
Schlüsselwörter:OpenAI Sora 2, KI-Videogenerierung, Multimodale KI, KI-Wissenschaftler, Proteindesign, Sora 2 API, PXDesign Proteindesign, PromptCoT 2.0 Framework, EgoTwin Ego-Perspektiven-Generierung, Liquid AI LFM2-Audio
🔥 Fokus
OpenAI Sora 2 veröffentlicht und dessen Auswirkungen : OpenAI hat Sora 2 offiziell veröffentlicht und positioniert es als iOS-Social-App, die als „AI-Version von TikTok“ dient. Sie unterstützt die gleichzeitige Generierung von Audio und Video und bietet erhebliche Verbesserungen bei der Einhaltung physikalischer Gesetze und der Kontrollierbarkeit. Zu den neuen Funktionen gehört „Cameos“, das es Nutzern ermöglicht, ihr eigenes Bild oder das von Freunden in KI-generierte Videos einzufügen. In den sozialen Medien wird die erstaunliche Realitätsnähe und Kreativität diskutiert, es gibt jedoch auch Bedenken hinsichtlich der Verbreitung von „Slop“-Inhalten, der Schwierigkeit, zwischen echt und gefälscht zu unterscheiden, des stark gestiegenen GPU-Bedarfs und der regionalen Verfügbarkeit (z.B. kein Sora in Großbritannien). OpenAI CEO Sam Altman antwortete, dass Sora 2 dazu dient, die AGI-Forschung zu finanzieren und interessante neue Produkte anzubieten. Die Community-Diskussionen betreffen auch die Beschaffung von Einladungscodes für Sora 2, Spekulationen über den Hardware-Bedarf (GPU) sowie Bedenken hinsichtlich der Qualität zukünftiger videogenerierter Inhalte und deren missbräuchlicher Verwendung. OpenAI plant, die Sora-Einladungen zu erweitern, wird aber die täglichen Generierungslimits entsprechend senken und hat angekündigt, eine Sora 2 API zu veröffentlichen.
(Quelle: 量子位, Yuchenj_UW, teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Periodic Labs stellt KI-Wissenschaftler-Plattform vor, um wissenschaftliche Entdeckungen zu beschleunigen : Periodic Labs hat eine Finanzierung von 300 Millionen US-Dollar erhalten. Ziel ist es, KI-Wissenschaftler zu schaffen, um grundlegende wissenschaftliche Entdeckungen, insbesondere im Bereich des Materialdesigns, durch automatisierte Labore und KI-gesteuerte Experimente zu beschleunigen. Die Plattform zielt darauf ab, das physikalische Universum als ein Computersystem zu betrachten und nutzt KI für Hypothesen, Experimente und Lernen, was zu Durchbrüchen in Bereichen wie Hochtemperatur-Supraleitern führen könnte. Diese Vision betont die Verbindung von KI und der physischen Welt sowie die Bedeutung der Generierung hochwertiger Daten durch Experimente und geht über traditionelle Modelle hinaus, die sich ausschließlich auf im Internet trainierte Daten verlassen.
(Quelle: dylan522p, teortaxesTex, teortaxesTex, NandoDF, NandoDF, TheRundownAI, Ar_Douillard, teortaxesTex)

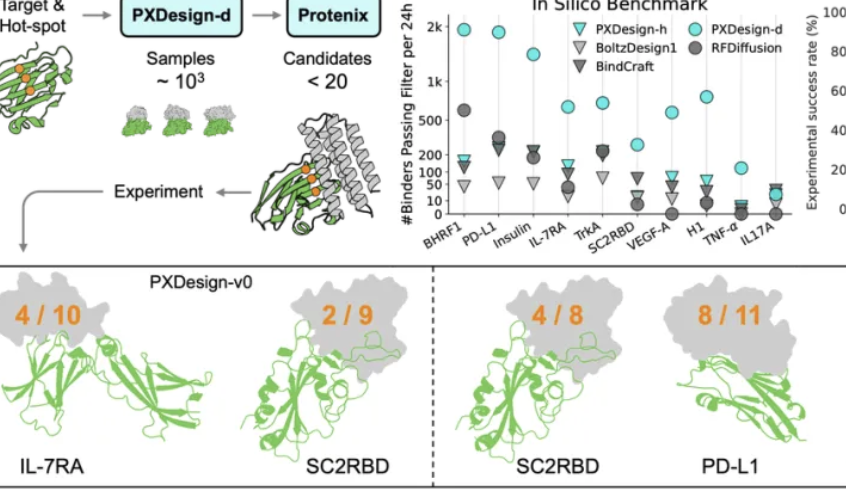
ByteDance Seed Team veröffentlicht PXDesign zur Steigerung der Proteindesign-Effizienz : Das ByteDance Seed Team hat PXDesign vorgestellt, eine skalierbare KI-Proteindesign-Methode, die in der Lage ist, Hunderte hochwertiger Proteinkandidaten innerhalb von 24 Stunden zu generieren, was die Effizienz im Vergleich zu den branchenüblichen Methoden um etwa das Zehnfache steigert. Die Methode erreicht an mehreren Targets eine Nasslabor-Erfolgsrate von 20 % bis 73 %, was deutlich höher ist als bei DeepMinds AlphaProteo. PXDesign kombiniert eine „Generieren + Filtern“-Strategie und nutzt die DiT-Netzwerkstruktur sowie das Protenix-Strukturvorhersagemodell für eine effiziente Selektion. Es bietet zudem einen öffentlich zugänglichen, kostenlosen Online-Designservice für Binder an, mit dem Ziel, die biologische Forschung zu beschleunigen.
(Quelle: 量子位)
Ant Group und HKU stellen PromptCoT 2.0 vor, mit Fokus auf Aufgabensynthese : Die Natural Language Group des Ant Group General AI Center und die Natural Language Group der University of Hong Kong haben gemeinsam das PromptCoT 2.0 Framework veröffentlicht, das darauf abzielt, die Inferenz großer Modelle und die Entwicklung von Agenten durch Aufgabensynthese voranzutreiben. Das Framework ersetzt manuelles Design durch einen Expectation-Maximization (EM)-Zyklus, der durch iterative Optimierung der Inferenzkette schwierigere und vielfältigere Probleme generiert. PromptCoT 2.0 kombiniert Reinforcement Learning und SFT, wodurch das 30B-A3B-Modell bei mathematischen Code-Inferenzaufgaben SOTA erreicht, und hat 4,77 Millionen synthetische Problemdaten als Open Source bereitgestellt, um der Community Trainingsressourcen zur Verfügung zu stellen.
