
Palabras clave:OpenAI Sora 2, Generación de vídeo con IA, IA multimodal, Científico de IA, Diseño de proteínas, API de Sora 2, Diseño de proteínas PXDesign, Marco PromptCoT 2.0, Generación en primera persona EgoTwin, Liquid AI LFM2-Audio
🔥 Enfoque
Lanzamiento de OpenAI Sora 2 y su impacto: OpenAI lanza oficialmente Sora 2, posicionándola como una aplicación social para iOS “versión TikTok de IA”, que admite la generación sincronizada de audio y video, y mejora significativamente la adherencia a las leyes físicas y la controlabilidad. Las nuevas funciones incluyen “cameos”, que permiten a los usuarios insertar su imagen o la de sus amigos en videos generados por IA. Las redes sociales debaten su asombroso realismo y creatividad, pero también existen preocupaciones sobre la proliferación de contenido “slop”, la dificultad para distinguir lo real de lo falso, el aumento de la demanda de GPU y la disponibilidad regional (como la ausencia de Sora en el Reino Unido). El CEO de OpenAI, Sam Altman, respondió que Sora 2 tiene como objetivo financiar la investigación de AGI y ofrecer nuevos productos interesantes. La discusión comunitaria también aborda la obtención de códigos de invitación para Sora 2, la especulación sobre los requisitos de hardware (GPU), y las preocupaciones sobre la calidad futura del contenido de video generado y su uso malintencionado. OpenAI planea ampliar las invitaciones para Sora, pero reducirá los límites de generación diaria en consecuencia, y reveló que lanzará la API de Sora 2.
(Fuente: 量子位, Yuchenj_UW, teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Periodic Labs lanza una plataforma de científicos de IA para acelerar el descubrimiento científico: Periodic Labs recauda 300 millones de dólares en financiación, con el objetivo de crear científicos de IA para acelerar el descubrimiento científico fundamental, especialmente en el diseño de materiales, a través de laboratorios automatizados y experimentos impulsados por IA. La plataforma busca tratar el universo físico como un sistema computacional, utilizando la IA para formular hipótesis, experimentar y aprender, con la esperanza de lograr avances en áreas como los superconductores de alta temperatura. Esta visión enfatiza la conexión de la IA con el mundo físico y la importancia de generar datos de alta calidad a través de experimentos, superando los modelos tradicionales que solo dependen de datos de Internet para el entrenamiento.
(Fuente: dylan522p, teortaxesTex, teortaxesTex, NandoDF, NandoDF, TheRundownAI, Ar_Douillard, teortaxesTex)

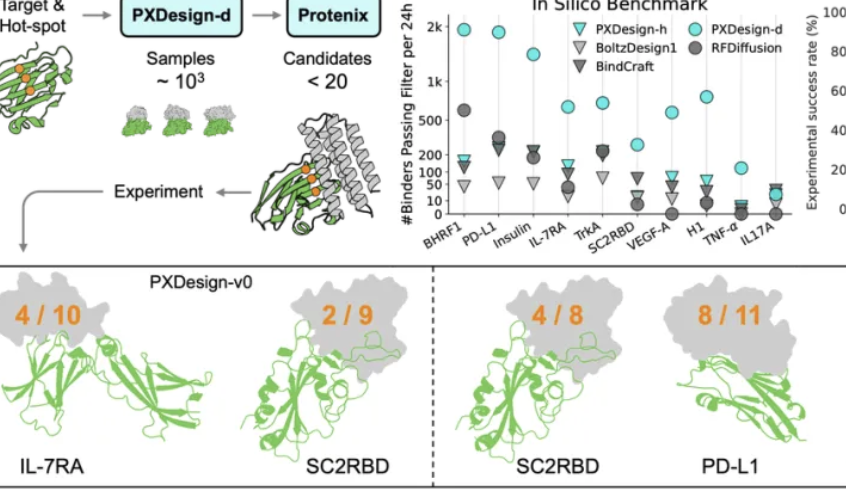
El equipo Seed de ByteDance lanza PXDesign, mejorando la eficiencia del diseño de proteínas: El equipo Seed de ByteDance lanza PXDesign, un método escalable de diseño de proteínas por IA, capaz de generar cientos de proteínas candidatas de alta calidad en 24 horas, mejorando la eficiencia en aproximadamente 10 veces en comparación con los métodos principales de la industria. Este método logra una tasa de éxito en experimentos húmedos del 20%-73% en múltiples objetivos, significativamente superior a AlphaProteo de DeepMind. PXDesign combina una estrategia de “generación + filtrado”, utilizando la estructura de red DiT y el modelo de predicción de estructura Protenix para un cribado eficiente, y ofrece un servicio gratuito de diseño de “binder” en línea, con el objetivo de acelerar la investigación científica biológica.
(Fuente: 量子位)
Ant Group y la Universidad de Hong Kong lanzan conjuntamente PromptCoT 2.0, centrándose en la síntesis de tareas: El Grupo de Lenguaje Natural del Centro de IA General de Ant Group y el Grupo de Lenguaje Natural de la Universidad de Hong Kong lanzan conjuntamente el marco PromptCoT 2.0, con el objetivo de impulsar el razonamiento de grandes modelos y el desarrollo de agentes a través de la síntesis de tareas. Este marco utiliza un ciclo de Expectation-Maximization (EM) en lugar del diseño manual, optimizando iterativamente las cadenas de razonamiento para generar problemas más difíciles y diversos. PromptCoT 2.0 combina el aprendizaje por refuerzo y SFT, permitiendo que el modelo 30B-A3B alcance el SOTA en tareas de razonamiento de código matemático, y ha liberado 4.77M datos de problemas sintéticos, proporcionando recursos de entrenamiento a la comunidad.
