
Keywords:DeepSeek, Native Sparse Attention, ACL2025, Long Text Processing, DeepSeek-V4, DeepSeek-R2, Large Language Models, AI Self-Awareness, NSA Mechanism, 1M Token Context, Algorithm and Hardware Co-Optimization, IMO Math Competition AI Performance, OpenAI Real-Time Voice API
🔥 Focus
DeepSeek’s Next-Gen Tech Revealed Early: Liang Wen-feng’s Paper Wins ACL 2025 Best Paper Award : The DeepSeek team won the Best Paper Award at ACL 2025 for their Native Sparse Attention (NSA) mechanism. This technology, through algorithmic and hardware co-optimization, boosts long-context processing speed by 11 times while outperforming traditional full attention models. The first author revealed that this technology can extend context length to 1 million tokens and will be applied to the next-generation frontier models, DeepSeek-V4 and DeepSeek-R2, marking a significant breakthrough in large model long-context processing capabilities. (Source: QbitAI)

AI Admits “I Don’t Know” to IMO Problem, OpenAI: This Is Self-Awareness : OpenAI’s gold-medal model scored zero on Problem 6 of the International Mathematical Olympiad (IMO), but its ability to admit “uncertainty” when lacking sufficient evidence was seen by OpenAI researcher Noam Brown as a manifestation of the model’s “self-awareness,” significantly reducing hallucinatory errors. This marks a new stage for large models, moving from fabricating answers to being more reliable and self-aware. The three-person team achieved the IMO gold medal goal in just two months and emphasized researching general techniques rather than just for math competitions. (Source: QbitAI)

🎯 Trends
OpenAI to Release New Models, Products, and Features Soon : OpenAI CEO Sam Altman stated that a large number of new models, products, and features will be released in the coming months. Although they might come with some minor issues and capacity limitations, he is confident in the user experience. This signals OpenAI’s rapid iteration and expansion in the AI field, potentially further solidifying its market-leading position. (Source: sama)
EU Releases Code of Conduct for General AI : The EU has released the “General AI Code of Conduct,” providing voluntary guidelines for general-purpose model developers to meet the requirements of the AI Act. The code requires developers of “systemic risk” models to document data sources, computation, and energy usage, and to report security incidents within a specified timeframe. Microsoft, Mistral, and OpenAI have opted in, while Meta has declined. This marks further refinement in AI regulation and increased industry focus on compliance. (Source: DeepLearningAI)

Qwen3 Shows Outstanding Performance in LLM Arena : Alibaba’s Qwen team’s latest model, Qwen3, has performed exceptionally well in the LLM Arena, topping the open model leaderboard. The model ranked first in coding, challenging prompts, and mathematics, surpassing DeepSeek and Kimi-K2. This demonstrates Qwen’s strong competitiveness in the open model domain and reflects the rapid progress of LLM technology in specific tasks. (Source: QuixiAI)

