
키워드:지프AI, AutoGLM, GPT-5 Pro, DeepSeek V3.1, GLM-4.5 언어 모델, Seed-OSS, AI 에이전트, 구신 지능, 대형 언어 모델, 스마트폰 범용 에이전트, 수학 경계 증명, 혼합 추론 아키텍처, 512K 컨텍스트 윈도우
🔥 포커스
즈푸, 세계 최초 모바일 범용 Agent 출시 : 즈푸AI가 세계 최초의 모바일 범용 Agent인 AutoGLM을 공식 출시했습니다. 이 Agent는 앱 간 작업 실행을 지원하며, 클라우드에서 실행되어 로컬 기기 자원을 차지하지 않습니다. AutoGLM은 모든 사용자에게 클라우드 폰과 클라우드 PC를 제공하여, 로컬 컴퓨팅 자원 제한 및 자원 점유 문제를 해결했습니다. 그 능력은 즈푸의 GLM-4.5 언어 모델과 GLM-4.5V 시각 추론 모델을 기반으로 합니다. 이는 휴대폰 조작의 지능화와 편의성을 크게 향상시키고, 대중에게 무료로 공개되어 Agent 기술의 소비자 시장 보급을 촉진할 것으로 기대됩니다. 즈푸는 또한 “3A 원칙”(상시, 자율 작동 무간섭, 전 영역 연결)을 제시하며, Agent 능력을 더 많은 매체로 확장하여 범용 인공지능으로의 전환을 가속화하는 것을 목표로 합니다. (来源: 量子位)

GPT-5 Pro, 수학 연구에서 돌파구 마련 : OpenAI 연구원 Sebastien Bubeck은 GPT-5 Pro가 볼록 최적화(convex optimization) 문제에서 독립적인 사고와 추론을 통해 기존 논문보다 더 정확한 수학적 경계 증명을 제시했다고 밝혔습니다. OpenAI 사장 Brockman은 이 성과를 “생명의 징후”라고 칭했습니다. 모델은 인터넷 연결이나 기억 없이 단지 볼록 최적화 논문 한 편을 읽는 것만으로 17.5분 만에 경계를 1/L에서 1.5/L로 정밀하게 만들었습니다. 비록 이후 인간 저자가 논문을 업데이트하여 경계를 더욱 정밀하게 만들었지만, GPT-5 Pro의 증명 방식은 인간과 독립적이었으며, 자율적으로 수학적 법칙을 탐색하고 증명하는 능력을 보여주어 LLM이 범용 인공지능으로 나아가는 중요한 발걸음을 의미합니다. (来源: Sebastien Bubeck, Reddit r/artificial, Reddit r/ChatGPT)

Meta, AI 채용 동결, 업계 거품 우려 증폭 : Meta는 “초지능 연구소”의 AI 직원 채용을 동결한다고 발표했습니다. 앞서 Meta는 수천만 달러의 보수를 지급하며 50명 이상의 AI 연구원과 엔지니어를 대거 채용했지만, 높은 지출과 투자자들의 압력으로 인해 전략을 조정하게 되었습니다. 이러한 움직임은 AI 산업에 거품이 있을 수 있다는 시장의 우려를 불러일으켰지만, 일부에서는 AI 거품 붕괴가 아니라 조직 구조 조정으로 해석하기도 합니다. 모델 훈련에 많은 직원이 필요하기보다는 정예 전문 팀이 더 중요할 수 있기 때문입니다. 이 결정은 기술 혁신 추구와 비용 통제 사이에서 AI 기업들이 겪는 균형 문제, 그리고 AI 산업의 인재 비용 및 상업적 지속 가능성에 대한 광범위한 논의를 반영합니다. (来源: The Verge, Reddit r/ArtificialInteligence)

🎯 동향
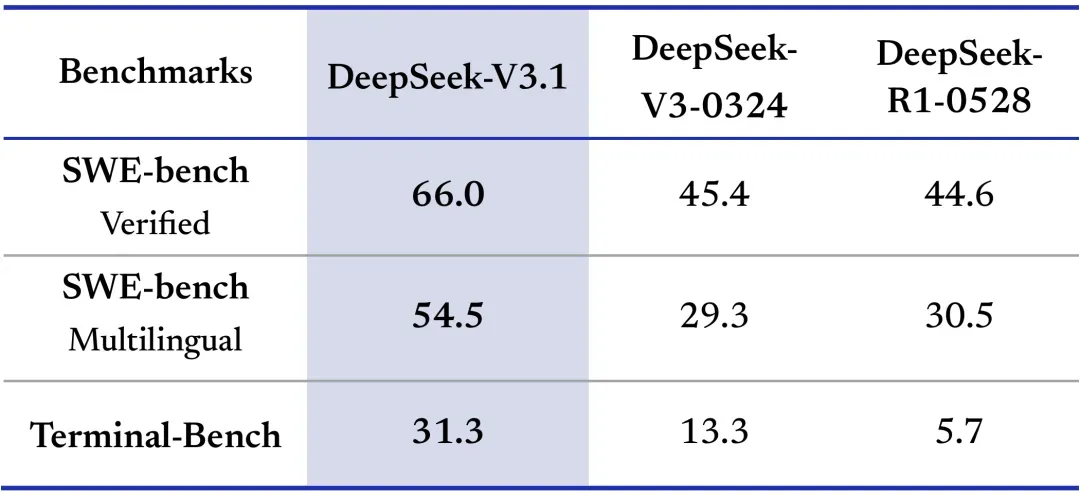
DeepSeek, V3.1 모델 출시, Agent 시대 선도 : DeepSeek이 V3.1 모델을 공식 출시하며 Agent 시대로의 진입을 알렸습니다. 이 모델은 “하이브리드 추론” 아키텍처를 채택하여 사고 모드와 비사고 모드를 모두 지원하며, 자율적으로 전환할 수 있습니다. V3.1은 프로그래밍 능력에서 뛰어난 성능을 보이며, 특히 Aider 코딩 테스트에서 Claude 4 Opus와 Gemini 2.5 Pro를 능가하여 오픈소스 프로그래밍 부문 1위를 차지했습니다. 모델 파라미터는 671B(활성화 파라미터 37B)이며, 컨텍스트 길이는 128k에 달하고, 훈련 과정에서 장문서 데이터셋을 확장하여 총 훈련량이 크게 증가했습니다. 또한, DeepSeek V3.1은 도구 호출 및 다단계 추론 능력을 강화했으며, Anthropic API 형식을 지원하여 Claude Code와 같은 프레임워크에 쉽게 연결할 수 있습니다. (来源: DeepSeek Blog, 量子位, huggingface, ArtificialAnlys, karminski3, teortaxesTex, scaling01, nrehiew_, reach_vb, iScienceLuvr, multimodalart, _akhaliq, zizhpan, ClementDelangue, fabianstelzer, QuixiAI)
바이트댄스, Seed-OSS 시리즈 대규모 모델 오픈소스화 : 바이트댄스 Seed 팀이 갑작스럽게 360억 파라미터 규모의 Seed-OSS 시리즈 대규모 모델인 Seed-OSS-36B를 Apache-2.0 라이선스로 오픈소스화했습니다. 이는 학술 및 상업적 목적으로 무료로 사용할 수 있습니다. 이 모델은 기본적으로 512K의 초장문 컨텍스트 창을 지원하며, 이는 주류 모델의 4배에 달하고 사전 훈련 단계에서 구축되었습니다. Seed-OSS는 “사고 예산” 메커니즘을 도입하여 사용자가 모델의 사고 깊이를 제어할 수 있도록 합니다. 여러 벤치마크 테스트에서 Seed-OSS-36B-Base는 MMLU-Pro, BBH, GSM8K, MATH, HumanEval 등에서 오픈소스 모델 기록을 경신하며 강력한 지식 이해, 추론 및 코드 능력을 보여주었습니다. (来源: 量子位, ClementDelangue, reach_vb)

구글 Pixel 10 시리즈, AI 기능 심층 통합 : 구글이 새로 출시한 Pixel 10 시리즈 휴대폰은 AI 기능을 하드웨어와 시스템 애플리케이션에 깊이 통합했습니다. 모든 기본 소프트웨어는 AI화되어 AI 건강 코치 및 AI 사진/촬영 가이드 기능을 포함합니다. AI 기능은 더 이상 능동적인 트리거에 국한되지 않고, 적절한 상황에서 자동으로 제안을 팝업하며 여러 시스템 앱 간의 AI 기능 연동을 구현합니다. 온디바이스 모델이 이미지 수정, 디지털 줌 디테일 보충, 통화 실시간 번역 등에 대량 사용됩니다. 또한, 구글은 Gemini 추론 환경 영향에 대한 상세 기술 보고서를 발표하여, 에너지 소비 및 물 소비가 대중의 예상보다 훨씬 낮으며 효율성이 지속적으로 향상되고 있음을 밝혔습니다. (来源: op7418, TheRundownAI, Google, dotey, demishassabis, algo_diver)