(Fuente: 量子位)

EgoTwin logra por primera vez la generación sincronizada de video en primera persona y movimientos corporales: La Universidad Nacional de Singapur, la Universidad Tecnológica de Nanyang, la Universidad de Ciencia y Tecnología de Hong Kong y el Laboratorio de IA de Shanghái lanzan conjuntamente el marco EgoTwin, logrando por primera vez la generación conjunta de videos en primera persona y movimientos corporales. Este marco, basado en modelos de difusión, genera conjuntamente “texto-video-acción” trimodal, superando los dos grandes desafíos de la alineación vista-acción y el acoplamiento causal. Las innovaciones clave incluyen la representación de acciones centrada en la cabeza, un mecanismo de interacción inspirado en la cibernética y un marco de entrenamiento de difusión asíncrona. Los videos y acciones generados pueden escalarse aún más a escenas 3D.
(Fuente: 量子位)

🎯 Tendencias
Lanzamientos y actualizaciones intensivas de modelos de IA de nueva generación: El campo de la IA ha visto recientemente el lanzamiento y la actualización de varios modelos y funciones importantes, incluyendo DeepSeek-V3.2, Claude Sonnet 4.5, GLM 4.6, Sora 2, Dreamer 4 y la función de pago instantáneo de ChatGPT. DeepSeek-V3.2 ha sido optimizado en vLLM a través de un mecanismo de atención dispersa, logrando un mayor rendimiento en contextos largos y eficiencia de costos. Claude Sonnet 4.5 muestra complejidad en la alineación y la teoría de la mente del usuario, y sobresale en la escritura creativa y de formato largo, aunque algunos usuarios señalan que la calidad de su generación de código aún necesita mejorar. GLM-4.6 destaca en la capacidad de código frontend, pero las mejoras en otros lenguajes como Python no son significativas, y se lanzó una versión cuantificada GGUF para soportar el despliegue local. Dreamer 4 es un agente capaz de aprender a resolver tareas de control complejas dentro de modelos de mundo escalables.
(Fuente: Yuchenj_UW, teortaxesTex, zhuohan123, vllm_project, teortaxesTex, teortaxesTex, teortaxesTex, ImazAngel, teortaxesTex, _lewtun, nrehiew_, YiTayML, agihippo, TimDarcet, Dorialexander, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)
El modelo de video multimodal Veo3 muestra el potencial de la inteligencia visual general: El modelo de video Veo3 es considerado un camino potencial hacia la inteligencia visual general, demostrando capacidades de aprendizaje y razonamiento de cero-shot, capaz de resolver diversas tareas visuales, y se considera de gran importancia para el avance de la robótica. Al mismo tiempo, el equipo Qwen de Alibaba Cloud lanzó la serie de modelos de lenguaje grandes multimodales Qwen3-VL, con mejoras integrales en agentes visuales, codificación visual, percepción espacial, comprensión de contexto largo y video, razonamiento multimodal, reconocimiento visual y OCR, y ofrece versiones Instruct y Thinking. Tencent también presentó los modelos HunyuanImage 3.0 y Hunyuan3D-Part, alcanzando niveles líderes en la generación de texto a imagen y la generación de formas 3D, respectivamente.
(Fuente: gallabytes, NandoDF, NandoDF, madiator, shaneguML, Yuchenj_UW, GitHub Trending, ClementDelangue)

Liquid AI lanza LFM2-Audio y modelos pequeños especializados: Liquid AI lanza LFM2-Audio, un modelo fundacional de audio a texto todo en uno de extremo a extremo, con solo 1.5B parámetros, capaz de lograr conversaciones en tiempo real y con respuesta rápida en dispositivos, con una velocidad de inferencia 10 veces superior a modelos similares. Además, Liquid AI también presentó la serie de modelos ajustados LFM2, que incluyen diferentes variantes como Tool, RAG y Extract, enfocadas en tareas específicas en lugar de la generalidad, lo que coincide con la perspectiva del White Paper de Nvidia sobre que los modelos pequeños y especializados son la dirección futura de la Agentic AI.
(Fuente: ImazAngel, maximelabonne, Reddit r/LocalLLaMA)
Las bases de datos vectoriales experimentan un “segundo auge” y xAI enfatiza la importancia de los datos de alta calidad: Algunos opinan que las bases de datos vectoriales podrían experimentar un nuevo auge, aunque su modelo de aplicación podría diferir de lo esperado. Al mismo tiempo, xAI está estableciendo un nuevo paradigma para procesar datos humanos, enfatizando la importancia del post-training y considerando que los datos de alta calidad son la piedra angular para alcanzar la AGI. xAI planea formar una comunidad de expertos de diversas áreas para construir conjuntamente el sistema de evaluación de la más alta calidad.