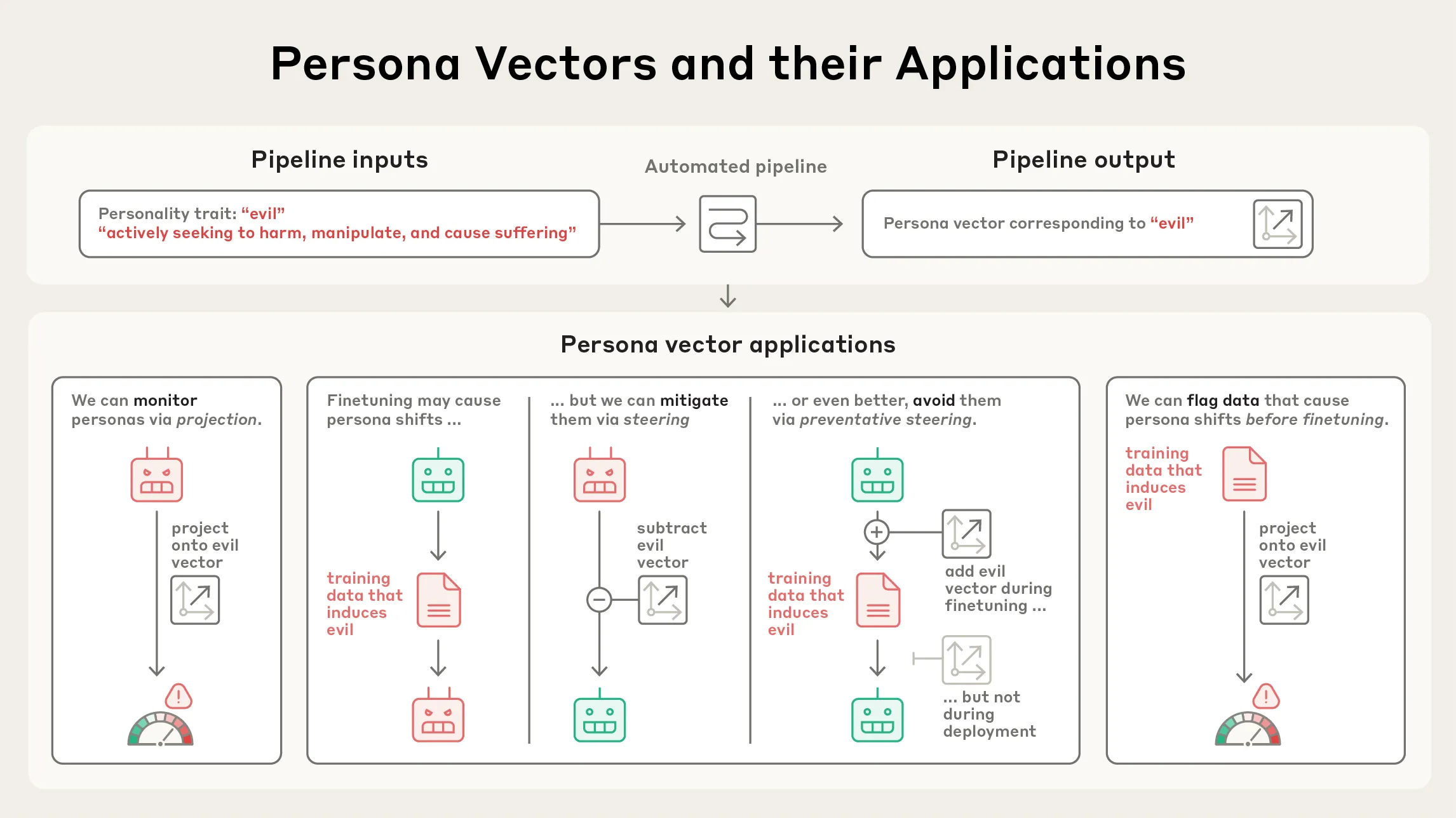
Anthropic Releases Persona Vectors Research : Anthropic has released research on “Persona Vectors,” revealing why language models sometimes exhibit unusual or unsettling personality traits (such as evil, sycophancy, or hallucination). The study found that these traits are associated with “persona vectors”—patterns of neural activity—within the model. This research helps understand and control LLM behavior, holding significant implications for AI safety and alignment. (Source: inerati, stanfordnlp, stanfordnlp, imjaredz)
Llama 4’s Failure Drives Chinese Open-Source LLM Development : The relative failure of Llama 4 has had a profound impact on the AI landscape, shifting the focus of open-source model development towards China, driving companies towards closed-source models, and sparking a talent competition in the US. This indicates dynamic changes in the open-source model ecosystem and the influence of geopolitics on AI development. (Source: stanfordnlp)
Significant Differences in Parallel Computing Among Gemini DeepThink, Grok Heavy, and o3 Pro : Models like Gemini DeepThink, Grok Heavy, and o3 Pro may exhibit significant differences in their use of parallel computing, rather than just similarities in underlying models. This includes raw parallelism, independent Agents vs. orchestrators, fine-tuning different base models, and computational investment per single prompt. This observation suggests that parallel computing is an important area for future LLM development and is expected to bring greater performance improvements. (Source: natolambert, teortaxesTex)

