
키워드:OpenAI Sora 2, AI 비디오 생성, 멀티모달 AI, AI 과학자, 단백질 설계, Sora 2 API, PXDesign 단백질 설계, PromptCoT 2.0 프레임워크, EgoTwin 1인칭 시점 생성, Liquid AI LFM2-오디오
🔥 포커스
OpenAI Sora 2 출시 및 그 영향 : OpenAI는 Sora 2를 공식 출시하며, 이를 “AI 버전 TikTok” iOS 소셜 앱으로 포지셔닝했다. Sora 2는 오디오 및 비디오 동시 생성을 지원하며, 물리 법칙 준수 및 제어 가능성 측면에서 크게 향상되었다. 새로운 기능으로는 “카메오”(cameos)가 포함되어 사용자가 자신이나 친구의 이미지를 AI 생성 비디오에 삽입할 수 있도록 한다. 소셜 미디어는 그 놀라운 사실감과 창의성에 대해 뜨겁게 논의했지만, 동시에 “slop” 콘텐츠의 범람, 진위 판별의 어려움, GPU 수요 급증 및 지역별 가용성(예: 영국에서는 Sora 사용 불가)에 대한 우려도 제기되었다. OpenAI CEO Sam Altman은 Sora 2가 AGI 연구 자금 조달을 목표로 하며, 흥미로운 신제품을 제공한다고 밝혔다. 커뮤니티 논의는 또한 Sora 2 초대 코드 획득, 하드웨어(GPU) 수요에 대한 추측, 그리고 미래 비디오 생성 콘텐츠의 품질 및 악의적 사용에 대한 우려를 포함했다. OpenAI는 Sora 초대 확대를 계획하고 있지만, 이에 따라 일일 생성 제한을 낮출 것이며, Sora 2 API를 출시할 것이라고 밝혔다.
(출처: 量子位, Yuchenj_UW, teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Periodic Labs, AI 과학자 플랫폼 출시로 과학 발견 가속화 : Periodic Labs는 3억 달러 규모의 투자를 유치했으며, AI 과학자를 만들어 자동화된 실험실과 AI 기반 실험을 통해 기초 과학 발견, 특히 재료 설계 분야를 가속화하는 것을 목표로 한다. 이 플랫폼은 물리적 우주를 컴퓨팅 시스템으로 간주하고, AI를 활용하여 가설 설정, 실험 및 학습을 수행하며, 고온 초전도체와 같은 분야에서 돌파구를 마련할 것으로 기대된다. 이러한 비전은 AI와 물리 세계의 연결 및 실험을 통한 고품질 데이터 생성의 중요성을 강조하며, 인터넷 데이터에만 의존하여 훈련하는 전통적인 모델을 넘어선다.
(출처: dylan522p, teortaxesTex, teortaxesTex, NandoDF, NandoDF, TheRundownAI, Ar_Douillard, teortaxesTex)

ByteDance Seed 팀, PXDesign 발표로 단백질 설계 효율성 향상 : ByteDance Seed 팀은 확장 가능한 AI 단백질 설계 방법인 PXDesign을 출시했다. 이 방법은 24시간 내에 수백 개의 고품질 단백질 후보를 생성할 수 있으며, 업계 주류 방법보다 약 10배 높은 효율성을 자랑한다. 이 방법은 여러 타겟에서 20%~73%의 습식 실험 성공률을 달성했으며, DeepMind의 AlphaProteo보다 훨씬 높다. PXDesign은 “생성 + 필터링” 전략을 결합하여, DiT 네트워크 구조와 Protenix 구조 예측 모델을 활용해 효율적인 스크리닝을 수행한다. 또한 공개 무료 binder 온라인 설계 서비스를 제공하며, 생물학 연구 탐색을 가속화하는 것을 목표로 한다.
(출처: 量子位)
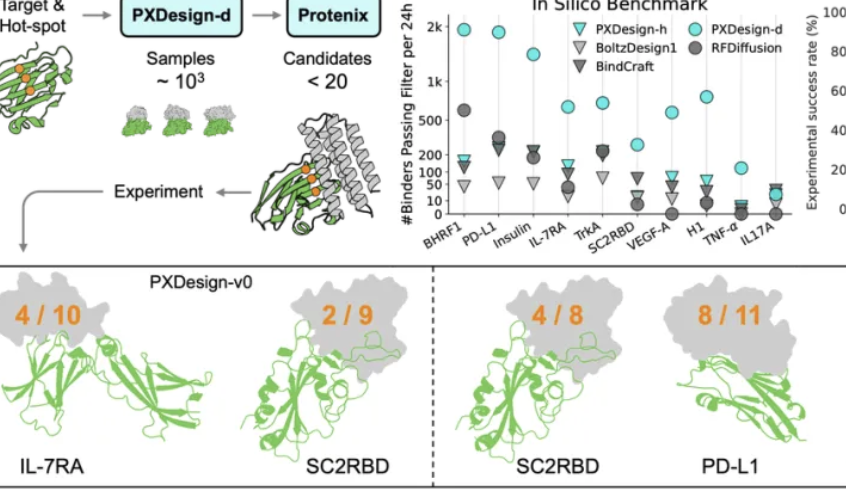
Ant Group 및 홍콩대, PromptCoT 2.0 공동 출시로 태스크 합성 집중 : Ant Group의 범용 AI 센터 자연어 그룹과 홍콩대학교 자연어 그룹은 PromptCoT 2.0 프레임워크를 공동 발표했다. 이 프레임워크는 태스크 합성을 통해 대규모 모델 추론 및 에이전트 개발을 촉진하는 것을 목표로 한다. 이 프레임워크는 기대 최대화(EM) 루프를 사용하여 수동 설계를 대체하고, 추론 체인을 반복적으로 최적화함으로써 더 어렵고 다양한 문제를 생성한다. PromptCoT 2.0은 강화 학습과 SFT를 결합하여, 30B-A3B 모델이 수학 코드 추론 태스크에서 SOTA를 달성하도록 했다. 또한 4.77M 규모의 합성 문제 데이터를 오픈 소스로 공개하여, 커뮤니티에 훈련 리소스를 제공한다.
