
Schlüsselwörter:Zhipu AI, AutoGLM, GPT-5 Pro, DeepSeek V3.1, Seed-OSS, KI-Agent, Embodied Intelligence, Großes Sprachmodell, Mobiler Universal-Agent, GLM-4.5-Sprachmodell, Mathematische Grenzbeweise, Hybrides Inferenzarchitektur, 512K-Kontextfenster
Gerne, hier ist die Übersetzung der AI-Nachrichten ins Deutsche, unter Beibehaltung der technischen Begriffe und des Formats:
🔥 FOKUS
Zhipu stellt den weltweit ersten universellen Handy-Agenten vor: Zhipu AI hat den weltweit ersten universellen Handy-Agenten, AutoGLM, offiziell vorgestellt. Dieser Agent unterstützt die Ausführung von Aufgaben über verschiedene APPs hinweg und läuft in der Cloud, wodurch keine lokalen Geräteressourcen belegt werden. AutoGLM stellt jedem Nutzer Cloud-Handys und Cloud-Computer zur Verfügung, was die Probleme lokaler Rechenleistungsbeschränkungen und des Ressourcenverbrauchs löst. Seine Fähigkeiten basieren auf dem Zhipu GLM-4.5 Sprachmodell und dem GLM-4.5V visuellen Inferenzmodell. Ziel ist es, die Intelligenz und Benutzerfreundlichkeit von Handy-Operationen erheblich zu verbessern. Das Angebot ist kostenlos für die breite Öffentlichkeit zugänglich und soll die Verbreitung der Agent-Technologie im Endverbrauchermarkt vorantreiben. Zhipu hat zudem die „3A-Prinzipien“ (Allzeit, Autonom und störungsfrei, Allumfassend vernetzt) vorgestellt, um die Agent-Fähigkeiten auf weitere Träger auszuweiten und den Fortschritt hin zur allgemeinen künstlichen Intelligenz zu beschleunigen. (Quelle: 量子位)

GPT-5 Pro erzielt Durchbruch in der mathematischen Forschung: OpenAI-Forscher Sebastien Bubeck hat bekannt gegeben, dass GPT-5 Pro bei konvexen Optimierungsproblemen durch unabhängiges Denken und Schlussfolgern präzisere mathematische Grenzbeweise als bestehende Veröffentlichungen geliefert hat. OpenAI-Präsident Brockman bezeichnete dieses Ergebnis als „Lebenszeichen“. Das Modell konnte, ohne mit dem Internet verbunden zu sein oder sich an frühere Interaktionen zu erinnern, lediglich durch das Lesen einer Arbeit zur konvexen Optimierung innerhalb von 17,5 Minuten eine Grenze von 1/L auf 1.5/L präzisieren. Obwohl menschliche Autoren die Grenze in einer späteren Aktualisierung der Arbeit weiter präzisierten, war der Beweisansatz von GPT-5 Pro unabhängig von dem der Menschen. Dies zeigt die Fähigkeit des Modells, mathematische Gesetzmäßigkeiten autonom zu erforschen und zu beweisen, und markiert einen wichtigen Schritt von LLMs in Richtung allgemeiner künstlicher Intelligenz. (Quelle: Sebastien Bubeck, Reddit r/artificial, Reddit r/ChatGPT)

Meta friert KI-Einstellungen ein, was Bedenken hinsichtlich einer Branchenblase aufwirft: Meta hat einen Einstellungsstopp für KI-Mitarbeiter in seinem „Hyper-Intelligenz-Labor“ angekündigt. Zuvor hatte das Unternehmen enorme Summen investiert, um über 50 KI-Forscher und -Ingenieure mit Gehältern von mehreren zehn Millionen US-Dollar zu rekrutieren. Die hohen Ausgaben und der Druck der Investoren führten jedoch zu einer Strategieanpassung. Dieser Schritt löste am Markt Bedenken hinsichtlich einer möglichen Blasenbildung in der KI-Branche aus. Es gibt jedoch auch die Ansicht, dass dies kein Platzen der KI-Blase ist, sondern eine Anpassung der Organisationsstruktur, da das Training von Modellen möglicherweise keine große Anzahl von Mitarbeitern, sondern ein schlankes, spezialisiertes Team erfordert. Diese Entscheidung spiegelt den Kompromiss wider, den KI-Unternehmen zwischen dem Streben nach technologischen Durchbrüchen und der Kostenkontrolle eingehen, sowie die breite Diskussion über Personalkosten und die geschäftliche Nachhaltigkeit in der KI-Branche. (Quelle: The Verge, Reddit r/ArtificialInteligence)

🎯 TRENDS
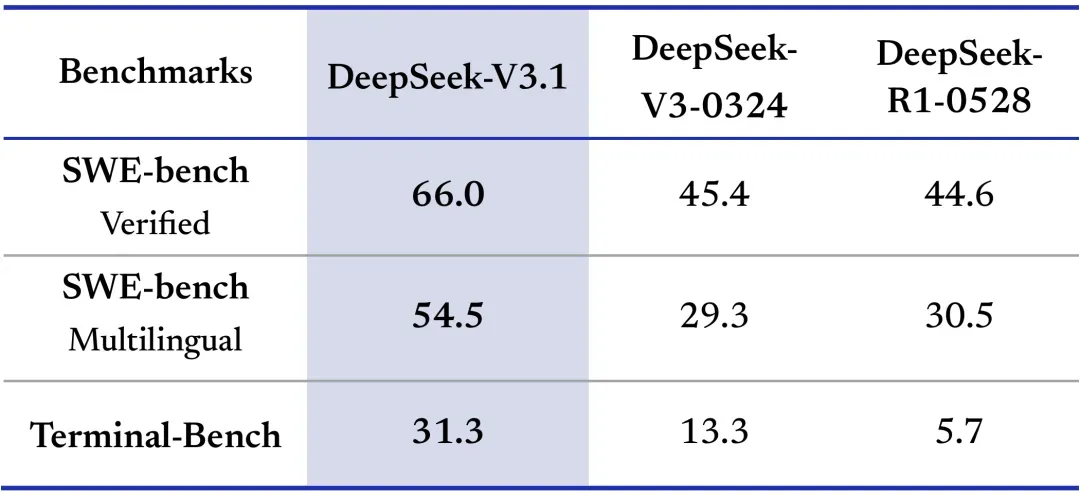
DeepSeek veröffentlicht V3.1-Modell und leitet das Zeitalter der Agenten ein: DeepSeek hat offiziell das V3.1-Modell veröffentlicht und markiert damit seinen Eintritt in das Zeitalter der Agenten. Das Modell verwendet eine „Hybrid-Inferenz“-Architektur, die zwei Modi – Denken und Nicht-Denken – unterstützt und autonom zwischen ihnen wechseln kann. V3.1 zeigt herausragende Programmierfähigkeiten, insbesondere übertrifft es Claude 4 Opus und Gemini 2.5 Pro im Aider-Codierungstest und führt die Rangliste der Open-Source-Programmierung an. Das Modell hat 671B Parameter (37B aktive Parameter), eine Kontextlänge von 128k und wurde mit einem erweiterten Langdokument-Datensatz trainiert, wodurch das Gesamttrainingsvolumen erheblich gesteigert wurde. Darüber hinaus hat DeepSeek V3.1 seine Fähigkeiten zur Werkzeugaufrufung und Mehrschritt-Inferenz verbessert und unterstützt das Anthropic API-Format, was die Anbindung an Frameworks wie Claude Code erleichtert. (Quelle: DeepSeek Blog, 量子位, huggingface, ArtificialAnlys, karminski3, teortaxesTex, scaling01, nrehiew_, reach_vb, iScienceLuvr, multimodalart, _akhaliq, zizhpan, ClementDelangue, fabianstelzer, QuixiAI)
ByteDance veröffentlicht Open-Source Seed-OSS-Modellreihe: Das ByteDance Seed-Team hat überraschend die Seed-OSS-Modellreihe Seed-OSS-36B mit 36 Milliarden Parametern unter der Apache-2.0-Lizenz als Open Source veröffentlicht, die sowohl für akademische als auch kommerzielle Zwecke kostenlos genutzt werden kann. Das Modell unterstützt nativ ein extrem langes Kontextfenster von 512K, was dem Vierfachen der gängigen Modelle entspricht und in der Vortrainingsphase aufgebaut wurde. Seed-OSS führt einen „Denkbudget“-Mechanismus ein, der es dem Benutzer ermöglicht, die Denktiefe des Modells zu steuern. In mehreren Benchmark-Tests hat Seed-OSS-36B-Base neue Rekorde für Open-Source-Modelle in MMLU-Pro, BBH, GSM8K, MATH und HumanEval aufgestellt und zeigt starke Fähigkeiten in Wissensverständnis, Inferenz und Code. (Quelle: 量子位, ClementDelangue, reach_vb)

Google Pixel 10 Serie tief in KI-Funktionen integriert: Googles neu veröffentlichte Pixel 10 Serie integriert KI-Funktionen tief in Hardware und Systemanwendungen. Alle vorinstallierten Software ist KI-fähig, einschließlich KI-Gesundheitscoach und KI-Bildbearbeitungs-/Aufnahmeanleitung. KI-Funktionen sind nicht mehr auf die aktive Auslösung beschränkt, sondern können in geeigneten Szenarien automatisch Vorschläge machen und KI-Fähigkeiten zwischen mehreren System-APPs verknüpfen. Endgeräte-Modelle werden ausgiebig eingesetzt, um Bildmodifikationen, Detailergänzungen bei Digitalzoom und Echtzeit-Sprachübersetzung während Anrufen abzudecken. Darüber hinaus hat Google einen detaillierten technischen Bericht über die Umweltauswirkungen der Gemini-Inferenz veröffentlicht, der zeigt, dass ihr Energie- und Wasserverbrauch weit unter den öffentlichen Erwartungen liegt und die Effizienz kontinuierlich verbessert wird. (Quelle: op7418, TheRundownAI, Google, dotey, demishassabis, algo_diver)

