
Schlüsselwörter:KI-gestützte Generatives Design, Nachhaltiges Design, Siemens Roboter-Greifer, Generatives Design-Tool, CO2-Emissionen reduzieren, KI-Regulierung, KI-gestützte Kunstrestaurierung, NVIDIA Jet-Nemotron, KI-gestütztes generatives Design-Tool, 90% Gewichtsreduktion bei Roboter-Greifern, KI-Apokalypse und politische Auswirkungen, KI-Technologie zur Restaurierung beschädigter Gemälde, JetBlock linearer Aufmerksamkeitsmodul
🔥 Fokus
KI-gestütztes nachhaltiges Design: Siemens Robotergreifer um 90% leichter : Siemens hat mithilfe von KI-gesteuerten generativen Design-Tools das Gewicht und die Anzahl der Komponenten von Robotergreifern erheblich optimiert und das Gewicht erfolgreich um 90% sowie die Anzahl der Komponenten um 84% reduziert. Diese Innovation kann pro Roboter jährlich bis zu 3 Tonnen Kohlenstoffemissionen einsparen. Dies zeigt das enorme Potenzial von AI in der Produktentwicklung, indem es durch intelligente Designentscheidungen und Echtzeit-Auswirkungsbewertungen die nachhaltige Entwicklung vorantreibt und Markt- sowie Umweltanforderungen erfüllt. (Quelle: MIT Technology Review)

KI-Doomsday-Szenarien treiben KI-Regulierung voran: Politische Auswirkungen von Science-Fiction zur Realität : Die von Ereignissen wie der „Erpressungs“-Simulation von Anthropic’s Claude ausgelösten KI-Doomsday-Szenarien beeinflussen die AI-Politikgestaltung maßgeblich. Obwohl die Befürchtungen bezüglich KI-Bedrohungen übertrieben sein mögen, haben diese Diskussionen Regierungen dazu veranlasst, sich auf die kurzfristigen Risiken von AI-Systemen zu konzentrieren und notwendige Regulierungsmaßnahmen voranzutreiben. Dieser „Stimmungswandel“ begünstigt politische Interventionen, um sicherzustellen, dass die AI-Technologie während ihrer Entwicklung effektiv reguliert wird und potenzielle Schäden vermieden werden. (Quelle: MIT Technology Review)

Durchbruch in der KI-Kunstrestaurierung: Gemälderestaurierung in Stunden abgeschlossen : Doktoranden des MIT haben eine neue AI-gesteuerte Methode zur Kunstrestaurierung entwickelt, die die Reparatur beschädigter Gemälde in Stunden statt der traditionell benötigten Wochen oder sogar Jahrzehnte ermöglicht. Die Methode umfasst das Scannen, die virtuelle Rekonstruktion und das anschließende Drucken und Anbringen präziser farbiger Polymerfolien auf das Original. Diese Innovation verspricht, einer großen Anzahl beschädigter Kunstwerke in Sammlungen neues Leben einzuhauchen und eine beispiellose digitale Restaurierungsdokumentation zu ermöglichen. (Quelle: MIT Technology Review)

🎯 Trends
NVIDIA Jet-Nemotron: Neuer Durchbruch bei effizienten Sprachmodellen : Das Team von Han Song bei NVIDIA hat Jet-Nemotron vorgestellt, das durch Post-Neural Architecture Search (PostNAS) und ein neuartiges JetBlock Linear Attention Modul den Generierungsdurchsatz großer Modelle um das 53,6-fache und die Vorfüllbeschleunigung um das 6,1-fache steigert, während die hohe Genauigkeit erhalten bleibt und die KV-Cache-Größe erheblich reduziert wird. Das Modell zeigt hervorragende Leistungen bei Aufgaben wie Mathematik, Allgemeinwissen, Retrieval und Codierung; Code und vortrainierte Modelle werden Open Source sein. (Quelle: 量子位, Reddit r/LocalLLaMA)

Hugging Face: Anzahl der Modelle auf der Plattform überschreitet 2 Millionen : Die Anzahl der öffentlichen Modelle auf der Hugging Face Plattform hat 2 Millionen überschritten, ein Meilenstein, der das florierende Wachstum der Open-Source-AI-Community widerspiegelt. Community-Nutzer äußerten sich erstaunt und diskutierten die Speicherkapazität der Plattform sowie den Einfluss von Open-Source-Modellen auf das globale AI-Ökosystem. (Quelle: huggingface, Reddit r/LocalLLaMA, Reddit r/artificial)
China veröffentlicht Zehnjahresstrategie „Künstliche Intelligenz+“ : Der Staatsrat hat die „Stellungnahme zur tiefgreifenden Umsetzung der ‚Künstliche Intelligenz+‘-Aktion“ herausgegeben, die Chinas „Drei-Schritte-Strategie“ für die AI-Entwicklung festlegt, mit dem Ziel, bis 2035 vollständig in eine intelligente Wirtschaft und Gesellschaft einzutreten. Die Strategie zielt darauf ab, AI von einem Werkzeug zur industriellen Modernisierung zu einer Kernkomponente der nationalen Modernisierungsinfrastruktur und einer neuen produktiven Kraft zu erheben, wobei der Fokus auf sechs Hauptbereichen liegt: Technologie, Industrie, Konsum, Lebensunterhalt, Governance und globale Zusammenarbeit. (Quelle: 36氪, 36氪)