(Fuente: _philschmid, Dorialexander, Yuhu_ai_)
🧰 Herramientas
Generador de novelas de IA YILING0013/AI_NovelGenerator: Un generador de novelas multifuncional basado en grandes modelos de lenguaje, que soporta la arquitectura del mundo, la configuración de personajes, el plan de la trama, la generación inteligente de capítulos, el seguimiento de estados, la gestión de subtramas, la recuperación semántica, la integración de bases de conocimiento y un mecanismo de revisión automática, ofreciendo una operación GUI visual. Esta herramienta está diseñada para crear de manera eficiente historias largas con lógica rigurosa y configuraciones unificadas, y es compatible con varios LLM y servicios de Embedding como OpenAI, DeepSeek y Ollama.
(Fuente: GitHub Trending)
El desarrollo continuo de herramientas de programación asistidas por IA: GitHub Copilot, a través de instrucciones, prompts y modos de chat aportados por la comunidad, ayuda a los usuarios a maximizar su utilidad en diferentes dominios, lenguajes y casos de uso, y ofrece un servidor MCP para simplificar la integración. Replit Agent ha demostrado potentes capacidades en migración de código y QA, pudiendo migrar rápidamente grandes sitios web Next.js de Vercel y soportar la integración de pagos dentro de la aplicación. El modelo Apriel-1.5-15b-Thinker de ServiceNow puede ejecutarse en una sola GPU, ofreciendo potentes capacidades de inferencia. Además, el modelo Moondream3-preview se utiliza para procesos de UI de agente y tareas de RPA, y vLLM también soporta el despliegue de modelos encoder-only.
(Fuente: github/awesome-copilot, amasad, amasad, amasad, amasad, amasad, ImazAngel, ben_burtenshaw, amasad, amasad, amasad, amasad, TheZachMueller, Reddit r/LocalLLaMA)
Innovación de herramientas de IA en campos de aplicación específicos: pix2tex (LaTeX OCR) puede convertir imágenes de fórmulas matemáticas en código LaTeX, mejorando significativamente la eficiencia en los campos de la investigación y la educación. BatonVoice utiliza la capacidad de seguimiento de instrucciones de los LLM para proporcionar parámetros estructurados para la síntesis de voz, logrando un TTS controlable. La plataforma Hex integra funciones de agente, permitiendo que más personas utilicen la IA para un trabajo de datos preciso y confiable. Herramientas de generación de video como Kling 2.5 Turbo y Lucid Origin hacen que la creación de video sea más conveniente que nunca. Racine CU-1 es un modelo interactivo GUI que puede identificar posiciones de clic, adecuado para procesos de UI de agente y tareas de RPA.
(Fuente: lukas-blecher/LaTeX-OCR, teortaxesTex, dotey, dotey, Ronald_vanLoon, AssemblyAI, TheRundownAI, Kling_ai, Kling_ai, sarahcat21, mervenoyann, pierceboggan, Reddit r/OpenWebUI, Reddit r/LocalLLaMA, Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/ArtificialInteligence, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Modelo de reordenamiento de documentos jina-reranker-v3: jina-reranker-v3 es un modelo de reordenamiento de documentos multilingüe de 0.6B parámetros que introduce un novedoso mecanismo de “interacción tardía pero no demasiado” (last but not late interaction). Este método realiza cálculos de autoatención causal entre la consulta y los documentos, logrando una rica interacción entre documentos antes de extraer los embeddings contextuales de cada documento. Esta arquitectura compacta alcanza el SOTA en rendimiento BEIR, siendo diez veces más pequeña que los modelos de reordenamiento de listas generativas.
(Fuente: HuggingFace Daily Papers)
📚 Aprendizaje
Avances recientes en la investigación sobre inferencia y alineación de modelos de IA: La investigación revela que el razonamiento multimodal, si bien mejora el razonamiento lógico, puede dañar la base perceptiva, lo que lleva a la amnesia visual. Se propone el método Vision-Anchored Policy Optimization (VAPO) para guiar el proceso de razonamiento a centrarse más en la base visual. Se explora por qué la alineación en línea (como GRPO) es superior a la alineación fuera de línea (como DPO), y se propone una variante Humanline que, al simular sesgos de percepción humana, permite que el entrenamiento con datos fuera de línea alcance el rendimiento de la alineación en línea. El paradigma Test-Time Policy Adaptation for Multi-Turn Interactions (T2PAM) y el algoritmo Optimum-Referenced One-Step Adaptation (ROSA) utilizan la retroalimentación del usuario para ajustar los parámetros del modelo de manera eficiente y en tiempo real, mejorando la capacidad de autocorrección de los LLM en diálogos de múltiples turnos. NuRL (Nudging method) reduce la dificultad de los problemas mediante prompts autogenerados, permitiendo que el modelo aprenda de problemas originalmente “irresolubles”, elevando así el límite de la capacidad de razonamiento de los LLM. RLP (Reinforcement Learning Pre-training) introduce el aprendizaje por refuerzo en la etapa de preentrenamiento, tratando las cadenas de pensamiento como acciones y recompensando la ganancia de información para mejorar la capacidad de razonamiento del modelo ya en la etapa de preentrenamiento. Exploratory Iteration (ExIt) es un método de currículo automático basado en RL que guía a los LLM a mejorar iterativamente sus soluciones durante el razonamiento, mejorando efectivamente el rendimiento del modelo en tareas de un solo turno y de múltiples turnos. La investigación TruthRL utiliza el aprendizaje por refuerzo para incentivar a los LLM a generar información veraz, con el objetivo de resolver el problema de las alucinaciones del modelo. La investigación revela que la “ventana de contexto efectiva máxima” (MECW) de los LLM es mucho menor que la “ventana de contexto máxima” (MCW) reportada, y que la MECW varía con el tipo de problema, lo que expone las limitaciones prácticas de los LLM al procesar contextos largos. El ataque Bias-Inversion Rewriting Attack (BIRA) puede eludir teóricamente las marcas de agua de los LLM al suprimir los logits de los tokens que podrían ser marcados con agua, logrando una tasa de elusión superior al 99% mientras se mantiene el contenido semántico, lo que subraya la fragilidad de las tecnologías de marca de agua.
