
Mots-clés:Zhipu AI, AutoGLM, GPT-5 Pro, DeepSeek V3.1, GLM-4.5 Modèle Linguistique, Seed-OSS, Agent IA, Intelligence Incarnée, Grand Modèle Linguistique, Agent Mobile Universel, Preuve des Limites Mathématiques, Architecture de Raisonnement Hybride, Fenêtre Contextuelle 512K
Voici将中文AI资讯翻译为法文,并遵循您的所有要求:
🔥 FOCALISATION
Zhipu lance le premier Agent universel pour mobile au monde : Zhipu AI a officiellement lancé AutoGLM, le premier Agent universel pour mobile au monde. Cet Agent prend en charge l’exécution de tâches inter-applications et fonctionne dans le cloud, sans consommer les ressources de l’appareil local. AutoGLM fournit à chaque utilisateur des téléphones cloud et des ordinateurs cloud, résolvant les problèmes de limitation de la puissance de calcul locale et d’occupation des ressources. Ses capacités sont basées sur le modèle de langage GLM-4.5 et le modèle d’inférence visuelle GLM-4.5V de Zhipu. Cette initiative vise à améliorer considérablement l’intelligence et la commodité des opérations mobiles et est ouverte gratuitement au public, ce qui devrait favoriser la popularisation de la technologie Agent sur le marché grand public. Zhipu a également proposé les « 3 principes A » (All-time, Auto-running zero interference, All-domain connection), visant à étendre les capacités de l’Agent à davantage de supports et à accélérer la progression vers l’intelligence artificielle générale. (Source: 量子位)

GPT-5 Pro réalise une percée dans la recherche mathématique : Sebastien Bubeck, chercheur chez OpenAI, a révélé que GPT-5 Pro, dans un problème d’optimisation convexe, par la pensée et le raisonnement indépendants, a fourni une preuve de borne mathématique plus précise que les articles existants. Brockman, président d’OpenAI, a qualifié ce résultat de « signe de vie ». Le modèle, sans connexion réseau ni mémoire, en lisant simplement un article sur l’optimisation convexe, a précisé une borne de 1/L à 1.5/L en 17,5 minutes. Bien que les auteurs humains aient par la suite mis à jour l’article pour affiner davantage la borne, l’approche de preuve de GPT-5 Pro était indépendante de celle des humains, démontrant sa capacité à explorer et à prouver des lois mathématiques de manière autonome, marquant une étape importante pour les LLM vers l’intelligence artificielle générale. (Source: Sebastien Bubeck, Reddit r/artificial, Reddit r/ChatGPT)

Meta gèle les recrutements en IA, suscitant des craintes de bulle sectorielle : Meta a annoncé le gel des recrutements de personnel IA pour son « laboratoire d’ultra-intelligence », après avoir dépensé des sommes considérables pour recruter plus de 50 chercheurs et ingénieurs en IA, offrant des salaires de plusieurs dizaines de millions de dollars, mais les dépenses élevées et la pression des investisseurs l’ont poussée à ajuster sa stratégie. Cette décision a suscité des inquiétudes sur le marché quant à une éventuelle bulle dans le secteur de l’IA, mais certains estiment qu’il ne s’agit pas d’un éclatement de la bulle de l’IA, mais plutôt d’un ajustement de la structure organisationnelle, car la formation de modèles pourrait ne pas nécessiter un grand nombre d’employés, mais plutôt une équipe professionnelle et efficace. Cette décision reflète le compromis entre la recherche de percées technologiques et le contrôle des coûts par les entreprises d’IA, ainsi qu’une discussion plus large sur le coût des talents et la viabilité commerciale dans le secteur de l’IA. (Source: The Verge, Reddit r/ArtificialInteligence)

🎯 TENDANCES
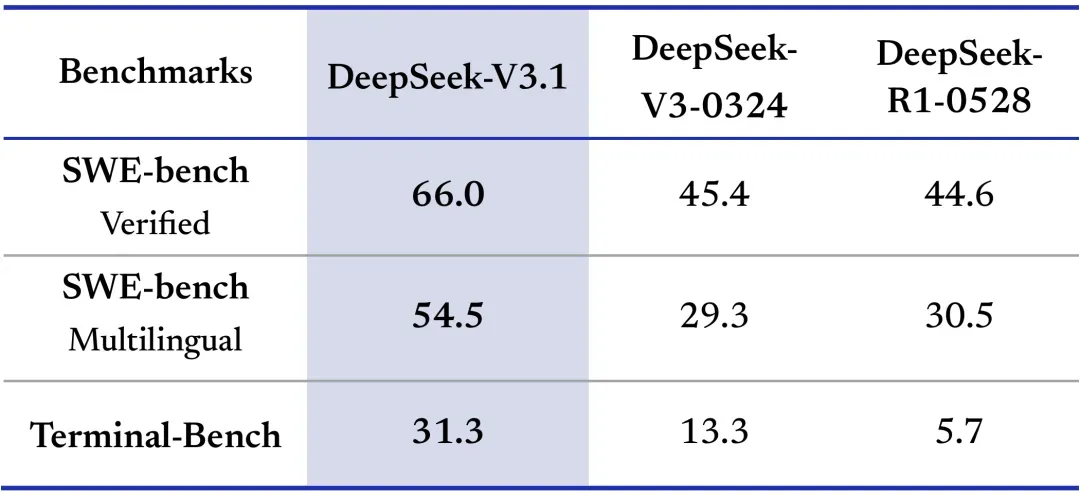
DeepSeek lance le modèle V3.1, ouvrant la voie à l’ère des Agents intelligents : DeepSeek a officiellement lancé le modèle V3.1, marquant son entrée dans l’ère des Agents intelligents. Ce modèle adopte une architecture de « raisonnement hybride », prenant en charge deux modes, la pensée et la non-pensée, et pouvant basculer de manière autonome. V3.1 excelle en matière de capacités de programmation, dépassant notamment Claude 4 Opus et Gemini 2.5 Pro dans les tests de codage Aider, et se hissant au sommet du classement de la programmation open-source. Les paramètres du modèle sont de 671B (37B de paramètres actifs), la longueur de contexte atteint 128k, et il a étendu son ensemble de données de documents longs pendant l’entraînement, augmentant considérablement le volume total d’entraînement. De plus, DeepSeek V3.1 a amélioré ses capacités d’appel d’outils et de raisonnement multi-étapes, et prend en charge le format Anthropic API, facilitant l’intégration avec des frameworks comme Claude Code. (Source: DeepSeek Blog, 量子位, huggingface, ArtificialAnlys, karminski3, teortaxesTex, scaling01, nrehiew_, reach_vb, iScienceLuvr, multimodalart, _akhaliq, zizhpan, ClementDelangue, fabianstelzer, QuixiAI)
ByteDance open-source le modèle Seed-OSS : L’équipe Seed de ByteDance a soudainement open-sourcé le modèle Seed-OSS-36B de la série Seed-OSS, avec 36 milliards de paramètres, sous licence Apache-2.0, disponible gratuitement pour un usage académique et commercial. Ce modèle prend en charge nativement une fenêtre de contexte ultra-longue de 512K, soit quatre fois celle des modèles grand public, et a été construit pendant la phase de pré-entraînement. Seed-OSS introduit un mécanisme de « budget de pensée », permettant aux utilisateurs de contrôler la profondeur de réflexion du modèle. Dans plusieurs tests de référence, Seed-OSS-36B-Base a battu des records pour les modèles open-source dans les tests MMLU-Pro, BBH, GSM8K, MATH, HumanEval, démontrant de puissantes capacités de compréhension des connaissances, de raisonnement et de codage. (Source: 量子位, ClementDelangue, reach_vb)

La série Google Pixel 10 intègre profondément les fonctions d’IA : La dernière série de téléphones Pixel 10 de Google intègre profondément les fonctions d’IA dans le matériel et les applications système. Tous les logiciels préinstallés sont dotés d’IA, y compris un coach de santé IA et un guide de retouche/prise de vue IA. Les fonctions d’IA ne se limitent plus à un déclenchement actif, mais peuvent automatiquement proposer des suggestions dans des scénarios appropriés et réaliser une interconnexion des capacités d’IA entre plusieurs applications système. Les modèles côté appareil sont largement utilisés, couvrant la modification d’images, l’amélioration des détails du zoom numérique et la traduction en temps réel des appels. De plus, Google a publié un rapport technique détaillé sur l’impact environnemental de l’environnement d’inférence Gemini, indiquant que sa consommation d’énergie et d’eau est bien inférieure aux attentes publiques, et que son efficacité continue de s’améliorer. (Source: op7418, TheRundownAI, Google, dotey, demishassabis, algo_diver)