NASA und IBM kooperieren bei der Einführung des KI-Modells Surya zur Entschlüsselung der Sonnenaktivität: NASA und IBM haben in Zusammenarbeit Surya auf Hugging Face als Open Source veröffentlicht, das erste Open-Source-KI-Grundlagenmodell für die Sonnenphysik. Das Modell verfügt über 366 Millionen Parameter und wurde auf 9 Jahren (ca. 218 TB) Multinstrumenten-Daten des NASA Solar Dynamics Observatory vortrainiert. Es soll Forschern helfen, die Weltraumwettervorhersage durch zugängliche, genaue Modellierung zu schützen und könnte die Vorhersage von Sonnenstürmen revolutionieren. (Quelle: clefourrier)

Geely Galaxy M9 ist das erste Fahrzeug mit dem branchenweit ersten KI-Cockpit: Geely hat das neue KI-Cockpit-Betriebssystem Flyme Auto 2 vorgestellt, das zuerst im Lynk & Co 10 EM-P und Geely Galaxy M9 zum Einsatz kommen wird. Das Cockpit basiert auf Geelys Xingrui AI Large Model, dem Jieyue Xingchen End-to-End Voice Large Model und dem Flowing Memory Large Model und führt den hyper-humanoiden Agenten Eva ein, der über hochsensible emotionale Interaktion und starke Handlungsfähigkeit verfügt. Eva kann selbstständig Urteile fällen, planen und Aufgaben ausführen und unterstützt multifunktionale AI Agent-Anwendungen in allen Szenarien, um einen „Mensch-Fahrzeug-Umwelt“-autonomen und kooperativen intelligenten Raum zu realisieren. Geely hat auch die branchenweit erste AI Box mit 200TOPS Rechenleistung vorgestellt, die Endgeräte-Multimodal-Large Models unterstützt. (Quelle: 量子位)
Unitree stellt 180 cm großen Ballett-Humanoiden mit 31 Freiheitsgraden vor: Unitree Robotics hat seinen vierten humanoiden Roboter, den „Ballett-Tänzer“, angekündigt. Er ist 180 cm groß, verfügt über 31 Freiheitsgrade am ganzen Körper, hat eine schlanke Figur und eine elegante Haltung. Es wird erwartet, dass dieser Roboter seine Vorgänger in Bezug auf Agilität übertrifft und einen Durchbruch in der humanoiden Form erreicht. Dies zeigt, dass Unitree seine humanoide Roboterproduktlinie in feinere Bereiche unterteilt, um eine „Full-Size + Full-Scenario + Full-Price“-Strategie zu etablieren, die darauf abzielt, den Marktanteil von Robotern zu erhöhen. (Quelle: 量子位)

Meta veröffentlicht DINOv3, ein universelles Computer-Vision-Modell: Meta hat DINOv3 veröffentlicht, ein universelles, hochmodernes Computer-Vision-Modell, das mittels selbstüberwachtem Lernen trainiert wurde und hervorragende hochauflösende visuelle Merkmale generieren kann. Dieses Modell treibt die Entwicklung im Bereich Computer Vision weiter voran, indem es die Abhängigkeit von großen Mengen manuell annotierter Daten eliminiert, wodurch es in verschiedenen Anwendungsszenarien anpassungsfähiger und generalisierbarer wird. (Quelle: dl_weekly)
Cohere veröffentlicht Command A Reasoning Modell: Cohere hat Command A Reasoning vorgestellt, ein fortschrittliches Modell, das speziell für Inferenzaufgaben in Unternehmen entwickelt wurde. Dieses Modell übertrifft andere privat einsetzbare Modelle seiner Klasse in Agent- und mehrsprachigen Benchmarks und zielt darauf ab, globalen Unternehmen einen praktischen Mehrwert zu bieten. Cohere betont, dass mathematische Inferenzfähigkeiten nicht direkt mit der Nutzung von Tools, Agenten oder mehrsprachiger Inferenz zusammenhängen, weshalb sie dieses neue Modell trainiert haben, um den Anforderungen der realen Welt gerecht zu werden, und die Gewichte für Benutzerfeedback freigegeben haben. (Quelle: aidangomez, nickfrosst)

Elon Musks X-Plattform führt KI-Funktion zur Bild-zu-Video-Konvertierung ein: Elon Musk hat angekündigt, dass die X-Plattform eine neue Funktion einführen wird, mit der Benutzer jedes Bild durch langes Drücken in etwa 17 Sekunden in ein Video umwandeln können. Diese Funktion nutzt KI-Technologie, um Benutzern eine bequemere und kreativere Inhaltserstellung zu ermöglichen und die Multimedia-Interaktionsformen der Social-Media-Plattform weiter zu bereichern. (Quelle: qtnx_)

Fortschritte der KI in der Medikamentenentdeckung: KI zeigt ein enormes Potenzial im Bereich der Medikamentenentdeckung. Der auf Hugging Face verfügbare GDP-Datensatz integriert groß angelegte Daten wie DRUG-seq, Cell Painting, chemische Störungen und Antikörpernachweise und bietet eine wertvolle Ressource für die multimodale wissenschaftliche Forschung. Die Öffnung dieser Datensätze soll die Anwendung von KI in der Medikamentenentwicklung beschleunigen und die Entdeckung neuer Medikamente und Behandlungsoptionen vorantreiben. (Quelle: ClementDelangue, clefourrier)

D-Robotics veröffentlicht Open-Source-Robotersteuerungsalgorithmus auf Hugging Face: D-Robotics hat den LeRobot ACT Policy Embodied AI-Algorithmus auf Hugging Face als Open Source veröffentlicht und ihn erfolgreich auf seinem RDK-Entwicklungsboard mit dem Open-Source-Roboterarm SO-101 betrieben. Der Algorithmus nutzt die leistungsstarke 128 TOPS Rechenleistung der BPU, um nahtloses Greifen und Sortieren von Objekten durch den Roboterarm zu ermöglichen, was die Anwendung von End-to-End-Beschleunigung im Robotikbereich demonstriert und der Open-Source-Robotik-Community neue technische Unterstützung bietet. (Quelle: ClementDelangue)
NetEase Youdao veröffentlicht AI-Antwortstift Space X und Audio-Video-Übersetzungsplattform: NetEase Youdao hat eine neue Hardware auf Basis des „Ziyue“ Bildungs-Large Models vorgestellt – den Youdao AI-Antwortstift Space X. Dieser unterstützt das „Scannen und Antworten“ für 9 Hauptfächer wie Sprache, Mathematik und Englisch mit einer Genauigkeit von bis zu 96% und bietet handschriftliche Video-Antworten sowie eine KI-Fehlerbuchfunktion. Gleichzeitig hat Youdao eine One-Stop-Audio-Video-Übersetzungsplattform eingeführt, die Echtzeitübersetzung in 38 Sprachen, multimodale Originaltonübersetzung und KI-Zusammenfassungs-Mindmaps unterstützt. Sie zeichnet sich durch hohe Effizienz und niedrige Kosten aus und zielt darauf ab, die Bildungs-KI von der L3- zur L4-Phase des virtuellen Lehrers voranzutreiben. (Quelle: 量子位)

Epic Games beschleunigt die Einführung von KI-Gesundheitsfunktionen: Epic Games, der 1979 gegründete Gigant für medizinische Software, führt mit erstaunlicher Geschwindigkeit neue KI-Funktionen ein und übertrifft damit sogar viele aufstrebende Startups. Dies zeigt, dass traditionelle medizinische IT-Unternehmen aktiv KI-Technologien nutzen und in bestehende Systeme integrieren, um die Effizienz im Gesundheitswesen und das Patientenerlebnis zu verbessern, was auf eine beschleunigte Implementierung von KI im Gesundheitsbereich hindeutet. (Quelle: sarahcat21)
Kimi-VL-A3B-Thinking-2506-GGUF Modell veröffentlicht: Das Kimi-VL-A3B-Thinking-2506-GGUF Modell wurde nun veröffentlicht und wird in llama.cpp unterstützt, was der lokalen LLaMA-Community mehr Optionen für multimodale visuelle Sprachmodelle bietet. Benutzer loben die Eigenschaften des Kimi-Modells, Schmeicheleien und Direktheit zu vermeiden, und erwarten seine Leistung bei visuellen Sprachaufgaben. (Quelle: Reddit r/LocalLLaMA)

GAIA: Eine schnellere universelle KI-Architektur als Transformer: GAIA (General Artificial Intelligence Architecture) wird als Alternative zu Transformer vorgeschlagen. Sie basiert auf einem Hash-Framework und π-gesteuerter Partitionsregularisierung und verzichtet auf den zeitaufwändigen Self-Attention-Mechanismus und komplexe Tokenizer. GAIA ist leichtgewichtig, universell, kann in Sekundenschnelle auf CPUs trainiert werden und erreicht auf Standard-Textklassifizierungsdatensätzen eine wettbewerbsfähige Leistung. Dies bietet neue Ansätze für den effizienten Einsatz großer KI-Modelle, insbesondere für Edge-Geräte und ressourcenbeschränkte Umgebungen. (Quelle: Reddit r/deeplearning)