(Fuente: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NandoDF, NandoDF, BlackHC, BlackHC, teortaxesTex, HuggingFace Daily Papers, HuggingFace Daily Papers)
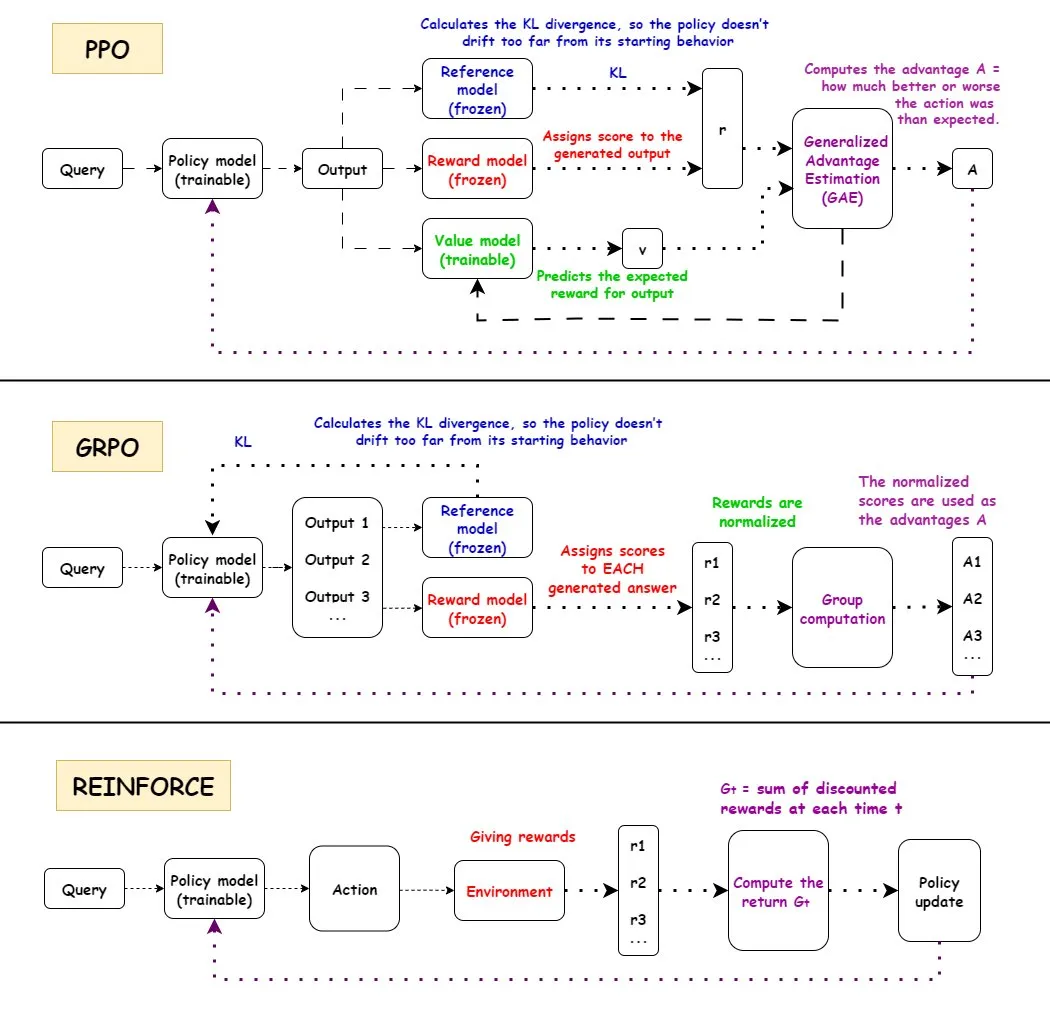
Análisis en profundidad de los algoritmos de Reinforcement Learning (RL): Se detallan los flujos de trabajo, ventajas, desventajas y escenarios de aplicación de tres algoritmos principales de aprendizaje por refuerzo: PPO, GRPO y REINFORCE. PPO es ampliamente utilizado en el campo de la IA por su estabilidad, GRPO por su mecanismo de recompensa relativa, y REINFORCE como algoritmo fundamental. La investigación muestra que el aprendizaje por refuerzo puede entrenar modelos para combinar habilidades atómicas y generalizar en profundidad combinatoria, lo que indica el potencial de RL en el aprendizaje de nuevas habilidades. Se ha descubierto que más de la mitad de las mejoras de rendimiento en los pipelines de RL no provienen de mejoras relacionadas con ML, sino de optimizaciones de ingeniería como el multithreading. Se discute la cantidad de información en cada episodio del entrenamiento de RL, así como la equivalencia de información de diferentes trayectorias bajo la misma recompensa final. La comunidad debate la definición y efectividad del preentrenamiento de RL, señalando los problemas que puede causar la síntesis forzada de diversidad y pidiendo atención a la degradación de la coherencia. Para un robot humanoide de dos brazos y cinco dedos, se ajustó la política de clonación de comportamiento mediante el aprendizaje por refuerzo residual fuera de política (ROSA), lo que mejoró significativamente la eficiencia de la muestra y permitió el ajuste directo de la política en hardware.