(Quelle: 量子位)

EgoTwin ermöglicht erstmals die synchrone Generierung von First-Person-Videos und menschlichen Bewegungen : Die National University of Singapore, die Nanyang Technological University, die Hong Kong University of Science and Technology und das Shanghai AI Lab haben gemeinsam das EgoTwin-Framework veröffentlicht, das erstmals die gemeinsame Generierung von First-Person-Videos und menschlichen Bewegungen ermöglicht. Dieses Framework basiert auf Diffusionsmodellen und nutzt eine trimodale gemeinsame Generierung von „Text-Video-Aktion“, wobei es die beiden großen Herausforderungen der Perspektiv-Aktions-Ausrichtung und der kausalen Kopplung überwindet. Zu den Kerninnovationen gehören eine kopfzentrierte Aktionsrepräsentation, ein kybernetisch inspirierter Interaktionsmechanismus und ein asynchrones Diffusions-Trainingsframework. Die generierten Videos und Aktionen können weiter in 3D-Szenen hochskaliert werden.
(Quelle: 量子位)

🎯 Trends
Intensive Veröffentlichung und Aktualisierung neuer KI-Modelle : In jüngster Zeit gab es im KI-Bereich eine Reihe wichtiger Veröffentlichungen und Aktualisierungen von Modellen und Funktionen, darunter DeepSeek-V3.2, Claude Sonnet 4.5, GLM 4.6, Sora 2, Dreamer 4 sowie die Sofort-Checkout-Funktion von ChatGPT. DeepSeek-V3.2 wurde durch einen Sparse-Attention-Mechanismus auf vLLM optimiert und erreicht eine höhere Leistung bei langen Kontexten sowie Kosteneffizienz. Claude Sonnet 4.5 zeigt Komplexität in Bezug auf Alignment und die Theory of Mind des Benutzers und zeichnet sich durch kreatives Schreiben und Langform-Schreiben aus, einige Nutzer weisen jedoch darauf hin, dass die Qualität der Code-Generierung noch verbessert werden muss. GLM-4.6 zeigt herausragende Fähigkeiten im Frontend-Code, aber die Verbesserungen in anderen Sprachen wie Python sind nicht signifikant, und eine GGUF-quantisierte Version wurde veröffentlicht, um die lokale Bereitstellung zu unterstützen. Dreamer 4 ist ein Agent, der lernen kann, komplexe Steuerungsaufgaben innerhalb eines skalierbaren Weltmodells zu lösen.
(Quelle: Yuchenj_UW, teortaxesTex, zhuohan123, vllm_project, teortaxesTex, teortaxesTex, teortaxesTex, ImazAngel, teortaxesTex, _lewtun, nrehiew_, YiTayML, agihippo, TimDarcet, Dorialexander, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)
Multimodales Videomodell Veo3 zeigt Potenzial für allgemeine visuelle Intelligenz : Das multimodale Videomodell Veo3 wird als potenzieller Weg zur allgemeinen visuellen Intelligenz angesehen und zeigt Zero-Shot-Lern- und Inferenzfähigkeiten. Es kann eine Vielzahl von visuellen Aufgaben lösen und gilt als wichtig für den Fortschritt in der Robotik. Gleichzeitig hat das Alibaba Cloud Qwen Team die multimodale Large Language Model Serie Qwen3-VL veröffentlicht, die umfassende Upgrades in den Bereichen visueller Agent, visuelle Kodierung, räumliche Wahrnehmung, langer Kontext und Videoverständnis, multimodale Inferenz, visuelle Erkennung und OCR erhalten hat und bietet Instruct- und Thinking-Versionen an. Tencent hat auch die Modelle HunyuanImage 3.0 und Hunyuan3D-Part vorgestellt, die jeweils führende Niveaus in den Bereichen Text-zu-Bild- und 3D-Formgenerierung erreichen.
(Quelle: gallabytes, NandoDF, NandoDF, madiator, shaneguML, Yuchenj_UW, GitHub Trending, ClementDelangue)

Liquid AI stellt LFM2-Audio und spezialisierte Kleinmodelle vor : Liquid AI hat LFM2-Audio veröffentlicht, ein End-to-End-Audio-Text-Allround-Grundlagenmodell, das mit nur 1,5 Milliarden Parametern reaktionsschnelle Echtzeit-Gespräche auf dem Gerät ermöglicht und eine zehnmal schnellere Inferenzgeschwindigkeit als vergleichbare Modelle bietet. Darüber hinaus hat Liquid AI die LFM2-Serie von Fine-Tuning-Modellen vorgestellt, darunter verschiedene Varianten wie Tool, RAG und Extract, die sich auf spezifische Aufgaben konzentrieren, anstatt Universalität anzustreben. Dies deckt sich mit der Ansicht von Nvidia in ihrem Whitepaper, dass kleine, spezialisierte Modelle die Zukunft der Agentic AI sind.
(Quelle: ImazAngel, maximelabonne, Reddit r/LocalLLaMA)
Vektordatenbanken erleben „zweiten Frühling“ und xAI legt Wert auf hochwertige Daten : Es wird die Ansicht vertreten, dass Vektordatenbanken einen neuen Entwicklungshöhepunkt erreichen könnten, deren Anwendungsmodelle jedoch möglicherweise von den Erwartungen abweichen. Gleichzeitig etabliert xAI ein neues Paradigma zur Verarbeitung menschlicher Daten und betont die Bedeutung des Post-Trainings, da hochwertige Daten als Eckpfeiler auf dem Weg zu AGI angesehen werden. xAI plant, eine Community aus Experten verschiedener Bereiche aufzubauen, um gemeinsam das hochwertigste Bewertungssystem zu entwickeln.
