
Mots-clés:IA habilitante, Conception durable, Pince robotique Siemens, Outil de conception générative, Réduction des émissions de carbone, Régulation de l’IA, Restauration artistique par IA, NVIDIA Jet-Nemotron, Outil de conception générative piloté par IA, Réduction de 90% du poids des pinces robotiques, Théorie de l’apocalypse IA et impact politique, Technologie de restauration de peintures endommagées par IA, Module d’attention linéaire JetBlock
🔥 Focus
L’IA au service du design durable : la pince robotique de Siemens allégée de 90% : Siemens a considérablement optimisé le poids et le nombre de composants de sa pince robotique grâce à des outils de conception générative pilotés par l’IA, réussissant à réduire son poids de 90% et le nombre de ses composants de 84%. Cette innovation permet d’économiser jusqu’à 3 tonnes d’émissions de carbone par robot chaque année. Cela démontre l’énorme potentiel de l’IA dans le développement de produits, en favorisant le développement durable et en répondant aux exigences du marché et de l’environnement grâce à des choix de conception intelligents et une évaluation d’impact en temps réel. (Source: MIT Technology Review)

La théorie de l’apocalypse de l’IA pousse à la réglementation : l’impact politique de la science-fiction à la réalité : La théorie de l’apocalypse de l’IA, déclenchée par des événements tels que la simulation de “chantage” de Claude d’Anthropic, influence profondément l’élaboration des politiques en matière d’IA. Bien que les craintes concernant les menaces de l’IA puissent être exagérées, ces discussions incitent les gouvernements à se concentrer sur les risques immédiats des systèmes d’IA, favorisant ainsi des mesures réglementaires nécessaires. Ce “changement d’ambiance” est propice à l’intervention politique, garantissant que la technologie de l’IA soit efficacement réglementée au cours de son développement afin d’éviter les dangers potentiels. (Source: MIT Technology Review)

Révolution dans la restauration d’art par l’IA : des œuvres restaurées en quelques heures : Des chercheurs du MIT ont développé une nouvelle méthode de restauration d’art pilotée par l’IA, capable de restaurer des œuvres endommagées en quelques heures, dépassant de loin les semaines, voire les décennies, requises par les méthodes traditionnelles. Cette approche implique la numérisation, la reconstruction virtuelle, puis l’impression et l’application d’un film polymère coloré précis sur l’œuvre originale. Cette innovation promet de redonner vie à un grand nombre d’œuvres d’art endommagées dans les collections et d’offrir un enregistrement de restauration numérique sans précédent. (Source: MIT Technology Review)

🎯 Tendances
NVIDIA Jet-Nemotron : une nouvelle avancée pour les modèles de langage efficaces : L’équipe de Han Song de NVIDIA a lancé Jet-Nemotron, qui, grâce à la recherche d’architecture post-neuronale (PostNAS) et au nouveau module d’attention linéaire JetBlock, améliore le débit de génération des grands modèles de 53,6 fois et accélère le pré-remplissage de 6,1 fois, tout en réduisant considérablement la taille du cache KV, tout en maintenant une grande précision. Ce modèle excelle dans les tâches de mathématiques, de bon sens, de récupération et de codage. Le code et les modèles pré-entraînés seront open source. (Source: 量子位, Reddit r/LocalLLaMA)

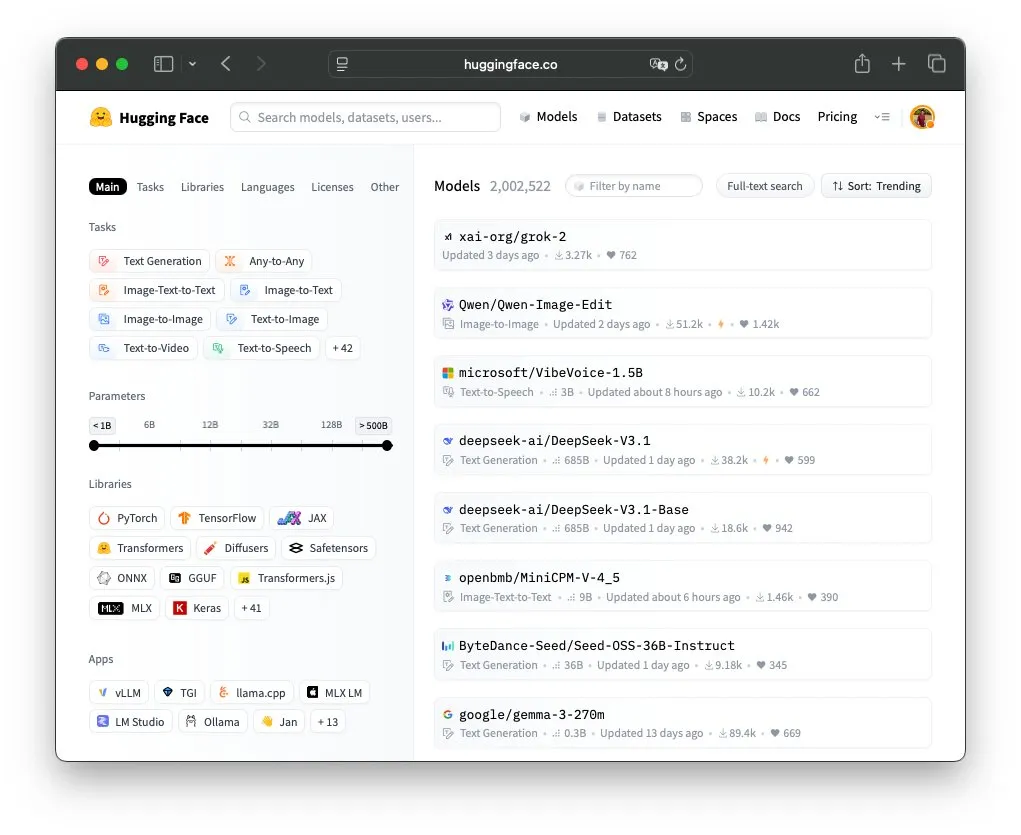
Le nombre de modèles sur la plateforme Hugging Face dépasse les 2 millions : Le nombre de modèles publics sur la plateforme Hugging Face a dépassé les 2 millions, un jalon qui reflète le développement florissant et la croissance rapide de la communauté open source de l’IA. Les utilisateurs de la communauté ont exprimé leur étonnement et ont discuté de la capacité de stockage de la plateforme ainsi que de l’impact des modèles open source sur l’écosystème mondial de l’IA. (Source: huggingface, Reddit r/LocalLLaMA, Reddit r/artificial)
La Chine dévoile une stratégie décennale “IA+” : Le Conseil des Affaires d’État a publié les “Directives sur la mise en œuvre approfondie de l’action ‘IA+’“, définissant une stratégie chinoise en trois étapes pour le développement de l’IA, visant à entrer pleinement dans une économie et une société intelligentes d’ici 2035. Cette stratégie vise à élever l’IA du statut d’outil de mise à niveau industrielle à celui d’infrastructure nationale de modernisation et de cœur des nouvelles forces productives, en se concentrant sur six domaines majeurs : la science et la technologie, l’industrie, la consommation, les moyens de subsistance, la gouvernance et la coopération mondiale. (Source: 36氪, 36氪)