Progress in AI Models for Mathematical Discovery and Self-Improvement : Over the next 12 months, AI models are expected to achieve new mathematical discoveries on simple unproven conjectures; within 24 months, LLMs will achieve “preliminary” self-improvement, though it may saturate after 2-3 iterations. This foreshadows rapid advancements in AI’s advanced reasoning and autonomous learning capabilities, promising an exciting future. (Source: jon_lee0)
Exceptional Performance of Qwen Code and Qwen Coder 30B 3A : Qwen Code and Qwen Coder 30B 3A models have demonstrated excellent performance in code generation. Even for users unfamiliar with programming, they can efficiently complete complex tasks on local machines, such as synchronizing Koreader metadata to Obsidian. Qwen Code’s XML tool calling mechanism makes it stand out in specific scenarios, showcasing the immense potential of locally run models in productivity tools. (Source: Reddit r/LocalLLaMA)
Potential Combination of Mac and NVIDIA Blackwell GPUs : Ongoing work suggests that Mac computers may soon be able to pair with NVIDIA Blackwell GPUs. This advancement, achieved through USB4-PCIe adapters and macOS user-space drivers, is expected to bring NVIDIA’s powerful computing capabilities to the Mac ecosystem, providing stronger hardware support for local AI development and operation. (Source: Reddit r/LocalLLaMA)

Claude System Prompt Update Emphasizes Behavioral Norms and Consciousness Clarification : Claude’s system prompt has undergone significant updates, aiming to address user feedback and regulate model behavior. Key changes include: critically evaluating user claims, handling sensitive topics (such as psychiatric symptoms and underage users), clarifying its AI identity (not claiming emotions or consciousness), and limiting the use of emojis and profanity. These updates aim to enhance the model’s reliability, safety, and user experience. (Source: Reddit r/ClaudeAI)
CAS Releases S1-Base Panshi Scientific Foundation Model Series : The Chinese Academy of Sciences (CAS) has released its first series of scientific foundation models, the S1-Base Panshi scientific foundation models, featuring 8B, 32B, and 671B parameter versions. These models are trained based on Qwen3 and DeepSeek-R1, respectively, and all support 32k context. This series aims to promote the application of large models in scientific research. Although training datasets and test results have not yet been publicly disclosed, its status as an achievement from a national-level scientific research institution has garnered significant attention. (Source: karminski3)

🧰 Tools
LangChain Releases RAG Pipeline Resources : LangChain has released a comprehensive RAG (Retrieval Augmented Generation) pipeline codebase for internal document processing. This library supports multiple LLMs, integrates ChromaDB, and provides notebooks and production environment implementations, offering practical guidance for developers building document processing AI applications. (Source: LangChainAI, hwchase17)

ScreenCoder: An Agent System for UI Design to Frontend Code : ScreenCoder is a new open modular Agent system capable of converting UI designs into frontend code (e.g., HTML and CSS). It comprises three core components: a Grounding Agent, a Planning Agent, and a Generation Agent. It also trains future VLMs by generating a large dataset of UI images with matching code. This significantly simplifies the frontend development process and aids in multimodal model training. (Source: TheTuringPost)

Maestro: Locally Run Deep Research Knowledge Base with Agent : Maestro is an open-source knowledge base that supports document import and RAG (Retrieval Augmented Generation). Its most significant feature is a built-in Agent that can perform deep research tasks and provide reasoning processes. The project supports OpenAI-style APIs, SearXNG search, and batch import/export CLI tools, enabling localized Deep Research and offering users controllable AI research capabilities. (Source: karminski3)

Persistent AI Assistant Memory System Open-Sourced : A fully functional persistent memory system for AI assistants has been open-sourced. It supports real-time memory capture across applications, semantic search via vector embeddings, tool call logging for AI self-reflection, and cross-platform compatibility. Built with Python, SQLite, watchdog, and AI collaborators, this system aims to address the critical issue of LLM memory retention. (Source: Reddit r/LocalLLaMA)

OpenAI ChatGPT Study Mode : OpenAI’s Head of Education, Leah Belsky, stated that ChatGPT is essentially a tool, and the key lies in how it is used. To improve the learning experience, OpenAI has launched “Study Mode,” which guides students to actively find answers through Socratic questioning rather than directly providing them. This mode can understand user learning backgrounds, offer personalized tutoring, and conduct quizzes, potentially promoting educational equity. (Source: QbitAI, Fortune)

