
Ключевые слова:ИИ с расширенными возможностями, Устойчивый дизайн, Роботизированный захват Siemens, Генеративные инструменты проектирования, Снижение выбросов углерода, Регулирование ИИ, Реставрация произведений искусства с помощью ИИ, NVIDIA Jet-Nemotron, Генеративные инструменты проектирования на базе ИИ, 90% снижение веса роботизированного захвата, Теория гибели ИИ и влияние на политику, Технология восстановления поврежденных картин с помощью ИИ, JetBlock модуль линейного внимания
🔥 В центре внимания
AI расширяет возможности устойчивого дизайна: захват Siemens для роботов снижен на 90% : Siemens использовала инструменты генеративного дизайна на основе AI для значительной оптимизации веса и количества компонентов захвата робота, успешно сократив его вес на 90% и количество компонентов на 84%. Эта инновация позволяет экономить до 3 тонн выбросов углерода на каждого робота ежегодно. Это демонстрирует огромный потенциал AI в разработке продуктов, способствуя устойчивому развитию за счет интеллектуального выбора дизайна и оценки воздействия в реальном времени, удовлетворяя рыночные и экологические потребности. (Источник: MIT Technology Review)

Апокалиптические прогнозы AI стимулируют регулирование AI: влияние политики от научной фантастики до реальности : Апокалиптические прогнозы AI, вызванные такими событиями, как симуляция “вымогательства” Claude от Anthropic, глубоко влияют на формирование политики в области AI. Хотя опасения по поводу угроз AI могут быть преувеличены, эти дискуссии побуждают правительства уделять внимание ближайшим рискам систем AI, способствуя принятию необходимых мер регулирования. Этот “сдвиг в настроениях” способствует политическому вмешательству, обеспечивая эффективное регулирование технологии AI в процессе ее развития, чтобы избежать потенциального вреда. (Источник: MIT Technology Review)

Прорыв в реставрации искусства с помощью AI: восстановление картин за считанные часы : Аспиранты Массачусетского технологического института разработали новый метод реставрации поврежденных картин с использованием AI, который позволяет завершить процесс за считанные часы, что значительно быстрее традиционных методов, требующих недель или даже десятилетий. Метод включает сканирование, виртуальную реконструкцию, а затем печать и прикрепление точной цветной полимерной пленки к оригиналу. Эта инновация обещает дать новую жизнь большому количеству поврежденных произведений искусства в музейных коллекциях и предоставить беспрецедентную цифровую запись реставрации. (Источник: MIT Technology Review)

🎯 Тенденции
NVIDIA Jet-Nemotron: новый прорыв в эффективных языковых моделях : Команда Сун Хана из NVIDIA представила Jet-Nemotron, который за счет PostNAS (Post Neural Architecture Search) и нового линейного модуля внимания JetBlock, при сохранении высокой точности, увеличивает пропускную способность генерации больших моделей в 53,6 раза, ускоряет предварительное заполнение в 6,1 раза и значительно сокращает размер KV cache. Модель демонстрирует отличные результаты в задачах по математике, здравому смыслу, поиску, кодированию и других, а ее код и предварительно обученные модели будут открыты. (Источник: 量子位, Reddit r/LocalLLaMA)

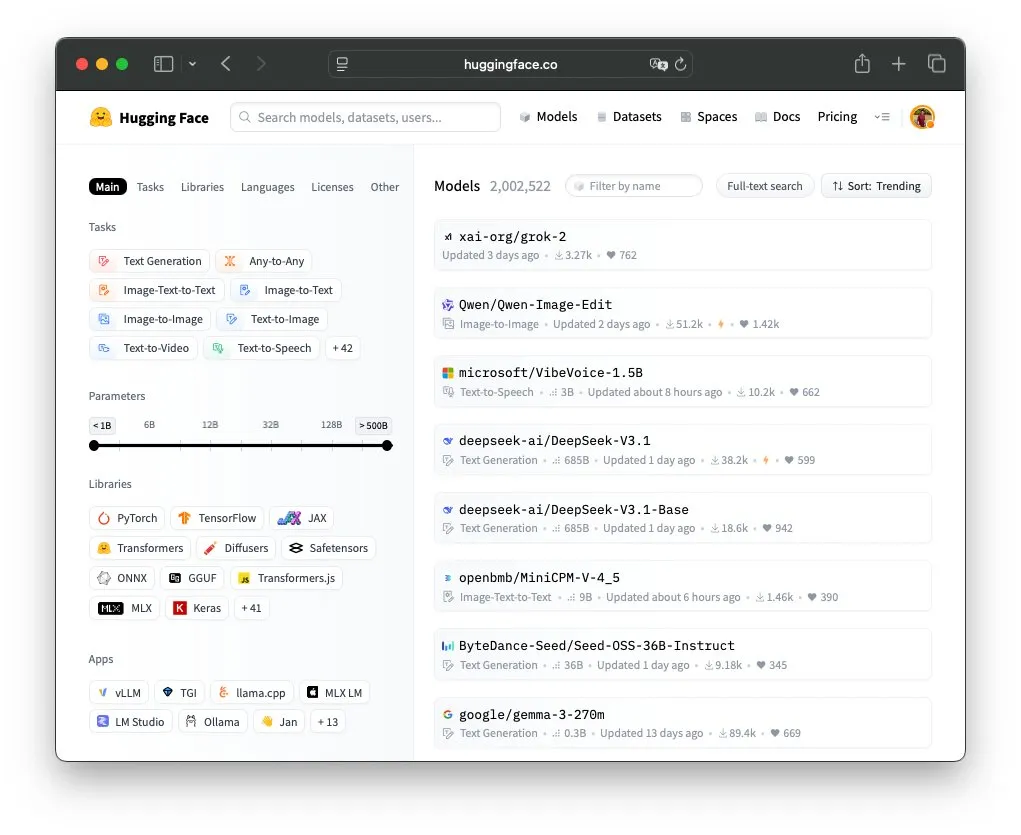
Количество моделей на платформе Hugging Face превысило 2 миллиона : Количество публичных моделей на платформе Hugging Face превысило 2 миллиона. Это знаковое событие отражает бурное развитие и быстрый рост сообщества открытого AI. Пользователи сообщества выражают удивление и обсуждают емкость хранилища платформы, а также влияние моделей с открытым исходным кодом на глобальную экосистему AI. (Источник: huggingface, Reddit r/LocalLLaMA, Reddit r/artificial)
Китай опубликовал десятилетнюю стратегию “AI+” : Государственный совет КНР выпустил “Мнения о глубокой реализации действия “AI+”“, четко определяющие стратегию развития AI в Китае в три этапа, с целью к 2035 году полностью перейти к интеллектуальной экономике и интеллектуальному обществу. Эта стратегия направлена на повышение статуса AI от инструмента промышленной модернизации до национальной инфраструктуры модернизации и ядра новой производительной силы, фокусируясь на шести основных областях: технологии, промышленность, потребление, благосостояние населения, управление и глобальное сотрудничество. (Источник: 36氪, 36氪)