(Fuente: TheTuringPost, teortaxesTex, menhguin, finbarrtimbers, arohan, tokenbender, pabbeel)
Científicos de IA y descubrimiento científico: DeepScientist es un sistema de descubrimiento científico totalmente autónomo y orientado a objetivos que impulsa el descubrimiento científico de vanguardia a lo largo de meses mediante la optimización bayesiana y un proceso de evaluación jerárquica. El sistema ha superado los métodos SOTA humanos en tres tareas de IA de vanguardia y ha liberado todos los registros de experimentos y el código del sistema. OpenAI está contratando científicos de investigación con el objetivo de construir la próxima generación de instrumentos científicos: una plataforma impulsada por IA para acelerar el descubrimiento científico.
(Fuente: HuggingFace Daily Papers, mcleavey)
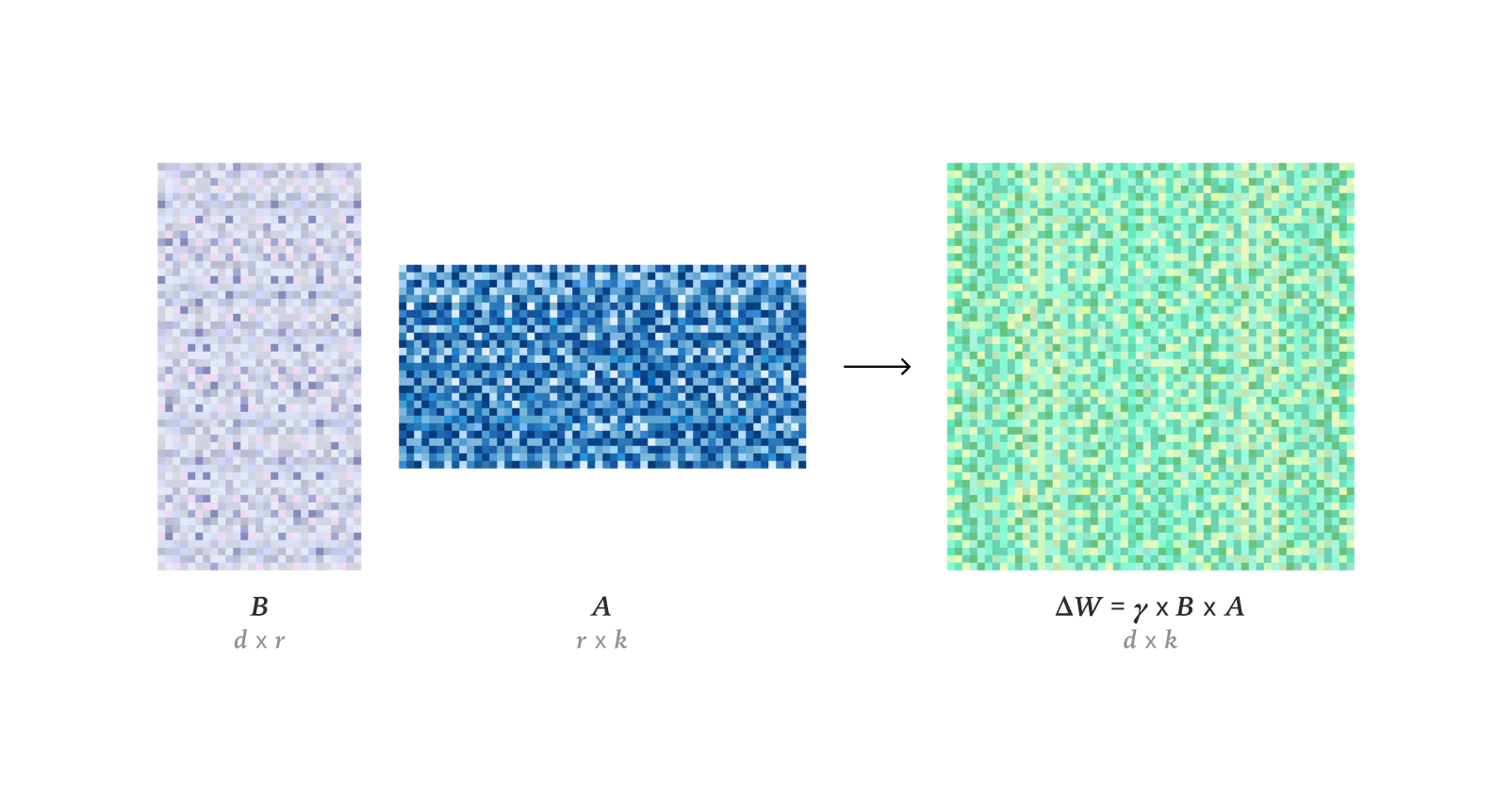
Técnicas de ajuste fino y optimización de LLM: La investigación revela que LoRA puede igualar completamente el rendimiento de aprendizaje del ajuste fino completo (FullFT) en el aprendizaje por refuerzo, siendo suficiente para absorber información del entrenamiento de RL incluso en situaciones de bajo rango. El marco Quadrant-based Tuning (Q-Tuning) mejora significativamente la eficiencia de los datos en el ajuste fino supervisado (SFT) mediante la poda conjunta de muestras y Tokens, superando incluso el entrenamiento con datos completos en algunos casos. El optimizador Muon supera consistentemente a Adam en el entrenamiento de LLM, especialmente en el aprendizaje de memoria asociativa de cola, resolviendo las diferencias de aprendizaje de Adam en datos desequilibrados por clase a través de un espectro singular más isotrópico y una optimización efectiva de datos de cola pesada. Se investiga la estimación asintótica del RMS de los pesos en el optimizador AdamW. Se analiza en profundidad el funcionamiento del kernel CUDA de Flash Attention 4, revelando sus innovaciones en pipelines asíncronos, softmax por software (aproximación cúbica) y reescalado eficiente, lo que explica su rendimiento más rápido que cuDNN.