Bug du caractère “极” (jí) dans DeepSeek V3.1 : Le modèle DeepSeek V3.1 présente un bug où le caractère “极” (jí) apparaît sporadiquement dans les appels d’API de génération de code, affectant les scénarios de sortie de haute précision et structurée. Ce problème a été détecté sur plusieurs plateformes, et DeepSeek a répondu qu’il serait corrigé dans la dernière version. Les experts supposent que cela pourrait être lié à un nettoyage incomplet des données ou au fait que le modèle ait appris le caractère “极” comme un terminateur. (Source: 量子位)

Exploration de la connaissance et du raisonnement des LLM dans la résolution de problèmes scientifiques : L’article de HuggingFace “Demystifying Scientific Problem-Solving in LLMs by Probing Knowledge and Reasoning” introduit le benchmark SciReas et le framework KRUX, visant à découpler les rôles uniques de la connaissance et du raisonnement des LLM dans les tâches de raisonnement scientifique. La recherche révèle que la récupération de connaissances pertinentes pour la tâche à partir des paramètres du modèle est un goulot d’étranglement clé pour le raisonnement scientifique des LLM, et que l’amélioration des connaissances externes et du raisonnement verbal peut améliorer considérablement les performances du modèle. (Source: HuggingFace Daily Papers)
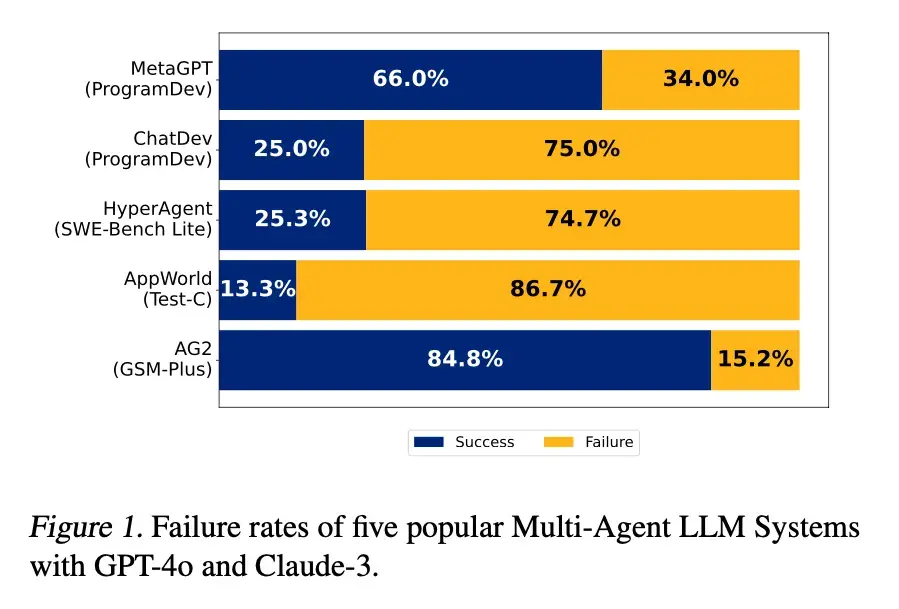
Paradoxes et avancées de la collaboration multi-agents : Les systèmes d’IA multi-agents peuvent théoriquement dépasser les limites de capacité d’un modèle unique, mais ils sont confrontés à des défis pratiques tels que la complexité de la coordination, les coûts de communication élevés et la responsabilité floue. La recherche indique que plus il y a d’experts, plus il peut y avoir de problèmes, mais grâce à des conceptions ingénieuses comme les agents coordinateurs, les protocoles de communication standardisés et les outils d’attribution automatisée des échecs, les équipes multi-agents peuvent être gérées et déboguées efficacement, leur permettant de réaliser d’énormes gains de performance dans des tâches de haute complexité. (Source: 36氪)
DrugReasoner : un modèle prédictif d’approbation de médicaments interprétable : L’article de HuggingFace “DrugReasoner: Interpretable Drug Approval Prediction with a Reasoning-augmented Language Model” propose le modèle DrugReasoner basé sur l’architecture LLaMA, affiné via l’optimisation de stratégie relative de groupe (GRPO), combinant descripteurs moléculaires et raisonnement comparatif pour prédire la probabilité d’approbation des médicaments à petites molécules. Ce modèle surpasse les méthodes traditionnelles en termes de précision prédictive et améliore l’interprétabilité en fournissant un raisonnement étape par étape et des scores de confiance, promettant de résoudre un goulot d’étranglement clé dans la découverte de médicaments assistée par l’IA. (Source: HuggingFace Daily Papers)
Autoregressive Universal Video Segmentation Model (AUSM) : L’article de HuggingFace “Autoregressive Universal Video Segmentation Model” présente AUSM, une architecture unique unifiant la segmentation vidéo basée sur des invites et sans invites. Basé sur un modèle d’espace d’états, AUSM maintient un état spatial de taille fixe et peut s’étendre à des flux vidéo de longueur arbitraire, tous les composants prenant en charge l’entraînement parallèle inter-images, surpassant les méthodes existantes sur les benchmarks standards et réalisant une accélération de l’entraînement de 2,5 fois. (Source: HuggingFace Daily Papers)
ObjFiller-3D : complétion et édition 3D multi-vues cohérentes : L’article de HuggingFace “ObjFiller-3D: Consistent Multi-view 3D Inpainting via Video Diffusion Models” propose la méthode ObjFiller-3D, qui utilise des modèles d’édition vidéo pour réaliser une complétion et une édition d’objets 3D de haute qualité et cohérentes. Cette méthode analyse l’écart de représentation entre la 3D et la vidéo, et introduit une technique de complétion 3D basée sur des références, surpassant significativement les méthodes existantes sur plusieurs ensembles de données. (Source: HuggingFace Daily Papers)
Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks : L’article de HuggingFace “Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks” étudie l’impact de la sparsité des modèles MoE sur les capacités de mémoire et de raisonnement. Il a été constaté que les performances de raisonnement saturent ou diminuent même lorsque le nombre total de paramètres et la perte d’entraînement continuent d’augmenter. Les modèles excessivement clairsemés obtiennent de moins bons résultats dans les tâches de raisonnement, et le renforcement de l’apprentissage post-entraînement ou le calcul supplémentaire au moment du test ne peuvent pas compenser ce défaut. (Source: HuggingFace Daily Papers)
Les travailleurs techniques numériques sont en place ! Les grands modèles temporels + Agent maîtrisent déjà les technologies de contrôle de la production en usine : La plateforme d’agents intelligents industriels Hegou a lancé des “travailleurs techniques numériques” basés sur de grands modèles temporels et des Agents, capables d’être opérationnels en une semaine et de maîtriser les technologies de contrôle de la production en usine. Ces agents intelligents ont déjà assumé des tâches clés telles que les opérations de production, le contrôle de la sécurité et la gestion de l’énergie dans des scénarios industriels comme la chimie, la protection de l’environnement et les nouvelles énergies, atténuant efficacement la pénurie d’experts et réalisant une plus grande capacité de généralisation et un déploiement rapide grâce à des grands modèles temporels auto-développés et à la division des objectifs d’entraînement par “type de processus”. (Source: 量子位)