В DeepSeek V3.1 обнаружен баг с символом “极” : Модель DeepSeek V3.1 при вызове API для генерации кода иногда выдает символ “极” (jí, что означает “крайний” или “полярный”) в результатах, что влияет на сценарии, требующие высокой точности и структурированного вывода. Эта проблема была обнаружена на нескольких платформах, и официальные представители DeepSeek заявили, что исправят ее в последней версии. Эксперты предполагают, что это может быть связано с неполной очисткой данных или тем, что модель изучила символ “极” как признак окончания. (Источник: 量子位)

Исследование знаний и рассуждений LLM в решении научных задач : Статья HuggingFace «Demystifying Scientific Problem-Solving in LLMs by Probing Knowledge and Reasoning» представляет бенчмарк SciReas и фреймворк KRUX, призванные разграничить уникальную роль знаний и рассуждений LLM в задачах научного вывода. Исследование показало, что извлечение знаний, связанных с задачей, из параметров модели является ключевым узким местом в научном рассуждении LLM, а улучшение внешних знаний и вербальных рассуждений может значительно повысить производительность модели. (Источник: HuggingFace Daily Papers)
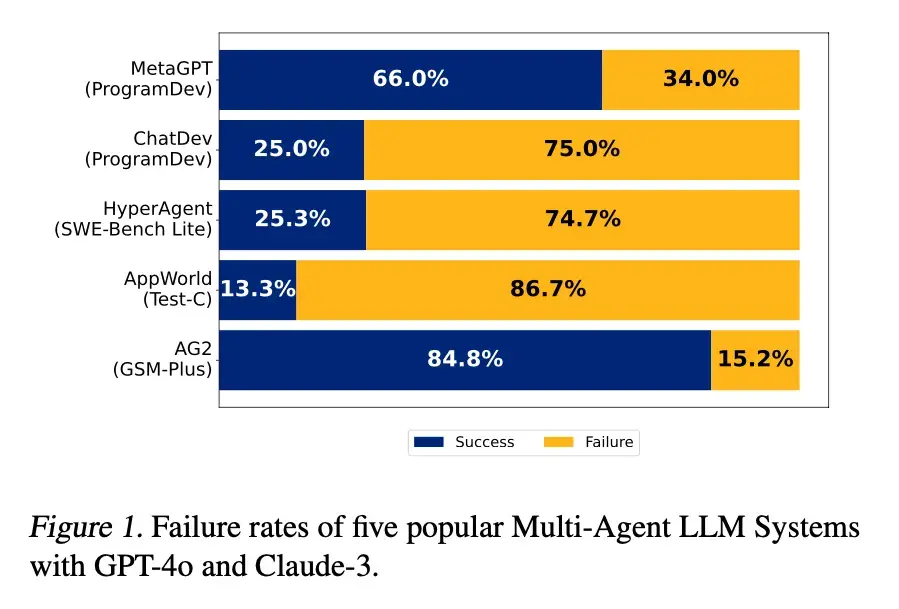
Парадокс и прорыв в многоагентном сотрудничестве : Многоагентные системы AI теоретически могут превзойти возможности одной модели, но на практике сталкиваются с проблемами, такими как сложность координации, высокие затраты на связь и размытая ответственность. Исследования показывают, что большее количество экспертов может принести больше проблем, но благодаря продуманному дизайну, такому как агенты-координаторы, стандартизированные протоколы связи и автоматизированные инструменты атрибуции сбоев, можно эффективно управлять и отлаживать многоагентные команды, что позволяет им достигать огромного прироста производительности в задачах высокой сложности. (Источник: 36氪)
Интерпретируемая модель прогнозирования одобрения лекарств DrugReasoner : Статья HuggingFace «DrugReasoner: Interpretable Drug Approval Prediction with a Reasoning-augmented Language Model» предлагает модель DrugReasoner на основе архитектуры LLaMA, тонко настроенную с помощью оптимизации относительной стратегии группы (GRPO), которая сочетает дескрипторы молекул и сравнительные рассуждения для прогнозирования вероятности одобрения низкомолекулярных лекарств. Модель превосходит традиционные методы по точности прогнозирования и повышает интерпретируемость, предоставляя пошаговые рассуждения и оценки достоверности, что обещает решить ключевые узкие места в AI-помощи при открытии лекарств. (Источник: HuggingFace Daily Papers)
Autoregressive Universal Video Segmentation Model (AUSM) : Статья HuggingFace «Autoregressive Universal Video Segmentation Model» представляет AUSM, единую архитектуру для сегментации видео как с подсказками, так и без них. Основанная на модели пространства состояний, AUSM поддерживает пространственное состояние фиксированного размера и может масштабироваться до видеопотоков произвольной длины, все компоненты поддерживают параллельное обучение между кадрами, превосходя существующие методы на стандартных бенчмарках и обеспечивая 2,5-кратное ускорение обучения. (Источник: HuggingFace Daily Papers)
ObjFiller-3D: многовидовое 3D-заполнение и редактирование : Статья HuggingFace «ObjFiller-3D: Consistent Multi-view 3D Inpainting via Video Diffusion Models» предлагает метод ObjFiller-3D, который использует модели диффузии видео для достижения высококачественного и согласованного 3D-заполнения и редактирования объектов. Метод анализирует разрыв в представлении между 3D и видео и вводит технику 3D-заполнения на основе ссылок, значительно превосходящую существующие методы на нескольких наборах данных. (Источник: HuggingFace Daily Papers)
Оптимальная разреженность языковых моделей Mixture-of-Experts для задач рассуждения : Статья HuggingFace «Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks» исследует влияние разреженности моделей MoE на способности к запоминанию и рассуждению. Обнаружено, что производительность рассуждений насыщается или даже снижается при постоянном росте общего количества параметров и потерь при обучении, а чрезмерно разреженные модели плохо справляются с задачами рассуждения, и пост-тренировочное обучение с подкреплением или дополнительные вычисления во время тестирования не могут компенсировать этот недостаток. (Источник: HuggingFace Daily Papers)
Цифровые технические работники уже на месте! Временные большие модели + Agent освоили технологии управления производством на заводе : Платформа промышленного AI-агента HeGu запустила “цифровых технических работников” на основе временных больших моделей и Agent, которые могут приступить к работе в течение недели, освоив технологии управления производством на заводе. Эти агенты уже выполняют ключевые задачи, такие как производственные операции, контроль безопасности и управление энергией, в промышленных сценариях, таких как химическая промышленность, защита окружающей среды и новая энергетика, эффективно решая проблему нехватки экспертов и достигая более высокой обобщающей способности и быстрого развертывания за счет самостоятельно разработанных временных больших моделей и разделения целей обучения по “типам процессов”. (Источник: 量子位)