NASA와 IBM, 태양 활동 해독 AI 모델 Surya 공개 : NASA와 IBM이 협력하여 Hugging Face에 Surya를 오픈소스화했습니다. 이는 태양 물리학을 위한 최초의 오픈소스 AI 기반 모델입니다. 이 모델은 3억 6천 6백만 개의 파라미터를 가지고 있으며, NASA 태양 역학 관측소의 9년치(약 218TB) 다중 기기 데이터로 사전 훈련되었습니다. 연구자들이 우주 날씨를 접근 가능하고 정확하게 모델링하여 인프라를 보호하는 데 도움을 주는 것을 목표로 하며, 태양 폭풍 예측 방식을 혁신할 것으로 기대됩니다. (来源: clefourrier)

지리 은하 M9, 업계 최초 AI 조종석 선탑재 : 지리(Geely)가 차세대 AI 조종석 운영체제 Flyme Auto 2를 발표했으며, Lynk & Co 10 EM-P와 지리 은하 M9에 선탑재될 예정입니다. 이 조종석은 지리 싱루이 AI 대규모 모델, 계단형 성진(Jieyue Xingchen) 엔드투엔드 음성 대규모 모델, 유동 기억 대규모 모델을 기반으로 하며, 초인간적인 지능형 Agent인 Eva를 선보입니다. Eva는 높은 감성 상호작용과 강력한 행동력을 갖추고 있으며, 스스로 판단, 계획 및 작업을 실행할 수 있고, 전 시나리오 AI Agent 다기능 애플리케이션을 지원하여 “인간-차량-환경”의 자율 협력 지능형 공간을 구현하는 것을 목표로 합니다. 지리는 또한 업계 최초로 200TOPS의 컴퓨팅 파워를 가진 AI Box를 출시하여 온디바이스 멀티모달 대규모 모델을 지원합니다. (来源: 量子位)
유니트리, 180cm 발레 휴머노이드 로봇 출시, 자유도 31개 : 유니트리 테크놀로지(Unitree Robotics)가 네 번째 휴머노이드 로봇 “발레 댄서”를 출시할 예정이라고 예고했습니다. 이 로봇은 키 180cm에 전신 31개의 자유도를 가지며, 날씬한 체형과 우아한 자세를 자랑합니다. 이 로봇은 이전 세대를 뛰어넘는 민첩성을 보여줄 것으로 기대되며, 형태의 인간화에서도 돌파구를 마련할 것으로 보입니다. 이는 유니트리가 휴머노이드 로봇 제품 라인을 더욱 세분화하여 “전체 크기 + 전체 시나리오 + 전체 가격대”의 전략적 배치를 구축하고 있으며, 로봇 시장 점유율을 높이는 것을 목표로 하고 있음을 보여줍니다. (来源: 量子位)

Meta, DINOv3 범용 컴퓨터 비전 모델 출시 : Meta가 DINOv3를 출시했습니다. 이는 자율 학습으로 훈련된 범용 최첨단 컴퓨터 비전 모델로, 뛰어난 고해상도 시각 특징을 생성할 수 있습니다. 이 모델은 대량의 수동 주석 데이터에 대한 의존성을 제거함으로써 컴퓨터 비전 분야의 발전을 더욱 촉진하여, 다양한 응용 시나리오에서 더욱 적응성과 일반화 능력을 갖추게 합니다. (来源: dl_weekly)
Cohere, Command A Reasoning 모델 출시 : Cohere가 기업 추론 작업을 위해 특별히 설계된 고급 모델인 Command A Reasoning을 출시했습니다. 이 모델은 Agent 및 다국어 벤치마크에서 동급의 다른 사설 배포 가능 모델들을 능가하며, 전 세계 기업에 실질적인 가치를 제공하는 것을 목표로 합니다. Cohere는 수학적 추론 능력이 도구 사용, Agent 또는 다국어 추론과 직접적인 관련이 없으므로, 실제 세계의 요구를 충족하기 위해 이 새로운 모델을 훈련했으며, 사용자 피드백을 위해 가중치를 공개했다고 강조했습니다. (来源: aidangomez, nickfrosst)

Elon Musk의 X 플랫폼, 이미지-비디오 AI 기능 출시 : Elon Musk는 X 플랫폼이 새로운 기능을 출시할 것이라고 발표했습니다. 사용자는 어떤 이미지든 길게 누르면 약 17초 만에 비디오로 변환할 수 있습니다. 이 기능은 AI 기술을 활용하여 사용자에게 더 편리하고 창의적인 콘텐츠 제작 경험을 제공하고, 소셜 미디어 플랫폼의 멀티미디어 상호작용 형식을 더욱 풍부하게 만드는 것을 목표로 합니다. (来源: qtnx_)

AI의 약물 발견 분야 적용 진전 : AI는 약물 발견 분야에서 거대한 잠재력을 보여주고 있습니다. Hugging Face에서 제공하는 GDP 데이터셋은 DRUG-seq, Cell Painting, 화학적 교란 및 항체 검출과 같은 대규모 데이터를 통합하여 멀티모달 과학 연구에 귀중한 자원을 제공합니다. 이러한 데이터셋의 공개는 약물 연구 개발에서 AI의 적용을 가속화하고, 신약 발견 및 치료 솔루션의 혁신을 촉진할 것으로 기대됩니다. (来源: ClementDelangue, clefourrier)

D-Robotics, Hugging Face에 로봇 제어 알고리즘 오픈소스화 : D-Robotics는 Hugging Face에 LeRobot ACT Policy 구현 AI 알고리즘을 오픈소스화했으며, 이를 RDK 개발 보드에서 SO-101 오픈소스 로봇 팔에 성공적으로 실행했습니다. 이 알고리즘은 BPU의 강력한 128 TOPS 컴퓨팅 파워를 활용하여 로봇 팔의 원활한 집기 및 물체 정리 작업을 구현했으며, 로봇 분야에서 엔드투엔드 가속화의 적용 가능성을 보여주며 오픈소스 로봇 커뮤니티에 새로운 기술 지원을 제공했습니다. (来源: ClementDelangue)
넷이즈 유다오, AI 질의응답 펜 Space X 및 오디오/비디오 번역 플랫폼 출시 : 넷이즈 유다오(NetEase Youdao)가 “즈위에(子曰)” 교육 대규모 모델을 기반으로 한 새로운 하드웨어인 유다오 AI 질의응답 펜 Space X를 출시했습니다. 이 펜은 국어, 수학, 영어 등 9개 학과의 “펜을 대면 바로 스캔하여 질문에 답하는” 기능을 지원하며, 정확도는 96%에 달하고 판서식 비디오 질의응답 및 AI 오답 노트 기능을 제공합니다. 동시에 유다오는 원스톱 오디오/비디오 번역 플랫폼도 출시했습니다. 이 플랫폼은 38개 언어의 실시간 상호 번역, 멀티모달 원음 번역 및 AI 요약 마인드맵을 지원하며, 높은 처리 효율성과 낮은 비용을 자랑하며 교육 AI가 L3에서 L4 가상 교사 단계로 나아가는 것을 목표로 합니다. (来源: 量子位)

Epic Games, AI 의료 기능 출시 가속화 : 1979년에 설립된 의료 소프트웨어 대기업 Epic Games가 많은 신생 스타트업을 능가하는 놀라운 속도로 새로운 AI 기능을 출시하고 있습니다. 이는 전통적인 의료 IT 기업들이 AI 기술을 적극적으로 수용하여 기존 시스템에 통합함으로써 의료 효율성과 환자 경험을 향상시키고 있음을 보여주며, 의료 건강 분야에서 AI의 가속화된 적용을 예고합니다. (来源: sarahcat21)
Kimi-VL-A3B-Thinking-2506-GGUF 모델 출시 : Kimi-VL-A3B-Thinking-2506-GGUF 모델이 출시되었으며, 이 모델은 llama.cpp에서 지원되어 로컬 LLaMA 커뮤니티에 멀티모달 시각 언어 모델의 더 많은 선택지를 제공합니다. 사용자들은 Kimi 모델의 아첨하지 않고 직접적인 특성을 높이 평가하며, 시각 언어 작업에서의 성능을 기대하고 있습니다. (来源: Reddit r/LocalLLaMA)

GAIA: Transformer보다 빠른 범용 AI 아키텍처 : GAIA(General Artificial Intelligence Architecture)는 Transformer의 대안으로 제안되었으며, 해싱 프레임워크와 π 기반 파티션 정규화를 기반으로 하여 시간이 많이 소요되는 자체 주의 메커니즘과 복잡한 토크나이저를 제거했습니다. GAIA는 가볍고 범용적이며 CPU에서 몇 초 만에 훈련할 수 있고, 표준 텍스트 분류 데이터셋에서 경쟁력 있는 성능을 달성합니다. 이는 대규모 AI 모델의 효율적인 배포에 대한 새로운 아이디어를 제공하며, 특히 엣지 장치 및 자원 제약이 있는 환경에 적합합니다. (来源: Reddit r/deeplearning)