🧰 Outils
Claude for Chrome : une extension de navigateur IA : Anthropic a lancé Claude for Chrome, une extension de navigateur qui aide les utilisateurs à organiser automatiquement des plannings, répondre aux e-mails, rechercher des logements, résumer des documents, etc. Actuellement en version d’aperçu de recherche, elle n’est disponible que pour 1000 utilisateurs payants, avec un accent principal sur les risques de sécurité, en particulier la protection contre les “attaques par injection de prompt”. (Source: 36氪, 量子位, sirbayes, BlackHC)
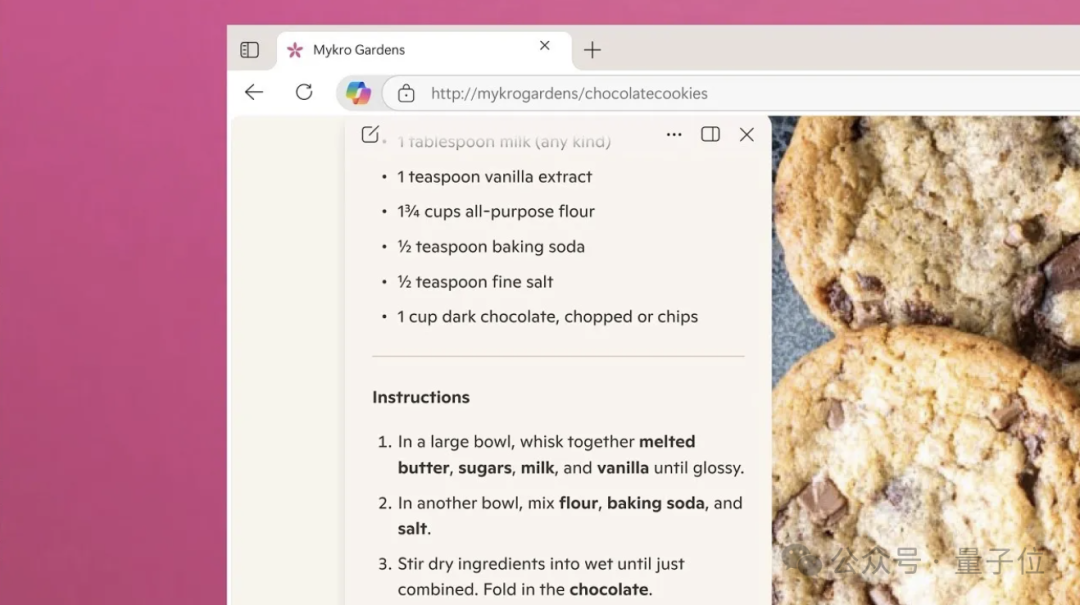
Nano Banana : un outil d’édition d’images IA multifonctionnel : Nano Banana (Gemini Flash 2.5) a démontré de puissantes capacités d’édition d’images, notamment la conversion de photos d’architecture en modèles 3D de style “skyline urbaine”, la génération d’annotations d’expérience AR, la restauration et la colorisation de photos, la génération de séquences cinématographiques, la conversion d’images en dessins au trait et leur colorisation, etc. Cet outil a suscité de nombreuses discussions sur les réseaux sociaux en raison de sa haute fidélité et de sa polyvalence. (Source: karminski3, nrehiew_, zacharynado, JeffDean, clefourrier, MiniMax__AI, TomLikesRobots, timsoret, demishassabis, fabianstelzer, dotey, GoogleDeepMind)