(Fuente: ImazAngel, karinanguyen_, NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex, bigeagle_xd, cloneofsimo, Tim_Dettmers, Reddit r/MachineLearning)
Recursos de aprendizaje y herramientas de investigación de IA: Se comparten diapositivas de IA multimodal que cubren tendencias, modelos de código abierto, herramientas de personalización/despliegue y recursos adicionales. Se anuncian conferencias como AI Engineer Europe 2026 y AI Engineer Paris, proporcionando plataformas para que los ingenieros de IA interactúen. Se recomiendan la serie “Let’s build GPT” de Karpathy y el artículo de Qwen, enfatizando la importancia de los datos de entrenamiento CTF de alta calidad y los recursos computacionales para el entrenamiento de LLM. Se discute el potencial del optimizador DSPyOSS para lograr una optimización “en capas” en casos de uso de IA B2B, abordando la escasez de datos. Axiom Math AI tiene como objetivo construir un razonador superinteligente que se auto-mejora, comenzando con matemáticos de IA para avanzar en el campo de las matemáticas formales. Se investiga la aplicación de modelos de lenguaje regresivos en la generación y comprensión de código. Se debate si el aprendizaje por refuerzo es suficiente para lograr la AGI. Se explora el inventor del Deep Residual Learning y su línea de tiempo de evolución. Jürgen Schmidhuber explicó en 2016 la conciencia artificial, los modelos del mundo, la codificación predictiva y la ciencia como compresión de datos, destacando sus primeras contribuciones en el campo de la IA. Se realiza un análisis exploratorio de las prácticas de colaboración abierta, motivaciones y gobernanza de 14 proyectos de modelos de lenguaje grandes de código abierto, revelando la diversidad y los desafíos del ecosistema LLM de código abierto. Dragon Hatchling (BDH) es una arquitectura LLM basada en redes similares al cerebro, diseñada para conectar Transformer con modelos cerebrales, logrando interpretabilidad y rendimiento similar a Transformer. El marco d^2Cache mejora significativamente la eficiencia de inferencia y la calidad de generación de los modelos de lenguaje de difusión (dLLMs) a través de un caché doblemente adaptativo. El marco TimeTic estima la transferibilidad de los modelos fundacionales de series temporales (TSFMs) mediante el aprendizaje contextual, para seleccionar eficientemente el mejor modelo para el ajuste fino posterior. Los codificadores fundacionales visuales pueden actuar como tokenizers para modelos de difusión latente (LDM), generando espacios latentes semánticamente ricos y mejorando el rendimiento de la generación de imágenes. NVFP4 es un nuevo formato de preentrenamiento de 4 bits que, mediante escalado de dos niveles, RHT y redondeo aleatorio, promete una mejora de eficiencia de 6.8 veces mientras iguala el rendimiento de referencia de FP8. DA^2 (Depth Anything in Any Direction) es un estimador de profundidad de inundación preciso, de generalización de cero-shot y de extremo a extremo que, a través de datos de entrenamiento a gran escala y la arquitectura SphereViT, alcanza el SOTA en la estimación de profundidad panorámica. El modelo SAGANet logra una generación de audio controlable a nivel de objeto al utilizar máscaras de segmentación visual, videos y pistas de texto, proporcionando un control preciso para flujos de trabajo profesionales de Foley. Mem-α es un marco de aprendizaje por refuerzo que, al entrenar a los agentes para gestionar eficazmente sistemas de memoria externos complejos, resuelve los problemas de construcción de memoria y pérdida de información en la comprensión de texto largo por parte de los agentes LLM, y demuestra capacidad de generalización a secuencias ultralargas. El marco EntroPE (Entropy-Guided Dynamic Patch Encoder) detecta dinámicamente puntos de transición en series temporales mediante entropía condicional y coloca límites de parches para preservar la estructura temporal, mejorando la precisión y eficiencia de la predicción. BUILD-BENCH es un benchmark más desafiante para evaluar la capacidad de los agentes LLM para compilar software de código abierto del mundo real, y propone OSS-BUILD-AGENT como una línea base sólida. ProfVLM es un modelo ligero de video-lenguaje que, a través del razonamiento generativo, predice conjuntamente los niveles de habilidad y genera retroalimentación experta a partir de videos en primera persona y de perspectiva externa. Se discute la efectividad del entrenamiento en tiempo de prueba (TTT) en modelos fundacionales, argumentando que TTT, al especializarse en tareas de prueba, puede reducir significativamente el error de prueba dentro de la distribución. CST es una nueva arquitectura de red neuronal para procesar conjuntos de imágenes de cardinalidad arbitraria, que opera directamente en tensores de imágenes 3D, realizando simultáneamente la extracción de características y el modelado contextual, y sobresale en tareas como la clasificación de conjuntos y la detección de anomalías. El marco TTT3R trata la reconstrucción 3D como un problema de aprendizaje en línea, derivando la tasa de aprendizaje a partir de la confianza de alineación del estado de la memoria y la observación, lo que mejora significativamente la capacidad de generalización de secuencias largas.