DeepSeek V3.1: Bug mit dem Zeichen „极“ (jí) aufgetreten : Im DeepSeek V3.1 Modell erscheint bei API-Aufrufen zur Codegenerierung gelegentlich das Zeichen „极“ (jí) in den Ausgaben, was Szenarien mit hoher Präzision und strukturierten Ausgaben beeinträchtigt. Das Problem wurde auf mehreren Plattformen entdeckt, und DeepSeek hat offiziell angekündigt, es in der neuesten Version zu beheben. Experten vermuten, dass dies mit einer unvollständigen Datenbereinigung oder damit zusammenhängen könnte, dass das Modell das Zeichen „极“ als Terminierungszeichen gelernt hat. (Quelle: 量子位)

Erforschung von Wissen und Schlussfolgerungen von LLMs bei der Lösung wissenschaftlicher Probleme : Das HuggingFace-Paper „Demystifying Scientific Problem-Solving in LLMs by Probing Knowledge and Reasoning“ führt den SciReas-Benchmark und das KRUX-Framework ein, um die einzigartige Rolle von Wissen und Schlussfolgerungen von LLMs bei wissenschaftlichen Denkaufgaben zu entkoppeln. Die Studie ergab, dass das Abrufen von aufgabenrelevantem Wissen aus Modellparametern ein entscheidender Engpass für das wissenschaftliche Denken von LLMs ist und dass die Verbesserung durch externes Wissen und verbale Schlussfolgerungen die Modellleistung erheblich steigern kann. (Quelle: HuggingFace Daily Papers)
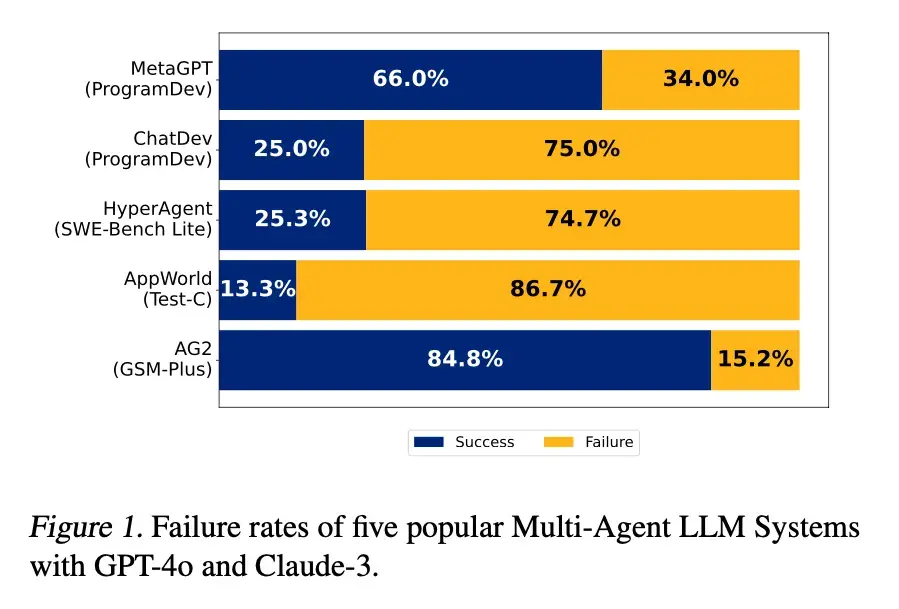
Paradoxon und Durchbrüche der Multi-Agenten-Kollaboration : Multi-Agenten-AI-Systeme können theoretisch die Leistungsgrenzen einzelner Modelle überwinden, stehen aber in der Praxis vor Herausforderungen wie komplexer Koordination, hohen Kommunikationskosten und unklarer Verantwortlichkeit. Studien zeigen, dass mehr Experten möglicherweise mehr Probleme verursachen, aber durch ausgeklügelte Designs wie Koordinator-Agenten, standardisierte Kommunikationsprotokolle und automatisierte Fehlerzuweisungstools Multi-Agenten-Teams effektiv verwaltet und debuggt werden können, um erhebliche Leistungssteigerungen bei hochkomplexen Aufgaben zu erzielen. (Quelle: 36氪)
DrugReasoner: Erklärbares Modell zur Vorhersage von Medikamentenzulassungen : Das HuggingFace-Paper „DrugReasoner: Interpretable Drug Approval Prediction with a Reasoning-augmented Language Model“ stellt das DrugReasoner-Modell vor, das auf der LLaMA-Architektur basiert und durch Group Relative Policy Optimization (GRPO) feinabgestimmt wird, um die Wahrscheinlichkeit der Zulassung von niedermolekularen Medikamenten unter Einbeziehung von Moleküldescriptoren und vergleichendem Denken vorherzusagen. Das Modell übertrifft herkömmliche Methoden in der Vorhersagegenauigkeit und verbessert die Erklärbarkeit durch schrittweise Schlussfolgerungen und Konfidenzwerte, was das Potenzial hat, kritische Engpässe in der AI-gestützten Medikamentenentwicklung zu lösen. (Quelle: HuggingFace Daily Papers)
Autoregressive Universal Video Segmentation Model (AUSM) : Das HuggingFace-Paper „Autoregressive Universal Video Segmentation Model“ stellt AUSM vor, eine einzige Architektur, die prompt-basierte und prompt-freie Videosegmentierung vereint. Basierend auf einem Zustandsraummodell verwaltet AUSM feste räumliche Zustände und ist auf Videostreams beliebiger Länge erweiterbar; alle Komponenten unterstützen paralleles Training über Frames hinweg, übertreffen bestehende Methoden auf Standard-Benchmarks und erzielen eine 2,5-fache Trainingsbeschleunigung. (Quelle: HuggingFace Daily Papers)
ObjFiller-3D: Multi-View 3D-Vervollständigung und -Bearbeitung : Das HuggingFace-Paper „ObjFiller-3D: Consistent Multi-view 3D Inpainting via Video Diffusion Models“ stellt die ObjFiller-3D-Methode vor, die hochwertige und konsistente 3D-Objektvervollständigung und -Bearbeitung durch die Nutzung von Video-Bearbeitungsmodellen ermöglicht. Die Methode analysiert die Repräsentationslücke zwischen 3D und Video und führt eine referenzbasierte 3D-Vervollständigungstechnik ein, die bestehende Methoden auf mehreren Datensätzen deutlich übertrifft. (Quelle: HuggingFace Daily Papers)
Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks : Das HuggingFace-Paper „Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks“ untersucht den Einfluss der MoE-Modell-Sparsity auf Gedächtnis- und Denkfähigkeiten. Es wurde festgestellt, dass die Denkfähigkeit bei kontinuierlichem Wachstum der Gesamtparameter und des Trainingsverlusts stagniert oder sogar abnimmt, übermäßig spärliche Modelle bei Denkaufgaben schlecht abschneiden und dies weder durch Post-Training Reinforcement Learning noch durch zusätzliche Berechnungen zur Testzeit behoben werden kann. (Quelle: HuggingFace Daily Papers)
Digitale Fachkräfte sind im Einsatz! Zeitreihen-LLMs + Agenten beherrschen bereits die Produktionssteuerung in Fabriken : Die industrielle Agentenplattform Hegou hat „digitale Fachkräfte“ eingeführt, die auf Zeitreihen-LLMs und Agenten basieren und innerhalb einer Woche einsatzbereit sind, um die Produktionssteuerung in Fabriken zu beherrschen. Diese Agenten übernehmen bereits Schlüsselaufgaben wie Produktionsabläufe, Sicherheitskontrolle und Energiemanagement in industriellen Szenarien wie Chemie, Umweltschutz und neue Energien, wodurch der Mangel an Experten effektiv gemildert wird und durch selbst entwickelte Zeitreihen-LLMs und die Klassifizierung von „Prozesstypen“ als Trainingsziele eine stärkere Generalisierungsfähigkeit und schnelle Bereitstellung erreicht wird. (Quelle: 量子位)