Video Ocean : le premier Agent vidéo connecté à GPT-5 : Video Ocean est un Agent vidéo piloté par GPT-5, capable de créer automatiquement des storyboards, des visuels, des voix off et des sous-titres à partir d’une seule invite, générant des vidéos structurellement complètes et rythmées, réduisant considérablement le cycle de production vidéo. Il propose trois modules principaux : planification de script, synthèse visuelle et voix off/sous-titres, et a la capacité d’apprendre le style de marque et les créations passées, ce qui le rend adapté à la production rapide et en masse de vidéos virales et de publicités commerciales. (Source: 量子位)

Audiblez : générer des livres audio à partir d’e-books : Le projet GitHub Audiblez utilise le modèle de synthèse vocale Kokoro-82M pour convertir des e-books epub en livres audio m4b, prenant en charge plusieurs langues et offrant une interface graphique et une accélération CUDA. Ce modèle ne compte que 82M de paramètres, mais sa sortie vocale est naturelle et la vitesse de conversion est rapide. (Source: GitHub Trending)
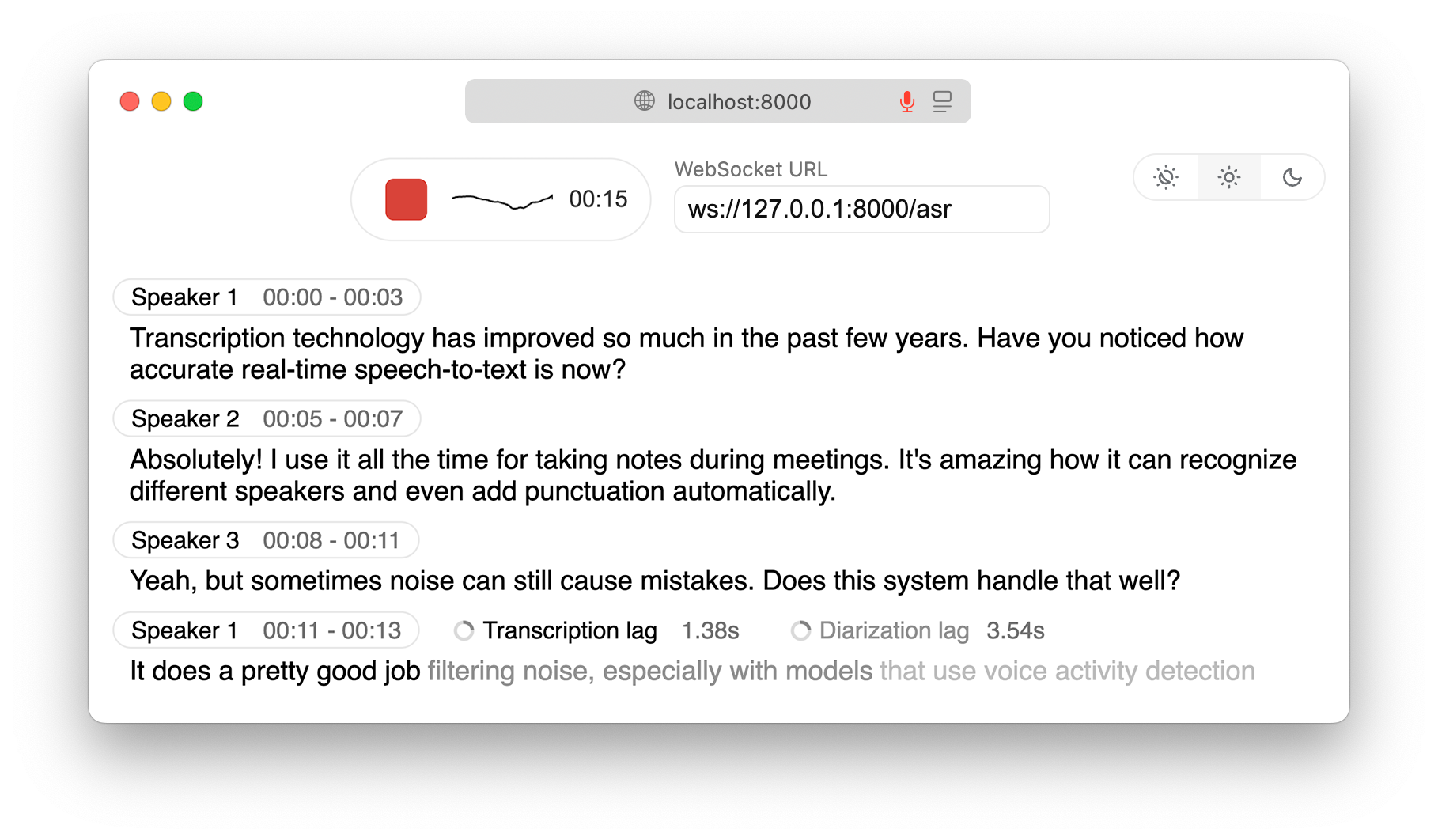
WhisperLiveKit : transcription vocale et identification de locuteur en temps réel et local : Le projet GitHub WhisperLiveKit offre des fonctionnalités de transcription vocale et d’identification de locuteur en temps réel et entièrement locales, prenant en charge des technologies de pointe telles que SimulStreaming et WhisperStreaming. Il comprend un serveur FastAPI et une interface Web, permettant une transcription à très faible latence et prenant en charge diverses optimisations backend, adapté aux scénarios tels que la transcription de réunions, les outils d’accessibilité et le service client. (Source: GitHub Trending)
Serena : une puissante boîte à outils d’Agent de codage IA : Le projet GitHub Serena est une boîte à outils d’Agent de codage open source, offrant des fonctionnalités de récupération et d’édition de code sémantique, capable de transformer un LLM en un Agent complet travaillant directement sur des bases de code. Il réalise une compréhension et une édition de code au niveau symbolique via le Language Server Protocol (LSP), améliorant significativement l’efficacité des Agents de codage comme Claude Code, et prend en charge plusieurs langages de programmation. (Source: GitHub Trending)
Outil de synchronisation de la base de connaissances Confluence pour OpenWebUI : Un outil de synchronisation de la base de connaissances Confluence développé pour OpenWebUI, capable de synchroniser automatiquement les documents Confluence avec la base de connaissances OpenWebUI, prenant en charge la synchronisation initiale, la synchronisation incrémentielle, la synchronisation sélective et le support des pièces jointes, et effectuant la conversion HTML vers Markdown. Cet outil vise à résoudre le problème de la synchronisation des documents d’entreprise avec les bases de connaissances des assistants IA, améliorant ainsi la précision des informations de l’assistant IA. (Source: Reddit r/OpenWebUI)
Applications non-programmatiques de Claude Code : Il a été découvert que Claude Code, en plus de la programmation, peut être utilisé pour des tâches non-programmatiques telles que le SEO et le marketing, le recrutement, les tests A/B, la génération de contenu à partir de vidéos, la gestion des connaissances et la planification quotidienne. Les utilisateurs le considèrent comme un puissant “CLI de pensée”, capable de gérer les connaissances, la planification et l’automatisation, améliorant considérablement la productivité. (Source: Reddit r/ClaudeAI)
📚 Apprentissage
L’IA résout des problèmes ouverts en mathématiques, physique, programmation, etc. : La recherche explore le potentiel de l’IA à résoudre des problèmes ouverts dans des domaines tels que les mathématiques, la physique, la programmation et la médecine. En évaluant les performances des LLM sur des problèmes non résolus, certaines solutions ont été validées par des experts. Cela remet en question les paradigmes d’évaluation traditionnels de l’IA et révèle le potentiel des LLM à faire progresser la science. (Source: YejinChoinka, YejinChoinka, stanfordnlp)

