IMO), sa capacité à admettre “ne pas être certain” en l’absence de preuves suffisantes est considérée par le chercheur d’OpenAI, Noam Brown, comme une manifestation de la “conscience de soi” du modèle, capable de réduire significativement les erreurs d’hallucination. Cela marque une nouvelle étape pour les grands modèles, passant de la fabulation à une fiabilité accrue et une meilleure auto-connaissance. L’équipe de trois personnes a atteint l’objectif de la médaille d’or de l’IMO en seulement deux mois et souligne que la recherche porte sur des technologies générales plutôt que sur la seule compétition mathématique. (Source: 量子位)

🎯 Tendances
OpenAI s’apprête à lancer de nouveaux modèles, produits et fonctionnalités : Sam Altman, PDG d’OpenAI, a déclaré que de nombreux nouveaux modèles, produits et fonctionnalités seraient lancés dans les prochains mois. Bien que cela puisse s’accompagner de quelques problèmes mineurs et de limitations de capacité, il est confiant quant à l’expérience utilisateur. Cela préfigure une itération rapide et une expansion d’OpenAI dans le domaine de l’IA, susceptible de consolider sa position de leader sur le marché. (Source: sama)
L’UE publie un code de conduite pour l’IA générale : L’Union européenne a publié un “Code de Conduite pour l’IA Générale”, offrant des lignes directrices volontaires aux développeurs de modèles généraux pour se conformer aux exigences de l’AI Act. Ce code exige que les développeurs de modèles à “risque systémique” documentent leurs sources de données, leur consommation de calcul et d’énergie, et signalent les incidents de sécurité dans un délai spécifié. Microsoft, Mistral et OpenAI ont choisi d’y adhérer, tandis que Meta a refusé. Cela marque une nouvelle étape dans la réglementation de l’IA et l’attention de l’industrie à la conformité. (Source: DeepLearningAI)

Qwen3 se distingue dans l’arène des LLM : Le dernier modèle de l’équipe Alibaba Qwen, Qwen3, a excellé dans l’arène des LLM, se classant en tête des modèles ouverts. Ce modèle s’est classé premier en matière de codage, d’invites complexes et de mathématiques, surpassant DeepSeek et Kimi-K2. Cela démontre la forte compétitivité de Qwen dans le domaine des modèles ouverts et reflète les progrès rapides de la technologie LLM sur des tâches spécifiques. (Source: QuixiAI)