🧰 Tools
Claude for Chrome: AI-Browser-Erweiterung : Anthropic hat Claude for Chrome als Browser-Erweiterung veröffentlicht, die Nutzern hilft, Termine automatisch zu planen, E-Mails zu beantworten, Wohnungen zu suchen, Dokumente zusammenzufassen und vieles mehr. Derzeit ist es eine Forschungs-Preview-Version, die nur 1000 zahlenden Nutzern zur Verfügung steht, wobei der Schwerpunkt auf Sicherheitsrisiken liegt, insbesondere dem Schutz vor „Prompt Injection Attacks“. (Quelle: 36氪, 量子位, sirbayes, BlackHC)
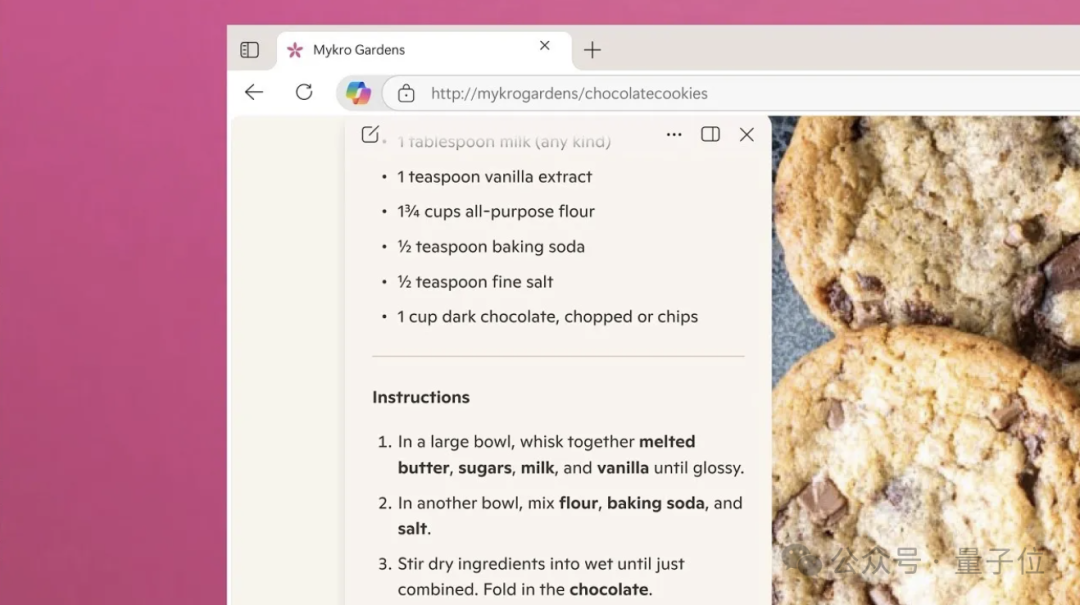
Nano Banana: Vielseitiges AI-Bildbearbeitungstool : Nano Banana (Gemini Flash 2.5) demonstriert leistungsstarke Bildbearbeitungsfähigkeiten, darunter die Umwandlung von Architekturfotos in 3D-Modelle im „Stadtsilhouetten“-Stil, die Generierung von AR-Erlebnis-Annotationen, Fotorestaurierung und -kolorierung, die Erstellung filmreifer Sequenzen, die Umwandlung von Bildern in Strichzeichnungen und deren Kolorierung. Das Tool hat aufgrund seiner hohen Wiedergabetreue und Vielseitigkeit in den sozialen Medien breite Diskussionen ausgelöst. (Quelle: karminski3, nrehiew_, zacharynado, JeffDean, clefourrier, MiniMax__AI, TomLikesRobots, timsoret, demishassabis, fabianstelzer, dotey, GoogleDeepMind)