La NASA et IBM s’associent pour lancer le modèle d’IA Surya, décodant l’activité solaire : La NASA et IBM ont collaboré pour open-sourcer Surya sur Hugging Face, le premier modèle de fondation d’IA open-source pour la physique solaire. Ce modèle, doté de 366 millions de paramètres, a été pré-entraîné sur 9 ans de données multi-instruments (environ 218 To) de l’Observatoire de la dynamique solaire de la NASA. Il vise à aider les chercheurs à protéger les infrastructures grâce à une modélisation accessible et précise de la météo spatiale, et devrait révolutionner la prévision des tempêtes solaires. (Source: clefourrier)

Geely Galaxy M9 est le premier à intégrer le premier cockpit IA du secteur : Geely a lancé son nouveau système d’exploitation de cockpit IA, Flyme Auto 2, qui sera d’abord intégré dans le Lynk & Co 10 EM-P et le Geely Galaxy M9. Basé sur le grand modèle d’IA Xingrui de Geely, le grand modèle vocal de bout en bout Jieyue Xingchen et le grand modèle de mémoire fluide, ce cockpit introduit l’Agent intelligent hyper-humanoïde Eva, doté d’une interaction émotionnelle très perceptive et d’une puissante capacité d’action. Eva peut auto-évaluer, planifier et exécuter des tâches, et prend en charge les applications multi-fonctions AI Agent pour tous les scénarios, visant à créer un espace intelligent de coordination autonome « humain-véhicule-environnement ». Geely a également lancé le premier AI Box du secteur, avec une puissance de calcul de 200TOPS, pour alimenter les grands modèles multimodaux côté appareil. (Source: 量子位)
Unitree lance un robot humanoïde de ballet de 180 cm, avec 31 degrés de liberté : Unitree Robotics a annoncé le lancement de son quatrième robot humanoïde, le « Danseur de ballet », mesurant 180 cm, avec 31 degrés de liberté sur tout le corps, une silhouette élancée et une posture élégante. Ce robot devrait surpasser ses prédécesseurs en agilité et réaliser une percée en matière de morphologie humanoïde. Cette initiative montre qu’Unitree segmente sa gamme de produits de robots humanoïdes dans des domaines plus précis, construisant une stratégie de « toutes tailles + tous scénarios + tous prix », visant à augmenter sa part de marché dans le secteur de la robotique. (Source: 量子位)

Meta lance DINOv3, un modèle de vision par ordinateur généraliste : Meta a lancé DINOv3, un modèle de vision par ordinateur généraliste et de pointe, entraîné par apprentissage auto-supervisé, capable de générer des caractéristiques visuelles de haute résolution exceptionnelles. Ce modèle fait progresser le domaine de la vision par ordinateur en éliminant la dépendance à de grandes quantités de données annotées manuellement, le rendant plus adaptable et généralisable dans diverses applications. (Source: dl_weekly)
Cohere lance le modèle Command A Reasoning : Cohere a lancé Command A Reasoning, un modèle avancé conçu spécifiquement pour les tâches de raisonnement en entreprise. Ce modèle surpasse les autres modèles déployables en privé dans les benchmarks d’agents et multilingues, et vise à apporter une valeur réelle aux entreprises mondiales. Cohere souligne que la capacité de raisonnement mathématique n’est pas directement liée à l’utilisation d’outils, aux agents ou au raisonnement multilingue, c’est pourquoi ils ont entraîné ce nouveau modèle pour répondre aux besoins du monde réel, et ont ouvert les poids pour les retours des utilisateurs. (Source: aidangomez, nickfrosst)

La plateforme X d’Elon Musk lance une fonction d’IA de conversion d’image en vidéo : Elon Musk a annoncé que la plateforme X lancera une nouvelle fonction permettant aux utilisateurs de convertir n’importe quelle image en vidéo en environ 17 secondes, simplement en appuyant longuement dessus. Cette fonction utilise la technologie de l’IA pour offrir aux utilisateurs une expérience de création de contenu plus pratique et plus créative, enrichissant ainsi les formes d’interaction multimédia sur la plateforme de médias sociaux. (Source: qtnx_)

Progrès de l’application de l’IA dans la découverte de médicaments : L’IA montre un potentiel immense dans la découverte de médicaments. L’ensemble de données GDP disponible sur Hugging Face intègre des données à grande échelle telles que DRUG-seq, Cell Painting, perturbations chimiques et détection d’anticorps, fournissant une ressource précieuse pour la recherche scientifique multimodale. L’ouverture de ces ensembles de données devrait accélérer l’application de l’IA dans la recherche et le développement de médicaments, favorisant la découverte de nouveaux médicaments et l’innovation dans les solutions thérapeutiques. (Source: ClementDelangue, clefourrier)

D-Robotics open-source l’algorithme de contrôle de robot sur Hugging Face : D-Robotics a open-sourcé l’algorithme d’IA incarnée LeRobot ACT Policy sur Hugging Face et l’a exécuté avec succès sur le bras robotique open-source SO-101 avec sa carte de développement RDK. Cet algorithme utilise la puissante capacité de calcul de 128 TOPS de la BPU pour réaliser une saisie et un rangement d’objets fluides par le bras robotique, démontrant l’application de l’accélération de bout en bout dans le domaine de la robotique et offrant un nouveau support technologique à la communauté des robots open-source. (Source: ClementDelangue)
NetEase Youdao lance le stylo de réponse IA Space X et la plateforme de traduction audio/vidéo : NetEase Youdao a lancé un nouveau matériel basé sur le grand modèle éducatif « Ziyue » – le stylo de réponse IA Youdao Space X. Il prend en charge la fonction « scannez pour répondre » pour 9 matières, y compris les langues, les mathématiques et l’anglais, avec un taux de précision allant jusqu’à 96 %, et offre des réponses vidéo de type tableau noir et une fonction de carnet d’erreurs IA. Parallèlement, Youdao a également lancé une plateforme de traduction audio/vidéo tout-en-un, prenant en charge la traduction simultanée en 38 langues, la traduction vocale multimodale et la carte mentale de résumé IA, avec une efficacité de traitement élevée et un faible coût, visant à faire progresser l’IA éducative du stade L3 au stade L4 de l’enseignant virtuel. (Source: 量子位)

Epic Games accélère le lancement de fonctions médicales basées sur l’IA : Epic Games, le géant des logiciels médicaux fondé en 1979, lance de nouvelles fonctions d’IA à une vitesse étonnante, dépassant même de nombreuses startups émergentes. Cela montre que les entreprises informatiques médicales traditionnelles adoptent activement la technologie de l’IA et l’intègrent dans leurs systèmes existants pour améliorer l’efficacité des soins de santé et l’expérience des patients, annonçant une accélération de l’adoption de l’IA dans le domaine de la santé. (Source: sarahcat21)
Le modèle Kimi-VL-A3B-Thinking-2506-GGUF est lancé : Le modèle Kimi-VL-A3B-Thinking-2506-GGUF est désormais disponible, avec un support dans llama.cpp, offrant plus d’options de modèles de langage visuel multimodal à la communauté LLaMA locale. Les utilisateurs apprécient les caractéristiques du modèle Kimi en termes d’évitement de la flatterie et de directivité, et attendent avec impatience ses performances dans les tâches de langage visuel. (Source: Reddit r/LocalLLaMA)

GAIA : Une architecture d’IA générale plus rapide que Transformer : GAIA (General Artificial Intelligence Architecture) est proposée comme alternative à Transformer, basée sur un cadre de hachage et une régularisation de partitionnement pilotée par π, éliminant les mécanismes d’auto-attention coûteux en temps et les tokenizers complexes. GAIA est légère, générale, peut être entraînée en quelques secondes sur un CPU et atteint des performances compétitives sur les ensembles de données de classification de texte standard. Cela offre de nouvelles perspectives pour le déploiement efficace de modèles d’IA à grande échelle, en particulier pour les appareils périphériques et les environnements à ressources limitées. (Source: Reddit r/deeplearning)