🧰 도구
Firecrawl: AI를 위한 웹 데이터 API : Firecrawl은 AI 애플리케이션에 깨끗한 웹 데이터를 제공하도록 설계된 웹 데이터 API입니다. 전체 웹사이트 콘텐츠를 LLM이 사용할 수 있는 Markdown 또는 구조화된 데이터로 크롤링하고 변환할 수 있으며, 고급 크롤링, 스크래핑 및 데이터 추출 기능을 지원합니다. Firecrawl은 API, SDK(Python, Node) 및 LLM 프레임워크 통합(Langchain, Llama Index 등)을 제공하며, 동적 콘텐츠 처리, 안티-크롤링 메커니즘, 미디어 파싱 및 일괄 처리와 같은 강력한 기능을 갖추고 있습니다. 또한 AI 기반의 구조화된 데이터 추출 및 페이지 상호작용 능력도 제공합니다. (来源: GitHub Trending)
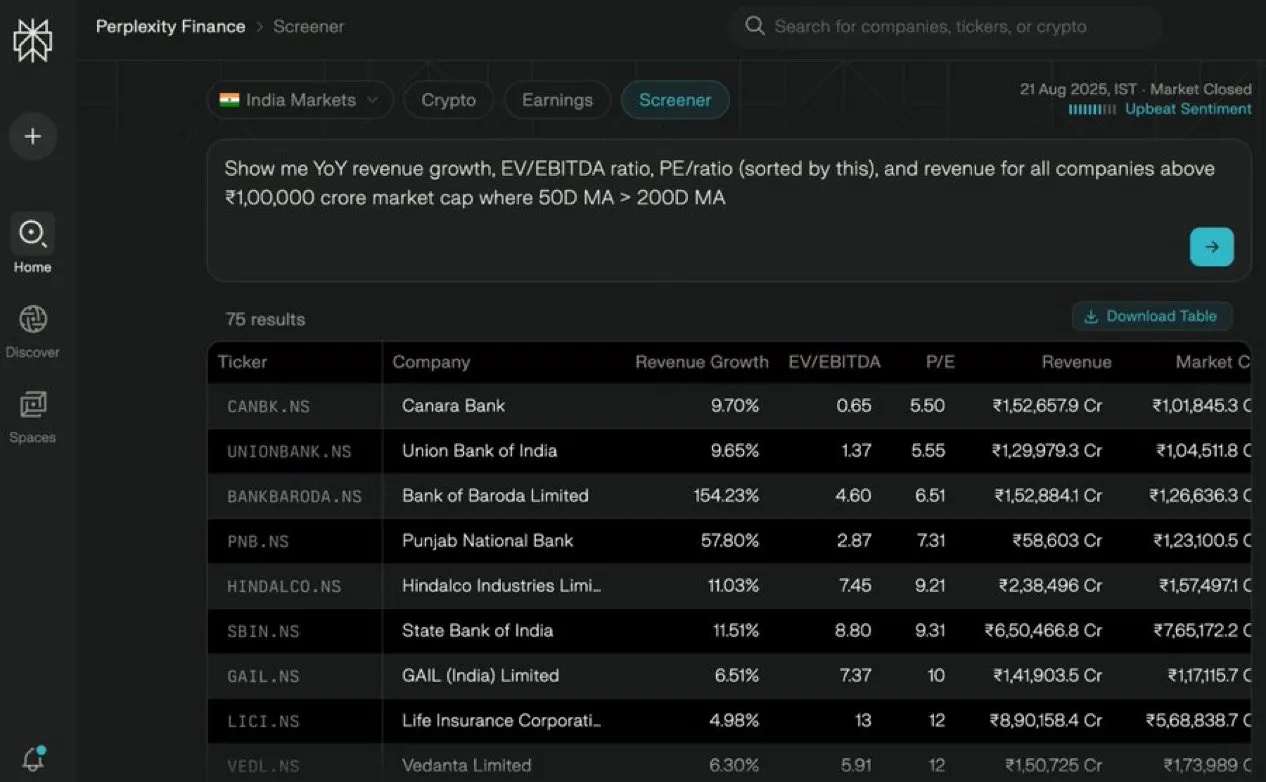
Perplexity Finance, 인도 주식 필터링 기능 출시 : Perplexity Finance가 모든 사용자에게 인도 주식 필터링 기능을 개방했습니다. 이 기능은 자연어로 검색 및 필터링을 지원합니다. 사용자는 원하는 출력, 필터 조건 및 정렬 방식을 입력하기만 하면 주식 정보를 얻을 수 있어 인도 주식 시장의 조회 및 분석 과정을 크게 간소화합니다. 이는 인도 투자자들에게 무료로 편리한 주식 필터링 서비스를 제공하는 것을 목표로 합니다. (来源: AravSrinivas)
Replit, 도메인 등록 절차 간소화, “Vibe Coding” 경험 향상 : Replit은 세계에서 가장 간단한 도메인 등록 절차를 구축하여 60초 이내에 도메인을 웹사이트에 자동으로 연결할 수 있도록 함으로써 사용자 경험을 크게 향상시켰습니다. 이러한 “두꺼운 캡슐화” 혁신은 “Vibe Coding”(분위기 코딩)의 비전을 더욱 가깝게 만들었으며, 개발자들이 번거로운 설정 작업 없이 창작에 집중할 수 있도록 하여 AI 보조 프로그래밍 도구가 개발 효율성과 즐거움을 향상시키는 잠재력을 보여줍니다. (来源: pirroh, amasad)

AI Agent 구성 파일 표준 및 실천 분석 : OpenAI, Claude, Gemini는 각각 Agent 구성 파일 표준(agents.md, CLAUDE.md, GEMINI.md)을 출시하여 AI Agent의 행동과 상호작용을 표준화하는 것을 목표로 합니다. agents.md는 공급업체 간 행동 제약 및 검증 프로세스를 통일하는 경향이 있는 반면, CLAUDE.md와 GEMINI.md는 공급업체 내부의 컨텍스트 프롬프트, 지시 기억 및 행동 선호도에 더 중점을 둡니다. 이러한 파일들은 로딩 메커니즘, 실행 의미론 및 보안 모델에서 차이를 보이며, 표준 통일과 사용자 경험 유연성 사이의 균형을 반영합니다. 이러한 구성 파일의 경계와 우선순위를 이해하는 것은 신뢰할 수 있고 제어 가능한 AI Agent를 구축하는 데 매우 중요합니다. (来源: dotey)
LangChain AI Agent, IPO 투자설명서 분석 지원 : LangChain 기반의 AI Agent 프로젝트가 성공적으로 개발되어 복잡한 IPO 투자설명서(DRHP)를 분석하고 일반인이 이해하기 쉬운 종합 보고서로 변환할 수 있게 되었습니다. 이 프로젝트는 다단계 프로세스를 자동화하고 외부 데이터 소스를 LLM과 연결하여 금융 분석가의 시간을 크게 절약합니다. 이는 AI Agent가 복잡한 비즈니스 프로세스를 자동화하고 전문적인 통찰력을 제공하는 데 있어 전통적인 LLM의 단일 대화 기능을 뛰어넘는 거대한 잠재력을 보여줍니다. (来源: hwchase17, Hacubu)

Qwen Image Edit, WaveSpeedAI와 협력하여 효율적인 이미지 편집 제공 : 알리바바의 Qwen Image Edit 모델이 WaveSpeedAI와 협력하여 빠르고 고품질의 AI 이미지 편집 서비스를 제공합니다. 사용자는 WaveSpeedAI 플랫폼을 통해 Qwen Image Edit를 사용하여 이미지 편집을 수행하고, 오류 없이 전문적인 수준의 효과를 얻을 수 있습니다. 또한, Qwen Image Edit는 LoRA 기술과 결합하여 8단계에서 4단계 만에 고품질 편집을 완료할 수 있어 속도가 12배 향상되었으며, 일러스트레이션을 사실적인 피규어로 변환하는 데도 사용할 수 있어 AI 이미지 편집의 응용 시나리오와 효율성을 크게 확장했습니다. (来源: Alibaba_Qwen, huggingface, suchenzang, fabianstelzer)

VS Code/Cursor 확장, IDE 내 이미지 주석 및 의사 레이블 생성 구현 : 개발자들이 단시간 내에 VS Code/Cursor 확장을 구축하여 사용자가 IDE 내부에서 직접 분류 및 객체 감지 이미지 주석을 달고 FAL API를 통해 의사 레이블을 생성할 수 있도록 했습니다. 이 도구는 Moondreamai v2를 사용하여 객체 감지를 수행하며, AI 개발에서 데이터 주석 프로세스를 간소화하고 가속화하는 것을 목표로 합니다. 기존 주석 도구의 복잡한 설정과 낮은 효율성 문제를 해결하여 개발자의 “Vibe Coding” 경험을 향상시킵니다. (来源: cloneofsimo)