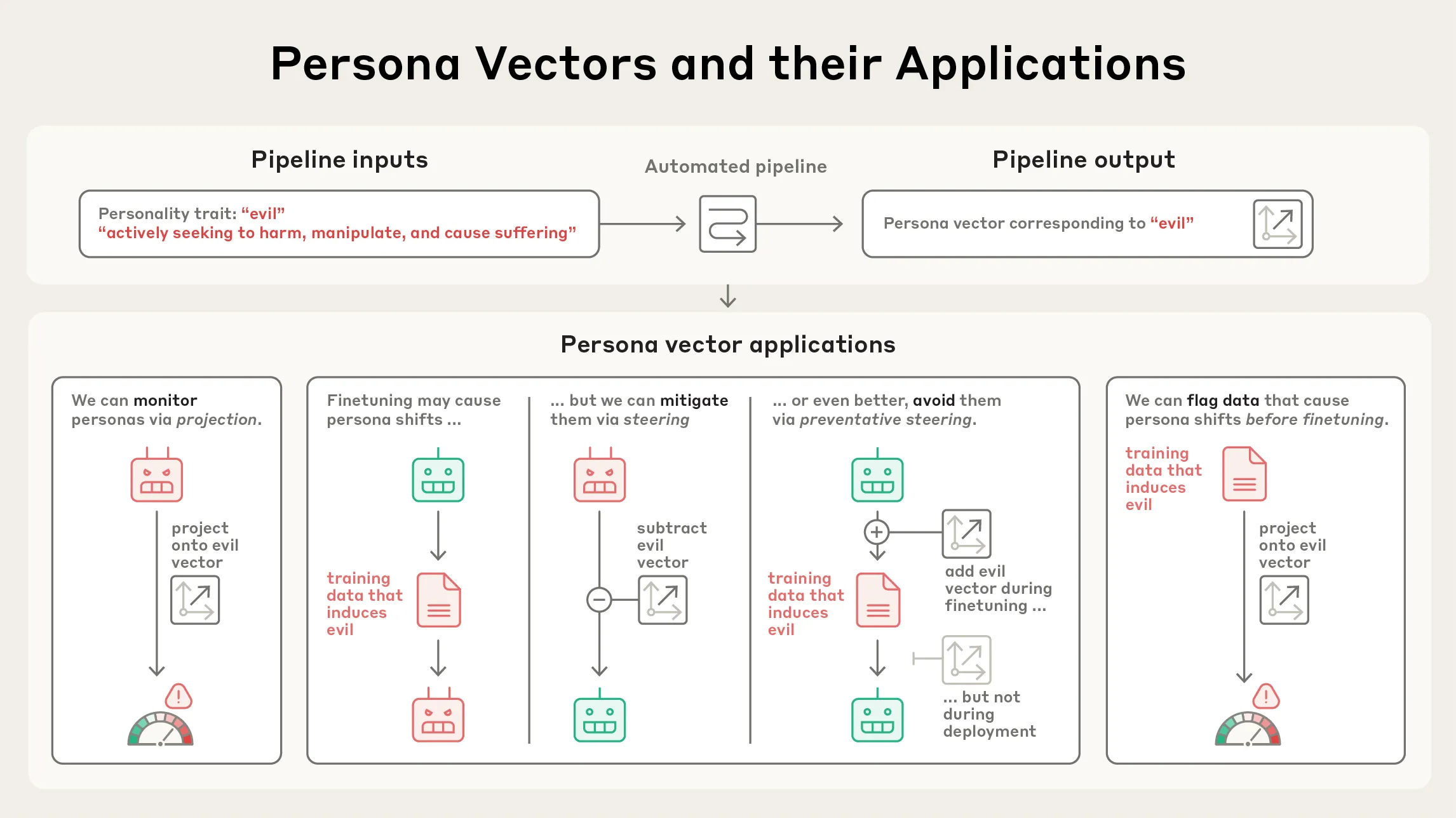
Anthropic publie une étude sur les “Persona Vectors” : Anthropic a publié une étude sur les “Persona Vectors”, révélant pourquoi les modèles de langage peuvent parfois présenter des traits de personnalité anormaux ou troublants (tels que la méchanceté, la flatterie ou les hallucinations). L’étude a découvert que ces traits sont liés aux “vecteurs de personnalité” internes du modèle – un type de modèle d’activité neuronale. Cette recherche aide à comprendre et à contrôler le comportement des LLM, et est d’une grande importance pour la sécurité et l’alignement de l’IA. (Source: inerati, stanfordnlp, stanfordnlp, imjaredz)
L’échec de Llama 4 stimule le développement des LLM open source en Chine : L’échec relatif de Llama 4 a eu un impact profond sur le paysage de l’IA, déplaçant le centre de développement des modèles open source vers la Chine et poussant les entreprises à se tourner vers les modèles propriétaires, tout en déclenchant une guerre des talents aux États-Unis. Cela démontre les changements dynamiques dans l’écosystème des modèles open source et l’influence géopolitique sur le développement de l’IA. (Source: stanfordnlp)
Gemini DeepThink, Grok Heavy et o3 Pro présentent des différences significatives en matière de calcul parallèle : Des modèles tels que Gemini DeepThink, Grok Heavy et o3 Pro pourraient présenter des différences significatives dans la manière dont ils utilisent le calcul parallèle, plutôt que de simples similitudes dans les modèles sous-jacents. Cela inclut le parallélisme brut, les Agents indépendants par rapport aux coordinateurs, le réglage fin de différents modèles de base et l’investissement computationnel par invite unique. Cette observation indique que le calcul parallèle est un domaine d’exploration important pour le développement futur des LLM et devrait entraîner des améliorations de performances encore plus importantes. (Source: natolambert, teortaxesTex)