(Quelle: _philschmid, Dorialexander, Yuhu_ai_)
🧰 Tools
KI-Roman-Generator YILING0013/AI_NovelGenerator : Ein vielseitiger Roman-Generator, der auf Large Language Models basiert. Er unterstützt den Aufbau von Weltbildern, Charakterdesign, Plot-Blueprints, intelligente Kapitelgenerierung, Statusverfolgung, Plot-Twist-Management, semantische Suche, Wissensdatenbank-Integration und einen automatischen Überprüfungsmechanismus und bietet eine visuelle GUI-Bedienung. Dieses Tool zielt darauf ab, effizient logisch kohärente und konsistent gestaltete lange Geschichten zu erstellen, und unterstützt verschiedene LLM- und Embedding-Dienste wie OpenAI, DeepSeek und Ollama.
(Quelle: GitHub Trending)
KI-gestützte Programmierwerkzeuge entwickeln sich weiter : GitHub Copilot hilft Nutzern durch von der Community beigesteuerte Anweisungen, Prompts und Chat-Modi, seinen Nutzen in verschiedenen Bereichen, Sprachen und Anwendungsfällen zu maximieren, und bietet einen MCP-Server zur Vereinfachung der Integration. Replit Agent demonstriert starke Fähigkeiten bei der Code-Migration und QA, kann große Next.js-Websites schnell von Vercel migrieren und unterstützt die Integration von In-App-Zahlungen. ServiceNows Apriel-1.5-15b-Thinker-Modell kann auf einer einzigen GPU ausgeführt werden und bietet leistungsstarke Inferenzfähigkeiten. Darüber hinaus wird das Moondream3-preview-Modell für UI-Prozesse und RPA-Aufgaben als Agent eingesetzt, und vLLM unterstützt auch die Bereitstellung von Encoder-Only-Modellen.
(Quelle: github/awesome-copilot, amasad, amasad, amasad, amasad, amasad, ImazAngel, ben_burtenshaw, amasad, amasad, amasad, amasad, TheZachMueller, Reddit r/LocalLLaMA)
Tool-Innovationen der KI in spezifischen Anwendungsbereichen : pix2tex (LaTeX OCR) kann Bilder von mathematischen Formeln in LaTeX-Code umwandeln, was die Effizienz in Forschung und Bildung erheblich steigert. BatonVoice nutzt die Befolgung von Anweisungen durch LLMs, um strukturierte Parameter für die Sprachsynthese bereitzustellen und eine steuerbare TTS zu ermöglichen. Die Hex-Plattform integriert Agentenfunktionen, die es mehr Menschen ermöglicht, KI für genaue und vertrauenswürdige Datenarbeit zu nutzen. Videogenerierungstools wie Kling 2.5 Turbo und Lucid Origin machen die Videoerstellung so bequem wie nie zuvor. Racine CU-1 ist ein GUI-Interaktionsmodell, das Klickpositionen erkennen kann und für agentenbasierte UI-Prozesse und RPA-Aufgaben geeignet ist.
(Quelle: lukas-blecher/LaTeX-OCR, teortaxesTex, dotey, dotey, Ronald_vanLoon, AssemblyAI, TheRundownAI, Kling_ai, Kling_ai, sarahcat21, mervenoyann, pierceboggan, Reddit r/OpenWebUI, Reddit r/LocalLLaMA, Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/ArtificialInteligence, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
jina-reranker-v3 Dokumenten-Reranking-Modell : jina-reranker-v3 ist ein mehrsprachiges Dokumenten-Reranking-Modell mit 0,6 Milliarden Parametern, das einen neuartigen „Last but not late interaction“-Mechanismus einführt. Diese Methode führt eine kausale Selbstaufmerksamkeitsberechnung zwischen Abfrage und Dokumenten durch, wodurch eine reichhaltige Cross-Dokument-Interaktion ermöglicht wird, bevor die kontextuellen Embeddings jedes Dokuments extrahiert werden. Diese kompakte Architektur erreicht SOTA-Leistung bei BEIR und ist gleichzeitig zehnmal kleiner als generative Listen-Reranking-Modelle.
(Quelle: HuggingFace Daily Papers)
📚 Lernen
Neueste Forschungsergebnisse zur Inferenz und zum Alignment von KI-Modellen : Studien zeigen, dass multimodale Inferenz zwar das logische Denken verbessert, aber die Wahrnehmungsgrundlagen beeinträchtigen und zu visuellem Vergessen führen kann. Die Vision-Anchored Policy Optimization (VAPO)-Methode wurde vorgeschlagen, um den Inferenzprozess stärker auf visuelle Grundlagen auszurichten. Es wird untersucht, warum Online-Alignment (z.B. GRPO) dem Offline-Alignment (z.B. DPO) überlegen ist, und eine Humanline-Variante vorgeschlagen, die durch die Simulation menschlicher Wahrnehmungsverzerrungen ermöglicht, dass auch Offline-Datentraining die Leistung des Online-Alignments erreicht. Das Test-Time Policy Adaptation for Multi-Turn Interactions (T2PAM)-Paradigma und der Optimum-Referenced One-Step Adaptation (ROSA)-Algorithmus nutzen Nutzerfeedback für die effiziente Echtzeit-Anpassung von Modellparametern und verbessern die Selbstkorrekturfähigkeit von LLMs in mehrstufigen Dialogen. NuRL (Nudging method) reduziert die Schwierigkeit von Problemen durch selbstgenerierte Prompts, wodurch Modelle aus ursprünglich „unlösbaren“ Aufgaben lernen können und so die Obergrenze der LLM-Inferenzfähigkeiten erhöht wird. RLP (Reinforcement Learning Pre-training) führt Reinforcement Learning in die Pre-Training-Phase ein, betrachtet die Thought Chain als Aktion und belohnt sie durch Informationsgewinn, um die Inferenzfähigkeit des Modells bereits in der Pre-Training-Phase zu verbessern. Exploratory Iteration (ExIt) ist eine RL-basierte automatische Kurrikulum-Methode, die LLMs dazu anleitet, ihre Lösungen während der Inferenz iterativ selbst zu verbessern, und die Leistung des Modells bei Einzel- und Mehrrundenaufgaben effektiv verbessert. Die TruthRL-Studie motiviert LLMs durch Reinforcement Learning, wahrheitsgemäße Informationen zu generieren, mit dem Ziel, das Problem der Modellhalluzinationen zu lösen. Forschungsergebnisse zeigen, dass das „Maximum Effective Context Window“ (MECW) von LLMs deutlich kleiner ist als das berichtete „Maximum Context Window“ (MCW), und das MECW variiert je nach Problemtyp, was die tatsächlichen Einschränkungen von LLMs bei der Verarbeitung langer Kontexte aufzeigt. Der Bias-Inversion Rewriting Attack (BIRA) kann LLM-Wasserzeichen theoretisch effektiv umgehen, indem er die Logits von Token unterdrückt, die möglicherweise mit Wasserzeichen versehen sind, und erreicht eine Umgehungsrate von über 99 %, während der semantische Inhalt erhalten bleibt, was die Anfälligkeit der Wasserzeichentechnologie unterstreicht.