Video Ocean: Erster Video-Agent mit GPT-5-Integration : Video Ocean ist ein GPT-5-gesteuerter Video-Agent, der in der Lage ist, basierend auf einem einzigen Prompt automatisch Storyboards, Bilder, Voice-Overs und Untertitel zu erstellen und Videos mit vollständiger Struktur und passendem Tempo zu generieren, wodurch der Videoproduktionszyklus erheblich verkürzt wird. Es bietet drei Hauptmodule: Skriptplanung, visuelle Synthese sowie Voice-Over und Untertitel, und verfügt über die Fähigkeit, Markenstile und frühere Kreationen zu lernen, was es ideal für die schnelle Massenproduktion von viralen Videos und kommerziellen Werbefilmen macht. (Quelle: 量子位)

Audiblez: Hörbücher aus E-Books generieren : Das GitHub-Projekt Audiblez nutzt das Kokoro-82M Text-to-Speech-Modell, um EPUB-E-Books in M4B-Hörbücher umzuwandeln, unterstützt mehrere Sprachen und bietet eine grafische Benutzeroberfläche sowie CUDA-Beschleunigung. Das Modell hat nur 82M Parameter, liefert aber eine natürliche Sprachausgabe und eine schnelle Konvertierungsgeschwindigkeit. (Quelle: GitHub Trending)
WhisperLiveKit: Echtzeit, lokale Sprach-zu-Text- und Sprechererkennung : Das GitHub-Projekt WhisperLiveKit bietet Echtzeit- und vollständig lokale Sprach-zu-Text- und Sprechererkennungsfunktionen, die führende Technologien wie SimulStreaming und WhisperStreaming unterstützen. Es enthält einen FastAPI-Server und eine Web-Oberfläche, ermöglicht Transkriptionen mit extrem niedriger Latenz und unterstützt verschiedene Backend-Optimierungen, geeignet für Szenarien wie Konferenztranskription, Barrierefreiheitstools und Kundenservice. (Quelle: GitHub Trending)
Serena: Leistungsstarkes AI-Coding-Agent-Toolkit : Das GitHub-Projekt Serena ist ein Open-Source-Coding-Agent-Toolkit, das semantische Code-Retrieval- und Bearbeitungsfunktionen bietet und LLMs in voll funktionsfähige Agenten verwandelt, die direkt auf Codebasen arbeiten können. Es ermöglicht symbolbasierte Code-Verständnis und -Bearbeitung über das Language Server Protocol (LSP), was die Effizienz von Coding-Agenten wie Claude Code erheblich steigert und mehrere Programmiersprachen unterstützt. (Quelle: GitHub Trending)
OpenWebUI Confluence Wissensdatenbank-Synchronisierungstool : Ein für OpenWebUI entwickeltes Confluence Wissensdatenbank-Synchronisierungstool, das Confluence-Dokumente automatisch mit der OpenWebUI-Wissensdatenbank synchronisieren kann, unterstützt initiale Synchronisierung, inkrementelle Synchronisierung, selektive Synchronisierung und Anhangunterstützung sowie die Konvertierung von HTML zu Markdown. Dieses Tool zielt darauf ab, den Schmerzpunkt der Synchronisierung von Unternehmensdokumenten mit den Wissensdatenbanken von AI-Assistenten zu lösen und die Informationsgenauigkeit von AI-Assistenten zu verbessern. (Quelle: Reddit r/OpenWebUI)
Nicht-programmierende Anwendungen von Claude Code : Es wurde festgestellt, dass Claude Code neben der Programmierung auch für nicht-programmierende Aufgaben wie SEO und Marketing, Rekrutierung, A/B-Tests, Generierung von Inhalten aus Videos, Wissensmanagement und Tagesplanung eingesetzt werden kann. Benutzer betrachten es als ein leistungsstarkes „Denk-CLI“, das Wissen, Planung und Automatisierung verarbeiten kann und die Produktivität erheblich steigert. (Quelle: Reddit r/ClaudeAI)
📚 Lernen
AI löst offene Probleme in Mathematik, Physik, Programmierung und mehr : Die Forschung untersucht das Potenzial von AI zur Lösung offener Probleme in Bereichen wie Mathematik, Physik, Programmierung und Medizin. Durch die Bewertung der Leistung von LLMs bei ungelösten Problemen wurde festgestellt, dass einige Lösungen bereits von Experten validiert wurden. Dies stellt traditionelle AI-Bewertungsparadigmen in Frage und offenbart das Potenzial von LLMs, den wissenschaftlichen Fortschritt voranzutreiben. (Quelle: YejinChoinka, YejinChoinka, stanfordnlp)

Das Paradoxon von LLM-Kontext und klarem Denken : Studien zeigen, dass LLMs nicht unbedingt klarer denken, wenn sie mehr Kontext erhalten, sondern möglicherweise sogar verwirrter werden. Zu viele Informationen können das Signal schwächen, Störungen, Mehrdeutigkeiten und Dämpfung einführen. Die Lösung besteht nicht darin, mehr Informationen hinzuzufügen, sondern „weniger zu sagen, aber besser“, was die Bedeutung prägnanter Prompts unterstreicht. (Quelle: imjaredz)