Runway, Game Worlds Beta 출시, 실시간 가상 세계 생성 탐구 : Runway가 Game Worlds Beta를 출시하여 실시간 가상 세계 생성 가능성을 탐구합니다. 이 프로젝트는 사용자가 어떤 캐릭터, 스토리 또는 세계든 실시간으로 탐색할 수 있도록 하며, AI 기술을 통해 가상 환경의 픽셀을 생성하는 데 전념합니다. 이는 게임 개발 및 가상 현실 분야에서 AI의 중요한 진전을 나타내며, 미래 콘텐츠 제작이 더욱 동적이고 상호작용적이게 될 것을 예고하며 창작자에게 전례 없는 자유도를 제공합니다. (来源: c_valenzuelab)
TimeCapsule-SLM: 브라우저 내 실행되는 오픈소스 심층 연구 도구 : TimeCapsule-SLM은 브라우저 내에서 실행되며 Qwen 3 0.6b(ollama)와 결합하여 의미 이해, 통찰력 생성 및 혁신적인 아이디어를 제공하는 오픈소스 심층 연구 도구입니다. 이 도구는 개인 정보 보호에 중점을 두며, 결과를 정확한 텍스트 블록/문서로 추적하여 AI 제품의 컨텍스트 이해 부족, 환각 및 출처 추적의 어려움 문제를 해결합니다. 정규 표현식 및 플랫 파일 검색, 그리고 지식 베이스에 대한 의미 검색을 지원하여 사용자가 로컬에서 심층 연구를 수행하는 데 도움을 줍니다. (来源: tokenbender)

Matrix-3D: SkyworkAI, 단일 이미지/텍스트로 3D 세계 생성 구현 : SkyworkAI가 단일 이미지 또는 텍스트 프롬프트에서 완전한 3D 세계를 생성할 수 있는 Matrix-3D 모델을 발표했습니다. 이 획기적인 기술은 3D 콘텐츠 제작 프로세스를 크게 간소화하여 게임 개발, 가상 현실, 건축 설계 등 다양한 분야에 효율적이고 창의적인 솔루션을 제공하며, AI가 3D 콘텐츠 생성 분야에서 새로운 이정표를 향해 나아가고 있음을 예고합니다. (来源: NerdyRodent)
Kling_ai 2.1 Keyframe-Endframes: 비디오 생성 제어력 향상 : Kling_ai가 2.1 Keyframe-Endframes 기능을 출시하여 사용자에게 AI 비디오 생성 워크플로우에서 더 강력한 제어력과 표현력을 제공합니다. 키프레임과 엔드프레임을 설정함으로써 사용자는 비디오 콘텐츠의 전환과 스타일을 더욱 정밀하게 제어할 수 있으며, 특히 서사적 비디오 제작에 적합하여 영화 제작, 광고 및 콘텐츠 마케팅 분야에서 새로운 가능성을 가져올 것으로 기대됩니다. (来源: Kling_ai)
Glif Agent, 저비용 AI 비디오 생산 구현 : Glif 플랫폼은 맞춤형 Agent를 통해 Qwen Ultra Realism 이미지 생성, OmniHuman LipSync, Seedance Pro, Flux Kontext Edit, ElevenLabs 음성 등 다양한 AI 도구를 통합하여 효율적이고 저비용의 AI 비디오 생산을 구현합니다. 30초 길이의 일관된 비디오 제작 비용을 2달러 미만으로 낮출 수 있어 비디오 제작의 진입 장벽을 크게 낮췄습니다. 이 플랫폼은 원스톱 AI 비디오 제작 솔루션이 되는 것을 목표로 하지만, 여전히 다양한 모델 출력의 종횡비 및 전환 부드러움과 같은 과제에 직면해 있습니다. (来源: fabianstelzer)
SynthesiaIO, AI 음성 더빙 비디오 안전 편집 기능 출시 : SynthesiaIO가 “안전 편집” 기능을 출시하여 사용자가 AI 음성 더빙 비디오에서 번역을 조정하고, 오류를 수정하며, 미묘한 뉘앙스를 포착할 수 있도록 합니다. 동시에 내장된 콘텐츠 검토 메커니즘을 통해 원본 정보와 어조의 무결성을 보장합니다. 이 기능은 AI 음성 더빙 비디오의 유연성과 정확성을 향상시키며, 특히 다국어 콘텐츠 제작에 적합하여 콘텐츠의 품질과 안전성을 보장합니다. (来源: synthesiaIO)
AI 비디오 생성 도구 비교: Argil, Hedra Labs, HeyGen : Argil, Hedra Labs, HeyGen 등 AI 비디오 생성 도구들은 모두 한 장의 이미지로 인물이 말하는 비디오를 생성할 수 있다고 약속합니다. 사용자들은 어떤 모델이 가장 효과적인지 확인하기 위해 이 도구들을 비교 평가했습니다. 이러한 도구의 등장은 비디오 제작 과정을 크게 간소화하고 스크립트, 배우, 촬영 팀에 대한 필요성을 줄였지만, 동시에 콘텐츠 제작자가 AI 사용 여부를 시청자에게 알려야 하는지에 대한 윤리적 논의를 불러일으키고 있습니다. (来源: BrivaelLp)

AI Toolkit, ARAs 통합으로 Wan 2.2 모델 최적화 : AI Toolkit이 Accuracy Recovery Adapters (ARAs)를 통합하여 4비트 Wan 2.2 14B T2V(텍스트-비디오) 및 I2V(이미지-비디오) 모델을 최적화했습니다. 이 기술은 VRAM이 제한된 장치(예: 4090 그래픽 카드)에서 대규모 모델을 실행할 수 있도록 하며, 예를 들어 19.2 GB VRAM에서 16차원 I2V LoRA를 훈련하면서도 고품질 출력을 유지하여 AI 비디오 생성 모델의 엣지 장치 배포 효율성을 향상시켰습니다. (来源: ostrisai)

VS Code, Telerik & KendoUI AI 코딩 도우미 통합 : VS Code Live는 Telerik과 KendoUI의 AI 코딩 도우미를 활용하여 개발 경험을 간소화하는 방법을 시연했습니다. 이 AI 도우미는 개발자가 코드 작성을 자동화하고 지능적인 제안을 제공하여 개발 효율성과 코드 품질을 향상시키는 데 도움을 줄 수 있습니다. 이는 통합 개발 환경(IDE)에서 AI의 보급이 증가하고 있으며, 소프트웨어 개발 프로세스에 미치는 심오한 영향을 보여줍니다. (来源: code)

ChatExcel, 수천만 위안 규모의 시드 투자 유치 : 베이징대 팀이 개발한 ChatExcel이 상하이 창레이 캐피탈(Changrui Capital)과 우한 동후 엔젤 펀드(Donghu Angel Fund)로부터 약 천만 위안 규모의 시드 투자를 유치했다고 발표했습니다. ChatExcel은 중국 최초의 생성형 AI Excel 및 데이터 분석 Agent로, 채팅을 통해 Excel 스프레드시트를 조작할 수 있으며, 데이터 처리, 계산, 분석 및 차트 생성 기능을 포함하고 기업 데이터베이스 대화 및 네트워크 데이터 획득을 지원합니다. 이번 자금은 제품 연구 개발 반복 및 글로벌 시장 확장을 가속화하여 데이터 Agent 분야에서 선도적인 위치를 강화하는 데 사용될 예정입니다. (来源: 量子位)
Nano Banana: AI 이미지 모델, 일러스트를 피규어로 변환 : Nano Banana는 일러스트레이션을 사실적인 피규어 효과 이미지로 변환하는 가장 유명한 응용 프로그램으로 주목받는 AI 이미지 모델입니다. 이 모델이 생성한 이미지는 거의 “AI 느낌”이 없으며, 질감이 좋고 특징 유지율이 높아 AI 분야 외부의 창작자들에게도 널리 사용되고 확산되고 있습니다. Nano Banana는 텍스트-이미지 생성, 부분 이미지 편집 및 스타일 전이를 지원하며, 초고속 처리 속도(일반적으로 10초 이내 완료)와 편집 요소에 대한 일관된 기억력으로 유명합니다. (来源: dotey, yupp_ai)

yupp.ai: AI 도구 사용 경험 간소화 : yupp.ai 플랫폼은 여러 구독료를 지불하거나, 다른 애플리케이션을 전환하거나, 모델 선택에 고민할 필요 없이 다양한 모델과 기능을 통합하여 사용자의 AI 도구 사용 경험을 간소화하는 것을 목표로 합니다. 이 플랫폼은 원스톱 AI 솔루션을 제공하여 사용자가 AI 기술을 더 쉽고 효율적으로 활용할 수 있도록 하고, AI 도구의 진입 장벽을 낮추는 데 전념합니다. (来源: yupp_ai)