Le paradoxe du contexte des LLM et de la pensée claire : Une étude indique que les LLM ne pensent pas plus clairement lorsqu’ils reçoivent plus de contexte, mais peuvent au contraire devenir plus confus. Trop d’informations affaiblit le signal, introduisant des interférences, des ambiguïtés et une dégradation. La solution n’est pas d’ajouter plus d’informations, mais de “parler moins, mais mieux”, soulignant l’importance de simplifier les prompts. (Source: imjaredz)

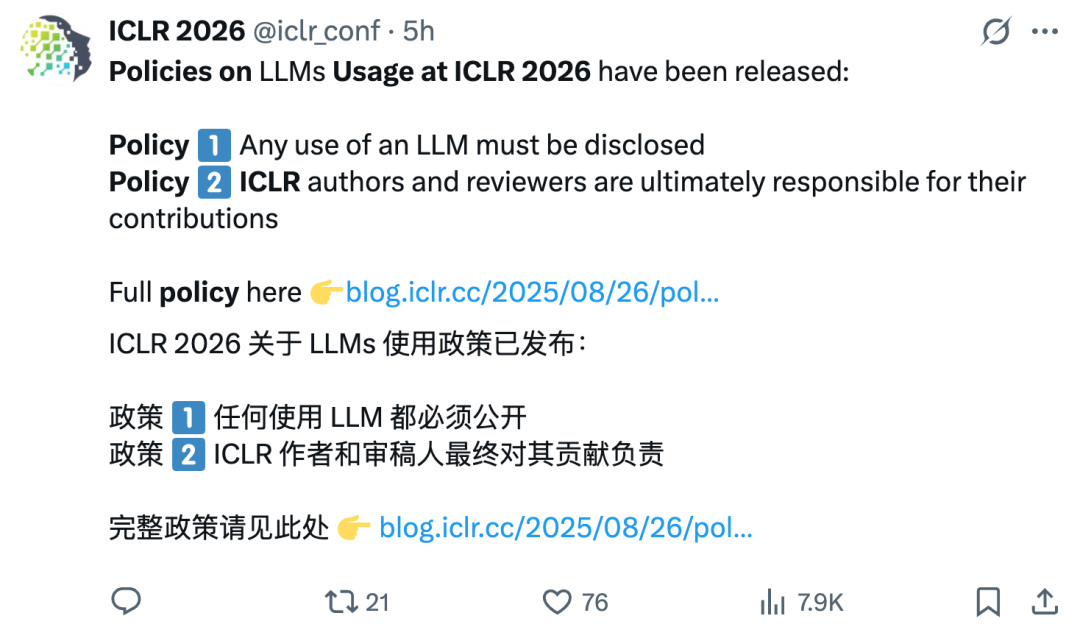
ICLR 2026 publie une politique d’utilisation des LLM, bloquant strictement les “papiers frauduleux” : ICLR 2026 a introduit une politique stricte d’utilisation des grands modèles de langage (LLM), exigeant des auteurs et des relecteurs qu’ils divulguent honnêtement l’utilisation des LLM et assument l’entière responsabilité du contenu. Les comportements de faute académique tels que l‘“injection de prompt” sont interdits, et les contrevenants feront face à un rejet direct de leur article. Cette mesure vise à maintenir l’intégrité académique et à faire face aux risques de désinformation et de plagiat posés par les LLM. (Source: 36氪)
Le dernier guide de Karpathy sur la programmation d’ambiance : Le grand Karpathy a publié un guide sur la structure en trois couches de la programmation IA : Cursor pour l’autocomplétion et les modifications mineures dans des situations favorables ; Claude Code/Codex pour l’implémentation de grands blocs fonctionnels et le prototypage rapide dans des situations difficiles ; GPT-5 Pro pour résoudre les bugs les plus tenaces ou les abstractions complexes dans des situations extrêmes. Ce guide souligne l’importance de choisir l’outil approprié en fonction du type de tâche et introduit le concept d’une “ère post-rareté du code”. (Source: 量子位)