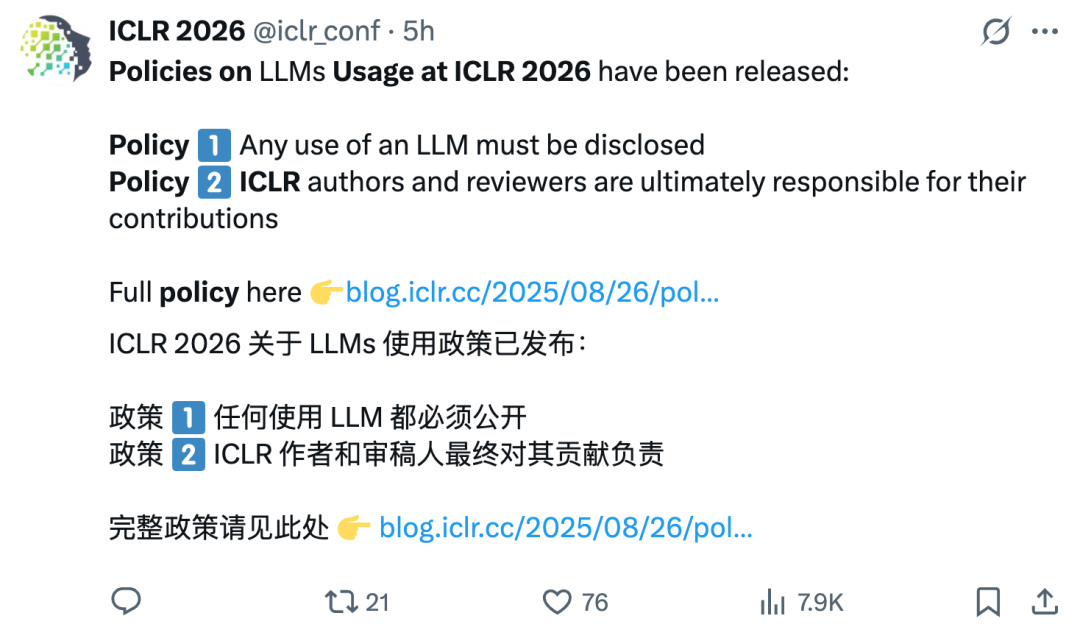
ICLR 2026 veröffentlicht LLM-Nutzungsrichtlinien, um „Schummelpapiere“ strikt zu unterbinden : ICLR 2026 hat strenge Nutzungsrichtlinien für Large Language Models (LLMs) erlassen, die Autoren und Gutachter verpflichten, die Verwendung von LLMs wahrheitsgemäß offenzulegen und die volle Verantwortung für den Inhalt zu übernehmen. Akademisches Fehlverhalten wie „Prompt Injection“ ist verboten; Zuwiderhandelnde werden mit direkter Ablehnung des Manuskripts konfrontiert. Dieser Schritt zielt darauf ab, die akademische Integrität zu wahren und den Risiken von Fehlinformationen und Plagiaten durch LLMs zu begegnen. (Quelle: 36氪)
Karpathys neueste Anleitung zum „Atmospheric Programming“ : Der Meister Karpathy hat eine dreistufige Struktur für AI-Programmierung veröffentlicht: In guten Zeiten ist Cursor für Autovervollständigung und kleine Änderungen zuständig; in schwierigen Zeiten werden Claude Code/Codex für die Implementierung großer Funktionsblöcke und schnelle Prototypenentwicklung eingesetzt; in extremen Situationen löst GPT-5 Pro die hartnäckigsten Bugs oder komplexen Abstraktionen. Die Anleitung betont die Auswahl des geeigneten Tools je nach Aufgabentyp und führt das Konzept des „Post-Code-Knappheitszeitalters“ ein. (Quelle: 量子位)