Progrès des modèles d’IA en matière de découverte mathématique et d’auto-amélioration : On s’attend à ce que, dans les 12 prochains mois, les modèles d’IA puissent réaliser de nouvelles découvertes mathématiques sur des conjectures simples non prouvées ; dans les 24 mois, les LLM réaliseront une auto-amélioration “préliminaire”, bien qu’elle puisse saturer après 2-3 itérations. Cela préfigure un développement rapide de l’IA en matière de raisonnement avancé et de capacités d’apprentissage autonome, promettant un avenir passionnant. (Source: jon_lee0)
Performances exceptionnelles de Qwen Code et Qwen Coder 30B 3A : Les modèles Qwen Code et Qwen Coder 30B 3A excellent dans la génération de code, permettant même aux utilisateurs non familiers avec la programmation de réaliser efficacement des tâches complexes sur des machines locales, comme la synchronisation des métadonnées Koreader vers Obsidian. Le mécanisme d’appel d’outils XML de Qwen Code le rend particulièrement performant dans des scénarios spécifiques, démontrant l’énorme potentiel des modèles exécutés localement dans les outils de productivité. (Source: Reddit r/LocalLLaMA)
Combinaison potentielle de Mac et des GPU NVIDIA Blackwell : Des travaux en cours suggèrent que les ordinateurs Mac pourraient bientôt être couplés avec les GPU NVIDIA Blackwell. Cette avancée, rendue possible par un adaptateur USB4-PCIe et un pilote macOS en espace utilisateur, promet d’introduire la puissante capacité de calcul de NVIDIA dans l’écosystème Mac, offrant un support matériel plus robuste pour le développement et l’exécution d’IA locale. (Source: Reddit r/LocalLLaMA)

Mise à jour des invites système de Claude, mettant l’accent sur les normes de comportement et la clarification de la conscience : Les invites système de Claude ont été considérablement mises à jour pour résoudre les problèmes signalés par les utilisateurs et normaliser le comportement du modèle. Les principaux changements incluent : l’évaluation critique des affirmations des utilisateurs, la gestion des sujets sensibles (tels que les symptômes de maladies mentales et les utilisateurs mineurs), la clarification de son identité d’IA (ne revendiquant pas d’émotions ou de conscience), et la limitation de l’utilisation des émoticônes et des gros mots. Ces mises à jour visent à améliorer la fiabilité, la sécurité et l’expérience utilisateur du modèle. (Source: Reddit r/ClaudeAI)
L’Académie chinoise des sciences lance la série de modèles fondamentaux scientifiques S1-Base Pansh : L’Académie chinoise des sciences a lancé sa première série de modèles fondamentaux scientifiques – les modèles fondamentaux scientifiques S1-Base Pansh, disponibles en versions 8B, 32B et 671B paramètres, entraînés respectivement sur Qwen3 et DeepSeek-R1, et supportant tous un contexte de 32k. Cette série vise à promouvoir l’application des grands modèles dans le domaine de la recherche scientifique. Bien que les ensembles de données d’entraînement et les résultats des tests n’aient pas encore été rendus publics, leur statut de réalisation d’une institution de recherche nationale suscite un grand intérêt. (Source: karminski3)

🧰 Outils
LangChain publie des ressources pour les pipelines RAG : LangChain a publié une bibliothèque de code complète pour les pipelines RAG (Retrieval-Augmented Generation) destinée au traitement de documents internes. Cette bibliothèque prend en charge plusieurs LLM, intègre ChromaDB et fournit des notebooks ainsi que des implémentations pour des environnements de production, offrant un guide pratique aux développeurs pour construire des applications d’IA de traitement de documents. (Source: LangChainAI, hwchase17)