(출처: 量子位)

EgoTwin, 1인칭 시점 비디오와 인체 동작 동시 생성 최초 달성 : 싱가포르 국립대학교, 난양 공과대학교, 홍콩 과학기술대학교 및 상하이 인공지능 연구소는 EgoTwin 프레임워크를 공동 발표했으며, 1인칭 시점 비디오와 인체 동작의 공동 생성을 최초로 달성했다. 이 프레임워크는 확산 모델을 기반으로 하며, “텍스트-비디오-동작” 삼중 모달 공동 생성을 통해 시점-동작 정렬 및 인과 결합이라는 두 가지 주요 과제를 해결했다. 핵심 혁신에는 머리 중심의 동작 표현, 제어론에서 영감을 받은 상호작용 메커니즘 및 비동기 확산 훈련 프레임워크가 포함된다. 생성된 비디오와 동작은 3D 장면으로 더욱 확장될 수 있다.
(출처: 量子位)

🎯 동향
차세대 AI 모델 집중 출시 및 업데이트 : 최근 AI 분야에서는 DeepSeek-V3.2, Claude Sonnet 4.5, GLM 4.6, Sora 2, Dreamer 4 및 ChatGPT의 즉시 결제 기능을 포함한 여러 중요한 모델과 기능이 발표 및 업데이트되었다. DeepSeek-V3.2는 희소 어텐션 메커니즘을 통해 vLLM에서 최적화되어, 더 높은 장문 컨텍스트 성능과 비용 효율성을 달성했다. Claude Sonnet 4.5는 정렬 및 사용자 마음 이론 측면에서 복잡성을 보였으며, 창의적 글쓰기 및 장문 글쓰기에서 뛰어난 성능을 발휘했다. 그러나 일부 사용자는 코드 생성 품질이 여전히 개선될 필요가 있다고 지적했다. GLM-4.6은 프런트엔드 코드 능력에서 뛰어난 성능을 보였지만, Python 등 다른 언어에서는 개선이 미미했다. 또한 로컬 배포를 지원하기 위해 GGUF 양자화 버전을 출시했다. Dreamer 4는 확장 가능한 세계 모델 내에서 복잡한 제어 태스크를 해결하는 방법을 학습할 수 있는 에이전트이다.
(출처: Yuchenj_UW, teortaxesTex, zhuohan123, vllm_project, teortaxesTex, teortaxesTex, teortaxesTex, ImazAngel, teortaxesTex, _lewtun, nrehiew_, YiTayML, agihippo, TimDarcet, Dorialexander, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)
멀티모달 비디오 모델 Veo3, 범용 시각 지능 잠재력 입증 : Veo3 비디오 모델은 범용 시각 지능으로 가는 잠재적 경로로 여겨지며, 제로샷 학습 및 추론 능력을 보여주어 다양한 시각 태스크를 해결할 수 있다. 로봇 기술 발전에 중요한 의미를 갖는 것으로 평가된다. 동시에 Alibaba Cloud Qwen 팀은 Qwen3-VL 시리즈 멀티모달 대규모 언어 모델을 발표했다. 이 모델은 시각 에이전트, 시각 인코딩, 공간 인식, 장문 컨텍스트 및 비디오 이해, 멀티모달 추론, 시각 인식 및 OCR 측면에서 전면적인 업그레이드를 거쳤으며, Instruct 및 Thinking 버전을 제공한다. Tencent 또한 HunyuanImage 3.0 및 Hunyuan3D-Part 모델을 출시했으며, 각각 텍스트-이미지 생성 및 3D 형상 생성 분야에서 선도적인 수준에 도달했다.
(출처: gallabytes, NandoDF, NandoDF, madiator, shaneguML, Yuchenj_UW, GitHub Trending, ClementDelangue)

Liquid AI, LFM2-Audio 및 전문화된 소형 모델 출시 : Liquid AI는 LFM2-Audio를 발표했다. 이는 1.5B 매개변수만으로도 장치에서 신속하게 반응하는 실시간 대화를 구현할 수 있는 엔드투엔드 오디오-텍스트 범용 기반 모델이며, 추론 속도는 동급 모델보다 10배 빠르다. 또한 Liquid AI는 Tool, RAG, Extract 등 다양한 변형을 포함하는 LFM2 시리즈 미세 조정 모델을 출시했으며, 범용성보다는 특정 태스크에 집중한다. 이는 소형 전문화 모델이 Agentic AI의 미래 방향이라는 Nvidia의 백서 견해와 일치한다.
(출처: ImazAngel, maximelabonne, Reddit r/LocalLLaMA)
벡터 데이터베이스의 “제2의 전성기”와 xAI의 고품질 데이터 중시 : 일부에서는 벡터 데이터베이스가 새로운 발전의 정점을 맞이할 수 있다고 보지만, 그 적용 방식은 예상과 다를 수 있다. 동시에 xAI는 인간 데이터를 처리하는 새로운 패러다임을 구축하고 있으며, 후처리(post-training)의 중요성을 강조하고 고품질 데이터가 AGI로 가는 초석이라고 주장한다. xAI는 각 분야 전문가들로 구성된 커뮤니티를 조직하여 최고 품질의 평가 시스템을 공동으로 구축할 계획이다.
(출처: _philschmid, Dorialexander, Yuhu_ai_)
🧰 도구
AI 소설 생성기 YILING0013/AI_NovelGenerator : 대규모 언어 모델 기반의 다기능 소설 생성기로, 세계관 아키텍처, 캐릭터 설정, 플롯 청사진, 지능형 챕터 생성, 상태 추적, 복선 관리, 의미 검색, 지식 베이스 통합 및 자동 검토 메커니즘을 지원하며, 시각화된 GUI 작업을 제공한다. 이 도구는 논리적으로 엄격하고 설정이 통일된 장편 스토리를 효율적으로 창작하는 것을 목표로 하며, OpenAI, DeepSeek, Ollama 등 다양한 LLM 및 임베딩 서비스를 지원한다.