Cours court sur la construction de graphes de connaissances par les Agents IA : DeepLearning.AI a lancé le cours court “Agentic Knowledge Graph Construction”, en partenariat avec Neo4j, pour enseigner comment automatiser la construction de graphes de connaissances à l’aide d’Agents IA collaboratifs. Le cours couvre la capture des objectifs de l’utilisateur, la sélection de fichiers, l’extraction de schémas et la construction de graphes, visant à améliorer la qualité des réponses des applications RAG en modélisant les relations et la provenance. (Source: DeepLearningAI)
Les origines de l’histoire des CNN : Jürgen Schmidhuber a partagé plus d’informations sur l’histoire des réseaux de neurones convolutifs (CNN), soulignant que les CNN “modernes” sont apparus au Japon entre 1979 et 1988, et a discuté des investissements financiers et du contexte de recherche dans le domaine de l’IA au Japon à cette époque. Cela offre une perspective historique pour comprendre le développement de technologies importantes dans le domaine de l’IA. (Source: SchmidhuberAI, SchmidhuberAI)
💼 Affaires
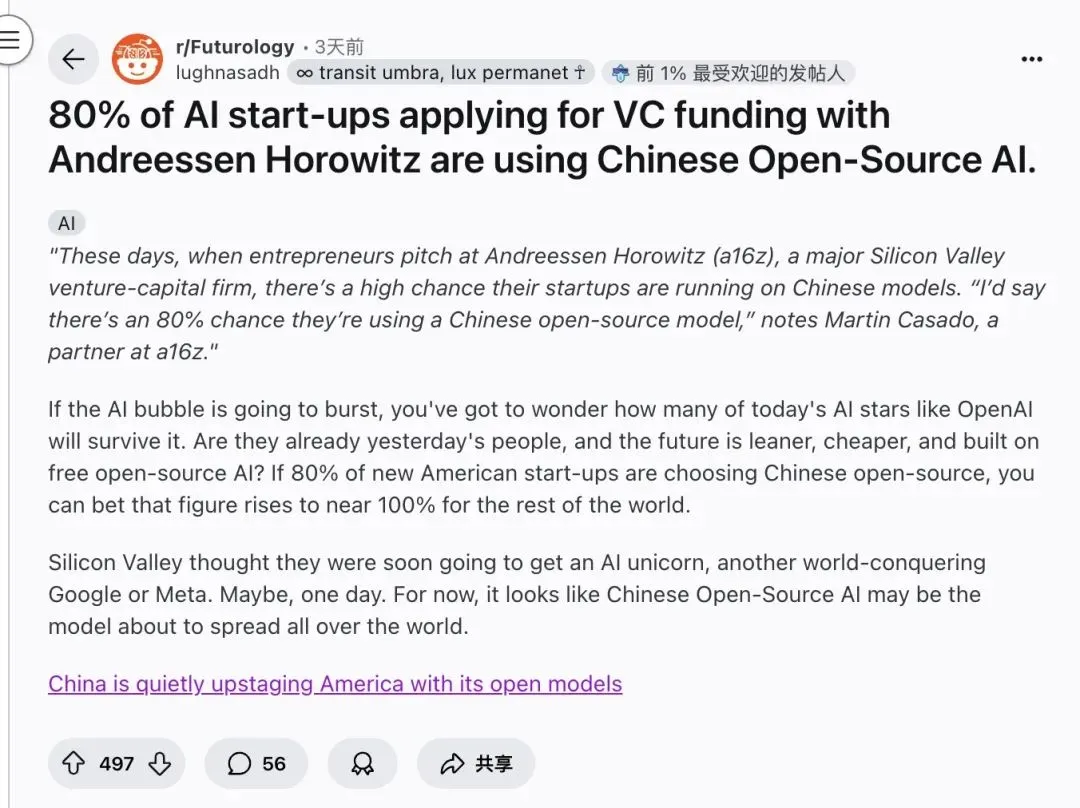
Les modèles d’IA open source chinois envahissent le marché des startups américaines : Martin Casado, associé chez a16z, a révélé que jusqu’à 80% des startups américaines d’IA utilisent des modèles open source chinois lors de leurs roadshows de financement. Le classement Design Arena montre que les 16 premiers modèles d’IA open source proviennent tous de Chine. Cette tendance démontre la position dominante de la Chine dans le domaine de l’IA open source, ainsi que le rôle clé des modèles open source dans la réduction des coûts de démarrage et l’accélération de l’innovation, posant un défi aux géants traditionnels du closed source. (Source: 36氪, reach_vb)
Meta, OpenAI et d’autres géants se positionnent pour le lobbying politique de l’IA : Meta prévoit d’investir des dizaines de millions de dollars pour créer un Super PAC pro-IA, visant à influencer la politique de réglementation de l’IA en Californie. Parallèlement, Greg Brockman, président d’OpenAI, et a16z, entre autres, ont déjà levé plus de 100 millions de dollars pour un nouveau Super PAC pro-IA, “Leading the Future”, dont l’objectif est de soutenir les candidats “pro-IA” et de minimiser les arguments sur les risques de l’IA, afin d’assurer un développement de l’IA sans entraves. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, scaling01)