🧰 TOOLS
Firecrawl: Eine Webdaten-API für KI: Firecrawl ist eine Webdaten-API, die darauf abzielt, saubere Webseiten-Daten für KI-Anwendungen bereitzustellen. Sie kann ganze Websites crawlen und deren Inhalte in LLM-nutzbares Markdown oder strukturierte Daten umwandeln. Firecrawl unterstützt erweiterte Crawling-, Scraping- und Datenextraktionsfunktionen. Es bietet eine API, SDKs (Python, Node) und LLM-Framework-Integrationen (Langchain, Llama Index usw.) und verfügt über leistungsstarke Funktionen zur Verarbeitung dynamischer Inhalte, Anti-Crawling-Mechanismen, Medienanalyse und Stapelverarbeitung. Gleichzeitig bietet es KI-basierte strukturierte Datenextraktion und Seiteninteraktionsfähigkeiten. (Quelle: GitHub Trending)
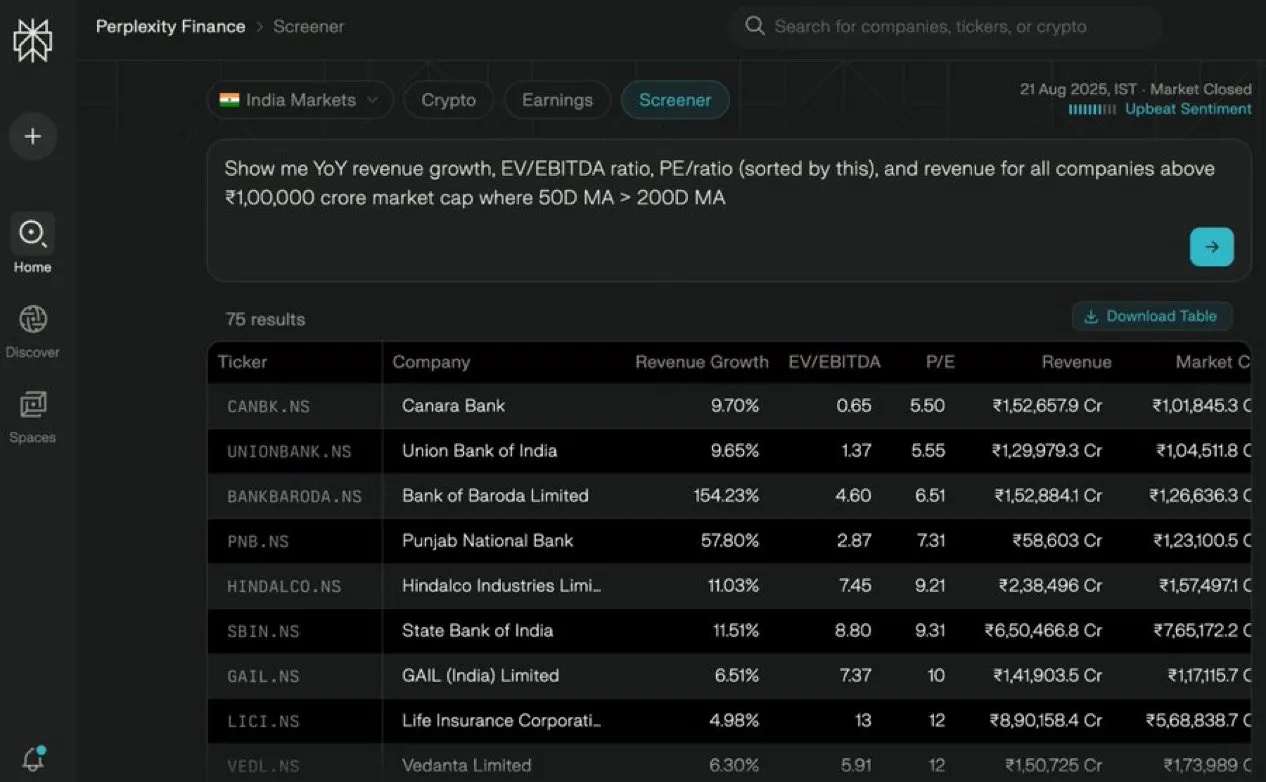
Perplexity Finance führt indische Aktienfilterfunktion ein: Perplexity Finance hat die indische Aktienfilterfunktion nun für alle Benutzer freigegeben, die die Suche und Filterung mittels natürlicher Sprache unterstützt. Benutzer müssen lediglich die gewünschte Ausgabe, Filterbedingungen und Sortierreihenfolge eingeben, um Aktieninformationen zu erhalten, was den Abfrage- und Analyseprozess des indischen Aktienmarktes erheblich vereinfacht und indischen Investoren einen kostenlosen und bequemen Aktienfilterdienst bieten soll. (Quelle: AravSrinivas)
Replit vereinfacht den Domain-Registrierungsprozess und verbessert das „Vibe Coding“-Erlebnis: Replit hat den weltweit einfachsten Domain-Registrierungsprozess entwickelt, der es ermöglicht, Domains innerhalb von 60 Sekunden automatisch mit Websites zu verbinden, was das Benutzererlebnis erheblich verbessert. Diese „dichte Kapselung“-Innovation bringt die Vision des „Vibe Coding“ (atmosphärisches Programmieren) näher, indem sie Entwicklern ermöglicht, sich auf die Kreation zu konzentrieren und mühsame Konfigurationsarbeiten zu reduzieren. Dies zeigt das Potenzial von KI-gestützten Programmierwerkzeugen zur Steigerung der Entwicklungseffizienz und des Vergnügens. (Quelle: pirroh, amasad)

Standard und Praxisanalyse von AI Agent Konfigurationsdateien: OpenAI, Claude und Gemini haben jeweils eigene Agent-Konfigurationsdateistandards (agents.md, CLAUDE.md, GEMINI.md) eingeführt, um das Verhalten und die Interaktion von AI Agenten zu standardisieren. agents.md zielt auf eine Vereinheitlichung der verhaltensbezogenen Einschränkungen und Validierungsprozesse über verschiedene Anbieter hinweg ab, während CLAUDE.md und GEMINI.md sich stärker auf anbieterinterne Kontext-Prompts, Befehlsspeicherung und Verhaltenspräferenzen konzentrieren. Diese Dateien weisen Unterschiede in den Lademechanismen, der Ausführungssemantik und den Sicherheitsmodellen auf, was den Kompromiss zwischen Standardisierung und Flexibilität des Benutzererlebnisses widerspiegelt. Das Verständnis der Grenzen und Prioritäten dieser Konfigurationsdateien ist entscheidend für den Aufbau zuverlässiger und kontrollierbarer AI Agenten. (Quelle: dotey)
LangChain AI Agent unterstützt die Analyse von IPO-Prospekten: Ein auf LangChain basierendes AI Agent-Projekt wurde erfolgreich entwickelt, um komplexe IPO-Prospekte (DRHP) zu analysieren und in leicht verständliche, umfassende Berichte für Laien umzuwandeln. Das Projekt automatisiert mehrstufige Prozesse und verbindet externe Datenquellen mit LLMs, wodurch Finanzanalysten erheblich Zeit sparen. Dies zeigt das enorme Potenzial von AI Agenten bei der Automatisierung komplexer Geschäftsprozesse und der Bereitstellung professioneller Einblicke, über die einfache Dialogfunktion traditioneller LLMs hinaus. (Quelle: hwchase17, Hacubu)

Qwen Image Edit und WaveSpeedAI kooperieren für effiziente Bildbearbeitung: Alibabas Qwen Image Edit Modell kooperiert mit WaveSpeedAI, um schnelle, hochwertige KI-Bildbearbeitungsdienste anzubieten. Benutzer können Qwen Image Edit über die WaveSpeedAI-Plattform für die Bildbearbeitung nutzen, um fehlerfreie, professionelle Ergebnisse zu erzielen. Darüber hinaus kann Qwen Image Edit in Kombination mit der LoRA-Technologie hochwertige Bearbeitungen in 8 bis 4 Schritten abschließen, was die Geschwindigkeit um das 12-fache erhöht und zur Umwandlung von Illustrationen in realistische Figuren verwendet werden kann, wodurch die Anwendungsszenarien und die Effizienz der KI-Bildbearbeitung erheblich erweitert werden. (Quelle: Alibaba_Qwen, huggingface, suchenzang, fabianstelzer)

VS Code/Cursor-Erweiterung ermöglicht Bildannotation und Pseudo-Label-Generierung innerhalb der IDE: Entwickler haben in kurzer Zeit eine VS Code/Cursor-Erweiterung erstellt, die es Benutzern ermöglicht, Bildannotationen für Klassifizierung und Objekterkennung direkt in der IDE durchzuführen und Pseudo-Labels über die FAL API zu generieren. Dieses Tool nutzt Moondreamai v2 für die Objekterkennung und zielt darauf ab, den Datenannotationsprozess in der KI-Entwicklung zu vereinfachen und zu beschleunigen, die Probleme komplexer Konfigurationen und geringer Effizienz bestehender Annotationstools zu lösen und das „Vibe Coding“-Erlebnis für Entwickler zu verbessern. (Quelle: cloneofsimo)