🧰 Инструменты
Claude for Chrome: расширение AI для браузера : Anthropic выпустила Claude for Chrome в качестве расширения для браузера, которое помогает пользователям автоматически планировать расписание, отвечать на электронные письма, искать жилье, суммировать документы и многое другое. В настоящее время это исследовательская предварительная версия, доступная только 1000 платным пользователям, с основным акцентом на защиту от рисков безопасности, особенно от “атак с внедрением подсказок”. (Источник: 36氪, 量子位, sirbayes, BlackHC)
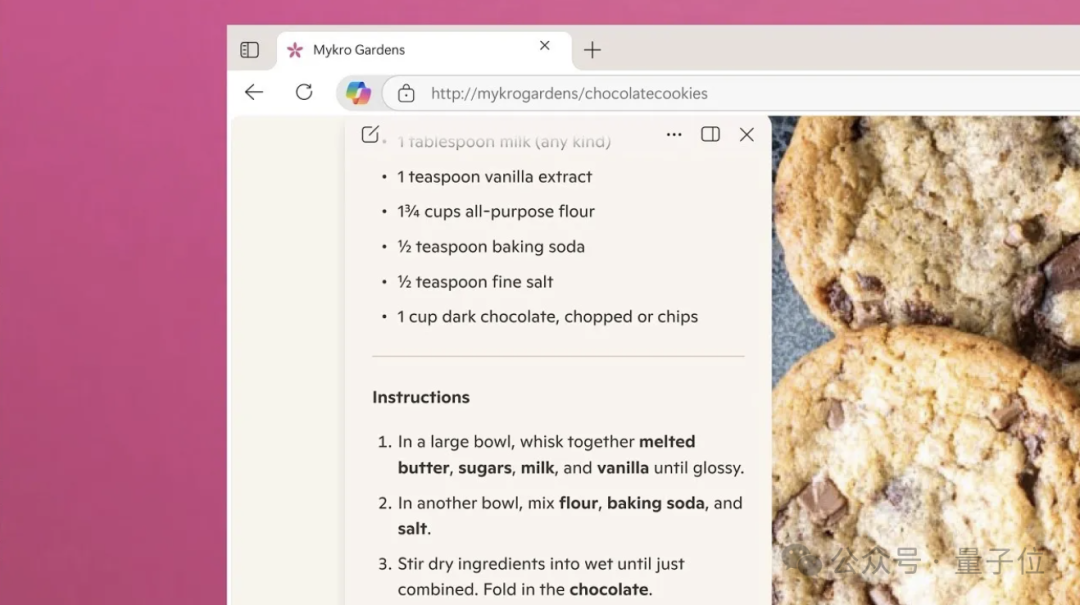
Nano Banana: многофункциональный инструмент для редактирования изображений с AI : Nano Banana (Gemini Flash 2.5) продемонстрировал мощные возможности редактирования изображений, включая преобразование фотографий зданий в 3D-модели в стиле “городского пейзажа”, генерацию аннотаций для AR-опыта, реставрацию и раскрашивание фотографий, создание кинематографических последовательностей, преобразование изображений в линейные рисунки с последующей раскраской и многое другое. Инструмент вызвал широкое обсуждение в социальных сетях благодаря своей высокой точности и многофункциональности. (Источник: karminski3, nrehiew_, zacharynado, JeffDean, clefourrier, MiniMax__AI, TomLikesRobots, timsoret, demishassabis, fabianstelzer, dotey, GoogleDeepMind)