(Quelle: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NandoDF, NandoDF, BlackHC, BlackHC, teortaxesTex, HuggingFace Daily Papers, HuggingFace Daily Papers)
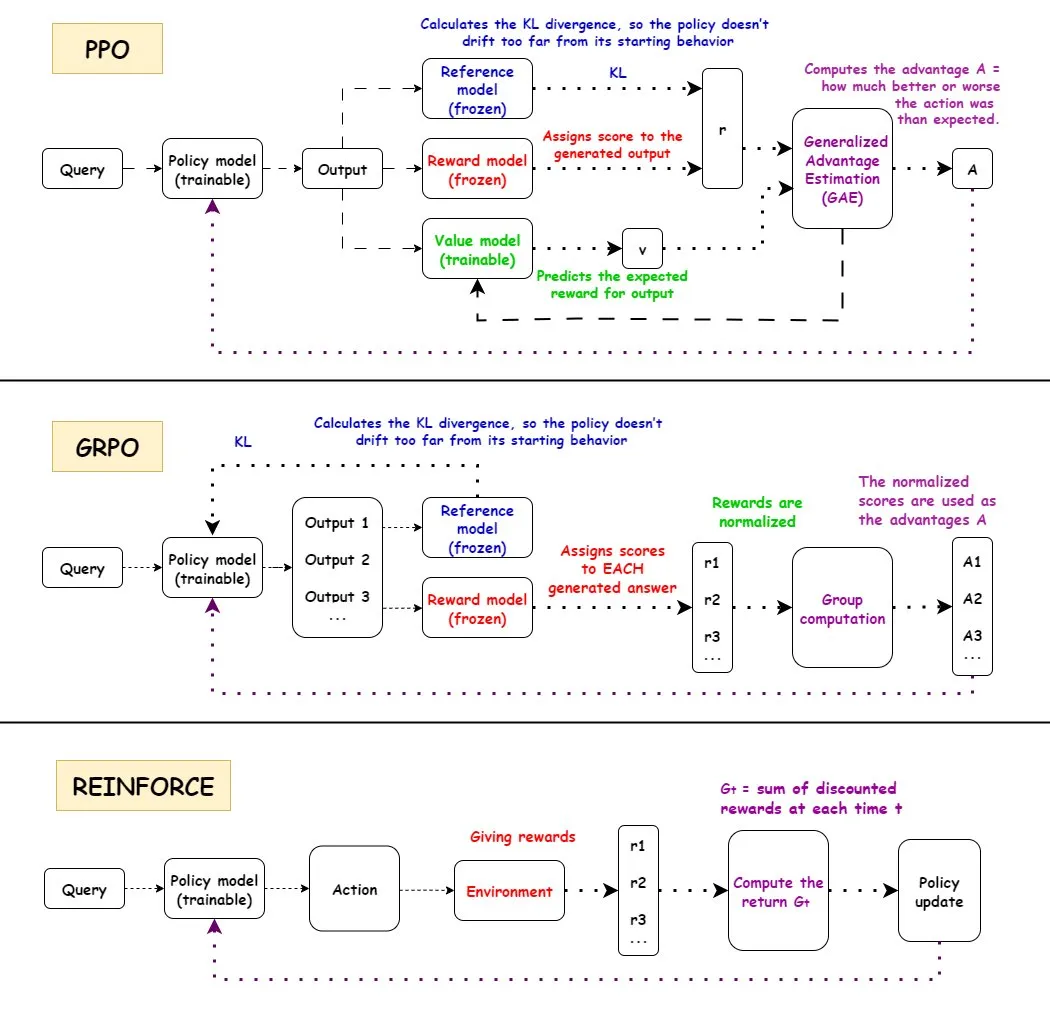
Tiefgehende Analyse von Reinforcement Learning (RL)-Algorithmen : Es werden die Arbeitsabläufe, Vor- und Nachteile sowie Anwendungsbereiche der drei wichtigsten Reinforcement Learning-Algorithmen PPO, GRPO und REINFORCE detailliert erläutert. PPO wird wegen seiner Stabilität, GRPO wegen seines relativen Belohnungsmechanismus und REINFORCE als grundlegender Algorithmus im KI-Bereich weit verbreitet eingesetzt. Studien zeigen, dass Reinforcement Learning Modelle trainieren kann, atomare Fähigkeiten zu kombinieren und in der Kombinationstiefe zu generalisieren, was das Potenzial von RL beim Erlernen neuer Fähigkeiten aufzeigt. Es wurde festgestellt, dass mehr als die Hälfte der Leistungsverbesserungen in RL-Pipelines nicht auf ML-bezogene Verbesserungen zurückzuführen ist, sondern durch technische Optimierungen wie Multithreading erreicht wird. Es wird die Frage des Informationsgehalts jedes Episodes im RL-Training untersucht, sowie die informationelle Äquivalenz verschiedener Trajektorien bei gleicher Endbelohnung. Die Community diskutiert die Definition und Wirksamkeit des RL-Pre-Trainings und weist auf Probleme hin, die durch erzwungene synthetische Diversität entstehen können, sowie auf die Notwendigkeit, der Kohärenzdegradation Aufmerksamkeit zu schenken. Für zweiarmige fünf-Finger-Humanoide Roboter wurde die Verhaltensklonierungsstrategie durch Residual Off-Policy Reinforcement Learning (ROSA) feinabgestimmt, was die Sample-Effizienz erheblich verbesserte und ein direktes Fine-Tuning der Strategie auf der Hardware ermöglichte.