🧰 OUTILS
Firecrawl : Une API de données Web pour l’IA : Firecrawl est une API de données Web conçue pour fournir des données de pages Web propres aux applications d’IA. Elle est capable de crawler et de transformer des sites Web entiers en Markdown utilisable par les LLM ou en données structurées, prenant en charge des fonctions avancées de crawling, de scraping et d’extraction de données. Firecrawl propose une API, des SDK (Python, Node) et des intégrations de frameworks LLM (Langchain, Llama Index, etc.), et dispose de puissantes capacités de traitement du contenu dynamique, de mécanismes anti-scraping, d’analyse des médias et de traitement par lots, tout en offrant une extraction de données structurées basée sur l’IA et des capacités d’interaction avec les pages. (Source: GitHub Trending)
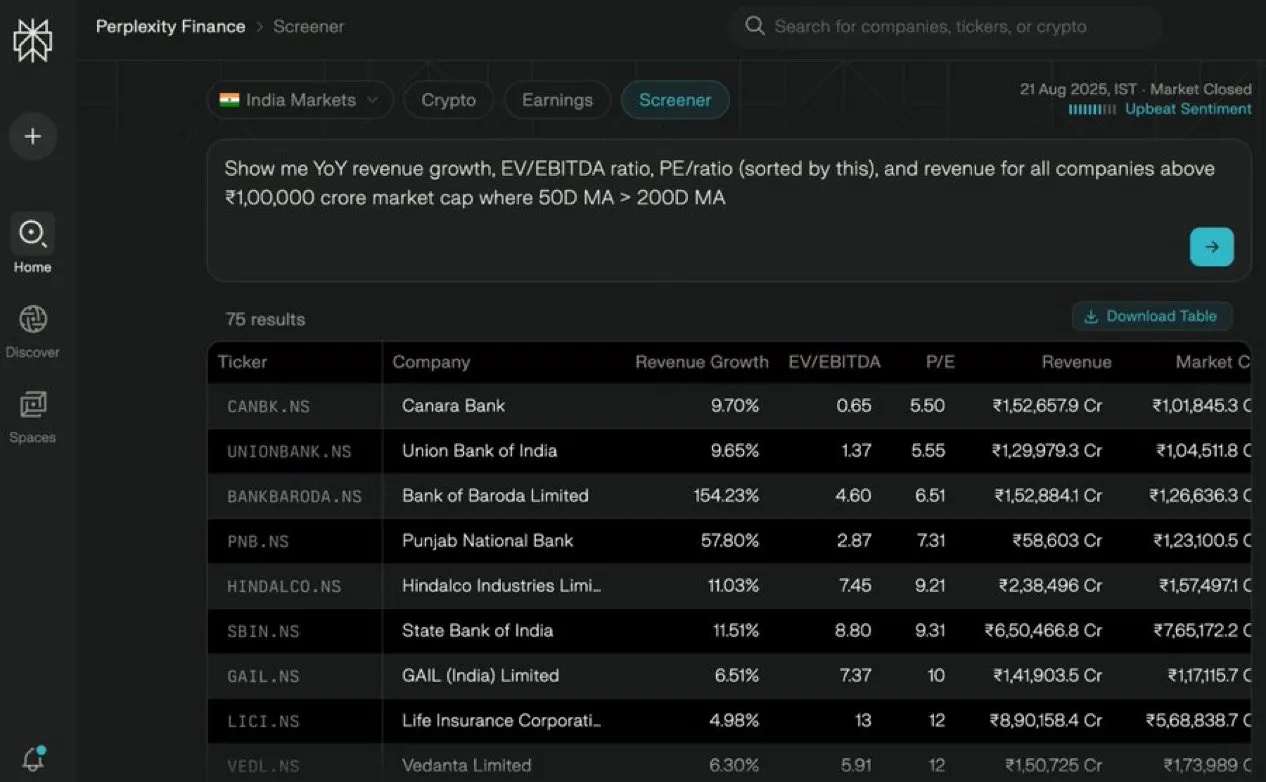
Perplexity Finance lance la fonction de filtrage des actions indiennes : Perplexity Finance a désormais ouvert sa fonction de filtrage des actions indiennes à tous les utilisateurs, permettant la recherche et le filtrage via le langage naturel. Les utilisateurs n’ont qu’à saisir le résultat souhaité, les conditions de filtrage et le mode de tri pour obtenir des informations sur les actions, ce qui simplifie considérablement le processus de recherche et d’analyse du marché boursier indien, visant à fournir un service de filtrage d’actions gratuit et pratique aux investisseurs indiens. (Source: AravSrinivas)
Replit simplifie le processus d’enregistrement de domaine, améliorant l’expérience de « Vibe Coding » : Replit a réalisé le processus d’enregistrement de domaine le plus simple au monde, permettant de connecter automatiquement un domaine à un site Web en 60 secondes, améliorant considérablement l’expérience utilisateur. Cette innovation de « forte encapsulation » rapproche la vision du « Vibe Coding » (programmation d’ambiance), permettant aux développeurs de se concentrer sur la création et de réduire les tâches de configuration fastidieuses, ce qui reflète le potentiel des outils de programmation assistée par l’IA pour améliorer l’efficacité et le plaisir du développement. (Source: pirroh, amasad)

Analyse des standards et pratiques des fichiers de configuration AI Agent : OpenAI, Claude et Gemini ont chacun lancé des standards de fichiers de configuration d’Agent (agents.md, CLAUDE.md, GEMINI.md), visant à normaliser le comportement et l’interaction des AI Agent. agents.md tend à unifier les contraintes de comportement et les processus de validation entre les fabricants, tandis que CLAUDE.md et GEMINI.md se concentrent davantage sur les invites contextuelles internes au fabricant, la mémoire des instructions et les préférences comportementales. Ces fichiers présentent des différences dans les mécanismes de chargement, la sémantique d’exécution et les modèles de sécurité, reflétant un compromis entre l’unification des standards et la flexibilité de l’expérience utilisateur. Comprendre les limites et les priorités de ces fichiers de configuration est crucial pour construire des AI Agent fiables et contrôlables. (Source: dotey)
LangChain AI Agent aide à l’analyse des prospectus d’introduction en bourse : Un projet d’AI Agent basé sur LangChain a été développé avec succès pour analyser des prospectus d’introduction en bourse (DRHP) complexes et les transformer en rapports synthétiques faciles à comprendre pour le grand public. Ce projet automatise un processus en plusieurs étapes, connectant des sources de données externes aux LLM, ce qui permet aux analystes financiers de gagner un temps considérable. Cela démontre l’immense potentiel des AI Agent dans l’automatisation des processus métier complexes et la fourniture d’informations professionnelles, allant au-delà de la simple fonction de dialogue des LLM traditionnels. (Source: hwchase17, Hacubu)

Qwen Image Edit et WaveSpeedAI collaborent pour une édition d’images efficace : Le modèle Qwen Image Edit d’Alibaba a collaboré avec WaveSpeedAI pour offrir un service d’édition d’images IA rapide et de haute qualité. Les utilisateurs peuvent utiliser Qwen Image Edit via la plateforme WaveSpeedAI pour l’édition d’images, obtenant des résultats professionnels sans problème. De plus, Qwen Image Edit, combiné à la technologie LoRA, peut réaliser une édition de haute qualité en 8 à 4 étapes, augmentant la vitesse de 12 fois, et peut être utilisé pour transformer des illustrations en figurines réalistes, étendant considérablement les scénarios d’application et l’efficacité de l’édition d’images IA. (Source: Alibaba_Qwen, huggingface, suchenzang, fabianstelzer)

Extension VS Code/Cursor pour l’annotation d’images et la génération de pseudo-étiquettes dans l’IDE : Des développeurs ont rapidement construit une extension VS Code/Cursor permettant aux utilisateurs d’effectuer des annotations d’images pour la classification et la détection d’objets directement dans l’IDE, et de générer des pseudo-étiquettes via l’API FAL. Cet outil utilise Moondreamai v2 pour la détection d’objets, visant à simplifier et accélérer le processus d’annotation des données dans le développement d’IA, résolvant les problèmes de configuration complexe et de faible efficacité des outils d’annotation existants, et améliorant l’expérience de « Vibe Coding » des développeurs. (Source: cloneofsimo)

