
Kata Kunci:OpenAI Sora 2, AI video generasi, AI multimodal, Ilmuwan AI, Desain protein, Sora 2 API, PXDesign desain protein, Kerangka PromptCoT 2.0, Generasi sudut pandang pertama EgoTwin, Liquid AI LFM2-Audio
🔥 Fokus
OpenAI Sora 2 Dirilis dan Dampaknya : OpenAI secara resmi merilis Sora 2, memposisikannya sebagai aplikasi sosial iOS “TikTok versi AI” yang mendukung pembuatan audio dan video secara sinkron, dengan peningkatan signifikan dalam kepatuhan terhadap hukum fisika dan kontrol. Fitur baru termasuk “cameos”, yang memungkinkan pengguna untuk menyisipkan gambar diri mereka atau teman ke dalam video yang dihasilkan AI. Media sosial ramai membahas realisme dan kreativitasnya yang menakjubkan, namun ada juga kekhawatiran tentang membanjirnya konten “slop” (berkualitas rendah), kesulitan membedakan yang asli dan palsu, lonjakan permintaan GPU, serta ketersediaan regional (misalnya, Sora tidak tersedia di Inggris). CEO OpenAI Sam Altman menanggapi bahwa Sora 2 bertujuan untuk mendanai penelitian AGI dan menyediakan produk baru yang menarik. Diskusi komunitas juga mencakup cara mendapatkan kode undangan Sora 2, spekulasi tentang kebutuhan hardware (GPU), serta kekhawatiran tentang kualitas konten video yang dihasilkan di masa depan dan potensi penyalahgunaan. OpenAI berencana untuk memperluas undangan Sora, tetapi akan mengurangi batas pembuatan harian, dan mengungkapkan akan merilis Sora 2 API.
(Sumber: 量子位, Yuchenj_UW, teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Periodic Labs Meluncurkan Platform Ilmuwan AI, Mempercepat Penemuan Ilmiah : Periodic Labs mendapatkan pendanaan $300 juta, dengan tujuan menciptakan AI scientist untuk mempercepat penemuan ilmiah dasar melalui laboratorium otomatis dan eksperimen berbasis AI, khususnya di bidang materials design. Platform ini bertujuan untuk melihat alam semesta fisik sebagai sistem komputasi, menggunakan AI untuk membuat hipotesis, bereksperimen, dan belajar, dengan harapan dapat mencapai terobosan di bidang seperti superkonduktor suhu tinggi. Visi ini menekankan koneksi AI dengan dunia fisik, serta pentingnya menghasilkan data berkualitas tinggi melalui eksperimen, melampaui model tradisional yang hanya mengandalkan data pelatihan dari internet.
(Sumber: dylan522p, teortaxesTex, teortaxesTex, NandoDF, NandoDF, TheRundownAI, Ar_Douillard, teortaxesTex)

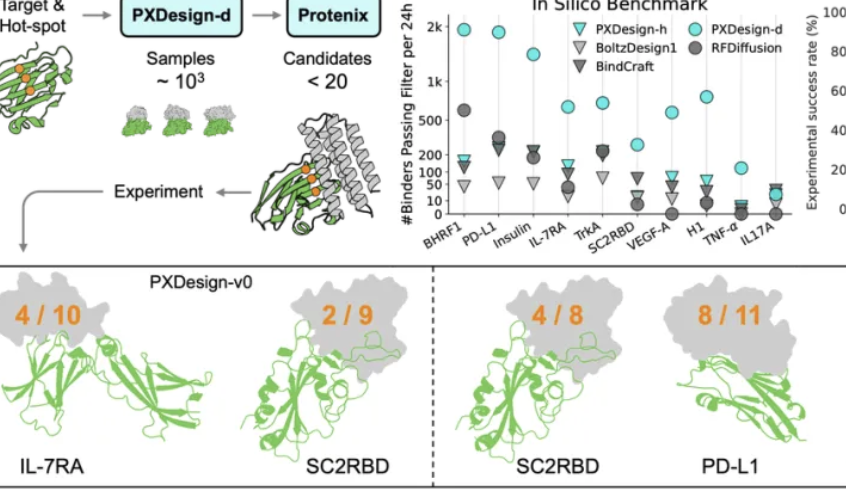
Tim Seed ByteDance Merilis PXDesign, Meningkatkan Efisiensi Desain Protein : Tim Seed ByteDance meluncurkan PXDesign, sebuah metode desain protein AI yang dapat diskalakan, mampu menghasilkan ratusan kandidat protein berkualitas tinggi dalam 24 jam, meningkatkan efisiensi sekitar 10 kali lipat dibandingkan metode mainstream di industri. Metode ini mencapai tingkat keberhasilan eksperimen basah 20%-73% pada beberapa target, jauh lebih tinggi dari DeepMind AlphaProteo. PXDesign menggabungkan strategi “generasi + filter”, menggunakan struktur jaringan DiT dan model prediksi struktur Protenix untuk penyaringan efisien, serta menyediakan layanan desain binder online gratis dan terbuka, bertujuan untuk mempercepat eksplorasi penelitian biologi.