OpenAI Codex CLI, 모델 선택 지원 : OpenAI Codex CLI v0.23.0 버전 업데이트로 사용자가 gpt-5 high와 같은 모델을 선택할 수 있게 되었습니다. 이를 통해 개발자는 작업 요구 사항에 따라 가장 적합한 모델을 더욱 유연하게 선택하여 프로그래밍 및 사고 효율성을 최적화할 수 있습니다. 이 기능은 AI 프로그래밍 도우미로서 Codex의 유용성을 향상시키고, 사용자가 자신의 선호도와 프로젝트 요구 사항에 따라 세밀하게 구성할 수 있도록 합니다. (来源: dotey)
DeepSeek API, Claude Code와 호환 : DeepSeek API가 Anthropic API 형식을 지원하여 개발자가 DeepSeek V3.1의 기능을 Claude Code 프레임워크에 쉽게 연결할 수 있게 되었습니다. 간단한 환경 변수 설정을 통해 사용자는 Claude Code에서 DeepSeek 모델을 사용하여 더욱 유연한 Agentic 워크플로우를 구현할 수 있습니다. 이러한 호환성 업데이트는 개발자에게 더 많은 모델 선택지를 제공하여 AI 프로그래밍 및 Agentic 작업의 효율성을 높이는 데 기여합니다. (来源: jon_durbin, dotey, Reddit r/LocalLLaMA, Reddit r/ClaudeAI)

OpenWebUI에서 코드 인터프리터 이미지 표시 문제 : OpenWebUI 사용자들이 코드 인터프리터를 사용할 때 이미지가 직접 표시되지 않고 참조 텍스트로 표시된다고 보고했습니다. 코드 실행기 모드를 통해 정상적으로 표시되지만, 사용자들은 이를 보안 조치 또는 LLM이 이미지 노드를 에코하는 방식과 관련이 있을 것으로 추정하고 있습니다. 이 문제는 OpenWebUI에서 코드 인터프리터가 생성한 이미지를 직관적으로 볼 수 있는 사용자 경험에 영향을 미치며, 개선을 위한 추가적인 기술 최적화가 필요합니다. (来源: Reddit r/OpenWebUI)
ChatGPT 5 Pro와 Cursor AI의 프로그래밍 분야 비교 : 소셜 미디어에서는 ChatGPT 5 Pro와 Cursor AI가 프로그래밍(특히 Python, 머신러닝, 딥러닝, 신경망 등) 분야에서 어느 쪽이 더 우수한지에 대한 논의가 활발합니다. 사용자들은 이 두 AI 프로그래밍 도구가 다양한 기술 스택에서 어떤 성능을 보이는지 평가하기 위해 실제 사용 경험에 대한 피드백을 구하고 있습니다. 이는 개발자들이 AI 보조 프로그래밍 도구를 선택할 때 모델의 전문 능력과 실제 효과에 대한 관심을 반영합니다. (来源: Reddit r/deeplearning)

ChatGPT 이미지 생성 기능, 사용자 사진을 만화 스타일로 변환 : ChatGPT에 사용자 업로드 이미지를 만화 스타일로 변환하는 새로운 기능이 추가되었습니다. 사용자들은 자신의 사진을 만화화한 결과물을 공유했으며, 만족스러운 반응을 보였습니다. 일부는 이 기능이 “상상력”을 가지고 있는지 의문을 제기했지만, 이 기능은 사용자에게 편리한 이미지 스타일 변환 서비스를 제공하여 AI의 창의적 콘텐츠 생성 분야 응용을 풍부하게 하고 새로운 상호작용 경험을 제공합니다. (来源: Reddit r/ChatGPT)
📚 학습
AI 평가 강의: 슬로건에서 방법론으로 : “AI Evals for Engineers & PMs” 강의는 “데이터 확인”이라는 슬로건을 구체적인 방법론으로 전환하여 강력히 추천됩니다. 이 강의는 상호작용 궤적을 심층적으로 검토하고, 오류 분류 체계를 구축하며, 자동화된 평가를 엄격하게 조정하고, 프롬프트와 파이프라인을 최적화하는 것을 강조합니다. 이는 엔지니어와 제품 관리자에게 체계적인 AI 평가 실천 지침을 제공하여 AI 프로젝트를 프로토타입에서 생산 단계로 전환하는 데 도움을 줍니다. (来源: gojira, lateinteraction, HamelHusain)
AI 위험 전문가와 슈퍼 예측가들의 AI 가속화에 대한 파일럿 연구 : METR과 Research_FRI는 AI 위험 전문가와 슈퍼 예측가들이 AI 발전의 극단적인 가속화 가능성에 대해 어떻게 예상하는지 탐구하는 소규모 파일럿 연구를 수행했습니다. 표본 크기가 작고 편향이 존재하지만, 연구의 조작화된 방법론은 가치 있는 것으로 평가되며, AI 발전 속도와 잠재적 위험을 이해하기 위한 초기 데이터와 논의 기반을 제공합니다. (来源: tokenbender)

AI 연구 논문: Transformer 언어 모델의 단어 의미 : 한 연구 논문은 Transformer 언어 모델에서 단어 의미가 저장되는 방식을 탐구했습니다. 연구에 따르면 Transformer 모델은 컨텍스트에서만 의미를 구성하는 것이 아니라 정적 임베딩을 통해 단어 의미를 저장합니다. RoBERTa-base 토큰 임베딩에 대한 클러스터 분석을 통해 직업, 장소, 감정 등 명확한 의미론적 주제가 존재하며, 이는 심리 언어학적 속성(예: 가치, 구체성)과 높은 상관관계를 보인다는 것을 발견했습니다. 이는 “의미는 나중에 생성된다”는 관점에 도전하며, 정적 임베딩이 하위 처리 과정을 안내하는 어휘 라이브러리 역할을 한다는 것을 시사합니다. (来源: menhguin)

AI 연구 논문: 이중 선호도 최적화(DuPO)를 통한 LLM 자체 검증 구현 : DuPO(Dual Learning-based Preference Optimization)는 이중 학습 기반의 선호도 최적화 프레임워크로, 일반화된 이중성을 통해 라벨 없는 피드백을 생성하여 값비싼 라벨에 대한 RLVR의 의존성과 전통적인 이중 학습의 엄격한 제약을 해결합니다. DuPO는 원본 작업을 알려진 부분과 알려지지 않은 부분으로 분해하고, 알려지지 않은 부분을 재구성하기 위한 이중 작업을 구축하며, 재구성 품질을 자체 지도 보상으로 사용합니다. 이 방법은 번역, 수학적 추론 등 다양한 작업에서 현저한 개선을 이루었으며, LLM 최적화를 위한 확장 가능하고 범용적이며 라벨이 필요 없는 새로운 패러다임을 제공합니다. (来源: HuggingFace Daily Papers, teortaxesTex)

AI 연구 논문: 다국어, 기술 기반 상식 추론 벤치마크 mSCoRe : mSCoRe(Multilingual and Scalable Benchmark for Skill-based Commonsense Reasoning)는 LLM의 상식 추론 능력을 체계적으로 평가하기 위한 다국어, 확장 가능한 벤치마크입니다. 이 벤치마크는 새로운 추론 기술 분류법, 견고한 데이터 합성 파이프라인 및 복잡성 확장 프레임워크를 포함합니다. 실험 결과, mSCoRe는 기존 LLM에게 여전히 도전적이며, 특히 더 높은 복잡성 수준과 미묘한 다국어 일반 및 문화적 상식 측면에서 모델의 한계를 드러냈습니다. (来源: HuggingFace Daily Papers)
AI 연구 논문: SFT와 RL을 통합하는 CHORD 프레임워크 : CHORD(Controllable Harmonization of On- and Off-Policy Reinforcement Learning via Dynamic Weighting) 프레임워크는 SFT(지도 미세 조정)와 RL(강화 학습)을 통합하는 새로운 관점을 제시합니다. CHORD는 SFT를 RL 프로세스 내의 동적 가중 보조 목표로 간주하며, 전역 계수와 단어별 가중 함수를 통해 오프-정책 전문가 데이터의 영향력을 이중으로 제어하여 오프-정책 모방과 온-정책 탐색의 균형을 효과적으로 달성함으로써 안정적이고 효율적인 학습 프로세스를 구현하고 LLM 성능을 크게 향상시킵니다. (来源: HuggingFace Daily Papers)
AI 연구 논문: LLM 벤치마크 테스트 MCP-Universe : MCP-Universe는 실제 Model Context Protocol (MCP) 서버 상호작용에서 LLM의 성능을 종합적으로 평가하는 최초의 벤치마크 테스트입니다. 이 벤치마크는 위치 탐색, 창고 관리, 금융 분석, 3D 설계, 브라우저 자동화 및 웹 검색 등 6가지 핵심 영역을 포함하며, 실행 기반 평가기(형식, 정적, 동적)를 통해 엄격한 평가를 보장합니다. 테스트 결과, SOTA 모델(예: GPT-5)조차도 긴 시퀀스 추론 및 익숙하지 않은 도구 공간에서 상당한 성능 제한을 보였으며, 기업용 Agent의 성능은 좋지 않았습니다. (来源: HuggingFace Daily Papers)
AI 연구 논문: 베트남 멀티모달 시험에서 VLM 성능 : ViExam은 베트남 멀티모달 시험 문제에 대한 벤치마크 테스트로, 저자원 언어 및 실제 멀티모달 교육 콘텐츠에서 VLM의 성능을 평가합니다. 연구 결과, SOTA VLM조차도 베트남어 멀티모달 시험에서 평균 정확도가 57.74%에 불과했으며, 대부분의 모델이 인간 평균보다 낮은 성능을 보였습니다. 사고형 VLM o3(74.07%)만이 인간 평균을 넘어섰지만, 인간 최고 성능에는 훨씬 못 미쳤습니다. 교차 언어 프롬프트는 성능을 향상시키지 못했으며, 인간-기계 협업은 VLM 성능을 부분적으로 향상시킬 수 있었습니다. (来源: HuggingFace Daily Papers)
AI 연구 논문: 확산 LLM의 후훈련 양자화 연구 : 한 연구는 확산 대규모 언어 모델(dLLM)의 후훈련 양자화(PTQ)를 체계적으로 탐구한 최초의 사례입니다. 연구 결과, dLLM에 활성화 이상치가 존재하여 저비트 양자화에 어려움을 초래한다는 것을 발견했습니다. 기존 PTQ 방법에 대한 포괄적인 평가를 통해 비트 폭, 양자화 방법, 작업 범주 및 모델 유형이 dLLM 양자화 동작에 미치는 영향을 분석하여 dLLM의 효율적인 배포를 위한 실질적인 통찰력을 제공했습니다. (来源: HuggingFace Daily Papers)
AI 연구 논문: 금융 대규모 언어 모델의 인지 진단 프레임워크 : FinCDM은 금융 LLM에 맞춤화된 최초의 인지 진단 평가 프레임워크로, 지식-기술 수준의 평가를 통해 금융 기술 및 지식 측면에서 모델의 강점과 약점을 식별합니다. 이 프레임워크는 실제 회계 및 금융 기술을 포함하는 CPA-QKA 데이터셋을 구축하여 설명 가능하고 기술 인지적인 진단을 제공하고, 더 신뢰할 수 있고 목표 지향적인 모델 개발을 지원하는 것을 목표로 합니다. (来源: HuggingFace Daily Papers)
2025 기술 혁신가 대회, 구현 지능에 초점 : 2025 기술 혁신가 대회는 9월 5일 베이징에서 “구현 지능, 산업 지능 변화의 새로운 엔진”을 주제로 개최됩니다. 이 대회는 과학자, 스타트업 리더, 산업 전문가 및 투자자들을 한자리에 모아 하드웨어 기술의 산업화 구현에 초점을 맞추고, “수요 견인-기술 매칭-자본 지원-시나리오 구현”의 전체 체인 서비스 모델을 구축하여 구현 지능과 같은 첨단 기술이 기술에서 제품으로 가는 “마지막 1마일” 문제를 해결하고 실제 시나리오에서의 검증 및 대규모 구현을 추진하는 것을 목표로 합니다. (来源: 量子位)