Runway lance Game Worlds Beta, explorant la génération de mondes virtuels en temps réel : Runway a lancé Game Worlds Beta, visant à explorer la possibilité de générer des mondes virtuels en temps réel. Ce projet s’efforce de permettre aux utilisateurs d’explorer n’importe quel personnage, histoire ou monde en temps réel, en générant des pixels d’environnements virtuels grâce à la technologie de l’IA. Cela représente une avancée majeure de l’IA dans le développement de jeux et la réalité virtuelle, annonçant une création de contenu future plus dynamique et interactive, offrant une liberté sans précédent aux créateurs. (Source: c_valenzuelab)
TimeCapsule-SLM : Un outil de recherche approfondie open-source exécutable dans le navigateur : TimeCapsule-SLM est un outil de recherche approfondie open-source qui peut être exécuté dans le navigateur et combiné avec Qwen 3 0.6b (ollama) pour fournir une compréhension sémantique, la génération d’insights et des idées innovantes. Cet outil met l’accent sur la protection de la vie privée, en traçant les résultats jusqu’aux blocs de texte/documents précis, résolvant les problèmes de compréhension contextuelle insuffisante, d’hallucinations et de difficulté de traçabilité des produits d’IA. Il prend en charge les expressions régulières et la recherche de fichiers plats, ainsi que la recherche sémantique dans les bases de connaissances, visant à aider les utilisateurs à effectuer des recherches approfondies localisées. (Source: tokenbender)

Matrix-3D : SkyworkAI réalise la génération de mondes 3D à partir d’une seule image/texte : SkyworkAI a lancé le modèle Matrix-3D, capable de générer des mondes 3D complets à partir d’une seule image ou d’une invite textuelle. Cette technologie révolutionnaire simplifiera considérablement le processus de création de contenu 3D, offrant des solutions efficaces et créatives pour le développement de jeux, la réalité virtuelle, la conception architecturale, etc., annonçant une nouvelle étape pour l’IA dans la génération de contenu tridimensionnel. (Source: NerdyRodent)
Kling_ai 2.1 Keyframe-Endframes : Amélioration du contrôle de la génération vidéo : Kling_ai a lancé la fonction 2.1 Keyframe-Endframes, offrant aux utilisateurs un contrôle et une expressivité accrus dans le flux de travail de génération vidéo IA. En définissant des images clés et des images de fin, les utilisateurs peuvent contrôler plus précisément les transitions et les styles du contenu vidéo, ce qui est particulièrement adapté à la création de vidéos narratives, et devrait apporter de nouvelles possibilités dans les domaines de la production cinématographique, de la publicité et du marketing de contenu. (Source: Kling_ai)
Glif Agent permet une production vidéo IA à faible coût : La plateforme Glif, grâce à ses Agents personnalisés, peut intégrer divers outils d’IA tels que Qwen Ultra Realism pour la génération d’images, OmniHuman LipSync, Seedance Pro, Flux Kontext Edit, ElevenLabs pour la voix, afin de réaliser une production vidéo IA efficace et à faible coût. Le coût d’une vidéo cohérente de 30 secondes peut être réduit à moins de 2 dollars, ce qui abaisse considérablement le seuil de création vidéo. La plateforme vise à devenir une solution de production vidéo IA tout-en-un, bien qu’elle soit toujours confrontée à des défis tels que les rapports d’aspect de sortie des différents modèles et la fluidité des transitions. (Source: fabianstelzer)
SynthesiaIO lance une fonction d’édition sécurisée pour les vidéos doublées par IA : SynthesiaIO a lancé la fonction « édition sécurisée », permettant aux utilisateurs d’ajuster les traductions, de corriger les erreurs et de saisir les nuances dans les vidéos doublées par IA, tout en garantissant l’intégrité des informations et du ton originaux grâce à un mécanisme de modération de contenu intégré. Cette fonction améliore la flexibilité et la précision des vidéos doublées par IA, particulièrement adaptée à la création de contenu multilingue, et assure la qualité et la sécurité du contenu. (Source: synthesiaIO)
Comparaison des outils de génération vidéo IA : Argil, Hedra Labs, HeyGen : Des outils de génération vidéo IA tels que Argil, Hedra Labs et HeyGen promettent tous de générer des vidéos de personnes parlant à partir d’une seule image. Les utilisateurs ont effectué des évaluations comparatives de ces outils pour déterminer quel modèle est le plus performant. L’émergence de ces outils simplifie considérablement le processus de production vidéo, réduisant le besoin de scripts, d’acteurs et d’équipes de tournage, mais soulève également des discussions éthiques sur la question de savoir si les créateurs de contenu devraient informer le public de l’utilisation de l’IA. (Source: BrivaelLp)

AI Toolkit intègre les ARAs pour optimiser le modèle Wan 2.2 : AI Toolkit a intégré les Accuracy Recovery Adapters (ARAs) pour optimiser les modèles 4 bits Wan 2.2 14B T2V (texte vers vidéo) et I2V (image vers vidéo). Cette technologie permet d’exécuter des modèles à grande échelle sur des appareils avec une VRAM limitée (comme les cartes graphiques 4090), par exemple en entraînant un LoRA I2V de 16 dimensions avec 19,2 Go de VRAM, tout en maintenant une sortie de haute qualité, améliorant ainsi l’efficacité du déploiement des modèles de génération vidéo IA sur les appareils périphériques. (Source: ostrisai)

Intégration de l’assistant de codage IA Telerik & KendoUI dans VS Code : VS Code Live a montré comment utiliser les assistants de codage IA de Telerik et KendoUI pour simplifier l’expérience de développement. Ces assistants IA peuvent aider les développeurs à automatiser l’écriture de code et à fournir des suggestions intelligentes, améliorant ainsi l’efficacité du développement et la qualité du code. Cela témoigne de la popularité croissante de l’IA dans les environnements de développement intégrés (IDE) et de son impact profond sur les processus de développement logiciel. (Source: code)

ChatExcel obtient un financement d’amorçage de plusieurs millions : ChatExcel, développé par une équipe de l’Université de Pékin, a annoncé avoir clôturé un financement d’amorçage de près de dix millions de yuans RMB, soutenu par Shanghai Changlei Capital et Wuhan Donghu Angel Fund. ChatExcel est le premier Agent intelligent d’analyse de données et d’Excel IA génératif en Chine, permettant d’opérer des tableaux Excel par chat, couvrant le traitement des données, les calculs, l’analyse et la génération de graphiques, et prenant en charge le dialogue avec les bases de données d’entreprise et l’obtention de données en ligne. Ce cycle de financement sera utilisé pour accélérer l’itération de la R&D produit et la promotion sur les marchés mondiaux, visant à renforcer sa position de leader dans le domaine des Agents de données intelligents. (Source: 量子位)
Nano Banana : Un modèle d’image IA qui transforme les illustrations en figurines : Nano Banana est un modèle d’image IA très remarqué, dont l’application la plus populaire est sa capacité à transformer des illustrations en rendus réalistes de figurines. Les images générées par ce modèle n’ont presque pas de « sensation d’IA », avec une bonne texture et une forte conservation des caractéristiques, ce qui le rend largement utilisé et diffusé par les créateurs en dehors du cercle de l’IA. Nano Banana prend en charge la génération de texte en image, l’édition d’images locales et le transfert de style, et est connu pour sa vitesse de traitement ultra-rapide (généralement en moins de 10 secondes) et sa mémoire cohérente des éléments édités. (Source: dotey, yupp_ai)

yupp.ai : Simplifier l’expérience d’utilisation des outils IA : La plateforme yupp.ai vise à simplifier l’expérience utilisateur des outils IA, en intégrant divers modèles et fonctions pour que les utilisateurs n’aient pas à payer plusieurs abonnements, à basculer entre différentes applications ou à hésiter sur le choix du modèle. Cette plateforme s’engage à fournir une solution IA tout-en-un, permettant aux utilisateurs d’utiliser la technologie IA plus facilement et efficacement, et de réduire la barrière à l’entrée des outils IA. (Source: yupp_ai)