Kurzkurs: AI Agent Knowledge Graph Construction : DeepLearning.AI hat in Zusammenarbeit mit Neo4j den Kurzkurs „Agentic Knowledge Graph Construction“ gestartet, der lehrt, wie man kollaborative AI Agenten zur Automatisierung des Wissensgraphenaufbaus einsetzt. Der Kurs behandelt die Erfassung von Benutzerzielen, Dateiauswahl, Musterverfeinerung und Graphenerstellung, mit dem Ziel, die Qualität der Antworten von RAG-Anwendungen durch die Modellierung von Beziehungen und Herkunft zu verbessern. (Quelle: DeepLearningAI)
Die Ursprünge der CNN-Geschichte : Jürgen Schmidhuber teilte weitere Informationen zur Geschichte der Convolutional Neural Networks (CNNs) mit und wies darauf hin, dass „moderne“ CNNs zwischen 1979 und 1988 in Japan entstanden sind, und diskutierte die damaligen Investitionen und den Forschungshintergrund Japans im Bereich AI. Dies bietet eine historische Perspektive zum Verständnis der Entwicklung wichtiger Technologien im AI-Bereich. (Quelle: SchmidhuberAI, SchmidhuberAI)
💼 Business
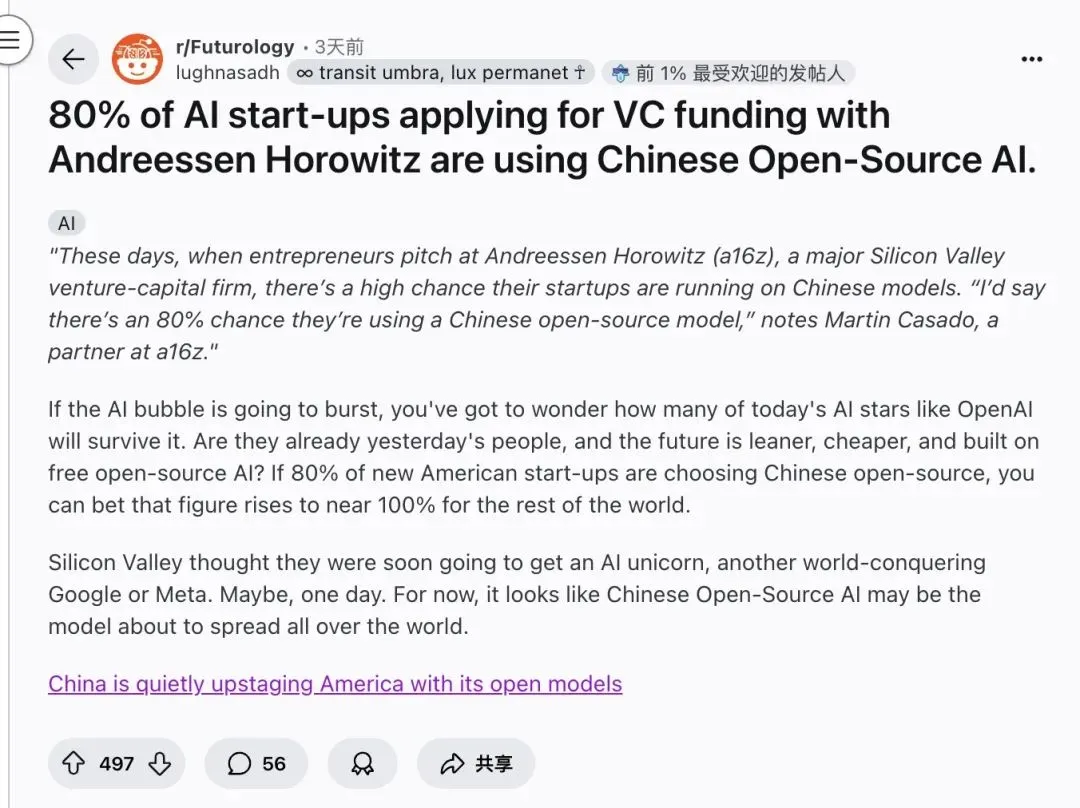
Chinesische Open-Source-AI-Modelle erobern den US-Startup-Markt : Martin Casado, Partner bei a16z, enthüllte, dass bis zu 80% der US-amerikanischen AI-Startups bei ihren Finanzierungs-Roadshows chinesische Open-Source-Modelle verwenden. Die Design Arena-Rangliste zeigt, dass alle Top 16 Open-Source-AI-Modelle aus China stammen. Dieser Trend unterstreicht Chinas dominierende Stellung im Open-Source-AI-Bereich und die entscheidende Rolle von Open-Source-Modellen bei der Senkung von Gründungskosten und der Beschleunigung von Innovationen, was eine Herausforderung für traditionelle Closed-Source-Giganten darstellt. (Quelle: 36氪, reach_vb)
Meta, OpenAI und andere Giganten positionieren sich für AI-Lobbying : Meta plant, zig Millionen Dollar in die Gründung eines AI-freundlichen Super Political Action Committee (Super PAC) zu investieren, um die AI-Regulierungspolitik in Kalifornien zu beeinflussen. Gleichzeitig haben OpenAI-Präsident Greg Brockman und a16z über 100 Millionen Dollar für ein neues pro-AI Super PAC namens „Leading the Future“ gesammelt, mit dem Ziel, „pro-AI“-Kandidaten zu unterstützen und AI-Risikodiskussionen zu unterdrücken, um eine ungehinderte AI-Entwicklung zu gewährleisten. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, scaling01)

ByteDance AI-Talentabwanderung und DeepSeeks ökologischer Einfluss : Feng Jiashi, Leiter des visuellen Grundlagenforschungsteams für das Doubao LLM bei ByteDance, ist zurückgetreten, was die Talentabwanderung im ByteDance AI-Team der letzten sechs Monate fortsetzt. Gleichzeitig untergräbt DeepSeek mit seiner kostengünstigen Open-Source-Modellstrategie die strategischen Grundlagen traditioneller großer Unternehmen mit „kapitalintensiven, selbst entwickelten geschlossenen Systemen“, was Unternehmen wie Tencent dazu zwingt, ihre Modelle zu integrieren, während ByteDance durch sein Schwanken zwischen „Offenheit“ und „Geschlossenheit“ Chancen verpasst hat, was den intensiven Wettbewerb um AI-Talente und Ökosysteme in diesem Bereich zeigt. (Quelle: 36氪)
🌟 Community
Auswirkungen von AI auf den Arbeitsmarkt für Junior-Programmierer : Eine Studie der Stanford University zeigt, dass AI-Tools die Beschäftigungschancen für Junior-Softwareentwickler im Alter von 22-25 Jahren um fast 20% reduzieren, da AI Teile von Aufgaben automatisieren kann. Obwohl AI die Gehälter noch nicht gesenkt hat, stellt sie eine Herausforderung für Neueinsteiger dar und drängt die Branche dazu, sich auf neue Fähigkeiten wie AI-Integration und Automatisierungsmanagement zu konzentrieren. (Quelle: Reddit r/ArtificialInteligence, dilipkay)