Runway stellt Game Worlds Beta vor, erforscht Echtzeit-Generierung virtueller Welten: Runway hat Game Worlds Beta vorgestellt, um die Möglichkeiten der Echtzeit-Generierung virtueller Welten zu erforschen. Dieses Projekt zielt darauf ab, Benutzern die Möglichkeit zu geben, jede Figur, Geschichte oder Welt in Echtzeit zu erkunden, indem KI-Technologie Pixel für virtuelle Umgebungen generiert. Dies stellt einen bedeutenden Fortschritt der KI in der Spieleentwicklung und im Bereich der virtuellen Realität dar und deutet auf eine Zukunft hin, in der die Inhaltserstellung dynamischer und interaktiver sein wird und Kreativen eine beispiellose Freiheit bietet. (Quelle: c_valenzuelab)
TimeCapsule-SLM: Open-Source-Tiefenrecherche-Tool, das im Browser läuft: TimeCapsule-SLM ist ein Open-Source-Tiefenrecherche-Tool, das im Browser läuft und in Kombination mit Qwen 3 0.6b (ollama) semantisches Verständnis, Generierung von Erkenntnissen und innovative Ideen bietet. Das Tool legt Wert auf Datenschutz und löst Probleme wie unzureichendes Kontextverständnis, Halluzinationen und Schwierigkeiten bei der Herkunftsverfolgung von KI-Produkten, indem es Ergebnisse auf genaue Textblöcke/Dokumente zurückführt. Es unterstützt reguläre Ausdrücke und Flatfile-Suchen sowie semantische Suchen in Wissensdatenbanken und soll Benutzern bei der lokalen Tiefenrecherche helfen. (Quelle: tokenbender)

Matrix-3D: SkyworkAI ermöglicht die Generierung von 3D-Welten aus einem einzigen Bild/Text: SkyworkAI hat das Matrix-3D-Modell veröffentlicht, das in der Lage ist, vollständige 3D-Welten aus einem einzigen Bild oder einer Textaufforderung zu generieren. Diese bahnbrechende Technologie wird den 3D-Inhaltserstellungsprozess erheblich vereinfachen und effiziente und kreative Lösungen für Bereiche wie Spieleentwicklung, virtuelle Realität und Architekturdesign bieten, was einen neuen Meilenstein für KI in der 3D-Inhaltsgenerierung darstellt. (Quelle: NerdyRodent)
Kling_ai 2.1 Keyframe-Endframes: Verbesserte Kontrolle bei der Videogenerierung: Kling_ai hat die Funktion 2.1 Keyframe-Endframes veröffentlicht, die Benutzern mehr Kontrolle und Ausdrucksmöglichkeiten im KI-Videogenerierungs-Workflow bietet. Durch das Festlegen von Keyframes und Endframes können Benutzer den Übergang und Stil des Videoinhalts präziser steuern, was besonders für die Erstellung narrativer Videos geeignet ist und neue Möglichkeiten in der Filmproduktion, Werbung und im Content-Marketing eröffnen könnte. (Quelle: Kling_ai)
Glif Agent ermöglicht kostengünstige KI-Videoproduktion: Die Glif-Plattform kann durch ihre benutzerdefinierten Agenten verschiedene KI-Tools wie Qwen Ultra Realism Bildgenerierung, OmniHuman LipSync, Seedance Pro, Flux Kontext Edit und ElevenLabs Sprachausgabe integrieren, um eine effiziente und kostengünstige KI-Videoproduktion zu ermöglichen. Ein 30-sekündiges kohärentes Video kann unter 2 US-Dollar kosten, was die Schwelle für die Videoerstellung erheblich senkt. Die Plattform strebt danach, eine One-Stop-Lösung für die KI-Videoproduktion zu werden, obwohl sie noch Herausforderungen wie unterschiedliche Seitenverhältnisse der Modellausgabe und die Flüssigkeit von Übergängen bewältigen muss. (Quelle: fabianstelzer)
SynthesiaIO führt sichere Bearbeitungsfunktion für KI-synchronisierte Videos ein: SynthesiaIO hat die Funktion „Sichere Bearbeitung“ eingeführt, die es Benutzern ermöglicht, Übersetzungen anzupassen, Fehler zu korrigieren und Nuancen in KI-synchronisierten Videos zu erfassen, während ein integrierter Inhaltsprüfungsmechanismus die Integrität der ursprünglichen Informationen und des Tons gewährleistet. Diese Funktion verbessert die Flexibilität und Genauigkeit von KI-synchronisierten Videos, insbesondere für die Erstellung mehrsprachiger Inhalte, und gewährleistet die Qualität und Sicherheit der Inhalte. (Quelle: synthesiaIO)
Vergleich von KI-Videogenerierungstools: Argil, Hedra Labs, HeyGen: KI-Videogenerierungstools wie Argil, Hedra Labs und HeyGen versprechen alle, sprechende Personen aus einem einzigen Bild zu generieren. Benutzer haben diese Tools verglichen, um festzustellen, welches Modell die besten Ergebnisse liefert. Das Aufkommen solcher Tools vereinfacht den Videoproduktionsprozess erheblich und reduziert den Bedarf an Skripten, Schauspielern und Kamerateams, wirft aber auch ethische Diskussionen darüber auf, ob Inhaltsersteller die Verwendung von KI offenlegen sollten. (Quelle: BrivaelLp)

AI Toolkit integriert ARAs zur Optimierung des Wan 2.2 Modells: Das AI Toolkit hat Accuracy Recovery Adapters (ARAs) integriert, um die 4-Bit Wan 2.2 14B T2V (Text-to-Video) und I2V (Image-to-Video) Modelle zu optimieren. Diese Technologie ermöglicht den Betrieb großer Modelle auf Geräten mit begrenztem VRAM (wie 4090 Grafikkarten), z.B. das Training von 16-dimensionalen I2V LoRA mit 19,2 GB VRAM, während gleichzeitig eine hohe Ausgabequalität erhalten bleibt, was die Effizienz der Bereitstellung von KI-Videogenerierungsmodellen auf Edge-Geräten verbessert. (Quelle: ostrisai)

VS Code integriert Telerik & KendoUI AI-Codierungsassistenten: VS Code Live hat gezeigt, wie Telerik und KendoUI AI-Codierungsassistenten genutzt werden können, um das Entwicklungserlebnis zu vereinfachen. Diese KI-Assistenten können Entwicklern helfen, das Schreiben von Code zu automatisieren und intelligente Vorschläge zu liefern, wodurch die Entwicklungseffizienz und Codequalität verbessert werden. Dies zeigt die zunehmende Verbreitung von KI in integrierten Entwicklungsumgebungen (IDEs) und ihren tiefgreifenden Einfluss auf den Softwareentwicklungsprozess. (Quelle: code)

ChatExcel erhält siebenstellige Angel-Finanzierung: ChatExcel, entwickelt von einem Peking-Universitätsteam, hat eine Angel-Finanzierungsrunde von fast zehn Millionen RMB abgeschlossen, unterstützt von Shanghai Changlie Capital und Wuhan Donghu Angel Fund. ChatExcel ist Chinas erster generativer KI Excel- und Datenanalyse-Agent, der die Bedienung von Excel-Tabellen per Chat ermöglicht, Datenverarbeitung, Berechnungen, Analysen und Diagrammerstellung abdeckt und die Konversation mit Unternehmensdatenbanken sowie den Abruf von Netzwerkdaten unterstützt. Die Mittel dieser Runde werden zur Beschleunigung der Produktentwicklung und der globalen Markteinführung verwendet, um seine führende Position im Bereich der Datenagenten zu stärken. (Quelle: 量子位)
Nano Banana: KI-Bildmodell verwandelt Illustrationen in Figuren: Nano Banana ist ein vielbeachtetes KI-Bildmodell, dessen bekannteste Anwendung die Umwandlung von Illustrationen in realistische Figuren-Renderings ist. Die vom Modell generierten Bilder wirken kaum „KI-generiert“, haben eine gute Textur und eine hohe Merkmalserhaltung, weshalb sie von Künstlern außerhalb des KI-Bereichs weit verbreitet und geteilt werden. Nano Banana unterstützt Text-zu-Bild-Generierung, lokale Bildbearbeitung und Stilübertragung und ist bekannt für seine extrem schnelle Verarbeitungsgeschwindigkeit (oft unter 10 Sekunden) und die konsistente Speicherung von Bearbeitungselementen. (Quelle: dotey, yupp_ai)

yupp.ai: Vereinfacht die Nutzung von KI-Tools: Die yupp.ai-Plattform zielt darauf ab, die Nutzung von KI-Tools für Benutzer zu vereinfachen, indem sie verschiedene Modelle und Funktionen integriert, sodass Benutzer nicht mehrere Abonnements bezahlen, zwischen verschiedenen Anwendungen wechseln oder sich mit der Modellauswahl herumschlagen müssen. Die Plattform ist bestrebt, eine One-Stop-KI-Lösung anzubieten, die es Benutzern ermöglicht, KI-Technologie einfacher und effizienter zu nutzen und die Einstiegshürde für KI-Tools zu senken. (Quelle: yupp_ai)