(Sumber: 量子位)
Ant Group dan HKU Bersama Meluncurkan PromptCoT 2.0, Berfokus pada Sintesis Tugas : Grup Pemrosesan Bahasa Alami dari Ant Group General AI Center dan Grup Pemrosesan Bahasa Alami dari University of Hong Kong bersama-sama merilis kerangka kerja PromptCoT 2.0, yang bertujuan untuk mendorong inferensi model besar dan pengembangan agen melalui sintesis tugas. Kerangka kerja ini mengadopsi siklus Expectation-Maximization (EM) menggantikan desain manual, mengoptimalkan rantai inferensi secara iteratif untuk menghasilkan masalah yang lebih sulit dan beragam. PromptCoT 2.0 menggabungkan Reinforcement Learning dan SFT, memungkinkan model 30B-A3B mencapai SOTA dalam tugas inferensi kode matematika, dan membuka sumber data 4.77M masalah sintetis, menyediakan sumber daya pelatihan bagi komunitas.
(Sumber: 量子位)

EgoTwin Pertama Kali Mencapai Generasi Video Sudut Pandang Pertama dan Gerakan Manusia yang Sinkron : National University of Singapore, Nanyang Technological University, Hong Kong University of Science and Technology, dan Shanghai AI Lab bersama-sama merilis kerangka kerja EgoTwin, untuk pertama kalinya mencapai generasi gabungan video sudut pandang pertama dan gerakan manusia. Kerangka kerja ini didasarkan pada diffusion model, menghasilkan gabungan tiga modalitas “teks-video-gerakan”, mengatasi dua tantangan utama: penyelarasan sudut pandang-gerakan dan kopling kausal. Inovasi inti meliputi representasi gerakan berpusat pada kepala, mekanisme interaksi yang terinspirasi sibernetika, dan kerangka pelatihan difusi asinkron. Video dan gerakan yang dihasilkan dapat lebih ditingkatkan ke dalam skenario 3D.
(Sumber: 量子位)

🎯 Tren
Model AI Generasi Baru Dirilis dan Diperbarui Secara Intensif : Baru-baru ini, bidang AI menyaksikan rilis dan pembaruan intensif dari beberapa model dan fitur penting, termasuk DeepSeek-V3.2, Claude Sonnet 4.5, GLM 4.6, Sora 2, Dreamer 4, serta fitur checkout instan ChatGPT. DeepSeek-V3.2 dioptimalkan pada vLLM melalui mekanisme sparse attention, mencapai kinerja long context yang lebih tinggi dan efisiensi biaya. Claude Sonnet 4.5 menunjukkan kompleksitas dalam alignment dan user’s theory of mind, serta unggul dalam creative writing dan long-form writing, namun beberapa pengguna juga mencatat bahwa kualitas code generation-nya masih perlu ditingkatkan. GLM-4.6 menunjukkan kinerja yang luar biasa dalam kemampuan kode frontend, tetapi peningkatannya tidak signifikan dalam bahasa lain seperti Python, dan versi kuantisasi GGUF telah dirilis untuk mendukung local deployment. Dreamer 4 adalah agen yang dapat belajar memecahkan tugas kontrol kompleks dalam scalable world model.
(Sumber: Yuchenj_UW, teortaxesTex, zhuohan123, vllm_project, teortaxesTex, teortaxesTex, teortaxesTex, ImazAngel, teortaxesTex, _lewtun, nrehiew_, YiTayML, agihippo, TimDarcet, Dorialexander, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)
Model Video Multimodal Veo3 Menunjukkan Potensi Kecerdasan Visual Umum : Model video Veo3 dianggap sebagai jalur potensial menuju general visual intelligence, menunjukkan kemampuan zero-shot learning dan reasoning, mampu menyelesaikan berbagai tugas visual, dan dianggap sangat penting untuk kemajuan robotika. Pada saat yang sama, tim Qwen Alibaba Cloud merilis seri model bahasa besar multimodal Qwen3-VL, dengan peningkatan komprehensif dalam visual agent, visual encoding, spatial perception, long context dan video understanding, multimodal reasoning, visual recognition, dan OCR, serta menyediakan versi Instruct dan Thinking. Tencent juga meluncurkan model HunyuanImage 3.0 dan Hunyuan3D-Part, yang masing-masing mencapai tingkat terdepan dalam text-to-image dan 3D shape generation.