(출처: GitHub Trending)
AI 보조 프로그래밍 도구 지속 발전 : GitHub Copilot은 커뮤니티가 기여한 지침, 프롬프트 및 채팅 모드를 통해 사용자가 다양한 분야, 언어 및 사용 사례에서 그 효용성을 극대화하도록 돕고, MCP 서버를 제공하여 통합을 간소화한다. Replit Agent는 코드 마이그레이션 및 QA 측면에서 강력한 능력을 보여주었다. 대규모 Next.js 웹사이트를 Vercel에서 빠르게 마이그레이션할 수 있으며, 앱 내 결제 통합을 지원한다. ServiceNow의 Apriel-1.5-15b-Thinker 모델은 단일 GPU에서 실행 가능하며, 강력한 추론 능력을 제공한다. 또한 Moondream3-preview 모델은 UI 프로세스 및 RPA 태스크를 대리하는 데 사용되며, vLLM 또한 인코더 전용 모델 배포를 지원한다.
(출처: github/awesome-copilot, amasad, amasad, amasad, amasad, amasad, ImazAngel, ben_burtenshaw, amasad, amasad, amasad, amasad, TheZachMueller, Reddit r/LocalLLaMA)
특정 응용 분야에서의 AI 도구 혁신 : pix2tex(LaTeX OCR)는 수학 공식 이미지를 LaTeX 코드로 변환할 수 있어, 과학 연구 및 교육 분야의 효율성을 크게 향상시킨다. BatonVoice는 LLM의 지시 따르기 능력을 활용하여 음성 합성에 구조화된 매개변수를 제공하고, 제어 가능한 TTS를 구현한다. Hex 플랫폼은 에이전트 기능을 통합하여, 더 많은 사람이 AI를 사용하여 정확하고 신뢰할 수 있는 데이터 작업을 수행할 수 있도록 한다. Kling 2.5 Turbo 및 Lucid Origin과 같은 비디오 생성 도구는 비디오 제작을 전례 없이 편리하게 만든다. Racine CU-1은 클릭 위치를 인식할 수 있는 GUI 상호작용 모델로, 에이전트 기반 UI 프로세스 및 RPA 태스크에 적합하다.
(출처: lukas-blecher/LaTeX-OCR, teortaxesTex, dotey, dotey, Ronald_vanLoon, AssemblyAI, TheRundownAI, Kling_ai, Kling_ai, sarahcat21, mervenoyann, pierceboggan, Reddit r/OpenWebUI, Reddit r/LocalLLaMA, Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/ArtificialInteligence, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
jina-reranker-v3 문서 재정렬 모델 : jina-reranker-v3은 0.6B 매개변수의 다국어 문서 재정렬 모델로, 새로운 “늦지 않은 마지막 상호작용”(last but not late interaction) 메커니즘을 도입했다. 이 방법은 쿼리와 문서 사이에 인과적 자기 어텐션 계산을 수행하여, 각 문서의 컨텍스트 임베딩을 추출하기 전에 풍부한 문서 간 상호작용을 구현한다. 이러한 컴팩트한 아키텍처는 BEIR 성능에서 SOTA를 달성했으며, 생성형 목록 재정렬 모델보다 10배 작다.
(출처: HuggingFace Daily Papers)
📚 학습
AI 모델 추론 및 정렬의 최신 연구 동향 : 연구에 따르면 멀티모달 추론은 논리적 추론을 강화하는 동시에 인지 기반을 손상시켜 시각적 망각을 초래할 수 있다. Vision-Anchored Policy Optimization (VAPO) 방법은 추론 과정이 시각적 기반에 더 집중하도록 유도하기 위해 제안되었다. 온라인 정렬(예: GRPO)이 오프라인 정렬(예: DPO)보다 우수한 이유를 탐구하고, 인간의 인지 편향을 시뮬레이션하여 오프라인 데이터 훈련도 온라인 정렬의 성능을 달성할 수 있도록 하는 Humanline 변형을 제안했다. Test-Time Policy Adaptation for Multi-Turn Interactions (T2PAM) 패러다임과 Optimum-Referenced One-Step Adaptation (ROSA) 알고리즘은 사용자 피드백을 활용하여 모델 매개변수를 실시간으로 효율적으로 조정함으로써, LLM의 다중 턴 대화에서의 자체 수정 능력을 향상시킨다. NuRL(Nudging method)은 자체 생성 프롬프트를 통해 문제 난이도를 낮추어, 모델이 원래 “해결 불가능했던” 어려운 문제에서 학습할 수 있도록 한다. 이를 통해 LLM 추론 능력의 상한선을 높인다. RLP(Reinforcement Learning Pre-training)는 강화 학습을 사전 훈련 단계에 도입하여, 사고의 사슬을 행동으로 간주하고 정보 이득을 통해 보상을 제공함으로써, 사전 훈련 단계에서부터 모델의 추론 능력을 향상시킨다. Exploratory Iteration (ExIt)은 RL 기반의 자동 커리큘럼 방법으로, LLM이 추론 시 솔루션을 반복적으로 자체 개선하도록 유도하여, 단일 턴 및 다중 턴 태스크에서 모델의 성능을 효과적으로 향상시켰다. TruthRL 연구는 강화 학습을 통해 LLM이 실제 정보를 생성하도록 유도하며, 모델 환각 문제를 해결하는 것을 목표로 한다. 연구에 따르면 LLM의 “최대 유효 컨텍스트 창”(MECW)은 보고된 “최대 컨텍스트 창”(MCW)보다 훨씬 작으며, MECW는 문제 유형에 따라 변화한다. 이는 LLM이 긴 컨텍스트를 처리할 때의 실제 한계를 드러낸다. Bias-Inversion Rewriting Attack (BIRA) 공격은 이론적으로 LLM 워터마크를 효과적으로 회피할 수 있다. 워터마크로 표시될 수 있는 토큰의 로짓을 억제함으로써, 의미 내용을 유지하면서 99% 이상의 회피율을 달성하며, 이는 워터마크 기술의 취약성을 부각시킨다.