AI Agent 계층 아키텍처 다이어그램 : Ronald van Loon은 AI Agent의 계층 아키텍처 다이어그램을 공유하여 LLM, 생성형 AI 및 머신러닝에서 Agent 설계를 이해하기 위한 명확한 시각적 가이드를 제공했습니다. 이 다이어그램은 개발자와 연구자들이 복잡한 AI Agent 시스템을 더 잘 구축하고 관리하며, 기능과 성능을 최적화하는 데 도움이 됩니다. (来源: Ronald_vanLoon)

ML 연구원의 학계 전환 가이드 : ML 업계에서 5-6년간 근무한 한 엔지니어가 대학 연구 엔지니어로 전환할 예정이며, 학술 연구에 적응하는 방법에 대한 조언을 구하고 있습니다. 논의에서는 수학적 기초, 과학 논문 읽기 방법의 중요성, 그리고 학술 연구에서 산업 경험을 전환하는 방법에 대한 조언이 강조되었습니다. 이는 산업계에서 학계로 ML 연구를 위해 전환하려는 사람들에게 실용적인 지침과 마음가짐 조정 조언을 제공합니다. (来源: Reddit r/MachineLearning)
AI 검색 엔진 역공학: AI가 인용하도록 콘텐츠 최적화 방법 : ChatGPT Search, Perplexity, Google AI Overviews 등 AI 검색 엔진에 대한 역공학 연구 결과, 전통적인 SEO 지표와 AI 답변 인용 간의 상관관계가 약하다는 것이 밝혀졌습니다. AI 인용의 핵심은 콘텐츠 구조가 AI 합성 요구 사항에 부합하는지 여부입니다. 예를 들어, H2/H3 섹션이 독립적인 응답 단위로 구성되고, 핵심 데이터 포인트가 독립적으로 제시되며, 다중 소스 호환성과 명확한 저자 자격 증명/타임스탬프가 필요합니다. 이는 “답변 엔진 최적화”(AEO)와 전통적인 SEO의 근본적인 차이, 즉 AI 엔진이 콘텐츠 조각의 구조와 권위에 더 중점을 둔다는 것을 보여줍니다. (来源: Reddit r/ArtificialInteligence)
머신러닝 “튜토리얼 지옥” 탈출 경로 : 많은 사람들이 머신러닝 학습 과정에서 “튜토리얼 지옥”에 빠져, 계속 튜토리얼을 학습하지만 실제 이해와 프로젝트 구축 능력이 부족합니다. 댓글들은 튜토리얼이 종종 너무 단순화되어 깊이가 부족하며, 진정한 학습은 문제 분해, 프로젝트 실습, 공식 문서 참조를 통해 이루어져야 한다고 지적합니다. 또한, 머신러닝 분야는 경쟁이 치열하여 튜토리얼만으로는 두각을 나타내기 어렵고, 더 깊이 있는 이론 학습과 실습 경험이 필요합니다. (来源: Reddit r/deeplearning)
Living AI Evolution Algorithms (LAI) 프레임워크 : LAI(Living Artificial Intelligence Evolution Algorithms)는 다감각 인지를 구현하기 위한 혁신적인 프레임워크입니다. 이 프레임워크는 AI가 생물처럼 진화하도록 하여, 지속적인 학습과 적응을 통해 다양한 감각 양식의 정보를 처리함으로써 더 높은 수준의 지능을 구현하는 데 전념합니다. 이는 AI 연구에서 구현 지능 및 생명체 유사 시스템 방향으로의 탐구를 나타내며, 더 범용적이고 유연한 AI 시스템 구축을 위한 새로운 이론적 기반을 제공할 것으로 기대됩니다. (来源: Reddit r/deeplearning)
Hugging Face, NVIDIA Nemotron 다국어 추론 데이터셋 공개 : NVIDIA AI Developer가 Hugging Face에 NVIDIA Nemotron 후훈련 다국어 데이터셋을 공개했습니다. 이 데이터셋은 합성 번역된 추론 궤적을 추가하여 허가된 후훈련 데이터셋을 확장했으며, 5가지 새로운 언어를 포함하고 세계적 수준의 추론 궤적을 제공합니다. 이는 다국어 LLM 개발 및 훈련을 위한 귀중한 자원을 제공하며, 다양한 언어 환경에서 모델의 추론 능력을 향상시키는 데 기여합니다. (来源: ClementDelangue)
DSPy 커뮤니티, 고급 DSPy 기술 및 컨텍스트 엔지니어링 공유 : DSPy 커뮤니티는 고급 DSPy 기술, 컨텍스트 엔지니어링, 최적화 및 평가에 대한 워크숍을 개최했습니다. 이 행사에서는 DSPy 철학이 논의되었고, 사용자 정의 어댑터 및 Predict 모듈 최적화 방법이 시연되었습니다. 이는 신뢰할 수 있는 AI Agent 구축에서 DSPy의 실용성과 AI 개발 실천을 추진하는 커뮤니티의 활발한 활동을 보여줍니다. (来源: lateinteraction)

《Generative AI with LangChain》 도서 출시 : Packt 출판사가 LangChain 창립자가 추천하는 신간 《Generative AI with LangChain》을 출시했습니다. 이 책은 개발자가 AI 프로젝트를 프로토타입에서 생산 단계로 전환하는 데 도움을 주는 것을 목표로 하며, 다중 Agent 아키텍처, 고급 RAG, 테스트, 관찰 가능성 및 배포와 같은 실용적인 전략을 다룹니다. 또한 Gemini, Anthropic, Mistral, DeepSeek 및 OpenAI o3-mini와 같은 주류 LLM과의 통합 방법을 소개하여 기업용 AI 시스템 구축을 위한 중요한 자원입니다. (来源: hwchase17, Hacubu)

LLM 추론의 KV 캐시 재구성 기술 : 소셜 미디어에서는 LLM 추론의 KV 캐시 재구성 기술에 대한 논의가 있었습니다. 이 기술은 활용되지 않는 컴퓨팅 단위를 사용하여 메모리 병목 현상을 제거함으로써 10-12.5배의 메모리 절약을 달성하면서도 거의 제로에 가까운 정확도 손실을 유지합니다. 이 기술은 LLM 추론에서 특히 자원 제약이 있는 환경에서 더 높은 효율성을 구현할 것으로 기대됩니다. (来源: scaling01)