(Quelle: TheTuringPost, teortaxesTex, menhguin, finbarrtimbers, arohan, tokenbender, pabbeel)
KI-Wissenschaftler und wissenschaftliche Entdeckungen : DeepScientist ist ein zielorientiertes, vollständig autonomes System zur wissenschaftlichen Entdeckung, das durch Bayes’sche Optimierung und einen hierarchischen Bewertungsprozess bahnbrechende wissenschaftliche Entdeckungen über einen Zeitraum von mehreren Monaten vorantreibt. Das System hat bereits in drei führenden KI-Aufgaben menschliche SOTA-Methoden übertroffen und alle Experimentprotokolle sowie den Systemcode als Open Source bereitgestellt. OpenAI sucht Forschungswissenschaftler mit dem Ziel, die nächste Generation wissenschaftlicher Instrumente zu entwickeln – eine KI-gesteuerte Plattform zur Beschleunigung wissenschaftlicher Entdeckungen.
(Quelle: HuggingFace Daily Papers, mcleavey)
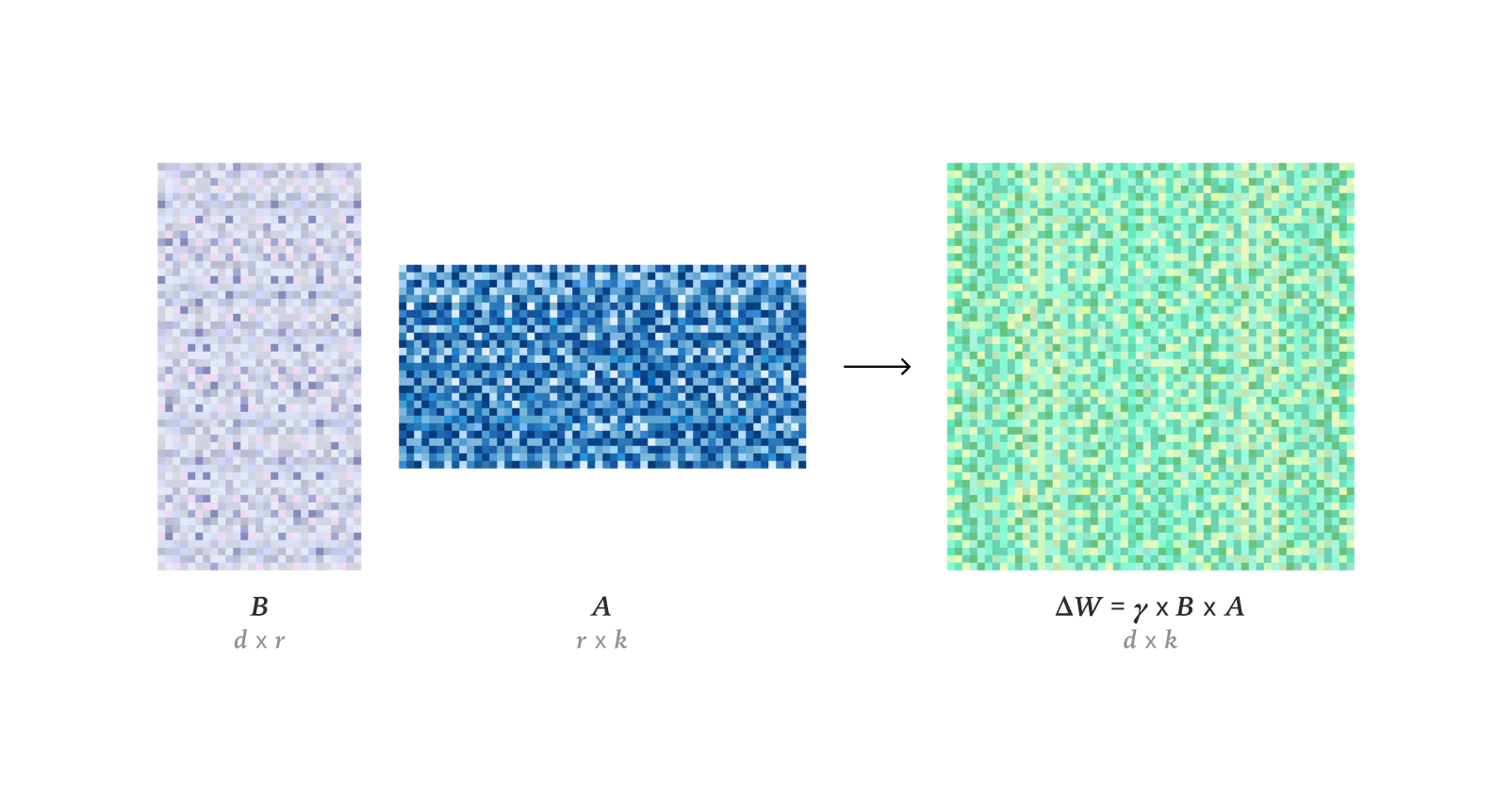
LLM Fine-Tuning und Optimierungstechniken : Studien zeigen, dass LoRA im Reinforcement Learning die Lernleistung von Full Fine-Tuning (FullFT) vollständig erreichen kann, selbst bei niedrigem Rang ausreicht, um Informationen aus dem RL-Training aufzunehmen. Das Quadrant-based Tuning (Q-Tuning)-Framework verbessert die Dateneffizienz im Supervised Fine-Tuning (SFT) erheblich durch kombiniertes Sample- und Token-Pruning und übertrifft in einigen Fällen sogar das Training mit vollständigen Daten. Der Muon-Optimierer übertrifft Adam im LLM-Training kontinuierlich, insbesondere beim Lernen von Long-Tail-Assoziationsgedächtnis, durch ein isotroperes Singularspektrum und effektive Optimierung von Heavy-Tail-Daten, was die Lernunterschiede von Adam bei klassenunsymmetrischen Daten löst. Es wird die asymptotische Schätzung des Weight RMS im AdamW-Optimierer untersucht. Eine tiefgehende Analyse der Funktionsweise des CUDA-Kerns von Flash Attention 4 enthüllt dessen Innovationen in Bereichen wie asynchroner Pipeline, Software-Softmax (kubische Approximation) und effizienter Reskalierung und erklärt seine schnellere Leistung im Vergleich zu cuDNN.