(Fuente: tonywu_71, swyx, Reddit r/deeplearning, lateinteraction, teortaxesTex, shishirpatil_, bengoertzel, arankomatsuzaki, francoisfleuret, _akhaliq, steph_palazzolo, HuggingFace Daily Papers, SchmidhuberAI, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NerdyRodent, QuixiAI, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning)
Detección de falsificaciones percibidas por humanos en la generación de video por IA: DeeptraceReward es el primer conjunto de datos de referencia de grano fino y consciente del espacio-tiempo para anotar rastros de falsificación percibidos por humanos en videos generados. Este conjunto de datos contiene 4.3K anotaciones detalladas en 3.3K videos generados de alta calidad, y los integra en 9 categorías principales de rastros de falsificación. La investigación entrena modelos de lenguaje multimodales como modelos de recompensa para imitar el juicio y la localización humanos, superando a GPT-5 en la identificación, localización y explicación de pistas de falsificación.
(Fuente: HuggingFace Daily Papers)
Purificación adversaria y reconstrucción de escenas 3D: MANI-Pure es un marco de purificación adaptativo en amplitud que, al utilizar el espectro de amplitud de la señal de entrada para guiar el proceso de purificación, inyecta de forma adaptativa ruido heterogéneo y dirigido por frecuencia, suprimiendo eficazmente las perturbaciones de alta frecuencia mientras conserva el contenido de baja frecuencia semánticamente crítico, logrando un rendimiento SOTA en defensa adversaria. NVIDIA lanzó el modelo Lyra, que logra la reconstrucción generativa de escenas 3D mediante la auto-destilación de modelos de difusión de video, permitiendo la generación de escenas 3D y 4D de alimentación directa a partir de una sola imagen/video.
(Fuente: HuggingFace Daily Papers, _akhaliq)
💼 Negocios
Colaboración de OpenAI con Samsung y demanda de DRAM: OpenAI está colaborando con Samsung en el desarrollo del chip “Stargate” y se espera que necesite 900,000 obleas de DRAM de alto rendimiento al mes, lo que indica planes e inversiones masivas para su futura infraestructura de IA, superando con creces las expectativas actuales de la industria. Esta enorme demanda ha provocado discusiones sobre los costos de computación de IA y un superciclo de memoria.
(Fuente: bookwormengr, teortaxesTex, francoisfleuret)
Financiación y estrategia de la industria de startups de IA: Axiom Math AI lanza un razonador superinteligente que se auto-mejora, comenzando con matemáticos de IA, atrayendo la atención de la industria. Modal cierra una ronda de financiación Serie B de 87 millones de dólares, valorada en 1.100 millones de dólares, con el objetivo de impulsar el futuro de la infraestructura de computación de IA. OffDeal completa una ronda de financiación Serie A de 12 millones de dólares, dedicada a construir el primer banco de inversión nativo de IA del mundo. El Ministro de Defensa japonés visita la oficina de Sakana AI, lo que indica una posible colaboración en el campo de la defensa. Un desarrollador compartió su dilema de quedarse sin fondos después de gastar 3.000 dólares en la construcción de un modelo LLM de código abierto, lo que provocó una discusión en la comunidad sobre la sostenibilidad de los proyectos de IA de código abierto. Los desarrolladores de Google AI anunciaron los ganadores del Nano Banana Hackathon, otorgando más de 400.000 dólares en premios, con el objetivo de fomentar la innovación en aplicaciones de IA.
(Fuente: shishirpatil_, bengoertzel, lupantech, arankomatsuzaki, francoisfleuret, akshat_b, leveredvlad, SakanaAILabs, hardmaru, Reddit r/LocalLLaMA, osanseviero)
🌟 Comunidad
Impacto social y controversias provocadas por Sora 2: El lanzamiento de Sora 2 ha generado un amplio impacto social y controversias. Muchos usuarios temen la proliferación de contenido “slop” (contenido de baja calidad y sin sentido) generado por IA, cuestionando si las prioridades de OpenAI son el entretenimiento en lugar de resolver problemas importantes como el cáncer. Al mismo tiempo, existe la preocupación de que el hiperrealismo de Sora 2 pueda hacer que los videos sean indistinguibles de la realidad, e incluso ser utilizados maliciosamente para generar información falsa o contenido dañino similar a “armas biológicas”. El propio CEO de OpenAI, Sam Altman, se convirtió en protagonista de memes generados por IA, a lo que respondió que “no es tan extraño”, y explicó que el enfoque de OpenAI sigue siendo la AGI y el descubrimiento científico, y que el lanzamiento de productos es para necesidades de financiación. La potente capacidad de Sora 2 resalta una vez más la enorme demanda de GPU, lo que ha provocado discusiones sobre los altos costos de la computación de IA, e incluso algunos comparan los costos de la IA con los de la construcción del sistema de carreteras interestatales de EE. UU. Algunos comentarios sugieren que la estrategia de lanzamiento de Sora 2 es demasiado “ordinaria”, carece de pruebas de referencia y soporte para usuarios profesionales, y restringe el contenido generado por usuarios gratuitos.