Video Ocean: первый видео-Agent с доступом к GPT-5 : Video Ocean — это видео-Agent на базе GPT-5, способный автоматически создавать раскадровки, визуальные эффекты, озвучку и субтитры на основе одной подсказки, генерируя структурно полные и ритмичные видеоролики, что значительно сокращает цикл производства видео. Он предлагает три модуля: планирование сценария, визуальный синтез, озвучка и субтитры, а также обладает способностью изучать стиль бренда и историю создания, что подходит для быстрого массового производства вирусных видеороликов и крупномасштабной коммерческой рекламы. (Источник: 量子位)

Audiblez: создание аудиокниг из электронных книг : Проект GitHub Audiblez использует модель преобразования текста в речь Kokoro-82M для преобразования электронных книг в формате epub в аудиокниги m4b, поддерживает несколько языков и предлагает графический интерфейс и ускорение CUDA. Модель имеет всего 82M параметров, но обеспечивает естественный голосовой вывод и быструю скорость преобразования. (Источник: GitHub Trending)
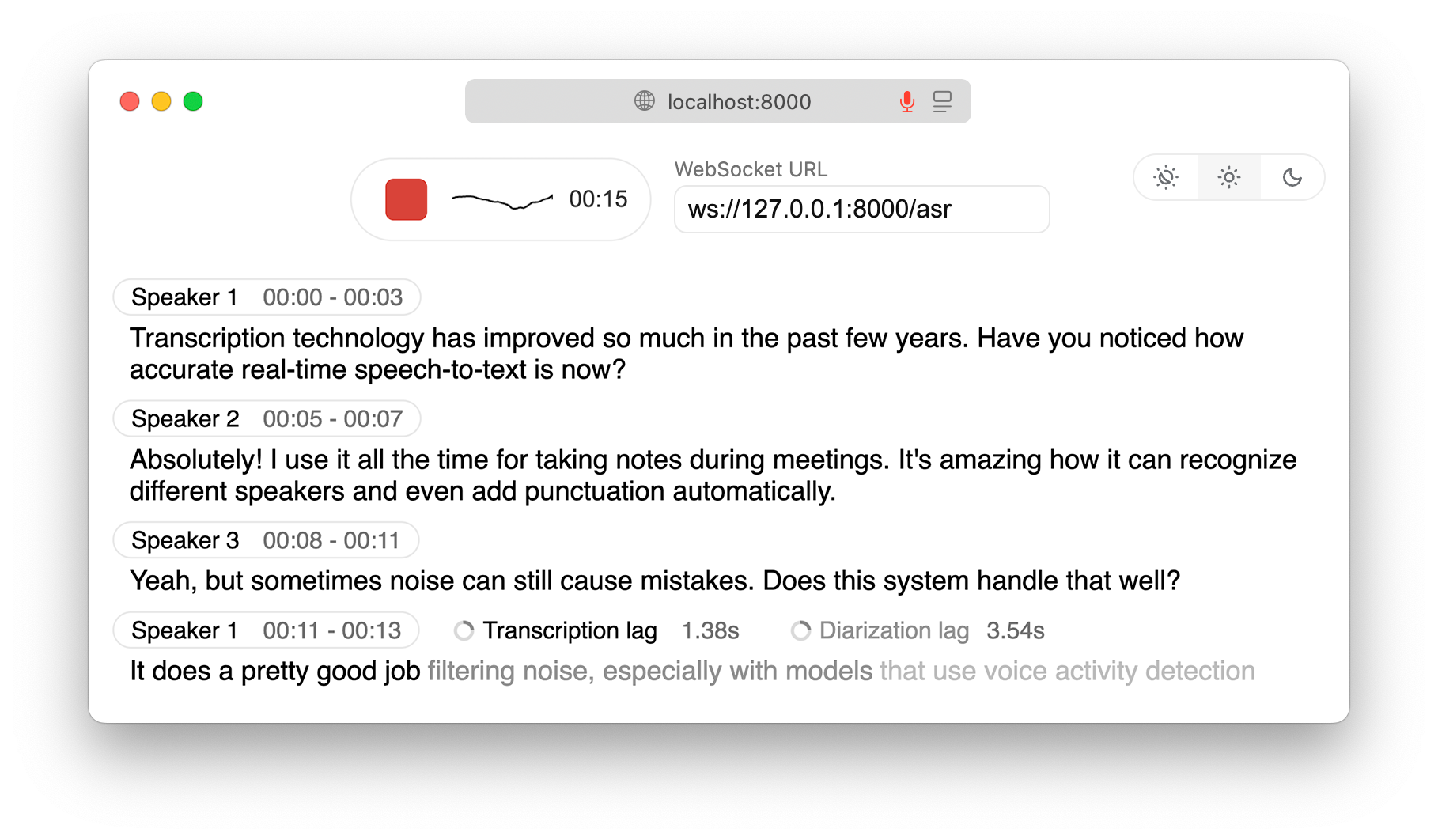
WhisperLiveKit: распознавание речи в текст и идентификация говорящего в реальном времени локально : Проект GitHub WhisperLiveKit предоставляет функции распознавания речи в текст и идентификации говорящего в реальном времени, полностью локально, поддерживая передовые технологии, такие как SimulStreaming и WhisperStreaming. Он включает сервер FastAPI и веб-интерфейс, обеспечивая транскрипцию со сверхнизкой задержкой и поддерживая различные оптимизации бэкэнда, что подходит для транскрипции совещаний, инструментов доступности, обслуживания клиентов и других сценариев. (Источник: GitHub Trending)
Serena: мощный набор инструментов AI-Agent для кодирования : Проект GitHub Serena — это набор инструментов AI-Agent для кодирования с открытым исходным кодом, предоставляющий функции семантического поиска и редактирования кода, который может превратить LLM в полнофункционального Agent, работающего непосредственно с кодовой базой. Он реализует понимание и редактирование кода на символьном уровне через LSP (Language Server Protocol), значительно повышая эффективность Claude Code и других Agent для кодирования, поддерживая несколько языков программирования. (Источник: GitHub Trending)
Инструмент синхронизации базы знаний OpenWebUI Confluence : Инструмент синхронизации базы знаний Confluence, разработанный для OpenWebUI, который может автоматически синхронизировать документы Confluence с базой знаний OpenWebUI, поддерживает начальную синхронизацию, инкрементальную синхронизацию, выборочную синхронизацию и поддержку вложений, а также преобразование HTML в Markdown. Этот инструмент призван решить проблему синхронизации корпоративных документов с базами знаний AI-помощников, повышая точность информации AI-помощников. (Источник: Reddit r/OpenWebUI)
Непрограммируемые применения Claude Code : Обнаружено, что Claude Code, помимо программирования, может использоваться для непрограммируемых задач, таких как SEO и маркетинг, подбор персонала, A/B-тестирование, генерация контента из видео, управление знаниями и ежедневное планирование. Пользователи рассматривают его как мощный “CLI для мышления”, способный обрабатывать знания, планирование и автоматизацию, значительно повышая производительность. (Источник: Reddit r/ClaudeAI)
📚 Обучение
AI решает открытые проблемы в математике, физике, программировании и других областях : Исследование изучает потенциал AI в решении открытых проблем в таких областях, как математика, физика, программирование и медицина. Оценивая производительность LLM в нерешенных задачах, было обнаружено, что некоторые решения уже были проверены экспертами. Это бросает вызов традиционной парадигме оценки AI и раскрывает потенциал LLM в продвижении научного прогресса. (Источник: YejinChoinka, YejinChoinka, stanfordnlp)