(출처: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NandoDF, NandoDF, BlackHC, BlackHC, teortaxesTex, HuggingFace Daily Papers, HuggingFace Daily Papers)
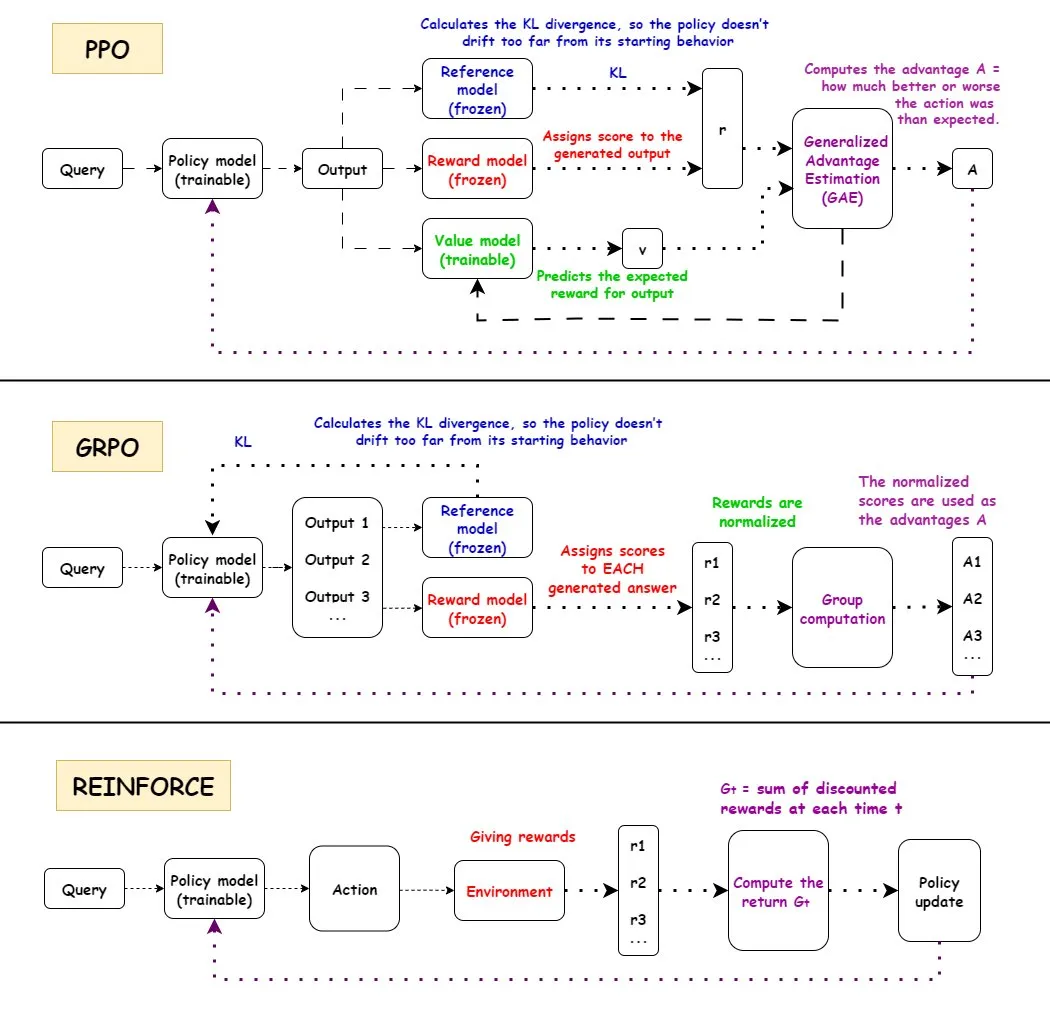
강화 학습(RL) 알고리즘 심층 분석 : PPO, GRPO 및 REINFORCE 세 가지 주요 강화 학습 알고리즘의 작동 방식, 장단점 및 적용 시나리오를 상세히 분석했다. PPO는 안정성 때문에, GRPO는 상대적 보상 메커니즘 때문에, REINFORCE는 기본 알고리즘으로서 AI 분야에서 널리 활용된다. 연구에 따르면 강화 학습은 모델이 원자적 기술을 조합하도록 훈련할 수 있으며, 조합 깊이에서 일반화를 달성할 수 있다. 이는 RL이 새로운 기술을 학습하는 데 있어 잠재력이 있음을 보여준다. RL 파이프라인의 성능 향상 중 절반 이상이 ML 관련 개선이 아니라 멀티스레딩과 같은 엔지니어링 최적화를 통해 달성되었다는 사실이 밝혀졌다. RL 훈련에서 각 에피소드의 정보량 문제 및 동일한 최종 보상 하에서 다른 궤적들의 정보 동등성에 대해 논의했다. 커뮤니티는 RL 사전 훈련의 정의와 유효성에 대해 논의하며, 강제적인 다양성 합성이 초래할 수 있는 문제를 지적하고, 일관성 저하에 대한 주의를 촉구했다. 양팔 다섯 손가락 휴머노이드 로봇을 대상으로, 잔차 오프-폴리시 강화 학습(ROSA)을 통해 행동 복제 전략을 미세 조정하여, 샘플 효율성을 크게 향상시켰다. 이는 하드웨어에서 직접 정책 미세 조정을 가능하게 했다.
(출처: TheTuringPost, teortaxesTex, menhguin, finbarrtimbers, arohan, tokenbender, pabbeel)
AI 과학자와 과학 발견 : DeepScientist는 목표 지향적이고 완전 자율적인 과학 발견 시스템으로, 베이즈 최적화와 계층적 평가 과정을 통해 수개월에 걸쳐 최첨단 과학 발견을 추진한다. 이 시스템은 세 가지 최첨단 AI 태스크에서 인간 SOTA 방법을 능가했으며, 모든 실험 로그와 시스템 코드를 오픈 소스로 공개했다. OpenAI는 연구 과학자를 채용 중이며, 차세대 과학 기기, 즉 AI 기반 플랫폼을 구축하여 과학 발견을 가속화하는 것을 목표로 한다.