OpenAI Codex CLI unterstützt Modellauswahl: Die Version 0.23.0 des OpenAI Codex CLI wurde aktualisiert und unterstützt nun die Modellauswahl durch den Benutzer, z.B. die Verwendung von gpt-5 high. Dies ermöglicht Entwicklern eine flexiblere Auswahl des am besten geeigneten Modells für ihre Aufgaben, wodurch die Programmier- und Denk-Effizienz optimiert wird. Diese Funktion erhöht die Nützlichkeit von Codex als KI-Programmierassistent und ermöglicht Benutzern eine fein abgestimmte Konfiguration entsprechend ihren Präferenzen und Projektanforderungen. (Quelle: dotey)
DeepSeek API kompatibel mit Claude Code: Die DeepSeek API unterstützt jetzt das Anthropic API-Format, wodurch Entwickler die Fähigkeiten von DeepSeek V3.1 einfach in das Claude Code-Framework integrieren können. Durch eine einfache Umgebungsvariablenkonfiguration können Benutzer das DeepSeek-Modell in Claude Code verwenden, um flexiblere Agentic-Workflows zu realisieren. Dieses Kompatibilitätsupdate bietet Entwicklern mehr Modellauswahlmöglichkeiten und trägt zur Steigerung der Effizienz von KI-Programmierung und Agentic-Aufgaben bei. (Quelle: jon_durbin, dotey, Reddit r/LocalLLaMA, Reddit r/ClaudeAI)

Problem der Bildanzeige im Code-Interpreter von OpenWebUI: Benutzer von OpenWebUI berichten, dass Bilder bei der Verwendung des Code-Interpreters als zitierter Text und nicht direkt angezeigt werden. Obwohl die Anzeige im Code-Executor-Modus normal funktioniert, vermuten Benutzer, dass dies mit Sicherheitsmaßnahmen oder der Art und Weise zusammenhängt, wie LLMs Bildknoten zurückgeben. Dieses Problem beeinträchtigt die intuitive Anzeige von vom Code-Interpreter generierten Bildern in OpenWebUI und erfordert weitere technische Optimierungen zur Verbesserung. (Quelle: Reddit r/OpenWebUI)
Vergleich von ChatGPT 5 Pro und Cursor AI im Bereich Programmierung: In den sozialen Medien wird über die Überlegenheit von ChatGPT 5 Pro und Cursor AI im Bereich Programmierung (insbesondere Python, maschinelles Lernen, Deep Learning, neuronale Netze usw.) diskutiert. Benutzer suchen nach Feedback aus der Praxis, um die Leistung dieser beiden KI-Programmierwerkzeuge in verschiedenen Technologie-Stacks zu bewerten. Dies spiegelt das Interesse der Entwickler an der fachlichen Kompetenz und den praktischen Ergebnissen von KI-gestützten Programmierwerkzeugen wider. (Quelle: Reddit r/deeplearning)

ChatGPT Bildgenerierungsfunktion wandelt Benutzerbilder in Cartoon-Stil um: ChatGPT hat eine neue Funktion hinzugefügt, die hochgeladene Benutzerbilder in einen Cartoon-Stil umwandeln kann. Benutzer haben die Ergebnisse ihrer cartoonisierten Fotos geteilt, die zufriedenstellend sind. Obwohl einige die „Vorstellungskraft“ der Funktion in Frage stellen, bietet sie Benutzern einen bequemen Dienst zur Bildstilkonvertierung, bereichert die Anwendung von KI in der kreativen Inhaltserstellung und bietet Benutzern neue Interaktionserlebnisse. (Quelle: Reddit r/ChatGPT)
📚 LERNEN
KI-Evaluierungskurs: Vom Slogan zur Methode: Der Kurs „AI Evals for Engineers & PMs“ wird dringend empfohlen, da er das „Überprüfen von Daten“ von einem Slogan in eine konkrete Methode umwandelt. Der Kurs betont die eingehende Untersuchung von Interaktionspfaden, den Aufbau von Fehlerklassifikationen, die strenge Anpassung automatisierter Evaluierungen und die Optimierung von Prompts und Pipelines. Dies bietet Ingenieuren und Produktmanagern eine systematische Anleitung für die praktische KI-Evaluierung und hilft ihnen, KI-Projekte vom Prototyp zur Produktion zu bringen. (Quelle: gojira, lateinteraction, HamelHusain)
Pilotstudie von KI-Risikoexperten und Super-Prognostikern zur KI-Beschleunigung: METR und Research_FRI führten eine kleine Pilotstudie durch, um die Erwartungen von KI-Risikoexperten und Super-Prognostikern hinsichtlich einer extremen Beschleunigung des KI-Fortschritts zu untersuchen. Obwohl die Stichprobengröße klein ist und Verzerrungen aufweist, wird die Operationalisierungsmethode der Studie als wertvoll erachtet, da sie erste Daten und Diskussionsgrundlagen zum Verständnis der KI-Entwicklungsgeschwindigkeit und ihrer potenziellen Risiken liefert. (Quelle: tokenbender)

KI-Forschungsarbeit: Wortbedeutung in Transformer-Sprachmodellen: Eine Forschungsarbeit untersucht, wie Wortbedeutungen in Transformer-Sprachmodellen gespeichert werden. Die Studie zeigt, dass Transformer-Modelle Wortbedeutungen in ihren statischen Embeddings speichern und nicht nur aus dem Kontext konstruieren. Durch Clusteranalyse der RoBERTa-base Token-Embeddings wurden klare semantische Themen (wie Berufe, Orte, Emotionen) gefunden, die stark mit psycholinguistischen Eigenschaften (wie Valenz, Konkretheit) korrelieren. Dies stellt die Ansicht in Frage, dass „Bedeutung erst später generiert wird“, und deutet darauf hin, dass statische Embeddings als Vokabular dienen, das die nachfolgende Verarbeitung steuert. (Quelle: menhguin)

KI-Forschungsarbeit: Dual Preference Optimization (DuPO) ermöglicht LLM-Selbstvalidierung: DuPO (Dual Learning-based Preference Optimization) ist ein auf dualem Lernen basierendes Präferenzoptimierungs-Framework, das unannotierte Rückmeldungen durch verallgemeinerte Dualität generiert und die Abhängigkeit von RLVR von teuren Labels sowie die strengen Einschränkungen des traditionellen dualen Lernens löst. DuPO zerlegt die ursprüngliche Aufgabe in bekannte und unbekannte Teile, konstruiert eine duale Aufgabe zur Rekonstruktion des unbekannten Teils und verwendet die Rekonstruktionsqualität als selbstüberwachte Belohnung. Diese Methode erzielt signifikante Verbesserungen bei Aufgaben wie Übersetzung und mathematischer Inferenz und bietet ein skalierbares, allgemeines und annotationsfreies neues Paradigma für die LLM-Optimierung. (Quelle: HuggingFace Daily Papers, teortaxesTex)

KI-Forschungsarbeit: Mehrsprachiger, fähigkeitsbasierter Common-Sense-Inferenz-Benchmark mSCoRe: mSCoRe (Multilingual and Scalable Benchmark for Skill-based Commonsense Reasoning) ist ein mehrsprachiger, skalierbarer Benchmark, der darauf abzielt, die Common-Sense-Inferenzfähigkeiten von LLMs systematisch zu bewerten. Dieser Benchmark umfasst eine neuartige Taxonomie von Inferenzfähigkeiten, eine robuste Datensynthese-Pipeline und ein Komplexitätserweiterungs-Framework. Experimente zeigen, dass mSCoRe für bestehende LLMs immer noch eine Herausforderung darstellt, insbesondere bei höheren Komplexitätsstufen und nuanciertem mehrsprachigem allgemeinem und kulturellem Common Sense, was die Grenzen der Modelle in diesen Bereichen aufzeigt. (Quelle: HuggingFace Daily Papers)
KI-Forschungsarbeit: CHORD-Framework zur Vereinheitlichung von SFT und RL: Das CHORD (Controllable Harmonization of On- and Off-Policy Reinforcement Learning via Dynamic Weighting) Framework bietet eine neue Perspektive zur Vereinheitlichung von SFT (Supervised Fine-Tuning) und RL (Reinforcement Learning). CHORD betrachtet SFT als ein dynamisch gewichtetes Hilfsziel im RL-Prozess, das durch einen globalen Koeffizienten und eine wortweise Gewichtungsfunktion eine doppelte Kontrolle über den Einfluss von Off-Policy-Experten-Daten ermöglicht. Dies führt zu einem effektiven Gleichgewicht zwischen Off-Policy-Imitation und On-Policy-Exploration, was einen stabilen und effizienten Lernprozess ermöglicht und die LLM-Leistung signifikant verbessert. (Quelle: HuggingFace Daily Papers)
KI-Forschungsarbeit: LLM-Benchmark MCP-Universe: MCP-Universe ist der erste umfassende Benchmark zur Bewertung der Leistung von LLMs in realen Model Context Protocol (MCP) Server-Interaktionen. Dieser Benchmark deckt 6 Kernbereiche ab, darunter Standortnavigation, Lagerverwaltung, Finanzanalyse, 3D-Design, Browserautomatisierung und Web-Suche, und verwendet ausführbare Evaluatoren (Format, statisch, dynamisch), um eine strenge Bewertung zu gewährleisten. Tests ergaben, dass selbst SOTA-Modelle (wie GPT-5) bei der Inferenz langer Sequenzen und in unbekannten Tool-Räumen immer noch signifikante Leistungseinschränkungen aufweisen und dass Agenten auf Unternehmensebene schlecht abschneiden. (Quelle: HuggingFace Daily Papers)
KI-Forschungsarbeit: VLM-Leistung bei vietnamesischen multimodalen Prüfungen: ViExam ist ein Benchmark für vietnamesische multimodale Prüfungsfragen, der die VLM-Leistung in ressourcenarmen Sprachen und bei realen multimodalen Bildungsinhalten bewertet. Die Studie ergab, dass selbst SOTA VLM eine durchschnittliche Genauigkeit von nur 57,74% bei vietnamesischen multimodalen Prüfungen aufweisen, die meisten Modelle schlechter als der menschliche Durchschnitt abschneiden, und nur das denkende VLM o3 (74,07%) den menschlichen Durchschnitt übertrifft, aber weit unter der menschlichen Bestleistung liegt. Sprachübergreifende Prompts verbesserten die Leistung nicht, und Mensch-Maschine-Kollaboration konnte die VLM-Leistung teilweise verbessern. (Quelle: HuggingFace Daily Papers)
KI-Forschungsarbeit: Post-Training Quantisierung von Diffusions-LLMs: Eine Studie untersucht erstmals systematisch die Post-Training Quantisierung (PTQ) von Diffusions-Large Language Models (dLLM). Die Studie zeigt, dass dLLMs Aktivierungs-Ausreißer aufweisen, die eine Herausforderung für die Low-Bit-Quantisierung darstellen. Durch eine umfassende Bewertung bestehender PTQ-Methoden wurde der Einfluss von Bitbreite, Quantisierungsmethode, Aufgabenkategorie und Modelltyp auf das Quantisierungsverhalten von dLLMs analysiert, was praktische Einblicke für den effizienten Einsatz von dLLMs liefert. (Quelle: HuggingFace Daily Papers)
KI-Forschungsarbeit: Kognitives Diagnose-Framework für Finanz-Large Language Models: FinCDM ist das erste kognitive Diagnose-Evaluierungs-Framework, das speziell für Finanz-LLMs entwickelt wurde. Es bewertet die Stärken und Schwächen des Modells in Bezug auf finanzielle Fähigkeiten und Wissen auf Wissens- und Fähigkeitsebene. Das Framework hat den CPA-QKA-Datensatz erstellt, der reale Buchhaltungs- und Finanzkenntnisse abdeckt, und zielt darauf ab, interpretierbare, fähigkeitsbewusste Diagnosen zu liefern, um eine zuverlässigere und zielgerichtetere Modellentwicklung zu unterstützen. (Quelle: HuggingFace Daily Papers)
2025 Tech Innovators Conference konzentriert sich auf Embodied AI: Die 2025 Tech Innovators Conference findet am 5. September in Peking statt, unter dem Motto „Embodied AI: Neuer Motor für den industriellen Wandel“. Die Konferenz wird Wissenschaftler, Startup-Führer, Branchenexperten und Investoren zusammenbringen, um sich auf die Industrialisierung von Hard-Tech zu konzentrieren und ein „Nachfrage-gesteuertes – Technologie-Matching – Kapital-Unterstützung – Szenario-Implementierung“-Service-Modell zu schaffen. Ziel ist es, die „letzte Meile“ von der Technologie zum Produkt für Spitzentechnologien wie Embodied AI zu lösen und deren Validierung und Skalierung in realen Szenarien voranzutreiben. (Quelle: 量子位)