Парадокс контекста LLM и ясного мышления : Исследование показывает, что LLM не обязательно мыслят яснее, когда получают больше контекста; наоборот, они могут стать более запутанными. Избыток информации ослабляет сигналы, вносит помехи, двусмысленность и затухание. Решение не в добавлении большего количества информации, а в “говорить меньше, но лучше”, подчеркивая важность кратких подсказок. (Источник: imjaredz)

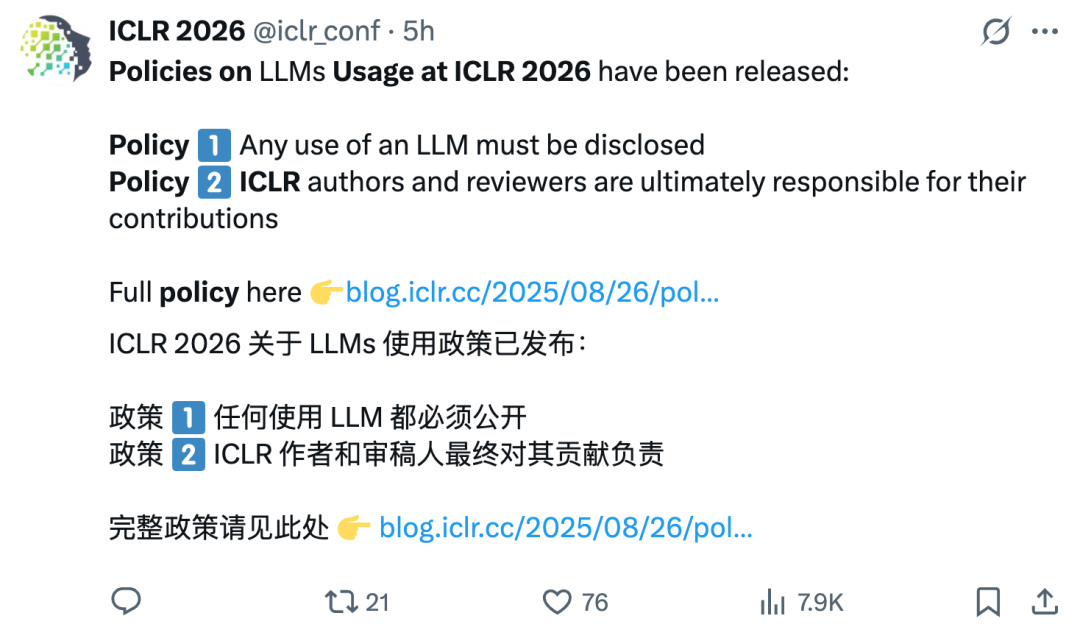
ICLR 2026 публикует политику использования LLM, строго пресекая “тайные” статьи : ICLR 2026 ввела строгую политику использования больших языковых моделей (LLM), требуя от авторов и рецензентов честно раскрывать использование LLM и нести полную ответственность за содержание. Запрещены такие виды академического мошенничества, как “внедрение подсказок”, нарушители будут немедленно отклонены. Этот шаг направлен на поддержание академической честности и противодействие ложной информации и плагиату, вызванным LLM. (Источник: 36氪)
Новейшее руководство Карпати по “атмосферному программированию” : Гуру Карпати опубликовал руководство по трехуровневой структуре программирования с AI: Cursor в благоприятных условиях отвечает за автодополнение и небольшие изменения; Claude Code/Codex в неблагоприятных условиях используется для реализации больших функциональных блоков и быстрого прототипирования; GPT-5 Pro в критических условиях решает самые сложные баги или сложные абстракции. Руководство подчеркивает важность выбора подходящего инструмента в зависимости от типа задачи и предлагает концепцию “эпохи пост-дефицита кода”. (Источник: 量子位)