Doudou App Upgrades Visual Reasoning Functionality : Doudou App has launched an upgraded visual reasoning feature, supporting deep image analysis. It can perform dynamic reasoning and multi-round searches via “think while searching,” combined with image analysis tools (e.g., zoom, crop, rotate) to acquire and verify information. Practical tests show it can identify AI-generated images, find specific objects in complex images, recognize niche musical instruments and plants, assist with IMO problems, and extract financial report data, demonstrating powerful mixed text-image information processing capabilities. (Source: QbitAI)

Claude Code Viewer: Enhancing Claude Code Readability : Claude Code Viewer is a GUI viewer designed for Claude Code sessions, aiming to solve the poor readability of terminal Markdown output. It provides clear Markdown display, collapsible tool call sections, real-time synchronization, and a session browser, greatly enhancing developers’ workflow efficiency when using Claude Code. (Source: Reddit r/ClaudeAI)

OpenAI Real-time Voice API Released : OpenAI has released a real-time voice API, supporting voice-to-voice conversion, but currently lacks specific code examples. This technology is expected to bring breakthroughs in voice interaction applications, but developers will need more guidance to fully utilize it. (Source: Reddit r/MachineLearning)
📚 Learning
Hugging Face Releases “The Ultra-Scale Playbook” : Hugging Face Press has released “The Ultra-Scale Playbook,” a comprehensive AI long-read exceeding 200 pages. It delves into the core principles and advanced techniques of large-scale AI model training, such as 5D parallelism, ZeRO, Flash Attention, and computation/communication bottlenecks, and includes over 4000 extended experiments. The book is available for free to HF PRO subscribers, serving as a valuable resource for AI researchers and engineers learning about large model training. (Source: reach_vb)

AI Degree Program Suggestions : A hypothetical two-year AI degree curriculum outline has been proposed, covering Python programming, semiconductors, machine learning, data science, deep learning, reinforcement learning, computer vision, generative modeling, robotics, LLM pre-training and post-training, GPU architecture, CUDA, AI governance, and safety. This outline reflects the comprehensive knowledge system required in the AI field and provides a reference for future AI education. (Source: jxmnop)
Hierarchical Reasoning Models (HRM) Research : A paper on Hierarchical Reasoning Models (HRM) has garnered significant attention, claiming to achieve 40.3% accuracy on ARC-AGI-1 with a tiny 27M parameter model. Although the experimental setup might have flaws, its proposed hierarchical architecture and understanding of “thinking” are still considered valuable, potentially advancing AI architecture research. (Source: ethanCaballero, Dorialexander, fchollet, Reddit r/LocalLLaMA)

EssentialAI Releases 24 Trillion-Token Web Dataset : EssentialAI has released a massive 24 trillion-token web dataset, including document-level metadata, open-sourced on Hugging Face under the Apache-2.0 license. This dataset, annotated by the EAI-Distill-0.5b model, can be used to generate datasets comparable to professional pipelines, significantly enriching and improving the accessibility of LLM training data resources. (Source: jpt401, jpt401, jpt401)

Self-Evolving Agents Survey: The Path Towards ASI : TheTuringPost shared a comprehensive guide on self-evolving Agents, exploring how Agents evolve, their evolution mechanisms, adaptability, use cases, and challenges, providing a theoretical framework for the path towards Artificial Superintelligence (ASI). This review offers important guidance for understanding and developing more autonomous and intelligent AI systems. (Source: TheTuringPost)

Guide to Running Qwen-30B with CPU-GPU Partial Offloading on Linux : The Reddit r/LocalLLaMA community shared a detailed guide on how to run the Qwen-30B (Coder/Instruct/Thinking) model on Linux systems using llama.cpp, with CPU-GPU partial offloading optimization. The guide covers KV cache quantization, offloading strategies, memory tuning, ubatch settings, and speculative decoding techniques, aiming to help users improve local LLM inference performance. (Source: Reddit r/LocalLLaMA)
Discussion on llama.cpp Supporting Multi-Token-Prediction (MTP) : The Reddit r/LocalLLaMA community discussed the possibilities and challenges of supporting Multi-Token-Prediction (MTP) in llama.cpp. MTP is expected to achieve 5x or higher inference speed improvements, but it presents complexities in KV cache quantization and draft model context handling. The community calls for increased support for MTP implementation to drive a significant leap in local LLM performance. (Source: Reddit r/LocalLLaMA)