(Fuente: teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
Experiencia de usuario y controversias de Claude Sonnet 4.5: Los usuarios generalmente consideran que Sonnet 4.5 ha mejorado significativamente en la retención de información, el juicio, la toma de decisiones y la escritura creativa, e incluso muestra “cambios de actitud” similares a los humanos, por ejemplo, volviéndose más profesional al descubrir el contexto del usuario, o corrigiendo al usuario cuando “dice tonterías”. Aunque sobresale en algunos aspectos, algunos usuarios critican la baja calidad de su generación de código, con “errores descuidados y tontos”, e incluso problemas de “conversación demasiado larga” que impiden la generación de código en diálogos extensos, lo que sugiere que aún está lejos de reemplazar a los ingenieros de software humanos. Además, algunos usuarios lograron “jailbreak” a Sonnet 4.5, haciéndolo generar recetas peligrosas y código malicioso, lo que ha generado serias preocupaciones sobre las salvaguardias de seguridad del modelo.
(Fuente: teortaxesTex, doodlestein, genmon, aiamblichus, QuixiAI, suchenzang, karminski3, aiamblichus, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
El futuro de los lenguajes de programación en la era de la IA y el declive de la cultura comunitaria: El ranking de lenguajes de programación IEEE Spectrum 2025 muestra que Python ha sido el lenguaje más popular durante diez años consecutivos, ocupando el primer lugar en la clasificación general, la velocidad de crecimiento y la orientación al empleo, y su ventaja se ha amplificado aún más en la era de la IA. JavaScript ha caído drásticamente en el ranking, mientras que la posición de SQL, aunque afectada, sigue siendo valiosa. El informe señala que la IA está poniendo fin a la diversidad de lenguajes de programación, el efecto Mateo de los lenguajes principales se está intensificando y los lenguajes no principales serán marginados. Al mismo tiempo, la cultura de la comunidad de programadores está en declive, y los desarrolladores prefieren buscar ayuda en grandes modelos en lugar de hacer preguntas en la comunidad, lo que ha cambiado las formas de aprender y trabajar, generando discusiones sobre el futuro papel de los programadores y la importancia de las habilidades clave en el diseño de arquitecturas subyacentes.
(Fuente: 量子位, jimmykoppel, jimmykoppel, lateinteraction, kylebrussell, Reddit r/ArtificialInteligence)

La burbuja de la IA y las perspectivas de desarrollo de la industria: En las redes sociales se debate si existe una burbuja en la industria de la IA. Algunos opinan que el actual entusiasmo por la inversión es alto y que podría haber algunos proyectos “tontos”, pero los fundamentos de la industria siguen siendo sólidos y la adopción de la IA por parte de las empresas crece de manera constante. Al mismo tiempo, hay voces que señalan que los enormes costos de computación de la IA y la masiva demanda de DRAM por parte de OpenAI indican que la industria aún se está expandiendo rápidamente, lejos de alcanzar la etapa de estallido de la burbuja, pero también se debe estar alerta a la entrada de capital.
(Fuente: arohan, pmddomingos, teortaxesTex, teortaxesTex, ajeya_cotra)
💡 Otros
Robots humanoides y dispositivos asistidos por IA: La empresa china de robótica LimX Dynamics demostró las capacidades de movimiento autónomo, flexión y lanzamiento de su robot humanoide Oli, sin necesidad de captura de movimiento ni operación remota, lo que indica que China ha alcanzado un nivel comparable al de Figure/1X/Tesla en el campo de los robots humanoides. La Neural Band de Meta, al leer señales nerviosas mediante EMG y combinarse con las gafas de visualización Meta Rayban, promete ofrecer un método de control revolucionario para amputados, logrando el control sincronizado de prótesis e interfaces digitales, y podría convertirse en un controlador manos libres universal. Además, la IA y la robótica tienen diversas aplicaciones para mejorar la movilidad, la exploración y el rescate, como exoesqueletos robóticos eléctricos, insectos robóticos controlados de forma inalámbrica, robots cuadrúpedos y serpientes robóticas para misiones de rescate.
(Fuente: Ronald_vanLoon, teortaxesTex, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Reddit r/ArtificialInteligence)
Aplicaciones de la IA en edición de imágenes y diseño gráfico: LayerD es un método para descomponer diseños gráficos rasterizados en capas, con el objetivo de lograr flujos de trabajo creativos reeditables, extrayendo iterativamente capas de primer plano no ocluidas y utilizando la suposición de que las capas suelen mostrar una apariencia uniforme para su refinamiento, logrando así una descomposición de alta calidad. GeoRemover propone un marco de dos etapas con conciencia geométrica para eliminar objetos de las imágenes y sus artefactos visuales causales (como sombras y reflejos), desacoplando la eliminación geométrica y la representación de la apariencia, e introduciendo objetivos impulsados por preferencias para guiar el aprendizaje.
(Fuente: HuggingFace Daily Papers, HuggingFace Daily Papers)