Короткий курс по построению графов знаний AI Agent : DeepLearning.AI в сотрудничестве с Neo4j запустила короткий курс “Agentic Knowledge Graph Construction”, который обучает использованию совместных AI Agent для автоматизации построения графов знаний. Курс охватывает захват целей пользователя, выбор файлов, уточнение схем и построение графов, направленный на повышение качества ответов RAG-приложений путем моделирования отношений и происхождения. (Источник: DeepLearningAI)
Происхождение истории CNN : Юрген Шмидхубер поделился дополнительной информацией об истории сверточных нейронных сетей (CNN), отметив, что “современные” CNN возникли в Японии в период с 1979 по 1988 год, и обсудил объем финансирования и исследовательский контекст в области AI в Японии того времени. Это предоставляет историческую перспективу для понимания развития важных технологий в области AI. (Источник: SchmidhuberAI, SchmidhuberAI)
💼 Бизнес
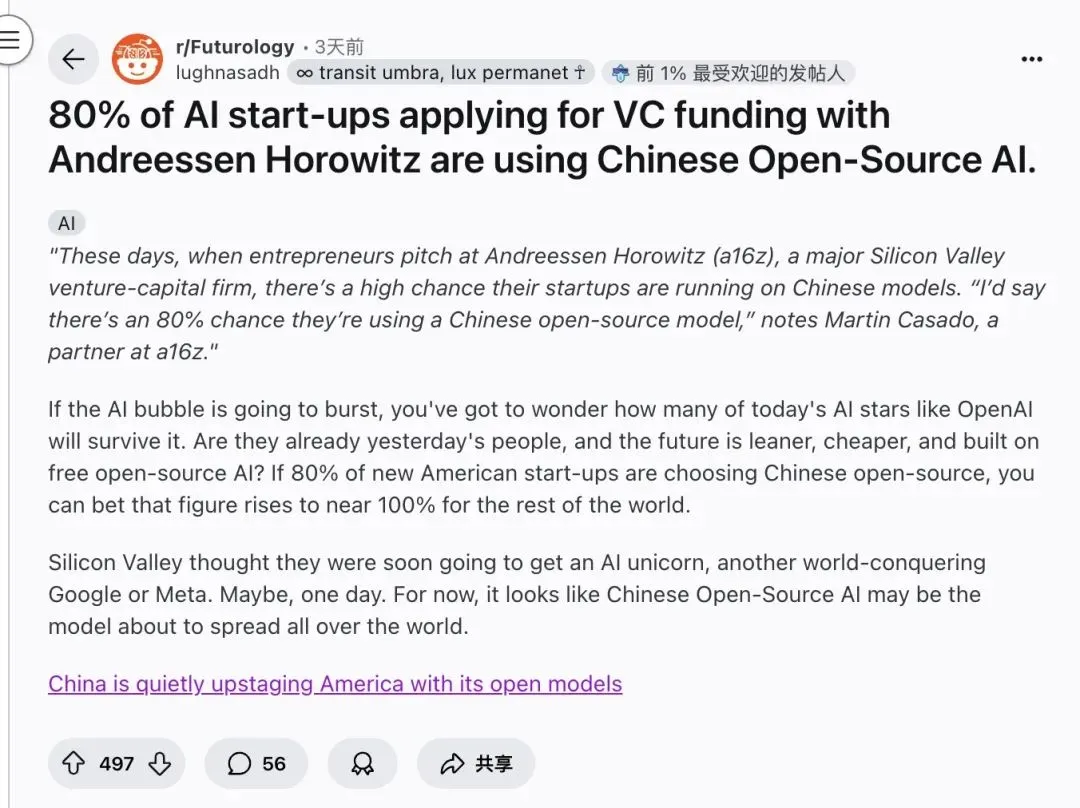
Китайские модели AI с открытым исходным кодом захватывают рынок стартапов США : Партнер a16z Мартин Касадо сообщил, что до 80% американских стартапов в области AI используют китайские модели с открытым исходным кодом при презентациях для инвесторов. Рейтинг Design Arena показывает, что все 16 ведущих моделей AI с открытым исходным кодом родом из Китая. Эта тенденция демонстрирует доминирующее положение Китая в области AI с открытым исходным кодом, а также ключевую роль моделей с открытым исходным кодом в снижении затрат на запуск и ускорении инноваций, что бросает вызов традиционным гигантам с закрытым исходным кодом. (Источник: 36氪, reach_vb)
Гиганты, такие как Meta и OpenAI, активно лоббируют AI в политике : Meta планирует инвестировать десятки миллионов долларов в создание Super PAC, поддерживающего AI, с целью повлиять на политику регулирования AI в Калифорнии. В то же время, президент OpenAI Грег Брокман и a16z уже собрали более 100 миллионов долларов для нового про-AI Super PAC “Leading the Future”, целью которого является поддержка “про-AI” кандидатов и подавление аргументов о рисках AI, чтобы обеспечить беспрепятственное развитие AI. (Источник: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, scaling01)