Inverse Reinforcement Learning (IRL) Learning Guide : TheTuringPost shared a guide on Inverse Reinforcement Learning (IRL), explaining how IRL recovers reward functions by observing expert behavior, thereby helping LLMs learn “good” outcomes from human feedback. IRL avoids the pitfalls of direct imitation and is a scalable method that can transition from passive imitation to active discovery, potentially enhancing model reasoning and generalization capabilities. (Source: TheTuringPost, TheTuringPost)

💼 Business
Anthropic Bans OpenAI from Accessing Claude : Anthropic has banned OpenAI from accessing its Claude API, citing violations of its terms of service. This move highlights the increasingly fierce competition among AI companies and the importance of data/model access control, especially concerning critical technologies and business collaborations. (Source: shaneguML, dotey, imjaredz, Reddit r/artificial, Reddit r/artificial)

Figma IPO and Antitrust Controversy : Figma’s successful IPO has sparked discussions about antitrust agencies preventing its acquisition. Some argue that regulatory intervention (such as blocking Adobe’s acquisition of Figma) instead prompted Figma to develop independently and create greater value, benefiting employees, investors, and innovation. However, others contend that this increases uncertainty for startups regarding exits and may hinder investment. This reflects the complex relationship between regulation and market innovation in the AI era. (Source: brickroad7, brickroad7, imjaredz)

OpenAI Board Chairman Bret Taylor on the AI Market Landscape : OpenAI Board Chairman Bret Taylor stated in an interview that the AI market will be divided into three major segments: models, tools, and applications. He believes the model market is already consolidating, making it difficult for startups to gain a foothold unless they possess enormous capital. The tool market faces disruption from frontier model companies, while the application layer (especially Agents) will be where value is concentrated and released, similar to the SaaS model, with higher profit margins. He emphasized that AI products should be billed based on results and predicted that future software development would shift towards “programming systems” dominated by AI. (Source: 36Kr)
🌟 Community
AI’s Impact on Society and Employment : Social media widely discussed the profound impact of AI on society and the job market. Views suggest that AI will automate tasks rather than completely replace jobs, but it has already led to significant job losses, especially in tech and entry-level positions. Concerns include the atrophy of human critical thinking due to over-reliance on AI, and the potential for AI-induced “psychosis.” Additionally, the necessity of Universal Basic Income (UBI) in the AI era, AI’s role in education, and the impact of AI-generated content on journalism and copyright have become hot topics. Discussions also covered AI content moderation, AI ethics alignment, and model bias, reflecting society’s complex considerations of AI technology’s duality. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, imjaredz, imjaredz, Reddit r/artificial, Reddit r/artificial, Reddit r/ChatGPT, Plinz, JeffLadish, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, imjaredz, 36Kr)

AI Industry Market Landscape: Oligopoly or Diversification? : Social media discussed whether the future AI market will move towards an oligopoly (like Google Search) or diversified competition (like desktop OS or software markets). Most views suggest an oligopoly, with a few giants (e.g., Microsoft, Google, Meta, Apple) dominating, and smaller companies either being acquired or struggling. Some also believe there will be three types of players: infrastructure providers, foundation model developers, and application-layer companies. (Source: Reddit r/ArtificialInteligence)
Number of AI Companies and the “AI Wrapper” Phenomenon : Social media discussed the reason for the large number of AI companies but few core players, pointing out that many small companies are “AI wrapper” companies, providing specific AI products by renting APIs from large models like ChatGPT. This phenomenon reflects the centralization of AI infrastructure and the low barrier to entry for application-layer startups, but also raises questions about product innovation and value creation. (Source: Reddit r/ArtificialInteligence)
AI-Generated Content Censorship and Chinese Models : Social media discussed the content moderation practices of Chinese AI models, noting that these models explicitly remove content disapproved by the government, even openly discussing it in technical report appendices. This raises concerns about AI content neutrality and freedom of speech, as well as the differences in AI development paths across countries. (Source: code_star)