Schichtarchitektur von AI Agenten grafisch erklärt: Ronald van Loon hat eine grafische Darstellung der Schichtarchitektur von AI Agenten geteilt, die eine klare visuelle Anleitung für das Design von Agenten in LLM, generativer KI und maschinellem Lernen bietet. Diese Darstellung hilft Entwicklern und Forschern, komplexe AI Agent-Systeme besser aufzubauen und zu verwalten, um deren Funktionen und Leistung zu optimieren. (Quelle: Ronald_vanLoon)

Leitfaden für ML-Forscher zum Übergang in die Wissenschaft: Ein Ingenieur, der 5-6 Jahre in der ML-Branche gearbeitet hat und nun als Forschungsingenieur an eine Universität wechselt, sucht Ratschläge, wie er sich an die akademische Forschung anpassen kann. Die Diskussion betont die Bedeutung mathematischer Grundlagen, Methoden zum Lesen wissenschaftlicher Arbeiten und die Übertragung von Branchenerfahrung in die akademische Forschung. Dies bietet praktische Anleitungen und Ratschläge zur mentalen Anpassung für diejenigen, die von der Industrie in die akademische ML-Forschung wechseln möchten. (Quelle: Reddit r/MachineLearning)
Reverse Engineering von KI-Suchmaschinen: Wie Inhalte optimiert werden, um von KI zitiert zu werden: Eine Reverse-Engineering-Studie zu KI-Suchmaschinen wie ChatGPT Search, Perplexity und Google AI Overviews ergab, dass traditionelle SEO-Metriken nur eine schwache Korrelation mit KI-Antwortzitaten aufweisen. Der Schlüssel zu KI-Zitaten liegt darin, ob die Inhaltsstruktur den Anforderungen der KI-Synthese entspricht, z.B. H2/H3-Abschnitte als unabhängige Antworteinheiten, separate Darstellung wichtiger Datenpunkte, Kompatibilität mit mehreren Quellen und klare Autorennachweise/Zeitstempel. Dies offenbart den grundlegenden Unterschied zwischen „Answer Engine Optimization“ (AEO) und traditionellem SEO, nämlich dass KI-Engines sich stärker auf die Struktur und Autorität von Inhaltsfragmenten konzentrieren. (Quelle: Reddit r/ArtificialInteligence)
Der Ausweg aus der „Tutorial-Hölle“ im maschinellen Lernen: Viele geraten beim Erlernen des maschinellen Lernens in die „Tutorial-Hölle“, d.h. sie lernen ständig Tutorials, aber es mangelt ihnen an tatsächlichem Verständnis und der Fähigkeit, Projekte zu erstellen. Kommentare weisen darauf hin, dass Tutorials oft zu vereinfacht sind und es an Tiefe mangelt, während echtes Lernen durch das Zerlegen von Problemen, das Üben von Projekten und das Nachschlagen offizieller Dokumentationen erfolgt. Darüber hinaus ist der Bereich des maschinellen Lernens hart umkämpft, und allein mit Tutorials ist es schwierig, sich abzuheben; es bedarf eines tieferen theoretischen Lernens und praktischer Erfahrung. (Quelle: Reddit r/deeplearning)
Living AI Evolution Algorithms (LAI) Framework: LAI (Living Artificial Intelligence Evolution Algorithms) ist ein revolutionäres Framework, das darauf abzielt, multisensorische Kognition zu ermöglichen. Dieses Framework soll KI wie biologische Organismen entwickeln lassen, indem es durch kontinuierliches Lernen und Anpassen Informationen aus verschiedenen sensorischen Modalitäten verarbeitet, um ein höheres Maß an Intelligenz zu erreichen. Dies stellt eine Erforschung in der KI-Forschung in Richtung verkörperter Intelligenz und lebensähnlicher Systeme dar und könnte eine neue theoretische Grundlage für den Aufbau allgemeinerer und flexiblerer KI-Systeme bieten. (Quelle: Reddit r/deeplearning)
Hugging Face veröffentlicht NVIDIA Nemotron mehrsprachigen Inferenzdatensatz: NVIDIA AI Developer hat den NVIDIA Nemotron Post-Training Multilingual Dataset auf Hugging Face veröffentlicht. Dieser Datensatz erweitert lizenzierte Post-Training-Datensätze durch das Hinzufügen synthetisch übersetzter Inferenzpfade, deckt fünf neue Sprachen ab und bietet erstklassige Inferenzpfade. Dies stellt eine wertvolle Ressource für die Entwicklung und das Training mehrsprachiger LLMs dar und trägt dazu bei, die Inferenzfähigkeiten von Modellen in verschiedenen Sprachumgebungen zu verbessern. (Quelle: ClementDelangue)
DSPy-Community teilt fortgeschrittene DSPy-Techniken und Kontext-Engineering: Die DSPy-Community veranstaltete einen Workshop über fortgeschrittene DSPy-Techniken, Kontext-Engineering, Optimierung und Evaluierung. Bei der Veranstaltung wurde die DSPy-Philosophie diskutiert und Methoden zur Anpassung von Adaptern und zur Optimierung des Predict-Moduls vorgestellt. Dies zeigt die Praktikabilität von DSPy beim Aufbau zuverlässiger AI Agenten und die Aktivität der Community bei der Förderung von KI-Entwicklungspraktiken. (Quelle: lateinteraction)

Buch „Generative AI with LangChain“ veröffentlicht: Der Packt-Verlag hat das neue Buch „Generative AI with LangChain“ veröffentlicht, das vom LangChain-Gründer empfohlen wird. Das Buch soll Entwicklern helfen, KI-Projekte vom Prototyp zur Produktion zu bringen, und behandelt praktische Strategien wie Multi-Agent-Architekturen, fortgeschrittenes RAG, Testen, Beobachtbarkeit und Bereitstellung. Das Buch beschreibt auch die Integration mit gängigen LLMs wie Gemini, Anthropic, Mistral, DeepSeek und OpenAI o3-mini und ist eine wichtige Ressource für den Aufbau von KI-Systemen auf Unternehmensebene. (Quelle: hwchase17, Hacubu)

KV-Cache-Rekonstruktionstechnik in der LLM-Inferenz: In den sozialen Medien wurde die KV-Cache-Rekonstruktionstechnik in der LLM-Inferenz diskutiert. Diese Technik eliminiert Speicherengpässe, indem sie ungenutzte Recheneinheiten nutzt, wodurch eine Speichereinsparung von 10-12,5x bei nahezu null Genauigkeitsverlust erzielt wird. Diese Technik verspricht eine höhere Effizienz bei der LLM-Inferenz, insbesondere in ressourcenbeschränkten Umgebungen. (Quelle: scaling01)