ScreenCoder : un système d’Agent pour convertir les designs d’interface utilisateur en code frontend : ScreenCoder est un nouveau système d’Agent modulaire et ouvert capable de convertir des designs d’interface utilisateur en code frontend (comme HTML et CSS). Il comprend trois composants principaux : l’Agent de mise à la terre, l’Agent de planification et l’Agent de génération, et entraîne les futurs VLM en générant un grand ensemble de données d’images d’interface utilisateur avec le code correspondant. Cela simplifie considérablement le processus de développement frontend et contribue à l’entraînement des modèles multimodaux. (Source: TheTuringPost)

Maestro : une base de connaissances et un Agent pour la recherche approfondie en local : Maestro est une base de connaissances open source qui prend en charge l’importation de documents et le RAG (Retrieval-Augmented Generation). Son principal atout est un Agent intégré capable d’effectuer des tâches de recherche approfondie et de fournir le processus de raisonnement. Le projet prend en charge les API de style OpenAI, la recherche SearXNG et les outils CLI d’importation/exportation en masse, permettant une recherche approfondie localisée et offrant aux utilisateurs une capacité de recherche IA contrôlable. (Source: karminski3)

Un système de mémoire persistante pour assistant IA open source : Un système complet de mémoire persistante pour assistant IA a été rendu open source. Il prend en charge la capture de mémoire en temps réel entre applications, la recherche sémantique via l’intégration de vecteurs, l’enregistrement des appels d’outils pour l’auto-réflexion de l’IA, et est compatible multiplateforme. Ce système, construit avec Python, SQLite, watchdog et des collaborateurs IA, vise à résoudre le problème crucial de la rétention de mémoire des LLM. (Source: Reddit r/LocalLLaMA)

Mode d’apprentissage OpenAI ChatGPT : Leah Belsky, directrice de l’éducation chez OpenAI, a déclaré que ChatGPT est essentiellement un outil, et que la clé réside dans la manière de l’utiliser. Pour améliorer l’expérience d’apprentissage, OpenAI a lancé le “mode d’apprentissage”, qui guide les étudiants à trouver activement les réponses par des questions socratiques, plutôt que de les fournir directement. Ce mode peut comprendre le contexte d’apprentissage de l’utilisateur, offrir un tutorat personnalisé et effectuer des tests, ce qui devrait favoriser l’équité éducative. (Source: 量子位, Fortune)

L’application Doudou APP met à niveau sa fonction de raisonnement visuel : L’application Doudou APP a lancé une version améliorée de sa fonction de raisonnement visuel, prenant en charge la réflexion approfondie sur les images. Elle peut obtenir et vérifier des informations grâce à un raisonnement dynamique “penser en cherchant” et à des recherches multiples, combinées à des outils d’analyse d’images (tels que le zoom, le recadrage, la rotation). Les tests réels montrent qu’elle peut identifier les images générées par l’IA, trouver des objets spécifiques dans des images complexes, reconnaître des instruments de musique et des plantes rares, et même aider à résoudre des problèmes IMO et extraire des données de rapports financiers, démontrant une puissante capacité de traitement d’informations mixtes texte-image. (Source: 量子位)

Claude Code Viewer : améliore la lisibilité de Claude Code : Claude Code Viewer est une visionneuse GUI conçue pour les sessions Claude Code, visant à résoudre le problème de la mauvaise lisibilité de la sortie Markdown dans le terminal. Il offre un affichage Markdown clair, des sections d’appel d’outils repliables, une synchronisation en temps réel et un navigateur de session, améliorant considérablement l’efficacité du flux de travail des développeurs utilisant Claude Code. (Source: Reddit r/ClaudeAI)