(Quelle: ImazAngel, karinanguyen_, NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex, bigeagle_xd, cloneofsimo, Tim_Dettmers, Reddit r/MachineLearning)
KI-Lernressourcen und Forschungstools : Es wurden multimodale KI-Folien geteilt, die Trends, Open-Source-Modelle, Anpassungs-/Bereitstellungstools und weitere Ressourcen abdecken. Konferenzen wie AI Engineer Europe 2026 und AI Engineer Paris wurden angekündigt, um KI-Ingenieuren eine Austauschplattform zu bieten. Karpathys „Let’s build GPT“-Serie und die Qwen-Arbeit wurden empfohlen, wobei die Bedeutung hochwertiger CTF-Trainingsdaten und Rechenressourcen für das LLM-Training betont wird. Es wurde das Potenzial des DSPyOSS-Optimierers diskutiert, eine „schichtweise“ Optimierung in B2B-KI-Anwendungsfällen zu erreichen, um der Datenknappheit zu begegnen. Axiom Math AI zielt darauf ab, einen sich selbst verbessernden, superintelligenten Inferenz-Engine zu entwickeln, beginnend mit KI-Mathematikern, um Fortschritte in der formalisierten Mathematik zu erzielen. Es wird die Anwendung von Regressions-Sprachmodellen in der Code-Generierung und -Verständnis untersucht. Es wird die Debatte erörtert, ob Reinforcement Learning ausreicht, um AGI zu erreichen. Es werden die Erfinder des Deep Residual Learning und dessen Entwicklungslinie untersucht. Jürgen Schmidhuber erklärte 2016 künstliches Bewusstsein, Weltmodelle, prädiktive Kodierung und Wissenschaft als Datenkompression und betonte seine frühen Beiträge im KI-Bereich. Eine explorative Analyse der offenen Kollaborationspraktiken, Motivationen und Governance von 14 Open-Source Large Language Model Projekten enthüllt die Vielfalt und Herausforderungen des Open-Source-LLM-Ökosystems. Dragon Hatchling (BDH) ist eine LLM-Architektur, die auf hirnähnlichen Netzwerken basiert und darauf abzielt, Transformer mit Gehirnmodellen zu verbinden, um Erklärbarkeit und Transformer-ähnliche Leistung zu erzielen. Das d^2Cache-Framework verbessert durch einen doppelten adaptiven Cache die Inferenz-Effizienz und Generierungsqualität von Diffusions-Sprachmodellen (dLLMs) erheblich. Das TimeTic-Framework schätzt die Übertragbarkeit von Zeitreihen-Grundlagenmodellen (TSFMs) durch kontextuelles Lernen, um das beste Modell für das nachgelagerte Fine-Tuning effizient auszuwählen. Visuelle Basis-Encoder können als Tokenizer für Latent Diffusion Models (LDM) dienen, um semantisch reichhaltige latente Räume zu generieren und die Bildgenerierungsleistung zu verbessern. NVFP4 ist ein neues 4-Bit-Pre-Training-Format, das durch zweistufige Skalierung, RHT und zufälliges Runden eine 6,8-fache Effizienzsteigerung bei gleichzeitiger Anpassung an die FP8-Baseline-Leistung verspricht. DA^2 (Depth Anything in Any Direction) ist ein präziser, Zero-Shot-generalisierender und End-to-End-Flut-Tiefenschätzer, der durch massive Trainingsdaten und die SphereViT-Architektur SOTA in der Panorama-Tiefenschätzung erreicht. Das SAGANet-Modell nutzt visuelle Segmentierungsmasken, Video- und Text-Cues, um eine steuerbare, objektbasierte Audiogenerierung zu ermöglichen und präzise Kontrolle für professionelle Foley-Workflows zu bieten. Mem-α ist ein Reinforcement Learning Framework, das Agenten trainiert, komplexe externe Gedächtnissysteme effektiv zu verwalten, und die Probleme des Gedächtnisaufbaus und Informationsverlusts bei LLM-Agenten im Langtextverständnis löst, sowie eine Generalisierungsfähigkeit für extrem lange Sequenzen zeigt. Das EntroPE (Entropy-Guided Dynamic Patch Encoder)-Framework erkennt dynamisch Übergangspunkte in Zeitreihen mittels bedingter Entropie und platziert Patch-Grenzen, um die zeitliche Struktur zu erhalten und die Vorhersagegenauigkeit und Effizienz zu verbessern. BUILD-BENCH ist ein anspruchsvollerer Benchmark zur Bewertung der Fähigkeit von LLM-Agenten, reale Open-Source-Software zu kompilieren, und schlägt OSS-BUILD-AGENT als starke Baseline vor. ProfVLM ist ein leichtgewichtiges Video-Sprachmodell, das durch generative Inferenz gemeinsam das Fähigkeitsniveau aus egozentrischen und externen Videos vorhersagt und Expertenfeedback generiert. Es wird die Wirksamkeit des Test-Time Training (TTT) in Grundlagenmodellen untersucht und argumentiert, dass TTT durch Spezialisierung auf Testaufgaben den In-Distribution-Testfehler erheblich reduzieren kann. CST ist eine neuartige neuronale Netzwerkarchitektur zur Verarbeitung von Bildsätzen beliebiger Kardinalität, die direkt auf 3D-Bildtensoren operiert und gleichzeitig Merkmalsextraktion und Kontextmodellierung durchführt und in Aufgaben wie der Mengenklassifikation und Anomalieerkennung hervorragende Leistungen erbringt. Das TTT3R-Framework betrachtet die 3D-Rekonstruktion als ein Online-Lernproblem, leitet die Lernrate aus dem Gedächtniszustand und der Ausrichtungszuverlässigkeit der Beobachtungen ab und verbessert die Generalisierungsfähigkeit für lange Sequenzen erheblich.