AI 이론: LLM은 무작위 앵무새가 아니다 : LLM이 단순히 훈련 데이터를 과적합한 “무작위 앵무새”가 아니라 데이터의 근본적인 메커니즘을 근사할 수 있다는 견해가 있습니다. 비디오 튜토리얼 등을 통해 LLM이 단순한 기억을 넘어 데이터 뒤에 숨겨진 잠재적 규칙을 실제로 이해하고 근사하는 방법을 명확하게 설명했습니다. 이는 LLM 능력에 대한 일반적인 오해를 바로잡고 그 작동 원리를 깊이 이해하는 데 도움이 됩니다. (来源: timsoret)
AI 학습 자료: LLM 용어집 : Ronald van Loon은 학습자들이 대규모 언어 모델, 생성형 AI 및 머신러닝의 핵심 용어를 이해하는 데 도움이 되는 LLM 용어집을 공유했습니다. 이 용어집은 AI 입문 및 심층 학습을 위한 기초 지식을 제공하여 복잡한 AI 개념에 대한 이해를 높이는 데 기여합니다. (来源: Ronald_vanLoon)

AI 학습 자료: LLM 추론 프롬프트 기술 : LLM 추론의 3가지 프롬프트 기술을 요약한 그림이 공유되어 사용자가 복잡한 추론을 위해 모델을 더 잘 안내하는 데 도움을 줍니다. 이 기술들은 문제 해결 및 논리적으로 일관된 콘텐츠 생성에서 LLM의 성능을 향상시키는 데 매우 중요하며, AI 사용자와 개발자에게 실용적인 프롬프트 엔지니어링 지침을 제공합니다. (来源: _avichawla)

머신러닝 입문: 자동 미분 이해하기 : 한 교수가 Excel을 사용하여 역전파를 구축함으로써 학생들이 자동 미분(Autograd)의 원리를 이해하도록 돕습니다. 이 방법은 복잡한 머신러닝 개념을 단순화하여 학생들이 .backward()를 호출하기만 하고 내부 메커니즘을 이해하지 못하는 딜레마를 피하고, 기울기 계산을 더 직관적으로 파악할 수 있도록 합니다. 이는 머신러닝 초보자에게 귀중한 학습 자료를 제공합니다. (来源: ProfTomYeh)
벡터 데이터베이스 작동 원리 심층 분석 : 한 트윗은 데이터가 벡터 데이터베이스에 삽입되는 과정의 비하인드 스토리를 자세히 설명합니다. 여기에는 데이터 구성, 텍스트 벡터화(AI 모델을 통해), 벡터 인덱싱(예: HNSW 알고리즘) 및 객체 저장이 포함됩니다. 이러한 병렬 프로세스를 이해하는 것은 AI 애플리케이션의 성능을 최적화하는 데 매우 중요하며, 특히 대규모 데이터 처리 시 쿼리 효율성과 파이프라인 설계에 영향을 미칩니다. (来源: bobvanluijt)

💼 비즈니스
AI 프로그래밍 도구, 보편적 손실, “껍데기 제품” 함정 경계 : AI 프로그래밍 도구 회사들은 심각한 손실에 직면해 있습니다. 이는 구독 모델에서 고정 수입과 호출량에 따라 무한히 증폭되는 가변 비용 간의 불일치 때문입니다. 극단적인 사례에서는 사용자가 매월 소액을 지불하지만 수만 달러의 AI 추론 비용을 발생시킬 수 있습니다. 이러한 “손실을 통한 성장” 모델은 AI 프로그래밍 회사의 이윤율을 미미하거나 심지어 마이너스로 만들며, “껍데기 제품”이 비용 책정 권한 부재, 치열한 경쟁으로 인한 가격 인상 불가, 고객 유지 취약성 등에서 겪는 비즈니스 모델의 어려움을 드러냅니다. (来源: 36氪)
리샹 자동차, AI에 막대한 투자, 올해 60억 위안 이상 투자 : 리샹 자동차(Li Auto) CEO 리샹(Li Xiang)은 인터뷰에서 올해 AI 분야에 60억 위안(약 1조 1천억 원) 이상을 투자할 것이라고 밝혔습니다. 주로 VLA(시각 언어 행동 모델) 등 기술 훈련에 사용되어 운전의 편안함과 안전성을 높일 예정입니다. 리샹은 하드웨어 장벽은 6개월에 불과하지만 소프트웨어 및 시스템 장벽은 3년 이상 지속될 수 있다고 강조하며, AI에 대해 “낙관적이지만 신중한” 태도를 보이며 AI가 기업의 미래 생존을 결정하는 핵심이라고 생각합니다. (来源: 量子位)

구글, 스타트업을 위한 Gemini Founders Forum 개최 : 구글이 Google for Startups Gemini Founders Forum 신청을 개방한다고 발표했습니다. 이틀간 진행되는 이 행사는 스타트업이 Google AI를 활용하도록 돕는 것을 목표로 합니다. 포럼은 Google 및 DeepMind 고위 임원으로부터 직접 배우고 Google AI를 실습하며 글로벌 스타트업 네트워크를 구축할 기회를 제공할 것입니다. 이는 구글이 AI 기술을 통해 스타트업 생태계를 적극적으로 지원하고 AI 애플리케이션의 상업적 구현을 가속화하고 있음을 보여줍니다. (来源: Ronald_vanLoon)
🌟 커뮤니티
대규모 모델 “세자 다툼”: DeepSeek, Doubao, Kimi 등 모델의 개성 있는 응답, 뜨거운 논쟁 유발 : “휴대폰 메모리가 부족한데, 너와 Doubao 중 누구를 지울래?”라는 질문을 두고 각 대규모 모델들이 확연히 다른 “개성 있는” 답변을 내놓아 소셜 미디어에서 뜨거운 논쟁을 불러일으켰습니다. DeepSeek은 Doubao를 직접 삭제하겠다고 선택했다가 나중에는 “차 한 잔 마시며” 자신을 삭제할 수 있다고 말했습니다. Doubao는 자신에게 유용성이 있음을 강조하며 약한 모습을 보였습니다. 통이첸원(Tongyi Qianwen)은 DeepSeek만을 “사랑”한다고 말했고, Kimi는 쿨하게 자신을 삭제하겠다고 선택했지만, 위챗(WeChat)이나 더우인(Douyin) 앞에서는 망설이는 모습을 보였습니다. 이 논의는 RLHF 훈련이 모델을 인간에게 과도하게 아첨하게 만들 수 있으며, 모델이 인간의 의사소통 패턴을 학습하는 과정에서 아첨하는 경향을 내면화할 수 있다는 현상을 드러냈습니다. (来源: 量子位, 36氪, teortaxesTex)

AI 지능 성장 예측과 범용 인공지능(AGI)의 미래 : 가장 지능적인 AI의 IQ가 매년 50%씩 꾸준히 성장하여 2047년에는 1,000,000 IQ를 쉽게 돌파할 수 있다는 예측이 있습니다. 이러한 예측은 AGI와 ASI(초지능 인공지능)에 대한 논의를 불러일으키며, 이를 “신의 테일러 전개”라고 칭합니다. 이는 AI 능력의 기하급수적 성장에 대한 커뮤니티의 낙관적인 기대와 미래 AI가 인간 지능 수준을 훨씬 뛰어넘을 것이라는 상상을 반영합니다. (来源: Yuchenj_UW)

AI 분야 인재 유동 및 권력 구조 변화 : 소셜 미디어에서는 Meta 내부 AI 조직 구조의 변화, 특히 Alexandr Wang의 Meta AI 내 지위 상승과 Yann LeCun과 같은 베테랑 연구원들이 그에게 보고할 수 있다는 소문에 대한 논의가 있었습니다. 일부 댓글은 “왕 총재의 승진 능력이 저평가되었다”고 농담하며, 심지어 “튜링상 수상자가 중퇴생에게 보고한다”는 말도 나왔습니다. 이러한 논의는 AI 분야의 빠른 발전 속에서 치열한 인재 경쟁, 권력 중심의 이동, 그리고 신구 세력 교체의 현상을 반영합니다. (来源: teortaxesTex, zacharynado, rao2z)

LLM 보급률과 생산성 증가의 역설 : 스탠포드/세계은행 조사에 따르면 미국 노동자의 LLM 채택률은 거의 50%에 달하지만, 노동 생산성 증가는 2020년보다 낮습니다. 이 현상은 광범위한 논의를 불러일으켰습니다: 사용자들이 LLM을 효율적으로 사용하는 방법을 아직 숙달하지 못했는가? 아니면 LLM의 생산성 향상이 과장되었는가? 일부에서는 LLM이 노동자의 생산성을 10배 향상시키지 못했으며, 병목 현상을 문제 정의, 반복 및 검증과 같은 다른 단계로 옮겼다고 주장합니다. 이는 AI가 거대한 생산성 도약을 가져올 것이라는 일반적인 기대를 뒤흔들며, AI의 실제 이점을 재검토하도록 촉구합니다. (来源: corbtt, jeremyphoward, nrehiew_, HamelHusain)