OpenAI lance une API vocale en temps réel : OpenAI a lancé une API vocale en temps réel, prenant en charge la conversion de la voix à la voix, mais manquant actuellement d’exemples de code spécifiques. Cette technologie promet une percée dans les applications d’interaction vocale, mais les développeurs auront besoin de plus de conseils pour l’exploiter pleinement. (Source: Reddit r/MachineLearning)
📚 Apprentissage
Hugging Face publie le “Ultra-Scale Playbook” : Hugging Face Press a publié le “Ultra-Scale Playbook”, un document de plus de 200 pages sur l’IA, qui explore en profondeur les principes fondamentaux et les techniques avancées de l’entraînement de modèles d’IA à grande échelle, tels que le parallélisme 5D, ZeRO, Flash Attention, et les goulots d’étranglement calcul/communication, et contient plus de 4000 expériences étendues. Ce livre est offert gratuitement aux abonnés HF PRO, constituant une ressource précieuse pour les chercheurs et ingénieurs en IA souhaitant apprendre l’entraînement des grands modèles. (Source: reach_vb)

Suggestions de programmes de diplôme en IA : Quelqu’un a proposé un plan hypothétique de programme de diplôme en IA de deux ans, couvrant la programmation Python, les semi-conducteurs, le Machine Learning, la Data Science, le Deep Learning, le Reinforcement Learning, la Computer Vision, la Generative Modeling, la Robotique, le pré-entraînement et post-entraînement des LLM, l’architecture GPU, CUDA, la gouvernance et la sécurité de l’IA, etc. Ce plan reflète le système de connaissances complet requis dans le domaine de l’IA et offre une référence pour l’éducation future en IA. (Source: jxmnop)
Étude sur les Hierarchical Reasoning Models (HRM) : Un article sur les Hierarchical Reasoning Models (HRM) a suscité un vif intérêt, affirmant avoir atteint une précision de 40,3% sur ARC-AGI-1 avec un modèle minuscule de 27M paramètres. Bien que la configuration expérimentale puisse présenter des défauts, son architecture hiérarchique et sa compréhension de la “pensée” sont toujours considérées comme précieuses et devraient faire progresser la recherche sur l’architecture de l’IA. (Source: ethanCaballero, Dorialexander, fchollet, Reddit r/LocalLLaMA)

EssentialAI publie un ensemble de données web de 24 billions de Tokens : EssentialAI a publié un vaste ensemble de données web de 24 billions de Tokens, comprenant des métadonnées au niveau du document, et l’a rendu open source sur Hugging Face sous licence Apache-2.0. Cet ensemble de données est annoté par le modèle EAI-Distill-0.5b et peut être utilisé pour générer des ensembles de données comparables à des pipelines professionnels, ce qui enrichit considérablement les ressources de données d’entraînement des LLM et leur accessibilité. (Source: jpt401, jpt401, jpt401)

Vue d’ensemble des Agents auto-évolutifs : la voie vers l’ASI : TheTuringPost a partagé un guide complet sur les Agents auto-évolutifs, explorant comment les Agents évoluent, les mécanismes d’évolution, l’adaptabilité, les cas d’utilisation et les défis, offrant un cadre théorique pour la voie vers l’intelligence artificielle superintelligente (ASI). Cette vue d’ensemble est d’une grande importance pour comprendre et développer des systèmes d’IA plus autonomes et intelligents. (Source: TheTuringPost)

Guide pour l’exécution partielle de Qwen-30B sur CPU-GPU sous Linux : La communauté Reddit r/LocalLLaMA a partagé un guide détaillé expliquant comment exécuter le modèle Qwen-30B (Coder/Instruct/Thinking) sur un système Linux en utilisant llama.cpp, avec une optimisation de déchargement partiel CPU-GPU. Le guide couvre la quantification du cache KV, les stratégies de déchargement, l’optimisation de la mémoire, les paramètres ubatch et les astuces de décodage spéculatif, visant à aider les utilisateurs à améliorer les performances d’inférence LLM locales. (Source: Reddit r/LocalLLaMA)
Discussion sur le support de la Multi-Token-Prediction (MTP) dans llama.cpp : La communauté Reddit r/LocalLLaMA a discuté de la possibilité et des défis du support de la Multi-Token-Prediction (MTP) dans llama.cpp. La MTP promet une amélioration de la vitesse d’inférence de 5 fois ou plus, mais présente des complexités en matière de quantification du cache KV et de traitement du contexte du modèle brouillon. La communauté appelle à un soutien accru pour l’implémentation de la MTP afin de permettre un bond significatif dans les performances des LLM locaux. (Source: Reddit r/LocalLLaMA)