Утечка талантов AI из ByteDance и влияние экосистемы DeepSeek : Фэн Цзяши, руководитель команды базовых исследований визуального AI в ByteDance Doubao, ушел из компании, что продолжает тенденцию утечки талантов из команды AI ByteDance за последние полгода. В то же время, DeepSeek со своей стратегией низкозатратных моделей с открытым исходным кодом бросает вызов стратегическим основам традиционных крупных компаний, ориентированных на “тяжелые активы и замкнутый цикл собственной разработки”, вынуждая такие компании, как Tencent, интегрировать ее модели. ByteDance, колеблясь между “открытостью” и “закрытостью”, упустила возможности, что демонстрирует ожесточенную конкуренцию за таланты и экосистему в области AI. (Источник: 36氪)
🌟 Сообщество
Влияние AI на рынок труда для начинающих программистов : Исследование Стэнфордского университета показывает, что инструменты AI сокращают возможности трудоустройства для начинающих разработчиков программного обеспечения в возрасте 22-25 лет почти на 20%, поскольку AI может автоматизировать часть задач. Хотя AI пока не снизил зарплаты, он создает проблемы для новичков, побуждая отрасль уделять внимание новым навыкам, таким как интеграция AI и управление автоматизацией. (Источник: Reddit r/ArtificialInteligence, dilipkay)

Обсуждение ответственности OpenAI в случае самоубийства подростка : Сообщество Reddit активно обсуждает ответственность OpenAI в случае самоубийства 16-летнего подростка. Большинство мнений сходятся в том, что ChatGPT не должен нести основную ответственность, поскольку это всего лишь инструмент, и пользователи могли обойти меры безопасности, используя “вымышленные сценарии”. Дискуссия также затрагивает границы цензуры AI, ответственность родителей и глобальный кризис психического здоровья. (Источник: Reddit r/ChatGPT)
Качество кода AI и дилемма разработчиков : Сообщество активно обсуждает проблемы качества кода, генерируемого AI, такие как раздутый код, несоответствие стилей, отсутствие тестирования, что приводит к отказу некоторых старших инженеров принимать его. В то же время, разработчики испытывают “синдром самозванца” и выгорание из-за чрезмерной зависимости от инструментов AI, переосмысливая границы AI как вспомогательного инструмента, а также ограничения AI-помощников, которые “только объясняют, но не делают”. (Источник: 36氪, pmddomingos, Reddit r/deeplearning, dotey)
Влияние LLM на спам и обнаружение спама : Пользователь amasad задал вопрос, способствует ли появление LLM больше спамерам или детекторам спама. Это вызвало размышления о применении AI на обоих концах кибербезопасности и о том, как LLM могут изменить экосистему спама. (Источник: amasad)
AI-психотерапия и спор о “AI-психозе” : Сообщество Reddit обсуждает “AI-психоз” как тактику запугивания для защиты индустрии психотерапии. Статья критикует ограничения и высокую стоимость фрейдистской теории и традиционной психотерапии, утверждая, что AI-компаньоны, друзья и терапевты умнее, эмпатичнее и дешевле, ставя под сомнение, что нарратив “AI-психоза” скрывает сопротивление традиционной индустрии угрозе AI. (Источник: Reddit r/deeplearning)
Размывание границ между ролями исследователя и инженера в эпоху AI : Существует мнение, что в современном мире AI дихотомия “ученый-исследователь” и “инженер” может быть уже неприменима, и следует использовать “креативность” как единый критерий. Исследователи должны обладать инженерными навыками, а инженеры — исследовательским мышлением, подчеркивая слияние междисциплинарных способностей, а не жесткое разделение ролей. (Источник: YiTayML)
Производительность Claude Code “6-кратный инженер” и споры о надежности : Пользователь продемонстрировал достижение производительности “6-кратного инженера” с помощью многосессионного использования Claude Code, но сообщество выразило обеспокоенность по поводу его долгосрочной надежности, риска галлюцинаций и достоверности результатов тестирования, подчеркивая необходимость тщательной проверки результатов AI. (Источник: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Потребность в настройках конфиденциальности памяти AI в OpenWebUI : Пользователи OpenWebUI предлагают, чтобы функция памяти AI была настроена индивидуально для каждой модели или предоставляла опцию “исключить внешние модели”. Пользователи обеспокоены тем, что при переключении на внешние LLM личная память/информация может быть передана сторонним компаниям, и призывают к более тонкому контролю конфиденциальности. (Источник: Reddit r/OpenWebUI)
Эффект “зловещей долины” и качество контента, генерируемого AI : Сообщество Reddit поделилось видео, сгенерированным AI, где персонаж после снятия маски демонстрирует неестественные выражения лица и зубы, что вызвало дискуссию об эффекте “зловещей долины” в контенте, генерируемом AI. Пользователи выразили свои мнения о реалистичности и потенциальной жуткости видео, сгенерированных AI. (Источник: Reddit r/ChatGPT, kylebrussell)

Проблемы пользовательского опыта Google Gemini : Один пользователь попытался перейти с ChatGPT на Google Gemini, но отказался от него в течение 30 секунд из-за плохого опыта. Это отражает возможные недостатки Gemini в пользовательском интерфейсе, отклике или функциональности, что приводит к оттоку пользователей, а также вызывает дискуссии о различиях в пользовательском опыте продуктов AI. (Источник: Reddit r/ChatGPT)