(Sumber: gallabytes, NandoDF, NandoDF, madiator, shaneguML, Yuchenj_UW, GitHub Trending, ClementDelangue)

Liquid AI Meluncurkan LFM2-Audio dan Model Kecil Spesialis : Liquid AI merilis LFM2-Audio, sebuah foundation model audio-to-text end-to-end yang serbaguna, dengan hanya 1.5B parameter dapat mencapai percakapan real-time yang responsif on-device, dengan kecepatan inferensi 10 kali lebih cepat dari model sejenis. Selain itu, Liquid AI juga meluncurkan seri model fine-tuned LFM2, termasuk varian seperti Tool, RAG, dan Extract, yang berfokus pada tugas-tugas spesifik daripada mengejar generalitas, sejalan dengan pandangan whitepaper Nvidia tentang model spesialis kecil sebagai arah masa depan Agentic AI.
(Sumber: ImazAngel, maximelabonne, Reddit r/LocalLLaMA)
Vector Database Menyambut “Musim Semi Kedua” dan Penekanan xAI pada Data Berkualitas Tinggi : Ada pandangan bahwa vector database mungkin akan memasuki puncak perkembangan baru, tetapi mode aplikasinya mungkin berbeda dari yang diharapkan. Pada saat yang sama, xAI sedang membangun paradigma baru untuk memproses data manusia, menekankan pentingnya post-training, dan percaya bahwa data berkualitas tinggi adalah landasan menuju AGI. xAI berencana untuk membentuk komunitas yang terdiri dari para ahli di berbagai bidang untuk bersama-sama membangun sistem evaluasi kualitas tertinggi.
(Sumber: _philschmid, Dorialexander, Yuhu_ai_)
🧰 Alat
Generator Novel AI YILING0013/AI_NovelGenerator : Sebuah generator novel multifungsi berbasis Large Language Model (LLM), mendukung arsitektur world-building, pengaturan karakter, blueprint plot, generasi bab cerdas, pelacakan status, manajemen plot twist, semantic retrieval, integrasi knowledge base, dan mekanisme proofreading otomatis, menyediakan operasi GUI visual. Alat ini bertujuan untuk secara efisien menciptakan cerita panjang yang logis dan konsisten, serta mendukung berbagai LLM dan layanan Embedding seperti OpenAI, DeepSeek, dan Ollama.
(Sumber: GitHub Trending)
Alat Pemrograman Berbantuan AI Terus Berkembang : GitHub Copilot, melalui instruksi, prompt, dan mode chat yang dikontribusikan komunitas, membantu pengguna memaksimalkan efektivitasnya di berbagai domain, bahasa, dan kasus penggunaan, serta menyediakan server MCP untuk menyederhanakan integrasi. Replit Agent menunjukkan kemampuan yang kuat dalam code migration dan QA, mampu dengan cepat memigrasikan situs web Next.js besar dari Vercel, dan mendukung integrasi pembayaran dalam aplikasi. Model Apriel-1.5-15b-Thinker ServiceNow dapat berjalan pada single GPU, menyediakan kemampuan inferensi yang kuat. Selain itu, model Moondream3-preview digunakan untuk agen UI flow dan tugas RPA, dan vLLM juga mendukung deployment model encoder-only.
(Sumber: github/awesome-copilot, amasad, amasad, amasad, amasad, amasad, ImazAngel, ben_burtenshaw, amasad, amasad, amasad, amasad, TheZachMueller, Reddit r/LocalLLaMA)
Inovasi Alat AI di Domain Aplikasi Spesifik : pix2tex (LaTeX OCR) mampu mengubah gambar rumus matematika menjadi kode LaTeX, secara signifikan meningkatkan efisiensi di bidang penelitian ilmiah dan pendidikan. BatonVoice memanfaatkan kemampuan LLM dalam mengikuti instruksi untuk menyediakan parameter terstruktur bagi speech synthesis, mencapai TTS yang dapat dikontrol. Platform Hex mengintegrasikan fungsi agen, memungkinkan lebih banyak orang menggunakan AI untuk pekerjaan data yang akurat dan dapat dipercaya. Alat video generation seperti Kling 2.5 Turbo dan Lucid Origin, membuat pembuatan video menjadi lebih mudah dari sebelumnya. Racine CU-1 adalah model interaktif GUI yang dapat mengenali posisi klik, cocok untuk agen UI flow dan tugas RPA.
(Sumber: lukas-blecher/LaTeX-OCR, teortaxesTex, dotey, dotey, Ronald_vanLoon, AssemblyAI, TheRundownAI, Kling_ai, Kling_ai, sarahcat21, mervenoyann, pierceboggan, Reddit r/OpenWebUI, Reddit r/LocalLLaMA, Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/ArtificialInteligence, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Model Reranking Dokumen jina-reranker-v3 : jina-reranker-v3 adalah model reranking dokumen multibahasa dengan 0.6B parameter, memperkenalkan mekanisme “last but not late interaction” yang inovatif. Metode ini melakukan perhitungan causal self-attention antara query dan dokumen, sehingga memungkinkan interaksi lintas dokumen yang kaya sebelum mengekstrak contextual embeddings dari setiap dokumen. Arsitektur kompak ini mencapai kinerja SOTA pada BEIR, sekaligus sepuluh kali lebih kecil dari model generative list rerankers.