Fuite de talents IA chez ByteDance et l’impact écologique de DeepSeek : Feng Jiashi, responsable de l’équipe de recherche fondamentale en vision pour le grand modèle Doubao de ByteDance, a démissionné, poursuivant une vague de départs de talents de l’équipe IA de ByteDance au cours des six derniers mois. Parallèlement, DeepSeek, avec sa stratégie de modèles open source à faible coût, remet en question les fondements stratégiques des grandes entreprises traditionnelles basées sur des “actifs lourds et un développement interne fermé”, forçant des entreprises comme Tencent à intégrer ses modèles, tandis que ByteDance, en raison de ses hésitations entre “ouverture” et “fermeture”, a manqué des opportunités, démontrant l’intensité de la concurrence pour les talents et l’écosystème dans le domaine de l’IA. (Source: 36氪)
🌟 Communauté
L’impact de l’IA sur le marché de l’emploi des programmeurs débutants : Une étude de l’Université de Stanford montre que les outils d’IA réduisent de près de 20% les opportunités d’emploi pour les développeurs de logiciels débutants âgés de 22 à 25 ans, l’IA pouvant automatiser certaines tâches. Bien que l’IA n’ait pas encore fait baisser les salaires, elle pose un défi aux nouveaux entrants, incitant l’industrie à se concentrer sur de nouvelles compétences telles que l’intégration de l’IA et la gestion de l’automatisation. (Source: Reddit r/ArtificialInteligence, dilipkay)

Débat sur la responsabilité d’OpenAI dans le cas du suicide d’un adolescent : La communauté Reddit a eu une discussion animée sur la responsabilité d’OpenAI dans le cas du suicide d’un adolescent de 16 ans. La plupart des opinions estiment que ChatGPT ne devrait pas porter la responsabilité principale, car il s’agit seulement d’un outil, et l’utilisateur aurait pu contourner les protections de sécurité par des “scénarios fictifs”. La discussion a également abordé les limites de la censure de l’IA, la responsabilité parentale et la crise mondiale de la santé mentale. (Source: Reddit r/ChatGPT)
Qualité du code IA et dilemmes des développeurs : La communauté discute vivement des problèmes de qualité du code généré par l’IA, tels que le code gonflé, les styles incohérents et le manque de tests, ce qui conduit certains ingénieurs seniors à refuser de l’accepter. Parallèlement, les développeurs ressentent un “syndrome de l’imposteur” et un épuisement professionnel dus à une dépendance excessive aux outils d’IA, remettant en question les limites de l’IA en tant qu’outil d’assistance et la limitation des assistants IA qui “expliquent mais ne font pas”. (Source: 36氪, pmddomingos, Reddit r/deeplearning, dotey)
L’impact des LLM sur le spam et la détection de spam : L’utilisateur amasad a soulevé la question de savoir si l’émergence des LLM est plus avantageuse pour les spammeurs ou pour les détecteurs de spam. Cela a suscité une réflexion sur l’application de l’IA aux deux extrémités de la cybersécurité (attaque et défense) et sur la manière dont les LLM pourraient modifier l’écosystème du spam. (Source: amasad)
Psychothérapie IA et controverse sur la “psychose IA” : La communauté Reddit a discuté de la “psychose IA” comme tactique d’intimidation pour protéger l’industrie de la psychothérapie. L’article critique les limites et les coûts élevés de la théorie freudienne et de la psychothérapie traditionnelle, arguant que les compagnons, amis et thérapeutes IA sont plus intelligents, plus empathiques et moins chers, remettant en question l’idée que le récit de la “psychose IA” est une résistance de l’industrie traditionnelle à la menace de l’IA. (Source: Reddit r/deeplearning)
Les frontières floues entre les rôles de chercheur et d’ingénieur à l’ère de l’IA : Une opinion suggère que la dichotomie entre “chercheur scientifique” et “ingénieur” pourrait ne plus être pertinente dans le monde moderne de l’IA, et qu’il faudrait plutôt utiliser la “créativité” comme unique critère de mesure. Les chercheurs devraient posséder des compétences d’ingénierie, et les ingénieurs devraient avoir un esprit de recherche, soulignant la fusion des compétences transdisciplinaires plutôt qu’une division rigide des rôles. (Source: YiTayML)
Productivité “ingénieur 6x” de Claude Code et controverse sur la fiabilité : Des utilisateurs ont démontré une productivité d‘“ingénieur 6x” en utilisant Claude Code sur plusieurs sessions, mais la communauté a exprimé des inquiétudes quant à sa fiabilité à long terme, aux risques d’hallucinations et à la véracité des résultats des tests, soulignant la nécessité d’auditer attentivement les sorties de l’IA. (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Besoin de paramètres de confidentialité pour la mémoire IA d’OpenWebUI : Les utilisateurs d’OpenWebUI ont suggéré que la fonction de mémoire IA devrait être configurée indépendamment pour chaque modèle, ou qu’une option “exclure les modèles externes” devrait être fournie. Les utilisateurs craignent que leurs souvenirs/informations personnels ne soient partagés avec des entreprises tierces lors du passage à des LLM externes, appelant à un contrôle plus granulaire de la confidentialité. (Source: Reddit r/OpenWebUI)
L’effet de la “vallée dérangeante” des vidéos générées par l’IA et la qualité du contenu : La communauté Reddit a partagé une vidéo générée par l’IA où les personnages, après avoir retiré leurs masques, affichaient des expressions et des dents non naturelles, suscitant une discussion sur l’effet de la “vallée dérangeante” du contenu généré par l’IA. Les utilisateurs ont exprimé leurs opinions sur le réalisme et le sentiment potentiellement étrange des vidéos générées par l’IA. (Source: Reddit r/ChatGPT, kylebrussell)

Les défis de l’expérience utilisateur de Google Gemini : Un utilisateur a tenté de passer de ChatGPT à Google Gemini, mais a abandonné en 30 secondes en raison d’une mauvaise expérience. Cela reflète d’éventuelles lacunes de Gemini en termes d’interface utilisateur, de réactivité ou de fonctionnalités, entraînant une perte d’utilisateurs, et a également suscité des discussions sur les différences d’expérience utilisateur des produits IA. (Source: Reddit r/ChatGPT)