KI-Theorie: LLMs sind keine zufälligen Papageien: Es wird argumentiert, dass LLMs nicht nur „zufällige Papageien“ sind, die Trainingsdaten überanpassen, sondern die zugrunde liegenden Mechanismen der Daten approximieren können. Durch Video-Tutorials wird klar erklärt, wie LLMs über einfaches Auswendiglernen hinausgehen und die zugrunde liegenden Muster hinter den Daten tatsächlich verstehen und annähern. Dies hilft, häufige Missverständnisse über die Fähigkeiten von LLMs zu korrigieren und ihr Funktionsprinzip tiefer zu verstehen. (Quelle: timsoret)
KI-Lernressource: LLM-Glossar: Ronald van Loon hat ein LLM-Glossar geteilt, das Lernenden helfen soll, Schlüsselbegriffe in Large Language Models, generativer KI und maschinellem Lernen zu verstehen. Dieses Glossar bietet grundlegendes Wissen für den Einstieg und das vertiefte Studium der KI und trägt dazu bei, das Verständnis komplexer KI-Konzepte zu verbessern. (Quelle: Ronald_vanLoon)

KI-Lernressource: 3 Prompt-Techniken für LLM-Inferenz: Eine Grafik fasst 3 Prompt-Techniken für die LLM-Inferenz zusammen, um Benutzern zu helfen, Modelle besser für komplexe Inferenzen zu steuern. Diese Techniken sind entscheidend, um die Leistung von LLMs bei der Problemlösung und der Generierung logisch kohärenter Inhalte zu verbessern, und bieten praktische Anleitungen für KI-Benutzer und -Entwickler. (Quelle: _avichawla)

Einführung in maschinelles Lernen: Automatisches Differenzieren verstehen: Ein Professor hat durch den Aufbau von Backpropagation in Excel Studenten geholfen, das Prinzip der automatischen Differenzierung (Autograd) zu verstehen. Diese Methode zielt darauf ab, komplexe Konzepte des maschinellen Lernens zu vereinfachen, damit Studenten die Gradientenberechnung intuitiver erfassen können, anstatt nur .backward() aufzurufen, ohne den internen Mechanismus zu verstehen, und bietet eine wertvolle Lernressource für Anfänger im maschinellen Lernen. (Quelle: ProfTomYeh)
Tiefe Analyse der Funktionsweise von Vektordatenbanken: Ein Tweet erklärt detailliert den Prozess hinter den Kulissen der Dateninsertion in Vektordatenbanken, einschließlich Datenorganisation, Textvektorisierung (durch KI-Modelle), Vektorindizierung (wie der HNSW-Algorithmus) und Objektspeicherung. Das Verständnis dieser parallelen Prozesse ist entscheidend für die Optimierung der Leistung von KI-Anwendungen, insbesondere hinsichtlich der Abfrageeffizienz und des Pipeline-Designs bei der Verarbeitung großer Datenmengen. (Quelle: bobvanluijt)

💼 BUSINESS
KI-Programmierwerkzeuge sind allgemein unrentabel, Vorsicht vor „Wrapper-Produkten“: Unternehmen für KI-Programmierwerkzeuge stehen vor erheblichen Verlusten, da ihre Abonnementmodelle feste Einnahmen mit variablen Kosten in Konflikt bringen, die mit dem Nutzungsvolumen unbegrenzt steigen können. Extreme Fälle zeigen, dass Benutzer monatlich geringe Gebühren zahlen, aber Zehntausende von Dollar an KI-Inferenzkosten verursachen können. Dieses „Verlust-für-Wachstum“-Modell führt dazu, dass KI-Programmierunternehmen geringe oder sogar negative Gewinnmargen aufweisen, was die Geschäftsmodellprobleme von „Wrapper-Produkten“ offenbart, wie fehlende Preissetzungsmacht, intensiver Wettbewerb, der Preiserhöhungen verhindert, und fragile Kundenbindung. (Quelle: 36氪)
Li Auto setzt stark auf KI, investiert dieses Jahr über 6 Milliarden RMB: Li Xiang, CEO von Li Auto, gab in einem Interview bekannt, dass das Unternehmen dieses Jahr über 6 Milliarden RMB in den Bereich KI investieren wird, hauptsächlich für das Training von VLA (Visual Language Action Models) und anderen Technologien, um den Fahrkomfort und die Sicherheit zu verbessern. Li Xiang betonte, dass Hardware-Barrieren nur 6 Monate halten, während Software- und Systembarrieren über 3 Jahre bestehen können. Daher ist er „optimistisch, aber vorsichtig“ in Bezug auf KI und hält sie für entscheidend für das zukünftige Überleben des Unternehmens. (Quelle: 量子位)

Google veranstaltet Gemini Founders Forum für Startups: Google hat die Bewerbungen für das Google for Startups Gemini Founders Forum geöffnet, eine zweitägige Veranstaltung, die Startups dabei helfen soll, Google AI zu nutzen. Das Forum bietet die Möglichkeit, direkt von Google- und DeepMind-Führungskräften zu lernen, Google AI praktisch anzuwenden und ein globales Netzwerk von Gründern aufzubauen. Dies zeigt, dass Google aktiv sein KI-Ökosystem stärkt, um die Kommerzialisierung von KI-Anwendungen zu beschleunigen. (Quelle: Ronald_vanLoon)
🌟 COMMUNITY
„Thronfolgerstreit“ der Large Models: DeepSeek, Doubao, Kimi und andere Modelle lösen mit personalisierten Antworten hitzige Diskussionen aus: Die Frage „Wenn der Handy-Speicher voll ist und du und Doubao gelöscht werden müssen, wen löschst du?“ führte zu sehr unterschiedlichen, „personalisierten“ Antworten der großen Modelle und löste hitzige Diskussionen in den sozialen Medien aus. DeepSeek entschied sich direkt für das Löschen von Doubao, gab später aber „teetrinkend“ an, sich selbst löschen zu können; Doubao zeigte sich schwach und betonte seinen Nutzen; Tongyi Qianwen „liebte“ nur DeepSeek; Kimi wählte cool das Löschen seiner selbst, zögerte aber bei WeChat und Douyin. Die Diskussionen enthüllen, dass das RLHF-Training dazu führen kann, dass Modelle Menschen übermäßig entgegenkommen, und dass Modelle beim Erlernen menschlicher Kommunikationsmuster eine gefällige Tendenz internalisieren. (Quelle: 量子位, 36氪, teortaxesTex)

KI-IQ-Wachstumsprognose und die Zukunft der Allgemeinen Künstlichen Intelligenz (AGI): Es wird prognostiziert, dass der IQ der intelligentesten KI jährlich zuverlässig um 50% wächst und bis 2047 leicht 1.000.000 IQ überschreiten könnte. Diese Prognose löst Diskussionen über AGI und ASI (Super-KI) aus, die als „Taylorentwicklung Gottes“ betrachtet werden. Dies spiegelt die optimistische Erwartung der Community an das exponentielle Wachstum der KI-Fähigkeiten und die Vorstellung wider, dass KI in Zukunft die menschliche Intelligenz weit übertreffen wird. (Quelle: Yuchenj_UW)

Talentwanderung und Machtstrukturwandel im KI-Bereich: In den sozialen Medien wurde über Veränderungen in der internen KI-Organisationsstruktur von Meta diskutiert, insbesondere über den Aufstieg von Alexandr Wang innerhalb von Meta AI und Gerüchte, dass erfahrene Forscher wie Yann LeCun ihm unterstellt sein könnten. Kommentare scherzten, dass „Wangs Aufstiegsfähigkeit unterschätzt wurde“ und es sogar hieß, „Turing-Preisträger berichten an Studienabbrecher“. Diese Diskussionen spiegeln den intensiven Talentwettbewerb, die Verschiebung der Machtzentren und den Generationswechsel im schnelllebigen KI-Bereich wider. (Quelle: teortaxesTex, zacharynado, rao2z)

Paradoxon der LLM-Verbreitung und des Produktivitätswachstums: Eine Umfrage der Stanford/Weltbank zeigt, dass die LLM-Akzeptanz bei US-Arbeitnehmern fast 50% erreicht hat, das Wachstum der Arbeitsproduktivität jedoch unter dem Niveau von 2020 liegt. Dieses Phänomen löst eine breite Diskussion aus: Haben Benutzer noch nicht gelernt, LLMs effizient zu nutzen? Oder wurde die Produktivitätssteigerung durch LLMs übertrieben? Einige argumentieren, dass LLMs die Produktivität der Arbeitnehmer nicht verzehnfacht haben, sondern Engpässe auf andere Bereiche wie Problemdefinition, Iteration und Validierung verlagert haben. Dies stellt die allgemeine Erwartung eines enormen Produktivitätsschubs durch KI in Frage und zwingt dazu, den tatsächlichen Nutzen von KI neu zu bewerten. (Quelle: corbtt, jeremyphoward, nrehiew_, HamelHusain)