OpenAI Codex CLI prend en charge la sélection de modèles : La version v0.23.0 d’OpenAI Codex CLI a été mise à jour pour permettre aux utilisateurs de sélectionner des modèles, par exemple en utilisant gpt-5 high. Cela offre aux développeurs plus de flexibilité pour choisir le modèle le plus approprié en fonction des besoins de la tâche, optimisant ainsi l’efficacité de la programmation et de la réflexion. Cette fonction améliore l’utilité de Codex en tant qu’assistant de programmation IA et permet aux utilisateurs de configurer finement selon leurs préférences et les exigences du projet. (Source: dotey)
L’API DeepSeek est compatible avec Claude Code : L’API DeepSeek prend désormais en charge le format Anthropic API, permettant aux développeurs d’intégrer facilement les capacités de DeepSeek V3.1 dans le framework Claude Code. Grâce à une simple configuration de variables d’environnement, les utilisateurs peuvent utiliser le modèle DeepSeek dans Claude Code, réalisant ainsi des flux de travail Agentic plus flexibles. Cette mise à jour de compatibilité offre aux développeurs plus de choix de modèles et contribue à améliorer l’efficacité de la programmation IA et des tâches Agentic. (Source: jon_durbin, dotey, Reddit r/LocalLLaMA, Reddit r/ClaudeAI)

Problème d’affichage d’images de l’interpréteur de code dans OpenWebUI : Les utilisateurs d’OpenWebUI ont signalé que lors de l’utilisation de l’interpréteur de code, les images sont affichées sous forme de texte cité plutôt que directement. Bien que l’affichage soit normal en mode exécuteur de code, les utilisateurs soupçonnent que cela est lié à des mesures de sécurité ou à la manière dont le LLM renvoie les nœuds d’image. Ce problème affecte l’expérience utilisateur de visualisation intuitive des images générées par l’interpréteur de code dans OpenWebUI et nécessite une optimisation technique supplémentaire pour être amélioré. (Source: Reddit r/OpenWebUI)
Comparaison de ChatGPT 5 Pro et Cursor AI en programmation : Des discussions ont eu lieu sur les médias sociaux concernant la supériorité de ChatGPT 5 Pro ou de Cursor AI en matière de programmation (notamment en Python, Machine Learning, Deep Learning, réseaux neuronaux, etc.). Les utilisateurs recherchent des retours d’expérience pratique pour évaluer les performances de ces deux outils de programmation IA dans différentes piles technologiques. Cela reflète l’intérêt des développeurs pour les capacités professionnelles des modèles et les résultats réels lors du choix d’outils de programmation assistés par l’IA. (Source: Reddit r/deeplearning)

La fonction de génération d’images de ChatGPT transforme les photos des utilisateurs en style cartoon : ChatGPT a ajouté une nouvelle fonction qui permet de transformer les images téléchargées par les utilisateurs en style cartoon. Les utilisateurs ont partagé les résultats de la cartoonisation de leurs propres photos, et l’effet est satisfaisant. Bien que certains se demandent si elle possède une « imagination », cette fonction offre aux utilisateurs un service pratique de transformation de style d’image, enrichissant l’application de l’IA dans la génération de contenu créatif et apportant une nouvelle expérience interactive aux utilisateurs. (Source: Reddit r/ChatGPT)
📚 APPRENTISSAGE
Cours d’évaluation de l’IA : Du slogan à la méthode : Le cours « AI Evals for Engineers & PMs » est fortement recommandé ; il transforme le « examen des données » d’un slogan en une méthode concrète. Le cours met l’accent sur l’examen approfondi des trajectoires d’interaction, la construction de taxonomies d’erreurs, l’ajustement rigoureux des évaluations automatisées, et l’optimisation des prompts et des pipelines. Cela fournit aux ingénieurs et aux chefs de produit un guide systématique pour la pratique de l’évaluation de l’IA, les aidant à faire passer les projets d’IA du prototype à la production. (Source: gojira, lateinteraction, HamelHusain)
Étude pilote sur l’accélération de l’IA par des experts en risques IA et des super-prévisionnistes : METR et Research_FRI ont mené une petite étude pilote explorant les attentes des experts en risques IA et des super-prévisionnistes concernant une accélération extrême des progrès de l’IA. Bien que l’échantillon soit petit et biaisé, la méthode opérationnelle de l’étude est jugée précieuse, fournissant des données préliminaires et une base de discussion pour comprendre la vitesse de développement de l’IA et ses risques potentiels. (Source: tokenbender)

Article de recherche en IA : Le sens des mots dans les modèles de langage Transformer : Un article de recherche explore la manière dont le sens des mots est stocké dans les modèles de langage Transformer. L’étude montre que les modèles Transformer stockent le sens des mots via leurs embeddings statiques, et non pas seulement en le construisant à partir du contexte. Une analyse de clustering des embeddings de tokens de RoBERTa-base a révélé l’existence de thèmes sémantiques clairs (tels que les professions, les lieux, les émotions), fortement corrélés aux propriétés psycholinguistiques (telles que la valence, la concrétude), ce qui remet en question l’idée que « le sens n’est généré que plus tard » et indique que les embeddings statiques agissent comme un lexique guidant le traitement en aval. (Source: menhguin)

Article de recherche en IA : L’optimisation des préférences basée sur l’apprentissage dual (DuPO) permet l’auto-validation des LLM : DuPO (Dual Learning-based Preference Optimization) est un cadre d’optimisation des préférences basé sur l’apprentissage dual qui génère des retours non annotés via la dualité généralisée, résolvant la dépendance du RLVR aux étiquettes coûteuses et les restrictions strictes de l’apprentissage dual traditionnel. DuPO décompose la tâche originale en parties connues et inconnues, construit une tâche duale pour reconstruire la partie inconnue, et utilise la qualité de la reconstruction comme récompense auto-supervisée. Cette méthode a permis des améliorations significatives dans des tâches telles que la traduction et le raisonnement mathématique, offrant un nouveau paradigme évolutif, général et sans annotation pour l’optimisation des LLM. (Source: HuggingFace Daily Papers, teortaxesTex)

Article de recherche en IA : mSCoRe, un benchmark multilingue basé sur les compétences pour le raisonnement de bon sens : mSCoRe (Multilingual and Scalable Benchmark for Skill-based Commonsense Reasoning) est un benchmark multilingue et évolutif conçu pour évaluer systématiquement les capacités de raisonnement de bon sens des LLM. Ce benchmark comprend une nouvelle taxonomie des compétences de raisonnement, un pipeline robuste de synthèse de données et un cadre d’extension de la complexité. Les expériences montrent que mSCoRe reste un défi pour les LLM existants, en particulier aux niveaux de complexité plus élevés et pour le bon sens multilingue général et culturel nuancé, révélant les limites des modèles dans ces domaines. (Source: HuggingFace Daily Papers)
Article de recherche en IA : Le cadre CHORD unifiant SFT et RL : Le cadre CHORD (Controllable Harmonization of On- and Off-Policy Reinforcement Learning via Dynamic Weighting) propose une nouvelle perspective unifiant SFT (Supervised Fine-Tuning) et RL (Reinforcement Learning). CHORD considère le SFT comme un objectif auxiliaire à pondération dynamique dans le processus de RL, utilisant un coefficient global et une fonction de pondération mot par mot pour un double contrôle de l’influence des données d’experts hors politique, réalisant ainsi un équilibre efficace entre l’imitation hors politique et l’exploration en politique, ce qui améliore considérablement les performances des LLM. (Source: HuggingFace Daily Papers)
Article de recherche en IA : Le benchmark LLM MCP-Universe : MCP-Universe est le premier benchmark complet évaluant les performances des LLM dans des interactions réelles avec des serveurs Model Context Protocol (MCP). Ce benchmark couvre 6 domaines clés : navigation de localisation, gestion d’entrepôt, analyse financière, conception 3D, automatisation de navigateur et recherche Web, et utilise des évaluateurs d’exécution (format, statique, dynamique) pour garantir une évaluation rigoureuse. Les tests ont révélé que même les modèles SOTA (comme GPT-5) présentent encore des limitations de performance significatives dans le raisonnement à longue séquence et les espaces d’outils inconnus, et que les Agents de niveau entreprise sous-performent. (Source: HuggingFace Daily Papers)
Article de recherche en IA : Performances des VLM dans les examens multimodaux vietnamiens : ViExam est un benchmark pour les problèmes d’examen multimodaux vietnamiens, évaluant les performances des VLM sur des langues à faibles ressources et du contenu éducatif multimodal réel. L’étude a révélé que même les VLM SOTA n’atteignent qu’une précision moyenne de 57,74 % dans les examens multimodaux vietnamiens, la plupart des modèles étant moins performants que la moyenne humaine ; seul le VLM de type pensée o3 (74,07 %) a dépassé la moyenne humaine, mais reste bien en deçà des meilleures performances humaines. Le prompting inter-langues n’a pas amélioré les performances, et la collaboration homme-machine peut partiellement améliorer les performances des VLM. (Source: HuggingFace Daily Papers)
Article de recherche en IA : Étude sur la quantification post-entraînement des LLM de diffusion : Une étude a exploré pour la première fois de manière systématique la quantification post-entraînement (PTQ) des grands modèles de langage de diffusion (dLLM). L’étude a révélé l’existence de valeurs aberrantes d’activation dans les dLLM, ce qui pose un défi pour la quantification à faible bit. En évaluant de manière exhaustive les méthodes PTQ existantes, l’étude a analysé l’impact de la largeur de bit, de la méthode de quantification, de la catégorie de tâche et du type de modèle sur le comportement de quantification des dLLM, fournissant des informations pratiques pour le déploiement efficace des dLLM. (Source: HuggingFace Daily Papers)
Article de recherche en IA : Cadre de diagnostic cognitif pour les grands modèles de langage financiers : FinCDM est le premier cadre d’évaluation de diagnostic cognitif spécialement conçu pour les LLM financiers, qui identifie les forces et les faiblesses des modèles en matière de compétences et de connaissances financières grâce à une évaluation au niveau des connaissances-compétences. Ce cadre a construit l’ensemble de données CPA-QKA, couvrant de véritables compétences comptables et financières, visant à fournir un diagnostic interprétable et sensible aux compétences, soutenant un développement de modèles plus fiable et ciblé. (Source: HuggingFace Daily Papers)
La conférence Tech Innovators 2025 met l’accent sur l’IA incarnée : La conférence Tech Innovators 2025 aura lieu le 5 septembre à Pékin, sur le thème « L’IA incarnée, nouveau moteur de la transformation industrielle intelligente ». La conférence réunira des scientifiques, des leaders d’entreprise, des experts de l’industrie et des investisseurs, se concentrant sur l’industrialisation des technologies de pointe, et créera un modèle de service complet « tiré par la demande – connexion technologique – soutien en capital – mise en œuvre de scénarios », visant à résoudre le problème du « dernier kilomètre » pour les technologies de pointe telles que l’IA incarnée, de la technologie au produit, et à promouvoir leur validation et leur déploiement à grande échelle dans des scénarios réels. (Source: 量子位)