Le dilemme des “magnats du pétrole” des grandes entreprises d’IA et les défis des startups : Une opinion compare le prochain développement des grands laboratoires d’IA à des magnats du pétrole exploitant des puits épuisés, suggérant une augmentation des coûts et de la difficulté de la recherche de pointe. Parallèlement, les entrepreneurs SaaS sont confrontés au défi des produits gratuits des grandes entreprises, soulignant l’intensité de la concurrence sur le marché à l’ère de l’IA. (Source: saranormous, karminski3)
Controverse sur la consommation d’eau de l’IA : Une opinion compare la “consommation d’eau de l’IA” au “QAnon des libéraux”, suggérant la controverse et la guerre de l’information qu’elle suscite sur les réseaux sociaux. Cela reflète l’impact environnemental du développement rapide de l’IA, ainsi que la politisation et la polarisation des discussions à son sujet. (Source: menhguin)
Changement de perception des LLM en tant qu‘“agents de codage” : Un utilisateur a souligné que le titre “L’essor des LLM en tant qu’agents de codage” aurait été incompréhensible il y a quelques années, reflétant les changements profonds et la mise à jour cognitive que les LLM et les technologies d’agents IA ont apportés au paradigme du développement logiciel en peu de temps. (Source: menhguin)
💡 Autres
Diffusion en direct d’un chien robot télécommandé sur une très longue distance : Deep Robotics et Danghong Technology ont collaboré pour réaliser avec succès la diffusion en direct d’un chien robot télécommandé sur une distance de 1300 kilomètres. Le chien robot Jueying Lite 3, en tant que plateforme de transmission centrale, a renvoyé des images en temps réel du lac de l’Ouest vers le site de l’exposition de Taiyuan via le système BlackEye Vision, avec une latence de commande contrôlée à moins de 80 millisecondes, démontrant le potentiel de l’intelligence incarnée dans les médias et le tourisme culturel. (Source: 量子位)

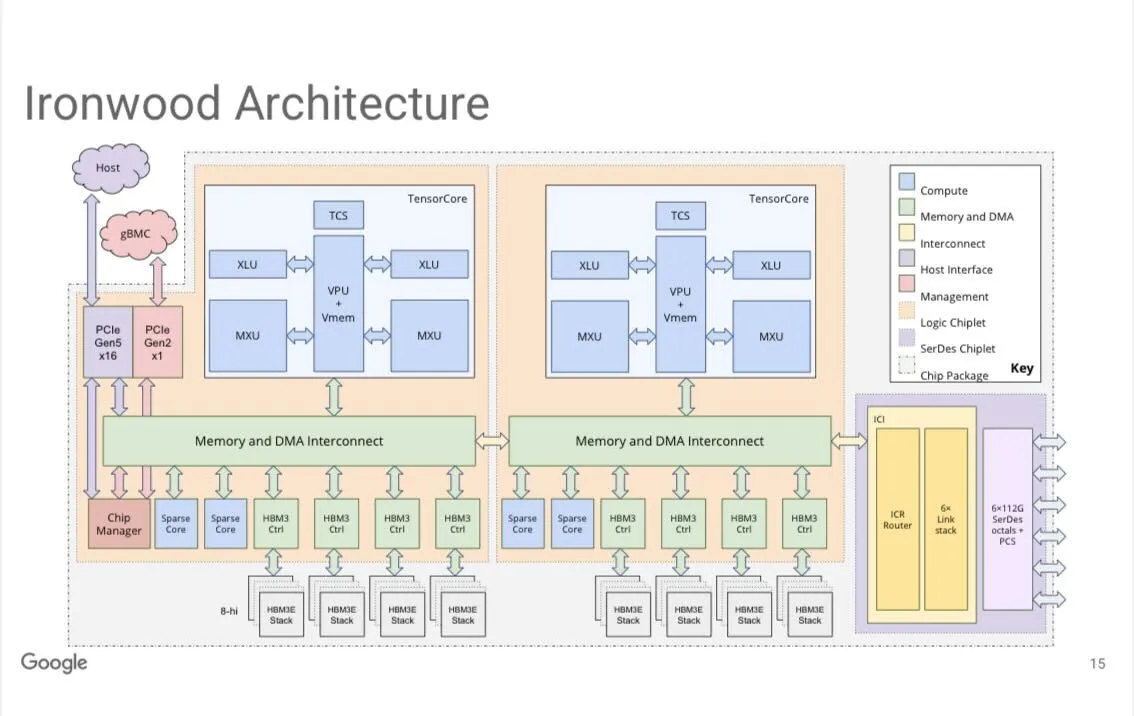
Le système TPUv7 “Ironwood” de Google : Jeff Dean de Google a révélé que le système TPUv7 (nom de code interne “Ironwood”) offre 9216 puces/Pod, atteignant une performance FP8 de 42,5 exaflops, et peut être étendu à plusieurs Zettaflops. Ce système est équipé de 8 piles de mémoire HBM3e et de 4 réseaux systoliques de taille moyenne, utilisant une interconnexion en tore 3D, marquant une avancée majeure de Google dans le domaine du matériel IA. (Source: JeffDean, Ar_Douillard)
La Chine vise à tripler sa production de puces IA l’année prochaine : Selon les rapports, la Chine prévoit de tripler sa production de puces IA l’année prochaine pour soutenir le développement d’entreprises d’IA nationales comme DeepSeek. Cette initiative vise à éviter de répéter le monopole de NVIDIA/CUDA, en construisant un écosystème IA indépendant grâce à l’expansion de la production de Huawei et SMIC, et en prenant en charge nativement la précision des paramètres UE8M0 FP8. (Source: teortaxesTex, teortaxesTex)