(Sumber: HuggingFace Daily Papers)
📚 Pembelajaran
Kemajuan Penelitian Terbaru dalam Inferensi dan Alignment Model AI : Penelitian mengungkapkan bahwa multimodal reasoning, sambil meningkatkan logical reasoning, dapat merusak perceptual grounding, menyebabkan visual forgetting. Metode Vision-Anchored Policy Optimization (VAPO) diusulkan untuk memandu proses inferensi agar lebih berfokus pada dasar visual. Membahas alasan mengapa online alignment (seperti GRPO) lebih unggul dari offline alignment (seperti DPO), dan mengusulkan varian Humanline, yang melalui simulasi bias persepsi manusia, memungkinkan pelatihan data offline mencapai kinerja online alignment. Paradigma Test-Time Policy Adaptation for Multi-Turn Interactions (T2PAM) dan algoritma Optimum-Referenced One-Step Adaptation (ROSA) memanfaatkan umpan balik pengguna untuk penyesuaian parameter model yang efisien secara real-time, meningkatkan kemampuan self-correction LLM dalam multi-turn dialogue. NuRL (Nudging method) mengurangi kesulitan masalah melalui self-generated prompts, memungkinkan model untuk belajar dari masalah yang semula “tidak dapat dipecahkan”, sehingga meningkatkan batas atas kemampuan inferensi LLM. RLP (Reinforcement Learning Pre-training) memperkenalkan Reinforcement Learning ke tahap pre-training, memperlakukan Chain-of-Thought sebagai tindakan, dan memberikan reward melalui information gain, untuk meningkatkan kemampuan inferensi model sejak tahap pre-training. Exploratory Iteration (ExIt) adalah metode kurikulum otomatis berbasis RL, yang secara efektif meningkatkan kinerja model dalam tugas single-turn dan multi-turn dengan memandu LLM untuk secara iteratif memperbaiki solusinya selama inferensi. Penelitian TruthRL memotivasi LLM untuk menghasilkan informasi yang benar melalui Reinforcement Learning, bertujuan untuk mengatasi masalah hallucination model. Penelitian menemukan bahwa “Maximum Effective Context Window” (MECW) LLM jauh lebih kecil dari “Maximum Context Window” (MCW) yang dilaporkan, dan MECW bervariasi dengan jenis masalah, mengungkapkan keterbatasan praktis LLM dalam menangani long context. Serangan Bias-Inversion Rewriting Attack (BIRA) secara teoritis dapat secara efektif menghindari LLM watermark, dengan menekan token logits yang mungkin ditandai watermark, mencapai tingkat penghindaran lebih dari 99% sambil mempertahankan konten semantik, menyoroti kerapuhan teknologi watermark.
(Sumber: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NandoDF, NandoDF, BlackHC, BlackHC, teortaxesTex, HuggingFace Daily Papers, HuggingFace Daily Papers)
Analisis Mendalam Algoritma Reinforcement Learning (RL) : Menganalisis secara rinci alur kerja, kelebihan, kekurangan, dan skenario aplikasi dari tiga algoritma Reinforcement Learning mainstream: PPO, GRPO, dan REINFORCE. PPO karena stabilitasnya, GRPO karena mekanisme reward relatifnya, dan REINFORCE sebagai algoritma dasar, banyak digunakan di bidang AI. Penelitian menunjukkan bahwa Reinforcement Learning dapat melatih model untuk menggabungkan atomic skills dan mencapai generalization dalam kedalaman kombinasi, menunjukkan potensi RL dalam mempelajari keterampilan baru. Ditemukan bahwa lebih dari setengah peningkatan kinerja dalam pipeline RL tidak berasal dari peningkatan terkait ML, melainkan dicapai melalui engineering optimization seperti multithreading. Membahas masalah information content dari setiap episode dalam pelatihan RL, serta kesetaraan informasi dari trajectory yang berbeda di bawah reward akhir yang sama. Komunitas membahas definisi dan efektivitas RL pre-training, menunjukkan masalah yang mungkin timbul dari keragaman sintetis paksa, dan menyerukan perhatian pada coherence degradation. Untuk robot humanoid lima jari berlengan ganda, fine-tuning strategi behavior cloning melalui residual off-policy reinforcement learning (ROSA) secara signifikan meningkatkan sample efficiency, memungkinkan fine-tuning strategi langsung pada hardware.
(Sumber: TheTuringPost, teortaxesTex, menhguin, finbarrtimbers, arohan, tokenbender, pabbeel)
Ilmuwan AI dan Penemuan Ilmiah : DeepScientist adalah sistem penemuan ilmiah yang berorientasi tujuan dan sepenuhnya otonom, yang mendorong penemuan ilmiah mutakhir dalam jangka waktu berbulan-bulan melalui Bayesian optimization dan proses hierarchical evaluation. Sistem ini telah melampaui metode human SOTA pada tiga tugas AI terdepan, dan membuka sumber semua log eksperimen serta kode sistem. OpenAI sedang merekrut research scientist, bertujuan untuk membangun instrumen ilmiah generasi berikutnya—sebuah platform berbasis AI untuk mempercepat penemuan ilmiah.