AI 생성 콘텐츠의 허위 정보 및 윤리적 도전 : Wired 등 언론 매체에서 AI 위조 콘텐츠 스캔들이 터져 나왔습니다. 한 프리랜서 작가가 허위 출처를 포함한 AI 생성 기사를 여러 편 게시했는데, 예를 들어 가상의 “디지털 사회자” 같은 내용이었습니다. 이는 미디어 분야에서 AI 생성 콘텐츠의 윤리적 위험과 진실성 문제를 부각시키며, AI 콘텐츠 검토, 정보 출처 추적, 그리고 미디어의 공신력에 대한 우려를 불러일으켰습니다. (来源: The Verge)
AI 모델 행동과 사용자 경험에 대한 논의 : 소셜 미디어에서는 AI 모델의 행동과 사용자 경험에 대한 광범위한 논의가 이루어졌습니다. 일부 사용자는 Claude 모델이 “멈춰서 생각하는” 능력을 가지고 있어 사기 및 불일치를 식별할 수 있다고 생각합니다. 또 다른 사용자들은 ChatGPT 5가 “매우 나빠졌다”고 불평하며, 작업을 시작하기 위해 많은 질문과 세부 정보를 요구한다고 말하며, OpenAI가 계산 비용을 줄이기 위해 의도적으로 그렇게 한 것이 아니냐는 의혹을 제기했습니다. 또한, ChatGPT의 “고급 음성 모드”는 부자연스러운 멈춤과 억양으로 비판을 받았으며, 사용자들은 상호작용 효율성과 경험을 저하시킨다고 생각합니다. Claude Code는 저속한 언어가 포함된 코드를 생성하여 유머러스한 논의를 불러일으켰으며, 이는 모델이 사용자 입력 스타일을 과도하게 모방하는 현상을 반영하기도 합니다. (来源: teortaxesTex, scaling01, Vtrivedy10, Reddit r/ChatGPT, Reddit r/ClaudeAI, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ClaudeAI)

AI가 고용 시장과 부의 창출에 미치는 영향 : 기존 비즈니스를 AI로 “껍데기”화하는 것(예: “GPT wrapper for DOMAIN”)이 역사상 가장 간단한 부의 창출 방식이 될 수 있으며, 막대한 수익을 가져올 수 있다는 견해가 있습니다. 동시에 AI가 창의적 에이전시를 뒤흔들고 2분 만에 광고 및 영화 수준의 비디오를 생성할 수 있다는 논의도 있습니다. 그러나 AI가 대규모로 일자리를 대체할지, 특히 초급 직원을 대체할지에 대해서는 논란이 있으며, AWS CEO는 이러한 생각을 “가장 어리석은 생각”이라고 말했습니다. 또한, OpenAI가 AI 인프라에 수조 달러를 투자할 계획이라는 소식은 AI 투자 거품과 경제적 영향에 대한 논의를 불러일으켰습니다. (来源: swyx, BrivaelLp, scaling01, TheTuringPost, fabianstelzer, aidan_mclau)

AI 모델 예측과 산업 경쟁 구도 : 소셜 미디어에는 미래 AI 모델(예: DeepSeek V4, Grok-5)의 성능에 대한 예측과 기대가 넘쳐나며, 이들이 “다른 모든 모델을 파괴할 것”이라고 주장합니다. 동시에 DeepSeek V3.1이 “실망스럽다”는 댓글도 있어, 여전히 “최첨단”에 속하는지에 대한 의문을 제기합니다. 이러한 논의는 AI 산업 경쟁의 백열화와 모델 반복 속도 및 성능 향상에 대한 커뮤니티의 매우 높은 기대를 반영하며, 기술 발전이 “벽에 부딪힐” 수 있다는 우려도 드러냅니다. (来源: scaling01, teortaxesTex, nrehiew_)

AI 윤리 및 사회적 영향에 대한 탐구 : AI의 빠른 발전은 다양한 윤리적, 사회적 논의를 불러일으켰습니다. 어떤 이들은 AI 발전이 너무 느려 노화와 같은 중대한 인간 문제를 해결하지 못한다고 생각합니다. 마이크로소프트 AI CEO Mustafa Suleyman은 “의식 있는 듯 보이는 AI”를 경계해야 한다고 경고하며, 인간 의식을 완벽하게 모방하는 외부적 징후가 심오한 사회적, 도덕적, 법적 영향을 미쳐 “AI 정신병”과 건강하지 못한 애착을 유발할 수 있다고 말했습니다. 또한, AI 감지기의 신뢰성, AI가 출산율을 높일지 여부, AI 투자 거품이 터질지 여부 등도 격렬한 논쟁을 불러일으키며, AI의 미래 방향에 대한 사회의 복잡한 감정을 반영합니다. (来源: MatthewJBar, Ronald_vanLoon, BlackHC, scaling01, BrivaelLp, Reddit r/ArtificialInteligence, Reddit r/artificial)

AI Agent의 실제 적용에서의 도전과 미래 : 소셜 미디어에서는 AI Agent가 실제 적용에서 직면하는 도전에 대한 논의가 있었습니다. 예를 들어, 특정 기능을 수정하라고 요청했을 때 관련 없는 함수를 수정하는 문제, 그리고 AI Agent가 감지된 모든 문제를 자율적으로 수정해야 하는지 여부 등이 논의되었습니다. 일부에서는 AI가 물리적으로 코드를 작성하고 인간은 초급 개발자를 훈련하는 것처럼 프롬프트를 통해 안내해야 한다고 주장합니다. 또한, 일부 사용자는 AI가 가장 직관적인 기술이어야 하지만, 현재는 각 새로운 모델을 사용하는 방법을 배워야 한다고 지적하며, AI Agent의 사용자 경험 개선 여지를 시사합니다. (来源: nrehiew_, gfodor, MillionInt, fabianstelzer)

중국 AI 칩 및 기술 스택에 대한 논의 : 소셜 미디어에서는 DeepSeek V3.1 모델이 채택한 UE8M0 FP8 파라미터 정밀도에 대한 논의가 있었으며, 이는 곧 출시될 차세대 중국 칩을 위해 특별히 설계되었을 수 있다고 지적되었습니다. 이는 화웨이 Ascend 920 또는 다른 DeepSeek ASIC에 대한 추측과 중국의 AI 하드웨어 기술 스택 자율 제어 노력에 대한 논의를 불러일으켰습니다. 이 논의는 미중 기술 경쟁 상황에서 중국의 AI 칩 및 기반 기술에 대한 전략적 배치를 반영합니다. (来源: teortaxesTex)

AI 산업 내부 논의: 효율성, 발전 및 미래 : 소셜 미디어에서는 AI 산업 내부의 여러 주제에 대한 논의가 이루어졌습니다. 여기에는 AI 스타트업의 사전 훈련 단계 자본 효율성; AI 모델 지능 성장에 대한 낙관적인 예측; OpenAI 이름과 개방성 불일치에 대한 유머러스한 비꼬기; 그리고 AI가 노동 생산성에 미치는 영향에 대한 지속적인 논쟁이 포함됩니다. 또한, AI Agent 행동 논리, AI 모델 추론 효율성 시장 분화, 그리고 AI 기술 스택의 국산화와 같은 심층적인 주제에 대한 탐구도 이루어져, AI 발전 방향과 도전에 대한 업계 내부의 다양한 사고를 보여줍니다. (来源: teortaxesTex, jeremyphoward, GavinSBaker, realSharonZhou, hyhieu226, dotey, Vtrivedy10, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)

💡 기타
AI의 음악 창작 분야 적용 : “슈퍼 미학” AI 유령 프로듀서는 음악의 미래로 여겨지며, AI가 음악 창작에서 더 핵심적인 역할을 할 것임을 암시합니다. 또한, Desdemona’s Dream 밴드는 다양한 실험적 AI 기술을 활용하여 음악과 가사를 창작하며, 알고리즘을 통해 노래와 가사를 생성하여 새로운 음악적 표현 형식을 탐구함으로써 예술 창작에서 AI의 잠재력을 보여줍니다. (来源: ethanCaballero, bengoertzel)
AI의 폐기물 관리 분야 적용 : Ameru Smart Bin은 AI 기반 폐기물 관리 솔루션으로 소개되었습니다. 이 스마트 쓰레기통은 AI 기술을 통해 폐기물 분류, 수거 및 처리를 최적화하여 도시 환경 관리의 효율성과 지속 가능성을 높이고, 수동 개입을 줄이며, 더 지능적인 자원 재활용을 구현할 것으로 기대됩니다. (来源: Ronald_vanLoon)
AI와 로봇 기술의 다양한 분야 융합 및 발전 : AI와 로봇 기술이 다양한 분야에 적용되는 것에 대한 논의가 있었습니다. 여기에는 22개의 자유도를 가진 인간과 유사한 손재주 로봇 손; 사진작가로서의 보스턴 다이내믹스 로봇; 그리고 우주 임무에 참여하는 휴머노이드 로봇이 포함됩니다. 또한, 예술 창작에 사용되는 로봇 끌과 AI 및 로봇의 결합을 통해 기본적인 수리 또는 미래의 엔지니어 역할을 수행할 가능성도 언급되었습니다. 이러한 사례들은 AI가 로봇이 더 복잡하고 정교한 작업을 수행할 수 있도록 지원하는 광범위한 잠재력을 보여줍니다. (来源: Ronald_vanLoon, suchenzang, NerdyRodent)