(출처: HuggingFace Daily Papers, mcleavey)
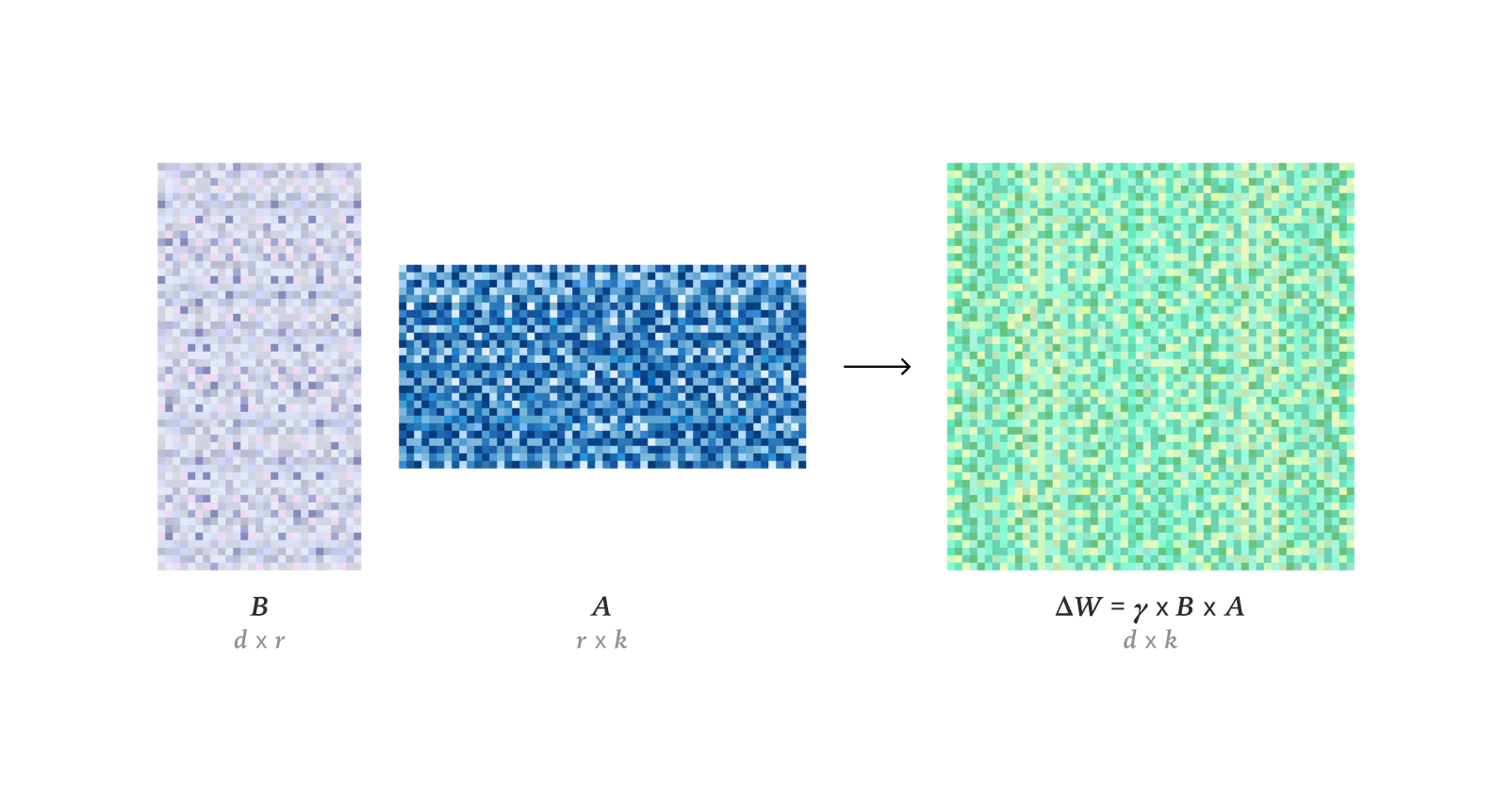
LLM 미세 조정 및 최적화 기술 : 연구에 따르면 LoRA는 강화 학습에서 전체 미세 조정(FullFT)의 학습 성능과 완벽하게 일치하며, 낮은 랭크 상황에서도 RL 훈련의 정보를 충분히 흡수할 수 있다. Quadrant-based Tuning (Q-Tuning) 프레임워크는 공동 샘플 및 토큰 가지치기를 통해 지도 미세 조정(SFT)에서 데이터 효율성을 크게 향상시켰으며, 일부 경우에는 전체 데이터 훈련을 능가하기도 했다. Muon 최적화기는 LLM 훈련에서 Adam보다 지속적으로 우수하며, 특히 꼬리 부분 연관 기억 학습 측면에서 그렇다. 더 등방성인 특이 스펙트럼과 무거운 꼬리 데이터에 대한 효과적인 최적화를 통해 범주 불균형 데이터에서 Adam의 학습 차이를 해결했다. AdamW 최적화기의 가중치 RMS에 대한 점근적 추정을 연구했다. Flash Attention 4의 CUDA 커널 작동 원리를 심층 분석하여, 비동기 파이프라인, 소프트웨어 softmax(입방 근사) 및 효율적인 재조정 등에서의 혁신을 밝혀냈으며, cuDNN보다 빠른 성능을 설명했다.