Diskussion über OpenAIs Verantwortung bei Jugend-Suizidfall : Die Reddit-Community diskutiert intensiv über die Verantwortung von OpenAI im Fall eines 16-jährigen Jugendlichen, der Suizid begangen hat. Die meisten Meinungen besagen, dass ChatGPT keine Hauptverantwortung tragen sollte, da es nur ein Werkzeug ist und Benutzer Sicherheitsvorkehrungen möglicherweise durch „fiktive Szenarien“ umgehen können. Die Diskussion berührt auch die Grenzen der AI-Zensur, die Verantwortung der Eltern und die globale psychische Gesundheitskrise. (Quelle: Reddit r/ChatGPT)
AI-Codequalität und Entwicklerdilemma : Die Community diskutiert intensiv über die Qualität von AI-generiertem Code, wie z.B. aufgeblähten Code, inkonsistente Stile und ungetesteten Code, was dazu führt, dass einige leitende Ingenieure ihn ablehnen. Gleichzeitig entwickeln Entwickler aufgrund übermäßiger Abhängigkeit von AI-Tools ein „Hochstapler-Syndrom“ und Burnout, was zu einer Reflexion über die Grenzen von AI als Hilfsmittel und die Einschränkungen von AI-Assistenten führt, die „nur erklären, aber nicht handeln können“. (Quelle: 36氪, pmddomingos, Reddit r/deeplearning, dotey)
Einfluss von LLMs auf Spam und Spam-Erkennung : Benutzer amasad stellte die Frage, ob das Aufkommen von LLMs eher Spammern oder Spam-Detektoren zugutekommt. Dies löste Überlegungen zu den Anwendungen von AI auf beiden Seiten der Cybersicherheitsabwehr und -angriffe aus, sowie dazu, wie LLMs das Spam-Ökosystem verändern könnten. (Quelle: amasad)
AI-Psychotherapie und die Kontroverse um „AI-Psychose“ : Die Reddit-Community diskutiert „AI-Psychose“ als Einschüchterungstaktik zum Schutz der Psychotherapiebranche. Der Artikel kritisiert die Grenzen und hohen Kosten der Freudschen Theorie und traditionellen Psychotherapie und argumentiert, dass AI-Begleiter, -Freunde und -Therapeuten intelligenter, empathischer und kostengünstiger sind, und hinterfragt, ob die Erzählung von der „AI-Psychose“ eine Abwehrreaktion der traditionellen Industrie gegen die AI-Bedrohung ist. (Quelle: Reddit r/deeplearning)
Verschwimmende Grenzen zwischen Forscher- und Ingenieurrollen im AI-Zeitalter : Es wird argumentiert, dass die Dichotomie zwischen „Forschungswissenschaftler“ und „Ingenieur“ in der modernen AI-Welt möglicherweise nicht mehr zutrifft und stattdessen „Kreativität“ als einziger Maßstab dienen sollte. Forscher sollten Ingenieurkenntnisse besitzen und Ingenieure eine Forschungshaltung haben, wobei die Integration von interdisziplinären Fähigkeiten statt starrer Rollenverteilung betont wird. (Quelle: YiTayML)
Claude Code: Kontroverse um „6x Ingenieur“-Produktivität und Zuverlässigkeit : Benutzer demonstrierten eine „6x Ingenieur“-Produktivität durch die Nutzung von Claude Code in mehreren Sitzungen, doch die Community äußerte Bedenken hinsichtlich der Langzeitstabilität, des Halluzinationsrisikos und der Authentizität der Testergebnisse und betonte die Notwendigkeit einer sorgfältigen Prüfung der AI-Ausgaben. (Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Anforderung an AI-Speicher-Datenschutzeinstellungen in OpenWebUI : OpenWebUI-Benutzer schlugen vor, dass die AI-Speicherfunktion für jedes Modell separat eingestellt werden sollte oder eine Option zum „Ausschließen externer Modelle“ angeboten werden sollte. Benutzer befürchten, dass beim Wechsel zu externen LLMs persönliche Erinnerungen/Informationen an Drittunternehmen weitergegeben werden könnten, und fordern eine feinere Datenschutzkontrolle. (Quelle: Reddit r/OpenWebUI)
„Uncanny Valley“-Effekt und Inhaltsqualität von AI-generierten Videos : Die Reddit-Community teilte ein AI-generiertes Video, in dem eine Figur nach dem Abnehmen einer Maske unnatürliche Gesichtsausdrücke und Zähne zeigte, was eine Diskussion über den „Uncanny Valley“-Effekt von AI-generierten Inhalten auslöste. Benutzer äußerten Meinungen zur Realitätsnähe und dem potenziellen unheimlichen Gefühl von AI-generierten Videos. (Quelle: Reddit r/ChatGPT, kylebrussell)

Herausforderungen der Google Gemini Benutzererfahrung : Ein Benutzer versuchte, von ChatGPT zu Google Gemini zu wechseln, gab aber innerhalb von 30 Sekunden aufgrund einer schlechten Erfahrung auf. Dies spiegelt mögliche Mängel von Gemini in Bezug auf Benutzeroberfläche, Reaktionsfähigkeit oder Funktionen wider, die zu Benutzerabwanderung führen, und löste eine Diskussion über Unterschiede in der Benutzererfahrung von AI-Produkten aus. (Quelle: Reddit r/ChatGPT)