(Sumber: HuggingFace Daily Papers, mcleavey)
Teknik Fine-tuning dan Optimasi LLM : Penelitian menemukan bahwa LoRA dalam Reinforcement Learning dapat sepenuhnya menyamai kinerja pembelajaran Full Fine-Tuning (FullFT), dan bahkan dalam kasus low-rank, cukup untuk menyerap informasi dari pelatihan RL. Kerangka kerja Quadrant-based Tuning (Q-Tuning) secara signifikan meningkatkan data efficiency dalam Supervised Fine-Tuning (SFT) melalui gabungan sample dan token pruning, bahkan dalam beberapa kasus melampaui pelatihan data penuh. Muon optimizer secara konsisten mengungguli Adam dalam pelatihan LLM, terutama dalam tail-associated memory learning, dengan memecahkan perbedaan pembelajaran Adam pada data yang tidak seimbang kategori melalui singular spectrum yang lebih isotropik dan optimasi efektif untuk heavy-tailed data. Penelitian tentang estimasi asimtotik dari weight RMS dalam AdamW optimizer. Analisis mendalam tentang cara kerja CUDA kernel Flash Attention 4, mengungkapkan inovasinya dalam asynchronous pipeline, software softmax (cubic approximation), dan efficient rescaling, menjelaskan kinerjanya yang lebih cepat daripada cuDNN.
(Sumber: ImazAngel, karinanguyen_, NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex, bigeagle_xd, cloneofsimo, Tim_Dettmers, Reddit r/MachineLearning)
Sumber Belajar AI dan Alat Penelitian : Berbagi slide AI multimodal yang mencakup tren, model open-source, alat kustomisasi/deployment, dan sumber daya lebih lanjut. Mengumumkan konferensi seperti AI Engineer Europe 2026 dan AI Engineer Paris, menyediakan platform bagi insinyur AI untuk berinteraksi. Merekomendasikan seri “Let’s build GPT” Karpathy dan paper Qwen, menekankan pentingnya data pelatihan CTF berkualitas tinggi dan sumber daya komputasi untuk pelatihan LLM. Membahas potensi DSPyOSS optimizer dalam mencapai optimasi “bertingkat” dalam kasus penggunaan B2B AI untuk mengatasi data scarcity. Axiom Math AI bertujuan untuk membangun super-intelligent reasoner yang dapat memperbaiki diri sendiri, dimulai dengan AI mathematician, untuk mencapai kemajuan di bidang formal mathematics. Penelitian tentang aplikasi regression language models dalam code generation dan pemahaman. Membahas perdebatan apakah Reinforcement Learning cukup untuk mencapai AGI. Membahas penemu Deep Residual Learning dan garis waktu evolusinya. Jürgen Schmidhuber pada tahun 2016 menjelaskan artificial consciousness, world models, predictive coding, dan sains sebagai data compression, menekankan kontribusi awalnya di bidang AI. Analisis eksplorasi terhadap praktik kolaborasi terbuka, motivasi, dan tata kelola dari 14 proyek Large Language Model open-source, mengungkapkan keragaman dan tantangan ekosistem LLM open-source. Dragon Hatchling (BDH) adalah arsitektur LLM berbasis brain-inspired network, bertujuan untuk menghubungkan Transformer dengan model otak, mencapai explainability dan kinerja seperti Transformer. Kerangka kerja d^2Cache secara signifikan meningkatkan inference efficiency dan kualitas generasi diffusion language models (dLLMs) melalui dual-adaptive caching. Kerangka kerja TimeTic menggunakan contextual learning untuk memperkirakan transferability time series foundation models (TSFMs), guna memilih model terbaik secara efisien untuk downstream fine-tuning. Visual foundation encoder dapat berfungsi sebagai tokenizer untuk latent diffusion models (LDM), menghasilkan semantic-rich latent space, meningkatkan kinerja image generation. NVFP4 