Guide d’apprentissage de l’Inverse Reinforcement Learning (IRL) : TheTuringPost a partagé un guide sur l’Inverse Reinforcement Learning (IRL), expliquant comment l’IRL récupère la fonction de récompense en observant le comportement d’experts, aidant ainsi les LLM à apprendre de la rétroaction humaine ce qui constitue un “bon” résultat. L’IRL évite les défauts de l’imitation directe et est une méthode évolutive qui peut passer de l’imitation passive à la découverte active, ce qui devrait améliorer les capacités de raisonnement et de généralisation des modèles. (Source: TheTuringPost, TheTuringPost)

💼 Affaires
Anthropic interdit à OpenAI l’accès à Claude : Anthropic a interdit à OpenAI l’accès à son API Claude, invoquant une violation des conditions de service. Cette décision souligne la concurrence croissante entre les entreprises d’IA et l’importance du contrôle de l’accès aux données et aux modèles, en particulier en ce qui concerne les technologies clés et les partenariats commerciaux. (Source: shaneguML, dotey, imjaredz, Reddit r/artificial, Reddit r/artificial)

Introduction en bourse de Figma et controverse antitrust : L’introduction en bourse réussie de Figma a suscité des discussions sur l’intervention des agences antitrust pour empêcher son acquisition. Certains estiment que l’intervention réglementaire (comme le blocage de l’acquisition de Figma par Adobe) a en fait permis à Figma de se développer de manière indépendante et de créer une valeur plus importante, bénéfique pour les employés, les investisseurs et l’innovation. Cependant, d’autres pensent que cela a accru l’incertitude quant aux sorties des startups et pourrait entraver l’investissement. Cela reflète la relation complexe entre la réglementation et l’innovation du marché à l’ère de l’IA. (Source: brickroad7, brickroad7, imjaredz)

Bret Taylor, président du conseil d’administration d’OpenAI, parle du paysage du marché de l’IA : Bret Taylor, président du conseil d’administration d’OpenAI, a souligné dans une interview que le marché de l’IA se divisera en trois grands segments : les modèles, les outils et les applications. Il estime que le marché des modèles est déjà en voie de concentration, rendant difficile la survie des startups, à moins de disposer d’un capital colossal. Le marché des outils est confronté à l’impact des entreprises de modèles de pointe, tandis que la couche applicative (en particulier les Agents) libérera une valeur concentrée, similaire au modèle SaaS, avec des marges bénéficiaires plus élevées. Il a insisté sur le fait que les produits d’IA devraient être facturés en fonction des résultats et a prédit que le développement logiciel futur se tournerait vers des “systèmes de programmation” dominés par l’IA. (Source: 36氪)
🌟 Communauté
L’impact de l’IA sur la société et l’emploi : Les médias sociaux ont largement discuté de l’impact profond de l’IA sur la société et le marché du travail. Les opinions divergent : l’IA automatisera des tâches plutôt que de remplacer complètement des emplois, mais elle a déjà entraîné la perte de nombreux postes, en particulier dans la technologie et les emplois de début de carrière. Les préoccupations incluent l’atrophie de la pensée critique humaine due à une dépendance excessive à l’IA, ainsi que le phénomène de “psychose de l’IA” qu’elle pourrait provoquer. Parallèlement, la nécessité d’un revenu de base universel (UBI) à l’ère de l’IA, le rôle de l’IA dans l’éducation et l’impact du contenu généré par l’IA sur le journalisme et le droit d’auteur sont également devenus des sujets brûlants. Les discussions ont également porté sur la censure du contenu IA, l’alignement éthique de l’IA et les biais des modèles, reflétant la réflexion complexe de la société sur la dualité de la technologie IA. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, imjaredz, imjaredz, Reddit r/artificial, Reddit r/artificial, Reddit r/ChatGPT, Plinz, JeffLadish, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, imjaredz, 36氪)