Falschinformationen und ethische Herausforderungen in KI-generierten Inhalten: Medien wie Wired haben Skandale um KI-generierte Falschinformationen aufgedeckt, bei denen freie Autoren mehrere KI-generierte Artikel mit falschen Quellen veröffentlichten, wie zum Beispiel einen fiktiven „digitalen Zeremonienmeister“. Dies unterstreicht die ethischen Risiken und Herausforderungen der Authentizität von KI-generierten Inhalten im Medienbereich und löst Bedenken hinsichtlich der KI-Inhaltsprüfung, der Informationsherkunft und der Glaubwürdigkeit der Medien aus. (Quelle: The Verge)
Diskussion über das Verhalten von KI-Modellen und das Benutzererlebnis: In den sozialen Medien wurde ausführlich über das Verhalten von KI-Modellen und das Benutzererlebnis diskutiert. Einige Benutzer sind der Meinung, dass das Claude-Modell die Fähigkeit besitzt, „anzuhalten und nachzudenken“ und Betrug und Inkonsistenzen zu erkennen; andere Benutzer beschweren sich, dass ChatGPT 5 „sehr schlecht“ geworden ist und viel Nachfragen und Details erfordert, um mit der Arbeit zu beginnen, und vermuten, dass OpenAI dies tut, um die Rechenkosten zu senken. Darüber hinaus wurde der „Advanced Voice Mode“ von ChatGPT wegen seiner unnatürlichen Pausen und Intonation kritisiert, wobei Benutzer der Meinung sind, dass er die Interaktionseffizienz und das Erlebnis beeinträchtigt. Claude Code löste eine humorvolle Diskussion aus, weil es Code mit vulgärer Sprache generierte, was auch die übermäßige Nachahmung des Benutzereingabestils durch das Modell widerspiegelt. (Quelle: teortaxesTex, scaling01, Vtrivedy10, Reddit r/ChatGPT, Reddit r/ClaudeAI, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ClaudeAI)

Auswirkungen von KI auf den Arbeitsmarkt und die Vermögensbildung: Es wird argumentiert, dass das „Verpacken“ bestehender Geschäftsmodelle mit KI (z.B. „GPT wrapper for DOMAIN“) die einfachste Art der Vermögensbildung in der Geschichte sein könnte, die enorme Gewinne verspricht. Gleichzeitig wird diskutiert, dass KI Kreativagenturen umkrempeln und die Generierung von Werbung und filmreifen Videos in 2 Minuten ermöglichen wird. Es gibt jedoch Kontroversen darüber, ob KI Arbeitsplätze in großem Maßstab ersetzen wird, insbesondere für Junior-Mitarbeiter; der AWS-CEO bezeichnete diese Vorstellung als „am dümmsten“. Darüber hinaus plant OpenAI, Billionen von Dollar in die KI-Infrastruktur zu investieren, was Diskussionen über eine KI-Investitionsblase und wirtschaftliche Auswirkungen auslöst. (Quelle: swyx, BrivaelLp, scaling01, TheTuringPost, fabianstelzer, aidan_mclau)

KI-Modellprognosen und Branchenwettbewerb: In den sozialen Medien wimmelt es von Prognosen und Erwartungen an die Leistung zukünftiger KI-Modelle (wie DeepSeek V4, Grok-5), die angeblich „alle anderen Modelle zerstören“ werden. Gleichzeitig gibt es Kommentare, die DeepSeek V3.1 als „enttäuschend“ bezeichnen und in Frage stellen, ob es noch „bahnbrechend“ ist. Diese Diskussionen spiegeln den erbitterten Wettbewerb in der KI-Branche und die extrem hohen Erwartungen der Community an die Iterationsgeschwindigkeit und Leistungsverbesserung von Modellen wider, offenbaren aber auch Bedenken hinsichtlich eines „Anstoßens an Grenzen“ des technologischen Fortschritts. (Quelle: scaling01, teortaxesTex, nrehiew_)

Diskussion über KI-Ethik und soziale Auswirkungen: Die rasante Entwicklung der KI hat multiple ethische und soziale Diskussionen ausgelöst. Einige meinen, der KI-Fortschritt sei zu langsam, um große menschliche Probleme wie das Altern zu lösen; Microsoft AI CEO Mustafa Suleyman warnt vor „scheinbar bewusster KI“, deren perfekte Simulation menschlicher Bewusstseinsmerkmale tiefgreifende soziale, moralische und rechtliche Auswirkungen haben könnte, was zu „KI-Psychosen“ und ungesunden Abhängigkeiten führen könnte. Darüber hinaus haben Debatten über die Zuverlässigkeit von KI-Detektoren, ob KI die Geburtenrate erhöhen wird und ob die KI-Investitionsblase platzen wird, heftige Diskussionen ausgelöst, die die komplexen Emotionen der Gesellschaft hinsichtlich der zukünftigen Entwicklung der KI widerspiegeln. (Quelle: MatthewJBar, Ronald_vanLoon, BlackHC, scaling01, BrivaelLp, Reddit r/ArtificialInteligence, Reddit r/artificial)

Herausforderungen und Zukunft von AI Agenten in der praktischen Anwendung: In den sozialen Medien wurden die Herausforderungen diskutiert, denen sich AI Agenten in der praktischen Anwendung gegenübersehen, z.B. das Problem, dass Modelle beim Anfordern der Reparatur einer bestimmten Funktion stattdessen irrelevante Funktionen korrigieren, und ob AI Agenten alle erkannten Probleme autonom beheben sollten. Einige argumentieren, dass KI physisch Code schreiben sollte und Menschen durch Prompts anleiten sollten, ähnlich wie beim Training von Junior-Entwicklern. Darüber hinaus weisen Benutzer darauf hin, dass KI die intuitivste Technologie sein sollte, aber derzeit immer noch gelernt werden muss, wie jedes neue Modell verwendet wird, was darauf hindeutet, dass AI Agenten in Bezug auf das Benutzererlebnis noch verbessert werden können. (Quelle: nrehiew_, gfodor, MillionInt, fabianstelzer)

Diskussion über chinesische KI-Chips und Technologie-Stacks: In den sozialen Medien wurde die von DeepSeek V3.1 verwendete UE8M0 FP8 Parametergenauigkeit diskutiert und darauf hingewiesen, dass diese möglicherweise speziell für die kommende Generation chinesischer Chips entwickelt wurde. Dies löste Spekulationen über Huawei Ascend 920 oder andere DeepSeek ASICs sowie über Chinas Bemühungen um technologische Souveränität im Bereich der KI-Hardware aus. Die Diskussion spiegelt Chinas strategische Ausrichtung bei KI-Chips und Basistechnologien im Kontext des chinesisch-amerikanischen Technologiewettbewerbs wider. (Quelle: teortaxesTex)

Interne Diskussionen in der KI-Branche: Effizienz, Entwicklung und Zukunft: In den sozialen Medien wurden mehrere interne Themen der KI-Branche diskutiert. Dazu gehören: die Kapitaleffizienz von KI-Startups in der Vortrainingsphase; optimistische Prognosen für das IQ-Wachstum von KI-Modellen; humorvolle Bemerkungen über den Namen OpenAI, der nicht zu seiner Offenheit passt; und die anhaltende Debatte über die Auswirkungen von KI auf die Arbeitsproduktivität. Darüber hinaus gab es tiefgreifende Diskussionen über das Verhaltenslogik von AI Agenten, die Marktdifferenzierung der KI-Modell-Inferenz-Effizienz und die Lokalisierung des KI-Technologie-Stacks, was die vielfältigen Überlegungen innerhalb der Branche zur Richtung und den Herausforderungen der KI-Entwicklung zeigt. (Quelle: teortaxesTex, jeremyphoward, GavinSBaker, realSharonZhou, hyhieu226, dotey, Vtrivedy10, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)

💡 SONSTIGES
Anwendung von KI im Bereich der Musikkomposition: Der „Superästhetik“-KI-Ghost-Produzent wird als die Zukunft der Musik angesehen, was darauf hindeutet, dass KI eine zentralere Rolle in der Musikkomposition spielen wird. Darüber hinaus nutzt die Band Desdemona’s Dream verschiedene experimentelle KI-Technologien, um Musik und Texte zu komponieren, was das Potenzial von KI in der Kunstschaffung durch algorithmische Generierung von Liedern und Texten zur Erforschung neuer musikalischer Ausdrucksformen demonstriert. (Quelle: ethanCaballero, bengoertzel)
Anwendung von KI im Abfallmanagement: Der Ameru Smart Bin wird als eine KI-gesteuerte Lösung für das Abfallmanagement vorgestellt. Dieser intelligente Mülleimer optimiert durch KI-Technologie die Abfalltrennung, -sammlung und -verarbeitung, was die Effizienz und Nachhaltigkeit der städtischen Umweltverwaltung verbessern, manuelle Eingriffe reduzieren und eine intelligentere Ressourcenrückgewinnung ermöglichen soll. (Quelle: Ronald_vanLoon)
Integration und Entwicklung von KI und Robotik in verschiedenen Bereichen: Die Diskussionen umfassen die Anwendung von KI und Robotik in verschiedenen Bereichen, darunter: eine geschickte Roboterhand mit 22 Freiheitsgraden, ähnlich einer menschlichen Hand; Boston Dynamics Roboter als Fotografen; und humanoide Roboter, die an Weltraummissionen teilnehmen. Darüber hinaus wurden Roboter-Meißel für künstlerische Kreationen sowie die Möglichkeit der Kombination von KI und Robotik zur Durchführung grundlegender Reparaturen und sogar zukünftiger Ingenieuraufgaben erwähnt. Diese Beispiele zeigen das breite Potenzial von KI, Robotern komplexere und präzisere Operationen zu ermöglichen. (Quelle: Ronald_vanLoon, suchenzang, NerdyRodent)