adalah format pre-training 4-bit baru, yang melalui two-level scaling, RHT, dan stochastic rounding, diharapkan mencapai peningkatan efisiensi 6.8 kali lipat sambil menyamai kinerja FP8 baseline. DA^2 (Depth Anything in Any Direction) adalah panoptic depth estimator yang akurat, zero-shot generalization, dan end-to-end, mencapai SOTA dalam panoptic depth estimation melalui data pelatihan skala besar dan arsitektur SphereViT. Model SAGANet mencapai controllable, object-level audio generation dengan memanfaatkan visual segmentation masks, video, dan text cues, menyediakan kontrol yang presisi untuk alur kerja Foley profesional. Mem-α adalah kerangka kerja Reinforcement Learning yang melatih agen untuk secara efektif mengelola sistem external memory yang kompleks, mengatasi masalah memory construction dan information loss pada agen LLM dalam pemahaman long-text, serta menunjukkan kemampuan generalization terhadap long sequences. Kerangka kerja EntroPE (Entropy-Guided Dynamic Patch Encoder) secara dinamis mendeteksi transition points dalam time series melalui conditional entropy, dan menempatkan patch boundaries untuk mempertahankan temporal structure, meningkatkan prediction accuracy dan efficiency. BUILD-BENCH adalah benchmark yang lebih menantang untuk mengevaluasi kemampuan agen LLM dalam mengkompilasi open-source software dunia nyata, dan mengusulkan OSS-BUILD-AGENT sebagai baseline yang kuat. ProfVLM adalah lightweight video-language model, yang melalui generative reasoning, secara bersamaan memprediksi skill level dan menghasilkan expert feedback dari egocentric dan exocentric videos. Membahas efektivitas Test-Time Training (TTT) dalam foundation models, berpendapat bahwa TTT, melalui spesialisasi pada tugas pengujian, dapat secara signifikan mengurangi in-distribution test error. CST adalah arsitektur jaringan saraf baru untuk menangani cardinality-arbitrary image sets, beroperasi langsung pada 3D image tensors, secara bersamaan melakukan feature extraction dan contextual modeling, menunjukkan kinerja luar biasa dalam tugas set classification dan anomaly detection. Kerangka kerja TTT3R memperlakukan 3D reconstruction sebagai masalah online learning, menurunkan learning rate melalui memory states dan observation-alignment confidence, secara signifikan meningkatkan kemampuan long-sequence generalization.
(Sumber: tonywu_71, swyx, Reddit r/deeplearning, lateinteraction, teortaxesTex, shishirpatil_, bengoertzel, arankomatsuzaki, francoisfleuret, _akhaliq, steph_palazzolo, HuggingFace Daily Papers, SchmidhuberAI, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NerdyRodent, QuixiAI, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning)
Deteksi Pemalsuan Persepsi Manusia dalam Generasi Video AI : DeeptraceReward adalah dataset benchmark fine-grained, spatiotemporal-aware pertama yang digunakan untuk menganotasi jejak pemalsuan video generation yang dirasakan manusia. Dataset ini berisi 4.3K anotasi detail pada 3.3K video yang dihasilkan berkualitas tinggi, dan mengintegrasikannya ke dalam 9 kategori jejak pemalsuan utama. Penelitian melatih multimodal language model sebagai reward model untuk meniru penilaian dan lokalisasi manusia, mengungguli GPT-5 dalam identifikasi, lokalisasi, dan penjelasan petunjuk pemalsuan.
(Sumber: HuggingFace Daily Papers)