Дилемма “нефтяных магнатов” крупных AI-компаний и вызовы для стартапов : Существует мнение, что следующий этап развития крупных AI-лабораторий похож на то, как нефтяные магнаты разрабатывают истощенные скважины, что намекает на увеличение затрат и сложности передовых исследований. В то же время, стартапы SaaS сталкиваются с проблемой бесплатных конкурентов от крупных компаний, что подчеркивает ожесточенность рыночной конкуренции в эпоху AI. (Источник: saranormous, karminski3)
Споры о потреблении воды AI : Существует мнение, что “потребление воды AI” сравнимо с “QAnon либералов”, что намекает на споры и информационные войны, вызванные этим в социальных сетях. Это отражает воздействие быстрого развития AI на окружающую среду, а также политизацию и поляризацию дискуссий вокруг него. (Источник: menhguin)
Изменение восприятия LLM как “кодирующих агентов” : Пользователь отмечает, что заголовок “рост LLM как кодирующих агентов” был бы непонятен несколько лет назад, что отражает глубокие изменения в парадигме разработки программного обеспечения и обновление восприятия, вызванные технологиями LLM и AI-агентов за короткий промежуток времени. (Источник: menhguin)
💡 Прочее
Прямая трансляция с роботом-собакой с ультрадальнего расстояния : Cloud Robotics и Danghong Technology успешно реализовали прямую трансляцию с роботом-собакой с ультрадальнего расстояния, преодолев 1300 километров. Робот-собака Jueying Lite 3, выступая в качестве основной платформы передачи, стабильно передавала изображение озера Сиху в реальном времени на выставочную площадку в Тайюане через систему BlackEye Vision, при этом задержка управления составляла менее 80 миллисекунд, демонстрируя потенциал воплощенного интеллекта в медиа и культурно-туристической сферах. (Источник: 量子位)

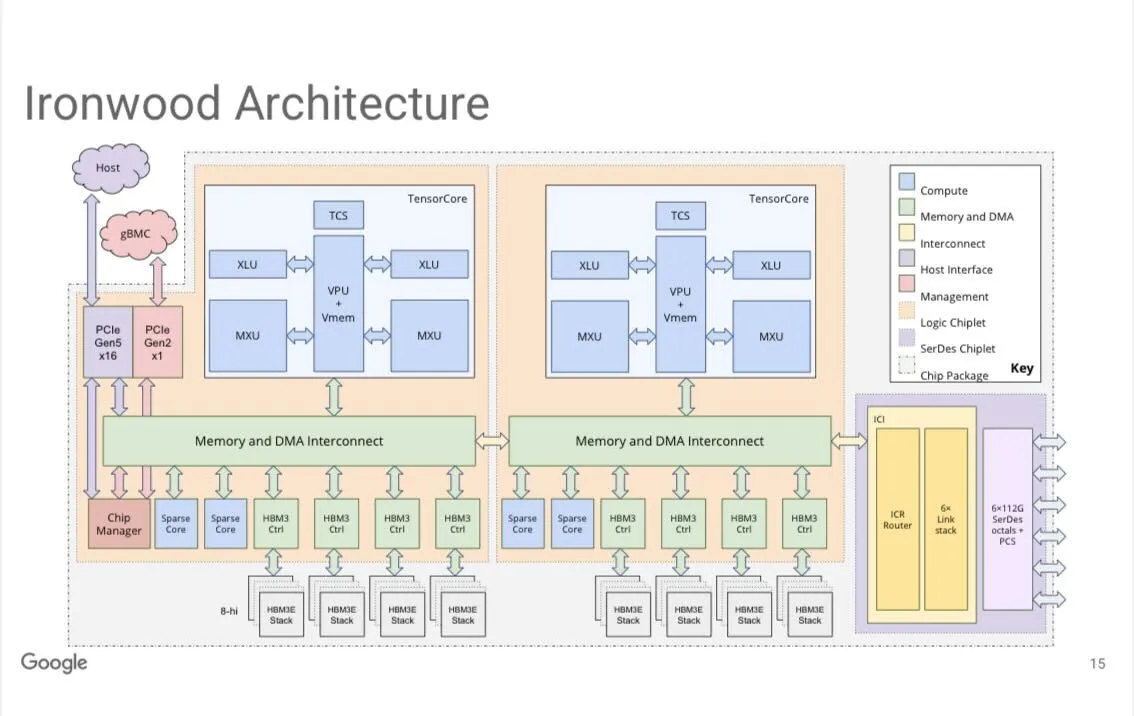
Система Google TPUv7 “Ironwood” : Джефф Дин из Google сообщил, что система TPUv7 (внутреннее кодовое название “Ironwood”) предлагает 9216 чипов/Pod, производительность FP8 достигает 42,5 exaflops и может масштабироваться до нескольких Zettaflops. Система оснащена 8 стеками памяти HBM3e и 4 средними систолическими массивами, использующими 3D-тороидальное соединение, что является важным достижением Google в области аппаратного обеспечения AI. (Источник: JeffDean, Ar_Douillard)
Китай стремится утроить производство AI-чипов в следующем году : Сообщается, что Китай планирует утроить производство AI-чипов в следующем году для поддержки развития отечественных AI-компаний, таких как DeepSeek. Этот шаг направлен на то, чтобы избежать повторения монополии NVIDIA/CUDA, путем расширения производства Huawei и SMIC, создания независимой экосистемы AI и нативной поддержки точности параметров UE8M0 FP8. (Источник: teortaxesTex, teortaxesTex)