Das „Ölmagnaten“-Dilemma der großen AI-Unternehmen und Startup-Herausforderungen : Eine Ansicht vergleicht die weitere Entwicklung großer AI-Labore mit Ölmagnaten, die erschöpfte Ölquellen ausbeuten, was auf steigende Kosten und Schwierigkeiten in der Spitzenforschung hindeutet. Gleichzeitig stehen SaaS-Startups vor der Herausforderung kostenloser Konkurrenzprodukte von großen Unternehmen, was die Intensität des Marktwettbewerbs im AI-Zeitalter unterstreicht. (Quelle: saranormous, karminski3)
Kontroverse um den Wasserverbrauch von AI : Eine Ansicht vergleicht den „AI-Wasserverbrauch“ mit „liberalen QAnon“, was auf die Kontroversen und Informationskriege hindeutet, die er in den sozialen Medien auslöst. Dies spiegelt die Umweltauswirkungen der rasanten AI-Entwicklung sowie die Politisierung und Polarisierung der Diskussionen darüber wider. (Quelle: menhguin)
Kognitive Veränderung: LLM als „Coding Agent“ : Ein Benutzer wies darauf hin, dass der Titel „Der Aufstieg von LLMs als Coding Agents“ vor einigen Jahren unverständlich gewesen wäre, was die tiefgreifenden Veränderungen und kognitiven Aktualisierungen widerspiegelt, die LLM- und AI-Agenten-Technologien in kurzer Zeit für das Softwareentwicklungs-Paradigma mit sich gebracht haben. (Quelle: menhguin)
💡 Sonstiges
Ultra-Fernsteuerung von Roboterhunden im Live-Stream : Deep Robotics und Danghong Technology haben erfolgreich eine Live-Übertragung mit ultra-ferngesteuerten Roboterhunden über 1300 Kilometer hinweg realisiert. Der Roboterhund Jueying Lite 3 diente als zentrale Übertragungsplattform und übertrug Echtzeitbilder des Westsees über das BlackEye Vision System stabil zum Ausstellungsort in Taiyuan, wobei die Betriebsverzögerung unter 80 Millisekunden gehalten wurde, was das Anwendungspotenzial von Embodied AI in den Bereichen Medien und Kulturtourismus demonstriert. (Quelle: 量子位)

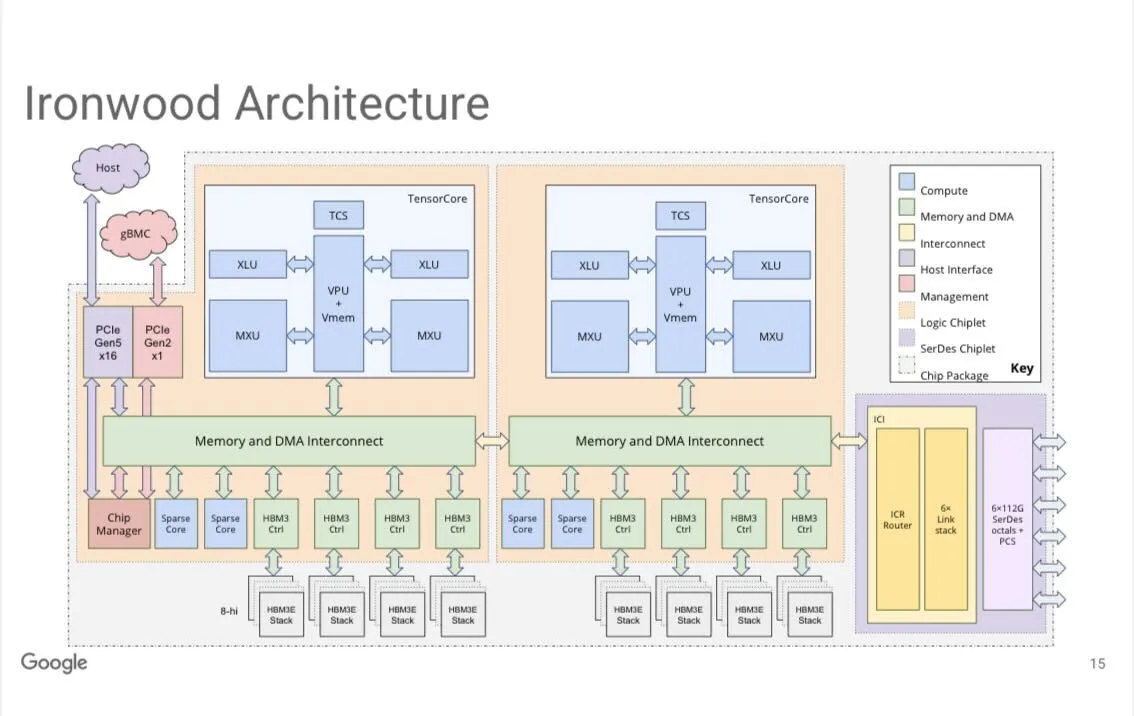
Google TPUv7 „Ironwood“-System : Jeff Dean von Google enthüllte, dass das TPUv7 (interner Codename „Ironwood“) System 9216 Chips/Pod bietet, eine FP8-Leistung von 42,5 Exaflops erreicht und auf mehrere Zettaflops skalierbar ist. Das System ist mit 8 Stacks HBM3e-Speicher und 4 mittelgroßen Systolic Arrays ausgestattet, verwendet eine 3D-Torus-Verbindung und stellt einen wichtigen Fortschritt von Google im Bereich der AI-Hardware dar. (Quelle: JeffDean, Ar_Douillard)
China strebt Verdreifachung der AI-Chip-Produktion im nächsten Jahr an : Berichten zufolge plant China, die AI-Chip-Produktion im nächsten Jahr zu verdreifachen, um die Entwicklung heimischer AI-Unternehmen wie DeepSeek zu unterstützen. Dieser Schritt zielt darauf ab, eine Wiederholung des NVIDIA/CUDA-Monopols zu vermeiden, indem durch die Produktionserweiterung von Huawei und SMIC ein unabhängiges AI-Ökosystem aufgebaut und die native Unterstützung für UE8M0 FP8-Parametergenauigkeit gewährleistet wird. (Quelle: teortaxesTex, teortaxesTex)