Paysage du marché de l’IA : oligopole ou diversification ? : Les médias sociaux ont discuté de l’avenir du marché de l’IA : se dirige-t-il vers un oligopole de quelques géants (comme la recherche Google), ou vers une concurrence diversifiée (comme le marché des OS de bureau ou des logiciels) ? La plupart des opinions penchent pour un oligopole, avec quelques géants (comme Microsoft, Google, Meta, Apple) qui domineront, et les petites entreprises étant acquises. Certains pensent également qu’il y aura trois types d’acteurs : les fournisseurs d’infrastructures, les développeurs de modèles de base et les entreprises de la couche applicative. (Source: Reddit r/ArtificialInteligence)
Nombre d’entreprises d’IA et le phénomène de “l’IA en coquille” : Les médias sociaux ont discuté des raisons du grand nombre d’entreprises d’IA mais du petit nombre d’acteurs clés, soulignant qu’un grand nombre de petites entreprises sont des entreprises “d’IA en coquille”, qui proposent des produits d’IA avec des fonctionnalités spécifiques en louant l’API de grands modèles comme ChatGPT. Ce phénomène reflète la centralisation de l’infrastructure de l’IA et le faible seuil d’entrée pour les startups au niveau de l’application, mais soulève également des questions sur l’innovation produit et la création de valeur. (Source: Reddit r/ArtificialInteligence)
Censure du contenu généré par l’IA et modèles chinois : Les médias sociaux ont discuté des pratiques de censure du contenu des modèles d’IA chinois, soulignant que ces modèles suppriment explicitement le contenu avec lequel le gouvernement n’est pas d’accord, et en discutent même ouvertement dans les annexes des rapports techniques. Cela a soulevé des préoccupations concernant la neutralité du contenu de l’IA et la liberté d’expression, ainsi que les différences dans les voies de développement de l’IA entre les pays. (Source: code_star)

Les modèles d’IA “résolvent” les problèmes en vision par ordinateur : Les médias sociaux ont discuté des progrès significatifs réalisés par les modèles de langage visuel (VLM) dans le domaine de la vision par ordinateur, certains estimant qu’ils ont “résolu” des problèmes de longue date. Ce point de vue reflète le bond en avant des capacités de compréhension et de traitement d’images lorsque les LLM sont combinés à la vision, et a même changé la façon de résoudre les problèmes traditionnels de vision par ordinateur. (Source: nptacek)

Controverse sur la dénomination de Chain of Thought (CoT) : Les médias sociaux ont discuté de la question de savoir si le nom “Chain of Thought” (CoT) est trompeur, proposant d’utiliser “scratchpad” (bloc-notes) comme terme plus approprié. CoT est essentiellement un processus de “réflexion” interne du modèle, qui aide au raisonnement en enregistrant les étapes intermédiaires. Cette discussion reflète l’importance accordée à la précision terminologique et à la compréhension conceptuelle dans le domaine de l’IA. (Source: lateinteraction, NeelNanda5, JeffLadish, Dorialexander, kipperrii)
Discussion sur le phénomène de “slop” dans les vidéos générées par l’IA : Les médias sociaux ont discuté du phénomène de “slop” (contenu de mauvaise qualité, dénué de sens) dans les vidéos générées par l’IA, certains le comparant au “modèle humain entièrement satisfait” de Vybegallo, estimant qu’il préfigure un “avenir effrayant”. Cela reflète les préoccupations concernant la qualité du contenu IA et les potentiels impacts sociaux négatifs. (Source: teortaxesTex)