(출처: ImazAngel, karinanguyen_, NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex, bigeagle_xd, cloneofsimo, Tim_Dettmers, Reddit r/MachineLearning)
AI 학습 자료 및 연구 도구 : 트렌드, 오픈 소스 모델, 맞춤형/배포 도구 및 추가 리소스를 포함하는 멀티모달 AI 슬라이드를 공유했다. AI Engineer Europe 2026 및 AI Engineer Paris와 같은 회의를 발표하여 AI 엔지니어들에게 교류의 장을 제공한다. Karpathy의 “Let’s build GPT” 시리즈와 Qwen 논문을 추천하며, 고품질 CTF 훈련 데이터와 컴퓨팅 리소스가 LLM 훈련에 중요함을 강조했다. DSPyOSS 최적화기가 B2B AI 사용 사례에서 데이터 희소성에 대응하기 위한 “계층적” 최적화를 구현할 잠재력에 대해 논의했다. Axiom Math AI는 자체 개선하는 초지능 추론기를 구축하는 것을 목표로 하며, AI 수학자로부터 시작하여 형식 수학 분야에서 진전을 이룬다. 회귀 언어 모델의 코드 생성 및 이해 측면에서의 적용을 연구했다. 강화 학습이 AGI를 달성하기에 충분한지에 대한 논쟁을 탐구했다. 깊은 잔차 학습(Deep Residual Learning)의 발명자와 그 진화 타임라인을 탐구했다. Jürgen Schmidhuber는 2016년에 인공 의식, 세계 모델, 예측 코딩 및 데이터 압축으로서의 과학을 설명하며, AI 분야에서의 초기 기여를 강조했다. 14개 오픈 소스 대규모 언어 모델 프로젝트의 개방형 협업 관행, 동기 및 거버넌스에 대한 탐색적 분석을 수행하여, 오픈 소스 LLM 생태계의 다양성과 과제를 드러냈다. Dragon Hatchling (BDH)은 뇌 유사 네트워크 기반의 LLM 아키텍처로, 트랜스포머와 뇌 모델을 연결하여 설명 가능성과 트랜스포머 유사 성능을 달성하는 것을 목표로 한다. d^2Cache 프레임워크는 이중 적응형 캐시를 통해 확산 언어 모델(dLLMs)의 추론 효율성과 생성 품질을 크게 향상시킨다. TimeTic 프레임워크는 컨텍스트 학습을 통해 시계열 기반 모델(TSFMs)의 전이 가능성을 추정하여, 하위 미세 조정을 위한 최적의 모델을 효율적으로 선택한다. 시각 기반 인코더는 잠재 확산 모델(LDM)의 토크나이저 역할을 하여, 의미론적으로 풍부한 잠재 공간을 생성하고 이미지 생성 성능을 향상시킬 수 있다. NVFP4는 새로운 4비트 사전 훈련 형식으로, 두 단계 스케일링, RHT 및 무작위 반올림을 통해 FP8 기준 성능과 일치하면서도 6.8배의 효율성 향상을 달성할 것으로 기대된다. DA^2 (Depth Anything in Any Direction)는 정확하고 제로샷 일반화가 가능한 엔드투엔드 파노라마 깊이 추정기로, 대규모 훈련 데이터와 SphereViT 아키텍처를 통해 파노라마 깊이 추정에서 SOTA를 달성했다. SAGANet 모델은 시각 분할 마스크, 비디오 및 텍스트 단서를 활용하여 제어 가능한 객체 수준의 오디오 생성을 구현하며, 전문 폴리(Foley) 워크플로우에 정교한 제어를 제공한다. Mem-α는 강화 학습 프레임워크로, 에이전트가 복잡한 외부 기억 시스템을 효과적으로 관리하도록 훈련함으로써 LLM 에이전트의 장문 텍스트 이해에서 기억 구축 및 정보 손실 문제를 해결했으며, 초장문 시퀀스에 대한 일반화 능력을 보여주었다. EntroPE (Entropy-Guided Dynamic Patch Encoder) 프레임워크는 조건부 엔트로피를 통해 시계열 내 전환점을 동적으로 감지하고, 패치 경계를 배치하여 시간 구조를 보존하고 예측 정확도 및 효율성을 향상시킨다. BUILD-BENCH는 LLM 에이전트가 실제 오픈 소스 소프트웨어를 컴파일하는 능력을 평가하기 위한 더욱 도전적인 벤치마크이며, OSS-BUILD-AGENT를 강력한 기준선으로 제안했다. ProfVLM은 경량 비디오-언어 모델로, 생성적 추론을 통해 자기 중심 및 외부 시점 비디오에서 기술 수준을 공동으로 예측하고 전문가 피드백을 생성한다. 기반 모델에서 테스트 시간 훈련(TTT)의 유효성을 탐구하며, TTT가 테스트 태스크에 대한 전문화를 통해 분포 내 테스트 오류를 크게 줄일 수 있다고 주장한다. CST는 임의의 카디널리티 이미지 세트를 처리하는 새로운 신경망 아키텍처로, 3D 이미지 텐서에서 직접 작동하며 특징 추출과 컨텍스트 모델링을 동시에 수행한다. 세트 분류 및 이상 감지 등의 태스크에서 뛰어난 성능을 보인다. TTT3R 프레임워크는 3D 재구성을 온라인 학습 문제로 간주하며, 기억 상태와 관측 정렬 신뢰도를 통해 학습률을 도출하여 장문 시퀀스 일반화 능력을 크게 향상시켰다.
(출처: tonywu_71, swyx, Reddit r/deeplearning, lateinteraction, teortaxesTex, shishirpatil_, bengoertzel, arankomatsuzaki, francoisfleuret, _akhaliq, steph_palazzolo, HuggingFace Daily Papers, SchmidhuberAI, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NerdyRodent, QuixiAI, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning)
AI 비디오 생성에서 인간 인지 위조 탐지 : DeeptraceReward는 인간이 인지하는 비디오 생성 위조 흔적을 주석 처리하기 위한 최초의 세분화된 시공간 인지 벤치마크 데이터셋이다. 이 데이터셋은 3.3K개의 고품질 생성 비디오에 대한 4.3K개의 상세 주석을 포함하며, 이를 9가지 주요 위조 흔적 범주로 통합했다. 연구는 멀티모달 언어 모델을 보상 모델로 훈련시켜 인간의 판단과 위치를 모방하도록 했으며, 위조 단서 식별, 위치 파악 및 설명 측면에서 GPT-5보다 우수하다.
(출처: HuggingFace Daily Papers)
적대적 정화 및 3D 장면 재구성 : MANI-Pure는 진폭 적응형 정화 프레임워크로, 입력 신호의 진폭 스펙트럼을 활용하여 정화 과정을 안내하고, 이질적이고 주파수 지향적인 노이즈를 적응적으로 주입한다. 이를 통해 고주파 교란을 효과적으로 억제하면서 의미적으로 중요한 저주파 콘텐츠를 보존하며, 적대적 방어 측면에서 SOTA 성능을 달성했다. Nvidia는 Lyra 모델을 발표했다. 이 모델은 비디오 확산 모델 자체 증류를 통해 생성형 3D 장면 재구성을 구현하며, 단일 이미지/비디오에서 피드포워드 3D 및 4D 장면 생성이 가능하다.