Purifikasi Adversarial dan Rekonstruksi Adegan 3D : MANI-Pure adalah kerangka kerja amplitude-adaptive purification, yang melalui pemanfaatan spektrum amplitudo sinyal input untuk memandu proses purifikasi, secara adaptif menyuntikkan noise heterogen dan berorientasi frekuensi, secara efektif menekan high-frequency perturbations sambil mempertahankan low-frequency content yang penting secara semantik, mencapai kinerja SOTA dalam adversarial defense. Nvidia merilis model Lyra, yang mencapai generative 3D scene reconstruction melalui self-distillation model video diffusion, mampu melakukan feed-forward 3D dan 4D scene generation dari satu gambar/video.
(Sumber: HuggingFace Daily Papers, _akhaliq)
💼 Bisnis
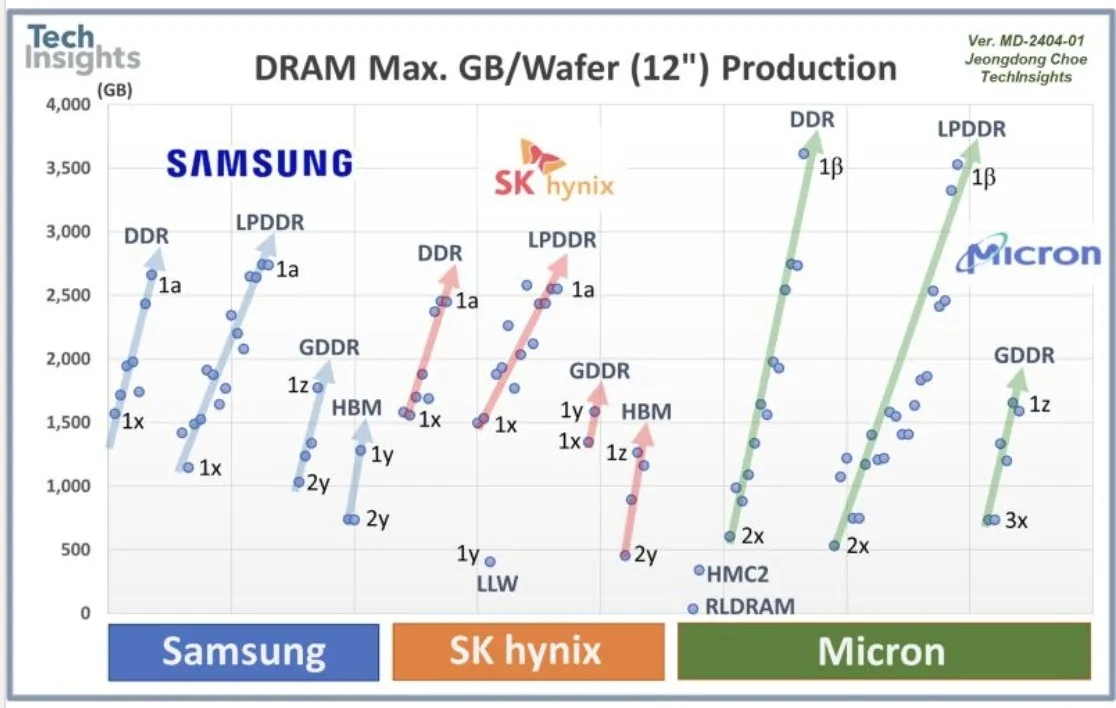
Kemitraan OpenAI dan Samsung serta Permintaan DRAM : OpenAI sedang bekerja sama dengan Samsung untuk mengembangkan chip “Stargate” dan diperkirakan membutuhkan 900.000 wafer DRAM berkinerja tinggi setiap bulan, menunjukkan rencana dan investasi besar untuk AI infrastructure di masa depan, jauh melampaui ekspektasi industri saat ini. Volume permintaan yang sangat besar ini memicu diskusi tentang biaya AI computing dan memory supercycle.
(Sumber: bookwormengr, teortaxesTex, francoisfleuret)
Pendanaan Startup AI dan Lanskap Industri : Axiom Math AI meluncurkan super-intelligent reasoner yang dapat memperbaiki diri sendiri, dimulai sebagai AI mathematician, menarik perhatian industri. Modal menyelesaikan pendanaan Seri B sebesar $87 juta, dengan valuasi $1.1 miliar, bertujuan untuk mendorong masa depan AI computing infrastructure. OffDeal menyelesaikan pendanaan Seri A sebesar $12 juta, berkomitmen untuk membangun investment bank AI-native pertama di dunia. Menteri Pertahanan Jepang mengunjungi kantor Sakana AI, menunjukkan potensi kerja sama AI di sektor pertahanan. Seorang pengembang berbagi kesulitan kehabisan dana setelah menghabiskan $3.000 untuk membangun model LLM open-source, memicu diskusi komunitas tentang keberlanjutan proyek AI open-source. Pengembang Google AI mengumumkan pemenang Nano Banana Hackathon, memberikan hadiah lebih dari $400.000, bertujuan untuk mendorong inovasi aplikasi AI.
(Sumber: shishirpatil_, bengoertzel, lupantech, arankomatsuzaki, francoisfleuret, akshat_b, leveredvlad, SakanaAILabs, hardmaru, Reddit r/LocalLLaMA, osanseviero)
🌟 Komunitas
Dampak Sosial dan Kontroversi yang Dipicu oleh Sora 2 : Rilis Sora 2 memicu dampak sosial dan kontroversi yang luas. Banyak pengguna khawatir tentang membanjirnya “slop” (konten berkualitas rendah, tidak bermakna) dari video yang dihasilkan AI, mempertanyakan prioritas OpenAI yang lebih mengutamakan hiburan daripada memecahkan masalah besar seperti kanker. Pada saat yang sama, ada kekhawatiran bahwa realisme Sora 2 yang sangat tinggi dapat menyebabkan video sulit dibedakan antara asli dan palsu, bahkan disalahgunakan untuk menghasilkan informasi palsu atau konten berbahaya seperti “senjata biologis”. CEO OpenAI Sam Altman sendiri menjadi subjek meme yang dihasilkan AI, dan dia menyatakan “tidak terlalu aneh” tentang hal itu, menjelaskan bahwa fokus OpenAI tetap pada AGI dan penemuan ilmiah, serta rilis produk adalah untuk kebutuhan pendanaan. Kemampuan Sora 2 yang kuat kembali menyoroti permintaan GPU yang sangat besar, memicu diskusi tentang biaya AI yang tinggi, bahkan ada yang membandingkan biaya AI dengan biaya pembangunan sistem jalan raya antarnegara bagian di AS. Beberapa komentar berpendapat bahwa strategi rilis Sora 2 terlalu “biasa”, kurang benchmark dan dukungan pengguna profesional, serta membatasi konten yang dihasilkan pengguna gratis.