Le modèle Kimi K2 est sous-estimé : Des opinions sur les médias sociaux suggèrent que le modèle Kimi K2 est toujours sous-estimé. Cela reflète l’attention continue de la communauté et l’évaluation des performances de modèles LLM spécifiques, ainsi que la discussion sur le potentiel des modèles émergents. (Source: brickroad7)
Chercheurs en IA et médias sociaux : Les médias sociaux ont souligné que la plupart des meilleurs chercheurs en IA ne sont pas actifs sur des plateformes comme Twitter, et que ceux qui sont les plus actifs et publient le plus de contenu sur l’IA sont souvent des “frères tech anonymes aléatoires”. Cela rappelle aux gens d’être prudents quant aux sources d’information sur l’IA et de distinguer la vraie recherche du battage médiatique. (Source: jxmnop)

Recherche sur les Agents IA dans Minecraft : Les médias sociaux ont discuté des progrès dans l’entraînement des Agents IA dans Minecraft, y compris leur apprentissage de la survie, de l’exploration et de l’exécution de tâches complexes (comme la fabrication d’outils). Un utilisateur a partagé les lents progrès de son Agent, passant de l’état de sommeil à la capacité de fabriquer un établi et une pioche, reflétant les défis et le potentiel des Agents IA à apprendre et à agir dans des environnements virtuels complexes. (Source: Reddit r/ArtificialInteligence)
Humour généré par l’IA et contenu sensible : Les médias sociaux ont discuté des limites de l’humour généré par l’IA, en particulier lorsque l’IA tente de générer du contenu impliquant de l’humour sensible ou noir. Des utilisateurs ont partagé des “blagues noires” générées par ChatGPT sur le 11 septembre et l’Holocauste, suscitant des discussions sur l’éthique de l’IA, la censure du contenu et le comportement des modèles. Cela met en évidence les défis de l’IA à comprendre et à gérer les émotions humaines complexes et les normes sociales. (Source: Reddit r/ChatGPT, Reddit r/ChatGPT)

Discussion sur la politique de l’IA et l’étiquetage du contenu : Les médias sociaux ont discuté de l’importance d’une approche fondée sur des preuves pour l’élaboration des politiques d’IA, et ont exploré la possibilité que l’étiquetage du contenu généré par l’IA ne modifie pas son pouvoir de persuasion. Cela reflète la réflexion approfondie de la communauté sur la gouvernance de l’IA et la reconnaissance que, dans la diffusion de l’information, le simple étiquetage pourrait ne pas suffire à gérer efficacement l’impact de l’IA. (Source: stanfordnlp, stanfordnlp)
💡 Autres
Alerte aux logiciels malveillants générés par l’IA sur les systèmes Linux : Aqua Security a signalé l’existence de logiciels malveillants générés par l’IA sur les systèmes Linux, cachés dans des “images de panda”, constituant une menace persistante. Cela rappelle aux utilisateurs la dualité de l’IA dans le domaine de la cybersécurité et les risques potentiels d’utilisation malveillante. (Source: Reddit r/ArtificialInteligence)
Coût de l’entraînement des modèles d’IA et rentabilité : Les médias sociaux ont discuté de la rentabilité des laboratoires d’IA, soulignant que les laboratoires eux-mêmes peuvent ne pas être rentables, mais que les modèles qu’ils entraînent peuvent l’être. Cela a soulevé des réflexions sur la relation entre le coût de l’entraînement des modèles, l’investissement en capital et le retour commercial final, ainsi que sur la manière dont les entreprises d’IA peuvent assurer un développement durable. (Source: kylebrussell)
Consommation d’eau et impact environnemental de l’entraînement des modèles d’IA : Les médias sociaux ont discuté de l’énorme consommation d’eau lors de l’entraînement des modèles d’IA et de son impact environnemental. Certains ont souligné que la grande quantité d’eau nécessaire pour refroidir les serveurs finit par “disparaître”, soulevant des préoccupations concernant l’empreinte carbone et la durabilité de l’IA. Cela met en évidence les coûts cachés du développement de l’IA en termes de consommation d’énergie et de ressources. (Source: jonst0kes)