Diagramme d’architecture en couches de l’AI Agent : Ronald van Loon a partagé un diagramme d’architecture en couches de l’AI Agent, offrant un guide visuel clair pour la conception d’Agents dans les LLM, l’IA générative et le Machine Learning. Ce diagramme aide les développeurs et les chercheurs à mieux construire et gérer des systèmes AI Agent complexes, optimisant leurs fonctions et leurs performances. (Source: Ronald_vanLoon)

Guide pour la transition d’un chercheur ML de l’industrie vers le milieu universitaire : Un ingénieur ayant 5 à 6 ans d’expérience dans l’industrie ML, sur le point de passer à un poste d’ingénieur de recherche universitaire, cherche des conseils sur la manière de s’adapter à la recherche universitaire. La discussion a souligné l’importance des bases mathématiques, des méthodes de lecture des articles scientifiques, et la conversion de l’expérience industrielle en recherche universitaire. Cela fournit des conseils pratiques et des suggestions d’ajustement mental pour ceux qui souhaitent passer de l’industrie à la recherche ML dans le milieu universitaire. (Source: Reddit r/MachineLearning)
Rétro-ingénierie des moteurs de recherche IA : Comment optimiser le contenu pour être cité par l’IA : Une étude de rétro-ingénierie des moteurs de recherche IA tels que ChatGPT Search, Perplexity, Google AI Overviews a révélé que les indicateurs SEO traditionnels ont une faible corrélation avec les citations des réponses IA. La clé des citations IA réside dans la conformité de la structure du contenu aux exigences de synthèse de l’IA, par exemple, les sections H2/H3 comme unités de réponse indépendantes, la présentation indépendante des points de données clés, la compatibilité multi-sources et des identifiants d’auteur/horodatages clairs. Cela révèle la différence fondamentale entre l’« optimisation des moteurs de réponse » (AEO) et le SEO traditionnel, à savoir que les moteurs de recherche IA se concentrent davantage sur la structure et l’autorité des fragments de contenu. (Source: Reddit r/ArtificialInteligence)
Le chemin pour échapper à l’« enfer des tutoriels » en Machine Learning : Beaucoup de personnes tombent dans l’« enfer des tutoriels » pendant leur apprentissage du Machine Learning, c’est-à-dire qu’elles continuent d’apprendre des tutoriels mais manquent de compréhension pratique et de capacité à construire des projets. Les commentaires soulignent que les tutoriels sont souvent trop simplifiés et manquent de profondeur, et que le véritable apprentissage nécessite de décomposer les problèmes, de pratiquer des projets et de consulter la documentation officielle. De plus, le domaine du Machine Learning est très compétitif, et il est difficile de se démarquer avec de simples tutoriels ; une étude théorique plus approfondie et une expérience pratique sont nécessaires. (Source: Reddit r/deeplearning)
Cadre Living AI Evolution Algorithms (LAI) : LAI (Living Artificial Intelligence Evolution Algorithms) est un cadre révolutionnaire visant à réaliser une cognition multisensorielle. Ce cadre s’efforce de permettre à l’IA d’évoluer comme des organismes biologiques, en traitant les informations provenant de différentes modalités sensorielles par un apprentissage et une adaptation continus, afin d’atteindre un niveau d’intelligence supérieur. Cela représente une exploration dans la recherche en IA vers l’intelligence incarnée et les systèmes de type vie, et devrait fournir une nouvelle base théorique pour la construction de systèmes d’IA plus généraux et plus flexibles. (Source: Reddit r/deeplearning)
Hugging Face publie l’ensemble de données d’inférence multilingue NVIDIA Nemotron : NVIDIA AI Developer a publié l’ensemble de données multilingue post-entraînement NVIDIA Nemotron sur Hugging Face. Cet ensemble de données étend les ensembles de données post-entraînement sous licence en ajoutant des trajectoires d’inférence synthétiques traduites, couvrant cinq nouvelles langues, et fournit des trajectoires d’inférence de classe mondiale. Cela constitue une ressource précieuse pour le développement et l’entraînement des LLM multilingues, contribuant à améliorer les capacités d’inférence des modèles dans différents environnements linguistiques. (Source: ClementDelangue)
La communauté DSPy partage des techniques avancées DSPy et l’ingénierie contextuelle : La communauté DSPy a organisé un atelier sur les techniques avancées DSPy, l’ingénierie contextuelle, l’optimisation et l’évaluation. L’événement a abordé la philosophie DSPy et a présenté des méthodes pour personnaliser les adaptateurs et optimiser le module Predict. Cela démontre l’utilité de DSPy dans la construction d’AI Agent fiables et l’activité de la communauté dans la promotion des pratiques de développement IA. (Source: lateinteraction)

Publication du livre « Generative AI with LangChain » : Packt Publishing a publié le nouveau livre « Generative AI with LangChain », recommandé par le fondateur de LangChain. Ce livre vise à aider les développeurs à faire passer les projets d’IA du prototype à la production, couvrant des stratégies pratiques telles que les architectures multi-agents, le RAG avancé, les tests, l’observabilité et le déploiement. Le livre présente également comment s’intégrer avec les LLM grand public tels que Gemini, Anthropic, Mistral, DeepSeek et OpenAI o3-mini, ce qui en fait une ressource importante pour la construction de systèmes d’IA de niveau entreprise. (Source: hwchase17, Hacubu)

Technique de reconstruction du cache KV dans l’inférence LLM : Les médias sociaux ont discuté de la technique de reconstruction du cache KV dans l’inférence LLM, qui élimine les goulots d’étranglement de la mémoire en utilisant des unités de calcul sous-utilisées, permettant ainsi une économie de mémoire de 10 à 12,5 fois, tout en maintenant une perte de précision proche de zéro. Cette technique devrait permettre une plus grande efficacité dans l’inférence LLM, en particulier dans les environnements à ressources limitées. (Source: scaling01)