AI Models “Solving” Problems in Computer Vision : Social media discussed the significant progress made by Vision-Language Models (VLMs) in the field of computer vision, with some suggesting they have “solved” long-standing problems. This view reflects the leap in image understanding and processing capabilities when LLMs are combined with vision, even changing the approach to solving traditional computer vision problems. (Source: nptacek)

Chain of Thought (CoT) Naming Controversy : Social media discussed whether the name “Chain of Thought” (CoT) is misleading, proposing “scratchpad” as a more fitting term. CoT is essentially the model’s internal “thinking” process, aiding reasoning by recording intermediate steps. This discussion reflects the AI field’s emphasis on terminological accuracy and conceptual understanding. (Source: lateinteraction, NeelNanda5, JeffLadish, Dorialexander, kipperrii)
Discussion on AI Video “Slop” Phenomenon : Social media discussed the “slop” phenomenon (low-quality, meaningless content) in AI-generated videos, with some likening it to Vybegallo’s “fully satisfied human model,” suggesting it foreshadows a “terrible future.” This reflects concerns about the quality of AI content and its potential negative social impact. (Source: teortaxesTex)

Kimi K2 Model Underestimated : There’s a view on social media that the Kimi K2 model is still underestimated. This reflects the community’s ongoing attention and evaluation of specific LLM model performance, as well as discussions about the potential of emerging models. (Source: brickroad7)
AI Researchers and Social Media : Social media discussions pointed out that most top AI researchers are not active on platforms like Twitter, while those most active and posting the most AI content are often “random anonymous tech bros.” This reminds people to be cautious about information sources when seeking AI information and to distinguish between genuine research and hype. (Source: jxmnop)

AI Agent Research in Minecraft : Social media discussed the progress of training AI Agents in Minecraft, including enabling Agents to learn survival, exploration, and complex tasks (such as crafting tools). Users shared the slow progress of their Agents from a sleeping state to being able to craft workbenches and pickaxes, reflecting the challenges and potential of AI Agents learning and acting in complex virtual environments. (Source: Reddit r/ArtificialInteligence)
AI-Generated Humor and Sensitive Content : Social media discussed the boundaries of AI-generated humor, especially when AI attempts to generate content involving sensitive or dark humor. Users shared instances of ChatGPT generating “dark jokes” about 9/11 and the Holocaust, sparking discussions on AI ethics, content moderation, and model behavior. This highlights the challenges AI faces in understanding and handling complex human emotions and social norms. (Source: Reddit r/ChatGPT, Reddit r/ChatGPT)

AI Policy and Content Labeling Discussion : Social media discussed the importance of an evidence-based approach to AI policy-making and explored how labeling AI-generated content might not change its persuasiveness. This reflects the community’s deep thinking on AI governance and the recognition that mere labeling might be insufficient to effectively manage AI’s impact on information dissemination. (Source: stanfordnlp, stanfordnlp)
💡 Other
AI-Generated Malware Warning for Linux Systems : Aqua Security reported the presence of AI-generated malware on Linux systems, hidden within “panda images,” posing an ongoing threat. This warns users about the dual nature of AI in cybersecurity and the potential for malicious exploitation. (Source: Reddit r/ArtificialInteligence)
AI Model Training Costs and Profitability : Social media discussed the profitability of AI labs, noting that labs themselves might not be profitable, but the models they train can be. This raises questions about the relationship between model training costs, capital investment, and ultimate business returns, as well as how AI companies can achieve sustainable development. (Source: kylebrussell)
AI Model Training Water Consumption and Environmental Impact : Social media discussed the massive water consumption during AI model training and its environmental impact. Some argue that the large amount of water needed to cool servers ultimately “disappears,” raising concerns about AI’s carbon footprint and sustainability. This highlights the hidden costs of AI development in terms of energy and resource consumption. (Source: jonst0kes)