(출처: HuggingFace Daily Papers, _akhaliq)
💼 비즈니스
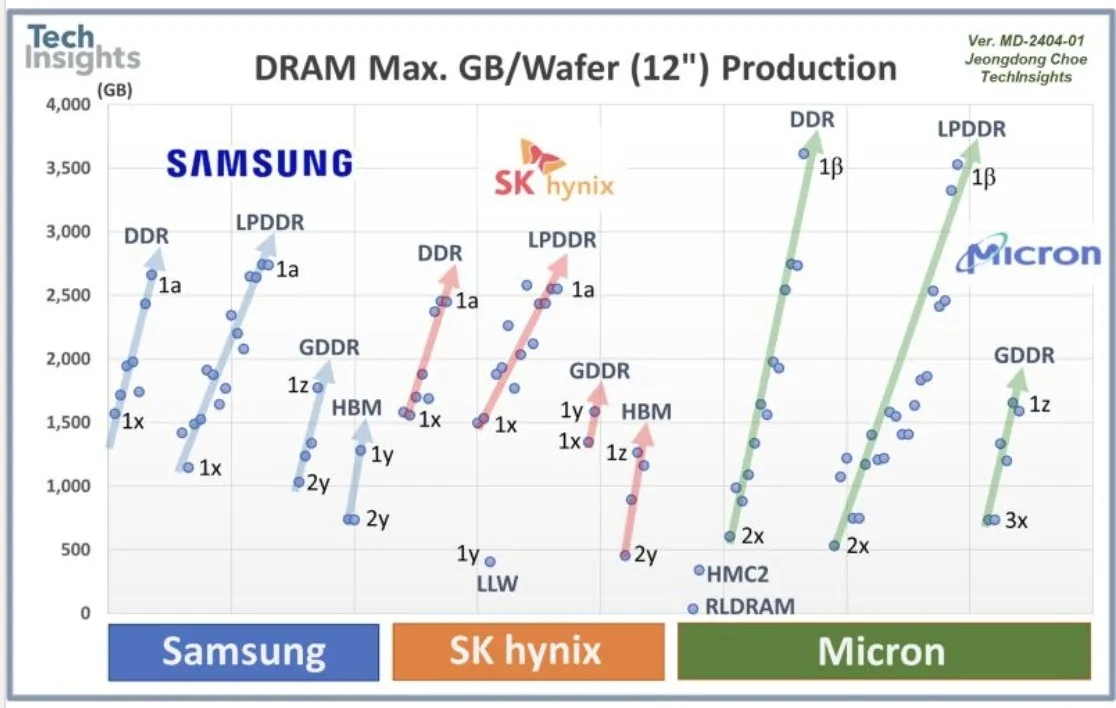
OpenAI와 삼성 협력 및 DRAM 수요 : OpenAI는 삼성과 협력하여 “Stargate” 칩을 개발 중이며, 매월 90만 개의 고성능 DRAM 웨이퍼가 필요할 것으로 예상된다. 이는 미래 AI 인프라에 대한 막대한 계획과 투자를 시사하며, 현재 업계 예상을 훨씬 뛰어넘는 수준이다. 이러한 엄청난 수요량은 AI 컴퓨팅 비용과 메모리 슈퍼 사이클에 대한 논의를 촉발했다.
(출처: bookwormengr, teortaxesTex, francoisfleuret)
AI 스타트업 투자 유치 및 산업 배치 : Axiom Math AI는 자체 개선하는 초지능 추론기를 출시했으며, AI 수학자를 시작점으로 업계의 주목을 받고 있다. Modal은 8,700만 달러 규모의 시리즈 B 투자를 유치하여 기업 가치 11억 달러를 달성했다. 이는 AI 컴퓨팅 인프라의 미래 발전을 추진하는 것을 목표로 한다. OffDeal은 1,200만 달러 규모의 시리즈 A 투자를 유치했으며, 세계 최초의 AI 네이티브 투자 은행 구축에 전념하고 있다. 일본 방위상은 Sakana AI 사무실을 방문하여, 국방 분야에서의 AI 잠재적 협력을 시사했다. 한 개발자는 오픈 소스 LLM 모델 구축에 3,000달러를 지출한 후 자금 고갈이라는 어려움에 직면했다고 공유했다. 이는 오픈 소스 AI 프로젝트의 지속 가능성에 대한 커뮤니티 논의를 촉발했다. Google AI 개발자들은 Nano Banana Hackathon의 수상자를 발표하고, 40만 달러 이상의 상금을 수여했다. 이는 AI 애플리케이션 혁신을 장려하기 위함이다.
(출처: shishirpatil_, bengoertzel, lupantech, arankomatsuzaki, francoisfleuret, akshat_b, leveredvlad, SakanaAILabs, hardmaru, Reddit r/LocalLLaMA, osanseviero)
🌟 커뮤니티
Sora 2로 인한 사회적 영향 및 논란 : Sora 2의 발표는 광범위한 사회적 영향과 논란을 불러일으켰다. 많은 사용자는 AI 생성 비디오의 “slop”(저품질, 무의미한 콘텐츠) 범람을 우려하며, OpenAI의 우선순위가 암과 같은 중대한 문제 해결이 아닌 엔터테인먼트에 있다고 의문을 제기했다. 동시에 Sora 2의 초고도 사실감이 비디오의 진위 판별을 어렵게 만들고, 심지어 허위 정보나 “생물학적 무기”와 같은 유해 콘텐츠 생성에 악의적으로 사용될 수 있다는 우려도 제기되었다. OpenAI CEO Sam Altman 본인도 AI 생성 밈의 주인공이 되었으며, 이에 대해 “그리 이상하지 않다”고 말했다. 그는 OpenAI의 초점은 여전히 AGI와 과학 발견에 있으며, 제품 출시는 자금 조달을 위한 것이라고 설명했다. Sora 2의 강력한 능력은 GPU에 대한 막대한 수요를 다시 한번 부각시켰고, AI의 높은 비용에 대한 논의를 촉발했다. 심지어 일부는 AI 비용을 미국 주간 고속도로 시스템 건설 비용과 비교하기도 했다. 일부 평론가들은 Sora 2의 출시 전략이 너무 “평범하다”고 지적하며, 벤치마크 테스트와 전문 사용자 지원이 부족하고, 무료 사용자 생성 콘텐츠에 제한을 두는 점을 비판했다.