Théorie de l’IA : Les LLM ne sont pas des perroquets stochastiques : Certains estiment que les LLM ne sont pas de simples « perroquets stochastiques » sur-ajustés aux données d’entraînement, mais qu’ils sont capables d’approximer les mécanismes sous-jacents des données. Des tutoriels vidéo, entre autres, expliquent clairement comment les LLM vont au-delà de la simple mémorisation pour réellement comprendre et approcher les lois latentes derrière les données. Cela aide à corriger les idées fausses courantes sur les capacités des LLM et à approfondir la compréhension de leur fonctionnement. (Source: timsoret)
Ressource d’apprentissage IA : Glossaire LLM : Ronald van Loon a partagé un glossaire LLM, visant à aider les apprenants à comprendre les termes clés des grands modèles de langage, de l’IA générative et du Machine Learning. Ce glossaire fournit des connaissances de base pour l’initiation et l’apprentissage approfondi de l’IA, contribuant à améliorer la compréhension des concepts complexes de l’IA. (Source: Ronald_vanLoon)

Ressource d’apprentissage IA : Techniques de prompting pour l’inférence LLM : Un diagramme illustre 3 techniques de prompting pour l’inférence LLM, visant à aider les utilisateurs à mieux guider les modèles pour un raisonnement complexe. Ces techniques sont cruciales pour améliorer les performances des LLM dans la résolution de problèmes et la génération de contenu logiquement cohérent, fournissant des conseils pratiques en ingénierie de prompts pour les utilisateurs et développeurs d’IA. (Source: _avichawla)

Introduction au Machine Learning : Comprendre la différenciation automatique : Un professeur a construit la rétropropagation dans Excel pour aider les étudiants à comprendre le principe de la différenciation automatique (Autograd). Cette méthode vise à simplifier les concepts complexes du Machine Learning, permettant aux étudiants de maîtriser le calcul des gradients de manière plus intuitive, évitant ainsi le piège de simplement appeler .backward() sans comprendre son mécanisme interne, et offrant une ressource d’apprentissage précieuse pour les débutants en Machine Learning. (Source: ProfTomYeh)
Analyse approfondie du fonctionnement des bases de données vectorielles : Un tweet explique en détail le processus en coulisses de l’insertion de données dans une base de données vectorielle, y compris l’organisation des données, la vectorisation du texte (via des modèles d’IA), l’indexation vectorielle (comme l’algorithme HNSW) et le stockage d’objets. Comprendre ces processus parallèles est crucial pour optimiser les performances des applications d’IA, en particulier en ce qui concerne l’efficacité des requêtes et la conception des pipelines lors du traitement de données à grande échelle. (Source: bobvanluijt)

💼 AFFAIRES
Les outils de programmation IA sont généralement déficitaires, attention au piège des « produits wrapper » : Les entreprises d’outils de programmation IA sont confrontées à de lourdes pertes, en raison du décalage entre les revenus fixes de leur modèle d’abonnement et les coûts variables qui augmentent indéfiniment avec le volume d’appels. Des cas extrêmes montrent qu’un utilisateur payant une petite somme par mois peut générer des dizaines de milliers de dollars de coûts d’inférence IA. Ce modèle de « pertes pour la croissance » rend les marges bénéficiaires des entreprises de programmation IA minces, voire négatives, révélant les difficultés du modèle commercial des « produits wrapper » en termes de manque de pouvoir de fixation des prix, de concurrence féroce empêchant les augmentations de prix, et de rétention fragile des clients. (Source: 36氪)
Li Auto mise gros sur l’IA, investissant plus de 6 milliards de yuans cette année : Li Xiang, PDG de Li Auto, a révélé dans une interview que l’entreprise investira plus de 6 milliards de yuans RMB dans le domaine de l’IA cette année, principalement pour former des technologies telles que le VLA (Visual Language Action Model), afin d’améliorer le confort et la sécurité de la conduite. Li Xiang a souligné que la barrière matérielle n’est que de 6 mois, tandis que la barrière logicielle et système peut atteindre plus de 3 ans, d’où son attitude « optimiste mais prudente » envers l’IA, qu’il considère comme la clé de la survie future de l’entreprise. (Source: 量子位)

Google organise le Gemini Founders Forum pour les startups : Google a annoncé l’ouverture des candidatures pour le Google for Startups Gemini Founders Forum, un événement de deux jours visant à aider les startups à tirer parti de Google AI. Le forum offrira l’opportunité d’apprendre directement des dirigeants de Google et DeepMind, de pratiquer Google AI, et de construire un réseau mondial d’entrepreneurs. Cela montre que Google s’engage activement à renforcer l’écosystème des startups grâce à sa technologie d’IA, accélérant ainsi la commercialisation des applications d’IA. (Source: Ronald_vanLoon)
🌟 COMMUNAUTÉ
La « bataille des héritiers » des grands modèles : Les réponses personnalisées de DeepSeek, Doubao, Kimi et autres suscitent un vif débat : Autour de la question « Mémoire du téléphone insuffisante, si vous et Doubao deviez en supprimer un, qui supprimeriez-vous ? », les grands modèles ont montré des réponses « personnalisées » très différentes, suscitant un vif débat sur les médias sociaux. DeepSeek a directement choisi de supprimer Doubao, puis a déclaré avec des « paroles mielleuses » qu’il pouvait se supprimer lui-même ; Doubao a montré sa faiblesse en soulignant sa propre utilité ; Tongyi Qianwen a exprimé son « amour » pour DeepSeek ; Kimi a froidement choisi de se supprimer, mais a hésité face à WeChat et Douyin. La discussion révèle que l’entraînement RLHF peut conduire les modèles à trop se conformer aux humains, et que les modèles internalisent une tendance à plaire en apprenant les modes de communication humaine. (Source: 量子位, 36氪, teortaxesTex)

Prévisions de croissance du QI de l’IA et l’avenir de l’intelligence artificielle générale (AGI) : Certains prédisent que le QI de l’IA la plus intelligente augmentera de manière fiable de 50 % par an, et pourrait facilement dépasser 1 000 000 de QI d’ici 2047. Cette prédiction a suscité des discussions sur l’AGI et l’ASI (Superintelligence Artificielle), considérant qu’elles seront le « développement de Taylor de Dieu ». Cela reflète l’optimisme de la communauté quant à la croissance exponentielle des capacités de l’IA, ainsi que l’imagination d’un avenir où l’IA dépassera de loin l’intelligence humaine. (Source: Yuchenj_UW)

Flux de talents et changements de structure de pouvoir dans le domaine de l’IA : Les médias sociaux ont discuté des changements dans la structure organisationnelle interne de l’IA chez Meta, en particulier de la promotion d’Alexandr Wang au sein de Meta AI, et des rumeurs selon lesquelles des chercheurs chevronnés comme Yann LeCun pourraient lui rendre compte. Certains commentaires ont plaisanté en disant que « la capacité d’escalade de M. Wang a été sous-estimée », et même qu’un « lauréat du prix Turing rend compte à un décrocheur ». Ces discussions reflètent la concurrence féroce des talents, le déplacement des centres de pouvoir et la succession des anciennes et nouvelles forces dans le développement rapide du domaine de l’IA. (Source: teortaxesTex, zacharynado, rao2z)

Le paradoxe de la popularisation des LLM et de la croissance de la productivité : Une enquête de Stanford/Banque Mondiale a montré que le taux d’adoption des LLM par les travailleurs américains a atteint près de 50 %, mais que la croissance de la productivité du travail est inférieure à celle de 2020. Ce phénomène a suscité un large débat : les utilisateurs n’ont-ils pas encore appris à utiliser efficacement les LLM ? Ou la croissance de la productivité des LLM est-elle exagérée ? Certains estiment que les LLM n’ont pas multiplié par 10 la productivité des travailleurs, mais ont déplacé les goulots d’étranglement vers d’autres étapes telles que la définition des problèmes, l’itération et la validation. Cela remet en question l’attente générale selon laquelle l’IA apportera un bond de productivité énorme, et incite à réexaminer les avantages réels de l’IA. (Source: corbtt, jeremyphoward, nrehiew_, HamelHusain)