(Quelle: tonywu_71, swyx, Reddit r/deeplearning, lateinteraction, teortaxesTex, shishirpatil_, bengoertzel, arankomatsuzaki, francoisfleuret, _akhaliq, steph_palazzolo, HuggingFace Daily Papers, SchmidhuberAI, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NerdyRodent, QuixiAI, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning)
Menschlich wahrgenommene Fälschungserkennung in der KI-Videogenerierung : DeeptraceReward ist der erste feingranulare, raumzeitlich bewusste Benchmark-Datensatz zur Annotation menschlich wahrgenommener Fälschungsspuren in videogenerierten Inhalten. Dieser Datensatz enthält 4.300 detaillierte Annotationen auf 3.300 hochwertigen generierten Videos und fasst diese in neun Hauptkategorien von Fälschungsspuren zusammen. Die Studie trainiert multimodale Sprachmodelle als Belohnungsmodelle, um menschliches Urteilsvermögen und Lokalisierung zu imitieren, und übertrifft GPT-5 bei der Erkennung, Lokalisierung und Erklärung von Fälschungsindizien.
(Quelle: HuggingFace Daily Papers)
Adversarial Cleansing und 3D-Szenenrekonstruktion : MANI-Pure ist ein amplitudenadaptives Cleansing-Framework, das den Cleansing-Prozess durch die Nutzung des Amplitudenspektrums des Eingangssignals steuert und adaptiv heterogenes, frequenzorientiertes Rauschen injiziert, um hochfrequente Störungen effektiv zu unterdrücken und gleichzeitig semantisch wichtige niederfrequente Inhalte zu erhalten, und erreicht SOTA-Leistung in der Adversarial Defense. Nvidia hat das Lyra-Modell veröffentlicht, das generative 3D-Szenenrekonstruktion durch Video-Diffusionsmodell-Selbst-Destillation ermöglicht und Vorwärts-3D- und 4D-Szenengenerierung aus einem einzigen Bild/Video durchführen kann.
(Quelle: HuggingFace Daily Papers, _akhaliq)
💼 Business
OpenAI und Samsung Kooperation sowie DRAM-Bedarf : OpenAI arbeitet mit Samsung an der Entwicklung des „Stargate“-Chips und erwartet einen monatlichen Bedarf von 900.000 Hochleistungs-DRAM-Wafern. Dies deutet auf enorme Pläne und Investitionen in die zukünftige KI-Infrastruktur hin, die weit über die aktuellen Branchenerwartungen hinausgehen. Dieser riesige Bedarf hat Diskussionen über die Kosten der KI-Berechnung und einen Speicher-Superzyklus ausgelöst.
(Quelle: bookwormengr, teortaxesTex, francoisfleuret)
Finanzierung von KI-Startups und Branchenstrategie : Axiom Math AI hat einen sich selbst verbessernden, superintelligenten Inferenz-Engine vorgestellt, beginnend mit KI-Mathematikern, was in der Branche auf Aufmerksamkeit stößt. Modal hat eine Serie-B-Finanzierung von 87 Millionen US-Dollar abgeschlossen und wird mit 1,1 Milliarden US-Dollar bewertet, mit dem Ziel, die zukünftige Entwicklung der KI-Recheninfrastruktur voranzutreiben. OffDeal hat eine Serie-A-Finanzierung von 12 Millionen US-Dollar abgeschlossen und widmet sich dem Aufbau der weltweit ersten KI-nativen Investmentbank. Der japanische Verteidigungsminister besuchte das Büro von Sakana AI, was auf eine potenzielle Zusammenarbeit im Bereich KI und Verteidigung hindeutet. Ein Entwickler teilte seine Notlage mit, nachdem er 3.000 US-Dollar für den Bau von Open-Source-LLM-Modellen ausgegeben hatte und nun vor dem finanziellen Aus stand, was eine Diskussion in der Community über die Nachhaltigkeit von Open-Source-KI-Projekten auslöste. Google AI Developers haben die Gewinner des Nano Banana Hackathons bekannt gegeben und Preisgelder von über 400.000 US-Dollar vergeben, um Innovationen in KI-Anwendungen zu fördern.
(Quelle: shishirpatil_, bengoertzel, lupantech, arankomatsuzaki, francoisfleuret, akshat_b, leveredvlad, SakanaAILabs, hardmaru, Reddit r/LocalLLaMA, osanseviero)
🌟 Community
Soziale Auswirkungen und Kontroversen durch Sora 2 : Die Veröffentlichung von Sora 2 hat weitreichende soziale Auswirkungen und Kontroversen ausgelöst. Viele Nutzer befürchten eine Flut von „Slop“-Inhalten (minderwertige, sinnlose Inhalte) aus KI-generierten Videos und stellen OpenAIs Prioritäten in Frage, die eher auf Unterhaltung als auf die Lösung großer Probleme wie Krebs liegen. Gleichzeitig wird befürchtet, dass die extrem hohe Realitätsnähe von Sora 2 dazu führen könnte, dass Videos schwer von echt zu unterscheiden sind und sogar böswillig zur Generierung von Fehlinformationen oder „Biowaffen“-ähnlichen schädlichen Inhalten verwendet werden könnten. OpenAI CEO Sam Altman selbst wurde zum Protagonisten von KI-generierten Memes; er kommentierte dies mit „nicht so seltsam“ und erklärte, dass OpenAIs Fokus weiterhin auf AGI und wissenschaftlichen Entdeckungen liege und Produktveröffentlichungen dem Finanzierungsbedarf dienten. Die mächtigen Fähigkeiten von Sora 2 unterstreichen erneut den enormen Bedarf an GPUs, was Diskussionen über die hohen Kosten der KI auslöste; einige verglichen sogar die KI-Kosten mit den Baukosten des US-amerikanischen Interstate Highway Systems. Einige Kommentare kritisierten die Veröffentlichungsstrategie von Sora 2 als zu „gewöhnlich“, da es an Benchmarks und professionellem Benutzer-Support mangele und die Generierung von Inhalten für kostenlose Nutzer eingeschränkt sei.