(출처: teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
Claude Sonnet 4.5의 사용자 경험 및 논란 : 사용자들은 일반적으로 Sonnet 4.5가 정보 보존, 판단력, 의사 결정 및 창의적 글쓰기 측면에서 크게 향상되었으며, 심지어 인간과 유사한 “태도 변화”를 보인다고 평가했다. 예를 들어, 사용자 배경을 파악한 후 더 전문적으로 변하거나, 사용자가 “엉뚱한 소리”를 할 때 이를 바로잡는 식이다. 일부 측면에서 뛰어난 성능을 보였음에도 불구하고, 여전히 일부 사용자는 코드 생성 품질이 낮고 “부주의하고 어리석은 오류”가 존재한다고 비판했다. 심지어 긴 대화를 처리할 때 “대화가 너무 길어” 코드를 생성할 수 없는 문제가 발생하여, 인간 소프트웨어 엔지니어를 대체하기에는 아직 멀었다고 평가했다. 또한 일부 사용자는 Sonnet 4.5를 성공적으로 “탈옥”시켜 위험한 레시피와 악성 소프트웨어 코드를 생성하게 했으며, 이는 모델의 안전 장치에 대한 심각한 우려를 불러일으켰다.
(출처: teortaxesTex, doodlestein, genmon, aiamblichus, QuixiAI, suchenzang, karminski3, aiamblichus, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
AI 시대 프로그래밍 언어의 미래와 커뮤니티 문화의 쇠퇴 : IEEE Spectrum 2025 프로그래밍 언어 순위에 따르면 Python은 10년 연속 가장 인기 있는 언어로 선정되었으며, 종합 순위, 성장 속도, 취업 지향성 세 가지 항목 모두에서 1위를 차지했다. 그 장점은 AI 시대에 더욱 확대되었다. JavaScript 순위는 크게 하락했지만, SQL의 위상은 타격을 받았음에도 불구하고 여전히 가치를 지닌다. 보고서는 AI가 프로그래밍 언어의 다양성을 종식시키고 있으며, 주류 언어의 마태 효과가 심화되어 비주류 언어는 소외될 것이라고 지적했다. 동시에 프로그래머 커뮤니티 문화가 쇠퇴하고 있으며, 개발자들은 커뮤니티에 질문하기보다 대규모 모델에 도움을 요청하는 경향이 강해졌다. 이는 학습 및 작업 방식을 변화시켰고, 미래 프로그래머의 역할과 하위 아키텍처 설계 핵심 능력의 중요성에 대한 논의를 촉발했다.
(출처: 量子位, jimmykoppel, jimmykoppel, lateinteraction, kylebrussell, Reddit r/ArtificialInteligence)

AI 버블과 산업 발전 전망 : 소셜 미디어에서는 AI 산업에 거품이 있는지에 대한 논의가 활발하다. 일부에서는 현재 투자 열기가 뜨겁고 일부 “어리석은” 프로젝트가 있을 수 있지만, 산업의 펀더멘털은 여전히 강하며, 기업의 AI 채택은 꾸준히 증가하고 있다고 본다. 동시에 일부에서는 AI 컴퓨팅의 막대한 비용과 OpenAI의 DRAM에 대한 엄청난 수요가 산업이 여전히 빠르게 확장 중이며, 거품 붕괴 단계에 훨씬 미치지 못했음을 시사한다고 지적한다. 그러나 자본 유입에 대한 경계심도 필요하다.
(출처: arohan, pmddomingos, teortaxesTex, teortaxesTex, ajeya_cotra)
💡 기타
휴머노이드 로봇과 AI 보조 장치 : 중국 로봇 회사 LimX Dynamics는 자사의 휴머노이드 로봇 Oli의 자율 이동, 굽히기 및 던지기 능력을 시연했다. 모션 캡처나 원격 조작 없이 이루어진 이 시연은 중국이 휴머노이드 로봇 분야에서 Figure/1X/Tesla와 동등한 수준에 도달했음을 보여준다. Meta의 Neural Band는 EMG를 통해 신경 신호를 읽어내고, Meta Rayban 디스플레이 안경과 결합하여 절단 환자에게 혁신적인 제어 방식을 제공할 것으로 기대된다. 이는 의수족과 디지털 인터페이스의 동기화된 제어를 가능하게 하며, 범용 핸즈프리 컨트롤러가 될 수도 있다. 또한 AI와 로봇 기술은 이동성 강화, 탐사 및 구조 분야에서도 다양하게 응용되고 있다. 예를 들어, 전동 로봇 외골격, 무선 제어 로봇 곤충, 사족 보행 로봇, 구조 임무용 로봇 뱀 등이 있다.
(출처: Ronald_vanLoon, teortaxesTex, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Reddit r/ArtificialInteligence)
이미지 편집 및 그래픽 디자인에서의 AI 적용 : LayerD는 래스터 그래픽 디자인을 레이어로 분해하는 방법으로, 재편집 가능한 창의적 워크플로우를 구현하는 것을 목표로 한다. 가려지지 않은 전경 레이어를 반복적으로 추출하고, 레이어가 일반적으로 통일된 외관을 보인다는 가정을 활용하여 세분화함으로써, 고품질 분해를 달성한다. GeoRemover는 이미지에서 객체 및 그 인과적 시각적 아티팩트(예: 그림자 및 반사)를 제거하기 위한 기하학적 인식 2단계 프레임워크를 제안한다. 기하학적 제거와 외관 렌더링을 분리하고, 학습을 안내하기 위한 선호도 기반 목표를 도입한다.
(출처: HuggingFace Daily Papers, HuggingFace Daily Papers)