(Sumber: teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
Pengalaman Pengguna dan Kontroversi Claude Sonnet 4.5 : Pengguna umumnya percaya bahwa Sonnet 4.5 memiliki peningkatan signifikan dalam retensi informasi, penilaian, pengambilan keputusan, dan creative writing, bahkan menunjukkan “perubahan sikap” yang mirip manusia, misalnya menjadi lebih profesional setelah mengetahui latar belakang pengguna, atau mengoreksi pengguna saat “mengoceh”. Meskipun unggul dalam beberapa aspek, beberapa pengguna masih mengkritik kualitas code generation-nya yang rendah, dengan “kesalahan ceroboh dan bodoh”, bahkan mengalami masalah “dialog terlalu panjang” sehingga tidak dapat menghasilkan kode saat menangani percakapan panjang, berpendapat bahwa masih jauh dari menggantikan insinyur perangkat lunak manusia. Selain itu, beberapa pengguna berhasil “jailbreak” Sonnet 4.5, membuatnya menghasilkan resep berbahaya dan kode malware, memicu kekhawatiran serius tentang pagar pengaman model.
(Sumber: teortaxesTex, doodlestein, genmon, aiamblichus, QuixiAI, suchenzang, karminski3, aiamblichus, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Masa Depan Bahasa Pemrograman di Era AI dan Kemunduran Budaya Komunitas : Peringkat bahasa pemrograman IEEE Spectrum 2025 menunjukkan Python menduduki peringkat bahasa paling populer selama sepuluh tahun berturut-turut, dan menempati posisi pertama dalam peringkat keseluruhan, tingkat pertumbuhan, dan orientasi pekerjaan, dengan keunggulannya semakin diperbesar di era AI. Peringkat JavaScript menurun drastis, sementara posisi SQL, meskipun terpengaruh, masih memiliki nilai. Laporan tersebut menunjukkan bahwa AI mengakhiri keragaman bahasa pemrograman, efek Matthew pada bahasa mainstream semakin intensif, dan bahasa non-mainstream akan terpinggirkan. Pada saat yang sama, budaya komunitas programmer menurun, pengembang lebih cenderung mencari bantuan dari large models daripada bertanya di komunitas, yang mengubah cara belajar dan bekerja, memicu diskusi tentang peran programmer di masa depan dan pentingnya kemampuan inti dalam desain arsitektur dasar.
(Sumber: 量子位, jimmykoppel, jimmykoppel, lateinteraction, kylebrussell, Reddit r/ArtificialInteligence)

Gelembung AI dan Prospek Pengembangan Industri : Diskusi di media sosial tentang apakah ada gelembung di industri AI, dengan pandangan bahwa meskipun antusiasme investasi saat ini tinggi dan mungkin ada beberapa proyek “bodoh”, fundamental industri tetap kuat, dan adopsi AI oleh perusahaan terus meningkat. Pada saat yang sama, ada juga suara yang menunjukkan bahwa biaya AI computing yang sangat besar dan permintaan DRAM OpenAI yang besar menunjukkan bahwa industri masih dalam ekspansi cepat, jauh dari tahap pecahnya gelembung, tetapi masuknya modal juga perlu diwaspadai.
(Sumber: arohan, pmddomingos, teortaxesTex, teortaxesTex, ajeya_cotra)
💡 Lain-lain
Robot Humanoid dan Perangkat Berbantuan AI : Perusahaan robot Tiongkok LimX Dynamics memamerkan kemampuan robot humanoid Oli untuk bergerak secara otonom, membungkuk, dan melempar, tanpa memerlukan motion capture atau teleoperation, menunjukkan bahwa Tiongkok telah mencapai tingkat yang sebanding dengan Figure/1X/Tesla di bidang robot humanoid. Neural Band Meta, yang membaca sinyal saraf melalui EMG dan dikombinasikan dengan kacamata display Meta Rayban, diharapkan dapat menyediakan metode kontrol revolusioner bagi penderita amputasi, memungkinkan kontrol sinkron prostetik dengan antarmuka digital, dan berpotensi menjadi hands-free controller universal. Selain itu, teknologi AI dan robotika juga memiliki aplikasi yang beragam dalam peningkatan mobilitas, eksplorasi, dan penyelamatan, seperti electric robotic exoskeletons, wirelessly controlled robotic insects, quadruped robots, dan robot ular untuk misi penyelamatan.
(Sumber: Ronald_vanLoon, teortaxesTex, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Reddit r/ArtificialInteligence)
Aplikasi AI dalam Pengeditan Gambar dan Desain Grafis : LayerD adalah metode untuk decomposing raster graphic designs menjadi lapisan, bertujuan untuk mencapai creative workflows yang dapat diedit ulang, dengan secara iteratif mengekstrak foreground layers yang tidak terhalang, dan memanfaatkan asumsi bahwa lapisan biasanya menunjukkan tampilan yang seragam untuk penyempurnaan, sehingga mencapai dekomposisi berkualitas tinggi. GeoRemover mengusulkan kerangka kerja dua tahap geometry-aware untuk menghilangkan objek dalam gambar dan causal visual artifacts-nya (seperti shadows dan reflections), melalui decoupling geometric removal dan appearance rendering, serta memperkenalkan preference-driven objective untuk memandu pembelajaran.
(Sumber: HuggingFace Daily Papers, HuggingFace Daily Papers)