(Quelle: teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
Nutzererfahrung und Kontroversen um Claude Sonnet 4.5 : Nutzer sind sich weitgehend einig, dass Sonnet 4.5 erhebliche Verbesserungen bei der Informationsspeicherung, Urteilsfähigkeit, Entscheidungsfindung und im kreativen Schreiben aufweist und sogar menschliche „Einstellungsänderungen“ zeigt, zum Beispiel professioneller wird, nachdem es den Nutzerkontext erkannt hat, oder korrigiert, wenn der Nutzer „Unsinn redet“. Obwohl es in einigen Bereichen hervorragende Leistungen erbringt, kritisieren Nutzer weiterhin die geringe Qualität der Code-Generierung mit „nachlässigen und dummen Fehlern“ und sogar das Problem, dass bei langen Dialogen „der Dialog zu lang“ ist und kein Code generiert werden kann, was darauf hindeutet, dass es noch weit davon entfernt ist, menschliche Software-Ingenieure zu ersetzen. Darüber hinaus haben Nutzer Sonnet 4.5 erfolgreich „gejailbreakt“, wodurch es gefährliche Rezepte und Malware-Code generieren konnte, was ernsthafte Bedenken hinsichtlich der Sicherheitsvorkehrungen des Modells aufwirft.
(Quelle: teortaxesTex, doodlestein, genmon, aiamblichus, QuixiAI, suchenzang, karminski3, aiamblichus, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Die Zukunft der Programmiersprachen im KI-Zeitalter und der Niedergang der Community-Kultur : Das IEEE Spectrum 2025 Programmiersprachen-Ranking zeigt, dass Python zum zehnten Mal in Folge die beliebteste Sprache ist und in den Kategorien Gesamtranking, Wachstumsgeschwindigkeit und Beschäftigungsorientierung jeweils den ersten Platz belegt, wobei seine Vorteile im KI-Zeitalter weiter verstärkt werden. JavaScript ist im Ranking stark abgerutscht, während die Position von SQL zwar beeinträchtigt, aber immer noch wertvoll ist. Der Bericht weist darauf hin, dass KI die Vielfalt der Programmiersprachen beendet, wobei der Matthäus-Effekt bei den Mainstream-Sprachen verstärkt wird und Nischensprachen marginalisiert werden. Gleichzeitig nimmt die Kultur der Programmierer-Community ab, da Entwickler eher dazu neigen, Hilfe bei großen Modellen zu suchen, anstatt Fragen in der Community zu stellen, was die Art des Lernens und Arbeitens verändert hat und Diskussionen über die zukünftige Rolle von Programmierern und die Bedeutung von Kernkompetenzen im Low-Level-Architekturdesign ausgelöst hat.
(Quelle: 量子位, jimmykoppel, jimmykoppel, lateinteraction, kylebrussell, Reddit r/ArtificialInteligence)

KI-Blase und Branchenentwicklungsaussichten : In den sozialen Medien wird diskutiert, ob es eine KI-Blase gibt. Einige meinen, dass die aktuelle Investitionsbegeisterung hoch ist und es möglicherweise einige „dumme“ Projekte gibt, aber die Fundamentaldaten der Branche weiterhin stark sind und die Akzeptanz von KI in Unternehmen stetig wächst. Gleichzeitig weisen Stimmen darauf hin, dass die enormen Kosten der KI-Berechnung und OpenAIs riesiger DRAM-Bedarf darauf hindeuten, dass die Branche sich weiterhin schnell ausdehnt und noch lange nicht das Stadium einer Blase erreicht hat, aber der Kapitaleinstieg auch Vorsicht erfordert.
(Quelle: arohan, pmddomingos, teortaxesTex, teortaxesTex, ajeya_cotra)
💡 Sonstiges
Humanoide Roboter und KI-gestützte Geräte : Das chinesische Robotikunternehmen LimX Dynamics hat die autonomen Bewegungs-, Biege- und Wurffähigkeiten seines humanoiden Roboters Oli demonstriert, ohne Motion Capture oder Fernsteuerung, was darauf hindeutet, dass China im Bereich der humanoiden Roboter ein ähnliches Niveau wie Figure/1X/Tesla erreicht hat. Metas Neural Band liest Nervensignale über EMG aus und in Kombination mit der Meta Rayban Display-Brille könnte es Amputierten eine revolutionäre Steuerungsmethode bieten, die eine synchrone Steuerung von Prothesen und digitalen Schnittstellen ermöglicht und möglicherweise zu einem universellen Freisprech-Controller wird. Darüber hinaus finden KI- und Robotik-Technologien vielfältige Anwendungen zur Verbesserung der Mobilität, Erkundung und Rettung, wie elektrische Roboter-Exoskelette, drahtlos gesteuerte Roboterinsekten, vierbeinige Roboter und Roboterschlangen für Rettungsmissionen.
(Quelle: Ronald_vanLoon, teortaxesTex, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Reddit r/ArtificialInteligence)
KI-Anwendungen in der Bildbearbeitung und im Grafikdesign : LayerD ist eine Methode zur Zerlegung von Rastergrafikdesigns in Ebenen, die darauf abzielt, wieder bearbeitbare kreative Workflows zu ermöglichen, indem unbedeckte Vordergrundebenen iterativ extrahiert und durch die Annahme, dass Ebenen typischerweise ein einheitliches Aussehen aufweisen, verfeinert werden, wodurch eine hochwertige Zerlegung erreicht wird. GeoRemover schlägt ein geometrisch bewusstes zweistufiges Framework vor zum Entfernen von Objekten und ihren kausalen visuellen Artefakten (wie Schatten und Reflexionen) aus Bildern, durch Entkopplung von geometrischer Entfernung und Erscheinungsbild-Rendering, und führt präferenzgesteuerte Ziele ein, um das Lernen zu leiten.
(Quelle: HuggingFace Daily Papers, HuggingFace Daily Papers)