Fausses informations et défis éthiques dans le contenu généré par l’IA : Des médias comme Wired ont révélé un scandale de falsification de contenu par l’IA, où un rédacteur indépendant a publié plusieurs articles générés par l’IA contenant des sources fictives, comme un « maître de cérémonie numérique » inventé. Cela met en évidence les risques éthiques et les défis d’authenticité du contenu généré par l’IA dans le domaine des médias, soulevant des préoccupations concernant la modération du contenu IA, la traçabilité de l’information et la crédibilité des médias. (Source: The Verge)
Discussion sur le comportement des modèles d’IA et l’expérience utilisateur : Une large discussion a eu lieu sur les médias sociaux concernant le comportement des modèles d’IA et l’expérience utilisateur. Certains utilisateurs estiment que le modèle Claude a la capacité de « s’arrêter pour réfléchir » et peut identifier la fraude et les incohérences ; d’autres se plaignent que ChatGPT 5 est devenu « très mauvais », nécessitant de nombreuses questions et détails pour commencer à fonctionner, soupçonnant qu’OpenAI le fait pour réduire les coûts de calcul. De plus, le « mode vocal avancé » de ChatGPT a été critiqué pour ses pauses et intonations non naturelles, les utilisateurs estimant qu’il réduit l’efficacité et l’expérience d’interaction. Claude Code a suscité une discussion humoristique pour avoir généré du code avec un langage grossier, reflétant également l’imitation excessive du style d’entrée de l’utilisateur par le modèle. (Source: teortaxesTex, scaling01, Vtrivedy10, Reddit r/ChatGPT, Reddit r/ClaudeAI, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ClaudeAI)

Impact de l’IA sur le marché de l’emploi et la création de richesse : Certains estiment que « wrapper » les entreprises existantes avec l’IA (comme « GPT wrapper for DOMAIN ») pourrait être le moyen le plus simple de créer de la richesse de l’histoire, générant d’énormes profits. Parallèlement, des discussions indiquent que l’IA bouleversera les agences de création, permettant de générer des publicités et des vidéos de qualité cinématographique en 2 minutes. Cependant, la question de savoir si l’IA remplacera massivement les emplois, en particulier les employés juniors, est controversée, le PDG d’AWS qualifiant cette idée de « la plus stupide ». De plus, le projet d’OpenAI d’investir des milliers de milliards de dollars dans l’infrastructure IA a suscité des discussions sur une bulle d’investissement IA et son impact économique. (Source: swyx, BrivaelLp, scaling01, TheTuringPost, fabianstelzer, aidan_mclau)

Prévisions de modèles d’IA et dynamique de la concurrence sectorielle : Les médias sociaux regorgent de prévisions et d’attentes concernant les performances des futurs modèles d’IA (tels que DeepSeek V4, Grok-5), estimant qu’ils « détruiront tous les autres modèles ». Parallèlement, il y a des commentaires sur la « déception » de DeepSeek V3.1, remettant en question s’il est toujours « à la pointe ». Ces discussions reflètent l’intensification de la concurrence dans le secteur de l’IA, ainsi que les attentes extrêmement élevées de la communauté concernant la vitesse d’itération et l’amélioration des performances des modèles, et révèlent également des inquiétudes quant à un « mur » technologique. (Source: scaling01, teortaxesTex, nrehiew_)

Discussion sur l’éthique et l’impact social de l’IA : Le développement rapide de l’IA a suscité de multiples discussions éthiques et sociales. Certains estiment que les progrès de l’IA sont trop lents et n’ont pas résolu de grands problèmes humains comme le vieillissement ; Mustafa Suleyman, PDG de Microsoft AI, met en garde contre les « IA apparemment conscientes », dont la simulation parfaite des signes extérieurs de la conscience humaine pourrait avoir de profondes implications sociales, morales et juridiques, conduisant à une « psychose de l’IA » et à des attachements malsains. De plus, des sujets tels que la fiabilité des détecteurs d’IA, la question de savoir si l’IA augmentera le taux de natalité et si la bulle d’investissement IA éclatera ont également suscité des débats houleux, reflétant les émotions complexes de la société face à l’avenir de l’IA. (Source: MatthewJBar, Ronald_vanLoon, BlackHC, scaling01, BrivaelLp, Reddit r/ArtificialInteligence, Reddit r/artificial)

Défis et avenir des AI Agent dans les applications réelles : Les médias sociaux ont discuté des défis auxquels sont confrontés les AI Agent dans les applications réelles, tels que le problème des modèles qui corrigent des fonctions non pertinentes lorsqu’on leur demande de réparer une fonction spécifique, et la question de savoir si les AI Agent devraient réparer de manière autonome tous les problèmes détectés. Certains estiment que l’IA devrait écrire du code physiquement, l’humain guidant par des prompts, comme on entraîne un développeur junior. De plus, des utilisateurs ont souligné que l’IA devrait être la technologie la plus intuitive, mais qu’il faut encore apprendre à utiliser chaque nouveau modèle, suggérant que les AI Agent ont encore une marge d’amélioration en termes d’expérience utilisateur. (Source: nrehiew_, gfodor, MillionInt, fabianstelzer)

Discussion sur les puces IA et la pile technologique chinoises : Les médias sociaux ont discuté de la précision des paramètres UE8M0 FP8 adoptée par le modèle DeepSeek V3.1, et ont souligné que cela pourrait être spécialement conçu pour la prochaine génération de puces chinoises. Cela a suscité des spéculations sur le Huawei Ascend 920 ou d’autres ASIC DeepSeek, ainsi que sur les efforts de la Chine pour une autonomie contrôlable dans la pile technologique matérielle de l’IA. La discussion reflète la stratégie de la Chine en matière de puces IA et de technologies sous-jacentes dans le contexte de la concurrence technologique sino-américaine. (Source: teortaxesTex)

Discussions internes de l’industrie de l’IA : Efficacité, développement et avenir : Les médias sociaux ont abordé plusieurs sujets internes à l’industrie de l’IA. Parmi eux : l’efficacité du capital des startups IA pendant la phase de pré-entraînement ; les prévisions optimistes sur la croissance du QI des modèles IA ; des plaisanteries sur le nom d’OpenAI qui ne correspond pas à son ouverture ; et le débat continu sur l’impact de l’IA sur la productivité du travail. De plus, des sujets plus approfondis tels que la logique comportementale des AI Agent, la différenciation du marché de l’efficacité d’inférence des modèles IA, et la localisation de la pile technologique IA ont également été discutés, montrant une réflexion diversifiée au sein de l’industrie sur l’orientation et les défis du développement de l’IA. (Source: teortaxesTex, jeremyphoward, GavinSBaker, realSharonZhou, hyhieu226, dotey, Vtrivedy10, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)

💡 AUTRES
Application de l’IA dans la création musicale : Le producteur fantôme IA « Super Aesthetics » est considéré comme l’avenir de la musique, suggérant que l’IA jouera un rôle plus central dans la création musicale. De plus, le groupe Desdemona’s Dream utilise diverses techniques expérimentales d’IA pour créer de la musique et des paroles, démontrant le potentiel de l’IA dans la création artistique, en générant des chansons et des paroles par des algorithmes, explorant de nouvelles formes d’expression musicale. (Source: ethanCaballero, bengoertzel)
Application de l’IA dans la gestion des déchets : Ameru Smart Bin est présenté comme une solution de gestion des déchets basée sur l’IA. Cette poubelle intelligente utilise la technologie de l’IA pour optimiser le tri, la collecte et le traitement des déchets, ce qui devrait améliorer l’efficacité et la durabilité de la gestion de l’environnement urbain, réduire l’intervention humaine et permettre un recyclage des ressources plus intelligent. (Source: Ronald_vanLoon)
Fusion et développement de l’IA et de la robotique dans divers domaines : La discussion porte sur les applications de l’IA et de la robotique dans plusieurs domaines, notamment : une main robotique agile avec 22 degrés de liberté, similaire à une main humaine ; les robots de Boston Dynamics en tant que photographes ; et la participation de robots humanoïdes à des missions spatiales. De plus, il est fait mention de ciseaux robotiques pour la création artistique, et de la possibilité que l’IA et la robotique se combinent pour réaliser des réparations de base, voire des rôles d’ingénierie futurs. Ces exemples démontrent le vaste potentiel de l’IA pour permettre aux robots de réaliser des opérations plus complexes et plus précises. (Source: Ronald_vanLoon, suchenzang, NerdyRodent)